Latent Representations of Dynamical Systems: When Two is Better Than One
Max Tegmark (MIT)

TL;DR
This paper demonstrates that using separate latent mappings for present and future states in dynamical systems prediction is theoretically optimal and outperforms traditional single-mapping methods, especially for non-time-reversible systems.
Contribution
It introduces a novel approach that employs two different latent representations for present and future, challenging the common single-mapping paradigm in dynamical system prediction.
Findings
Two-mapping approach outperforms PCA and single-mapping methods
Optimality of separate mappings for non-time-reversible systems
Illustrated with coupled harmonic oscillators with noise and dissipation
Abstract
A popular approach for predicting the future of dynamical systems involves mapping them into a lower-dimensional "latent space" where prediction is easier. We show that the information-theoretically optimal approach uses different mappings for present and future, in contrast to state-of-the-art machine-learning approaches where both mappings are the same. We illustrate this dichotomy by predicting the time-evolution of coupled harmonic oscillators with dissipation and thermal noise, showing how the optimal 2-mapping method significantly outperforms principal component analysis and all other approaches that use a single latent representation, and discuss the intuitive reason why two representations are better than one. We conjecture that a single latent representation is optimal only for time-reversible processes, not for e.g. text, speech, music or out-of-equilibrium physical systems.
Click any figure to enlarge with its caption.
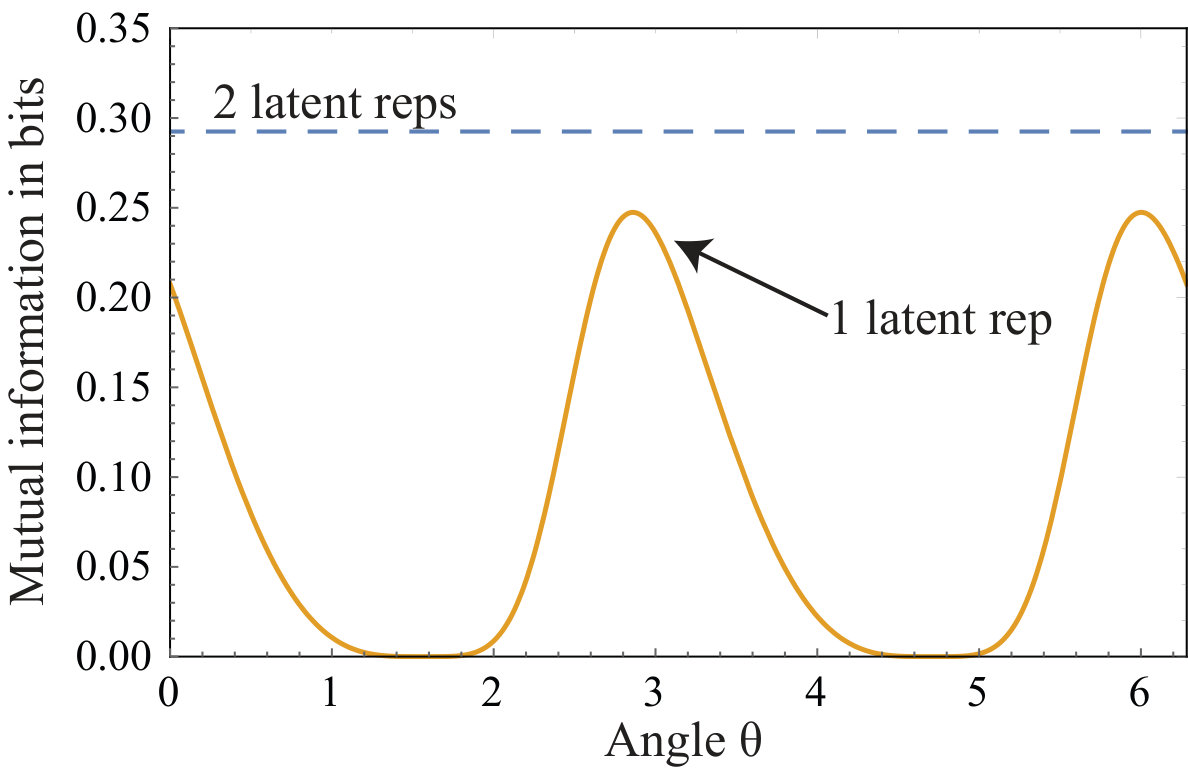 Figure 1
Figure 1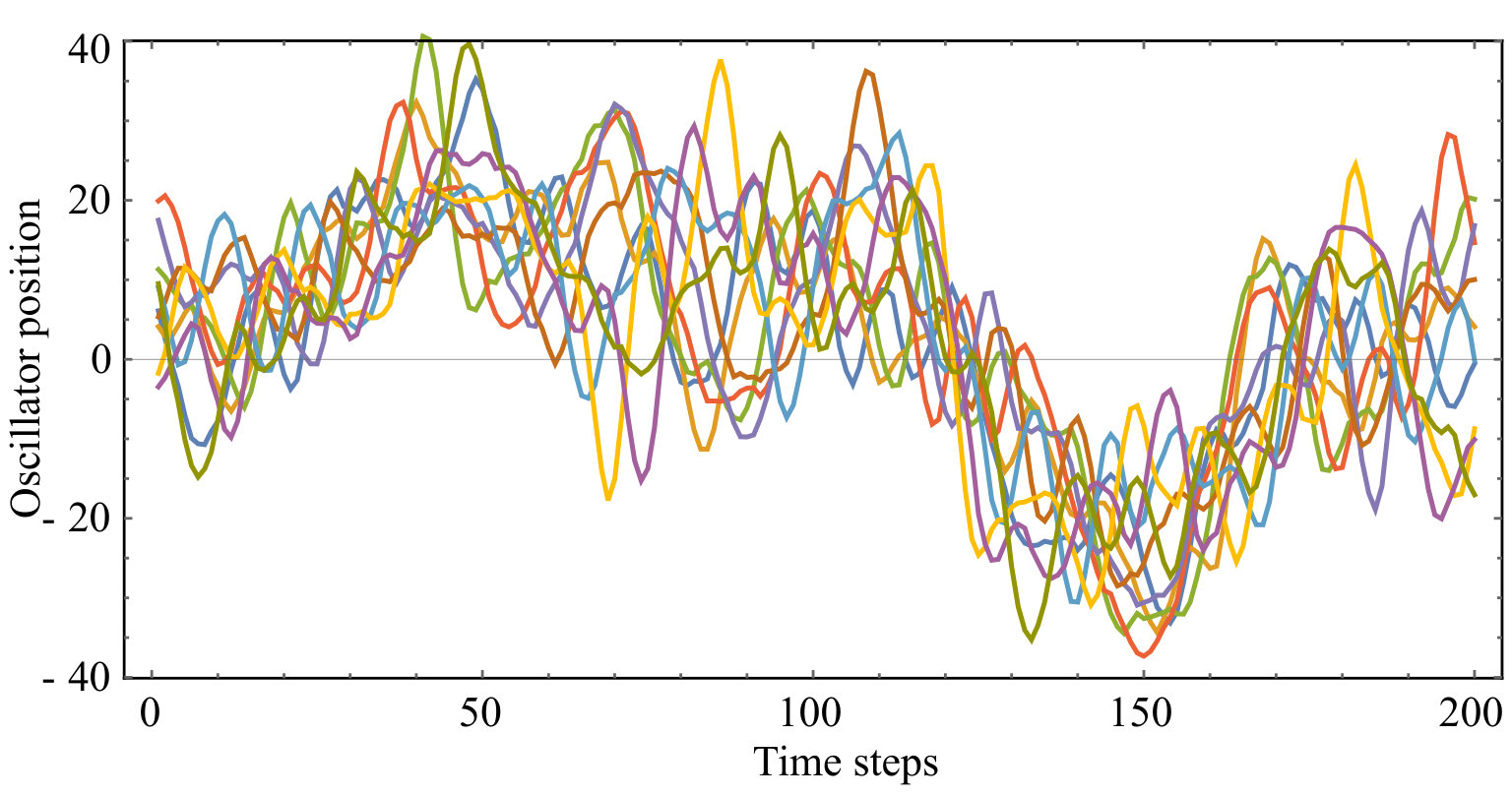 Figure 2
Figure 2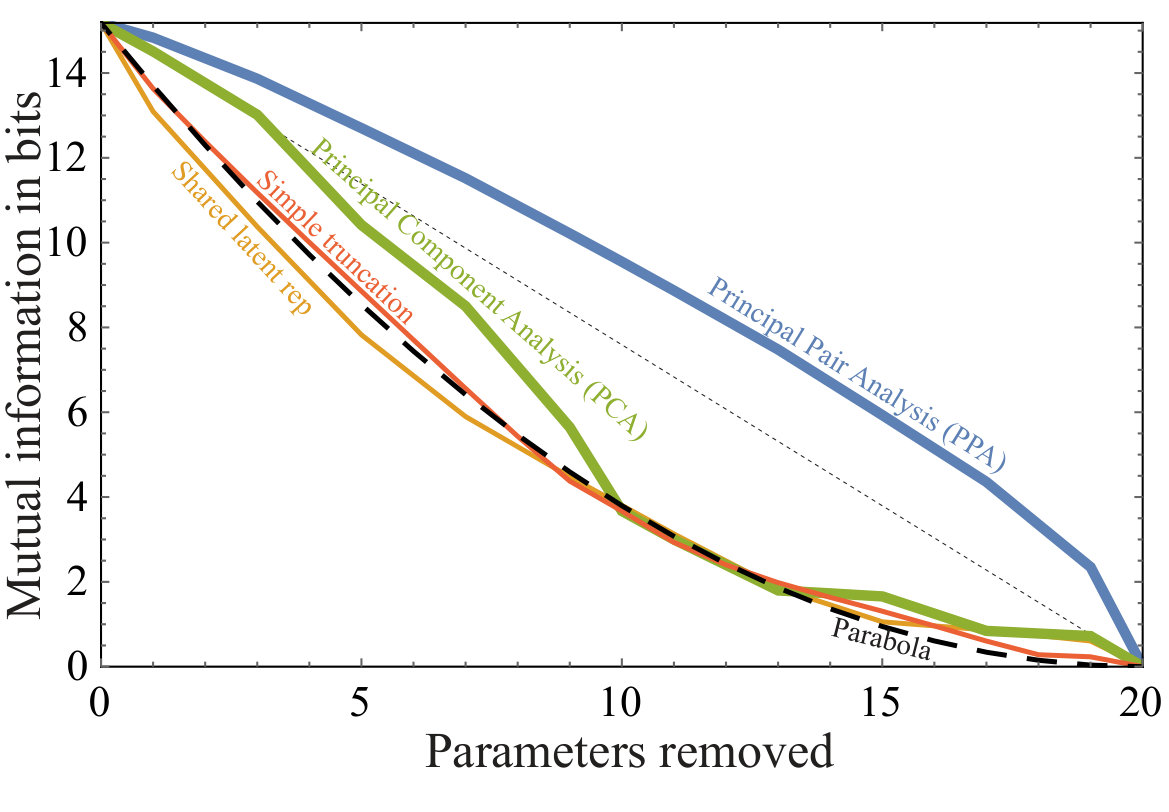 Figure 3
