TL;DR
This paper introduces an end-to-end deep learning approach that accurately predicts 3D hand shape and pose from in-the-wild RGB images, leveraging a model-based decoder and weak supervision for improved generalization.
Contribution
It presents the first deep learning method combining shape and pose prediction with a model-based decoder for in-the-wild images, achieving state-of-the-art results.
Findings
State-of-the-art 3D hand pose prediction performance.
Geometrically valid and plausible 3D reconstructions.
Effective use of weak supervision with 2D and 3D annotations.
Abstract
We present in this work the first end-to-end deep learning based method that predicts both 3D hand shape and pose from RGB images in the wild. Our network consists of the concatenation of a deep convolutional encoder, and a fixed model-based decoder. Given an input image, and optionally 2D joint detections obtained from an independent CNN, the encoder predicts a set of hand and view parameters. The decoder has two components: A pre-computed articulated mesh deformation hand model that generates a 3D mesh from the hand parameters, and a re-projection module controlled by the view parameters that projects the generated hand into the image domain. We show that using the shape and pose prior knowledge encoded in the hand model within a deep learning framework yields state-of-the-art performance in 3D pose prediction from images on standard benchmarks, and produces geometrically valid and…
Click any figure to enlarge with its caption.
 Figure 0
Figure 0 Figure 0
Figure 0 Figure 1
Figure 1 Figure 2
Figure 2 Figure 1
Figure 1 Figure 1287
Figure 1287 Figure 1342
Figure 1342 Figure 1351
Figure 1351 Figure 1473
Figure 1473 Figure 159
Figure 159 Figure 18943
Figure 18943 Figure 2
Figure 2 Figure 246
Figure 246 Figure 99
Figure 99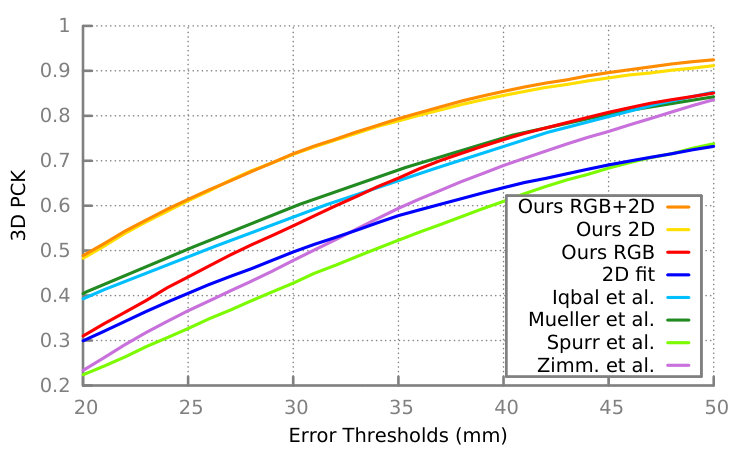 Figure 15
Figure 15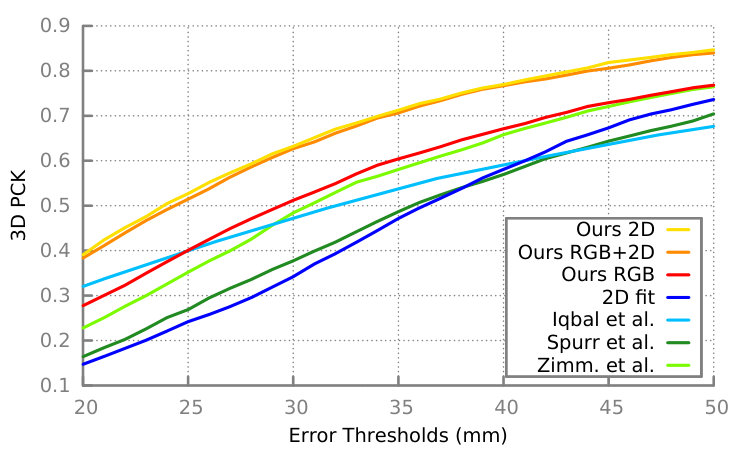 Figure 16
Figure 16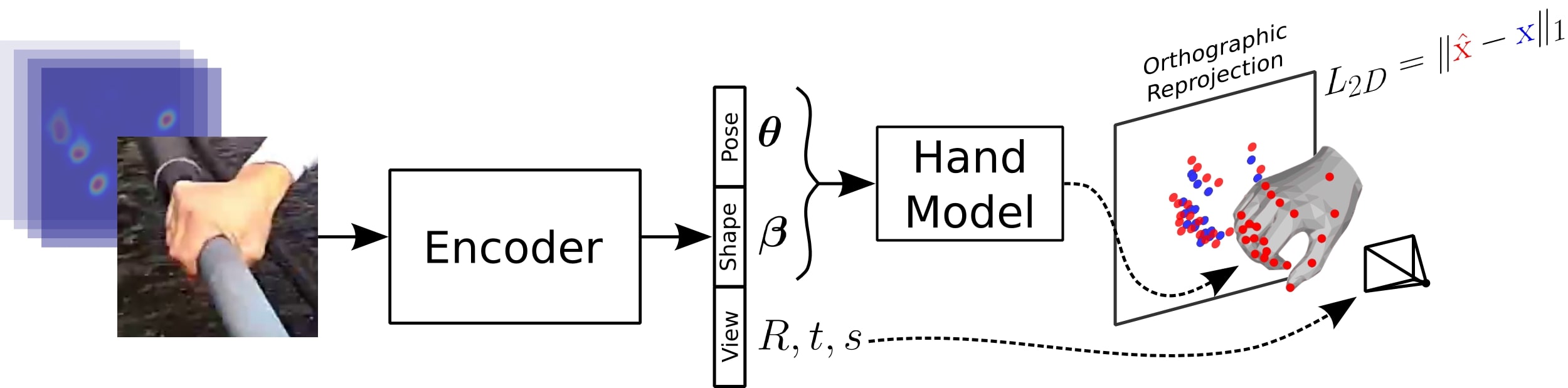 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27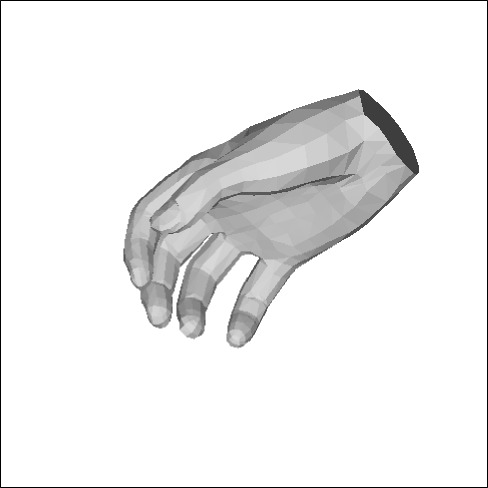 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31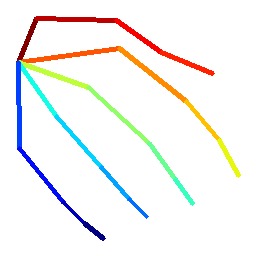 Figure 32
