Bounds for the VC Dimension of 1NN Prototype Sets
Iain A. D. Gunn, Ludmila I. Kuncheva

TL;DR
This paper establishes explicit bounds on the VC dimension of 1-nearest neighbor classifiers with fixed prototype sets, providing insights into their learning capacity and training data requirements.
Contribution
It offers the first explicit lower and upper bounds for the VC dimension of fixed-size 1NN classifiers, including a new geometric lower bound for 2D cases.
Findings
Derived explicit VC dimension bounds for 1NN classifiers.
Discussed implications for training set size and learning accuracy.
Introduced a new geometric lower bound for 2D classifiers.
Abstract
In Statistical Learning, the Vapnik-Chervonenkis (VC) dimension is an important combinatorial property of classifiers. To our knowledge, no theoretical results yet exist for the VC dimension of edited nearest-neighbour (1NN) classifiers with reference set of fixed size. Related theoretical results are scattered in the literature and their implications have not been made explicit. We collect some relevant results and use them to provide explicit lower and upper bounds for the VC dimension of 1NN classifiers with a prototype set of fixed size. We discuss the implications of these bounds for the size of training set needed to learn such a classifier to a given accuracy. Further, we provide a new lower bound for the two-dimensional case, based on a new geometrical argument.
Click any figure to enlarge with its caption.
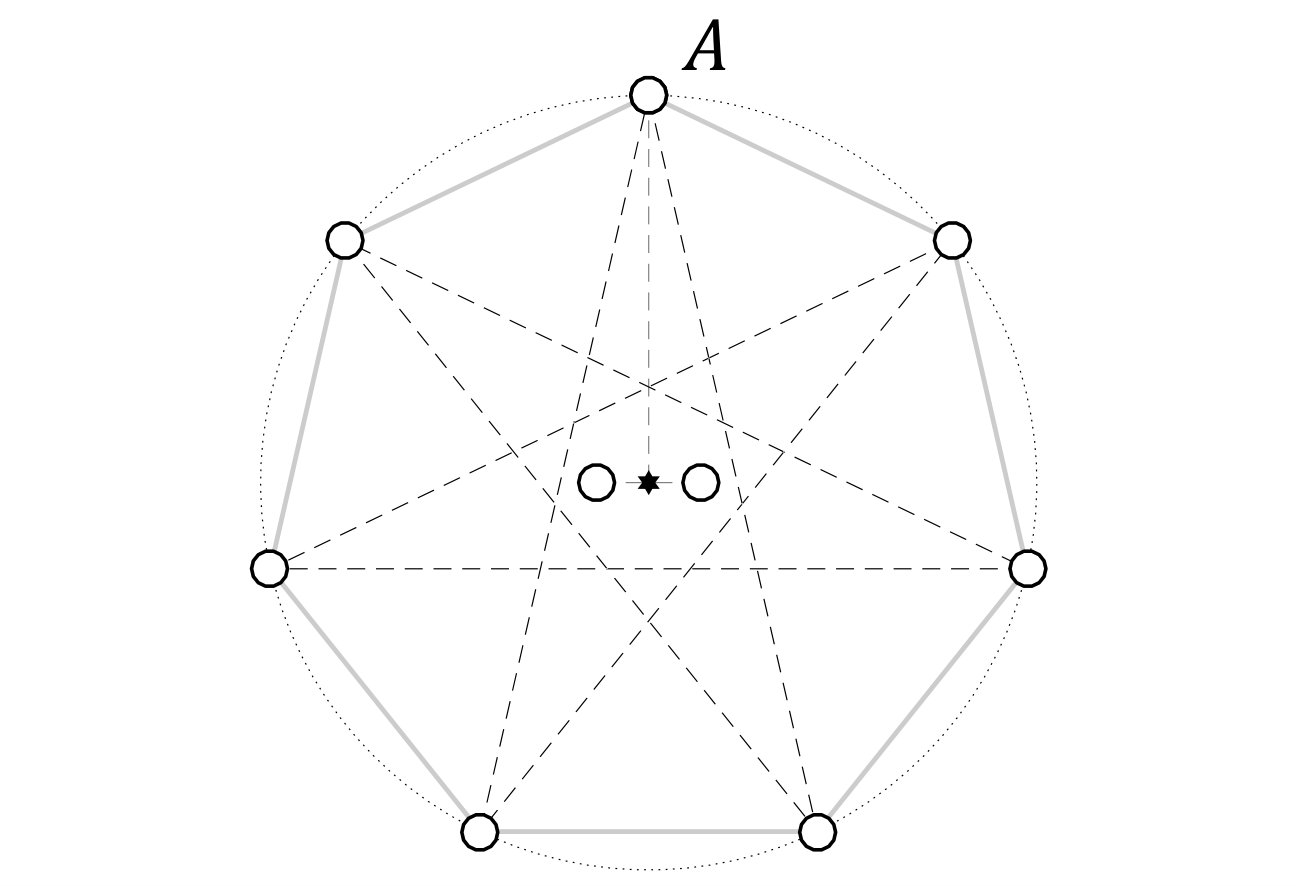 Figure 1
Figure 1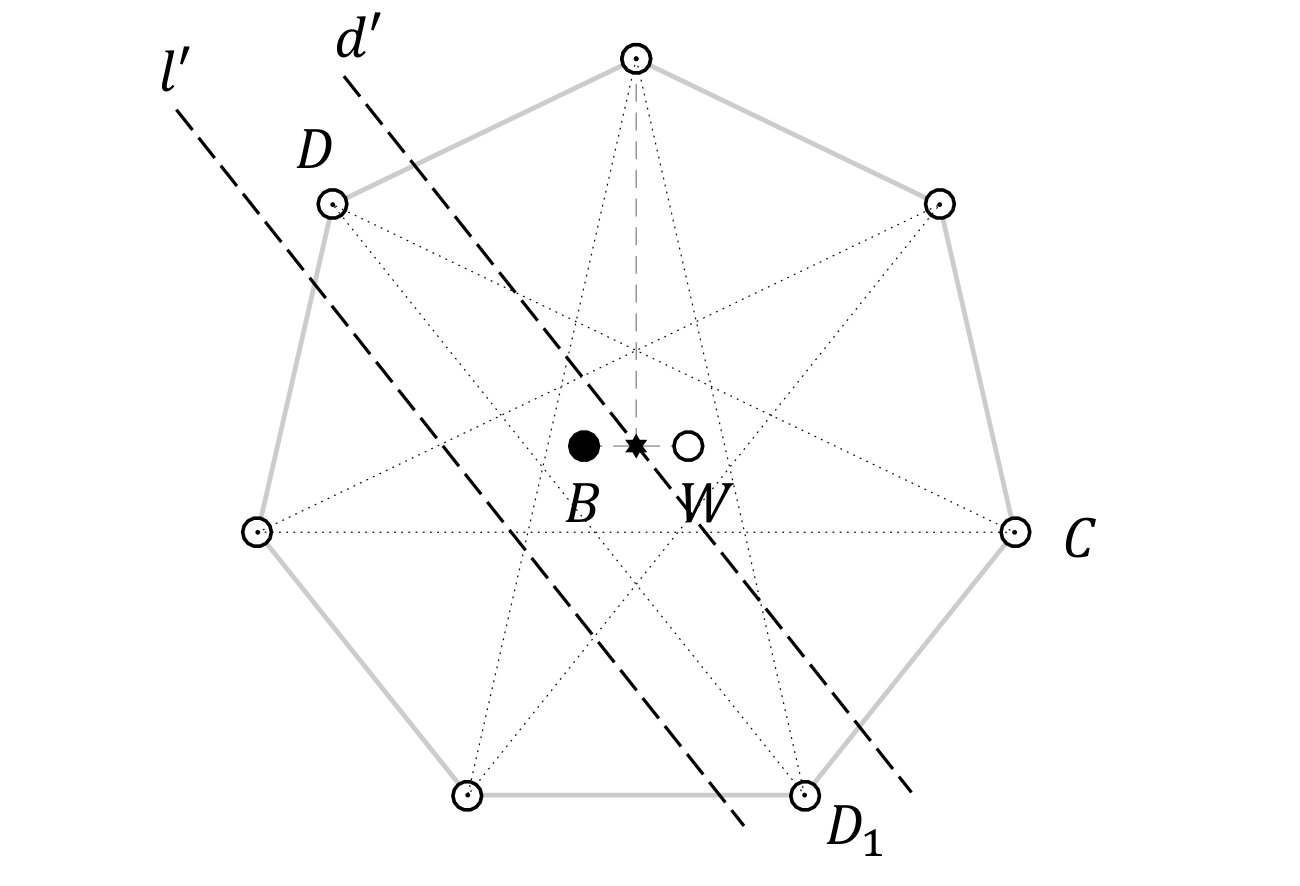 Figure 2
Figure 2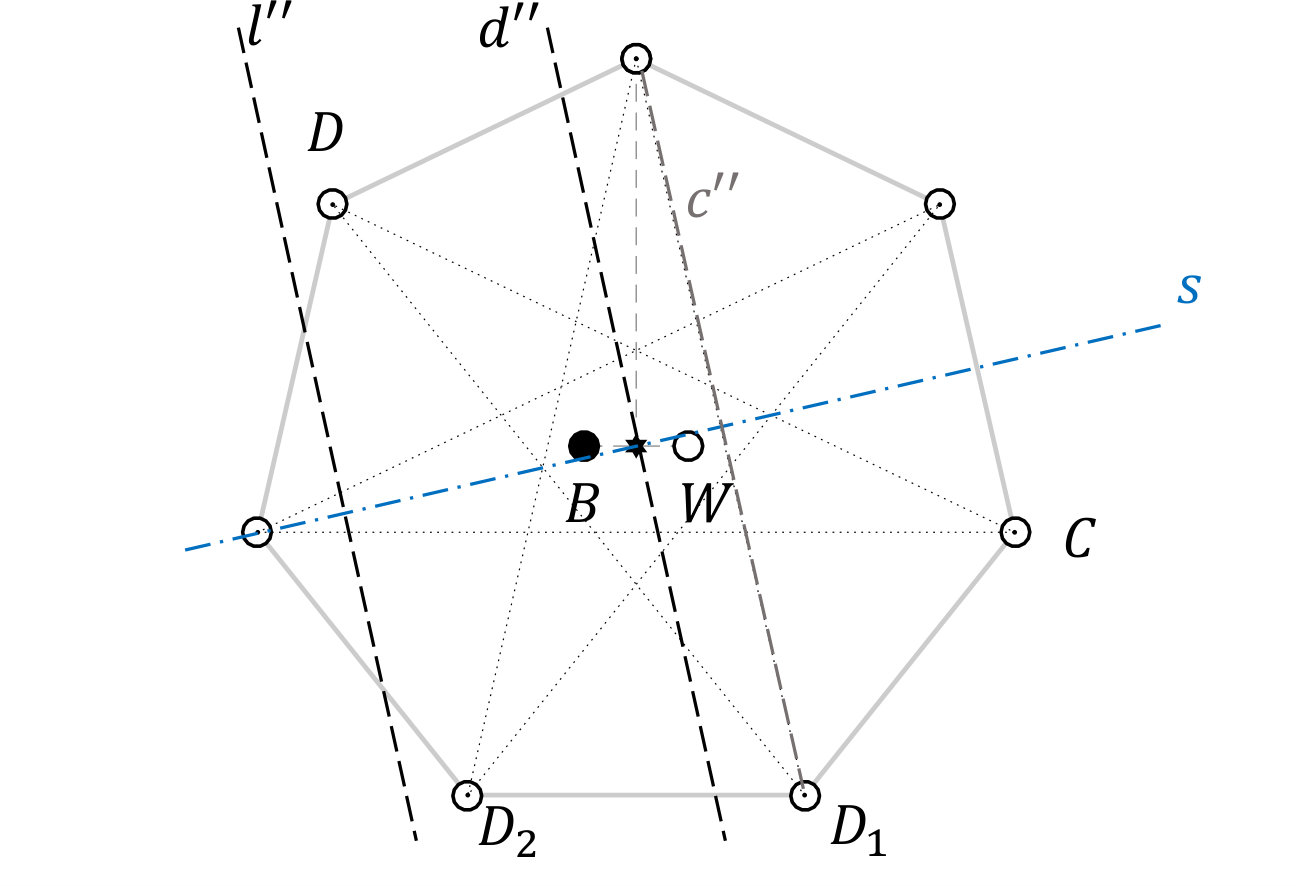 Figure 3
