Accelerated Sampling Kaczmarz Motzkin Algorithm for The Linear Feasibility Problem
Md Sarowar Morshed, Md Saiful Islam, Md. Noor-E-Alam

TL;DR
This paper introduces an Accelerated Sampling Kaczmarz Motzkin (ASKM) algorithm that improves convergence for large-scale linear feasibility problems, especially in ill-conditioned cases, outperforming existing methods.
Contribution
The paper proposes a novel accelerated version of the SKM algorithm with proven convergence improvements for solving large-scale linear inequalities.
Findings
ASKM outperforms SKM, IPM, and ASM on various test instances.
ASKM converges faster on ill-conditioned problems.
Numerical experiments validate the effectiveness of ASKM.
Abstract
The Sampling Kaczmarz Motzkin (SKM) algorithm is a generalized method for solving large scale linear systems of inequalities. Having its root in the relaxation method of Agmon, Schoenberg, and Motzkin and the randomized Kaczmarz method, SKM outperforms the state of the art methods in solving large-scale Linear Feasibility (LF) problems. Motivated by SKM's success, in this work, we propose an Accelerated Sampling Kaczmarz Motzkin (ASKM) algorithm which achieves better convergence compared to the standard SKM algorithm on ill conditioned problems. We provide a thorough convergence analysis for the proposed accelerated algorithm and validate the results with various numerical experiments. We compare the performance and effectiveness of ASKM algorithm with SKM, Interior Point Method (IPM) and Active Set Method (ASM) on randomly generated instances as well as Netlib LPs. In most of the test…
Click any figure to enlarge with its caption.
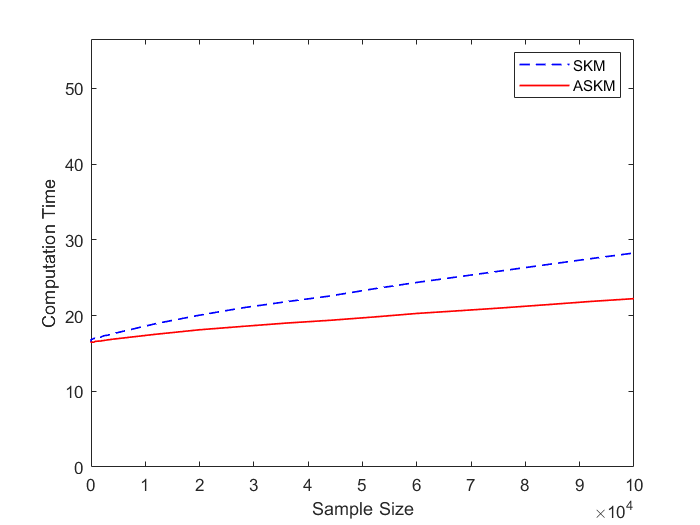 Figure 1
Figure 1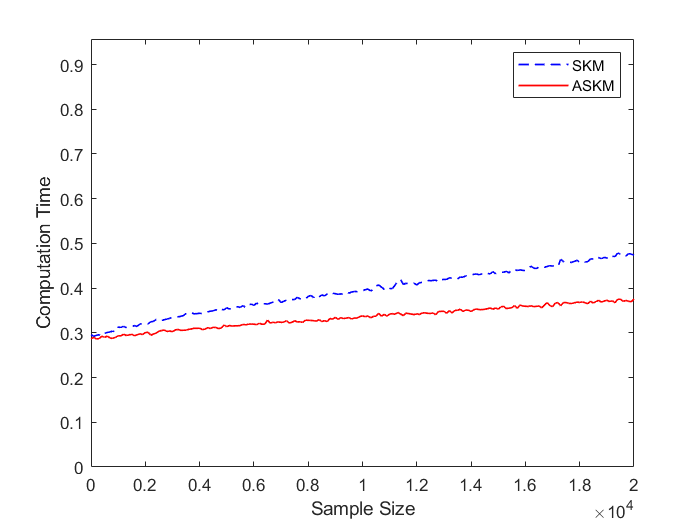 Figure 2
Figure 2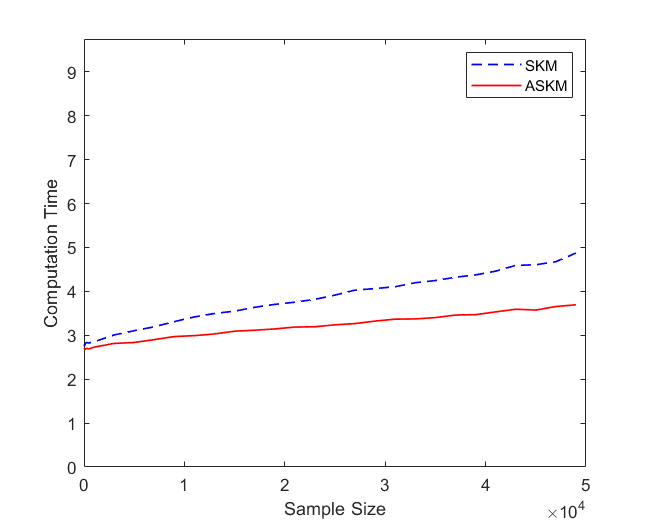 Figure 3
Figure 3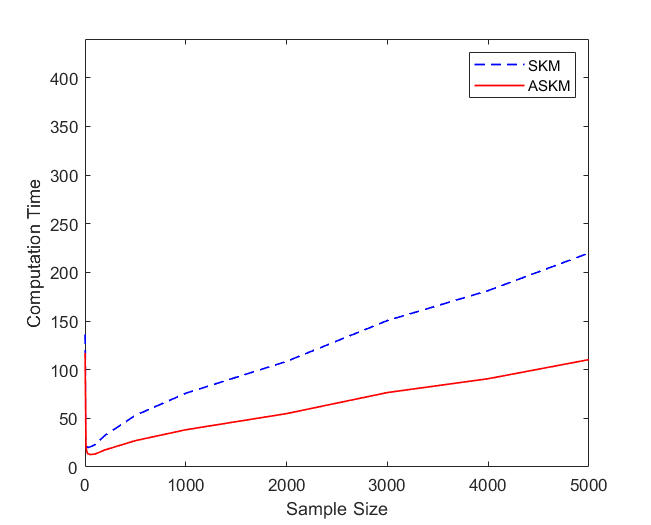 Figure 4
Figure 4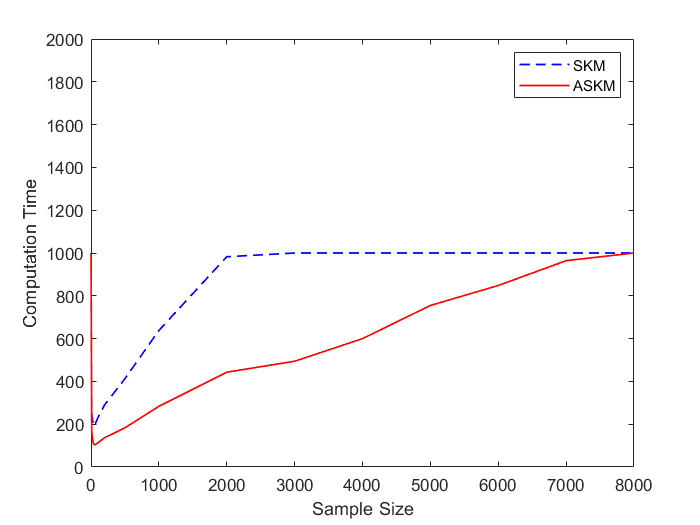 Figure 5
Figure 5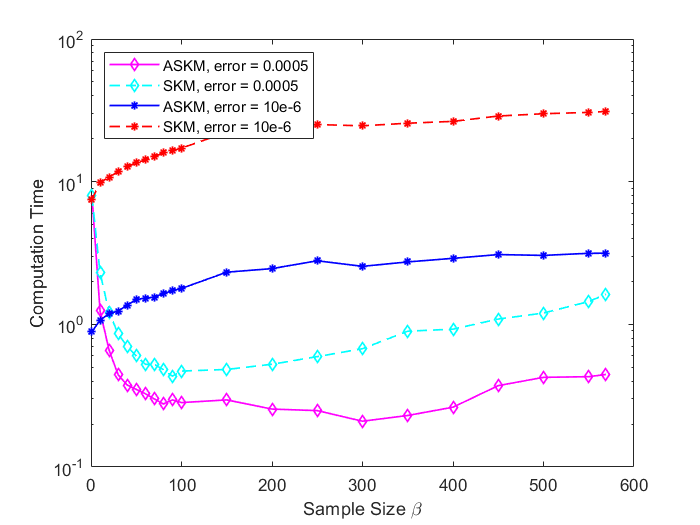 Figure 6
Figure 6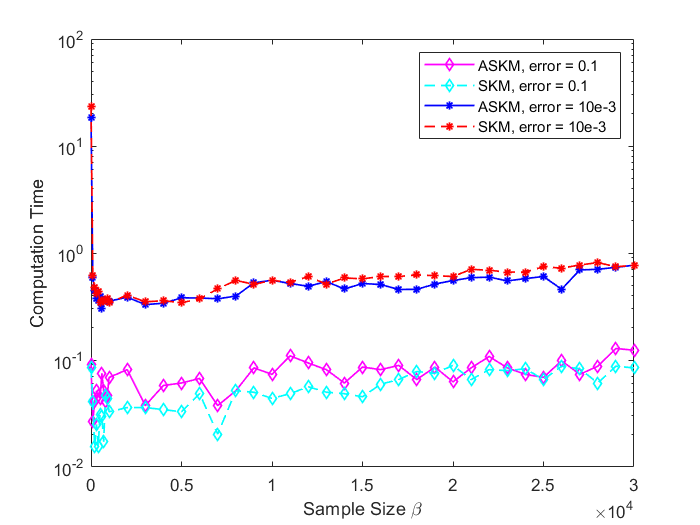 Figure 7
Figure 7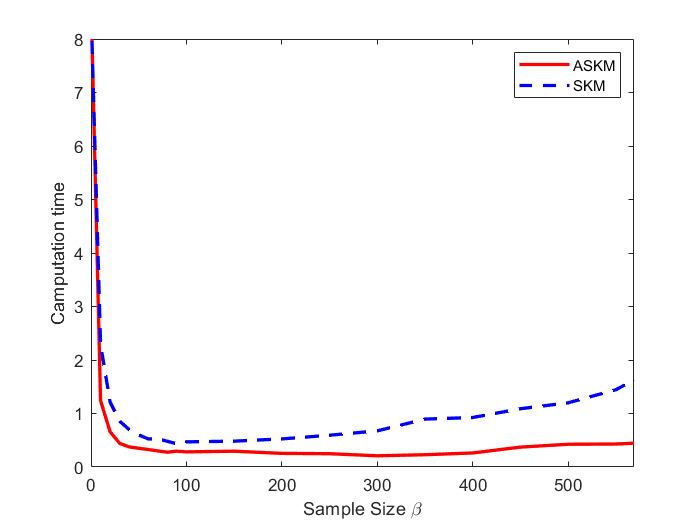 Figure 8
Figure 8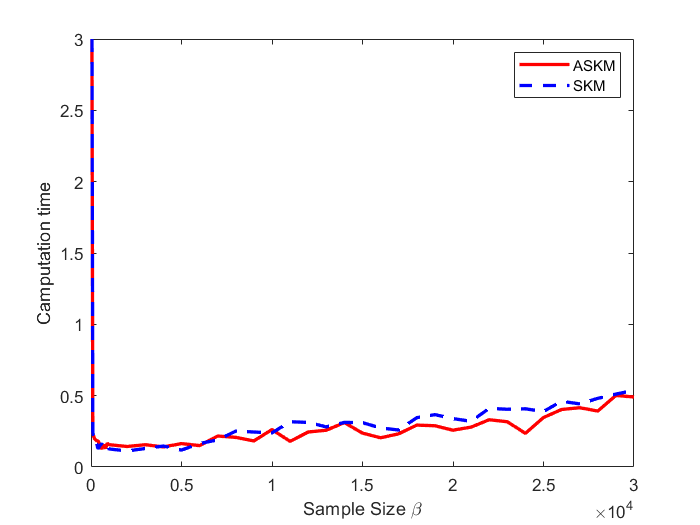 Figure 9
Figure 9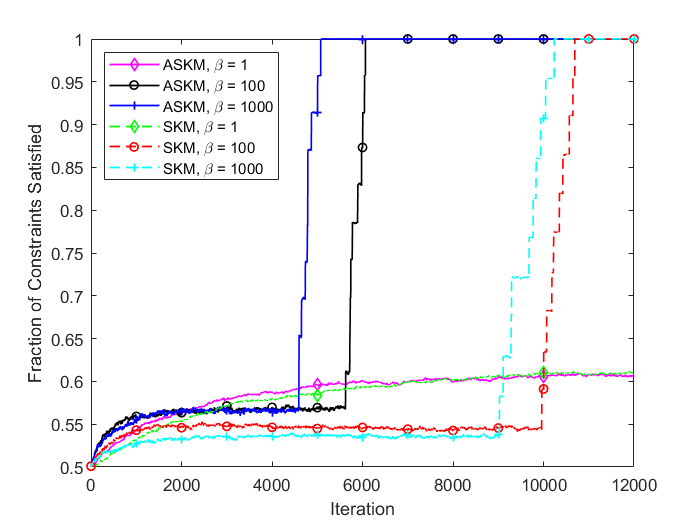 Figure 10
Figure 10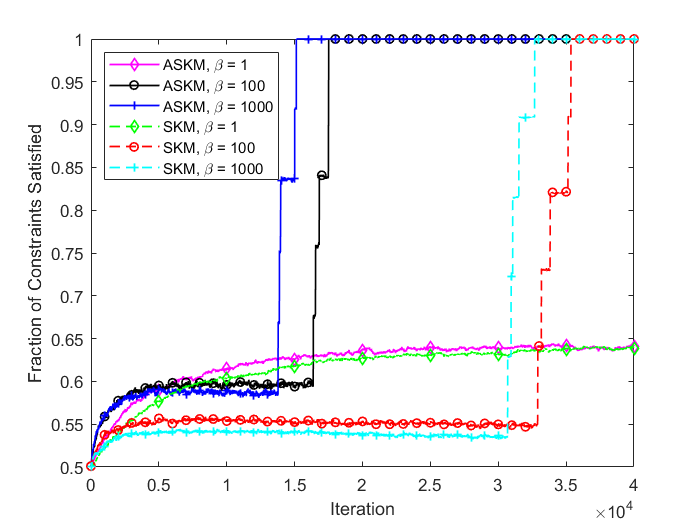 Figure 11
Figure 11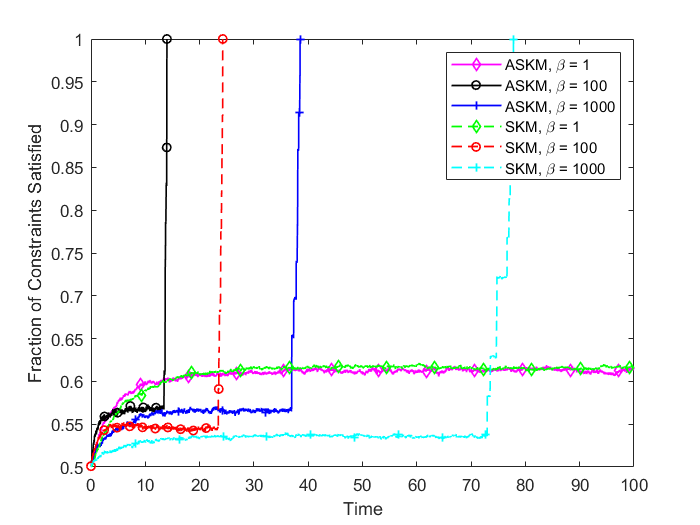 Figure 12
