Censored Quantile Regression Forests
Alexander Hanbo Li, Jelena Bradic

TL;DR
This paper introduces Censored Quantile Regression Forests, a novel non-parametric method for estimating time-to-event quantiles in censored data, improving predictive accuracy without parametric assumptions.
Contribution
It develops a new regression adjustment for censored data based on adaptive estimating equations, extending random forests to censored quantile regression.
Findings
Demonstrates consistency under mild conditions
Shows superior performance in numerical studies
Enables quantile estimation without parametric models
Abstract
Random forests are powerful non-parametric regression method but are severely limited in their usage in the presence of randomly censored observations, and naively applied can exhibit poor predictive performance due to the incurred biases. Based on a local adaptive representation of random forests, we develop its regression adjustment for randomly censored regression quantile models. Regression adjustment is based on new estimating equations that adapt to censoring and lead to quantile score whenever the data do not exhibit censoring. The proposed procedure named censored quantile regression forest, allows us to estimate quantiles of time-to-event without any parametric modeling assumption. We establish its consistency under mild model specifications. Numerical studies showcase a clear advantage of the proposed procedure.
Click any figure to enlarge with its caption.
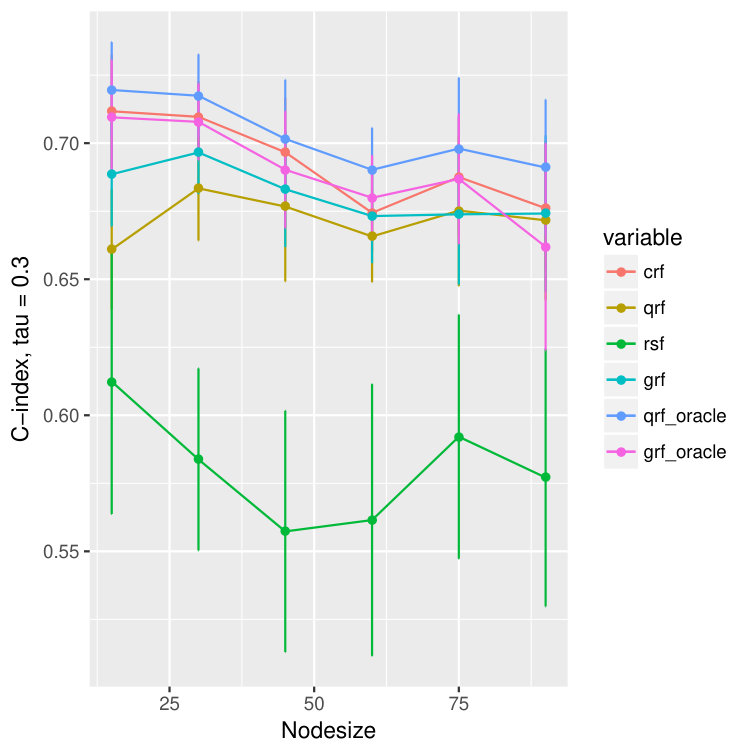 Figure 1
Figure 1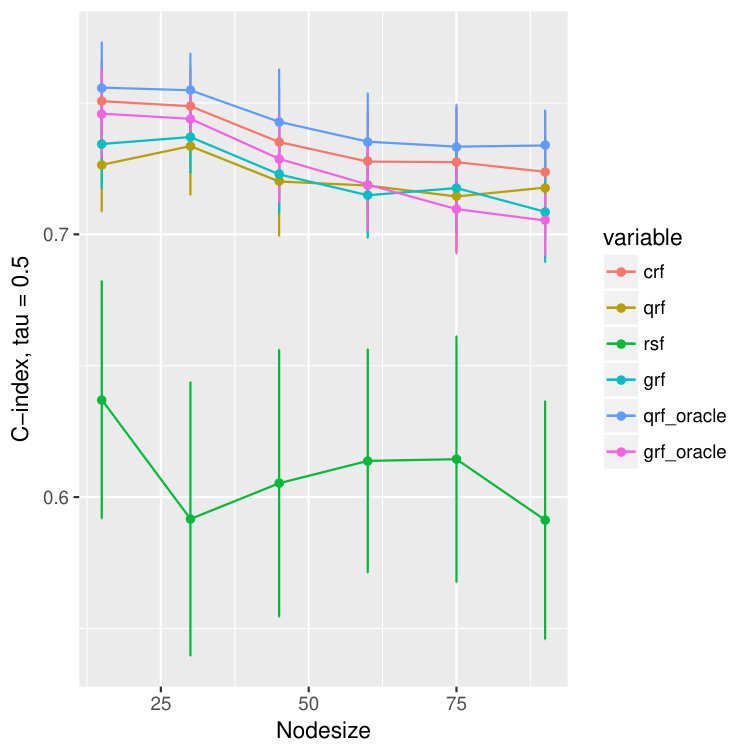 Figure 2
Figure 2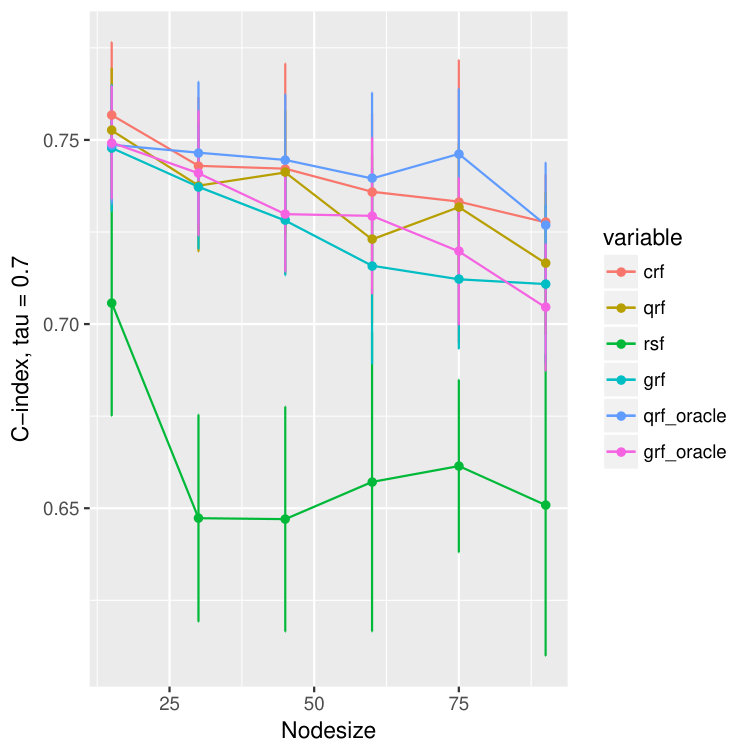 Figure 3
Figure 3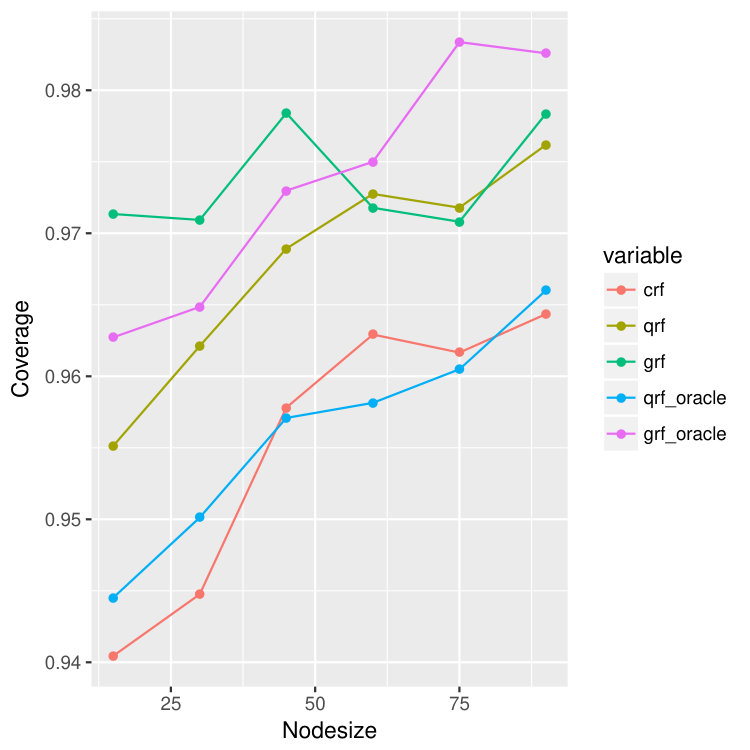 Figure 4
Figure 4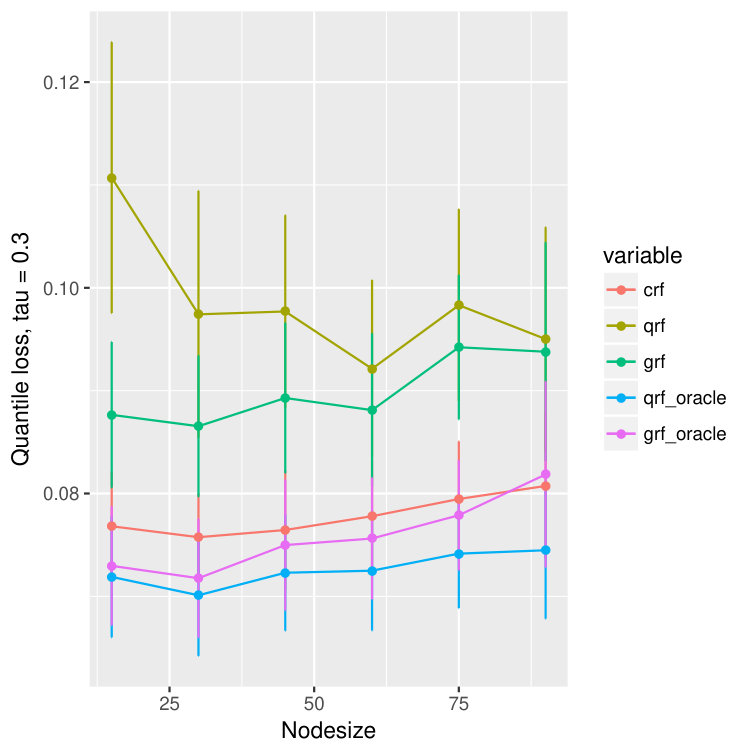 Figure 5
Figure 5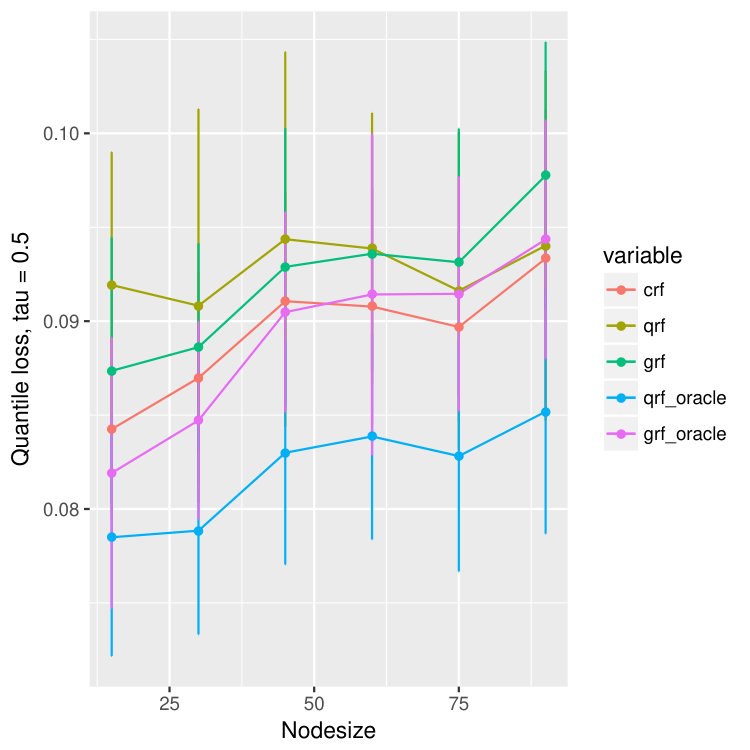 Figure 6
Figure 6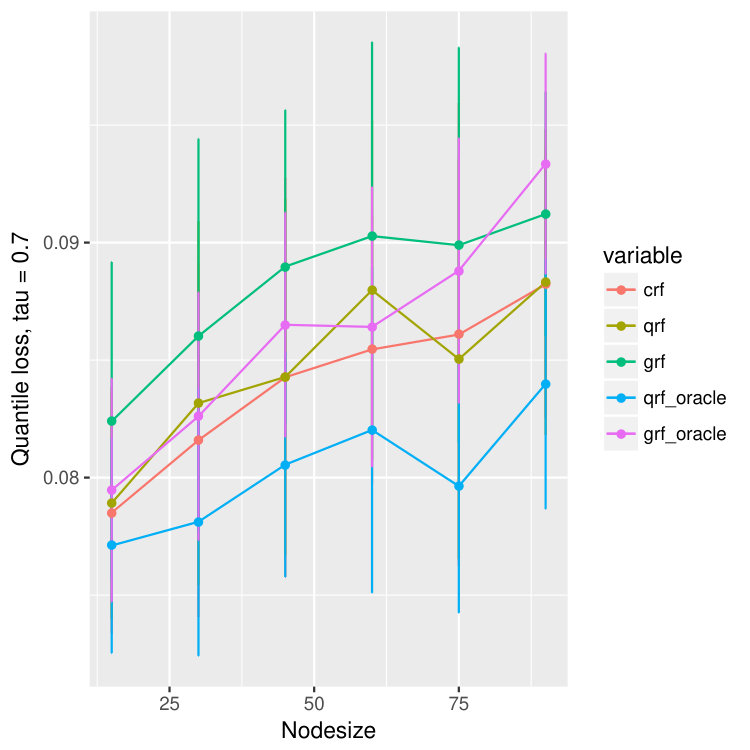 Figure 7
Figure 7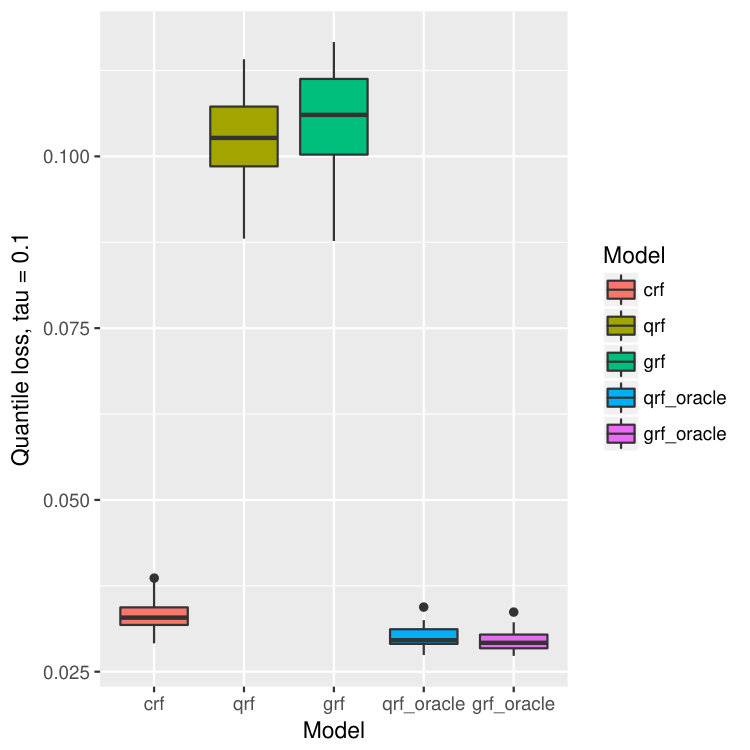 Figure 8
Figure 8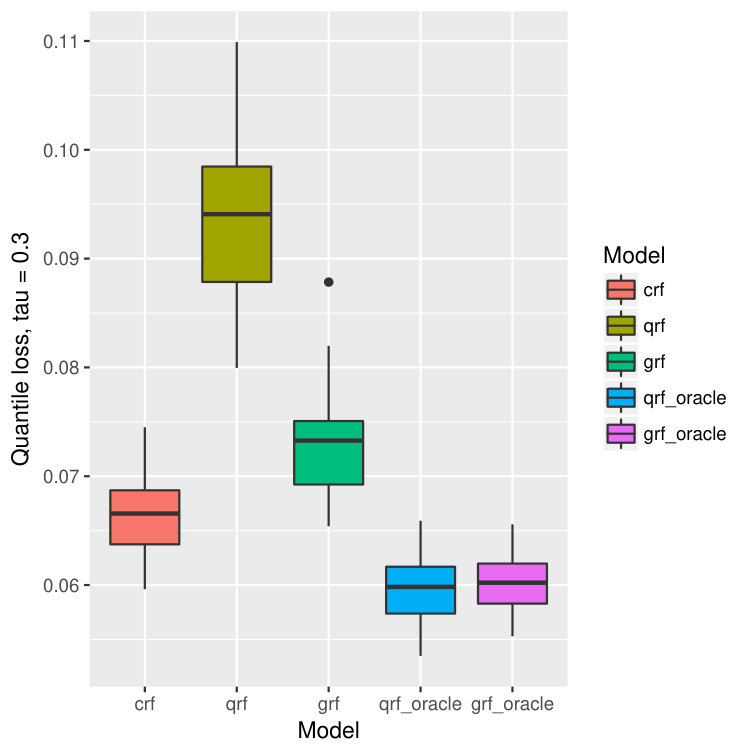 Figure 9