Figure 3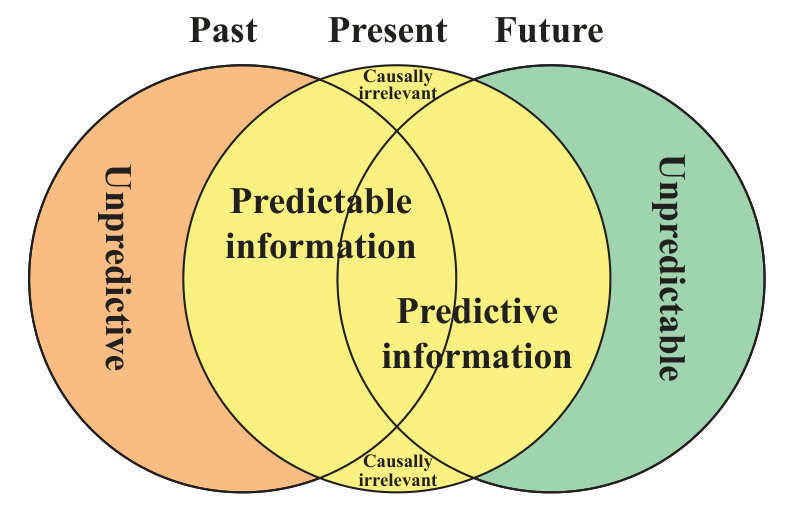 Figure 4
Figure 4| Random | What is | Probability distribution | |
|---|---|---|---|
| vectors | distilled? | Gaussian | Non-Gaussian |
| 1 | Entropy | PCA | Autoencoder |
| u=f(x) | |||
| 2 | Mutual information | CCA | Latent reps |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsTime Series Analysis and Forecasting · Topic Modeling · Artificial Intelligence in Games
Latent Representations of Dynamical Systems: When Two is Better Than One
Max Tegmark
Dept. of Physics, MIT Kavli Institute & Center for Brains, Minds & Machines, Massachusetts Institute of Technology, Cambridge, MA 02139; [email protected]
Abstract
A popular approach for predicting the future of dynamical systems involves mapping them into a lower-dimensional “latent space” where prediction is easier. We show that the information-theoretically optimal approach uses different mappings for present and future, in contrast to state-of-the-art machine-learning approaches where both mappings are the same. We illustrate this dichotomy by predicting the time-evolution of coupled harmonic oscillators with dissipation and thermal noise, showing how the optimal 2-mapping method significantly outperforms principal component analysis and all other approaches that use a single latent representation, and discuss the intuitive reason why two representations are better than one. We conjecture that a single latent representation is optimal only for time-reversible processes, not for e.g. text, speech, music or out-of-equilibrium physical systems.
I Introduction
A core challenge in physics (and in life quite generally) is data distillation: keeping only a manageably small fraction of our available data that nonetheless retains most of the information that is useful to us. Ideally, the information can be partitioned into a set of independent chunks and sorted from most to least useful, enabling us to select the number of chunks to retain so as to optimize our tradeoff between utility and and data size.
