Sparsity Promoting Reconstruction of Delta Modulated Voice Samples by Sequential Adaptive Thresholds
Mahdi Boloursaz Mashhadi, Saber Malekmohammadi, and Farokh Marvasti

TL;DR
This paper introduces IMATDM, a novel sparsity-promoting reconstruction method for delta modulated voice signals, which significantly improves signal quality over traditional lowpass filtering by leveraging adaptive thresholds and sparse signal assumptions.
Contribution
The paper proposes a new iterative reconstruction algorithm, IMATDM, with adaptive thresholds for delta modulation signals, enhancing reconstruction quality by exploiting sparsity and noise suppression.
Findings
IMATDM outperforms conventional lowpass filtering in SNR by 7.6 dB.
The method effectively exploits signal sparsity and quantization noise suppression.
Experimental results confirm improved reconstruction performance over existing sparsity methods.
Abstract
In this paper, we propose the family of Iterative Methods with Adaptive Thresholding (IMAT) for sparsity promoting reconstruction of Delta Modulated (DM) voice signals. We suggest a novel missing sampling approach to delta modulation that facilitates sparsity promoting reconstruction of the original signal from a subset of DM samples with less quantization noise. Utilizing our proposed missing sampling approach to delta modulation, we provide an analytical discussion on the convergence of IMAT for DM coding technique. We also modify the basic IMAT algorithm and propose the Iterative Method with Adaptive Thresholding for