Meta-Curvature
Eunbyung Park, Junier B. Oliva

TL;DR
Meta-Curvature (MC) is a novel framework that enhances model-agnostic meta-learning by learning to transform gradients through a curvature-aware approach, leading to improved generalization, faster convergence, and superior few-shot learning performance.
Contribution
MC introduces a new way to learn curvature information by decomposing the curvature matrix into smaller tensors, improving meta-learning efficiency and effectiveness.
Findings
Outperforms previous MAML variants and state-of-the-art methods.
Achieves faster convergence in meta-training.
Enhances generalization in few-shot learning tasks.
Abstract
We propose meta-curvature (MC), a framework to learn curvature information for better generalization and fast model adaptation. MC expands on the model-agnostic meta-learner (MAML) by learning to transform the gradients in the inner optimization such that the transformed gradients achieve better generalization performance to a new task. For training large scale neural networks, we decompose the curvature matrix into smaller matrices in a novel scheme where we capture the dependencies of the model's parameters with a series of tensor products. We demonstrate the effects of our proposed method on several few-shot learning tasks and datasets. Without any task specific techniques and architectures, the proposed method achieves substantial improvement upon previous MAML variants and outperforms the recent state-of-the-art methods. Furthermore, we observe faster convergence rates of the…
Click any figure to enlarge with its caption.
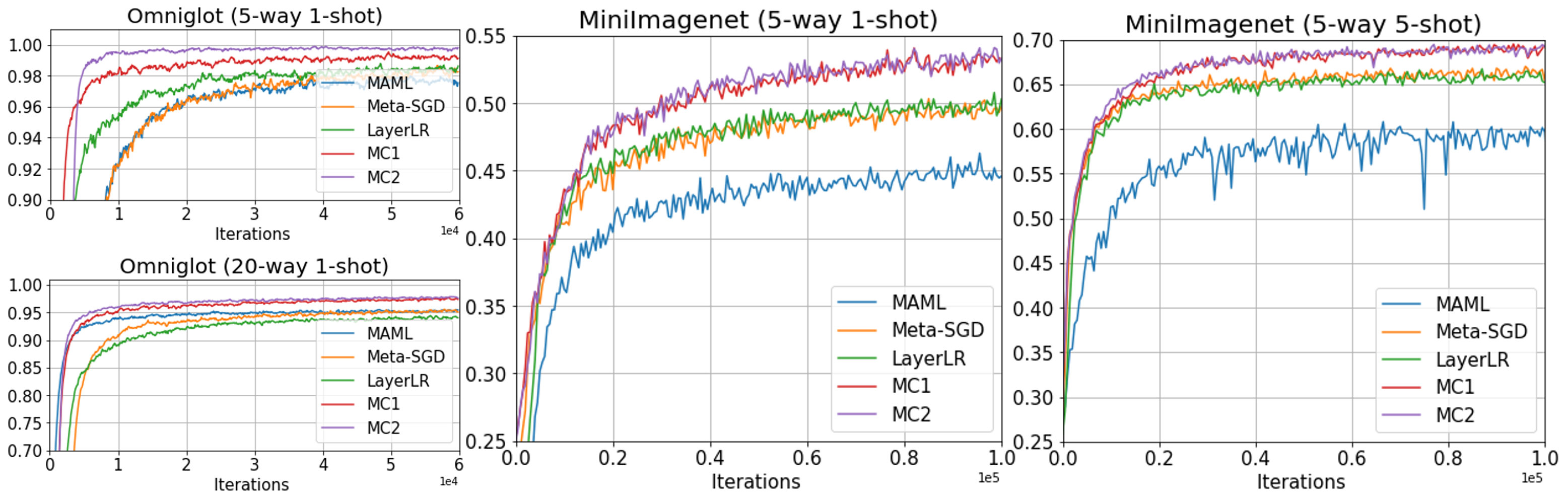 Figure 1
Figure 1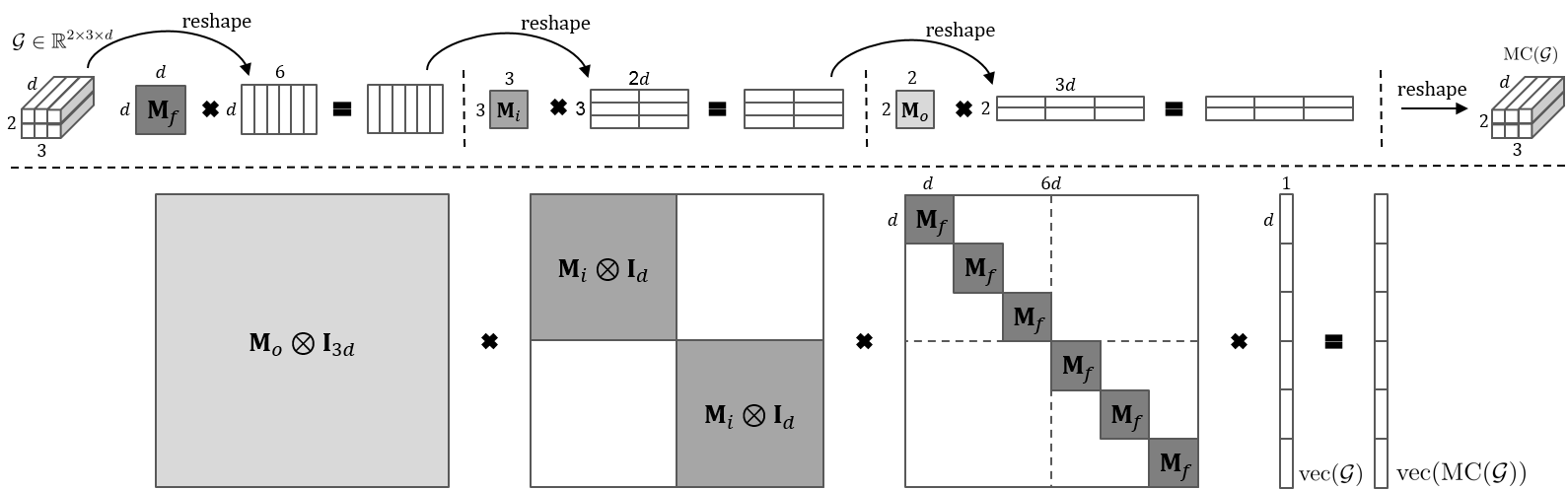 Figure 2
Figure 2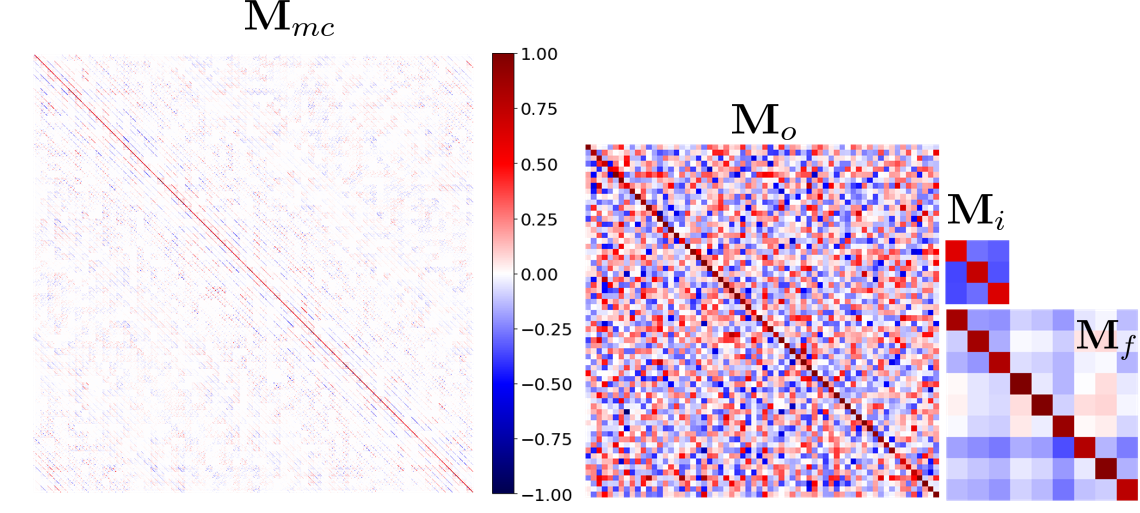 Figure 3
Figure 3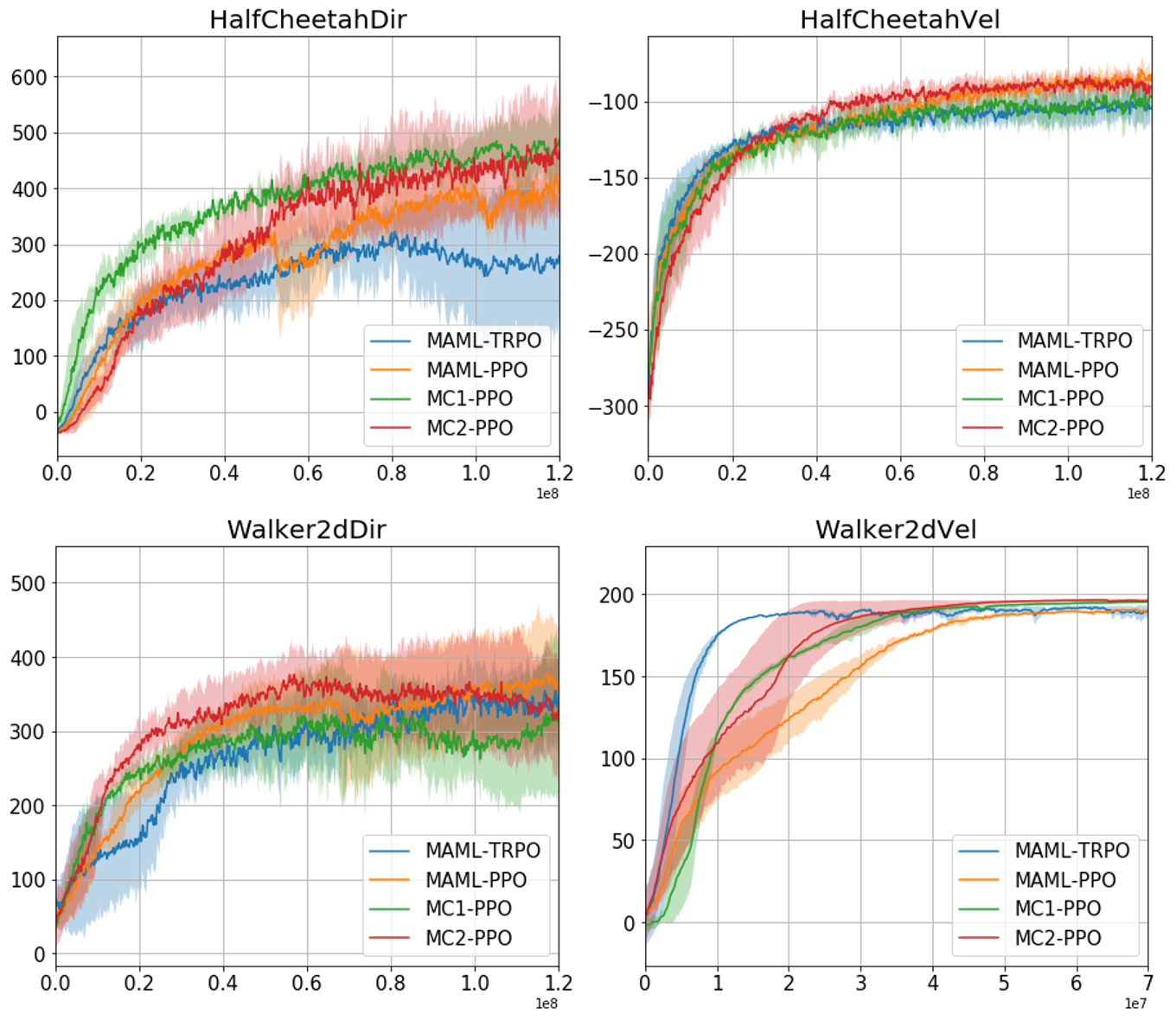 Figure 4
Figure 4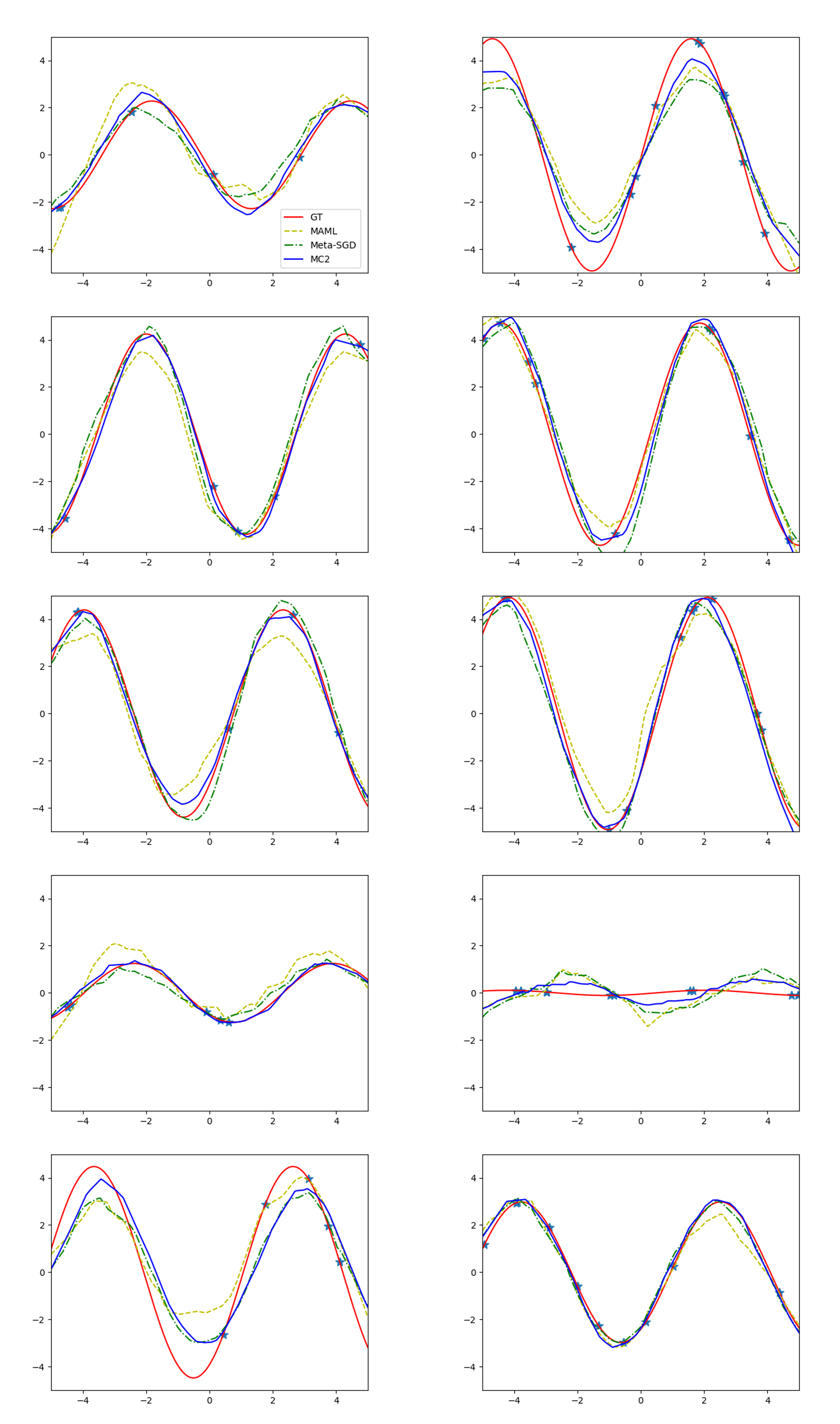 Figure 5
Figure 5| Method | 5-shot | 10-shot |
|---|---|---|
| MAML | 0.686 0.070 | 0.435 0.039 |
| Meta-SGD | 0.482 0.061 | 0.258 0.026 |
| LayerLR | 0.528 0.068 | 0.269 0.027 |
| MC1 | 0.426 0.054 | 0.239 0.025 |
| MC2 | 0.405 0.048 | 0.201 0.020 |
| 5-way 1-shot | 5-way 5-shot | 20-way 1-shot | 20-way 5-shot | |
| SNAIL [27] | 99.07 0.16 | 99.78 0.09 | 97.64 0.30 | 99.36 0.18 |
| GNN [12] | 99.2 | 99.7 | 97.4 | 99.0 |
| MAML | 98.7 0.4 | 99.9 0.1 | 95.8 0.3 | 98.9 0.2 |
| Meta-SGD | 99.53 0.26 | 99.93 0.09 | 95.93 0.38 | 98.97 0.19 |
