BFT Protocols for Heterogeneous Resource Allocations in Distributed SDN Control Plane
Ermin Sakic, Wolfgang Kellerer

TL;DR
This paper introduces optimized Byzantine Fault Tolerance protocols for distributed SDN control planes, enhancing throughput, reducing response time, and lowering communication overhead while maintaining correctness and consistency.
Contribution
It proposes new agreement-and-execution group-based BFT protocols and a state-hashing approach for causally ordered switch reconfigurations in SDN controllers.
Findings
Decreased system response time compared to existing methods
Reduced signaling overhead in the proposed protocols
Validated effectiveness on realistic topologies and applications
Abstract
Distributed Software Defined Networking (SDN) controllers aim to solve the issue of single-point-of-failure and improve the scalability of the control plane. Byzantine and faulty controllers, however, may enforce incorrect configurations and thus endanger the control plane correctness. Multiple Byzantine Fault Tolerance (BFT) approaches relying on Replicated State Machine (RSM) execution have been proposed in the past to cater for this issue. The scalability of such solutions is, however, limited. Additionally, the interplay between progressing the state of the distributed controllers and the consistency of the external reconfigurations of the forwarding devices has not been thoroughly investigated. In this work, we propose an agreement-and-execution group-based approach to increase the overall throughput of a BFT-enabled distributed SDN control plane. We adapt a proven sequencing-based…
Click any figure to enlarge with its caption.
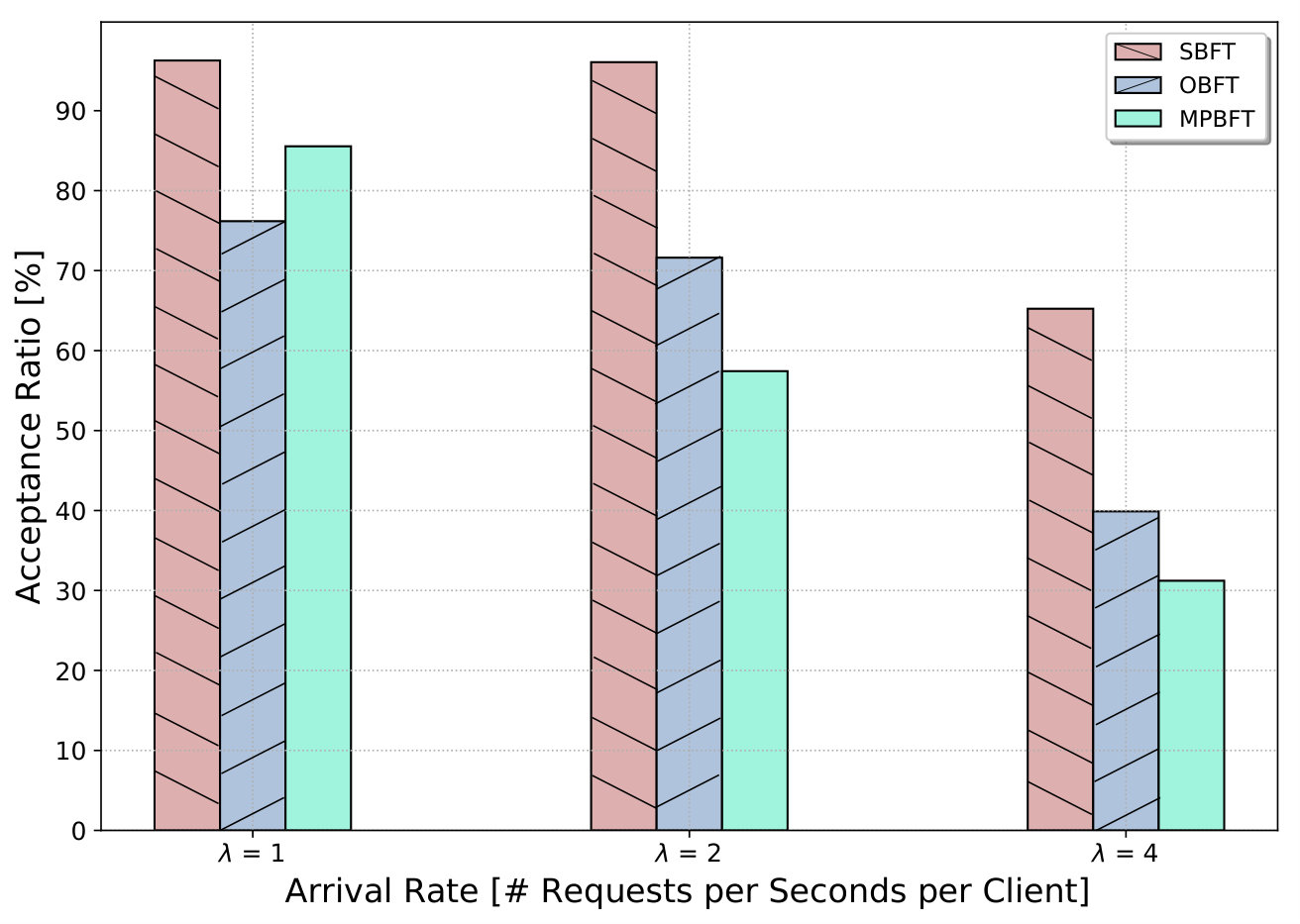 Figure 1
Figure 1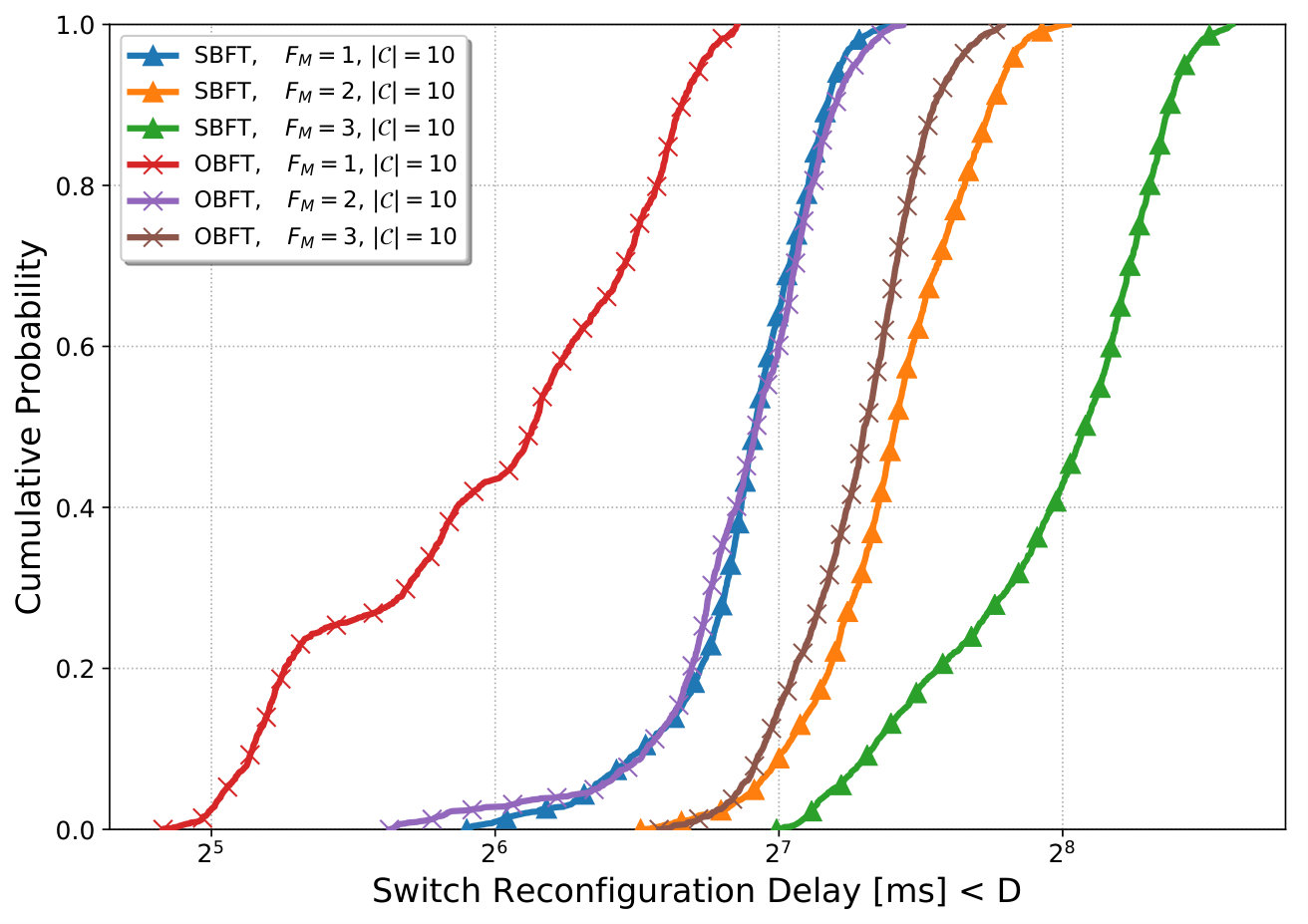 Figure 1
Figure 1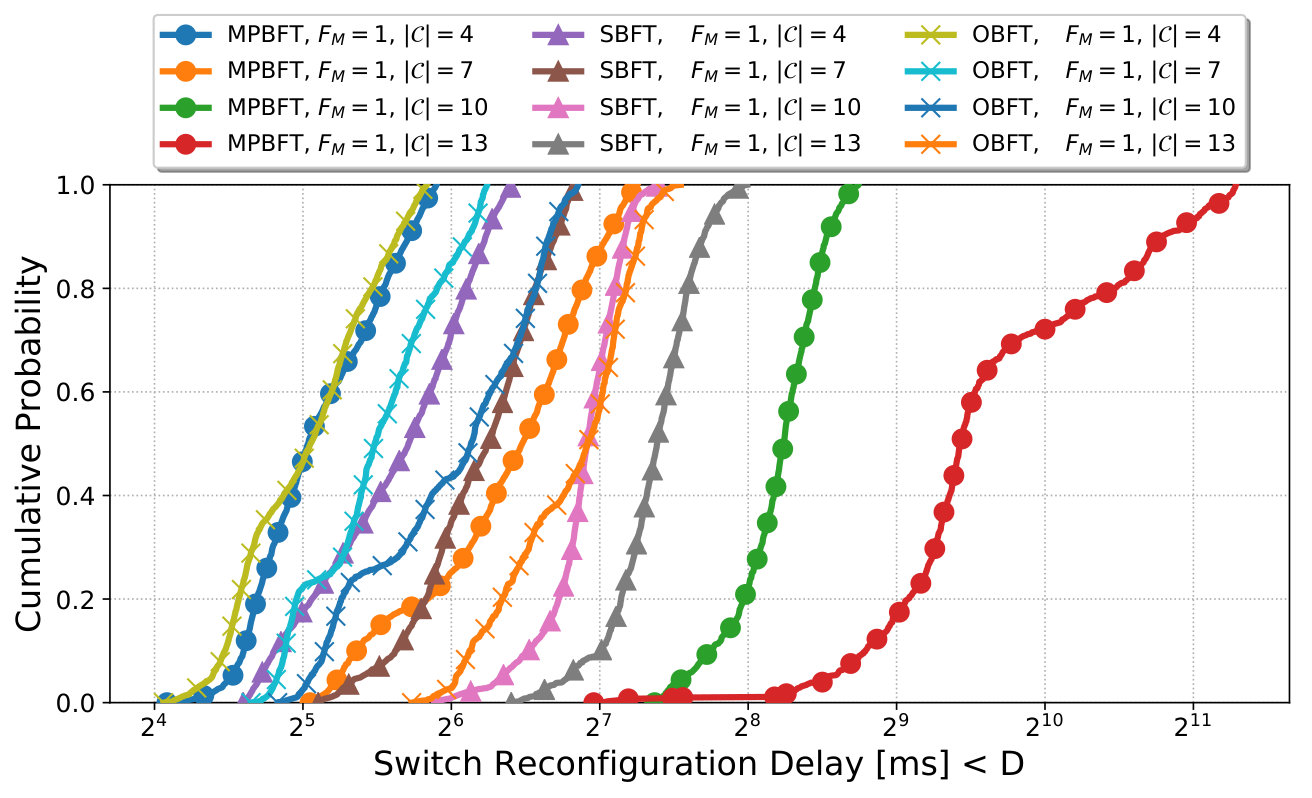 Figure 2
Figure 2 Figure 1
Figure 1 Figure 2
Figure 2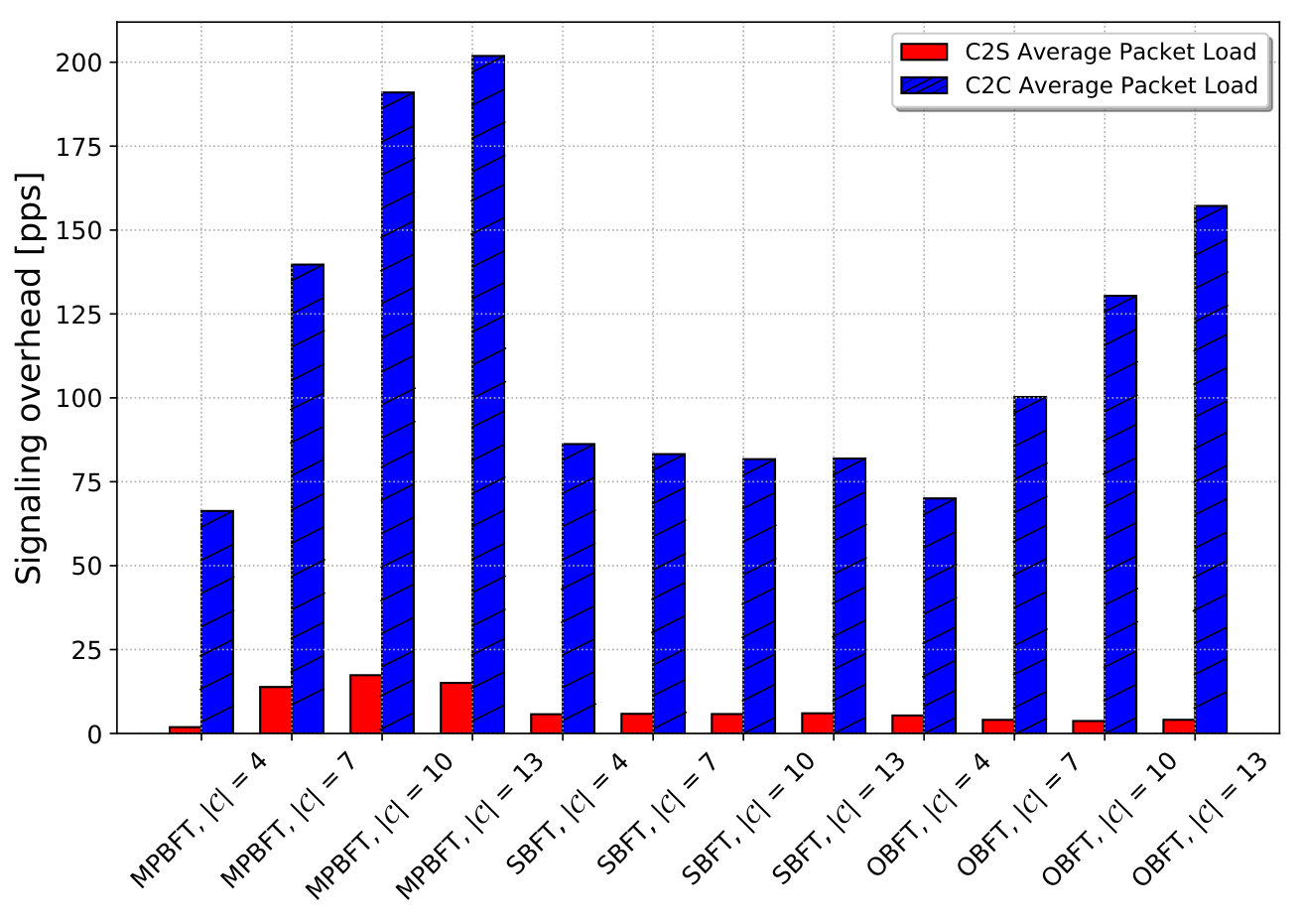 Figure 6
Figure 6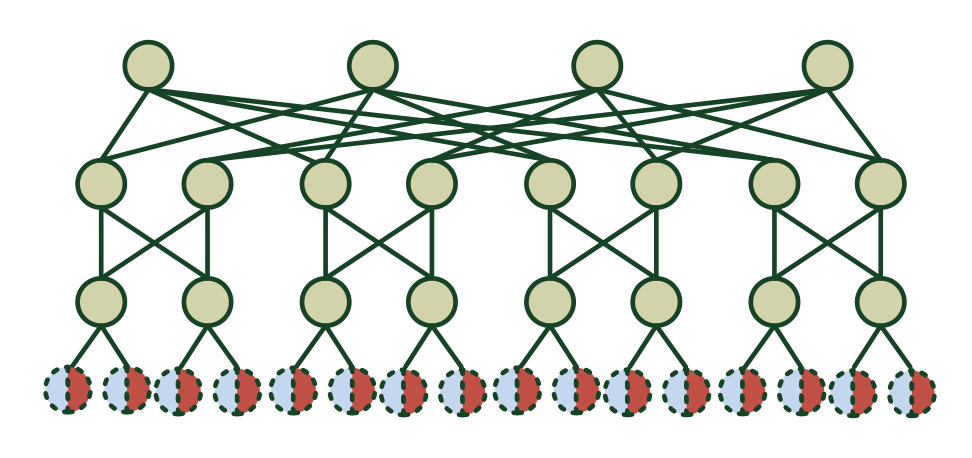 Figure 7
Figure 7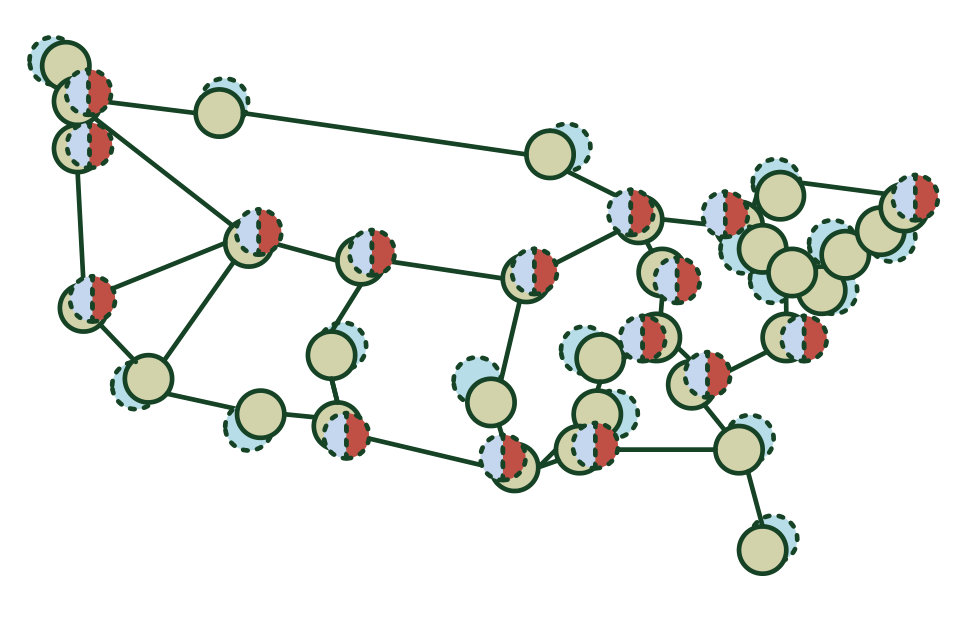 Figure 8
Figure 8| Alg. | Name | Type | No. Rounds |
|---|---|---|---|
| MPBFT | Modified PBFT | Agreement-based | |
| SBFT | Serialized A Priori BFT | Agreement-based | |
| OBFT | Opportunistic A Posteriori BFT | Opportunistic |
| Symbol | Meaning |
|---|---|
| Set of active controllers in the system | |
| No. of tolerated Byzantine faults in a single A&E group | |
| Time-variant no. of controllers [6] that must be assigned to each switch, to tolerate the Byzantine failures | |
| Set of switches in the system | |
| Total available controller ’s capacity. | |
| Request processing load stemming from the northbound client and edge switch , respectively. | |
| Max. tolerable delay for controller-switch communication. | |