Consider a random vector , and partition its elements into two parts:
[TABLE]
We may, for example, interpret the vectors and as observations of two separate systems at the same time, or as two separate observations of the same system some fixed time interval apart. Let us now consider various forms of ideal data distillation, as summarized in Table 1.
If we distill as a whole, then we would ideally like to find a function such that the so-called latent representation retains the full entropy , decomposed into independent111When implementing any distillation algorithm in practice, there is always a one-parameter tradeoff between compression and information retention which defines a Pareto frontier. A key advantage of the latent variables (or variable pairs) being statistically independent is that this allows the Pareto frontier to be trivially computed, by simply sorting them by decreasing information content and varying the number retained.
parts with vanishing mutual infomation: For the special case where has a multivariate Gaussian distribution, the optimal solution is Principal Component Analysis (PCA) Pearson (1901), which has long been a workhorse of statistical physics and many other disciplines: here is simply a linear function mapping into the eigenbasis of the covariance matrix of . The general case remains unsolved, and it is easy to see that it is hard: if where implements some state-of-the-art cryptographic code, then finding (to recover the independent pieces of information and discard the useless parts) would generically require breaking the code. Great progress has nonetheless been made for many special cases, using techniques such as nonlinear autoencoders Vincent et al. (2008) and Generative Adversarial Networks (GANs) Goodfellow et al. (2014).
Now consider the case where we wish to distill and separately, into and , retaining the mutual information between the two parts. Then we ideally have , This problem has attracted great interest, especially for time series where and for some sequence of states () in physics or other fields, where one typically maps the state vectors into some lower-dimensional vectors , after which the prediction is carried out in this latent space. For the special case where has a multivariate Gaussian distribution, the optimal solution is Canonical Correlation Analysis (CCA) Hotelling (1936): here both and are linear functions, computed via a singular-value decomposition (SVD) Eckart and Young (1936) of the cross-correlation matrix after prewhitening and . The general case remains unsolved, and is obviously even harder than the above-mentioned 1-vector autoencoding problem. The recent DeepMind paper Oord et al. (2018) reviews the state-of-the art as well as presenting Contrastive Predictive Coding, a powerful new distillation technique for time series, following the long tradition of setting .
The purpose of this paper is to further investigate the case for choosing . We will do this by studying the lower-left quadrant of Table 1, where information-theoretically optional results can be derived, and using these results to discuss implications for the harder problem in the lower-right quadrant. The rest of this paper is organized as follows. Section II discusses analytic results for the lower-left quadrant. In Section III, the optimal method is benchmarked on a physics example, showing significant improvement over methods. Our conclusions are discussed in Section IV.
