TL;DR
StampNet is an unsupervised neural network that simultaneously localizes and categorizes objects in images, effectively discovering recurring patterns without supervision, demonstrated on shape datasets and pedestrian localization.
Contribution
It introduces StampNet, a novel autoencoder with a discrete latent space for unsupervised multi-object localization and categorization in images.
Findings
Successfully localizes and clusters overlapping shapes.
Effectively categorizes objects in MNIST digits.
Applies to pedestrian localization in depth-maps.
Abstract
Unsupervised object discovery in images involves uncovering recurring patterns that define objects and discriminates them against the background. This is more challenging than image clustering as the size and the location of the objects are not known: this adds additional degrees of freedom and increases the problem complexity. In this work, we propose StampNet, a novel autoencoding neural network that localizes shapes (objects) over a simple background in images and categorizes them simultaneously. StampNet consists of a discrete latent space that is used to categorize objects and to determine the location of the objects. The object categories are formed during the training, resulting in the discovery of a fixed set of objects. We present a set of experiments that demonstrate that StampNet is able to localize and cluster multiple overlapping shapes with varying complexity including the…
Click any figure to enlarge with its caption.
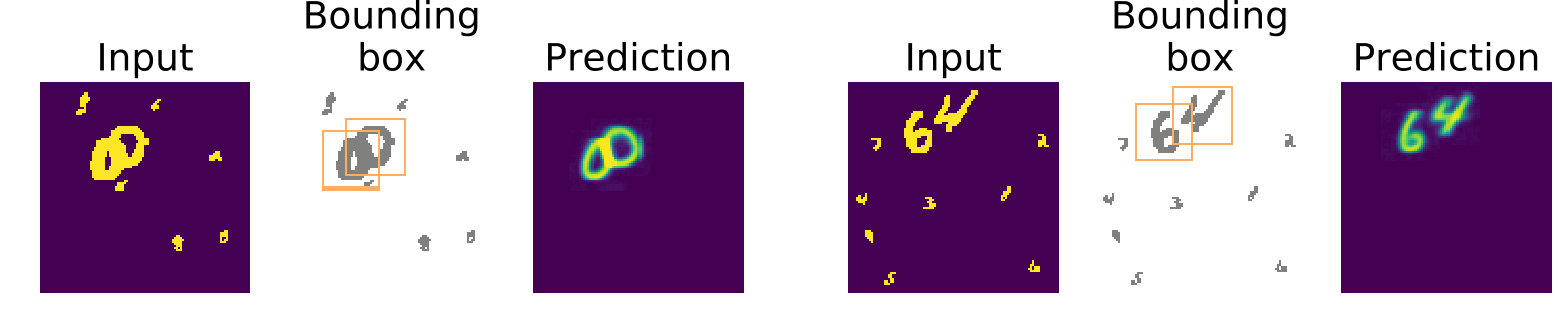 Figure 1
Figure 1 Figure 2
Figure 2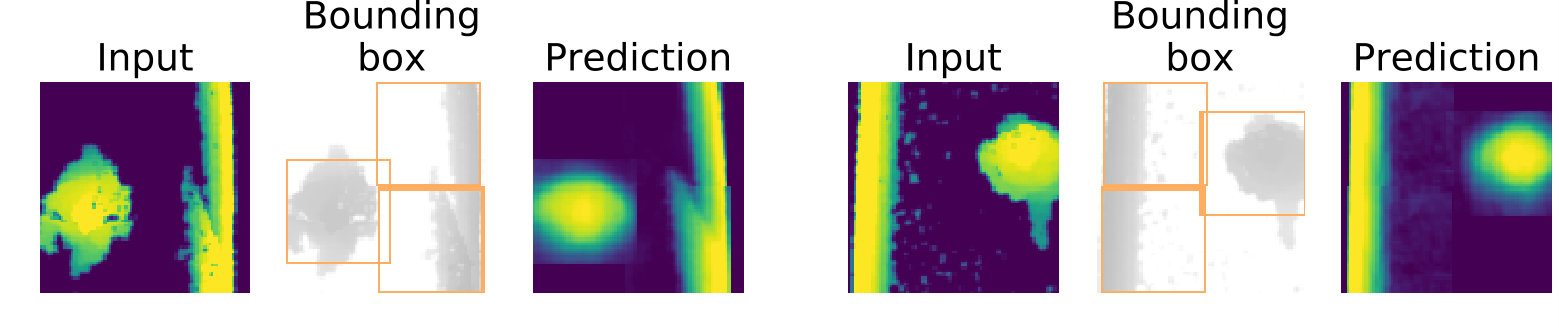 Figure 3
Figure 3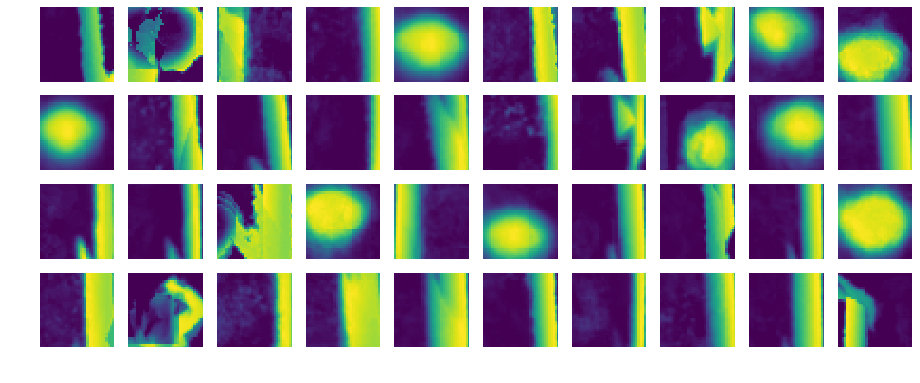 Figure 4
Figure 4 Figure 5
Figure 5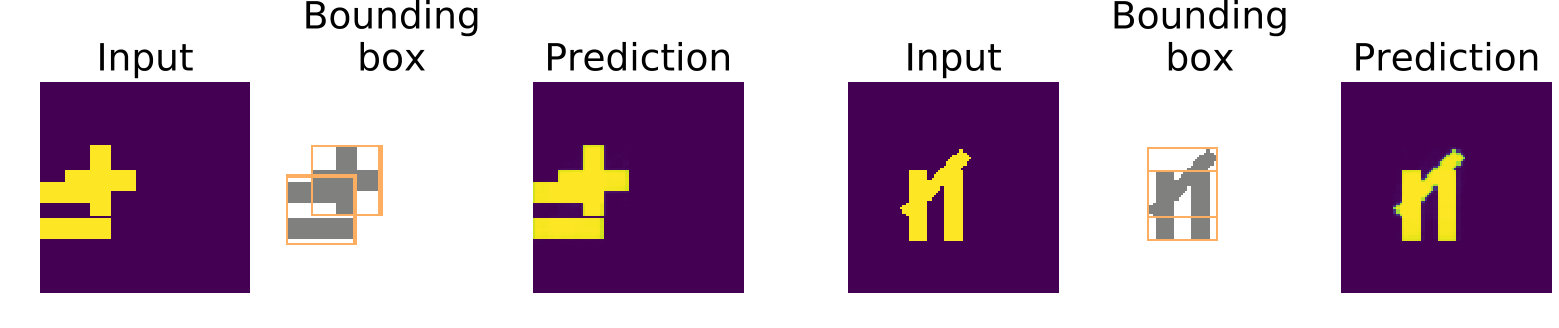 Figure 6
Figure 6 Figure 7
