Image Decomposition and Classification through a Generative Model
Houpu Yao, Malcolm Regan, Yezhou Yang, Yi Ren

TL;DR
This paper introduces a generative model that enhances image classification robustness by decomposing inputs into components, effectively handling adversarial attacks and distribution shifts, demonstrated on multiple datasets.
Contribution
A conditional variational autoencoder is proposed to simultaneously decompose images and classify components, improving robustness against adversarial and distributional challenges.
Findings
Effective decomposition of overlapping components in multiMNIST.
High robustness to gradient and non-gradient attacks on MNIST and NORB.
Successful recognition of novel component combinations in traffic signs.
Abstract
We demonstrate in this paper that a generative model can be designed to perform classification tasks under challenging settings, including adversarial attacks and input distribution shifts. Specifically, we propose a conditional variational autoencoder that learns both the decomposition of inputs and the distributions of the resulting components. During test, we jointly optimize the latent variables of the generator and the relaxed component labels to find the best match between the given input and the output of the generator. The model demonstrates promising performance at recognizing overlapping components from the multiMNIST dataset, and novel component combinations from a traffic sign dataset. Experiments also show that the proposed model achieves high robustness on MNIST and NORB datasets, in particular for high-strength gradient attacks and non-gradient attacks.
Click any figure to enlarge with its caption.
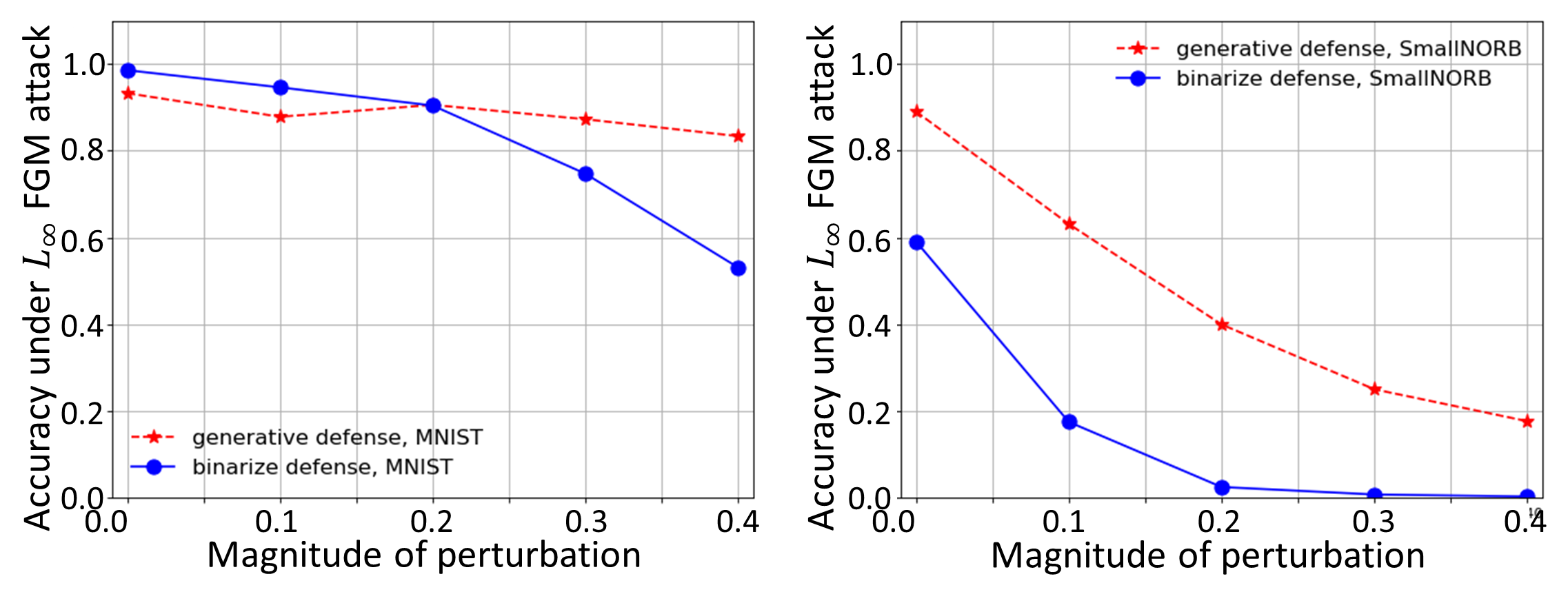 Figure 1
Figure 1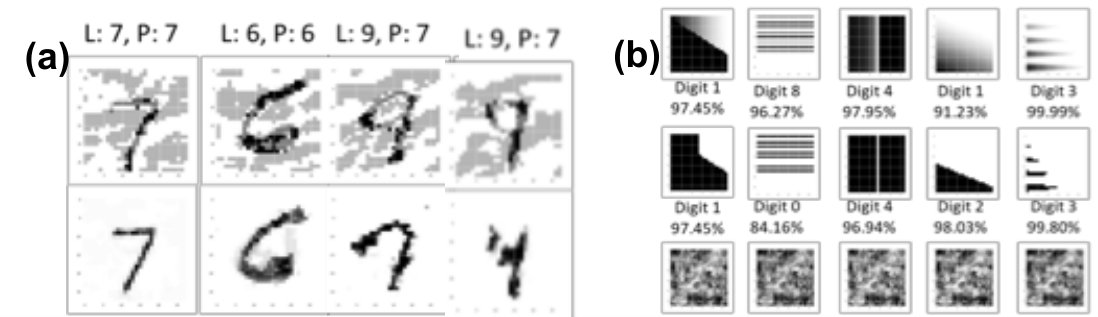 Figure 2
Figure 2 Figure 3