| MAML++† [4] | 99.47 | 99.93 | 97.65 0.05 | 99.33 0.03 |
| MC1 | 99.47 0.27 | 99.57 0.12 | 97.60 0.29 | 99.23 0.08 |
| MC2 | 99.77 0.17 | 99.79 0.10 | 97.86 0.26 | 99.24 0.07 |
| MC2† | 99.97 0.06 | 99.89 0.06 | 99.12 0.16 | 99.65 0.05 |
| 1-shot | 5-shot | |||
| Inner steps | 1 step | 5 step | 1 step | 5 step |
| *MAML | 48.7 1.84 | 63.1 0.92 | ||
| *Meta-SGD | 50.47 1.87 | 64.03 0.94 | ||
| *MAML++† | 51.05 0.31 | 52.15 0.26 | 68.32 0.44 | |
| MAML | 46.28 0.89 | 48.85 0.88 | 59.26 0.72 | 63.92 0.74 |
| Meta-SGD | 49.87 0.87 | 48.99 0.86 | 66.35 0.72 | 63.84 0.71 |
| LayerLR | 50.04 0.87 | 50.55 0.87 | 65.06 0.71 | 66.64 0.69 |
| MC1 | 53.37 0.88 | 53.74 0.84 | 68.47 0.69 | 68.01 0.73 |
| MC2 | 54.23 0.88 | 54.08 0.93 | 67.94 0.71 | 67.99 0.73 |
| MC2† | 54.90 0.90 | 55.73 0.94 | 69.46 0.70 | 70.33 0.72 |
| miniImagenet | tieredImagenet | |||
| 1-shot | 5-shot | 1-shot | 5-shot | |
| [33]‡ | 59.60 0.41 | 73.74 0.19 | ||
| LEO (center)‡ [39] | 61.76 0.08 | 77.59 0.12 | 66.33 0.05 | 81.44 0.09 |
| LEO (multiview)‡ [39] | 63.97 0.20 | 79.49 0.70 | ||
| MetaOptNet-SVM‡† [20] | 64.09 0.62 | 80.00 0.45 | 65.81 0.74 | 81.75 0.53 |
| Meta-SGD (center) | 56.58 0.21 | 68.84 0.19 | 59.75 0.25 | 69.04 0.22 |
| MC2 (center) | 61.22 0.10 | 75.92 0.17 | 66.20 0.10 | 82.21 0.08 |
| MC2 (center)‡ | 61.85 0.10 | 77.02 0.11 | 67.21 0.10 | 82.61 0.08 |
| MC2 (multiview)‡ | 64.40 0.10 | 80.21 0.10 | ||
| Method | 5-shot | 10-shot | 20-shot |
|---|---|---|---|
| MAML | 0.686 0.070 | 0.435 0.039 | 0.228 0.024 |
| Meta-SGD | 0.482 0.061 | 0.258 0.026 | 0.127 0.013 |
| LayerLR | 0.528 0.068 | 0.269 0.027 | 0.134 0.014 |
| MC1 | 0.426 0.054 | 0.239 0.025 | 0.125 0.013 |
| MC2 | 0.405 0.048 | 0.201 0.020 | 0.112 0.011 |
| Hyperparameters | miniImagenet | tieredImagenet | ||||
|---|---|---|---|---|---|---|
| Features | center | multiview | center | |||
| 1-shot | 5-shot | 1-shot | 5-shot | 1-shot | 5-shot | |
| Batch size | 16 | |||||
| Total training iterations | 100,000 | |||||
| Learning rate (inner loop) | 0.01 | |||||
| Learning rate (outer loop) | 0.0005 | 0.0003 | 0.0005 | 0.0003 | 0.00075 | 0.0001 |
| The number of inner steps | 1 | 5 | 1 | 5 | 1 | 5 |
| The number of hidden units | 1024 | 1024 | 512 | 4096 | 4096 | 4096 |
| Dropout rate over WRN-28-10 features | 0.5 | 0.3 | 0.5 | 0.7 | 0.5 | 0.5 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsDomain Adaptation and Few-Shot Learning · Human Pose and Action Recognition · Advanced Neural Network Applications
