BOLT-SSI: A Statistical Approach to Screening Interaction Effects for Ultra-High Dimensional Data
Min Zhou, Mingwei Dai, Yuan Yao, Jin Liu, Can Yang, Heng Peng

TL;DR
This paper introduces BOLT-SSI, a fast and statistically guaranteed method for screening interaction effects in ultra-high dimensional data, capable of handling over 300,000 predictors efficiently.
Contribution
The paper proposes BOLT-SSI, a novel fast algorithm for interaction screening in ultra-high dimensional data, with proven sure screening properties and superior computational efficiency.
Findings
BOLT-SSI outperforms competitors in speed and accuracy.
Effective for datasets with over 300,000 predictors.
Theoretical guarantees support its reliability.
Abstract
Detecting interaction effects among predictors on the response variable is a crucial step in various applications. In this paper, we first propose a simple method for sure screening interactions (SSI). Although its computation complexity is , SSI works well for problems of moderate dimensionality (e.g., ), without the heredity assumption. To ultra-high dimensional problems (e.g., ), motivated by discretization associated Boolean representation and operations and the contingency table for discrete variables, we propose a fast algorithm, named "BOLT-SSI". The statistical theory has been established for SSI and BOLT-SSI, guaranteeing their sure screening property. The performance of SSI and BOLT-SSI are evaluated by comprehensive simulation and real case studies. Numerical results demonstrate that SSI and BOLT-SSI can often outperform their competitors in…
Click any figure to enlarge with its caption.
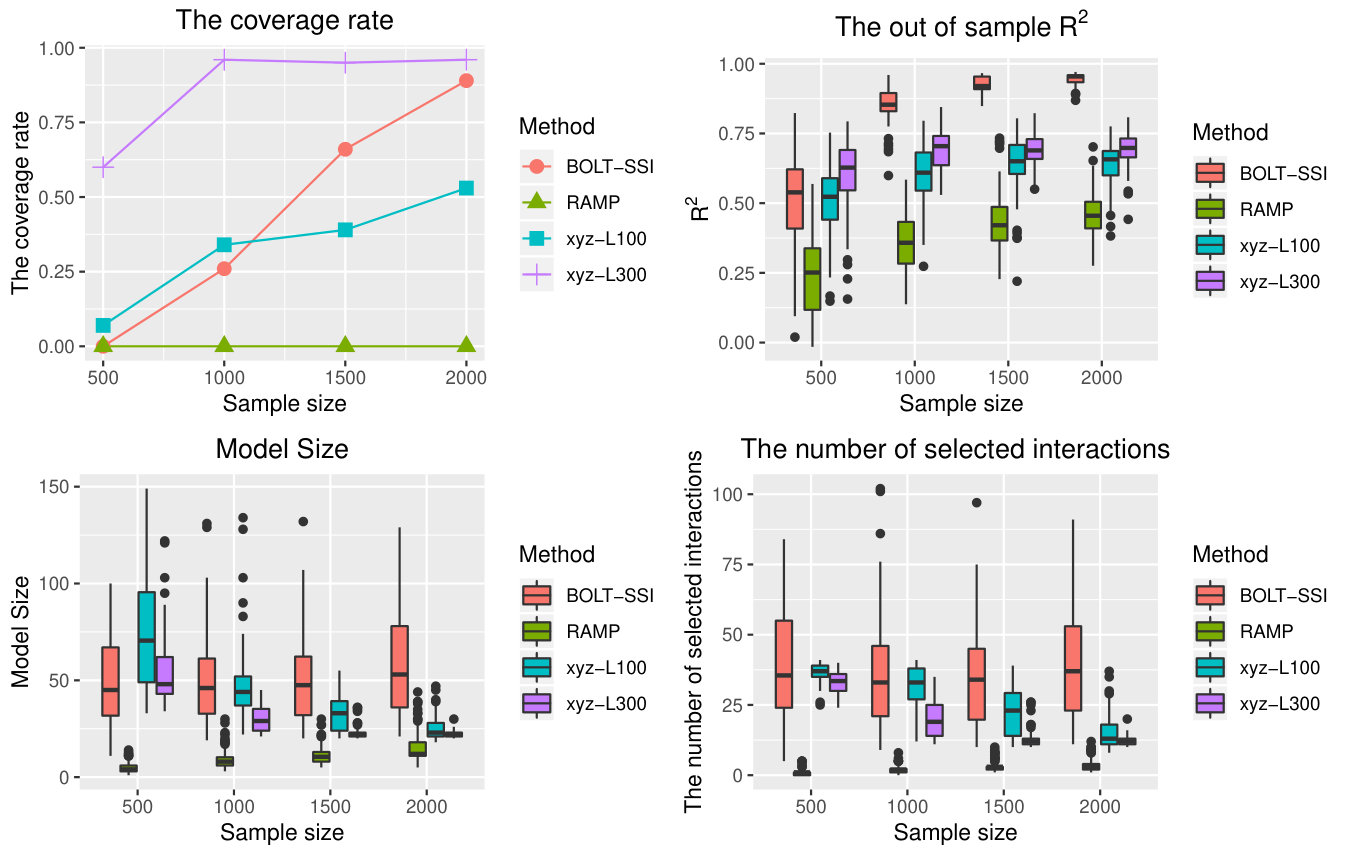 Figure 1
Figure 1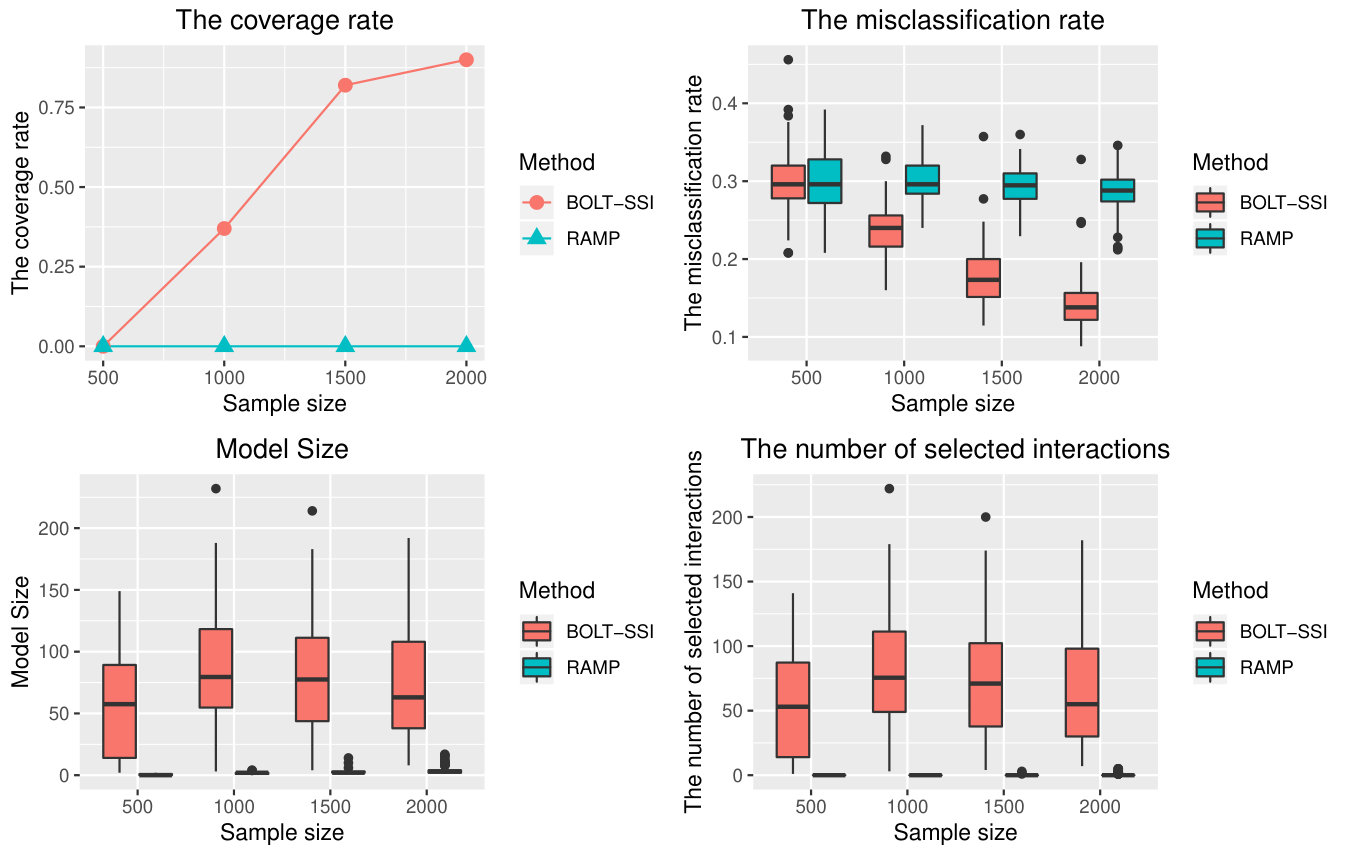 Figure 2
Figure 2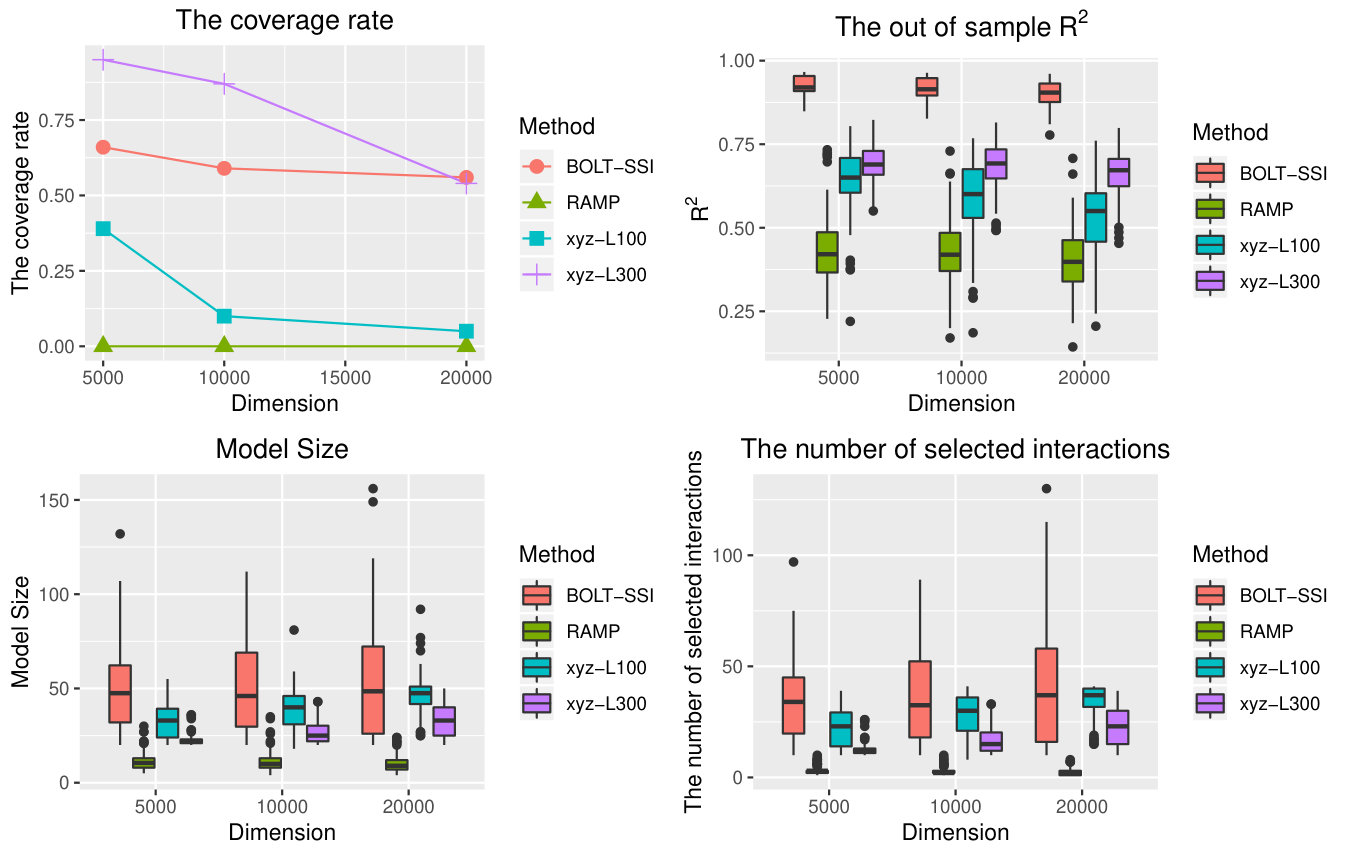 Figure 3
Figure 3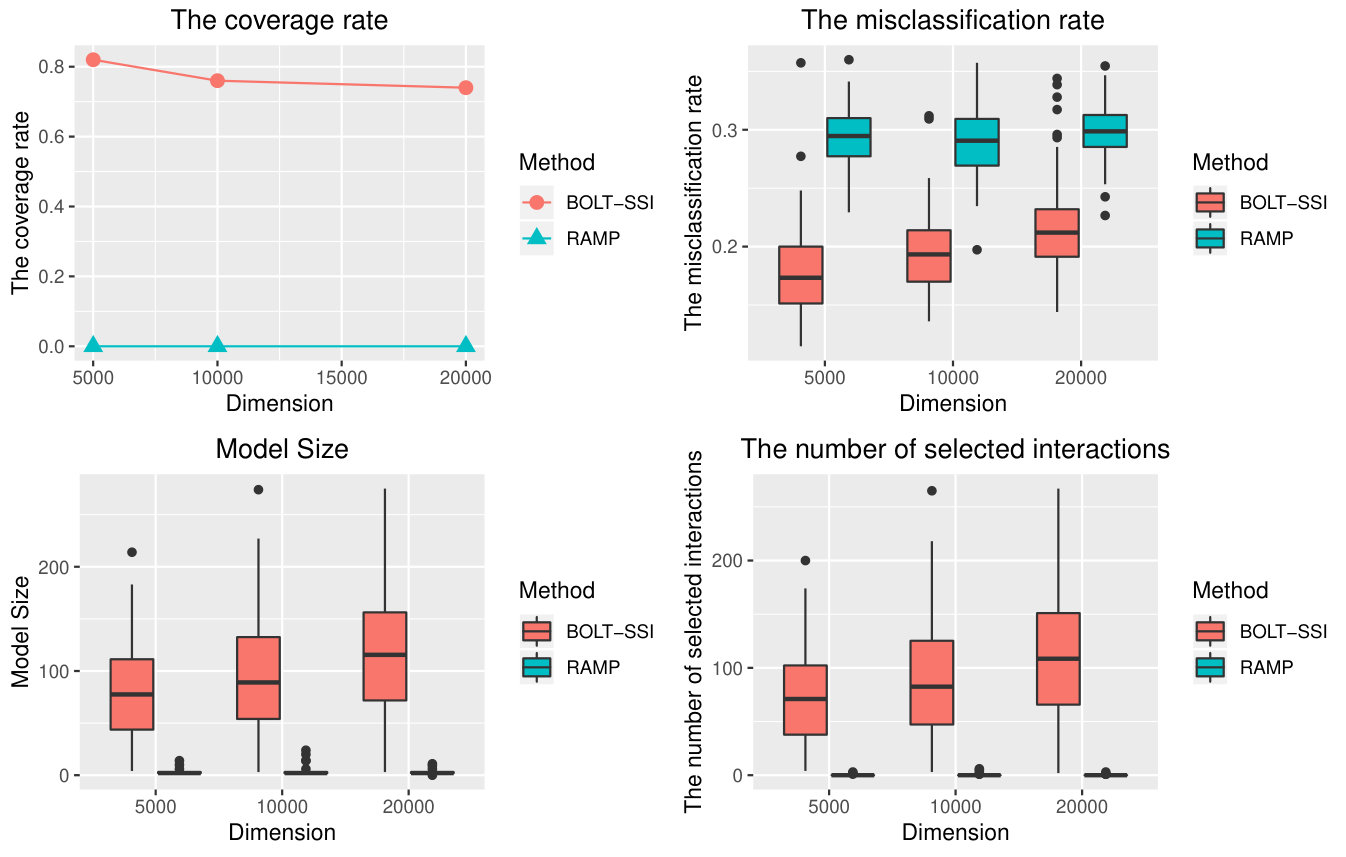 Figure 4
Figure 4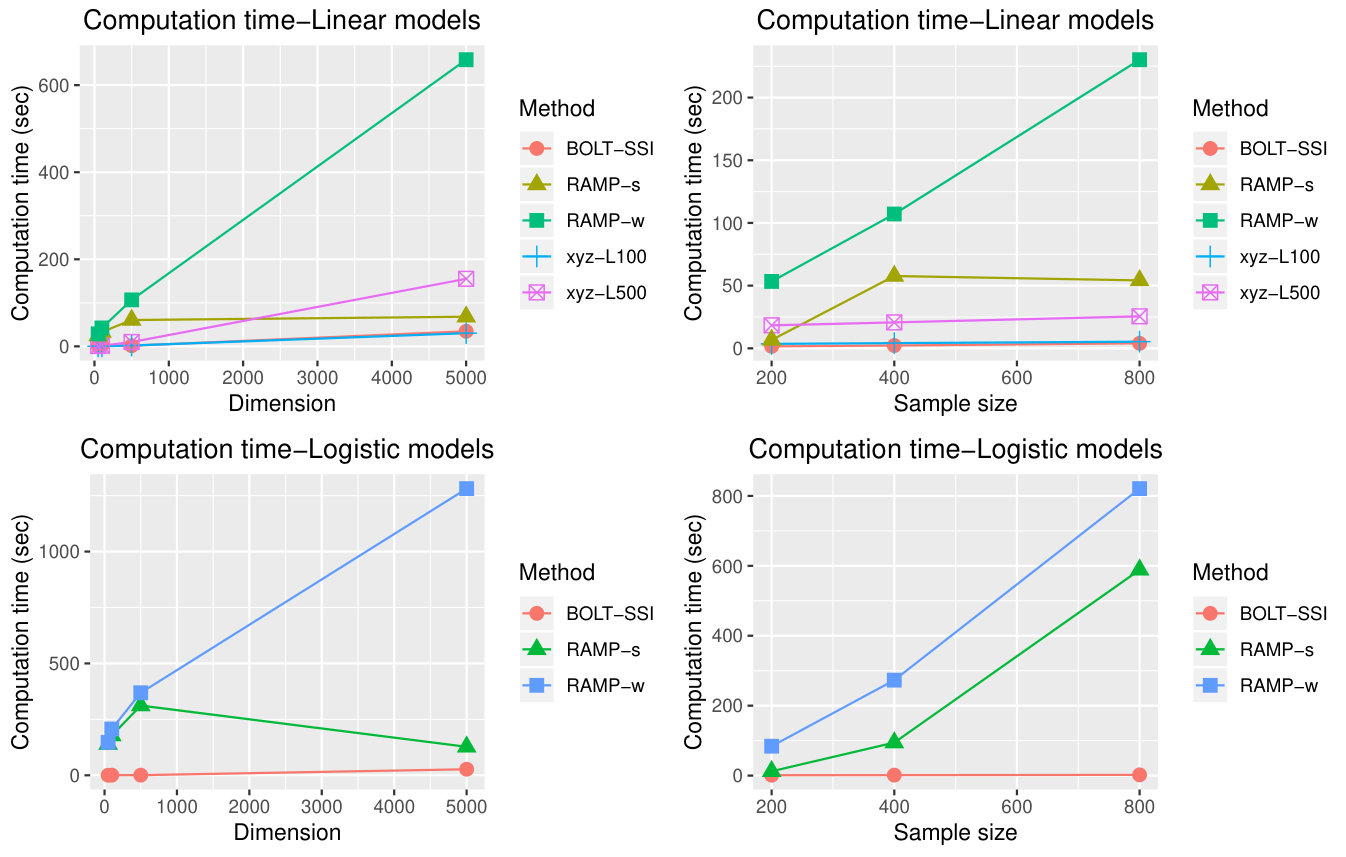 Figure 5
Figure 5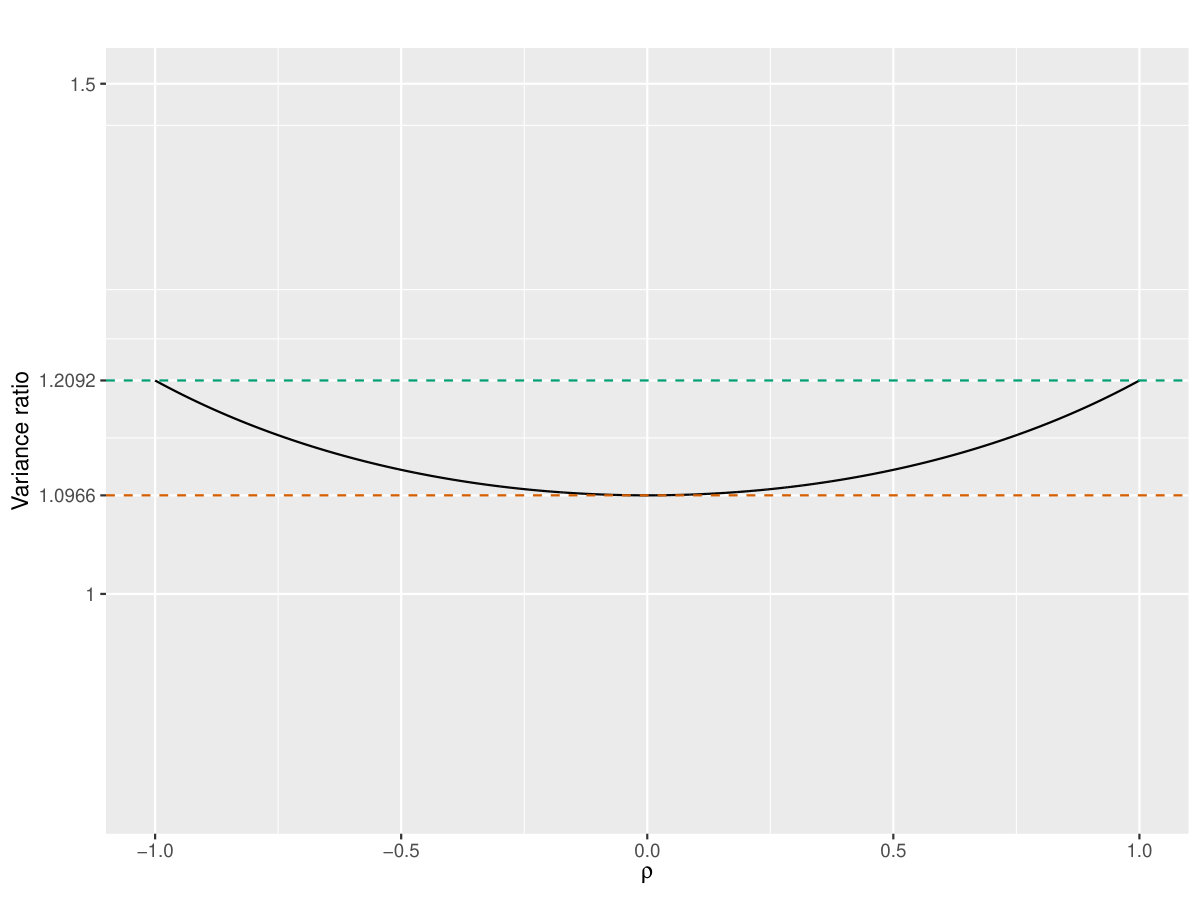 Figure 6
Figure 6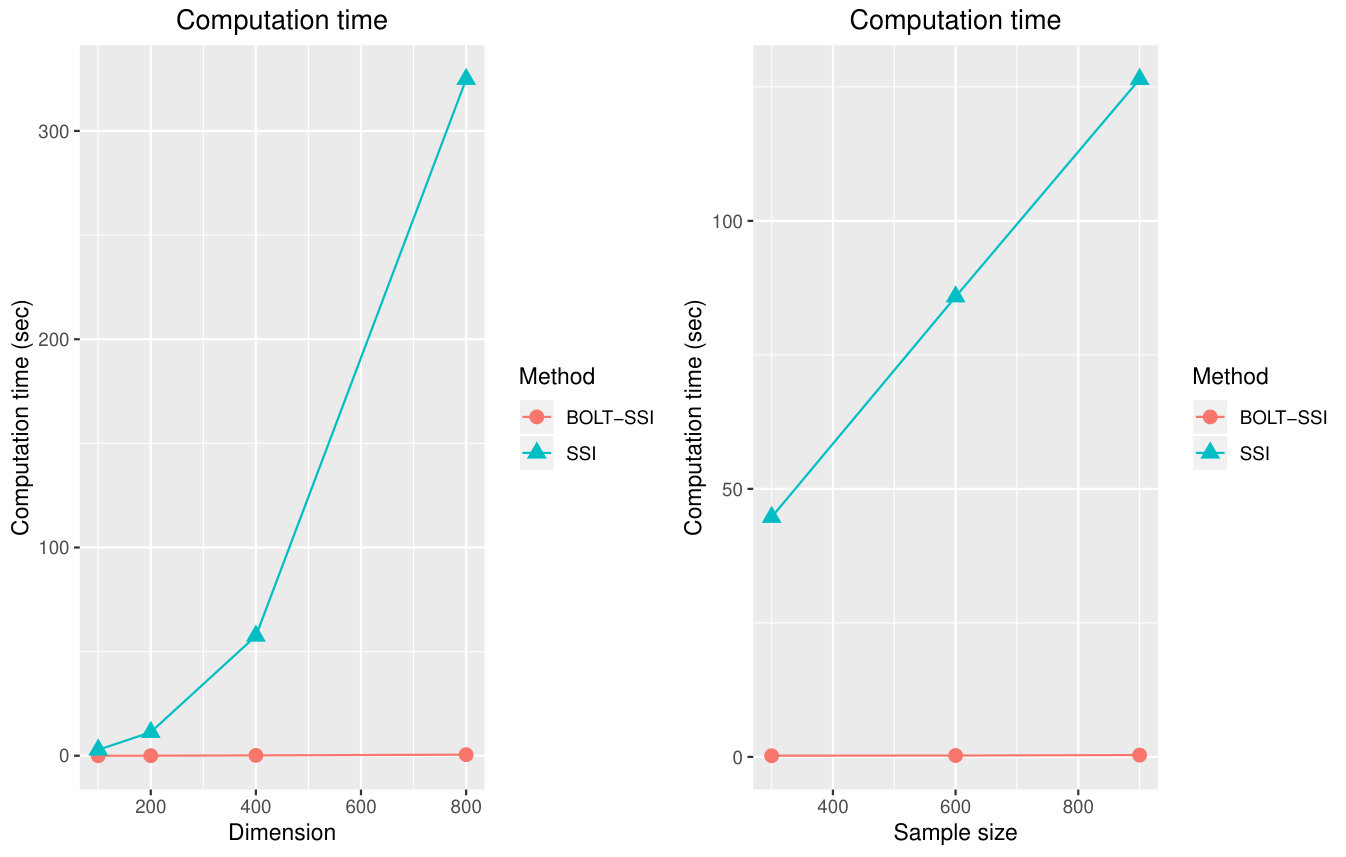 Figure 7
Figure 7| Methods | SSI | BOLT-SSI | BOLT-SSI(p) | IP | xyz-L10 | xyz-L100 | xyz-L1000 | |
|---|---|---|---|---|---|---|---|---|
| ()=(500, 5000, 0) | ||||||||
| 2 | 0.98 | 0.03 | 0.64 | 0.73 | 0.00 | 0.01 | 0.76 | |
| Example 1 | 3 | 0.94 | 0.00 | 0.60 | 0.70 | 0.00 | 0.04 | 0.73 |
| 4 | 0.80 | 0.00 | 0.48 | 0.59 | 0.00 | 0.01 | 0.55 | |
| ()=(500, 5000, 0.5) | ||||||||
| 2 | 1.00 | 0.80 | 0.98 | 0.99 | 0.29 | 0.52 | 0.52 | |
| Example 1 | 3 | 1.00 | 0.58 | 0.94 | 0.99 | 0.22 | 0.51 | 0.52 |
| 4 | 1.00 | 0.43 | 0.88 | 0.98 | 0.14 | 0.50 | 0.50 | |
| ()=(500, 5000, 0) | ||||||||
| 2 | 0.90 | 0.01 | 0.38 | 0.03 | 0.00 | 0.04 | 0.56 | |
| Example 2 | 3 | 0.82 | 0.01 | 0.36 | 0.01 | 0.00 | 0.00 | 0.41 |
| 4 | 0.73 | 0.00 | 0.00 | 0.01 | 0.00 | 0.01 | 0.31 | |
| ()=(500, 5000, 0.5) | ||||||||
| 2 | 0.73 | 0.03 | 0.60 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Example 2 | 3 | 0.71 | 0.02 | 0.57 | 0.01 | 0.00 | 0.00 | 0.00 |
| 4 | 0.67 | 0.00 | 0.45 | 0.00 | 0.00 | 0.00 | 0.00 | |
| ()=(500, 5000, 0) | ||||||||
| 2 | 0.89 | 0.03 | 0.62 | 0.03 | 0.00 | 0.02 | 0.56 | |
| Example 3 | 3 | 0.82 | 0.03 | 0.44 | 0.02 | 0.00 | 0.01 | 0.53 |
| 4 | 0.73 | 0.00 | 0.45 | 0.01 | 0.00 | 0.00 | 0.46 | |
| ()=(500, 5000, 0.5) | ||||||||
| 2 | 1.00 | 0.33 | 0.81 | 0.74 | 0.28 | 0.53 | 0.53 | |
| Example 3 | 3 | 1.00 | 0.23 | 0.74 | 0.72 | 0.25 | 0.50 | 0.50 |
| 4 | 1.00 | 0.11 | 0.73 | 0.68 | 0.14 | 0.51 | 0.51 | |
| ()=(500, 5000, 0) | ||||||||
| 2 | 0.91 | 0.00 | 0.44 | 0.06 | 0.00 | 0.03 | 0.47 | |
| Example 4 | 3 | 0.82 | 0.00 | 0.42 | 0.05 | 0.00 | 0.03 | 0.48 |
| 4 | 0.69 | 0.00 | 0.23 | 0.03 | 0.00 | 0.00 | 0.34 | |
| ()=(500, 5000, 0.5) | ||||||||
| 2 | 0.80 | 0.07 | 0.75 | 0.27 | 0.00 | 0.01 | 0.01 | |
| Example 4 | 3 | 0.78 | 0.05 | 0.73 | 0.28 | 0.00 | 0.01 | 0.01 |
| 4 | 0.76 | 0.02 | 0.66 | 0.28 | 0.00 | 0.01 | 0.01 | |
| Methods | SSI | BOLT-SSI | BOLT-SSI(p) | SSI | BOLT-SSI | BOLT-SSI(p) | ||
|---|---|---|---|---|---|---|---|---|
| 1 | 0.02 | 0.00 | 0.35 | 0.53 | 0.08 | 0.76 | ||
| Example 5 | 2 | 0.40 | 0.04 | 0.56 | 0.84 | 0.30 | 0.86 | |
| 3 | 0.77 | 0.12 | 0.66 | 0.83 | 0.27 | 0.86 | ||
| 1 | 0.02 | 0.00 | 0.28 | 0.00 | 0.00 | 0.39 | ||
| Example 6 | 2 | 0.31 | 0.02 | 0.34 | 0.32 | 0.01 | 0.49 | |
| 3 | 0.56 | 0.06 | 0.63 | 0.44 | 0.05 | 0.66 | ||
| 1 | 0.02 | 0.00 | 0.35 | 0.53 | 0.08 | 0.76 | ||
| Example 7 | 2 | 0.40 | 0.04 | 0.56 | 0.84 | 0.30 | 0.86 | |
| 3 | 0.77 | 0.12 | 0.66 | 0.83 | 0.27 | 0.86 | ||
| 1 | 0.00 | 0.00 | 0.28 | 0.04 | 0.00 | 0.43 | ||
| Example 8 | 2 | 0.33 | 0.05 | 0.57 | 0.24 | 0.04 | 0.63 | |
| 3 | 0.52 | 0.05 | 0.70 | 0.41 | 0.13 | 0.68 | ||
| Assumption | Methods | ACR | AMS | PMR | ||
|---|---|---|---|---|---|---|
| BOLT-SSI | 0.98 | 53.91(2.5) | 94.52(0.22) | — | ||
| Example 1 | RAMP | 0.16 | 21.67(0.7) | 76.29(1.60) | — | |
| xyz-L100 | 0.73 | 28.10(0.7) | 58.46(0.95) | — | ||
| xyz-L500 | 1 | 23.94(0.2) | 60.07(0.82) | — | ||
| BOLT-SSI | 0.62 | 45.80(2.3) | 87.16(0.62) | — | ||
| Example 2 | RAMP | 1.00 | 20.35(0.1) | 95.34(0.01) | — | |
| xyz-L100 | 0.23 | 72.70(2.9) | 58.5(1.16) | — | ||
| xyz-L500 | 0.97 | 35.64(0.5) | 76.43 (0.56) | — | ||
| BOLT-SSI | 0.93 | 47.61(1.8) | 90.94(0.33) | — | ||
| Example 3 | RAMP | 0.00 | 4.5(0.6) | 13.96(0.11) | — | |
| xyz-L100 | 0.80 | 27.85(7.1) | 58.48(1.31) | — | ||
| xyz-L500 | 1 | 23.94(0.2) | 59.36(1.20) | — | ||
| BOLT-SSI | 0.53 | 49.38(1.9) | 88.53(0.50) | — | ||
| Example 4 | RAMP | 0.00 | 15.54(0.6) | 61.83(0.79) | — | |
| xyz-L100 | 0.34 | 47.26(1.8) | 59.53(1.05) | — | ||
| xyz-L500 | 1 | 28.47(0.5) | 68.44(0.89) | — | ||
| Example 5 | BOLT-SSI | 0.53 | 36.09(4.0) | - | 23.26(0.32) | |
| RAMP | 0.00 | 0.14(0.1) | - | 25.62(0.03) | ||
| Example 6 | BOLT-SSI | 0.42 | 47.75(4.9) | - | 26.73(0.62) | |
| RAMP | 0.00 | 6.80(0.5) | - | 28.15(0.60) | ||
| Example 7 | BOLT-SSI | 0.62 | 79.80(5.0) | - | 20.98(0.31) | |
| RAMP | 0.00 | 2.97(0.2) | - | 28.67(0.31) | ||
| Example 8 | BOLT-SSI | 0.53 | 79.26(5.1) | - | 22.85(0.41) | |
| RAMP | 0.00 | 1.69(0.1) | - | 25.34(0.24) |
| BOLT-SSI | hierNet-s | hierNet-w | xyz-L100 | xyz-L500 | RAMP-s | RAMP-w | ||
| Linear Regression Models | ||||||||
| 500 | 50 | 1.13 | 75.26 | 4.92 | 0.22 | 0.86 | 25.00 | 28.85 |
| 500 | 100 | 2.55 | 321.88 | 22.43 | 0.39 | 1.61 | 33.11 | 42.44 |
| 500 | 500 | 1.66 | — | 669.99 | 2.10 | 10.07 | 60.65 | 106.82 |
| 500 | 5000 | 34.75 | — | — | 30.38 | 155.22 | 68.20 | 658.42 |
| 200 | 1000 | 1.62 | — | — | 3.58 | 18.35 | 6.69 | 53.35 |
| 400 | 1000 | 2.26 | — | — | 4.15 | 20.69 | 57.68 | 107.11 |
| 800 | 1000 | 4.02 | — | — | 5.32 | 25.52 | 54.18 | 230.20 |
| Logistic Regression Models | ||||||||
| 500 | 50 | 0.44 | 306.91 | 11.53 | — | — | 139.52 | 147.16 |
| 500 | 100 | 0.82 | 1105.96 | 37.16 | — | — | 177.84 | 207.08 |
| 500 | 500 | 0.74 | — | 511.21 | — | — | 311.87 | 368.86 |
| 500 | 5000 | 27.15 | — | — | — | — | 127.52 | 1281.45 |
| 200 | 1000 | 1.10 | — | — | — | — | 12.34 | 83.98 |
| 400 | 1000 | 1.38 | — | — | — | — | 94.48 | 273.06 |
| 800 | 1000 | 2.18 | — | — | — | — | 588.62 | 820.87 |
| main size | inter size | Time(s) | ||
| SSI | 18.01(0.62) | 42.47(1.54) | 98.24(0.16) | 1.15 |
| BOLT-SSI | 19.00(0.79) | 27.06(1.35) | 98.11(0.12) | 1.48 |
| RAMP-s | 8.40(0.10) | 7.53(1.81) | 98.54(0.10) | 3.79 |
| RAMP-w | 3.74(0.07) | 11.33(0.24) | 98.59(0.10) | 7.74 |
| xyz-L10 | 1(0) | 1.19(0.04) | 90.23(0.71) | 0.97 |
| xyz-L100 | 1(0) | 1.27(0.05) | 90.58(0.49) | 6.67 |
| xyz-L500 | 1(0) | 1.31(0.06) | 91.29(0.58) | 31.17 |
| LASSO-CV5 | 27.33(0.69) | —— | 97.77(0.10) | 0.10 |
| LASSO-AIC | 1.14(0.05) | —— | 94.22(0.14) | 0.01 |
| LASSO-BIC | 1(0) | —— | 94.15(0.13) | 0.01 |
| main size | inter size | ||
| BOLT-SSI | 196.19(3.79) | 42.43(1.13) | 93.95(0.15) |
| SSI | 107.70(0.73) | 10.90(0.37) | 92.73(0.14) |
| xyz-L10 | 37.80(0.26) | 12.61(0.25) | 87.03(0.26) |