Delta Modulation (IMATDM) algorithm for improved reconstruction performance for DM coded signals. Experimental results show that in terms of the reconstruction SNR, this novel method outperforms the conventional DM reconstruction techniques based on lowpass filtering. It…
Click any figure to enlarge with its caption.
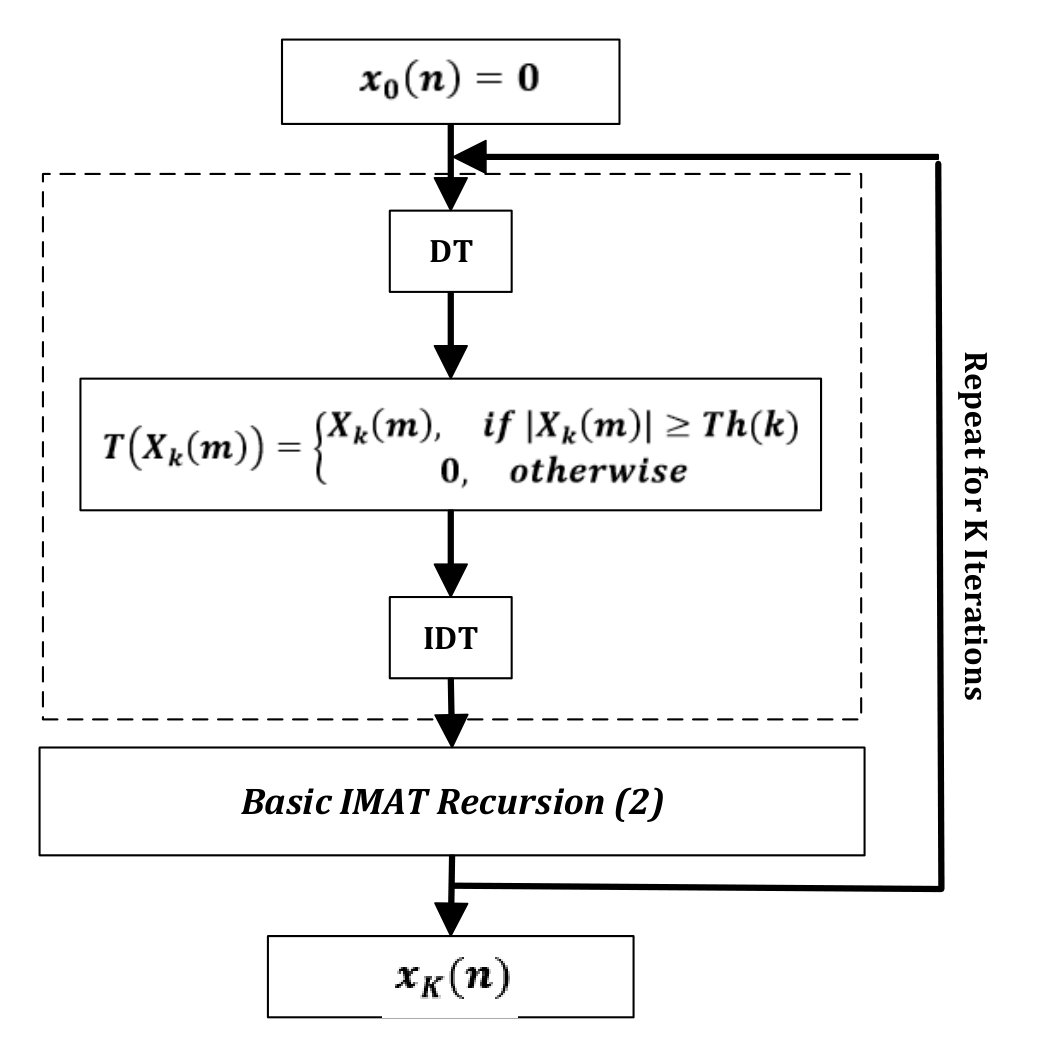 Figure 1
Figure 1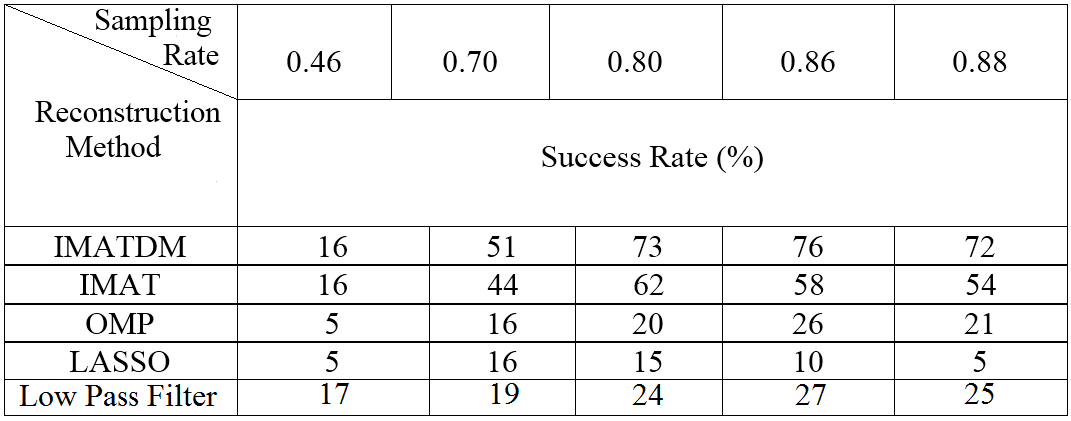 Figure 2
Figure 2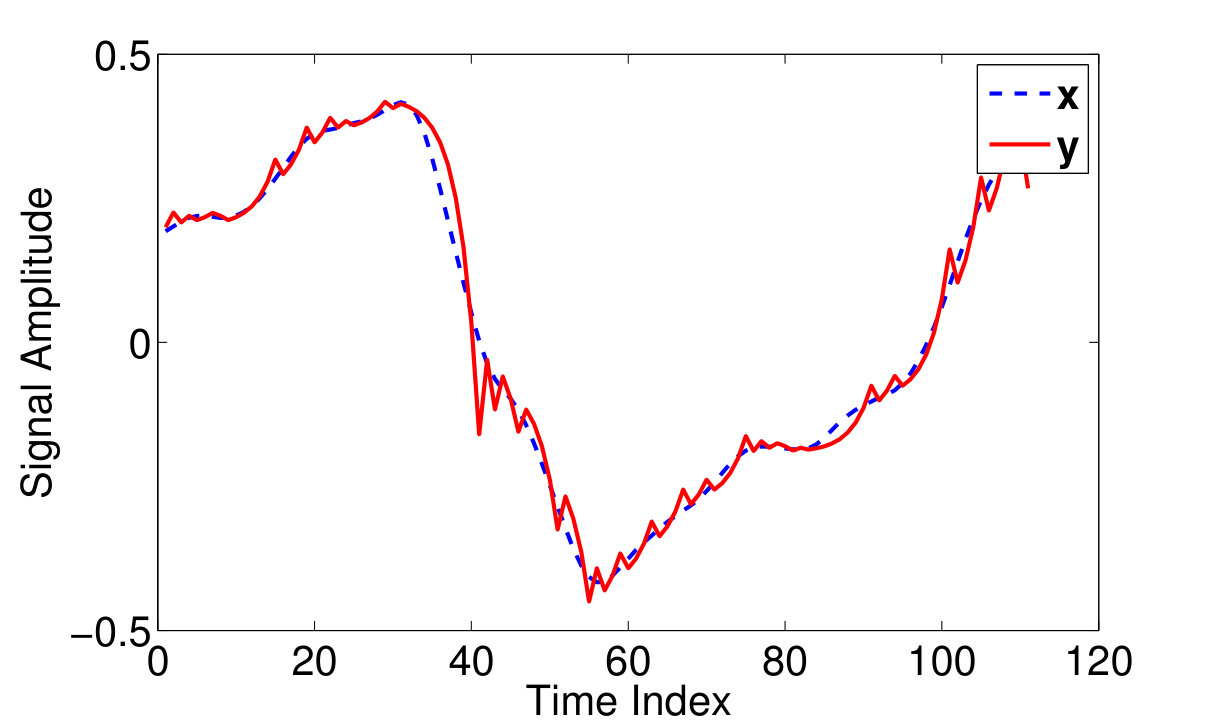 Figure 3
Figure 3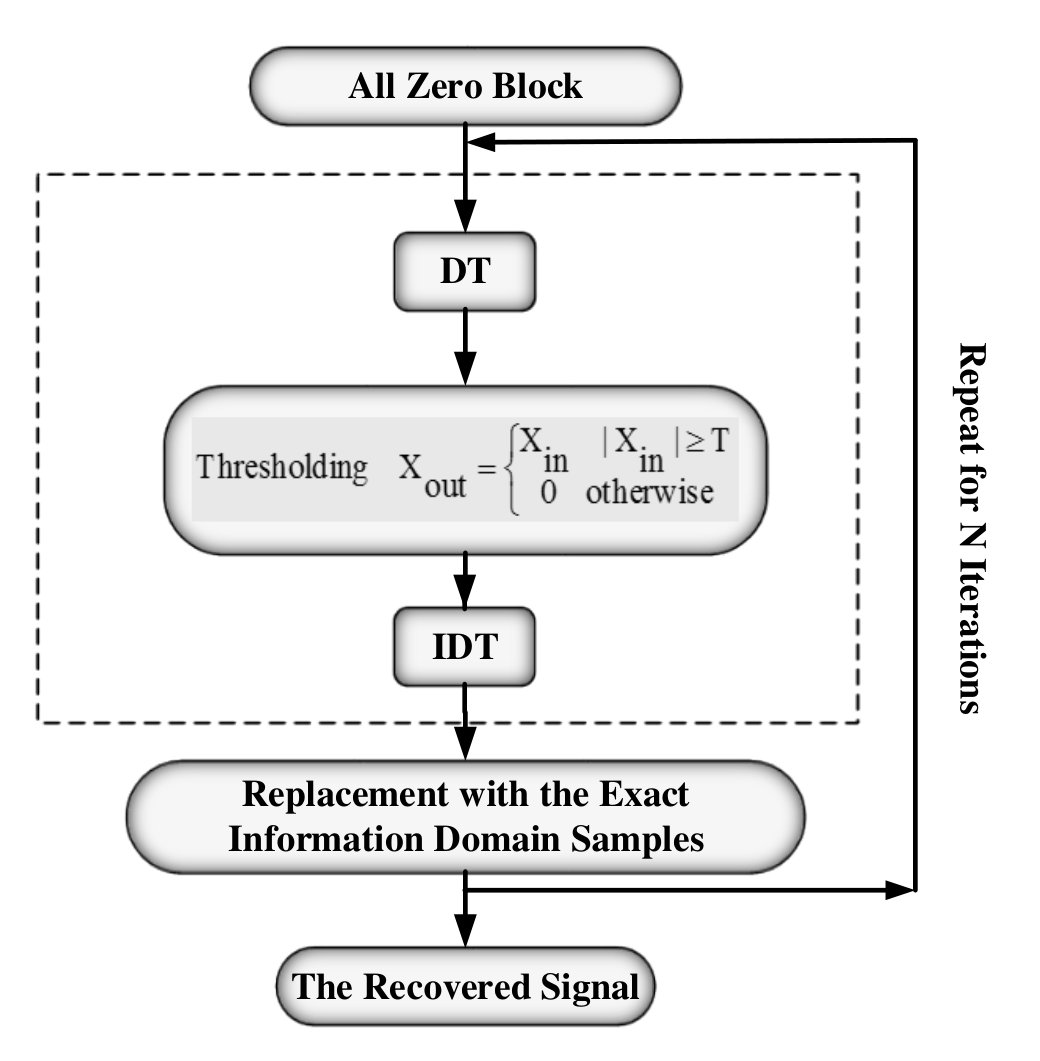 Figure 4
Figure 4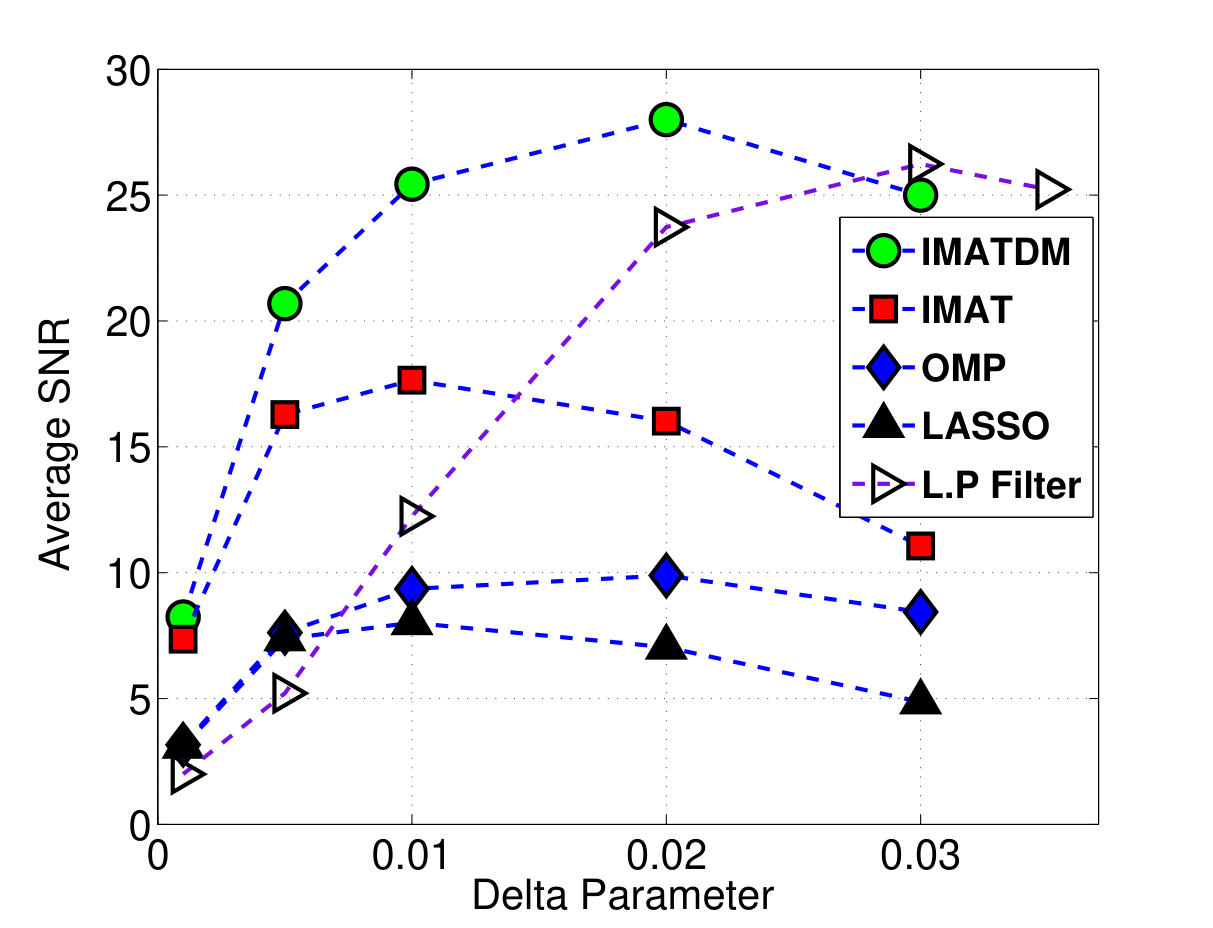 Figure 5
Figure 5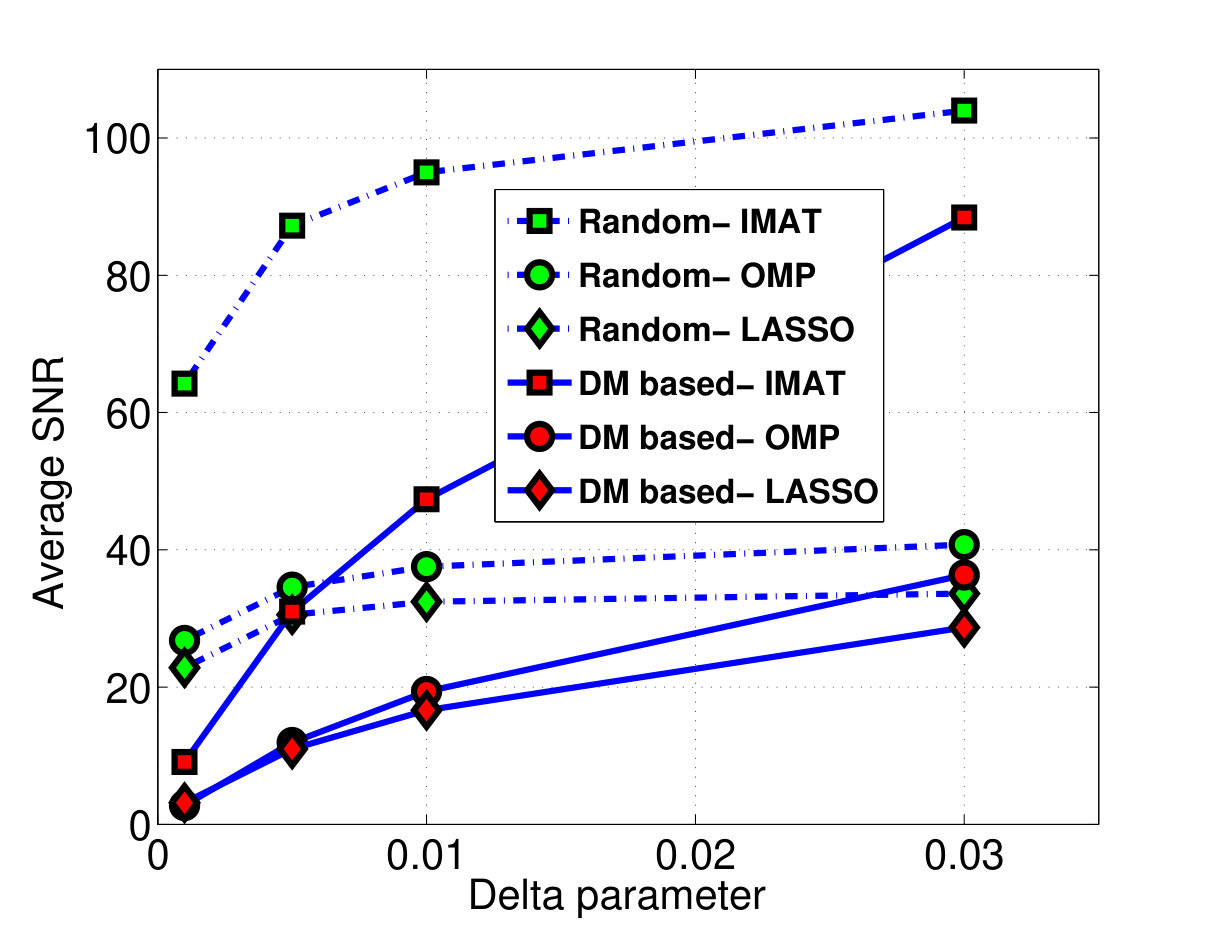 Figure 6
Figure 6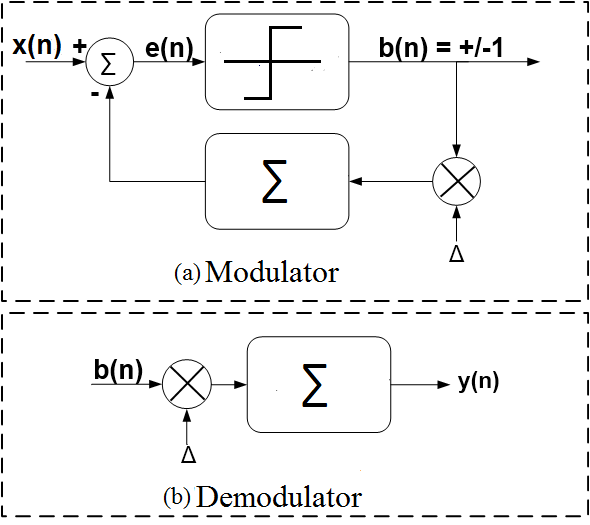 Figure 7
Figure 7 Figure 8
Figure 8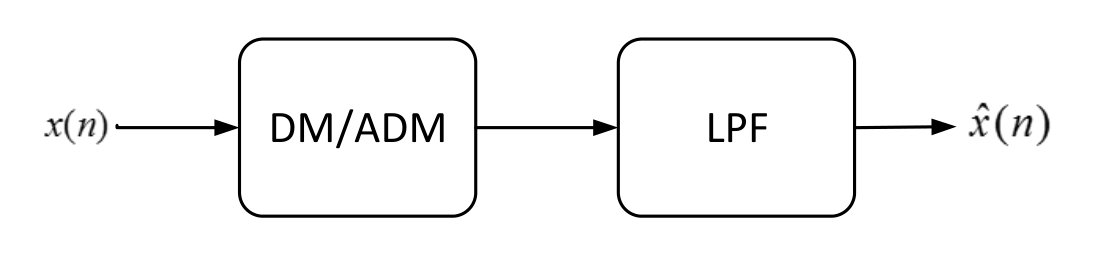 Figure 9
Figure 9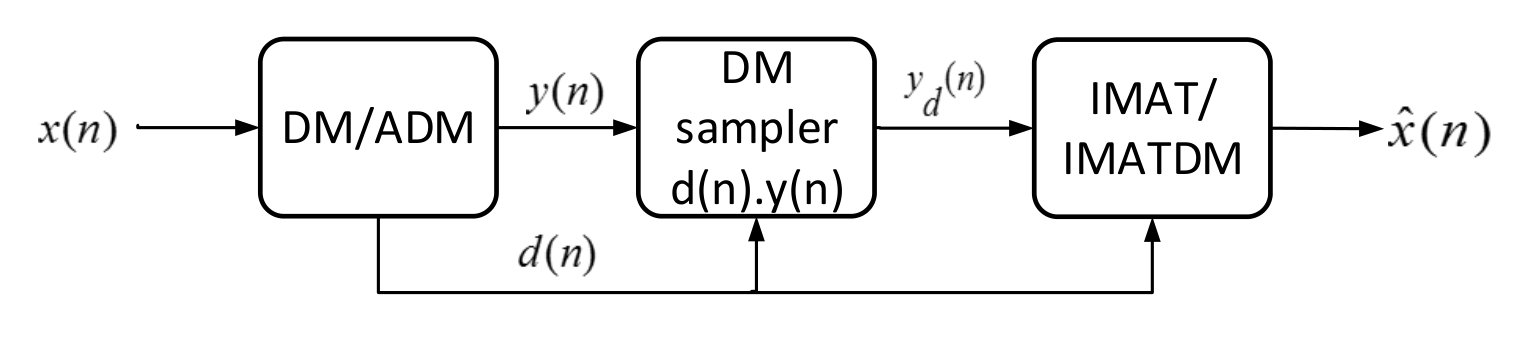 Figure 10
Figure 10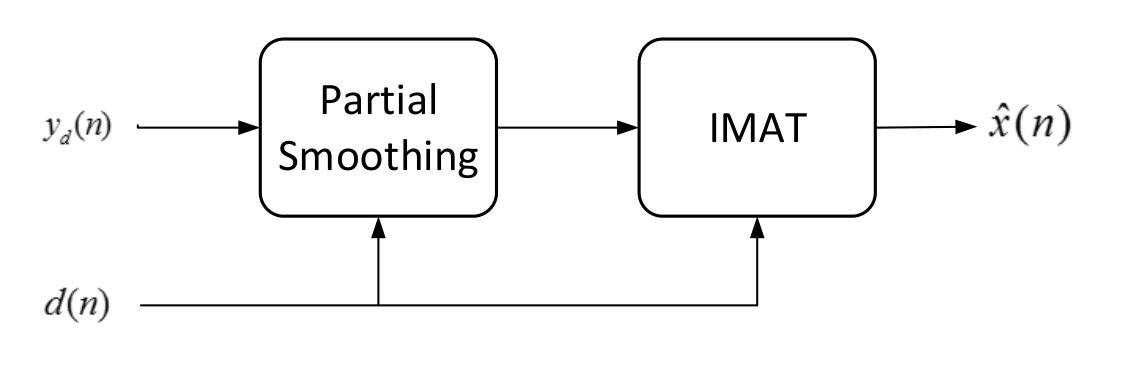 Figure 11
Figure 11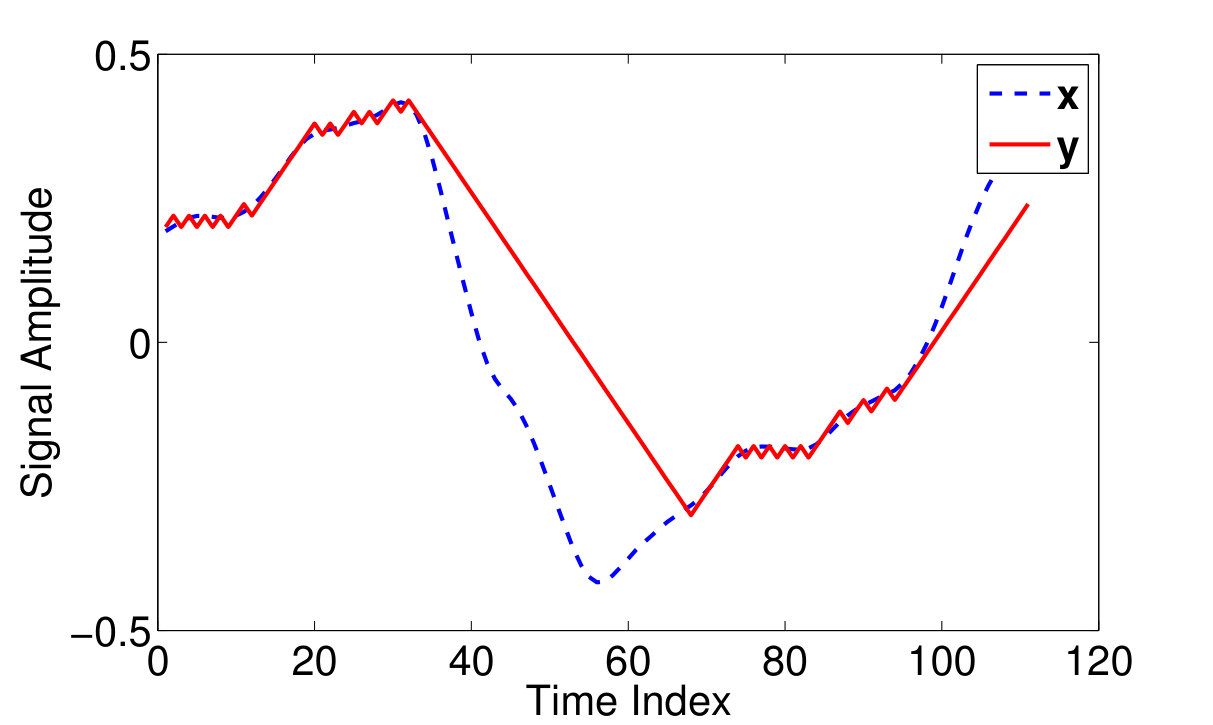 Figure 12
Figure 12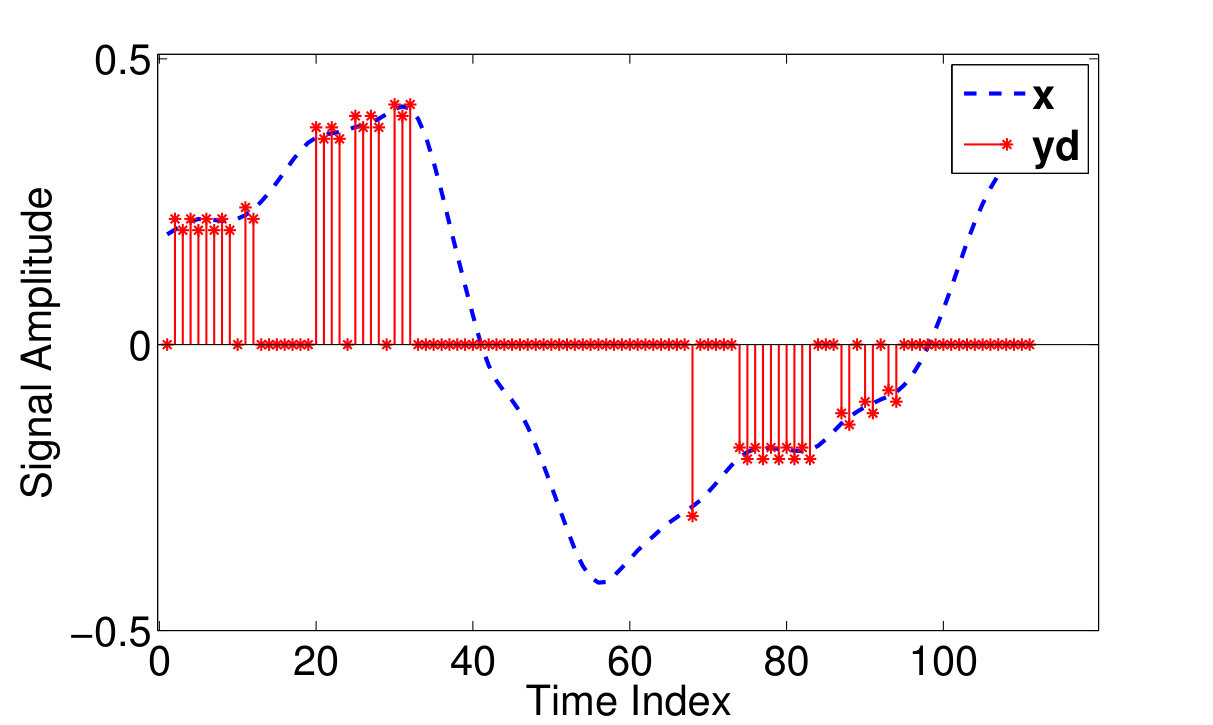 Figure 13
Figure 13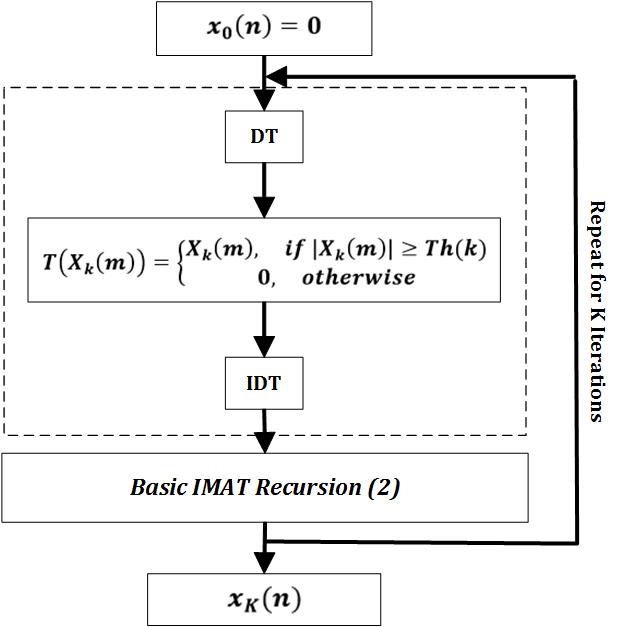 Figure 14
Figure 14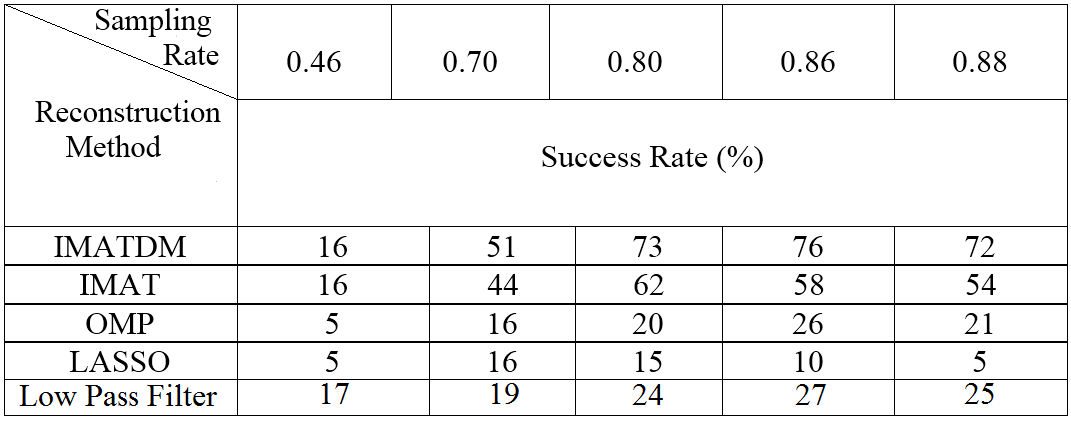 Figure 15
Figure 15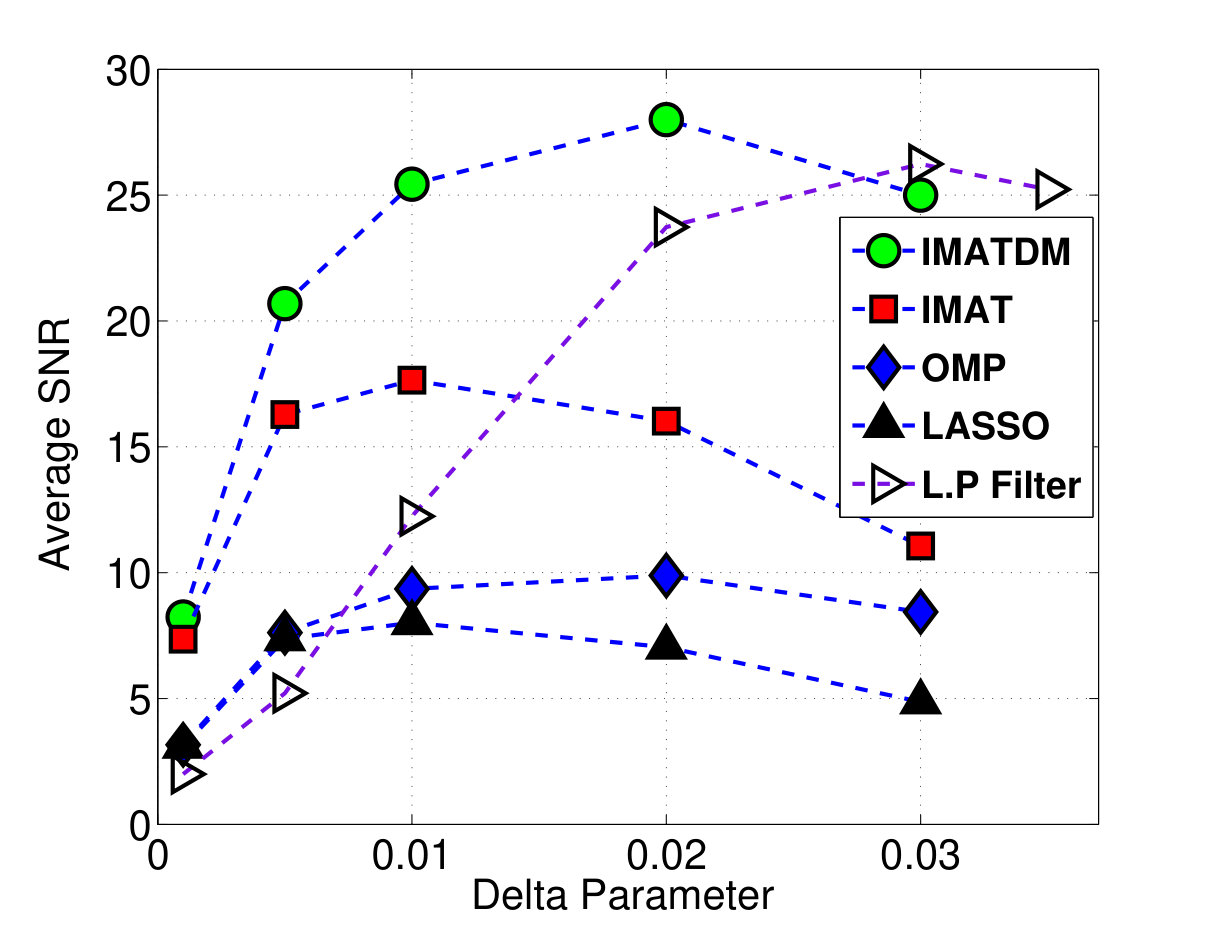 Figure 16
Figure 16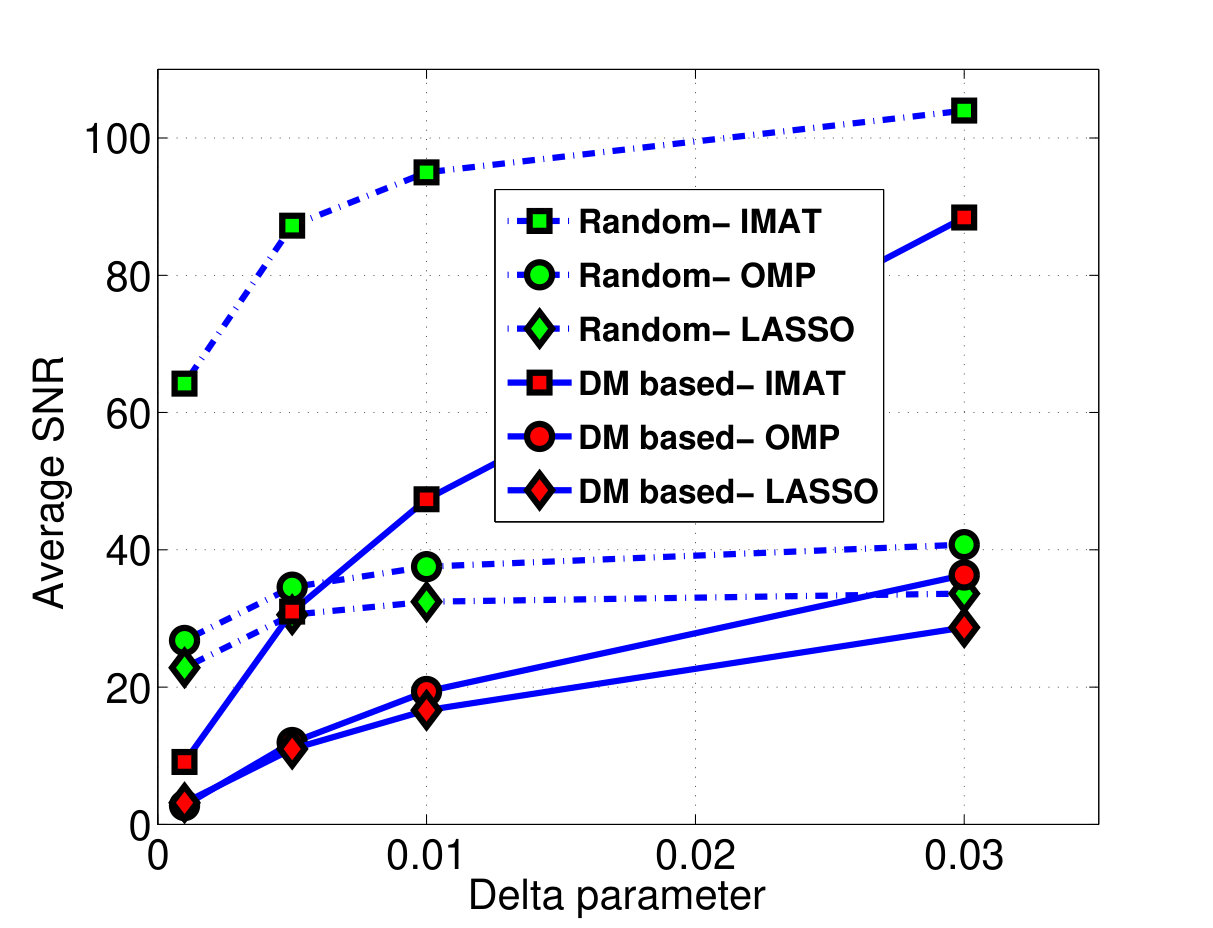 Figure 17
Figure 17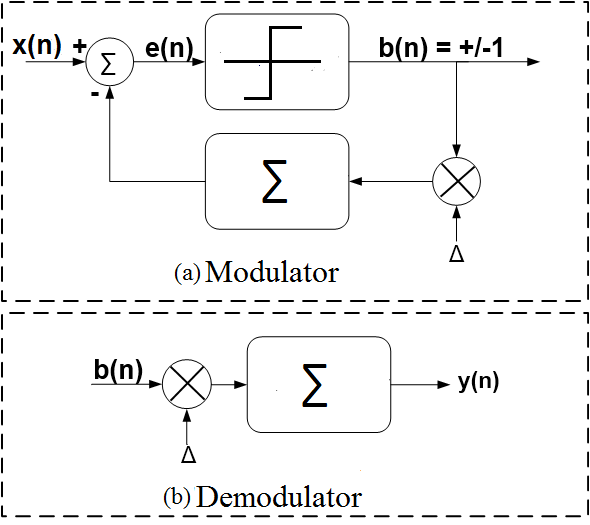 Figure 18
Figure 18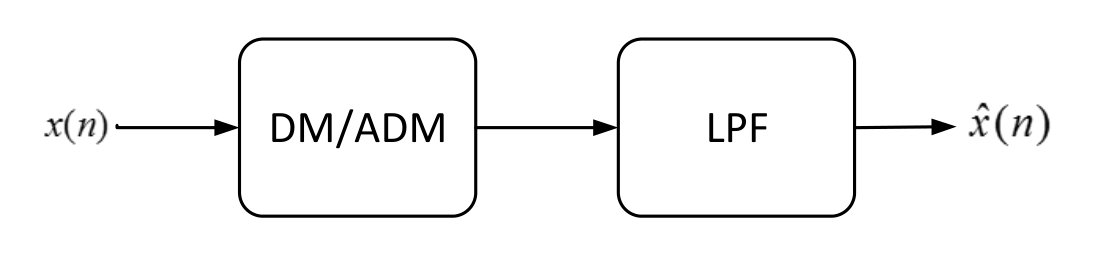 Figure 19
Figure 19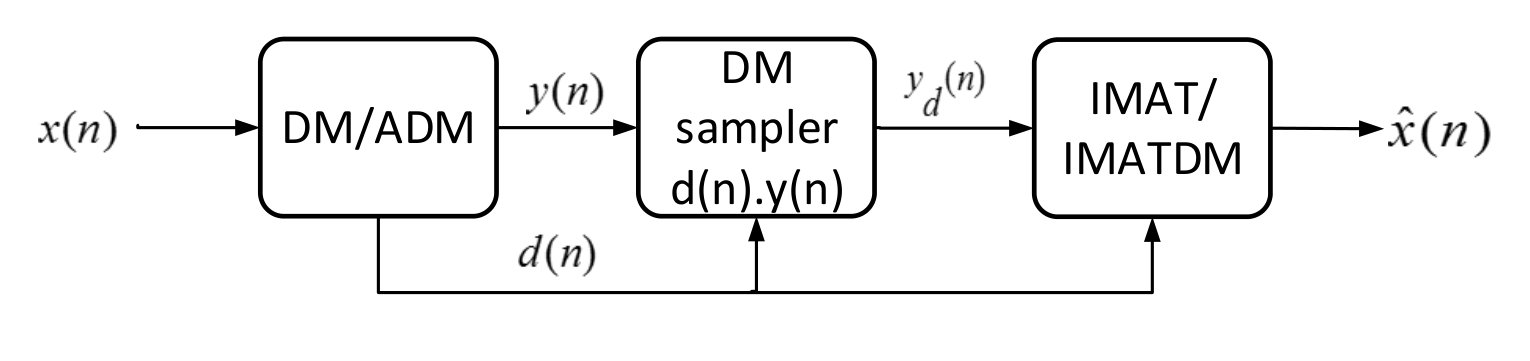 Figure 20
Figure 20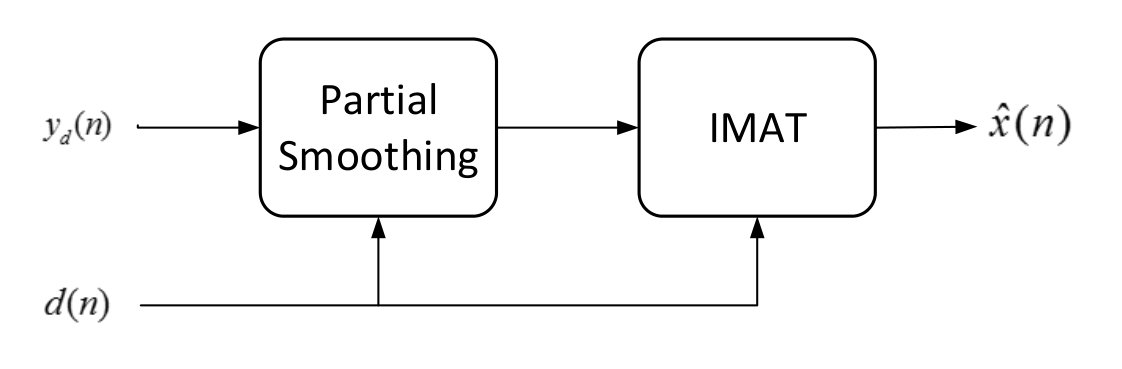 Figure 21
Figure 21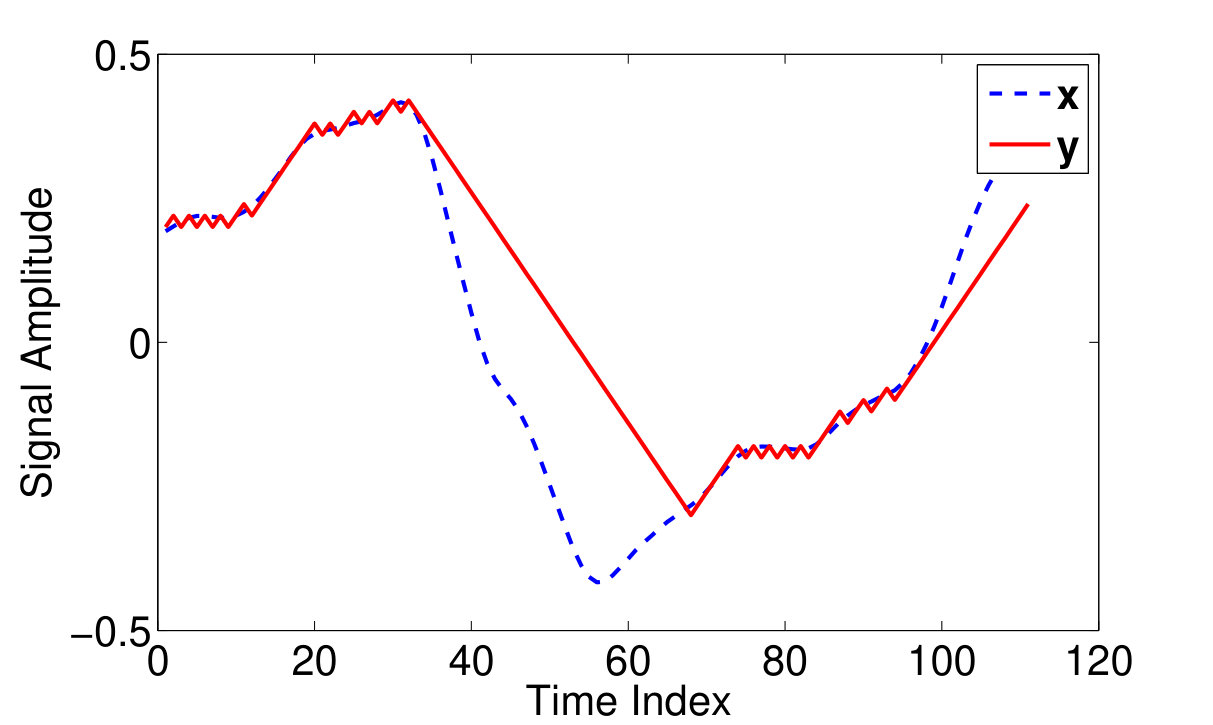 Figure 22