MethodsModel-Agnostic Meta-Learning
Meta-Curvature
Eunbyung Park
Department of Computer Science
University of North Carolina at Chapel Hill
&Junier B. Oliva
Department of Computer Science
University of North Carolina at Chapel Hill
Abstract
We propose meta-curvature (MC), a framework to learn curvature information for better generalization and fast model adaptation. MC expands on the model-agnostic meta-learner (MAML) by learning to transform the gradients in the inner optimization such that the transformed gradients achieve better generalization performance to a new task. For training large scale neural networks, we decompose the curvature matrix into smaller matrices in a novel scheme where we capture the dependencies of the model’s parameters with a series of tensor products. We demonstrate the effects of our proposed method on several few-shot learning tasks and datasets. Without any task specific techniques and architectures, the proposed method achieves substantial improvement upon previous MAML variants and outperforms the recent state-of-the-art methods. Furthermore, we observe faster convergence rates of the meta-training process. Finally, we present an analysis that explains better generalization performance with the meta-trained curvature.
1 Introduction
††The code is available at https://github.com/silverbottlep/meta_curvature
Despite huge progress in artificial intelligence, the ability to quickly learn from few examples is still far short of that of a human. We are capable of utilizing prior knowledge from past experiences to efficiently learn new concepts or skills. With the goal of building machines with this capability, learning-to-learn or meta-learning has begun to emerge with promising results.
One notable example is model-agnostic meta-learning (MAML) [9, 30], which has shown its effectiveness on various few-shot learning tasks. It formalizes learning-to-learn as meta objective function and optimizes it with respect to a model’s initial parameters. Through the meta-training procedure, the resulting model’s initial parameters become a very good prior representation and the model can quickly adapt to new tasks or skills through one or more gradient steps with a few examples. Although this end-to-end approach, using standard gradient descent as the inner optimization algorithm, was theoretically shown to approximate any learning algorithm [10], recent studies indicate that the choice of the inner-loop optimization algorithm affects performance. [22, 4, 13].