| xyz-L100 | 35.54(0.24) | 14.40(0.23) | 86.94(0.22) |
| xyz-L500 | 35.26(0.25) | 14.84(0.24) | 86.59(0.28) |
| RAMP-AIC | 229.18(1.68) | 94.53 (1.06) | 90.48(0.23) |
| RAMP-BIC | 101.17(3.25) | 34.36(1.65) | 91.18(0.20) |
| RAMP-EBIC | 29.27(1.01) | 3.07(0.29) | 89.67(0.31) |
| RAMP-GIC | 30.71(0.92) | 3.20(0.30) | 90.08(0.28) |
| iFORT | ——– | ——– | 88.91(0.17) |
| iFORM | ——– | ——– | 88.66(0.18) |
| LASSO-AIC | 264.28 (0.91) | 0(0) | 92.04(0.18) |
| LASSO-BIC | 63.47 (0.77) | 0(0) | 90.76(0.20) |
| LASSO-EBIC | 15.62(0.46) | 0(0) | 72.09(0.53) |
| LASSO-GIC | 19.19 (0.74) | 0(0) | 75.05(0.58) |
| LASSO-AIC-m | 30.72(0.61) | ——– | 82.65(0.40) |
| LASSO-BIC-m | 13.21(0.22) | ——– | 69.58(0.48) |
| Methods | BOLT-SSI | SSI | xyz-L10 | xyz-L100 | xyz-L500 | RAMPs | RAMPw |
|---|---|---|---|---|---|---|---|
| Time(s) | 98.81 | 431.55 | 59.09 | 463.15 | 2252.95 | 33.75 | NULL |
| Inter1 | Inter2 | Exact Test Statistic |
|---|---|---|
| Insulin | HDL | 63.332 |
| CRP | SysBP | 53.566 |
| Glucose | Insulin | 53.455 |
| Insulin | TG | 51.407 |
| CRP | Insulin | 46.678 |
| Insulin | SysBP | 42.337 |
| rs1638742 | rs1958050 | 40.016 |
| rs2707941 | rs1958050 | 40.010 |
| rs10217074 | rs7957938 | 39.341 |
| rs17074280 | rs1890472 | 38.916 |
| Inter1 | Inter2 | Exact Test Statistic |
|---|---|---|
| CRP | TG | 29.662 |
| rs7631436 | rs7906313 | 7.617 |
| rs232101 | rs7262267 | 6.479 |
| rs2250648 | rs7104767 | 4.048 |
| Inter1 | Inter2 | Exact Test Statistic |
|---|---|---|
| CRP | TG | 29.662 |
| rs9368950 | rs2474619 | 5.474 |
| rs1481872 | rs2896268 | 4.532 |
| rs1355889 | rs969539 | 2.046 |
| rs11982066 | rs1074742 | 1.519 |
| Methods | SSI | BOLT-SSI | BOLT-SSI(p) | IP | xyz-L10 | xyz-L100 | xyz-L1000 | |
|---|---|---|---|---|---|---|---|---|
| ()=(400, 2000, 0) | ||||||||
| 2 | 0.96 | 0.07 | 0.56 | 0.76 | 0.00 | 0.29 | 0.85 | |
| Example 1 | 3 | 0.92 | 0.02 | 0.48 | 0.70 | 0.02 | 0.21 | 0.84 |
| 4 | 0.81 | 0.03 | 0.45 | 0.64 | 0.00 | 0.14 | 0.71 | |
| ()=(400, 2000, 0.5) | ||||||||
| 2 | 1.00 | 0.60 | 0.95 | 1.00 | 0.51 | 0.61 | 0.61 | |
| Example 1 | 3 | 1.00 | 0.56 | 0.91 | 1.00 | 0.48 | 0.61 | 0.61 |
| 4 | 1.00 | 0.36 | 0.82 | 1.00 | 0.43 | 0.60 | 0.60 | |
| ()=(400, 2000, 0) | ||||||||
| 2 | 0.90 | 0.03 | 0.45 | 0.08 | 0.01 | 0.11 | 0.69 | |
| Example 2 | 3 | 0.78 | 0.00 | 0.38 | 0.06 | 0.00 | 0.06 | 0.64 |
| 4 | 0.63 | 0.00 | 0.41 | 0.05 | 0.00 | 0.05 | 0.48 | |
| ()=(400, 2000, 0.5) | ||||||||
| 2 | 0.77 | 0.04 | 0.58 | 0.11 | 0.01 | 0.01 | 0.01 | |
| Example 2 | 3 | 0.71 | 0.03 | 0.49 | 0.08 | 0.01 | 0.01 | 0.01 |
| 4 | 0.64 | 0.01 | 0.43 | 0.06 | 0.01 | 0.03 | 0.01 | |
| ()=(400, 2000, 0) | ||||||||
| 2 | 0.90 | 0.01 | 0.56 | 0.12 | 0.01 | 0.21 | 0.82 | |
| Example 3 | 3 | 0.80 | 0.03 | 0.50 | 0.08 | 0.00 | 0.14 | 0.72 |
| 4 | 0.69 | 0.01 | 0.36 | 0.04 | 0.01 | 0.08 | 0.55 | |
| ()=(400, 2000, 0.5) | ||||||||
| 2 | 1.00 | 0.27 | 0.75 | 0.72 | 0.62 | 0.69 | 0.69 | |
| Example 3 | 3 | 1.00 | 0.21 | 0.78 | 0.71 | 0.55 | 0.68 | 0.68 |
| 4 | 0.99 | 0.20 | 0.82 | 0.68 | 0.47 | 0.65 | 0.65 | |
| ()=(400, 2000, 0) | ||||||||
| 2 | 0.90 | 0.04 | 0.47 | 0.11 | 0.00 | 0.14 | 0.70 | |
| Example 4 | 3 | 0.85 | 0.01 | 0.42 | 0.13 | 0.01 | 0.08 | 0.61 |
| 4 | 0.64 | 0.00 | 0.32 | 0.09 | 0.00 | 0.08 | 0.51 | |
| ()=(400, 2000, 0.5) | ||||||||
| 2 | 0.84 | 0.09 | 0.70 | 0.45 | 0.02 | 0.03 | 0.03 | |
| Example 4 | 3 | 0.77 | 0.07 | 0.65 | 0.46 | 0.03 | 0.04 | 0.03 |
| 4 | 0.72 | 0.03 | 0.56 | 0.42 | 0.04 | 0.04 | 0.04 | |
| Methods | SSI | BOLT-SSI | RAMP | xyz-L100 | xyz-L500 | hierNet-w | ||
|---|---|---|---|---|---|---|---|---|
| 2 | 1 | 0.95 | 0.00 | 1 | 1 | 1 | ||
| ACR | 3 | 1 | 0.95 | 0.00 | 1 | 1 | 1 | |
| 4 | 1 | 0.90 | 0.00 | 0.99 | 0.98 | 1 | ||
| 2 | 54.4(1.0) | 52.0(1.0) | 12.1(0.3) | 27.3(0.3) | 27.5(3.5) | 230.6(4.4) | ||
| Example 1 | AMS | 3 | 56.8(1.0) | 53.2(1.0) | 11.2(0.4) | 31.0(0.6) | 29.2(0.5) | 216.6(4.4) |
| 4 | 58.4(1.0) | 53.9(1.0) | 10.6(0.4) | 31.7(0.6) | 31.2(0.7) | 195.8(4.8) | ||
| 2 | 95.4(0.15) | 91.3(0.37) | 58.5(1.34) | 53.3(2.02) | 53.3(1.59) | 94.1(0.18) | ||
| 3 | 90.0(0.27) | 86.4(0.47) | 54.3(1.62) | 50.5(1.64) | 48.7(1.02) | 87.2(0.39) | ||
| 4 | 83.1(0.44) | 79.5(0.63) | 48.8(1.64) | 48.9(1.72) | 47.9(1.02) | 78.4(0.60) | ||
| 2 | 1 | 0.68 | 0.00 | 0.49 | 1 | 1 | ||
| ACR | 3 | 0.99 | 0.58 | 0.00 | 0.48 | 1 | 0.99 | |
| 4 | 0.97 | 0.47 | 0.00 | 0.30 | 0.99 | 0.81 | ||
| 2 | 60.7(1.1) | 52.1(1.5) | 15.5(0.2) | 27.7(0.3) | 34.6(0.4) | 301.3(3.9) | ||
| Example 2 | AMS | 3 | 65.9(1.1) | 54.7(1.5) | 14.7(0.3) | 31.1(0.4) | 39.0(0.4) | 262.8(5.4) |
| 4 | 68.2(1.1) | 55.6(1.5) | 13.7(0.3) | 35.3(0.4) | 40.4(0.4) | 167.7(7.3) | ||
| 2 | 92.4(0.24) | 81.6(0.86) | 77.2(1.14) | 85.4(0.48) | 72.9(1.06) | 89.2(0.31) | ||
| 3 | 84.5(0.35) | 74.2(0.82) | 71.0(1.20) | 83.6(0.42) | 64.8(1.33) | 76.1(0.77) | ||
| 4 | 74.6(0.51) | 63.5(1.04) | 63.2(1.34) | 79.5(0.50) | 58.9(1.12) | 58.6(1.08) | ||
| 2 | 1 | 0.84 | 0.00 | 1 | 1 | 1 | ||
| ACR | 3 | 1 | 0.82 | 0.00 | 1 | 1 | 1 | |
| 4 | 1 | 0.78 | 0.00 | 1 | 1 | 1 | ||
| 2 | 51.3(0.9) | 47.7(1.3) | 4.3(0.4) | 28.1(0.4) | 28.1(0.3) | 383.5(3.6) | ||
| Example 3 | AMS | 3 | 53.8(1.0) | 50.8(1.6) | 4.2(0.5) | 31.4(0.6) | 30.4(0.6) | 340.1(3.8) |
| 4 | 56.6(1.1) | 49.1(1.3) | 3.9(0.4) | 31.7(0.6) | 32.7(0.6) | 297.6(4.3) | ||
| 2 | 95.3(0.17) | 87.0(0.66) | 14.6(1.82) | 58.4(1.45) | 57.8(1.41) | 92.3(0.20) | ||
| 3 | 89.9(0.27) | 81.6(0.81) | 13.4(1.85) | 51.6(1.65) | 50.7(1.67) | 84.4(0.40) | ||
| 4 | 83.0(0.42) | 75.5(0.81) | 12.4(1.80) | 48.7(1.69) | 48.4(1.71) | 74.2(0.63) | ||
| 2 | 0.94 | 0.69 | 0.00 | 1 | 1 | 1 | ||
| ACR | 3 | 0.97 | 0.60 | 0.00 | 0.99 | 1 | 1 | |
| 4 | 0.95 | 0.61 | 0.00 | 0.97 | 1 | 0.98 | ||
| 2 | 54.7(0.9) | 49.1(1.4) | 10.2(0.4) | 31.7(0.4) | 31.1(0.3) | 332.8(3.6) | ||
| Example 4 | AMS | 3 | 58.3(1.0) | 50.5(1.2) | 9.6(0.4) | 35.9(0.5) | 35.2(0.4) | 292.1(3.7) |
| 4 | 61.6(1.2) | 52.1(1.5) | 8.7(0.4) | 36.9(0.4) | 37.0(0.5) | 240.6(5.8) | ||
| 2 | 93.4(0.24) | 84.0(0.72) | 51.9(1.52) | 63.6(1.15) | 63.5(1.41) | 90.8(0.24) | ||
| 3 | 86.6(0.37) | 77.2(0.80) | 47.7(1.65) | 58.3(1.12) | 60.0(1.31) | 80.5(0.51) | ||
| 4 | 78.2(0.52) | 70.0(0.96) | 41.9(1.62) | 54.8(1.09) | 55.2(1.37) | 67.1(0.85) |
| Methods | SSI | BOLT-SSI | RAMP | hierNet-w | ||
|---|---|---|---|---|---|---|
| 1 | 0.34 | 0.38 | 0.00 | 0.17 | ||
| ACR | 2 | 0.64 | 0.18 | 0.00 | 0.28 | |
| 3 | 0.74 | 0.26 | 0.00 | 0.30 | ||
| 1 | 63.1(3.8) | 56.9(3.1) | 6.7(0.4) | 36.9(3.3) | ||
| Example 5 | AMS | 2 | 69.2(3.4) | 15.7(1.8) | 0.7(0.2) | 83.6(7.4) |
| 3 | 61.3(3.7) | 15.8(1.3) | 0.2(0.1) | 103.8(9.2) | ||
| 1 | 28.2(0.54) | 25.5(0.46) | 26.8(0.62) | 25.7(0.47) | ||
| PMR | 2 | 24.6(0.44) | 27.1(0.49) | 28.6(0.45) | 38.5(0.52) | |
| 3 | 22.7(0.46) | 23.5(0.46) | 26.2(0.39) | 41.7(0.55) | ||
| 1 | 0.07 | 0.11 | 0.00 | 0.21 | ||
| ACR | 2 | 0.73 | 0.31 | 0.00 | 0.34 | |
| 3 | 0.88 | 0.34 | 0.00 | 0.28 | ||
| 1 | 39.0(3.0) | 41.9(2.1) | 3.9(0.2) | 53.4(3.2) | ||
| Example 6 | AMS | 2 | 74.7(3.5) | 49.0(2.6) | 4.3(0.4) | 82.3(4.9) |
| 3 | 76.2(3.1) | 35.1(2.5) | 2.3(0.3) | 82.3(7.1) | ||
| 1 | 24.3(0.51) | 23.1(0.45) | 26.8(0.62) | 21.0(0.48) | ||
| PMR | 2 | 24.7(0.48) | 25.1(0.54) | 31.1(0.76) | 29.0(0.47) | |
| 3 | 22.8(0.52) | 26.5(0.67) | 33.6(0.58) | 32.3(0.46) | ||
| 1 | 0.53 | 0.14 | 0.00 | 0.09 | ||
| ACR | 2 | 0.77 | 0.44 | 0.00 | 0.18 | |
| 3 | 0.85 | 0.46 | 0.00 | 0.13 | ||
| 1 | 58.9(3.0) | 41.8(1.6) | 3.4(0.1) | 93.7(6.2) | ||
| Example 7 | AMS | 2 | 69.8(2.5) | 46.1(1.9) | 1.8(0.1) | 94.1(7.9) |
| 3 | 76.7(3.3) | 37.8(1.8) | 1.1(0.1) | 65.6(8.0) | ||
| 1 | 18.2(0.37) | 18.4(0.39) | 25.3(0.44) | 20.8(0.37) | ||
| PMR | 2 | 19.6(0.45) | 19.0(0.47) | 27.4(0.51) | 24.3(0.54) | |
| 3 | 19.2(0.42) | 19.6(0.46) | 25.7(0.42) | 23.4(0.43) | ||
| 1 | 0.20 | 0.10 | 0.00 | 0.19 | ||
| ACR | 2 | 0.68 | 0.32 | 0.00 | 0.28 | |
| 3 | 0.81 | 0.42 | 0.00 | 0.14 | ||
