A Game of Drones: Cyber-Physical Security of Time-Critical UAV Applications with Cumulative Prospect Theory Perceptions and Valuations
Anibal Sanjab, Walid Saad, and Tamer Ba\c{s}ar

TL;DR
This paper develops a mathematical game-theoretic framework incorporating cumulative prospect theory to analyze the cyber-physical security of time-critical UAV operations, revealing how subjective perceptions influence strategic interactions.
Contribution
It introduces a novel security game model for UAVs that integrates PT to account for bounded rationality, providing new analytical tools and algorithms for equilibrium analysis.
Findings
PT significantly affects the equilibrium strategies.
Bounded rationality disadvantages the UAV operator.
Algorithms effectively compute game equilibria.
Abstract
In this paper, a novel mathematical framework is introduced for modeling and analyzing the cyber-physical security of time-critical UAV applications. A general UAV security network interdiction game is formulated to model interactions between a UAV operator and an interdictor, each of which can be benign or malicious. In this game, the interdictor chooses the optimal location(s) from which to target the drone system by interdicting the potential paths of the UAVs. Meanwhile, the UAV operator responds by finding an optimal path selection policy that enables its UAVs to evade attacks and minimize their mission completion time. New notions from cumulative prospect theory (PT) are incorporated into the game to capture the operator's and interdictor's subjective valuations of mission completion times and perceptions of the risk levels facing the UAVs. The equilibrium of the game, with and…
Click any figure to enlarge with its caption.
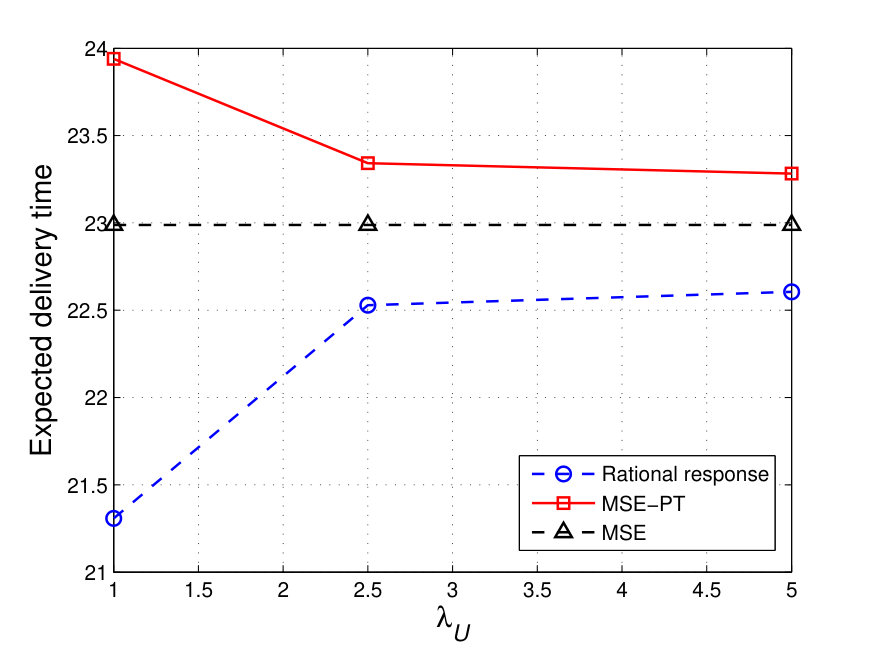 Figure 1
Figure 1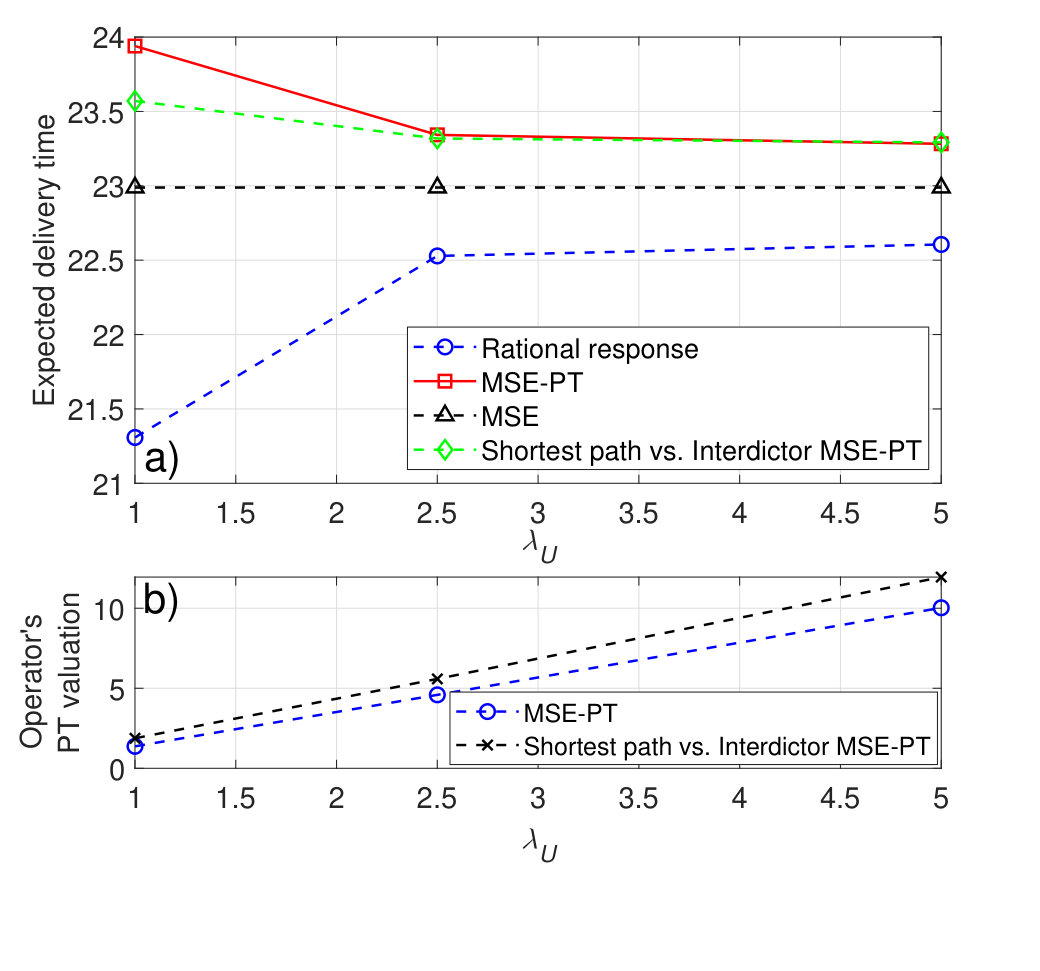 Figure 2
Figure 2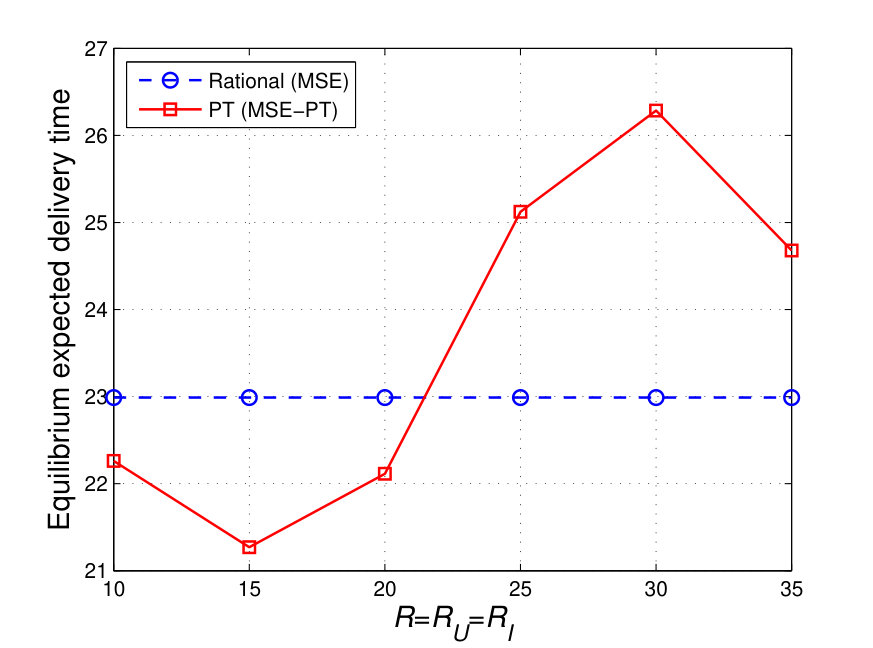 Figure 3
Figure 3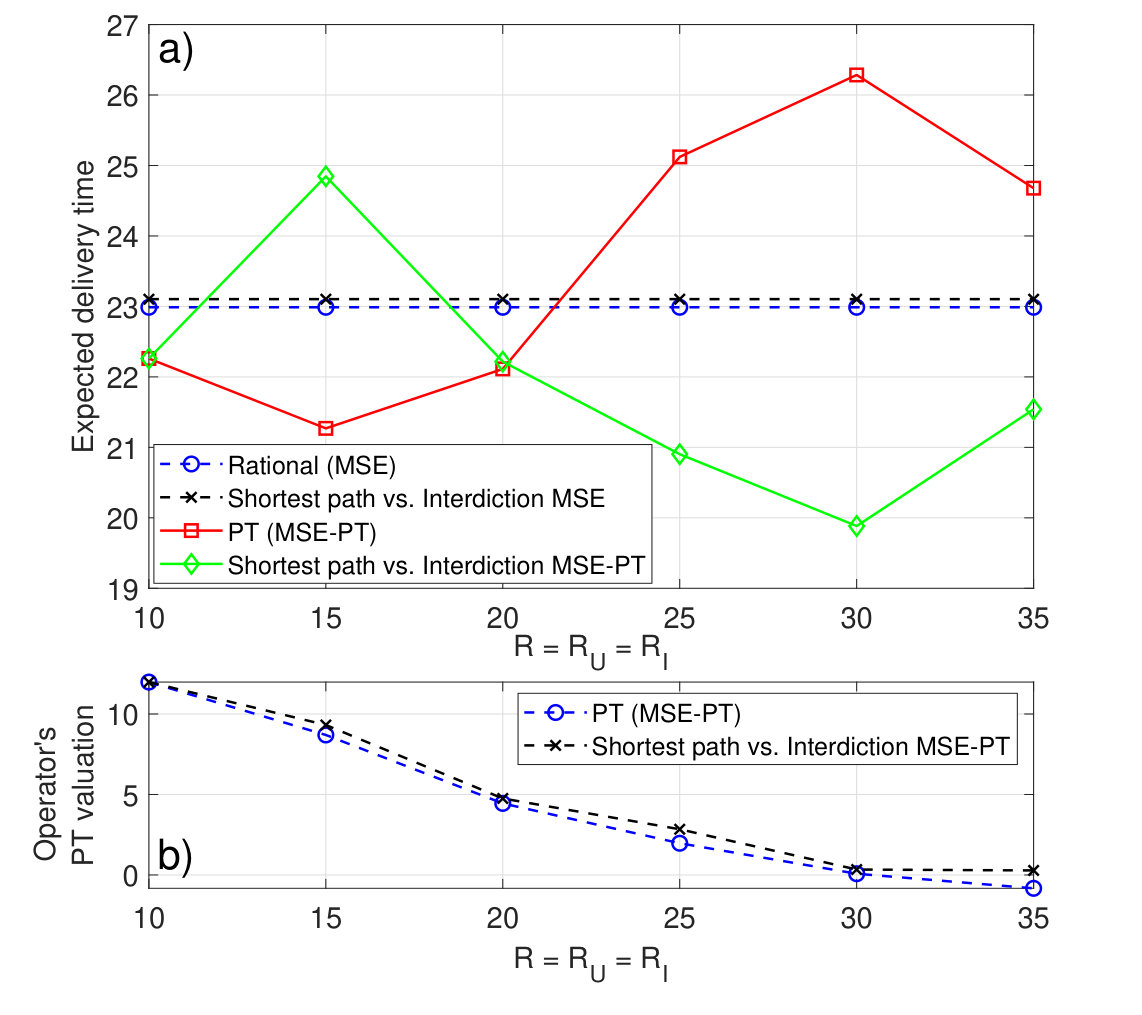 Figure 4
Figure 4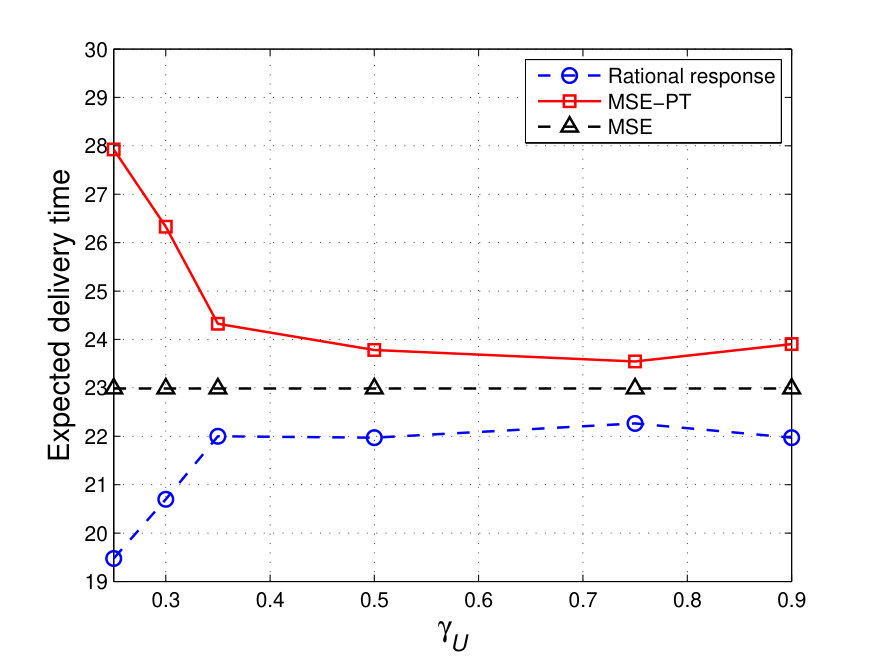 Figure 5
Figure 5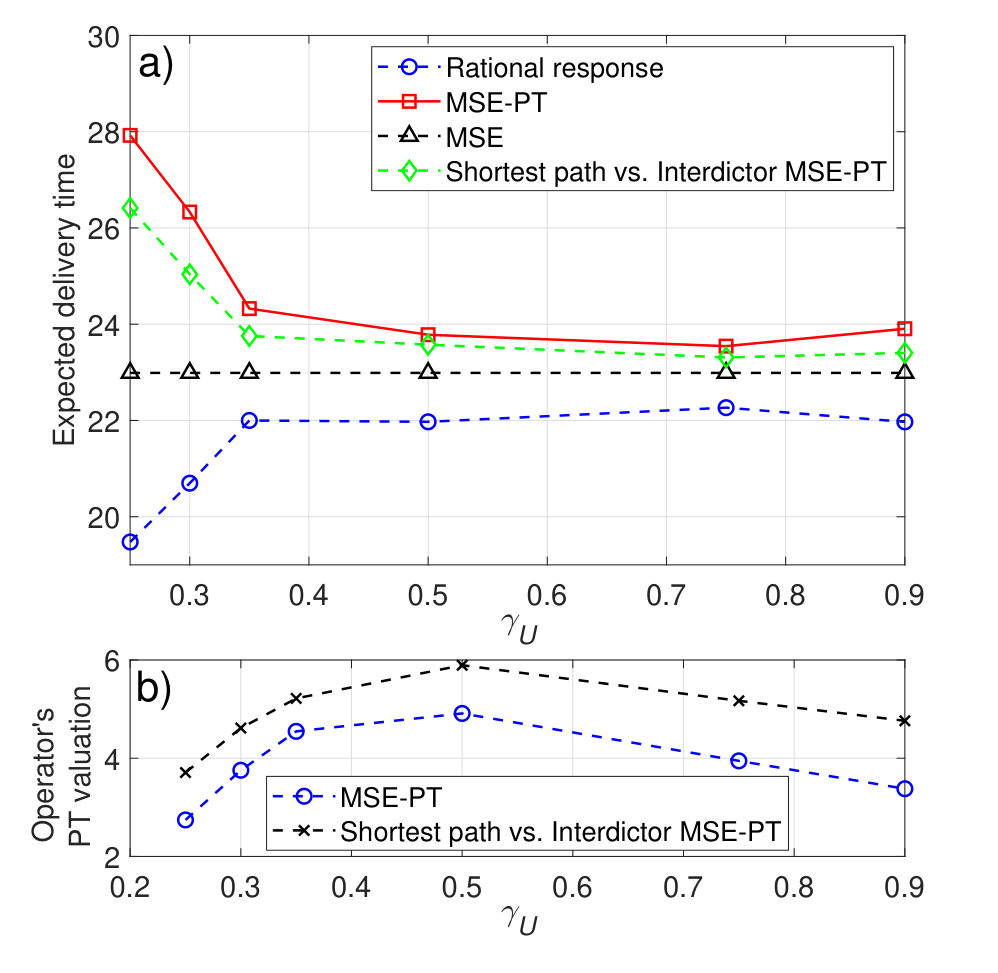 Figure 6
Figure 6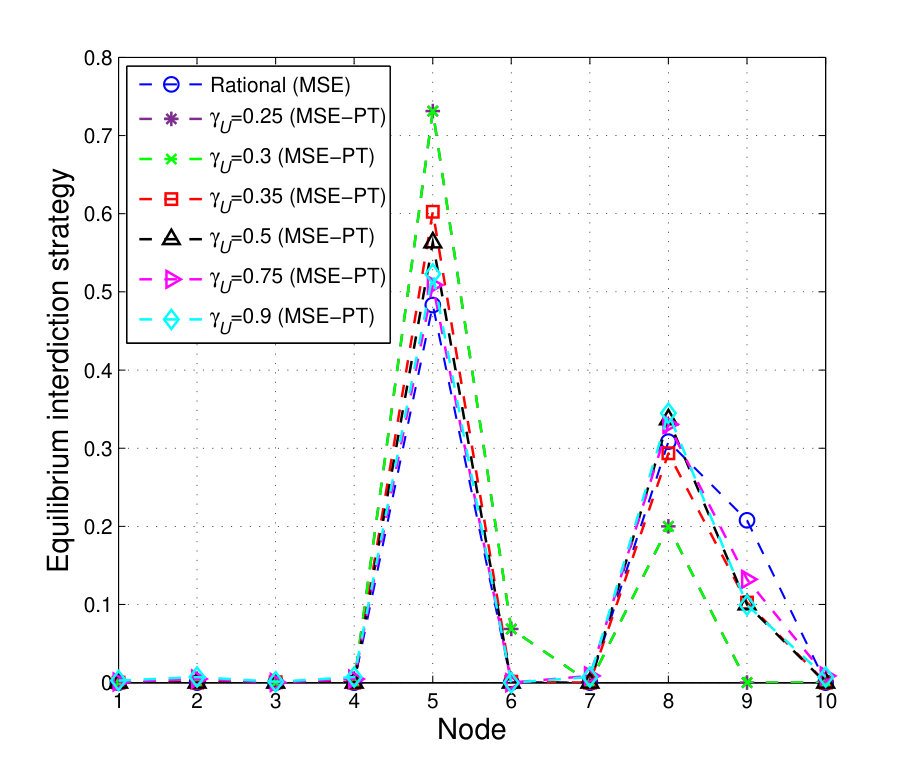 Figure 7
Figure 7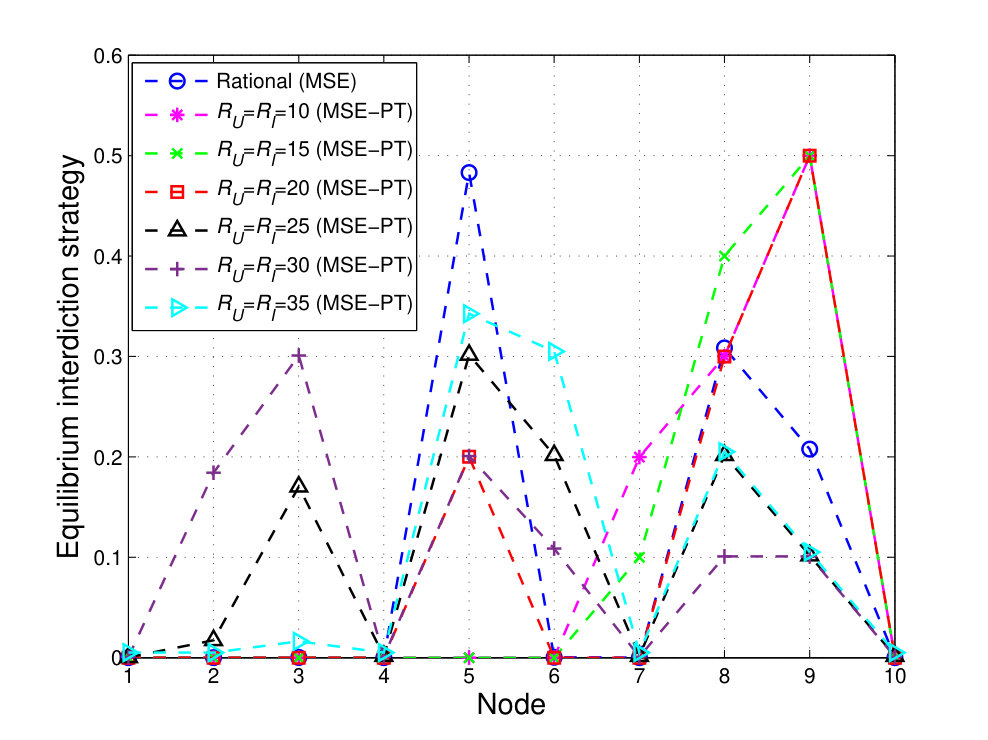 Figure 8
Figure 8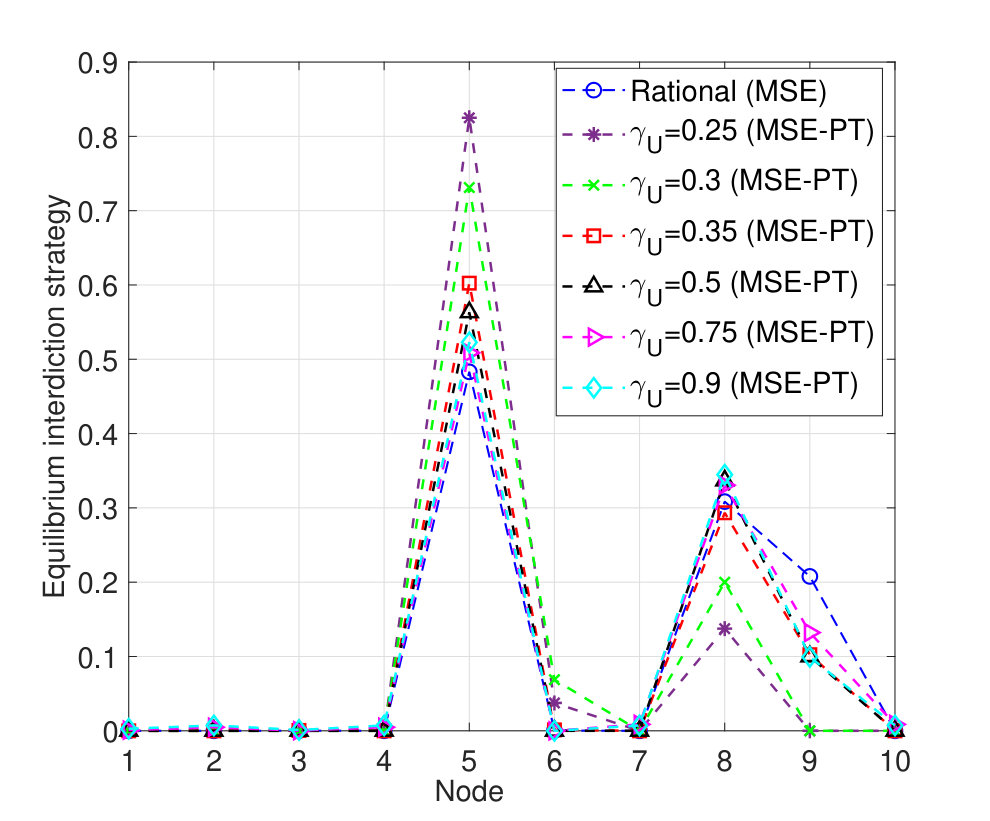 Figure 9
Figure 9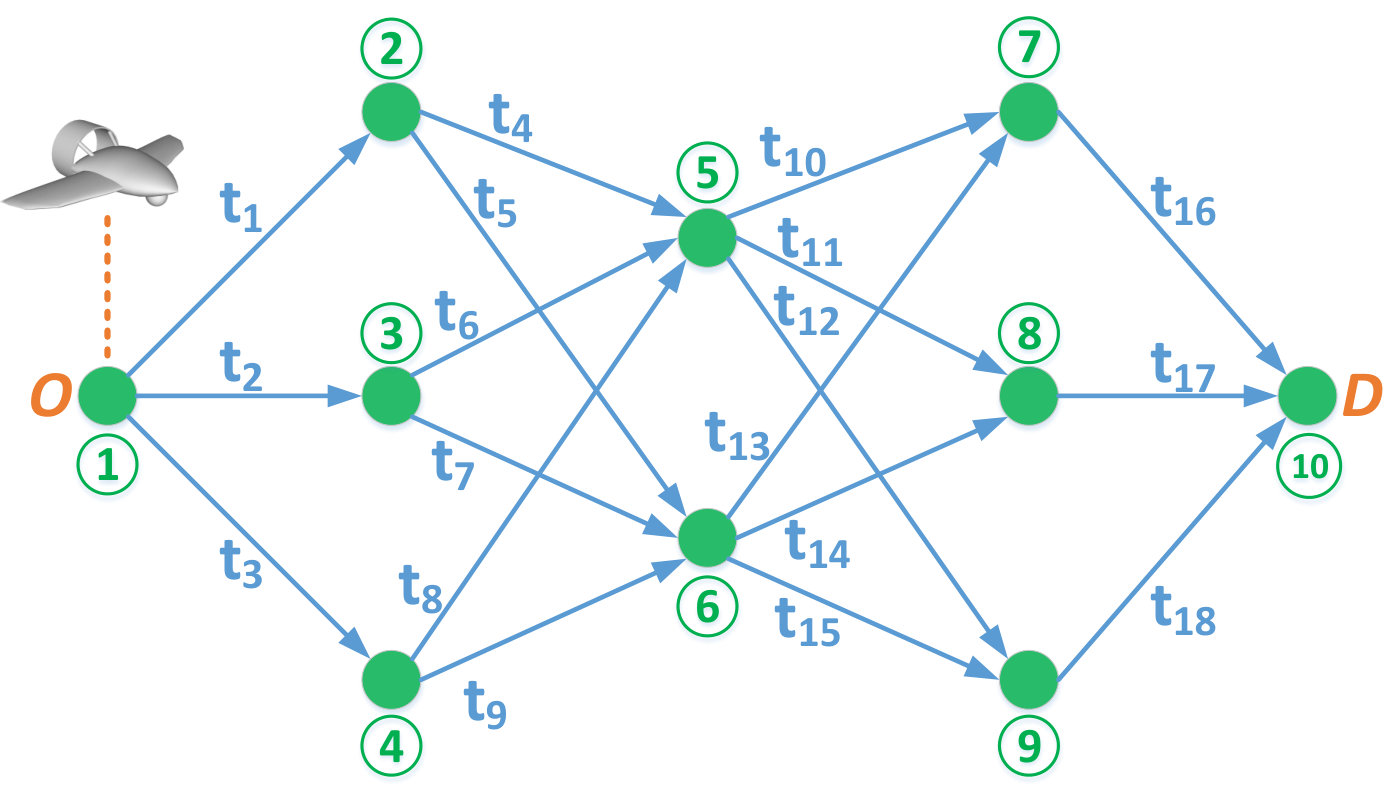 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14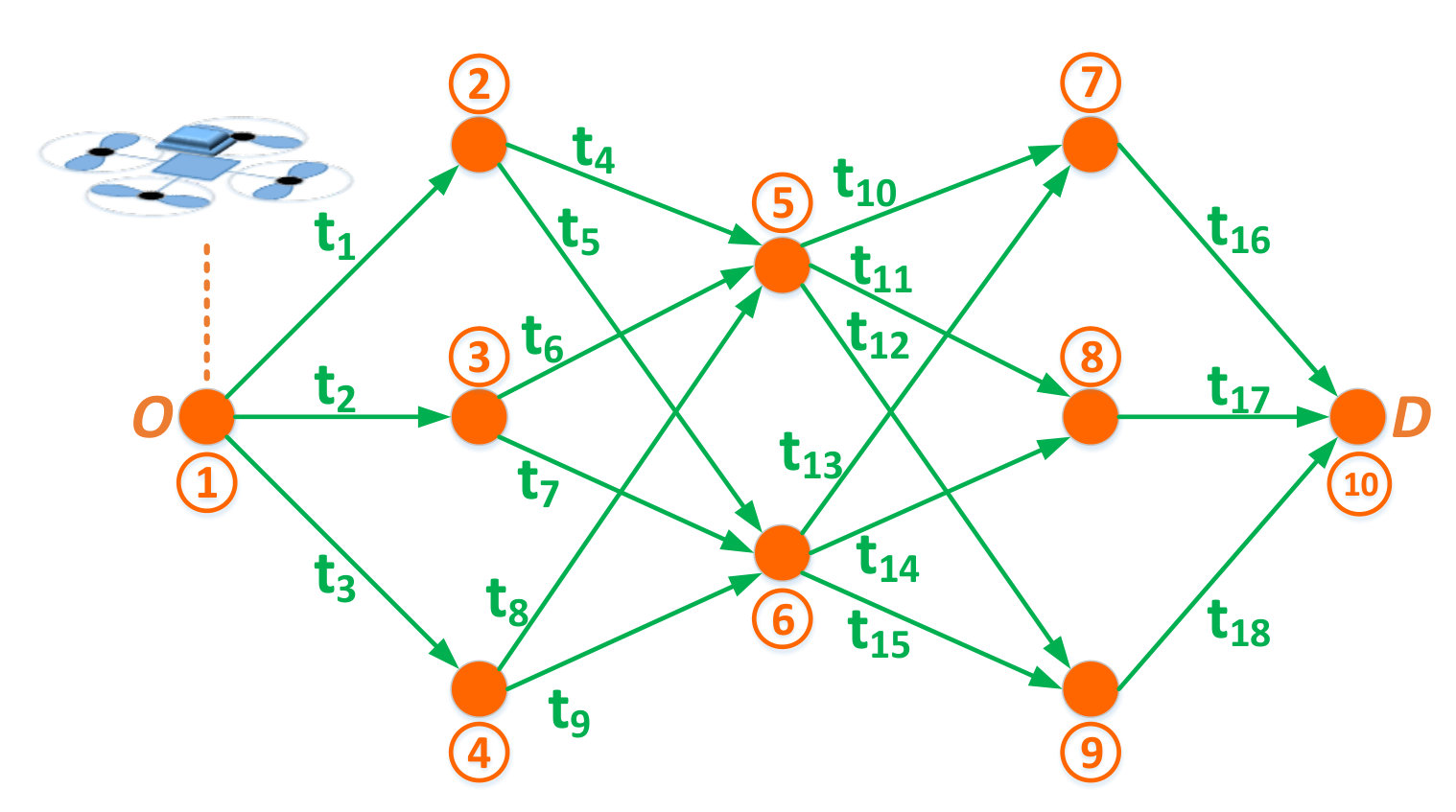 Figure 15
Figure 15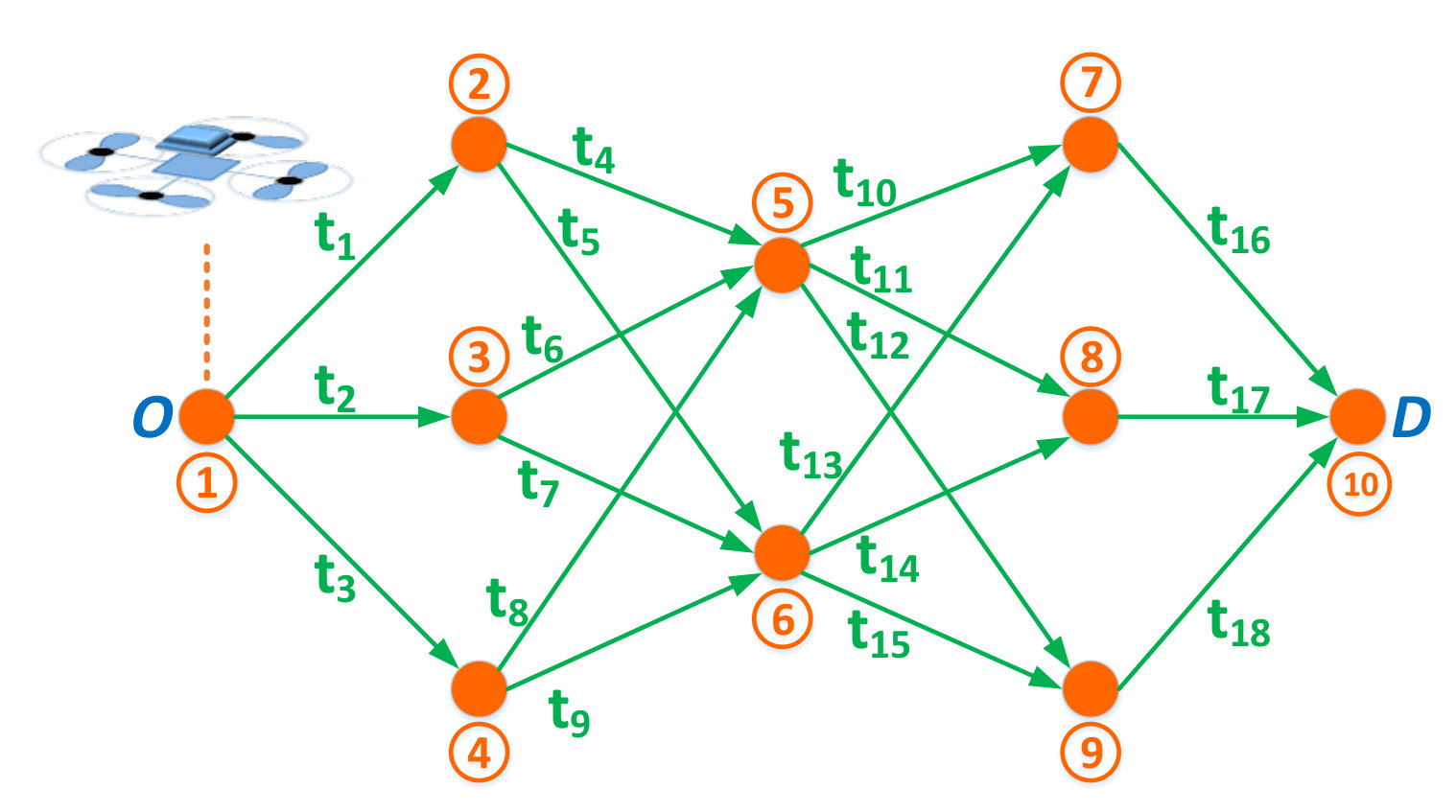 Figure 16
Figure 16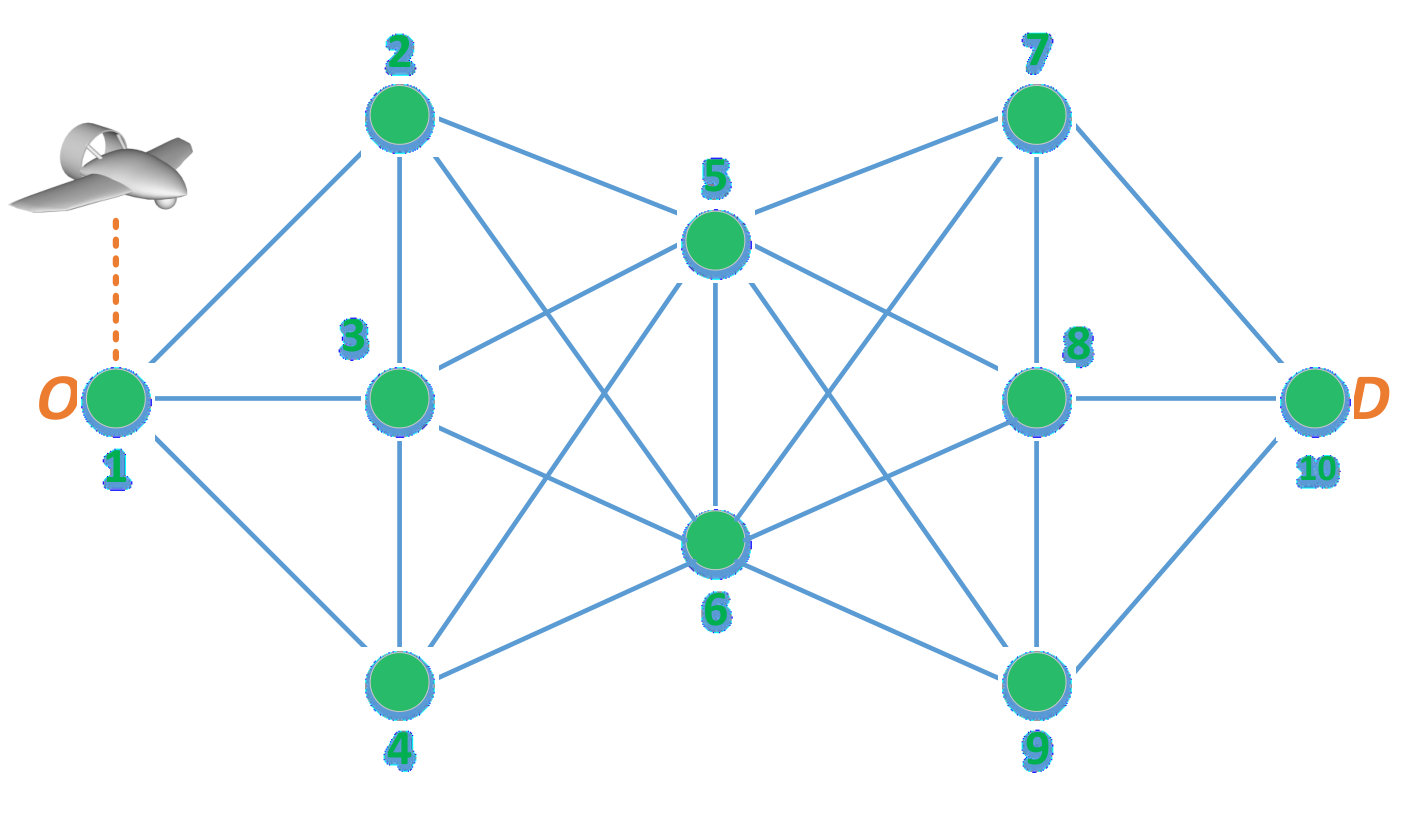 Figure 17
Figure 17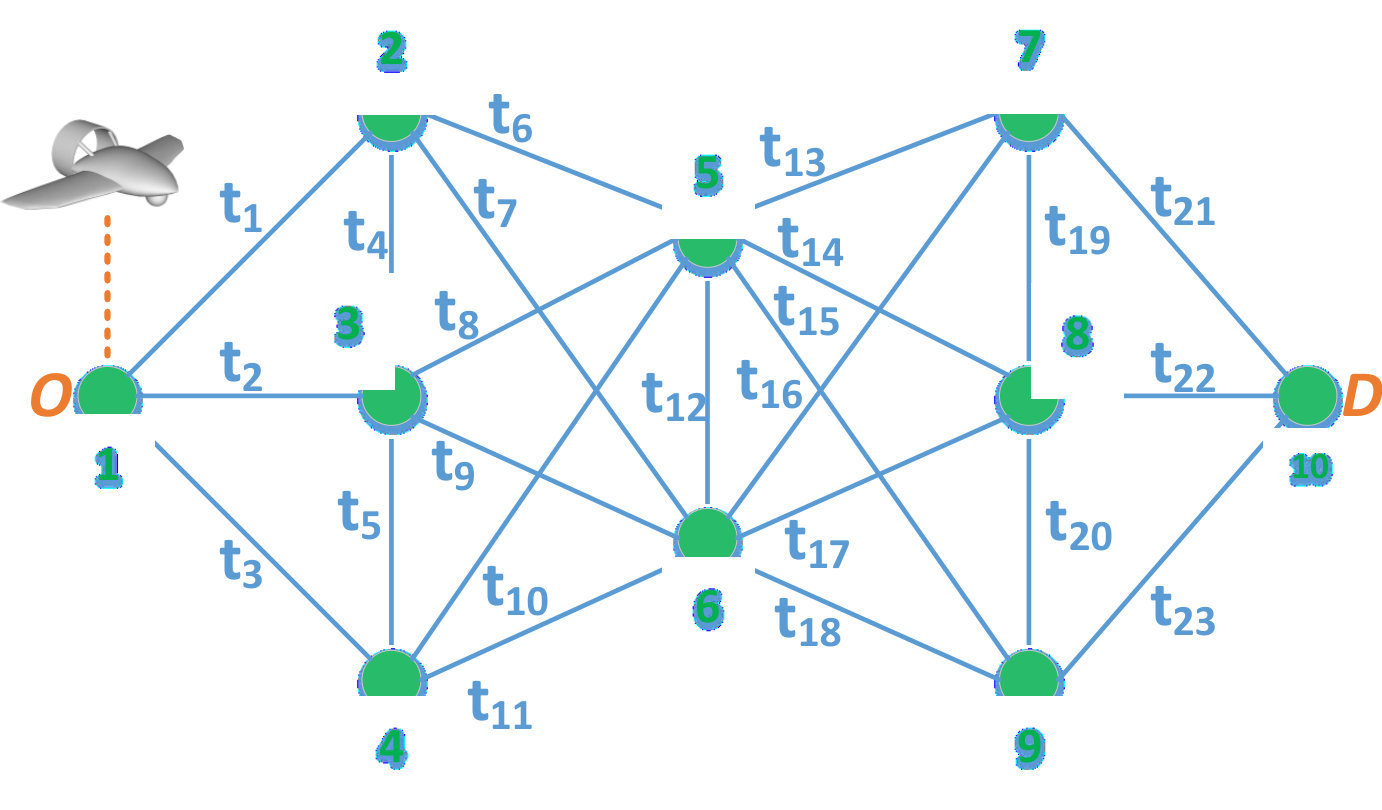 Figure 18
Figure 18 Figure 19
Figure 19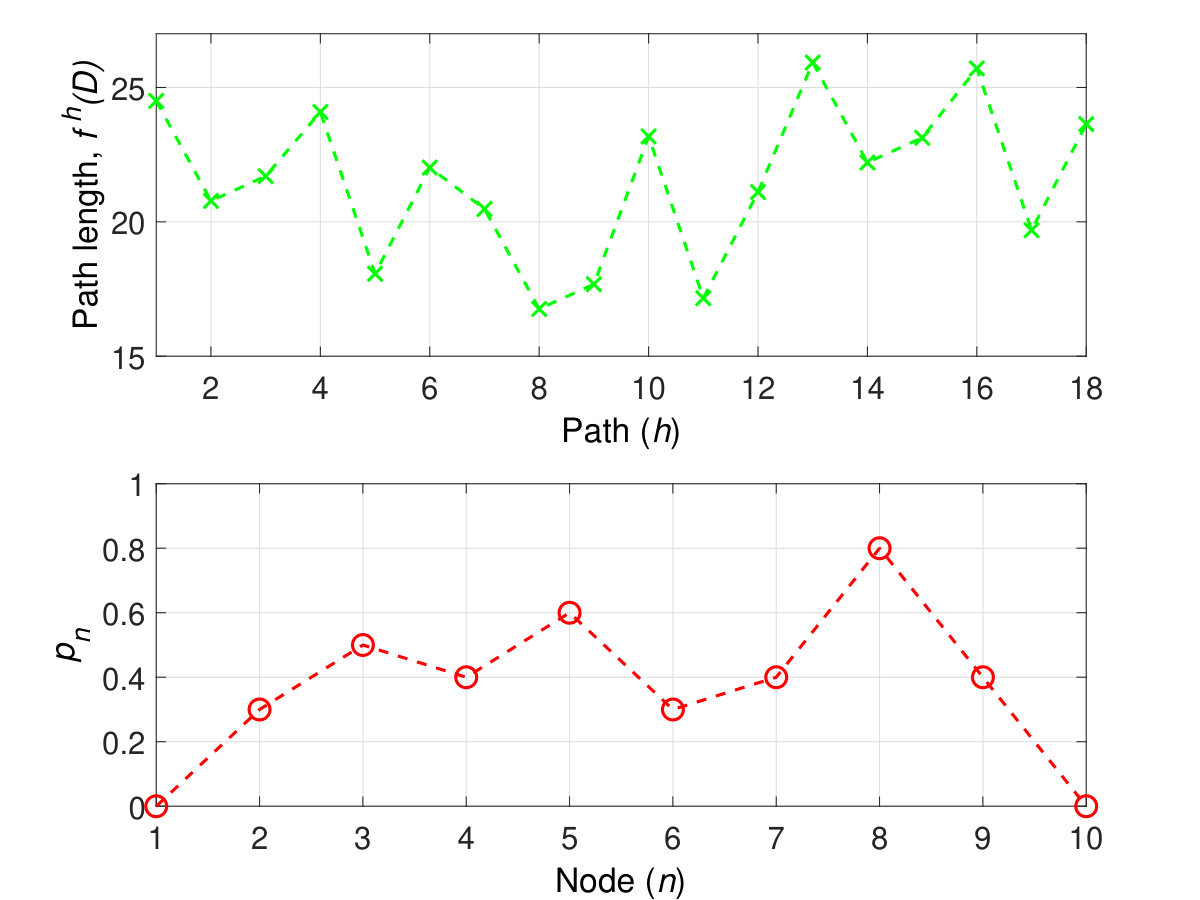 Figure 20
Figure 20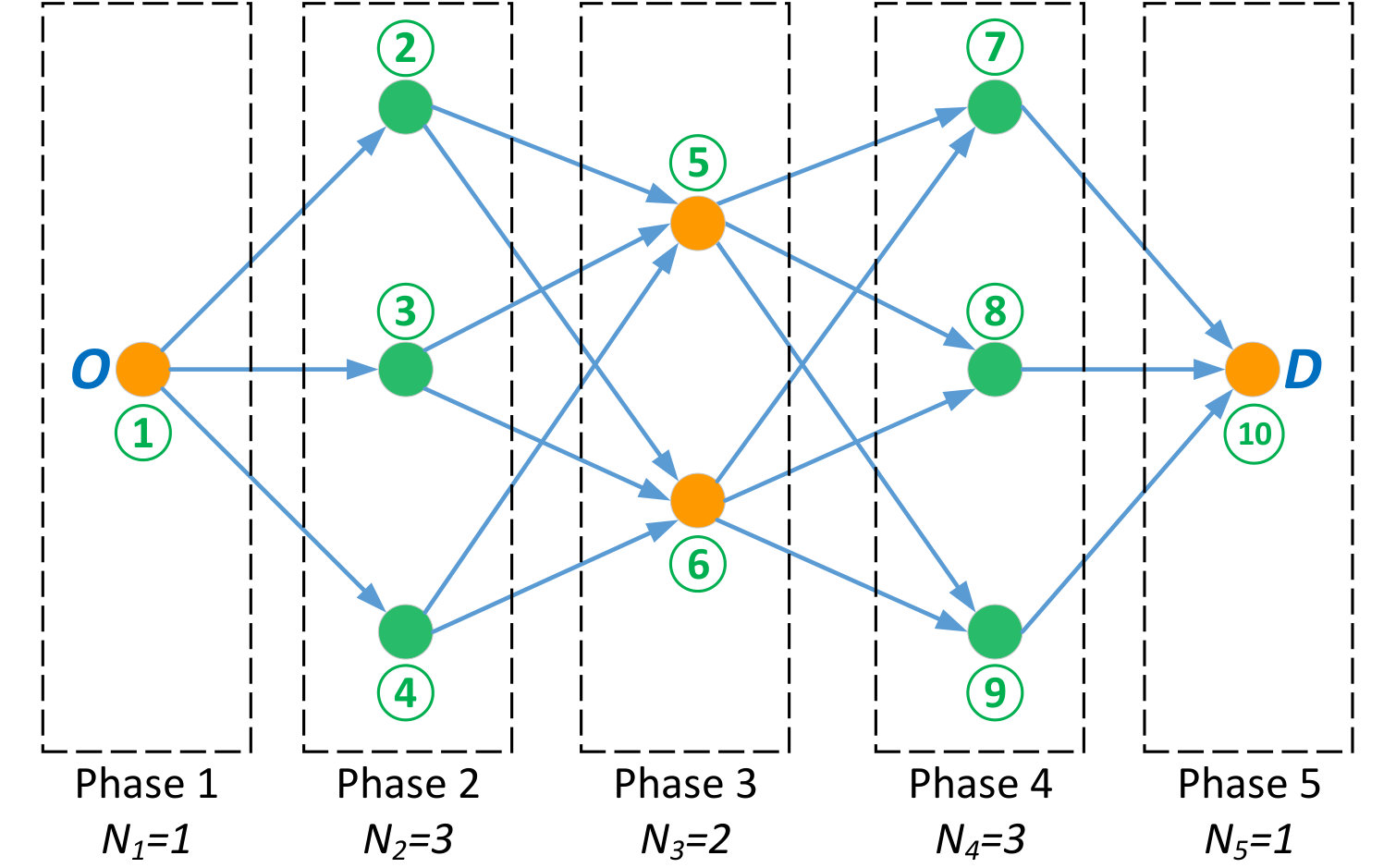 Figure 21