Figure 12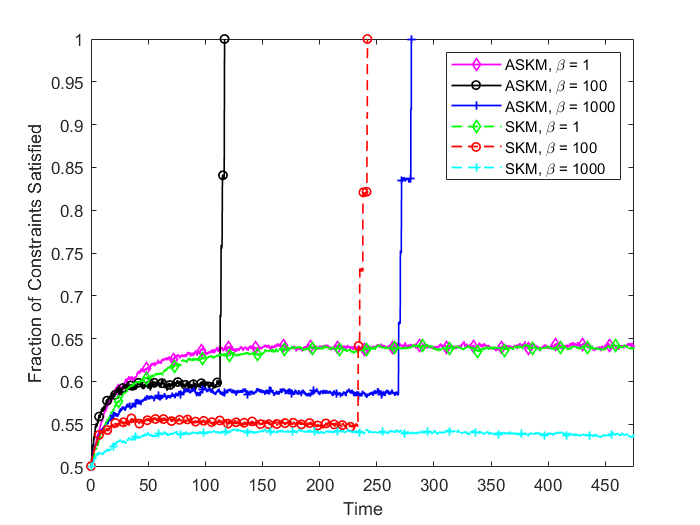 Figure 13
Figure 13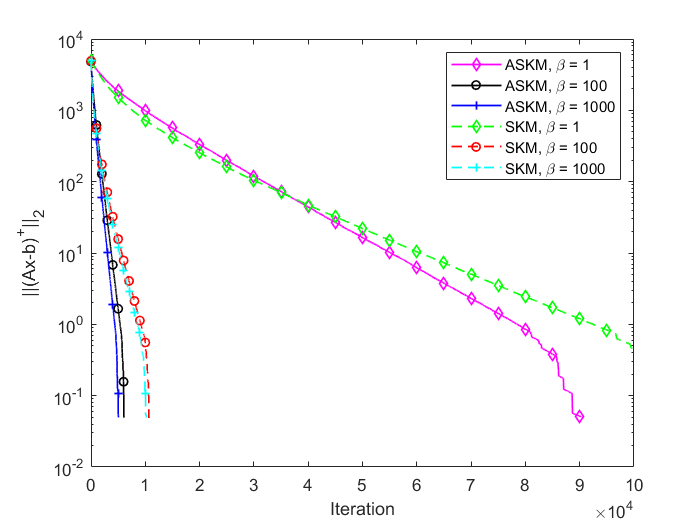 Figure 14
Figure 14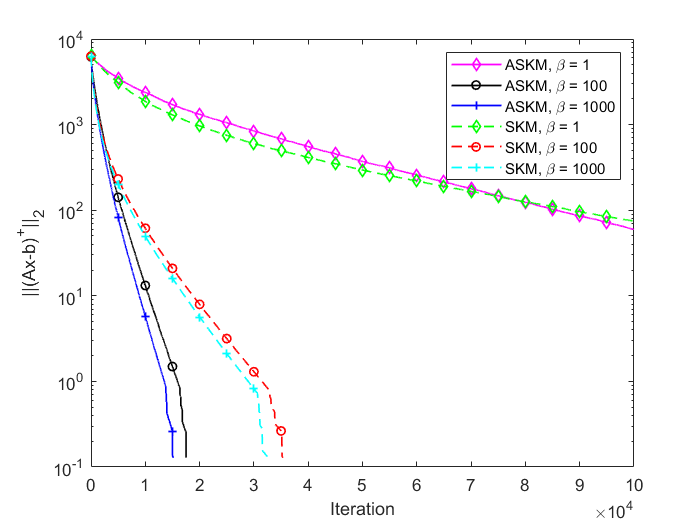 Figure 15
Figure 15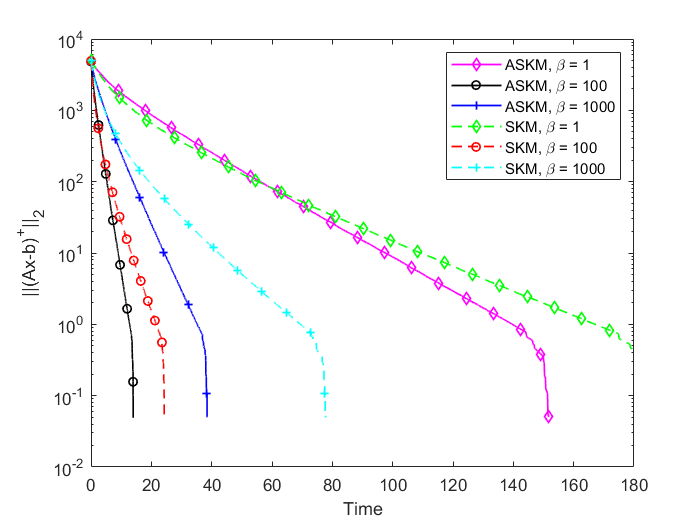 Figure 16
Figure 16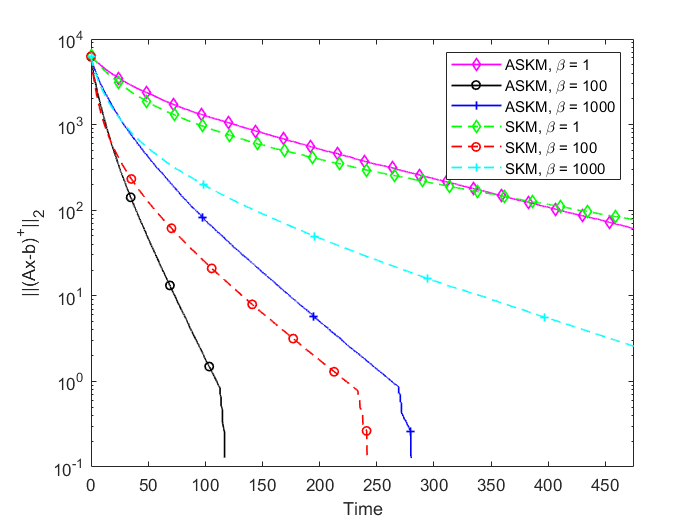 Figure 17
Figure 17| Instance | Dimensions | ASKM | SKM |
|
|
||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| lp_brandy | 0.007 | 0.0117 | 16.97 | 63.11 | 0.1 | 50 | |||||
| lp_blend | 0.41 | 0.56 | 2.28 | 4.62 | 0.001 | 20 | |||||
| lp_agg | 0.059 | 0.088 | 0.01 | 50 | |||||||
| lp_adlittle | 0.0008 | 0.002 | 2.16 | 4.96 | 0.01 | 10 | |||||
| lp_bandm | 0.28 | 0.24 | 14.57 | 0.01 | 70 | ||||||
| lp_degen2 | 8.29 | 10.16 | 7.13 | 21038 | 0.01 | 200 | |||||
| lp_finnis | 0.13 | 0.15 | 0.005 | 100 | |||||||
| lp_recipe | 0.19 | 0.27 | 0.89 | 63.24 | 0.002 | 30 | |||||
| lp_scorpion | 6.83 | 11.86 | 17.68 | 8.02 | 0.005 | 200 | |||||
| lp_stocfor1 | 0.31 | 0.37 | 2.13 | 2.52 | 0.001 | 50 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Accelerated Sampling Kaczmarz Motzkin Algorithm for the Linear Feasibility Problem
Md Sarowar Morshed Department of Mechanical Industrial Engineering, Northeastern University, Boston, MA 02115, USA
Md Saiful Islam 11footnotemark: 1
Md Noor-E-Alam 11footnotemark: 1 Corresponding Author: [email protected]
Abstract
The Sampling Kaczmarz Motzkin (SKM) algorithm is a generalized method for solving large-scale linear systems of inequalities. Having its root in the relaxation method of Agmon, Schoenberg, and Motzkin and the randomized Kaczmarz method, SKM outperforms the state-of-the-art methods in solving large-scale Linear Feasibility (LF) problems. Motivated by SKM’s success, in this work, we propose an Accelerated Sampling Kaczmarz Motzkin (ASKM) algorithm which achieves better convergence compared to the standard SKM algorithm on ill-conditioned problems. We provide a thorough convergence analysis for the proposed accelerated algorithm and validate the results with various numerical experiments. We compare the performance and effectiveness of ASKM algorithm with SKM, Interior Point Method (IPM) and Active Set Method (ASM) on randomly generated instances as well as Netlib LPs. In most of the test instances, the proposed ASKM algorithm outperforms the other state-of-the-art methods.