Figure 32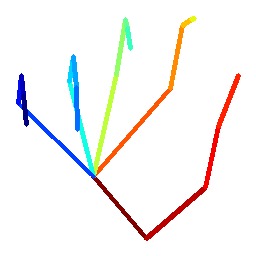 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35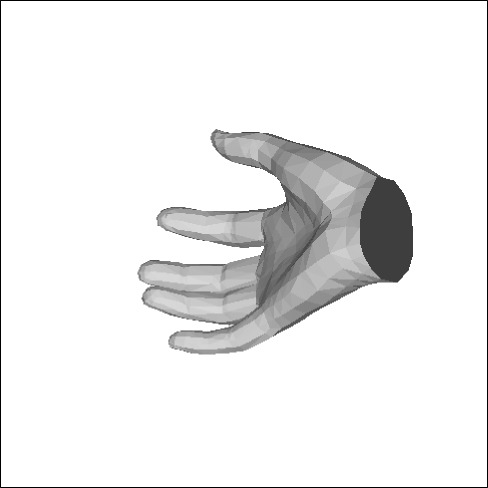 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40| Ours RGB | Ours RGB+2D | Ours 2D | 2D fit | |
| 3D distance | 9.76 | 10.18 | 10.46 | 23.21 |
| Ours RGB | Ours RGB+2D | Ours 2D | 2D fit | Spurr et al. | Zimm. et al. | |
| 3D distance | 33.16 | 25.53 | 25.93 | 41.18 | 40.20 | 34.75 |
| Ours RGB | Ours RGB+2D | Ours 2D | 2D fit | Spurr et al. | Zimm. et al. | |
| 3D distance | 51.87 | 45.58 | 45.33 | 56.59 | 56.92 | 52.77 |
| Ours RGB | Ours RGB+2D | Ours 2D | 2D fit | Zimm. et al. | |
| 2D distance | 23.04 | 18.95 | 20.65 | 22.36 | 59.40 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
3D Hand Shape and Pose from Images in the Wild
Adnane Boukhayma1
Rodrigo de Bem1,2
Philip H.S. Torr1
1 University of Oxford
UK
2 Federal University of Rio Grande
Brazil
{adnane.boukhayma, rodrigo.andradedebem, philip.torr}@eng.ox.ac.uk
Abstract
We present in this work the first end-to-end deep learning based method that predicts both 3D hand shape and pose from RGB images in the wild. Our network consists of the concatenation of a deep convolutional encoder, and a fixed model-based decoder. Given an input image, and optionally 2D joint detections obtained from an independent CNN, the encoder predicts a set of hand and view parameters. The decoder has two components: A pre-computed articulated mesh deformation hand model that generates a 3D mesh from the hand parameters, and a re-projection module controlled by the view parameters that projects the generated hand into the image domain. We show that using the shape and pose prior knowledge encoded in the hand model within a deep learning framework yields state-of-the-art performance in 3D pose prediction from images on standard benchmarks, and produces geometrically valid and plausible 3D reconstructions. Additionally, we show that training with weak supervision in the form of 2D joint annotations on datasets of images in the wild, in conjunction with full supervision in the form of 3D joint annotations on limited available datasets allows for good generalization to 3D shape and pose predictions on images in the wild.