Figure 21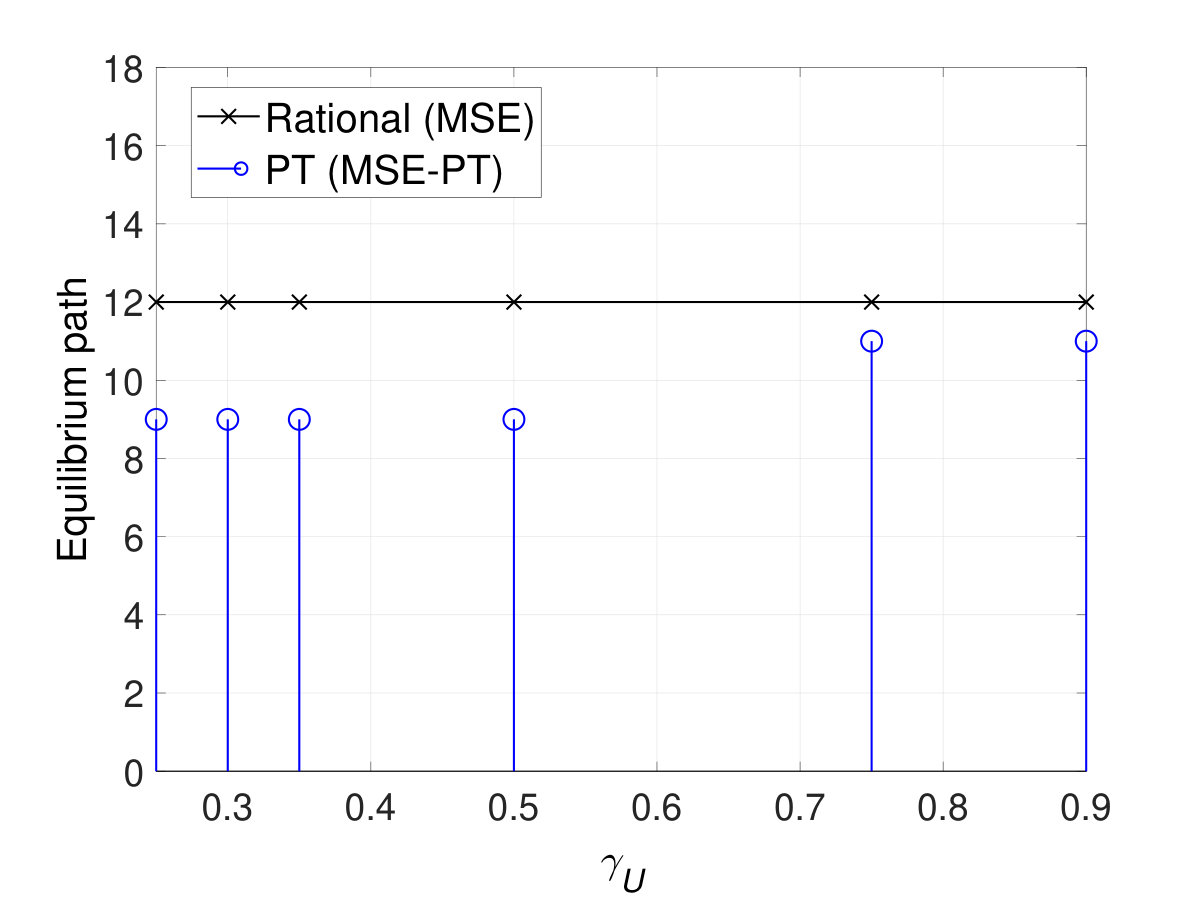 Figure 22
Figure 22 Figure 23
Figure 23| Directed security graph | |
|---|---|
| : Origin node, : Destination node | |
| Set of -to- paths over | |
| Travel time from node to over | |
| Attack success probability at | |
| Re-handling time | |
| Travel time from to following | |
| Set of players: (interdcitor), (UAV operator) | |
| Generic mixed-strategy interdiction | |
| Expected deliver time for pure-strategy interdiction at and UAV path | |
| MDP transition probability from state to for a mixed-strategy interdiction and ’s action | |
| MDP to state transition instantaneous cost/reward | |
| Path selection policy for MDP defined by | |
| -to- path resulting from policy | |
| Expected delivery time under policy | |
| PT valuation by of strategy pair | |
| PT valuation by of strategy pair |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
A Game of Drones: Cyber-Physical Security of Time-Critical UAV Applications with Cumulative Prospect Theory Perceptions and Valuations
Anibal Sanjab1,2, Walid Saad1, and Tamer Başar3
1 Wireless@VT, Bradley Department of Electrical and Computer Engineering, Virginia Tech, Blacksburg, VA, USA,
Emails: {anibals,walids}@vt.edu
2 Flemish Institute for Technological Research, VITO/EnergyVille, Genk, Belgium, Email: [email protected]
3 Coordinated Science Laboratory, University of Illinois at Urbana-Champaign, IL, USA, Email: [email protected]
Abstract
In this paper, a novel mathematical framework is introduced for modeling and analyzing the cyber-physical security of time-critical UAV applications. A general UAV security network interdiction game is formulated to model interactions between a UAV operator and an interdictor, each of which can be benign or malicious. In this game, the interdictor chooses the optimal location(s) from which to target the drone system by interdicting the potential paths of the UAVs. Meanwhile, the UAV operator responds by finding an optimal path selection policy that enables its UAVs to evade attacks and minimize their mission completion time. New notions from cumulative prospect theory (PT) are incorporated into the game to capture the operator’s and interdictor’s subjective valuations of mission completion times and perceptions of the risk levels facing the UAVs. The equilibrium of the game, with and without PT, is then analytically characterized and studied. Novel algorithms are then proposed to reach the game’s equilibria under both PT and classical game theory. Simulation results show the properties of the equilibrium for both the rational and PT cases. The results show that the operator’s and interdictor’s bounded rationality is more likely to be disadvantageous to the UAV operator.
