Wireless Networks Design in the Era of Deep Learning: Model-Based, AI-Based, or Both?
Alessio Zappone, Marco Di Renzo, M\'erouane Debbah

TL;DR
This paper explores how deep learning can complement traditional mathematical models in wireless network design, emphasizing hybrid approaches that leverage both data-driven and model-based techniques for improved efficiency and performance.
Contribution
It provides a comprehensive overview of deep learning methodologies, surveys current literature, and presents novel case studies demonstrating the benefits of hybrid model-based and AI-based approaches in wireless networks.
Findings
Deep learning reduces data requirements for network design.
Hybrid approaches outperform purely model-based or data-driven methods.
Neural networks effectively optimize various wireless communication tasks.
Abstract
This work deals with the use of emerging deep learning techniques in future wireless communication networks. It will be shown that data-driven approaches should not replace, but rather complement traditional design techniques based on mathematical models. Extensive motivation is given for why deep learning based on artificial neural networks will be an indispensable tool for the design and operation of future wireless communications networks, and our vision of how artificial neural networks should be integrated into the architecture of future wireless communication networks is presented. A thorough description of deep learning methodologies is provided, starting with the general machine learning paradigm, followed by a more in-depth discussion about deep learning and artificial neural networks, covering the most widely-used artificial neural network architectures and their training…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1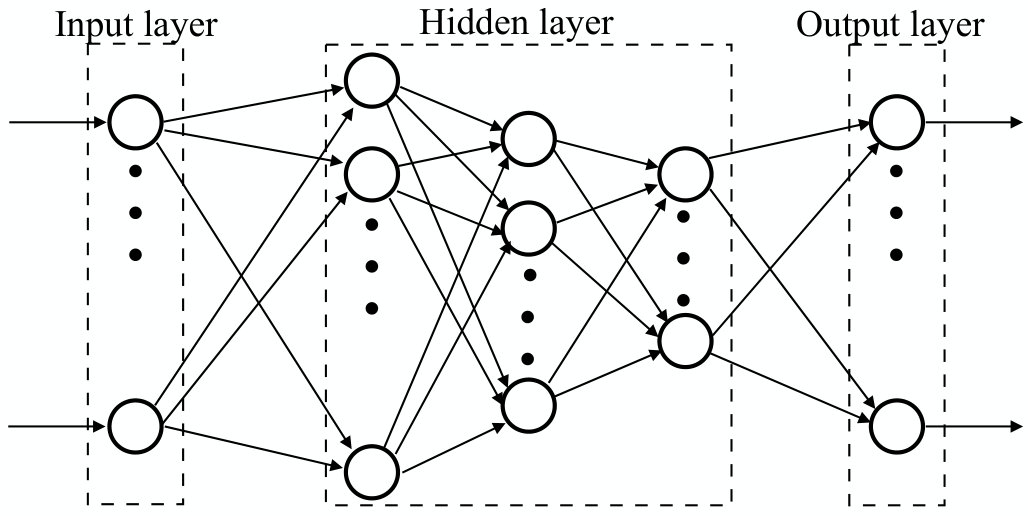 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4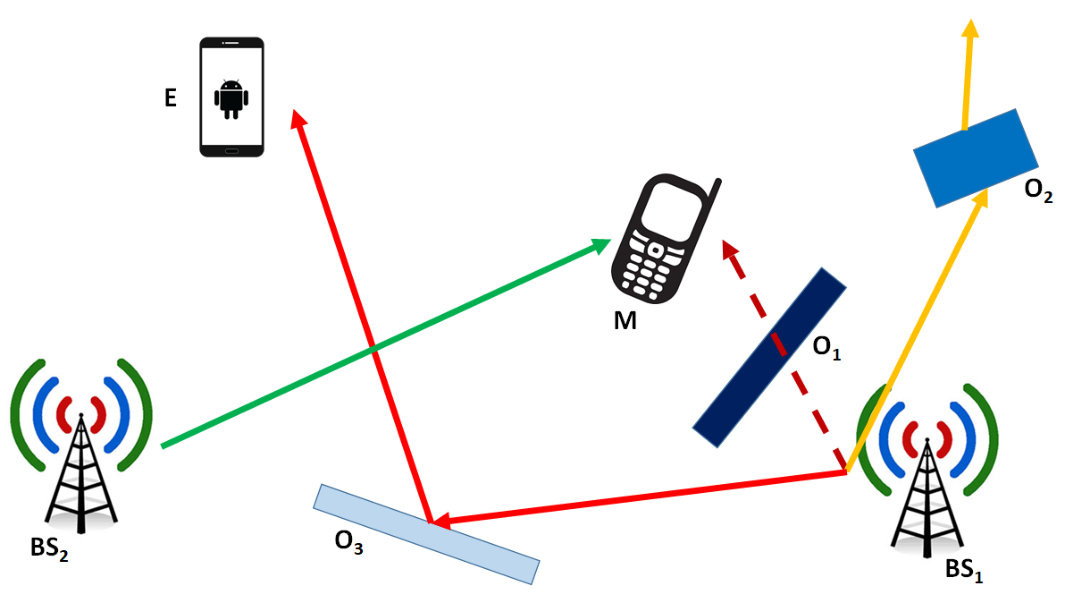 Figure 5
Figure 5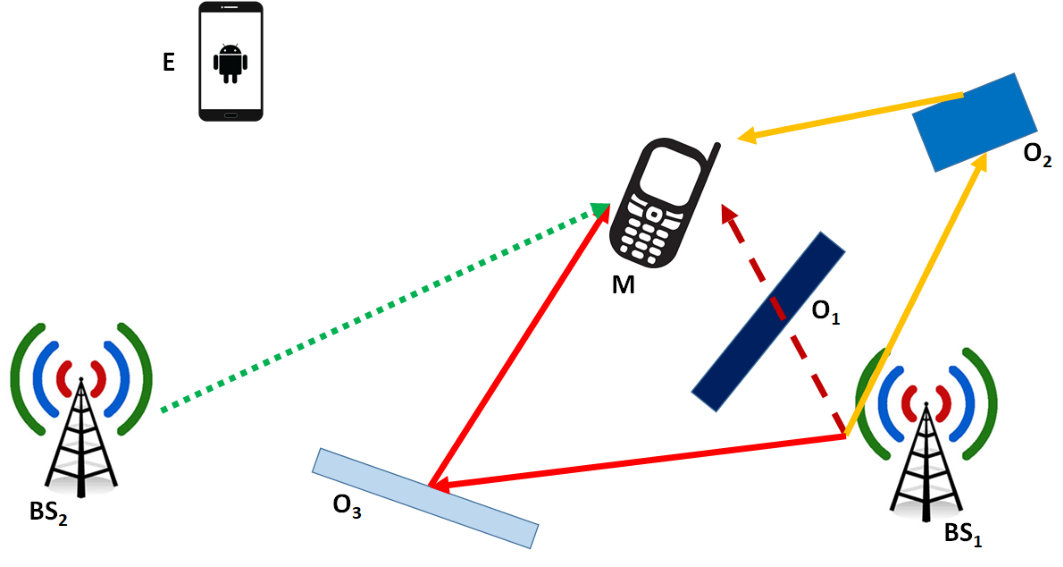 Figure 6
Figure 6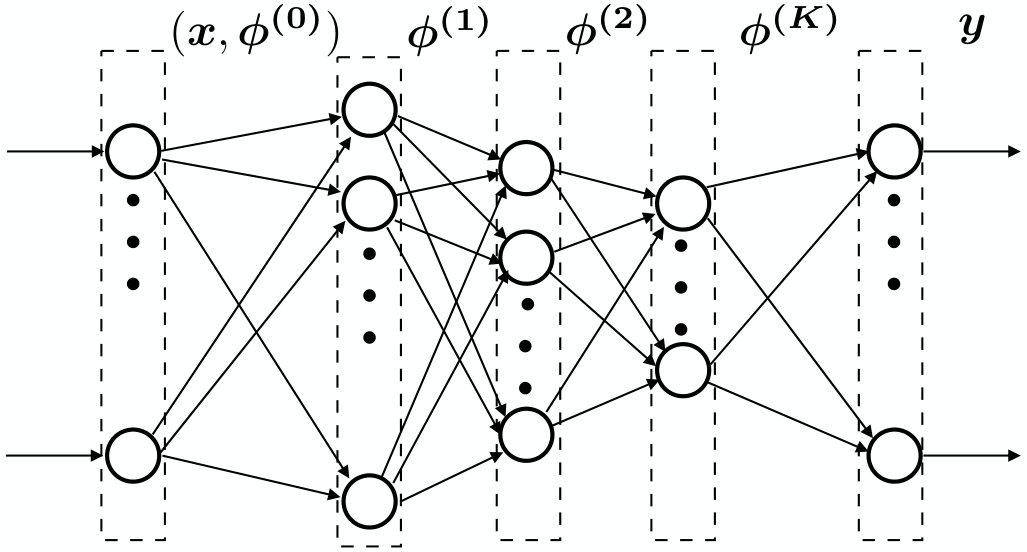 Figure 7
Figure 7 Figure 8
Figure 8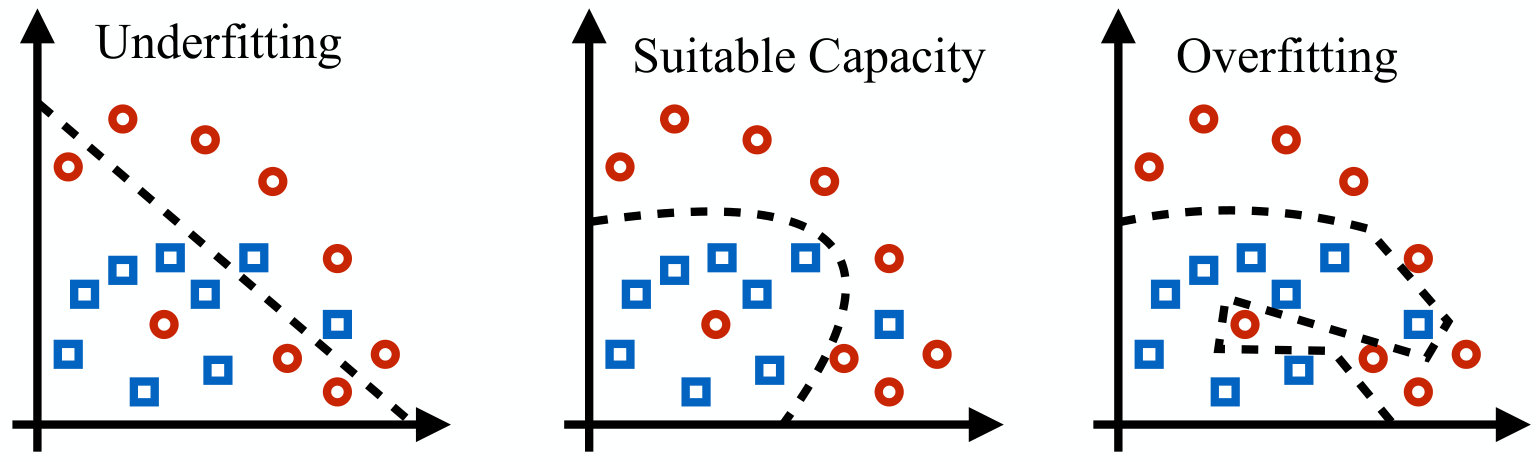 Figure 9
Figure 9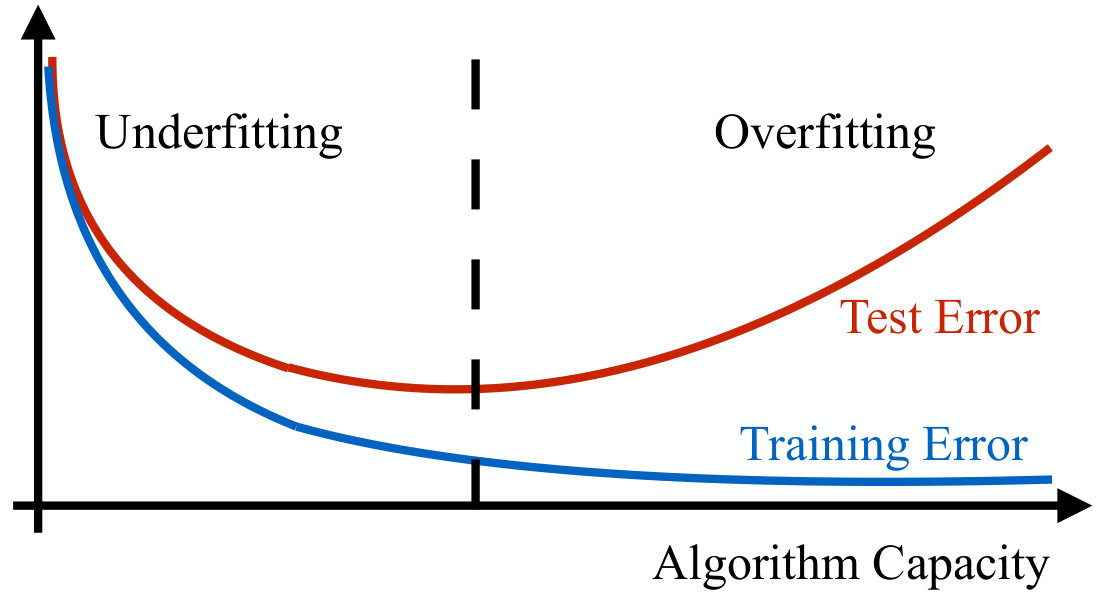 Figure 10
Figure 10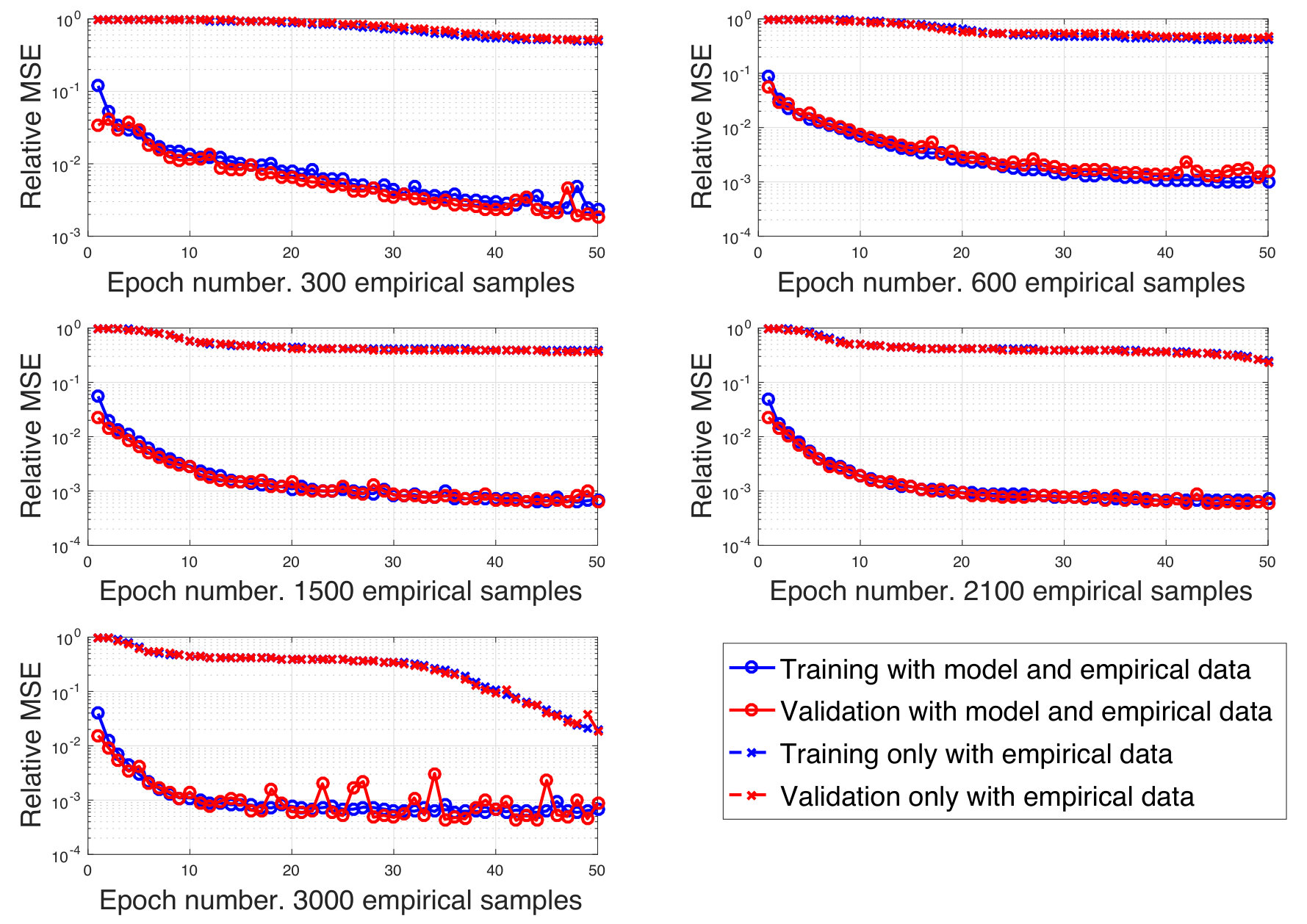 Figure 11
Figure 11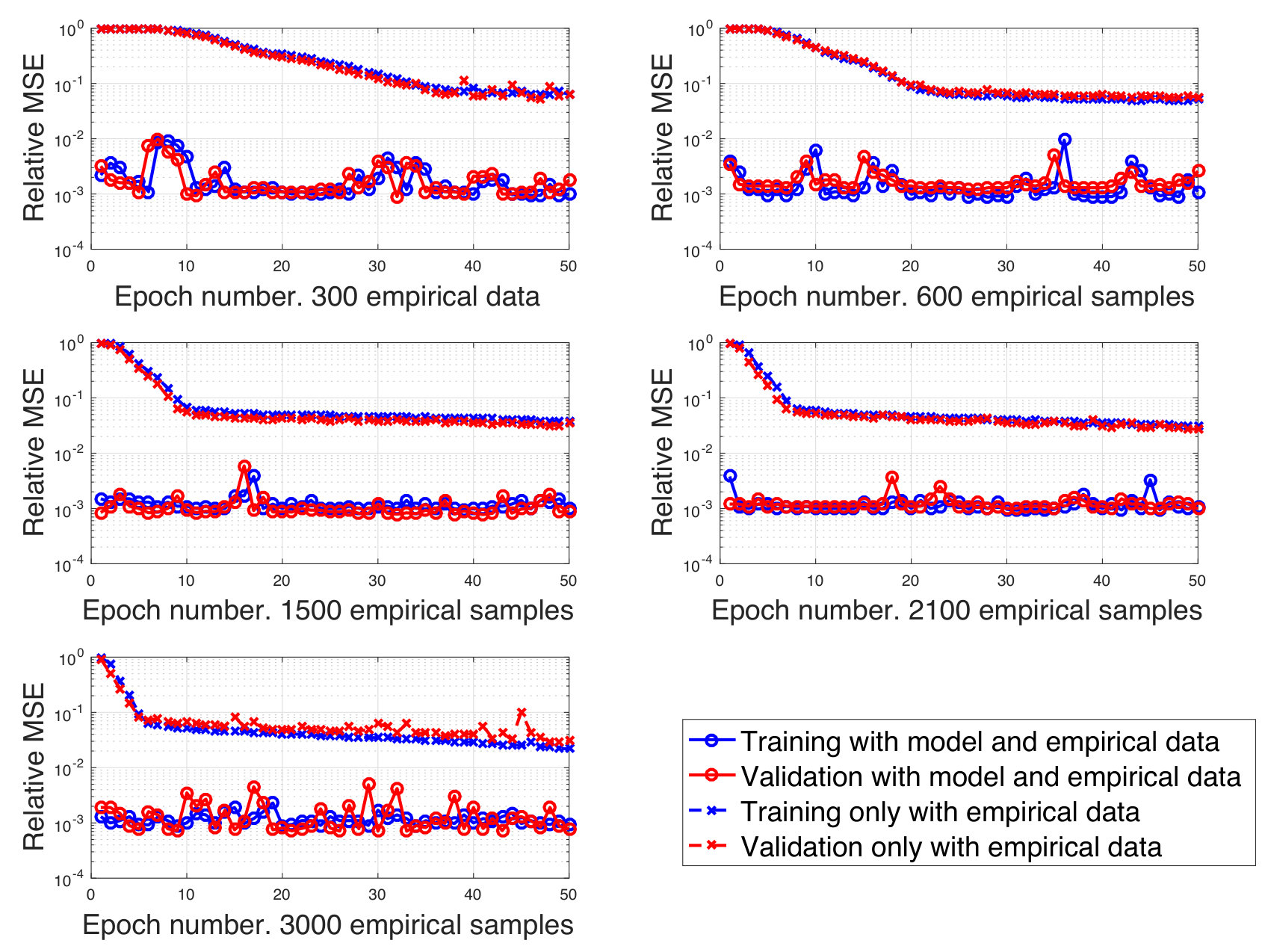 Figure 12
Figure 12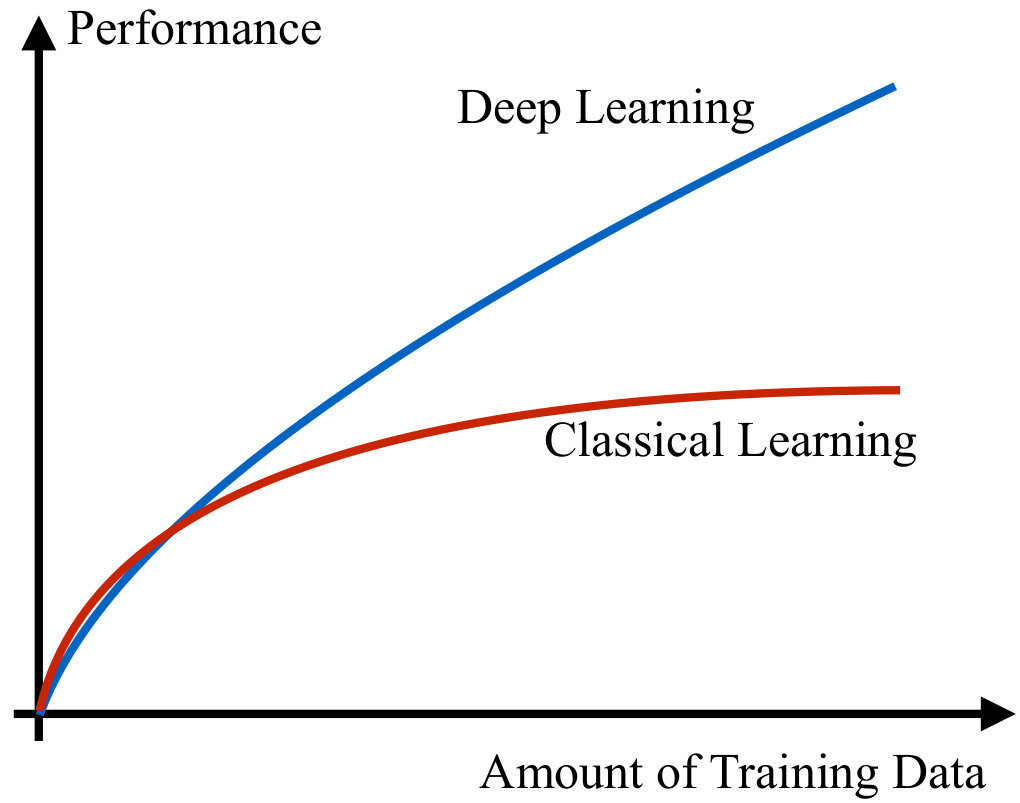 Figure 13
Figure 13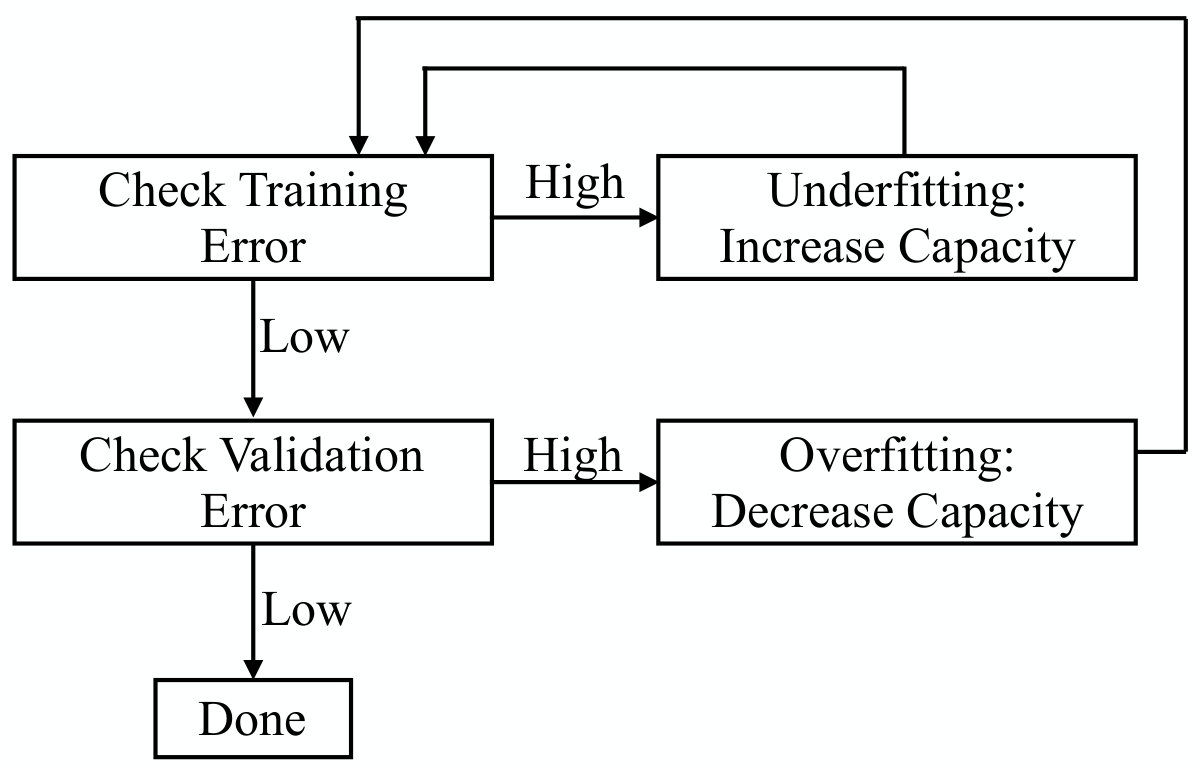 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17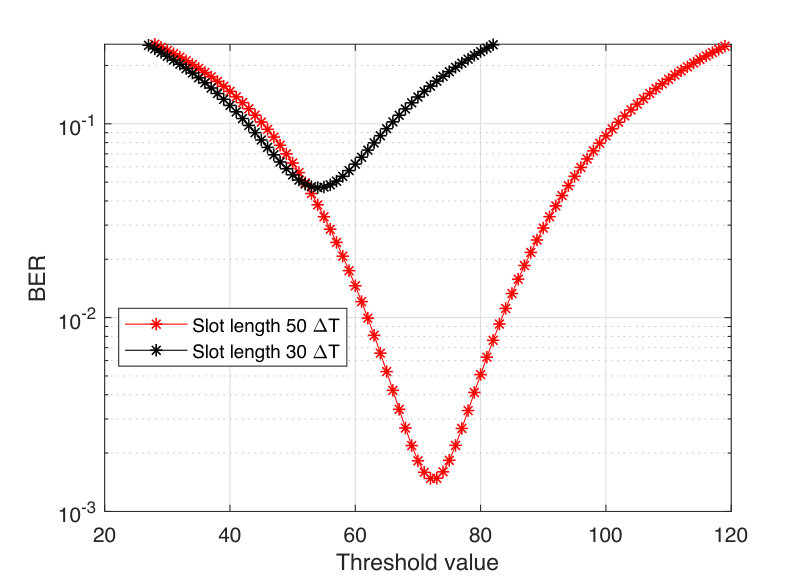 Figure 18
Figure 18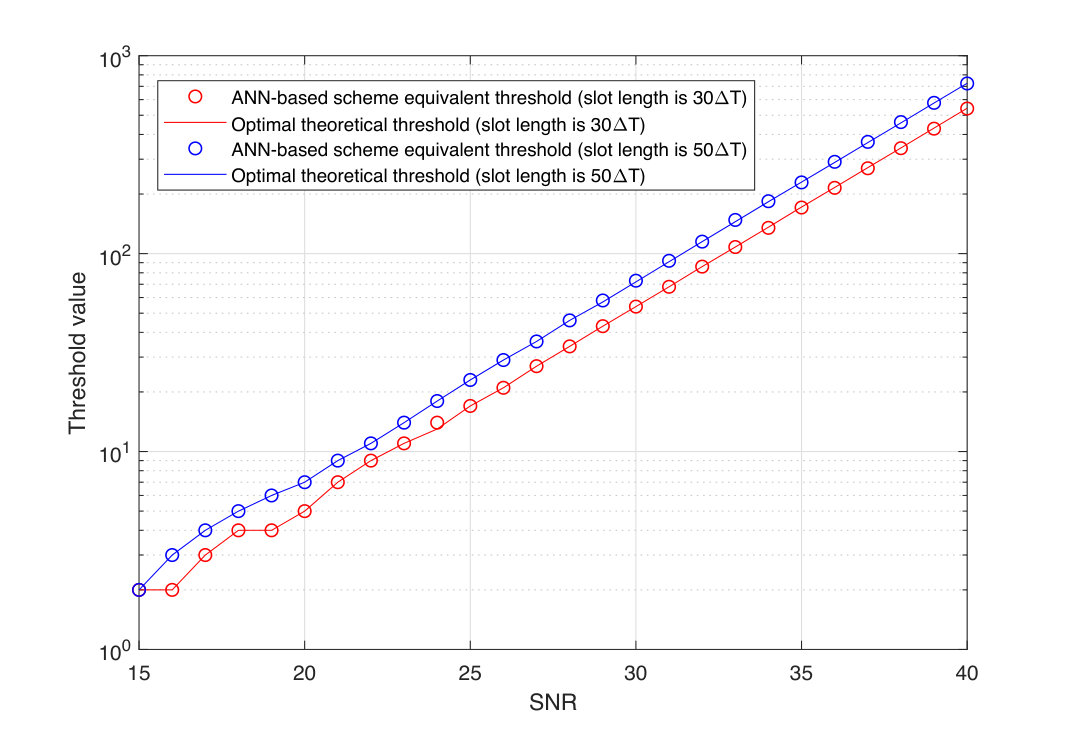 Figure 19
Figure 19 Figure 20
Figure 20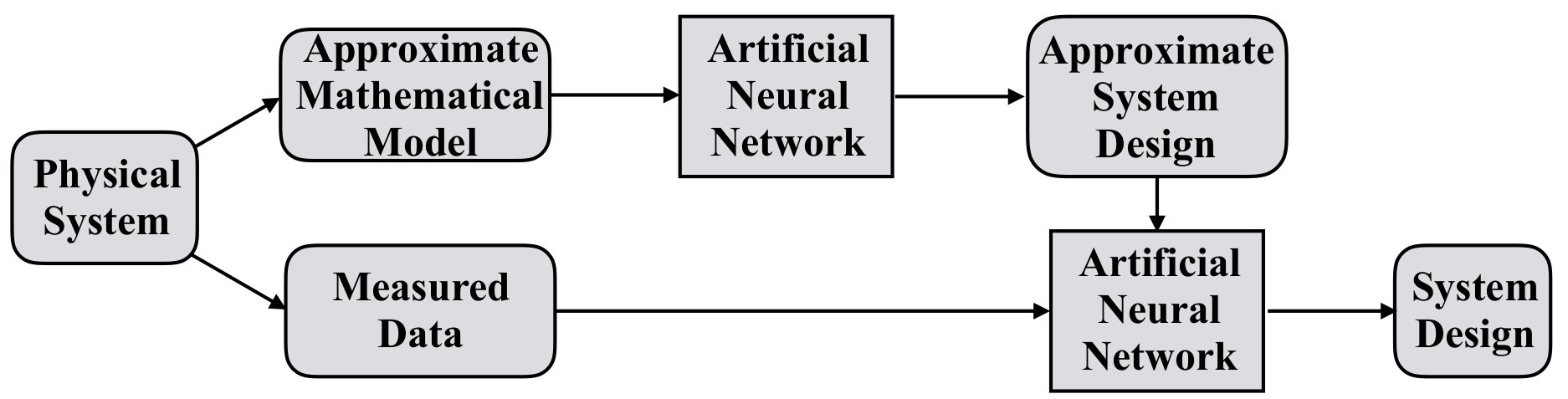 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25| Training MSE | Validation MSE | |
|---|---|---|
| Epoch 1 | 0.0113 | |
| Epoch 5 | 0.0116 | |
| Epoch 10 | 0.0104 | |
| Epoch 15 | 0.0096 | |
| Epoch 20 | 0.0091 | |
| Epoch 25 | 0.0089 | |
| Epoch 30 | 0.0092 | |
| Epoch 35 | 0.0087 | |
| Epoch 40 | 0.0089 | |
| Epoch 45 | 0.0087 | |
| Epoch 50 | 0.0090 |
|
|
|
|
||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2.0434 | 95.56% | 83.32% | |||||||||
| 2.0375 | 95.24% | 83.60% | |||||||||
| 2.0372 | 98.11% | 83.32% | |||||||||
| 2.0347 | 96.54% | 83.37% | |||||||||
| 2.0310 | 95.28% | 83.29% | |||||||||
| 2.0284 | 98.18% | 83.21% |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Wireless Networks Design in the Era of Deep Learning: Model-Based, AI-Based, or Both?
Alessio Zappone, Senior Member, IEEE, Marco Di Renzo, Senior Member, IEEE, Mérouane Debbah, *Fellow, IEEE
*(Invited Paper) A. Zappone and M. Debbah are with the Large Networks and Systems Group, CentraleSupelec, Université Paris-Saclay, 3 rue Joliot-Curie, 91192 Gif-sur-Yvette, France,([email protected], [email protected]). M. Debbah is also with the Mathematical and Algorithmic Sciences Lab, Huawei France R&D, Paris, France ([email protected]). The work of A. Zappone and M. Debbah has been supported by the H2020 MSCA IF BESMART, Grant 749336. M. Di Renzo is with the Laboratory of Signals and Systems (CNRS - CentraleSupelec - Univ. Paris-Sud), Université Paris-Saclay, 3 rue Joliot-Curie, 91192 Gif-sur-Yvette, France, ([email protected]).
Abstract
This work deals with the use of emerging deep learning techniques in future wireless communication networks. It will be shown that data-driven approaches should not replace, but rather complement traditional design techniques based on mathematical models.
Extensive motivation is given for why deep learning based on artificial neural networks will be an indispensable tool for the design and operation of future wireless communication networks, and our vision of how artificial neural networks should be integrated into the architecture of future wireless communication networks is presented.
A thorough description of deep learning methodologies is provided, starting with the general machine learning paradigm, followed by a more in-depth discussion about deep learning and artificial neural networks, covering the most widely-used artificial neural network architectures and their training methods. Deep learning will also be connected to other major learning frameworks such as reinforcement learning and transfer learning.
A thorough survey of the literature on deep learning for wireless communication networks is provided, followed by a detailed description of several novel case-studies wherein the use of deep learning proves extremely useful for network design. For each case-study, it will be shown how the use of (even approximate) mathematical models can significantly reduce the amount of live data that needs to be acquired/measured to implement data-driven approaches.
Finally, concluding remarks describe those that in our opinion are the major directions for future research in this field.
I Introduction and Vision
Our society is undergoing a digitization revolution, with a dramatic increase of both Internet users and connected devices. The fifth generation of wireless communication networks will be rolled out shortly, featuring innovative technologies such as infrastructure densification, antenna densification, use of frequency bands in the mmWave range, energy-efficient network management [1, 2, 3], which promise to achieve the targets of 1000x higher data-rates and 2000x higher bit-per-Joule energy efficiency compared to the previous wireless generation [4]. However, as the 5G standardization phase is ongoing, it appears doubtful that a single 5G technology will be able to achieve the desired requirements. Indeed, it is widely believed that 5G will employ multiple technologies at the same time. This points towards extremely complex systems, characterized by an infrastructure that becomes denser and denser to accommodate the exponentially increasing number of devices demanding connections. As a consequence, operational expenditures (OPEX) and capital expenditures (CAPEX), which are already a major challenge in present wireless networks [5], will significantly increase.
Moreover, global IP traffic will continue increasing in the next years. Between 2020 and 2030, the Compound Annual Growth Rate (CAGR) will rise by 55% annually, reaching 607 exabytes in 2025 and 5,016 exabytes in 2030 [6]. In addition, another critical challenge for future wireless networks is the extreme heterogeneity of the services to provide. Future wireless networks will have to support many innovative vertical services, each with its own specific requirements [7], e.g.
- •
End-to-end latency of and reliability higher than for Ultra Reliable Low Latency Communications (URLLC).
- •
Terminal densities of million of terminals per square kilometer for massive Internet of Things (mIoT) applications.
- •
Per-user data-rate larger than for mobile broadband (mBB) applications.
- •
Terminal location accuracy of the order of for Vehicular-to-X (V2X) communications.
These numbers are beyond what 5G networks have been designed to handle, and the integration of such diverse vertical services into the same network architecture calls for an extremely flexible and adaptive architecture, which clashes against today’s “one-size-fits-all” paradigm. Therefore, new approaches to increase the network flexibility have recently started attracting research attention, such as software networks and the use of Unmanned Aerial Vehicless (UAVs).
Software networks are primarily based on the network slicing paradigm, which proposes to logically separate the control and data plane, thus effectively slicing the physical network into multiple virtual networks co-existing over a common shared physical infrastructure. Each network slice constitutes a logically separate virtual network that can be customized to meet the specific requirements of a specific vertical service, by using techniques like Software Defined Networking (SDN) [8] and Network Function Virtualization (NFV) [9]. Network slicing applies to both the core and access network segments and paves the way for a new generation of programmable and software-oriented wireless networks, that are able to support flexible and on-demand network resources provisioning, allowing service providers to tailor the use of resources to the specific needs of the different classes of services to be provided.
Besides increasing the flexibility of the network through network slicing and reprogrammability, the use of UAVs is meant to increase the flexibility of the physical network infrastructure. UAVs like drones and other flying objects will act as flying access points, that can be redeployed based on heterogeneous traffic conditions to support on-demand connectivity requests [10].
Thus, future wireless networks will be characterized by an unprecedented level of complexity, which makes traditional approaches to network deployment, design, and operation no longer adequate. Every aspect of past and present wireless communication networks is regulated by mathematical models, that are either derived from theoretical considerations, or from field measurement campaigns. Mathematical models are used for initial network planning and deployment, for network resource management, as well as for network maintenance and control. However, any model is always characterized by an inherent trade-off between their accuracy and their tractability. Very complex scenarios like those of future wireless networks are unlikely to admit a mathematical description that is at the same time accurate and tractable. In other words, we are rapidly reaching the point at which the quality and heterogeneity of the services we demand of communication systems will exceed the capabilities and applicability of present modeling and design approaches.
In order to face this complexity crunch challenge, for the first time since the inception of wireless communications, it is not enough to simply devise a more performing transmission technology. Being simply able to transmit data at a faster rate does not ensure the flexibility required to accommodate diverse classes of users with extremely heterogeneous service requirements. Besides developing faster transmission technologies, future research efforts should be aimed also at improving the network infrastructure itself, making it intelligent enough to flexibly and automatically adapt to sudden wireless scenario changes and rapid traffic evolutions. In order to provide end-users with a perceived seamless and limitless connectivity, the re-configuration of network resources and/or the re-deployment of network nodes in response to new data demands, as well as to connectivity problems and/or failures of hardware components, must be prompt and timely. To this end, it is necessary to make the network fully self-organizing, automating all management, operation, and maintenance tasks, limiting direct human intervention as much as possible. This is the concept of Self-Organzing Networks (SON), which is not new to wireless networks, as it was introduced by the Next Generation Mobile Networks (NGMN) alliance, and even standardized by 3GPP for LTE networks. However, despite having garnered much attention since its inception, SON failed to achieve the expected end-goal of fully automated networks. It was employed primarily for specific Radio Access Network (RAN) applications, but without providing a true end-to-end solution. In our opinion, this is mainly due to the lack of intelligence and cognition in past and present networks. In order to enable truly self-organizing networks, it is essential to have an infrastructure capable of cognitive behavior. Intelligence must be spread across all network segments, making network nodes self-aware, self-organizing, and self-healing, by sensing the surrounding environment and processing the acquired data. These requirements have recently given rise to the concept of smart radio environments, which is discussed in detail in [11]. It is estimated that a fully automated and self-aware network, with self-configuration and self-healing capabilities would reduce CAPEX and OPEX by a factor 5 relative to 2010 levels [12], i.e. relative to a period when the complexity and expected performance of wireless networks were quite lower than today. Therefore, the gain compared to the extremely more complex networks of the future is expected to be significant.