| 1 | 47.5(2.8) | 44.7(2.3) | 3.4(0.1) | 80.8(5.1) | ||
| Example 8 | AMS | 2 | 70.1(2.7) | 41.1(2.2) | 2.5(0.1) | 94.7(5.1) |
| 3 | 76.3(3.4) | 31.4(1.9) | 1.5(0.2) | 62.9(6.0) | ||
| 1 | 20.6(0.43) | 20.5(0.47) | 26.2(0.45) | 20.3(0.42) | ||
| PMR | 2 | 21.6(0.51) | 22.3(0.49) | 30.0(0.55) | 25.1(0.44) | |
| 3 | 21.1(0.44) | 23.8(0.52) | 29.7(0.48) | 28.1(0.48) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsTheoretical and Computational Physics
BOLT-SSI: A Statistical Approach to Screening Interaction Effects for Ultra-High Dimensional Data
Min Zhou
BNU-HKBU United International College
Mingwei Dai
Southwestern University of Finance and Economics
Yuan Yao
Victoria University of Wellington
Jin Liu
Duke-NUS Medical School
Can Yang
The Hong Kong University of Science and Technology
and Heng Peng
Hong Kong Baptist University
Abstract
Detecting interaction effects among predictors on the response variable is a crucial step in various applications. In this paper, we first propose a simple method for sure screening interactions (SSI). Although its computation complexity is , SSI works well for problems of moderate dimensionality (e.g., ), without the heredity assumption. To ultra-high dimensional problems (e.g., ), motivated by discretization associated Boolean representation and operations and the contingency table for discrete variables, we propose a fast algorithm, named “BOLT-SSI”. The statistical theory has been established for SSI and BOLT-SSI, guaranteeing their sure screening property. The performance of SSI and BOLT-SSI are evaluated by comprehensive simulation and real case studies. Numerical results demonstrate that SSI and BOLT-SSI can often outperform their competitors in terms of computational efficiency and statistical accuracy. The proposed method can be applied for fully detecting interactions with more than 300,000 predictors. Based on this study, we believe that there is a great need to rethink the relationship between statistical accuracy and computational efficiency. We have shown that the computational performance of a statistical method can often be greatly improved by exploring the advantages of computational architecture with a tolerable loss of statistical accuracy.
Keywords: Trade-off between statistical efficiency and computational complexity, Discretization, Sure independent screening for interaction detection, Ultra-high dimensionality, Package “BOLTSSIRR”.
1 Introduction
The recent two decades are the golden age for the development of statistical science on high dimensional problems. A large number of innovative algorithms have been proposed to address the computational challenges in statistical inference for high dimensional problems. Despite a fruitful achievement in statistical science, there still exists a gap between the established statistical theory and computational performance of developed algorithms. On one hand, many statistical models can deal with the high dimensional problems under some theoretically mild conditions, but their computational cost can be too expensive to be affordable when dimensionality becomes extremely large. On the other hand, to address many real problems, many algorithms are not developed in a principled way, leading to computational results without statistical guarantees. As argued by Chandrasekaran & Jordan (2013), there is a great need to rethink the relationship between statistical accuracy and computational efficiency.
To bridge the gap, most statistical literatures focus on reducing the theoretical complexity of an algorithm, or simply using parallel computing to speed it up, without paying not enough attention to taking advantage of the computational architecture. In fact, the computational performance of statistical models can often be greatly improved by designing new data structures or using hardware acceleration (e.g., graphical processing units for training deep neural networks). In this paper, we use the interaction detection problem in high dimensional models as an example, to demonstrate that it is possible to design statistically guaranteed algorithms to overcome seemingly unaffordable computational cost by taking advantage of the computational architecture.
1.1 Related work for interaction effect detection
The word “interaction”, in Oxford English Dictionary, is illustrated as the reciprocal action, or influence of persons or things on each other. It is one kind of relationship among two or more objects, which have mutual influence upon one another. There is a long history of investigating the interaction effects in many different scientific fields. For example, in physical chemistry, the main topics are interactions between atoms and molecules. A simple example in the real-world is that neither of carbon and steel has much effect on the strength, but a combination of them has substantial effects. In medicine and pharmacology, the interaction effects of multiple drugs have been widely observed (Lees et al. (2004)). In genomics, gene-gene interactions and gene-environment interactions have been widely studied by bio-medical researchers since the seminal work of Bateson (1909). In recent years, increasing interest has been focusing on detecting gene-gene interactions from genome-wide association studies (GWAS) (Cordell (2009)).
In this paper, we investigate the interaction effects from a statistical perspective, where the interaction effect is characterized by the statistical departure from the additive effects of two or more factors (see Fisher (1918); Cox (1984)). In the framework of high dimensional regression, it is common to use products of explanatory variables to study interaction effects of explanatory variables on response variables. Consider three explanatory variables , and , their two-way interaction terms are , and . By including these interaction terms, the standard linear regression model becomes
[TABLE]
where is the response variable, is the intercept term, is the coefficient of main effect term , is the coefficient of interaction term , and is the independent error. For the high dimensional data, the number of variables can be much larger than the sample size . Clearly, the number of parameters to be determined would be if all two-way interaction terms are included. For example, in GWAS, there are millions of genotyped genetic variants, i.e., . The number of interaction terms goes up to an astronomical number at the order of . The computational cost of detecting interaction effects in such a scale becomes seemingly un-affordable, making the theoretical guarantees with mild conditions (e.g. sparsity assumptions) useless.
To reduce the computational cost, methods developed recently often make two types of heredity assumptions: the strong heredity assumption means that the interaction effect is important only if its both parent are significant, while the weak heredity assumption illustrates that the interaction term is important only if at least one of its parent is included in the model. To name a few, Choi et al. (2010) extended the LASSO method and identified the significant interaction terms in the linear model and generalized linear models under the strong heredity assumption. Choi et al. (2010) proved that their method possessed the oracle property (Fan & Li (2001) and Fan & Peng (2004)), that is, it performed well as if the true model was known in advance. The algorithm hierNet was developed by Bien et al. (2013) to select the interactions, which added a set of convex constraints to LASSO in the linear model and constructed the sparse interaction model with the strong or weak heredity assumptions. For the linear model, Hao & Zhang (2014) also proposed two algorithms iFORT and iFORM, and identified the interaction effects in a greedy fashion under the heredity assumption. Hao et al. (2018) further improved interaction detection by proposing a regularization algorithm under marginality principle (RAMP). To deviate from these heredity assumptions for interaction detection, Fan et al. (2016) suggested a flexible sure screening procedure, called the interaction pursuit (IP), in ultra-high dimensional linear interaction models, applying a strong assumption on the joint normality between the response and predictor variables. The idea of the IP method is to select the “active interaction variables” by screening significant predictor variables with the strong Pearson correlation between and firstly, and then detect the interaction effects among those identified active interaction variables. Kong et al. (2017) extended IP to the ultra-high dimensional linear interaction model with multiple responses by identifying the active interactive variables using the distance correlation with and the multiple response {\mbox{\boldmathY}}^{2}, where {\mbox{\boldmathY}}=(Y_{1},\ldots,Y_{q}) be a -dimensional vector of responses and {\mbox{\boldmathY}}^{2}=(Y_{1}^{2},\ldots,Y_{q}^{2}).