Figure 9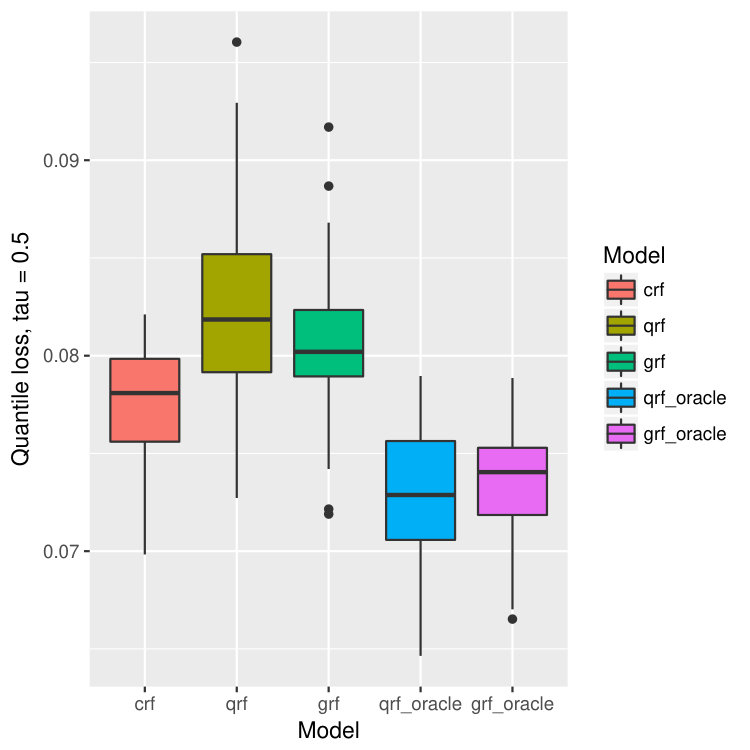 Figure 10
Figure 10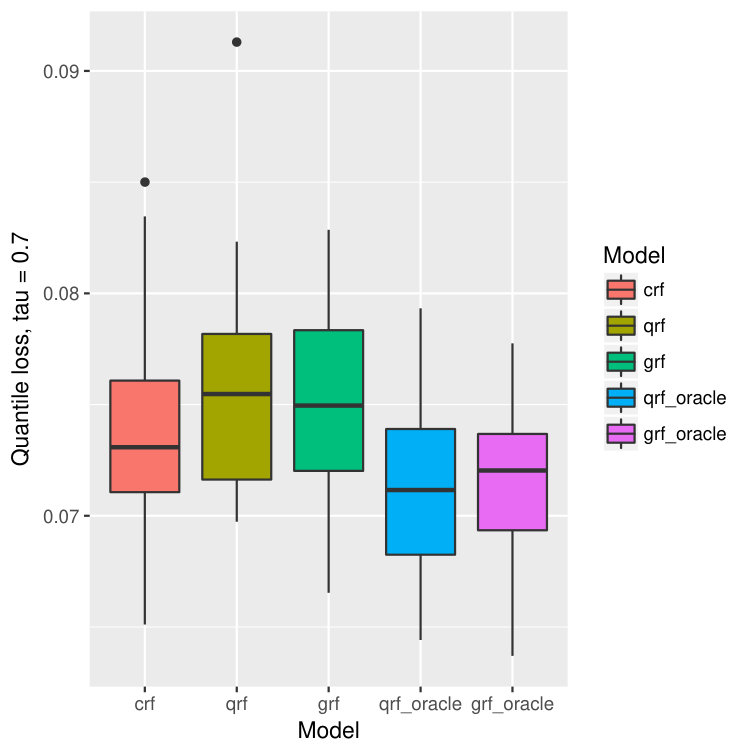 Figure 11
Figure 11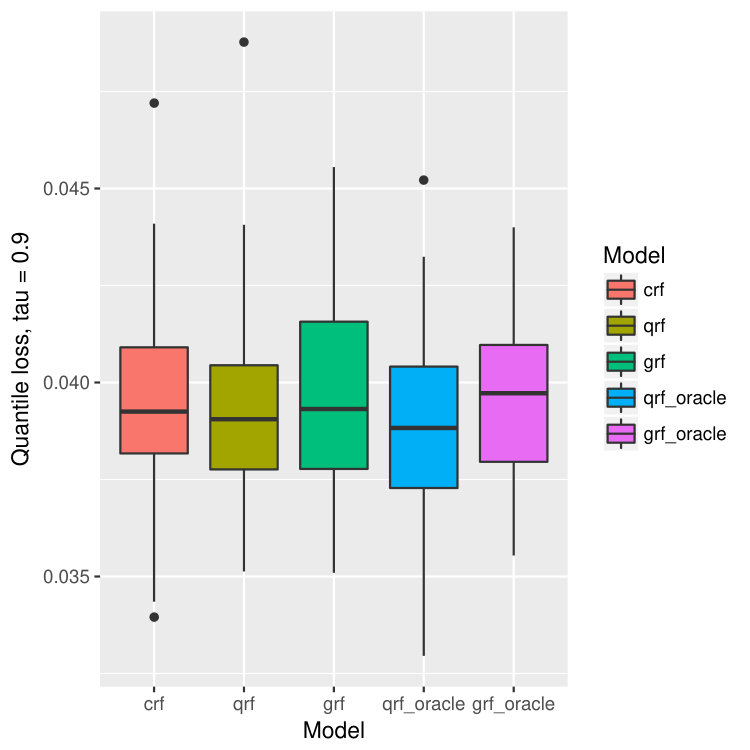 Figure 12
Figure 12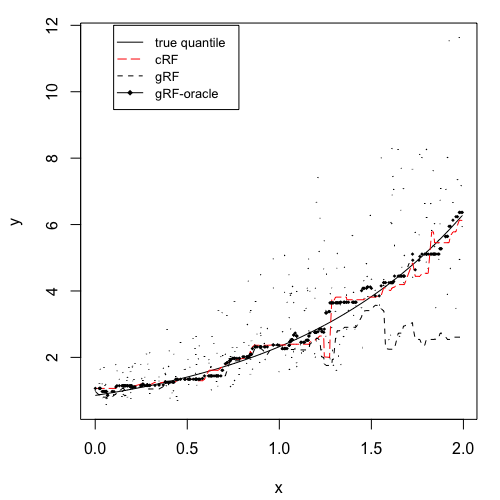 Figure 13
Figure 13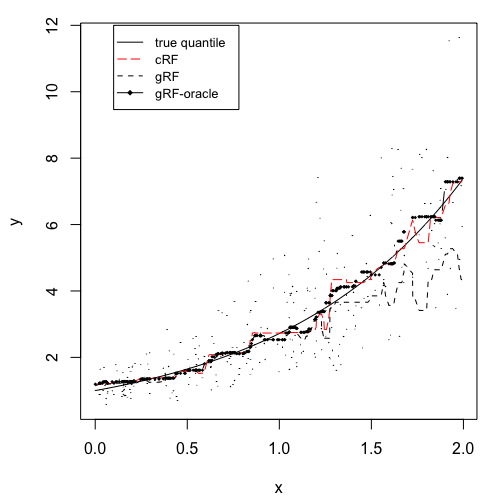 Figure 14
Figure 14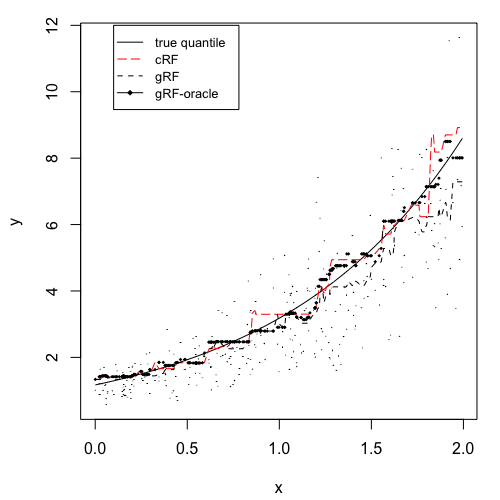 Figure 15
Figure 15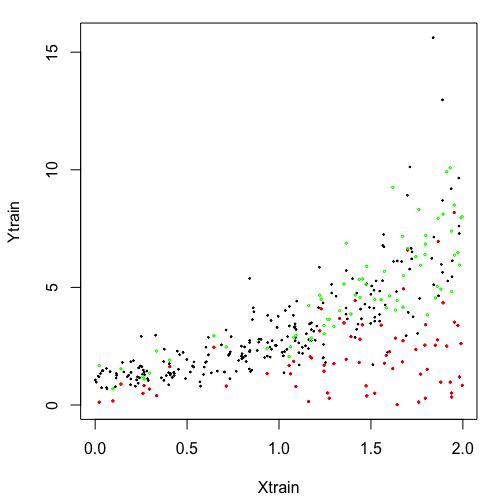 Figure 16
Figure 16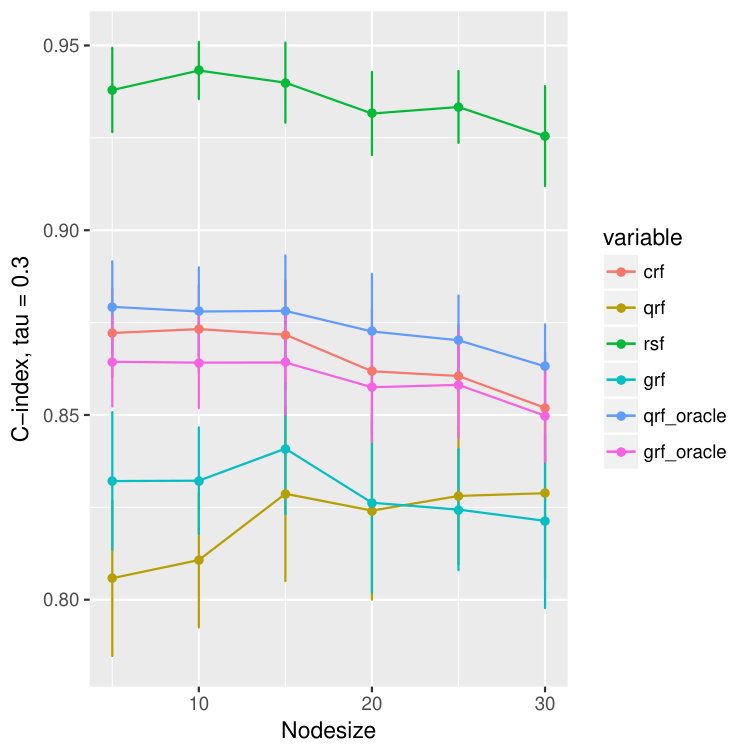 Figure 17
Figure 17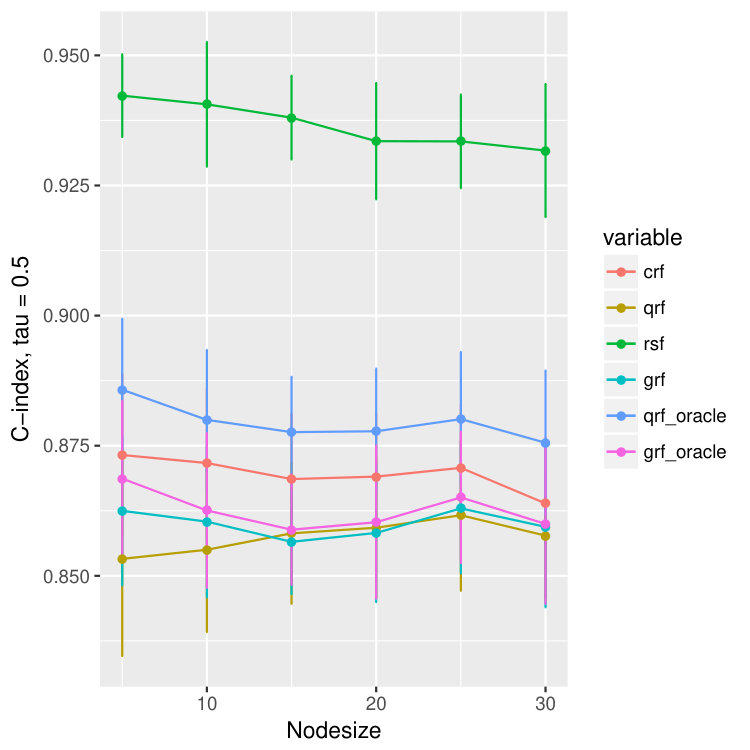 Figure 18
Figure 18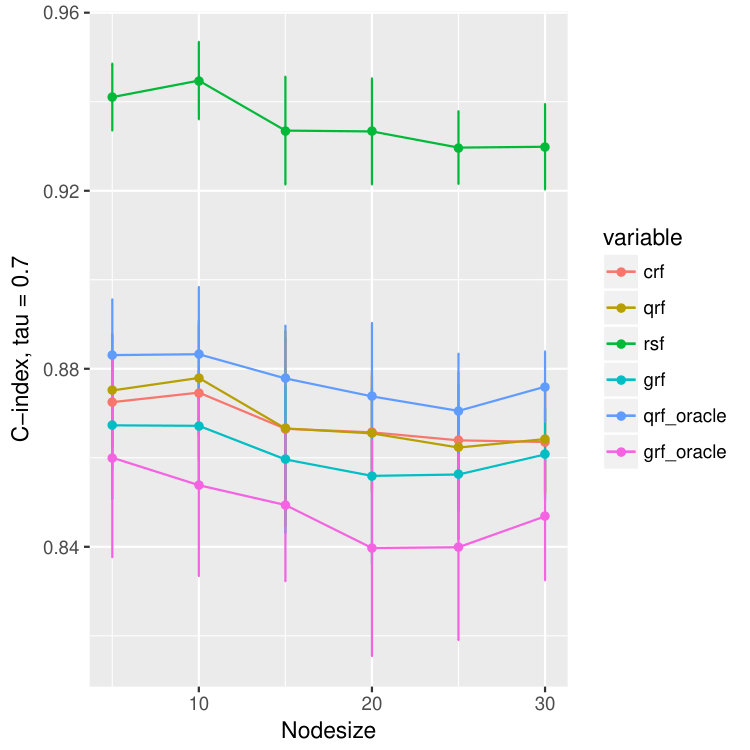 Figure 19
Figure 19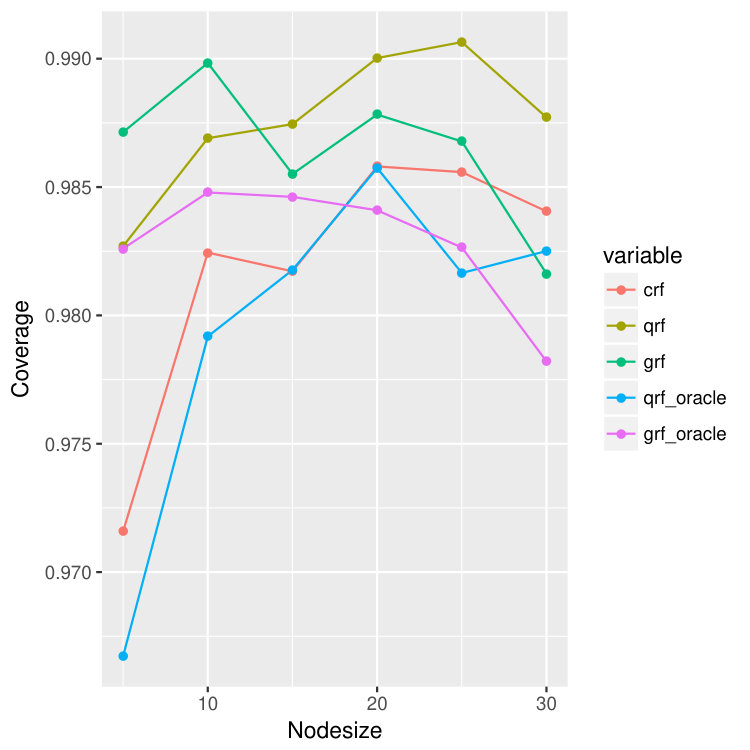 Figure 20
Figure 20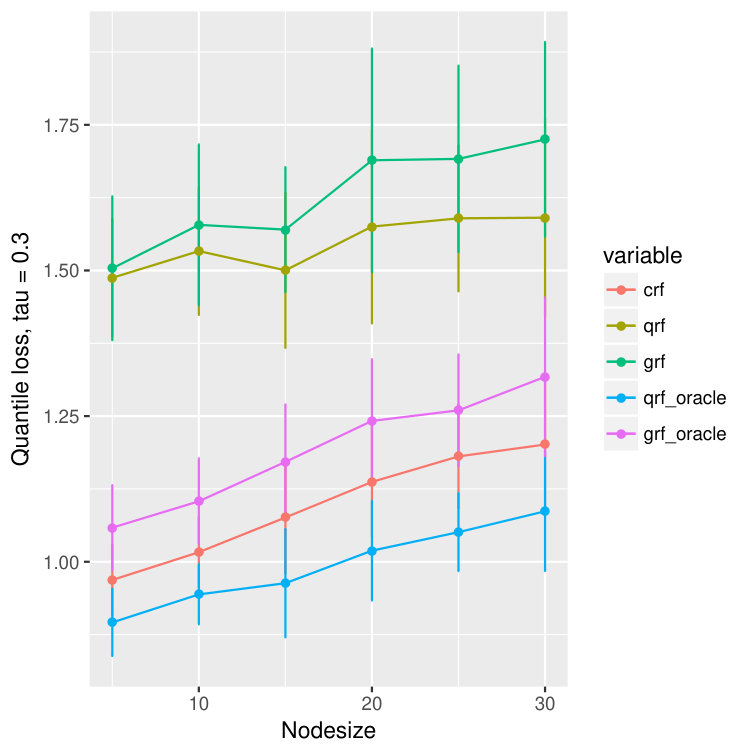 Figure 21
Figure 21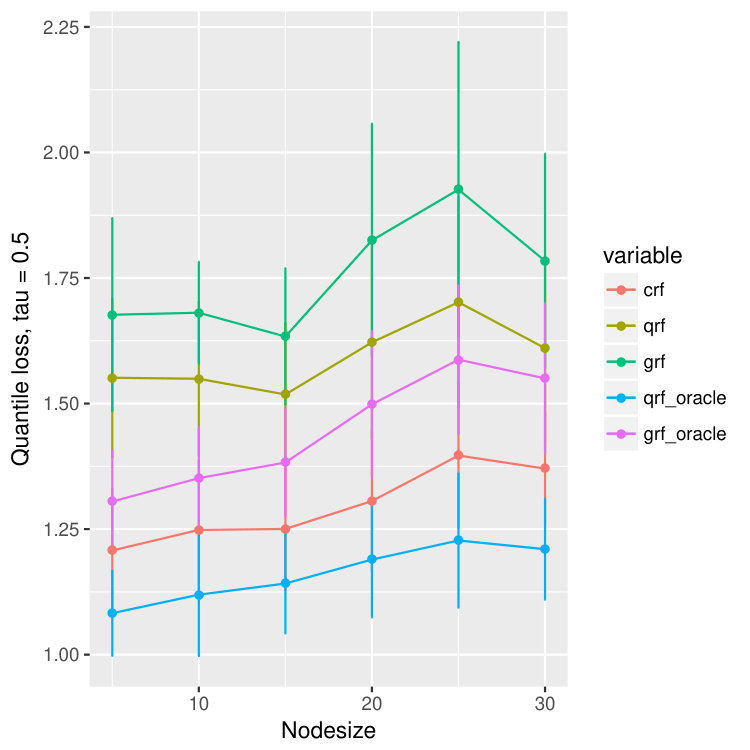 Figure 22
Figure 22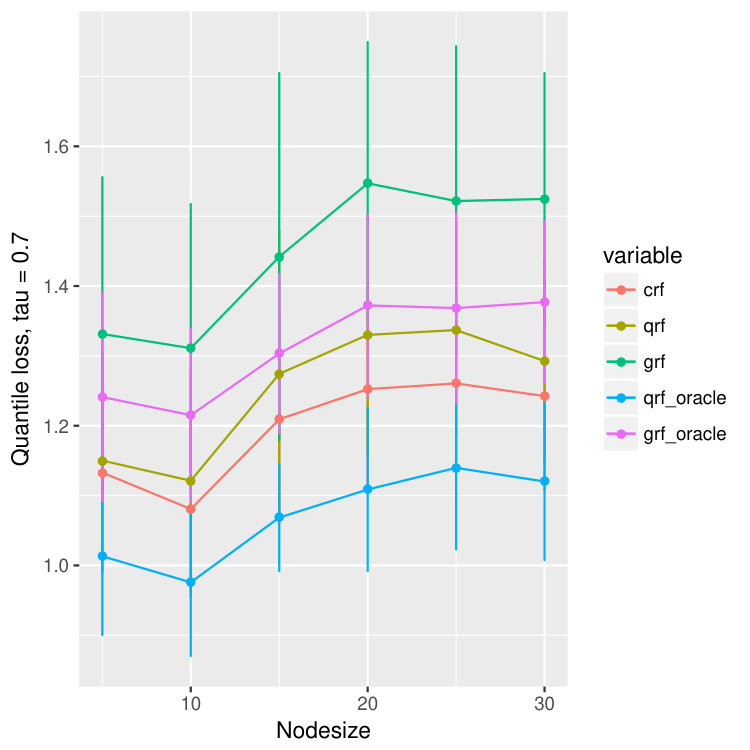 Figure 23
Figure 23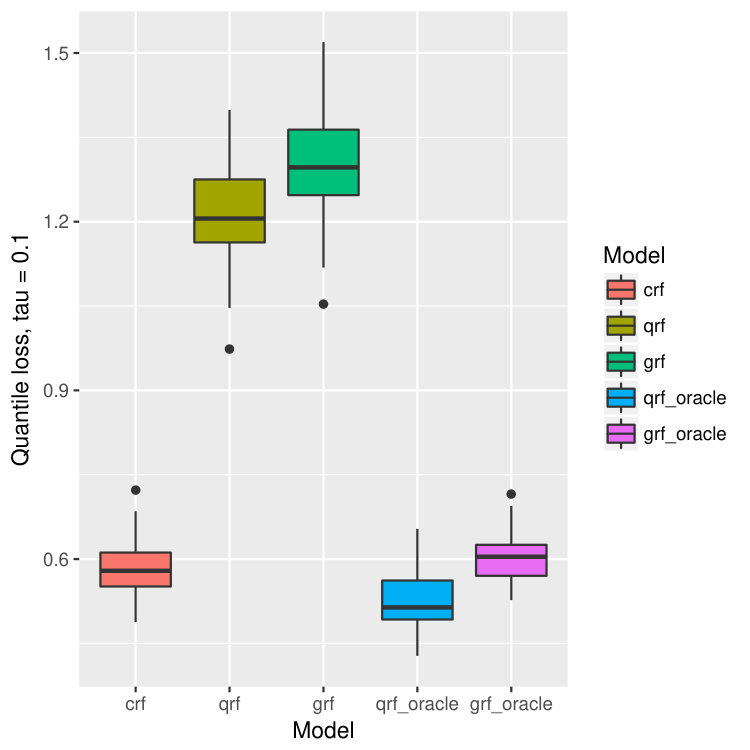 Figure 24
Figure 24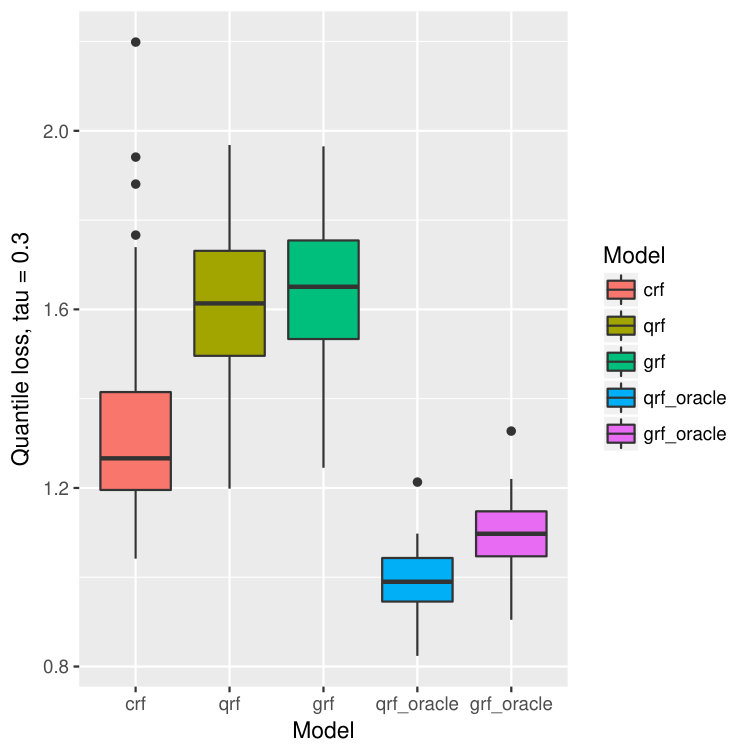 Figure 25
Figure 25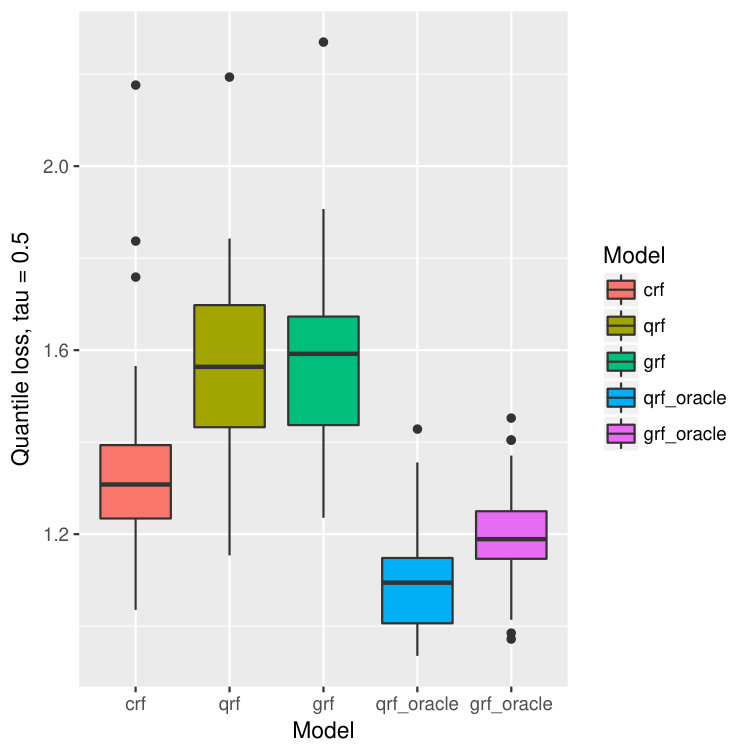 Figure 26