1 Introduction
Human hand pose estimation and reconstruction in 3D is a long standing problem in the computer vision and graphics communities that has applications in various domains such as virtual and augmented reality and human-machine interaction [35, 15, 46, 13]. With the abundance of affordable commodity depth cameras, the research literature focused naturally more on estimating 3D hand pose through depth observations (e.g. [62, 66, 10, 36, 61]), and many works also explored this problem in multi-view setups [33, 65, 41, 8, 31, 50]. When it comes to a monocular color input, the problem becomes inherently ill posed due to the increased depth and scale ambiguities, but that did not prevent several researchers [4, 9, 51, 57, 63, 39] from attempting to solve it in the past albeit with limited results. More recently, the unprecedented success of deep learning on similar tasks motivated new work with encouraging results for 3D hand pose from single images [68, 27, 7, 47, 14]. Nevertheless, this task remains particularly difficult: Unlike clothed human bodies or faces, hands have an almost uniform appearance and lack characteristic local features such as eyes and mouths in faces. Unlike bodies, they can have more complex pose configurations and they can be captured from a much wider range of views. Furthermore when observed in the wild, as in dataset Mpii+Nzsl [44] (Figure 9), their images usually contain external occlusion, self-occlusion, clutter and blur due to their motion. Besides, hands are often small in size compared to the scene so cropped patches around them have low resolutions.
The main obstacles for 3D hand pose estimation from images with deep learning include: (i) The lack of large datasets annotated with reliable 3D ground-truth and (ii) the incapability of the current 3D annotated datasets to make networks generalize greatly to challenging images in the wild.
