TL;DR
This paper introduces approximately invertible architectures for image-to-image translation that are memory-efficient, enabling deeper models and achieving superior results on benchmark datasets.
Contribution
It proposes invertible architectures that are inherently cycle-consistent and memory-efficient, allowing for deeper networks and improved translation quality.
Findings
Superior quantitative results on Cityscapes and Maps datasets
Models are approximately invertible by design, ensuring cycle-consistency
Constant memory complexity enables arbitrarily deep architectures
Abstract
The Pix2pix and CycleGAN losses have vastly improved the qualitative and quantitative visual quality of results in image-to-image translation tasks. We extend this framework by exploring approximately invertible architectures which are well suited to these losses. These architectures are approximately invertible by design and thus partially satisfy cycle-consistency before training even begins. Furthermore, since invertible architectures have constant memory complexity in depth, these models can be built arbitrarily deep. We are able to demonstrate superior quantitative output on the Cityscapes and Maps datasets at near constant memory budget.
Click any figure to enlarge with its caption.
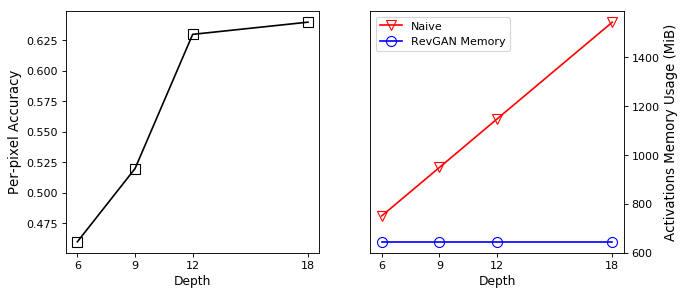 Figure 1
Figure 1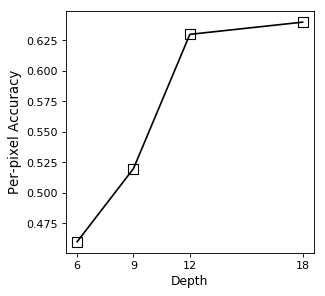 Figure 2
Figure 2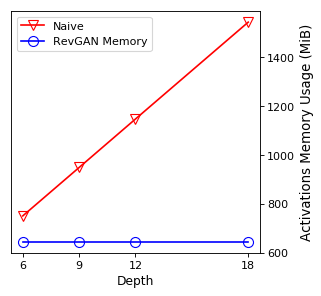 Figure 3
Figure 3 Figure 4
Figure 4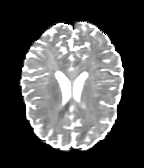 Figure 5
Figure 5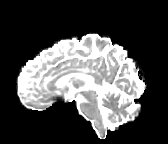 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8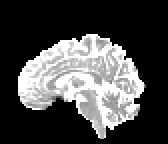 Figure 9
Figure 9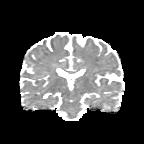 Figure 10
Figure 10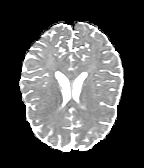 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15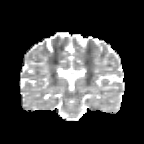 Figure 16
Figure 16 Figure 17
Figure 17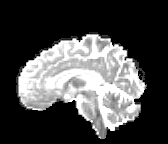 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20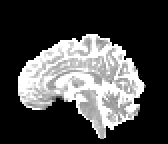 Figure 21
Figure 21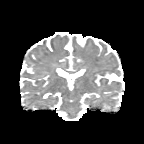 Figure 22
Figure 22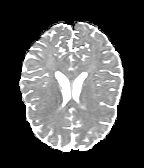 Figure 23
Figure 23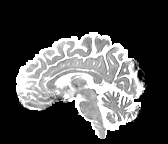 Figure 24
Figure 24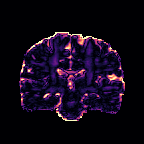 Figure 25
Figure 25 Figure 26
Figure 26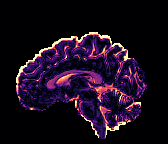 Figure 27
Figure 27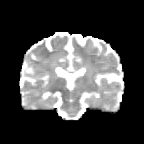 Figure 28
Figure 28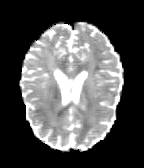 Figure 29
Figure 29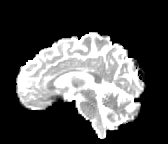 Figure 30
Figure 30 Figure 31
Figure 31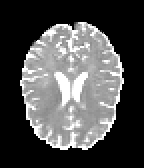 Figure 32
Figure 32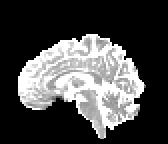 Figure 33
Figure 33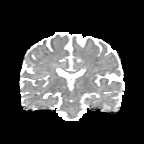 Figure 34
Figure 34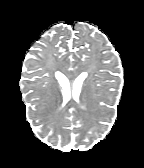 Figure 35
Figure 35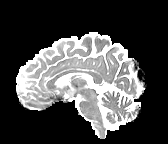 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40| \pbox2cmModel | \pbox2cmWidth | \pbox2cmParams | photolabel | labelphoto | |||||
|---|---|---|---|---|---|---|---|---|---|
| Per-pixel acc. | Per-class acc. | Class IOU | Per-pixel acc. | Per-class acc. | Class IOU | ||||