Figure 26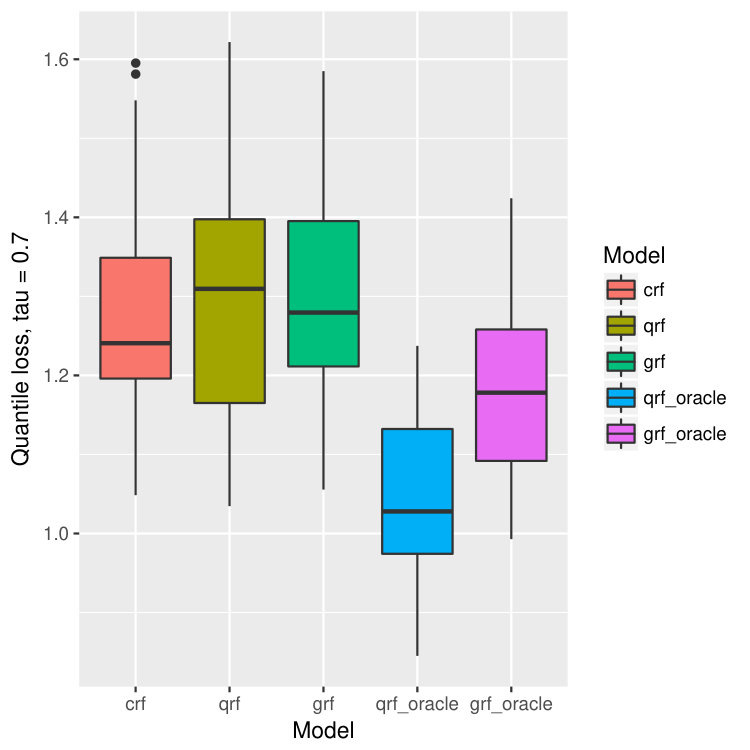 Figure 27
Figure 27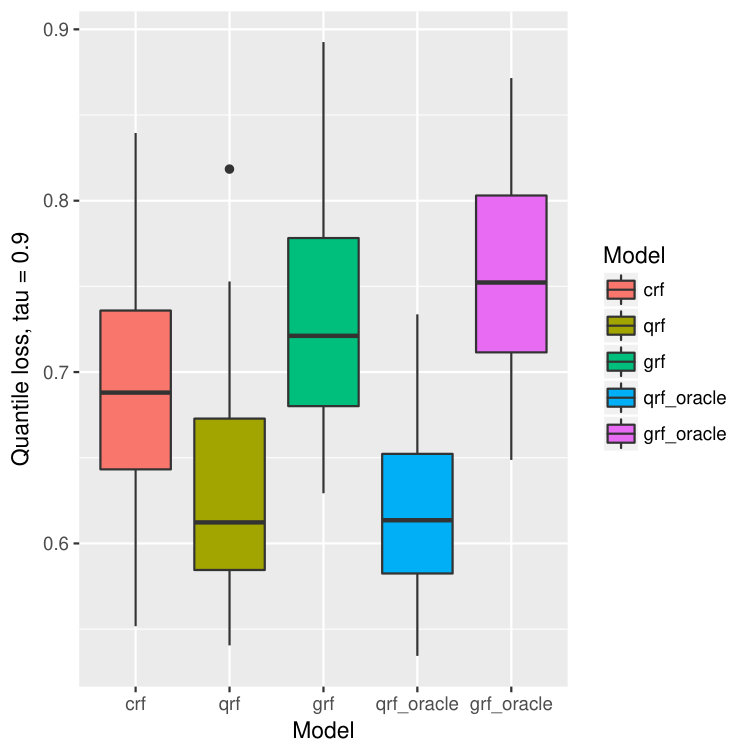 Figure 28
Figure 28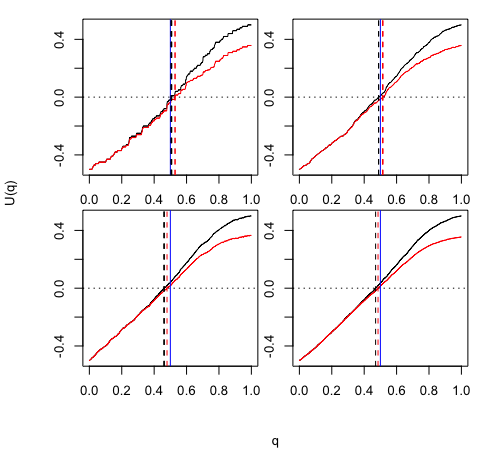 Figure 29
Figure 29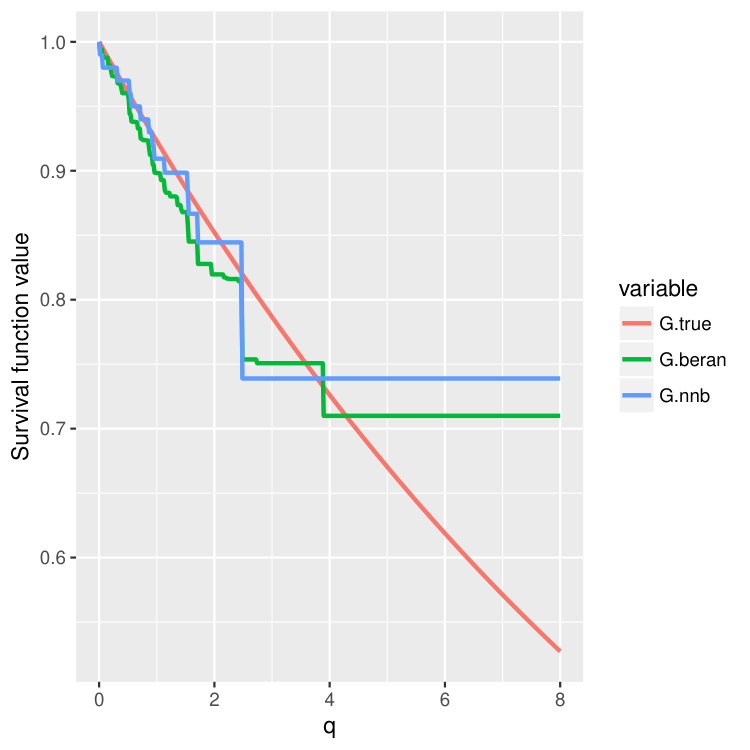 Figure 30
Figure 30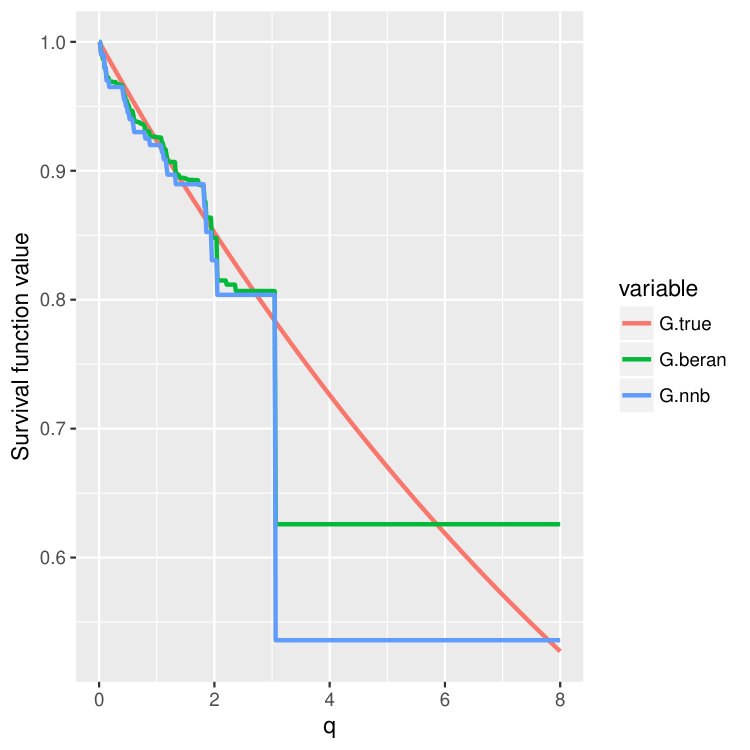 Figure 31
Figure 31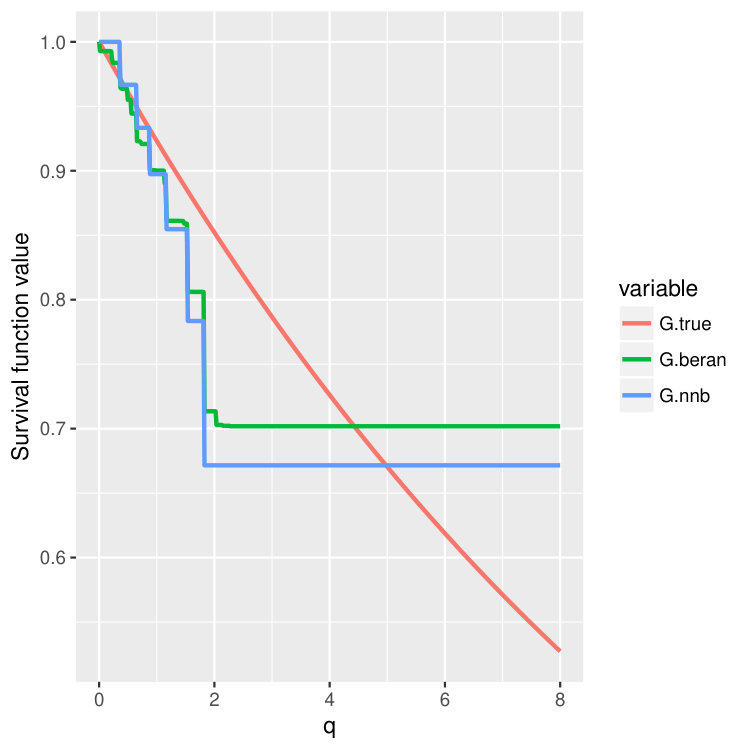 Figure 32
Figure 32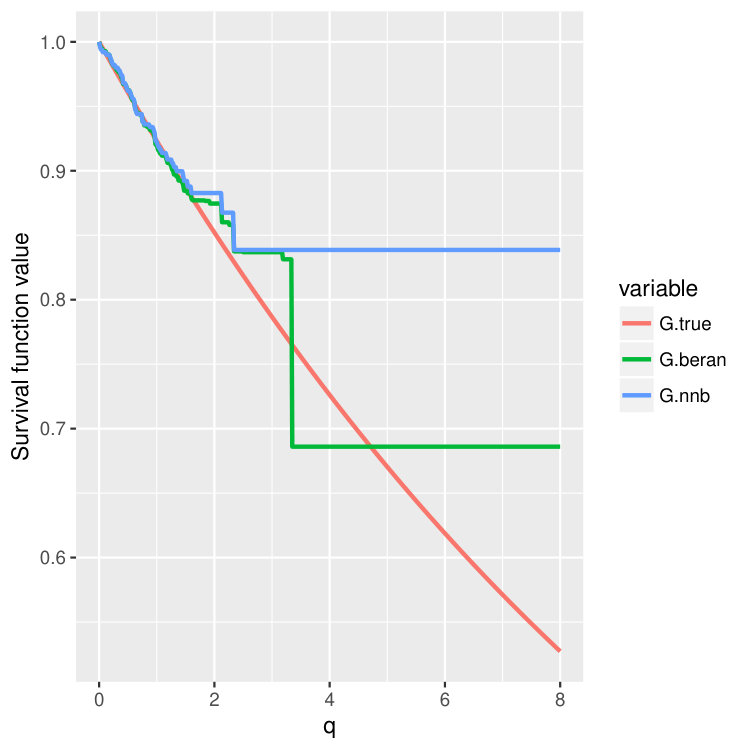 Figure 33
Figure 33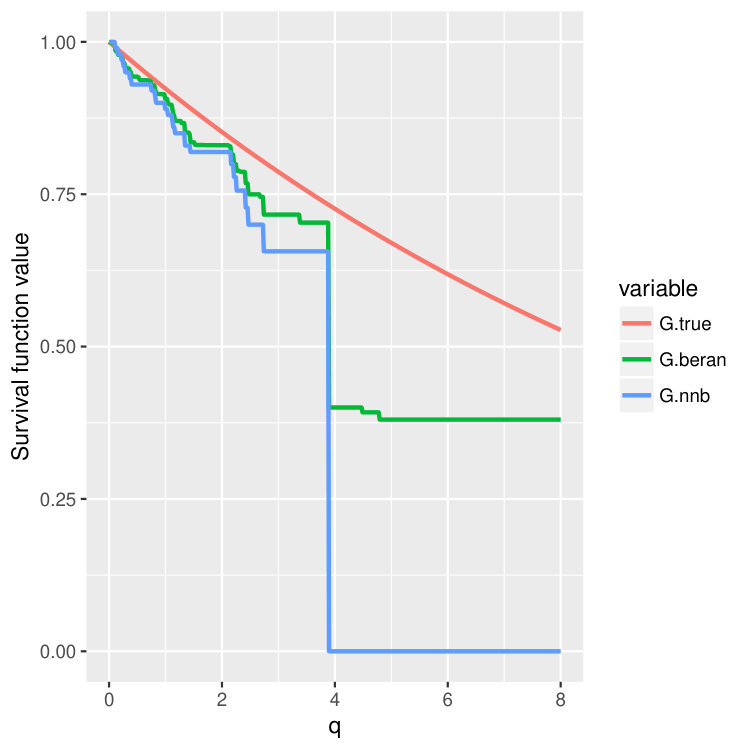 Figure 34
Figure 34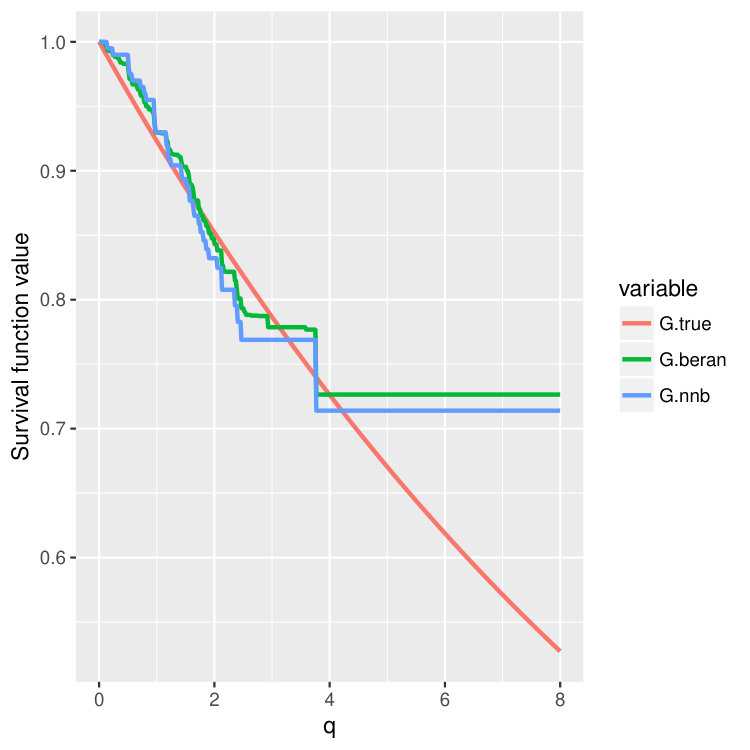 Figure 35
Figure 35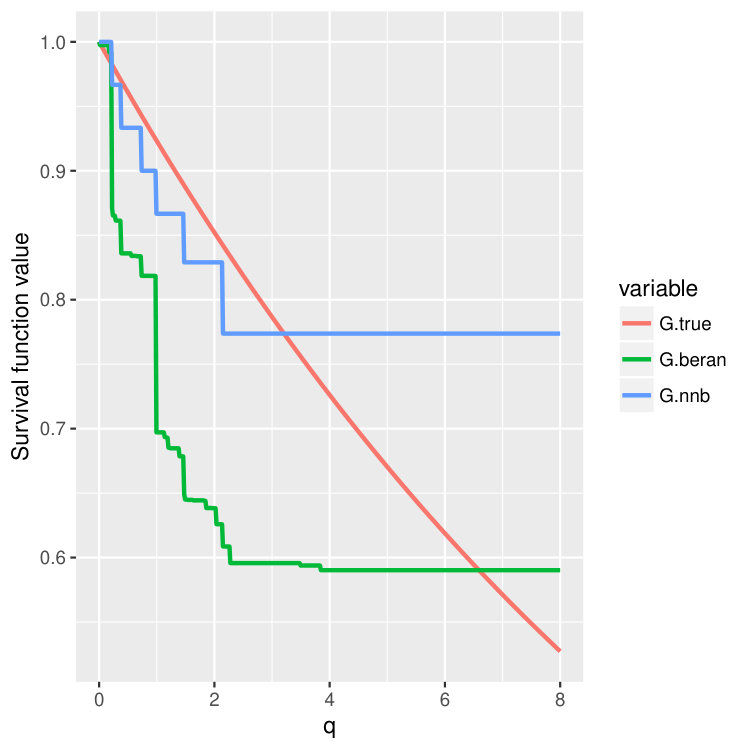 Figure 36
Figure 36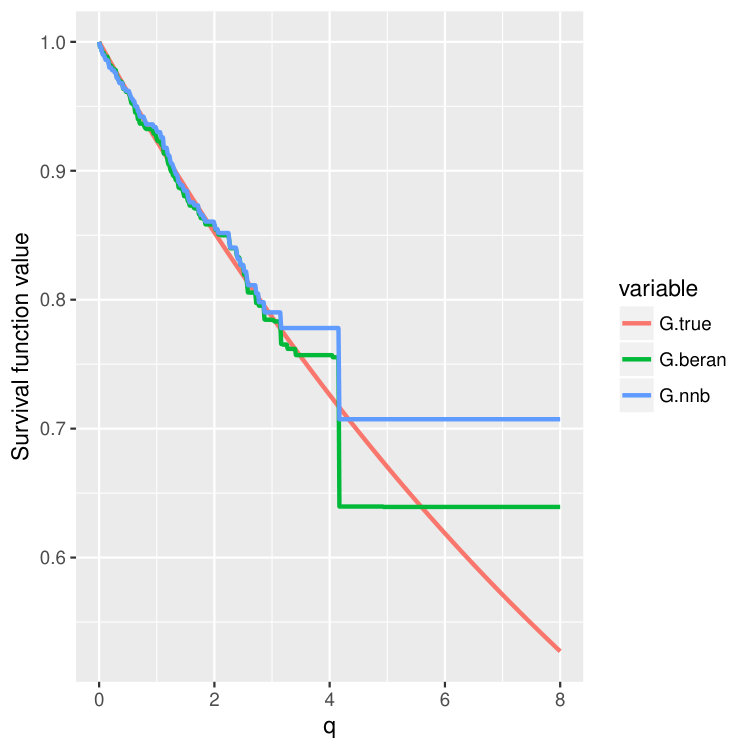 Figure 37
Figure 37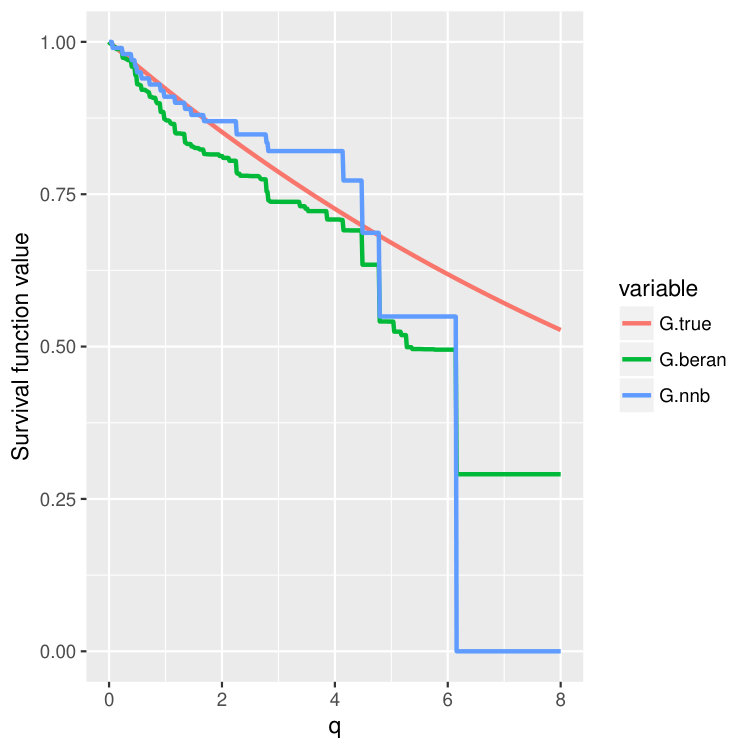 Figure 38
Figure 38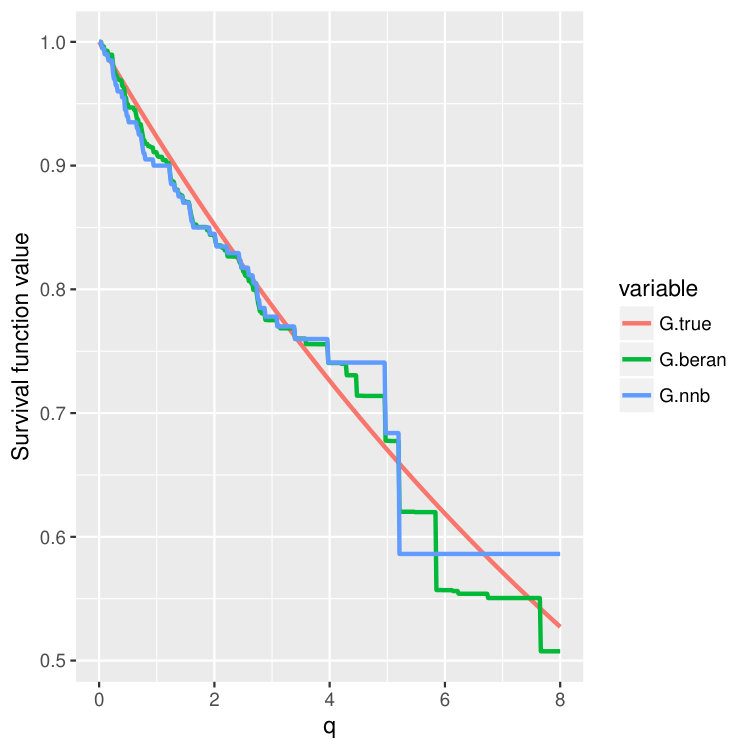 Figure 39
Figure 39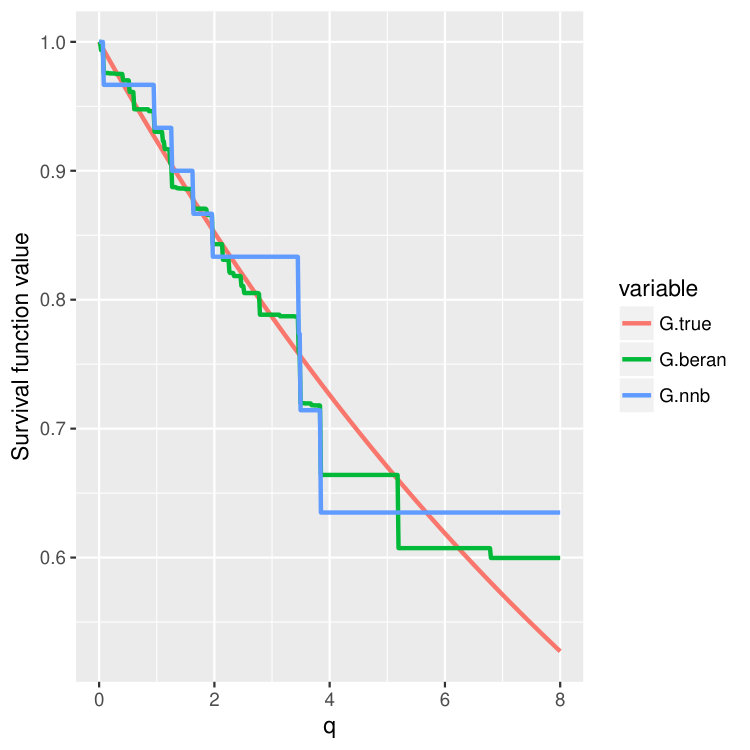 Figure 40
Figure 40Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods and Inference · Probabilistic and Robust Engineering Design · Advanced Multi-Objective Optimization Algorithms
Censored Quantile Regression Forests
Alexander Hanbo Li
Department of Mathematics
University of California San Diego
Jelena Bradic
Department of Mathematics
University of California San Diego
Abstract
Random forests are powerful non-parametric regression method but are severely limited in their usage in the presence of randomly censored observations, and naively applied can exhibit poor predictive performance due to the incurred biases. Based on a local adaptive representation of random forests, we develop its regression adjustment for randomly censored regression quantile models. Regression adjustment is based on new estimating equations that adapt to censoring and lead to quantile score whenever the data do not exhibit censoring. The proposed procedure named censored quantile regression forest, allows us to estimate quantiles of time-to-event without any parametric modeling assumption. We establish its consistency under mild model specifications. Numerical studies showcase a clear advantage of the proposed procedure.