However, the heredity assumption may not be satisfied in practice due to the existence of pure interaction effects. In human genetics, a number of gene-gene interaction effects have been detected in the absence of their main effects (Cordell (2009) and Wan et al. (2010)). This motivates new methods to detect interactions without any heredity assumptions. Recently, a new algorithm based on random projection was introduced by Thanei et al. (2018) to screen interaction effects. This algorithm does not rely on the heredity assumption, thus it can detect interaction effects in the absence of the corresponding main effects. Based on our empirical observations, however, its performance in the real applications is not entirely satisfactory because its accuracy of detecting interaction effects largely depends on the number of random projections. Yet, computationally efficient algorithms with statistically guaranteed performance for interaction detection are still lacking.
1.2 Our Contribution
Our contribution is to develop a computationally efficient and statistically guaranteed method for interaction detection in high dimensional problems:
- a.
We propose a new sure screening procedure (SSI) based on the increment of log-likelihood function to fully detect significant interactions for the high dimensional generalized linear models. Furthermore, in order to reduce the computational burden, we take the advantages of computer architecture such as parallel techniques and Boolean operations to construct more computationally efficient algorithm BOLT-SSI, and make available the detection for interaction effects in a large-scale data set. For example, for the data set Northern Finland Birth Cohort (NFBC) with individuals and SNPs, the number of interactions is about . BOLT-SSI can quickly screen all these interactions with a short time. The details can be seen in section 6.
- b.
Moreover, we investigate the sure screening properties of SSI and BOLT-SSI from theoretical insights, and show that our computationally efficient methods are statistically guaranteed. We provide implementations of both the core SSI algorithm and its extension BOLT-SSI in the R package BOLT-SSI, available on the authors’ website (https://github.com/daviddaigithub/BOLTSSIRR).
- c.
More importantly, our work is a practical attempt to integrate the advantages of well-designed computer architecture and statistically rigorous methodology. We take it as an example to promote the application of computational structure in the statistical modeling and practice, especially in the era of “Big Data”. We hope this example motivates more combination of statistical methods and computational techniques, greatly improving the computational performance of statistical methods.
The rest of this paper is organized as follows. In Sections 2 and 3, we propose the sure screening algorithms SSI and BOLT-SSI for detecting interactions in ultra-high dimensional generalized linear regression model, where we briefly introduce the Boolean representation and operations. The theoretical properties of sure screening for the proposed methods are investigated in Section 4. In Section 5, we examine the finite sample performance of SSI and BOLT-SSI in comparison to alternative methods, RAMP, -algorithm, and IP, through simulation studies. In Section 6, three real data sets are used to demonstrate the utility of our approaches. Our findings and conclusions are summarized in Section 7. The details of the proof are given in the Appendix.
2 Sure Screening Methods for Interaction in GLM
2.1 Generalized linear models(GLM) with Two-way Interaction
Assume that given the predictor vector , the conditional distribution of the random variable belongs to an exponential family, whose probability density function has the canonical form
[TABLE]
where and are some known functions and \theta({\mbox{\boldmathx}}) is a canonical natural parameter. Here we ignore the dispersion parameter in (2), since we only concentrate on the estimation of mean regression function. It is well known that the distributions in the exponential family include the Binomial, Gaussian, Gamma, Inverse-Gaussian and Poisson distributions.
We consider the following generalized linear model with two-way interactions:
[TABLE]
for the canonical link function with
[TABLE]
where {\mbox{\boldmathX}}=({\mbox{\boldmathX}}_{\mathcal{C}}^{T},{\mbox{\boldmathX}}_{\mathcal{I}}^{T})^{T} with {\mbox{\boldmathX}}_{\mathcal{C}}=(X_{0},X_{1},X_{2},X_{3},\ldots,X_{p})^{T} and {\mbox{\boldmathX}}_{\mathcal{I}}=(X_{12},X_{13},\ldots,X_{(p-1)p})^{T}. For simplicity, we assume that and each of the other predictor variables is standardized with zero mean and unit variance. The corresponding sets of coefficient are
[TABLE]
where
In the ultra-high dimensional regression model, we usually assume that there is a sparse structure in the underlying model. It means that only a few of predictor variables or features are significantly correlated with response . Hence for the above model with two-way interactions, we assume there are only a small number of interactions contributing to the response . Denote that the true parameter {\mbox{\boldmath\beta}}^{\star}=({{\mbox{\boldmath\beta}}_{\mathcal{C}}^{\star}}^{T},{{\mbox{\boldmath\beta}}_{\mathcal{I}}^{\star}}^{T})^{T}, where {\mbox{\boldmath\beta}}_{\mathcal{C}}^{\star}=(\beta_{0}^{\star},\beta_{1}^{\star},\beta_{2}^{\star},\ldots,\beta_{p}^{\star})^{T}\in\mathbb{R}^{p+1} for main effects, and {\mbox{\boldmath\beta}}_{\mathcal{I}}^{\star}=(\beta_{12}^{\star},\beta_{13}^{\star},\ldots,\beta_{(p-1)p}^{\star})^{T}\in\mathbb{R}^{q} with for interactions.
Let
[TABLE]
and denote that , then the non-sparsity size is a relative small number compared to the dimension of the model.
2.2 SSI for two-way interaction in GLM
The model (3) can be simply rewritten as an ordinary generalized linear regression model form
[TABLE]
Fan et al. (2009) suggested to select the important variables by sorting the marginal likelihood, and Fan & Song (2010) pointed out that such technique can be considered as the marginal likelihood ratio screening, which builds on the difference between two marginal log-likelihood functions. If we regard the interaction variable the same as other main effects from predictor variables , by considering the marginal likelihood of , we could directly apply the sure screening techniques of Fan et al. (2009) and Fan & Song (2010) to detect the significant interaction effects. But such a direct screening method ignores the main effects of and , as argued by Jaccard et al. (1990), it often leads to false discoveries for the pure significant interaction effects. Hence we consider the following sure screening procedure to detect pure interaction effects in the model (3).
