
TL;DR
This paper introduces Architecture Compression, a novel method that encodes neural network architectures into a continuous space for efficient compression, optimizing for accuracy and parameter count, demonstrated on multiple visual recognition datasets.
Contribution
The paper presents a new architecture-based compression method using a learned embedding space and gradient-based optimization, differing from traditional weight or filter compression techniques.
Findings
Achieves over 20x compression on CIFAR-10.
Effective on multiple datasets including CIFAR-100, Fashion-MNIST, and SVHN.
Outperforms traditional compression methods in architecture efficiency.
Abstract
In this paper we propose a novel approach to model compression termed Architecture Compression. Instead of operating on the weight or filter space of the network like classical model compression methods, our approach operates on the architecture space. A 1-D CNN encoder-decoder is trained to learn a mapping from discrete architecture space to a continuous embedding and back. Additionally, this embedding is jointly trained to regress accuracy and parameter count in order to incorporate information about the architecture's effectiveness on the dataset. During the compression phase, we first encode the network and then perform gradient descent in continuous space to optimize a compression objective function that maximizes accuracy and minimizes parameter count. The final continuous feature is then mapped to a discrete architecture using the decoder. We demonstrate the merits of this…
Click any figure to enlarge with its caption.
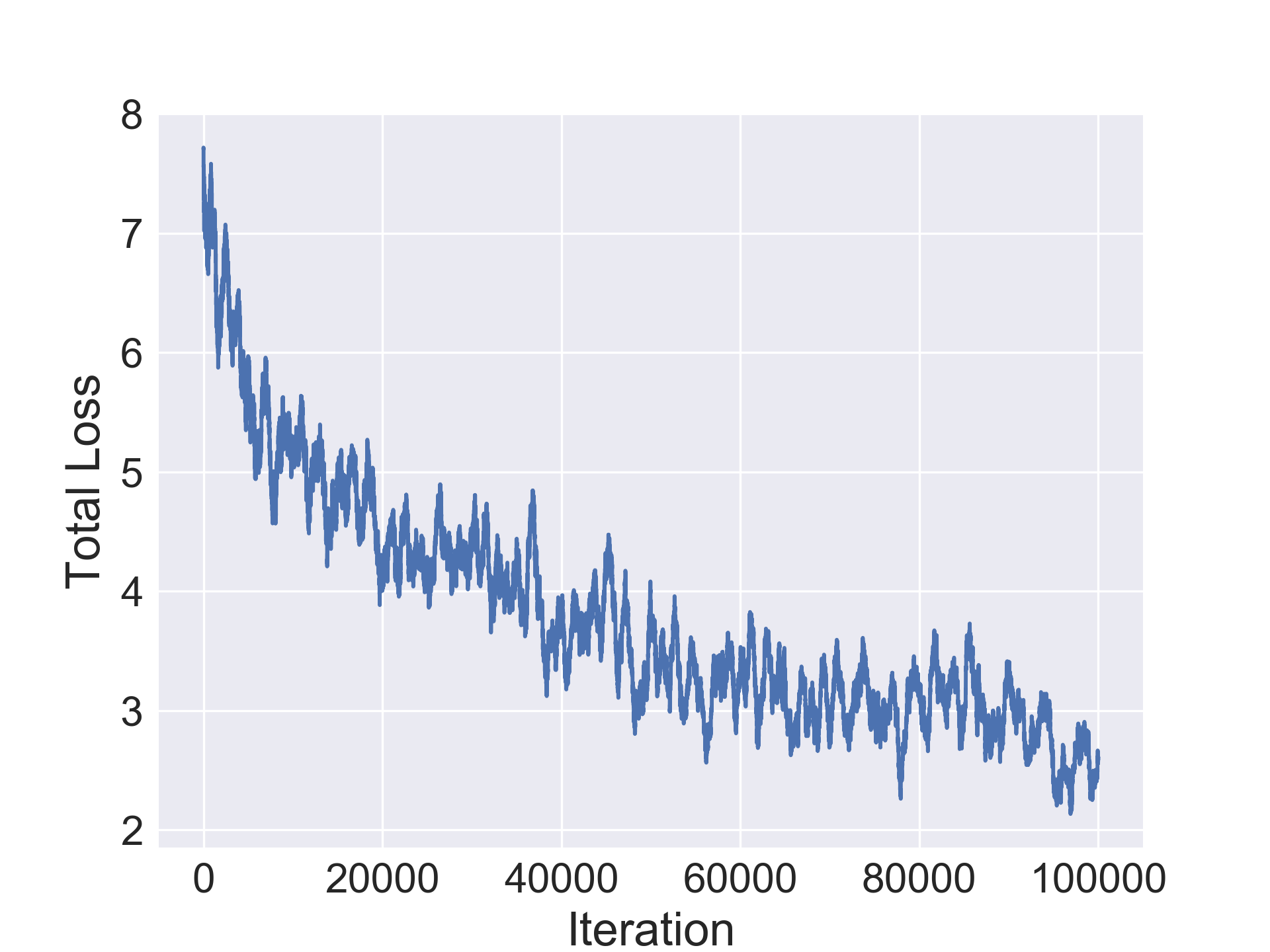 Figure 1
Figure 1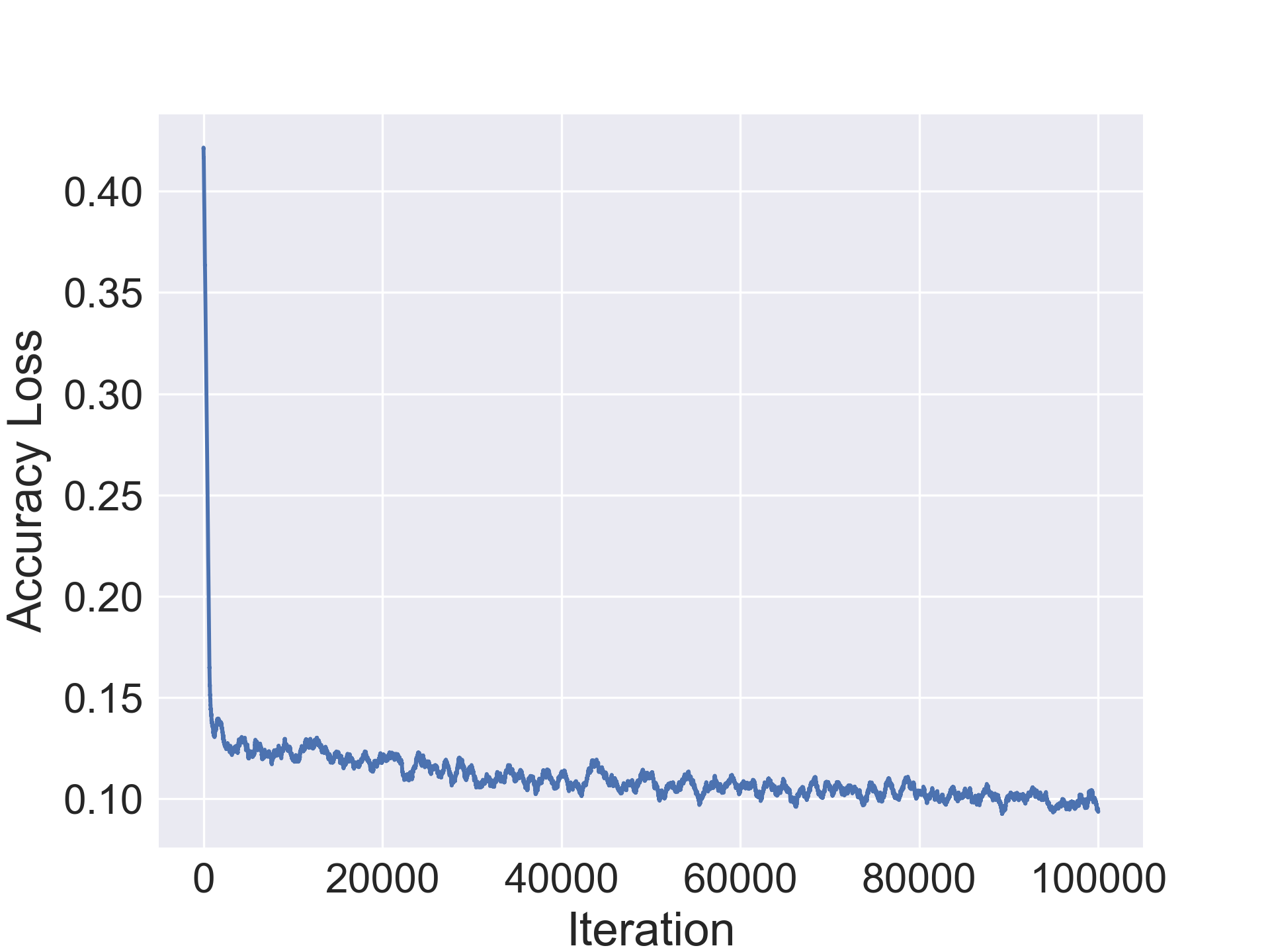 Figure 2
Figure 2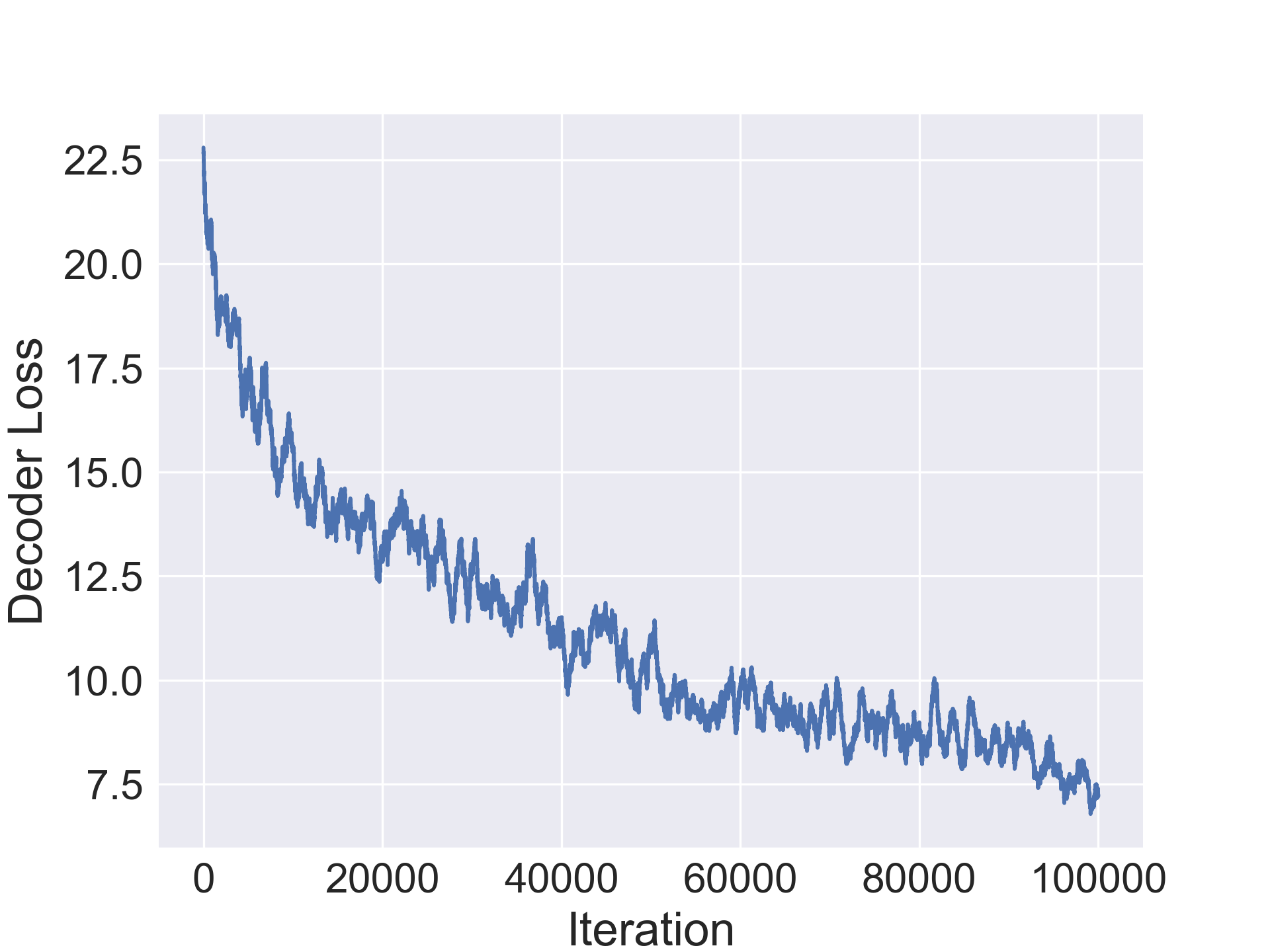 Figure 3
Figure 3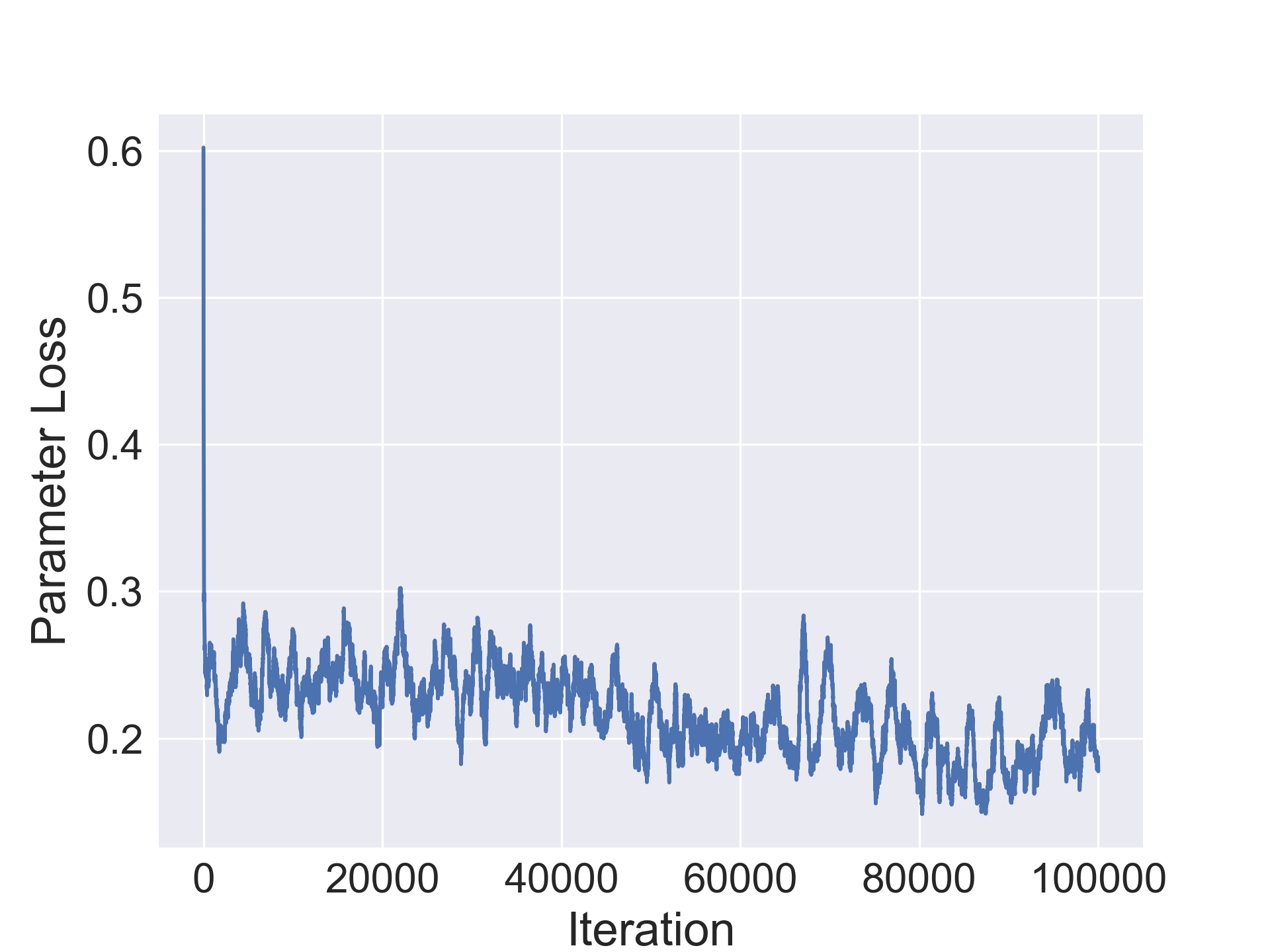 Figure 4
Figure 4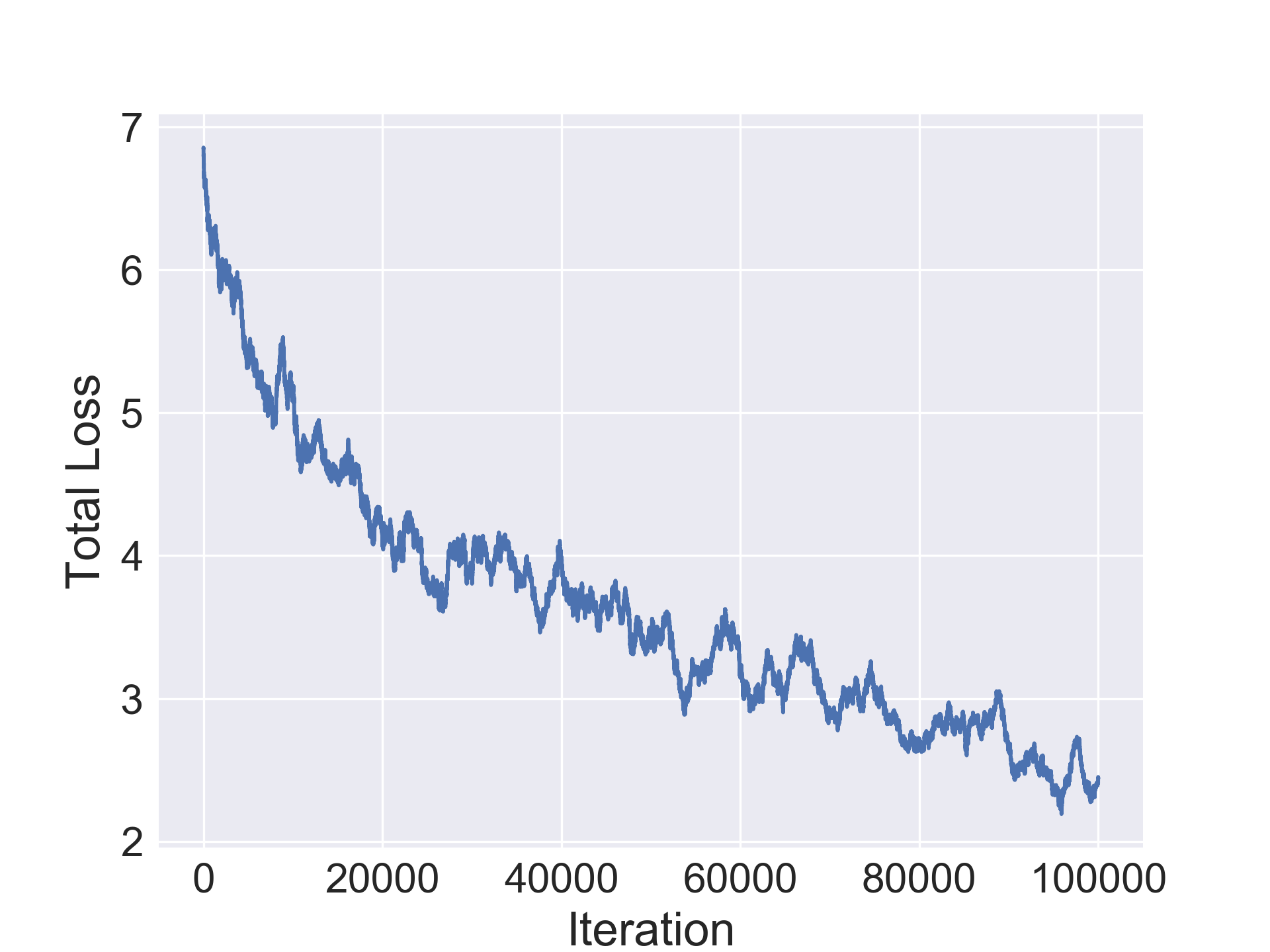 Figure 5
Figure 5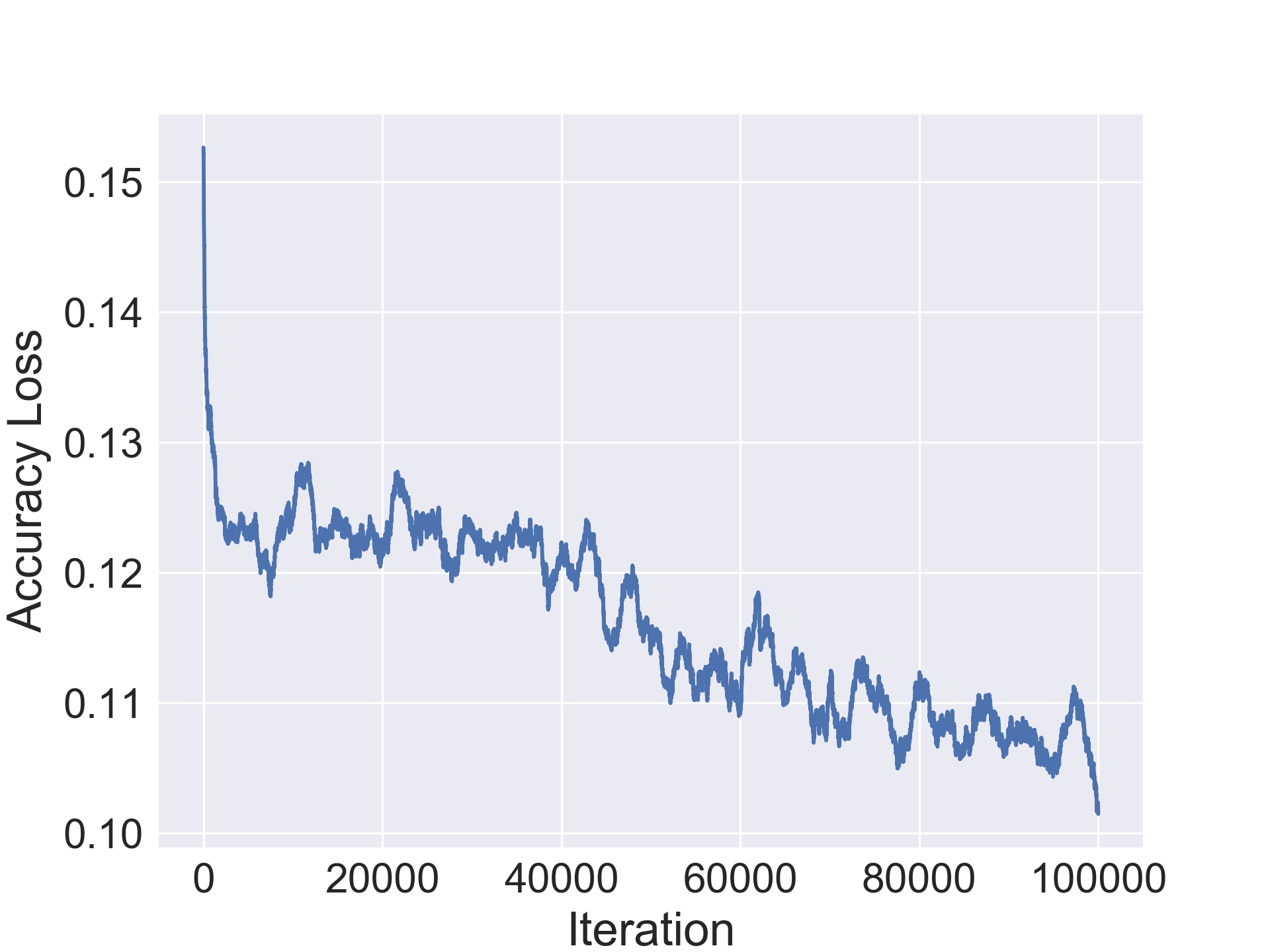 Figure 6
Figure 6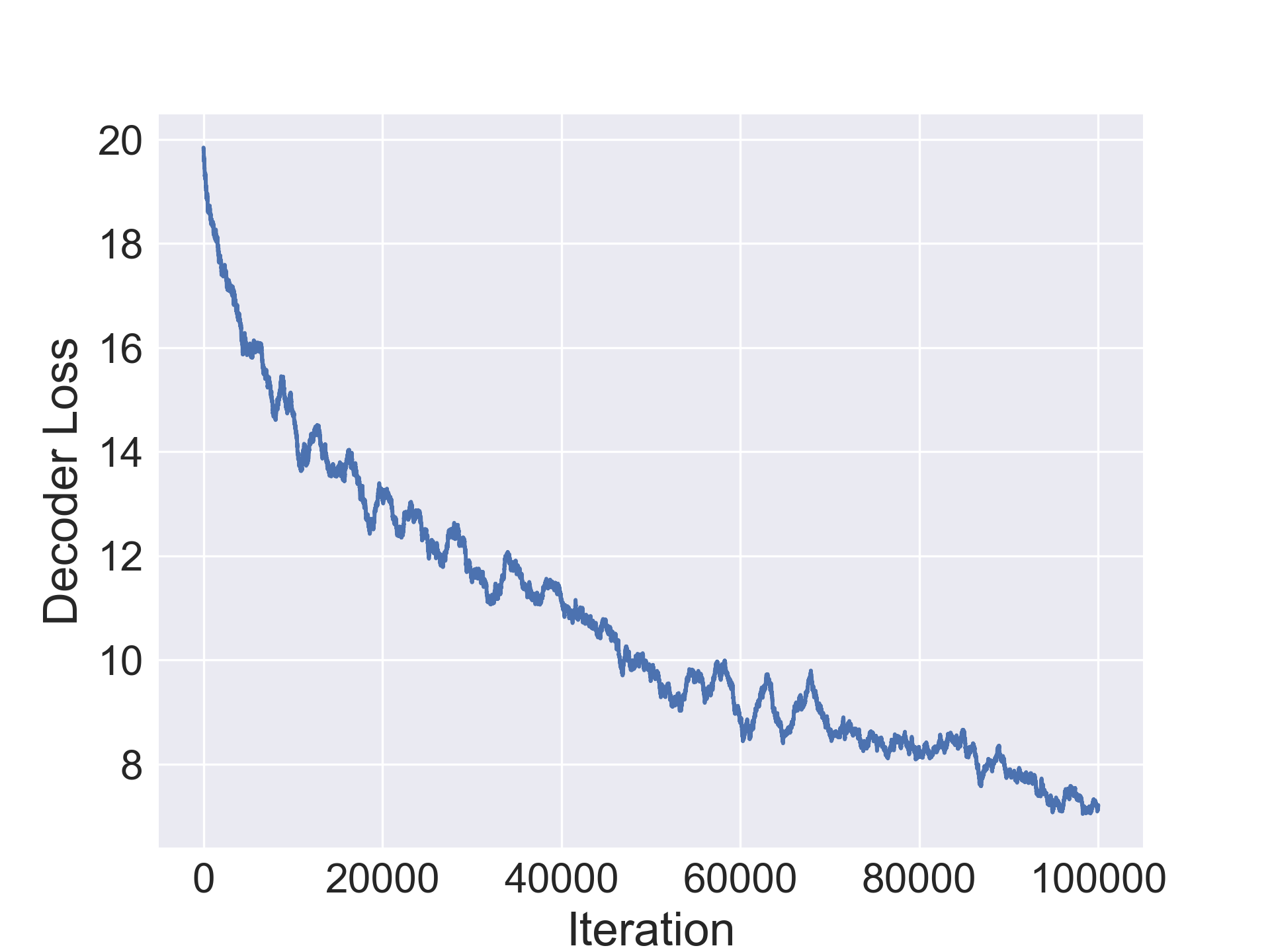 Figure 7
Figure 7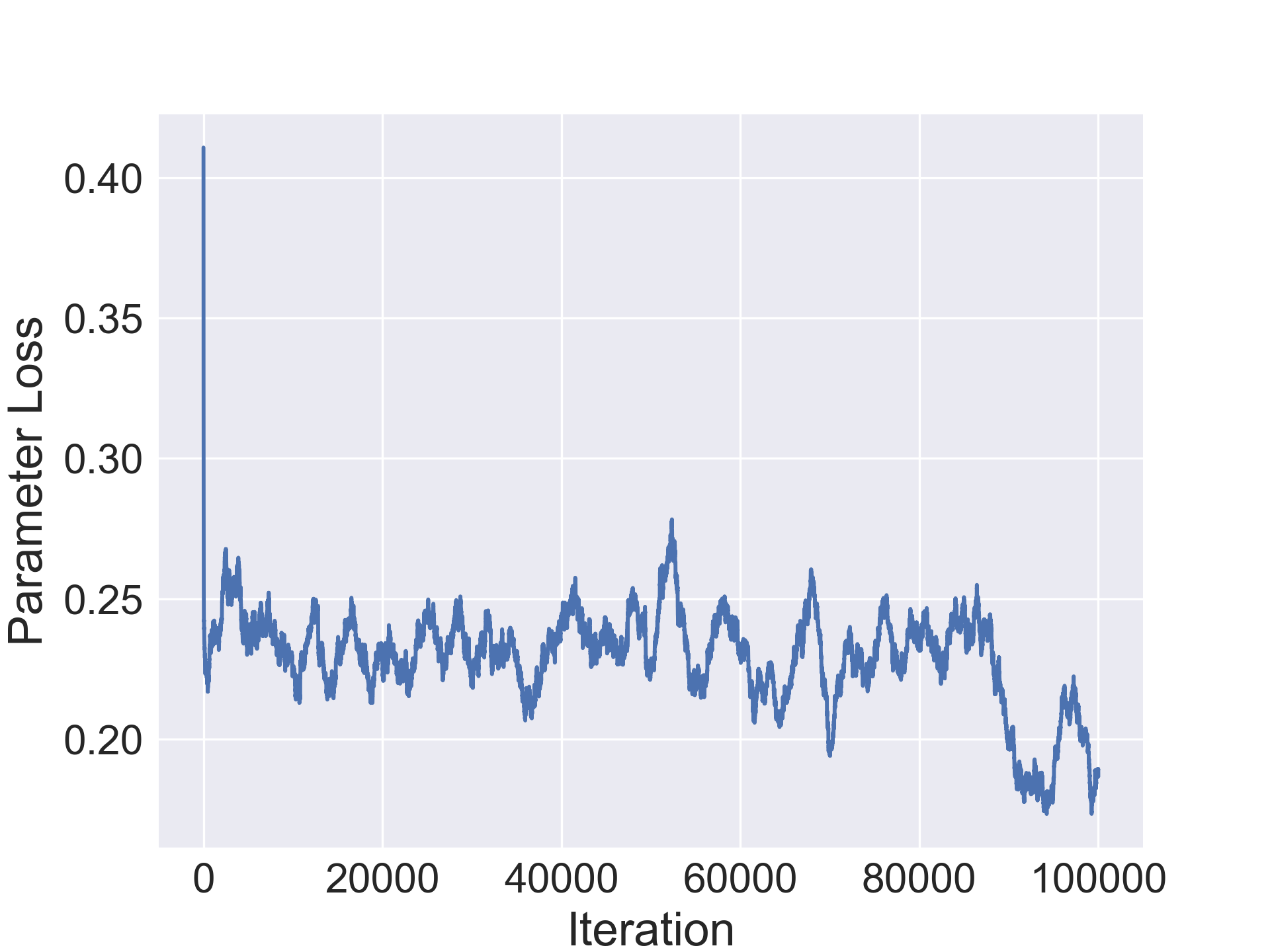 Figure 8
Figure 8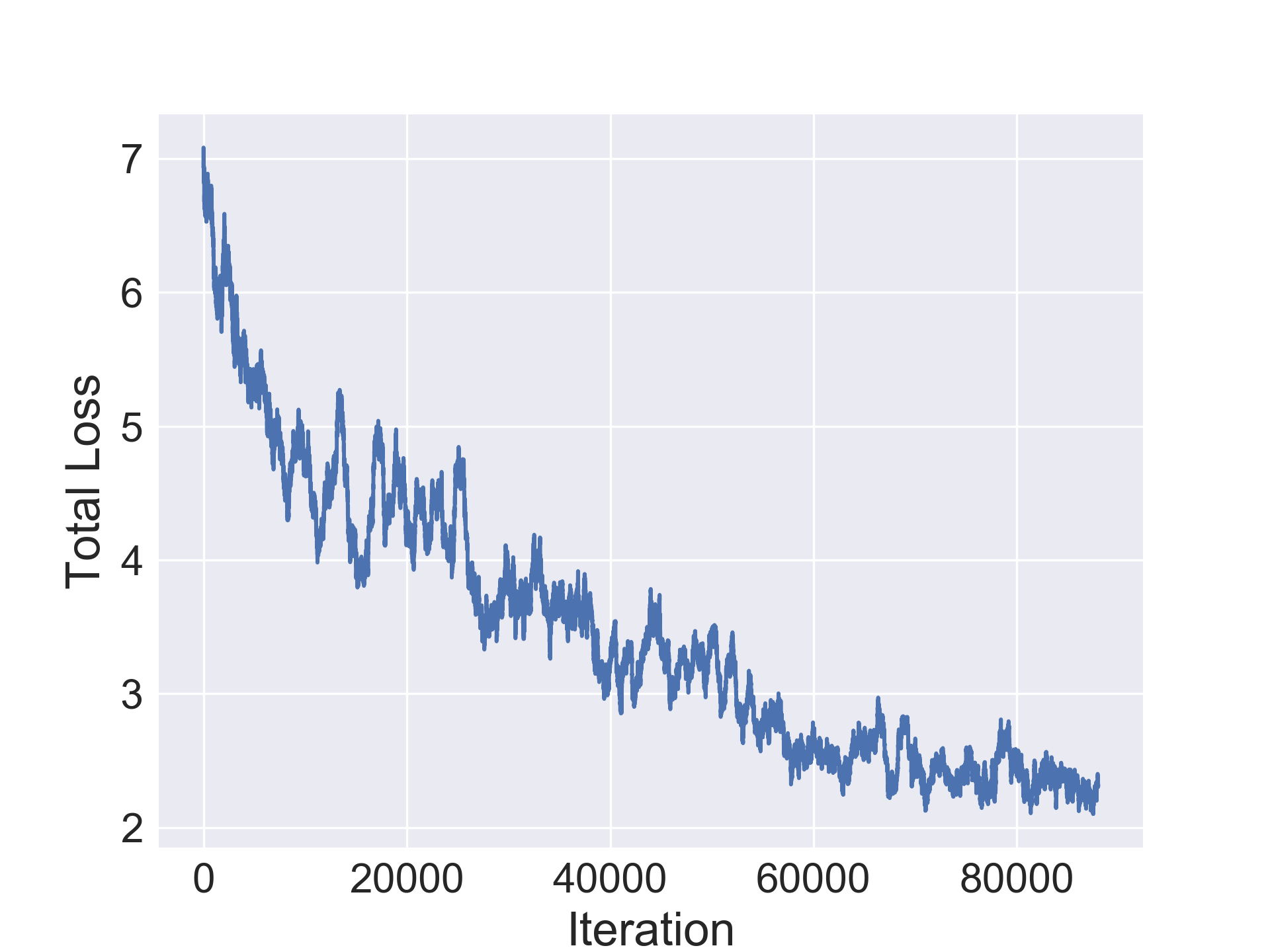 Figure 9
Figure 9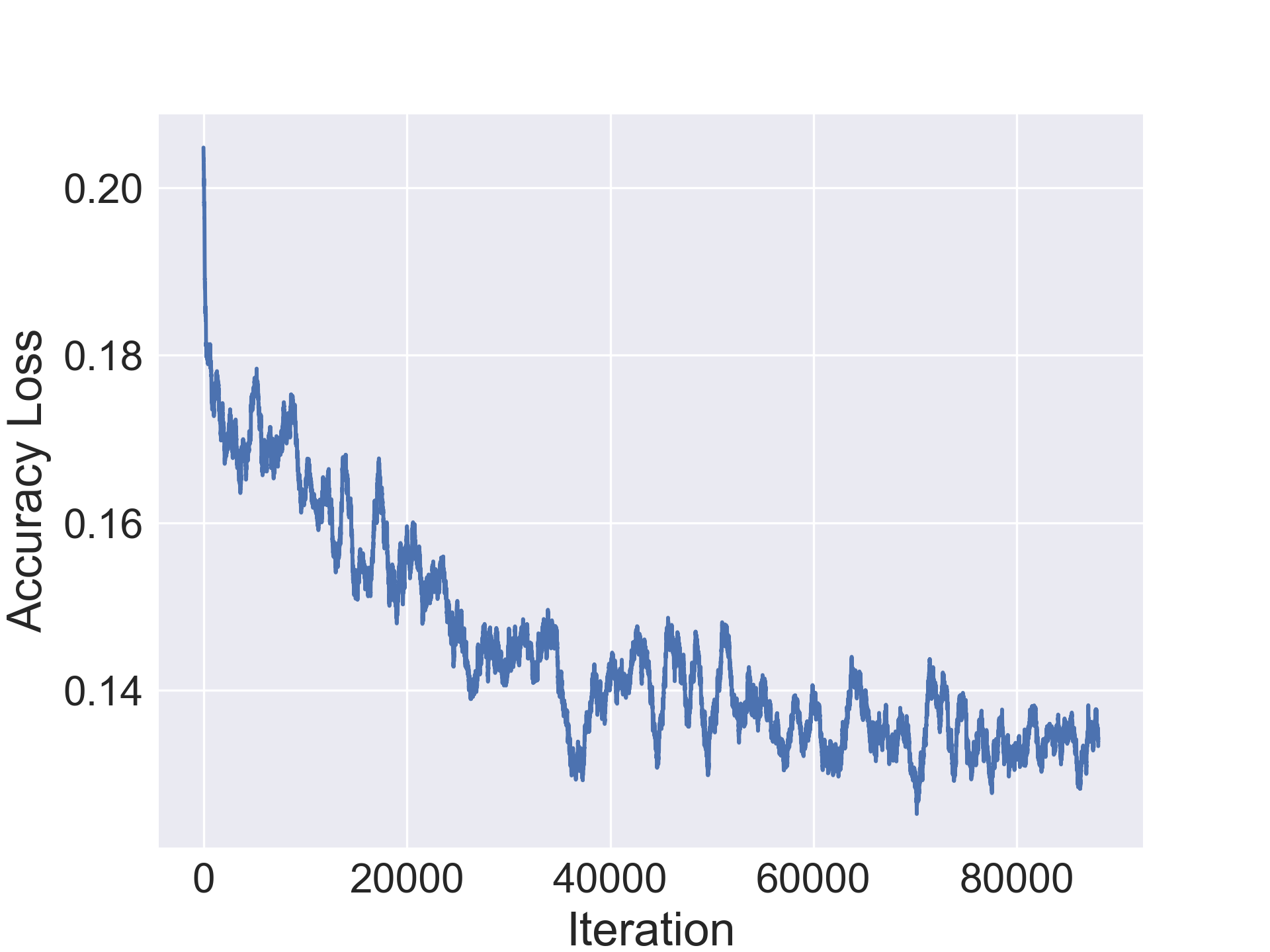 Figure 10
Figure 10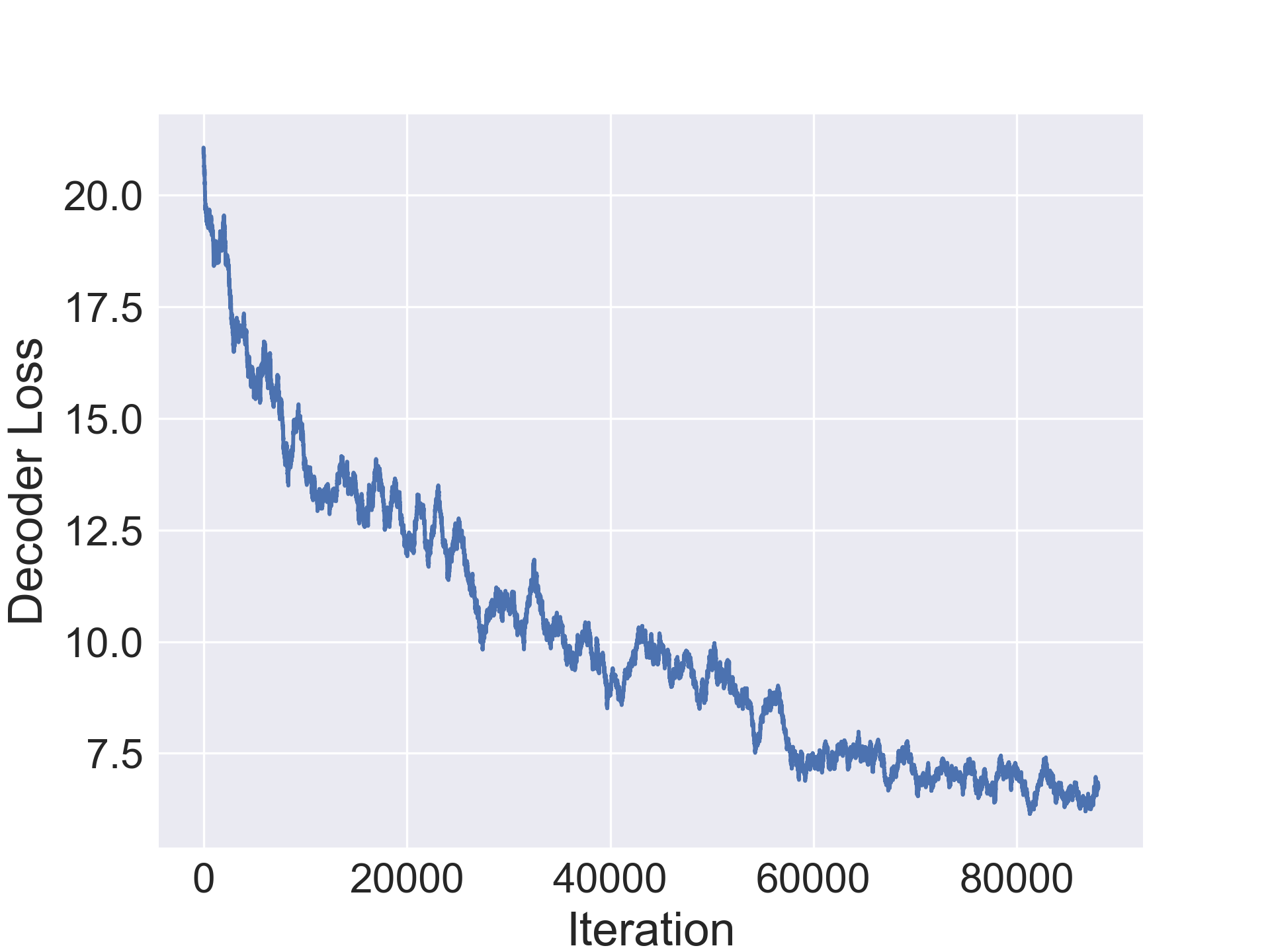 Figure 11
Figure 11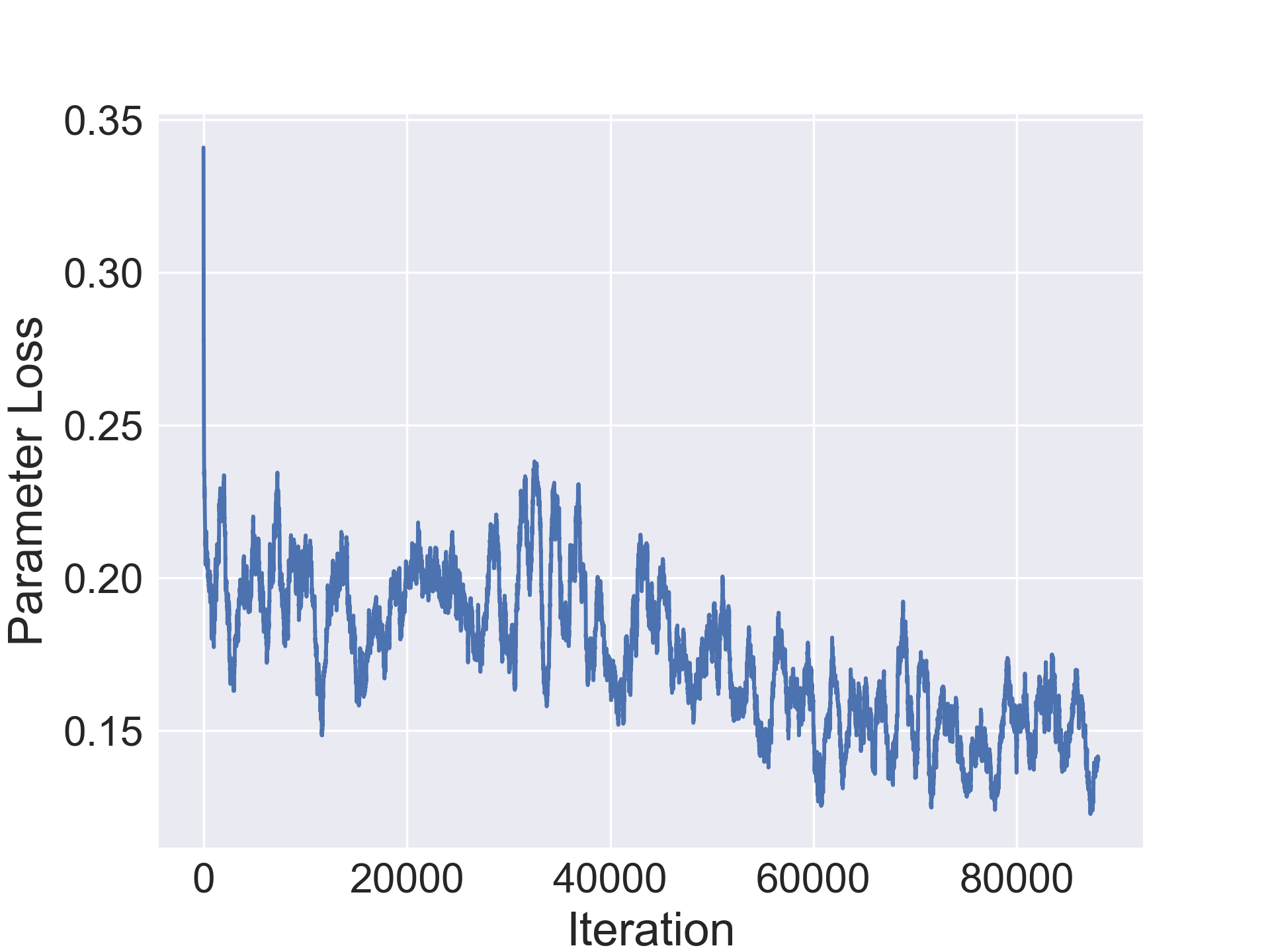 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15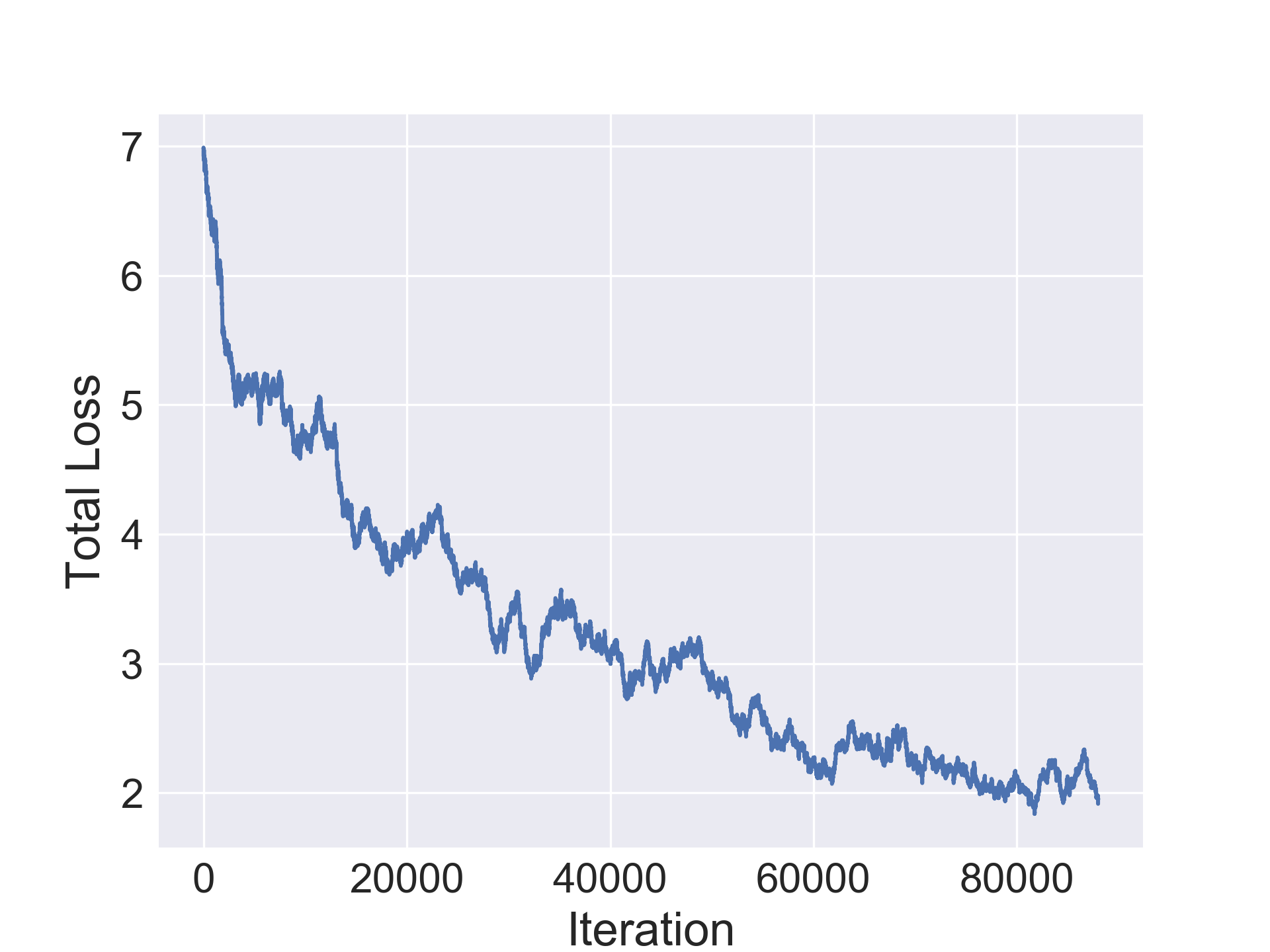 Figure 16
Figure 16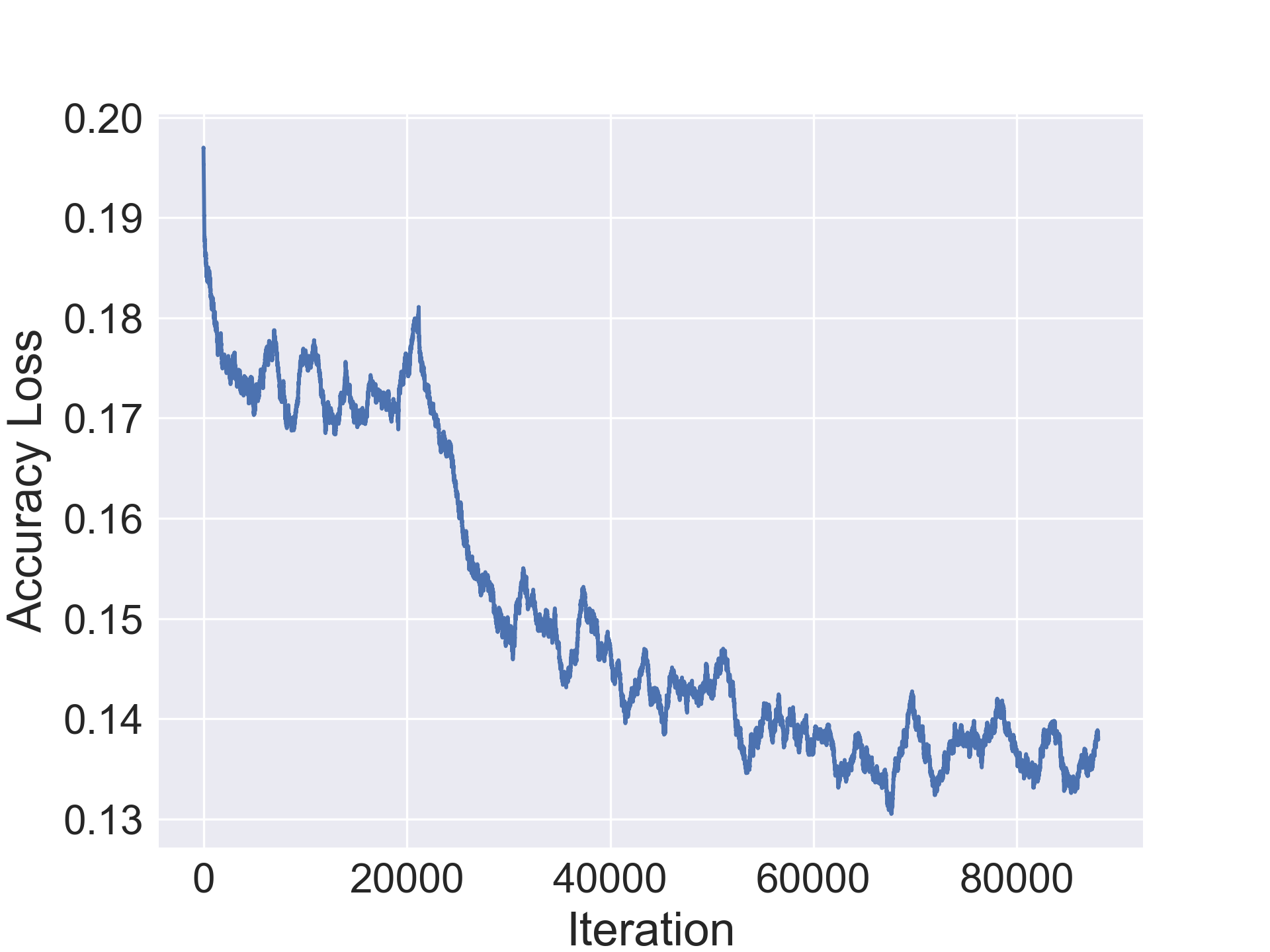 Figure 17
Figure 17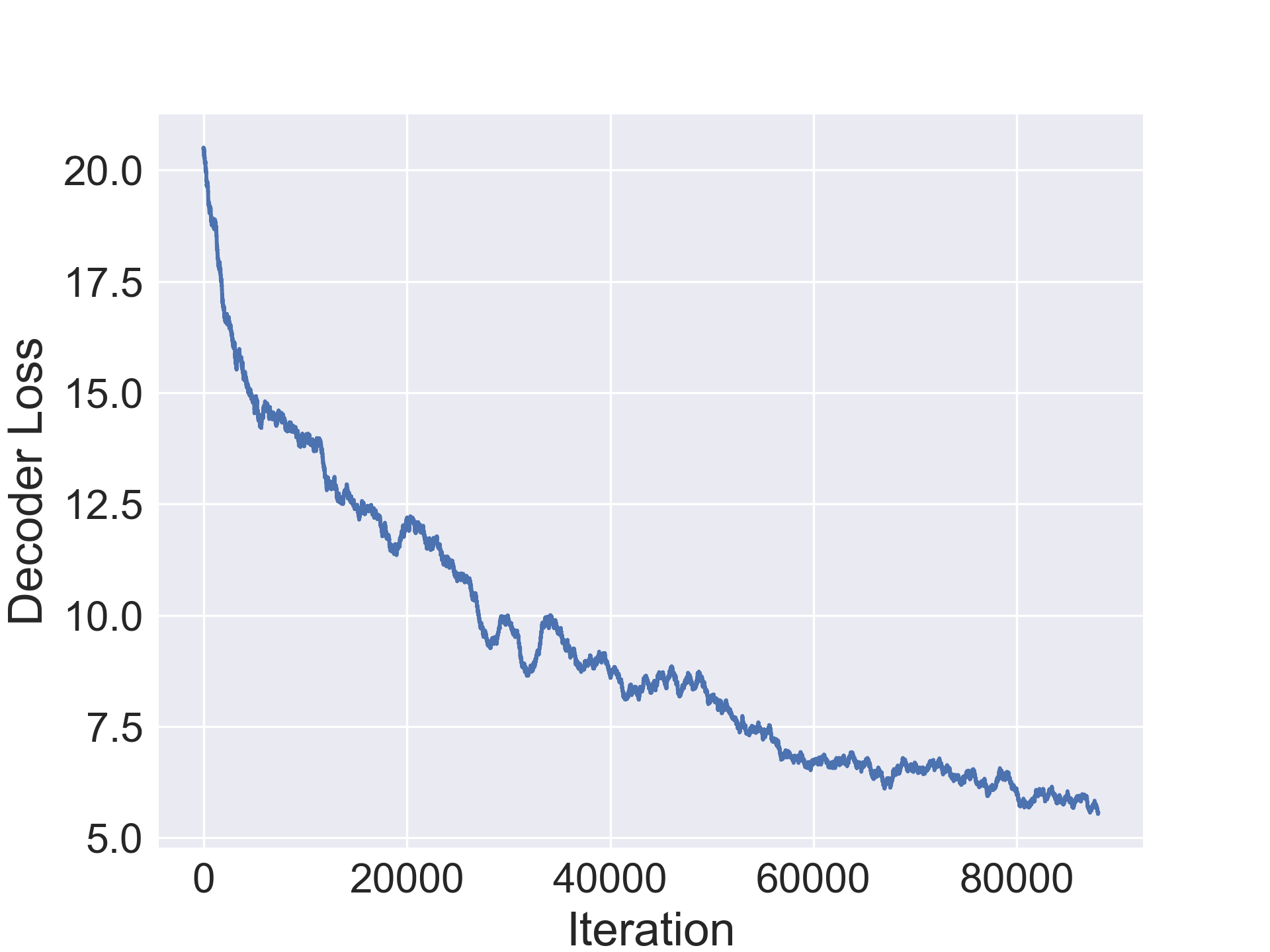 Figure 18
Figure 18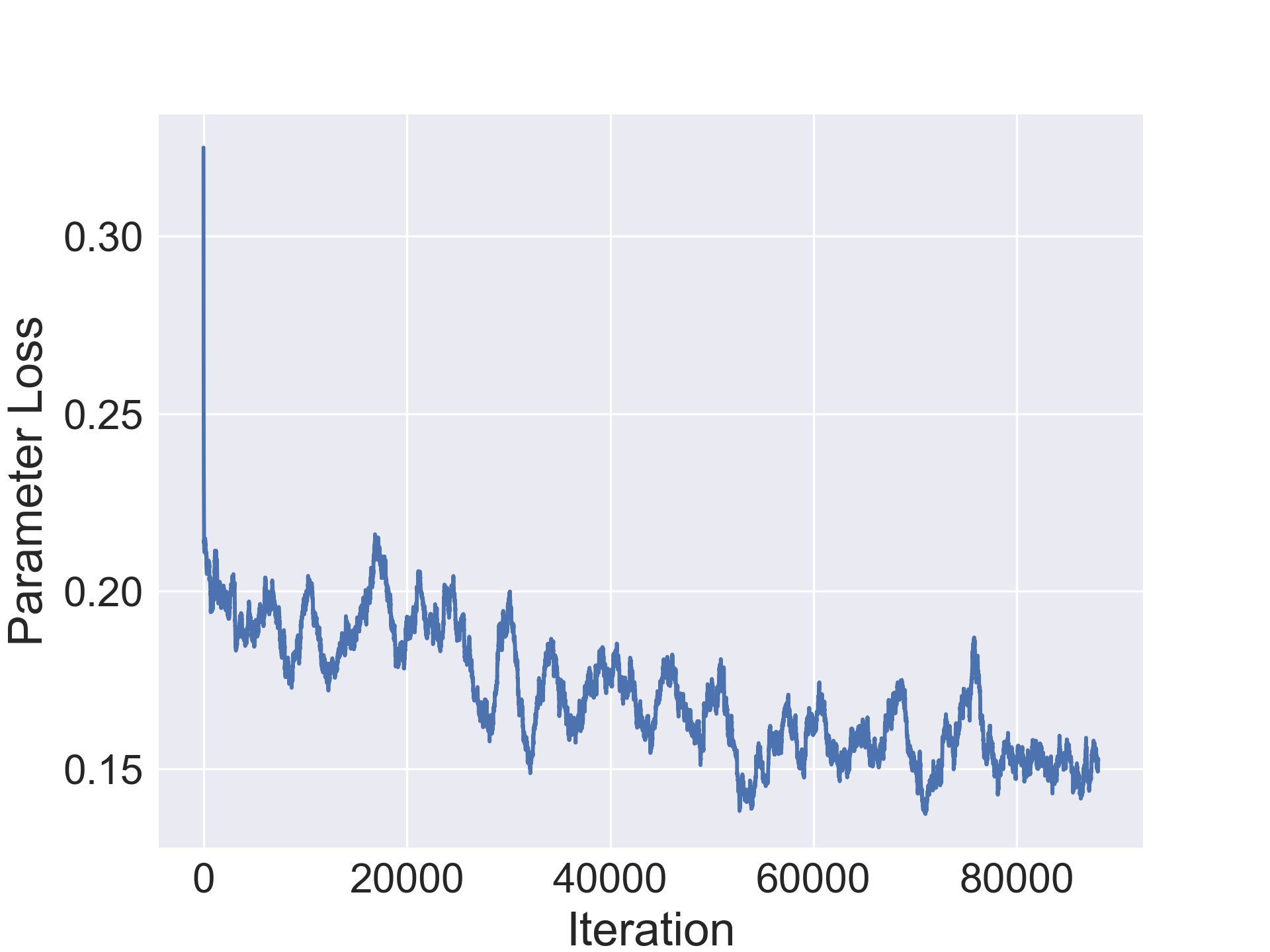 Figure 19
Figure 19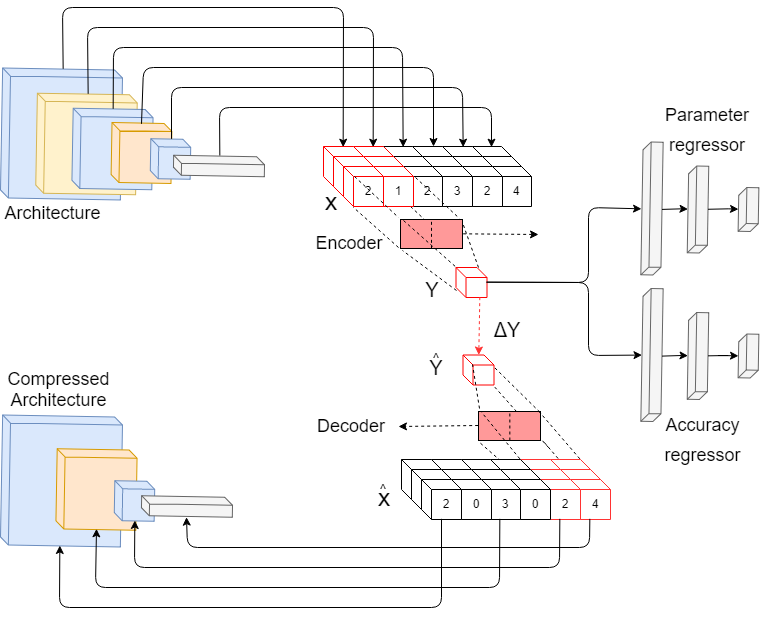 Figure 20
Figure 20| Model | Acc. | #Params | Acc. | Compr |