Figure 22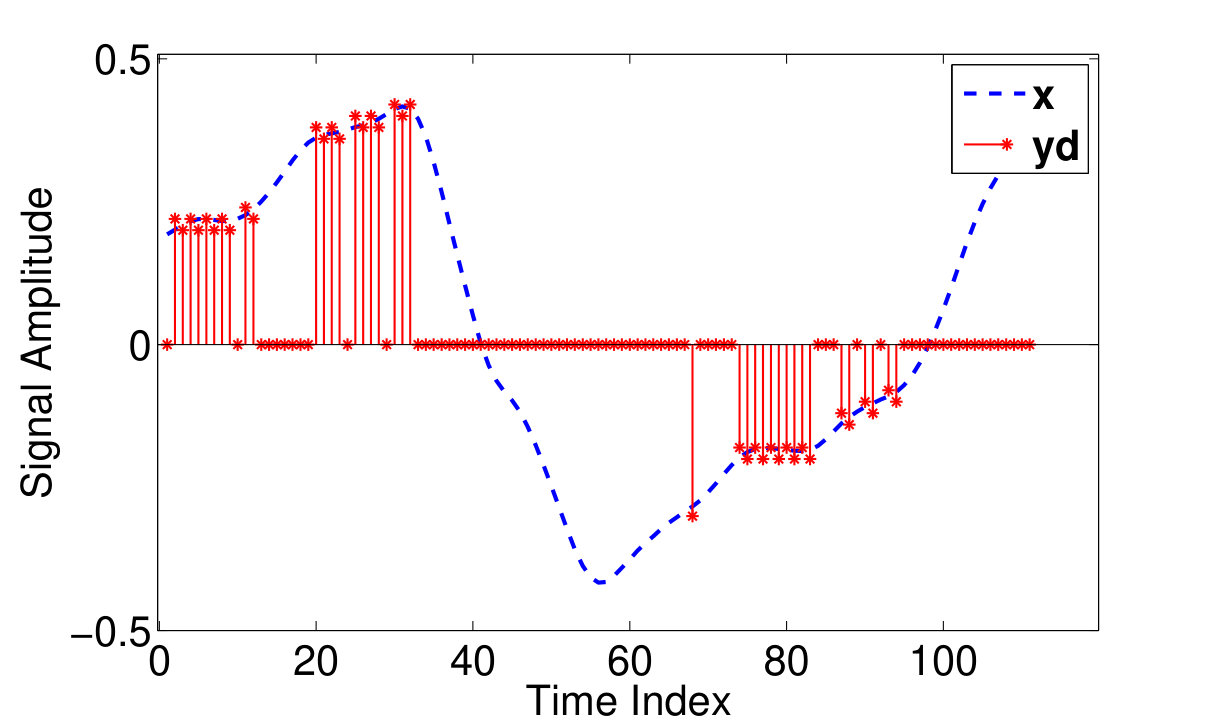 Figure 23
Figure 23Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSpeech and Audio Processing · Ultrasonics and Acoustic Wave Propagation · Speech Recognition and Synthesis
Sparsity Promoting Reconstruction of Delta Modulated Voice Samples by Sequential Adaptive Thresholds
∗ Mahdi Boloursaz Mashhadi, Saber Malekmohammadi, Student Members, IEEE, and Farokh Marvasti, Senior Member, IEEE ∗ Mahdi Boloursaz Mashhadi and Farokh marvasti are with the Advanced Communications Research Institute (ACRI), EE Department, Sharif University of Technology (SUT), Tehran, Iran. Saber Malekmohammadi is with the EE Department, University of Waterloo, ON, Canada. email: [email protected].
Abstract
In this paper, we propose the family of Iterative Methods with Adaptive Thresholding (IMAT) for sparsity promoting reconstruction of Delta Modulated (DM) voice signals. We suggest a novel missing sampling approach to delta modulation that facilitates sparsity promoting reconstruction of the original signal from a subset of DM samples with less quantization noise. Utilizing our proposed missing sampling approach to delta modulation, we provide an analytical discussion on the convergence of IMAT for DM coding technique. We also modify the basic IMAT algorithm and propose the Iterative Method with Adaptive Thresholding for Delta Modulation (IMATDM) algorithm for improved reconstruction performance for DM coded signals. Experimental results show that in terms of the