Global analysis of luminosity- and colour-dependent galaxy clustering in the Sloan Digital Sky Survey
Niladri Paul, Isha Pahwa, Aseem Paranjape

TL;DR
This paper introduces a novel Halo Occupation Distribution analysis of galaxy clustering in SDSS, using a combined likelihood approach and direct halo correlation functions to accurately model luminosity and colour dependencies.
Contribution
It presents a new global likelihood method for HOD analysis that incorporates direct halo correlation functions and models colour-dependent clustering without group-finding algorithms.
Findings
Luminosity dependence of HOD parameters is well described by simple functions.
The satellite red fraction varies with luminosity, showing a shallower trend than in group catalogues.
The methods enable realistic mock galaxy catalogues for low-redshift universe simulations.
Abstract
We present a Halo Occupation Distribution (HOD) analysis of the luminosity- and colour-dependent galaxy clustering in the Sloan Digital Sky Survey. A novelty of our technique is that it uses a combination of clustering measurements in luminosity bins to perform a global likelihood analysis, simultaneously constraining the HOD parameters for a range of luminosity thresholds. We present simple, smooth fitting functions which accurately describe the resulting luminosity dependence of the best-fit HOD parameters. To minimise systematic halo modelling effects, we use theoretical halo 2-point correlation functions directly measured and tabulated from a suite of -body simulations spanning a large enough dynamic range in halo mass and spatial separation. Thus, our modelling correctly accounts for non-linear and