| Fashion-MNIST | ||||
| CONV-7 | 91.46% | 708K | +0.98% | 7.61x |
| CIFAR-10 | ||||
| CONV-10 | 92.35% | 24.4M | -0.04% | 20.33x |
| CIFAR-100 | ||||
| CONV-10 | 70.95% | 24.4M | -1.32% | 4.51x |
| SVHN | ||||
| CONV-10 | 96.02% | 24.4M | -0.63% | 8.76x |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Database Systems and Queries · Advanced Malware Detection Techniques · Graph Theory and Algorithms
Architecture Compression
Anubhav Ashok
Abstract
In this paper we propose a novel approach to model compression termed Architecture Compression. Instead of operating on the weight or filter space of the network like classical model compression methods, our approach operates on the architecture space. A 1-D CNN encoder/decoder is trained to learn a mapping from discrete architecture space to a continuous embedding and back. Additionally, this embedding is jointly trained to regress accuracy and parameter count in order to incorporate information about the architecture’s effectiveness on the dataset. During the compression phase, we first encode the network and then perform gradient descent in continuous space to optimize a compression objective function that maximizes accuracy and minimizes parameter count. The final continuous feature is then mapped to a discrete architecture using the decoder. We demonstrate the merits of this approach on visual recognition tasks such as CIFAR-10/100, Fashion-MNIST and SVHN and achieve a greater than 20x compression on CIFAR-10.