I-A AI-Based Wireless Networks
The need for an intelligent wireless network motivates to endow each network segment with Artificial Intelligence (AI) capabilities and to employ a data-driven paradigm in which network nodes are able to determine the best policy to employ based on the experience obtained by processing previous data. On the one hand, this clearly reduces the reliance on mathematical models as far as network design and operation is concerned, but, on the other hand, it does not necessarily imply that traditional mathematical-oriented models and approaches should be dismissed. In fact, it is our opinion that there is much to be gained by the joint use of model-based and AI-based techniques and we envision future wireless networks where model-based and AI-based techniques are used in synergy. A major goal of this work is to support this point, and indeed Section IV will present specific approaches for cross-fertilization between these two seemingly contrasting approaches, together with the related quantitative analysis.
But how to develop artificially intelligent wireless networks? A framework that enables this is machine learning, in particular through one of its techniques, namely deep learning. Machine learning provides several techniques that endow computers with the ability to learn from data, instead of being explicitly programmed [13]. Machine learning techniques are not new to communication systems, and indeed several machine learning approaches have been developed and proposed to aid the design and operation of communication systems, e.g. support vector machines, decision-tree learning, Bayesian networks, genetic algorithms, rule-based learning, and inductive logical programming, among others. Detailed surveys and tutorials about machine learning and its applications to wireless networks can be found in [14, 15, 16, 17, 18], and its use to enable SON networks has been proposed in [19]. However, deep learning [20, 21, 22], which is the most popular machine learning technique in many fields of science, has started attracting the attention of the communication community only very recently.
Deep learning is a particular machine learning technique that implements the learning process elaborating the data through Artificial Neural Networks (ANNs). As it will be explained in more detail in Section II, the use of ANNs is the key factor that makes deep learning more performing than other machine learning schemes, especially when a large amount of data is available. This has made deep learning the first among the top ten AI technology trends of 2018 [23], and the leading machine learning technique in many scientific fields such as image classification, text recognition, speech recognition, audio and language processing, robotics. Despite all this, as already said, its use in communication systems has been envisioned only very recently [24], and its potential is at the moment almost untapped. In our opinion, this is mainly due to the fact that, unlike other fields of science, communication engineers could traditionally rely on mathematical models for system design, thereby making the use of data-driven approaches not strictly necessary. However, as we have described, this fundamental postulate is going to be weakened in the near future, which puts forth the need for deep learning in communication systems. Moreover, recent technological advancements make deep learning a viable technology for application to future communication networks. More precisely:
- •
In order to gain the most out of deep learning algorithms, it is necessary to process large datasets. At present, exactly the exponential increase of wireless devices results in a corresponding growth of traffic data [25, 26, 27].
- •
Modern advancements in computing capacity makes it possible to execute larger and more complex algorithms much faster. In particular, Graphics Processing Units (GPUs) can be repurposed to execute deep learning algorithms at speeds many times faster than traditional processor chips.
Recently, several leading telecommunication companies have supported the use of deep learning for communications [28, 29]. Moreover, initial steps towards the standardization of intelligent wireless communication systems have already been taken. European Telecommunications Standards Institute (ETSI) activated an Industry Specification Group named Experiential Network Intelligence, with the purpose to define a cognitive network management architecture capable of using AI techniques and context-aware policies to adjust the services that are offered, based on changes in user needs, environmental conditions, and business goals. Such a paradigm is referred to as the observe-orient-decide-act control paradigm and represents the first standardization step towards the definition of an experiential system, i.e. a system that learns from previous experience to improve its knowledge of how to act in the future. This is anticipated to help operators automate their network configuration and monitoring processes, thereby reducing their operational expenditure and improving the use and maintenance of their networks. Similarly, a standardization initiative for machine learning in future mobile networks has been activated by the International Telecommunication Union (ITU), with the aim of specifying an architectural framework for machine learning in future networks, defining the integration of machine learning functionalities into the architecture of future mobile networks, as well as identifying techniques for network management in future wireless environments. More specifically, the recently approved “ITU-T Y.3172 architectural framework for machine learning in future networks including IMT-2020” [30], constitutes another important component for the adoption of machine learning to operate and optimize wireless networks.
On the other hand, in order to make the vision of AI-based wireless networks true, there are also some challenges that must be overcome. In particular, two challenges appear today as the most relevant ones:
- •
Data acquisition. As already mentioned, in order to get the most out of deep learning algorithms, a large amount of data is required. As stated above, this is nowadays possible since the increase of traffic provides a huge amount of data that can be collected and exploited. However, the question remains of how to acquire the necessary amount of data in a practical and cost-effective way, e.g., by taking into account the overhead, time, and energy costs, especially in scenarios with high mobility and fast varying network conditions. In our opinion, the first half of the solution lies in the pervasive use of new, intelligent, materials, known as meta-materials, which have communication as well as data storage and processing abilities. As detailed in Section I-C, meta-materials can provide the fabric for AI-enabled wireless networks. As for the second half of the solution, in our opinion it lies in the cross-fertilization between AI-based and model-based techniques, which, as detailed in Section IV, can significantly reduce the amount of data that needs to be physically acquired through field measurement campaigns.
- •
AI** integration into communication networks.** While it appears clear that future communication networks will have to rely on AI, it is not clear how ANNs should be integrated into the architecture of communication networks. Should the acquired data be stored at a centralized location, where a single ANN manages a large network domain, or should each network device store its own data and run a local ANN? Our answer to this question is provided in Section I-D, where it is argued that a decentralized paradigm is to be preferred, and two possible approaches are described.
Before concluding this section, we believe it is important to emphasize that machine learning is anticipated to be a game-changing technology not only for mainstream wireless communication networks, but also for emerging communication technologies that are being investigated as a way to complement traditional wireless approaches in specific scenarios. Among others, we mention optical wireless communications [31, 32], which promise very high data rates by communicating over the visible spectrum, and molecular communications, which are not based on electromagnetic waves but exploit chemical signals as information carriers, thus enabling communication through media where electromagnetic signals do not propagate well, such as water, inside human bodies or the walls of buildings [33, 34]. Both technologies have garnered much interest in recent years, but they share the main drawback of being difficult to be accurately described by tractable mathematical models. Therefore, model-less, AI-driven approaches can provide a decisive contribution to the practical implementation of wireless optical and molecular communication systems, as, for example, observed in [35], which employs deep learning to solve Schrödinger equations in fiber-optic communications.
I-B Contributions and Organization
The vast majority of survey contributions on machine learning focus on different fields than communication networks, e.g. [21, 22, 20, 16, 13, 36, 37]. As far as communications are concerned, most previous surveys discuss general machine learning techniques [14, 17, 38, 39, 40, 18], without providing a dedicated analysis of deep learning. Only a few very recent overview works focus specifically on deep learning and ANNs for wireless communications [24, 41, 42]. All these three previous contributions envision the use of deep learning in future wireless networks, identifying AI as the key technology of the future and identifying many use-cases and scenarios in which deep learning has the potential of simplifying the design and improving the performance. In addition, none of the above works provides at the same time an in-depth quantitative analysis of several applications of deep learning for the design of wireless networks, an extensive overview of wireless applications of deep learning, as well as a self-contained mathematical treatment of deep learning by ANNs that discusses the main types of ANNs and the related training algorithms. Moreover, none of the above works addresses possible approaches for cross-fertilization between deep learning techniques and traditional mathematical modeling design approaches. In this context, our work provides the following five major contributions (C.1-C.5):
- (C.1)
The connection between model-based and data-driven methodologies is elaborated. A systematic framework to embed the prior knowledge contained in available mathematical models into deep learning techniques is described, and is shown to significantly reduce the amount of training data that is needed to achieve good communication performance. 2. (C.2)
A possible network architecture based on the use of the emerging technology of meta-materials is put forth. It is shown in particular that it facilitates the acquisition of the data required to train ANNs. Also, the issue of managing and operating an AI-based communication networks based on meta-materials is discussed. 3. (C.3)
Several case-studies where deep learning is proved to be useful are described. For each considered case-study, the mathematical formulation of the problem, the specific ANN architecture that is used, and the corresponding analysis and numerical results are discussed. 4. (C.4)
A solid and self-contained description of the theoretical foundations of deep learning, the most relevant ANNs architectures and training methods, as well as the most widely-used guidelines for hyper-parameters tuning are given. 5. (C.5)
The connection between deep learning and other machine learning frameworks, such as deep reinforcement learning, deep federated learning, and deep transfer learning are discussed. Several case-studies where these learning frameworks are jointly used are quantitatively analyzed. Moreover, the approach of deep unfolding is proposed as a way to map iterative algorithms to ANNs architectures.