The first point is tackled by the literature through training with synthetic images [68], populating datasets by transforming synthetic images into real looking ones [27], or leveraging auxiliary types of data in training like depth [7, 47]. We propose a different and simple yet efficient approach to alleviate both challenges (i) and (ii) by circumventing heavy dependence of 3D data in training: Instead of relying on images paired with 3D joint annotations to learn a prior on hand geometry, we exploit a recently proposed differentiable articulated mesh deformation hand model [40] built with linear blend skinning [18], and we reformulate the prediction problem into a learning-based model fitting, that can be trained using both 3D and 2D joint annotations. Training with 2D annotated images allows access to larger datasets (e.g. Panoptic [44]) with a fair share of annotated images in the wild (e.g. Mpii+Nzsl [44]) compared to datasets with 3D ground-truth, thus helping improve generalization to this type of challenging data. Given an input image, and optionally 2D joint detections obtained from an independent CNN, a deep convolutional encoder predicts the hand shape and pose parameters and view parameters. The model-based decoder uses the latter to generate a 3D triangulated hand mesh and its underlying skeleton, along with their re-projection in image domain (see Figure 1).
Our contributions in this paper are as follows: This work is the first to propose end-to-end learning of both 3D hand shape and pose from a single RGB image. We also show for the first time that the prior knowledge of factored hand shape and pose in a pre-computed linear blend skinning [18] hand model [40] combined with a deep-convolutional encoder yields state-of-the-art performance in 3D pose prediction from images, and produces geometrically valid and plausible 3D reconstructions, without the need for post-processing optimizations [27]. We show that this strategy combined with training on 2D annotated datasets of images in the wild produces good generalization in 3D hand reconstruction for challenging images in uncontrolled environments.
We evaluate our work both quantitatively in terms of 3D pose estimation and qualitatively using various public datasets. These evaluation sets account for cases of hand interaction with objects, occlusion and clutter, and contain egocentric view images, third person view images, and images in the wild. Our method obtains state of-the-art results on standard benchmarks, even compared to methods using additional depth information in training [7, 47], camera intrinsics [27, 34], and post-processing optimization [27]. Our method shows superior qualitative results on a challenging dataset of images in the wild (Figure 9 & supplementary material).
2 Related work
There is a rich literature on 3D hand pose and reconstruction from depth [62, 66, 10, 36, 61, 11, 43, 45, 19, 20, 24, 30, 37, 48, 52, 53, 59, 64], image and depth [26, 32, 49, 28], stereo [33, 65, 41] and multiple images [8, 31, 50]. We focus hereby on research material that solely considers a single color input image.
3D hand pose from a single image
Pre-deep learning
There have been attempts to solve 3D hand pose estimation from a monocular color input prior to deep learning with both discriminative and generative approaches [4, 9, 51, 57, 63, 39]. However, most of these methods have limited performance and depend on various requirements such as careful initialization and prior knowledge of the background.
Deep learning
The work of [68] was the first to propose 3D hand pose estimation from single images using deep learning. Their method consists of the concatenation of three networks that segment the hand, predict 2D joints, and then predict 3D joints subsequently. The work of [27] shows that the previous method generalizes poorly to real world images since a major part of their training data is synthetic. In turn, they ([27]) propose to use Cycle-GAN [67] to transform synthetic 3D annotated images of hands into real looking ones. The resulting data is used to train a regressor to predict 2D and 3D hand joints. A final optimization step fits a 3D skeleton to the former 2D and 3D predictions using the camera intrinsics. The method in [34] consists in an optimization that fits a hand model to 2D joint detections obtained from a state-of-the-art CNN [44]. We also use a pre-defined hand model [40] but within a pipeline trained end-to-end.
Depth regularization
Recent works tackle depth ambiguity in 3D hand pose prediction from images by leveraging depth maps in training. [7] proposes to reduce the dependency on noisy 3D annotations in real datasets by introducing a network that predicts full depth maps from the 3D joints. This depth regularizer is trained with ground-truth depth data for both real and synthetic training images, while the 3D predictions are only supervised by the reliable synthetic labels. The authors in [47] use multiple variational auto-encoders sharing the same latent space each auto-encoding a separate hand data modality (e.g. images, 2D joints, 3D joints). They show that the auxiliary auto-encoders help regularize the latent space and produce improved cross-modal predictions (e.g. image to 3D joints). [14] shows that predicting an implicit 2.5D heat-map representation yields improved 3D predictions even without explicit full depth-map supervision.