Given the sensitivity to the inner-loop optimization algorithm, second order optimization methods (or preconditioning the gradients) are worth considering. They have been extensively studied and have shown their practical benefits in terms of faster convergence rates [31], an important aspect of few-shot learning. In addition, the problems of computational and spatial complexity for training deep networks can be effectively handled thanks to recent approximation techniques [24, 38]. Nevertheless, there are issues with using second order methods in its current form as an inner loop optimizer in the meta-learning framework. First, they do not usually consider generalization performance. They compute local curvatures with training losses and move along the curvatures as far as possible. It can be very harmful, especially in the few-shot learning setup, because it can overfit easily and quickly.
In this work, we propose to learn a curvature for better generalization and faster model adaptation in the meta-learning framework, we call meta-curvature. The key intuition behind MAML is that there are some representations are broadly applicable to all tasks. In the same spirit, we hypothesize that there are some curvatures that are broadly applicable to many tasks. Curvatures are determined by the model’s parameters, network architectures, loss functions, and training data. Assuming new tasks are distributed from the similar distribution as meta-training distribution, there may exist common curvatures that can be obtained through meta-training procedure. The resulting meta-curvatures, coupled with the simultaneously meta-trained model’s initial parameters, will transform the gradients such that the updated model has better performance on new tasks with fewer gradient steps. In order to efficiently capture the dependencies between all gradient coordinates for large networks, we design a multilinear mapping consisting of a series of tensor-products to transform the gradients. It also considers layer specific structures, e.g. convolutional layers, to effectively reflects our inductive bias. In addition, meta-curvature can be easily implemented (simply transform the gradients right before passing through the optimizers) and can be plugged into existing meta-learning frameworks like MAML without additional, burdensome higher-order gradients.