Figure 3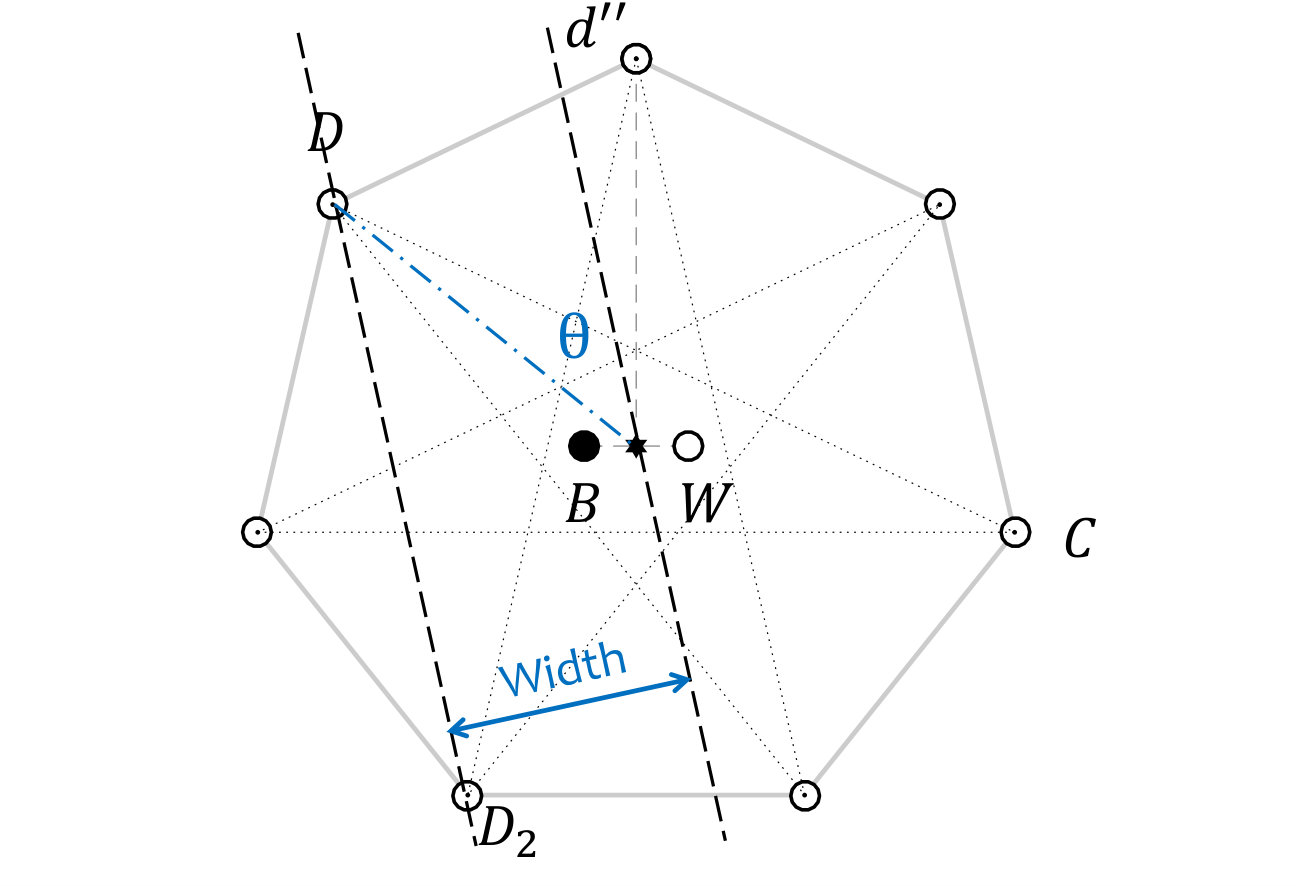 Figure 4
Figure 4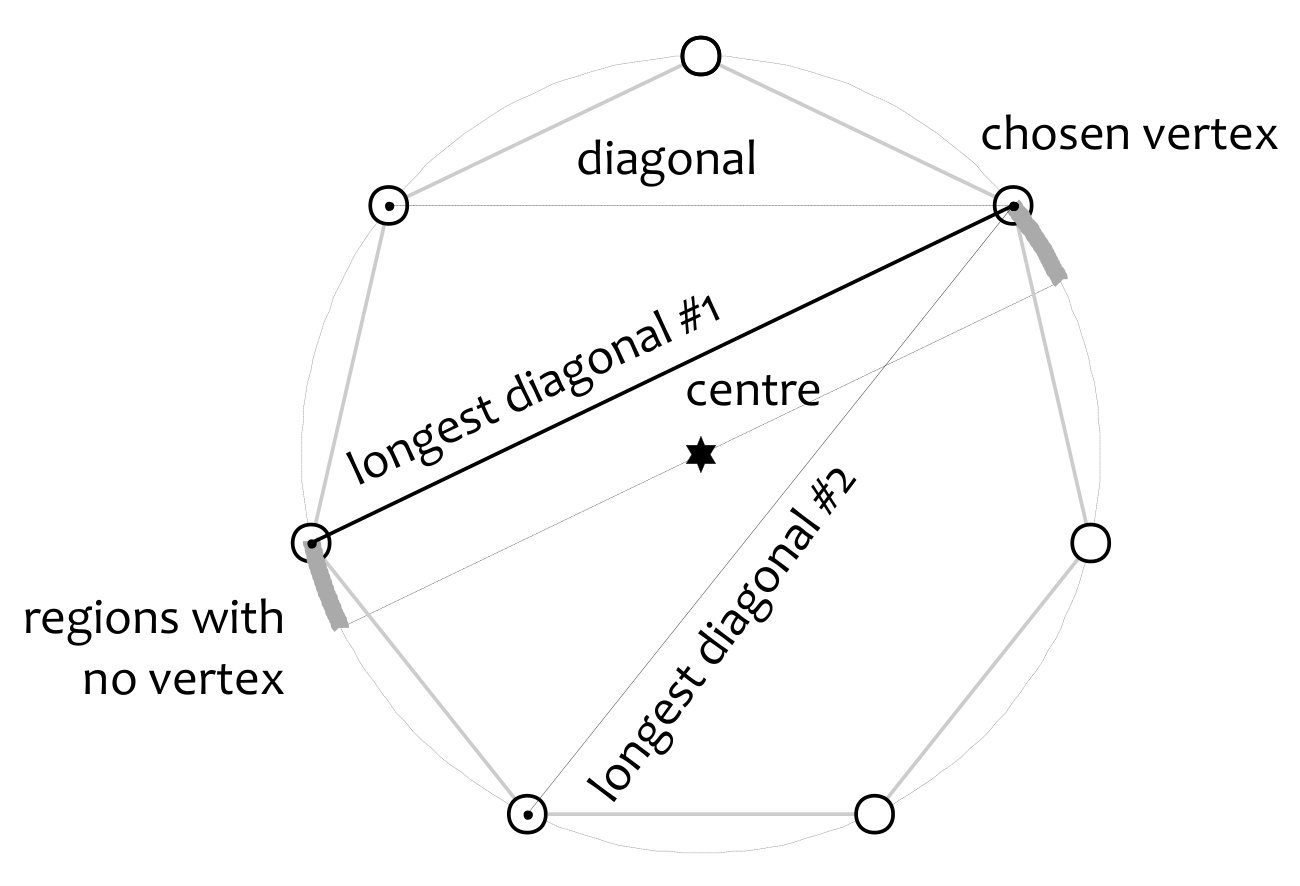 Figure 5
Figure 5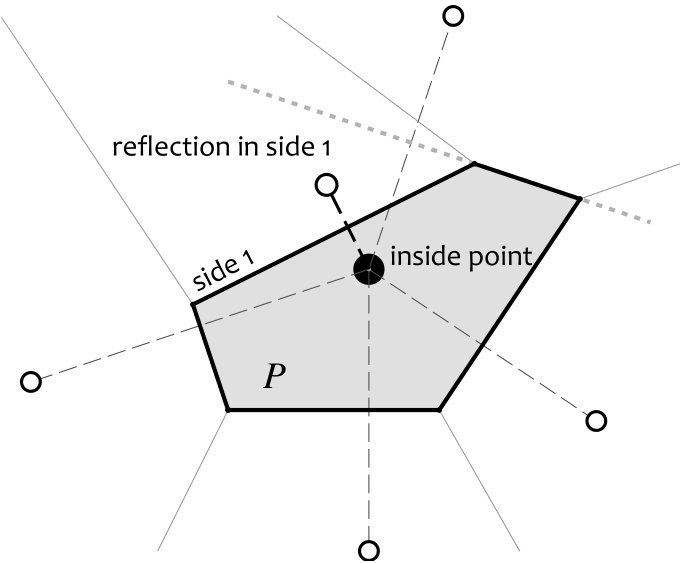 Figure 6
Figure 6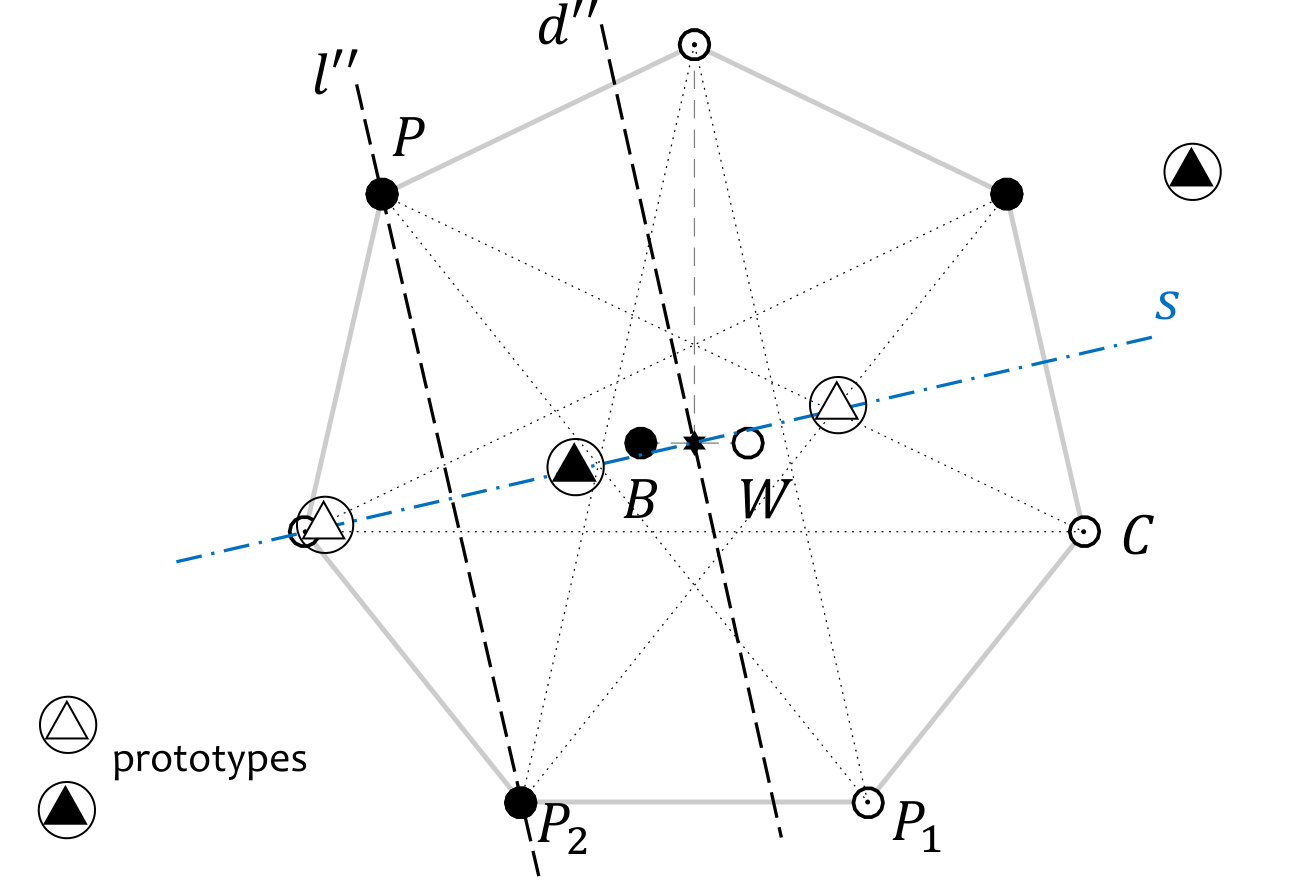 Figure 7
Figure 7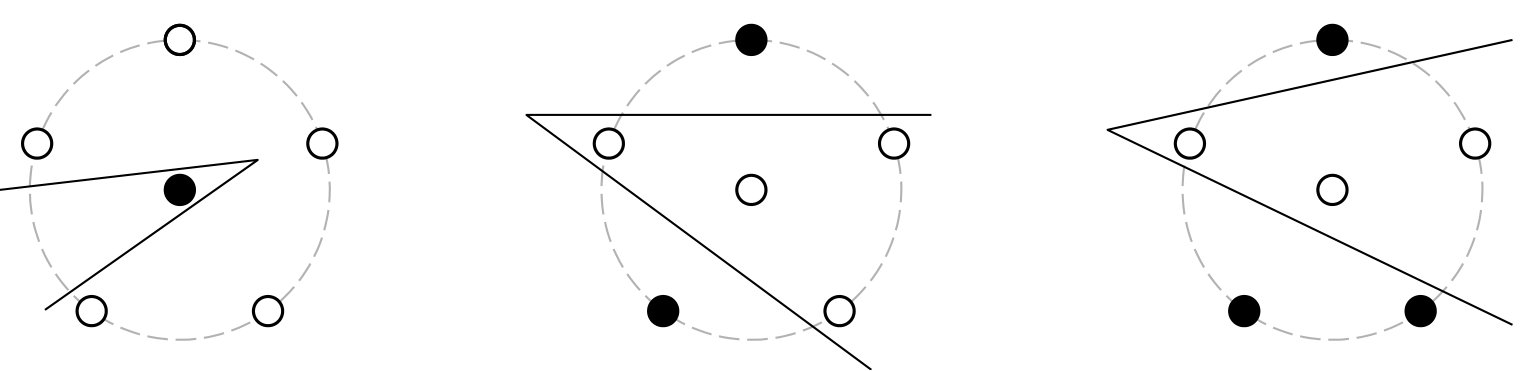 Figure 8
Figure 8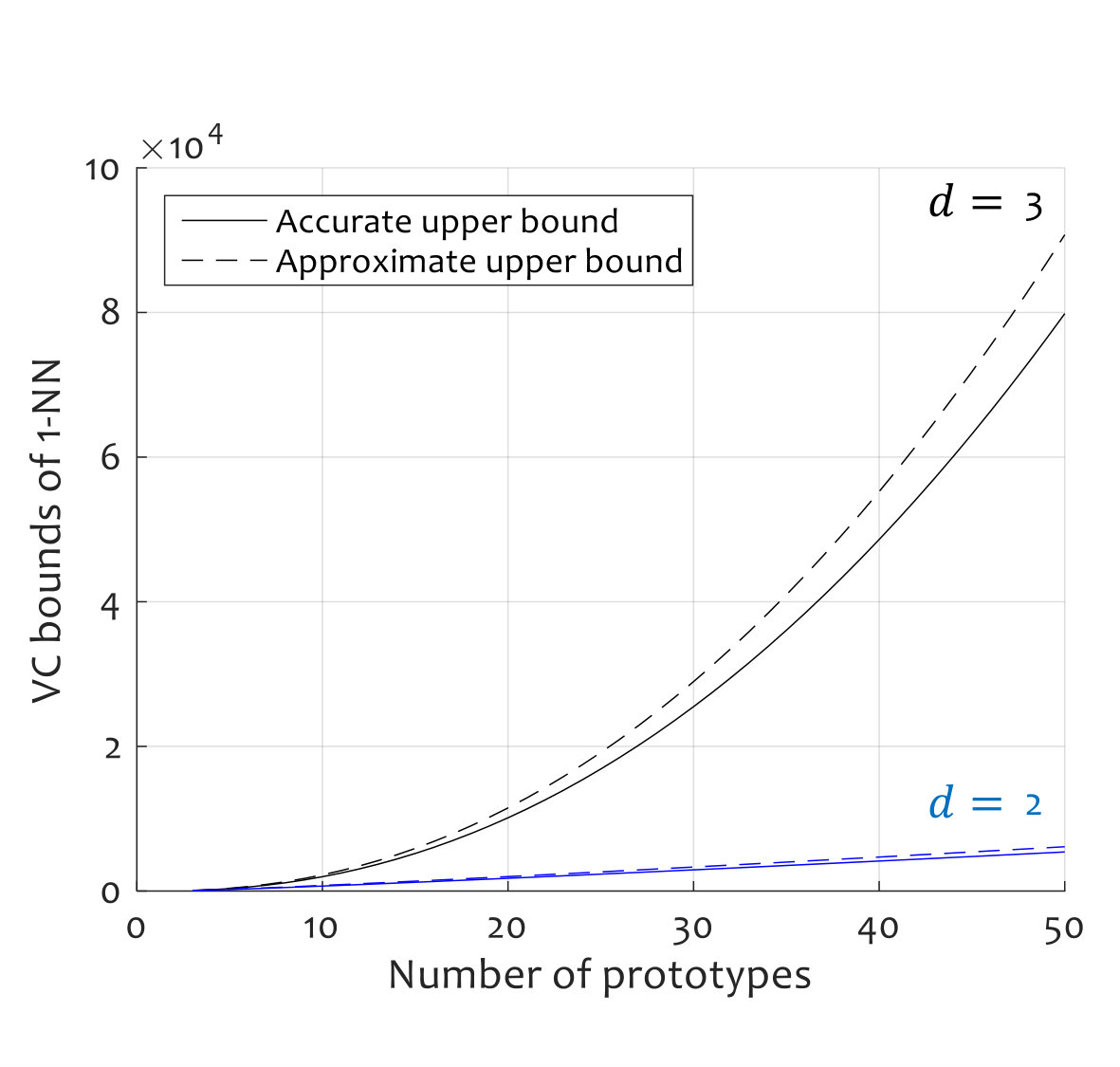 Figure 9
Figure 9| Type of bound | Dimensionality | Expression |
|---|---|---|
| Lower | ||
| Lower | ||
| Upper | ||
| Upper |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMachine Learning and Data Classification · Teaching and Learning Programming · Advanced Multi-Objective Optimization Algorithms
Bounds for the VC Dimension of 1NN Prototype Sets
\nameIain A. D. Gunn \[email protected]
\nameLudmila I. Kuncheva \[email protected]
\addrSchool of Computer Science,
Bangor University,
Dean Street,
Bangor, Gwynedd,
Wales LL57 2NJ,
UK
Abstract
In Statistical Learning, the Vapnik-Chervonenkis (VC) dimension is an important combinatorial property of classifiers. To our knowledge, no theoretical results yet exist for the VC dimension of edited nearest-neighbour (1NN) classifiers with reference set of fixed size. Related theoretical results are scattered in the literature and their implications have not been made explicit. We collect some relevant results and use them to provide explicit lower and upper bounds for the VC dimension of 1NN classifiers with a prototype set of fixed size. We discuss the implications of these bounds for the size of training set needed to learn such a classifier to a given accuracy. Further, we provide a new lower bound for the two-dimensional case, based on a new geometrical argument.