Figure 7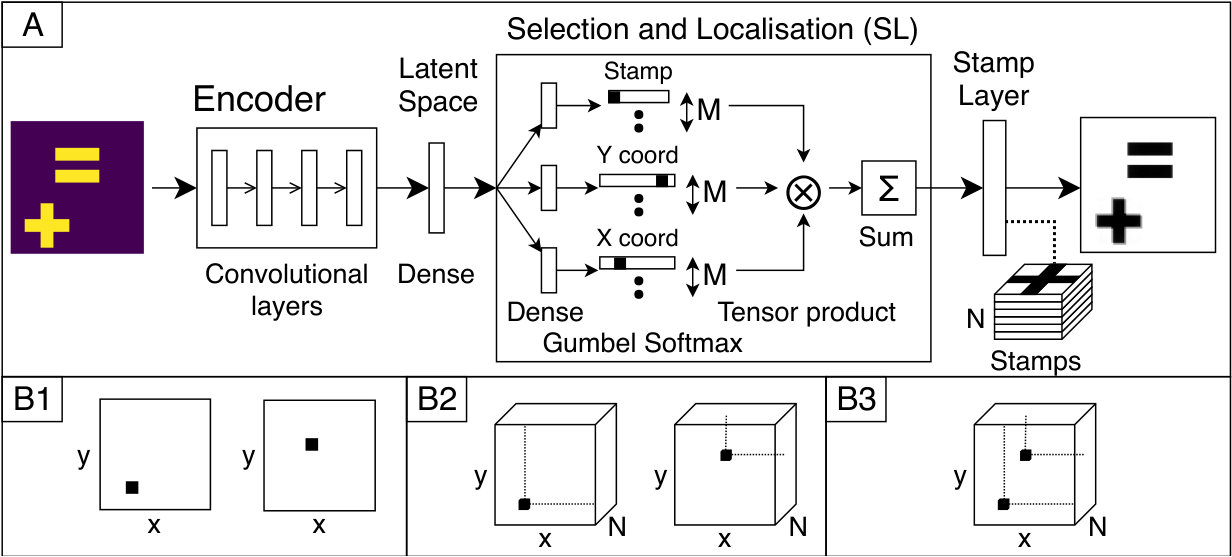 Figure 8
Figure 8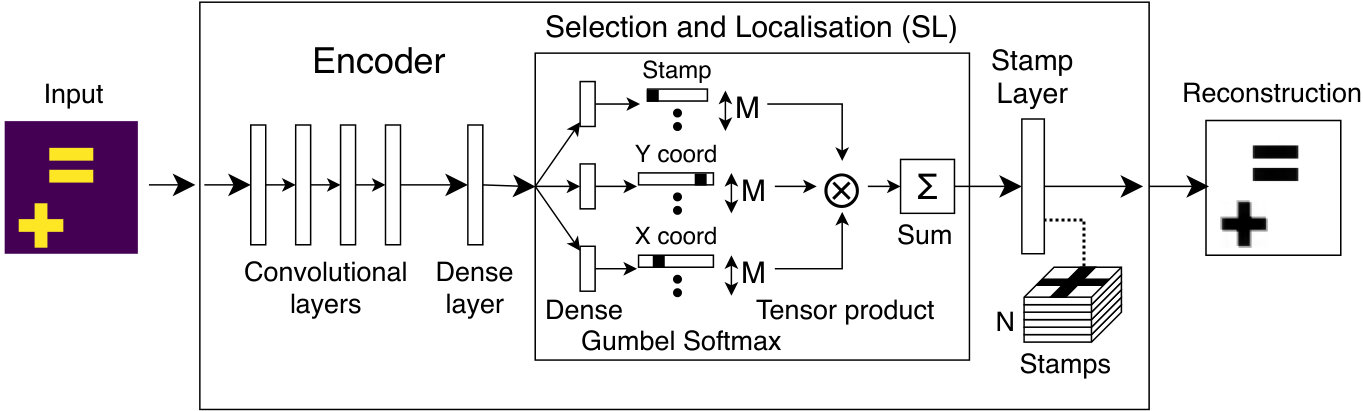 Figure 9
Figure 9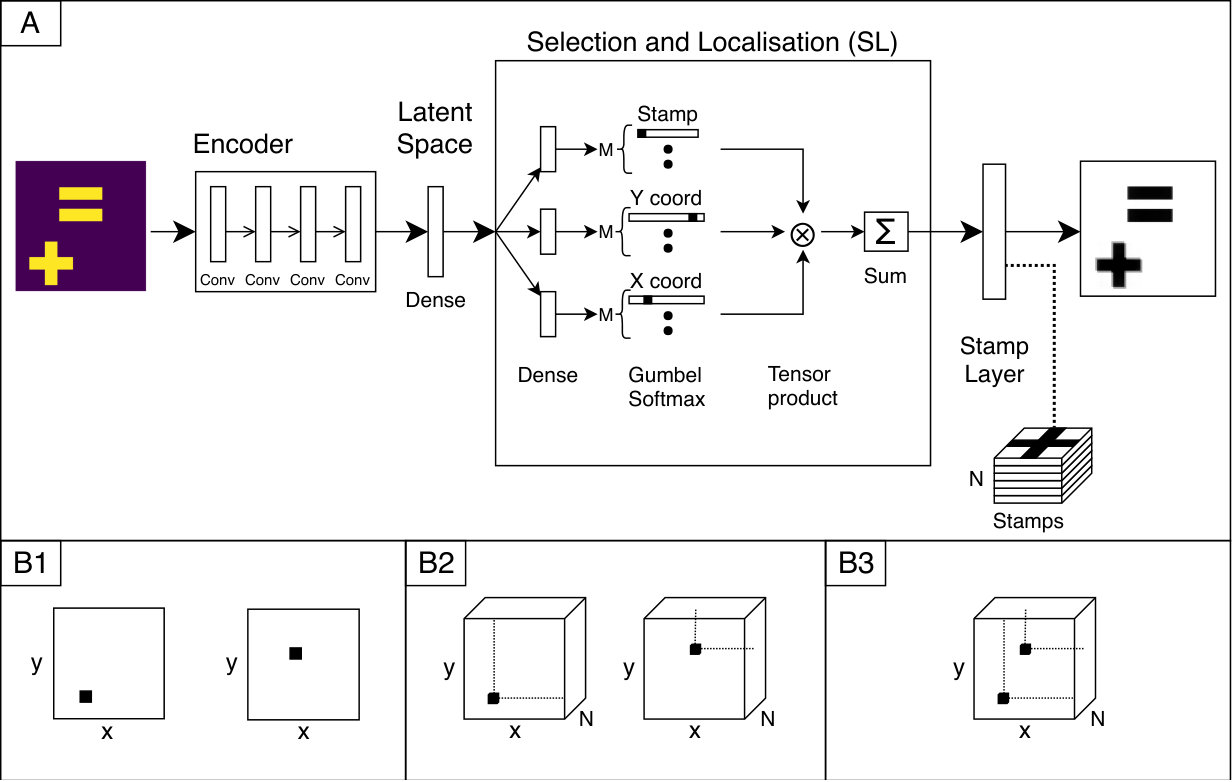 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12| Dataset | CorLoc | IoU | Purity |
|---|---|---|---|
| Simple Shapes | 0.9999 | 0.9718 | 0.9928 |
| Simple Shapes | 0.9828 | 0.9500 | 0.9564 |
| T-MNIST | 0.9983 | 0.8925 | 0.7891 |
| T-MNIST | 0.9729 | 0.8537 | 0.5277 |
| CT-MNIST | 0.9972 | 0.8912 | 0.8113 |
| CT-MNIST | 0.9545 | 0.8394 | 0.6149 |
| Pedestrian Tracking | 0.7816a | 0.6308a | 0.9597 |
| aCalculated for localizing the pedestrian, not the walls. | |||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
StampNet: unsupervised multi-class object discovery
Abstract
Unsupervised object discovery in images involves uncovering recurring patterns that define objects and discriminates them against the background. This is more challenging than image clustering as the size and the location of the objects are not known: this adds additional degrees of freedom and increases the problem complexity. In this work, we propose StampNet, a novel autoencoding neural network that localizes shapes (objects) over a simple background in images and categorizes them simultaneously. StampNet consists of a discrete latent space that is used to categorize objects and to determine the location of the objects. The object categories are formed during the training, resulting in the discovery of a fixed set of objects. We present a set of experiments that demonstrate that StampNet is able to localize and cluster multiple overlapping shapes with varying complexity including the digits from the MNIST dataset. We also present an application of StampNet in the localization of pedestrians in overhead depth-maps.