We demonstrate the effectiveness of our proposed method on the few-shot learning tasks done by [47, 34, 9]. We evaluated our methods on few-shot regression and few-shot classification tasks over Omniglot [19], miniImagenet [47], and tieredImagnet [35] datasets. Experimental results show significant improvements on other MAML variants on all few-shot learning tasks. In addition, MC’s simple gradient transformation outperformed other more complicated state-of-the-art methods that include additional bells and whistles.
2 Background
2.1 Tensor Algebra
We review basics of tensor algebra that will be used to formalize the proposed method. We refer the reader to [17] for a more comprehensive review. Throughout the paper, tensors are defined as multidimensional arrays and denoted by calligraphic letters, e.g. th-order tensor, . Matrices are second-order tensors and denoted by boldface uppercase, e.g. .
Fibers: Fibers are a higher-order generalization of matrix rows and columns. A matrix column is a mode- fiber and a matrix row is a mode- fiber. The mode-1 fibers of a third order tensor are denoted as , where a colon is used to denote all elements of a mode.
Tensor unfolding: Also known as flattening (reshaping) or matricization, is the operation of arranging the elements of an higher-order tensors into a matrix. The mode- unfolding of a th-order tensor , arranges the mode-n fibers to be the columns of the matrix, denoted by , where . The elements of the tensor, are mapped to , where , with .
n-mode product: It defines the product between tensors and matrices. The -mode product of a tensor with a matrix is denoted by and computed as
[TABLE]
More concisely, it can be written as . Despite cumbersome notation, it is simply -mode unfolding (reshaping) followed by matrix multiplication.
2.2 Model-Agnostic Meta-Learning (MAML)
MAML aims to find a transferable initialization (a prior representation) of any model such that the model can adapt quickly from the initialization and produce good generalization performance on new tasks. The meta-objective is defined as validation performance after one or few step gradient updates from the model’s initial parameters. By using gradient descent algorithms to optimize the meta-objective, its training algorithm usually takes the form of nested gradient updates: inner updates for model adaptation to a task and outer-updates for the model’s initialization parameters. Formally,
[TABLE]
where denotes a loss function for a validation set of a task , and for a training set, or for brevity. The inner update is defined as a standard gradient descent with fixed learning rate . For conciseness, we assume as single adaptation step, but it can be easily extended to more steps. For more details, we refer to [9]. Several variations of inner update rules were suggested. Meta-SGD [22] suggested coordinate-wise learning rates, , where is the learnable parameters and is element wise product. Recently, [4] proposed a learnable learning rate per each layers for more flexible model adaptation. To alleviate computational complexity, [30] suggested an algorithm that do not require higher order gradients.
2.3 Second order optimization
The biggest motivation of second order methods is that first-order optimization such as standard gradient descent performs poorly if the Hessian of a loss function is ill-conditioned, e.g. a long narrow valley loss surface. There are a plethora of works that try to accelerate gradient descent by considering local curvatures. Most notably, the update rules of Newton’s method can be written as , with Hessian matrix and a step size [31]. Every step, it minimizes a local quadratic approximation of a loss function, and the local curvature is encoded in the Hessian matrix. Another promising approach, especially in neural network literature, is natural gradient descent [2]. It finds a steepest descent direction in distribution space rather than parameter space by measuring KL-divergence as a distance metric. Similar to Newton’s method, it preconditions the gradient with the Fisher information matrix and a common update rule is . In order to mitigate computational and spatial issues for large scale problems, several approximation techniques has been proposed, such as online update methods [31, 38], Kronecker-factored approximations [24], and diagonal approximations of second order matrices [45, 16, 8].
3 Meta-Curvature
We propose to learn a curvature along with the model’s initial parameters simultaneously via the meta-learning process. The goal is that the meta-learned curvature works collaboratively with the meta-learned model’s initial parameters to produce good generalization performance on new tasks with fewer gradient steps. In this work, we focus on learning a meta-curvature and its efficient forms to scale large networks. We follow the meta-training algorithms suggested in [9] and the proposed method can be easily plugged in.
3.1 Motivation
We begin with the hypothesis that there are broadly applicable curvatures to many tasks. In training a neural network with a loss function, local curvatures are determined by the model’s parameters, the network architecture, the loss function, and training data. Since new tasks are sampled from the same or similar distributions and all other factors are fixed, it is intuitive idea that there may exist some curvatures found via meta-training that can be effectively applied to the new tasks. Throughout the meta-training, we can observe how the gradients affect the validation performance and use those experiences to learn how to transform or correct the gradient from the new task.
We take a learning approach because existing curvature estimations do not consider generalization performance, e.g. Hessian and the Fisher-information matrix. The local curvatures are approximated with only current training data and loss functions. Therefore, these methods may end up converging fast to a poor local minimum. This is especially true when we have few training examples.
3.2 Method
First, we present a simple and efficient form of the meta-curvature computation through the lens of tensor algebra. Then, we present a matrix-vector product view to provide intuitive idea of the connection to the second order matrices. Lastly, we discuss the relationships to other methods.
3.2.1 Tensor product view
We consider neural networks as our models. With a slight abuse of notation, let the model’s parameters and its gradients of loss function , at each layers . To avoid cluttered notation, we will omit the superscript . We choose superscripts and dimensions with 2D convolutional layers in mind, but the method can be easily extended to higher dimension convolutional layers or other layers that consists of higher dimension parameters. , and are the number of output channels, the number of input channels, and the filter size respectively. is height width in convolutional layers and 1 in fully connected layers. We also define meta-curvature matrices, , , and . Now a meta-curvature function takes a multidimensional tensor as an input and has all meta-curvature matrices as learnable parameters:
[TABLE]
Figure 1 (top) shows an example of computational illustration with an input tensor . First, it performs linear transformations for all -mode fibers of . In other words, captures the parameter dependencies between the elements within a -mode fiber, e.g. all gradient elements in a channel of a convolutional filter. Secondly, the -mode product models the dependencies between 3-mode fibers computed from the previous stage. All -mode fibers are updated by linear combinations of other -mode fibers belonging to the same output channel (linear combinations of -mode fibers in a convolutional filter). Finally, the -mode product is performed in order to model the dependencies between the gradients of all convolutional filters. Similarly, the gradients of all convolutional filters are updated by linear combinations of gradients of other convolutional filters.
A useful property of -mode products is the fact that the order of the multiplications is irrelevant for distinct modes in a series of multiplications. For example, . Thus, the proposed method indeed examines the dependencies of the elements in the gradient all together.