reconstruction SNR, this novel method outperforms the conventional DM reconstruction techniques based on lowpass filtering. It is observed that by migrating from the conventional low pass reconstruction technique to the sparsity promoting reconstruction technique of IMATDM, the reconstruction performance is improved by an average of 7.6 dBs. This is due to the fact that the proposed IMATDM makes simultaneous use of both the sparse signal assumption and the quantization noise suppression effects by smoothing. The proposed IMATDM algorithm also outperforms some other sparsity promoting reconstruction methods.
Index Terms:
Delta Modulation (DM) Voice Coding, Adaptive Delta Modulation (ADM), Missing Sampling, Sparsity Promoting Reconstruction.
I introduction
Uniform sampling is a prior technique for Analog to Digital (A/D) conversion which samples the signal amplitudes at uniformly spaced time instances. If the Shannon-Nyquist criteria is met by the sampling process, then perfect reconstruction of the original analog signal from noiseless uniform samples is guaranteed[1, 2]. Alternative nonuniform sampling approaches to A/D conversion such as Level Crossing Sampling [3, 4], Delta Modulation (DM) [5, 6] and Sigma-Delta Modulation techniques [6] are also commonly used. Delta modulation [7] and its improved version Adaptive Delta Modulation (ADM) [8] are major waveform coding techniques that have found widespread applications in current voice and video coding systems[9, 10, 11, 12, 13].