| CycleGAN (baseline)† | 32 | 3.9 M | 0.60 | 0.27 | 0.19 | 0.42 | 0.15 | 0.10 | |
| Unpaired RevGAN | 32 | 1.3 M | 0.52 | 0.21 | 0.14 | 0.36 | 0.14 | 0.09 | |
| Unpaired RevGAN† | 56 | 3.9 M | 0.66 | 0.25 | 0.18 | 0.65 | 0.24 | 0.17 | |
| Pix2pix (baseline)† | 32 | 3.9 M | 0.82 | 0.43 | 0.32 | 0.61 | 0.22 | 0.16 | |
| Paired RevGAN | 32 | 1.3 M | 0.81 | 0.41 | 0.31 | 0.57 | 0.20 | 0.15 | |
| Paired RevGAN† | 56 | 3.9 M | 0.82 | 0.44 | 0.33 | 0.60 | 0.21 | 0.16 | |
| Model | RMSE (Interior) | RMSE (Total) | |
|---|---|---|---|
| Paired w/o (3D-SRCNN) | 7.03 0.31 | 12.41 0.57 | |
| Paired+2R w/o | 7.02 0.32 | 12.41 0.57 | |
| Paired+4R w/o | 6.68 0.30 | 11.85 0.56 | |
| Paired+8R w/o | 18.43 1.03 | 21.40 0.98 | |
| Paired (3D-Pix2pix) | 11.94 0.65 | 20.73 1.05 | |
| Paired+2R | 9.61 0.40 | 17.36 0.76 | |
| Paired+4R | 8.43 0.37 | 14.81 0.61 | |
| Paired+8R | 7.82 0.35 | 13.76 0.60 | |
| Unpaired (3D-CycleGAN) | 17.23 0.73 | 26.94 1.20 | |
| Unpaired+2R | 11.05 0.51 | 17.76 1.38 | |
| Unpaired+4R | 18.98 1.22 | 28.06 1.44 | |
| Unpaired+8R | 18.96 0.85 | 27.94 1.09 |
| \pbox2cmModel | \pbox2cmWidth | \pbox2cmParams | mapssatellite | satellitemaps | |||||
|---|---|---|---|---|---|---|---|---|---|
| MAE | PSNR | SSIM | MAE | PSNR | SSIM | ||||
| CycleGAN † | 32 | 5.7 M | 139.85 15.52 | 14.62 1.16 | 0.31 0.05 | 138.86 20.57 | 26.25 3.64 | 0.81 0.06 | |
| Unpaired RevGAN | 32 | 1.7 M | 133.57 18.09 | 14.59 0.96 | 0.31 0.05 | 142.56 18.94 | 26.23 3.89 | 0.81 0.06 | |
| Unpaired RevGAN † | 58 | 5.6 M | 134.63 14.25 | 14.54 1.09 | 0.30 0.06 | 148.98 16.83 | 25.47 4.27 | 0.80 0.08 | |
| Unpaired RevGAN | 64 | 6.8 M | 135.48 19.19 | 14.55 1.24 | 0.26 0.04 | 133.12 17.18 | 23.66 2.80 | 0.67 0.10 | |
| Pix2pix † | 32 | 5.7 M | 139.63 13.14 | 14.78 1.08 | 0.30 0.05 | 129.16 16.11 | 27.11 3.11 | 0.82 0.04 | |
| Paired RevGAN | 32 | 1.7 M | 139.23 12.76 | 14.73 1.07 | 0.30 0.05 | 129.80 15.54 | 26.84 3.35 | 0.81 0.05 | |
| Paired RevGAN † | 58 | 5.6 M | 140.74 12.45 | 14.91 1.13 | 0.31 0.05 | 128.55 12.71 | 27.27 3.12 | 0.82 0.05 | |
| Paired RevGAN | 64 | 6.8 M | 140.59 13.64 | 14.85 1.20 | 0.31 0.06 | 133.09 12.09 | 27.37 3.06 | 0.82 0.04 | |
| \pbox2cmDepth | CycleGAN | Unpaired RevGAN | |||
|---|---|---|---|---|---|
| Model | Activations | Model | Activations | ||
| 6 | 434.3 | + 752.0 | 374.4 | + 646.1 | |
| 9 | 482.3 | + 949.0 | 385.4 | + 646.1 | |
| 12 | 530.3 | + 1148.1 | 398.5 | + 646.1 | |
| 18 | 626.3 | + 1543.9 | 423.4 | + 646.1 | |
| 30 | 818.7 | + 2335.8 | 626.3 | + 646.1 | |
| Parameter | 2D | 3D |
|---|---|---|
| Data size | \pbox3cm or | |
| Weight initialization | ||
| Normalization | Instance Norm | |
| Dropout | No | |
| Optimizer | Adam [21] | |
| Optimizer params | ||
| Epochs | 200 | 20 |
| Batch size | 1 | |
| Learning rate | 0.002 | |
| Learning rate decay | \pbox6cmKeep fixed first half of epochs. | |
| Linearly decay to 0 in second half of epochs. | ||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsResidual Connection · Tanh Activation · Residual Block · Instance Normalization · GAN Least Squares Loss · Cycle Consistency Loss · Cardano Customer Service Number +1-833-534-1729 · Concatenated Skip Connection · PatchGAN · *Communicated@Fast*How Do I Communicate to Expedia?