Denote that the random samples \{({\mbox{\boldmathX}}^{(k)},Y^{(k)},k=1,\ldots,n\} are i.i.d. from the model (3) with the canonical link. Let {\mbox{\boldmathX}}_{ij}=(1,X_{i},X_{j},X_{ij})^{T} and {\mbox{\boldmathX}}_{i,j}=(1,X_{i},X_{j})^{T}. And their coefficients are expressed as {\mbox{\boldmath\beta}}_{ij}=(\beta_{ij0},\beta_{i},\beta_{j},\beta_{ij})^{T} and {\mbox{\boldmath\beta}}_{i,j}=(\beta_{i,j0},\beta_{i,},\beta_{j,})^{T}, respectively.
The first step of the Sure Screening procedure to detect the Interaction effects (SSI) is to calculate the maximum marginal likelihood estimator \hat{{\mbox{\boldmath\beta}}}_{ij}^{M} by the minimizer of the marginal regression
[TABLE]
where and {\mathbb{P}}_{n}f({\mbox{\boldmathX}},Y)=n^{-1}\sum_{k=1}^{n}f({\mbox{\boldmathX}}^{(k)}_{i},Y^{(k)}_{i}) is the empirical measure. Similarly, we can calculate the maximum marginal likelihood estimator \hat{{\mbox{\boldmath\beta}}}_{i,j}^{M} without the interaction effect by the minimizer of the marginal regression
[TABLE]
Correspondingly, let the population version of the above minimizers of the marginal regressions be
[TABLE]
and
[TABLE]
In fact, the coefficient can measure the importance of the interaction terms from population insight. Though the real joint regression parameter would not be the same as the marginal regression coefficient , we could still expect that, under mild conditions, or the increment of the marginal log-likelihood function
[TABLE]
is large, if and only if is some large.
Hence the second step of the SSI procedure is to calculate the increment of the empirical maximum marginal likelihood function,
[TABLE]
and {\mbox{\boldmathL}}_{n}=(L_{12,n},\ldots,L_{(p-1)p,n})^{T}\in\mathbb{R}^{q} . Then measures the strength of the interaction in the marginal model from the empirical version. The larger , similar to , the more the interaction contributes to the response .
The final step of the SSI procedure is to sort the vector {\mbox{\boldmathL}}_{n} in a decreasing order and given threshold value , select the following interaction effect variables
[TABLE]
as the final candidates of the significant pure interaction effects.
Under regularized conditions and similar as the classical approach, it is not difficult to show that SSI has the so-called “sure screening properties”. So here we delegate those investigations of SSI properties to our supplement file. From practical insight, the proposed SSI procedure’s computational complexity is in the order of . When is of moderate size (), SSI can quickly screen all interaction terms. It can be further accelerated by parallel computing because all the interaction terms can be evaluated independently.
3 BOLT-SSI
Despite the simplicity of SSI, it can not be scaled up to handle the case that dimensionality is very large, e.g., . To such a scenario, as other methods, we could impose similar uncheckable heredity assumptions to shrink the screening space of SSI to detect the interaction effects. But for such an approach, some significant interaction effects could never be discovered. Hence, even though we could have enough large observational samples, the method’s efficiency could still be worst. The other approach is to use a rough but fast algorithm or calculation method to approximate and accelerate SSI’s speed to deal with ultra-high dimensional scenarios. Though from theoretical insight, it would not decrease the original SSI algorithm’s complexity and has to sacrifice SSI stability; such an approach would not lose much information about the data and miss essential discoveries. Especially, as the number of observations is large enough, such an approach’s statistical efficiency could be satisfied by the requirement of real applications as our experience. It is the other kind of trade-off between statistical efficiency and computational efficiency.
In this paper, utilizing the computer’s computational architecture, we follow the second approach and present a computationally efficient algorithm named “BOLT-SSI” to detect interactions in ultra-high dimensional problems. The BOLT-SSI algorithm is motivated by the following fact: when , and all are discrete variables, the interaction effects of and on measured by logistic regression can be exactly calculated based on a few numbers in the contingency table of , and . These numbers can be efficiently obtained by designing a new data structure and its associated operations, i.e., Boolean representation and Boolean operations. To handle continuous variables, we propose discretization first and then use the above strategy for screening. This section describes the details of BOLT-SSI algorithm and establishes statistical theory to guarantee its performance in the next section.
3.1 Equivalence between the logistic models and log-linear models
When all predictors and the response are categorical variables, we usually take the logistic model (for binary response) or baseline-category logit models (for the response with several categories) to fit the data set. Actually, the logistic regression models or baseline-category logit models have their corresponding log-linear regression models for the contingency table when the predictor and the response are categorical (See Agresti & Kateri (2011), Chapter 9 Section 9.5). Based on this equivalence, the significance of interaction effects can be measured by the increment of the corresponding log-linear regression models.
Assume that we consider the following two logistic models with main effects and full model, respectively:
[TABLE]
and
[TABLE]
Denote that and be the sample version of the negative maximum log-likelihood for the logistic regression models with main effects (5) and full model (6), respectively. The increment of the log-likelihood function is defined as . The corresponding log-linear regression models can be expressed as
[TABLE]
and
[TABLE]
Let and be the sample version of the negative maximum log-likelihood for the homogeneous association regression model (7) and the saturated model (8), respectively. is the corresponding increment of log-likelihood function. Thus, we can take advantage of to screen the interaction terms instead of using .
Now we want to obtain the difference . Suppose that we have one three-way () table with cell counts of random variables , and . The kernel of the log-likelihood function for this contingency table is
[TABLE]
Denote that is the marginal probability of and is the number of samples with , is the marginal probability of and and is the corresponding count. Similarly, , , , , , , , .
For the saturated model (8), we know that and directly get the estimation . For the homogeneous association regression model (7), the iterative proportional fitting (IPF) algorithm Deming & Stephan (1940) is used to calculate the estimate of efficiently. Three steps are included in the first cycle of the IPF algorithm:
[TABLE]
where , , , . This cycle does not stop until the process converges and the convergence property has been proved by Fienberg et al. (1970) and Haberman (1974). We count the number by using the Boolean representation, thus the contingency table for and given can be quickly constructed in a fast manner. In this way, the estimation will be obtained.
Consequently, we can take advantage of this equivalence to efficiently estimate the corresponding increment of log-likelihood function by the IPF algorithm when the predictors and the response are qualitative. If some variables are continuous, we can discretize them and the details can be seen in the next section. In section 4, we show that our algorithm is still statistically guaranteed after discretization.
3.2 Discretization
In the case that some of the predictors and/or response are continuous, we suggest discretizing them simply binned by equal width or frequency. Considering the variation of random observations, it would be more reasonable to use the equal-frequency method by quantiles to split the domain of variables to several intervals. The number of intervals is called “arity” in the discretization context (See Liu et al. (2002)). Assume that the arity is denoted by , and then is the maximum number of cut-points of the continuous features.
For more detail, we follow the assumption of Fan & Song (2010), and consider variable or feature selection of the generalized linear model:
[TABLE]
where {\mbox{\boldmathX}}=(X_{1},\ X_{2},\ \ldots,\ X_{p})^{T} is a random vector, {\mbox{\boldmath\beta}}=\{\beta_{1},\ \beta_{2},\ \ldots,\ \beta_{p}\} is the parameter vector, is the response, is the canonical link function, and assume that
[TABLE]
is the set of indexes of nonzero parameter. Define the marginal log-likelihood increment
[TABLE]
where , {\mbox{\boldmathX}}_{k}^{T}=\{1,X_{k}\}, {\mbox{\boldmath\beta}}_{k}^{M}=\{\beta_{k,0},\beta_{k}^{M}\}^{T} and
[TABLE]
Furthermore, and , . Let and , be the independent copies of .
Assume that and are the support sets of variables and , respectively. Denote that and are partitions of their supports, which means that
[TABLE]
and
[TABLE]
where and are two positive constants. Here, the quantiles and quantiles are considered as the break points for the partitions of variables and . Define
[TABLE]
and then variables and are discretized to two categorical variables and , respectively. Furthermore, denote that , and , , where is the indicator function. After discretization, we have the new increment of log-likelihood function as
[TABLE]
Now consider the discretization for the marginal model with the interaction effect. Assume that , and are the support sets of variables , and , respectively. Denote that , and are partitions of their supports, which means that
[TABLE]
[TABLE]
and
[TABLE]
where , and are positive constants. Here, we still consider the quantiles, quantiles and quantiles as the break points for the partitions of variables , and , respectively. Define
[TABLE]
Furthermore, denote that
[TABLE]
And also, we define the discretized response ,
[TABLE]
Hence, we have the new categorical predictor , and response , respectively. And also, we get the new interaction variable . Furthermore, denote that
[TABLE]
and , , where is the indicator function. After discretization, the new increment of log-likelihood function in population version is defined as
[TABLE]
Remark 3.1
Actually, there is a trade-off between the arity and the accuracy of screening procedures. Higher arity would lead to a more accurate sure screening. However, when the sample size of data is large enough, the relatively small arity could also guarantee the accuracy of the screening procedure from our theoretical investigation and numerical studies. Hence though large for different continuous features can be also used. we recommend using to make a trade-off between the computation burden and efficiency of model estimation for our proposed BOLT-SSI when the sample size of the data is relatively large.
Furthermore, if is a continuous response, similarly we also suggest to use 2-quantile (median) to split the response , that is, and
[TABLE]
where is the median of the response .
3.3 Boolean Representation and Logical Operations
After discretization, the Boolean operation can be used to speed up the SSI procedure, especially the algorithm to calculate . The Boolean Representation and its operations is a classical and fundamental computer computing technique. A standard floating computation that provides a basic operation for many statistical software is composed of hundreds of Boolean operations under a lower level of the computer computing. Hence if the Boolean operation can be directly applied to realize the proposed algorithm, the computational speed could be much improved.
Assume that the continuous data set is one matrix with observations and predictors, be the response. After discretizing data set and response , each predictor has levels and has categories. Here, we take and as an example. Assuming that has two values (0 and 1), then instead of using one row for each predictor , the new representation uses 3 rows since 3 levels are included in each . Each row consists of two-bit strings, one for samples with and the other for them with , and each bit can represent one sample in the string. The values (0 and 1) illustrate whether the sample belongs to such a categorical level for each predictor . For instance, we have one discretized data set \widetilde{{\mbox{\boldmathX}}} with 2 predictors and 16 samples, where the first 8 columns represent samples with and the others represent samples with :
[TABLE]
and its Boolean representation is
[TABLE]
From the Boolean representation \widetilde{{\mbox{\boldmathX}}}_{bit}, we can easily find that the first sample belongs to the first category of and the third category of . Further, we can quickly obtain the number of observations that belong to any two categories by taking the logic operation. For example, if we want to calculate the number of samples with and in the category , we just conduct the logical AND operation:
[TABLE]
and then, we count the number of 1s in the final string “00000100”, that is 1. As a result, it is more efficient by using \widetilde{{\mbox{\boldmathX}}}_{bit} to construct the contingency table for any two discretized predictors. Since the fast logic operation with \widetilde{{\mbox{\boldmathX}}}_{bit} is utilized, we can accelerate our computation for our algorithm.
Obviously, \widetilde{{\mbox{\boldmathX}}} and \widetilde{{\mbox{\boldmathX}}}_{bit} are equivalent and they store the same amount of information. Because one byte is composed of 8 bits, \widetilde{{\mbox{\boldmathX}}}_{bit} uses 128 bits to save the data, but \widetilde{{\mbox{\boldmathX}}} would use bits, 16 times of the space of \widetilde{{\mbox{\boldmathX}}}_{bit}, to save the same data if our computer is a 64-bit computer system. As a result, the Boolean representation could dramatically reduce the storage space of the data. So all of the large data could be directly uploaded into the RAM, or even be saved in the cache. The transferring amount of time for the data between hard disk and RAM, and between RAM and cache can be largely reduced. This is the other advantage of the Boolean representation or the discretization.
3.4 New algorithm “BOLT-SSI”
Now, we illustrate our algorithm BOLT-SSI in details. For our ultra-high dimensional generalized linear model (3), instead of calculating the increment for any pair of and , we compute the new increment of the log-likelihood function by the IPF method. Then, by taking the thresholding value or choosing the large or , the selected sure screening set is obtained. Our algorithm BOLT-SSI is summarized as follows:
For any pair of the continuous variables and , , transform them to the corresponding discretized variables with level and with level , and change the response to a categorical variable if necessary.
Directly calculate and use the IPF algorithm to approximately estimate , and then compute for all pairs of and .
Choose the threshold and select the following interactions:
[TABLE]
Usually, we select the largest , where .
Sometimes, the dimension is very large and can be in the order of tens of millions. The IPF method may be time-consuming for computing all . Here, we propose to use an approximation tool to prune interaction terms in the second step. For the homogeneous association regression model (7), Kirkwood Superposition Approximation (KSA), which was firstly proposed by Kirkwood (1935), is utilized to provide an estimator for in (7). That is,
[TABLE]
where is a normalization term, . And then, we get the approximation for . Wan et al. (2010) shows that is an upper bound of , i.e.,
[TABLE]
Based on this boundary and by setting up one threshold , in the second step, we can filter out many insignificant interaction terms quickly and then reduce the size of a pool of all interaction effects. The value can be defined by the conservative Bonferroni correction or specified by user. Obviously, if , no interaction term is deleted in this step. In the final step, for the remaining interaction terms, we compute their by the IPF algorithm. Then select the largest , where or , or take the thresholding value to obtain the sure screening set . The term can be taken as the Bonferroni correction % percentile decided by the test with degree freedom for any one interaction between and .
In summary, our algorithm BOLT-SSI with KSA is summarized as follows:
For any pairs of continuous variables and , , transform them to corresponding discretized variables with level and with level , and change the response to a categorical variable if necessary.
By using the KSA to approximate of the IPF algorithm for all pairs of and , we compute and set up the threshold to remove a part of interaction terms.
For the remaining interaction effects, we compute and further identify the important interaction effects by -test with degree freedom , or directly select the largest .
So far, we have specified the procedures of our new algorithm “BOLT-SSI”. Apparently, the new method “BOLT-SSI” will be much faster than the original method “SSI”. Even though BOLT-SSI loses some statistical efficiency by discretizing predictor variables or response variable; its sure screening properties can still be guaranteed for moderate or large sample sizes. Moreover, compared to other screening methods, BOLT-SSI does not rely on hierarchy assumptions but screen significant two-way interactions for all pairs among the predictors.
4 Sure Screening Properties of BOLT-SSI
In this section, we derive the sure screening properties of BOLT-SSI by discussing SIS’s relationship and discretization SIS. The details of sure screening properties of SSI can be seen in section 1 of the Appendix. And also we demonstrate the efficiency loss by discretization in the last part of this section.
4.1 Properties of Discretization SIS
First, without considering interaction effects we investigate the connection between the marginal likelihood and the marginal likelihood after discrization of the predictor variables and response variables, i.e., the connection between SIS and Discretized SIS. As discussed in Section 3.1, after discretization we have such new increment of log-likelihood function
[TABLE]
with and .
We need some marginally symmetric conditions for further studies. Those conditions are used to investigate sure screening properties of a rank robust SIS procedure by Li et al. (2012).
(M1) Let (), () be the independent copies of ().Denote and , where . The conditional distribution of given is a symmetric finite mixture distribution, i.e., , where is symmetric unimodal probability distribution and is a symmetric probability distribution function and , are conditional variances related to , . Furthermore, there exists a given positive constant such that for any .
(M2) is a positive constant and is free of .
(M3) The predictors {\mbox{\boldmathX}}_{i}=(X_{i1},\ \ldots,\ X_{ip})^{T} and the error term are independent, .
Theorem 4.1
Under the marginally symmetric condition (M1)-(M3) and the condition of Theorem 3 in Fan and Song (2010), i.e., for ,
[TABLE]
*where is a positive constant and . After using 2-quantile and quantiles to discretize the response and the predictor , we have
(1) at least one such that*
[TABLE]
*for some positive constant .
(2) Furthermore,*
[TABLE]
for some positive constant and is the corresponding increments of the log-likelihood after discretization.
Theorem 4.1 ensures that if predictor variables in the original scale are associated with the response, they are also related to each other after discretization. Therefore, as our argument above, by combining Boolean representation, logical operation, and discretization it could provide us a super-fast way to screen the predictor variables in high dimensional generalized linear models without losing much efficiency. This stimulates us to apply discretization to the interaction pursuit. Based on the results above, we also get a similar connection between SSI and discretized SSI (BOLT-SSI) as the following.
4.2 Properties of BOLT-SSI
Similar to above, we need the following some marginally symmetric conditions to investigate the screening properties of BOLT-SSI.