Delta modulation is characterized by the fact that each sample is coded by a single binary symbol which leads to a rather simple hardware implementation [7]. This technique adds modulation noise [14] to the original signal. This noise may either be due to the slope overloading phenomenon during rapid jumps/falls of the signal or due to the oscillations of the modulator output during slowly varying portions of the signal which is called the granular noise [15], [16].
Efficient reconstruction of the original signal from DM samples is a major issue. The conventional reconstruction method is based on low pass filtering the modulator output at the demodulator [6],[17]. However, in this research, we migrate to the emergent theory of sparse signal processing [18] for reconstructing DM coded signals. To this end, we propose the missing sampling approach to Delta Modulation in which the more accurate DM samples taken from the signal during low slope portions are used to recover the original signal utilizing a specific sparse reconstruction technique. We show by simulations that by replacing the conventional low pass signal assumption with sparse signal assumption, we achieve an average improvement of 7.6 dBs in reconstructing voice signals from DM coded samples. This is due to the fact that the sparse reconstruction approach is capable of reconstructing the less significant but still considerable high frequency components that are commonly discarded by the low pass reconstruction techniques. To achieve more comprehensive results, we consider both conventional and adaptive delta modulation sampling schemes. We compare the performance of different sparse reconstruction algorithms (OMP [19], LASSO [20] and IMAT [21]) in the proposed scenario and observe that the Iterative Method with Adaptive Tresholding (IMAT) algorithm achieves superior results. Further we modify the basic IMAT and propose the IMATDM algorithm for improved reconstruction performance in DM scenario. Finally, we analytically prove convergence of the IMAT algorithm for DM reconstruction scenario and derive the final reconstruction SNR in presence of the quantization noise.
The rest of paper is organized as follows. Section II explains the proposed missing sampling approach to delta modulation. In section III we explain the basic IMAT algorithm and propose its modified version IMATDM for improved reconstruction performance in the DM scenario. In section IV we analytically prove the convergence of IMAT in the proposed DM scenario. In section V, we discuss the simulation results to support our previous claims. Finally, we conclude this work in section VI.
II the missing sampling approach to delta modulation
Delta Modulation (DM) is a basic analog-to-digital conversion technique used for efficient coding of voice signals. DM is the simplest form of differential pulse code modulation (DPCM) where the difference between successive samples are encoded to bit streams. In delta modulation, the transmitted samples are reduced to 1-bit symbols. Figure 1 gives the block diagram for the basic delta modulation/demodulation technique.