Keywords: Kaczmarz Method, Nesterov’s Acceleration, Motzkin Method, Sampling Kaczmarz Motzkin Algorithm
MSC 2010: 90C05, 65F10, 90C25, 15A39, 68W20
1 Introduction
We consider the problem of solving large-scale systems of linear inequalities:
[TABLE]
Since, iterative methods are usually better suited to problems with large number of constraints compared to the number of variables, we confine the scope of this work to the regime. We denote the rows of matrix by for . In addition, we make the following assumptions: (1) the system is consistent, (2) matrix has no zero rows and (3) the rows of are normalized (i.e. ). It is worth noting that the last assumption is not a significantly important requirement for algorithmic efficiency, but it helps in the convergence analysis.
While most classical iterative methods are deterministic, recent works [1, 2, 3, 4, 5, 6, 7, 8] suggest that randomization can play a huge role in the design of efficient algorithms for solving LF problems and randomized algorithms often perform better than existing deterministic methods. As shown in [9], randomized iterative methods can outperform state-of-the-art methods (i.e., IPM, ASM) for large-scale LF. In the field of large-scale optimization, mainly IPMs, there is a growing interest in approximate Newton-type methods ([10, 11, 12, 13, 14, 15, 16]) which use fast sub-schemes for calculating approximate solutions of large-scale Linear System (LS).
The Kaczmarz method for solving LS, discovered in 1937 [17], remained unnoticed to the western research community until the early 1980s, when it found an important application in the area of Algebraic Reconstruction Techniques (ART) for image reconstruction [18]. Since then it has been used for several other areas like digital signal processing, computer tomography, and belongs to a general category of methods including row-action, component solution, cyclic projection, and successive projection methods (see [19]). It gained immense popularity in the research community after the convergence analysis done in 2009 for the randomized version [1]. The convergence analysis of Strohmer [1] encouraged numerous extensions and generalizations of the randomized Kaczmarz method (see [2, 3, 5, 6, 7, 20], for instance when we replace the equality constraints with inequality constraints we get a variant of the original problem.
Motzkin’s relaxation method is a variation of the Kaczmarz method which was introduced in the early 1950s [21, 22] for solving systems of linear inequalities. Since then, it has been rediscovered several times. For instance, the famous perceptron algorithm in machine learning [23, 24, 25] can be thought of as a member of this family of methods. Additionally, the relaxation method has been referred to as the Kaczmarz method with the “most violated constraint control” or the “maximal-residual control” [19, 26, 27]. The rate of convergence of Motzkin’s method depends on step lengths and the so called Hoffman constants [21, 28].
Combining both the Kaczmarz and Motzkin method together, the SKM algorithm proposed in [9] for solving LF problem given in (1) requires only memory storage and it has a linear convergence rate. As shown by the authors, SKM is much more efficient than the state-of-the-art techniques such as IPMs, ASMs, and Kaczmarz Methods. Roughly, the SKM algorithm selects a row out of rows (sampled from ) by the maximum violation criterion (i.e. choose the row with ) and then updates the next point as follows:
[TABLE]
In equation (2), can be . Without the loss of generality, we consider in this work. The SKM method described in [9] overcomes the drawbacks of the individual methods (Kaczmarz, Motzkin) and combines their strengths. By selecting the maximum violated hyperplane from a sample, SKM achieves faster convergence compared to the randomized Kaczmarz method. In addition, per iteration computational cost is cheaper compared to Motzkin’s method. Recently, Wright et. al [20] applied the acceleration scheme of Nesterov to the randomized Kaczmarz method. In a different work, Xu et. al [29] investigated the acceleration scheme in the context of the extended randomized Kaczmarz method for least square problems. Moreover, there is a recent work in applying Nesterov scheme in IPMs for solving large-scale linear programming problems [30]. The above-mentioned works showed that the introduction of Nesterov’s acceleration scheme fasten the convergence of the original method.
In this work, we apply Nesterov’s acceleration scheme [31, 32, 33, 34, 35] to the generalized SKM algorithm. This can be seen as a generalized accelerated scheme for both randomized Kaczmarz method for solving linear systems as well as linear system of inequalities. It can be noted that with some modification, like the one stated in the work of Lewis et. al [2], we can apply this method to linear systems with both equality and inequality constraints. The overarching goal of this paper is to incorporate the ideas of the Kaczmarz method [1, 17, 36] for LS and Motzkin’s relaxation [9] for LF problem and develop an accelerated randomized scheme for solving large-scale LF problem. The paper is organized as follows. The proposed algorithm is discussed in section 2, and the convergence analysis of the proposed algorithm is given in section 3. Extensive Numerical experiments performed on random and Netlib LP instances are provided in section 4. And finally the paper is concluded with the conclusion in section 5.
2 ASKM Algorithm
2.1 Notation:
We follow the standard notation in this work. For example, will be used to denote the set of real numbers. Matrix with rows and columns belong to , with denoting the real-valued element in row and column . will be used to denote the transpose of matrix , with , , and denoting the trace, determinant, and diagonal of matrix respectively. will be used as the identity matrix.
Furthermore, we use vectors and as the standard -th basis vector. A function maps its domain, , into set . As it is customary, we use and to represent the gradient and Hessian of . Finally, denotes the standard inner product and as the euclidean () norm. are set to be the minimum and maximum nonzero eigenvalues of respectively. is the spectral norm of the matrix and denote the Frobenius norm. Moreover, is the Moore-Penrose pseduinverse of and the corresponding compact singular value decomposition of as , where are unitary matrices with appropriate size and is the non-singular and diagonal matrix with singular value on the diagonal. Throughout the paper, we denote as the condition number of matrix . The notation denotes the Euclidean norm projection of onto the feasible region of . In this section, we review the proposed SKM algorithm in [9] and then based on the motivation from the accelerated randomized Kaczmarz algorithm in [20] and accelerated extended Kaczmarz algorithm in [29], we develop ASKM algorithm.
In the above algorithm, we propose to use the acceleration scheme discovered by Nesterov [31, 32, 33, 34, 35] in the SKM algorithm framework to achieve second order convergence rate as compared to the linear rate shown in [9]. The ASKM algorithm uses the acceleration procedure [33], which is more famous in the context of gradient descent algorithm. Note that, Nesterov’s acceleration scheme uses two new sequences and and update the sequences as follows:
[TABLE]
In equation (2.1), is the gradient of the given function and is the step-size. The main contribution for the above scheme is that it uses appropriate values for the parameters , which in turn yield better convergence in the context of standard gradient descent. Now, using the general setup of Nesterov’s scheme [35] for coordinate descent and the idea in [20], we developed ASKM algorithm shown above (Algorithm 2).