Hand models
Many hand models have been proposed in the literature primarily aiming at tracking depth and color data, where the hand is modelled using various techniques such as assembled geometric primitives [32], sum of Gaussians [50], sphere meshes [58] or loop subdivision of a control mesh [20]. In order to better capture the shape of the hand, [32] defines scaling terms to allow bone length to vary, while [54] pre-calibrates the shape to fit the hand of interest. The work in [20] was the first to learn hand shape variation from scans with linear blend skinning [18]. The model proposed recently in [40] and referred to as MANO improves on the latter by learning pose dependent corrective blend shapes [25], thus modelling both hand shape and pose and generating more realistic posed meshes. We use the MANO [40] model in this work.
Model-based decoders
Several works propose to combine deep convolutional encoders with generative models as decoders for human face [56, 55] and body [17, 60] 3D reconstruction. In many of these works, the decoder is a combination of a parametric model (e.g. linear face model [6], SMPL [25]) and a re-projection/rendering module. While most works fix these decoders, some propose to tune them after a supervised initialization [2, 22, 55]. This is the first work to propose a combination of a CNN encoder with a fixed generative hand model [40] for the problem of 3D hand reconstruction from images.
3 Overview
As illustrated in Figure 1, our pipeline takes as input an image of a hand and optionally 2D joint heat-maps from an independent hand detector. A deep convolutional encoder processes the input and generates a set of hand shape and pose parameters, and a set of view parameters , and . The hand parameters are fed to a differentiable articulated mesh deformation hand model that generates a triangulated 3D mesh and its underlying 3D skeleton. These outputs are then re-projected into the image domain through a weak perspective camera model controlled by the view parameters. The re-projection module and the hand model together form a model-based decoder whose parameters are fixed and do not require training. The encoder is pre-trained with synthetic examples that we created as elaborated in Section 6. We note that the training of our pipeline is done end-to-end using 2D and 3D joint annotations without supervision on the hand and view parameters, except for a regularization on the hand parameters to ensure their magnitude is small. We detail and explain the functioning of the various parts of the pipeline in the following.
4 Hand model
We use the MANO hand model [40] which is based on the SMPL model for human bodies [25]. It is an articulated mesh deformation model represented with a differentiable function taking as input two sets of parameters and that control the shape and pose of the generated hand respectively:
[TABLE]
where is a linear blend skinning [18] function applied to a template hand triangulated mesh rigged with a kinematic tree of joints. represents the joint locations and it is learned as a sparse linear regressor from mesh vertices, and are the blend weights.
In order to reduce the artifacts of linear blend skinning such as overly smooth outputs and mesh collapse around joints, the hand template is obtained by deforming a mean mesh with both shape and pose corrective blend shapes, and respectively, as follows:
[TABLE]
where is the element of a vector concatenating rotation matrix coefficients from all joints for pose and is the rest pose. The model constants are learned using registered hand scans from subjects performing roughly hand poses.
In the SMPL model, the pose vector stacks the angle-axis values of the joints. To help the hand model generate physically plausible poses, the authors in [40] reduce this pose representation to a linear embedding by performing Principal Component Analysis on angle-axis values of the joints in the data collected to build the model. The pose vector contains the resulting main coefficients from PCA instead of the angle-axis values. coefficients are retained for the pose (), and coefficients are used to represent the shape as well ().
Given input shape and pose parameters, we obtain a hand mesh of vertices and faces, along with the corresponding 3D joints where is the global rigid transformation induced by pose . As the hand skeleton in MANO does not contain finger tip joints, we append with 5 vertices from the hand mesh that correspond to these key-points. The final 3D joint output counts key-points.
5 Camera model
In order to re-project the 3D hand mesh vertices and 3D joints into the 2D image plane, we use the weak perspective model. This approximation allows us to train with annotated images even in the absence of camera intrinsics, which is the case of images in the wild obtained from Youtube videos for instance (e.g. dataset Mpii+Nzsl). Given a global rotation matrix , a translation and a scaling , the projection writes:
[TABLE]
[TABLE]
where is the orthographic projection.
6 Encoder
Given an input hand image, the goal of the encoder is to predict the corresponding hand pose and shape parameters and camera parameters . We use the ResNet-50 network [12] and we adjust the final fully connected layer to output a vector . We note that global rotation is encoded with axis-angle values and is hence represented with parameters. We also experiment with feeding 2D hand joint heat-maps obtained with a state of the art method [44] as additional channel input to the hand RGB image.