scale-dependent halo bias as well as any departure of halo profiles from…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2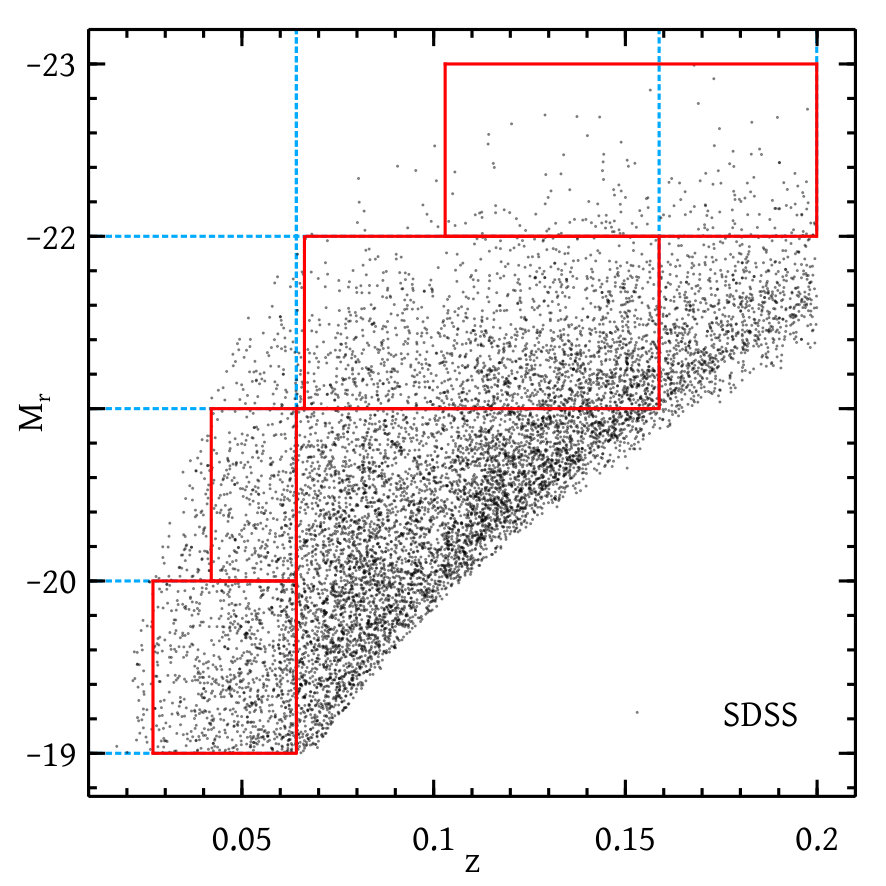 Figure 3
Figure 3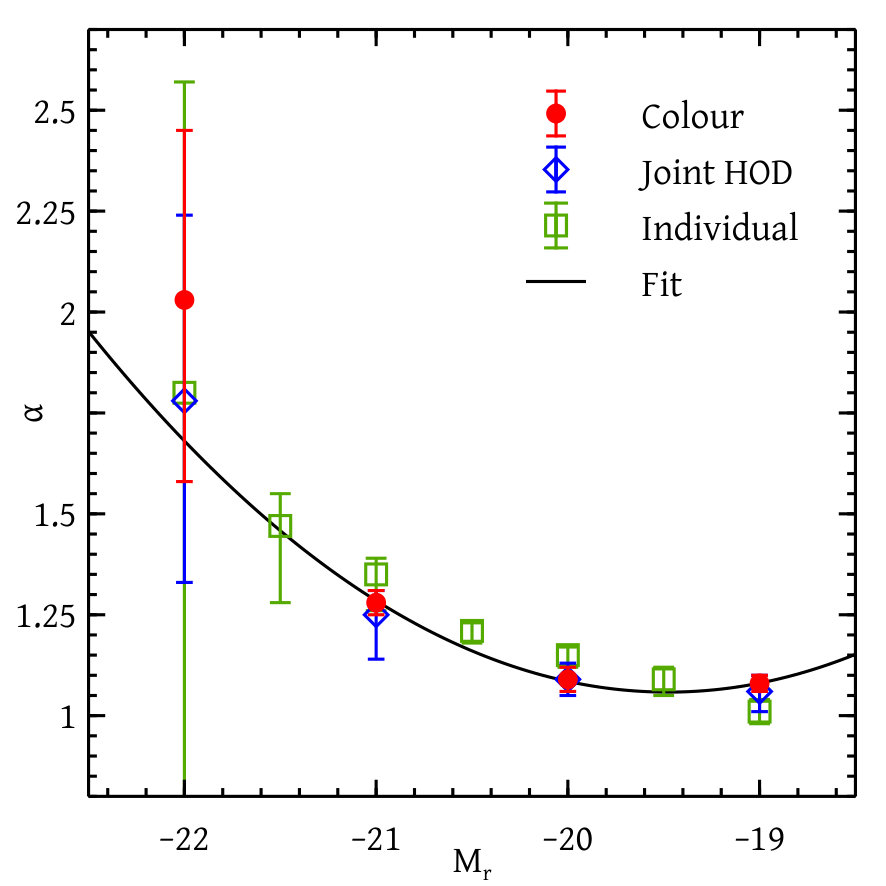 Figure 4
Figure 4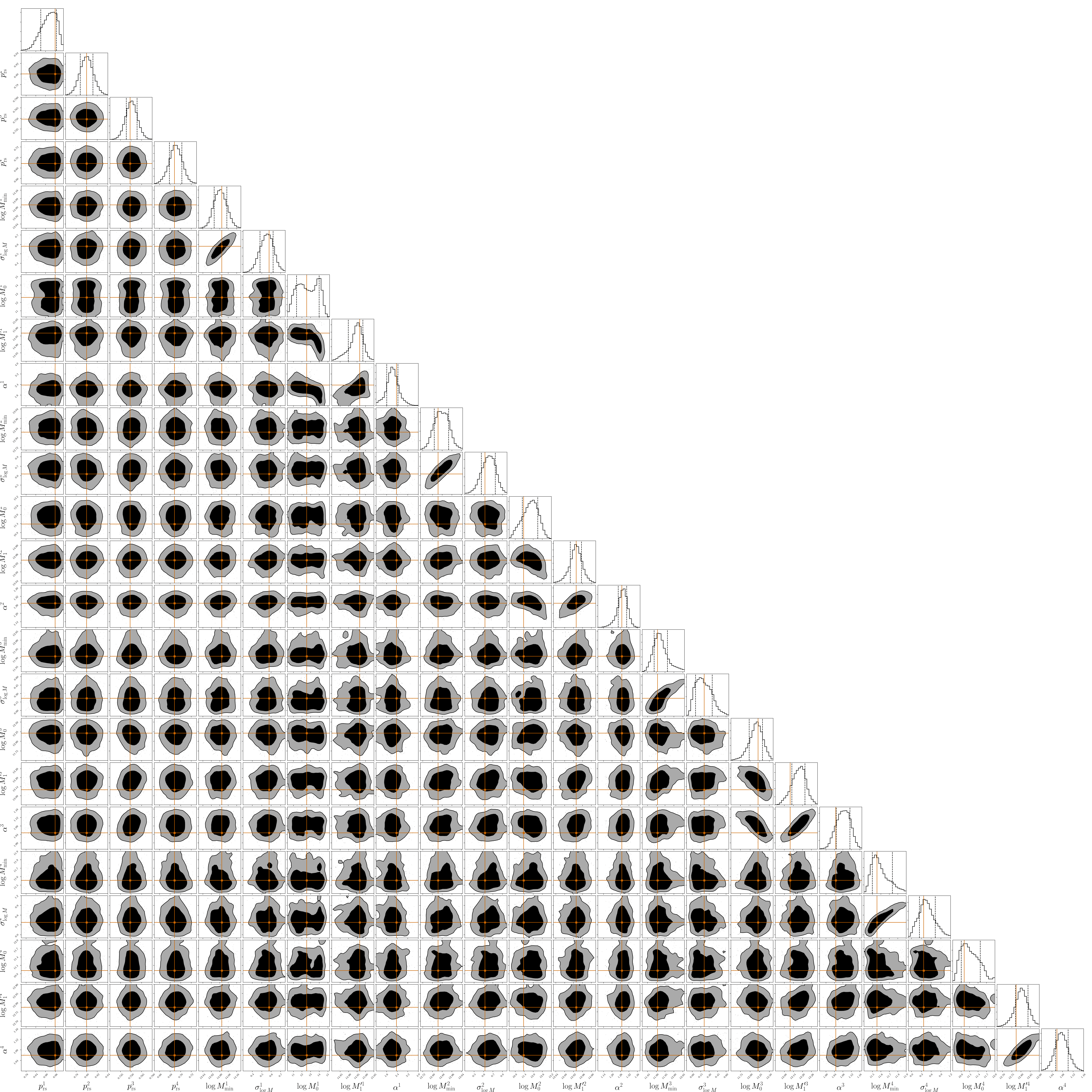 Figure 5
Figure 5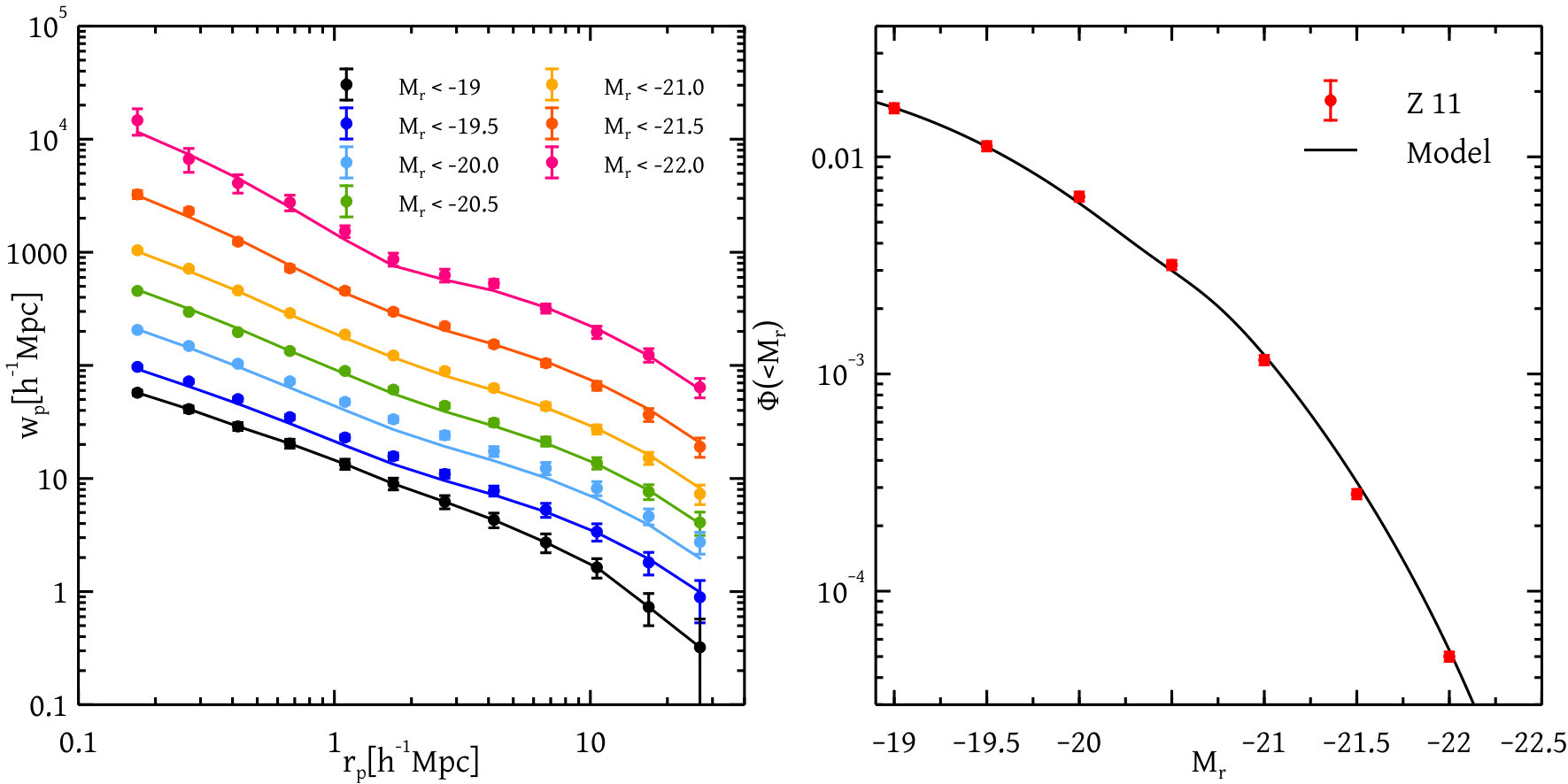 Figure 6
