Word embeddings for idiolect identification
Konstantinos Perifanos, Eirini Florou, Dionysis Goutsos

TL;DR
This paper investigates how social media user embeddings, derived from neural language models and matrix factorization, can serve as stylistic fingerprints for individual idiolect identification, advancing authorship attribution methods.
Contribution
It compares neural probabilistic language models and matrix factorization techniques for learning stylistic embeddings of social media users.
Findings
Embeddings reflect individual writing styles effectively.
Neural models and matrix factorization show comparable performance.
Stylistic embeddings improve authorship attribution accuracy.
Abstract
The term idiolect refers to the unique and distinctive use of language of an individual and it is the theoretical foundation of Authorship Attribution. In this paper we are focusing on learning distributed representations (embeddings) of social media users that reflect their writing style. These representations can be considered as stylistic fingerprints of the authors. We are exploring the performance of the two main flavours of distributed representations, namely embeddings produced by Neural Probabilistic Language models (such as word2vec) and matrix factorization (such as GloVe).
Click any figure to enlarge with its caption.
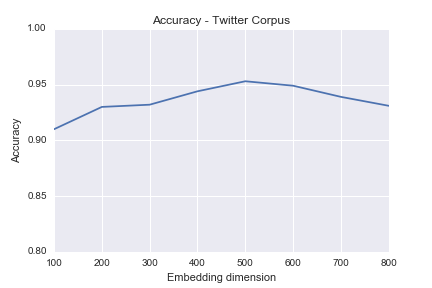 Figure 1
Figure 1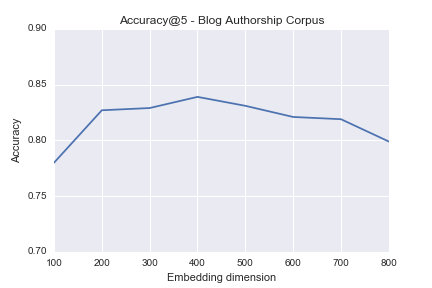 Figure 2
Figure 2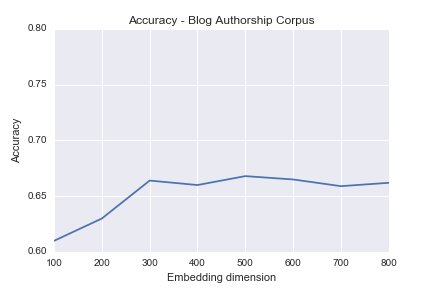 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAuthorship Attribution and Profiling · Topic Modeling · Natural Language Processing Techniques
\SetWatermarkText
PRE-PRINT \SetWatermarkLightness.85 \SetWatermarkScale.8
Word embeddings for idiolect identification
Konstantinos Perifanos1, Eirini Florou2, Dionysis Goutsos3
Department of Linguistics, National and Kapodistrian University of Athens
[email protected], [email protected], [email protected]
Abstract
The term idiolect refers to the unique and distinctive use of language of an individual and it is the theoretical foundation of Authorship Attribution. In this paper we are focusing on learning distributed representations (embeddings) of social media users that reflect their writing style. These representations can be considered as stylistic fingerprints of the authors. We are exploring the performance of the two main flavours of distributed representations, namely embeddings produced by Neural Probabilistic Language models (such as word2vec) and matrix factorization (such as GloVe).
††publicationid: pubid: 978-1-5386-8161-9/18/
I Introduction
The introduction of the term idiolect in sociolingustics appears in the 19th century by Neogramarian Herman Paul [1]. The theoretical concept and the existence of idiolect is the foundation of Authorship Attribution [2]. Here, we introduce a new way of capturing and quantifying author style, by producing an author’s "stylistic fingerprint" using word embeddings. Our method is not limited by the corpus vocabulary size and it is scalable to thousands of authors.
II Motivation and Related Work
Stylistic similarity has various practical applications, including authorship attribution (given a disputed text between two or more authors, identify the author of the text) [3], plagiarism detection [4], online harassment and abuse [5]. Applications of stylistic similarity are not limited in natural language problems and text; they are also applied in similar problems related to source code [24], music scores [6] etc. Similar techniques can also be considered as extensions to content recommendation systems, for example for news sites, literature recommendations as well as sub-components of content personalisation engines.