Figure 3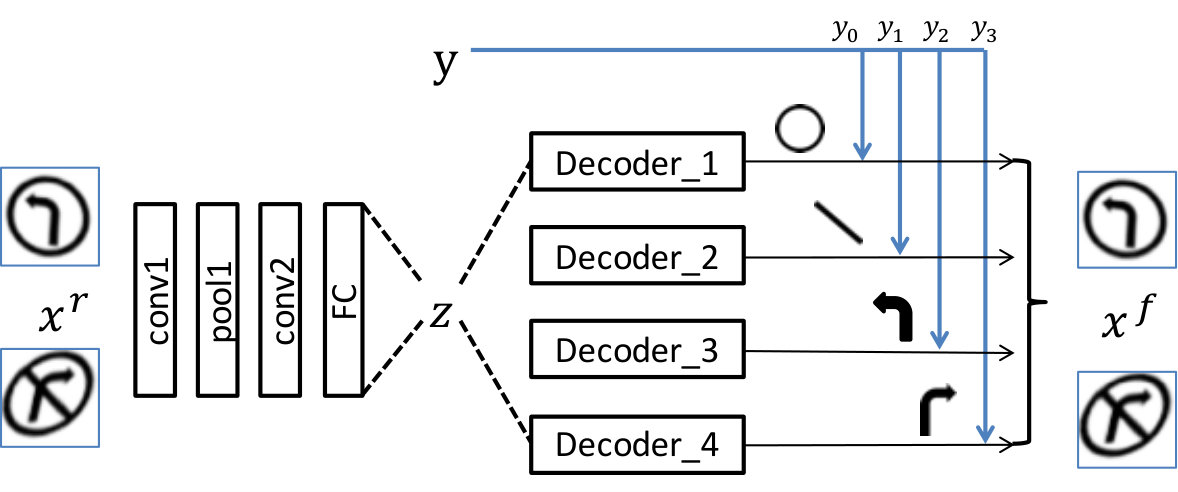 Figure 4
Figure 4 Figure 5
Figure 5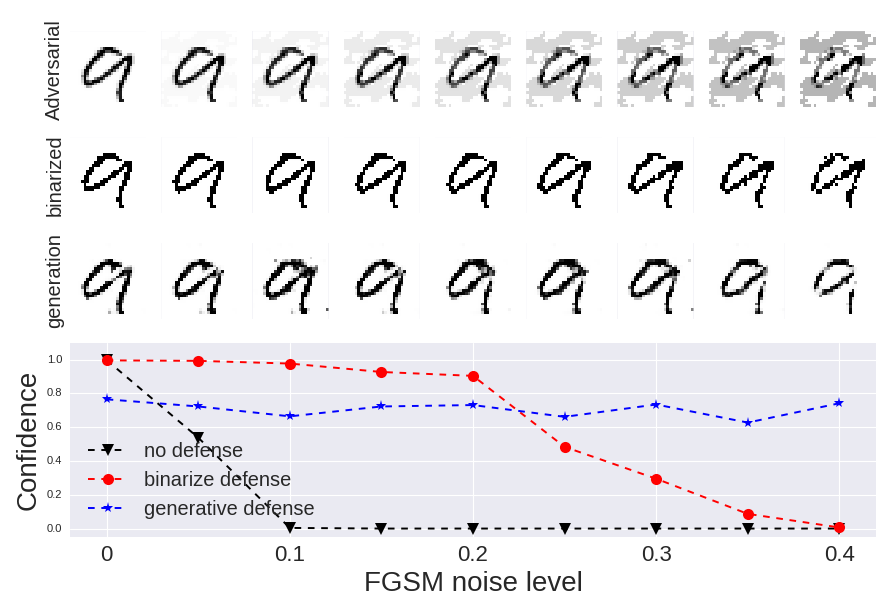 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9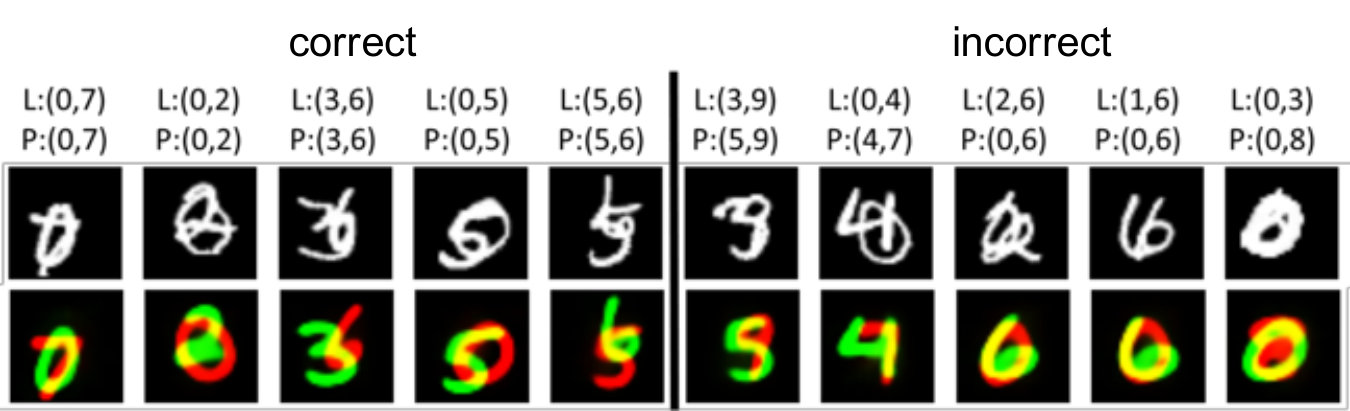 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12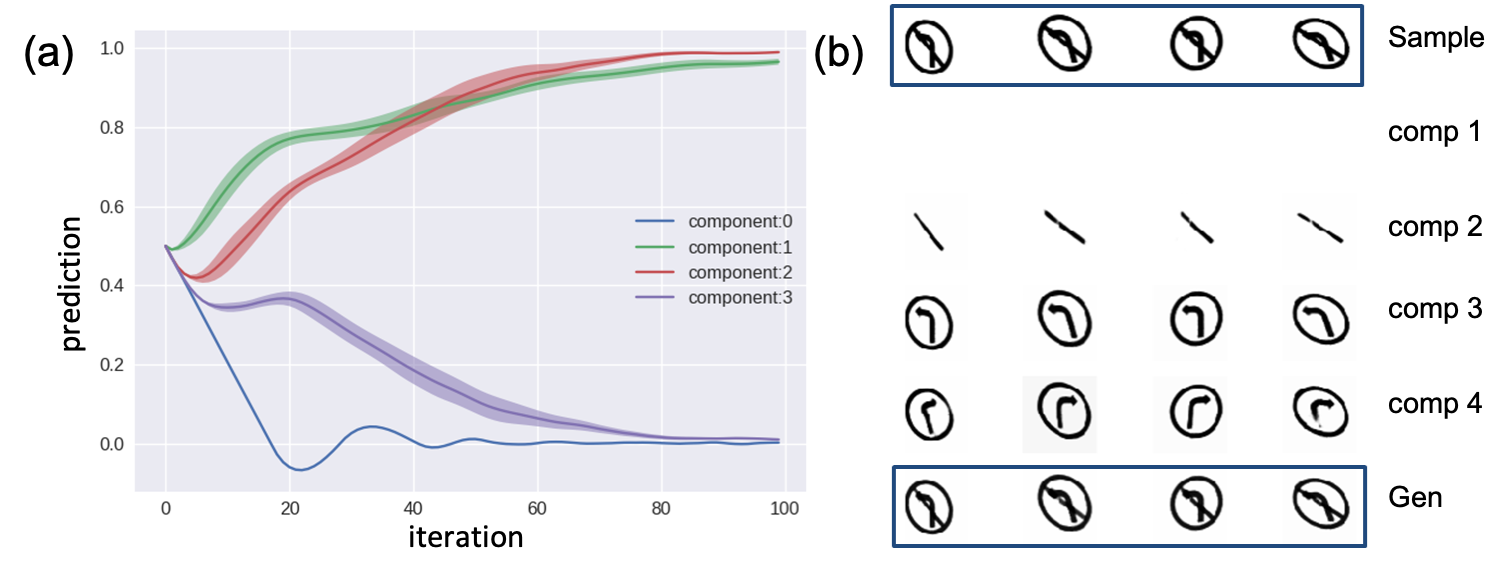 Figure 13
Figure 13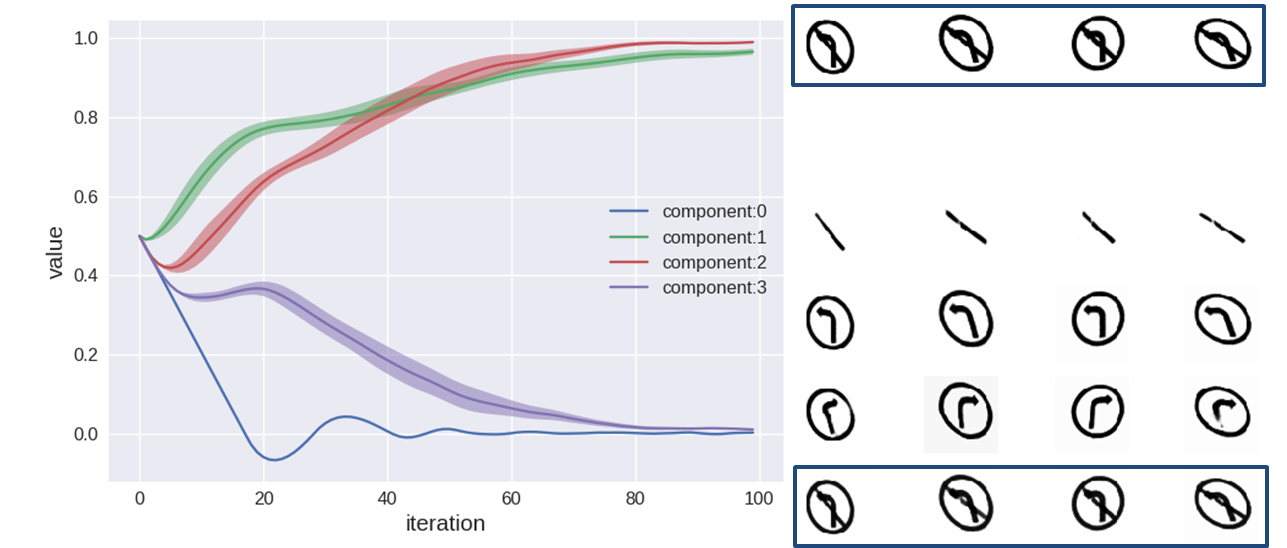 Figure 14
Figure 14| 0.0 | 0.1 | 0.2 | 0.3 | 0.4 | ||
|---|---|---|---|---|---|---|
| MNIST | baseline | 0.97 | 0.95 | 0.90 | 0.76 | 0.51 |
| MNIST | proposed | 0.95 | 0.87 | 0.91 | 0.87 | 0.82 |
| NORB | baseline | 59.8 | 18.3 | 2.8 | 0.8 | 0.2 |
| NORB | proposed | 87.1 | 61.9 | 40.1 | 24.6 | 18.8 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdversarial Robustness in Machine Learning · Anomaly Detection Techniques and Applications · Domain Adaptation and Few-Shot Learning
MethodsSolana Customer Service Number +1-833-534-1729
Image Decomposition and Classification through a Generative Model
Abstract
We demonstrate in this paper that a generative model can be designed to perform classification tasks under challenging settings, including adversarial attacks and input distribution shifts. Specifically, we propose a conditional variational autoencoder that learns both the decomposition of inputs and the distributions of the resulting components. During test, we jointly optimize the latent variables of the generator and the relaxed component labels to find the best match between the given input and the output of the generator. The model demonstrates promising performance at recognizing overlapping components from the multiMNIST dataset, and novel component combinations from a traffic sign dataset. Experiments also show that the proposed model achieves high robustness on MNIST and NORB datasets, in particular for high-strength gradient attacks and non-gradient attacks.