The rest of this work is organized as follows:
- •
The rest of this section elaborates on contribution C.2, by discussing the potential and advantages of AI-based wireless networks, for application to network deployment and planning, resource management, and maintenance and operation. Furthermore, our vision on data gathering and management in AI-based networks is presented.
- •
Section II discusses in detail the connection between machine learning and deep learning. First, the fundamental paradigms of supervised learning, unsupervised learning, and reinforcement learning are introduced, and then the role of deep learning and ANN in this general framework is explained.
- •
Section III is focused, together with Section II, on contribution C.4, providing the theoretical description of deep learning, introducing the basic components of ANNs, the most widely-used ANN architectures and training methods. In addition, the connection between deep learning, reinforcement learning, transfer learning, and deep unfolding are explained, providing Contribution C.5.
- •
Contributions C.1 and C.3 are addressed in Section IV. First, a detailed overview of the applications and research contributions of deep learning to wireless communications is provided. Next, several examples and use-cases of practical interest are presented, in which the joint use of mathematical models and deep learning methods are shown to yield significant gains compared to state-of-the-art approaches. For each use-case, a quantitative analysis is explicitly carried out, by describing the design of an ANN to tackle the problem and discussing the resulting performance.
- •
Finally Section V concludes this paper by outlining the major challenges to overcome in order to fully enable the rise of AI-based wireless communication networks.
I-C Deep Learning for Network Deployment and Planning
Future wireless networks will be more than allowing people, mobile devices, and objects to communicate with each other [43]. Future wireless networks will be turned into a distributed intelligent wireless communication, sensing, and computing platform, which, besides communications, will be capable of sensing the environment to realize the vision of smart living in smart cities by providing context-awareness capabilities, of locally storing and processing information in order to accommodate the time critical, ultra-reliable, and energy efficient delivery of data, of accurately localizing people and objects in environments and scenarios where the global positioning system is not an option. Future wireless networks will have to fulfill the challenging requirement of interconnecting the physical and digital worlds in a seamless and sustainable manner [44], [45].
To fulfill these challenging requirements, we think that it is not sufficient anymore to rely solely on wireless networks whose logical operation is software-controlled and optimized [46]. The wireless environment itself needs to be turned into an intelligent software-reconfigurable entity [47], whose operation is optimized to enable uninterrupted connectivity. Future wireless networks need a smart environment, i.e., a wireless environment that is turned into a reconfigurable space that plays an active role in transferring and processing information. We refer to this emerging wireless future as “smart radio environment” [11].
To better elucidate our notion of reconfigurable and programmable wireless environment, let us consider the block diagram illustrated in Fig. 1. Conceptually, the difference between current wireless networks and a smart radio environment can be summarized as follows. According to Shannon [48], the system model is given and is formulated in terms of transition probabilities (i.e., ). According to Wiener [49], the system model is still given, but its output is feedback to the input, which is optimized by taking the output into account. For example, the channel state is sent from a receiver back to a transmitter for channel-aware beamforming. In a smart radio environment, the environmental objects are capable of sensing the system’s response to the radio waves (the physical world) and feed it back to the input (the digital world). Based on the sensed data, the input signal and the response of the environmental objects to the radio waves are jointly optimized and configured through a software controller, respectively. For example, the input signal is steered towards a given environmental object, which reflects it towards the receiver by suitably-optimized phase shifts. In turn, the receiver is also steered towards the incoming signal.
Different solutions towards realizing the vision of smart radio environments are currently emerging [50]-[51]. Among them, the use of reconfigurable meta-surfaces constitutes a promising and enabling solution to fulfill the challenging requirements of future wireless networks [52]. Meta-surfaces are thin meta-material layers that are capable of modifying the propagation of the radio waves in fully customizable ways [53], thus having the potential of making the transfer and processing of information more reliable [54]. Also, they constitute a suitable distributed platform to perform low-energy and low-complexity sensing [55], storage [56], and analog computing [57]. In [51], in particular, the authors have put forth a network scenario where every environmental object is coated with reconfigurable meta-surfaces, whose response to the radio waves is software-programmed by capitalizing on the enabling technology and hardware platform currently being developed in [58].
An example of using reconfigurable meta-surfaces in a cellular network scenario is sketched in Figs. 2 and 3. In Fig. 2, a mobile terminal (M) wants to connect to the Internet via a cellular network. In the absence of environmental objects (O1, O2, O3), BS1 is the base station that provides the best signal to M. Due to the blocking object O1, however, the received signal from BS1 is not sufficiently strong, and M connects to the Internet via BS2, while BS1 is kept active to serve other users. Since BS2 is far from M, its received signal is not sufficient for high rate transmission. Because of the refractive object O2, the signal emitted by BS1 generates strong interfering signals in other locations. Also, the reflective object O3 generates a strong reflected signal towards a malicious user (E) that can intercept the signal from BS1. In Fig. 3, by contrast, we illustrate the operation of cellular networks in a smart radio environment. The objects O1, O2, O3 are now coated with reconfigurable meta-surfaces that modify the radio waves according to the generalized laws of reflection and refraction [53]. Figure 3 shows how the operation of wireless networks changes fundamentally. The link BS1-M is still obstructed by O1. The responses of the reconfigurable meta-surfaces on O2 and O3 are, however, appropriately controlled and optimized: O2 refracts the signal from BS1 towards M and avoids interfering other users. O3 reflects the signal towards M and protects BS1 against E. In contrast to Fig. 2, the reflected and refracted signals at M allow it to reliably connect to the Internet. Now, BS2 serves other users at, e.g., a higher speed.
Current research efforts towards realizing the vision of smart radio environments are primarily focused on implementing hardware testbeds, e.g., reflect-arrays and meta-surfaces, and on realizing point-to-point experimental tests [50]-[51]. To the best of the authors knowledge, on the other hand, there exist no theoretic and algorithmic methodologies that provide one with the ultimate performance limits of this emerging wireless future, and with the algorithms and protocols for achieving those limits. We argue, in addition, that the design of smart radio environments is unlikely to be possible by relying solely on conventional methods. We believe, on the other hand, that deep learning and AI will play a major role in this context. In the following two sections, we will first discuss in deeper details the difference and potential advantages of smart radio environments against current wireless network solutions, and then discuss the importance of deep learning in this context.
I-C1 Current Networks vs. Future Smart Radio Environments
To better elucidate the difference and significance of smart radio environments with respect to the most advanced technologies employed in wireless networks at present, let us consider, as an example, a typical cellular network.
The distinguishable feature of cellular networks lies in the users’ mobility. The locations of the base stations cannot, in general, be modified according to the user’s locations. Some exceptions, however, exist [59], [60], and we will elaborate on this below. The mobility of the users throughout a location-static deployment of base stations renders the user distribution uneven throughout the network, which results in some base stations to be severely overloaded and some others to be under-utilized. This is a well-known issue in cellular networks, and is tackled in different ways, among which load balancing [61] and the densification of base stations (ultra-dense networks). Network densification is certainly a promising approach, but has its own limitations [62], [63]. It is known, e.g., that network densification increases the network power consumption as the number of base stations per square kilometer increases. This is exacerbated even more with the advent of the Internet of Things (IoT), where the circuit power consumption increases with the number of users per square kilometer [64], [65]. Ultra-dense network deployments, in addition, enhance the level of interference, which needs to be appropriately controlled in order to achieve good performance. Furthermore, each base station necessitates a backhaul connection, which may not be always available. Other solutions based on massive Multiple-Input-Multiple-Output (MIMO) schemes could be employed, but they usually necessitate a large number of individually controllable radio transmitters and advanced signal processing algorithms [66]. Similar comments (i.e., power consumption, hardware complexity, blocking of links, etc.) apply to using millimeter-wave communications [67], [68]. It is worth mentioning that millimeter-wave systems can take advantage of the presence of reconfigurable meta-surfaces as a source of controllable reflectors that can overcome non-line-of-sight propagation conditions, and enable the otherwise impossible communication between the devices [69]. Without pretending to be exhaustive, other relevant solutions that are typically employed in wireless encompass retransmission methods that negatively impact the network spectral efficiency, the optimized deployment of specific network elements, e.g., relays, which increase the network power consumption as they are made of active elements (e.g., power amplifiers), and that either reduce the achievable link rate if operated in half-duplex mode or are subject to severe self-interference if operated in full-duplex mode [70]-[71].
Meta-surfaces-enabled smart radio environments are fundamentally different. The meta-surfaces are made of low-cost passive elements that do not require any active power sources for transmission [45]. Their circuitries can be powered with energy harvesting modules, too [72]. They do not apply any sophisticated signal processing algorithms (coding, decoding, etc.), but primarily rely on the programmability and re-configurability of the meta-surfaces and on their capability of shaping the radio waves impinging upon them [73]. They can operate in full-duplex mode without significant or any self-interference, and do not need any backhaul connections. Even more importantly, the meta-surfaces are deployed where the issue naturally arises: where the environmental objects, which, in current wireless networks, reflect, refract, distort, etc. the radio waves in undesirable and uncontrollable ways, are located. Since the input-output response of the meta-surfaces is not subject to conventional Snell’s laws anymore, the locations of the objects that assist a pair of transmitter and receiver to communicate, and the functions that they apply on the received signals can be chosen to minimize the impact of multi-hop-like signal attenuation. In addition, the phase of the many atomic elements (i.e. the scattering particles), that constitute the meta-surfaces can be optimized to coherently focus the waves towards the intended destination, thus obtaining a substantial beamforming gain without using active elements. These functionalities, in addition, are transparent to the users, as there is no need to change the hardware and software of the devices. Furthermore, the number of environmental objects can potentially exceed the number of antennas at the endpoint radios, which implies that the number of parameters for system optimization will exceed that of current wireless network deployments [74]. The freedom of controlling the response of each meta-surface and choosing their location via a software-programmable interface makes, in addition, the optimization of wireless networks agnostic to the underlying physics of wireless propagation and meta-materials. Despite the practical challenges of deploying robotic (terrestrial) base stations capable of autonomously moving throughout a given region [59], [60], experimental results conducted in an airport environment, where the base stations were deployed on a rail located in the ceiling of a terminal building [75], showed promising gains. The possibility to deploy mobile reconfigurable meta-surfaces is, on the contrary, practically viable. The meta-surfaces can be easily attached to and removed from objects (e.g., facades of buildings, indoor walls and ceilings, advertising displays), respectively, thus yielding a high flexibility for their deployment. The position of small-size meta-surfaces on large-size objects, e.g., walls, can be adaptively optimized as an additional degree of freedom for system optimization: Thanks to their 2D structure, the meta-surfaces can be mechanically displaced, e.g., along a discrete set of possible locations (moving grid) on a given wall. It is apparent, therefore, that the concept of smart radio environment can potentially impact wireless networks immensely. First contributions that investigate the use of meta-surfaces for the design of wireless networks have appeared in [76, 77].
I-C2 The role of deep learning in smart radio environments
As discussed, the concept of smart radio environment is a fundamental paradigm shift compared to the current designs of wireless networks. But what is the interplay between smart radio environments and AI-based communication networks? We believe the two paradigms are intertwined, at the same time enabling and being enabled by each other. As already mentioned, besides the ability of improving the communication performance, meta-surfaces are expected to be equipped with sensors that allow them to estimate the current conditions of the environment. This equips them with the capability of acquiring lots of data that can be locally stored and processed, and/or sent to fusion centers. Thus, meta-surfaces provide the fabric of future AI-based wireless networks. Thanks to the pervasive use of meta-surfaces, smart radio environments will be naturally able to acquire and harness a large amount of data that travels over communication networks and that is required to maximize the performance of deep learning algorithms based on ANNs. In this sense, smart radio environments constitute an enabler for the implementation of AI-based communication networks.
On the other hand, the massive use of meta-surfaces, reconfigurable reflect-arrays, reconfigurable large-intelligent surfaces, provides a large number of degrees of freedom whose optimization entails a large computational complexity. By direct inspection of Fig. 1, it is apparent that smart radio environments are much more difficult to optimize than current wireless networks. In a smart radio environment, the operation of each environmental object may be optimized, besides the operation of the transmitter and receiver (the end points of the network). Accurately modeling such an emerging network scenario and optimizing it in real time and at a low complexity is an open issue. Indeed, it is very challenging to devise a model that is sufficiently accurate to account for customizable reflections, refractions, blocking, displacements of the surfaces, etc. Moreover, even if such a model could be developed, it would be very unlikely amenable to optimization due to the large number of variables to optimize and the complexity of the resulting utility functions. Compared with current network models, in addition, Fig. 1 highlights that smart radio environments need much more context-aware information for configuring and optimizing the operation of all the environmental objects, which results in a larger feedback overhead that has a strong impact in applications with high mobility. Unfortunately, in order to optimize such a complex system, with so many degrees of freedom, typical optimization-oriented approaches are not feasible, as they would require a too high complexity overhead. Luckily, as discussed in the the coming subsection I-D, deep learning can be used to significantly simplify the resource management task. In this sense, AI by deep learning and ANNs makes smart radio environments practically implementable, especially when model-based and AI-based approaches are used jointly, as discussed in detail in Section IV.
I-D Deep Learning for Network Resource Management
The goal of resource management is to allocate the available network resources in order to maximize one or more performance metrics. Transmit powers, beamforming vectors, receive filters, frequency chunks, computing power, memory space, etc., can be scheduled among the network terminals based on traffic demands, propagation channel conditions, terminals requirements, so as to optimize the network throughput, the communication latency, the energy efficiency, while at the same time ensuring that all end-users experience the guaranteed quality-of-service (QoS). Formally speaking, denoted by the performance function to maximize and by the resource to allocate, with the set containing the admissible values of , the resource allocation problem can be cast as the optimization program
[TABLE]
Thus, the conventional approach to resource management is based on the use of traditional optimization theory techniques. However, as already mentioned, this approach only works if one is able to come up with a suitable mathematical model of the problem, i.e. with tractable, but accurate, formulas describing the objective and the feasible set . This is typically not the case in interference-limited systems, where the presence of multi-user interference makes most relevant radio resource allocation problems NP-hard. For example, power allocation for sum-rate maximization is known to be NP-hard in interference-limited networks [78], which implies that also beamforming problems and energy efficiency maximization problems are NP-hard [3] as well. Moreover, even if we could solve NP-hard problem with affordable complexity, the optimal resource allocation will inevitably depend on the system parameters, e.g. the users’ positions, the number of connected users, the slow-fading or fast fading channel realizations. Anytime one of these parameters changes, which occurs quite frequently in mobile environments, the optimization problem needs to be solved anew. This causes a significant complexity overhead, that limits the real-time implementation of available optimization frameworks, especially in large and complex systems like future wireless communication networks. Clearly, all of these issues become even more prominent in smart radio environments where the number of variables to optimize will far exceed conventional numbers. In this context, the use of deep learning techniques based on ANNs can significantly reduce the burden of system design, enabling true online resource management. A first contribution that demonstrates the use of deep learning for the design of a meta-surface-enabled wireless network has appeared in [79].
Our proposed approach to solve resource allocation problems by deep learning is based on the observation that the general resource allocation problem in (1) can be regarded as an unknown function mapping from the ensemble of all network parameters of interest, denoted by \mbox{\boldmathc}\in\mathbb{R}^{N}, with the number of system parameters of interest, to the corresponding optimal resource allocation . Formally, we can view Problem (1) as the non-linear map
[TABLE]
Thus, our proposal is to convert Problem (1) into learning the unknown map (2), a task that ANNs are able to tackle. Indeed, as it will be discussed in Section II, ANNs are, under very mild assumptions, universal approximators, i.e., if properly trained, they are able to learn the input-output relation between the system parameters and the desired resource allocation to use, thus emulating the function in (2). This means that we can optimize a desired performance function for given system parameters without explicitly having to solve any optimization problem, but rather letting an ANN compute the resource allocation for us. A detailed analysis of this approach will be presented in Section IV.
With this in mind, the natural question that arises is how to integrate ANN-based resource management into the topology and architecture of a wireless network. Where should we store the data required by the ANN tasked with network resource management, and where should the related computations be executed? Ideally, the optimal approach would be to have a cloud-based approach in which an “artificial brain” placed in a single point oversees all tasks related to resource management across the whole network or at least a network segment. All available data should be collected and stored in this artificial brain which is tasked with executing all required computations and with feeding back the resulting optimal resource allocation policy to all other network terminals. Unfortunately, such a centralized approach is not compatible with future wireless networks due to at least three major reasons:
Latency. Some vertical sectors of future wireless networks, e.g. URLLC, require strict end-to-end communication latency requirements, lower than a millisecond. Thus, for these applications, it is not possible to wait for the cloud to perform the computations and then feed the results back to the end-users. Instead, it would be more convenient to perform the computations locally at the users’ terminals. 2. 2.
Privacy. Unlike previous wireless networks generations, future wireless networks will not be simply limited to realizing faster mobile network or to providing richer functions in smartphones. The integration of innovative vertical services aims at making the vision of the “everything connected world” true, but this comes with critical privacy and security requirements. Accordingly, for some vertical applications it is not desirable to share information with the cloud, which makes cloud-based deep learning not a convenient approach. In this context, it should be mentioned that, even if network security methods exist and provide us with privacy, integrity, and authentication, their use represents an overhead in terms of additional complexity and additional data to transmit [80]. Indeed, commercial solutions to privacy and/or authentication require the use of specific cryptographic algorithms such as Advanced Encryption Standard (AES) and Rivest-Shamir-Adleman (RSA), which run on top of the physical layer and require to execute finite fields operations on each block of transmitted data. Moreover, data integrity is typically guaranteed by the use of Hash codes, which also require the execution of specific operations to generate the Hash code for each packet of transmitted bits. Clearly, this results in overheads that might significantly reduce the communication performance of large-scale networks. Moreover, the perceived level of trust by the end-users will be inherently higher if no sensible data needs to be transmitted. 3. 3.
Connectivity. Future wireless networks promise ubiquitous service delivery. This means that a user terminal should be able to operate also in areas or times in which a poor connection to the cloud exists. This requirement is not compatible with a pure cloud-based implementation, but instead each user device should have some “local intelligence” to be able to operate in these scenarios, too.
Therefore, in order to make deep learning compatible with future wireless communication networks, the intelligence can not be concentrated only in a centralized network brain. Instead, some intelligence should be distributed across the network mobile devices, implementing a Mobile AI architecture. It is interesting to observe that this approach resembles the way in which human knowledge is developed: like human societies in which there is a collective intelligence that belongs to everybody, and an individual intelligence, the mobile AI paradigm envisions both a cloud intelligence, which every node of the network can access by connecting to the cloud, and a device intelligence specific to each network device.
In order to implement this mobile AI paradigm, a first natural approach that we put forth is to regard each device in the network as a rational and independent decision-maker, which acquires its own local dataset and uses it to build its own local ANN model. This technique does not require any interaction between the network infrastructure and the edge users, as far as data sharing and processing are concerned, and has the potential of enabling the 5G vision of distributed, self-managing networks true. On the other hand, due to limited storage and processing capabilities, mobile devices might not be able to develop accurate models on their own and the resulting performance gap must be analyzed. Moreover, the self-organizing nature of the devices poses questions about reaching a stable network operating point and about the efficiency of such a point. The Noble-prize-winner framework of game theory appears as the natural way to answer at least the last points, as it provides sophisticated mathematical tools to analyze the interactions among independent decision-makers [81, 82, 83]. Game theory has been already extensively used for resource management in wireless communication networks [18, 84, 85], although never in connection with deep learning.
A second approach that we envision is based on the use of the so-called federated learning technique [86, 87]. The main idea of federated learning is to distribute the data and computation tasks among a federation of local devices that are coordinated by a central server. The server owns a global ANN model that is built by appropriately combining the local models from the devices, which are developed based on local datasets. The server, on the other hand, is updated only with the updates of the global model, without the need of collecting and processing the datasets themselves. By leveraging this approach, the individual intelligence owned by each device contributes to the collective intelligence of the whole federation of devices, which is maintained by the server. As a refinement of this approach, [88] proposes not to exchange the updates of the model, but rather the updates of the algorithm that is used to compute the model. In other words, each local model is computed by processing the local dataset by some algorithm, and the devices do not communicate the model to the server, but instead send only an update of the parameters of the algorithm that is used to compute the global model.
Regardless of the specific approach that is employed, the mobile AI paradigm comes with several fundamental open problems. In a scenario where each wireless node has cognitive abilities (i.e. its own ANN), and whose behavior is influenced by its own local experience (i.e. local data), different wireless devices will learn how to behave based on datasets that might differ in both quantity (different nodes might have different measurement and storage capabilities) and quality (different nodes might experience different data perturbations due, for example, to the non-ideality of the measurement sensors). This could potentially lead to instabilities and, in the worst case, could cause the communication network to collapse. Hence, new control mechanisms are necessary in order to ensure the correct evolution over time of AI-based communication networks.
I-E Deep Learning for Network Operation and Maintenance
Maintenance and operation of a wireless network is a broad field that involves many different tasks, such as users’ localization, channel estimation, quality-of-service monitoring, fault and anomaly detection, hand-over execution, intrusion detection, etc. Although seemingly quite diverse, operation and maintenance tasks have a common denominator, as they both involve the acquisition of some measurable data, from which the desired information must be extracted. Formally speaking, all above tasks can be formulated as the task of guessing the realization of some random vector based on the observation of another random vector , that is somehow correlated to , i.e. that was generated from through some unknown transformation. Such a problem can be cast into the framework of classical decision and estimation theory, but classical detection and estimation methods require the conditional distribution f(\mathbf{x}|\mbox{\boldmathy}) and the prior distribution , whose availability is strongly related to the availability of a tractable model for the specific problem at hand. Even in present wireless applications, this is an unrealistic assumption for several operation and maintenance tasks. A notable example is that of hand-overs of users moving along the boundary of two cells, a crucial problem in cellular networks. This is typically (and heuristically) handled by comparing the users’ signal-to-noise ratio (SNR) towards the neighboring cells over a given time window. However, deriving a statistical model for this scenario that accounts for the users’ mobility patterns is quite challenging, and indeed the optimization of the thresholds for hand-overs is an open problem even in present cellular networks. Given the foreseen complexity increase in future wireless communication networks, statistical approaches will become less and less practical.
A suitable way of coping with the lack of models and statistical information about the random vectors and is represented by machine learning. Indeed, operation and maintenance is probably the field of wireless communications in which machine learning approaches have been used first. Recent surveys on applications of machine learning for maintenance tasks have appeared in [89, 90, 91, 92], and have shown how machine learning performs well even without any statistical distribution information. Specifically, available solutions assume that a training set containing examples of correct matches between the realizations of and is available, e.g. based on observing and storing previous traffic data. By processing the training set according to specific procedures called training algorithms, machine learning methods are able to learn a rule for predicting the value of corresponding to unobserved values of .
As far as the integration of deep learning for network maintenance into future wireless architectures is concerned, it is our opinion that it could be carried out following a more centralized approach than for the resource management scenario described in Section I-D. Indeed, most operation and maintenance tasks (e.g. fault and anomaly detection, hand-overs, intrusion detection) are inherently centralized in the sense that all computations are executed by network infrastructure nodes and do not require any specific information exchange with edge-users. On the other hand, in case of very large datasets and very demanding computations to perform, we envision the use of a distributed or federated learning approach, but only among dedicated network nodes. More in detail, a suitable approach consists of sharing storage and computation tasks among a cluster of fixed infrastructure nodes connected by high-speed links and deployed in different points of the network. In this case, each node of the cluster could either be tasked with operating and maintaining only a specific part of the network, or the data and computing power of each cluster node could be jointly exploited via a federated learning approach.