Keywords: Random Forest; Censored quantile regression; Nonparametric regression; Kaplan-Meier estimation.
1 Introduction
In many applications, we want to predict and estimate the effect of a covariate on survival time of interests. Examples include treatment, surgical procedure, or immunization on survival time of patients, who for example, could be individuals who have metastatic breast cancer, military casualties suffering from various injuries, or survival time of infectious diseases. Classically, most datasets have been too small to meaningfully examine the heterogeneity of the data beyond dividing them into a few sub-populations. In the past few years, however, there has been an explosion of experimental settings where it is potentially feasible to explore heterogeneity to its full extent.
An impediment to exploring heterogeneous effects is the fear that scientists with two opposite agendas could hypothetically string together two opposite but coherent results by searching through many different possible models and then reporting only the very extreme ones – highlighting solely spurious results (Olken, 2015). Thus, protocols for clinical trials must specify in advance the pre-analysis plans and then learn from the data. However, such restrictions can make it challenging to discover unexpected effects due to heterogeneity. Here, we aim to address this challenge by developing a robust, non-parametric method for estimation in regression settings with censored response variable, which yields consistent estimator that adapts to the heterogeneity of the data and hence can be broadly applied to many different models and achieves further improvement. One example is the accelerated failure time model.
Classical approaches to accelerated failure time model include non-parametric maximum likelihood method, semi-parametric approaches, as well as traditional parametric approaches; see e.g., Zeng and Lin (2007), Robins and Tsiatis (1992), Robins (1992), as well as Koul et al. (1981), Wei (1992), Huang et al. (2007) etc. These methods perform well in settings where the model error is correctly specified, but quickly break down when the distribution of the error has any heterogeneous, asymmetric, or outlier structure. Other non-parametric methods, like Louis (1981), Hoover et al. (1998), and rank-based methods, like Jin et al. (2003), strive to achieve certain level of assumption-lean modeling of the mean in the accelerated failure time model. In this paper, we explore the use of ideas from the machine learning literature to improve the performance of these classical methods in a non-parametric fashion that is adaptive to heterogeneous or heavy-tailed error distributions.
Random forest algorithms introduced by Breiman (2001) allow for flexible modeling of covariate interactions, and are related to kernels and nearest-neighbor methods in the sense that they make predictions using a weighted average of “nearby” observations. However, random forests depart from the above principles in that they have a data-driven way to determine which nearby observations receive more weight, something that is especially important in environments with many covariates or complex interactions among covariates.
Despite their wide-spread success at estimation and prediction, application of random forests to censored regression models is far from being easily understood. Not all response variables being observed makes it difficult to understand how to evaluate the prediction arising from simple tree structures. Namely, a simple average is only enough for conditional mean estimation without censoring. Median estimates, and quantiles more generally, are not easy to construct. In particular, quantile random forests (Meinshausen, 2006) have mainly been undeveloped for censored observations.
This paper addresses these limitations, developing a forest-based method for estimation of quantiles for randomly censored observations (right or left censored). More formally, let be a real-valued latent variable (e.g., survival time) and be a (possibly high-dimensional) predictor variable. Let denote the censoring variable, which prevents us from observing all of the information regarding . In left-censored data, we only observe , whereas in right-censored data, we only observe . Our goal is to estimate the -th quantile of , non-parametrically, using observations where .
We take on the perspective of random forests as that of an nonparametric, adaptive kernel smoothing method. This interpretation follows work by Athey et al. (2018), Bloniarz et al. (2016), Hothorn et al. (2004), Li and Martin (2017), and Meinshausen (2006), and supplements the customary view of forests as an ensemble method (i.e., an average of predictions made by separate trees). In this view, random forest predictions, of the mean for example, evaluated at a new test point , can be represented by
[TABLE]
where the weights encode the similarity between the new test point and the observed covariates . It is worth pointing that for the conditional mean, the averaging and weighting views of random forests are equivalent; however, once we move to more general settings, the weighting-based perspective proves substantially more powerful. The goal is then to utilize these local neighborhood weights and quantile regression adjustments to design a new non-parametric quantile estimate of
[TABLE]
based on observations . In their simplest form, censored quantile forests just take the forest weights, , and use them for quantile regression:
[TABLE]
where denotes any -norm with . Here, we define a new score function, , that is censoring and quantile adaptive:
[TABLE]
with denoting an estimate of , the survival function of the censoring time given . In the rest of the document we focus on the case of ; however, results remain true for general cases of as well.
Formally, we study the performance of the above non-parametric quantile estimator of (1) while considering right-censored observations. All of our results can be trivially extended to the left-censored case. Most of the theoretical work focuses on establishing Theorem 3 that ensures the consistency of the censored quantile forest estimator at a given test point while allowing minimal assumptions on the regression model as well as the distribution of the model error. This result also allows us to construct prediction intervals regarding (1) that adapt to the model structure of the data generating process. Censored quantile forest estimator improves on prediction error compared with many state-of-the-art censored regression methods, and yet it retains the flexibility of random forest methods designed for non-censored observations. Finally, we note that our method can also be seen as an improvement over classical non-parametric approaches for censored observations. While the latter only perform well in low-dimensional problems, ours performs well even with a large number of covariates. One important reason is that random forest weights adapt reasonably well to the dimensionality increase, whereas kernel methods suffer from the curse of dimensionality.
1.1 Related Work
There has been a long-time understanding that proportional hazard models, and cox’s model, in particular, are especially powerful for right-censored observations and regression problems. However, they do not adapt to possibly left-censored observations; besides, they heavily rely on the proportionality assumption which can sometimes be inappropriate, necessitating stratification of the baseline hazard or some other weakening of the proportional hazards condition (Koenker et al., 2008).
A more flexible approach for random censoring problem is to model the conditional quantiles of the response variable directly. This approach offers greater flexibility as it does not restrict the structure of the hazard function (Koenker et al., 2008) and merely is more intuitive. To estimate the conditional quantiles, Portnoy (2003) proposed a recursive method which estimates a sequence of linear conditional quantile functions recursively. It can be treated as a generalization to regression of the Kaplan Meier estimator. Another closely related quantile regression model proposed by Peng and Huang (2008) instead makes the linkage to the Nelson-Aalen estimator of the cumulative hazard function, upon which they developed a complete asymptotic theory. The closest work to ours is that of Backer et al. (2018) where authors propose a new censored loss function. However, they only discuss the properties of quantile estimates in the case of linear quantile model.
The parametric methods, including those mentioned above, always rely on the linearity assumption on the conditional quantiles, that is,
[TABLE]
Here, the transformation is arbitrary but popular in survival analysis and can be replaced by any monotone function. This linearity assumption is too restrictive in many cases, especially when data lie on a complex manifold. Therefore, non-parametric methods are necessary and play an important role in modeling data heterogeneity.
In the case of right censoring, most non-parametric recursive partitioning algorithms in the existing literature rely on survival tree or its ensembles. Ishwaran et al. (2008) proposed random survival forest (RSF) algorithm in which each tree is built by maximizing the between-node log-rank statistic. However, it is not directly estimating the conditional quantiles but instead estimating the cumulative hazard. Zhu and Kosorok (2012) proposed the recursively imputed survival trees (RIST) algorithm with the same splitting criterion for each individual tree but different ensemble scheme. Other similar methods relying on different kinds of survival trees were proposed in Gordon and Olshen (1985), Segal (1988), Davis and Anderson (1989), LeBlanc and Crowley (1992), and LeBlanc and Crowley (1993). All these methods as mentioned above use splitting rules specifically designed to deal with the right censored data. Despite different splitting strategies, they all rely on the proportional hazard assumption and cannot reduce to a loss-based method that might ordinarily be used in the situation with no censoring.
Molinaro et al. (2004) proposed a tree method based on the inverse probability censoring (Robins et al., 1994) weighted (IPCW) loss function which reduces to the full data loss function used by CART in the absence of censoring. Hothorn et al. (2005) then extended the IPCW idea and proposed a forest-type method in which each tree is trained on resampled observations according to inverse probability censoring weights. However, the censored data always get weights zero and hence only uncensored observations will be resampled. As pointed out by Robins et al. (1994), the inverse probability weighted estimators are inefficient because of their failure to utilize all the information available on observations with missing or partially missing data.
This work aims to build a non-parametric conditional quantile estimator for randomly censored data that reduces to the ordinal quantile forest estimators when full data are observed, and efficiently utilizes all available information on both uncensored and censored observations. Furthermore, it does not require the specific modification of ordinal regression tree (e.g., CART) to survival tree, and hence works on both left and right censored problems.
Fundamentally different from the aforementioned forests methods, in which the censoring information is considered directly in the tree constructing process, our method avoids this complexity and only requires building ordinal regression trees (e.g., CART) for the first step, treating all observations equally. The censoring effects are then taken care of in the second step by solving a locally weighted estimating equation. These local weights can be directly calculated from the random forest constructed in the first step; weights derived from the fraction of trees in which an observation appears in the same leaf as the target value of the covariate vector. This locally weighted view of random forests was previously advocated by Hothorn et al. (2005) and Bloniarz et al. (2016); original random forest algorithm (Breiman, 2001) utilized ensemble learning literature. Differently from kernel weights, typically employed in local maximum likelihood method, for example, and whose performance suffers greatly whenever the dimensionality of the covariate space is more than two or three, our random-forests weights adapt well to moderate dimensionality increases.