Reversible GANs for Memory-efficient Image-to-Image Translation
Tycho F.A. van der Ouderaa
University of Amsterdam
Daniel E. Worrall
University of Amsterdam
Abstract
The Pix2pix [17] and CycleGAN [40] losses have vastly improved the qualitative and quantitative visual quality of results in image-to-image translation tasks. We extend this framework by exploring approximately invertible architectures which are well suited to these losses. These architectures are approximately invertible by design and thus partially satisfy cycle-consistency before training even begins. Furthermore, since invertible architectures have constant memory complexity in depth, these models can be built arbitrarily deep. We are able to demonstrate superior quantitative output on the Cityscapes and Maps datasets at near constant memory budget.
1 Introduction
Computer vision was once considered to span a great many disparate problems, such as superresolution [12], colorization [8], denoising and inpainting [38], or style transfer [14]. Some of these challenges border on computer graphics (e.g. style transfer), while others are more closely related to numerical problems in the sciences (e.g. superresolution of medical images [35]). With the new advances of modern machine learning, many of these tasks have been unified under the term of image-to-image translation [17].
Mathematically, given two image domains and , the task is to find or learn a mapping , based on either paired examples or unpaired examples . Let’s take the example of image superresolution. Here may represent the space of low-resolution images, and would represent the corresponding space of high-resolution images. We might equivalently seek to learn a mapping . To learn both and it would seem sufficient to use the standard supervised learning techniques on offer, using convolutional neural networks (CNNs) for and . For this, we require paired training data and a loss function to measure performance. In the absence of paired training data, we can instead exploit the reciprocal relationship between and . Note how we expect the compositions and , where Id is the identity. This property is known as cycle-consistency [40]. The unpaired training objective is then to minimize or with respect to and , across the whole training set. Notice how in both of these expressions, we never require explicit pairs . Naturally, in superresolution exact equality to the identity is impossible, because the upsampling task is one-to-many, and the downsampling task is many-to-one.
The problem with the cycle-consistency technique is that while we can insert whatever and whatever we deem appropriate into the model, we avoid making use of the fact that and are approximate inverses of one another. In this paper, we consider constructing and as approximate inverses, by design. This is not a replacement to cycle-consistency, but an adjunct to it. A key benefit of this is that we need not have a separate and mapping, but just a single model, which we can run in reverse to approximate . Furthermore, note by explicitly weight-tying the and models, we can see that training in the direction will also train the reverse direction, which does not necessarily occur with separate models. Lastly, there is also a computational benefit that invertible networks are very memory-efficient [15]; intermediate activations do not need to be stored to perform backpropagation. As a result, invertible networks can be built arbitrarily deep, while using a fixed memory-budget—this is relevant because recent work has suggested a trend of wider and deeper networks performing better in image generation tasks [4]. Furthermore, this enables dense pixel-wise translation models to be shifted to memory-intensive arenas, such as 3D (see Section 5.3 for our experiements on dense MRI superresolution).
Our results indicate that by using invertible networks as the central workhorse in a paired or unpaired image-to-image translation model such as Pix2pix [17] or CycleGAN [40], we can not only reduce memory overhead, but also increase fidelity of the output. We demonstrate this on the Cityscapes and Maps datasets in 2D and on a diffusion tensor image MRI dataset for the 3D scenario (see Section 5).
2 Background and Related Work
In this section, we recap the basics behind Generative Adversarial Networks (GANs), cycle-consistency, and reversible/invertible networks.