Index Terms:
Unmanned Aerial Vehicles, Cyber-Physical Systems, Security, Network Interdiction Games, Game Theory, Cumulative Prospect Theory.
I Introduction
Recent developments in unmanned aerial vehicle (UAV) technology have led to its adoption in various applications such as telecommunications, surveillance, delivery systems, rescue operations, and intelligence missions [1, 2, 3, 4, 5, 6]. Due to their ability to reach relatively inaccessible locations (such as natural disaster sites, remote mountains, valleys, and forests) and their capacity to travel without being restricted to predefined pathways, UAVs can effectively carry out time-critical missions [1, 7, 8, 9].
I-A Time Critical UAV Applications and Security Challenges
One prominent time-critical UAV application is drone delivery systems [6, 7, 8, 9, 10, 11, 12, 13, 14, 15] which can be used to deliver consumer parcels [10, 6, 11, 12] (with Amazon Prime Air [10] and Google’s Project Wing [6] being key examples) as well as emergency medical products [7, 8, 9]. However, the practical deployment of drone delivery systems can be hindered by their vulnerability to a myriad of cyber and physical attacks [16, 17, 18, 19, 20, 21, 22]. On the physical side, to avoid conflict with manned and commercial aviations, the altitude of UAVs is typically limited to around 400 ft [23], putting them in the range of hunting rifles and firearms. Moreover, UAVs are vulnerable to a variety of cyber threats as demonstrated in [16, 17, 18, 19, 20, 21, 22]. For example, the work in [16] provided a general overview of cyber attacks which can target the confidentiality, integrity, and availability of UAV systems. The authors in [17] focused on the security of the communication links between ground control and unmanned aircrafts. Moreover, the authors in [18] successfully launched a man-in-the-middle attack against a typical UAV used by law enforcement agencies for critical applications. Meanwhile, the authors in [19] and [20] investigated GPS spoofing attacks to manipulate the trajectory of an autonomous UAV while the work in [21] considered jamming, spoofing, and eavesdropping attacks which can target UAV systems. In addition, the authors in [22] surveyed various detection and localization techniques as well as cyber-physical attacks which can be used against UAVs.
On the other hand, the ability of drones to reach secure or private locations has raised concerns regarding their possible usage for executing malicious missions, with recent real-world incidents at Gatwick airport in the UK [23]. For instance, a number of recent works, such as [22] and [24], studied the risks of potentially using UAVs to execute nefarious missions such as targeting a public, political, or military figure in a secure perimeter, intruding into a military secure perimeter, smuggling illicit products, or gaining unauthorized access to personal property. This has led to the development of what is known as anti-drone systems whose goal is to defend against intruding drones as discussed in [22] and [24]. The interactions between intruding drones and anti-drone systems is clearly another highly time-critical application of UAVs, beyond delivery systems.
Security analyses of these two time-critical UAV applications involve: a) a UAV aiming to achieve a mission (benign or malicious) in the shortest possible time and b) an interdictor (malicious, e.g., in drone delivery systems, or benign, e.g., in anti-drone systems) whose goal is to interdict and delay the UAV and compromise its mission. The highly intertwined decision making processes of these two scenarios motivate the need for a holistic strategic analysis which can capture this underlying interdependent decision making processes and identify optimal interdiction and security strategies. However, beyond our preliminary work in [25] on the security of drone delivery systems, which was limited to a static analysis111Our current work advances and generalizes our preliminary results presented in [25]. Our preliminary work [25] considered a static environment while the current work treats a general setting in which the UAV performs a repeated path selection decision making aiming at minimizing a cumulative mission completion time. In addition, the results in [25] mainly relied on numerical simulations while the current work presents rigorous analytical derivation and results., prior art [16, 17, 18, 20, 19, 21, 22, 24], and references therein, have somewhat remarkably ignored such interactive time-critical situations and, instead, have either provided qualitative analyses or focused on specific and isolated security experiments, rather than on a comprehensive study.
I-B Summary of Contributions
The main contribution of this paper is to develop the first comprehensive framework for the modeling and analysis of the cyber-physical security of time-critical UAV applications. We pose the general problem as a network interdiction game with a leader-follower structure between an interdictor (malicious or benign) and a UAV operator (benign or malicious). In this game, the interdictor (i.e. the leader) chooses the optimal attack locations along the area which can be traversed by the UAV to interdict the UAV, via a cyber or physical attack, with the goal of delaying the UAV and compromising its mission. On the other hand, the UAV (i.e. the follower) acts as an evader that chooses the best path selection policy from its origin to its destination, while evading attacks and minimizing its total expected travel time (hereinafter called the expected delivery time) needed to complete the mission. We consider both deterministic and probabilistic interdiction strategies. First, with deterministic interdiction strategies, we derive and analyze the Stackelberg equilibrium (SE) of the game. We then show that a probabilistic interdiction strategy gives rise to a game structure in which the UAV’s problem corresponds to finding an optimal policy in a Markov Decision Process (MDP) and the interdictor’s problem corresponds to setting the parameters of this MDP. In this regard, we characterize the SE of the game with mixed interdiction strategies, and propose practical algorithms to solve the underlying UAV operator’s and interdictor’s problems.
The aforementioned analysis captures the decision making processes of the agents considering that they are fully rational, i.e., they assess delivery times and perceive risk levels objectively. In order to capture wider practical application settings, our work also considers the interdictor’s and UAV operator’s potential subjectivity, i.e. bounded rationality. For instance, time-critical UAV applications aim at strictly accomplishing a mission within a target delivery time as delays in such applications can have tragic consequences. Given this time criticality, the merit of an achieved delivery time can be valued relatively to the target delivery time, rather than as an absolute quantity, and this valuation can be performed subjectively and differently by the UAV operator and the interdictor. In addition, the choices of interdiction and path selection strategies are influenced by various underlying uncertainties which stem, for example, from the probabilistic risk levels of a certain path and the likelihood with which a carried out cyber-physical attack is successful. Hence, due to these uncertainties, the likelihood of achieving a certain delivery time can be perceived and assessed differently by the interdictor and the UAV operator222The subjective valuation of outcomes and distorted perception of probabilities in decision making under risk have been repeatedly observed and quantified in various empirical analyses such as in [26] and [27].. Classical game theory does not capture such subjective valuations and perceptions as it assumes full rationality of the players, which for our game implies that both players assess delivery times and their probability of occurrence objectively and similarly. Thus, to capture these bounded rationality factors in our game, we extend our analysis by using tools from cumulative prospect theory333Cumulative prospect theory [26] provides a refinement and generalization of traditional prospect theory [27, 28, 29, 30] allowing it to accommodate a large number of outcomes as needed in this work. (PT) [26]. In this respect, we consider both deterministic and probabilistic strategies in the PT game analysis. We derive closed-from analytical expressions of the PT valuations of the interdictor and the UAV operator, and prove their convergence. Then, we analytically derive the SE of the deterministic PT game, and propose solution algorithms that deliver numerically the SE of the PT game with mixed interdiction strategies.
We complement our theoretical analysis with extensive simulations, where our results provide key insights into the effects of PT on the equilibrium strategies and achieved delivery times. For example, the numerical results show that the PT bounded rationality of the players is in general disadvantageous to the UAV operator, leading to expected delivery times that exceed the pre-set target delivery times and highlighting the need for proper PT game modeling when specifying such target times.
The rest of this paper is organized as follows. Section II presents the system model and formulates the proposed network interdiction game with fully rational players. Section III and Section IV study the game under deterministic and probabilistic interdiction strategies, respectively. Section V studies the PT game. Numerical results are presented in Section VI; while conclusions and future directions are discussed in Section VII. A summary of our main notations is given in Table I.
II System Model and Problem Formulation
II-A System Model
Consider a drone system in which a UAV, controlled by an operator, executes a time-critical mission requiring it to travel from a source location to a destination location in minimum time, referred to as the delivery time. Meanwhile, an interdictor seeks to interdict the UAV’s flight by choosing a certain area or location, among a number of “danger points” along its path from to , to launch a cyber-physical attack. The interdictor’s attacks[16, 17, 18, 19, 22] include physical attacks against the UAV (such as using rifles or a military defense system) as well as cyber attacks (such as de-authentication or GPS spoofing attacks) which cause the UAV operator to lose control of the drone. Our model readily captures two time-critical UAV use cases: a) The drone delivery system case in which the UAV is a benign player and the interdictor is malicious, and b) the anti-drone scenario in which the interdictor is an anti-drone system seeking to stop a rogue (or malicious) drone from reaching its destination.
A danger point represents a location (or area) along the possible paths between and , from which the UAV is exposed to possible cyber-physical attacks. Such points can represent locations of high altitude, which allow line-of-sight and spatial proximity (e.g., high hills, high-rise buildings, etc.) between a potential attacker and the UAV. As a result, the set of danger points between and correspond to inevitable locations along the drone’s flight paths that are susceptible to attacks by a malicious interdictor or an anti-drone system. The set of danger points between and define a security network represented by a directed graph , as shown in Fig. 1, in which the set of vertices, , is the set of danger points between and , and the set of edges, , such that , is the set of connections between these danger points. Given that, in practice, the UAV’s travel from origin to destination may not be restricted to predefined airways, there can be an infinite number of paths which connect to . However, each one of these paths will go through a number of danger points that may be shared among different paths. This infinite set of possible to paths can, from a security viewpoint, be represented by the set of danger points that each path traverses. Given the time-critical nature of the considered UAV applications, the defined set of edges in the security graph will comprise the shortest paths between each two danger points. For two neighboring points and connected by edge , we let , , be the time that the UAV needs to travel from to over .
We let be the probability with which an attack launched from point is successful. Without loss of generality, we consider that for any , ; and for , . We define to be the set of paths (containing no repeated vertices444Cycles are naturally dismissed by a UAV operator aiming to minimize delivery time.) from the origin, , to destination, , over the security graph . For each path555An -to- path is represented by its sequence of nodes connecting to . Hence, we use the notation to represent a node that is in . , we define a distance function , which takes an input node and returns the time needed by the UAV to reach from following path . For example, in Fig. 1, where .
On this security graph , the interdictor aims at finding the best interdiction strategy (a choice of danger points from which to launch an attack) to intercept/delay the travel of the UAV while the UAV acts as an evader who aims at finding the best travel policy, and as a result a path selection strategy, to reach from in a minimum delivery time.
II-B Game-Theoretic Problem Formulation
The UAV operator, denoted by player , must find the best possible path for the UAV to take over graph to reach from in minimum time while accounting for the presence of the interdictor (player ). In case the UAV is successfully compromised by the interdictor from a node , will have to resend a new UAV with the same mission from node , which leads to both financial losses and delayed delivery time. Hence, a successful attack by at node can be mathematically modeled as if the UAV had returned to the point of origin from which it needs to travel again to its destination. Hence, with the goal of minimizing delivery time, may not always choose the shortest -to- path if this path is suspected to be risky. Hence, the path selection strategy must account for possible interdiction strategies so as to successfully accomplish the -to- mission in a minimum delivery time. Similarly, the interdiction strategy must anticipate the possible paths that may be taken by the UAV to maximize this delivery time. To model and analyze these intertwined decision making processes of the interdictor and the UAV operator, we next introduce a novel time-critical network interdiction game.
In this game, the set of players is . chooses first an interdiction strategy which is a probability distribution over the set of danger points, , where (i.e. element of vector ) specifies the probability with which to launch an attack from node while satisfying . We refer to this probabilistic choice of as a mixed interdiction strategy. A special case of consists of restricting to pure interdiction strategies in which case for some and for . On the other hand, chooses a travel policy (i.e. a path selection strategy), which specifies the node to go to from each possible node , where is the set of outgoing neighbor nodes of in graph . Such a policy will result in a certain -to- path. Hence, the goal of is to choose the best interdiction strategy , while anticipating the path selection policy that could be taken by , to maximize the expected delivery time while the goal of is to respond to by choosing the best possible path to minimize the expected delivery time. This gives rise to a leader-follower (with as the leader and as the follower) hierarchical time-critical network interdiction game. We next separately study the games under pure interdiction and mixed interdiction strategies.