II Machine Learning and Deep Learning
The term machine learning broadly refers to algorithmic techniques able to perform a given task without running a fixed computer program explicitly written and designed for the problem at hand, but instead processing available data and progressively learning from it. Formally speaking, a computer program is said to learn from experience E with respect to a task T and performance measure P, if its performance at task T, as measured by P, improves with experience E [93].
The tasks that can be solved by machine learning are very diverse. In general, machine learning techniques prove extremely useful to execute tasks for which no explicit and/or viable programming approach exists to date, e.g. classification, regressions, pattern recognition, automatic language translation, anomaly detection, etc. As diverse as the task to perform may be, a machine learning algorithm can be mathematically described by the map
[TABLE]
wherein is a data vector whose components are the features describing the task to be solved, is the output produced by the machine learning algorithm representing the answer to the problem at hand, and are the sets in which and may vary. It is important not to confuse the task performed by a machine learning technique with the action of learning. The former is the final objective of the algorithm, while the latter is the method that is used to carry out the task.
In order to evaluate the ability of a machine learning algorithm to solve the assigned task, i.e. to produce output vectors close to the desired ones, a performance criterion P must be defined. Several performance measures can be considered and typically the best choice is application-dependent. Typical choices are the mean squared error (MSE) or the cross-entropy functions, which will be formally introduced in Section III-C, where the training procedure for ANNs is described.
The last component of a machine learning algorithm to be introduced is the experience E, i.e. the knowledge and data that the algorithm can exploit to carry out the task. Machine learning algorithms typically experience a set of data points , called training set. Depending on the information contained in , machine learning algorithms can be grouped into two main categories:
- •
Unsupervised learning: the experienced data training set contains only input features, i.e. . Based on , the machine learning algorithm must be able to extrapolate the statistical structure of the input or any other information needed to carry out the desired task.
- •
Supervised learning: the experienced data training set contains both input features and the corresponding desired outputs, referred to as labels or targets, i.e. {\cal S}=\{(\mathbf{x}_{1},\mbox{\boldmathy}_{1}),\ldots,(\mathbf{x}_{N},\mbox{\boldmathy}_{N})\}. Thus, in supervised learning, the training set provides a series of examples to instruct the algorithm how to behave when some specific inputs are considered.
In both supervised and unsupervised learning, the available dataset is fixed. This models a scenario in which the algorithm does not directly interact with the environment where it operates. Instead, a different machine learning paradigm that does not fall in the categorization above is that of reinforcement learning [94]. The approach of reinforcement learning is to enable a feedback loop between the algorithm and the environment, allowing the algorithm to experience a dataset that changes over time as a result of the interaction with the surrounding environment. The focus of this work will be primarily on supervised learning, which is the typical approach in deep learning. Reinforcement learning will also be considered, primarily considering its integration with deep learning tools, which leads to the recently introduced paradigm of deep reinforcement learning [95, 96].
Before continuing, it is important to remark that, while the setting described above bears some resemblance to the general problem of classical decision/estimation theory, a fundamental difference exists. Classical decision/estimation theory assumes that the probability distributions of the output vector given the input p(\mbox{\boldmathy}|\mathbf{x}) and that of the input vector are known. Instead, machine learning does not need this assumption and is able to operate based only on some realizations of the underlying distributions, even though the distributions themselves are not known.
II-A Overfitting and Underfitting
Any machine learning algorithm experiences a training set that contains some input features . In the supervised scenario, each input feature is also accompanied by the corresponding desired output. While this information is essential to configure the learning scheme, the key problem of any machine learning algorithm is to perform well on previously unseen inputs. This means that the algorithm needs to be able to grasp from a general rule to produce a suitable output also when . This is referred to as the algorithm generalization capability. During the training phase, the information in the training set is used to set the algorithm parameters in order to minimize any desired performance metric. As it will be detailed in the sequel, this amounts to solving an optimization problem. Machine learning however, is fundamentally different from optimization theory: its ultimate goal is to make the algorithm able to generalize well to new data inputs. In order to evaluate its generalization capability, after the algorithm has been designed as a result of the training phase, its performance is tested over a new set of different inputs , called the test set. For any given error measure, the error evaluated over the test set is called generalization error or test error. Similarly, the error evaluated over the training set is called the training error. Clearly, in order for the algorithm to generalize well, the data samples in the training set and in the test set need to be drawn from the same distribution, called data generating distribution, even though they should be drawn independently of each other. Clearly, the expected generalization error will be larger than the expected training error, and the gap between the two is called the generalization gap. Thus, minimizing the training error can be regarded as a necessary but not sufficient condition to obtain also a low generalization error. A machine learning algorithm is said to be:
- •
Underfitting if it is not able to make the error over the training set small.
- •
Overfitting if it is not able to make the gap between the training and test error small.
The factor that controls whether overfitting or underfitting occurs is the capacity of the algorithm, i.e. the ability of the algorithm to properly fit the training set. Intuitively, the capacity of the algorithm is related to the degrees of freedom or parameters that can be chosen when designing the algorithm. If the algorithm does not have enough free parameters, it will not have enough degrees of freedom to capture the structure of the training set and the algorithm will underfit. Instead, the overfitting scenario is subtler. One may think that increasing the number of free parameters will always lead to better performance, and that an upper limit is represented only by the computational complexity that we can sustain. This is, however, not the case. If the algorithm has too many degrees of freedom, it will learn the structure of the training set too well, memorizing specific properties that are peculiar only to the training set, but that do not hold in general. As a result, there is an optimal capacity that a machine learning algorithm should have to minimize the generalization gap.
As shown in Fig. 4, the training error decreases with the algorithm capacity, asymptotically reaching its minimum value. Instead, the test error has a U-shaped behavior, following the training error up to a capacity value, and then increasing, thereby originating the generalization gap. Fundamental results from statistical learning theory have established that the generalization gap is bounded from above, with the upper bound increasing for larger model capacity, and decreasing for larger training sets [97, 98, 99, 100]. On the other hand, a lower-bound to both the training and test error is given by the well-known Bayes error, i.e. the error obtained by an oracle with access to the true underlying distribution sampling from which the training and test set are obtained.
Another way to interpret the phenomenon of overfitting is to observe that any finite training set will also contain atypical realizations of the underlying distribution, that should be overlooked or given little importance when adjusting the algorithm parameters. However, if too many parameters to optimize are available, the algorithm will try to perfectly fit the complete training set, thus originating the overfitting phenomenon. This concept is illustrated in the example shown in Fig. 5, where it is assumed that a machine learning classifier must output a decision boundary to separate objects belonging to two different classes. It can be seen how a linear decision boundary is not able to properly separate the samples in the training set, thus causing underfitting. On the other hand, having enough degrees of freedom, one can design a complex boundary to perfectly separate the samples in the training set, even those samples that happen to be surrounded by samples of the other class. However, this leads to including in both decision regions areas that are likely to contain samples from the wrong class, thus causing overfitting. Instead, the curved, but more regular, decision region in the middle better captures the structure of the underlying distribution.
It is interesting to observe that choosing the decision boundary in the middle illustration of Fig. 5 is in agreement with the Occam’s razor principle, stating that among different and equally motivated explanations of a phenomenon, one should choose the simplest one. Of course one should also be careful not to oversimplify the model, so as not to underfit.
As mentioned above, one of the fundamental features that distinguishes machine learning theory from classical decision theory is the fact that the distribution underlying the task to perform is not known. This could lead to the belief that machine learning algorithms are universal, in the sense that the attainable performance depends only on how the parameters of the algorithm are set and on the size of the training set, but not on the properties of the underlying distribution, and, thus, not on the task to perform. Unfortunately, this belief is disproved by a fundamental result of machine learning, known as the no free lunch theorem, which states that the test error of any machine learning algorithm is the same when averaged over all possible underlying distributions. This means that there exists no machine learning algorithm that outperforms any other algorithm at every possible task. Instead, different algorithms will achieve different performance when tackling different tasks, i.e. when the underlying distribution varies.
II-B Hyperparameters and Validation Set
Besides the parameters that are to be optimized by the training procedure, machine learning algorithms also have hyperparameters, i.e. parameters that are not directly set during the training phase, either because they are difficult to optimize, or because they should not be learnt from the training set. The latter case corresponds to the optimization of the parameters that directly affect the capacity of the model. In fact, if a parameter that affects the model capacity is tuned based only on the training set, the result will be that it will be chosen in order to minimize the training error as much as possible. However, we have seen how this would lead to a poor generalization error, due to overfitting.
To be more specific, anticipating some notions about ANNs to be discussed in the next section, an ANN is composed of several nodes whose input-output relationship is defined by some weights and bias terms, which are the parameters to be tuned during the training phase. On the other hand, the total number of nodes in the network and the way in which the nodes are interconnected are hyperparameters that are considered fixed while the training algorithm is executed. Besides the difficulty to optimize these discrete parameters, a critical problem is that the number of nodes in an ANN is directly related to the capacity of the network, since more nodes imply more degrees of freedom. Therefore, if we optimized the number of nodes based only on the training set, the optimum would be to use as many nodes as physically possible, thus causing overfitting.
On the other hand, it is also not possible to use the test set to tune the hyperparameters, because all choices pertaining to the algorithm design must be independent of the data set that is used to assess the performance of the algorithm. Otherwise, the estimation of the generalization error will be biased. This implies that we need a third data set for hyperparameter tuning, the validation set. The validation set is typically obtained by partitioning the training data into the training set and the validation set. The training procedure fixes some values of the hyperparameters and optimizes the network parameters based only on the training set. Afterwards, an estimate of the generalization error obtained with the considered hyperparameter configuration is obtained through the validation set. This procedure is repeated for different hyperparameter configurations to identify the best model to use. After both the parameters and hyperparameters have been set, the true generalization error is computed by using the test set. The main steps of the whole procedure are summarized in Algorithm 1.
While Algorithm 1 provides one with a systematic procedure for training a machine learning algorithm, it does not address how to update the hyperparameter configuration in each loop. In general, there is no simple, algorithmic way to do this, and indeed hyperparameter tuning is more an art than a science. In particular, manual hyperparameter tuning is specific to the task to carry out and some guidelines will be discussed for application to deep learning in Section III-C2. Nevertheless, three systematic approaches for automated hyperparameter selection, which are general enough for many machine learning techniques, can be identified as follows:
- •
If the complexity of running the training procedure for a given hyperparameter configuration allows it, the hyperparameters can be learnt by means of a grid search.
- •
As a variation of the grid search, a random search has been shown to provide good performance, while at the same time significantly reducing the overall complexity [101].
- •
A nested learning procedure can be used, in which a second machine learning algorithm is wrapped around the algorithm to be trained, with the task of learning the best hyperparameters for the inner algorithm.
II-C Beyond classical machine learning
So far, the general principles at the basis of machine learning have been introduced, and some well-established machine learning algorithms have been mentioned. The rest of this section elaborates on their inherent limitations, motivating why a different approach is needed, especially when the complexity of the task increases.
The main challenge of machine learning is to learn how to generalize in response to previously unseen inputs. In order to reduce the generalization error, one could train the algorithm over a larger amount of data. In fact, increasing the size of the training set is surely helpful, but there is a limit in terms of computation and storage capacity, to the amount of data that can be processed. Therefore, an essential component of machine learning is the performance of the different algorithms as a function of the size of the training set. Deep learning will be formally introduced in the next section, but Fig. 6 anticipates how deep learning is able to improve the performance at a much faster rate than other machine learning techniques, as the dimension of the training data increases.
It has to be stressed that, instead, for small-to-medium training set sizes, the relation among deep learning and other machine learning techniques is not well-defined, and in many cases it turns out that classical machine learning algorithms can slightly outperform deep learning.
How can we explain the behavior in Fig. 6? The key phenomenon to consider is the so-called curse of dimensionality, which refers to the fact that the number of distinct configurations of a set increases exponentially with the number of variables describing each element of the set. Recalling the formal description of a learning algorithm as formulated in the map in (3), we emphasize that the dimensionality here does not directly refer to the size of the training set, but instead to the number of features describing each element in the set of possible inputs . Nevertheless, it is clear that as increases, we need more training samples to successfully learn the structure of , thus devising a map that is able to achieve a low generalization error. Conventional machine learning algorithms cope with the curse of dimensionality by using one of the following two approaches:
- •
Assuming prior beliefs about the structure that a good function should have, such as the smoothness prior, i.e. assuming that the function does not change drastically when evaluated at two neighboring points and . However, in high-dimensional spaces even a very smooth function can vary at a different scale along different dimensions. Moreover, even assuming that all the derivatives of the function are similar in the different directions, the smoothness assumption is reasonable only when the points and are sufficiently close to each other. Depending on the magnitude of the derivatives this may require an unfeasible amount of training data.
- •
Incorporating task-specific assumptions to perform manual feature selection, i.e. deciding which components of are relevant to the specific problem at hand and performing a customized processing of these features. However, this process requires the analysis of a realistic mathematical model for the problem at hand, which may not be available. Moreover, the settings used for one task are not general in the sense that they may not apply to other problems.
Deep learning adopts quite a different approach. It assumes that the data has been generated by a composition of factors with a hierarchical order and develops a learning method that is able to automatically understand the structure of the underlying distribution, extracting directly from the data the features that are important to devise a good map . In other words, deep learning assumes that some correlations exist among the behavior of over different regions of space, as a result of the structure of the underlying distribution of the data. This is clearly a more general assumption than the smoothness prior, which constraints the local behavior of in the neighborhood of each point. This has been shown to enable deep learning to generalize non-locally [102]. Moreover, deep learning is able to understand the structure of the underlying distribution, without requiring task-specific assumptions, thus enabling more general-purpose algorithms. These improvements are possible thanks to the use of ANNs, which constitute the tool used by deep learning to implement the learning process.
III Deep learning by artificial neural networks
As anticipated at the end of the previous section, ANNs are the enablers of deep learning [37, 103], thanks to their ability to learn, directly from the observed data, complex input-output relationships and statistical structures. ANNs are organized hierarchically in layers of elementary processing units, called neurons. More in detail, an ANN is characterized by:
- •
An input layer, which forwards the input data to the rest of the network.
- •
One or more hidden layers, which process the input data.
- •
An output layer which applies a final processing to the data before outputting it.
- •
Weights and bias terms that model the strength of the connections among the neurons.
If the network has only one hidden layer, it is referred to as a shallow network, whereas if it has more than one hidden layer, it is referred to as a deep network, hence the name deep learning. As discussed in Section III-A, deep networks are preferred, since they usually require a lower number of neurons to achieve a given accuracy. It is probably the use of deep architectures in which multiple neurons process the information and propagate the result that has motivated the analogy between ANNs and natural neural networks, i.e. the human brain, which is also composed of a network of elementary processing units, the neurons, that elaborate information and then propagate the results to other neurons.
A first broad classification of ANNs is based on how the information flows from the input to the output. Specifically:
- •
Feed-forward Neural Networks (FNN) are neural networks in which each neuron is connected only to the neurons in the following layer and thus the input data can only propagate forward, from the input layer to the output layer, without the possibility of any feedback loop.
- •
Recurrent Neural Networks (RNN) are neural networks in which feedback loops are allowed, and the output of a neuron can become the input of the same neuron, as well as of other neurons in the same or in a previous layer.
Several neural networks architectures exist within each of the two main categories introduced above. A notable example is that of Convolutional Neural Networks (CNNs), described in Section III-A1, which have been extensively used for image processing and pattern recognition [104]. In this work, we have decided to adopt the broad classification above, because the differences with other neural networks architectures are somewhat blurry, since different kinds of layers can co-exist in the same neural network. Instead, a more specific classification can be made by considering the types of layers composing the ANN. The most common types of layers are the following:
- •
Fully-connected layer. It is the typical layer employed in FFNs, which is characterized by the fact that each neuron of the layer receives an input from all neurons of the preceding layer, and is connected to all neurons of the following layer. The input data is first linearly processed, then passed through a non-linearity, and finally propagated to the following layer.
- •
Convolutional layer. It is another kind of layer used in FFNs, and more precisely in CNNs. Similarly to a fully-connected layer, it filters the input by a linear operation, namely a convolution, then applies a non-linearity, and finally forwards the result. However, each neuron needs not be connected to all neurons in the following layer.
- •
Pooling layer. It is a layer usually used in CNNs which operates by dividing the input data into blocks, and then selecting either the maximum element of each block, or computing the average of the elements within each block.
- •
Recurrent layer It is the typical layer of RNNs. After performing an affine combination of the input and passing it through a non-linearity, the output is not just propagated forward, but a feedback loop is also present.
More details on the operation of the different kinds of layers are provided in the rest of this section.
III-A Feedforward Neural Networks
The focus of this section is on FFNs with fully-connected layers, which is the quintessential ANN architecture. Instead, convolutional layers will be discussed in Section III-A1.
The general structure of a FFN is depicted in Fig. 7. An -dimensional input vector is fed to the network through the neurons of the input layer. Afterwards, it passes through hidden layers, with Layer having neurons. Finally, the -dimensional output is retrieved from the neurons of the output layer.
To elaborate, let us denote by the input to the -th layer of the network. Then, for all and , the output of neuron in layer is obtained as:
[TABLE]
wherein \mbox{\boldmathw}_{n,\ell}\in\mathbb{R}^{N_{\ell-1}} with being the weight of the link between the -th neuron in layer and the -th neuron in layer , is the bias term of neuron in layer , while is the so-called activation function of neuron in layer . Thus, the processing performed by each neuron can be viewed as a two-step procedure in which first an affine combination of the inputs is computed with weights \mbox{\boldmathw}_{n,\ell} and bias term , yielding the intermediate term . Then, the final output is obtained by applying the activation function to .
As for the choice of the activation functions, over the years several functions have been considered. The first choice was to use sigmoidal functions
[TABLE]
or hyperbolic tangent functions
[TABLE]
The sigmoid function is able to produce feasible probability values, being limited between zero and one, and for this reason nowadays it is typically used as activation function of the output layer for applications that require to estimate a probability. However, its use for the hidden layers is no longer recommended, due to the fact that it saturates for a significant portion of its domain, thus having derivatives very close to zero when the argument is large in modulus. This causes the so-called vanishing gradient problem, which slows down the convergence of gradient-based training algorithms. Another way of looking at the problem is to say that sigmoid activation functions are able to learn only when the input is around zero, i.e. in their (approximately) linear region, where the output of the sigmoid function is sensitive to variations of the input. Instead, in other regions of its domain the sigmoid function saturates and the output tends to be approximately constant even in response to significant changes of the input, which does not yield much useful learning information. Similar considerations also apply to the hyperbolic tangent function, which is linked to the sigmoid function by the relation: .
Nowadays, the most widely-used choice for the activation function of the hidden layers is the Rectified Linear Unit (ReLU) function [105, 106, 107], defined as:
[TABLE]
ReLU functions are linear whenever the neuron is active, which makes them easier to optimize. Whenever the neuron produces a non-zero output, the gradient of the activation function is constantly equal to one, and no second-order effects are present. The drawback is that the ReLU function does not provide any useful learning information when its input is negative. To overcome this issue, some refinements of the ReLU function have introduced a non-zero slope also for negative inputs, considering the function:
[TABLE]
The Leaky ReLU function sets as proposed in [108]; the absolute value rectification approach proposed in [105] considers , while the parametric ReLU approach proposed in [109] treats as a parameter to be optimized during the training process.
Another generalization of the ReLU is the exponential linear unit (ELU), which behaves like the ReLU for positive inputs, but outputs
[TABLE]
when the input is negative, with a scalar typically set to , [110].
The properties of the ReLU function and its generalizations seem to lead to the conclusion that the best activation functions are linear functions. In fact, linear activation functions can be used at the output layer to perform specific operations such as computing arithmetic averages. However, their use in the hidden layers is not encouraged, as they might prevent the network from learning non-linear maps. For example, in the extreme case in which all activation functions were linear, the input-output relation of the FNN would reduce to being always linear, when instead one of the strengths of ANNs lies in their ability to combine multiple non-linearities to emulate virtually any input-output map. This fact was formally established in [111], where it is stated that any deterministic continuous function over a compact set can be approximated arbitrarily well by a single fully-connected layer with enough neurons and sigmoidal activation functions111The result is proved assuming squashing activation functions, which include sigmoid functions as special cases.. This fundamental result is known as the universal approximation theorem of ANNs and was later extended to a broader class of activation functions, including the ReLU function and its generalizations [112]. Nevertheless, despite its high theoretical importance the universal approximation theorem is not constructive, because:
- •
it does not establish the number of neurons that are required in order to obtain the desired level of approximation accuracy.
- •
it does not establish whether it is more convenient to use a shallow or deep architecture in order to improve the approximation accuracy or reduce the number of required neurons.
- •
it does not establish how to configure the ANN in order to obtain the desired approximation accuracy.
An answer to the first question was provided in [113], which provides bounds for the number of neurons in shallow ANNs in order to obtain a given approximation accuracy. Unfortunately, the bounds show that, in general, an exponential number of nodes is required.
As for the second issue, deep architectures seem to require a lower number of neurons, even though a formal proof of this result in a general setting is still an open problem. Nevertheless, some available results prove that certain classes of functions can be represented more efficiently by increasing the network depth, i.e. the number of layers. In [114], for example, it is shown that the number of regions of a piece-wise linear function that can be reliably represented scales exponentially with the number of layers . Moreover, many empirical results have shown that deep architectures provide lower generalization errors than shallow architectures [20, Sec. 6.4.1].
Finally, the third issue is perhaps the most problematic. Although the universal approximation theorem ensures that there exists an FNN able to learn the desired map, it provides no indication as to how to configure the weights \mbox{\boldmathw}_{n,\ell}\in\mathbb{R}^{N_{\ell-1}} and bias of each neuron. This shows that configuring the parameters of an ANN represents the most critical step when employing deep learning. The training process of ANNs will be addressed in Section III-C.
III-A1 Convolutional neural networks
CNNs are FFNs that have established themselves as the main tool for image processing, and, in general, for processing data with a spatial structure. The main ingredient of CNNs is the 3D-convolution operation, which amounts to a particular linear processing of the input data. For this reason, CNNs can be considered as a sub-category of FFNs.
When using a CNN, the input data is assumed to be organized in a multi-dimensional matrix with dimensions , where the parameter is called the number of channels and is typically equal either to when color images are processed, or to when black-and-white images are processed. Each node of a convolutional layer is also represented as a multi-dimensional matrix with dimensions (with ) containing the weights of the neuron. The 3D-convolution operation outputs a bi-dimensional matrix , with dimensions , obtained by sliding the weight matrix over the input matrix, and by computing each time the cross-correlation between the weight matrix and the corresponding chunk of the input matrix, as depicted in Fig. 8.
Mathematically, the -th element of the output matrix is expressed as:
[TABLE]
It can be seen that, as already mentioned, each element of the output matrix is obtained through a cross-correlation rather than a convolution, even though the term convolution is universally used in the ANN jargon to refer to the operation in (10). In the following, we embrace this terminology. After computing (10) for all and , the output of the node is obtained by first summing a scalar bias term and then applying an activation function to each component of , like in a traditional fully-connected layer. Finally, the bi-dimensional output of each node in the layer are stacked together to form a new matrix with dimensions , with the number of nodes in the convolutional layer, which is the input of the next layer of the CNN.
It is interesting to observe that (10) can be rewritten as a scalar product similar to a fully-connected layer, upon vectorizing the input and weight matrices. For example, denoting by and the and vectors obtained by vectorizing and , the output element \mbox{\boldmathY}_{1,1} can be obtained as
[TABLE]
wherein \widetilde{\mbox{\boldmathw}}=[\mbox{\boldmathw}\;\mbox{\boldmath{0}}_{(N^{2}-F^{2})N_{c}}]. All other elements of can be obtained in a similarly way, upon considering suitably zero-padded version of . As a result, each node of a convolutional layer is equivalent to nodes of a fully-connected layer, in which the weights of many connections are permanently set to zero. This sparsity of the connections is one of the major strengths of CNNs, since it enables to process very large data using a relatively small number of parameters, which helps avoid overfitting. On the other hand, the underlying assumption that justifies the use of CNNs is the presence of strong spatial correlations in the input. Only if this is fulfilled, as is in image processing, it is possible to apply the same filter to different parts of the input matrix, thus avoiding unnecessary connections among the neurons.