3 Convergence Analysis
In this section, we analyze the convergence of the proposed ASKM algorithm 2. Throughout the analysis, we make the assumptions: 1) for any , which implies and 2) is full dimensional. The following convergence result was proven in [9] for the SKM algorithm (Algorithm 1):
[TABLE]
In the above equation, is the Hoffman constant and is defined in the proof of Lemma 4. For the ASKM algorithm (Algorithm 2) shown above, we prove a better convergence result as stated in Theorem 1 compared to the one in (3) (we consider the case ).
Remark 1**.**
This framework for convergence in the context of acceleration follows the general idea developed by Nesterov [32] for the Gradient Descent method. The proof of Theorem 1 follows the generalized sketch developed by Nesterov [35] for proving the convergence result of Coordinate Descent method. Due to the similarity of acceleration methods derived in [20] for the randomized Kaczmarz method and our proposed method, we will use the same standard notation on this subject. In addition to that, the following results generalize results for acceleration in Kaczmarz types methods (i.e. if we select and use linear systems, we get the same results shown in [20]).
Theorem 1**.**
The ASKM algorithm defined above with and , then for all we have the following:
[TABLE]
Here, is a unique limit point of the ASKM iterates (for the uniqueness of see Lemma 2.2-2.4 in [9]), is the condition number of matrix and is the sample size of the random sampling process.
Before delving into Theorem 1, we start with the proof of some useful lemmas. For the expectation calculation of the random process described in our algorithm, we need a certain setup. Let, denote the smallest entry of the residual vector (if we order the entries of from smallest to largest, is the entry in position). Now, if we consider the size of all the entries of the residual vector , we can calculate the probability that a particular entry of the residual vector is selected. In this case, each sample has equal probability of selection (i.e., ). Moreover, the size of the residual vector controls the frequency that each entry of the residual vector will be expected to be selected (Algorithm 2, sample of constraints selection). For example, if we have only one sample then smallest entry will be selected and for the case of all samples, smallest entry will be selected. Therefore, if we expand the expectation of the residual (with respect to the probabilistic choice of sample constraints, , of size ), we get the following:
[TABLE]
where denotes the required expectation in accordance with the above sampling process ( is the sample size).
Lemma 2**.**
For any we have the following:
[TABLE]
Proof.
Let us define the singular value decomposition of as where both and are unitary matrices of appropriate dimension and is a positive diagonal. We can easily show that . Then, with the defined orientation above, we have the following:
[TABLE]
This proves Lemma 2. ∎
Lemma 3**.**
For any we have the following:
[TABLE]
Proof.
With the expression of expectation defined in (12) we have,
[TABLE]
This proves the Lemma 3. ∎
Lemma 4**.**
For any and that satisfies we have the following:
[TABLE]
Proof.
Let us define as the projection operator onto the feasible region , and denote as the number of zero entries in the residual , which also corresponds to number of satisfied constraints. We also define . Now, from the update formula shown in Algorithm 2, we know that ; where,
[TABLE]
Then we have,
[TABLE]
Now, taking expectation in both sides of equation (17), we have,
[TABLE]
The expectation above proves the Lemma 4. ∎
Definition: Let us define a function as follow:
[TABLE]
The gradient of the function is given by:
[TABLE]
Lemma 5**.**
For any and condition number of matrix , we have the following:
[TABLE]
Proof.
We first prove that is Lipschitz continuous with the constant . Using the definition given in (18), for any we have,
[TABLE]
The above equation shows that is Lipschitz continuous with the constant . Here, we use the common expression . Now using Lemma 1.2.3 proven in [33], as is Lipschitz continuous, for any we can write the following:
[TABLE]
Now, by simplifying (20), we get the following bound:
[TABLE]
The bound mentioned above proves the Lemma 5. ∎
Lemma 6**.**
For any and with the following definitions:
[TABLE]
both sequences lies in the interval if and only if satisfies the following property:
[TABLE]
Proof.
The proof of Lemma 6 is straightforward. If we consider the definitions of the sequences with the given condition, we find that implies that the following bound must hold:
[TABLE]
Conversely, if we assume the bound holds for , then we can easily find that it implies the sequences and lies in the interval . ∎
Lemma 7**.**
For any , if holds, then satisfies the bound in Lemma 6 and also lies in the interval .
Proof.
Let us define the function as follows:
[TABLE]
As we know from the definition, is the largest root of , then it satisfies . Now we have,
[TABLE]
Similarly,
[TABLE]
Therefore, we can write,
[TABLE]
This proves the first part of the Lemma. For the second part, notice that, assuming we have the following:
[TABLE]
Here, the last inequality follows from the assumed condition . In a similar fashion we have,
[TABLE]
In this case, we use the identity and . This proves the statement, . ∎
Remark 2**.**
Note that by taking limits as in Theorem 1 we have,
[TABLE]
Therefore, we can conclude that when , the ASKM algorithm converges with a linear rate. When , we get a sublinear convergence. But for the case of , we get a quadratic convergence, which is consistent with the convergence rate of the original accelerated algorithm of Nesterov [33] and also with the Accelerated Randomized Kaczmarz algorithm proposed in [20]. Furthermore, if we take , we get exactly the same convergence theorem proven in [20].
Proof.