Machine Learning, ICML
1 Introduction
The recent adoption of CNNs for real-time, on-device applications has fueled a great demand for better model compression. Conventional methods such as quantization, pruning and distillation have proven to be reliable approaches in reducing redundancies in networks. However, one avenue where there has been little progress is that of architecture space based compression.
Approaches such as (Iandola et al., 2016), (Howard et al., 2017), (Rastegari et al., 2016), have introduced hand defined heuristics to design networks that are efficient without sacrificing accuracy. However, designing such networks still remains a laborious task, requiring much human expertise. In such a context, an efficient dataset-driven approach to determine the optimal architecture is desirable.
Recent methods such as (Ashok et al., 2017; He et al., ; Zhou et al., 2018; Tan et al., 2018) have proposed dataset-driven architecture based model compression using reinforcement learning. However, one drawback of such RL based methods is that they are less sample-efficient, often requiring a large number of architecture evaluations and several hours or days of training to find a single compressed model. Furthermore, it is unclear how these approaches compare to random search and whether they only succeed due to large-scale exploration and evaluation of many architectures.
To the best of our knowledge, this is the first paper to introduce a novel gradient descent based approach to perform architecture compression. To facilitate learning, we describe a mapping from discrete architecture space to a continuous space that encodes the structure of architecture for a specific dataset. We train a one-dimensional convolutional encoder/decoder neural network to learn the structure of discrete architecture space while using accuracy and parameter regressors to impose the structure inherent to learning the dataset. For compression, we encode an input architecture and leverage this learned continuous latent space to perform gradient descent on the encoded feature. The augmented feature is then decoded into a compressed discrete architecture.
We demonstrate the effectiveness of our approach on several visual learning tasks of varying difficulty (Fashion-MNIST, SVHN, CIFAR-10, CIFAR-100) and show 5-20x compression on architectures. We also compare this approach to conventional compression methods such as pruning, distillation and reinforcement learning and show that our architectures are smaller and faster than those produced by the baseline methods.
2 Related works
2.1 Architecture Search
There have been recent works in architecture search such as (Zoph & Le, 2016), (Baker et al., 2016), (Miikkulainen et al., 2017), (Real et al., 2017), that use reinforcement learning or evolutionary algorithms to traverse the space of architectures. These approaches characterize architectures as discrete entities in a non-differentiable space and use either a constrained state space or heuristics to discover architectures. These approaches have been subject to criticism from the machine learning community for using large amounts of computation.
Work such as (Ashok et al., 2017), (Tan et al., 2018), (Zhou et al., 2018), (He et al., ) attempt to search for efficient architectures instead of just the best. However these approaches also currently rely on reinforcement learning. In contrast to these approaches, our method shows that we can leverage classical optimization techniques such as gradient descent to effectively search the space of architectures for a constrained objective. Methods such as (Liu et al., 2018) and (Luo et al., 2018) attempt to make the space of architectures differentiable however this work is focused on discovering repeatable convolutional cells instead of optimizing the architecture as a whole.