3.2.2 Matrix-vector product view
We can also view the proposed meta-curvature computation as a matrix-vector product analogous to that from other second order methods. Note that this is for the purpose of intuitive illustration and we cannot compute or maintain this large matrices for large deep networks. We can expand the meta-curvature matrices as follows.
[TABLE]
where is the Kronecker product, is dimensional identity matrix, and the three expanded matrices are all same size . Now we can transform the gradients with the meta-curvature as
[TABLE]
where . The expanded matrices satisfy commutative property, e.g. , as shown in the previous section. Thus, models the dependencies of the model parameters all together. Note that we can also write , but this is non-commutative, .
Figure 1 (bottom) shows a computational illustration. , which is equivalent computation to , can be interpreted as a giant matrix-vector multiplication with block diagonal matrix, where each block shares same meta-curvature matrix . It resembles the block diagonal approximation strategies in some second-order methods for training deep networks, but as we are interested in learning meta-curvature matrices, no approximation is involved. And matrix-vector product with and are used to capture inter-parameter dependencies and are computationally equivalent to -mode and -mode products of Eq. 3.
3.2.3 Relationship to other methods
Tucker decomposition [17] decomposes a tensor into low rank cores with projection factors and aims to closely reconstruct the original tensor. We maintain full rank gradient tensors, however, and our main goal is to transform the gradients for better generalization. [18] proposed to learn the projection factors in Tucker decomposition for fully connected layers in deep networks. Again, their goal was to find the low rank approximations of fully connected layers for saving computational and spatial cost.
Kronecker-factored Approximate Curvature (K-FAC) [24, 14] approximates the Fisher matrix by the Kronecker product, e.g. , where is computed from the activation of input units and is computed from the gradient of output units. Its main goal is to approximate the Fisher such that matrix vector products between its inversion and the gradient can be computed efficiently. However, we found that maintaining was quite expensive both computationally and spatially even for smaller networks. In addition, when we applied this factorization scheme to meta-curvature, it tends to easily overfit to meta-training set. On the contrary, we maintain two separated matrices, and , which allows us to avoid overfitting and heavy computation. More importantly, we learn meta-curvature matrices to improve generalization instead of directly computing them from the activation and the gradient of training loss. Also, we do not require expensive matrix inversions.
3.2.4 Meta-training
We follow a typical meta-training algorithm and initialize all meta-curvature matrices as identity matrices so that the gradients do not change at the beginning. We used the ADAM [16] optimizer for the outer loop optimization and update the model’s initial parameters and meta-curvatures simultaneously. We provide the details of algorithm in appendices.
4 Analysis
In this section, we will explore how a meta-trained matrix , or for brevity, can operate for better generalization. Let us take the gradient of meta-objective w.r.t for a task . With the inner update rule , and by applying chain rule,
[TABLE]
where is the parameter for the task after the inner update. It is the outer product between the gradients of validation loss and training loss. Note that there is a significant connection to the Fisher information matrix. For a task , if we define the loss function as negative log likelihood, e.g. a supervised classification task ], then the empirical Fisher can be defined as . There are three clear distinctions. First, the training and validation sets are treated separately in the meta-gradient , while the empirical Fisher is computed with only training set (validation set is not available during training). Secondly, the gradient of the validation set is evaluated at new parameters after the inner update in the meta-gradient. Finally, the Fisher is positive semi-definite by construction, but it is not the case for the meta-gradient. This is an attractive property since it guarantees that the transformed gradient is always a descent direction. However, we mainly care about generalization performance in this work. Hence, we rather not force this property in this work, but leave it for future work.
Now let us consider what the meta-gradient can do for good generalization performance. Given a fixed point and a meta training set , standard gradient descent from an initialization , gives the following update.
[TABLE]
where and are fixed inner/outer learning rates respectively. Here, we assume a standard gradient descent for simplicity. But the argument extends to other advanced gradient algorithms, such as momentum and ADAM.
We apply to the gradients of a new task, giving the transformed gradients
[TABLE]
Given , the second term in the R.H.S. of Eq. 10 can represent the final gradient direction for the new task. For Eq. 10, we used the Taylor expansion of vector-valued function, .
The term A of Eq. 10 is the inner product between the gradients of meta-training losses and new test losses. We can simply interpret this as how similar the gradient directions between two different tasks. This has been explicitly used in continual learning or multi-task learning setup to consider task similarity [7, 23, 36]. When we have a loss function in the form of finite sums, this term can be also interpreted as a kernel similarity between the respective sets of gradients (see Eq. 4 of [28]).
With the first term in B of Eq. 10, we compute a linear combination of the gradients of validation losses from the meta-training set. Its weighting factors are computed based on the similarities between the tasks from the meta-training set and the new task as explained above. Therefore, we essentially perform a soft nearest neighbor voting to find the direction among the validation gradients from the meta-training set. Given the new task, the gradient may lead the model to overfit (or underfit). However, the proposed method will extract the knowledge from the past experiences and find the gradients that gave us good validation performance during the meta-training process.
5 Related Work
Meta-learning: Model-agnostic meta-learning (MAML) highlighted the importance of the model’s initial parameters for better generalization [10] and there have been many extensions to improve the framework, e.g. for continuous adaptation [1], better credit assignment [37], and robustness [15]. In this work, we improve the inner update optimizers by learning a curvature for better generalization and fast model adaptation. Meta-SGD [22] suggests to learn coordinate-wise learning rates. We can interpret it as an diagonal approximation to meta-curvature in a similar vein to recent adaptive learning rates methods, such as [45, 16, 8], performing diagonal approximations of second-order matrices. Recently, [4] suggested to learn layer-wise learning rates through the meta-training. However, both methods do not consider the dependencies between the parameters, which was crucial to provide more robust meta-training process and faster convergence. [21] also attempted to transform the gradients. They used simple binary mask applied to the gradient update to determine which parameters are to be updated while we introduce dense learnable tensors to model second-order dependencies with a series of tensor products.