**Index Terms— ** Generative model, classification, adversarial defense
1 Introduction
Neural network architectures have been developed to achieve human-level performance on standard vision tasks [1, 2]. However, it is acknowledged that feedforward networks have difficulty at generalization under input distribution shifts, e.g., novel object sets [3] and objects with overlaps [4]. Furthermore, studies have shown that networks, even with high standard test accuracy, can suffer from imperceptible adversarial attacks [5]. While neither distribution shifting or adversarial attacks are common cases in standard test environments for image classifiers [6, 7], the demonstrated risk of existing models have raised concerns over their real-world applications (e.g., autonomous driving and security surveillance) where failed classification for a short amount of time can be catastrophic. These concerns have led to the question of whether semantic attributes or physical components of the inputs are truly understood by feedforward, albeit deep, networks [1, 2]. Indeed, evidence showed that state-of-the-art classification models have a drastically different accuracy changing pattern than human beings in classifying image sequences with diminishing details [8], suggesting that the two have different feature learning behaviors.
This concern over model generalizability and robustness is intrinsic to classifiers that perform bottom-up signal processing. Alternative models that integrate bottom-up processing with top-down reasoning through recursive inference have been studied [9, 10]. Of particular interest are recursive compositional models (e.g., AND-OR templates [10]) that learn to match deformable objects and infer graph states for detection and recognition. These models take advantage of highly structured generators, e.g., by explicitly modeling object edges and surfaces. However, the intrinsic trade-off between model and computational complexity (for both model learning and recognition/classification) may hamper their application to general inputs for which the recognition or classification tasks depend on a richer set of features. With the rapid advance in generative models (e.g. GAN [11], PixelCNN [12], and VAE [13, 14]), it is tempting to investigate top-down classification mechanisms that incorporate more flexible generators than compositional models.
To this end, we present in this paper a classification algorithm where input images are classified by minimizing the difference between the target image and the output of a generator. We choose Conditional Variational Autoencoder (c-VAE) as the backbone of our model due to its simplicity and good convergence property. Following the argument that attribute recognition is key to object classification [15, 16], we focus on the classification of attributes, or more specifically, the existence of object components from the input image, while assuming that the follow-up mapping from these components to the object class is established. As illustrated in Fig. 1, the model is built on a variational autoencoder whose decoder is composed of separate sub-networks, where each component is associated with a sub-network. Experiments show that the proposed model demonstrates promising performance at recognizing overlapping components from the multiMNIST dataset, and novel component combinations from a traffic sign dataset. The model also achieves high robustness on MNIST and NORB datasets, in particular for high-strength gradient attacks and non-gradient attacks.
2 related work
Conditional generative models have been heavily investigated in the literature. For example, VAE structure [13] is extended into c-VAE [14] by including attribute variables as extra inputs. Besides, the latent variables are disentangled into two sub-networks in [14] to perform foreground and background separation. In our work, we further extended the c-VAE idea to have more sub-networks where each sub-network corresponds to a component. And instead of generation or segmentation, we investigate the possibility to use the conditional generative model to perform robust classification.
The utility of generative model as a defense mechanism has been explored very recently. For example, defense GAN [17] finds the closest generation from a GAN to a given input image, and feeds the generated image to a vanilla classifier for prediction. Similar to our approach, Schott et al. [18] chose VAE to perform image generation and used the reconstruction error as a metric to perform classification directly, without feedforward classifier involved. Compared with [18], the proposed model has an optimized network structure and classification workflow, which makes it able to learn object decomposition and handle more tasks like novel or overlapping object recognition.
3 Proposed Method
3.1 Customized conditional variational autoencoder
We customize a conditional variational autoencoder to learn the decomposition of object components. Let and be the input images and their corresponding components, respectively. A binary component vector encodes the existence of components within . It is assumed that the maximum amount of possible components in the dataset is . Let be the latent variable generated from the encoder with parameters , and be the generated images from the set of decoders with parameters . is a segment of corresponding to the th component. Following the formulation of variational autoencoders, we define our training loss as:
[TABLE]
where is the sub-network-wise KL divergence of the distribution of from a standard normal distribution. In the presented experiments, Adam optimizer with a learning rate of 0.001 is used for training.