2.1 Generative Adversarial Networks (GANs)
Generative adversarial networks (GANs) [16] enjoy huge success in tasks such as image generation [4], image interpolation [20], and image re-editing [32]. They consist of two components, a generator mapping random noise to images and a discriminator mapping images to probabilities. Given a set of training images , the generator produces ‘fake’ images , where is a simple distribution such as a standard Gaussian, and the discriminator tries to predict the probability that the image was from the true image distribution. For training, an adversarial loss is defined:
[TABLE]
This loss is trained using a minimax regime where intuitively we encourage the generator to fool the discriminator, while also training the discriminator to guess whether the generator created an image or not. Mathematically this game [16] is
[TABLE]
At test time, the discriminator is discarded and the trained generator is used to hallucinate fake images from the same distribution [2] as the training set. The generator can be conditioned on an input image as well. This setup is called a conditional GAN [28].
2.2 Image-to-Image Translation
In a standard (paired) image-to-image translation problem [17], we seek to learn the mapping , where and are corresponding spaces of images. It is natural to model with a convolutional neural network (CNN). To train this CNN we minimize a loss function
[TABLE]
where is a loss function defined in the pixel-space between the prediction and the target . Traditional image-to-image translation tasks relying on pixel-level loss functions are hampered by the fact that these losses do not typically account for inter-pixel correlations [39], for instance, -losses treat each pixel as independent. Instead, since GANs do not apply the loss per-pixel, they can account for these inter-pixel correlational structures. GANs can be co-opted for image-to-image translation by adding the adversarial loss on top of a standard pixel-level loss function. This was first performed in the Pix2pix model [17], which is for paired image-to-image translation problems. Pix2pix replaces with a conditional generator , where is the domain of the random noise; although, in practice, we usually ignore the additional noise input [40]. The model combines a -loss that enforces the model to map images to the paired translations in a supervised manner with an adversarial loss that enforces the model to adopt the style of the target domain. The loss is
[TABLE]
where
[TABLE]
is a tuneable hyperparameter typically set in the range [17].
2.3 Cycle-consistency
The CycleGAN model was proposed as an alternative to Pix2pix for unpaired domains [40]. The model uses two generators and for the respective mappings between the two domains and (so, and ), and two discriminators and trained to distinguish real and generated images in both domains. Since there are no image pairings between domains, we cannot invoke the Pix2pix loss and instead CycleGAN uses a separate cycle-consistency loss that penalizes the distances and across the training set. This encourages that the mappings and are loose inverses of one another. This allows the model to train on unpaired data. The total loss is
[TABLE]
Given that and are loose inverses of one another, it seems wasteful to use separate models to model each. In this paper, we model and as approximate inverses of one another. For this, we make use of the new area of invertible neural networks.
2.4 Invertible Neural Networks (INNs)
In recent years, several studies have proposed invertible neural networks (INNs) in the context of normalizing flow-based methods [33] [23]. It has been shown that INNs are capable of generating high quality images [22], perform image classification without information loss in the hidden layers [18] and analyzing inverse problems [1]. Most of the work on INNs, including this study, heavily relies upon the transformations introduced in NICE [10] later extended in RealNVP [11]. Although INNs share interesting properties they remain relatively unexplored.
Additive Coupling
In our model, we obtain an invertible residual layer, as used in [15], using a technique called additive coupling [10]: first we split an input (typically over the channel dimension) into and then transform them using arbitrary complex functions and (such as a ReLU-MLPs) in the form (left):
[TABLE]
The inverse mappings can be seen on the right. Figure 1 shows a schematic of these equations.
Memory efficiency
Interestingly, invertible residual layers are very memory-efficient because intermediate activations do not have to be stored to perform backpropagation [15]. During the backward pass, input activations that are required for gradient calculations can be (re-)computed from the output activations because the inverse function is accessible. This results in a constant spatial complexity () in terms of layer depth (see Table 1).
3 Method
Our goal is to create a memory-efficient image-to-image translation model, which is approximately invertible by design. Below we describe the basic outline of our approach of how to create an approximately-invertible model, which can be inserted into the existing Pix2pix and CycleGAN frameworks. We call our model RevGAN.
Lifting and Projection
In general, image-to-image translation tasks are not one-to-one. As such, a fully invertible treatment is undesirable, and sometimes in the case of dimensionality mismatches, impossible. Furthermore, it appears that the high-dimensional, overcomplete representations used by most modern networks lead to faster training [29] and better all-round performance [4]. We therefore split the forward and backward mappings into three components. With each domain, and , we associate a high-dimensional feature space and , respectively. There are individual, non-invertible mappings between each image space and its corresponding high-dimensional feature-space; for example, for image space we have and . lifts the image into a higher dimensionality space and projects the image back down into the low-dimensional image space. We have used the terms encode and decode in place of ‘lifting’ and ‘projection’ to stay in line with the deep learning literature.
Invertible core
Between the feature spaces, we then place an invertible core , so the full mappings are
[TABLE]
For the invertible cores we use invertible residual networks based on additive coupling as in [15]. The full mappings and will only truly be inverses if and , which cannot be true, since the image spaces are lower dimensional than the feature spaces. Instead, these units are trained to be approximately invertible pairs via the end-to-end cycle-consistency loss. Since the encoder and decoder are not necessarily invertible they can consist of non-invertible operations, such as pooling and strided convolutions.