Let \zeta_{ij}=Y-b^{\prime}({\mbox{\boldmathX}}_{i,j}^{T}{\mbox{\boldmath\beta}}_{i,j}^{M}), and , be the independent copies of . We further centralize and denote that
[TABLE]
(M1*′*) Denote and , then the conditional distribution of given is a symmetric finite mixture distribution, i.e., , where is symmetric unimodal probability distribution and is a symmetric probability distribution function and , are conditional variances related to , . Furthermore, there exists a constant such that for any .
(M2*′*) is a positive constant and is free of .
(M3*′*) The predictors {\mbox{\boldmathX}}=(X_{1},\ \ldots,\ X_{p})^{T} and the error term are independent.
Remark 4.1
In fact, the marginally symmetric condition (M1)’ is also easily satisfied. Denote that . A special case is that under the linear model, the conditional distribution of given does not depend on and it has modes, where is finite. It implies that the conditional distribution is the same as the distribution of . Suppose that , follow a distribution with modes, that is, , where and . Moreover, assume that , , are the distributions of the difference , where and are independent and follow the distributions and , respectively. Therefore, the distribution of can be expressed as
[TABLE]
Obviously, are symmetric unimodal distributions because of the unimodal distributions , and then is symmetric and unimodal. And is a symmetric and multimodal density function. Moreover,
Theorem 4.2
Under the marginally symmetric conditions (M1′)(M3′) and the condition: for with
[TABLE]
*where is a positive constant and . After using 2-quantile, quantiles and quantiles to discretize the response and the predictors , , we have
(1) at least one such that*
[TABLE]
*for some positive constant .
(2) Furthermore,*
[TABLE]
for some positive constant and is the corresponding increments of the log-likelihood after discretization.
Theorem 4.2 claims that important interaction terms are still significant after discretization. Consequently, similar to sure screening properties of SSI, we can also show that the sure screening properties of BOLT-SSI, i.e., it can detect significant interaction effects with large probability even when the dimension of the model is ultra-high.
4.3 Discussion of Efficiency Loss by Discretization
By Theorem 4.1 and Theorem 4.2, and following steps in both Theorem A.5 and A.6 in Appendix, the sure screening properties of Discretization SIS and BOLT-SIS can be guaranteed as the sample size tends to infinity. However, there is information loss by discretization, and the efficiency of the proposed screening procedure could be much reduced, especially when the arity or 3.
To simplify our analysis to obtain the intuition about such efficiency loss by discretization, we just compare the estimation efficiency of the Pearson correlation between the sample correlation estimate and the estimate by our discretization for the bivariate normal random vector
[TABLE]
To discretize and , we consider the worst disretization with the largest information loss, i.e. , and and . Then based on the proof of Theroem 4.1 in the Appendix, we have
[TABLE]
where , in fact, is the kendall rank correlation of the bivariate normal random vector . It is well known that for the bivariate normal population, and hence if we have the estimate of the kendall rank correlation, then the pearson correlation of the bivariate normal random vector can be estimated as
[TABLE]
Let be the sample Pearson correlation of and , which is the optimal estimate of the Pearson correlation . Hotelling (1953) has shown that the asymptotic property of under normal assumption should be,
[TABLE]
which implies that when and are independent.
Next let be the sample correlation of and . As discussion above, in fact it is an estimate of the kendall rank correlation . By the results of Esscher (1924) and Kendall (1949) under the normal assumption, and based on the asymptotic normaility of U-statistics (Lee (2019)), the asymptotic distribution of the estimate is
[TABLE]
Then with Delta method and by simple calculation, the asymptotic normality of should be
[TABLE]
that is, when .
Therefore, the relative efficiency of these two procedures is
[TABLE]
As shown by the Figure 1, such relative efficiency is bounded between at and at or . It means we do not need much more samples to get the same accurate estimate of as our discretized estimate compared to the sample Pearson correlation estimate which is the optimal estimate of in some sense.
Though the above discussion is based on the assumption that follows bivariate normal population, if follows other bivariate distribution, by monotonic transformation, we could transfer to one of bivariate normal random vectors. Usually, under general conditions, such a monotonic transformation would not change the Pearson correlation between and much under general conditions. Furthermore, the discretized estimate is invariant. Hence in some sense, as the sample size of data is relatively large, can be used to screen the relationship between and without losing much efficiency.
The above discussion is based on the worst discretization that the arity . In such worst case, it has been shown that the statistical efficiency loss is relatively small, but as shown by our numerical studies, the computational complexity is reduced dramatically. Hence the discretization approach is an appropriate way to balance the trade-off between statistical efficiency and computational complexity. The statistical efficiency loss by discretization can be tolerated as long as the sample size of the data is relatively large.
5 Numerical Studies
In this section, we investigate the performance of the proposed SSI and BOLT-SSI by numerical studies. The methods, hierNet (Bien et al. (2013)), IP (Fan et al. (2016)) RAMP (Hao et al. (2018)) and xyz (Thanei et al. (2018)) are employed in comparisons with respect to the performance on the estimation and prediction.
We consider the linear model (10)
[TABLE]
and logistic model (11)
[TABLE]
We generate the covariates with , where varies in , and then generate the response by the linear model (10) and logistic model (11). For all settings, the set of the important main effects is with the true coefficients For the linear model, the error term with for different signal-to-noise ratio (SNR) situations. For the logistic model, we change the values of the coefficients of interactions, and let significant interaction effect coefficient to obtain the different SNR. We consider different heredity structures including strong heredity, weak heredity and anti heredity by the following interaction effect settings for linear regression model or logistic model.
- •
Example 1 - Linear Model with Strong Heredity. The set of 10 important interaction effects is defined as
[TABLE]
with corresponding coefficients (2,2,2,2,2,2,2,2,2,2).
- •
Example 2 - Linear Model with Weak Heredity. The set of 10 important interaction effects is defined as
[TABLE]
with corresponding coefficients (2,2,2,2,2,2,2,2,2,2). Here, for every significant interact effect, only one of its main effects is significant.
- •
Example 3 - Linear Model with Anti Heredity. The set of 10 important interaction effects is
[TABLE]
with corresponding coefficients (2,2,2,2,2,2,2,2,2,2). Here, none of the main effects that have significant interaction effects is included in the linear model (10).
- •
Example 4 - Linear Model with Mixed Heredity. Suppose that the set of 10 important interaction effects is
[TABLE]
with corresponding coefficients (2,2,2,2,2,2,2,2,2,2). Here, the first three interactions satisfy the strong heredity, next three satisfy weak heredity assumption, and the last fourth significant interact effects do not have their corresponding main effects in the model.
- •
Example 5 - Logistic Model with Strong Heredity. Consider the set of 10 important interaction effects is
[TABLE]
- •
Example 6 - Logistic Model with Weak Heredity. Denote that the set of 10 important interaction effects is
[TABLE]
- •
Example 7 - Logistic Model with Anti Heredity. Assume that the set of 10 important interaction effects is
[TABLE]
- •
Example 8 - Logistic Model with Mixed Heredity. Suppose that the set of 10 important interaction effects is
[TABLE]
We investigate the screening performance and post-screening performance of those interaction effect screening and variable selection methods under different examples.
Let with cardinality denote the significant interaction effects in the model, i.e., . For each scenario, we run Monte-Carlo simulations for each method. For the -th simulation, denote that the estimated interaction subsets as . We evaluate the performance on variable selection and model prediction based on the following criteria:
- •
The average coverage rate (ACR): the percentage of all true interactions included in the selected models.
- •
Average model size (AMS): , where is the model size of interaction effect predictors selected by the screening methods or post-model selection method in the -th simulation.
- •
The average out-of-sample for linear regression model:
[TABLE]
where ({\mbox{\boldmathX}}_{i}^{*},Y_{i}^{*}) is the testing data and \hat{{\mbox{\boldmath\beta}}} is the estimate of the coefficient based on the training data.
- •
Predictive misclassification rate (PMR) for logistic model:
[TABLE]
where is the true value of the testing data and is the predictive value of testing data based on the training model.
5.1 Screening Performance
For the screening procedures, we consider SSI, BOLT-SSI, and the employed methods, IP and xyz for the linear model and logistic model. For the method xyz, we choose top 500 interaction terms screened by it (Actually, 500 is the largest number of interactions that the package “xyz” can be selected by screening), and let the projection time of “xyz” be respectively. For the method IP, we choose the top screened interaction effect predictor variables as the active set. For our method SSI, similarly the top interaction effect terms are selected into the active set. For BOLT-SSI, we consider two cases: keeping the top , or the top significant interaction predictors as the screening selected active set. Since the methods IP and xyz are not available for the logistic model, we only investigate the screening properties of SSI and BOLT-SSI for Example 5-8.
From the results shown by Tables 1-2, the coverage rate will decrease when the signal-noise ratio is relatively small. The proposed SSI has a high coverage percentage in screening interaction effects for different heredity structures. For the methods xyz and IP, they have a lower converge percentage except for the strong heredity setting compared to SSI. For the proposed BOLT-SSI, though its performance is not better than SSI, its coverage rate is better than the other two methods when the top significant interaction effects are considered as the screening active set. By discretization, the data would lose some information, and hence BOLT-SSI would not be as efficient as SSI even though its speed is much faster than SSI. Hence it would increase much probability to keep the true active interaction effect predictors in the screened model by keeping the top significant interaction effect predictors in the active set after screening. All in all, the screening performances of SSI and BOLT-SSI() are more stable than the performance of other methods.
5.2 Post-Screening Performance
In this subsection, we compare the final model selection and prediction of existing methods (RAMP, xyz, hierNet) with the Lasso after screening by our proposed SSI and BOLT-SSI. For the method RAMP, the tuning parameter is selected by using EBIC with since the EBIC tends to work the best among most of the settings as shown by Hao et al. (2018). For the method xyz, we consider the projection time as 100, 500 and use 5-fold cross-validation (CV) to select the tuning parameter for the post-screening selection. For our methods SSI and BOLT-SSI, we use 5-folds CV and LASSO to further refine the model selection after screening. All of the simulation settings are the same as the Example 1-8 above. Especially, We set for all the studies. To compare the prediction, for every simulation, we let of the data set as the training data and the remaining data is considered as the testing data. Note that firstly we let be relatively small so that it is possible to compare the performance of hierNet(Bien et al. (2013)) in Tables 1-2 of Appendix, where “w” stands for weak heredity.
Note that the computation time for hierNet-s is very large for a single replicate. As a result, we omit the comparisons with hierNet for the other higher dimensional examples. In the high dimensional settings, we consider =(500,5000),(1000,5000),(1500,5000),
(2000,5000),(1500,10000),(1500,20000) and compare the performance of BOLT-SSI, RAMP, and xyz. Other methods are very time-consuming, and are not considered in this setting. Especially, we set for linear models, and for logistic models. All results of different methods with are summarized in Table 3. It is shown that our method still has a good performance in the high dimensional feature space. Furthermore, we also take Examples 5 and 8 to illustrate the patterns of our method. The results are shown in Figures 2-5. Obviously, as sample size increases, the performances of all methods become better, as shown in Figure 2 and Figure 4, and our method has the best performance. In Figures 3 and 5, though the performance of our method degrades as the dimension increases, its performance is still much better than others. The method RAMP is influenced by the heredity assumption, especially if the anti-heredity exists, the result of RAMP is worst.
5.3 Efficiency comparison
Here, we use Example 1 and Example 5 to study the efficiency of all the above methods. The machine we used equips Intel (R) Xenon(R) CPU E5-1603 v4 @ 2.80GHZ with 8.00 GB RAM. We compare the average computation time of variable selection among the following methods: SSI, BOLT-SSI, xyz, RAMP-s, RAMP-w, hierNet-s, hierNet-w, based on the 50 simulated data sets by the screening procedure and post-screening procedure, where “w” and “s” stand for weak heredity and strong heredity respectively. To make fair comparisons, we do not consider the selection of tuning parameters in modeling. Figures 6-7 and Table 4 summarize the average computation time (seconds per run) for each procedure. Since the differences of computation time are relative small for various and , we only present the results when , and . It is clear that the method hierNet spends much time on the computation no matter under the strong or weak heredity assumption and the method RAMP with weak heredity is also very slow. BOLT-SSI is consistently fast and its screening the algorithm does not rely on the heredity assumption of the data structure.
In summary, compared to the other methods, our proposed SSI and BOLT-SSI() have a stably high coverage rate in terms of the screening performance. When the dimension of data is not too large, by fine coding, SSI can also finish the screening task in a limited time. After discretization, some data information would be lost, and hence BOLT-SSI can not use all of the information for screening, and hence it is not as efficient as SSI. However, it is much faster than SSI and most of the other screening methods, and can finish screening for huge dimensional data in a relatively small time period. In fact, from our numerical studies, it is shown that BOLT-SSI makes a good trade-off between the computation complexity and the efficiency of screening. Consequently, SSI and BOLT-SSI have absolute competitiveness compared to other interaction screening and variable selection methods.
6 Real Data
6.1 Residential Building Data
The residential building dataset is available at https://archive.ics.uci.edu/ml/datasets/Residential+Building+Data+Set, which contains 8 project physical and financial variables, 19 economic variables and indices in 5-time lag numbers, and two output variables that are construction costs and sale prices. Totally, there are 103 predictors and 372 observations. The total number of interaction terms is . The data set was collected from Tehran, Iran between 1993 and 2008, which is a city with a metro population of around 8.2 million and much building construction activity. Usually, predicting the price of housing is of paramount importance for economic forecasting in any country. Therefore, our purpose is to use this data set to predict the sale prices. For convenience, the response and all predictors are standardized to have a unit variance before the analysis.
For the method “LASSO”, we only consider the main effects. For the method “xyz”, three different projection times are studied in this data set. Five-fold cross-validation is used to tune parameter in the method “xyz”, “SSI” and “BOLT-SSI”. The methods “RAMP-s” and “RAMP-w” represent the model with strong heredity and weak heredity assumption, respectively. The rule “EBIC” is used to select the final model in the method “RAMP”. For all methods, we randomly select 300 observations as the training set, and use the remaining 72 samples to form the testing data to compute the out-of-sample for the final model. The experiment is repeated 100 times. Time(s) is the average computation time of 100 experiments including variable selection and prediction. The machine still equips Intel (R) Xenon(R) CPU E5-1603 v4 @ 2.80GHZ with 8.00 GB RAM. The results are listed in the Table 5.
Since the variable “the price of the unit at the beginning of the project” has a high correlation with the response “sales prices”, that is 0.9764 based on the data set, we find that some methods only select several variables and the out-of-sample are very high from the results of Table 5. Our method BOLT-SSI can easily detect the significant main effect and interaction terms and improve the prediction effect, although the predict performance is a little worse compared with RAMP. It is reasonable because RAMP is based on the regularization method, which uses all of the correlation between predictors, not as the screening methods, which only consider marginal information between the response variable and predict variables. In this sense, our SSI or BOLT-SSI sacrifice some data information to balance the computation complexity. Because of a relatively small dimension of the data, though our methods are still beneficial and efficient for identifying the important interaction terms in this particular dataset for the prediction, the advantage of such trade-off is not apparent. However, compared to xyz and LASSO, our methods are more stable, and the sacrifice of the statistical efficiency is much small.
6.2 Supermarket Data
The supermarket data was collected from a major supermarket located in northern China and has been analyzed by Wang (2009) and Hao et al. (2018), which includes 6,398 predictors and 464 observations. The response is the number of customers on a particular day, and each predictor is the corresponding sale volume of the product. The supermarket manager wonders which products would be more associated with the number of customers, which means that he or she wants to select the most informative products to predict the response. Note that here, the total number of interaction terms for the supermarket data in modeling is about , much larger than the number of interaction effects to model the Residential Building Data.
Here, we randomly select 400 observations as the training data and the remaining 64 observations as the testing data and then use the out-of-sample to evaluate the prediction performance of our methods based on 100 random splits. And the settings of all methods are the same as that of the above example. The average performance is summarized in Table 6, which includes the average sizes of main effects and interaction effects, the average out-of-sample and their standard errors over 100 experiments. Besides the results of our methods, Table 6 displays the out-of-sample by other methods, including RAMP-AIC, RAMP-BIC, RAMP-EBIC, RAMP-GIC, iFORT & iFORM, and RAMP. The corresponding results are extracted directly from their papers. For the results of LASSO-AIC, LASSO-BIC, LASSO-EBIC, LASSO-GIC, we extract them from the paper of Hao et al. (2018) (RAMP). For LASSO-AIC-m, LASSO-BIC-m, we only consider the main effects.