| Controller replicas belonging to a single A&E group | |
| Sum of the tolerated Byzantine failures and the majority of correct replicas per A&E group: | |
| Sum of the tolerated Byzantine replicas and the majority of all correct active replicas: | |
| CMP | Comp. overhead of executing the packet comparison |
| E | Comp. overhead of executing SDN application operation |
| Algorithm | PRE-PREPARE | PREPARE | COMMIT | PRE-REPLY | REPLY |
| MPBFT | N/A | N/A | |||
| SBFT | N/A | ||||
| OBFT | N/A | N/A |
| Alg. | Computational Overhead | Communication Overhead |
|---|---|---|
| MPBFT | ) | |
| SBFT | ) | |
| OBFT | ) |
| Constraint | Formulation |
| Min. Assignment | \pbox 7cm |
| Unique Assignment | \pbox 7cm |
| Bounded Capacity | \pbox 7cm |
| Delay Bounds | \pbox 7cm |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSoftware-Defined Networks and 5G · Distributed systems and fault tolerance · Software System Performance and Reliability
\NewEnviron
scaletikzpicturetowidth[1]\BODY
\TPMargin5pt
BFT Protocols for Heterogeneous Resource Allocations in Distributed SDN Control Plane
Ermin Sakic12, Wolfgang Kellerer11Technical University Munich, Germany, 2 Siemens AG, Germany
E-Mail:1{ermin.sakic, wolfgang.kellerer}@tum.de, 2 [email protected]
Abstract