Keywords: Machine learning, classification, VC dimension, prototype generation, statistical learning theory, nearest neighbour
1 Introduction
The VC dimension is a measure of what is called the “capacity” of a classification algorithm: that is, roughly speaking, its flexibility or expressive power. The practical interest of this quantity arises from its role in the Probably Approximately Correct learning model and related models (see e.g. Shalev-Shwartz and Ben-David (2014, ch. 3), Holden and Niranjan ), where it appears in results relating the size of the training set to the classifier’s accuracy. The VC dimension is defined in terms of the concept of shattering (Vapnik, 1995). For a two-class problem in -dimensional space , a set of functions is said to shatter a set of points (in ) if any labelling of that set can be given by an element of . The VC dimension of is the size of the largest set which can be shattered by .
The nearest-neighbour (1NN) classification rule is a classic technique of supervised learning, first introduced by Fix and Hodges (1952). The 1NN rule determines a label for (“classifies”) a given point in a metric space by assigning it the label of the nearest point in a previously determined set of labelled reference points. In the original and simplest algorithm, the reference set is the set of all the training data. If the amount of training data is a priori unbounded, then the VC dimension of the set of associated 1NN-rule classifying functions is infinite: trivially, a set of points of any size is labelled correctly by a classifier whose reference set is the same set of labelled points.
However, it is often not practical to store all the training data, especially in an era of “big data”. Therefore many algorithms have been proposed which learn a smaller reference set from the training data: Garcia et al. (2012) and Triguero et al. (2012) survey more than 75 such algorithms between them. What is the VC dimension associated with these “editing” NN algorithms? If the reference set may grow without bound, then the VC dimension is infinite, as for the naïve classifier described above. But if the reference set is constrained not to exceed a given size, then the VC dimension is finite. The main results of the present work are lower and upper bounds for the VC dimension of the set of all 1NN-rule classifiers which use a reference set of given fixed size, in Euclidean space.
It should be noted that, in general, the size of the reference set to be formed by an editing algorithm is not fixed a priori. There are exceptions, an important one being the case where a classifier for a data stream is kept current by using a fixed window of the most recent points as its reference set (Gunn et al., under review). But it is very common to impose a maximum size limit on the reference set, if only by hand in an ad hoc fashion. Our upper bounds will apply to any algorithm for which the size of the reference set is bounded, though our lower bounds will apply only where the size is prescribed, and the algorithm is capable of returning any reference set of that size.
We believe that there is significant interest in the VC dimension of prototype classifiers with fixed-size reference sets, and that this is shown by the fact that an incorrect purported result (Karaçalı and Krim, 2002, Proposition 2) has been cited more than 50 times as giving the VC dimension of such classifier sets. Our study corrects the record.
We feel there is significant value in bringing together the existing theoretical results, some of which seem otherwise likely to remain obscure to practitioners. Beyond our deductions from existing theory, our novel contributions are 1) A new lower bound for the two-dimensional case, higher than that implied by previous results for polytopes (Proposition 5), and 2) an upper bound for all dimensions, slightly less tight than the best that can be deduced from existing theory, but avoiding the use of exotic functions and thereby facilitating a discussion of the asymptotic behaviour of the limits (Corollary 13).
We will discuss the theoretical framework in section 2, and briefly review the relevant literature in section 3. In sections 4 and 5 we derive lower bounds for the VC dimension, and in section 6 we determine upper bounds. Our results are summarised in section 8.
2 1NN classifiers in the VC theory
We use “classifier” to mean a function from the feature space to the set of classes, which is used to classify unlabelled examples. An algorithm which learns such a function from training data is a “classification algorithm”. The set of all classifiers which the algorithm might produce in response to all sets of training data is called the “hypothesis class” of that algorithm. (For example, the original Rosenblatt Perceptron selects among all functions which map one half-space to one class, and the other half-space to the other class: this set of functions is the hypothesis class of the Perceptron.) When we speak of the VC dimension of a classification algorithm, we mean the VC dimension of the hypothesis class from which that algorithm learns a classifier.
NN classification algorithms are not usually thought of as selecting a classifier from a fixed hypothesis class in this way (see e.g. Shalev-Shwartz and Ben-David, 2014, ch. 19). This is because the great practical advantage of 1NN classification is that a classifier function does not need to be explicitly evaluated when classifying an unlabelled example; the new point is simply assigned the class of the nearest prototype in the reference set, which can be identified efficiently using a -d tree. However, this process is equivalent to classifying the new point according to a classifier function which maps the Voronoi cell of each prototype to the label of that prototype. Thus, the hypothesis class of the 1NN rule with a reference set of prototypes in -dimensional space is the set of all labellings of all -cell Voronoi diagrams in the space; it is parameterised by the co-ordinates of the prototypes, and the choices of label.
We consider only features which take real values, thus classifiers whose domain is , and consider only the 1NN rule with the Euclidean metric. will denote the set of all classifiers which use the (Euclidean) nearest-neighbour rule with a reference set of size . will denote the VC dimension of a set of classifiers. The purpose of this paper is to give lower and upper bounds for .
3 Related Work
A number of existing theoretical results have implications for the VC dimension of the NN classifier with arbitrary reference set of fixed size. However, these results are scattered in the literature and their implications have not been made explicit. In particular, the results we use to establish lower bounds were developed for a class of polytope classifiers, without mention of NN classifiers. In the present section we give a brief overview of relevant theoretical work, starting with some brief historical context and going on to include the work whose implications we will directly use in subsequent sections.
Questions of “separating capacities” of families of decision surfaces were already considered before the advent of the Vapnik-Chervonenkis theory (see e.g. Cover (1965) and references therein). During and shortly after the years of the initial development of the VC theory, several authors used approaches from classical combinatorial geometry to derive results about the VC dimension (or related separability properties) of several simple sets. Readers interested in this literature will need to be aware of the distinction between the VC dimension of a set of classifiers, as we have defined it above, and the VC dimension of a set of subsets of the Euclidean space in question (called by some authors a “concept class”). See our discussion at the start of section 6, and Devroye et al. (1996, pp. 196, 199, and 215).
To give an example of the results obtained, Dudley (1979) reports that the set of balls in has VC dimension . (N.B. Dudley’s quantity is one greater than the quantity defined as the VC dimension in more recent literature.) Similarly, it may be shown that the set of all half-spaces in has VC dimension (see e.g. Devroye et al., 1996, ch. 13).
More recent authors have considered the intersection or union of half-spaces, which is to say, sets which are the interior or exterior of (possibly unbounded) polytopes. Blumer et al. (1989) show that the set of interiors of -gons has VC dimension . This result is quoted by Takács and Pataki (2007) as the starting point for their work in which they find upper and lower bounds for the VC dimension of convex polytope classifiers, from which we will derive a lower bound in section 5.
NN classifiers, like convex polytope classifiers, have decision boundaries which are the union of subsets of hyperplanes. However, the decision region for a NN classifier is not in general a simple intersection or union of half-spaces; it may be a complicated union of the interiors of polytopes formed by such intersections. This may explain why the question of the VC dimension of the NN classifier with an arbitrary reference set of fixed size has not previously, to our knowledge, been addressed, other than in Karaçalı and Krim (2002). (Devroye et al. (1996) consider the closely related property of the shatter coefficient of such classifiers; we will make explicit the implications of this work in section 6.)