Network pre-training
We pre-train the encoder to ensure that the camera and hand parameters converge towards acceptable values. For this purpose, we create a synthetic dataset of paired hand images with their ground-truth camera and hand parameters using the same generative model that we use as a decoder. Hand geometries are obtained by sampling poses and shapes then applying rotations , translations and scalings . Although the work of [40] does not model hand appearance, the authors provide the scans used to build the geometry model with their registered counterparts. The original scans come with 3D coordinates and RGB values for each vertex. We create example hand appearances using the registered scan topology: To each vertex in a registered mesh, we assign the RGB value of the closest vertex in the original corresponding scan, and we interpolate these values inside faces. The textured hands are finally rendered on top of random background images. Figure 2 shows examples from the resulting dataset.
7 Training objective
We combine multiple losses to train our pipeline: A 2D joint re-projection loss , a 3D joint loss , a hand mask loss and a model parameter regularization loss .
[TABLE]
where , and are weighting factors.
2D joint re-projection loss
This loss ensures that the re-projected hand joints in the image plane coincide with the ground-truth 2D hand joint annotations:
[TABLE]
where is a vector containing the ground-truth 2D hand joint coordinates. We use the loss to account for inaccuracies in hand annotations in our training datasets.
3D joint loss
When ground-truth 3D hand joint annotations are available (e.g Stereo dataset), this loss minimises the distance between the latter and the 3D hand joints generated by the hand model:
[TABLE]
where is a vector containing the ground-truth 3D hand joint coordinates.
Hand mask loss
We introduce this novel loss to help speed up the convergence of our training and refine hand shape predictions. This loss penalizes re-projected hand vertices that lie outside of the hand region in a binary mask, which is pre-computed prior to training:
[TABLE]
where is an occlusion-aware hand mask, i.e if pixel is inside the hand region even if the hand is occluded in the image, and otherwise. Notice that these masks cannot be obtained with hand skin segmentation methods (e.g.[23, 5]) as they are sensitive to occlusions.
We obtain an approximation of these masks (Figure 3) for training images using the GrabCut [42] algorithm, by initializing the foreground, background and probable foreground/background regions using the 2D hand joint annotations: As illustrated in Figure 3(b), we create an initial foreground by drawing lines of pixel width connecting joints according to the hand skeleton hierarchy. Pixels inside triangles formed by joints that belong anatomically to the hand surface are appended to the foreground as well. The undecided area is defined as the region within pixels at most from the foreground, and the remaining pixels are assigned to the initial background.
Regularization loss
This loss acts on the hand model parameters at the encoder output by reducing their magnitude for physically plausible hand reconstructions and reduced mesh distortions:
[TABLE]
where is a weighting factor.
8 Evaluation
We evaluate our method’s 3D pose estimates quantitatively and its 3D reconstructions qualitatively on several datasets and with respect to state-of-the-art methods. Without access to camera intrinsics, and trained merely with 2D and 3D joint annotations, our method outperforms deep learning based competing methods, including those using additional depth information in training or camera intrinsics in evaluation. We show particularly superior 3D reconstructions on images in the wild that present challenging situations such as blur, low resolution, occlusion, extremely varying viewpoints and hand pose configurations.
Similar to [44], input images are assumed to be crops of fixed size around the hand. To achieve this, we use a hand key-point detector [44] to find the tightest rectangular box of edge size containing the hand. Images are then cropped with a square patch of size centred at the same 2D location as the previously detected box. The resulting cropped images are subsequently resized to have a width and height of . As done in [44], we use the right hand model and images of left hands are flipped horizontally.
Finally, we train our pipeline (Figure 1) using the Adam solver [21] with a learning rate of and weight decay of .
Datasets
Our training set is made of dataset Panoptic [44] that counts images, the training set of Mpii+Nzsl [44] that counts images following the split in [44], and the training set of Stereo [65] that counts images following the split in [68]. This amounts to training images, (Stereo) with 3D joint annotations, and the remaining (Panoptic & Mpii+Nzsl) with 2D joint annotations only.