From the results in Table 6, the BOLT-SSI demonstrates the best performance, with the mean out-of-sample . Although the products selected by BOLT-SSI are a few more, and it is a challenging task for the supermarket manager to interpret them, more products can improve the whole supermarket’s profit. Therefore, our method is helpful for the supermarket manager to make a decision.
To fairly assess the efficiency of the methods “BOLT-SSI”, “SSI”, “xyz” and “RAMP” on this real data set, we still use the machine that equips Intel (R) Xenon(R) CPU E5-1603 v4 @ 2.80GHZ with 8.00 GB RAM. Time(s) is the average computation time of 5 experiments, including variable selection and prediction. The results are listed in Table 7.
Here, the result “NULL” means that the error exists. When we only run one time by “RAMP” with weak heredity assumption in the above machine, the following error will appear, that is, “can not allocate vector of size 1.1 Gb”, which implies that the method “RAMP” may not be widely used on some ordinary computers when the dimension of the data set is huge. From the above two tables, at the first step of our screening methods, we only use marginal information of the data or even sacrifice some information for the method BOLT-SSI. However, the advantages of computational efficiency are much evident, and especially for BOLT-SSI, the sacrifice of the data information can be ignored, which is consistent with our theoretical investigation.
6.3 Northern Finland Birth Cohort (NFBC) Data
To obtain further insights into the newly developed framework, we apply it to analyze a real GWAS data set from Finland. The Finland data (NFBC1966) contains 10 quantitative traits, including body mass index (BMI), C-reactive protein (CRP), glucose, insulin, high-density lipoprotein (HDL), low-density lipoprotein (LDL), triglycerides (TG), total cholesterol (TC), systolic blood pressure (SysBP), and diastolic blood pressure (DiaBP). And also, it consists of 5,123 individuals with multiple metabolic traits measured and 319,147 SNPs. We consider BMI as the response, other 9 phenotypes and all SNPs as the predictors.Hence, totally, the sample size is =5,123, and the dimension of predictors is . The total number of interaction terms is about .
Here, we just study the screening performance of our methods. From the BOLT-SSI, we obtain the top of all the interactions and list the top ten interactions as follows (Table 8):
Base on the Bonferroni correction, , and the critical value are and . We can find that the first 4 interactions are significant.
For the Method “xyz”, we randomly choose and times of projections and remain 500 significant interactions. There are only 4 same terms between the BOLTSSI’s results and xyz(L500)’s results, that is, (Table 9),
The xyz(L1000)’s result has the 5 same terms as the result of our method, that is, (Table 10),
Furthermore, the xyz(L500) and xyz(L1000) have 32 same interactions. Based on the screening results of the method “xyz”, the interaction terms screened by the method “xyz”, cannot pass the Bonferroni’s threshold.
From the efficiency, the screening times of the method “xyz” are 0.54 hours (L500) and 0.96 hours (L1000) in the server, respectively; and it takes 5.59 hours to screen the interaction terms by our method when the thread number is 30 in the server.
All in all, the performance of our method is much better than that of the method “xyz” on this data set, although the screening time of “xyz” is less than that of “BOLT-SSI”.
7 Conclusion and Discussion
In this paper, we study the screening method to detect important significant interaction effects in the generalized high dimensional linear model. A new and straightforward procedure SSI and its extension BOLT-SSI are proposed. Different from most of the other screening or variable selection methods for the interaction effects detecting, our proposed methods do not depend on the heredity assumption. The proposed screening methods conduct a full screening search for all of the interaction effects among the data. For ultra-high dimensional data, in some sense, such a task seems to be impossible to be completed. Here we show that, by taking advantage of computational structure, seemly impossible tasks can be done using a standard personal computer. Importantly, the statistical property of the proposed way is guaranteed by our established theory.
Generally speaking, most of the data analysis projects are similar to engineer projects. Though most of the theoretical research would be beneficial to projects, the requirement and expectation of the engineering projects are different from those of theoretical studies. How to combine the advantages of engineering techniques to complete those projects under the requirement and expectation of practice needs further investigation. Our study here attempts to pursuit such a direction by a small step.
8 Appendix
8.1 Properties of SSI
Denote that {\mbox{\boldmath\beta}}_{ij}=(\beta_{ij0},\beta_{i},\beta_{j},\beta_{ij})^{T} be the four-dimensional parameter, and let {\mbox{\boldmathX}}_{ij}=(1,X_{i},X_{j},X_{ij})^{T}. Since the log-likelihood function is of the concavity in the generalized linear model with the canonical link function, the function \mbox{E}l({\mbox{\boldmathX}}_{ij}^{T}{\mbox{\boldmath\beta}}_{ij},Y) can arrive at its unique minimum \mbox{E}l({\mbox{\boldmathX}}_{ij}^{T}{\mbox{\boldmath\beta}}_{ij}^{M},Y) over {\mbox{\boldmath\beta}}_{ij}\in\mathcal{B}, in which {\mbox{\boldmath\beta}}_{ij}^{M}=(\beta_{ij0}^{M},\beta_{i}^{M},\beta_{j}^{M},\beta_{ij}^{M})^{T} is an interior point of the set and is an area with the large width where the marginal likelihood is maximized. The following conditions are needed: (A) The marginal Fisher information: {\mbox{\boldmathI}}_{ij}({\mbox{\boldmath\beta}}_{ij})=\mbox{E}\{b^{\prime\prime}({\mbox{\boldmathX}}_{ij}^{T}{\mbox{\boldmath\beta}}_{ij}){\mbox{\boldmathX}}_{ij}{\mbox{\boldmathX}}_{ij}^{T}\} is finite and positive definite at {\mbox{\boldmath\beta}}_{ij}={\mbox{\boldmath\beta}}_{ij}^{M}, for Moreover, \|{\mbox{\boldmathI}}_{ij}({\mbox{\boldmath\beta}}_{ij})\|_{\mathcal{B}}=\sup\limits_{{\mbox{\boldmath\beta}}_{ij}\in\mathcal{B},\|{\mbox{\boldmathx}}\|=1}\|{\mbox{\boldmathI}}_{ij}({\mbox{\boldmath\beta}}_{ij})^{1/2}{\mbox{\boldmathx}}\| is bounded.
(B) (i) Let {\mbox{\boldmathX}}_{i,j}=(1,X_{i},X_{j})^{T}. As the definition of the conditional linear expectation, provided by Barut et al. (2016), is the best linearly fitted regression within the class of linear functions, we denote that
[TABLE]
and
[TABLE]
For , there exists a constant such that |\text{Cov}_{L}(Y,X_{ij}|{\mbox{\boldmathX}}_{i,j}^{T}{\mbox{\boldmath\beta}}_{i,j}^{M})|\geq c_{1}n^{-\kappa} for some .
(ii) Denote
[TABLE]
and for some constant , in which .
(C) For all {\mbox{\boldmath\beta}}_{ij}\in\mathcal{B}, \mbox{E}(l({\mbox{\boldmathX}}_{ij}^{T}{\mbox{\boldmath\beta}}_{ij},Y)-l({\mbox{\boldmathX}}_{ij}^{T}{\mbox{\boldmath\beta}}_{ij}^{M},Y))\geq V\|{\mbox{\boldmath\beta}}_{ij}-{\mbox{\boldmath\beta}}_{ij}^{M}\|^{2}, for some constant , for all .
(D) There exist constants , , , and , such that for sufficiently large ,
[TABLE]
and that
[TABLE]
(E) For the function , the second derivative is continuous and . There exists such that for all ,
[TABLE]
where is the indicator function and is an arbitrarily large constant such that for a given in , the function l({\mbox{\boldmathx}}^{T}{\mbox{\boldmath\beta}},y) satisfies the Lipschitz property with positive constant for all ({\mbox{\boldmathx}},y) in the set \Omega_{n}=\{({\mbox{\boldmathx}},y):\|{\mbox{\boldmathx}}\|_{\infty}\leq K_{n},|y|\leq K_{n}^{\star}\} with , where is the supremum norm.
(F) The variance \text{Var}({\mbox{\boldmathX}}^{T}{\mbox{\boldmath\beta}}^{\star})={\mbox{\boldmath\beta}}^{\star T}\mbox{\boldmath\Sigma}{\mbox{\boldmath\beta}}^{\star} and are bounded, where \mbox{\boldmath\Sigma}=\text{diag}(0,\mbox{\boldmath\Sigma}_{1}) with \mbox{\boldmath\Sigma}_{1}=\text{Var}({\mbox{\boldmathX}}).
(G) The minimum eigenvalue of the matrix \mbox{E}[m_{ij}{\mbox{\boldmathX}}_{ij}{\mbox{\boldmathX}}_{ij}^{T}] is larger than a positive constant for any , where is defined in Condition B(ii).
(H) Denote that {\mbox{\boldmath\beta}}_{ij-}^{M}=(\beta_{i,j0}^{M},0,\ldots,0,\beta_{i,}^{M},0,\ldots,0,\beta_{j,}^{M},0,\ldots,0)^{T}, \Delta{\mbox{\boldmath\beta}}_{ij}={\mbox{\boldmath\beta}}_{\mathcal{C}}^{\star}-{\mbox{\boldmath\beta}}_{ij-}^{M}. Let R_{ij}=\mbox{E}[X_{ij}{\mbox{\boldmathX}}_{\mathcal{C}}^{T}\Delta{\mbox{\boldmath\beta}}_{ij}] and {\mbox{\boldmathR}}=(R_{12},R_{13},\ldots,R_{(p-1)p})^{T}, then \|{\mbox{\boldmathR}}\|_{2}^{2}=o(\lambda_{\mbox{max}}(\mbox{\boldmath\Sigma}_{\mathcal{I}})), where \lambda_{\mbox{max}}(\mbox{\boldmath\Sigma}_{\mathcal{I}}) is the largest eigenvalue of the matrix \mbox{\boldmath\Sigma}_{\mathcal{I}}.
All conditions are similar to the ones proposed by Fan & Song (2010) and Barut et al. (2016), and are satisfied by most of the generalized linear models such as linear regression and logistic regression. By the strict convexity property of , is almost surely larger than 0. If , then and Condition B(ii) is automatically satisfied by the uniform bounded property of since and are normalized. The first part of Condition (D) builds an exponential bound on the tails of . Actually, since the event is a subset of the union of and , when and , we have that
[TABLE]
Then, we can take and by , the exponential bound on the tails is simultaneously available for main effect and interaction terms. Hence, the first part of Condition (D) also implies an exponential bound for the tails of . The second part of Condition (D) also guarantees that the response variable possesses the exponentially light tail, as shown by Lemma 1 of Fan & Song (2010).
To detect the important interactions in our model, one critical question would be: at what level the interactions of variables should be preserved by the screening procedure? If one interaction is jointly important i.e. , will it still be marginally important, i.e. ? On the other hand, when one interaction is jointly unimportant i.e., , will it still be marginally unimportant, i.e. ? The following theorems are trying to give the answers to these questions.
Theorem A.1 For , the marginal likelihood increment if and only if
Theorem A.2 For , the marginal regression parameters if and only if \text{Cov}_{L}(Y,X_{ij}|{\mbox{\boldmathX}}_{i,j}^{T}{\mbox{\boldmath\beta}}_{i,j}^{M})=0.
Corollary A.1 łabelssico1 For , the marginal likelihood increment if and only if \text{Cov}_{L}(Y,X_{ij}|{\mbox{\boldmathX}}_{i,j}^{T}{\mbox{\boldmath\beta}}_{i,j}^{M})=0.
The above theorems and corollary reveal that both the increment of the log-likelihood and the marginal regression parameters are measurements of the relationship between the interaction and the mean response function. They are equivalent under mild conditions.
To distinguish the active interactions and inactive interactions , we need to set up one appropriate threshold value , so that the minimum marginal signal strength is stronger than the stochastic noise and the sure screening property will be guaranteed. Theorem A.3 and Theorem A.4 show that active interaction set and inactive interaction set can be separated by the marginal coefficient of or the increment of marginal likelihood functions.
Theorem A.3 If Condition (B) holds, then there exists a positive constant such that
[TABLE]
Theorem A.4 Under the conditions (B) and (C), we have
[TABLE]
for some positive constant .
By the uniform convergence of the marginal likelihood ratio, we obtain the uniform convergence rate and sure screening properties of the proposed SSI by the following theorems. The convergence rate will help control the size of the selected set.
Theorem A.5 Assume that Conditions (A), (B), (C), (D) and (E) hold. Let , with given in Condition (E).
(i) If , then for any , there exists a constant such that
[TABLE]
where and .
(ii) If , then for any , there exist constants and such that
[TABLE]
(iii) In addition, by taking with , we have
[TABLE]
where is the size of active interactions.
Note that the sure screening property given in Theorem A.5(iii) only relates to the size of the active interaction effects. The dimensionality or does not affect the sure screening. For generalized linear model, such as logistic regression, , and is bounded. By Theorem 8.1(ii), the optimal order of is , and
[TABLE]
Thus, the tail probability will be exponentially small. That is, we can deal with the NP-dimensionality
[TABLE]
with for the special case of the bounded covariates and for normal covariates. Similar results for unconditional screening and conditional screening are shown in Fan & Song (2010) and Barut et al. (2016), respectively.
For SSI, the following theorem shows that the false selection rate can be controlled absolutely. In other words, the size of the set can be controlled, and hence the number of interactions would be significantly reduced for the final model estimation.
Theorem A.6 Under Conditions (A)-(H), we have
[TABLE]
where and .
From the proof of Theorem A.6, without Condition (H), Theorem 8.1 still holds with \mbox{\boldmath\Sigma}_{\mathcal{I}} replaced by \mbox{\boldmath\Sigma}_{\mathcal{I}}+{\mbox{\boldmathR}}{\mbox{\boldmathR}}^{T}. If \lambda_{\text{max}}(\mbox{\boldmath\Sigma}_{\mathcal{I}})=O(n^{\uptau}), the size of the selected set has order , the same order as in the approach of Fan & Lv (2008). Our result is an extension of the work of Fan & Lv (2008). Similar results have been shown in Fan & Song (2010), Fan et al. (2011), Li et al. (2012), and Barut et al. (2016).
8.2 Proofs
In this section, we will provide the proofs of the main theorems in this paper.
Proof of Theorem A.1: If , by the model identifiability, , and . Hence, . On the other hand, if , by Condition (C), {\mbox{\boldmath\beta}}_{i,j}^{M}={\mbox{\boldmath\beta}}_{ij}^{M}. It follows that , , and .
Proof of Theorem A.2: Note that the condition \text{Cov}_{L}(Y,X_{ij}|{\mbox{\boldmathX}}_{i,j}^{T}{\mbox{\boldmath\beta}}_{i,j}^{M})=0 is equivalent to E\{(Y-b^{\prime}({\mbox{\boldmathX}}_{i,j}^{T}{\mbox{\boldmath\beta}}_{i,j}^{M}))X_{ij}\}=0. We prove the necessarity first. The marginal regression coefficients {\mbox{\boldmath\beta}}_{ij}^{M} satisfy the score equation
[TABLE]
i.e.,
[TABLE]
and the coefficients {\mbox{\boldmath\beta}}_{i,j}^{M} satisfy the score equation
[TABLE]
If , by the equation (13), the first three components of {\mbox{\boldmath\beta}}_{ij}^{M}, should be equal to {\mbox{\boldmath\beta}}_{i,j}^{M} by the uniqueness of the solution to the score equation (14). Therefore, the score equation (12) on the component gives
[TABLE]
It follows that E\{(Y-b^{\prime}({\mbox{\boldmathX}}_{i,j}^{T}{\mbox{\boldmath\beta}}_{i,j}^{M}))X_{ij}\}=0, i.e., \text{Cov}_{L}(Y,X_{ij}|{\mbox{\boldmathX}}_{i,j}^{T}{\mbox{\boldmath\beta}}_{i,j}^{M})=0.
For the sufficiency, if E\{(Y-b^{\prime}({\mbox{\boldmathX}}_{i,j}^{T}{\mbox{\boldmath\beta}}_{i,j}^{M}))X_{ij}\}=0, we have the equation (15). By equation (14), (({\mbox{\boldmath\beta}}_{i,j}^{M})^{T},0)^{T} is a solution to the equation (12). By the property of solution’s uniqueness, it follows that {\mbox{\boldmath\beta}}_{ij}^{M}=(({\mbox{\boldmath\beta}}_{i,j}^{M})^{T},0)^{T}, so .
Proof of Corollary A.1: By Theorem A.1 and A.2, we can easily obtain this Corollary.