Distributed Software Defined Networking (SDN) controllers aim to solve the issue of single-point-of-failure and improve the scalability of the control plane. Byzantine and faulty controllers, however, may enforce incorrect configurations and thus endanger the control plane correctness. Multiple Byzantine Fault Tolerance (BFT) approaches relying on Replicated State Machine (RSM) execution have been proposed in the past to cater for this issue. The scalability of such solutions is, however, limited. Additionally, the interplay between progressing the state of the distributed controllers and the consistency of the external reconfigurations of the forwarding devices has not been thoroughly investigated. In this work, we propose an agreement-and-execution group-based approach to increase the overall throughput of a BFT-enabled distributed SDN control plane. We adapt a proven sequencing-based BFT protocol, and introduce two optimized BFT protocols that preserve the uniform agreement, causality and liveness properties. A state-hashing approach which ensures causally ordered switch reconfigurations is proposed, that enables an opportunistic RSM execution without relying on strict sequencing. The proposed designs are implemented and validated for two realistic topologies, a path computation application and a set of KPIs: switch reconfiguration (response) time, signaling overhead, and acceptance rates. We show a clear decrease in the system response time and communication overhead with the proposed models, compared to a state-of-the-art approach.
I Introduction and Problem Statement
Software Defined Networking (SDN) centralizes the decision-making in a dedicated controller component. Concepts for achieving crash-fault-tolerance and scalable operation of the controller have been presented in the past [1, 2]. By means of a logical distribution of controller replicas and the state synchronization, the controller instances are able to synchronize the results of their individual computations and come to consistent decisions independent of the instance that handled the client request. However, these approaches are based on weak crash-tolerant algorithms (e.g. RAFT [3] and Paxos [4]) that are unable to cater for malicious and incorrect (e.g., buggy [5]) controller decisions that have an individual controller instance fault as a root cause. Recent works have thus highlighted the importance of deploying Byzantine Fault Tolerance (BFT) protocols for achieving consensus, in scenarios where a subset of controllers is faulty due to a malicious adversary or internal bugs. Realizing a BFT SDN control plane comes with an additional controller deployment overhead, previously shown to range between [6] and [7] controller instances required to tolerate up to strictly Byzantine and fail-crash failures.