**Index Terms— ** object discovery, unsupervised learning, image localization, image clustering
1 Introduction
Discovery and localization of objects is an important task in computer vision and image analysis. There is a significant amount of existing methods that successfully address the challenge of object localization when objects are explicitly annotated with labels and bounding boxes. Deep convolutional neural networks such as YOLO [1] and Faster R-CNN [2] demonstrated significant success. Annotations, however, often require major human effort and thus come with significant costs.
In contrast, object discovery deals with localization in absence of annotations. This means finding and clustering recurring patterns that define the objects. Previous work on unsupervised localization typically addresses one object class in multiple images, which is referred to as object co-localization [3, 4]. However, unsupervised localization of multiple classes of objects remains a significant challenge. This problem is further adds complexity as we cannot assume that only a single object is present in the image. In other words, the model needs to simultaneously discover the objects (or form categories) and learn to perform localization.
As the object size and alignment is not predetermined the complexity of the clustering of the objects grows significantly with the degrees of freedom added by the localization. Analogously, the localization is difficult because during training objects categories are not predetermined. An additional complication is that the objects can overlap, which further increases the difficulty of clustering the objects.
To address these challenges we propose a novel autoencoding neural network architecture, StampNet, that discovers objects and localizes them simultaneously. StampNet has two characterizing features: first, it has a latent space consisting of discrete random variables that encode the cluster assignment and its location. Second, it has a final layer consisting of a fixed number of convolutional filters (stamps) that encode the discovered objects. The size and number of these filters determine the maximum size and maximum number of objects to be discovered respectively. We refer to this layer as a stamp layer and hence the name of the network StampNet.
This paper is structured as follows: in Section 2, we report on the state-of-the-art on unsupervised object discovery. In Section 3, we introduce the StampNet architecture. In Section 4, we show the results of StampNet on four datasets. The discussion Section 5 closes the paper.
2 Related works
Various studies have been performed on topics closely related to unsupervised object discovery. In co-localization and co-segmentation, the goal is to extract the position of common objects between images, using bounding boxes and segmentation respectively. Many of these studies obtain good results, but simplify the problem by assuming a single object class [3, 4, 5].
Recent studies have worked on the more difficult problem of multi-class co-localization [6] and co-segmentation [7]. Cho et al. [7] use an off-the-shelf region proposal system to form a set of candidate bounding boxes and match these across images. Wang et al. [6] use functional maps to model partial similarity across images, but they assume that the image set contains two classes of objects or very similar objects.
To the best of our knowledge, only one study has focussed on our task of multi-class object discovery: tackling simultaneous localization and classification without supervision. Murasaki et al. [8] extract deep features using a pre-trained neural network and clusters these features. However, their model is limited to a single single object in each image.
3 StampNet architecture
3.1 Architecture overview
In this section, we describe the architecture of StampNet (see sketch in Figure 1). StampNet is an autoencoder, i.e. a neural network which outputs a reconstruction of an input image based on an internal representation of the input. This representation is formed by the encoder under the training constraint of minimising Euclidean distance between the input and the output.
The encoder follows a VGG-like [9] structure with stacks of convolutional layers (with Leaky ReLU activations [10]) followed by a max pooling layer (Batch Normalization [11] and Dropout [12] are used during training).
The decoder, the peculiarity of StampNet, works in two stages: first, it predicts the coordinates and stamp type for each shape in the input image (Selection-and-localization layer); second, through the stamp layer, the selected stamps are placed according to the predicted positions to generate the output image. In the following subsection, we introduce the notation employed and we detail the selection-and-localization and the stamp layers.
3.2 Notation
We consider an input image of pixel size containing shapes indexed by the variable (i.e. , where the upper-bound to the number of shapes is pre-defined). We assume each shape to fit within one of stamps of pixel size . The set of stamps is stored in a collection of convolutional kernels of size , that form, as whole, a tensor of size . We finally name and the random variables respectively associated to the and coordinate of a shape and the categorical random variable defining the stamp type . Thus, it holds and .
3.3 Selection-and-localization layer
The selection-and-localization layer (SL-layer) predicts the coordinates (localization) and selects the clustered object to use (selection). As objects are clustered in the kernel of the stamp layer, these need to be convolved over the predicted location and only the selected object should be convolved. This happens when the output of the SL-layer is a one-hot tensor, (see Equation 2).