III Game under Pure Interdiction Strategies
III-A Game Formulation under Pure Strategies
Under pure strategies, chooses to be located at node (the action space of is, hence, ) while the UAV seeks to choose an -to- path . If contains node , when traveling from -to- along path , it will traverse all danger points without any risk of being attacked. However, when the UAV reaches danger point , it may continue its path with probability , i.e., the probability with which the attack launched from is not successful, or it may be sent back to with probability , i.e., the probability with which the attack launched from is successful. Let be the re-handling time, which is the time needed by the operator to send a new UAV, if the original one was compromised, captured, or destroyed. In other words, is the time span between the instant at which the drone is compromised or destroyed and the instant at which a new replacement drone is sent from . This time span would include the time delay for the operator to detect666We consider that when the UAV is attacked, can eventually detect (with a possible delay accounted for as part of ) that the UAV has been destroyed/compromised. Hence, the inclusion of allows our model to accommodate attack types which might not be promptly detected by . that an attack has taken place and the time the operator needs to prepare a new replacement drone. Then, the possible delivery times which can occur when and their probability of occurrence will be:
[TABLE]
for ; where , is the th possible delivery time, and is the probability of occurrence of . Hence, based on the possible delivery times and their likelihood, defined respectively in (1) and (2), the expected delivery time, ,777We also use the notations and to highlight whether or not path contains node in the computed expected delivery time. when the interdictor is located at and the UAV takes path is given in Proposition 1.
Proposition 1
The expected delivery time for an interdiction and path selection strategy pair, , is given by:
[TABLE]
Proof:
First, we consider the case in which . If the chosen path does not contain , then the UAV cannot be successfully attacked, which yields . Second, we consider the case in which contains node , i.e. . From (1), one can see that appears in every possible delivery time outcome, while is multiplied by the number of times the UAV had been successfully attacked at before it was successfully able to traverse . This latter component of (1) corresponds to the number of failures that the UAV experiences before the first success in traversing . Consider being successfully attacked at to be a failure of the UAV in traversing , which can occur with probability , and consider traversing to be a success for the UAV, which can occur with probability ; then, the expected delivery time will be: E_{d}(n\in h)\textrm{=}(\textrm{expected \# failures before 1^{\textrm{st}} success})(f^{h}(n)\textrm{+}t_{a})\textrm{+}f^{h}(D). The number of failures before the first success follows a geometric distribution whose mean is given by . As a result, E_{d}(n\in h)\textrm{=}\frac{p_{n}}{1-p_{n}}(f^{h}(n)+t_{a})+f^{h}(D).
∎
Hence, the term in (4) can be viewed as a delay penalty, which the UAV would endure for taking the risk of traversing a risky danger point at which the interdictor is located. The goal of the interdictor is to maximize this expected delivery time, , while the goal of the UAV operator is to minimize it, leading to a zero-sum game.
III-B Equilibrium in Pure Strategies
For each choice by the interdictor, can identify the optimal reaction strategy specifying the best path to take when chooses . The equilibrium concept of this hierarchical game structure is known as the Stackelberg equilibrium [31] and is defined as follows:
Definition 1
A strategy pair constitutes a Stackelberg equilibrium (SE) of the network interdiciton game if
[TABLE]
[TABLE]
where is as given in (3) and (4).
Denoting a shortest -to- path by and a shortest -to- path not containing a node by , the SE of our network interdiction game can be analytically characterized.
Theorem 1
The interdictor’s SE strategy, , is given by:
[TABLE]
where
[TABLE]
[TABLE]
[TABLE]
*The UAV operator’s SE strategy is given by *
[TABLE]
*In addition, the resulting SE expected delivery time is *
[TABLE]
Proof:
The proof is presented in Appendix A. ∎
The SE888The SE of the game is not necessarily unique. However, given the hierarchical structure of the game [31], all possible SEs will lead to an equal expected delivery time. This equally applies to the equilibria which we will derive for the games that ensue. highlights that, from a delivery time perspective, selecting the shortest path may still be optimal since it may result in an expected delivery time that is lower than all other alternative paths. This, in particular, occurs when . However, in general, as shown in Theorem 1, the optimal path selection strategy goes beyond simply considering the shortest -to- path, as is, for example, the case when .
IV Game under Mixed Interdiction Strategies
IV-A Game Formulation with Mixed-Strategy Interdiction
We now analyze the time-critical network interdiction game under a more general probabilistic choice of interdiction999Given the hierarchical structure of our game, considering mixed path selection policies by would not yield any advantage regarding the achieved expected delivery time as compared to the optimal deterministic path selection policy [31, 32]. Thus, we limit our analysis to deterministic path selection.. Here, the interdictor may prefer to choose a probabilistic (i.e. mixed) interdiction strategy to possibly prevent from predicting their exact actions and, hence, potentially achieving a better outcome. In this case, ’s mixed-strategy vector, specifies the probability with which plans to launch an attack on the UAV from the nodes in . Hence, under mixed-strategy interdiction, the UAV can be subject to successive probabilistic attacks from multiple nodes. Next, we show that when chooses a mixed interdiction strategy , ’s choice of optimal path becomes an MDP problem whose transition probabilities result from the choice by .
Consider the case in which had chosen strategy and the UAV was at node , at time , and then decides to go to a neighboring node . By reaching node (i.e. the proximity of danger point ) at time , the UAV could be subject to an attack. The probability with which the UAV is successfully attacked at node is equal to . Hence, if the UAV has reached node at time and then decided to go to node next, it can either reach node at time and not be successfully attacked at (with probability ), or it can be brought back to the origin when reaching node (if subject to a successful attack) with probability . This latter case implies that the UAV would reach node at time with probability . This security problem can be modeled as an MDP [32] whose transition probabilities depend on the security graph, , and on the choice of . We define the set of states of this MDP to be the set of nodes of . can then decide to go from a node to any of its neighboring nodes (i.e. next potential states). However, its transition to this state is stochastic because, if the attack is successful, instead of transitioning to a neighboring node, the UAV transitions to state .
The state transition probabilities, M\big{(}i,j;(\boldsymbol{x},k)\big{)}, specify the probability of transitioning from state to state when chooses strategy and chooses action when at (choosing action refers to choosing to move from node to node )101010M\big{(}i,j;(\boldsymbol{x},k)\big{)} can be alternatively represented as M\big{(}i,j;(\boldsymbol{x},i\rightarrow k)\big{)} to explicitly indicate that the action of is to move the UAV from node to node . However, for ease of notation, and since it is given that the UAV is initially at state , rather than using , we use only the end node to indicate the operator’s action.. M\big{(}i,j;(\boldsymbol{x},k)\big{)} is defined as:
[TABLE]
Here, we note the fundamental difference between the attempted action, , by and the MDP state to which the UAV transitions from state . In fact, in both (15) and (16), the attempted action is to move the UAV from node to node . However, the MDP state to which the UAV transitions is either or depending on whether or not the UAV is successfully attacked. The instantaneous cost to (reward to ) from a state transition from to , when chooses and chooses to move to node , can be expressed as follows:
[TABLE]
For every transition between two states, the UAV accumulates additional delivery time as expressed in (18) and (19), until the UAV reaches and the game ends. The goal of is hence to minimize this expected cumulative delivery time. Therefore, the choice of a mixed strategy by the interdictor, , defines an MDP111111Hence, hereinafter, we refer to this MDP as the MDP induced by . whose set of states is with transition probabilities as defined in (15)-(17) and instantaneous reward/cost structure as shown in (18) and (19). The goal of is to choose the best MDP policy to minimize its expected accumulated delivery time, where a policy specifies, for each node , the next node to which to go. We let be the set of all policies. We note that, given the state transitions in (15)-(17), a policy practically results in one realizable -to- path denoted by . This is due to the fact that under the MDP policy , only the nodes of a certain path will ever be reached. Hence, a policy reduces to a path selection strategy. Given the equivalence between a policy and its resulting -to- path , we next use the two notations interchangeably depending on whether the emphasis is on a general policy or on its resulting path . We define to be the value of the state when follows policy for the MDP induced by the mixed strategy, , of player . In other words, is the expected time that the UAV needs to reach from when policy is followed. Based on (15)-(19), we can express the values of the states, for a given policy , recursively; as follows:
[TABLE]
As such, the values of each two consecutive nodes, and ( being reached from based on ), are such that:
[TABLE]
Of particular interest to our analysis is the value at the origin, , which constitutes the expected delivery time when following policy . For a given choice by , the goal of is to find a policy which minimizes . The optimal values, , at each state – i.e. the minimum expected time for the UAV to reach from – are interdependent in a recursive manner following from the Bellman equation:
[TABLE]
Based on the recursive definition in (21), the value at the origin for an interdiction strategy and an MDP policy , inducing a path h_{\pi_{\boldsymbol{x}}}$$=$$( containing nodes with ordered indices, is given in Proposition 2.
Proposition 2
The expected delivery time, , for a mixed interdiction strategy and MDP policy , inducing path , is given by:
[TABLE]
*where is a function which takes either or inputs ( or consecutive nodes of a path , respectively) and which we define as g(k,m,n)$$=x_{n}p_{n}(t(m,n)+t_{a})$$+t(k,m), and g(m,n)$$=x_{n}p_{n}(t(m,n)$$+t_{a}), considering , , and to be three consecutive nodes of a path *
Proof:
The proof follows directly from (21) and from the fact that for any possible policy, since the expected delivery time starting from is equal to [math]. Details are omitted due to space limitations. ∎
To solve the game, we define the SE with mixed-strategy interdiction121212The MSE in Definition 2 is a saddle point of our underlying zero-sum game. An alternative approach for studying the equilibrium of the zero-sum game is to identify its corresponding saddle point in mixed strategies (i.e. considering mixed strategies for both players), where these saddle-point mixed strategies can be computed by solving a linear program [31]. However, the MSE in Definition 2 is tailored to the structure of our game, introduced in Section II, and does not follow a brute-force approach.:
Definition 2
A strategy pair constitutes a mixed interdiction Stackelberg equilibrium (MSE) of the network interdiction game if
[TABLE]
[TABLE]
This MSE can be also equivalently defined in terms of and the optimal path induced by , i.e., .
IV-B Game Equilibrium under Mixed-Strategy Interdiction
’s problem consists of computing the optimal policy (or optimal path) for the MDP induced by . This can be achieved using known methods such as value iteration and policy iteration methods [32]. Indeed, for obtaining the values at each state (i.e. node) resulting from a policy (known as policy evaluation), can be computed as shown in (23) and then used to find for each by starting from (whose value is ) and moving backwards while applying (21). As such, using policy iteration [32], starting from a certain MDP policy, policy evaluation and policy improvement steps can be sequentially taken to converge to the optimal policy.
In their traditional form, value and policy iteration methods seek to find an optimal policy specifying the best action to take from every state in the state space. However, as stated in our game formulation, a certain policy leads to a unique resulting -to- path resulting in a certain value at the origin as shown in (23). Next, we propose an alternative method for identifying ’s problem solution which does not seek to find the optimal action to be taken from each possible state, but rather an optimal -to- path. This method is dubbed the all-paths method and can be carried out by the following steps:
Find all possible paths, , from to , 2. 2.
Evaluate for each path using (23), 3. 3.
Find the optimal path which solves:
[TABLE]
Note that after computing , and given that , the resulting optimal values at the nodes of can be computed following (21).
Remark 1
The all-paths method is guaranteed to find a solution to ’s problem, given in (25), in iterations. By its definition, the all-paths method searches over all possible -to- paths. Due to the equivalence between a certain policy and its resulting path in terms of the achieved value at the origin, searching over all possible paths , requiring iterations, will guarantee obtaining the solution to (25).
The all-paths method can be considered an informed exhaustive search method. In fact, rather than searching over all possible policies, , whose size can be computed as , the all-paths method leverages the policy-path equivalence to search only over the set of possible -to- paths, . If the security graph, , can be split into phases where each two consecutive phases form a complete bipartite graph131313We refer to such graphs as phase-connected graphs, which reflect the practical case in which the UAV goes from one set of danger points to the other (e.g. between sets of hills and sets of high-rise buildings) with relatively safe conditions in between. (as is the case in Fig. 1 and Fig. 2), grows linearly in the number of nodes, , in a given phase. Indeed, in a phase-connected graph with phases, the total number of -to- paths is given by .
For example, in Fig. 2, and while ; the latter is the number of iterations needed for a standard exhaustive search. Hence, the all-paths method requires fewer iterations than the exhaustive search method, and in contrast to policy and value iterations, each iteration of the all-paths method is search-free (that is, it does not require a minimization step) and is only limited to arithmetic operations which can be efficiently performed.
From the interdictor’s side, after predicting the reaction for a chosen interdiction strategy , aims at solving the optimization problem defined in (24). The main challenge with solving this problem resides in the discontinuous changes in the objective function which can be induced by a slight modification to the chosen strategy . This is due to the fact that a minimal change to the chosen can lead to a complete modification of the resulting optimal reaction MDP policy of . Hence, due to the discontinuity of the objective function in (24), finding an exact globally optimal solution to the interdictor’s problem may not be guaranteed. The search for such a global optimum can be done using heuristic methods such as pattern search based methods [33]. By using pattern search based methods, an achievable solution to the interdictor’s problem can be obtained which leads to what we consider an achievable MSE. As such, the proposed all-paths method and pattern search are two complimentary methods, which when combined, allow computing an MSE of the network interdiction game.
V Game Analysis under PT
As established in Section III and Section IV, the choices of interdiction and path selection strategies are carried out under uncertainty. Indeed, every chosen interdiction strategy and path selection strategy give rise to a prospect: A set of possible achievable delivery times each of which can occur with a certain probability. In fact, when chooses and chooses path , and if we let be the number of times the UAV is successfully attacked at node , then the possible achieved delivery times and their associated probabilities of occurrence, , will be given by141414The expressions in (27) and (28) reduce, respectively, to (1) and (2) when considering pure-strategy interdiction.