Few-shot classification: As a good test bed to evaluate few-shot learning, huge progress has been made in the few-shot classification task. Triggered by [47], many recent studies have focused on discovering effective inductive bias on classification task. For example, network architectures that perform nearest neighbor search [47, 43] were suggested. Some improved the performance by modeling the interactions or correlation between training examples [26, 11, 44, 32, 29]. In order to overcome the nature of few-shot learning, the generative models have been suggested to augment the training data [42, 48] or generate model parameters for the specified task [39, 33]. The state-of-the-art results are achieved by additionally training 64-way classification task for pretraining [33, 39, 32] with larger ResNet models [33, 39, 29, 26]. In this work, our focus is to improve the model-agnostic few-shot learner that is broadly applicable to other tasks, e.g. reinforcement learning setup.
Learning optimizers: Our proposed method may fall within the learning optimizer category [34, 3, 49, 25]. They also take as input the gradient and transform it via a neural network to achieve better convergence behavior. However, their main focus is to capture the training dynamics of individual gradient coordinates [34, 3] or to obtain a generic optimizer that is broadly applicable for different datasets and architectures [49, 25, 3]. On the other hand, we meta-learn a curvature coupled with the model’s initialization parameters. We focus on a fast adaptation scenario requiring a small number of gradient steps. Therefore, our method does not consider a history of the gradients, which enables us to avoid considering a complex recurrent architecture. Finally, our approach is well connected to existing second order methods while learned optimizers are not easily interpretable since the gradient passes through nonlinear and multilayer recurrent neural networks.
6 Experiments
We evaluate the proposed method on a synthetic data few-shot regression task few-shot image classification tasks with Omniglot and MiniImagenet datasets. We test two versions of the meta-curvature. The first one, named as MC1, we fixed the Eq. 4. The second one, named as MC2, we learn all three meta-curvature matrices. We also report results on few-shot reinforcement learning in appendices.
6.1 Few-shot regression
To begin with, we perform a simple regression problem following [9, 22]. During the meta-training process, sinusoidal functions are sampled, where the amplitude and phase are varied within and respectively. The network architecture and all hyperparameters are same as [9] and we only introduce the suggested meta-curvature. We reported the mean squared error with 95% confidence interval after one gradient step in Figure 5. The details are provided in appendices.
6.2 Few-shot classification on Omniglot
The Omniglot dataset consists of handwritten characters from 50 different languages and 1632 different characters. It has been widely used to evaluate few-shot classification performance. We follow the experimental protocol in [9] and all hyperparameters and network architecture are same as [9]. Further experimental details are provided in appendices. Except 5-shot 5-way setting, our simple 4 layers CNN with meta-curvatures outperform all MAML variants and also achieved state-of-the-art results without additional specialized architectures, such as attention module (SNAIL [27]) or relational module (GNN [12]). We provide the training curves in Figure 2 and our methods converge much faster and achieve higher accuracy.
6.3 Few-shot classification on miniImagenet and tieredImagenet
Datasets: The miniImagenet dataset was proposed by [47, 34] and it consists of 100 subclasses out of 1000 classes in the original dataset (64 training classes, 12 validation classes, 24 test classes). The tieredImagenet dataset [35] is a larger subset, composed of 608 classes and reduce the semantic similarity between train/val/test splits by considering high-level categories.
baseline CNNs: We used 4 layers convolutional neural network with the batch normalization followed by a fully connected layer for the final classification. In order to increase the capacity of the network, we increased the filter size up to 128. We found that the model with the larger filter seriously overfit (also reported in [9]). To avoid overfitting, we applied data augmentation techniques suggested in [5, 6]. For a fair comparison to [4], we also reported the results of model ensemble. Throughout the meta-training, we saved the model regularly and picked 3 models that have the best accuracy on the meta-validation dataset. We re-implemented all three baselines and performed the experiments with the same settings. We provide further the details in the appendices.
Fig. 2 and Table 3 shows the results of baseline CNNs experiments on miniImagenet. MC1 and MC2 outperformed all other baselines for all different experiment settings. Not only does MC reach a higher accuracy at convergence, but also showed a much faster convergence rates for meta-training. Our methods share the same benefits as second order methods although we do not approximate any Hessian or Fisher matrices. Unlike other MAML variants, which required an extensive hyperparameter search, our methods are very robust to hyperparameter settings. Usually, MC2 outperforms MC1 because the more fine-grained meta-curvature enable us to effectively increase the model’s capacity.
WRN-28-10 features and MLP: To the best of our knowledge, [39, 33] are current state-of-the-art methods that use a pretrained WRN-28-10 [50] network (trained with 64-way classification task on entire meta-training set) as a feature extractor network. We evaluated our methods on this setting by adding one hidden layer MLP followed by a softmax classifier and our method again improved MAML variants by a large margin. Despite our best attempts, we could not find a good hyperparameters to train original MAML in this setting. Although our main goal is to push how much a simple gradient transformation in the inner loop optimization can improve general and broadly applicable MAML frameworks, our methods outperformed the recent methods that used various task specific techniques, e.g. task dependent weight generating methods [39, 33] and relational networks [39]. Our methods also outperformed the very latest state of the art results [20] that used extensive data-augmentation, regularization, and 15-shot meta-training schemes with different backbone networks.
7 Conclusion
We propose to meta-learn the curvature for faster adaptation and better generalization. The suggested method significantly improved the performance upon previous MAML variants and outperformed the recent state of the art methods. It also leads to faster convergence during meta-training. We present an analysis about generalization performance and connect to existing second order methods, which would provide useful insights for further research.
Appendix A Meta-training algorithm
Alg. 1 shows the details of the algorithm to train meta-curvature matrices and the initial model parameters. To avoid cluttered notation, we assumed the model has only one layer and it is straightforward to extend to multiple layers.
Appendix B Few-shot regression
Experimental setup We used the same experimental setups in [9]. During training and testing, the amplitude and the phase vary within and respectively, and data points are sampled from uniform distribution . We used one gradient step with the fixed learning rate 0.01 and Adam was used for meta-training with the outer loop learning rate 0.001. We used the same network architecture, which has two 40 dimension fully connected layers with ReLU activation. We sampled 25 tasks for every iterations and trained 70000 iterations. We reported the performance from the trained model that had the minimum loss value. [9] reported the MSE for 5-shot setting, and we could reproduced the results. [22] has slightly different settings, so the MSE are not directly comparable to theirs.
Qualitative results: We provide qualitative results of few-shot regression task on sinusoidal functions in Figure 3. The star shape markers are the few data points for training, and we draw the curves based on each methods, MAML, Meta-SGD, and the proposed MC2. The left column is 5-shot and the right column is 10-shot experiments.