Karaçalı and Krim (2002, Proposition 2) claim that the VC dimension of the NN classifier with reference set of size , in our notation, is exactly . Their argument consists of exhibiting a set of points which cannot be correctly classified by prototypes. They do not argue that a general set of points cannot be shattered. This apparently reflects a misunderstanding of the definition of VC dimension. The VC dimension is the largest number for which some set of that size can be shattered, not the largest number such that all sets of that size can be shattered. The latter quantity is called the Popper dimension, a quantity which thus far has not found a rôle in statistical learning theory (Corfield et al., 2009).
4 Lower bounds - two dimensions
Takács and Pataki (Takács, 2007; Takács and Pataki, 2007) prove bounds for the VC dimension of sets of classifiers whose decision boundaries are convex polytopes. These sets can easily be related to sets of nearest-neighbour classifiers, giving lower bounds for the latter. This is because a decision boundary which is an -faceted convex polytope can be obtained as the decision boundary of a 1NN classifier with prototypes, by placing a prototype of one label inside the polytope, and the remaining prototypes, with the opposite label, as the reflections of the first prototype in the facets of the desired decision boundary. See Figure 1 for an example construction with , . We formalise this observation as Proposition 1 below, and give a formal proof in the appendices.
We will use to denote the set of classifiers whose decision boundary is a convex -faceted polytope.
Lemma 1
The set of convex -faceted polytope classifiers is a subset of the set of NN classifiers with reference set of size , in the same Euclidean space. That is,
[TABLE]
Corollary 2
A lower bound for the VC dimension of is also a lower bound for the VC dimension of .
The corollary follows immediately: any set of points which can be shattered by an element of can be shattered by an element (the same element) of .
Takács gives the following result for two-dimensional Euclidean space:
Lemma 3
(Takács)
[TABLE]
for .
We give a sketch of the proof given in Takács (2007) in the appendices. By a more complicated argument, Takács establishes that this lower bound is also an upper bound for the VC dimension of polytope classifiers. In general, upper bounds for polytope classifiers are of no relevance to the more general set of NN-rule classifiers. But the case is an exception, and we make the following brief side remark about this case:
Remark 4
With three prototypes, the only decision surfaces an NN-rule classifier can form are an open 2-gon, or a pair of parallel lines. But any finite set of points which can be correctly dichotomised by a pair of parallel lines can also be correctly split by a digon formed by a suitably small adjustment of the lines such that they are non-parallel. So for this case, the set of NN-rule classifiers has no greater separating power than the related set of polygon classifiers. Thus a precise value for the VC dimension of this set of NN-rule classifiers is established:
[TABLE]
Now, for general , Lemma 3, with Corollary 2, implies a lower bound for :
[TABLE]
However, we can do better than this. For , the NN-rule classifier can create a larger class of decision surfaces than a single convex polytope. In Appendix C we present a new argument, inspired by the elementary geometrical approach of Takács but considerably more involved, demonstrating a stronger lower bound for , :
Proposition 5
[TABLE]
Though this improvement is the smallest possible, it establishes the principle that the VC dimension of 1NN classifiers with prototypes in is larger than that of the relevant comparable class of polygon decision boundaries (recall that Takács’ lower bound, Lemma 3, is also an upper bound for that class). That is, Proposition 5 establishes that 1NN classifiers in gain in expressivity from their ability (for ) to form boundaries other than convex polygons.
5 Lower bound – higher dimensions
Takács’ result was extended by Takács and Pataki to Euclidean spaces of dimension higher than two:
Proposition 6
(Takács and Pataki (2007))
[TABLE]
for , .
**Proof ** The geometrical arguments are less simple than for the two-dimensional case; we refer readers to Takács and Pataki (2007) for the proof.
Remark 7
Takács and Pataki also offer slightly stronger lower bounds for the special cases and : and ; but these require a higher minimum value for than Lemma 6 does.
As in the two-dimensional case, we can deduce a lower bound for the VC dimension of the NN classifier:
Corollary 8
[TABLE]
for , .
Remark 9
The relation does not hold for , : an NN-rule classifier with two prototypes in the plane has for its decision boundary a line, so cannot shatter four points: linear classifiers are, famously, unable to solve the XOR problem.
6 Upper bounds
The shatter coefficient of a family of sets (for our purposes, is a set of subsets of ) is a number closely related to VC dimension. It is called the “growth function” by some authors, but other authors give that term a different definition. The th shatter coefficient of , denoted , is the maximum number of different subsets of points that can be formed by intersection of the points with elements of : that is, the number of subsets that can be “picked out” using elements of . (The maximum is taken over all sets of points.)
The VC dimension of is then the largest such that . This is an expression of the concept of shattering for families of sets rather than classifiers: if the set of all subsets of the points which can be formed by intersection of the points with elements of is all possible subsets of the points, then the points are shattered by .
The VC dimension of a family of classifiers, as we defined it in section 1, is equal to the VC dimension of the associated family of decision regions, as just defined, and the shatter coefficient of a family of classifiers is defined equal to the shatter coefficient of the associated family of decision regions see (see Devroye et al., 1996, ch.12).
Devroye et al. give upper bounds for the shatter coefficients of the class :
Lemma 10
(Devroye, Györfi, and Lugosi) For ,
[TABLE]
**Proof ** See (Devroye et al., 1996, p. 312)
As before, is the dimension of the space and is the number of prototypes used by the classifier.
These upper bounds are based simply on the observation that for a reference set with prototypes there are at most Voronoi cell boundaries, so the number of points which can be shattered by the set of Voronoi diagrams with centres is bounded above by the number of points which can be shattered by hyperplanes. The stronger result for comes from a restriction on the number of edges of a planar graph, applied to the Delaunay triangulation which is the dual of the Voronoi diagram.
These bounds imply the following result for the VC dimension of the NN classifier:
Proposition 11
For ,
[TABLE]
where
[TABLE]
* is the Lambert W function; the branch is the relevant branch. The logarithms are natural logarithms.*
**Proof ** See appendix D.
We can obtain from this a looser but more easily interpretable upper bound by using a recent result which gives a lower bound for the branch of the Lambert function:
Lemma 12
(Chatzigeorgiou)
[TABLE]
for .
**Proof ** See Chatzigeorgiou (2013).
Using this result with proposition 11 gives the following looser bound on the VC dimension:
Corollary 13
Let , where is defined as in proposition 11. Then for ,
[TABLE]
This upper bound enables us to bound the the asymptotic rate of growth of . Now, grows monotonically with and with , and grows at least as fast as for increasing . So whether considering growth with increasing or growth with increasing , the fastest-growing term within the brackets of (14) is . So we have
[TABLE]
for large or .
Table 1 summarises the VC dimension bounds derived in this study.
7 Discussion of asymptotic behaviour
Considering first the rate of growth of the VC dimension with for fixed , equation 15 implies
[TABLE]
for fixed , with the better result
[TABLE]
for . Figure 2 illustrates the upper bounds as a function of , for the cases and .
It is interesting to compare the log-linear growth in given by equation (16) with recent results for neural networks given by Harvey et al. (2017). Consider a neural network with input neurons (the real coordinates of the feature space), and neurons in a single hidden layer with binary threshold activation functions. Each neuron in the hidden layer of such a network encodes a hyperplane decision boundary: the neuron will be in one or the other of its binary states depending on which side the input vector lies of a plane normal to the vector of weights of that neuron. So a network with hidden neurons is comparable to 1NN classifiers with prototypes, in the sense that both build their decision boundaries from parts of hyperplanes. Harvey et al. (2017) prove that a piecewise-linear neural network with parameters has VC dimension with asymptotic growth in the number of parameters. For the network just described, the number of parameters is , meaning the asymptotic growth of its VC dimension is , just as relation (15) gives as an upper bound for our 1NN classifiers. That is, the neural network achieves the (asymptotically) highest value it can for its VC dimension, given the number of hyperplane decision surfaces it has to work with. It is an interesting open question whether the same is true for 1NN classifiers.