Figure 6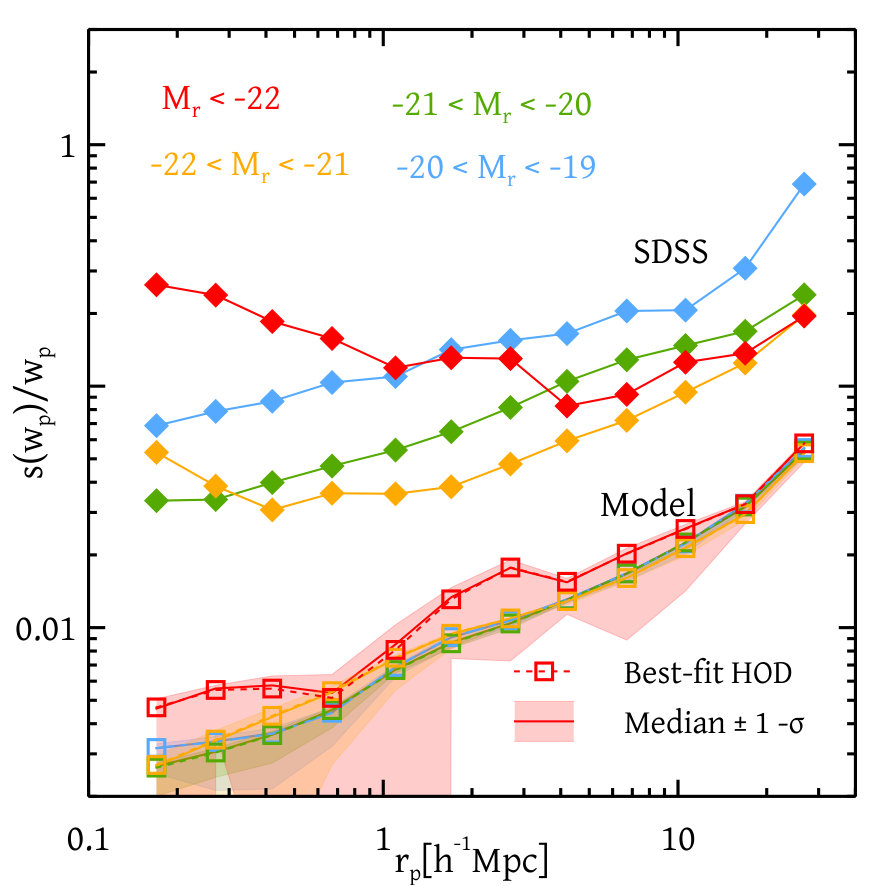 Figure 7
Figure 7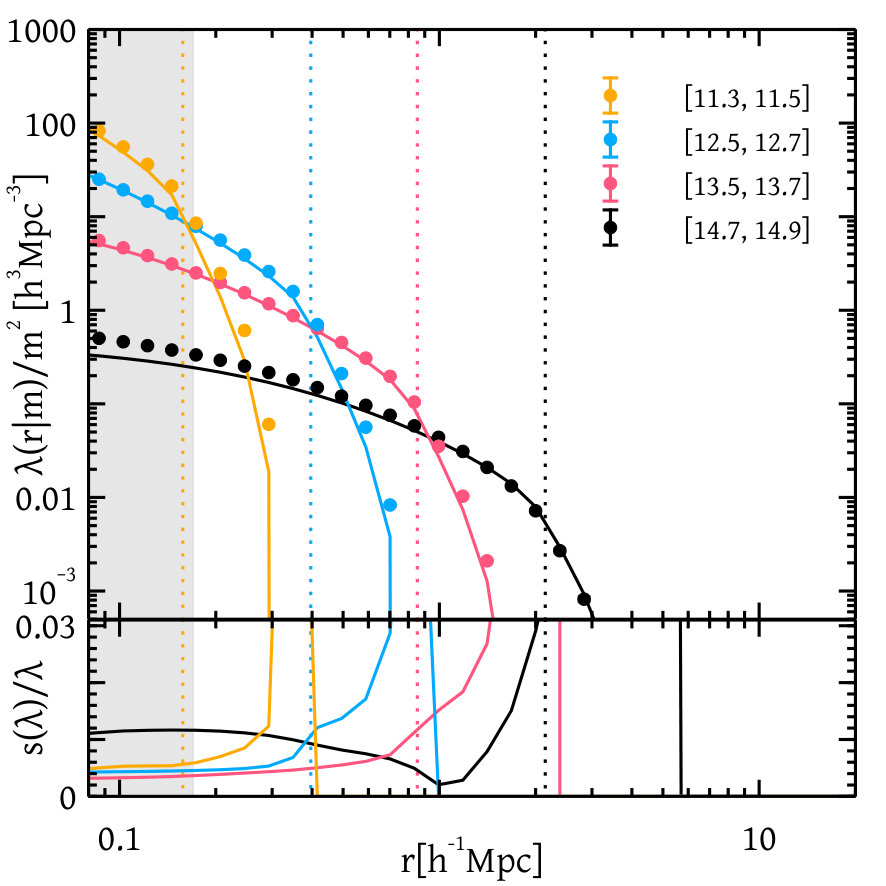 Figure 8
Figure 8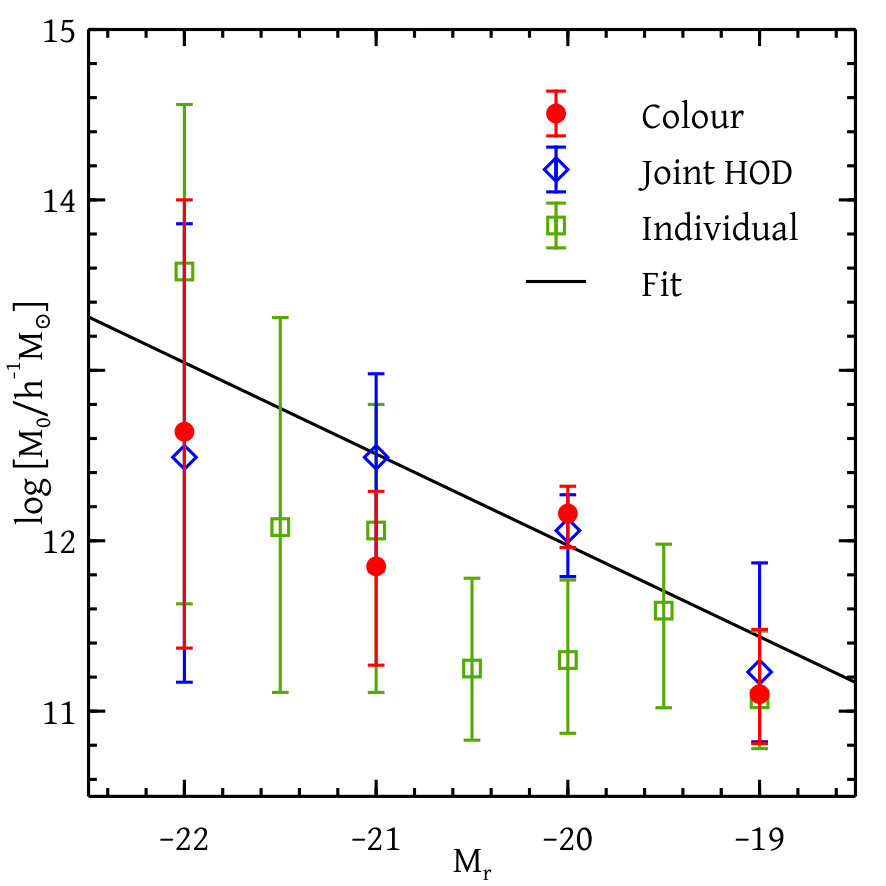 Figure 9
Figure 9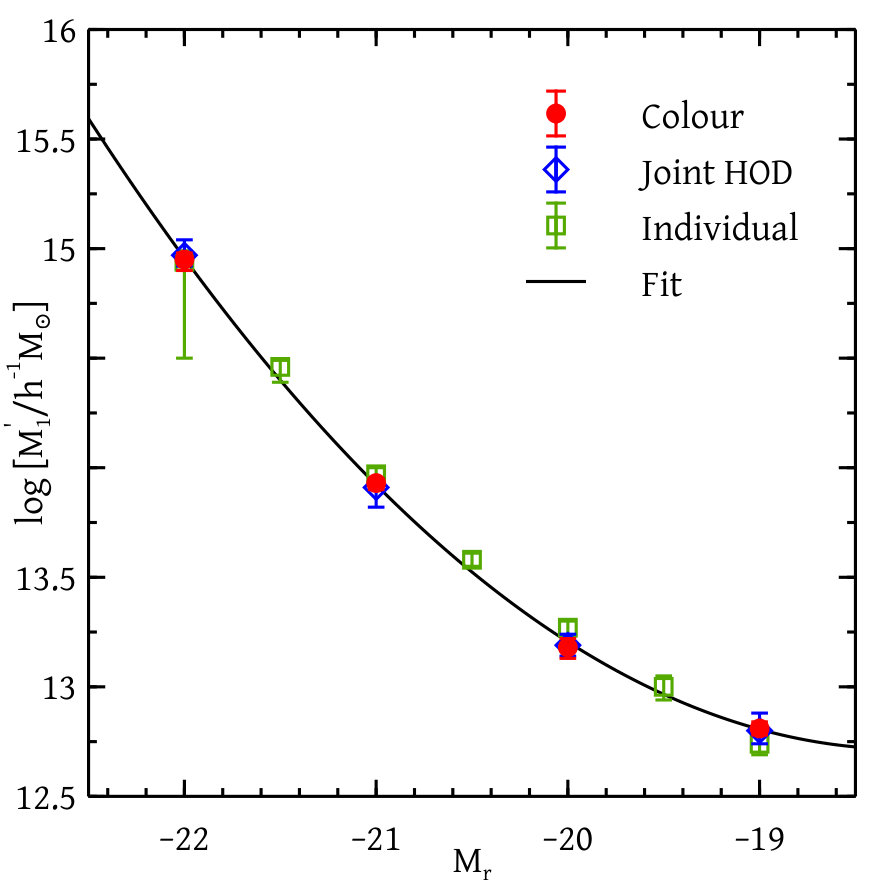 Figure 10
Figure 10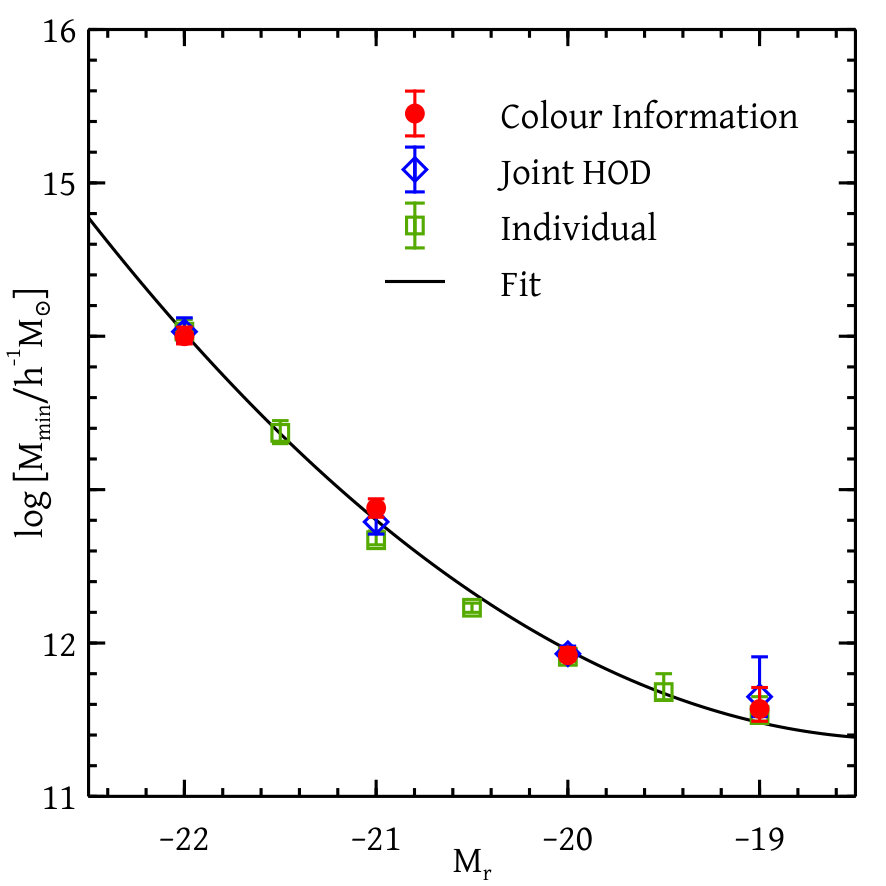 Figure 11
Figure 11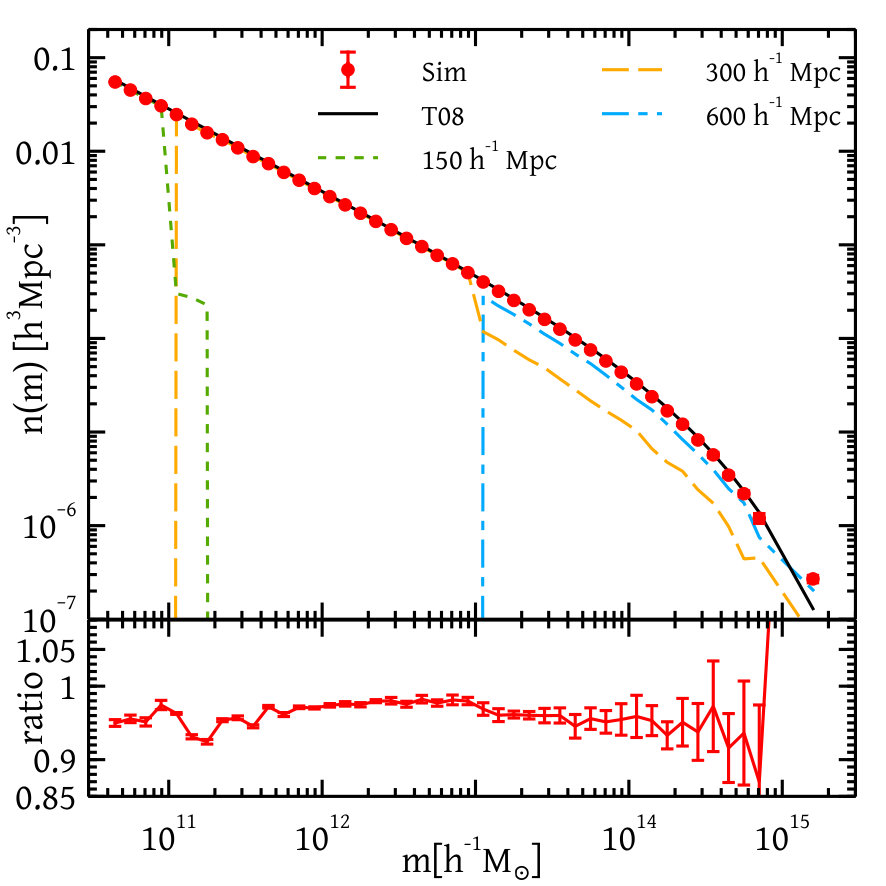 Figure 12