Fig 2.(a) depicts a typical voice frame and its corresponding DM output . As observed in this figure, during low activity periods where the input signal varies slowly with time, the DM output signal oscillates around the input. In contrary, in regions with slopes of higher absolute values where the input signal experiences rapid jumps/falls, DM output promotes or postpones the input. In both cases a coding error is introduced to the original signal. However, in the first case, DM samples provide a better approximation of the input signal with a maximum error of .
Since emergence, DM has been accompanied by subsequent low pass filters for reconstruction. Low pass filtering enforces the presumption that the underlying signal is either inherently low pass or is low pass filtered by the analog anti-aliasing filter prior to A/D conversion. The prior anti-aliasing filter omits the less significant but still considerable high frequency components from the input signal and hence degrades the reconstruction performance of A/D conversion. To avoid this phenomenon, we utilize techniques from the emergent theory of sparse reconstruction. To utilize the sparse reconstruction techniques, we need to provide a random sub-sample of the original signal for reconstruction. In this section, we propose a novel missing sampling approach to delta modulation to achieve this goal.
In the proposed approach, the more accurate DM samples taken in low slope regions of the input signal are utilized for its reconstruction during high activity regions. In other words, the less accurate samples taken during jumps/falls are discarded (missing samples) but estimated by the proposed reconstruction algorithm from the more accurate samples. Hence, in the proposed missing sampling model, only the oscillating samples are used for signal reconstruction. These oscillations are derived from the sign alternations in the delta modulator output sequence . In fact, the sampling mask is extracted from according to (3)
[TABLE]
Fig 2. b depicts the missing sampled signal corresponding to the typical voice frame in Fig 2. For further simplification of the analytical studies, we assume that ’s are independent identically distributed (iid) random variables that take one of the three values [math], and with probabilities , and respectively. In this formulation, denotes the sampling rate defined as the ratio of the ones in to its total length. Equivalently, we can write in which the coding error ’s are assumed iid random variables of Bernoulli distribution that take the values and with equal probabilities. ’s are also iid random variables of distribution and ’s are assumed independent of the sampling mask elements ’s.
It is noteworthy that the parameter plays a key role in our proposed model. A larger value gives a higher sampling ratio (i.e. the ratio of the reliable samples utilized for reconstruction to the total number of samples) but introduces more error to the samples utilized for reconstruction.
Finally, it should be noted that, there are different variants to the basic DM coding technique [8], [10], [22], etc. These variants mostly improve over the basic DM by proposing novel ideas to decrease the quantization noise at the modulator. Hence, although these techniques provide more accurate DM samples, but they still utilize the same low pass filtering stage for demodulation. Our proposed sparsity promoting reconstruction algorithms are applicable to any variant of the DM technique to improve the output signal quality. To confirm this claim, we also expand our proposed missing sampling model to the Adaptive Delta Modulation (ADM) scheme. In this scheme the parameter is adapted to the variations of the input signal. During low activity periods of the input, is decreased exponentially to achieve more accurate samples with less coding error. Alternatively, in regions where DM output is promoted or postponed, is increased exponentially in order to faster reach the input signal.
III sparsity promoting reconstruction by IMAT and IMATDM
To the best of the authors’ knowledge, this is the first work in the literature that considers DM coding in the sparse reconstruction paradigm. In fact, prior researches have considered the underlying signal to be low pass or band-limited [6],[17] but not spectrally sparse. In the this section, we demonstrate our sparsity promoting reconstruction technique namely, the Iterative Method with Adaptive Thresholding (IMAT) and its improved version IMAT for DM reconstruction (IMATDM) algorithms in Subsection A. Later in Subsection B, compares the structures of the sparsity promoting reconstruction methods of IMAT and IMATDM with the traditional lowpass filtering technique for reconstruction of DM voice samples. Later in section III, it is shown by extensive simulations that the proposed sparsity promoting IMAT and IMATDM algorithms not only outperform the conventional low pass reconstruction techniques, but also outperform other sparsity promoting reconstruction techniques of OMP, and Lasso.
III-A IMAT and IMATDM algorithms
The basic IMAT algorithm was originally proposed for sparse signal reconstruction from missing samples in [21]. IMAT proved to outperform Orthogonal Matching Pursuit (OMP) and Iterative Hard Thresholding (IHT) algorithms in some applications regarding performance or complexity [21, 23]. The basic IMAT algorithm progressively extracts the sparse signal components by iterative thresholding of the estimated signal promoting sparsity. The reconstruction formula for IMAT is given by (4)
[TABLE]
In (4), and denote the original signal and its reconstructed version at the ’th algorithm iteration and is the relaxation parameter that controls the convergence rate of the algorithm. denotes the thresholding operator and is the binary missing sampling mask extracted according to (3).
[TABLE]
In (5), denotes the Kronecker delta function, is the voice frame length, denotes the missing sampling time instances and is the sampling rate.
The thresholding block transforms the input signal to the sparse domain (FFT, DCT, etc.), sets the signal components with absolute values below the threshold to zero and finally transforms back to the original time domain. The threshold value Th is decreased exponentially by where is the iteration number. The algorithm performance is less dependent on the choice of the algorithm parameters and but these parameters are optimized empirically for the best performance in simulations. The block diagram for the basic IMAT algorithm is given in fig. 3. DT is the Discrete Transform (the simple FFT transfrom in this research) and converts the input signal to the sparse domain. Similarly, IDT is its inverse transform (IFFT).
Having demonstrated the basic IMAT algorithm, we proceed with IMATDM. According to fig. 4(a), IMATDM is obtained by adding a partial smoothing block prior to IMAT. This block performs a moving averaging of length on . As mentioned before, although DM samples are considered as a good approximation of the original signal during low activity intervals, they are still oscillating around the input in these regions and hence include a coding error . In fact, as investigated in section IV, reconstructing the signal from these noisy samples results in a noticeable performance degradation according to the power of the coding error which is proportional to . As these samples are oscillating around the original signal, it is obvious that a moving averaging of an even length causes the coding error terms to cancel out. On the other hand, as the original signal is slowly varying in these regions and does not experience sharp jumps/falls, the averaging operation does not cause much distortion. Applying this technique, more the samples used by IMAT for reconstruction are significantly more accurate and reconstruction leads to improved SNR values as observed by simulations in section V.
III-B Sparsity promoting vs. lowpass reconstruction
Fig. 4 compares our proposed reconstruction method with the traditional low pass filtering techniques. As observed in this figure, the traditional reconstruction technique applies the low pass signal assumption. In order for this assumption to be true, the input signal is usually filtered by an antialiasing low pass filter prior to DM coding. This antialiasing filter omits the high frequency signal components and degrades the signal quality. However, the proposed sparsity promoting reconstruction algorithms of IMAT and IMATDM bypass this antialiasing filter distortion. Hence, IMAT/IMATDM algorithms improve the reconstruction quality by well preserving the high frequency signal components in the high quality input voice. This phenomenon is justified by simulations in section V.
IV CONVERGENCE ANALYSIS
In this section, we prove the convergence of IMAT and IMATDM algorithms for DM coding using our proposed missing sampling model. To this end, we need to prove the following theorem.
Theorem 1**.**
The frequency transform of the delta modulation sampled signal is a random variable with mean and variance given by
[TABLE]
in which .
Proof.
According to the missing sampling model we assumed for DM coding, is a random variable that takes one of the values [math], and with probabilities , and respectively. Hence, we get and the first equation in (1) can be derived as (IV)
[TABLE]
This proves the expected value equation, for the variance equation we have
[TABLE]
Note that as and are assumed independent for , the second term in (IV) equals zero. Again considering the simplified model we assumed for delta modulation sampling, the first term is calculated as (IV)
[TABLE]
And the proof is complete. ∎
Theorem 2**.**
Considering IMAT reconstruction formula given by (4), is an unbiased estimator of for .
Proof.
To prove this theorem, we need to show that or equivalently . To this end, we prove that the error sequence forms a geometric progression with initial value and common ratio . Equivalently, IMAT reconstruction technique converges linearly (of order 1) to the original signal in the mean iff or .
Starting the algorithm from zero initial value, we have and hence . the statement is trivial for . According to (4) for , we have . Also applying theorem 1 we get and hence . Now, we rewrite the iterative IMAT formula (4) in transform domain as
[TABLE]
Now, taking from both sides of (10) and applying (1) we get
[TABLE]
[TABLE]
Utilizing (12) we get
[TABLE]
Now if , the thresholding operator can be omitted from the right side of (12) which yields (IV) and the required statement results.
[TABLE]
On the other hand, if is not picked by the threshold, we get and according to (12) we get . Hence, once a signal component is picked by the threshold in a specific iteration, its corresponding error sequence converges linearly to zero. As the threshold is strictly decreasing, all signal components will be gradually picked by the threshold and the proof is complete. ∎
Theorem 2 proves that is a random variable with its expected value approaching as . But in order to prove perfect reconstruction/convergence of the IMAT algorithm, we also need to show that the variance of this unbiased estimator approaches zero as . Theorem 2 explains this variance fluctuation issue as k approaches infinity. Before providing the formal statement for theorem 3 lets define the sparse signal support to be the set of all its nonzero frequency components as .
Theorem 3**.**
Assume that the threshold picks in the k’th iteration of the IMAT algorithm, this increases the spectrum variance if and increases the variance for .
Proof.