(Theorem 1) The proof of theorem 1 is general in the context of acceleration. We follow the standard notation and steps shown in [35], [20]. Using the definitions given in Lemma 6, we note that the following relation holds:
[TABLE]
Now, let us define . We can write,
[TABLE]
Now, we divide the RHS of equation (24) into three parts and simplify them separately. Since is a convex function and , part of (24) satisfies the following inequality:
[TABLE]
Let us denote as the index which represents the random selection at iteration . And let denote all random indices occurred before or at iteration , i.e.,
[TABLE]
The sequences are dependent on . In the next part of the proof, we use to represent the expectation of a random variable conditioned on with respect to the index . Note that,
[TABLE]
Also note that, from now on we use instead () to denote the expectation. Now, based on the Lemma 3 and Lemma 4, we can write the part of (24) as follows:
[TABLE]
Now, by using the definitions of the sequences and , we can simply show that the following identity holds:
[TABLE]
We use the identity of (29) in the next part of our proof. After taking expectation in the third term of equation (24), we get,
[TABLE]
Using the definition of the function defined in (18) and denoting , we get,
[TABLE]
Now, substituting equation (31) in (30) with the known identity, , we have,
[TABLE]
Now by substituting all three parts of (2), (28) and (32) in equation (24), we get,
[TABLE]
From now on, we will assume , which will simplify our algorithm. Let us define two sequences and as follows:
[TABLE]
Without loss of generality, we assume to be consistent with the definition . Also note that since , we have . Now using the definition of the sequence , we have,
[TABLE]
Equation (35) also implies that the sequence is an increasing sequence. Now, it is straightforward to check that the following identities hold.
[TABLE]
Now, multiplying both sides of (33) by and using the above identities we have,
[TABLE]
Furthermore, we have,
[TABLE]
Therefore, using (38) we can conclude the following bound,
[TABLE]
Now, we need to estimate the growth of the defined sequences and . Here, we follow the proof for the Accelerated Coordinate Descent method of Nesterov [35] and accelerated randomized Kaczmarz algorithm by Wright et. al [20] as they are more general in the context of acceleration. We have,
[TABLE]
Simplifying (40) we get,
[TABLE]
Here, we used the identity , which simplifies to:
[TABLE]
Similarly, note that,
[TABLE]
Above equation simplifies to the following:
[TABLE]
In this case, we used the identity , which leads to the following identity:
[TABLE]
By combining the two expressions of (41) and (42) in a LS we get,
[TABLE]
The Jordan decomposition of the matrix in the above expression is given by,
[TABLE]
Here, and . Using and the decomposition of (44), from equation (43) we have,
[TABLE]
The above gives us the following growth bound for the sequences and as follows:
[TABLE]
Substituting these above bounds of (45) and (46) in equation (39), we get the following bounds:
[TABLE]
The above equations complete the proof of Theorem 1. ∎
4 Numerical Experiments
We implemented the ASKM algorithm in MATLAB and performed the numerical experiments in a Dell Precision 7510 workstation with 32GB RAM, Intel Core i7-6820HQ CPU, processor running at 2.70 GHz. We divided the numerical experiments into three categories: experiments on randomly generated problems, experiments on real-world non-random problems and comparison among different methods. In these experiments, we compared ASKM with SKM and other state-of-the-art methods (i.e., IPM and ASM). As mentioned earlier, our main focus is on the over-determined systems regime (i.e., ), where iterative methods are applied in general. For all of the experiments, we ran the algorithms 10 times and report the averaged performance.
4.1 Comparison of SKM and ASKM on random data
We considered systems where the entries of and are chosen randomly from the corresponding distribution. To make sure that , we generated two vectors at random from the corresponding distributions, then multiplied them by and set as a convex combination of those two vectors. We considered two types of random data sets: highly correlated systems and Gaussian systems. In the highly correlated systems, entries of are chosen uniformly at random between and is chosen accordingly such that the system has a feasible solution. The entries of in the Gaussian systems are chosen from standard normal distribution and is chosen accordingly as before.
In Figure 1, we provide a comparison between SKM and ASKM for three randomly generated correlated systems. We compare the average computational time necessary for SKM and ASKM with several choices of sample size to reach positive residual error (i.e., ). We compare the two algorithms for the choice of 111 here is same as in De Loera et. al [9] . For the three test cases, we see that for any , ASKM significantly outperform SKM in terms of average computation time.
In Figure 2, we show the same comparison experiments for randomly generated Gaussian systems. Similar to the correlated systems, ASKM algorithm solves the Gaussian systems much faster than the SKM algorithm. Notice that in Figure 2(b) the computational time of SKM algorithm stays at 1000 seconds for sample size . This happens due to an additional terminating condition of maximum run time set at 1000 seconds. While SKM algorithm fails to converge within the limiting time for larger sample sizes (, ASKM algorithm finds a feasible solution for any sample size. Moreover, if we analyze the trend of ASKM’s average computational time in both figures (Figure 1 and 2), we see that ASKM accelerates the SKM algorithm and the nature of acceleration is quadratic which validates our claim of Theorem 1.
In Figure 3 and 4, we compare the positive residual error for SKM and ASKM for different sample sizes (). We plot iteration versus residual error and time versus residual error for random Gaussian systems. Based on the findings of Figure 3 and 4, we can conclude that irrespective of sample size selection, converges to zero much more faster for ASKM than for SKM. The convergence of for both ASKM and SKM are much slower for the choice of as expected.
For and , the convergence rate of ASKM takes over SKM after a small amount of time. In addition, the convergence rate remains similar for both the test case problems ( and ). To investigate the solution quality of both SKM and ASKM, we measure the number of satisfied constraints after each iteration and the corresponding computational time for both algorithms. We summarize our findings in Figure 5 and 6 for the above test sets. For simplification, we used the Fraction of satisfied constraints (FSC) as a measure of quality of the solution generated by both SKM and ASKM algorithms. After analyzing Figures 5 and 6, we can conclude that the choice of is the worst choice as both SKM and ASKM takes much more time to satisfy all the constraints. However, for the choice of and , ASKM takes much less time compared to SKM to find a solution within the error margin. For example, in Figure 5, the choice of ASKM takes approximately 37 seconds to satisfy all the 5000 constraints whereas SKM takes up to 75 seconds.
4.2 Comparison of SKM and ASKM for real-world non-random data
In this subsection, we consider two real-world non-random problems. We consider Support Vector Machine (SVM) instances with linear classification and feasibility problems arising in benchmark libraries. We considered the standard test cases given in [37, 38, 9].
We compare SKM and ASKM methods to solve the linear classification problem with SVM for 1) Wisconsin (diagnostic) breast cancer data set and 2) Credit card data set. The breast cancer data set includes data points whose features are computed from digitized images. Each data point is classified either as malignant or as benign. Our goal is to find a solution of the homogeneous system of inequalities, which represents the separating hyperplane between malignant and benign data points. The system of inequalities has 569 constraints (data points) and 30 variables (features). Since the data set is not separable, we set SKM and ASKM to find the minimized residual norm . For our setup, We consider the threshold and .