The operation defined in (10) is the normal convolution employed in CNNs. In some cases, it can be slightly modified by applying padding and stride.
- •
Padding. When computing (10), the components at the border of the input matrix are used less frequently than the components in the middle. In order to avoid this, it is possible to apply (10) to a zero-padded version of , in which rows and columns of zeros are appended to . Then, the resulting zero-padded input matrix has dimensions , and the output matrix has dimensions . If is odd, choosing
[TABLE]
yields an output with the same dimensions as the input.
- •
Stride. The convolution operation in (10) slides the weight matrix over the input matrix moving by one position at each step. This can be generalized by sliding the weight matrix by positions at each step, where is called the stride parameter. In this case, assuming a padding is used as well, the output matrix will have dimensions:
[TABLE]
While the convolution operation is the defining feature of CNNs, another widely used operation in a CNN is the Pooling. Unlike the convolution, which is individually performed by each neuron of a layer before the different bi-dimensional matrices are combined together, the pooling is performed at the layer level and operates separately on each channel of the input matrix . Two types of pooling are commonly used:
- •
Max Pooling. For each channel of the input matrix , say \mbox{\boldmathX}_{n_{c}}=\mbox{\boldmathX}(:,:,n_{c}), a max pooling layer with parameter selects the maximum element out of each sub-matrix of \mbox{\boldmathX}_{n_{c}}.
- •
Average Pooling. For each channel of the input matrix , say \mbox{\boldmathX}_{n_{c}}=\mbox{\boldmathX}(:,:,n_{c}), an average pooling layer with parameter computes the arithmetic average of each sub-matrix of \mbox{\boldmathX}_{n_{c}}.
In both cases, a stride can also be used, which implies that the sliding window over which the maximum or average are computed moves by positions each time. An example of pooling with is shown in Fig. 9.
As a final remark before concluding this section, it is worth mentioning that practical FFNs are composed of a mixture of convolutional, pooling, and fully-connected layers, normally performing convolutions and pooling in the first layers, thus decreasing the size of the data, and employing fully-connected layers at the end once the dimension of the data is more manageable.
III-B Recurrent neural networks
If CNNs are more suited to processing data exhibiting spatial correlations, RNNs are designed to work on temporal sequences of data with correlated samples. As already anticipated, the main difference compared to FFNs is that the information does not only propagate forward, but loops are allowed. More in detail, each layer of a RNN may receive as input its own activation value. To elaborate, using a similar notation as in Section III-A, the output of neuron in layer at time is obtained as:
[TABLE]
wherein and are neuron-dependent activation functions. Thus, each neuron in a recurrent layer combines with different weights not only the current input, but also the intermediate vector \mbox{\boldmatha}_{\ell} that is obtained in the previous step. This introduces a correlation among the different computations that is beneficial to exploit the temporal correlations hidden in the input sequence. Moreover, a recurrent layer has two activation functions, and . Popular choices here are to use the hyperbolic tangent or the ReLU for and the sigmoid function for .
The architecture described above is the general architecture of recurrent layers. Several variants exist that are commonly used in real-world RNNs. In addition, we stress that, typically, a deep RNN has just a few recurrent layers, and it is possible to have hybrid architectures composed of some initial recurrent layers, followed by feed-forward layers. More details on specific RNNs architectures can be found in specialized references on ANNs, like [20].
III-C Training Neural Networks
For ease of notation, and without loss of generality, this section focuses on FFNs with fully connected layers. Results directly apply to CNNs and can be extended to RNNs with minor modifications. Training a neural network is the process that tunes the parameter \mbox{\boldmathw}_{n,\ell}\in\mathbb{R}^{N_{\ell-1}} and in a supervised learning fashion in order for the FNN to learn the desired input-output relation. To elaborate, let us consider a training set composed of input samples with the corresponding desired output, namely
[TABLE]
For each layer , let us stack the weight vectors into the matrix \mbox{\boldmathW}_{\ell} and the bias terms into the vector \mbox{\boldmathb}_{\ell}, respectively defined as \mbox{\boldmathW}_{\ell}=\left[\mbox{\boldmathw}_{1,\ell},\ldots,\mbox{\boldmathw}_{N_{\ell},\ell}\right] and \mbox{\boldmathb}_{\ell}=\left[b_{1,\ell},\ldots,b_{N_{\ell},\ell}\right]^{T}. The actual output of the FNN when the input is the -th training sample depends on the network weights and bias terms, and is denoted as:
[TABLE]
The goal of the training algorithm is to optimize the ANN weights and bias terms in order to minimize the loss incurred between the actual output in (17), and the desired output defined by the training set in (16), for all , as quantified by the loss function
[TABLE]
wherein is a loss function that models the error between and the desired output . A natural and common choice for the loss function is the MSE, namely:
[TABLE]
The MSE has the advantage of being applicable to virtually any scenario, and enables a simple computation of its derivatives. However, in some cases it can slow down the learning algorithm. Instead, faster convergence of the learning algorithm is typically observed by using the cross-entropy loss function, defined as
[TABLE]
However, the applicability of (20) is not so wide as that of the MSE function. Indeed, clearly (20) applies only to those cases in which both the desired and actual output data belong to the interval , and thus can be interpreted as distributions of random variables. A notable case in which this holds true is when sigmoid activation functions are used in the output layer, aiming at estimating a probability distribution. Assuming that both and have entries in , the cross entropy in (20) represents a measure of the divergence between and , since the cross entropy of two distributions and is equal to the Kullbach-Leibler divergence between and plus the entropy of [115]. Applying this result, (20) can be rewritten as
[TABLE]
with and denoting the Kullbach-Leibler divergence and binary entropy, respectively. Then, since does not depend on the network parameters, minimizing the cross-entropy in (20) is equivalent to minimizing the Kullbach-Leibler divergence between the desired and actual outputs.
In any case, regardless of the loss function that is chosen, the training process mathematically amounts to solving the optimization problem222In case of RRNs, an additional sum over the time dimension is present to account for the loss over time of each training sample.
[TABLE]
wherein \mbox{\boldmathW}=\left\{\mbox{\boldmathW}_{\ell}\right\}_{\ell=1}^{L}, \mbox{\boldmathb}=\left\{\mbox{\boldmathb}_{\ell}\right\}_{\ell=1}^{L}. However, as mentioned in previous sections, the goal of deep learning is not so much to minimize the cost function in (22), i.e. the training error, but rather to ensure a low generalization gap. Tuning the parameters of the network to achieve a low training error is a prerequisite to achieving a low test error, but an equally important task is that of tuning the network hyperparameters, (e.g. the number of layers , the number of neurons per layer , the size of the training set ), to fit the training data, avoiding both underfitting and overfitting. The coming Section III-C1 discusses the design of suitable algorithms to tackle (22) in an efficient and effective way, while Section III-C2 provides some guidelines for hyperparameter tuning in FNNs.
III-C1 Parameter tuning - Tackling (22)
Traditionally, in optimization theory, convexity is the critical property that marks the watershed between problems that can be solved with affordable complexity, and problems that require an unfeasible complexity. A convex problem, defined as a problem whose objective and constraint functions are convex in the optimization variables [116, 117, 118], enjoys several useful properties, among which the following two have played a critical role in enabling the development of a consolidated theory of convex optimization, and practical algorithms with theoretical optimality guarantees:
- •
[P.1]: Every stationary point of a convex function is a global minimum, i.e. the minimization of a convex function can be performed by simply looking for a point where the gradient of the function vanishes. This property establishes that first-order optimality conditions are necessary and sufficient for convex functions.
- •
[P.2]: For any , the complexity required to find an -optimal solution of a generic convex problem with variables scales, in the worst case, as the fourth power of and as [118, Section 5]. This property establishes that convex problems can be solved with polynomial complexity in the number of variables.
Unfortunately, neither of the two properties above holds for Problem (22) because the objective function is not convex with respect to the optimization variables, due to the presence of multiple layers combining several non-linear activation functions. This implies that the cost function of Problem (22) might have stationary points that are either local minima, or local maxima, or saddle points, a circumstance that becomes more and more likely as the dimensionality of the problem increases. In fact, it is quite typical for fairly deep model to have a very large number of points where the gradient vanishes, but that are not global minima. Moreover, the complexity required in order to find the global solution of Problem (22) is not guaranteed to be polynomial, since it scales in general exponentially with the number of variables, which is equal to . As a result, finding the global solution of Problem (22) turns out to be a very challenging task, especially considering that realistic ANNs have a fairly large number of neurons and layers.
Based on these considerations, it might seem hopeless to perform an effective and efficient training of any reasonably-sized FNNs. Fortunately, this is not the case and several efficient algorithms to effectively train FNNs exist. To understand why the non-convexity of (22) does not pose a fundamental problem, one must recall that, although the training process amounts to solving an optimization problem, machine learning differs from pure optimization theory, in that the ultimate goal is not so much to minimize the training error, but rather to minimize the generalization error. As discussed in Section III, the training error lower bounds the generalization error, but there is no guarantee that a lower training error also results in a lower generalization error. Actually, aiming for a very low training error typically causes overfitting. Therefore, when tackling Problem (22), it is surely desirable to find a configuration of parameters that yields a low training error, so as to avoid underfitting, but it is also not necessary to pursue the global minimization of the training error, which would most likely lead to overfitting. Any training algorithm will aim at progressively reducing the training error, stopping as soon as the generalization error evaluated over the validation set is below a desired threshold, regardless of the value of the training error. It is not uncommon that a training algorithm stops when the training error is relatively large compared to its global minimum.
As a result, the presence of stationary points of the cost function of Problem (22) would be a major issue only if the training algorithm were likely to converge to a suboptimal point yielding a too high training error, thus causing underfitting. A definitive formal proof that this does not occur in practice is still an open research problem, but extensive experimental evidence has shown that, for ANNs with a sufficient amount of neurons, most local minima lead to a satisfactory training error [119, 120, 121, 122]. In addition, especially in higher-dimensional spaces, local minima and local maxima of random functions are much less frequent compared to saddle points [120]. This phenomenon has been proved for some specific shallow ANNs [123], while some theoretical arguments as well as experimental evidence that a similar behavior holds also in deep ANNs is provided in [119, 120, 122]. Therefore, the main issue related to the non-convexity of Problem (22) is not mainly related to local minima, but rather to the presence of saddle-points. In this respect, empirical evidence provided in [121] shows that first-order methods based on gradient descent are able to escape saddle points. This behavior can be theoretically justified by observing that gradient-based methods are not explicitly designed to find point with zero gradient. Rather, they are designed to reduce the cost function moving in the direction of maximum decrease which is pointed by the gradient. Of course, this implies that the algorithm stops if a point with rigorously zero gradient is reached, but it makes the algorithm capable of moving away from the neighborhood of a saddle point even for relatively small step-sizes. On the other hand, second-order methods like Newton’s method do not share this property, having a higher probability of being stuck around saddle points. A training algorithm based on an approximate Newton’s method with a regularization strategy is the Levenberg-Marquardt method [124, 125], which yields good performance as long as the negative eigenvalues of the Hessian of the cost function are relatively close to zero. Instead, a recent modification of Newton’s method, designed to be more robust to the saddle-point problem in FNNs, has been introduced in [120]. Despite enjoying stronger convergence properties in the convex case, at present the use of second-order methods to tackle the non-convex Problem (22) is not so well-established as the use of first-order methods based on gradient descent algorithms. For this reason, the rest of this section is focused on presenting the main first-order training methods for FNNs.
Backpropagation algorithm. The first problem that we encounter towards the implementation of a gradient-based training algorithm for FNNs is the complexity related to the computation of the gradient. In large ANNs with many neurons and large training sets, the direct computation of the derivatives of the training error in (22a) with respect to all network weights and bias terms would require an unmanageable complexity. Luckily, a fast algorithm to compute the gradient of the training error was developed in [126]. It makes a clever use of the chain rule from multivariable calculus, and was called backpropagation algorithm, for reasons that will become clear after describing its working operation.
To begin with, let us observe that the derivative of (22a) is written as the average of the derivatives of the loss function {\cal L}(\mathbf{x}_{L+1},\hat{\mathbf{x}}_{L+1}(\mbox{\boldmathW},\mbox{\boldmathb})) over the training set. In fact, the backpropagation algorithm provides a way of computing the derivatives of {\cal L}(\mathbf{x}_{L+1},\hat{\mathbf{x}}_{L+1}(\mbox{\boldmathW},\mbox{\boldmathb})). Specifically, given a training input sample , the first step of the backpropagation algorithm is to compute the corresponding actual output \hat{\mathbf{x}}_{L+1}(\mbox{\boldmathW},\mbox{\boldmathb}). This step is referred to as forward propagation because it propagates the input forward through the network, by computing (4) for all and .
After completing the forward propagation, the derivative of the cost function with respect to can be computed as
[TABLE]
The next step consists of computing the derivatives of the loss function with respect to , for all , in a recursive way. This is the step that gives the name to the algorithm, since the derivatives are computed backwards, proceeding from the last to the first layer. Specifically, it holds333Recall that the derivative with respect to of the function g(\mbox{\boldmathy}(x)), with \mbox{\boldmathy}(x)=[y_{1}(x),\ldots,y_{I}(x)], is given by \sum_{i=1}^{I}(\nabla_{y}g)^{T}J_{x}\mbox{\boldmathy}, where denotes the Jacobian operator with respect to .
[TABLE]
which can be easily computed based on the derivatives with respect to , obtained from Layer . Finally, based on (24) and recalling (4), the derivatives with respect to the weights and bias terms are readily obtained as:
[TABLE]
Thus, the backpropagation procedure can be stated as in Algorithm 2.
Its strength lies in exploiting the recursive structure of the derivatives to compute, which enables to obtain them by simply computing a forward pass through the network, plus the corresponding backward pass, that has a similar complexity as the forward pass. In contrast to the backpropagation algorithm, the direct computation of the derivatives requires the evaluation of the loss function for each derivative to compute, thus having to perform a number of forward passes equal to the number of weights and bias in the ANN, which, for large networks, leads to an unfeasible computational complexity.
Stochastic Gradient Descent. While the backpropagation algorithm is computationally more convenient compared to the direct computation of the derivative, its complexity scales with the size of the training set. In order to implement Algorithm 2, one must forward-propagate and backward-propagate all samples of the training set. This poses a complexity issue since typically large training sets are used by ANNs. In more general terms, any algorithm that tried to compute the true gradient of the loss function of Problem (22), i.e.
[TABLE]
would have a complexity proportional to . To address this issue, state-of-the-art training algorithms for FNNs employ a variant of the gradient descent algorithm known as Stochastic Gradient Descent (SGD) [127]. While the standard (or deterministic) implementation of the gradient descent requires computing (27), the stochastic variant of the gradient descent algorithm computes an estimate of (27) based on a randomly-selected subset of the entire training set, called mini-batch. More precisely, denoting by the set of indexes associated to the selected mini-batch, and by the cardinality of , an estimate of the gradient is given by:
[TABLE]
Each time a gradient descent step is taken, the estimated gradient in (28) is evaluated based on a new, randomly selected set , and is used in place of the true gradient. The overall procedure is provided in Algorithm 3.
In Algorithm 3, is usually referred to as the learning rate in the machine learning context, and it controls how fast the algorithm reduces the cost function, and thus learns. The learning rate is a key parameter of the SGD algorithm and must be carefully selected. While traditional gradient descent algorithms can use a fixed and converge as long as is not too large, the SGD uses a variable to be used in iteration , due to the inherent deviation of (28) from the true gradient. More formally, a sufficient condition for the convergence of Algorithm 3 is:
[TABLE]
A common approach is to update for the first iterations according to the formulas:
[TABLE]
while keeping constant after the -th iteration. Typically, should be roughly one hundredth of , but in practice the parameters , , and are typically chosen by trial and error methods that monitor the error obtained over the validation set for different configurations of parameters.
Remark 1
The computational complexity of SGD depends on the size of the mini-batches. If the algorithm reduces to standard gradient descent, also called deterministic or batch gradient descent. Instead, if , the algorithm is referred to as online gradient descent. Typically, SGD uses and the choice is also dictated by the particular hardware where the algorithm runs, since too low values of may underutilize modern multi-core architectures. Also, some architectures, e.g. GPUs are more efficient when , with an integer number.
Remark 2
Since the SGD operates based only on an estimate of the true gradient, it typically requires more iterations than its deterministic counterpart to converge. However, each iteration is computationally much faster and the total number of computations required to reach convergence is much lower compared with the deterministic gradient descent method. In particular, SGD has a complexity per update that does not scale with the total size of the training set , since it might converge also without having to pass through the entire training set. On the other hand, typically several passes through the training set, called epochs, are required to achieve satisfactory training results.
Momentum for Stochastic Gradient Descent. A drawback of SGD is that learning can be sometimes slow due to the fact that only an estimate of the gradient is computed in each iteration. The method of momentum is a general strategy in optimization theory [128], that can be used to accelerate the learning process. The basic idea of the momentum algorithm is to perform the gradient update by an exponentially decaying moving average, as stated in Algorithm 4.
Algorithm 4 introduces the new parameter , which is called velocity, in analogy with the fact that it controls the velocity with which the updates move through the parameter space. Due to the presence of the velocity term and to the exponential average of multiple gradient points, the magnitude of the step depends on the magnitude of the sequence of gradients, and also on how aligned these gradients are. This tends to smooth out the oscillations of the standard SGD algorithm. The velocity represents the cumulative effect of the past gradients, while the term weighs the relative importance of the current gradient with respect to the cumulated gradient. The larger is with respect to , the more the past gradients affect the direction of the update. If all the gradients of the sequence were equal to , the updates would accelerate in the direction of the common negative gradient until reaching a limit velocity
[TABLE]
Thus, the parameter determines the relative speed of the updates compared to the SGD method without momentum. Common values of are , , and , and it is also desirable to adapt as well as iteration after iteration, similarly to what is done for the basic SGD method.
Nesterov Momentum for Stochastic Gradient Descent. A variant of the momentum for SGD appeared in [129]. Following the approach of Nesterov’s gradient method [130], the idea is to compute an estimate of the gradient taking into account the velocity term, as shown in Algorithm 5.
Nesterov’s momentum enjoys several convenient properties when applied to convex functions, such as a quadratic convergence rate. However, these advantages are not guaranteed to hold in non-convex scenarios, which is the usual case when training FNNs.
AdaGrad algorithm. The AdaGrad algorithm belongs to the class of gradient-descent algorithms that adapt the learning rate based on the cumulated gradient evaluated over multiple mini-batches. Specifically, the AdaGrad scales the learning rate by a factor that is inversely proportional to the sum of the gradients of all used mini-batches [131]. The effect of this strategy is that the parameters with larger partial derivatives of the loss function decrease more rapidly than the parameters with smaller partial derivatives. The AdaGrad algorithm is reported in Algorithm 6, with the parameter being a small number (typically of the order of ), which is introduced to avoid a division by zero when updating the parameters.
RMSProp algorithm. AdaGrad algorithm enjoys several pleasant properties in the convex case. However, when dealing with non-convex problems, it has been empirically observed that summing over all squared gradients used in the training process can cause a premature and excessive decrease of the learning rate. As a consequence, the learning rate might have become already too small when the algorithm finally finds a region around a (local) minimum of the loss function. The RMSProp algorithm aims at improving this drawback of AdaGrad, by introducing a moving weighted average of the gradients to reduce the relevance of gradients observed many iterations before. The formal procedure is reported in Algorithm 7 and can be readily modified to include the use of Nesterov’s momentum to accelerate convergence.
Adam algorithm. The Adam algorithm was introduced in [132], and is based on the application of momentum to the RMSProp method. However, the momentum technique is used with a different flavor from the conventional momentum approach. Specifically, the Adam algorithm employs both the first and second moment of the gradient estimated in each mini-batch. Moreover, Adam applies a correction term to both first and second moments, scaling them by a factor approaching one as the algorithm progresses. The procedure is formally stated in Algorithm 8.
As far as Adam algorithm is concerned, the suggested value for is , whereas the two weighting parameters and are suggested to be initialized to and . Although Adam is usually quite robust to the choice of the hyperparameters, sometimes the default values need to be adjusted to obtain good convergence properties.
Parameters initialization. A critical issue of any training algorithm is the initialization of the parameters, and in particular of the weights444The initialization of the bias terms has been found to have a more limited impact on the final performance. . Given the non-convexity of the problem, the training algorithm will converge to some suboptimal point, and thus a suitable initialization point can make the difference between converging to an efficient or inefficient suboptimal point. Unfortunately, the design of efficient initialization strategies for ANNs is a little understood topic. Consolidated approaches from pure optimization theory should be applied with caution, since they focus on obtaining a low loss function, i.e. a low training error, but there is no guarantee that this will also result in a low generalization error.
At present, two general rules are widely used for the initialization of the ANN parameters:
- •
Two hidden nodes connected to the same input and with the same activation function should have different initial parameters. This is needed to avoid any redundancy, since otherwise any deterministic algorithm would update the parameters of these two nodes in the same way.
- •
All matrices \mbox{\boldmathW}_{\ell} should be initialized to full-rank matrices, since otherwise some patterns might be lost in the parameters null-space.
These two guidelines motivate a random initialization of the parameters. Accordingly, initialization values are typically chosen as independent random variables, following either the Gaussian or uniform distribution, but a critical issue is how to choose the parameters of these distributions. These choices affect the initial scale of the parameters, which can have a significant impact on the generalization error. Larger initial weights are able to suppress redundancy more effectively, but might cause vanishing gradients due to the saturation of sigmoidal activation functions, as well as other numerical problems. In [133] it is proposed to initialize the weights of Layer with values drawn from a uniform distribution in . Instead, [119] recommends initializing the weights to random orthogonal matrices, that are scaled by a specific gain factor depending on the particular non-linearity used in each layer. In [134], it is shown that, by properly choosing the gain factor, the orthogonality assumption of the weight matrices can be relaxed. In [135], a sparse initialization strategy is proposed in which each unit is initialized to have a pre-defined number of non-zero weights. In contrast to these methods, we show, in Section IV, that the weights and biases can be initialized by using prior knowledge about the system, which can be obtained from (even inaccurate) analytical models.
Regularization. When training an FNN it should always be kept in mind that the ultimate goal is to minimize the test error, rather than the training error. To this end, an essential technique is to perturb the training process so as to reduce the capacity of the ANN, thus avoiding overfitting. Any strategy aimed at reducing the test error at the expense of the training error is a regularization strategy. Empirical results have shown that applying regularization strategies to ANNs with high capacity is a more effective strategy compared with directly tuning the number of neurons and layers. Over the years, several regularization methods have been proposed, and the most widely used ones are discussed in the following.
a) regularization. A major regularization approach is to add a perturbation term proportional to the -th power of the norm of the weights, namely modifying (22) into
[TABLE]
wherein is a hyperparameter that weighs the relative contribution of the norm penalty term relative to the standard cost function. It should be stressed that the regularization term depends only on the weights and not also on the bias terms. This is because the weights have a more significant impact on the test error, as they directly link the input and output of a node, whereas the bias terms only directly affect the output. Thus, regularizing the weights is expected to be more important than regularizing the bias terms, which would only add to the complexity of the training process without bringing much improvement. This intuition has been experimentally confirmed in many research works over the years and motivates the current practice in neural networks to perform only weights regularization.
Among the different norms that can be considered in (32), the most widely used is the norm. This type of regularization is also called weight decay because it can be seen to reduce the magnitude of the weights, especially for larger . This results in limiting the impact of many network connections on the final output, thereby reducing the network capacity. Moreover, reducing the magnitude of the weights causes sigmoidal or hyperbolic tangent activation functions to operate in their linear regions, thus retaining the advantages of a linear model.