II CCA implications for latent representations: two is better than one
II.1 Notation
Without loss of generality, we take the random vector from equation (1) to have vanishing mean , and write its covariance matrix as
[TABLE]
Modeling the probability distribution of as a multivariate Gaussian, the mutual information between and is
[TABLE]
where we take to denote the logarithm in base 2 so that information is measured in bits.
As mentioned, PCA elegantly decomposes the information content in a single random vector into a mutually exclusive and collectively exhaustive set of information chunks corresponding to statistically independent numbers (eigenmodes coefficients) whose individual entropies add up to the total entropy. CCA generalizes this idea to mutual information, decomposing the total mutual information between and as a sum of the mutual information between a series of statistically independent pairs of numbers that are linear combinations of the two vectors, as summarized in Table 1 and in the following subsection.
II.2 CCA implementation
To do this, CCA first diagonalizes and as
[TABLE]
where and are orthogonal matrices and and are diagonal, with the eigenvalues (which are non-negative up to numerical rounding errors) sorted in decreasing order. It then constructs a prewhitening matrix
[TABLE]
where the function , and a function of a diagonal matrix is defined by applying it to each diagonal element. In many practical applications, some covariance matrix eigenvalues are near zero (and occasionally get evaluated as slightly negative due to numerical rounding errors), so below we implement CCA more robustly by instead defining
[TABLE]
for some desired numerical precision floor . The matrix transforms into a block form
[TABLE]
where the zero-rows correspond to the eigenvalues that are so tiny that we round them to zero, and the matrix can be interpreted as the Pearson correlation coefficients between the elements of the prewhitened vectors and . CCA now performs a singular-value decomposition (SVD) of Eckart and Young (1936):
[TABLE]
where the matrices and are orthogonal, is a diagonal matrix and . Defining
[TABLE]
we can now transform our original covariance matrix into the simple form
[TABLE]
This means that when the random vector is transformed into
[TABLE]
there are no correlations between any elements of except between what we will term “principal pairs” (to emphasize the analogy with principal components), matching elements in and , which have a Pearson correlation coefficient .
Mutual information is independent of invertible reparametrizations of and , so the mutual information from equation (3) now simplifies to
[TABLE]
if there are no numerically negligible eigenvalues. If there are numerically negligible eigenvalues, the practically useful mutual information is given by this same formula, since the corresponding eigenmodes are numerically untrustworthy. This mutual information shared between and can be intuitively interpreted as stemming from a common source, as explained in Appendix A.
II.3 One versus two latent representations
As mentioned, dimensionality reduction is a popular approach to predicting the future of a time series () in physics and other fields: the state vectors are mapped into some lower-dimensional vectors by an invertible mapping that hopefully captures the most relevant information, after which the prediction is carried out in this latent space. This mapping can be either linear, such as in PCA or Independent Component Analysis Hyvärinen and Oja (2000), or non-linear as in autoencoders Vincent et al. (2008), Generative Adversarial Networks Goodfellow et al. (2014) or Contrastive Predictive CodingOord et al. (2018).
For the special case of multivariate Gaussian probability distributions, the the formulas above imply that CCA provides the optimal dimensionality reduction, with the twist that the mappings into the latent space should generally be different for the predictor vector and the predicted vector: we can define the CCA dimensionality reduction as the mapping
[TABLE]
into the latent space , where
[TABLE]
and the projection matrix simply picks the first elements of vector following it. The CCA construction above is readily seen to imply that
[TABLE]
for any functions and mapping and into , and when the dimensionality is not reduced below that of both and .
Note that generically, , even for time series where and live in the same space. The following theorem shows that this is a feature, not a bug
Theorem: A single latent representation sometimes underperforms two separate ones, capturing less mutual information in some given number of variables.
**Proof: ** A simple counterexample (to the hypothesis that a single representation is equally good) is that is provided by four random variables , , , with unit variance and no correlations except that . The CCA described above shows that the mutual information can be entirely captured by a single principal pair ; specifically,
[TABLE]
If we instead transform both and using a single latent representation, then the maximal mutual information we can attain from a single principal pair is smaller:
[TABLE]
as can be seen in Figure 1. Here we have without loss of generality taken to be a unit vector , since the mutual information above is invariant under rescaling .