Additional challenges arise due to the random censoring nature of the observations. For fixed censoring, one observes all the censoring values and hence can straightforwardly modify the objective used in the general framework of Athey et al. (2018), for example. However, it is unclear how to develop a non-parametric estimator that adapts to unknown censoring in the observations.
1.2 Organization
The paper is organized as follows. In Section 2.1 we provide local adaptive nature of random forests and regression adjustment utilizing those weights. In Sections 2.2 and 2.3, we showcase the development of a new loss function and its power in predicting any conditional quantile of the latent variable by solving an ingenious estimating equation, which is designed to correct the censoring effect. The Algorithm is then described in details in Section 2.4. In Section 3, we analyze the time complexity of our algorithm and prove consistency of the proposed estimator. Section 4 contains extensive numerical studies where we compare our algorithm with other forest algorithms on simulated and real censored data sets. Proofs are collected in the Appendix.
2 Censored Quantile Regression Forest
The quantile random forest cannot be directly applied to censored data because the conditional quantile of is different from that of the latent variable due to the censoring. Moreover, there is no explicitly defined quantile loss function for randomly censored data. In this section, we design a new approach to achieve both tasks.
2.1 Regression adjustment for random forests
Let denote the random parameter determining how a tree is grown, and denote the training data. For each tree , let denotes its -th terminal leaf. Since the space is split into disjoint leaves by , we know for any , there is exactly one leaf containing . We let the index of the leaf be and we say .
Then for any single tree , the prediction on any data point is where
[TABLE]
Then a random forest containing trees formulates a prediction of as
[TABLE]
where
[TABLE]
From now on, we call the weight in (4) random forest weight. One can easily show that . The above representation of the random forest prediction of the mean can be equivalently obtained as a solution to the following least-squares optimization problem
[TABLE]
Therefore, a least-squares regression adjustment, as the above, is equivalent to Breiman (2001) representation of random forests. However, when we move to estimation quantities that are not the mean, the latter representation is very powerful. Namely, a quantile random forest of Meinshausen (2006) can be seen as a quantile regression adjustment (Li and Martin, 2017), i.e., as a solution to the following optimization problem
[TABLE]
where is the -th quantile loss function, defined as . Local linear regression adjustment was also recently utilized in Athey et al. (2018) to obtain a smoother and more poweful random forest algorithm.
2.2 Motivation
Let us consider the case of no censored observations. Full data serve as a motivation for developing suitable estimating equations. Following the regression adjustment reasoning, for the case of fully observed data, we could estimate the -th quantile of at , denoted as , as a solution to
[TABLE]
Equivalently, such estimate would solve the following estimating equations
[TABLE]
where the second equality is true because .
For simplicity and better illustration of the idea, we first assume the latent variable has the same conditional probability in a neighborhood of . Out of the data points, assume and when and [math] otherwise. Now the estimating equation becomes
[TABLE]
Now conditional on ,
[TABLE]
which will be zero at where , that is, when
Let’s now consider the case of right-censored setting, where we further have the censoring variable , which is independent of conditional on , and we could only observe and censoring indicator . In order to estimate , we cannot simply replace with in (6) as the -th quantile of is no longer the -th quantile of because of the censoring. However, we can observe and utilize the following relationship
[TABLE]
where is the survival function of at . That is to say, the -th quantile of is actually the -th quantile of at . Now, we define a new estimating equation that resembles (6) as follows
[TABLE]
If we substitute with , an intuitive explanation for (7) is that as the -th quantile of happens to be the -th quantile of at , instead of estimating the former which is not available because of the censoring, we turn to estimate the later one. Namely, the conditional expectation, , will still be zero at the same root for (6).
The survival function can be estimated by a consistent estimate, for example the Kaplan-Meier estimator using and , and we can then define
[TABLE]
2.3 Full model
In the previous subsection, we made an assumption that for all , where is a neighborhood of . But in reality, this assumption is not always true, and that is why plays an important rule in our final estimator, as it “corrects” the empirical probability of each at .
For example, say we have data points and have two cases: (1) at all ’s we have the same conditional probability of , i.e. for all ; (2) has different conditional probabilities at different locations. In the setting (1), ’s become irrelevant and the point mass on each is . We share the mass uniformly to the points ’s as they are equally important. When , it is known that for any ,
[TABLE]
However, in the case (2), the convergence (9) is no longer valid. We cannot simply put a mass on each because the probability of showing up at could be severely different than the probability it shows up at . An extreme example is when . Then if , any showing up at should not even be counted when estimating because . In another word, we should give mass [math] instead of .
Therefore, a measure of “similarity” between points and needs to come into play, because we can no longer uniformly distribute the mass; observe that some ’s are more important than others for estimating . For instance, if and in the previous example, then should be assigned much more weight than .
Now let denote the weight (mass) we assign to when we are estimating . In the setting (1), we just have uniformly. But in the setting (2), we should have when is more similar to than in some sense. Therefore, the estimator for is then
[TABLE]
and it becomes clear that a proper weight needs to satisfy:
[TABLE]
One may naively think that any fixed Kernel weights, , could be a suitable choice. However, they would not be able to satisfy the second condition in (10) for any distribution . Fortunately, as shown in Meinshausen (2006), the data-adaptive random forest weight introduced in Section 2.1 perfectly satisfy both conditions in (10). And therefore going back to (5), we now consider estimating equations,
[TABLE]
when . Then following the same logic of how we get (8), a heuristic extension of (5) to censoring case will be
[TABLE]
2.4 Forest Algorithm
In the simplified example in Section 2.2, we assume that has the same conditional probability in a neighborhood of , and hence, we can estimate by Kaplan-Meier estimator (Kaplan and Meier, 1958) (assuming no tied events)
[TABLE]
where . In the more complex case like in Section 2.3, many consistent estimators for the conditional survival functions exist. For example, the nonparametric estimator proposed by Beran (1981)
[TABLE]
is shown to be consistent (Beran, 1981; Dabrowska, 1987, 1989; Gonzalez-Manteiga and Cadarso-Suarez, 1994; Akritas, 1994; Li and Doss, 1995; Van Keilegom and Veraverbeke, 1996). Here, are the Nadaraya-Watson weights
[TABLE]
is a known kernel and is a bandwidth sequence tending to zero as n tends to infinity. We can then simply use as in (12).
However, since we already have an adaptive version of kernel – the random forest weights , we will propose the following two new estimators for .
Kaplan-Meier using nearest neighbors.
The first estimator is resembles that of (13). We first find the nearest neighbors of according to the weights . Denoting these points as a set , then we can simply use the Kaplan-Meier estimator on
[TABLE]
Here, the number of neighbors will be a tuning parameter.
Beran estimator with random forest weights.
In the second proposal, we will replace the Nadaraya-Watson weights in (14) with random forest weights and get
[TABLE]
One could observe that (15) is a special case of (16) when the weight for and [math] otherwise.
Finally, we summarize our main algorithm in Algorithm 1. The details for choosing the candidate set is in Section 3.1. The choice to minimize the absolute value of is arbitrary. The goal is to find the approximate root of .
3 Theoretical Develoments
In this section, we will assume the random forest has terminal node size , feature vector , sample size is , and nearest neighbors are chosen if using (15).
3.1 Time complexity
The step 6 in Algorithm 1 involves of finding the in a candidate set that sets the estimating equation closest to zero. We simply evaluate the function for all possible in and find the minimum point. Note that for any fixed , is a step function in with jumps at ’s because the discontinuities only happen at ’s for (both (15) and (16)) and . Therefore, the candidate set , and in the worst case.
But in fact, for any fixed , only ’s with the corresponding feature vector (15) or with (16) will be jump points, and hence, we can refine for (15) or for (16). We then have the following theorem. The proof is given in the Appendix 6.
Theorem 1**.**
For a fixed test point , depending on whether is estimated by (15) or (16), the time complexity for Algorithm 1 is or , respectively.
3.2 Consistency
In this section, we will show that for any fixed , in (12) will converge in probability to uniformly for .
Condition 1**.**
The density of is positive and bounded from above and below by positive constants on the support .
We note that Condition 1 is a very primitive condition on the distribution of the covariates. It is satisfied for example for Gaussian distribution and more broadly for most symmetric, continuous distributions with unbounded support. The case of bounded or discrete covariates is beyond the scope of the current work.
Condition 2**.**
The terminal node size and as . Furthermore, for each tree splitting, the probability that each variable is chosen for the split point is bounded from below by a positive constant, and every child node contains at least proportion of the data in the parent node, for some .
The two requirements of Condition 2 are also required in Meinshausen (2006) (see Assumptions 2 and 3 therein). This condition states that the leaf node size of each tree should increase with the sample size , but at a slower rate. Intuitively, first, the trees that we are using need to be shallow (i.e., with large leaves) in order to estimate a more complex model, reliably. Secondly, there can not be leaves with no samples, i.e., each leaf must be large enough to capture the local estimating equations more adequately. Our experiments also justify the necessity of Condition 2, as the performance of our model, will deteriorate if we keep a small leaf node size but increase the sample size. We will talk about this in detail in Section 4.2.6.
Condition 3**.**
Denote . There exists a constant such that is Lipschitz continuous with parameter , that is, for all ,
[TABLE]
We note that Condition 3 appears in all existing work related to quantile regression and inference thereafter.
Condition 4**.**
The response variable and the censoring variable are independent conditional on , and the conditional distribution and are both positive and strictly increasing in for all .
Conditional independence of and is a very standard assumption and can be traced back to Robins and Tsiatis (1992) among other works.
Condition 5**.**
For any , the estimator converges pointwisely to the true conditional survival function .
Condition 5 is satisfied, for example, by the Kaplan-Meier estimator (14) (Dabrowska, 1989). Please take a look at Figure 4 and Figure 5 where we compare finite sample properties of the newly introduced estimators (15) and (16). We observe that the new distributional estimators are more adaptive and yet seemingly inherit consistency to that of the traditional KM estimator.
We proceed to showcase asymptotic properties of the proposed estimating equations. We begin by illustrating a concentration of measure phenomenon for the introduced score equations.
Theorem 2**.**
Define
[TABLE]
Under Conditions 1 – 5, for any , , ,
[TABLE]
Next, we present our main result that illustrates an asymptotic consistency of the proposed conditional quantile estimator. The proof is given in Appendix 6.
Theorem 3**.**
Under Conditions 1 – 5, for fixed and , define to be the root of , and to be some constant so that . Also define to be . Then
[TABLE]
and as ,
[TABLE]
4 Experiments
In this section, we will compare our model, censored forest regression (crf) with generalized random forest (grf) (Athey et al., 2018), quantile random forest (qrf) (Meinshausen, 2006) and random survival forest (rsf) (Hothorn et al., 2005) on simulated and real data sets.
On the simulated data sets, we will apply qrf and grf to the censored data directly, and get biased models which we denote by qrf and grf, respectively. We also apply qrf and grf to the data with uncensored responses, and call the resulted models qrf-oracle and grf-oracle.
Throughout this section, we fix the number of trees for each forest to be 1000. The only tuning parameter we have is the node size of each tree. All other parameters are kept as default.
4.1 Illustrative example
In this section, we generate the true response, i.e., latent, variables , and consider the censoring variables . The censored responses, i.e. observed responses, are then taken as . We compare the estimating equation on the latent variables
[TABLE]
to the estimating equation of our proposed algorithm
[TABLE]
where is the one-dimensional Kaplan-Meier estimator for the survival function of censoring variable . The results are shown in Figure 1. We consider but the results persist for many other choices of .
In Figure 1 we present the two estimating equations as functions of and illustrate that the solutions to and are closer and closer together when the sample size grows. The solution for can be treated as an oracle solution where the oracle observes “uncensored” (true) response variable. Figure 1 therefore indicated that the root of our method’s estimating equation is very close to the oracle root and that we are therefore finding a good approximation to the unknown parameter of interest.
4.2 Simulation results
In this section, we will compare different forest algorithms on simulated data sets including accelerated failure time model (AFT) and many non-parametric censored regression models.
4.2.1 One-dimensional AFT model
We simulate data from an one-dimensional AFT model
[TABLE]
where and . Then the censoring variable , and the observed response and the censoring indicator . The average censoring rate is about . The number of training data, validation data and test data are all 300. All the forests consist of 1000 trees. The node size of each forest is determined by cross–validation. We plot out one set of training data and the corresponding quantile predictions for on a set of test data in Figure 2. We only show the results of crf, grf, and grf-oracle because in one dimension, qrf’s performance is visually indistinguishable from grf. There we observe a consistency of our method as well as superior behavior to the competing methods. Namely, the generalized random forest that ignores the censoring component of the data, incurs large bias; due to the right censoring, bias is larger for lower values of the quantiles. We observe that the proposed crf follows closely the oracle estimator and is extremely close to the true quantile regardless of the in the study.