Proof of Theorem A.3: Denote that the matrix {\bf A}=E(m_{ij}{\mbox{\boldmathX}}_{ij}{\mbox{\boldmathX}}_{ij}^{T}) and partition it as
[TABLE]
Hence, the matrix is a positive definite matrix. By the convexity of the function , almost surely. Therefore, for any nonzero constant vector , a^{T}{\bf A}a=E(m_{ij}a^{T}{\mbox{\boldmathX}}_{ij}{\mbox{\boldmathX}}_{ij}^{T}a)=E(m_{ij}a^{T}{\mbox{\boldmathX}}_{ij}{\mbox{\boldmathX}}_{ij}^{T}a)=E(m_{ij}(a^{T}{\mbox{\boldmathX}}_{ij})^{2})>0 and the inverse matrix exists.
Based on the equation (13) and (14), we have
[TABLE]
i.e., E\{[b^{\prime}({\mbox{\boldmathX}}_{ij}^{T}{\mbox{\boldmath\beta}}_{ij}^{M})-b^{\prime}({\mbox{\boldmathX}}_{i,j}^{T}{\mbox{\boldmath\beta}}_{i,j}^{M})]{\mbox{\boldmathX}}_{i,j}\}=0. Let \Delta_{{\mbox{\boldmath\beta}}_{ij}}=(\beta_{ij0}^{M},\beta_{i}^{M},\beta_{j}^{M})^{T}-{\mbox{\boldmath\beta}}_{i,j}^{M} and by the definition of , we have
[TABLE]
that is, \Delta_{{\mbox{\boldmath\beta}}_{ij}}=-A_{11}^{-1}A_{12}\beta_{ij}^{M}. Moreover,
[TABLE]
By the positive definiteness of Matrix , . Hence, by Condition (B),
[TABLE]
Letting , we have . The conclusion follows.
Proof of Theorem A.4: If Condition (B) holds, by Theorem A.3, we have for . Then by Condition (C), we have
[TABLE]
Letting , we have .
In order to prove Theorem A.5, we need some results in Fan and Song (2010) and Barut (2016), which are listed below.
Let {\mbox{\boldmath\beta}}_{0}=\operatorname*{arg\,min}\limits_{\mbox{\boldmath\beta}}El({\mbox{\boldmathX}}^{T}{\mbox{\boldmath\beta}},Y) be the population parameter. Assume that {\mbox{\boldmath\beta}}_{0} is an interior point of a sufficiently large, compact and convex set , and assume the conditions below.
(A1) The Fisher information
[TABLE]
is finite and positive definite at {\mbox{\boldmath\beta}}={\mbox{\boldmath\beta}}_{0}. Furthermore, \|{\mbox{\boldmathI}}({\mbox{\boldmath\beta}})\|_{\mathbf{B}}=\sup\limits_{{\mbox{\boldmath\beta}}\in\mathbf{B},\|{\mbox{\boldmathx}}\|=1}\|{\mbox{\boldmathI}}({\mbox{\boldmath\beta}})^{1/2}{\mbox{\boldmathx}}\| exists.
(B1) The function l({\mbox{\boldmathx}}^{T}{\mbox{\boldmath\beta}},Y) satisfies the Lipschitz property with positive constant : For any ,{\mbox{\boldmath\beta}}^{\prime}\in\mathbf{B} and ({\mbox{\boldmathx}},y)\in\Omega_{n}=\{({\mbox{\boldmathx}},y):\|{\mbox{\boldmathx}}\|_{\infty}\leq K_{n},|y|\leq K_{n}^{\star}\},
[TABLE]
for some sufficiently large positive constants and . Furthermore, there exists a sufficiently large constant such that
[TABLE]
where , is defined in Condition (C1) and I_{n}({\mbox{\boldmathx}},y)=I(({\mbox{\boldmathx}},y)\in\Omega_{n}).
(C1) The function l({\mbox{\boldmathX}}^{T}{\mbox{\boldmath\beta}},Y) is convex in and
[TABLE]
for some positive constant , where \|{\mbox{\boldmath\beta}}-{\mbox{\boldmath\beta}}_{0}\|\leq b_{n}, is defined in Condition (B1).
The proof of Theorem A.5 needs an exponential bound for the tail probability of the quasi maximum likelihood estimator \hat{{\mbox{\boldmath\beta}}}=\operatorname*{arg\,min}\limits_{{\mbox{\boldmath\beta}}}\mathbb{P}_{n}l({\mbox{\boldmathX}}^{T}{\mbox{\boldmath\beta}},Y).
Lemma A.1 (Fan and Song (2010)) Under conditions (A1)-(C1), for any ,
[TABLE]
Lemma A.2 (Fan and Song (2010)) Under condition (D), for any ,
[TABLE]
Lemma A.3 Under conditions (A1)-(C1), there exist positive constants , , and , such that
[TABLE]
Proof.
[TABLE]
For the terms , by Taylor’s expansion and \mathbb{P}_{n}l^{\prime}({\mbox{\boldmathX}}^{T}\hat{{\mbox{\boldmath\beta}}},Y)=0, we have
[TABLE]
where , \lambda_{max}(\mathbb{P}_{n}{\mbox{\boldmathX}}{\mbox{\boldmathX}}^{T}) is the maximum eigenvalue of the sample variance matrix \mathbb{P}_{n}b^{\prime\prime}(\mbox{\boldmath\xi}_{n}^{T}{\mbox{\boldmathX}}){\mbox{\boldmathX}}{\mbox{\boldmathX}}^{T}, and \mbox{\boldmath\xi}_{n} lies between \hat{{\mbox{\boldmath\beta}}} and {\mbox{\boldmath\beta}}_{0}. By Lemma A.1 and taking ,
[TABLE]
Furthermore, by the Hoeffding inequality (Hoeffding(1963)), for a random variable and any given , we have
[TABLE]
for any and . Therefore, with exception on a set with negligible probability and a constant , it follows that
[TABLE]
Consequently, S_{1}\leq D_{1}\|\hat{{\mbox{\boldmath\beta}}}-{\mbox{\boldmath\beta}}_{0}\|^{2} for some and then taking ,
[TABLE]
For the term , for any ,
[TABLE]
Since l({\mbox{\boldmathx}}^{T}{\mbox{\boldmath\beta}}_{0},y) satisfies the Lipschitz property, it can be bounded by some interval with length on the set for each . Using Hoeffding inequality again, we have
[TABLE]
Taking , we have
[TABLE]
Taking , we have
[TABLE]
Proof of Theorem A.5: (i) We want to use Lemma A.1 to get the exponential bound for the tail property, hence we need to check the conditions (A1)-(C1). By the conditions (A)-(E), we can easily find that most of the conditions are satisfied except for the second part of condition (B1). Now we check it. In our case,
[TABLE]
By condition (E), the first two terms are of order . For the last two terms, using the Cauchy-Schwarz inequality and Lemma A.2 with ,
[TABLE]
When tends to infinity, the last two terms can be very small. In summary, the second part of condition (B1) are satisfied. As a result, we have
[TABLE]
And then, using condition (D) and Lemma A.2 with , we have
[TABLE]
Next, by using the above inequalities and taking , it follows that
[TABLE]
for some positive constant . Consequently, by Bonferroni’s inequality with , we have
[TABLE]
(ii) By definition of and ,
[TABLE]
and
[TABLE]
Hence,
[TABLE]
Using Lemma A.3, we have
[TABLE]
Consequently, by Bonferroni’s inequality with and , we have
[TABLE]
(iii) Define the event
[TABLE]
By Theorem A.4, we have , and then for all ,
[TABLE]
Taking with , we have . Furthermore, . And then, by Theorem A.5(ii),we have
[TABLE]
Finally,
[TABLE]
Proof of Theorem A.6: The key idea of the proof is similar to that of Theorem 5 of Fan and Song (2010). The idea of this proof is to show that
[TABLE]
If so, by definition, we have
[TABLE]
Using Taylor’s expansion, for some , we have
[TABLE]
As a result, with vector form, we have
[TABLE]
Therefore, for any , the number of cannot exceed . Thus, on the set
[TABLE]
the number of cannot exceed the number of , which is bounded by . By taking , we have
[TABLE]
Consequently, the conclusion can follow from Theorem A.5(ii).
Now we prove the equation (16). By condition (B) and the proof of Theorem A.3, is uniformly bounded from below, we have
[TABLE]
for a positive constant . Using the Lipschitz continuity of , we have
[TABLE]
for some constant , where {\mbox{\boldmath\beta}}_{ij-}^{M}=(\beta_{i,j0}^{M},0,\ldots,0,\beta_{i,}^{M},0,\ldots,0,\beta_{j,}^{M},0,\ldots,0)^{T}, \Delta{\mbox{\boldmath\beta}}_{ij}={\mbox{\boldmath\beta}}_{\mathcal{C}}^{\star}-{\mbox{\boldmath\beta}}_{ij-}^{M}. Let R_{ij}=E[X_{ij}{\mbox{\boldmathX}}_{\mathcal{C}}^{T}\Delta{\mbox{\boldmath\beta}}_{ij}] and {\mbox{\boldmathR}}=(R_{12},R_{13},\ldots,R_{(p-1)p})^{T}. Therefore,
[TABLE]
and
[TABLE]
Now
[TABLE]
Since Var({\mbox{\boldmathX}}^{T}{\mbox{\boldmath\beta}}^{\star})=O(1), and by Condition (H), we have \|{\mbox{\boldmath\beta}}_{\mathcal{I}}^{M}\|^{2}=O(\lambda_{max}(\mbox{\boldmath\Sigma}_{\mathcal{I}})).
Proof of Theorem 4.1: (1)The idea is similar to the proof of Theorem 1 of Li et al. (2012). Denote that and , where and are the cumulative distribution functions of and , respectively; is the standard normal distribution function.
The condition is equivalent to
[TABLE]
Note that \text{Cov}(b^{\prime}({\mbox{\boldmathX}}^{T}{\mbox{\boldmath\beta}}^{\star}),\ X_{k})=E(b^{\prime}({\mbox{\boldmathX}}^{T}{\mbox{\boldmath\beta}}^{\star})X_{k})=E(E(Y|{\mbox{\boldmathX}})X_{k})=E(YX_{k})=\text{Cov}(Y,X_{k}). Since and are standardized, we have .
Firstly, we consider the special case and then and . We only need to prove that for some positive constant .
Furthermore, assume that and let , and , , thus, and follow the standard normal distribution. Consequently,
[TABLE]
Since the function and are two increasing functions, their inverse functions are also increasing. Therefore, we have
[TABLE]
Taking into account the symmetry of ,
[TABLE]
and
[TABLE]
where is the cumulative distribution function of given . Hence,
[TABLE]
According to Condition (M1),
[TABLE]
By the Gaussian inequality for the symmetric unimodal distribution (See Pukelshemim (1994), and Sellke (1997)),
[TABLE]
therefore,
[TABLE]
where is a unimodal random variable with a mode at the origin zero and variance . Using this Gaussian inequality, we have
[TABLE]
Since
[TABLE]
we have
[TABLE]
Define the variable and note that . By Condition (M1),
[TABLE]
and then by the law of total variance,
[TABLE]
Hence, for a given large positive constant , by Markov inequality,
[TABLE]
that is,
[TABLE]
which means that with at least probability , we have
[TABLE]
Consequently, by ,
[TABLE]
For the term ,
[TABLE]
Using the inequality , where and are i.i.d. random variables with , and by Condition (M2), we have
[TABLE]
and then, by the symmetry property of the distribution of ,
[TABLE]
On the other hand, according to Cauchy-Schwarz inequality,
[TABLE]
Consequently,
[TABLE]
As for the term , using Cauchy-Schwarz inequality again,
[TABLE]
Combing the above two inequalities for the terms and ,
[TABLE]
Taking the large positive value , it follows that
[TABLE]
where the positive constant .
If , by the similar steps as above, we also have .
In summary, if the condition (M1)-(M3) hold and |\text{Cov}(b^{\prime}({\mbox{\boldmathX}}^{T}{\mbox{\boldmath\beta}}^{\star}),\ X_{k})|\geq C_{1}n^{-\kappa} for any with a positive constant , and after discretizing the response and predictor, there exists a positive constant such that in the special case . Furthermore, following the above same steps, we also have that when .
In the following, we will consider the general case: and . By the above proof for the special case , if we divide the predictor into two parts, we have shown that for some positive constant ,
[TABLE]
and
[TABLE]
As for case , when is a even number,
[TABLE]
and
[TABLE]
Hence,
[TABLE]
and
[TABLE]
which means that there exists at least one term or , such that
[TABLE]
where is a positive constant number, that is,
[TABLE]
When is odd, the support set of is divided into parts and denote that are a series of cutting points (quantiles), and then , , , for . Therefore,
[TABLE]
and
[TABLE]
Based on two results of the case , we conclude that two cases will happen.
Case (i): There exists at least one term or , such that
[TABLE]
Take , our proof will be completed.
Case (ii): For all and , we have
[TABLE]
but
[TABLE]
and
[TABLE]
In this case, , and
[TABLE]
It follows that
[TABLE]
If the condition (M1)-(M2) hold and |\text{Cov}(b^{\prime}({\mbox{\boldmathX}}^{T}{\mbox{\boldmath\beta}}^{\star}),\ X_{k})|\geq C_{1}n^{-\kappa} for any with a positive constant , after using 2-quantile and quantiles to discretize the response and the predictor , there exists at least one such that for some positive constant , which is dependent on .
(2) Assume that satisfies for some positive constant and \widetilde{{\mbox{\boldmathX}}}_{k_{i}}=(1,\widetilde{X}_{k_{i}})^{T}. The coefficient \widetilde{{\mbox{\boldmath\beta}}}_{k_{i}}^{M} is defined as the minimizer of the componentwise regression
[TABLE]
Define \widetilde{\mathcal{M}}_{\star}=\{1\leq j\leq\tilde{p},\ \widetilde{{\mbox{\boldmath\beta}}}_{j}^{\star}\neq 0\}, where
[TABLE]
Consider the new categorical response and predictor \widetilde{{\mbox{\boldmathX}}}=\{1,\ \widetilde{X}_{1},\ \widetilde{X}_{2},\ \ldots,\ \widetilde{X}_{\tilde{p}}\}, we have
[TABLE]
By Theorem 3 in Fan and Song (2010), we have for some positive constant , and
[TABLE]
where is some positive constant and .
Proof of Theorem 4.2:
[TABLE]
After discretizing , and , that is, , and , is transformed into
[TABLE]
Hence, the support set of becomes the union of several intervals. Suppose that , where . By taking as the response of Theorem 4.1 and as the predictor in Theorem 4.1,there exists at least one term such that
[TABLE]
for some positive constant , where is related to and . Therefore,
[TABLE]
By taking ,
[TABLE]
(2) By the proof of Theorem A.3 and A.4, we directly have the conclusion.
8.3 Simulation Study
In this section, we provide some simulation results as the supplement to our paper. Table 11 provides the screening results with in the linear models by using different methods. Table 12-13 compare the post-screening performance of diffenent methods with realtively small , where “w” stands for weak heredity. In the setting with a small , it is clear that our methods SSI and BOLT-SSI outperform other methods, with respect to the coverage rate, the out-of-sample and the predictive misclassification rate for most examples. Sometimes, the method hierNet has a perfect coverage rate and the out-of-sample , but its average model size is much larger than the model size of our methods, especially in the linear models.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1)
- 2Agresti & Kateri (2011) Agresti, A. & Kateri, M. (2011), Categorical data analysis , Springer.
- 3Barut et al. (2016) Barut, E., Fan, J. & Verhasselt, A. (2016), ‘Conditional sure independence screening’, Journal of the American Statistical Association 111 (515), 1266–1277.
- 4Bateson (1909) Bateson, W. (1909), ‘Mendel’s principles of heredity’.
- 5Bien et al. (2013) Bien, J., Taylor, J. & Tibshirani, R. (2013), ‘A lasso for hierarchical interactions’, Annals of statistics 41 (3), 1111.
- 6Chandrasekaran & Jordan (2013) Chandrasekaran, V. & Jordan, M. I. (2013), ‘Computational and statistical tradeoffs via convex relaxation’, Proceedings of the National Academy of Sciences 110 (13), E 1181–E 1190.
- 7Choi et al. (2010) Choi, N. H., Li, W. & Zhu, J. (2010), ‘Variable selection with the strong heredity constraint and its oracle property’, Journal of the American Statistical Association 105 (489), 354–364.
- 8Cordell (2009) Cordell, H. J. (2009), ‘Detecting gene–gene interactions that underlie human diseases’, Nature Reviews Genetics 10 (6), 392.