To support stateful controller-based applications (i.e., resource-constrained routing, load-balancing, stateful firewalls), the controllers synchronize their internal state updates. Traditional BFT designs [8, 7] require active participation of all replicas in the system. Thus, they leverage an RSM approach to handle the client requests, where a majority of controller instances must come to the agreement about the order of the client requests, before subsequently executing them. Finally, the controllers reach consensus on the output of the computation in order to ensure the causality of subsequent decisions. We have identified two issues with this approach.
First, to preserve causality, the non-faulty replicas always participate in all system operations. In the absence of faults, more replicas execute the decision-making requests than required to make progress, thus strongly limiting the execution throughput of the system. Namely, the application execution is handled by each controller instance in the cluster. In heterogeneous environments, where particular controller replicas can be assigned a higher resource set compared to the others, this leads to an under-utilization of fast replicas, as the system progresses at best at the speed of the fastest replica ( is the number of deployed controllers) [2]. Second, these BFT implementations rely on reaching a successful agreement about the sequence number mapping for each arriving client request, prior to its actual execution. The agreement phase thus necessarily increases the total processing time of individual requests. We claim that the serialization of requests is a mean to an end and that the causality of configurations on individual external devices (i.e., switches) is a sufficient constraint.
II Our contribution
In this work we make a point that an optimal separation of the controller cluster into sufficiently-sized agreement and execution (A&E) groups leads to an overall higher utilization in request processing. In our approach, faster replicas may be leveraged in the intersection of different A&E groups, while slower replicas may run at their assigned speed without negatively influencing the faster replicas. To identify the A&E groups, we extend an existing ILP formulation for controller-switch assignment procedure [6]. The solver identifies an A&E group for each deployed switch element, while maximizing the overlap of the members of different groups. The formulation considers the execution capacity of individual controllers, as well as the switch-controller delays as its constraints. The solver executes during runtime, thus optimizing the assignment upon each discovered Byzantine/fail-crash failure.
To cater for the second issue, we adopt the classical Practical BFT (PBFT) approach [8] to realize a distributed sequencer in order to minimize the fail-over time in the case of a leader failure. We additionally introduce a group-based variant of this protocol, that leverages the partitioning of the total controller set into multiple A&E groups. Finally, in addition to the two agreement-based designs above, we present an opportunistic protocol design. With the opportunistic approach, successful handling of a client request implies reaching a consensus on a consistent device reconfiguration while preserving the causality of decisions, subsequent to the actual request handling. We achieve the causality and agreement by reaching consensus: i) on the controller state at the time of application execution; ii) on the actual computed output result (to guarantee the consistency of decisions).
We have implemented these three BFT protocols and have analyzed the overheads of switch reconfiguration time, the communication overhead and the request acceptances rates. We ran our evaluation for emulated Open vSwitch-based Internet2 and Fat-Tree topologies, comprising up to 34 Open vSwitch instances and up to 13 controllers, while considering a varied number of tolerated Byzantine failures.
Paper structure: Sec. III introduces the overall system model. Sec. IV details the proposed BFT protocols. Sec. IV-D discusses the ILP formulation for the optimal controller-switch assignment. Sec. V presents the evaluation methodology. Sec. VI discusses the results. Sec. VII summarizes the related work. Sec. VIII concludes this paper.
III System Model
In [6], we discussed the often neglected differentiation between state-independent (SIA) and state-dependent (SDA) SDN applications. The SDA require an up-to-date and synchronized application state in order to serve the client requests. In this work, we consider solely the global SDA operations where successfully handled client requests result in stateful write operations to the replicated data-store. The subsequent client request executions that result in new writes to the same state must consider the preceding writes for their correctness. The value of the write operation is determined by an execution of a multi-phase BFT protocol. We distinguish accepting and rejecting protocol executions. Rejecting executions are caused by replicas that interrupt the run because of a missing consensus in one of the protocol phases (caused by e.g., conflicting seq. no. proposals, faulty controllers and packet loss). We assume that clients retransmit the requests until a successful execution has been acknowledged by the controllers.
Our SDN architecture is comprised of: i) controllers that individually execute an instance of a BFT process; ii) the switches that implement a comparison mechanism for matching controller configuration messages (as per [6]); iii) the clients; iv) a REASSIGNER component that maintains the switch-controller assignments (as per [6]). The request-initiating clients comprise northbound clients (e.g., applications, administrators) and the switches capable of forwarding the client requests as (OpenFlow) packet-in messages to the SDN controllers (e.g., routing, load-balancing requests). The target clients represent the configuration targets, e.g., switches that are (re)configured as a result of request handling.
We assume a fair-loss link abstraction, where a message (re-)transmitted infinitely often is eventually delivered at the recipient. Packets may be arbitrarily dropped, lost, delayed, duplicated and delivered out of order during any of the BFT protocol phases. The SDN control plane is realized in either in-band or out-of-band manner. Control messages exchanged between the controller, switches and clients are assumed to be signed, thus ensuring: i) the integrity of messages exchanged using the SDN data plane; ii) message forging is impossible.