Therefore, we want to output a one-hot tensor at the predicted coordinates and predicted stamp. One way to output such tensor is to use a max function. This function, however, results in a gradient of [math] for all non-max values, making it unfitting for backpropagation. We provide a different solution: we model the coordinates and object-selector as categorical distributions. When we sample from these distributions, we get a one-hot tensor with the predicted stamp and coordinates. The gumbel softmax [13] (also known as the concrete distribution [14]) is a differentiable sampling of a smoothly deformed categorical distribution.
In the SL-layer, we first predict the probability distribution of the coordinate, coordinate and the stamp type . Then, we calculate a sampling using the gumbel softmax function. This function uses temperature that allows gradients to flow through during training and gradually anneals the temperature to become a sampling from a categorical distribution [13].
The network combines the three gumbel softmax output by performing, for each of the shapes, the tensor product of the coordinates and of the stamp selector probability vectors. We obtain individual selection-and-localization tensors (SL tensors), as they contain information on the position and type of each shape. In formulae, the individual SL tensor reads for all :
[TABLE]
Once every shape has been selected and localized, we combine them into the global selection-and-localization tensor summing on :
[TABLE]
3.4 The stamp layer
The output of the network, i.e. the reconstruction of the input, is provided by the stamp layer, which performs a convolution operation between the global tensor and the stamp tensor . We write , which in components satisfies:
[TABLE]
We constrain the kernel values in to be non-negative and smaller than the maximum image value with training-time clipping. Moreover, should two stamps be partially overlapped, and thus sum their values, the output is further clipped to avoid exceeding the maximum image value.
4 Results
We evaluate the performance of StampNet on several datasets. The first dataset contains five clearly distinguishable shapes, followed by more complex shapes of MNIST. The final dataset contains noisy overhead images of pedestrians. The performance of the network is evaluated on two tasks: (1) discovery and localization of each shape and (2) clustering performance of the extracted stamps. We evaluate the first task with CorLoc [7] and Intersection over Union (IoU) [15]. For the second task, we use clustering purity [16] to measure how well the model can differentiate between classes.
The network has been trained on a train set and evaluated on a separate test set. We use an annealing schedule of , updated every epoch for the gumbel softmax. For the results, we use a temperature of to enforce a one-hot choice.
4.1 Simple Shapes dataset
The Simple Shapes dataset uses five different simple shapes: a ‘plus’, an ‘equal’, a rotated ‘equal’, a ‘slash’, and a ‘triangle’. We randomly place shapes of size on an empty canvas of size . We consider generated training samples and generated test samples. The stamp layer contains stamps.
In 2(a), we report the stamps learned by the network. We observe that these stamps are nearly identical to the shapes used to generate the dataset. We detail sample predictions outputs in 2(b). In these samples, the network localizes overlapping shapes and assigns the correct stamp to each shape.
In Table 1, we quantify the IoU and purity of evaluated over the test set. We achieve high scores in IoU and purity on this dataset. The remaining errors are the result of the network assigning an inaccurate stamp to a shape, which primarily happens when shapes overlap.
4.2 Translated and Cluttered Translated MNIST
We evaluate the performance of our model on two MNIST datasets: (1) Translated MNIST (T-MNIST) and (2) Cluttered Translated MNIST (CT-MNIST) [17]. In T-MNIST, MNIST digits are uniformly placed on an empty canvas. CT-MNIST adds clutter to these images by uniformly placing smaller clutter digits of size to add noise to the dataset. We choose in T-MNIST a canvas size of and in CT-MNIST a canvas size of to best compare our results with existing literature. In both cases, we generate training samples and test samples. We test for and digits on the canvas with stamps.
We observe that the network discovers different MNIST digits in 2(d) and 2(f). The stamps learned by the network (2(c) and 2(e)) resemble different digits of MNIST.
The network discovers most MNIST digits, as the CorLoc measures (Table 1) indicate. Even when there are digits on a cluttered canvas, the network discovers over 95% of the digits. The added clutter results in a slight drop of localization (Table 1) and an increase in purity.