As mentioned, most published work uses merely a single latent representation for time series prediction. This is clearly not optimal for the general case, since we have just proven that it is not even optimal for the simple case of multivariate Gaussian distributions. But does this suboptimality really matter in practice? The suboptimality is seen to be only 0.05 bits in Figure 1), so it is natural to ask whether a single latent representation is generically close to optimal, or whether the further improved from adding a second reporesentation provides large enough an improvement to be worth the extra complication. We address this questions in the next section by a practical application.
III Example: Coupled harmonic oscillators with dissipation and thermal noise
To better compare the predictive abilities of CCA with other approaches, let us now consider the physics problem of predicting the future state of a set of coupled 1-dimensional harmonic oscillators that are damped by friction and perturbed by random thermal noise. We group the positions and momenta of the oscillators into the -dimensional vectors and , which we in turn group into a single -dimensional state vector . We set all masses equal to unity, so , and take the laws of motion to be for some positive semidefinite spring matrix and friction matrix . This means that we can write
[TABLE]
which has the solution
[TABLE]
All eigenvalues of are negative, so to prevent from simply decaying toward zero, we add random Gaussian noise of standard deviation to each position at every time step , Defining , we can thus rewrite our time-evolution as a Markovian autoregressive process:
[TABLE]
where , , , if and zero otherwise (the standard deviation is for position noise, zero for momentum noise). This random process will eventually converge to a stationary state whose probability distribution is time-independent, since all eigenvalues of have magnitude below unity, so that memory of the past gets exponentially damped over time. Figure 2 shows an example for oscillators arranged in a circle. Here and below we use time step , noise level , friction matrix with , and spring matrix corresponding to nearest-neighbor coupling and self-coupling , i.e., if , for nearest neighbors, and otherwise.
Once stationarity has been attained, the mean vanishes and equation (18) implies that the time-independent covariance matrix satisfies . This is known as the Lyapunov equation, and is readily solved for by special-purpose techniques or, rapidly enough, by simply iterating it to convergence.
We are interested in using the state vector to predict the subsequent state . Arranging these two -dimensional vectors into a single -dimensional vector , we can now compute the 2-time covariance matrix of equation (2) by iterating equation (18) times:
[TABLE]
Figure 3 shows the mutual information between the the state of our harmonic oscillators and their state time-steps later, as a function of the amount of dimensionality reduction performed. The CCA curve plotted is by definition the Pareto frontier for the tradeoff between compression and information retention, i.e., the the maximum amount of information that can be collectively retained in a given number of pairs. The CCA curve is seen to be concave because all Pareto frontiers by construction have non-positive second derivative.
Three other dimensionality reduction methods are also plotted for comparison, and are all seen to perform significantly worse than CCA. These all use the same latent representation for both and . The PCA curve keeps the top principal components, while the “simple truncation” curve simply retains the first elements of the vectors and . The “shared latent rep” curve uses the CCA-matrix to compress , and uses the same matrix (rather than ) to compress .
If each pair of numbers contained the same fraction of the total mutual information, then the Pareto frontier would be a straight line. The performance of the non-CCA methods is seen to be even worse in our example, closer to a parabola (dashed line). This is what one expects from any method where each number contains a random fraction of the total information, and the same holds for each number : then the mutual information , and the information fraction shared by numbers and numbers is – a parabola.
IV Conclusion
It is often useful to map data vectors into a lower-dimensional latent space, retaining only the information of interest, as summarized in Figure 1. For linear mappings and , the natural generalization of PCA is CCA, which distills two random vectors and into linear transformations and such that all components of both vectors are uncorrelated, except that matching “principal pairs” have correlation . For Gaussian random vectors, CCA conveniently decomposes the total mutual information between and as the sum of the mutual information between these principal pairs. Retention of only the most informative pairs thus falls on the Pareto frontier of optimal dimensionality reduction.
There is strong current interest in how to best generalize this to nonlinear mappings optimized for non-Gaussian random vectors. Most recent work for non-linear time-series prediction (see Oord et al. (2018) and references therein) focuses on the special case . As we have explored in detail, this can be far from optimal, even in the linear case. In the linear case, the reason why two different latent representations and are better than one ultimately traces back to the fact that the SVD in equation (8) produces different matrices when is asymmetric. For our harmonic oscillator example (or any physics time series whatsoever, for that matter), this asymmetry corresponds to time reversal asymmetry: the operation to predict the future state from the past is not the same as that predicting the past from the future. In our example, this asymmetry can be eliminated by ignoring all momentum information: Repeating CCA to predict from (as opposed to working with which includes both and ), we obtain .