Because both the core and its inverse are differentiable functions (with shared parameters), both functions can both occur in the forward-propagation pass and are trained simultaneously. Indeed, training will also train and vice versa. The invertible core essentially weight-ties in the and directions.
Given that we use the cycle-consistency loss it may be asked, why do we go to the trouble of including an invertible network? The reason is two-fold: firstly, while image-to-image translation is not a bijective task, it is close to bijective. A lot of the visual information in an image should reappear in its paired image , and by symmetry a lot of the visual information in the image should appear in . It thus seems sensible that the networks and should be at least initialized, if not loosely coupled to be weak inverses of one another. If the constraint of bijection is too high, then the models can learn to diverge from bijection via the non-invertible encoders and decoders. Secondly, there is a potent argument for using memory efficient networks in these memory-expensive, dense, pixel-wise regression tasks. The use of two separate reversible networks is indeed a possibility for both and . These would both have constant memory complexity in depth. Rather than having two networks, we can further reduce the memory budget by a rough factor of about two by exploiting the loose bijective property of the task, sharing the and models.
Paired RevGAN
We train our paired, reversible, image-to-image translation model, using the standard Pix2pix loss functions of Equation 4 from [17], applied in the and directions:
[TABLE]
We also experimented with extra input noise for the conditional GAN, but found it not to help.
Unpaired RevGAN
For unpaired RevGAN, we adapt the loss functions of the CycleGAN model [40], by replacing the loss with a cycle-consistency loss, so the total objective is:
[TABLE]
4 Implementation and datasets
The model we describe is very general and so below we explain in more detail the specifics of how to implement our paired and unpaired RevGAN models. We present 2D and 3D versions of the reversible models.
4.1 Implementation
Network Architectures
We use two main varieties of architecture. On the 2D problems, we modify the ResNet from [40], by replacing the inner convolutions with a reversible core. The core consists of 6 or 9 reversible residual layers, dependent on the dataset—we use 6 reversible residual layers for the core on (Cityscapes) data and 9 reversible residual layers on (Maps) data. A more detailed description of the network architectures can be found in the supplementary material. In 3D, we use an architecture based on the SRCNN of [12] (more details in supplementary material).
Training details
All model parameters were initialized from a Gaussian distribution with mean 0 and standard deviation 0.02. For training we used the Adam optimizer [21] with a learning rate of 0.0002 (and ). We keep the learning rate fixed for the first 100 epochs and then linearly decay the learning rate to zero over the next 100 epochs, for the 2D models. The 3D models are trained with a fixed learning rate for 20 epochs. We used a factor of for the unpaired models and a factor of for the paired models.
4.2 Datasets
We run tests on two 2D datasets and one 3D dataset. All three datasets have paired and domain images, and we can thus extract quantitative evaluations of image fidelity.
Cityscapes
The Cityscapes dataset [9] is comprised of urban street scenes with high quality pixel-level annotations. For comparison purposes, we used the same 2975 image pairs as used in [40] for training and the validation set for testing. All images were downsampled to .
For evaluation, we adopt commonly used semantic segmentation metrics: per-pixel accuracy, per-class accuracy and class intersection-over-union. The outputs of photolabel mappings can directly be evaluated. For the reverse mapping, labelphoto, we use the FCN-Score [40], by first passing our generated images through a FCN-8s semantic segmentation model [24] separately trained on the same segmentation task. We then measure the quality of the obtained segmentation masks using the same classification metrics. The intuition behind this (pseudo-)metric is that the segmentation model should perform well if images generated by the image-to-image translation model are of high quality.
Maps
The Maps dataset contains 1096 training images and an equally sized test set carefully scraped from Google Maps in and around New York City by [17]. The images in this dataset are downsampled to .
We evaluate the outputs with several commonly used metrics for image-quality: mean absolute error (MAE), peak signal-to-noise ratio (PSNR) and the structural similarity index (SSIM).
HCP Brains
The Human Connectome Project dataset consists of 15 brain volumes, of which 7 volumes are used for training. The value of each voxel is a vector representing the 6 free components of a symmetric diffusion tensor (used to measure water diffusivity in the brain). The brains are separated into high and low resolution versions. The low resolution images were upsampled using nearest neighbour so the input and output equal in size. This is a good task to trial on, since superresolution in 3D is a memory intensive task. For training, we split the brain volumes into patches of size omitting patches with less than brain matter, resulting in an average of 112 patches per volume.
We evaluate on full brain volumes with the root mean squared error (RMSE) between voxels containing brain matter in the ground-truth and the up-sampled volumes. We also calculate the error on the interior of the brain, defined by all voxels that are surrounded with a cube within the full brain mask, to stay in line with prior literature [35] [3].