Another widely used regularization norm is the norm. In comparison to regularization, regularization tends to produce a more sparse weight matrix , in which many connections in every layer are effectively turned off. Besides reducing the network capacity, this also reduces the memory required to store the model.
b) Early stopping. Perhaps the simplest form of regularization is represented by the early stopping technique. All training algorithms are designed to minimize the training error in (22) iteration after iteration. However, recalling also Fig. 4, the validation error initially decreases together with the training error, but at some point tends to increase again. Thus, the idea of early stopping is to stop the training phase when the validation error reaches its minimum value. In practice, the network parameters are saved after each gradient update and when the validation error has not improved for a pre-specified number of iterations, the training algorithm stops and the parameters corresponding to the lowest observed validation error are returned. It is observed in [136] and [137] that limiting the number of training iterations reduces the volume of parameter space reachable from the initial parameters, thereby reducing the capacity of the ANN and acting as a regularizer.
c) Dropout. The idea of dropout is to introduce a perturbation by randomly changing the topology of the neural network every time a new data sample is used [138]. Specifically, for each data sample, each neuron in the ANN has a probability of being included in the network and if it is not included the corresponding weights are not updated in that particular iteration of the algorithm. Dropout is an effective regularizer due to two main reasons:
- •
By randomly removing a subset of connections each time, dropout is actively weakening the coupling among neighboring neurons. This reduces the possibility of performing too complex operations, which could cause overfitting.
- •
Each time a subset of neurons is randomly disconnected, a different reduced network is being trained. As a result, using dropout effectively trains a large number of different, random ANNs, and then averages the results, which tends to reduce the net effect of overfitting.
Batch Normalization. One issue when working with gradient-based methods, is the different scale that the features in the input vector, as well as the activation values of each layer, might have. In the presence of vectors with components that have very different magnitude with one another, numerical problems can arise and gradient descent can be slow. In order to avoid this issue, [139] has proposed to normalize the input data and/or the activation values of each layer in the network.
Formally speaking, let us consider the training data points . Then, batch normalization modifies the operation performed by the input layer, which will not simply forward the input vector, but will apply the transformation:
[TABLE]
wherein the division is meant component-wise, is a vector with positive components of the order of , whose purpose is to avoid dividing by zero, while \mbox{\boldmath\mu}_{0} and \mbox{\boldmath\sigma}_{0} are mean and standard deviation vectors defined as
[TABLE]
where the square root operation is meant component-wise.
Denoting by \mbox{\boldmathz}_{\ell}^{(nt)} the -dimensional vector of activation values of layer when is the input of the network, a similar normalization technique can be applied to the vectors \{\mbox{\boldmathz}_{\ell}^{(1)},\ldots,\mbox{\boldmathz}_{\ell}^{(N_{S})}\} in each mini-batch, thus changing the arguments of the activation functions of the -th layer to be:
[TABLE]
with \mbox{\boldmath\mu}_{\ell} and \mbox{\boldmath\sigma}_{\ell} having similar definitions as in (34) and (35). In addition, when applied to a hidden layer, it is common to further modify the input to the activation functions in (36) as:
[TABLE]
with \mbox{\boldmath\gamma}_{\ell} and \mbox{\boldmath{\beta}}_{\ell} being -dimensional parameters to be learnt during the training phase. The operation in (37) is aimed at preserving the representational power of the ANN, which would be significantly diminished by constraining each layer to have zero-mean and unit-variance activation inputs. This approach might seem counterintuitive, since it seems to defeat the purpose of applying the normalization step in (36) in the first place. The advantage of using (37) lies in the fact that \mbox{\boldmath\gamma}_{\ell} and \mbox{\boldmath{\beta}}_{\ell} are parameters to be learnt based on the normalized values in \tilde{\mbox{\boldmathz}}_{\ell}, which are more conveniently handled by gradient descent algorithms. Moreover, while batch normalization increases the number of parameters to optimize during the training phase, applying (37) makes the bias terms in each node useless. In other words, when using batch normalization, it should be set \mbox{\boldmathb}_{\ell}=\mbox{\boldmath{0}} for any normalized layer, since the role of \mbox{\boldmathb}_{\ell} is played by \mbox{\boldmath{\beta}}_{\ell}. As a consequence, the only new parameters to be trained are the vectors \mbox{\boldmath\gamma}_{\ell} for the layers where normalization is applied.
It is also important to mention that batch normalization has a regularization effect, too, due to at least two main reasons:
- •
Since \mbox{\boldmath\mu}_{\ell} and \mbox{\boldmath\sigma}_{\ell} are computed on each mini-batch, they will be slightly different for each mini-batch. This introduces a slight perturbation that has a regularizing effect on the overall ANN, similarly to the dropout technique.
- •
The fact that batch normalization reduces the variability of the input data to each layer weakens the coupling among different layers, which results in a similar effect as the dropout technique.
So far, batch normalization has been described as a technique to aid the training process. However, since it modifies the structure and operation of the ANN, it also affects the network use at test time. In other words, if an ANN is trained using batch normalization, at test time (37) needs to be computed in each layer, by employing the trained parameters and . However, the issue of this approach is that at test time the dataset at our disposal may not be sufficiently large to compute reliable estimates of mean an variance for each activation input. This problem is typically solved by computing an exponentially-weighted average that accounts for the means and variances computed during the training phase on each mini-batch, in addition to the new data sample at test time.
III-C2 Hyperparameter tuning - Fitting the data
So far, many techniques have been presented to tune the parameters of an FNN in order to achieve a low generalization error. However, the performance of all algorithms that have been presented depends on several hyperparameters, which are not directly tuned during the training phase. Examples of hyper-parameters are the number of layers and neurons per layer, the size of the training set and of each mini-batch, the learning rate, the regularization coefficient, etc. Moreover, other choices that have a significant impact on the overall performance are related to the training algorithm that is used, to the initialization point that is adopted, to the regularization strategy to use, whether or not to use batch normalization, etc.
As discussed in Section II-B, hyperparameter tuning can be performed either manually or in an automated way. The three automated methods introduced in Section II-B, i.e. grid-search, random search, hyperparameter optimization, are general enough for application not just to deep learning, but to machine learning in general. However, grid search and hyperparameter optimization are rarely used in the context of deep learning. The former is deemed practical only when three or fewer hyperparameters need to be tuned. In this case, a logarithmic search scale is used to span a wider range of values. The latter is problematic due to the lack of an expression of the loss function with respect to some hyperparameters, as well as because any hyperparameter optimization algorithm in turn has its own hyperparameters to set, even though they are typically less problematic to tune. Instead, random search is considered to be a more feasible solution, and has been shown to reduce the validation error to acceptable values much faster than grid search [101].
Along with these automated methods, manual hyperparameter setting represents an effective way to achieve the desired performance at an affordable complexity. Nevertheless, compared to automated approaches, the manual tuning of the hyperparameters requires a higher degree of experience, and is typically carried out by monitoring both training and validation error during the training phase, thereby determining whether the network is underfitting or overfitting, and modifying the hyperparameters to adjust the network capacity accordingly. To this end, in general a trial and error procedure is required, since it is very challenging to know in advance the optimal configuration of hyperparameters for the specific problem at hand. Nonetheless, some general guidelines can be identified, recalling that the capacity of an ANN depends on three main factors: 1) the ability of the network to represent the problem at hand; 2) the ability of the learning algorithm to successfully minimize the loss function during the training phase; 3) the degree to which the training procedure regularizes the model, thus avoiding overfitting.
As shown in Fig. 10, when configuring an ANN, the first issue to take care of is to make sure that the network does not underfit. If the performance on the training set is not good enough, it means that the ANN can not fit the available training data and thus it is usually useless to gather more data. In this case, a good approach is to improve the optimization algorithm and the most important hyperparameter to this end is the learning rate. Unfortunately, each task has its own optimal learning rate, and trial and error is the de facto approach to find a learning rate that yields a low enough training error for the task at hand.
Apart from the learning rate, other strategies to increase the network capacity are to tune the other hyperparameters of the algorithm in use or to consider more sophisticated optimization algorithms. Widely-used choices are SGD with momentum, RMSProp, or Adam, possibly coupled with Nesterov’s momentum. Moreover, batch normalization can be included if the training error does not decrease as desired. If these strategies are not effective, the problem could be in the size of each mini-batch, which might be too small to provide a reliable estimate of the gradient. Finally, another conceptually simple way to increase the network capacity is to use more neurons and layers. This is a powerful approach to avoid underfitting, but comes at the expense of a larger complexity and its applicability depends on the available computational resources. If none of these strategies work, the problem might just be in the quality of the training data, which might be too noisy and/or might not include the most appropriate features to represent the problem at hand. In this case, it may be needed to collect different data and to use a different training set.
Once a low enough training error is obtained, the validation error needs to be checked. If it is unsatisfactory, then it is likely that overfitting is the issue. In this case, the most effective strategy is to just gather more data. However, gathering more data can be costly and requires higher storage and processing capabilities. A simpler way of reducing the network capacity is to employ a regularization technique. It is advisable to use early stopping as the first approach, while other regularizing techniques could be included during the training phase. Finally, a third approach consists of manually reducing the model size, limiting the number of neurons and layers. If these approaches do not work even after a careful tuning of their hyperparameters, then gathering more data remains the only possible approach to avoid overfitting.
Finally, it is worth emphasizing once again that the validation error is an estimate of the test error and the discussion above assumes that such an estimate is reliable. If the test error is high but the validation error is low, then the most effective approach is to increase the size of the validation set. However, if increasing the size of the validation set does not help, then either the validation procedure is not appropriate, or the problem might lie in a more fundamental issue. Typically, the loss function used for training and validation might not be appropriate for the task at hand, or the ANN model is not properly designed to learn the target objective, or there is a mismatch between validation data and real testing conditions.
III-D Deep Reinforcement Learning
This section presents the framework of deep reinforcement learning, which merges deep learning with reinforcement learning [96, 95]. The framework of reinforcement learning is not directly related to deep learning, but rather it is a different machine learning approach that implements the learning procedure in an adaptive way, namely by interacting with the environment by taking actions and receiving feedback on the result of the actions that have been taken. Nevertheless, recently it has been observed that deep learning can be used to improve and facilitate the implementation of reinforcement learning techniques, which has motivated the cross-fertilization between these two machine learning frameworks, leading to the development of the framework of deep reinforcement learning. The first part of this section provides a short introduction to reinforcement learning, whose purpose is to define basic terminology and provide a brief mathematical description of the typical scenarios where reinforcement learning is employed. For a dedicated and comprehensive treatment of the reinforcement learning framework, we refer the reader to [94].
Reinforcement learning applies to scenarios that can be mathematically described by a Markov Decision Process (MDP). An MDP is defined by the following quantities:
- •
, the set of possible states.
- •
, the set of possible actions that an agent can take.
- •
, the set of transition probabilities, with the probability of moving from state to state by taking action .
- •
, the set of rewards, with , and the reward obtained at step .
- •
, a discount factor adjusting the weight of more recent actions.
Based on this notation, it is possible to define the long-term reward as
[TABLE]
and a (stationary) policy as the probability of taking action at time , when being in state , namely:
[TABLE]
where the word stationary refers to the fact that the probability of taking action when in state does not depend on time.
A key concept when analyzing an MDP is that of action-value function, measuring the value, in terms of expected reward, of being in state and taking action , following policy , namely:
[TABLE]
The action-value function can be also rewritten as the sum of the reward at step , plus the long-term reward from to , namely:
[TABLE]
Reinforcement learning provides several approaches to determine the optimal sequence of actions to be taken in order to maximize the long-term reward. These approaches can be broadly classified in three main categories, namely,
- •
Value-based approaches, which aim at estimating the action-value function.
- •
Policy-based approaches, which aim at estimating the policy function.
- •
Actor-critic approaches, which exploit an estimate of both the action-value and the policy function.
Thus, regardless of the particular technique that is chosen, reinforcement learning requires full knowledge about the environment in order to estimate the action-value or the policy functions, which is not realistic in several applications. Moreover, in some cases, the complexity of the estimation rapidly increases with the cardinality of the action-state space, which makes reinforcement problems unfeasible by standard methods when the number of possible states and actions grow too large.
In this context, thanks to their universal function approximation ability, ANNs provide an efficient way to estimate the action-value and/or the policy functions, thereby enabling the practical solution of complex reinforcement learning problems in the realistic scenario in which the statistics and parameters of the environment are not fully known.
III-D1 Deep Q-Network. Estimating the action-value function
The goal of the Q-learning method is to compute the optimal action-value function, defined as
[TABLE]
Solving (43) for each pair provides a full characterization of the MDP problem, and allows determining the best policy to follow for each possible state and action. To this end, several methods are available, depending on the information available on the MDP. An optimality condition for Problem (43) is the so-called Bellman’s optimality equation, which however requires full knowledge of the MDP model and parameters to be solved.
However, in practical scenarios, assuming complete knowledge of the MDP model is often unrealistic. Typically, only the response from the environment is observable, but no information is available as to the statistics regulating the MDP process, such as the transition probabilities, which makes it impossible to compute the value of the function for any pair . In these cases, a possible approach is to obtain the values of the function from experience, i.e. by initiating the process from each possible pair, and then following different policies, observing the rewards returned by the environment at each step. However, this approach has the clear drawback of requiring a high computational complexity, especially when the number of possible pairs is large. A similar drawback is suffered by all other alternative methods aimed at building a table collecting the possible values , for all possible and .
In scenarios with a very large (possibly even infinite) number of pairs, the state-of-the-art approach is that of -learning. As the name implies, this approach is based on learning the values of the function. More specifically, -learning algorithms assume a functional form for the function , namely:
[TABLE]
with a known function, and a set of parameters to be determined by any machine learning method, with the goal of improving the accuracy of the approximation. More specifically, -learning methods assume that some points of the function, say , have been already determined, for example by trying some actions and observing the response of the environment. Then, the parameters in the vector are determined so as to minimize the mean squared error between the samples and the model (44).
Traditional -learning approaches typically employ a linear model for , but more recently it has been proposed to adopt an ANN with weights , that takes as input a pair and outputs the corresponding value . The parameters are trained by using the samples as the training set. This implementation of Q-learning is referred to as the Deep Q-Network approach [95, 96], which can be considered an algorithm belonging to the family of -learning methods, with the peculiarity that the approximate function \widehat{Q}(s,a,\mbox{\boldmathw}) is specified through an ANN. Thus, compared with other -learning methods, deep reinforcement learning has the significant advantage of not specifying a-priori the functional form of , leaving to the ANN the task of determining the best functional form to use. Since ANNs are universal function approximators, they will be able to approximate the true function within any desired tolerance, provided a proper training phase is performed.
III-D2 Deep Policy Iteration. Estimating the policy function
While the deep Q-network method aims at learning the action-value function, policy iteration methods aim at determining directly the policy function . To this end, the policy function is parametrized as
[TABLE]
with a vector of parameters to be learnt. Standard policy iteration methods assume a fixed functional form , and design in order to maximize the average reward function, defined as
[TABLE]
wherein denotes the stationary distribution of .
The maximization of with respect to is carried out by means of the gradient ascent method, wherein an expression of the gradient of (46) is provided by the policy gradient theorem, which proves that:
[TABLE]
In order to implement the gradient ascent algorithm, a standard approach is the so-called Monte-Carlo policy gradient, also known as the REINFORCE method [140], which employs stochastic gradient ascent wherein the instantaneous return observed from the environment provides an unbiased sample of the unknown function .
Similarly to the Deep Q-Network case, instead of assuming a fixed functional form for , an ANN can be trained to output an estimate of the values . Specifically, it is possible to use an ANN that takes as input a state , outputs for any action , and is trained by samples collected according to the target policy. In other words, the training set is built adaptively: given an input state, a realization of the output distribution is sampled and used as training label. Next, the sampled action is performed and the reward obtained from the environment is used to weigh the training loss function in order to refine the training. Also, the action that is taken brings the agent into a new state and the whole procedure is iterated.
III-D3 Deep Actor-Critic. Estimating the action-value and policy functions
Instead of employing the instantaneous returns as an estimate for the action-value function , deep actor-critic approaches improve purely policy-based methods by merging them with a Deep Q-Network that provides an estimate of . Thus, in order to maximize (47), actor-critic approaches assume both the models in (44) and (45), using a first ANN, called the critic ANN, to estimate the value Q_{\widehat{\pi}}(s,a,\mbox{\boldmathw}), and a second ANN, called the actor ANN, to estimate the policies .
Actor-critic methods typically perform better than purely policy-based methods and during the last years several improvements have been proposed. A notable example is the use of a so-called advantage function to reduce the estimation variance by subtracting it from the value function [141]. Namely, the method exploits the fact that:
[TABLE]
since
[TABLE]
wherein is the advantage function.
Other improvements of the actor-critic approach have been proposed in [142], [143], and [144]. In [142] the so-called asynchronous advantage actor-critic (A3C) approach is introduced, in which multiple actors and critics are deployed. The critics learn the action-value function while the actors are trained in parallel, being synchronized with each other with global parameters from time to time. A deterministic version of the A3C method, called synchronous advantage actor-critic (A2C) is also proposed, in which all critics are synchronized with the global parameters at the same time, hence the name “synchronous”. In [143], a deterministic version of the deep actor critic approach, the deep deterministic policy gradient (DDPG) is presented, in which the policy is no longer modeled as a distribution over actions, but rather as a deterministic function . The authors of [143] merge deep learning with the DPG approach, first introduced in [145]. Finally, in [144] the DDPG approach is extended to multi-agent environments, i.e. to scenarios in which multiple decision-makers coordinate among themselves to complete tasks based only on local information.
III-E Deep unfolding
As discussed, one of the issues of ANNs is to determine the number of neurons and layers to use. However, in some cases it is possible to match the iterations of iterative algorithms to the layers of an ANN by a technique called deep unfolding [146]. This provides a systematic approach to determine the hyperparameters of an ANN that implement a given number of iterations of a recursive algorithm.
To elaborate, the idea of deep unfolding applies to all algorithms that take as input a vector and produce as output a vector \mbox{\boldmathy}=[y_{1},\ldots,y_{M}] expressed by
[TABLE]
wherein is a vector containing all the parameters of the algorithm, while is iteratively updated according to the formula
[TABLE]
with the iteration index and the initial value. This formalism applies to detection tasks [147], as well as to the computation of posterior probabilities by the belief propagation method, or to inference techniques aimed at estimating a distribution by minimizing its divergence from an approximate distribution [146].
The main idea of deep unfolding lies in the observation that (50) can be regarded as the input-output relationship of an ANN, with (51) being the input-output relationship of Layer , and representing the parameters of the ANN, i.e. all weights and bias of each layer. Then, the iterative algorithm can be unfolded by mapping each iteration onto one layer of the ANN, which takes as inputs and , compute at the output of the -th hidden layer, and finally produce as output, as displayed in Fig. 11.
Two main points are to be highlighted:
- •
In deep unfolding, in contrast to typical ANNs, the number of nodes and layers is determined by the particular algorithm that is unfolded. Specifically, the number of layers is fixed by the number of iterations of the algorithm, while the number of nodes in each layer is fixed by the sizes of the vectors , , and .
- •
The advantage of unfolding an algorithm onto an ANN rather than implementing it directly, lies in the fact that the parameters of the algorithm are determined by an ANN, instead of being set by more conventional methods. Moreover, once the parameters are determined, the ANN can be directly used as an alternative and efficient implementation of the iterative algorithm to compute based on the chosen parameters .
In the context of jointly exploiting model-based and AI-based methods, deep unfolding, in combination with deep transfer learning described in the next section, offers the possibility of initializing a model-based ANN by unfolding the model onto the layers of the ANN, and then refining it by using empirical data. This approach has the advantage of not requiring the tuning of the number of layers and neurons, as they are obtained by directly unfolding the model on the ANN architecture.
III-F Deep Transfer learning
Deep transfer learning is another recent framework that combines deep learning with another machine learning framework, namely transfer learning. In the broadest sense, transfer learning studies how to transfer the knowledge that is used in a given context to execute a given task, into a different, but related context, to execute another task. Formally speaking, four fundamental components can be identified in a transfer learning problem:
- •
A source task, , i.e. the original task for whose execution the knowledge to be transferred was developed.
- •
A source domain, , i.e. the context in which the task was executed.
- •
A target task, , i.e. the new task to be executed thanks to the knowledge transfer.
- •
A target domain, , i.e. the new context in which the task must be executed.
Clearly, such a problem formulation is very general, and need not be related to any deep learning problem. However, transfer learning can be successfully used to facilitate the implementation of deep learning algorithms, especially by reducing the amount of data to be acquired for training and validation purposes. Indeed, the availability of large quantities of data is a prerequisite for deep learning to outperform other machine learning methods, but in the context of wireless communication networks the acquisition of large amount of data can be too expensive and/or not practical. In these cases, transfer learning can be used by transferring knowledge from other related scenarios in which data acquisition has been already performed. For example, datasets for similar communication systems can be used, and/or datasets generated according to (possibly inaccurate) mathematical models can be used. Concrete examples about the latter approach are analyzed in the next section.
Despite being a relatively recent approach, many techniques for deep transfer learning have already appeared in the literature and it is difficult to provide a general taxonomy. Here, following the taxonomy by the recent tutorial [148], we categorize transfer learning techniques into four main classes.
III-F1 Instance-based transfer learning
This approach assumes to have data from both the source domain and target domain . Then, the idea is to exploit both datasets to carry out the target task , by assigning a different weight to each instance of the source and target data. Otherwise stated, data from the source domain is used to augment the data from the target domain, but it must be weighted differently to ensure that instances that are specific to the source domain are given less or no importance during the training process. After this re-weighting step, the augmented data set is used as training set for the target task by any traditional training algorithm, with the re-weighting factors acting as hyperparameters to be adjusted during the validation process.
In principle, this method does not require having labeled data, in the sense that, once the new dataset has been built, it can be used in conjunction with any machine learning method. However, as far as training a neural network is concerned, it is required that the training set be labelled in order to implement available training algorithms. Recently, instance-based transfer learning has proved effective when employed in conjunction with the AdaBoost training algorithm, addressing both classification and regression problems [149, 150].
III-F2 Mapping-based transfer learning
Mapping-based transfer learning redefines the training cost function in order to account for the presence of data from both the source and target domains. Specifically, the cost function used during the training phase is defined as:
[TABLE]
wherein is the cost function for the source task, taking as input training samples from the source domain, is the cost function for the target task, taking as input training samples from the target domain, is a non-negative term weighting the relative importance of the two cost functions, and is a regularization function that accounts for the differences between source and target domains. More in detail, the regularizer is typically chosen as the maximum mean discrepancy function between the source and target domains, with respect to a generic representation , namely [151]
[TABLE]
wherein and denote the source and target available datasets. Thus, this approach requires having labelled data from both the source and target domains. Based on (52), any standard training algorithm can be executed, exploiting all available labeled data.
Recent studies on mapping-based transfer learning have focused on analyzing the performance when other regularizers are used. In [152] it is proposed to use a multiple kernel variant of the MMD (MK-MMD), while in [153] it is proposed to use the joint maximum mean discrepancy as regularizer. Finally, we mention [154], where Wasserstein’s distance is used as regularizer and is shown to achieve better performance than the MDD in some cases.
III-F3 Network-based transfer learning
Network-based deep transfer learning implements the transfer of knowledge by first training an ANN to execute the source task in the source domain , and then reusing and/or refining the obtained network configuration to execute the target task in the target domain . This general concept can be applied in several different ways. For example, it is possible to identify a part of the ANN that extracts general features that describe both the source and target tasks. Then, after training the ANN in the source domain, the part of the ANN that applies to both source and target tasks need not be trained again. This approach is taken in [155], where a language processing application is considered, and it is proposed to divide the ANN in two parts. The former extracts language-independent features, which can be reused for all languages, while the latter is language-specific and needs to be trained for each new language.
Nevertheless, a more common approach is to perform a two-step training. At first, the ANN is trained to execute the source task, yielding a tentative configuration of the network parameters. Next, a second training phase is performed in the target domain, which uses the configuration of the weights and bias from the first phase as the initialization point for the training algorithm. This approach is very useful in all situations in which a lot of training data is available in the source domain, whereas only a few labeled training samples are available (or are difficult/expensive to obtain) in the target domain. As described in Section IV, this is the typical scenario in wireless communications, and indeed Section IV will present several case-studies wherein this particular transfer learning method proves extremely useful. Techniques inspired to network-based transfer learning have been recently proposed for resource allocation in wireless communications in [156, 157].