The Panoptic dataset [44] contains hands in various poses observed from multiple views in the Panoptic studio [16]. The Mpii+Nzsl dataset [44] is a combination of manually annotated images from The MPII Human Pose dataset [3] containing images from YouTube videos, and images from the New Zealand Sign Language (NZSL) Exercises of the Victoria University of Wellington [38]. The Stereo dataset [65] shows an actor’s hand in third person view counting with the fingers and moving the hand randomly.
For evaluation, we use the Dexter+Object dataset [49] which shows interactions of an actor’s hand with a cuboid object from a third person view. To evaluate robustness to occlusions and clutter, we use the EgoDexter dataset [28] that displays a hand from an egocentric view interacting with various objects. We finally use the testing set of Mpii+Nzsl [44] to asses performance in the presence of blur, low resolution, varying viewpoints and hand pose configurations, among other characteristics of datasets of images in the wild.
Metrics
To quantitatively evaluate 3D hand pose estimations, we report the percentage of correct points in 3D (3D PCK) and the average 3D Euclidean distance between the estimated 3D joints and the ground-truth when the latter is available, where distances are expressed in millimeters (mm). When only ground-truth 2D joint annotations are available (dataset Mpii+Nzsl), we report 2D PCK and the average 2D Euclidean distance between the estimated 2D re-projected joints and the ground-truth, where distances are expressed in pixels (px).
Comparison to competing methods
We compare our results on the Stereo dataset to state-of-the-art methods in terms of 3D PCK in Figures 4 and 5, and we show 3D joint errors in Table 1. Figure 4 shows deep learning based methods (Cai et al. [7], Iqbal et al. [14], Spurr et al. [47], Mueller et al. [27], Zimm. et al [68]) and Figure 5 shows methods that do not rely on deep learning (Panteleris et al. [34], PSO, ICPPSO, CHPR [65] ). For this experiment, we add a key-point at the center of the hand palm in the MANO model [40] as an interpolation of several mesh vertices to match the annotation of the Stereo dataset. We reproduce the evaluation protocol initially introduced in [68] by training on sequences and testing on the remaining and aligning predictions to the ground-truth hand root joint. Additionally, for a fair comparison to works [7, 47, 14], we crop the hand images for this experiment such that the final image size is the size of the hand. Using RGB image input only, we obtain state-of-the results even though some of the competing methods use depth data in training ([7, 14]) in addition to images, while others ([27]) post-process their output with an optimization that fits their hand skeleton to their 3D and 2D joint predictions, and which uses the camera intrinsics as an additional input.
Figure 6 shows the performance of our method under occlusions and clutter with 3D PCK on the Dexter+Object dataset, and Table 2 shows 3D joint errors. Additionally, Figure 7 shows our results on a hand in ego-centric view and in interaction with various objects in terms of 3D PCK on the EgoDexter dataset, and Table 3 shows 3D joint errors. Our method outperforms the competition in these settings as illustrated in the Figures. We note that we show relative 3D pose estimates for all methods except [14] where the authors report absolute values.
We expect our method to perform particularly well on datasets of images in the wild, as our training set contains this type of data and accounts for hands in low resolution, blurry, occluded and in challenging views and pose configurations. In fact, we compare our results to [68] on the testing set of Mpii+Nzsl dataset in Figure 8 and Table 4 through 2D PCK and 2D joint error respectively. We outperform [68] with a substantial margin as the Figure shows. The superiority of our method on this dataset is visually confirmed in Figure 9.
Comparison to 2D fitting
In the case where 2D joint detections are used as input, an alternative way of solving 3D hand pose estimation is to perform a 2D fitting between the re-projected hand model joints and the key-points detected on the image, in a similar fashion to the work proposed by [34]. Our implementation of this strategy consists in minimizing the following objective function with respect to the weak perspective camera parameters and the hand shape and pose parameters :
[TABLE]
where is the hand joint estimate confidence provided by the detector CNN [44]. Similarly to the loss in Equation 9, regularization in the second line of Equation 10 is important to ensure plausible 3D hand reconstructions. We perform this optimization using Powell’s Dogleg method [29] within the Chumpy [1] framework.