State-updates distribution assumes an eventually synchronous model as per [9], where different replicas possess different views of the current configuration state for a limited time duration. Eventually, given an appropriately long quiescent period, all correct replicas converge to the same state. We assume that a bounded number of controllers may exhibit Byzantine behavior and/or fail-crash failures, respectively.
IV BFT Consensus Protocols and the Controller-Switch Assignment Methodology
The proposed protocols guarantee the following properties:
- •
Uniform Agreement: When a correct replica commits a particular internal state/switch update (i.e., computes a particular response), all correct replicas eventually commit the same update.
- •
Liveness: All correct replicas eventually finalize the processing of each client request. The resulting run is declared either accepting or rejecting.
- •
Causality: The updates to the controller data-store and the per-switch configuration updates are executed in a causally dependent order. The controller’s decision to reconfigure a switch take into account all preceding configurations of that switch.
We assume a deployment of a total of controllers per agreement and execution (A&E) group in order to tolerate an upper bound of individual Byzantine and fail-crash controller failures in that particular A&E group.
In the remainder of this section, we introduce the three BFT protocols: the agreement-based MPBFT and SBFT protocols, and the opportunistic OBFT (ref. Table I).
IV-A Pre-serialization model MPBFT (agreement-based)
Modified PBFT (MPBFT) imposes a single A&E group where each active controller replica is tasked with execution of an agreed command. The workflow of MPBFT is visualized in Fig. 1. A request-initiating client initially invokes its application request to all active controller replicas (REQUEST phase). For each incoming client request, each controller replica assigns a unique sequence number and distributes this sequence number proposal to the other controllers in the cluster (PREPARE phase). The replicas compare the sequence number proposals. If the correct majority of proposals are matching (i.e., the same sequence number is proposed by the majority of correct replicas), successful global agreement has been reached. At the begin of the COMMIT phase, each correct replicas executes the client request. The execution output is subsequently broadcasted by each replica to the remainder of the cluster and the collected output responses are once again compared in all replicas. Each controller deduces the correct majority response and eventually commits the output to its local data-store (i.e., a store of reservations) and finally reports the agreed output to the target clients (REPLY phase). After collecting consistent output messages, the target clients (e.g., switches) decide to apply the new configuration.
MPBFT is a variation of PBFT [8] that requires no leader and is thus tolerant to individual node failures. Compared to PBFT, we shorten the protocol execution by one round. Whereas PBFT proposes a PRE-PREPARE round, MPBFT skips this round by leveraging a client-initiated atomic multicast execution and a distributed sequencer. Namely, each new client request is multicasted to each replica of the system. The replicas propose a new seq. number for the request by incrementing the current counter as per Alg. 1. The seq. numbers for new client requests are assigned based on the current state of a local atomic counter. Following an arrival of a new request, the replicas yield the lowest unallocated seq. number value and propose this seq. number to the remaining replicas. After collecting a sufficient amount of matching PREPARE messages, all correct replicas decide to accept the seq. number contained in the correct majority proposal as the final seq. number for this request. Table III summarizes the exact amounts of required matching messages to progress the protocol execution.
If no correct majority vote is achieved during the agreement process on either the sequence number or the computed output, the replicas respond with a rejection status. If sufficient rejection messages are collected, the current execution is cancelled and the run is declared rejecting. Concurrent client requests can lead to same sequence numbers being assigned to different requests at different replicas, thus resulting in rejecting runs.
The execution capacity of MPBFT is limited by the slowest replica in the system. Consider the scenario , depicted in Fig. 1. Each controller is able to service request workload up to a capacity of per observation interval. The portrayed system is thus able to service computations up to , or requests/interval (imposed by the capacity of and ). Thus, Client 1 (with processing requirement of ) and Client 2 () cannot be serviced concurrently. One can alternatively portray the depicted rates as continuous execution workloads. While active participation of and in the system is unnecessary to tolerate a single Byzantine fault, they are included in execution and signaling and are necessary to progress the system state. MPBFT’s communication overhead is quadratic (ref. Table IV). With alternative protocol designs SBFT and OBFT, we next leverage the additional execution capacity by partitioning the control plane into multiple A&E groups.
IV-B Pre-serialization model SBFT (agreement-based)
With Serialized A Priori BFT (SBFT), agreement and execution processes are administered by multiple A&E groups. We assign for each request-initiating client (i.e., a northbound application, an edge switch) an A&E group according to the algorithm presented in Sec. IV-D. To tolerate Byzantine and fail-crash failures in the scope of a single A&E group, each group must comprise controllers. Multiple execution groups can process the client requests concurrently. SBFT design is depicted in Fig. 2. Compared to MPBFT, SBFT introduces the PRE-PREPARE step, where the replicas belonging to the A&E group propose and subsequently notify the remainder of the replicas of an assigned sequence number. In an accepting run, the group replicas collect the responses in the PREPARE phase and reach consensus by collecting matching sequence number proposals. Finally, the replicas of the A&E group execute the request in the COMMIT phase and broadcast the response to all remaining replicas. If matching outputs are received, the replicas apply the internal state reconfiguration and notify the target clients of the final result during REPLY. The communication overhead of SBFT is bounded , and grows linearly for a fixed A&E group size.