2.2 Pruning, Quantization, Hand designed models
Pruning-based methods preserve the weights that matter most and remove the redundant weights (LeCun et al., 1989), (Hassibi et al., 1993), (Srinivas & Babu, 2015), (Han et al., 2015b), (Han et al., 2015a), (Mariet & Sra, 2015), (Anwar et al., 2015), (Guo et al., 2016). While pruning-based approaches typically operate on weight space, our approach operates on the the model architecture. Additionally, our method offers greater flexibility as we can use memory, inference time, power, and other hardware constraints to guide the compression process, resulting in the optimal architecture for a given dataset and constraints.
Hand designed models such as (Iandola et al., 2016) and (Howard et al., 2017) have been shown to work well in practical applications such as self-driving cars and mobile phones. These are good stepping stones in making progress in designing efficient architectures. Our work focuses on designing a general method to design such architectures in a fully automated data-driven manner.
3 Structure of architecture compression space
In this section we show how to map certain classes of architectures to a unique vector representation in order to enable learning. We then analyze the cardinality of architecture space for compression and prove that this space has several desirable properties for learning a mapping.
3.1 Topological representation of architectures
We observe that most modern neural network architectures , with the exception of recurrent neural networks can be expressed as a directed acyclic graph (DAG). We use the property that every DAG has a topological ordering (Proof in section 7) to represent an architecture as a partially ordered sequence of layers, . Formally,
[TABLE]
where the operator denotes that the activation of is the input of . Furthermore, this topological ordering is unique (Proof in section 7.2) for standard convolutional networks and those with simple skip connections (e.g. ResNet). We will denote this ordered representation of an architecture as
[TABLE]
where is the topological sorting function. Note also that for unique, one-to-one mappings, there exists an inverse function to recover given
[TABLE]
3.2 Cardinality of architecture compression space
Let be an architecture that is parameterized by and trained on some dataset . Then we can model the accuracy as a continuous random variable stochastically sampled from a distribution , since is typically optimized using a variant of stochastic gradient descent.
The expected accuracy , while not exactly computable due to the large dimension of , can be approximated by training and evaluating the network under varying intializations , i.e.
[TABLE]
where minimizes an objective function over with respect to . Thus, we are interested in learning a mapping from discrete architecture space to the expected accuracy
[TABLE]
However, since we are interested in model compression, we also want to construct the inverse mapping from the expected accuracy to discrete architecture space for a given parameter count
[TABLE]
In the following subsections, we prove that such a mapping, while not unique, is feasible to learn since the range of valid discrete architectures is finite.
For the following sections, we will denote parametric layers i.e. convolutional layers, batch normalization and fully connected layers as , where is the activation of the previous layer and represents the parameters of the layer.
Non-parametric pooling layers as max pooling and average pooling layers are written as , where (no upsampling) is the stride of the layer. Lastly activations such as sigmoid, ReLU, softmax etc. are represented as .
We also make the following practical assumptions in the following proofs:
The input , where and are fixed. 2. 2.
For layers , if , , where is the set of possible activation functions. 3. 3.
Pooling layers reduce dimensions of input image by some discrete number in each spatial dimension (no padding).
Lemma 3.1**.**
For a spatial input of dimension , the number of pooling layers possible in a valid architecture is bounded by a function of the input dimension.
Proof.
Let be the input of the ith layer with spatial dimension . We observe that a pooling operation with stride and kernel size results in an output of . Thus, the smallest possible dimensionality reduction we can have per layer is 1 pixel in each spatial dimension, setting , . We can see the number of such pooling layers is upperbounded by ∎
Theorem 3.2**.**
For a given parameter constraint , the set of valid architectures that meet the parameter constraint is finite.
Proof.
Next, suppose we have a partially constructed network with parameter count . Then by assumption 2, we can add at most one activation function. Furthermore by Lemma 3.2, we have a finite choice of pooling layers such that the architecture still remains valid.
Suppose we add a parametric layer , the parameter constraint exceeded if . Thus, we have the upperbound . Since is discrete, we have a finite number of choices of layers such that the partially constructed network is still valid.
We then observe that since monotonically decreases if we add a pooling layer and the upperbound of monotonically decreases if we add a parametric layer.
Since at least every other layer has to be one of these types, the length of any valid architecture is finite. Thus, we arrive at the conclusion that there are a finite number of valid architectures for a given parameter constraint. ∎
4 Approach
Having proved that a mapping is feasible, we now describe our approach to train a 1-dimensional convolutional encoder/decoder, an accuracy regressor and a parameter regressor to learn such a mapping (Outline in Fig. 1).
The variable length input vector to the network denoted by is a topologically ordered representation of the architecture as per Section 3.1. Each layer is represented by the hyperparameters of each layer. Specifically, it is a discrete 5 dimensional vector as follows:
[TABLE]
where is the layer type, the kernel size, the number of output channels, the stride and the padding.
4.1 Encoder and decoder
The encoder is a one-dimensional convolutional neural network that takes as input the discrete architecture representation and outputs a continuous feature. Prior approaches (Zoph & Le, 2016; Zhou et al., 2018; Tan et al., 2018; He et al., ; Ashok et al., 2017) use recurrent networks such as LSTMs or bidirectional RNNs where backpropagating through large sequences can result in vanishing gradients and difficult credit assignment (Hochreiter et al., 2001).
In our approach, we use a 1D-CNN encoder for several reasons. It can operate on variable length sequences, CNNs with sufficient depth have a large receptive field over the input sequence and it does not suffer from vanishing gradients since the length of gradient propagation is no longer a function of the sequence length but a function of the depth of the inference network.
The encoder , computes the function:
[TABLE]
where is a variable length sequence representing the architecture and a continuous feature embedding. Details of the network can be found in the appendix.
The decoder has a similar residual 1D-CNN architecture as the encoder except that convolutions are replaced with transposed convolutions.
The decoder , computes the function:
[TABLE]
where is a continuous variable length sequence representing the architecture and a continuous feature embedding. The continuous variable is discretized to .
4.2 Accuracy and parameter regressors
The accuracy regressor and parameter regressor are two fully connected networks that take the continuous embedding of the architecture as input and predict the expected accuracy, and parameter count, of the architecture .
The accuracy regressor learns the function
[TABLE]
where is trained to predict (which is approximated as per 3.2 by training the network with multiple intitializations). This network consists of 3 fc-relu blocks with a sigmoid output activation to convert the output to .
The parameter regressor learns the function
[TABLE]
where is trained to match the ground truth parameter count . The ground truth parameter count is computed as where is the number of parameters of each layer in the network. The mean parameter count is subtracted to center the parameter count around 0 and the standard deviation of the parameter count , is used to scale the parameter count for better conditioning of the range of the output. This network consists of 3 fc-relu blocks with a ReLU function to predict a non-negative real scalar.
4.3 Optimization
In order to learn to encode/decode the architecture and predict accuracy/parameter count, we jointly optimize a multi-task loss function. While all four tasks are formulated as regression problems, each has a differing domain. To account for this, we choose appropriate loss functions to best suit each task.
The decoder is trained to approximate positive integral values of varying scale since we may have small values for padding, kernel size, type and stride and large values for number of outputs. To enable faster convergence, we use a mean squared error.
[TABLE]
A standard L-1 loss is used for the accuracy regressor since the output of the sigmoid function is bounded between .
[TABLE]
For training the parameter regressor, we use the Huber loss with . This loss is less sensitive to outliers in the data and does not suffer from exploding gradients as described in (Girshick, 2015). This is important since the domain of the parameter count is and it is possible that the training set may have outliers such as large networks that do not converge.
[TABLE]
The network is then trained to minimize the joint loss function:
[TABLE]
4.4 Architecture compression using gradient descent
Once the inference network has converged and can predict the accuracy and number of parameters of a network, we use the network for architecture compression.
In order to compress an architecture, we perform gradient descent on the continuous embedding space using the compression objective function.
[TABLE]
The compression objective function simultaneously minimizes the number of parameters and maximizes the accuracy of the network to achieve compression. We can also incorporate known hardware constraints or accuracy requirements to relax this objective function by modifying it as follows
[TABLE]
The gradient from this objective is then backpropagated to the continuous embedding with learning rate to generate a new embedding .
[TABLE]
The decoder converts this embedding into a temporal sequence that is then discretized and converted into an architecture .
5 Experiments
In this section, we empirically evaluate our approach, showing that it is capable of compressing networks by upwards of 10x by benchmarking them on modern classification tasks such as CIFAR-10, CIFAR-100, Fashion-MNIST and SVHN.We show that our approach outperforms current state of the art architecture compression techniques by comparing the results to several baselines.
In the following experiments, we used a randomly generated dataset of 1500 architectures for training the encoder/decoder and regressors. Each architecture was trained for each task for 5 epochs with m=5 different random initializations to obtain a target expected accuracy. As observed in (Ashok et al., 2017; Zoph & Le, 2016; Tan et al., 2018), 5 epochs of training seems to provide sufficient signal about the convergence characteristics of the network. All of the following experiments were run on 2x NVIDIA 1080TI GPUs. Additional training details such as choice of optimizer and hyperparameters are included in Section 5.2 in the appendix.
5.1 Datasets
Fashion-MNIST The Fashion-MNIST (Xiao et al., 2017) dataset consists of pixel grey-scale images depicting images of fashion products from 10 categories. We use the standard 60,000 training images and 10,000 test images for experiments.
CIFAR-10 The CIFAR-10 (Krizhevsky & Hinton, 2009) dataset consists of 10 classes of objects and is divided into 50,000 train and 10,000 test images (32x32 pixels). This dataset provides an incremental level of difficulty over the Fashion-MNIST dataset, using multi-channel inputs to perform model compression.
SVHN The Street View House Numbers (Netzer et al., 2011) dataset contains 32x32 colored digit images with 73257 digits for training, 26032 digits for testing. This dataset is slightly larger that CIFAR-10 and allows us to observe the performance on a wider breadth of visual tasks.
CIFAR-100 To further test the robustness of our approach, we evaluated it on the CIFAR-100 dataset. CIFAR-100 is a harder dataset with 100 classes instead of 10, but the same amount of data, 50,000 train and 10,000 test images (32x32). Since there is less data per class, there is a steeper size-accuracy tradeoff.
5.2 Training details
5.2.1 Randomly generated architectures
This section describes the implementation details for the training procedure of the randomly generated architectures. All the experiments used the Adam optimizer and were run on the PyTorch framework. The same procedure was used to train the final output architecture.
Fashion-MNIST The architectures for Fashion-MNIST were trained for 50 epochs with a starting learning rate of 0.01. The learning rate is reduced by a factor of 10 in the 30th epoch. A batch size of 64 was used.
CIFAR-10/100 The architectures for CIFAR-10/100 were trained for 150 epochs with a starting learning rate of 0.001. The learning rate is decreased by a factor of 10 in the 80th and 120th epochs. Standard data augmentation with horizontal mirroring (p=0.5), random cropping with padding of 4 pixels and mean subtraction of (0.5, 0.5, 0.5). A batch size of 128 was used.
SVHN The architectures for SVHN were trained for 150 epochs with a starting learning rate of 0.001. The learning rate is decreased by a factor of 10 in the 80th and 120th epochs. Mean subtraction of (0.5, 0.5, 0.5) and a batch size of 128 was used.