We compare this method (2D fit) to our proposed approach on datasets Stereo, Dexter+Object and EgoDexter with 3D PCK in Figures 5, 6 and 7 and 3D joint error in Tables 1, 2 and 3 respectively, and also on dataset Mpii+Nzsl with 2D PCK in Figure 8 and 2D joint error in Table 4. Results show that our approach outperforms the 2D fitting based strategy for all datasets. We observe that while the optimization catches up slightly with our method in 2D (Mpii+Nzsl), its performance drops considerably in 3D. Our method benefits clearly from solving the fitting problem in a learning framework and leverages visual cues in predicting the 3D hand position and configuration, while the 2D fitting relies merely on the 2D joint detection information. We also outperform the 2D fitting based method in [34] that uses a similar hand model to [32] and a perspective projection model on dataset Stereo in Figure 5.
Ablation study
We evaluate the difference between using images only (Ours RGB), using 2D joint heat-maps obtained from a state-of-the-art hand detector [44] only (Ours 2D), and finally using both together as input (Ours RGB+2D). We carry comparisons on datasets Stereo, Dexter+Object and EgoDexter with 3D PCK in Figures 5, 6 and 7 and 3D joint error in Tables 1, 2 and 3 respectively, and also on dataset Mpii+Nzsl with 2D PCK in Figure 8 and 2D joint error in Table 4. On dataset Stereo, training on images alone yields the best performance, while training with a combination of images and 2D joint heat-maps is generally the most suitable approach for the other datasets that we tested on.
Qualitative
Figure 9 shows our 3D hand reconstructions on the challenging testing set of Mpii+Nzsl. As shown in this Figure, the input data (9(a)) displays images of hands that are sometimes blurry, low resolved, occluded, viewed from varying viewpoints and in varying pose configurations. We show our 3D mesh overlaid on the input image (9(b)) and in alternative views (9(c), 9(d)). We also compare our hand skeleton (9(e)) to the 2D and 3D pose predictions of [68] (9(f), 9(g)) and the 3D predictions of [47] (9(h)). Our method obtains visually plausible results while the methods in [68] and [47] fail to predict good 3D pose estimates for many cases in the Mpii+Nzsl dataset. We show more examples in the supplementary material.
9 Conclusion
We presented a method to predict 3D hand pose and shape from a single RGB image. We combine a deep convolutional encoder with a generative hand model as decoder and train the resulting network end-to-end with 2D and 3D hand joint annotated images. The encoder predicts hand parameters that are inputted to the hand model, and view parameters that are used to re-project the generated 3D hand into the image domain. We generate state-of-the-art results on 3D pose benchmarks and show compelling 3D reconstruction on a challenging set of images in the wild. This method could benefit greatly from a hand appearance model by leveraging a photometric loss in training as proposed in [56, 55] for faces. One possible extension to this work could be to allow some components of the MANO [40] model such as the corrective blend shapes and (Equation 2) to be fine-tuned in training for improved performance.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] http://chumpy.org.
- 2[2] V. F. Abrevaya, S. Wuhrer, and E. Boyer. Multilinear autoencoder for 3d face model learning. In WACV , 2018.
- 3[3] M. Andriluka, L. Pishchulin, P. Gehler, and B. Schiele. 2d human pose estimation: New benchmark and state of the art analysis. In CVPR , 2014.
- 4[4] V. Athitsos and S. Sclaroff. Estimating 3d hand pose from a cluttered image. In CVPR , 2003.
- 5[5] S. Bambach, S. Lee, D. J. Crandall, and C. Yu. Lending a hand: Detecting hands and recognizing activities in complex egocentric interactions. In ICCV , 2015.
- 6[6] V. Blanz and T. Vetter. A morphable model for the synthesis of 3d faces. In Conference on Computer graphics and interactive techniques , 1999.
- 7[7] Y. Cai, L. Ge, J. Cai, and J. Yuan. Weakly-supervised 3d hand pose estimation from monocular rgb images. In ECCV , 2018.
- 8[8] T. E. de Campos and D. W. Murray. Regression-based hand pose estimation from multiple cameras. In CVPR , 2006.