III-F4 Adversarial-based transfer learning
The main idea of adversarial transfer learning is to identify the common features between source and target tasks through the use of an another deep neural network, called generative adversarial network (GAN) [158]. The first step of the approach is to divide the ANN that implements the source task into two segments, one that extracts the salient features of the source domain, and one that exploits these features to carry out the source task. Then, the output of the first segment of the ANN is also fed to another ANN, the GAN, which has the task of discriminating whether the input comes from the source domain or from the target domain. The two ANNs are trained together as if they were a single ANN, even though they have competing goals: the adversarial ANN aims at minimizing the error in the discrimination between target and source inputs, while the main ANN aims at minimizing the error on the source task, while at the same time aiming at maximizing the error that the adversarial ANN makes in discriminating between data coming from the source or target domain. If the adversarial ANN is not able to distinguish between source and target domains, then the first segment of the main ANN has determined a representation of the source domain that is virtually indistinguishable from the target domain, and thus the main ANN can be used to execute both the source and target tasks. The contrasting goals during the training process are modeled by defining the overall training cost function as:
[TABLE]
wherein is the error on the source task, is the error in discriminating between source and target inputs, is a factor weighting the relative importance of these two errors, and are the weights and bias terms of the main network, while and are the weights and bias of the adversarial ANN, and the overall cost function needs to be minimized with respect to \mbox{\boldmathW},\mbox{\boldmathb}, and maximized with respect to \mbox{\boldmathV},\mbox{\boldmathc}. By minimizing (54) with respect to \mbox{\boldmathW},\mbox{\boldmathb}, the primary ANN minimizes while at the same time maximizing . Instead, by maximizing (54) with respect to and the adversarial network is minimizing . As a result, unlike typical training procedures that aim at minimizing the training cost function, the goal here is to determine a saddle point of (54), which can be accomplished by several saddle-point algorithms based again on stochastic gradient descent techniques, as in regular training procedures [159, 160]. It is to be stressed that, in order to find a saddle point of (54), it is not required to know the desired output for each training sample. Indeed, each training sample must simply carry a label discriminating whether the sample comes from the source or target domain, but the desired output is required only if the sample comes from the source domain. This means that adversarial training can be used for ANN training even when the available target data is not labeled.
IV Applications to wireless communications
After presenting the main concepts and tools of the deep learning framework, this section describes practical applications to the design of wireless communication systems. First, a literature survey is performed, reviewing available contributions about the application of deep learning to wireless communication systems, and then several novel applications are presented.
IV-A State-of-the Art Review
The application of deep learning to the design of the physical layer of wireless communication networks has started attracting research attention only very recently, mostly in the last couple of years. For this reason, fewer contributions have appeared than in other areas of wireless communications. Nevertheless, two main research directions can be identified:
- •
deep learning to operate the physical layer, simplifying the execution of tasks such as data detection, decoding, channel estimation, localization, etc.
- •
deep learning to manage the physical layer, simplifying radio resource allocation tasks.
IV-A1 Operation of the physical layer
The first area of application of deep learning at the physical layer of wireless networks has been the use of ANN to simplify the implementation of detection and/or estimation operations such as information decoding, channel estimation, localization, etc. [161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187].
In [161], the authors use deep FFNs to emulate the transmitter and the receiver of point-to-point communication systems, while assuming the communication channel is known. The end-to-end system is modeled as a deep ANN composed of the cascade of an ANN implementing the data transmission process, one layer implementing the known channel (whose parameters are fixed and not trainable), and another ANN implementing the reception process. The overall network receives as input the information signal and provides as output the corresponding symbol estimate. This architecture is referred to as an auto-encoder, since the goal of the network is to reproduce the input data at the output. It is shown that, without having any information about the implementation of the transmitter/receiver chains, the auto-encoder is able to outperform traditional approaches that design the system based on (approximate) mathematical models of the transmitter/receiver chains. The work in [161] paved the way for many subsequent studies that exploited ANNs at the physical layer of wireless devices. In [162] it is proposed to use an auto-encoder to jointly minimize the system bit error rate and peak to average power ratio, and again an improvement over traditional methods is obtained. Deep learning is used for data detection in MIMO systems in [163, 164], in decode-and-forward relay channels [165], and for equalization and synchronization in OFDM systems in [166].
In all of these works, perfect knowledge about the communication channel is assumed. Several subsequent works have tried to relax this assumption. In [167] a two-stage approach is taken. At first, a synthetic channel model is used to provide a first training of the ANN. Next, this initial training is refined at the receiver based on the true channel characteristics. GANs are used in [168, 169, 170], by exploiting a surrogate channel for training purposes. A combination of supervised training and reinforcement learning is used in [171] to remove the need of channel knowledge. In [172], the auto-encoder approach is further extended to the case in which no channel state information is available by exploiting a stochastic perturbation approach. A similar scenario is considered in [173], where the auto-encoder approach is used for data detection without any channel knowledge, considering molecular communications as a main application scenario. The use of fully connected ANNs for molecular communications is also investigated in [174].
In [175] it is shown that a deep neural network can reliably learn the MMSE channel estimator, while in [176] convolutional neural networks are successfully used to implement a fingerprinting-based scheme for user localization. Channel estimation through neural networks is successfully demonstrated in [177] and also in [178], where an FDD massive MIMO system is considered, and the channels are assumed to be representable by a finite-size dictionary. Experiments showing the performance of deep learning methods for users localization in outdoor environments are provided in [179], showing that even simple ANNs architectures can achieve satisfactory performance. In [180] it is shown that deep learning can be successfully used to implement error correction tasks, while [181] shows that machine learning is able to provide reliable channel estimation from compressed measurements. Channel estimation in rapidly time-varying environments is discussed in [182], and it is shown that deep architectures are able to cope with this more challenging setup, while [183] proposes a deep learning approach for joint equalization and decoding in wireless networks. Surveys on the use of ANNs to implement encoding/decoding operation as well as channel estimation tasks with limited side information have appeared in [184, 185]. An information-theoretic study of the mutual information between input and output of a shallow neural network is provided in [186]. Channel estimation and signal detection are also performed through deep learning in [187], showing that similar performance as traditional methods can be achieved, but with a much lower computational complexity.
IV-A2 Management of the physical layer
A second emerging application area is the use of deep learning to perform radio resource allocation at the physical layer, with minimum complexity and/or side-information requirements [188, 189, 190, 191, 192, 193, 194, 195, 196, 197, 198, 156].
The works [188] and [189] put forward the idea of using ANNs for network resource management, providing an overview of potential applications of AI for network resource management in future 5G wireless networks, and discussing supervised, unsupervised, and reinforcement learning. In [192], a fully connected FNN is used for sum-rate maximization in interference-limited networks, by learning the input-output map of each iteration of the iterative weighted MMSE power control algorithm [199]. The proposed approach is able to mimic the performance of the weighted MMSE resource allocation algorithm, while at the same time significantly reducing the computational complexity. In [200, 156], the problem of energy efficiency maximization in wireless interference networks by a fully connected FNN is tackled. Unlike [192], in [200, 156] the FNN is directly trained based on the optimal energy-efficient power allocation, which can be computed offline using the novel global optimization procedure also proposed in [200]. The results indicate that the optimal performance can be approached with limited online complexity, thus enabling an online implementation. A similar approach is proposed in [194, 195] for power control and user-cell association in massive MIMO multi-cell systems. Instead, a different approach is taken in [197], where a fully connected ANN is trained to solve the sum-rate maximization problem subject to maximum power and minimum rate constraints. In order to reduce the complexity of building the training set, the authors propose to train the ANN using directly the system sum-rate as training cost function. The results show a gain compared with previous low-complexity optimization methods.
In [191] a cloud-RAN system with caching capabilities is considered. Echo-state neural networks, an instance of RNNs, are used to enable base stations to predict the content request distribution and mobility pattern of each user, thus determining the best content to cache. It is shown that the use of deep learning increases the network sum effective capacity of around 30% compared with baseline approaches based on random caching. In [190], deep reinforcement learning is used to develop a power control algorithm for a cognitive radio system in which a primary and secondary user share the spectrum. It is shown that both users can meet their QoS requirements despite the fact that the secondary user has no information about the primary user’s transmit power. The use of deep reinforcement learning is also considered in [196], where it is used to develop a power control algorithm for weighted sum-rate maximization in interference channels subject to maximum power constraints. The proposed algorithm exhibits fast convergence and satisfactory performance. A decentralized robust precoding scheme in a network MIMO system is developed in [198] by ANNs. In [201], online power allocation policies for a large and distributed system with energy-harvesting nodes are developed by merging deep reinforcement learning and mean field games. It is shown that the proposed method outperforms all other available online policies and suffers a limited gap compared to the use of non-causal offline policies.
IV-B Learning to optimize
The rest of this section describes several applications, primarily focusing on the most recent area of ANN-based physical layer resource allocation. In this context, a promising approach is to develop methodologies to embed prior available (expert) knowledge about the problem to solve into deep learning, rather than using only empirical data. The motivation for this approach lies in the consideration that purely data-driven approaches may become too complex for large-scale applications, due to the large amount of required data, and to the related processing complexity. Expert-knowledge-aided deep learning is an emerging topic even in fields of science where data-driven deep learning techniques are a consolidated reality. In [202], image processing for object position detection in robotics applications is considered, and it is observed that augmenting a small training set of real images with a large dataset of synthetic images significantly improves the estimation accuracy with respect to processing only the small dataset of real images. Similar results have been obtained in [203] with reference to speech recognition applications.
In the context of wireless communications, leveraging data-driven techniques based on deep learning, with expert knowledge coming from (even approximate) theoretical models holds an even greater potential. Indeed, despite their possible inaccuracy or cumbersomeness, theoretical wireless models provide important prior information compared to what is available in other fields of science. In our opinion, this clear advantage of wireless communications should not be wasted. More specifically, when performing resource allocation, depending on the system complexity, one is faced with one of the four cases shown in Tab. I:
While, it is clear that C.1 and C.4 should be handled by traditional model-based approaches, and fully data-driven techniques, respectively, the most appropriate way of tackling C.2 and C.3 is an open issue. Indeed, C.2 and C.3 offer the possibility of a cross-fertilization between model-aided and data-driven approaches, due to the fact that a model is available, even though it is inaccurate or cumbersome to optimize. Moreover, C.2 and C.3 are the typical situations in wireless communications, where models and optimization algorithms are usually available, despite being the result of some approximations and simplifications.
In order to tackle C.2 and C.3, we propose the following two methodological approaches:
- •
Optimizing a model. In Case C.2, an analytical expression of the performance metric to optimize is available. Then, an ANN can be trained to learn the map between the system parameters and the corresponding optimal resource allocation, following the technique anticipated in Section I-D. This approach is depicted in Fig. 12.
- •
Refining a model. In Case C.3, a two-step approach can be exploited. In the first step, an ANN is trained based on synthetic data generated from the approximate model. Next, a second training phase based on true, measured data can be used to refine the ANN configuration. This approach is depicted in Fig. 13.
As it will become clear from the applications illustrated in the sequel, the main advantages of the proposed approaches are:
- •
The significant complexity reduction compared to purely model-based methods, thus enabling real-time resource allocation with near-optimal performance.
- •
The significant reduction of the amount of empirical data compared to purely data-driven methods, thus dispensing with expensive and unpractical measurement campaigns.
With the exception of one case-study related to the auto-encoder approach, all applications described in the following address resource allocation problems by using one of the two methodologies described above.
IV-B1 Physical layer design: Optimizing the receiver of a molecular communication system
In this section, we consider the typical case study of optimizing the receiver of a communication system. As an example, we focus our attention on a molecular communication system, where chemical signals instead of electromagnetic signals are used to convey information [204]. The motivation of this choice is the complexity of modeling molecular communication systems, and the possibility of leveraging data-driven methods in this context [205]. A similar approach can be used to design and optimize the receivers of different communication systems. The objective is to prove that, by assuming that the system model is accurate, model-based and data-driven methods yield the same optimal receiver designs if they are both appropriately designed.
As a practical case study, we consider a molecular communication system where diffusion is employed for allowing information particles to propagate from a transmitter to a receiver. Due to the intrinsic characteristics of diffusion, the resulting transmission channel is usually affected by a non-negligible Inter-Symbol Interference (ISI), which, if not taken into account for system optimization, may severely degrade the system performance. For this reason, we focus our attention on optimizing the receiver operation in the presence of ISI. In particular, we consider a threshold-based demodulator and denote by the demodulation threshold. Let be the estimate of symbol at time-slot , a threshold-based demodulator operates as follows:
[TABLE]
where is the number of molecular received at time-slot .
Under the typical operating conditions discussed in detail in [206] for a binary modulation scheme, the error probability as a function of can be formulated as follows:
[TABLE]
where:
[TABLE]
and is the incomplete Gamma function, is the memory of the chemical channel, i.e., the length of the ISI, is the background noise power per unit time, is the duration of the time-slot, and is the average number of received information particles at the th time-slot.
In order to obtain appropriate performance and, thus, reduce the error probability, the detection threshold, , needs to be appropriately chosen and optimized. In Fig. 14, we depict the error probability as a function of for a typical system setup. We observe that an optimal value of exists that minimizes the error probability and that depends on the time slot duration , i.e., the amount of ISI for a given channel.
In mathematical terms, the optimal threshold that minimizes the error probability can be formulated as follows:
[TABLE]
Due to the analytical complexity of (58), it is not possible to compute explicitly, but it can be obtained numerically at an affordable complexity.
An alternative approach is to employ a data-driven approach that does not rely on any model but uses only empirical data, e.g., a large set of values for . More precisely, we consider an ANN whose aim is to demodulate the transmitted data by minimizing the error probability. An ANN-based demodulator is a system whose input is the number of received information particles, at the th time-slot, and the outputs are the probabilities that the transmitted bit is 0 or 1, i.e., and , respectively. Since, , only one of the two probabilities is needed. We use the notation . Based on the outputs, the ANN demodulate the received bits as follows:
[TABLE]
where the threshold 0.5 accounts for the fact that the bits are equiprobable.
In order to train the ANN, we consider a supervised learning approach, i.e., we compute the parameters (e.g., the bias factors and the weights) of the ANN by using a known sequence of transmitted bits. In particular, we use the Bayesian regularization back propagation technique, which updates the weights and biases by using the Levenberg-Marquardt optimization algorithm. The set of parameters to train and operate the ANN are as follows: The number of layers is 10, the learning rate is 0.01, the training epoch is 200, the number of validation bits is 100000, and the replication time is 50. In particular, the training is performed in a batch mode, and the replication time denotes the number of batches each of which is 1000-bit long.
In Fig. 15, we compare the optimal threshold computed numerically from (60) as a function of the signal-to-noise-ratio, and the demodulation threshold that is learnt by the ANN-based demodulator. In the latter case, the threshold is obtained, after completing the training of the ANN, and identifying the input, i.e., the number of information particles, for which the output probability is equal to 0.5. We observe that the ANN-based implementation is capable of learning the demodulation threshold in a very accurate manner.
In Fig. 16 and Fig. 17, we compare the bit error probability of the ANN-based demodulator against the bit error probability in (58) by considering a short symbol time (small ISI) and a long symbol time (large ISI), respectively. As for the analytical model, the optimal threshold is estimated from (60) for each value of the signal-to-noise-ratio. We note a very good agreement even with only 10 layers.
In summary, this section shows that an optimal receiver design can be obtained by relying solely on data-driven methods and that the resulting ANN can be used for system optimization, e.g., to optimize the demodulation threshold.
IV-B2 Optimizing a model: power control in wireless networks
This application focuses on the maximization of the bit-per-Joule energy efficiency in interference-limited networks. The importance of the energy efficiency as a key performance metric in communication systems has emerged recently, motivated by the need to provide 1000x higher data rates compared to present systems, while at the same time halving the energy consumption. Already 5G wireless networks are requested to increase the bit-per-Joule energy efficiency by a factor 2000 compared to previous wireless networks [4, 2].
Traditional approaches for energy efficiency maximization in wireless networks are based on the theory of fractional programming, the branch of optimization theory that focuses on the optimization of fractional functions. A tutorial on fractional programming methods for energy efficiency maximization in wireless networks is available in [3]. Therein, it is observed that achieving the global maximum of the energy efficiency metric requires exponential complexity whenever the communication system is interference-limited. Here, we will show how the global maximum of the energy efficiency can be approached with limited complexity by using ANNs.
To elaborate, let us consider an interference-limited network in which single-antenna transmitters communicate with receivers, each equipped with antennas. Denote by \mbox{\boldmathh}_{k,m} the channel from transmitter to receiver , by the transmit power of transmitter , by \mbox{\boldmathc}_{k} the receive vector used by the receiver associated to transmitter , and by the received noise power at receiver . Then, the signal to interference plus noise ratio (SINR) enjoyed by transmitter at its associated receiver is expressed as:
[TABLE]
with d_{k,j}=|\mbox{\boldmathc}_{k}^{H}\mbox{\boldmathh}_{j,m_{k}}|^{2}, for all and .
Based on (64), the network weighted sum energy efficiency (WSEE) is given by
[TABLE]
wherein is the communication bandwidth, is the hardware static power consumed to operate the -th communication link, the inverse of the power amplifier efficiency of transmitter , and is a non-negative weight modeling the priority given to the energy efficiency of user . It is important to stress that depends on system parameters such as the number of antennas and the efficiency of the system hardware components, but it is assumed not to depend on the transmit powers, and therefore the specific model expressing as a function of the system hardware components is inessential as far as maximizing (65) as a function of the transmit powers is concerned.
Thus, the power control problem is stated as the maximization of the weighted sum energy efficiency (WSEE) subject to power constraints, namely
[TABLE]
with and being the maximum feasible and minimum acceptable transmit powers for user . The challenge in tackling (66) lies both in the fact that the numerators of (66a) are not concave functions of due to the presence of multi-user interference, and to the sum-of-ratios functional form, which is regarded as the hardest fractional problem to tackle. Therefore, showing that an ANN can be used to solve (66) makes a very strong case towards the development of ANN-based solutions of generic energy-efficient resource allocation problems. To solve (66), global optimization methods are required to find the optimal power allocation, while more practical approaches guarantee only first-order optimality with a polynomial complexity. Moreover, Problem (66) needs to be solved anew whenever the channel realizations \{\mbox{\boldmathh}_{\ell,m_{k}}\}_{k,\ell} change. This represents a critical drawback, especially considering that the resource allocation process must be completed well before the end of the channel coherence time in order for the optimized power vector to be practically useful. This observation makes it difficult to employ even polynomial-complexity algorithms to perform resource allocation in real-time, i.e. following the small-scale variations of the channel coefficients.
In oder to address this issue and enable real-time resource allocation, it is possible to resort to deep ANNs paired with the use of energy efficiency models and traditional optimization approaches. Specifically, this case study is an instance of C.2 of Table I, since a model is available and has allowed us to formulate Problem (66). However, the model is too complex (for practical implementations) to be optimized by directly using traditional optimization methods. The idea is, therefore, to exploit the model by using it to train an ANN in order to learn the map between the system parameters, and the corresponding optimal power allocation. To elaborate, let us observe that Problem (66) can be regarded as an unknown function mapping from the coefficients and the maximum/minimum transmit powers and , to the optimal power allocation vector , namely
[TABLE]
Since ANNs are universal function approximators, it is possible to train an ANN so that its input-output relationship reproduces the unknown map (67). This leads to considering an ANN with input nodes and output nodes, to be trained so that it outputs the optimal power vector corresponding to a given input of system parameters . This enables to update the resource allocation without having to solve any optimization problem every time that the system parameters change, but by simply feeding the new vector to the ANN, and obtaining the corresponding power allocation as the output of the ANN.
It is important to emphasize that this entails a negligible computational complexity compared to using sophisticated numerical optimization algorithms. Indeed, once all the parameters and hyperparameters of the ANN are fixed, the ANN provides a closed-form expression of its input-output relationship, whose complexity amounts to computing real multiplications555The complexity related to additions is negligible compared to that related to multiplications and evaluating activation functions, with denoting the number of neurons in Layer in accordance with the notation of Section III-A.
Instead, a higher complexity is required to generate a suitable training set, because this requires to consider many different system parameters realizations \{\mbox{\boldmathd}_{nt}\}_{nt=1}^{N_{T}}, and to compute the corresponding desired power allocation vector by solving (66) times. At a first sight, this might seem to result in a complexity overhead that defeats the purpose of using ANNs to reduce the computational complexity of resource allocation problems. However, this is not the case for at least two major reasons that make the generation of the training set fundamentally different from solving Problem (66) in real-time:
- •
The training set can be generated and used offline to train the ANN. Thus, a higher complexity can be afforded and real-time constraints do not apply.
- •
The training set needs to be updated at a much longer time-scale than that with which the network parameters change.
In other words, the training process needs not be executed each time a system parameter changes, and the solution needs not be obtained within the channel coherence time. Thus, the use of traditional optimization theory to generate the training set does not defeat the practicality of the proposed ANN-based approach. On the contrary, the use of mathematical models to formulate the optimization problem and the use of traditional optimization techniques to build the training set, represent the expert knowledge that is exploited to facilitate the use of ANNs for real-time power control in wireless networks. In addition, we mention that recently a more efficient branch-and-bound solution to globally solve energy-efficient problems has been proposed in [200], which further facilitates the global solution of Problem (66).
Numerical performance analysis. Consider the uplink of a wireless interference network with single-antenna user equipments (UEs) placed in a square area with edge and communicating with 4 access points placed at coordinates , , , , and equipped with antennas each. The path-loss is modeled following [207], with carrier frequency and power decay factor equal to 4.5, while fast fading terms are modeled as realizations of zero-mean, unit-variance circularly symmetric complex Gaussian random variables. Moreover, and for all , respectively, while the noise power at each receiver is , with the receiver noise figure, the communication bandwidth, and the noise spectral density. All users have the same maximum transmit powers , while for all .
The proposed ANN-based solution of Problem (66) is implemented through a feedforward ANN with fully-connected layers, with the hidden layers having 128, 64, 32, 16, 8 neurons, respectively. The training set has been generated by solving Problem (66) for different realizations of the vector . When doing this, due to numerical reasons, the parameter vectors and the optimal output powers in the training set have been expressed in logarithmic units rather than in a linear scale. On the other hand, the use of logarithms may cause numerical problems when the optimal transmit powers are very close to zero. For this reason, logarithmic values approaching have been clipped at for . In our experiments, worked well.666Note that, although using a logarithmic scale, the transmit powers are not expressed in dBW, since the logarithmic values are not multiplied by 10. Thus , corresponds to . Summarizing, the considered normalized training set is
[TABLE]
where all functions are applied element-wise to the vectors in the training set.
The activation functions have been set as follows. The first hidden layer has an ELU activation, the other hidden layers alternate ReLU and ELU activation functions, while the output layer uses a linear activation function. The use of a linear activation in the output layer is motivated by the consideration that it allows the ANN to produce low training error as a result of a proper configuration of the hidden layers, instead of artificially reducing the output error thanks to the use of cut-off levels in the activation function. In other words, a linear output activation function allows the ANN to learn whether the present configuration of weights and biases is truly leading to a small output error.
The ANN is implemented in Keras 2.2.4 [208] with TensorFlow 1.12.0[209] as backend, using Glorot uniform initialization [133], the Adam training algorithm with Nesterov momentum, and the mean squared error as the loss function. The training is obtained by solving Problem (66) for 102,000 independent and identically distributed (i.i.d.) realizations of UEs’ positions and propagation channels, and different values of . In each scenario, the UEs are associated to the access point towards which they enjoy the strongest effective channel. A validation and a test set of 10,200 and 510,000 samples, respectively, were also generated following a similar procedure.
Considering training, validation, and test sets, 622,200 data samples were generated, which required solving the NP-hard Problem (66) 622,200 times. This has been accomplished by the newly proposed branch-and-bound method developed in [200], which required 8.4 CPU hours to solve all 622,200 instances of the WSEE maximization problem, on Intel Haswell nodes with Xeon E5-2680 v3 CPUs running at . This strongly supports the argument that the offline generation of a suitable training set for ANN-based power control is quite affordable. Finally, all performance results reported in the sequel have been obtained by averaging over 10 realizations of the network obtained by training the ANN on the same training set with different initialization of the underlying random number generator.777Note that this is not equivalent to model ensembling [210, Sect. 7.3.3] or bagging [20, Sect. 7.1]. The average training and validation losses for the final ANN are shown in Figure 18. It can be observed that both errors quickly decrease and approach a very small value, thus showing that the adopted ANN configuration is able to properly fit the training data, without underfitting or overfitting.
Next, we present the performance of the proposed method over the test set. Specifically, we have compared the proposed ANN-based method with the following benchmarks:
- •
SCAos: A first-order optimal method from [200] that leverages sequential convex approximation methods. For each value of , the algorithm initializes the transmit power to , for all .