The credit card data set described in [39, 9] consists of features describing the payment profile of user and binary variable for on-time or default payment in a certain billing cycle. Similar to the breast cancer data set, this problem can be solved by finding a solution to the corresponding homogeneous system of inequalities, which represents the separating hyperplane between given on-time and default data points. The resulting system of inequalities has 30000 constraints (30000 user profiles) and 23 variables (22 profile features). Since the data set is not separable, we set SKM and ASKM to find the minimized residual norm . For our setup, we considered the threshold as and .
Based on the comparison graphs shown in Figure 7, we can conclude ASKM performs much better than SKM for the breast cancer data set (Figure 7(a)). For the credit card data set ASKM performs marginally better than SKM for smaller error. Also note that, the computation time curve for credit card data is not as smooth as previous curves, which we can attribute to the irregularity of the coefficients. Such irregularity in the coefficients creates a dependence bias between residual error and actual constraints.
4.3 Comparison among SKM, ASKM and existing methods for Netlib LP
In this subsection, we investigate the comparative performance of the proposed ASKM algorithm with SKM and benchmark algorithms such as IPM and ASM on several Netlib LPs. For the implementation of SKM and ASKM to the Netlib LPs, we follow the framework given by De Loera et. al [9]. Each of these problems was formulated as a standard LP problem ( subject to with optimum value ). Loera et. al [9] transformed them into an equivalent LF problem , where and . We used this setup for all the experiments on Netlib LPs.
In Table 1, we provide the performance behaviour (computation time in seconds) of ASKM, SKM, IPM and ASM on the Netlib LPs. For fair comparison, we coded ASKM, SKM in MATLAB and compared with the MATLAB Optimization Toolbox function fmincon. Note that fmincon allows us to select both IPM and ASM methods.
At first, we solve the feasibility problem () using SKM and ASKM and recorded the CPU time in Table 1. But we didn’t solve the feasibility problem () directly using fmincon’s IPM and ASM algorithms since both of these methods fail to solve the feasibility problem due to the fact that in IPM, the Karush Kuhn Tucker (KKT) condition system in each iteration becomes singular and similarly ASM halts in the initial step of finding a feasible point.
For fairness of comparison, in Table 1, we list the CPU time as follows: for SKM and ASKM method we used the feasibility problem () and for the fmincon algorithms we used the original optimization LPs (). As noted in [9], this is not an obvious comparison. For a better comparison, following [9] we set the halting criterion for SKM and ASKM as and the halting criterion for the fmincon’s algorithms are set as and , where is listed in Table 1. For each problem, every method started with the same initial solution far from the feasible region.
The experiments show that the proposed ASKM method compares favorably with IPM and ASM methods. Notice that the improvement of ASKM over SKM method for some problems are marginal as the analyzed instances contain sparse matrices while our proposed ASKM is explicitly designed for dense problems. Following the method provided by Liu and Wright [20], we believe one can develop a sparse version of ASKM algorithm. The trick is to aggregate several steps to reduce the calculation by using the sparsity of the instances. For example, after calculating and , instead of updating to and , for we can update and using the recurrence relation which will reduce the computational effort significantly.
5 Conclusion
In this work, we have proposed an accelerated version of SKM algorithm for solving LF problem using the celebrated Nesterov acceleration of Gradient Descent method. The proposed algorithm also generalizes the accelerated randomized Kaczmarz algorithm for solving LS problems in the context of sample size . We have performed a series of numerical experiments to show the performance and effectiveness of our proposed algorithm in comparison with IPM and ASM methods. ASKM algorithm performs favourably in comparison with the original SKM method, IPM and ASM method for a wide range of test instances. The proposed algorithm as it is, including the convergence analysis, can be adopted effectively for both dense and sparse systems, however, we believe, a more efficient algorithm is possible for the sparse case. In the future, we plan to extend this work to solve large-scale real-world problems with greater sparsity on the constraint matrix. Furthermore, due to the introduction of the acceleration to the SKM algorithm, we have a set of parameters (i.e., etc.) which we plan to optimize based on the problem structure to further improve the efficiency of the proposed algorithm.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Thomas Strohmer and Roman Vershynin. A randomized kaczmarz algorithm with exponential convergence. Journal of Fourier Analysis and Applications , 15(2):262, Apr 2008.
- 2[2] Dennis Leventhal and Adrian S. Lewis. Randomized methods for linear constraints: Convergence rates and conditioning. Mathematics of Operations Research , 35(3):641–654, 2010.
- 3[3] Deanna Needell. Randomized kaczmarz solver for noisy linear systems. BIT Numerical Mathematics , 50(2):395–403, Jun 2010.
- 4[4] Petros Drineas, Michael W. Mahoney, Shan Muthukrishnan, and Tamás Sarlós. Faster least squares approximation. Numerische Mathematik , 117(2):219–249, Feb 2011.
- 5[5] Anastasios Zouzias and Nikolaos M. Freris. Randomized extended kaczmarz for solving least squares. SIAM Journal on Matrix Analysis and Applications , 34(2):773–793, 2013.
- 6[6] Yin Tat Lee and Aaron Sidford. Efficient accelerated coordinate descent methods and faster algorithms for solving linear systems. In Proceedings of the 2013 IEEE 54th Annual Symposium on Foundations of Computer Science , FOCS ’13, pages 147–156, Washington, DC, USA, 2013. IEEE Computer Society.
- 7[7] Anna Ma, Deanna Needell, and Aaditya Ramdas. Convergence properties of the randomized extended gauss seidel and kaczmarz methods. SIAM Journal on Matrix Analysis and Applications , 36(4):1590–1604, Jan 2015.
- 8[8] Zheng Qu, Peter Richtarik, Martin Takac, and Olivier Fercoq. SDNA: Stochastic Dual Newton Ascent for Empirical Risk Minimization. In Proceedings of The 33rd International Conference on Machine Learning , volume 48, pages 1823–1832, New York, USA, 20–22 Jun 2016. PMLR.