5 Results
In this section, we evaluate the performance of our paired and unpaired RevGAN model, both quantitatively and qualitatively, against Pix2pix and CycleGAN baselines. Additionally, we study the scalability of our method in terms of memory-efficiency and model depth. For easy comparison, we aim to use the same metrics as used in related literature.
5.1 Qualitative Evaluation
We present qualitative results of the RevGAN model on the Maps dataset in Figure 4 and on the Cityscapes dataset in Figure 3. We picked the first images in the dataset to avoid ‘cherry-picking’ bias. The images are generated by models with equal parameter counts, indicated with a ‘’ symbol in the quantitative results of the next section (Table 4, Table 2).
All models are able to produce images of similar or better visual quality. The greatest improvement can be seen in the unpaired model (compare CycleGAN with Unpaired RevGAN). Both paired tasks are visually more appealing than the unpaired tasks, which make intuitive sense, since paired image-to-image translation is an easier task to solve than the unpaired version. We therefore conclude that the RevGAN model does not seem to under-perform our non-reversible baselines in terms of observable visual quality. A more extensive collection of model outputs can be found in the supplementary material.
5.2 Quantitative Evaluation
Cityscapes
We provide quantitative evaluations of the performance of our RevGAN model on the Cityscapes dataset. To ensure fairness, the baselines use the code implementations from the original papers. For our model, we provide two versions, a low parameter count version and a parameter matched version . In Table 2 the performance on the photolabel mapping is given by segmentation scores in the center columns and the performance on the labelphoto is given by the FCN-Scores in the righthand columns.
In Table 2, we see that on the low parameter and parameter matched RevGAN models outperform the CycleGAN baselines on the per-pixel accuracy. This matches our qualitative observations from the previous section. For per-class and class IOU, we also beat the baseline on labelphoto, and from similar or marginally worse on the photolabel task.
On the paired tasks we see that the results are more mixed and we perform roughly similar to the Pix2pix baseline, again matching our qualitative observations. We presume that the paired task is already fairly easy and thus the baseline performance is saturated. Thus introducing our model will do nothing to improve the visual quality of outputs. On the other hand, the unpaired task is harder and so the provision of by-design, approximately-inverse photolabel and labelphoto generators improves visual quality. On the paired task, the main benefit comes in the form of the memory complexity (see Section 5.4), but on the unpaired task the RevGAN maintains low memory complexity, while generally improving numerical performance.
Maps
Results on the Maps dataset are shown in Table 4, which indicate that the RevGAN model performs similarly and sometimes better compared to the baselines. Again, similarly to the Cityscapes experiment, we see that the biggest improvements are found on the unpaired tasks; whereas, the paired tasks demonstrate comparable performance.
5.3 3D Volumes
We also evaluate the performance of our RevGAN model on a 3D super-resolution problem, using the HTC Brains dataset of [35]. As baseline, we use a simple SRCNN model [12] (see supplementary material for architectural details) consisting of a convolutional layer as encoder, followed by a convolutional layer as decoder. For the discriminator, we use a 3D variant of the PatchGAN also used in [40]. The RevGAN model, extends the architecture by inserting an invertible core between the encoder and the decoder.
As can be seen in Figure 5, we obtain higher quality results using models with additional reversible residual layers. Of course, it is not unusual that deeper models result in higher quality predictions. Increasing the model size, however, is often unfeasible due to memory constraints. Fitting the activations in GPU memory can be particularly difficult when dealing with large 3D volumes. This study suggests that we can train deeper neural image-to-image translation models by adding reversible residual layers to existing architectures, without requiring more memory to store model activations.
With and without adversarial loss
We performed the experiments on paired models with and without the adverarial loss . We found that models without such loss generally perform better in terms of pixel-distance, but that models with an adversarial loss typically obtain higher quality results upon visual inspection. A possible explanation of this phenomenon could be that models that solely minimize a pixel-wise distance, such as or , tend to ‘average out’ or blur the aleatoric uncertainty (natural diversity) that exists in the data, in order to obtain a low average loss. An adversarial loss enforces the model to output an image that could have been sampled from this uncertain distribution (thereby introduce realistic looking noise), often resulting in less blurry and visually more compelling renderings, but with a potentially higher pixel-wise error.
5.4 Introspection
Memory usage
In this experiment, we evaluate the GPU memory consumption of our RevGAN model for increasing depths and compare it with a CycleGAN baseline. We kept the widths of both models fixed at such a value that the model parameters are approximately equal (both 3.9 M) at depth 6.
As can be seen from Table 5, the total memory usage increases for deeper networks in both models. In contrast to CycleGAN, however, the memory cost to store activations stays constant on the RevGAN model. A 6 layer CycleGAN model has the same total memory footprint of an unpaired RevGAN with 18-30 layers. Note that for convolutional layers the memory cost of storing the model is fixed given the network architecture, while the memory usage cost to store activations also depends on the size of the data. Therefore, reducing the memory cost of the activations becomes particularly important when training models on larger data sizes (e.g. higher image resolutions or increased batch sizes).