Turning now to consider the rate of growth with for fixed , equation (15) implies
[TABLE]
Thus, the VC dimension grows polynomially in (asymptotically slower than ). This has implications for learnability: for example, polynomial growth of the VC dimension of a class with the dimension of the space is a necessary condition for the class to be properly polynomially learnable (Blumer et al., 1989, Theorem 3.1.1.).
8 Conclusions
The VC dimension for the set of all NN-rule classifiers in -dimensional Euclidean space with a reference set of size grows at least as fast as and not faster than ) as increases. For the case of two-dimensional Euclidean space, the VC dimension grows not faster than ).
Considering instead growth with , the VC dimension for the set of all NN-rule classifiers in -dimensional Euclidean space with a reference set of size grows at least as fast as and not faster than ) as increases.
Precise lower and upper bounds for this VC dimension are given in our Corollary 8 and Proposition 11 respectively, and summarised in Table 1.
The consequence of these bounds that is of interest to practitioners is the implication for the size of sample needed to learn an accurate classifier. In the Probably Approximately Correct learning model, the sample complexity is the number of training examples needed to learn a classifier of given accuracy with given probability. The sample complexity of a family of classifiers is known to depend linearly on the VC dimension (Shalev-Shwartz and Ben-David, 2014, Theorem 6.8). Therefore, the bounds we give above for the asymptotic growth of the VC dimension are also bounds on the asymptotic growth of the size of the training data set needed to learn (with given probability) an accurate NN classifier with reference set of given size. The lower bound applies only to classification algorithms which produce reference sets of given fixed size (and can produce any reference set of that size). The upper bound is significantly more broadly applicable. The upper bound applies to any NN classification algorithm which may not have more than points in its reference set.
Thus we may conclude: the size of the training set needed to learn an accurate NN-rule classifier with reference set of size in -dimensional Euclidean space grows not faster than ) as increases. For the case of two-dimensional Euclidean space, the size of the training set required grows not faster than ). Considering instead growth with for fixed , the size of the training set required grows not faster than ).
The fact that the growth rate of the upper bound is asymptotically faster (with ) for than for raises the interesting possibility that there may be something fundamentally different about the behaviour of NN-rule classifiers in 3 dimensions and higher from their behaviour in two-dimensional space. If future work were to establish an lower bound for , this would be confirmed. If, instead, an upper bound were established, implying the same behaviour for the 1NN classifier in higher dimensions as in 2 dimensions, this would imply instead an interesting discrepancy between the behaviour of 1NN classifiers and the behaviour of neural networks with access to an equal number of hyperplanes from which to construct their decision boundaries, as discussed in section 7.
Acknowledgment
This work was done under project RPG-2015-188 funded by The Leverhulme Trust, UK. While preparing the paper for publication, IG received support from the European Union’s Horizon 2020 research and Innovation programme under grant agreement No 731593.
A Proof of Lemma 1
**Proof ** We will show by construction that for an arbitrary convex polytope with facets, there is a labelled set of points such that an NN classifier using this set as a reference set will have for its decision boundary.
The reference set is constructed as follows: place one point, with the label of the interior region, anywhere in the interior of the polytope . The remaining points, with the opposite label, are placed as the reflections of this point in the hyperplanes which contain the facets of . The th hyperplane is therefore the locus of points equidistant from the interior point and the th exterior point. As the polytope is convex, no part of the interior of the polytope lies on the side of the th hyperplane closer to the exterior point (in particular, the placement of the th exterior point does not impact any boundary facet other than that formed by the th hyperplane). Conversely, if a point is on the interior side of all hyperplanes, then it is in the interior of the polytope.
Thus, by construction, the set of points closer to the interior point than to any exterior point is the intersection of the half-spaces which are closer to the interior point than to the respective exterior points. That is, the Voronoi cell of the interior point is the polytope : the decision boundary using the NN classifier is .
Each convex -faceted -tope classifier is therefore a NN classifier with a reference set of size . The set of all such polytope classifiers is therefore a subset of the set of all such NN classifiers.
B Proof of Lemma 3
**Proof ** To prove that the VC dimension of the -gon classifier is at least , we must show that there exists an arrangement of points which can be correctly labelled using an -gon decision boundary, for any possible partitioning of the points into two classes (i.e., the points can be shattered).
The points to be labelled are arranged as follows: place points on a circle, with the final point in the centre. Then an -gon can be constructed to include any subset of the points on the circle, together with the centre point, excluding the other points. The worst case is that, going round the circle, there are separate groups of points (of size one or two) of the opposite label to the centre point; the edges of the -gon may be arranged to exclude one of these groups each. It is always possible to place a line separating a sequence of points around the circle from the rest of the points on the circle, as the points on the circle are in convex position.
The case where a sequence of points of opposite label to the centre point extends more than half-way round the circle, as in Figure 3(a), must be considered separately but presents no difficulties.
Remark 14
In the case the decision boundary is two half-lines radiating from one point; in Takács’ terminology a “polygon” need not be bounded. Figure 3 illustrates examples of partitionings in the case of and six points. Any partition of the points into two groups can be constructed with the V-shaped border.
Remark 15
Devroye et al. (1996, p. 224)** make a similar construction with polygons and points on a circle, but use it only to prove that the class of all convex polygons has infinite VC dimension.
C Proof of proposition 5
We begin with some geometrical preliminaries, as illustrated in Figure 4. A diagonal of a polygon is a line segment joining two non-adjacent vertices. The vertices of a regular polygon all lie on the same circle, called the circumcircle of the polygon, and are equally spaced around it. Each vertex of a regular -gon (for ) is associated with two “longest diagonals”, which connect the vertex in question to the vertices which are furthest away from it (both around the perimeter and in Euclidean metric). The two longest diagonals are reflections of each other in the diameter of the circumcircle which passes through the given vertex.
Lemma 16
No vertices of a regular -gon lie between the line of a longest diagonal of the -gon and a line through the centre of the polygon which is parallel to this diagonal.
**Proof ** Recall that vertices of a regular polygon must all lie on the same circumcircle. If there were a vertex between the longest diagonal and a diameter of the circumcircle which does not intersect it, then a line from this vertex to the end of the longest diagonal further from it would be a diagonal longer than the longest diagonal.
We will now introduce the arrangement of points which we will subsequently argue can be shattered by a NN-rule classifier with prototypes.
Arrangement 17
(Figure 5.) Place points as the vertices of a regular -gon, . Two further points are placed on a line which runs through the centre of the -gon, and which is perpendicular to a line from one vertex (marked ‘’) through the centre. The two points are placed on this line at an equal distance either side of the centre. This distance is sufficiently small that neither of the two points is separated from the centre by any of the diagonals of the -gon. This is equivalent to requiring that the two points lie within the smaller -gon formed by the central sections of the longest diagonals of the original -gon, between their mutual intersections.
We now have two lemmata which establish some geometric properties of this arrangement of points. Lemma 18 will show that there are certain sets of three points, which include one of the two centre points but not the other, which can be separated from the remaining points by two parallel lines. This will be important when we come to demonstrate that the set of points can be shattered, because the labellings which are difficult to achieve are those for which the central points do not both have the same label.
Lemma 18
Let points be placed as Arrangement 17, . Call one of the inner points , and the other . Let be the vertex nearest to . Then, given any choice of vertex other than , there exist vertices , not adjacent to , such that can be separated from all other points by two parallel lines. (Figure 6.)
**Proof ** Denote the diameter of the circumcircle which passes through point by . One of the two longest diagonals from passes on the same side of as , and the other passes on the side of . One of the two points which we will prove has the desired property is the point at the opposite end of that longest diagonal from D which passes on the side of ; call this point .
We will construct two parallel lines such that , , and are between the lines, and the remaining points are not (Figure 6(a)). The required lines are parallel to . One of the lines is a diameter, . By Lemma 16 there is no vertex between and . The second parallel line, , is placed on the far side of from the centre. It can be placed arbitrarily close to , so it is always possible to place it such that that no vertices lie between and . Therefore the only points between and are , , and .
is the vertex adjacent to on the side of (Figure 6).