[TABLE]
where
[TABLE]
The previous analyses in Section III and Section IV had considered the situation where the uncertainty is managed by and in a fully rational and objective manner. In other words, the possible delivery times, in (27), and the probabilities of their occurrence, in (28), are similarly and objectively perceived by and , leading the players to assess a pair of strategies based on an expected value of their resulting prospect. However, given the time criticality of the studied drone applications (which must execute certain missions within a target time period), a certain achieved delivery time can be assessed subjectively and differently by and with respect to their chosen target delivery times. In addition, the perception of probabilities by and can be distorted, which makes them deviate from the rational objective perception, leading each player to assess the risk level of a certain path differently. Indeed, as has been shown in a number of psychological empirical studies, as in [26] and [27], when faced with risk and uncertainty (similarly to our time-critical network interdiction game), the decision making processes of individuals can significantly deviate from full rationality. Essentially, individuals have been found to subjectively evaluate outcomes and perceive probabilities [27, 26], hence assessing a certain prospect not based on its expected value but based on a subjective valuation assigned to this prospect.
To capture the interdictor’s and UAV operator’s potential subjective perceptions (i.e. bounded rationality)151515Although the proposed game policy will be implemented autonomously by the drone, the design of the game-theoretic policies are performed by a human operator whose perceptions are subjective and rationality is bounded., we incorporate the principles of cumulative prospect theory [26] in our game formulation. PT is a Nobel prize-winning theory which has been shown to successfully model and predict decision makers’ subjective behaviors, preferences, and valuations. Indeed, using PT, the subjective perception of the likelihood of occurrence of a probabilistic delivery time and the subjective evaluation of this delivery time with respect to a reference point becomes central to the decision making processes of and . Consider a prospect , listing each possible outcome and its probability of occurrence . Each is a possible delivery time in (27) and is its corresponding probability, , in (28). Under PT, for a maximizer, the value of an outcome , denoted by , with respect to a reference point is given by [26]:
[TABLE]
where is known as the loss multiplier and and are constant parameters which shape the value function. Based on the sign of , can be split into a negative prospect and positive prospect . The values in correspond to losses and the values in correspond to gains. Consider that contains terms, indexed from to , and contains terms, indexed from to . In addition, consider that each of the two prospects are ranked in ascending order based on the values, . Under PT, the valuations of the positive and negative prospects, and , are given by[26]:
[TABLE]
resulting in the valuation, , of prospect . and are decision weights defined based on the cumulative probability of occurrence of outcome :
[TABLE]
where and are the weighting functions associated with the positive and negative prospects, respectively, and are defined as follows (for a certain objective probability )[26]:
[TABLE]
where and are known as the rationality parameters. The higher the value of the rationality parameter, the closer are and to the rational probability .
The expressions in (33) showcase the way decision weights are formed from cumulative probabilities of outcomes in a prospect. In fact, corresponds to the probability that the outcome is at least as good as while corresponds to the probability that the outcome is strictly better than . Equivalently, corresponds to the probability that the outcome is at least as bad as while corresponds to the probability that the outcome is strictly worse than .
Next, we formulate our network interdiction game under PT, which we call the PT game. We also split our analysis of the PT game into pure and mixed interdiction cases. Here, we note that the notations of the constants used in (30), (31), and (34), i.e. , and , will be consistently used in the analyses that ensues but will be indexed by and depending on the player to which they refer.
V-A PT Game under Pure Interdiction Strategies
As discussed in Section III-A, when chooses path and is located on node , the possible outcomes, , and their associated probability of occurrence, , for , are as described, respectively, in (1) and (2). Hence, the strategy pair gives rise to a prospect, , in which the outcomes are ordered from lowest to highest, and is expressed as:
[TABLE]
As PT predicts, the interdictor and the UAV operator evaluate each possible outcome of this prospect subjectively, as shown in (30) and (31). In this regard, the valuation, , that the interdictor gives to the possible outcome, , is as follows:
[TABLE]
where
[TABLE]
Given that the interdictor aims at maximizing the expected delivery time, is seen as a gain while is seen as a loss. Equivalently, the valuation, , that the UAV operator gives to the possible outcome, , is as follows:
[TABLE]
where
[TABLE]
Since aims at minimizing the expected delivery time, is evaluated as a loss while is viewed as a gain.
Using PT principles, we derive the valuations that and assign to each possible choice of the pair of pure interdiction and path selection strategies . We denote these valuations by and for, respectively, and .
Theorem 2
The PT valuation that assigns to a strategy pair is given by
[TABLE]
where
[TABLE]
[TABLE]
where and are such that: for , , for , and .
Proof:
The proof is presented in Appendix B.
∎
Theorem 3
The PT valuation that assigns to a strategy pair is given by
[TABLE]
where
[TABLE]
[TABLE]
where and are such that: for , for , and .
Proof:
This proof follows steps similar to those in the proof of Theorem 2 while accounting for the valuations that assigns to each possible outcome given in (39)-(41).
∎
As shown in (45) and (49), and correspond to infinite summations, i.e. infinite series. Hence, to be able to compare between possible pairs of strategies , based on their valuations and , and to identify the equilibrium strategy pair, it is necessary for these sums to converge. We next show in Proposition 3 and Proposition 4 that and are convergent series.
Proposition 3
* is a convergent series.*
Proof:
Toward proving the convergence of , we first prove that , defined in (68) and composed of positive terms, converges using what is known as the ratio test. Following the ratio test, for a series with positive terms , is defined as . If , then converges. As such, we refer to the term of by , which is given by V^{I^{+}}_{k}=(\Delta I_{k})^{\beta_{I}^{+}}\Big{[}\omega_{I}^{+}\big{(}(p_{n})^{k}\big{)}\textrm{-}\omega_{I}^{+}\big{(}(p_{n})^{k+1}\big{)}\Big{]}, while follows from (34). In this respect,
[TABLE]
∎
Proposition 4
* is a convergent series.*
Proof:
The proof follows steps similar to those in the proof of Proposition 3. ∎
Under PT, the pure-strategy equilibrium of the game is based on the subjective valuations, and , that and respectively assign to the prospect resulting from the choice of strategy pair . As such, under PT, the game becomes a nonzero-sum game whose SE is analyzed next.
As in the analysis in Section III-B, can optimally react to a decision that had been taken by . However, for the PT game, this optimal reaction is based on the valuation rather than the expected delivery time . In this PT game, we denote the choice of a path by , as an optimal reaction to a node that had been chosen by , by , which is formally defined as:
[TABLE]
where is as given in Theorem 3.
Paralleling the SE for the fully rational game in Definition 1, an SE for the PT game (SE-PT) is defined as follows.
Definition 3
A strategy pair constitutes a Stackelberg equilibrium of the PT game if
[TABLE]
where is as defined in Theorem 2, and is as defined in (50).
’s problem corresponds, then, to choosing which solves
[TABLE]
Following a similar logic as in the derivation of the SE in Theorem 1, the SE-PT can be analytically characterized.
Theorem 4
*The interdictor’s SE-PT strategy, , is given by: *
[TABLE]
*where *
[TABLE]
[TABLE]
[TABLE]
and is the shortest -to- path not containing node .
The resulting UAV operator’s SE-PT strategy is given by
[TABLE]
Proof:
Due to space limitations, only a sketch of the proof is provided. ’s response to a choice by will either be or . always has an incentive to choose , since otherwise, , which results in the worst possible for . However, choosing an might also lead to deviate from to the best alternative . Hence, can split the nodes in into two sets, and , where the former set consists of nodes of which when attacked would not lead to deviate from , while the latter set consists of nodes which when attacked will lead to deviations to the best alternative. Hence, and in (54) and (55) represent the best two alternatives for . As such, in (53) corresponds to choosing the best of these two alternatives, and in (57) and (58) correspond to choosing the best reaction by to the choice made by . ∎
Theorem 4 analytically characterizes the SE of the PT game, which can be compared to the SE of the game with full rationality derived in Theorem 1. This comparison enables us to analyze the effect of the players’ subjective PT valuations and perceptions on their chosen equilibrium strategies. A main component of the choice of the SE and SE-PT strategies is the characterization of sets , in (10), and , in (56). By comparing (10) and (56), we can see that relies on the comparison between and for each ; while relies on comparing , which can be obtained from (49), with , which can be obtained from (48). This difference in and enables possible deviation of the SE-PT strategies from the SE strategies.
V-B PT Game under Mixed-Strategy Interdiction
Consider the case where chooses and chooses a policy that induces path h=($$O, . Then, the resulting possible delivery times, , and their associated probabilities of occurrence, , are given by (27) and (28), where is the number of times the UAV is successfully attacked at a node . Hence, the interdiction strategy , by , and response path , by , result in a prospect in which each outcome occurs with probability . Under PT, to compare strategy pairs , each of and generates a personal valuation of this prospect. As a result, their choices of optimal mixed interdiction and path selection strategies are based on these PT valuations. Given (27)-(29) and the value and weighting functions introduced in (30)-(34), we can generate the valuations assigned by and , and , to prospect by following steps similar to those in Section V-A. Based on and , the equilibrium of the PT game with mixed interdiction strategies can be characterized.
In this regard, the definition of the SE-PT equilibrium introduced in Definition 3 can be extended to the mixed-strategy interdiction case as follows:
Definition 4
A strategy pair constitutes a PT mixed-strategy interdiction Stackelberg equilibrium (MSE-PT) of the network interdiction game if
[TABLE]
where is the optimal reaction of to and is given by:
[TABLE]
Our solution approach presented in Section IV-B, which delivered the MSE of the game (under full rationality), also applies here to derive the MSE-PT of the PT game. Indeed, characterizing the MSE-PT requires solving ’s problem in (60) as well as ’s problem given in (59). The all-paths method proposed in Section IV-B can guarantee solving ’s problem.
Remark 2
*The all-paths method is guaranteed to find for each interdiction strategy . Finding corresponds to identifying the path obtained as . As such, by following steps to of the all-paths method, and considering instead of , the all-paths method performs a complete search over all possible -to- paths and returns path which results in the minimum , hence, determining . *
The interdictor’s problem corresponds to solving the following optimization problem:
[TABLE]
As in ’s problem in Section IV, obtaining an exact global solution to (61) cannot be guaranteed due to the non-convexity and discontinuity of the objective function stemming from the sudden changes to which can be triggered by minimal changes to . Hence, for obtaining a solution to (61), we propose using a pattern search based method, as discussed in Section IV-B.
VI Numerical Results
For our numerical analysis, we provide a tractable set of examples which showcase the different contributions of the derived analytical results and highlight the effects that the various PT parameters can have on the equilibrium strategies and achieved expected delivery times. For these simulation-based numerical analyses, we consider the graph shown in Fig. 1 composed of nodes and edges. We label the paths, from to , as follows: . Given that node 1 () and node 10 () are part of each path, a path ($$1, is, for convenience, referred to by . In addition, the travel times , for , in Fig. 1 are drawn from a uniform distribution in the interval yielding [$$6.89, 5.41$$]. We then choose the attack success probabilities as \boldsymbol{p}$$= [$$0, [math]. The length of each path , , and the risk probability at each node, , are shown in Fig. 3. Fig. 3 shows that path , i.e. , is the shortest path followed by paths , i.e. , and path , ; while node is the most risky node followed by nodes and , respectively. The re-handling and processing time is considered to be . For the PT parameters of and , unless stated otherwise, we consider , , , and .
We will first take the reference points (which represent, for example, a target delivery time) of both players to be equal, , and ranging from to . The resulting equilibrium interdiction strategies (i.e. ’s equilibrium strategies) are shown in Fig. 4, and ’s equilibrium strategies are shown in Fig. 5. Fig. 4 shows that the MSE interdiction strategy, , focuses solely on nodes , , and , (, , and ) each of which is at least part of one of the three shortest paths (paths , , and ). In addition, ’s MSE strategy, , corresponds to choosing path , which is composed of nodes , , and . Given that nodes and are not attacked by at the MSE and that and , path is a relatively safe path. The players’ MSE strategies lead to an MSE expected delivery time that is equal to around , as shown in Fig. 6.
Fig. 4 shows the difference between ’s MSE-PT interdiction strategies, , and the MSE interdiction strategies for different values of . Fig. 4 shows the shift in the PT interdiction strategy, , from mainly targeting the incoming neighbor nodes of (i.e. nodes , , and ), at , to a more spread out interdiction strategy targeting a larger number of nodes, at . At small values of , such as , all possible delivery times fall above . Hence, all possible outcomes are valued by as gains. Since the PT value function, in (30) and (31), leads to be risk averse in gains, choosing nodes , , and is appealing since any -to- path is guaranteed to pass by at least one of these nodes. Clearly, this choice of is a risk averse choice that guarantees a sure gain. However, when increases, some of the possible delivery times will fall below . Hence, for a choice by , and by , some of the outcomes will correspond to gains and some to losses leading to drift away from a mere risk averse strategy. In Fig. 5, we show the different MSE-PT strategies of as varies. Fig. 5 shows that at , chooses the shortest path at the MSE-PT. This is due to the fact that, for this small reference point , all possible delivery times are seen as losses by . The concavity of the value function for outcomes greater than renders risk seeking in losses. Hence, taking the shortest path (even if it is risky up to a certain extent) becomes more appealing to . When increases, ’s MSE-PT strategy will drift away from the shortest path, particularly at values of that are high enough to enable certain possible delivery times to fall below the reference delivery time, , leading to outcomes that are valued as gains.