Scalability
Reversible architectures can be trained arbitarily deep without increasing the memory cost needed to store activations. We evaluate the performance of larger RevGAN models on the Cityscapes dataset.
As shown in Figure 6, with successive increases in depth, the performance of the RevGAN model increases on the Cityscapes task. This effect seems to hold up until a certain depth () after which we find a slight decrease in performance again. We presume this decrease in performance is due to the longer training times of deeper models, which we have not been able to train to full convergence due to time-budgeting issues. Keep in mind that we tried to keep our network architectures and training parameters as close as possible to networks used in the original Pix2pix and CycleGAN models. Other research suggests that training models with much deeper reversible architectures can be very effective [5]. We leave the exploration of alternative reversible architectures to future work.
6 Limitations and Discussion
Our results indicate that we can train image-to-image translation models with close to constant memory requirements in depth (see Table 5). This enables us to scale up to very deep architectures. Our ablation studies also show that increasing depth can lead to higher quantitative results in terms of various semantic segmentation metrics. This ability to scale up, however, trades memory for time, and so there is a trade-off to be considered in practical situations where we may be concerned about how long to spend in the development phase of such models. This is evident in our ablation study in Figure 6, where we were not able to wait until full convergence of the deepest models.
We have also demonstrated empirically that given a constrained budget of trainable parameters, we are able to achieve improved performance on the Cityscapes and Maps datasets, especially for of an unpaired training regime. We accredit two mechanisms for this observation.
Due to the nature of the problem, our network is not fully invertible. As a result, we still need to use the cycle-consistency loss, which requires two forward propagation passes and two backward passes through the model. A possible way to circumvent using the the cycle-consistency loss is to design the encoders and decoders to be analytically pseudo-invertible. We in fact did experiments on this, by formulating the (strided-)convolutions as Toeplitz matrix–vector products [26]. Unfortunately, we found that exact pseudo-invertibility is computationally too slow to run. Another issue with our setup is that two discriminators are required during training time (one of each domain). These are not used at test time, and can thus be considered as superfluous networks, requiring a lot of extra memory. That said, this is a general problem with CycleGAN and Pix2pix models in general.
7 Conclusion
In this paper we have proposed a new image-to-image translation model using reversible residual layers. The proposed model is approximately invertible by design, essentially weight-tying in the forward and backward direction, hence training from domain to domain simulaneously trains the mapping from to . We demonstrate equivalent or improved performance in terms of image quality, compared to similar non-reversible methods. Additionally, we show that our model is more memory efficient, because activations of reversible residual layers do not have to be stored to perform backpropagation.
In future work we plan to explore techniques to get rid of the cycle-consistency loss, so that the network is automatically cycle-consistent to begin with.
Appendix A: Implementation Details
We provide a Pytorch [31] implementation on Github. Our code extends the image-to-image translation framework from [40] with several reversible models in 2D and 3D. The reversible blocks are implemented using a modified version of MemCNN [37].
7.1 Generator architecture
2d Architecture
All 2d models adapt network architectures similar to those used in [40] and [19]. The encoders consist of a convolutional layer that maps 3 input channels to channels, followed by two convolutional layers with stride 2 that spatially downsample () the signal and increase () the channel dimension. We also refer to as the width of our network. As reversible core , we use sequential reversible residual layers (with for Cityscapes data and for Maps data). We consider the amount of reversible residual layers in the core to be the depth of our network. The decoders and are build out of two fractionally-strided convolutional layers 111‘Fractionally-strided convolutional layers’ or ‘transposed convolutions’ are sometimes referred to as ‘deconvolutions’ in literature. To avoid confusion, especially in the context of invertibility, we follow this [13] guide on convolutional arithmetic, and only refer to the term ’deconvolution’ when we speak of the mathematical inverse of a convolution, which is different from the fractionally-strided convolution., followed by a convolutional layer projecting the final features to 3 output channels.
We apply reflection padding before every convolution to avoid spatial downsampling. Each convolutional layer is followed by an instance normalization layer [36] and a ReLU nonlinearity, except for the last convolutional layer which is directly followed by a Tanh non-linearity to scale the output within , just like the normalized data.
A full schematic version of the 2D architecture can be found in Figure 11. A diagram of the (identical) and functions used in the 2D reversible block are shown in Figure 12.