We note the results of others in the case of CT-MNIST in Table 2. We observe that without supervision, StampNet performance comes near these supervised alternatives (using purity as the measure for comparison, i.e when all stamps are labelled correctly). Note that these networks only classify a single digit, while our model can discover multiple digits in each image.
4.3 Pedestrian localization in overhead images
Overhead depth maps are an increasingly popular tool to perform high accuracy pedestrian tracking for studying the dynamics of human crowds in real-life venues (e.g. [21]). Overhead depth maps come in form of grey scale images where the value of each pixel encodes its distance from the camera plane. In overhead depth view pedestrians have similar “ovoid” shape, which is different from that of walls, objects and so on. The characteristics of this dataset make it a very suitable for the StampNet’s object discovery capability.
We consider here a reduced depth dataset from the real-life crowd tracking experiment [22], annotated with bounding boxes (image size: , bounding boxes size . See sample on the left side of 2(h), which displays a pedestrian on the left side and a wall on the right side).
We test StampNet considering stamps of size and evaluate both the accuracy of the localization and the capability of the network to differentiate between pedestrians and the wall on the side.
We illustrate samples of the results in 2(h) and the measures in Table 1. In both cases, we observe that the network places one stamp on the pedestrian and two stamps on the walls. The stamps extracted by the network (2(g)) show that different objects are successfully captured by the network, and, as evidenced by the high clustering purity, the network is capable to differentiate between pedestrians and walls. Furthermore, we obtain a CurLoc value of showing that we can localize with reasonable accuracy.
5 Conclusion
In this paper, we have introduced StampNet to localize multiple objects from multiple classes in an unsupervised manner. We accomplish this by incorporating the predictions of the bounding boxes into an autoencoder, removing the need of labels. We achieve this by placing the kernel of a convolutional layer on predicted location coordinates (Figure 1).
The results in 2(d) and 2(f) show that StampNet is able to detect and localize overlapping MNIST digits without the need for any labels. Furthermore, the network clusters the shapes in the dataset as stamps (2(e)). We demonstrate an example of the value of this in an application of pedestrian tracking in overhead images.
Nevertheless, there are limitations to our model. The network is only able to place stamps of a fixed size. Furthermore, as we make use of the kernel of a convolutional layer, the network can only capture simple prototypical shapes.
Future work can look into generating more complex kernels for the stamp layer by making use of information from the input.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Joseph Redmon and Ali Farhadi, “Yolov 3: An incremental improvement,” ar Xiv preprint ar Xiv:1804.02767 , 2018.
- 2[2] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,” in Advances in neural information processing systems , 2015, pp. 91–99.
- 3[3] Gunhee Kim and Antonio Torralba, “Unsupervised detection of regions of interest using iterative link analysis,” in Advances in neural information processing systems , 2009, pp. 961–969.
- 4[4] Kevin Tang, Armand Joulin, Li-Jia Li, and Li Fei-Fei, “Co-localization in real-world images,” in Proceedings of the IEEE conference on computer vision and pattern recognition , 2014, pp. 1464–1471.
- 5[5] Michael Rubinstein, Armand Joulin, Johannes Kopf, and Ce Liu, “Unsupervised joint object discovery and segmentation in internet images,” in Proceedings of the IEEE conference on computer vision and pattern recognition , 2013, pp. 1939–1946.
- 6[6] Fan Wang, Qixing Huang, Maks Ovsjanikov, and Leonidas J Guibas, “Unsupervised multi-class joint image segmentation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 2014, pp. 3142–3149.
- 7[7] Minsu Cho, Suha Kwak, Cordelia Schmid, and Jean Ponce, “Unsupervised object discovery and localization in the wild: Part-based matching with bottom-up region proposals,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 2015, pp. 1201–1210.
- 8[8] Kazuhiko Murasaki, Yukinobu Taniguchi, and Tetsuya Kinebuchi, “Unsupervised multi-class object discovery by spherical clustering of deep features,” ITE Transactions on Media Technology and Applications , vol. 7, no. 1, pp. 2–10, 2019.