There are several approaches in the literature trying to address the problem of stylistic similarity, from a computational-corpus linguistic point of vie1w.
Barlow [7] examines the corpus of five White House Secretaries and focuses the analysis on the distribution of bigrams and trigrams per author.
Mollin [8] focuses on the individual style of Tony Blair in comparison with British National Corpus (B.N.C.). She compares the Tony Blair Corpus (T.B.C.), which consists of Tony Blair’s speeches and interviews and quantifies the difference between the usage frequency of maximizer collocations such as "I entirely understand".
Hughes et.al [9] are investigating writing style in Literature, by examining 537 authors from Project Gutenberg. They analyze 7337 works, using the frequency of 307 content-free words. They generate feature vectors for each author based on the frequency of the content-free words and they are using symmetric Kullback–Leibler divergence as a distance measure.
In our approach, we are expanding and removing the limitations on the studies above, both in size of the vocabulary as well as in the number of authors. Our method is applied on large vocabulary sizes and not only top N stop words. Our method is applied and proven to be consistent in two corpora: A selection of tweets of 4494 authors, consisting of approximately 302 million words and corpus of blog posts consisting of 19320 authors and 140 million words.
III Corpora
Our work on idiolect and writing style focuses on Social Media, and more specifically on Twitter and blogs. Sociolinguistics research on Twitter and related Social Media Platforms is quite common in the literature for various reasons: volume of data available as well as variability in gender, geolocation etc. [10, 11, 12]
For the purposes of the work presented in this paper, we collected timelines from 4494 twitter users, mostly tweeting in Greek language. The corpus consists of 26103963 tweets, tweeted between 2008 and 2017 and 325,243,302 words (whitespace tokenized).
We also applied our methodology in the The Blog Authorship Corpus by Schler et. al. [13].
IV Word and Paragraph Embeddings
Word embeddings are essentially representations of words in a d-dimensional vector space. In the most typical scenario, embeddings are learned by applying Neural Probabilistic Language Models. Neural Language Models were introduced by Bengio et. al. [14] in 2003. They became popular and mainstream after the publishing of word2vec, an implementation of neural language model by Mikolov et. al.[15]. The word2vec tool provided the ability for fast training in large corpora (hundreds of millions of words). The produced embeddings have a very nice feature: Semantically related words tend to be close in the d-dimentional space. wor2vec introduces two architectures, Continuous Bag of Words (CBOW), where the neural network tries to predict the next word given context, and Skip-Gram where given the input word the model tries to predict the context. To speed up calculation, Mikolov et. al. [16] introduce Negative Sampling, a simplified variant of Noise-contrastive estimation [17]. In this scheme, instead of trying to calculate the softmax of all words in the vocabulary, a fixed number of negative samples are drawn from the vocabulary.
Following word2vec Le and Mikolov introduce the distributed representation of sentences and documents (Paragraph Vectors) [18]. This is a natural extention of word2vec, where metadata on sentence or even document level are treated as additional words/tokens and then are fed as additional input to the neural network. The resulting outcome is not only d-dimentional vectors for vocabulary words but also d-dimentional vectors for the sentence level metadata. Paragraph Vectors comes also in two flavours: Distributed Memory Model of Paragraph Vectors (PV-DM) and Distributed Bag of Words version of Paragraph Vector (PV-DBOW). PV-DM preserves word order in the context where PV-DBOW ignores word ordering.
V Experiment and results
In our work, we are learning Paragraph Vectors on author level. More concretely, we aggregate all tweets by the same user in a single document and we are feeding words and author id’s to the neural model. The corpus is preprocessed before training. Words are whitespace tokenized, all tweets are lowercased and we are removing @ mentions. The reason mentions are removed is because mentions are carrying information on social network interactions among users and they can be used to model user proximity in a social graph [19]. Since we want to learn user similariy based on vocabulary only choices, we are discarding all social interactions and we are focusing on language usage only.