Let’s decompose as
[TABLE]
In which only consists of signal support components and includes other components picked by the threshold. In other words, is the portion reconstructed by the algorithm up to the k’th iteration and is the non-support portion picked mistakenly by the threshold due to non-zero spectrum variance. Now, let’s also decompose as the sum of its reconstructed portion and a residual as
[TABLE]
Now, note that according to the missing sampling model for DM coding we have . Substituting (15) and (16) in (4)gives
[TABLE]
Now, note that the first two terms in (IV) are not multiplied by the sampling mask and hence their frequency transform are deterministic and do not contribute to the spectrum variance. According to theorem 1, the contribution of and terms to the spectrum variance equals and respectively. Similarly, according to theorem 1, the contribution of the coding error to the spectrum variance equals . This yields that
[TABLE]
In (IV), and denote the energies of the residual and mistakenly picked frequency components respectively. Now, each mistakenly picked component increases and consequently the spectrum variance. Similarly, for a correctly picked signal component , and consequently the spectrum variance is decreased. The above discussion completes the proof. ∎
Remark 1*.*
As stated previously, due to the non-zero spectrum variance, is non-zero for . Hence, the threshold parameters must be adjusted such that the threshold value always keeps above the standard deviation of the spectrum (e.g. , ) to prevent the algorithm from picking incorrect frequency components. In this case, and the spectrum variance is decreasing in each iteration .
Corollary 3.1**.**
Considering theorem 2, we conclude that IMAT estimation bias approaches zero as approaches infinity. On the other hand, the variance of IMAT estimation is decreasing provided that the condition in Remark 1 always holds. Now considering the fact that the Mean Square Error (MSE) of the estimator is given by (3.1)
[TABLE]
Now as both terms in (3.1) are decreasing, we conclude that is also decreasing. In other words, the cost function for IMAT algorithm is the Mean Square Error of the estimated signal in transform domain. As this cost function is convex and decreasing, it will converge to the global minimum.
Remark 2*.*
If the threshold value is decreased too fast, there exists the risk of picking signal components that are not in signal support. This will increase the spectrum variance or equivalently degrade the final quality of the reconstructed signal. On the other hand, slower decrease of the threshold value, slows down the algorithm’s convergence rate. Although the threshold doesn’t necessarily need to decrease exponentially, simulation results conveyed that the exponential parameters can always be optimized for acceptable performance.
V SIMULATION RESULTS
In this section, we first investigate the performance of the proposed missing sampling approach to DM coding in subsection A. In subsection B, we show superior performance of the proposed IMAT and IMATDM algorithms for DM/ADM reconstruction in comparison with both the classic low pass and some other sparsity promoting reconstruction algorithms.
It should be noted that we compare the performance of different sampling/reconstruction schemes in terms of the average reconstruction SNR and Success Rates (SR) achieved on a statistically sufficient number of voice frames. Each frame is 20ms long and is extracted from a high quality voice recorded at 48kHz. Each frame is 20ms long and is extracted from a database of high quality English voice (55% male, 45% female) sampled at 48kHz. Hence, the sampling frequency of the input voice is set at 48kHz to ensure that no frequency component in human audible range (20Hz to 20 kHz) is missed.
To gain an insight on the subjective quality achieved by different techniques, we also report PESQ (Perceptual Evaluation of Speech Quality) [24] scores achieved on the whole 10s voice recording. The PESQ score ranges from -0.5 to 4.5 with 4.5 standing for the best subjective quality.
The SNR values reported as the quality measure in this section are calculated as (20)
[TABLE]
The reported SR values are also defined as the percentage of the voice frames reconstructed with final SNRs above a preset threshold value.
Finally, note that a central contribution in this paper is to replace the traditional low pass signal assumption (e.g. 3.3 kHz as the bandwidth for voice) by the sparse signal assumption using the family of IMAT based reconstruction techniques. Hence, unlike the common assumption of 3.3 kHz for voice, we avoid the antialiasing filter on 3.3 kHz to be able to capture frequency components beyond 3.3 kHz. Consequently, the input sampling frequency must be so high (e.g. 48 kHz) as to make sure that all components in the human audible range [20-20k] Hz are accommodated. Although these high frequency components may seem negligible, but we observe that utilizing the sparse assumption, we achieve noticeable SNR and PESQ improvements in comparison with the traditional low pass based reconstruction techniques.
V-A Delta Modulation vs. Missing Sampling
As mentioned in the previous sections, we utilize the missing sampling model for DM coding both in reconstruction and analytical studies. Off course there exists some modeling mismatch in our proposed approach. To study the effects of this modeling mismatch, we compare these two sampling methods in terms of the average reconstruction SNR values achieved by them. It should be noted that in this subsection, we compare the reconstruction performance of the two sampling patterns/masks of missing and DM sampling. Hence we need to discard the quantization/coding error. The two sampling patterns are compared at equal sampling rates.
For DM sampling, as mentioned before, the sampling pattern () is extracted according to (3). But in order to discard the coding errors in reconstruction, is replaced by in (4). For the missing sampling approach, the mask elements ’s are generated by iid random variables of distribution in which is the same sampling rate achieved by DM coding. Again, is replaced by for reconstruction without quantization error.
The comparison is performed at different delta values of 0.001, 0.005, 0.01 and 0.03 that yield the sampling rates of 0.46, 0.70, 0.80 and 0.88, respectively. The simulation results has been shown in fig 5. According to this figure, as the delta parameter approaches 0.03, different reconstruction methods achieve almost equal results in terms of SNR for both random sampling and our proposed DM based missing sampling.
It can be concluded that DM is a suitable sampling method and its performance approaches the ideal case of random sampling as the sampling rate increases.
V-B Performance Comparisons between Different Reconstruction Methods
In this subsection we compare the performance of the proposed IMAT and IMATDM algorithms with both the classic low pass reconstruction technique and other sparsity promoting algorithms of OMP and LASSO. To this end, we apply DM coding at different values leading to different sampling rates. It should be noted that unlike the previous subsection the coding error is taken into account in the simulations of this subsection to facilitate a more meaningful comparison between different reconstruction techniques.
Figure 6 compares the average SNR (dB) values achieved by these algorithms for DM sampling with different values. The comparison is performed at delta values of 0.001, 0.005, 0.01, 0.02, and 0.03 that lead to sampling rates of 0.46, 0.70, 0.80, 0.86, and 0.88 respectively.
The corresponding Success Rate (SR) values defined as the ratio of successfully reconstructed voice frames in are also reported in table I . In this table, the SNR threshold considered as successful reconstruction is set at 15 dBs.
It can be concluded that the proposed reconstruction algorithms (IMAT and IMATDM) clearly outperform both sparsity promoting algorithms (OMP and LASSO) and low pass technique regarding SNR and SR.
Not that as an increase in leads to an increase in both sampling rate and the coding error, there is an optimum value for in each scenario. This phenomenon is also observed in fig. 6.
Finally, the PESQ scores achieved by IMATDM, IMAT, LASSO, OMP, and the classical Low pass techniques for DM reconstruction at p= 0.8 are 2.33, 2.08, 1.44, 1.1, and 1.49, respectively.
In order to achieve more comprehensive results, we also investigate the performance of the proposed reconstruction algorithms on the missing sampling based on ADM. It should be noted that as the parameter is changed adaptively according to the input signal for ADM, the sampling rate for ADM is less dependent on the initial value of and is almost 0.5 . The reconstruction SNR values achieved for ADM was 39.7, 31.9, 12.9, 14.21, and 39.5 dBs for IMATDM, IMAT, OMP, LASSO, and the classical Low Pass techniques, respectively. Similarly, the achieved SR values are 88.5, 52.1, 19.5, 9.5 and 40.8 for IMATDM, IMAT, OMP, LASSO, and the classical Low Pass techniques, respectively. Note that the SNR threshold considered as successful reconstruction is set at 20 dBs for SR calculations.
Finally, the PESQ scores achieved by IMATDM, IMAT, OMP, LASSO, and the classical Low pass technique are 3.1, 2.67 ,2.08 ,2.12 , and 2.9 in this scenario.
It is observed that, sampling by ADM and reconstructing by IMATDM achieves superior performance in comparison with other sampling/reconstruction pairs. It is also observed that the proposed IMATDM algorithm outperforms the basic IMAT by an average amount of 7.83 dBs.
VI CONCLUSION
In this paper, we proposed the family of iterative methods with adaptive thresholding (IMAT) for sparsity promoting reconstruction of Delta Modulated (DM) and Adaptive Delta Modulated (ADM) voice signals. By adding a prior partial smoothing block to IMAT, we proposed IMATDM algorithm for improved reconstruction quality for DM sampling. Utilizing our proposed missing sampling approach to delta modulation, we proved the convergence of IMAT and IMATDM algorithms analytically. The proposed algorithms also proved promoting reconstruction techniques of OMP and LASSO in terms of reconstruction SNR, Success Rate and PESQ scores by simulations.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] C. Shannon, “A mathematical theory of communication,” Bell Syst Tech. J. , vol. 27, 1948.
- 2[2] A. Jerri, “Shannon sampling theorem-its various extensions and applications: A tutorial review,” Proc. IEEE , vol. 65, 1977.
- 3[3] M. B. Mashhadi, N. Salarieh, E. S. Farahani, and F. Marvasti, “Level crossing speech sampling and its sparsity promoting reconstruction using an iterative method with adaptive thresholding,” IET Signal Processing , vol. 11, no. 6, pp. 721–726, 2017.
- 4[4] F. Marvasti and M. B. Mashhadi, “Wideband analog to digital conversion by random or level crossing sampling,” US Patent No. US 9729160 B 1 , 2017.
- 5[5] Y. Hu and et. al., “Reconstruction of uniformly sampled signals from non-uniform short samples in fractional fourier domain,” IET Signal Processing , November 2015.
- 6[6] F. Marvasti, in Nonuniform Sampling: Theory and Practice . Springer US, 2001.
- 7[7] J. Flood and M. Hawksford, “Exact model for delta-modulation processes,” Proceedings of the Institution of Electrical Engineers, IET , vol. 118, September 1971.
- 8[8] P. Wing, “Adaptive delta modulation,” Electronics Letters , vol. 5, pp. 191–192(1), May 1969.