Causality: To ensure that the causality property holds in MPBFT and SBFT, the controllers execute the sequenced request in order agreed during PREPARE. The replicas execute the COMMIT phase only if the outputs (i.e., the added reservations) for the preceding requests were seen by the executing replica. Thus, before handling subsequent requests, the status of preceding runs (accepting/rejecting) must be determined.
IV-C Post-negotiation model OBFT (opportunistic)
Opportunistic A Posteriori BFT (OBFT) is a speculative take on SBFT, where computations of the client requests execute prior to reaching consensus about the computed output values. A global sequencer is not used in OBFT and thus PRE-PREPARE and PREPARE phases are omitted. Instead, each replica maintains the hashes of current switch configurations, as well as a state array containing the hashes of the configurations of the switches at the time of request executions (TORC hashes). Following the output computation in the COMMIT phase, the replicas come to consensus about the updated switch state in the PRE-REPLY phase. This workflow is depicted in Fig. 3.
In contrast to MPBFT and SBFT, in their COMMIT phase, the replicas belonging to the same A&E group compute the outputs, and in addition to the computed response outputs, they broadcast the hash arrays denoting their view of the target clients’ configurations. Each accepting replica that is not part of the serving A&E group evaluates its actual current local view of the switch states, and iff: i) matching output values have been computed by the A&E replicas; and b) their current view of switch configuration hashes is matching with those of the A&E replicas; they answer with an accepting status. The execution replicas (belonging to the A&E group), instead compare the proposed hash array with their local TORC hashes for the target client (i.e., target switches) and notify other A&E replicas of their status. If sufficient (ref. Table III) positive confirmations have been collected at the end of PRE-REPLY phase, each active controller internally commits the output proposed by the correct majority of the A&E group. The A&E group members then notify the configuration targets of the agreed output in REPLY phase. OBFT’s comm. overhead is quadratic and grows with .
IV-D Dynamic Controller-Switch (Re)Assignment Procedure
In our design, each request-initiating client (i.e., a northbound client or a switch) is assigned a unique controller agreement and execution (A&E) group. Groups assigned to different switches are allowed to partially or fully overlap. Only the assigned controllers are required to contact the target clients and apply reconfigurations. Similarly, only these controllers are contacted by the request-initiating clients with new application requests. Our ILP formulation of the assignment problem aims to minimize the total overlap between the members of the active A&E groups, so to minimize the synchronization delay during the consensus executions. The proposed reassignment mechanism, the objective function and the constraints extend the formulation presented in [6]. For brevity, we do not discuss each constraint in detail here, but refer the reader to the summary in Table IV-D and [6]. The procedure is executed once at the system startup and dynamically during runtime, on each detected controller failure.
For each switch we can derive a bitstring comprised of ones for replicas actively assigned to and zeros for the unassigned replicas. We then formalize the objective function:
[TABLE]
where denotes the Hamming distance between the assignment bitstrings for and . Combined with the adapted minimum assignment constraint depicted in Table IV-D, we ensure the building of minimum-sized A&E groups that fulfill the capacity and delay constraints of the clients.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] D. Suh et al. , “On performance of Open Daylight clustering,” in Net Soft Conference and Workshops (Net Soft), 2016 IEEE . IEEE, 2016.
- 2[2] E. Sakic et al. , “Response Time and Availability Study of RAFT Consensus in Distributed SDN Control Plane,” IEEE Transactions on Network and Service Management , 2017.
- 3[3] H. Howard et al. , “Raft Refloated: Do we have Consensus?” ACM SIGOPS Operating Systems Review , vol. 49, no. 1, 2015.
- 4[4] L. Lamport et al. , “Paxos made simple,” ACM Sigact News , vol. 32, no. 4, 2001.
- 5[5] P. Vizarreta et al. , “Mining Software Repositories for Predictive Modelling of Defects in SDN Controller,” in IFIP/IEEE International Symposium on Integrated Network Management , 2019.
- 6[6] E. Sakic et al. , “MORPH: An Adaptive Framework for Efficient and Byzantine Fault-Tolerant SDN Control Plane,” IEEE Journal on Selected Areas in Communication , 2018.
- 7[7] H. Li et al. , “Byzantine-resilient secure software-defined networks with multiple controllers in cloud,” IEEE Transactions on Cloud Computing , vol. 2, no. 4, 2014.
- 8[8] M. Castro et al. , “Practical Byzantine fault tolerance,” in OSDI , vol. 99, 1999.