The set is separated from the rest of the points in the construction by two parallel lines as follows. Consider the line of symmetry of the polygon for which is the reflection of . The two lines required are perpendicular to (unless passes through the vertex defined in Arrangement 17 as , which case we discuss shortly). The first line, passes through the centre of the polygon. The second line, , is placed further from the centre than , a sufficiently small distance from that no vertices lie between it and .
We now argue that no vertices lie between and . Consider the longest diagonal from which does not go to . Call this longest diagonal . Now suppose there were a vertex on the arc of the circumcircle between and : then would not be an adjacent vertex to , which it is by definition. Suppose instead there were a vertex on the arc of the circle between and the vertex at the other end of from . Then a line segment from this vertex to would be a diagonal longer than the longest diagonal. Therefore there are no vertices between and . Now, is parallel to , therefore, by the symmetry of the regular -gon in , it is parallel to , and it is closer to than is, since it passes through the centre. So the region between and is entirely contained in the region between and , so the fact that there is no vertex in the latter region implies there is no vertex in the former region.
If is perpendicular to , then and are placed at a suitably small angle (it may be arbitrarily small) to the perpendicular to the line of symmetry, such that falls between the lines and does not.
We shall need to know the width of the strip constructed in the previous lemma to contain , , and .
Lemma 19
Let points be placed as Arrangement 17, . Let and be defined as in Lemma 18 (Figure 7). Then the distance from the centre of the polygon to is less than 0.63 times the circumradius.
**Proof ** By an elementary geometrical argument, the angle between the line passing through the centre and , and , is
[TABLE]
Therefore the distance between and the centre is
[TABLE]
where is the circumradius. This width decreases monotonically with . The largest value it may take in our construction is therefore associated with the smallest value of we consider, . In this case,
[TABLE]
We are now in a position to prove the proposition.
Proposition 20
[TABLE]
for .
**Proof ** We shall prove that the set of points placed as Arrangement 17 can be shattered by NN-rule classifiers using prototypes. That is, we will prove that all labellings of these points can be correctly classified by a NN-rule classifier with prototypes in the reference set.
If the two inner points have the same label, then the situation is the same as described for the polygon classifier in Appendix B: an -gon can be constructed containing the two central points and all the points on the circle of the same label, just as if there were only one central point.
Consider now the case where the two interior points are of different labels. We will refer to the class less-represented among a given labelling of the points as “black”, and the other class as “white”. The black class, by this definition, contains at most points. It remains to prove that all labellings in which the interior points have different colours can be labelled by a NN-rule classifier with prototypes.
Identify the black and white interior point with the points B and W respectively of Lemma 18. Point C is then defined as in that lemma.
Suppose there are points in the “black” class, of which are vertices of the polygon. Since , two of the black points must then be vertices of the polygon other than C. Let one of these these vertices be P, and define and to have the same relation to P as and have to in Lemma 18 (Figure 8). If either or is black, then that point, with P and the black centre point, can be separated from the remaining points by two parallel lines as described in Lemma 18. If both and are black, pick one of them arbitrarily to make the construction. By Lemma 19, the distance between these parallel lines is less than two thirds of the circumradius. These parallel lines can therefore be achieved as a decision surface by three prototypes all of which are inside the circle: a black prototype is placed on the line of the symmetry of the polygon which is perpendicular to these two lines, halfway between them, and therefore less than one third of the circumradius away from the centre of the circle. Two white prototypes are placed as the reflections of this black prototype in the two parallel lines; since the black prototype is less than one-third of the radius away from the centre, the white prototypes are within the circle. Each of the remaining black vertices can be separated from the rest of the points by a single line (due to the convexity of the polygon, as in the argument for the polygon classifier). This line can be achieved as a decision surface by placing a black prototype as the reflection in this line of the nearer white prototype. All vertices not so separated and not contained between the two parallel lines first constructed will be classified as white by the two white prototypes. Thus the points are classified correctly by prototypes, 3 within the polygon and outside it.
Now consider the case in which neither nor is black. In this case, black labels must be distributed among the vertices which are neither nor . Consider the case where no two adjacent vertices are both black. If no two adjacent vertices are both black, then there is only one possible arrangement (since and are adjacent): The vertices either side of the pair must both be black, and every second vertex between them (going around the circle) must be black. Let be a black vertex in this arrangement which is neither nor (recall that there must be at least one such vertex, because ). Let the two points , be the two points which have the same relation to as and have to in the proof of Lemma 18. At most one of and can be an element of , because is not . Therefore, since and are adjacent vertices, one of them must be black, and can therefore be separated along with and the black centre point by two parallel lines, allowing correct classification of all the points as in the case where or was black. Thus, either the points can be classified this way, or there are two adjacent vertices which are both black.
Two cases now remain to be considered. First, the case in which neither nor is black, but the remaining vertices do not have the only labelling which ensures no two adjacent vertices are black. Second, the case in which there are fewer than points in the black class. The construction is essentially the same for both of these cases. The construction proceeds as previously, but it is only necessary to contain two black points between the parallel lines. and one of the black vertices not part of the adjacent pair (if there is only one pair, or not the common vertex between two pairs if there are precisely three black vertices forming a run of three) are separated by two parallel lines (an arbitrarily small distance either side of the line containing these two points); these lines are achieved as a decision surface by three prototypes within the circle, a black prototype between two white prototypes as before. The remaining prototypes are black, and are placed as reflections of the nearer white prototype in a line separating a single black vertex or an adjacent pair of black vertices from the other points. Not all prototypes may be needed for this purpose, but unneeded prototypes may be placed at a large distance from the points so as not to affect the classification.
D Proof of Proposition 11
**Proof ** From the definition of VC dimension in terms of shatter coefficient, is given by the largest solving
[TABLE]
Now, if a continuous function satisfies
[TABLE]
and also grows more slowly than asymptotically, then the largest solving
[TABLE]
must be at least as large as the largest solving (23). The bounds of Lemma 10 satisfy these conditions, so we may substitute them into (25) to find that is bounded above by the largest solving
[TABLE]
Equation (26) is solved by
[TABLE]
where the solution on the branch is the largest real solution, which is therefore the upper bound.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Blumer et al. (1989) A Blumer, A Ehrenfeucht, D Haussler, and K Warmuth. Learnability and the Vapnik-Chervonenkis dimension. J. Assoc. Computing Machinery , 36(4):929–965, 1989.
- 2Chatzigeorgiou (2013) Ioannis Chatzigeorgiou. Bounds on the Lambert function and their application to the outage analysis of user cooperation. IEEE Communications Letters , 17(8):1505–1508, 2013.
- 3Corfield et al. (2009) D. Corfield, B. Schölkopf, and V. Vapnik. Falsificationism and statistical learning theory: Comparing the Popper and Vapnik-Chervonenkis dimensions. J. General Philosophy of Science , 40:51–58, 2009.
- 4Cover (1965) T. M. Cover. Geometrical and statistical properties of systems of linear inequalities with applications in pattern recognition. IEEE Trans. Electronic Computers , 3:326–334, 1965.
- 5Devroye et al. (1996) L Devroye, L Györfi, and G Lugosi. A probabilistic theory of pattern recognition . Springer-Verlag, New York, 1996.
- 6Dudley (1979) R Dudley. Balls in ℝ k superscript ℝ 𝑘 \mathbb{R}^{k} do not cut all subsets of k + 2 𝑘 2 k+2 points. Advances in Math. , 31:306–308, 1979.
- 7Fix and Hodges (1952) E. Fix and J. L. Hodges. Discriminatory analysis : Non parametric discrimination : Small sample performance. Technical Report Project 21 - 49 - 004 (11), USAF School of Aviation Medicine, Randolph Field, Texas, 1952.
- 8Garcia et al. (2012) Salvador Garcia, Joaquín Derrac, José Ramón Cano, and Francisco Herrera. Prototype selection for nearest neighbor classification: Taxonomy and empirical study. IEEE Trans. Pattern Analysis and Machine Intelligence , 34(3):417–435, 2012.