3d Architecture
For the 3-dimensional super-resolution task (HTC Brains), we consider our input and output to be equally sized. Therefore, we first up-sample the images from the low-resolution input domain, before feeding them to the model. It is known that this method also helps to prevent checkerboard-like artifacts [30]. The first layer in our model is a convolution layer that increases the channel dimension to , and is directly followed by an instance normalization layer and a ReLU non-linearity. Then we apply an arbitrary amount of 3D reversible blocks using additive coupling, with the following sequence for and : a convolutional layer, an instance normalization layer, a ReLU non-linearity and another convolution. We use reflection padding of 1 to ensure that the and are volume-preserving. Also, we initialize the reversible blocks perform as the identity mapping, by initializing the weights of the last convolutional layer in the reversible block with zeros. This trick has previously shown to be effective in the context of reversible networks [22].
A full schematic version of the 3D generator can be found in Figure 13. A diagram illustrating and used in the 3D reversible block is shown in Figure 14.
7.2 Discriminator Architecture
For the discriminator, we adapt the same architecture as used in [40], also known as PatchGAN. We use subsequent convolutional layers with stride 2 followed by LeakyReLU (with 0.2 slope) non-linearities. The first layer projects the input to 64 layers, followed by three layers each doubling the channel dimension. Finally, we obtain a 1-dimensional outputs by applying a convolution followed by a Sigmoid. The 3D models use a very similar architecture and solely replacing the 2D convolutional kernels by equally sized 3D convolutional layers (e.g. kernels become kernels).
7.3 Hyper-parameters
A summary of the used hyper-parameters can be found in Table 6 below.
Appendix B: Negative Results
- •
We tried to replace additive coupling with affine coupling, which has been applied succesfully in the context of reversible networks by [22]. In theory, affine coupling layers are more general and more expressive than additive coupling. We found, however, that affine coupling degraded performance and made training more unstable. Nevertheless, it would be interesting to see whether affine coupling outperforms additive coupling combined with other architectures or hyper-parameters.
- •
We tried to replace the down-sampling and up-sampling layers with sub-pixel convolutions [34] in our 2D and 3D models, which have also been applied succesfully in the context of invertible architectures [18], but found that it degraded performance. Sub-pixel convolutions were originally proposed to save memory in super-resolution problems by applying convolutions in lower-dimensional space rather than in the higher-dimensional target space. The RevGAN model, on the other hand, saves memory by not having to store the activations of the reversible layers.
- •
We found that the invertible core can be replaced with a continuous-depth residual networks introduced in [7] of which the forward and inverse pass are trained using an ordinary differential equation (ODE) solver. The method has some practical benefits, including constant memory cost as a function of depth, similar to reversible residual layers, and explicit control over the numerical error. Due to time constraints, we were not able to compare the method with residual layers. It would be interesting to explore the use of neural ordinary (or even stochastic) differential equations in the context of image-to-image translation.
- •
We tried Consensus Optimization [27] to stabilize training by encouraging agreement between the discriminators and the generators. Consensus optimization boils down to regularization term over the second-order derivative over our gradients, which is a computationally intensive task. We stopped using it because it slowed down training too much.
- •
We tried to replace the transposed convolutions used for up-sampling in our model with nearest-neighbour and bilinear upsampling to prevent checkerboard-like aftifacts as explained in [30], but found that it degraded performance. Furthermore, we observed that the checkerboard appeared in early training stages, but that they disappeared after a sufficient amount of training iterations.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] L. Ardizzone, J. Kruse, S. Wirkert, D. Rahner, E. W. Pellegrini, R. S. Klessen, L. Maier-Hein, C. Rother, and U. Köthe. Analyzing inverse problems with invertible neural networks. ar Xiv preprint ar Xiv:1808.04730 , 2018.
- 2[2] S. Arora and Y. Zhang. Do gans actually learn the distribution? an empirical study. Co RR , abs/1706.08224, 2017.
- 3[3] S. B. Blumberg, R. Tanno, I. Kokkinos, and D. C. Alexander. Deeper image quality transfer: Training low-memory neural networks for 3d images. In International Conference on Medical Image Computing and Computer-Assisted Intervention , pages 118–125. Springer, 2018.
- 4[4] A. Brock, J. Donahue, and K. Simonyan. Large scale gan training for high fidelity natural image synthesis. ar Xiv preprint ar Xiv:1809.11096 , 2018.
- 5[5] B. Chang, L. Meng, E. Haber, L. Ruthotto, D. Begert, and E. Holtham. Reversible architectures for arbitrarily deep residual neural networks. ar Xiv preprint ar Xiv:1709.03698 , 2017.
- 6[6] T. Chen, B. Xu, C. Zhang, and C. Guestrin. Training deep nets with sublinear memory cost. ar Xiv preprint ar Xiv:1604.06174 , 2016.
- 7[7] T. Q. Chen, Y. Rubanova, J. Bettencourt, and D. Duvenaud. Neural ordinary differential equations. ar Xiv preprint ar Xiv:1806.07366 , 2018.
- 8[8] Z. Cheng, Q. Yang, and B. Sheng. Deep colorization. In 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, December 7-13, 2015 , pages 415–423, 2015.