Moreover, we proceed further and for a set of values , we repeat the process 40 times, and for each time, we calculate the MSE and MAD between the estimated quantiles and the true quantiles, and the -th quantile loss. To be more specific, let be the response in test set (all uncensored), be the true -th quantile, and be the estimated quantile, then
[TABLE]
[TABLE]
[TABLE]
The reason we use to measure the quality of quantile predictions is that, by Meinshausen (2006), the -th quantile of at equals to . The results are illustrated in Figure 3 where besides the abose three measures we compare the concordance index (C-index) (Harrell Jr et al., 1982), which is related to the area under the ROC curve (Heagerty and Zheng, 2005). It estimates the probability that, in a randomly selected pair of cases, the case that fails first had a worse predicted outcome. In Ishwaran et al. (2008), they use the ensemble mortality as the predictive outcome for their random survival forest, and the predicted survival time for random forest regression. For our method crf and the other two methods, qrf and grf, we will use the -th conditional quantile as the predicted outcome. Since the outcomes will be different for different , we report the results for all .
In Figure 3 we observe an oracle like behavior of the proposed crf method in terms all four measures of the quality of estimation and/or prediction. Namely, we observe that MAD, MSE and quantile losses are extremely small whereas C-index is high and all are close to the corresponding oracle estimators (colored purple and blue). Moreover, we observe that the proposed crf method, although not primarily build for the hazard rates, is even better than survival random forest: see for example discrepancies between red and brown boxplots in the last row of Figure 3 where the larger the C-index is the better the method is.
4.2.2 Comparison of different conditional survival estimators
In this section, we will compare the two different conditional survival function estimators (15) and (16). We generate training data and test data from the one-dimensional AFT model defined in the previous section, but with two different censoring rate:
- •
, in this case, the censoring rate is about .
- •
, in this case, the censoring rate is about .
We then choose four test points , and then plot out the conditional survival function estimators by the two different methods (15) and (16) on these four points. The results are shown in Figure 4 and 5 for three different training sample sizes . For the nearest neighbor estimator (15), we set the number of neighbors to be , which is also the node size we choose.
We can observe that when increases, two curves become closer and are both good approximations of the true survival curve. But the first method (15) does have an extra tuning parameter – the number of nearest neighbors, so in the experiments, we always choose to use the second estimator (16), which is more adaptive and parameter free.
Note that the estimated survival function will degenerate at the tail of the distribution when the test point is small; see the first two columns in Figure 4 and 5. This is a common phenomenon even for the regular KM estimator because there is no censored observations beyond some time point. In the AFT model, the conditional distribution of the latent variable depends on the location . When is small, the conditional mean of is also small, and we could not observe most of the censoring values where , leading to degenerated survival curves. However, if we continue increasing the sample size , we should be able to recover the entire curve even for smaller . In fact, when we increase the censoring level from (Figure 4) to (Figure 5), we find that both estimators give better performance because we can observe more censored values.
4.2.3 One-dimensional censored sine model
Since our forest regression method crf is nonparametric and does not rely on any parametric assumption between response and explanatory variables, it can be used to estimate quantiles for any general model . In this section, we let and have the model
[TABLE]
where and . Then the censoring variable , and the responses . All the other settings are the same as in Section 4.2.1. We plot out the training data and the quantile predictions for in Figure 6. The censoring level is about . We observe that for all , crf can produce comparable quantile predictions to grf-oracle. Especially when , the quantile prediction by (blue dotted curve) severely deviates from the true quantile, while our method crf can still predict the correct quantile and performs as good as grf-oracle. We want to emphasize that grf-oracle uses the latent responses while our method only uses the observed responses and censoring indicators . We then repeat the experiments for 40 times and report the box plots in Figure 7. Again we can see that for all quantiles, our method crf behaves almost as good as qrf-oracle and grf-oracle, and consistently better than qrf and grf. For example the order of magnitude of our error is twice and sometimes more than two times smaller than that of quantile or generalized random forest.
4.2.4 Multi-dimensional AFT model results
In this section, we test our algorithm on a multi-dimensional AFT model
[TABLE]
where , , and . The censoring variable , and . The censoring level is about . The number of training data is 500 and the number of test points is 300. All the forests consist of 1000 trees. The result is in Figure 8. Our model crf still outperforms qrf and grf significantly, and is comparable to qrf-oracle and grf-oracle.
4.2.5 Multi-dimensional censored complex manifold
In this section, we construct a complex model
[TABLE]
where stands for -th dimension of , and . Then we consider a censoring variable independent of and : . The result is summarized in Figure 9. Although the model is highly non-linear our method is able to capture that and estimate the quantile of interest consistently. However, other methods are unable to be consistent. Behavior matches that of linear models closely. In this case we notice that the oracular generalized random forests have much better performance; note that since we are estimating equations, our algorithm can be easily tweaked to match grf-oracle – the only change would be to design the splits in the initial tree construction to match our estimating equations, use subsampling and save a separate sample for minimizing the equations themselves.
4.2.6 Node size
In this section, we investigate the impact of the choice of the node size on different methods. The data we use will be generated from the one-dimensional and multi-dimensional AFT and Sine models as defined in the previous sections. We increase the node size from 5 to 60 with step size of 5.
One-dimensional AFT and Sine models
The result of sine model is summarized in Figure 11. One can see that for both qrf and our model, crf, the quantile loss will first decrease when node size increases. It attains minimum around node size of 30. However, for grf, its quantile loss is almost monotonically increasing, and attains minimum at node size of 5. But both qrf-oracle and grf-oracle can attain the best quantile loss of about 0.125. And one impressive observation is that our model, crf, almost performs the same as qrf-oracle for all node sizes. Similar conclusion can be made from the AFT result which is in Figure 10.
Multi-dimensional AFT model
From Figure 12, we observe that qrf, qrf-oracle and grf-oracle all give similar results. The performance of our model crf is only slightly worse than qrf-oracle, but is even better than grf-oracle.
Multi-dimensional complex model
The result is summarized in Figure 13. The censoring level is about . From the figure, we observe that the behavior of crf is still only slightly worse than qrf-oracle. In this experiment, grf-oracle behaves the best. All of crf, qrf-oracle and grf-oracle are significantly better than the biased models qrf and grf. When , grf behaves slightly better than qrf-oracle when node size is small. The reason is that the conditional quantiles of and are closer when is larger, and grf is more stable and smooth on the data in this experiment. But we still observe that the performance of crf and qrf-oracle are very close.
4.3 Real Data
In this section, we compare our censored forest (crf) with quantile random forest (qrf) (Meinshausen, 2006) and generalized forest (grf) (Athey et al., 2018) on real datasets. In order to evaluate the performances unbiasedly, we manually add censoring to the data. In addition, we apply qrf and grf to the data without censoring and we call the resulted models qrf-oracle and grf-oracle, respectively.
For all these methods, bagged versions of the training data are used for each of the trees. We use 5-fold cross validation to select the best node sizes for different methods. For all the other parameters, we keep the default settings.
Datasets
We use datasets BostonHousing, Ozone from the R packages mlbench and alr3. For all the datasets, we sample censoring variables from Exponential distributions with set so that the censoring level is roughly . For BostonHousing dataset, we set . For Ozone, . For Abalone dataset, we random sample observations and take the log-transformation of the response variable rings. We then set .
Evaluation
For each dataset, we train our model on bootstrapped version of the data, and test the performance on out-of-bag observations. This process is repeated for 40 times, and we calculate the mean and standard deviation of the prediction errors. In our context, the prediction error is measured by the -th quantile loss for -th quantile estimation. The results are illustrated in Figure 14.
On all data sets, our proposed method behaves better than quantile forest and generalized forest in terms of quantile losses. Especially when , or , the performance of our method is significantly better than qrf and grf, and is even comparable to that of oracle qrf and grf. It agrees with our observation in the one-dimensional example (Figure 2 and 3). While estimating larger quantiles, the true -th quantile of and are close, and hence the performance of all five models are similar. But when is small, the -th quantile of and are different because of the censoring, and in this case, our model has superior advantage and find the true quantiles of almost as good as the oracle methods.
Nodesize
For each dataset, we train different models using different nodesizes and compare the performance. For each node size, we bootstrap the data and repeat the experiments for 20 times, and we calculate the mean and standard deviation of the quantile predictions for quantiles , , and . The result is in Figure 15. We observe that our method, crf, is uniformly better than qrf and grf, proving that crf is able to correct the bias introduced by censoring. Moreover, the quantile loss of crf is always competitive to that of qrf-oracle and grf-oracle, and is remarkably always better than grf-oracle, only slightly worse than qrf-oracle.
4.4 Prediction Intervals
All the forest methods can be used to get prediction intervals by predicting the and quantiles of the true response variable. Then for any location , a straightforward confidence interval will be . The result is illustrated in Figure 17 for the case of univariate censored sine model. For each data set, we bootstrap the data and calculate the and quantile for the out of bag points. Then for each node size, we repeat this process for 20 times and calculate the average coverage rate of the confidence intervals.
We observe that in all of the cases, our method crf and qrf-oracle give the coverage closest to . As can be seen from Figure 15, both qrf and grf perform much worse on predicting lower quantiles. They tend to under-estimate the lower quantiles and hence make the confidence intervals much wider than the true ones. Nevertheless, as seen in Figure 17, out method has great coverage that is never below , indicating certain efficiency of the proposed method.
5 Discussion
In this article, we introduced a censored quantile random forest, a novel non-parametric method for quantile regression problems that is integrated with the censored nature of the observations. While preserving information carried by the censored observations, the novel estimating equations maintain the flexibility of general random forest approaches. The estimating equations are equipped with both censoring information as well as random forest information simultaneously.
The statistical mechanism, particularly asymptotic normality, of ensemble tree-based methods is still not fully understood. Some insightful discussions and first steps towards this goal can be found in Zhu and Kosorok (2012). As noted in Athey et al. (2018) even consistency properties of censored based methods present significant theoretical challenges. Generalization of the results of Athey et al. (2018) to the case of censored observations involves non-trivial extensions of the theoretical advancements introduced therein. A generalization would require not only adaptation to censoring but as well as to an infinite-dimensional nuisance parameter; current results focus on finite dimensional nuisance parameters. Once the latter generalization is achieved then, utilizing our estimating equations, will allow for the generalization of the former.
One of the promising applications of the introduced method is in the estimation of heterogeneous treatment effects when the response variable is censored; treatment discovery with right-censored observations is important and yet poorly understood research area. Equipping this literature with a fully non-parametric approach would lead to a significant broadening of the now more known parametric approaches. Our method appears to be a nice fit for this setting; observe that our estimating equations can be easily replaced with another kind that targets treatment effects directly.
6 Appendix
Proof of Theorem 1.
To get the candidate set , if we use the k-nearest neighbor estimator (15), then the first step is to sort weights and choose the largest elements. This is in general a procedure. If we use the Beran estimator (16), then the time complexity is because we need to find all the nonzero weights.
After we have the candidate set , evaluating for all and finding the minimum is a procedure. For (15), ; and for (16), is in the order of by Lin and Jeon (2006). ∎
Proof of Theorem 2.
Conditional on , the random variable are i.i.d. uniform on . By Condition 4, for a given ,
[TABLE]
Then we can decompose
[TABLE]
The difference between the empirical distribution function and the truth can then be bounded by
[TABLE]
For part (I), since is uniform, we have
[TABLE]
Now since and , we have
[TABLE]
as , by Condition 2. Hence, by Chebyshev inequality, for every and ,
[TABLE]
Then by Bonferroni’s inequality,
[TABLE]
The proof of part (II)
[TABLE]
follows the same argument of Theorem 1 and Lemma 2 in Meinshausen (2006) by invoking Condition 2. Finally, we notice that by Condition 5, because is compact. ∎
Proof of Theorem 3.
By Van der Vaart (2000), we only need to show for any , ,
. 2. 2.
For any , . 3. 3.
.
Part 1 has been proved by Theorem 2. For part 2, note that
[TABLE]
The second equality is because of the conditionally independency between and . Fix an , and denote
[TABLE]
Since , by Condition 4, there exists some such that and
[TABLE]
for . Now for part 3, by the definition of , we know
[TABLE]
Also by definition of ,
[TABLE]
Then we get
[TABLE]
where the first inequality is because of the definition of and the triangular inequality. ∎
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Akritas (1994) Akritas, M. G. (1994). Nearest neighbor estimation of a bivariate distribution under random censoring. The Annals of Statistics , 1299–1327.
- 2Athey et al. (2018) Athey, S., J. Tibshirani, and S. Wager (2018). Generalized random forests. Forthcoming in the Annals of Statistics .
- 3Backer et al. (2018) Backer, M. D., A. E. Ghouch, and I. V. Keilegom (2018). An adapted loss function for censored quantile regression. Journal of the American Statistical Association 0 (ja), 1–40.
- 4Beran (1981) Beran, R. (1981). Nonparametric regression with randomly censored survival data. Technical report, Technical Report, Univ. California, Berkeley.
- 5Bloniarz et al. (2016) Bloniarz, A., A. S. Talwalkar, B. Yu, and C. Wu (2016). Supervised neighborhoods for distributed nonparametric regression. In AISTATS .
- 6Breiman (2001) Breiman, L. (2001). Random forests. Machine learning 45 (1), 5–32.
- 7Dabrowska (1987) Dabrowska, D. M. (1987). Non-parametric regression with censored survival time data. Scandinavian Journal of Statistics , 181–197.
- 8Dabrowska (1989) Dabrowska, D. M. (1989). Uniform consistency of the kernel conditional kaplan-meier estimate. The Annals of Statistics , 1157–1167.