Because we are interested in stylistic choices, word order is important and thus we are focusing only on the PV-DM model. As described by Mikolov et. al, the author token acts as memory that remembers what is missing from the current context. 111The implementation is based on the Gensim Python library [20], https://radimrehurek.com/gensim/
For evaluation purposes, we created a random subset of initially 100 users from the corpus. For each user in this set, we randomly splitting the tweets in two sets, , , each set containing 50% of the user’s tweets.
We then train the model and we are evaluating in the following way: We are extracting the distributed representation all users and we querying for most similar users against all learned distributed author representations. If is the most similar to this is considered as a positive match, negative otherwise. We are repeating this experiment for various values of embedding dimentionallity and calculate the accuracy as described above.
The accuracy drops in cases where a user has less than 500 tweets, which is a reasonable outcome given the fact that due to 140 character limitation in twitter statuses until 2017, the total words for 500 tweets are not enough to discriminate user style.
We are then repeating the process above by gradually increasing the number of twitter users to 4000. Accuracy remains consistent and always higher than 85%. The drop in accuracy is explained by the fact that the words/tweets distribution follows Zipfian distribution and as we are increasing the sample size for the test set, the probability of selecting a user with less than 500 tweets is increasing.
If we relax the definition of a positive match to "user in top K most similar tweets", we achieve accuracy always near to 100%. This is of huge practical importance in cases of Forensic Linguistics such as Doppelgänger Detection [21], where learned representations can be used as features in relevant models along with social graph information as well as metadata (Device, user habits etc).
VI Sociolect, style stability, applications and future work
Subsequently, given the vector representation of authors, we can apply clustering techniques to formulate clusters of "sociolect" and group users of similar or near identical writing style. This also reflects popularity, especially on twitter, where users tend to adopt trending words, phrases or slang words introduced by other popular users, in different contexts: From casual chat to marketing, politics and propaganda [22]. This method then can be used as a "who to follow" recommendation strategy for users with similar styles. One other potential direction is to apply network backbone analysis [23] to identify the most stylistically influential authors in the coprus.
One important question we are also invastigating is an individual’s idiolect stability over time. Again, by applying the same methodology as above, we are splitting user tweets in pairs (user,year) and we are querying and comparing most similar users to a given user_A in a given year, in all previous years. The results are promising, as we are achieving again high accuracy scores, near 80%. However, since now we are splitting users in multiple (user, year) pairs, accuracy drops. One obvious way to address that is to collect more data and repeat the experiments with more authors and tweets.
Finally, we aim to apply the same methodology on other text or text-like collections, such as News and Literature.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] H. Paul, Principles of the History of Language . Рипол Классик, 1890.
- 2[2] M. Coulthard, “Author identification, idiolect, and linguistic uniqueness,” Applied linguistics , vol. 25, no. 4, pp. 431–447, 2004.
- 3[3] R. M. Coyotl-Morales, L. Villaseñor-Pineda, M. Montes-y Gómez, and P. Rosso, “Authorship attribution using word sequences,” in Iberoamerican Congress on Pattern Recognition . Springer, 2006, pp. 844–853.
- 4[4] H. A. Maurer, F. Kappe, and B. Zaka, “Plagiarism-a survey.” J. UCS , vol. 12, no. 8, pp. 1050–1084, 2006.
- 5[5] E. Tan, L. Guo, S. Chen, X. Zhang, and Y. Zhao, “Unik: Unsupervised social network spam detection,” in Proceedings of the 22nd ACM international conference on Information & Knowledge Management . ACM, 2013, pp. 479–488.
- 6[6] P. Van Kranenburg and E. Backer, “Musical style recognition—a quantitative approach,” in Handbook of Pattern Recognition and Computer Vision . World Scientific, 2005, pp. 583–600.
- 7[7] M. Barlow, “Individual usage: a corpus-based study of idiolects,” Linguistics , vol. 18, no. 4, 2013.
- 8[8] S. Mollin, ““i entirely understand” is a blairism,” International Journal of Corpus Linguistics , vol. 14, no. 3, pp. 367–392, 2009.