Fig. 6a shows the resulting expected delivery times, at the MSE and MSE-PT, for the different values of . Clearly, for low values of , the MSE-PT results in a lower expected delivery time than the MSE. However, for relatively high values of , the MSE-PT results in an expected delivery time that is higher than the expected delivery time at the MSE. As shown in Fig. 6a, the percentage difference in expected delivery time at the MSE-PT compared to the MSE is at and at . Indeed, since at low values of , takes a risk averse non-aggressive attack strategy, as shown in Fig. 4, and chooses a risk-seeking shortest path, as shown in Fig. 5, this leads to achieving a relatively short expected delivery time since this shortest path (i.e. path ) is not heavily targeted by at the MSE-PT. However, for higher values of , considers more aggressive interdiction strategies and considers safer paths which results in expected delivery times that are higher at the MSE-PT than at the MSE. In addition, the results in Fig. 6a show that at the MSE-PT, except for and , was not able to achieve an expected delivery time that is below its target reference delivery time. However, at the MSE, ’s expected delivery time is lower than its target delivery time for . Hence, selecting strategies based on PT valuations is, based on this comparison, disadvantageous to . In addition, Fig. 6a shows the expected delivery time achieved when chooses the shortest path (i.e. path ) and chooses either its fully rational MSE interdiction strategy or its prospect-theoretic MSE-PT interdiction strategy (these strategies are shown in Fig. 3) – labeled, respectively, “Shortest path vs. Interdiction MSE” and “Shortest path vs. Interdiction MSE-PT” – for different values of . Fig. 6a shows that under full rationality, unilaterally deviating from the MSE path (i.e. path as shown in Fig. 5) to the shortest path (i.e. path ) results in an increase in the expected delivery time, which is not advantageous to . Under PT, deviating from the MSE-PT path to the shortest path results in a worse (i.e. higher) expected delivery time for , while it results in a better (i.e. lower) expected delivery time for . Indeed, under PT, aims at minimizing its PT valuation of the expected delivery time, , as shown in (60), rather than the objective expected delivery time. However, minimizing may not lead to achieving the minimum possible expected delivery time. In fact, Fig. 6b shows and , i.e., the PT valuation achieved by when choosing its MSE-PT strategy vs. ’s MSE-PT strategy () as compared to choosing the shortest path vs. . As shown in Fig. 6b, ’s valuation of choosing its equilibrium MSE-PT strategy is lower than the valuation achieved when choosing the shortest path. However, Fig. 6a shows that the deviation to the shortest path would have been advantageous to for . This, hence, highlights the effect of the subjective PT perceptions of , which may lead to a worse expected delivery time as compared to the expected delivery time which could have been achieved by a mere choice of a non-strategic shortest path.
Hereinafter, to characterize the effect of the various PT parameters on the resulting equilibrium strategies and outcomes, we consider the interdictor to be fully rational (i.e. , , , and ), while values outcomes and performs probability weighting following PT, with PT parameters similar to the ones used in the previous simulations, unless stated otherwise. We first study the effect of varying the rationality parameters of , i.e. and , on the MSE-PT and then study the effects of varying ’s loss parameter . First, we consider , and we let take the following values: , , , , , and .
Fig. 7 shows that the MSE-PT interdiction strategy approaches its MSE strategy at higher values of . However, one can see that ’s MSE-PT strategy does not completely coincide with its MSE even for high values of . This is due to the fact that even when ’s probability weighting is closer to full rationality, the way values the possible game outcomes (i.e. the possible delivery times) is based on its reference point and value function. Hence, even with a closely rational probability weighting, ’s MSE-PT may not equal its MSE strategy. This can, indeed, be seen from Fig. 8, which shows that even for , ’s MSE-PT strategy is different from its MSE strategy. Fig. 8 shows how ’s MSE-PT strategy changes with an increase in . At lower values of , ’s MSE-PT strategy consists of path , i.e. , while at higher values of , ’s MSE-PT strategy shifts to choosing path , i.e . As shown in Fig. 7, at lower values of , ’s optimal strategy is focused on nodes and making path , chosen by at the MSE-PT, highly risky. However, still chooses this path, at the MSE-PT, since at such low values of , ’s valuation of probabilities is highly distorted. In fact, the weighting functions and flatten for lower values of . Hence, would assess different paths as almost equally risky leading to choose path . However, when increases, ’s perception of probabilities becomes more rational. Hence, for these values of , can observe that path is highly risky and chooses instead the safer path , composed of nodes which are not attacked with a high probability by at the MSE-PT.
Fig. 9a shows the resulting expected delivery times at the MSE and at the MSE-PT for various values of . From Fig. 9a, we can see that the MSE-PT strategies result in expected delivery times that are longer than the expected delivery time achieved at the MSE. Indeed, for , the percentage difference between the expected delivery time at the MSE-PT and that at the MSE goes up to . The reason is that, as shown in Fig. 8, for low values of , admits a risky MSE-PT strategy leading to high expected delivery times. However, as increases, the shift in ’s MSE-PT strategy allows achieving better expected delivery times; which are, however, still longer than the MSE expected delivery time. Fig. 9a also shows an expected delivery time labeled “Rational response”. This corresponds to choosing a rational strategy in response to ’s MSE-PT strategy. In other words, rational response corresponds to choosing the path strategy which solves (26) for . In this scenario, assumes that admits PT valuations and would, hence, choose its MSE-PT strategy, . However, if is rather rational, it can take advantage of its knowledge of to achieve a better expected delivery time. Indeed, the rational response of consists of choosing path , for and , and path , for the higher values of , which result in achieving expected delivery times that are shorter than the expected delivery times at the MSE-PT and the MSE, as shown in Fig. 9a. In fact, as can be seen from Fig. 9a, at , choosing the rational response strategy (which corresponds to choosing path ) allows to achieve an expected delivery time that is lower than the expected delivery time achieved at the MSE-PT. Fig. 9a also shows the resulting expected delivery time when chooses the shortest -to- path and chooses its MSE-PT interdiction strategy, labeled “Shortest Path vs. Interdictor MSE-PT”, for different values of . As can be seen in Fig. 9a, a deviation from the MSE-PT path to the shortest path would have been advantageous to as it would lead to a lower expected delivery time for the entire investigated range of . However, as subjectively assesses expected delivery times under PT, the choice of the MSE-PT path is valued to be better than choosing the shortest path, as shown in Fig. 9b, as the MSE-PT path leads to a lower PT valuation. Hence, this further highlights the negative effect that the subjective PT perception of can have on its achieved expected delivery time. The rational response as well as the MSE strategies both lead to a better expected delivery time than the shortest path and the MSE-PT strategies, as shown in Fig. 9a.
Fig. 10a shows the resulting expected delivery times at the MSE and at the MSE-PT, for the various values of . Fig. 10a also shows the expected delivery time achieved when plays the rational response strategy, or the shortest path, as a reaction to choosing its MSE-PT strategy. Fig. 10a shows that the MSE-PT strategies chosen at different values of result in an expected delivery time that is only slightly higher than the one achieved at the MSE. At higher values of , this difference in expected delivery times decreases. Indeed, at , the percentage difference between the MSE-PT and the MSE expected delivery times is while this difference drops to only at . However, when plays a rational response strategy, in response to ’s MSE-PT strategy (which consists of choosing path for all the three values of , i.e. , and ), can achieve an expected delivery time that is up to lower than the expected delivery time achieved at the MSE. Choosing the shortest path by would lead to a better expected delivery time only for . Fig. 10b shows ’s valuation of the MSE-PT strategies as compared to choosing the shortest path, which highlights the reason for which a deviation from the MSE-PT path to the shortest path is not valued to be advantageous by as it leads to an increase in the valuation. In all cases, choosing the rational response is the most advantageous to , as shown in Fig. 10a.
VII Conclusion and Future Outlook
In this paper, we have introduced a novel mathematical framework for studying the cyber-physical security of time-critical UAV applications, such as drone delivery systems and anti-drone systems. We have provided a formulation of the problem using the framework of a network interdiction game between the UAV operator and the interdictor, while viewing either of them as malicious and the other one as benign. In addition, we have incorporated principles from cumulative prospect theory in the game formulation to account for the players’ potential bounded rationality. We have characterized Stackelberg (leader-follower) equilibria of the various types of games and studied their properties. Simulation results have shown that the subjectivity of the players can lead to delays in the expected delivery time.
This work paves the way for various future research steps. Indeed, the introduced time-critical network interdiction game can be studied in the presence of multiple UAVs and multiple adversaries as well as considering dynamically changing security graphs. In addition, the introduced time-critical model can be leveraged beyond the analysis of UAVs, by focusing on any autonomous system performing a time-critical mission. Each studied application yields different types of security graphs over which the game can be formulated and analyzed.
Appendix A Proof of Theorem 1
Proof:
We first prove that choosing a node is a dominated strategy for the interdictor. In fact, If \Rightarrow E_{d}(n\notin h_{s},\rho(n))\textrm{=}f^{h_{s}}(D)\leq E_{d}(n,\rho(n)) , since is the shortest possible expected delivery time. Hence, the interdictor should always choose a node that is part of a shortest -to- path, . Now, based on (3) and (4), for ,
[TABLE]
where condition (62) reflects that, even when the interdictor is located at , the shortest path, , results in a shorter expected delivery time than the best alternative, i.e., . When this condition is not met, a deviation from to the best alternative, , leads to a shorter expected delivery time as captured in (63). In this respect, we let denote the set of nodes that are part of but are such that \frac{p_{n}}{1-p_{n}}$$(f^{h_{s}}(n)$$\textrm{+}t_{a})$$+$$f^{h_{s}}(D)$$\leq$$f^{h_{n}}(D). is formally defined in (10). Hence, the two possible alternatives for the optimal choice of are and defined as:
[TABLE]
[TABLE]
which result, respectively, in expected delivery times:
[TABLE]
[TABLE]
The interdictor’s SE strategy consists, hence, of choosing the best of the two alternatives, and :
[TABLE]
which will result in SE strategies for and expected delivery times as stated in (11)-(14). ∎
Appendix B Proof of Theorem 2
Proof:
We start by considering the case in which . In this case, incorporating ’s valuation of each possible outcome, based on (36)-(38), in prospect , leads to the following prospect, :
[TABLE]
such that , for , and , for ; while is as defined in (38) for . can be further split into a negative prospect, , which includes the elements of with (i.e. for ), and a positive prospect, , which includes the elements of with (i.e. for ). The negative and positive prospects include, respectively, the outcomes that values as losses and outcomes that values as gains. and are expressed as:
[TABLE]
[TABLE]
We next consider the way values this prospect by incorporating not only its subjective valuation of outcomes but also its cumulative weighting of the probability of occurrence of each of these outcomes. We let denote the PT value that gives to prospect , which results from the PT valuation of the negative and positive components of ,
[TABLE]
Here,
[TABLE]
where is as defined in (38) for . Hence,
[TABLE]
However, based on geometric series, . Then,
[TABLE]
A similar analysis can be carried out to obtain the expression of . In this regard,
[TABLE]
In addition, based on geometric series, \textrm{=}q_{n}\Big{(}\sum_{j=0}^{\infty}(p_{n})^{j}\textrm{-}\sum_{j=0}^{i-1}(p_{n})^{j}\Big{)}=p_{n}^{i} which results in
[TABLE]
Hence, based on (66), (67), and (68),
[TABLE]
where .
Next, we consider the case of . When the chosen path does not include the interdiction node , the resulting delivery time does not result in a probabilistic prospect but is rather deterministic and equal to with a probability equal to , i.e., . As such, is valued by depending on whether is higher or lower than (i.e. a gain or a loss scenario). Hence, the value, , that associates to prospect , is:
[TABLE]
∎
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] K. P. Valavanis and G. J. Vachtsevanos, Handbook of Unmanned Aerial Vehicles . Springer, Dordrecht, 2015.
- 2[2] M. Mozaffari, W. Saad, M. Bennis, and M. Debbah, “Unmanned aerial vehicle with underlaid device-to-device communications: Performance and tradeoffs,” IEEE Transactions on Wireless Communications , vol. 15, no. 6, pp. 3949–3963, June 2016.
- 3[3] Y. A. Nijsure, G. Kaddoum, N. K. Mallat, G. Gagnon, and F. Gagnon, “Cognitive chaotic UWB-MIMO detect-avoid radar for autonomous UAV navigation,” IEEE Transactions on Intelligent Transportation Systems , vol. 17, no. 11, pp. 3121–3131, Nov. 2016.
- 4[4] M. Mozaffari, A. T. Z. Kasgari, W. Saad, M. Bennis, and M. Debbah, “Beyond 5G with UA Vs: Foundations of a 3D wireless cellular network,” IEEE Transactions on Wireless Communications , vol. 18, no. 1, pp. 357–372, Jan. 2019.
- 5[5] Y. Nijsure, M. F. A. Ahmed, G. Kaddoum, G. Gagnon, and F. Gagnon, “WSN-UAV monitoring system with collaborative beamforming and ADS-B based multilateration,” in Proc. IEEE Vehicular Technology Conference , Nanjing, China, May 2016, pp. 1–5.
- 6[6] M. Mc Farland, “Google drones will deliver chipotle burritos at Virginia Tech,” CNN Money , Sept. 2016.
- 7[7] R. Pahonie, R. Mihai, and C. Barbu, “Biomechanics of flexible wing drones usable for emergency medical transport operations,” in Proc. E-Health and Bioengineering Conference (EHB) , Iasi, Romania, Nov. 2015, pp. 1–4.
- 8[8] G. Xiang, A. Hardy, M. Rajeh, and L. Venuthurupalli, “Design of the life-ring drone delivery system for rip current rescue,” in Proc. IEEE Systems and Information Engineering Design Symposium (SIEDS) , Charlottesville, VA, Apr. 2016, pp. 181–186.