5.2.2 Architecture compression search
The encoder, decoder and regressors were optimized using the SGD optimizer with nesterov momentum=0.5 and a learning rate of 0.003. The CIFAR-10/100 networks were trained jointly for 100000 iterations while the SVHN and Fashion-MNIST ones were trained for 80000 iterations. Furthermore, learning rate decay was used with period 30 and decay multiplier 1/5.
5.3 Compression experiments
In this section we evaluate the ability of our approach to compress architectures. For our experiments, we use a standard convolutional architecture consisting of stacked conv-bn-relu blocks and a fully connected layer. We use a 7 block network CONV-7 for Fashion-MNIST and 10 block network CONV-10 for the others. Table 1 shows original average accuracy of the model on the validation set, followed by the number of parameters in the original model followed by two columns for the improvement in accuracy in the compressed architecture and the compression rate. We notice a minor improvement in accuracy by the compressed architecture in Fashion-MNIST while observing a minor drop in the other datasets. Additionally, our method is able to achieve solid compression on all the datasets and up to 20x compression on CIFAR-10 (1.2M parameters for final compressed architecture).
Analysis of the final models produced by the compressor reveals several frequently occurring patterns. First, the compressor seems to learn to reduce the capacity of the models by removing layers and replacing them with non-parametric layers. Examples of this include sequential ReLU layers, Max Pooling layers with kernel and stride of 1, sequential batch norm layers and Dropout layers with dropout probability of 0.
An extreme example of such behavior was observed by modifying the compression objective to bias more towards compression rather than accuracy preservation. The topology of the network is provided in the appendix.
Another interesting observation was that the compressor often produced models with a batch normalization layer before the first convolutional layer. It is interesting to note that this has already been suggested in the past by prior work that claims it better conditions the input without requiring explicit data whitening. This seems to indicate that further analysis of the networks produced by our compressor leads to novel network motifs and concepts.
Another interesting behavior we observed during the compression process was that the regressors seem to accurately predict the accuracy and compression ratio of the compressed network well for the initial (5 or so) iterations, but starts to diverge subsequently. This was especially true of out of training distribution networks that were used during test time. We observed that finetuning the compressor with a few iterations of supervised training and a small learning rate substantially improved the accuracy of the regressors.
5.3.1 Baselines
We compare our approach to various model compression baselines including reinforcement learning, pruning and knowledge distillation on the CIFAR-10 dataset. The experiments show that our approach is able to find a smaller and more accurate model than the other approaches.
In order to provide a fair comparison to the each of the baselines, the following methodology was used. For all the experiments below, we used the same base model that was used for the compression experiments.
For distillation, a FitNet model with a similar number of parameters to that produced by our method was used. This model was trained to convergence using the approach described in the paper.
For pruning, we stop pruning when 1. accuracy drops below 1% of the student model obtained by our method or 2. the number of parameters is less than our method. Pruning is done 5 times to control for variance and the best performing model is reported.
For the RL approach, we selected the output student model that was most similar to the model produced by our approach. Although the model has a higher number of parameters, our model still achieves a higher final accuracy than that produced by the RL approach.
6 Conclusion
In conclusion, we have described a novel approach to compress CNNs by first training a continuous embedding on a representation of the architecture and then performing gradient descent to determine an optimal architecture for the given task. We also introduced a novel theoretical analysis of CNNs which we hope will inspire future work. We also demonstrate that our method performs well over a variety of computer vision datasets. Given that this is a novel direction of research, we note that there exist multiple future directions to go. Expanding the search space to include networks of greater complexity such as ResNets or DenseNets would be of practical interest. Analyzing the transfer learning properties of this approach via the reuse of the weights for other tasks would be of great practical use as well.
7 Appendix
7.1 Topological ordering
Lemma 7.1**.**
If G is a directed acyclic graph (DAG), then G has a topological ordering
Proof.
We prove this by induction on , where .
Base case:
For , the statement is true since the topological ordering is .
**Hypothesis: **
Assume that there exists a topological ordering on all DAGs of size .
**Inductive step: **
Given a DAG with nodes, select a node with no incoming edges.
Then is a DAG since deleting cannot induce a cycle on .
Since , the hypothesis implies that has a topological ordering .
Since has no incoming edges, no partial order is violated by placing at the head of the topologically ordered sequence.
Thus is a valid topological ordering of and the lemma is proven. ∎
Lemma 7.2**.**
If a topological sort has the property that , then it is unique
Proof.
It follows directly that the above property implies that there exists a Hamiltonian path on the graph since traversing the graph in the topologically sorted order satisfies each node being visited once. We can then show that the existence of a Hamiltonian path in a DAG implies unique ordering.
Suppose a DAG has two Hamiltonian paths, then let be the first nodes on the paths () that differ.
This implies that there is a path from that is a subpath of and a path from that is a subpath of . This implies a cycle in the graph, which is a contradiction. ∎
7.2 Visualization of 1D-CNN filters
8 Details on 1-D CNN architecture
Let be the ith activation or in the case of the first layer, the discrete representation of an architecture. Then a 1-d convolution operation applies a filter to a window of features in the input vector. We then add a bias to this output, to produce a feature map . Finally we apply a batch normalization function , an activation function and add the residual to produce a new activation as follows. Appropriate padding is added to the output in order to preserve the dimension and allow element-wise addition of the residual.
[TABLE]
In the case of a strided convolution where the temporal dimension of the output is smaller than the original input, we apply a convolution with the same stride . The operations then become the following.
[TABLE]
where performs convolutions on input with stride , weights and bias .
9 Sampling of random architectures
In section 4.4, we describe a set of randomly generated architectures that are trained and then used to learn a continuous architecture search space. In this section, we detail how this set of architectures is generated.
In order to generate a sensible set of architectures, we randomly sample architectures and then reject degenerate architectures.
First we sample the length of the architecture randomly from a discrete unifrom distribution . We set the lower bound to be 2 since we need at least one classification layer (fully connected) and one convolution layer for the architecture to be valid. Furthermore, we set the upperbound to 50 layers as an arbitrary limit that is within experimental constraints.
After this, we sample the 5 layer configuration variables for each of the layers randomly. Specifically, where:
Convolution 2. 2.
MaxPool 3. 3.
BatchNorm 4. 4.
ReLU 5. 5.
Sigmoid 6. 6.
Dropout 7. 7.
AveragePool 8. 8.
Linear
Additionally, , , , .
For layers that do not have certain configuration variables (e.g. batch normalization has no stride), we set the variable to be 0. For certain layers like MaxPool, ReLU or BatchNorm that do not change the number of output channels, we set the variable to the number of input channels. Furthermore, We also enforce that the number of input channels to the first is the same as the input of the task example and that the final layer is a fully connected layer with the number of outputs corresponding to the number of classes in the task.
Lastly, we filter out degenerate architectures if they do not contain any convolutional layers, the output dimension is too small to proceed or the memory/computational footprint is too large to be practical.
10 Analysis
In order to analyze the behavior of the compressor, the following experiment was done by highly weighting the parameter reduction term of compression objective function relative to the accuracy term. The loss function used was: . Given the input network shown below, the compressor produced a compressed model consisting of many redudant layers that did not contribute substantially to the parameter count.
The input network was a standard convolutional network and the resulting output is shown below.
Input:
VGG( (features): Sequential( (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace) (3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (5): ReLU(inplace) (6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (7): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (8): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (9): ReLU(inplace) (10): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (11): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (12): ReLU(inplace) (13): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (14): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (15): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (16): ReLU(inplace) (17): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (18): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (19): ReLU(inplace) (20): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (21): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (22): ReLU(inplace) (23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (24): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (25): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (26): ReLU(inplace) (27): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(28): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (29): ReLU(inplace) (30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (31): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (32): ReLU(inplace) (33): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (34): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (35): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (36): ReLU(inplace) (37): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (38): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (39): ReLU(inplace) (40): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) ) (classifier): Sequential( (0): Linear(in_features=512, out_features=4096, bias=True) (1): ReLU(inplace) (2): Dropout(p=0.5) (3): Linear(in_features=4096, out_features=4096, bias=True) (4): ReLU(inplace) (5): Dropout(p=0.5) (6): Linear(in_features=4096, out_features=1000, bias=True) ))
Output:
Model( (features): Sequential( (0): ReLU() (1): BatchNorm2d(3, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU() (3): ReLU() (4): Dropout(p=0) (5): MaxPool2d(kernel_size=1, stride=1, padding=0, dilation=1, ceil_mode=False) (6): ReLU() (7): Conv2d(3, 15, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)) (8): ReLU() (9): ReLU() (10): ReLU() (11): ReLU() (12): Conv2d(15, 135, kernel_size=(2, 2), stride=(3, 3), padding=(1, 1)) (13): ReLU() (14): ReLU() (15): BatchNorm2d(135, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (16): BatchNorm2d(135, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (17): BatchNorm2d(135, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (18): BatchNorm2d(135, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (19): ReLU() (20): ReLU() (21): BatchNorm2d(135, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (22): ReLU() (23): BatchNorm2d(135, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (24): BatchNorm2d(135, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (25): BatchNorm2d(135, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (26): BatchNorm2d(135, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (27): BatchNorm2d(135, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (28): BatchNorm2d(135, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (29): ReLU() (30): BatchNorm2d(135, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (31): BatchNorm2d(135, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (32): ReLU() (33): BatchNorm2d(135, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (34): BatchNorm2d(135, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (35): ReLU() (36): Dropout(p=0) (37): ReLU() (38): ReLU() (39): Dropout(p=0) (40): MaxPool2d(kernel_size=1, stride=1, padding=0, dilation=1, ceil_mode=False) ) (classifier): Sequential( (0): Linear(in_features=4860, out_features=10, bias=True) ))
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Anwar et al. (2015) Anwar, S., Hwang, K., and Sung, W. Structured pruning of deep convolutional neural networks. ar Xiv preprint ar Xiv:1512.08571 , 2015.
- 2Ashok et al. (2017) Ashok, A., Rhinehart, N., Beainy, F., and Kitani, K. M. N 2N Learning: Network to Network Compression via Policy Gradient Reinforcement Learning. ar Xiv e-prints , art. ar Xiv:1709.06030, Sep 2017.
- 3Baker et al. (2016) Baker, B., Gupta, O., Naik, N., and Raskar, R. Designing neural network architectures using reinforcement learning. ar Xiv preprint ar Xiv:1611.02167 , 2016.
- 4Girshick (2015) Girshick, R. Fast r-cnn. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV) , ICCV ’15, pp. 1440–1448, Washington, DC, USA, 2015. IEEE Computer Society. ISBN 978-1-4673-8391-2. doi: 10.1109/ICCV.2015.169 . URL http://dx.doi.org/10.1109/ICCV.2015.169 . · doi ↗
- 5Guo et al. (2016) Guo, Y., Yao, A., and Chen, Y. Dynamic network surgery for efficient dnns. In Advances In Neural Information Processing Systems , pp. 1379–1387, 2016.
- 6Han et al. (2015 a) Han, S., Mao, H., and Dally, W. J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. ar Xiv preprint ar Xiv:1510.00149 , 2015 a.
- 7Han et al. (2015 b) Han, S., Pool, J., Tran, J., and Dally, W. Learning both weights and connections for efficient neural network. In Advances in Neural Information Processing Systems , pp. 1135–1143, 2015 b.
- 8Hassibi et al. (1993) Hassibi, B., Stork, D. G., and Wolff, G. J. Optimal brain surgeon and general network pruning. In Neural Networks, 1993., IEEE International Conference on , pp. 293–299. IEEE, 1993.