3.2 Classification
Based on the learned generative model, the classification process can be cast into an inverse problem, where we jointly find and that minimize the difference between the generated image and the target image in the image space:
[TABLE]
Note that Eq. (2) is a combinatorial problem, since is a binary vector. To make this problem feasible, we relax component labels to be continuous within , so that the optimization problem becomes differentiable and can be solved efficiently through gradient descent and back-propagation. In addition, a penalty is introduced to regularize non-zero components with weight . The regularization is needed so that a component will be correctly discarded (i.e., sub-network outputs suppressed) if its addition to the generated image does not improve the reconstruction quality significantly. Lastly, it is also found that minimizing the image-wise difference after a sigmoid transformation over the reconstruction further improves the defense performance. With these modifications, the classifier solves the following problem:
[TABLE]
where Sig(x)=\text{sigmoid}\big{(}\beta\cdot x+b\big{)}, and , are hyper-parameters.
Upon convergence, and obtained via Eq. (3) will be processed to derive the final classification result using the following logic flow: First, if the lowest reconstruction loss found is larger than a pre-set threshold , the input image will be classified as noise. This step is able to filter out adversarial attacks using non-gradient methods such as Neuroevolution of Augmenting Topologies (NEAT) [19]. After this initial filtering, we apply two thresholds and () to : an element is set to [math] if , and 1 if . For the remaining elements of between and , we will enumerate over all binary combinations of this subset to generate a candidate set for fine-tuning the prediction. Specifically, we compute for and set the classification result as . All hyper-parameters (,,,, and ) are determined based on a validation set, and are therefore dataset dependent.
3.3 Implementation details
The proposed model will be tested on MNIST, NORB [20], multiMNIST [4], and a Traffic Sign (TS) dataset. For NORB, similar to [4], we downscale the image resolution to 48-by-48. The multiMNIST dataset is synthesized by stacking two MNIST images into an image of resolution 36-by-36, which will result in 80% overlap between two digits on average. Every image label in multiMNIST has 2 ones and 8 zeros. A visualization of the multiMNIST dataset can be found in Fig. 4. The TS dataset is prepared with affine transformation to mimic traffic signs at different view angles. There are four different types of images in the dataset: “left turn”, “right turn”, “no left turn”, and “no right turn”. These images are in a resolution of 64-by-64, with examples visualized in Fig. 3. There are four components for TS images to represent the components: circle, slash, left arrow, and right arrow. For example, a “No right turn” image has label since it has circle, slash, and right arrow.
The number of sub-networks is equal to the number of total components in the dataset, which is 10 for MNIST and multiMNIST, 5 for NORB, and 4 for TS. Once the network has been trained, it is expected to decompose the input object into different components, as illustrated in Fig.1. To demonstrate the efficacy of the learning of decomposition, we visualize the latent space of each sub-networks trained on different datasets in Fig.2. One observation from the results is that the model is able to remove data redundancy automatically, which can be seen from the TS dataset: To recall, the first component of a TS image represents the existence of a circle. Since the circle exists in all TS images, the learned generative model combines the circle into the generation of the arrows and leaves the first sub-network blank.
4 Results and Discussion
In this section, we demonstrate the efficacy of our method through a set of challenging experiments. These include classifying overlapping and novel objects, and defense against both gradient-based (FGM [5]) and non-gradient based (NEAT [19]) adversarial attacks.
4.1 Classification of novel and overlapping objects
We first train our model on the TS dataset by only using “left turn”, “right turn” and “no right turn” images for training. After the model is trained, its performance is evaluated on “No left turn” images. This experiment is set up in a way that the network is asked to recognize novel objects not included in the training set by making use of the learned decomposition of image elements.
A traditional feedforward CNN classifier will completely fail under this setting, where 99% of the “no left turn” images are classified as “left turn”. This is due to the fact that the classifier will associate the “left arrow” feature with the “left turn” category during the training phase, and this correlation strongly affects the prediction during the testing phase. In contrast, our proposed model learns to decompose the TS dataset into components after training (as shown in Fig. 2b), and by combining these components together, it correctly recognizes 95% of all novel testing images. The classification result is shown in Fig. 3.