A natural conjecture for future work to investigate is that this generalizes to non-Gaussian time series where the optimal dimensionality reduction is nonlinear: that a single latent representation suffices for reversible Markov chains and other reversible processes, while a pair of representations performs better for processes that are truly different in reverse, for example text, speech, music or out-of-equilibrium physical systems.
Figure 4 motivates this conjecture: when the evolution of a dynamical system is not time-reversible, then the information about its state that is useful for predicting what will happen is often different from that which is useful for predicting what happened. Consider, for example, a table with an orange and a pencil balanced on its tip, both isolated from the rest of the world and seemingly at rest. If we are interested in predicting the future, we should pay more attention to the orange, since it will stay put while the pencil will tip over in less than 30 seconds in a direction that we cannot predict, as quantum-mechanical fluctuations get amplified by gravity. If we are interested in inferring the past, we should instead focus on the pencil, which was almost certainly at least as balanced then as it is now. The orange, on the other hand, is in a stable attractor state: it could either have just sat there, or slid/rolled and come to rest due to dissipation. In physics examples such as these, whether information is predictable, predictive or both thus depends on attractor dynamics and Lyapunov exponents: degrees of freedom in stable equilibria (with negative Lyapunov exponents) are predictive but unpredictable, while those in unstable equilibria (with positive Lyapunov exponents) are unpredictive but predictable.
The causally irrelevant information, that helps with neither, should obviously be discarded in latent representations; if most of the information is in this category, then non-causal approaches such as PCA, ICA and nonlinear autoencoders may mistakenly retain much of this information if it is easy to distill into a small number of variables. Renormalization in physics provides an example of a single latent representation where the vast majority of the information (typically information on very small scales/high frequencies) is discarded, while both the longer-term predictive and predictable information is retained. In other cases, the predictable and predictive degrees of freedom parts of the information may be closer to disjoint, in which case switching to two separate representations offers the opportunity of cutting the latent space dimensionality almost in half. An interesting challenge for future work is therefore to explore whether approaches such as Oord et al. (2018) can be further improved by using more than one latent representation, or by developing a single one that better optimizes for both predictiveness and predictability.
Acknowledgements: The author wishes to thank Tailin Wu for helpful comments, and for suggesting Figure 4 and the idea behind it. This work was supported by The Casey and Family Foundation, the Foundational Questions Institute, and by Theiss Research through TWCF grant #0322.
Appendix A Distillation interpretation
The following theorem allows an intuitive interpretation of correlation as stemming from a common source.
Theorem: Any random vector pair can be decomposed as the sum of a perfectly correlated part (“signal”) and a perfectly uncorrelated part (“noise”):
[TABLE]
where , , and .
Proof: Writing the last equation as , we have , and . Define . If and have the same length and no eigenvalues of or vanish, then define
[TABLE]
[TABLE]
It follows that
[TABLE]
as required, where we used equation (10) in the penultimate step. The case with vanishing eigenvalues and/or unequal length of and follows straightforwardly from zero-padding appropriately.
We can thus interpret as the distillation of all the correlated information in and , which is shared but diluted by noise.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Pearson (1901) K. Pearson, The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science 2 , 559 (1901).
- 2Vincent et al. (2008) P. Vincent, H. Larochelle, Y. Bengio, and P.-A. Manzagol, in Proceedings of the 25th international conference on Machine learning (ACM, 2008), pp. 1096–1103.
- 3Goodfellow et al. (2014) I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, in Advances in neural information processing systems (2014), pp. 2672–2680.
- 4Hotelling (1936) H. Hotelling, Biometrica 28 , 321 (1936).
- 5Oord et al. (2018) A. v. d. Oord, Y. Li, and O. Vinyals, ar Xiv preprint ar Xiv:1807.03748 (2018).
- 6Hyvärinen and Oja (2000) A. Hyvärinen and E. Oja, Neural networks 13 , 411 (2000).
- 7Eckart and Young (1936) C. Eckart and G. Young, Psychometrika 1 , 211 (1936).