- •
SCA: Again the first-order optimal method based on sequential convex approximation developed in [200], but with a double-initialization approach. Specifically, at maximum power initialization is used. However, for all values of , the algorithm is run twice, first with the maximum power initialization, and then initializing the transmit powers with the optimal solution obtained for the previous value. Then, the power allocation achieving the better WSEE value is retained.
- •
Max. Power: All UEs transmit at maximum power, i.e. , for all . This strategy is known to perform well in interference networks for low values.
- •
Best only: Only one UE is allowed to transmit, specifically that with the best effective channel. This approach is motivated for high values, as a naive way of nulling out multi-user interference.
The results are shown in Figure 19 and indicate that the ANN-based approach outperforms all other practical approaches. The only benchmark that performs comparably with the ANN-based approach is the SCA algorithm with the more sophisticated initialization rule, which requires to solve the WSEE maximization problem twice and for the complete range of values. Thus, this SCA approach is quite more complex than the ANN-based method, but, despite this, it performs slightly worse. In conclusion, we can argue that the ANN approach strikes a much better complexity-performance trade-off than state-of-the-art approaches, and thus it enables online power allocation in wireless communication networks.
IV-B3 Optimizing a model: user-cell association in massive MIMO networks
This application has a similar flavor as that in Section IV-B2, with the difference that instead of allocating the users’ transmit powers, the problem consists of deciding the assignment between transmitters and receivers in an interference network. This means that, while the case-study in Section IV-B2 tackles a continuous resource allocation problem, and thus can be regarded as a regression problem, here the focus is on a discrete resource allocation problem, which can be viewed as a classification problem. To elaborate, consider a massive MIMO multi-cell network with single-antenna users and base stations equipped with antennas each. Also, assume that each user can be associated to only one access point, and that each access point can serve at most users. In this context, the user-cell association sum-rate maximization problem is cast as:
[TABLE]
wherein is the spectral efficiency enjoyed by transmitter if associated to receiver , with the corresponding SINR accounting for typical massive MIMO impairments such as pilot contamination and imperfect channel state information, is a binary variable taking value when transmitter is served by receiver , , and is the communication bandwidth. Constraints (68b) and (68c) ensure that each transmitter can be associated to only one receiver and that each receiver can serve at most transmitters, while Constraint (68d) guarantees minimum QoS for each transmitter, and Constraint (68e) is due to the integrality of the association variables.
Typical approaches to solve linear programs such as (68) resort to branch-and-cut techniques, which require solving a series of continuous relaxations of (68). In some special cases, i.e. when is integer for all , the constraint matrix of Problem (68) can be shown to be totally uni-modular, which enables to solve (68) through just one continuos relaxation. Nevertheless, this still requires to employ numerical optimization algorithms, whose complexity might still be quite high, especially in large networks. Moreover, as in the power control example of Section IV-B2, the optimal association rule needs to be computed in real-time, thus implying that Problem (68) needs to be solved anew each time any of the coefficients changes. Moreover, in order to be useful, the solution needs to be obtained well before the coefficients change again.
In order to reduce the complexity of the resource allocation process, we observe that the considered problem is again an instance of C.2 in Table I, since a model is available and has allowed us to formulate Problem (68). Then, following a similar approach as in Section IV-B2, the optimization program in (68) can be seen as the problem of determining the unknown map:
[TABLE]
which can be tackled by resorting again to a fully-connected FFNs, taking -dimensional inputs and producing -dimensional outputs, with similar implementation and complexity considerations as those in Section IV-B2.
Numerical performance analysis. Consider the uplink of a massive MIMO system wherein base stations (BSs) are deployed in a square area with edge at points with coordinates , , , , serving users randomly placed in the coverage area. Each BS is equipped with antennas, while all mobile users have a single antenna. A uniform uplink power of is considered for all users, while a common receive noise power of is assumed for all BSs. The communication bandwidth is and the propagation channels follow the local scattering model [211].
A training set of samples has been generated by considering independent realizations of the users’ positions in the service area, and solving the corresponding instance of Problem (68), with for all . Out of these samples, 140000 have used as training set, while the remaining 15000 have been used as validation set for hyperparameter tuning. The considered ANN architecture is composed of fully connected layers with , , neurons, respectively, plus an output layer with neurons. Layers and have a ReLU activation function, while Layer and the output layer have a sigmoidal activation function. The Adam training algorithm with Nesterov’s momentum has been employed for training, using the mean squared error as loss function.
The training and validation MSEs are reported in Tab. II versus the training epoch number. The result show that the considered ANN architecture fits well the training data, without underfitting or overfitting.
After training and validation, the performance of the resulting ANN has been evaluated over a test set of data samples that have been generated independently from the training and validation samples. For each test sample, denoting by the ANN output, user has been associated to BS if , and then the resulting sum-rate performance has been compared to the optimal solution of Problem (68).
Fig. 20 shows the cumulative distribution function (CDF) of the average users’ rate over the test set for the following schemes:
- •
ANN-based association with MMSE reception.
- •
Optimal association with MMSE reception.
- •
ANN-based association with MR reception.
- •
Optimal association with MR reception.
It is seen that in all cases the ANN-based method performs similarly as the optimal user-cell association, while requiring a much lower computational complexity. Thus, once again, this motivates the use of ANN-based resource allocation methods.
IV-B4 Refining a model by deep transfer learning - Cellular networks beyond the Poisson point process
In this section, we consider the case study in which an analytical model exists and is analytically tractable, but it is not considered to be sufficiently accurate for system optimization. We assume, in addition, that more accurate network models are difficult to develop and/or are not suitable for system optimization. As a practical example, we consider the optimization of the Energy Efficiency (EE) [64] in non-Poisson cellular networks [212], which is known to be an intractable optimization problem because of the analytical complexity of the utility function to optimize.
As discussed in Section I-C, we propose to solve this issue by relying on deep transfer learning. Our proposed idea consists of jointly exploiting model-based and data-driven optimization. The approach consists of first optimizing the network using a mismatched, but simpler for optimization, model, and then refining the result with (few) empirical data. Let us assume, as a practical example, that the mismatched (approximated) model is the Poisson model. More precisely, we assume that the only inaccuracy of the system model is the spatial distribution of the cellular base stations, while all the other parameters and modeling assumptions as considered to be accurate. More general system setups can be considered, and another example is studied in the next section. In detail, the approximated model is assumed to be the Poisson point process model, while the “exact” point process model is assumed to be the square grid model [213]. This is a simple example that is chosen in order to shed light on our proposed approach, and that is also easy to simulate and reproduce.
From [64], we know that the EE in Poisson cellular networks is available in closed-form and is amenable to optimization. Thus, a large dataset of optimal values for the EE as a function of any system parameters can be readily obtained. This dataset is used to train a (mismatched) ANN with the desired accuracy. The issue, as mentioned, is that the original network model is non-Poisson. We assume, however, that the considered cellular network deployment is equipped with a sensing platform, e.g., by using the meta-surfaces discussed in Section I-C, that can sense and report some contextual data about the network, which is used to obtain a dataset of just a few empirical but optimal values of the EE, which account for the actual non-Poisson spatial model. This dataset is used to tune the ANN and to correct the mismatch. The intuition behind this proposed approach is that, despite mismatched, the initial ANN embeds the most important features of the cellular network already, and thus less data is needed compared with the case study in which no pre-training is performed. The objective of this section is to study the amount of empirical samples that the proposed approach based on transfer learning, which jointly combines model and data, requires to achieve similar performance as a pure data-driven method. If the amount of empirical data is not that large, the proposed approach will be successful and will also reduce the amount of overhead, to collect the empirical samples, that is needed for network optimization.
In the rest of this section, we discuss both pure model-based and data-driven approaches, and then combine them together based on transfer learning principles, and, more precisely on network-based transfer learning.
Model-based optimization. From [64], the EE in Poisson cellular networks can be formulated as follows:
[TABLE]
where
[TABLE]
[TABLE]
are the spectral efficiency and the power consumption of the cellular network, respectively.
Equations (71) and (72) depend on many parameters, which are all defined in [64]. As far as the present paper is concerned, we are interested in four main parameters: , which is the deployment density of the base stations, , which is the transmit power of the base stations, , which is the circuit power consumption of the base stations, and , which is the idle power consumption of the base stations. In this section and are assumed to be fixed, and they are further analyzed in the next section. The objective is to identify the optimal deployment density of the base stations, , given some values of the transmit power . In [64], it is proved that this optimization problem has a unique solution, which is formulated as the unique root of a non-linear equation. Therefore, the optimal density of the base stations that maximizes the EE can be computed efficiently, for any given values of the transmit power. By solving this optimization problem, we can easily obtain the optimal pairs , where . These pairs can then be used to train an ANN, with as the input, and as the output.
Data-driven optimization. Let us assume now that we cannot rely on any analytical models and that the EE needs to be estimated by collecting empirical samples from the cellular network, from which the optimal cellular network deployment needs to be inferred. In particular, the spectral efficiency and the power consumption can be estimated, respectively, as follows:
[TABLE]
[TABLE]
These two formulas can be interpreted as follows. Let us consider the spectral efficiency as an example. Each mobile terminal in the cellular network determines, based on the received signal, whether it is in coverage. This is performed by measuring the average signal-to-noise-ratio during the cell association phase and the signal-to-interference-ratio during data transmission (if the first phase was successful). This condition corresponds to the term , where is the indicator function. Each mobile terminal, reports whether it is in coverage or not to a network controller (one bit of information). Based on the number of mobile terminals that are in coverage on a given cell (say ), the corresponding base station equally allocates the available spectrum (say ) among them, and transmit data with a fixed rate . Based on the information gathered by all the mobile terminals, it is possible to identify the base stations that have at least one mobile terminal in their corresponding cells (say ) and to compute the number of mobile terminals that lie in each of them for each network realization. The spectral efficiency can then be estimated by summing the rates all of active base stations and by normalizing by the area of the network under analysis. It is worth mentioning that in order to identify, e.g., the optimal deployment density of the base stations, we need to repeat this procedure by considering all possible combinations of base station patterns, given the number of base stations actually deployed. If the optimization variable is the transmit power of the base stations, all possible values of transmit power need to be tested and the value corresponding to the optimal EE needs to be recorded and used to train an ANN, similar to the approach discussed for model-based optimization. Based on this simple description, we can readily understand that the amount of empirical data that is necessary to train an ANN may not be negligible, and, in any case, may strongly affect the overhead for network optimization.
Network-based transfer learning optimization. Network-based transfer learning is a solution to overcome the limitations of model-based and data-driven approaches, since it is apparent that both have advantages and limitations. As already mentioned, the idea is to first train and optimize an ANN by using a model-based approach, and then refine the obtained ANN by using some empirical data (data-driven approach). Once the first model-based ANN is obtained, in particular, we consider that its configuration, i.e., the number of layers, neurons, weights, and biases, constitute the initial configuration of the second ANN that is refined based on empirical data. In our case study, we assume that, during the refinement phase, the number of layers and neurons are not modified, while the weights and biases are finely-tuned in order to account for the empirical data and to capture those features of the actual network setup that the assumed model, in order to keep its complexity at a low level, is not capable of doing.
In Figures 21 and 22, we illustrate some numerical examples that compare the performance of the three proposed approaches. A feed-forward ANN architecture with fully-connected layers and ReLU activation functions is considered. Specifically, after trying many different ANN configurations, we found that an ANN with three hidden layers equipped with 8, 8, and 2 neurons, respectively, yields comparable performance as a much larger ANN that contains six hidden layers with 64, 32, 16, 8, 4, 2 neurons, respectively. Thus, in all our experiments, we have adopted the 8, 8, 2 ANN configuration, since it provides the best complexity-performance trade-off among all ANN architectures we tested.
Figure 21 shows the training and validation relative MSE versus the number of training epochs for the following approaches:
- •
the proposed deep transfer learning technique that employs both model-based and empirical data samples.
- •
the baseline approach, where only empirical data samples are used.
As for the first approach, the size of the training set is always set equal to 30,000 samples, out of which x samples follow the true base station distribution (square grid model), and (30,000-x) samples follow the Poisson distribution. As for the second approach, the adopted training set contains only the x empirical samples. Thus, this comparison is fair in terms of number of empirical data samples employed and is aimed at showing the performance that can be obtained by augmenting a small dataset of empirical data with a larger dataset of model-based data. For both approaches, the results for the values x = 300, 600, 1500, 2100, and 3000 are shown, and, for each value of x, it is seen that the proposed deep transfer learning method achieves much lower training and validation errors compared to the baseline approach.
This result is confirmed also in the testing phase. Fig. 22 shows the density of base stations as a function of their transmit power, considering a test set of 8,000 new transmit powers, which were not used during the training phase. Four schemes are compared:
- •
the optimal density computed through exhaustive search
- •
the density predicted by means of deep transfer learning, where 3,000 empirical samples are used in the second training step
- •
the density obtained without transfer learning and performing the training by using only 3,000 empirical samples
- •
the density obtained without transfer learning and performing the training by using only 30,000 model-based samples
Notably, we observe that using only the 3,000 empirical samples yields inaccurate estimates of the optimal deployment density of the base stations. Instead, combing model-based data with the same 3,000 samples of empirical data provides one with near-optimal performance. This highlights the relevance of performing the model-based pre-training before employing actual measurements for system optimization, while overcoming their inherent limitations. Moreover, it is interesting to observe that using only the 30,000 model-based samples does not lead to satisfactory performance, thus showing that it is necessary to merge model-based and empirical samples to obtain accurate performance.
In summary, based on the results reported in Figs. 21 and 22, we conclude that the proposed approach based on transfer learning constitutes a suitable approach to take the best of both model-based and data-driven methods.
IV-B5 Refining a model by deep transfer learning - Cellular networks with inaccurate power consumption models
In this section, we consider a similar optimization problem as in the previous section. Rather than focusing on the impact of the spatial distribution of the cellular base stations, we focus our attention on the power consumption model of the base stations. More precisely, we assume that the Poisson point process is sufficiently accurate to account for the distribution of the cellular base stations. As far as the power consumption model of the cellular base stations is concerned, on the other hand, we assume a model based on a uniform distribution for and , while the empirical model is assumed to be based on the Gaussian distribution. The optimization problem that we are interested in is still concerned with identifying the optimal deployment density of the base stations, but as a function of three variables: , , and . The model-based, the data-driven, and the transfer learning based approach are obtained by using the same approach as the one described in the previous section. As far as the architecture of the ANN is concerned, on the other hand, we consider a different ANN architecture, which is made of six layers and four neurons. The adopted ANN is, therefore, more complicated because three input parameters instead of one are considered in this case study.
For this scenario, the ANN configuration with the best complexity-performance trade-off has been found to be one with five hidden layers equipped with 8 neurons each, and ReLU activation functions. Remarkably, the performance granted by this ANN architecture is slightly worse than that of a much more complex ANN with 128-64-32-16-8 neurons in the five hidden layers. The training and validation performance of the adopted ANN are reported in Figure 23, and similar considerations as for Figure 21 apply. Thus, also in this case the proposed network-based transfer learning approach is a promising alternative to bridge the critical tension between modeling accuracy, optimization complexity, and sensing overhead for network optimization.
IV-B6 Deep reinforcement learning for power control in energy-harvesting wireless systems
As a last case-study, we consider the use of deep reinforcement learning, in the context of energy-harvesting communication systems.
Specifically, consider a time-slotted energy-harvesting node transmitting its data over block fading channels to an access point powered by traditional energy sources. Denote by the fading complex channel gain between the transmitter and the access point in time-slot , by the energy harvested during time-slot , which is modeled as a realization of a random variable with unknown distribution, and by the energy stored in the transmitter battery at time-slot . The battery is assumed to be perfectly efficient, with maximum capacity . At the transmitter, only causal information about energy arrivals and communication channels is assumed, i.e. neither the distribution of the energy arrival and channel processes, nor their future realizations are known at each time-slot . Also, denote by the transmit power in the -th time-slot, with the maximum feasible transmit power.
In this context, the goal is to maximize the system long-term achievable rate, by solving the following problem:
[TABLE]
wherein is the receive noise power, is the time-slot duration, and the battery state evolves as
[TABLE]
Constraint (75b) captures the fact that the maximum energy that can be used in time-slot is limited by the minimum between the amount of energy available in the battery, , and the maximum allowed transmit energy .
Since the information about the random energy arrivals and the channel realizations is only causally available, and the battery evolves in a Markovian fashion, according to (76), Problem (75) is a stochastic control problem which could be formulated as a MDP, with state space , action space , and reward at time-slot given by . Thus, in principle, upon discretization of the state space, standard MDP techniques can be used to solve (75). However, this poses at least the following three major challenges:
- •
Large feedback overhead, since global information about the battery and channel states of each network node is needed for the operation of the policy.
- •
The solution of the MDP requires statistical information about the energy-harvesting process and the wireless channel, which is often difficult to obtain.
- •
In order to obtain a good solution, a fine discretization step needs to be employed, which results in very large state and action spaces, thus further increasing the problem complexity.
These reasons motivate the use of deep reinforcement learning to tackle Problem (75).
Numerical performance analysis. Consider an energy-harvesting system in which the transmitter harvests energy according to a non-negative truncated Gaussian distribution888The energy-harvesting distribution is not assumed known at the design stage. with mean and variance . The harvested energy is stored in a battery with capacity and the maximum feasible transmit power in each time slot is .
The Deep Q-Network method is implemented by an ANN with 10 hidden layers equipped with 60, 60, 58, 58, 56, 56, 54, 54, 52, 52 neurons, respectively. The input layer contains neurons, the output layer contains 150 neurons, which implies that a discretization of the feasible transmit power levels with step has been considered. All hidden layers have ReLU activation functions, while the output layer employs linear activations, motivated by similar considerations as in previous case-studies. The Q-learning algorithm adopts a forgetting factor of and the performance of the three following algorithms has been compared:
- •
The deep reinforcement learning method that employs the deep Q-Network described above.
- •
The solution of the MDP. This approach yields, in principle, the optimal online policy, but on the other hand requires a complexity that increases proportionally with the number of considered power levels. For the problem at hand, the complexity of the MDP approach becomes unfeasible when the same discretization step of as in the deep reinforcement learning case is used. Therefore, a discretization step of has been used for the MDP approach.
- •
An offline policy that assumes non-causal knowledge of the channels and energy-harvesting realizations. Clearly, this approach is not practically implementable, and is considered only as a performance upper-bound of any online method.
Table III shows the performance of the three schemes above, with mean and different values of the variance . The results indicate that the deep Q-Network method is able to achieve performance very close to that of the offline policy that exploits non-causal information, while outperforming the MDP-based solution. It is worth mentioning that the latter result is due to the fact that deep reinforcement learning enables a finer discretization step compared to the MDP-based solution, thanks to its much lower computational complexity.
Finally, Figure 24 shows the convergence of the considered deep reinforcement learning method in terms of number of time slots until the value of the system throughput stabilizes, for and . It is seen that a few thousands of time-slots are required to reach convergence.
V Conclusions and future research directions
The complexity of future wireless communication networks makes deep learning an indispensable design tool. Moreover, recent technological advancements in the area of computer processing units and distributed data storage make the use of deep learning more practical than ever. Nevertheless, research in this field has just started, and a great deal of open problems must be solved before ANN-based wireless communication networks can be deployed.
The first challenge to be overcome is represented by the large amount of data that ANN need in order to ensure satisfactory performance. As remarked in Section II, deep learning outperforms other machine learning techniques in the large data regime. However, while this might not be an obstacle in other fields of science, the acquisition of large datasets in wireless networks requires measurement campaigns that could be too expensive and/or not practical. In addition, wireless networks are very dynamic, especially in outdoor environments, and it may be difficult to gather new accurate data within the coherence time of the channel of the environment itself [11].
As shown in this work, the most promising approach to overcome this challenge is the joint use of data-driven and model-based approaches. The transfer learning approach developed in Section IV demonstrates how even approximate mathematical models contain useful prior information that, if successfully transferred into deep learning techniques, can significantly reduce the amount of data required to achieve the desired performance. Nevertheless, this represents only the tip of the iceberg, and many open issues remain to be investigated. As far deep transfer learning is concerned, it is not clear how to set the hyperparameters (e.g. the amount of model-based data, the number of ANN layers and neurons, etc.) to prevent a negative transfer, i.e. that the ANN tuned with empirical data provides worse performance than the model-based ANN. Moreover, other transfer learning techniques remain to be explored, as well as other ways of embedding expert knowledge into ANNs, based for example on the deep unfolding and deep reinforcement learning methods. As an example, embedding some prior information into a deep reinforcement learning algorithm could potentially speed up its convergence. In addition, a research direction that could provide guidance to achieve a cross-fertilization between mathematical models and deep learning is aimed at deriving a theoretical explanation of how ANNs work and how to configure them to perform a certain task. Opening the black box of ANNs in order to understand the information-theoretic principles that regulate their behavior is surely a major topic for future investigation. A recent contribution in this direction is [214], which employs the so-called information bottleneck approach.
The second challenge to be overcome is the integration of ANN into future wireless network architectures. As motivated in this work, deep learning should be implemented in a distributed fashion. However, this poses several issues that need to be overcome in the next years. Integrating AI into distributed wireless networks will not only affect the transmission technologies, but it will also significantly impact the way the network is controlled through feedback signals to avoid instability and malfunctioning. A distributed network in which each node has its own ANN, that is trained based on a dataset acquired from local measurement and experience, inevitably leads to different nodes having different learning capabilities. Each distributed dataset might differ in size, since different nodes might have different measurement and storage capabilities, as well as quality, since different nodes might experience different data perturbations due to the non-ideality of the measurement sensors. This could potentially lead to instabilities and, in the worst case, cause the wireless network to collapse. Moreover, another issue to be addressed in distributed setups is the possibility for each node to optimize its own performance, rather than the system-wide utility, which might cause a device to learn how to cheat for individual gain. Thus, security mechanisms must be put in place to ensure the correct evolution of a distributed, ANN-based wireless communication network.
A third challenge to be overcome is to make deep learning robust against corrupted data. Indeed, due to inevitable errors over feedback channels or in the storage process of data into memory banks, the datasets used to train ANNs might be corrupted and possibly lead to undesirable training results. Techniques that are able to make the training process robust to these events are warranted, especially in light of the distributed implementation of ANN-based wireless networks, which makes the overall network highly prone to inconsistencies and failures.
In conclusion, it is apparent that deep learning is a promising tool to “make things work”. However, lots of data (for deep learning) or time (for reinforcement learning) is needed to achieve the desired performance. Compared with other fields of research, wireless is unique, since decades of research allowed us to gain deep expert knowledge. This prior information can be used to “initialize” deep learning, in order to reduce the amount of data, the computational complexity, the energy, and the overhead that are needed to achieve these gains. Communications theory still has a fundamental role in the era of deep learning.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] J. Andrews, S. Buzzi, W. Choi, S. Hanly, A. Lozano, A. C. K. Soong, and J. C. Zhang, “What will 5G be?” IEEE Journal on Selected Areas in Communications , vol. 32, no. 6, pp. 1065–1082, June 2014.
- 2[2] S. Buzzi, C.-L. I, T. E. Klein, H. V. Poor, C. Yang, and A. Zappone, “A survey of energy-efficient techniques for 5G networks and challenges ahead,” IEEE Journal on Selected Areas in Communications , vol. 34, no. 5, 2016.
- 3[3] A. Zappone and E. Jorswieck, “Energy efficiency in wireless networks via fractional programming theory,” Foundations and Trends® in Communications and Information Theory , vol. 11, no. 3-4, pp. 185–396, 2015.
- 4[4] “NGMN alliance 5G white paper,” https://www.ngmn.org/5g-white-paper/5g-white-paper.html , 2015.
- 5[5] C. G. Aliu et al. , “A survey of self organisation in future cellular networks,” IEEE Communications Surveys and Tutorials , vol. 15, no. 1, pp. 336–361, 2013.
- 6[6] ITU, “Imt traffic estimates for the years 2020 to 2030,” Report ITU-R M.2370-0 , 2015.
- 7[7] 5G-PPP, “5G empowering vertical industries,” Euro-5G Project Brochure , February 2016.
- 8[8] D. Kreutz, F. M. V. Ramos, P. Verissimo, C. E. Rothenberg, S. Azodolmolky, and S. Uhlig, “Software-defined networking: A comprehensive survey,” Proceedings of the IEEE , vol. 103, no. 1, pp. 14–76, 2015.