We now demonstrate that the proposed model is able to handle objects with large overlap using the multiMNIST dataset. After training, the proposed model learns the decomposition of individual digits successfully as shown in Fig.2a. Applying the learned model to classifying the test dataset leads to a classification accuracy of 65.6%. Successful and failed test samples and their classification results are shown in Fig.4. While the accuracy on multiMNIST is lower than that of a CapsNet [4](95%), investigation of the model performance shows that many of the misclassified samples are truly difficult to be separated even for human beings. It should also be noted that the accuracy of CapsNet is resulted from 60 million training data, while our model successfully decomposes the learns the component-wise latent spaces with only 128k data points. We expect improved classification accuracy by increasing the capacity of the generative model.
4.2 Defending adversarial attacks
We test the performance of our model under both gradient- and non-gradient-based adversarial attacks in this experiment. FGM and NEAT are chosen as the attack methods. NEAT performs evolution on Compositional Pattern Producing Networks (CPPN) [21], each of which represents an image. The fitness of the evolution is defined as , where is the classification result of a CPPN image by the source classification model and is the target class for the attack. If an adversarial image is misclassified with over confidence, the attack is considered successful and this adversarial image will be used for test.
We first compare our method with the binarization defense [22] under FGM attack in Tab.1. The performance of binarization drops quickly with increasing attack magnitudes, while the proposed model is able to maintain high accuracy even under relatively high attack magnitude. To further examine the cases where our model fails, we visualized adversarial MNIST samples with in Fig.5a, along with correctly classified samples. We note that many of the misclassified images are hard to be recognized even for human beings.
The comparison on NEAT attacks is shown in Fig.5b. The baseline classifier is fooled completely by the adversarial images with consistently high confidence for the targeted labels (shown in the first row of Fig.5b). Even after binarization, many NEAT images can still be misclassified with high confidence (shown in the second row of Fig.5b). In contrast, the proposed method is able to identify 90.6% of these attacks. This is because the generative model is not trained on these highly structured CPPN patterns, and is not able to reconstruct them during the test. Due to the high reconstruction error, the proposed model will conclude that these input images are out of the data distribution.
4.3 Discussion
While the presented experiments show promise of the proposed classification method, a deeper investigation is needed to better characterize the applicability and limitations of the proposed method to more complicated datasets (e.g., CIFAR10 and ImageNet) under more sophisticated settings (e.g. PGD adversarial attack [23]). Further improvements can be made to compress the generative model in order to accelerate the optimization during classification. Generative models with the capability to create fine-grained details should be studied and incorporated to further improve the performance.
5 Conclusions
In this paper, we investigate the utility of a tailored conditional variational autoencoder as a classifier, and test its generalizability and robustness under challenging tasks. Results show that the proposed training and classification formulations lead to promising performance: First, the model can recognize overlapping objects and novel component combinations that do not exist in the training phase. Second, our model is able to defend against adversarial attacks well, in particular under higher attack magnitudes and under none-gradient attacks.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition , 2016, pp. 770–778.
- 2[2] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna, “Rethinking the inception architecture for computer vision,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 2016, pp. 2818–2826.
- 3[3] Simon M Stringer and Edmund T Rolls, “Invariant object recognition in the visual system with novel views of 3d objects,” Neural Computation , vol. 14, no. 11, pp. 2585–2596, 2002.
- 4[4] Sara Sabour, Nicholas Frosst, and Geoffrey E Hinton, “Dynamic routing between capsules,” in Advances in Neural Information Processing Systems , 2017, pp. 3859–3869.
- 5[5] Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy, “Explaining and harnessing adversarial examples,” ar Xiv preprint ar Xiv:1412.6572 , 2014.
- 6[6] Nicolas Papernot, Patrick Mc Daniel, Ian Goodfellow, Somesh Jha, Z Berkay Celik, and Ananthram Swami, “Practical black-box attacks against deep learning systems using adversarial examples,” ar Xiv preprint ar Xiv:1602.02697 , 2016.
- 7[7] Jiajun Lu, Hussein Sibai, Evan Fabry, and David Forsyth, “Standard detectors aren’t (currently) fooled by physical adversarial stop signs,” ar Xiv preprint ar Xiv:1710.03337 , 2017.
- 8[8] Shimon Ullman, Liav Assif, Ethan Fetaya, and Daniel Harari, “Atoms of recognition in human and computer vision,” Proceedings of the National Academy of Sciences , vol. 113, no. 10, pp. 2744–2749, 2016.