Appendix C Few-shot classification on Omniglot dataset
We used the same experimental setups in [9]. Out of 1623 characters, we used 1100 characters for training, 100 characters for validation, and remaining 423 characters for testing. The network architecture is 4 convolutional layers with 64 filters and 1 fully connected layer for the final classification. We only used one inner gradient step with 0.4 learning rate for all meta-curvature experiments for training and testing. The batch size was set to 32 (5-way) and 16 (20-way), and outer loop learning rate is 0.001 and we trained 60000 iterations.
Appendix D Few-shot classification on miniImagenet and tieredImagenet dataset
D.1 Baseline CNNs
For both 5-way 1-shot and 5-way 5-shot classification, we set the batch size 4 for 1 step experiments and 2 for 5 step experiments. 15 examples per class were used for evaluating the model after updates. In total, we ran 100,000 iterations for 1 step experiments and 200,000 iterations for 2 step experiments. The inner/outer learning rates are . We apply dropout rate 0.2 in the final linear layer for only MC1 and MC2 (other methods did perform worse with dropout). For cutout data augmentation, we cut out random crops.
D.2 WRN-28-10 features and MLP
We used the WRN-28-10 features provided by [39]. For miniImagenet, we provided the results from both center and multi-view features (average of center and corner crops). The dimension of feature was 640 and we used one hidden layer with ReLU activation function followed by a softmax classifier. We used separate meta-curvature matrices for each inner updates. The details of hyperparameters used for training MC2 is provided in Table 6.
Appendix E Few-shot reinforcement learning
The goal of few-shot learning in reinforcement learning (RL) is that an agent can quickly adapt to a new task with little prior experience. A distinct feature from the few-shot supervised learning task is that the RL objective is not generally differentiable. Therefore, we use policy gradient methods to estimate the gradient both for inner and outer loop gradients. In addition, policy gradient methods are generally on-policy, which means that the training data depends on the agent’s initial policy. Therefore, the initial policy (with the meta-learned initial parameters) needs to explore as diverse experiences as possible to get proper feedback from a new task. We described the method and interpretation with respect to supervised classification tasks, but it can be easily modified to RL setting.
E.1 Experimental setup
We tested our method on complex high-dimensional locomotion tasks with the MuJoCo simulator [46]. Most of the settings are based on [9] for fair comparison. We consider two simulated robots (HalfCheetah and Walker2d) and two types of task environments (to run in a forward/backward direction or a particular velocity). The network architecture is two hidden layers of size 100 with ReLU activations for both. We used the standard linear feature baseline estimator. We evaluated the performance after one policy gradient step with 20 trajectories. We compare against MAML-TRPO and MAML-PPO. In the original MAML, TRPO [40] was used as the outer loop optimizer but we found out that using PPO [41] consistently outperformed the TRPO. MAML-PPO is also computationally more efficient since MAML-TRPO requires third-order gradients (or computed by hessian-vector product instead). To the best of our knowledge, MAML-PPO has not been tested on this setup. We evaluated two variations of meta-curvature similar to the classification setup, MC1 and MC2, and used PPO as the meta-optimizer. Note that this is a preliminary result, so this is not by no means conclusive. We provide this information for the readers who might be interested in this direction.
E.2 Experimental results
Fig. 4 shows the rewards obtained after one step policy gradient update. In the HalfCheetahDir experiment, our methods outperformed both strong baselines. MC1-PPO reached the same performance of a strong baseline, MAML-PPO three times faster. In HalfCheetahVel and Walker2dDir experiments, both MC2-PPO and MAML-PPO reached nearly the same performance, but in a more sample efficient manner. For Walker2dVel, MAML-TRPO showed the fastest convergence at the earlier meta-training stage, but our meta-curvatures outperformed eventually. In this setting, most of the rewards come from the survival reward (the agent gets reward for every step if they do not fall over). All methods were able to survive throughout the episode, but our methods run better at a given velocity. One thing we noticed that it stops obtaining more rewards and starts to degrade the performance in Walker2dDir experiment. The recently proposed approach [37] may alleviate this issue through better credit assignment in the meta-gradients. Combining it would be interesting direction to be explored.
Appendix F Visualization
Fig. 5 is a visualization of meta-trained meta-curvature matrices for 5-way 1-shot classification task. To visualize the full matrix, , we picked up the matrices from the first convolutional layer in the small model (filter size 64). Therefore with the 3 color input channels, , , , and . The diagonal elements are high values, mostly . Interestingly, there are also a lot of off-diagonal elements or . Thus, they capture the dependencies between the gradients.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Maruan Al-Shedivat, Trapit Bansal, Yuri Burda, Ilya Sutskever, Igor Mordatch, and Pieter Abbeel. Continuous Adaptation via Meta-Learning in Nonstationary and Competitive Environments. In International Conference on Learning Representations (ICLR) , 2018.
- 2[2] Shun-Ichi Amari. Natural gradient works efficiently in learning. Neural computation , 10(2):251–276, 1998.
- 3[3] Marcin Andrychowicz, Misha Denil, Sergio Gómez Colmenarejo, Matthew W. Hoffman, David Pfau, Tom Schaul, Brendan Shillingford, and Nando de Freitas. Learning to learn by gradient descent by gradient descent. In Neural Information Processing Systems (Neur IPS) , 2016.
- 4[4] Antreas Antoniou, Harrison Edwards, and Amos Storkey. How to train your MAML. International Conference on Learning Representations (ICLR) , 2019.
- 5[5] Ekin D. Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasudevan, and Quoc V. Le. Auto Augment: Learning Augmentation Policies from Data. ar Xiv:1805.09501 , 2018.
- 6[6] Terrance De Vries and Graham W. Taylor. Improved regularization of convolutional neural networks with cutout. ar Xiv:1708.04552 , 2017.
- 7[7] Yunshu Du, Wojciech M. Czarnecki, Siddhant M. Jayakumar, Razvan Pascanu, and Balaji Lakshminarayanan. Adapting Auxiliary Losses Using Gradient Similarity. ar Xiv:1812.02224 , 2018.
- 8[8] John Duchi, Elad Hazan, and Yoram Singer. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research , 12:2121–2159, 2011.