Figure 12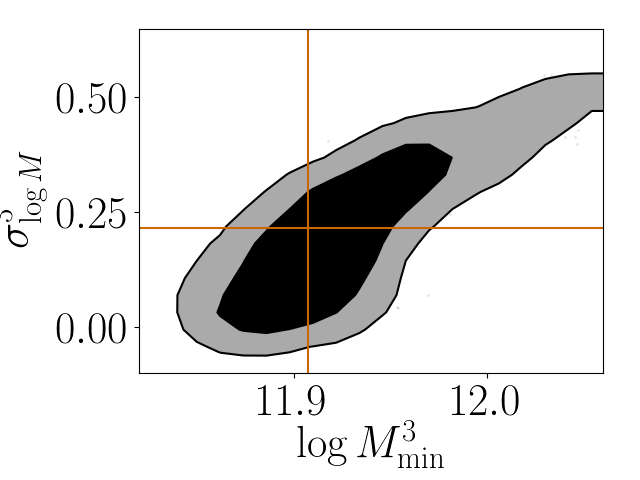 Figure 13
Figure 13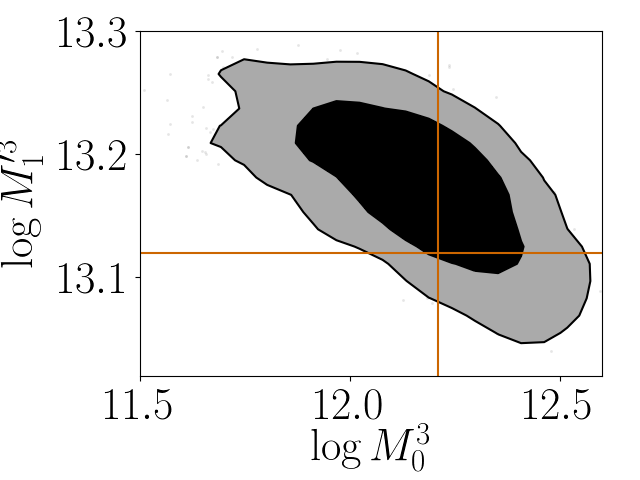 Figure 14
Figure 14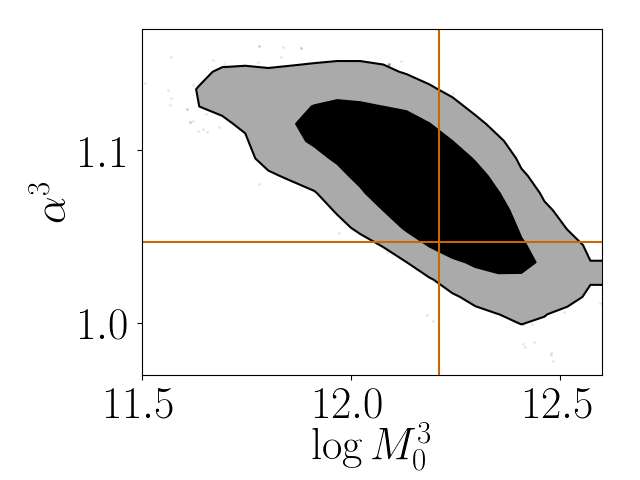 Figure 15
Figure 15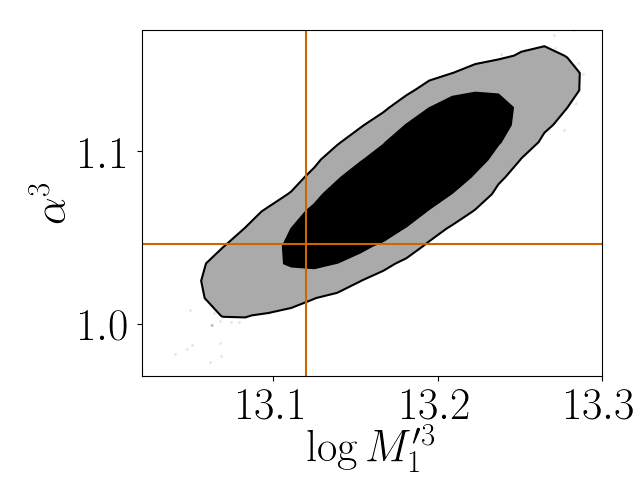 Figure 16
Figure 16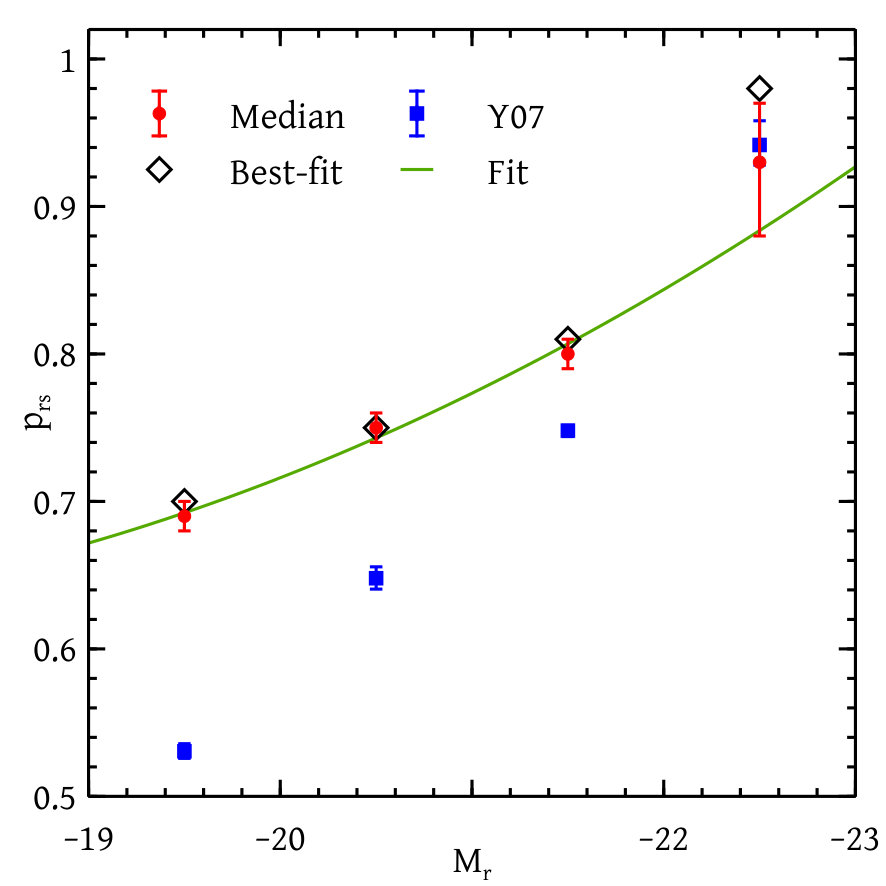 Figure 17
Figure 17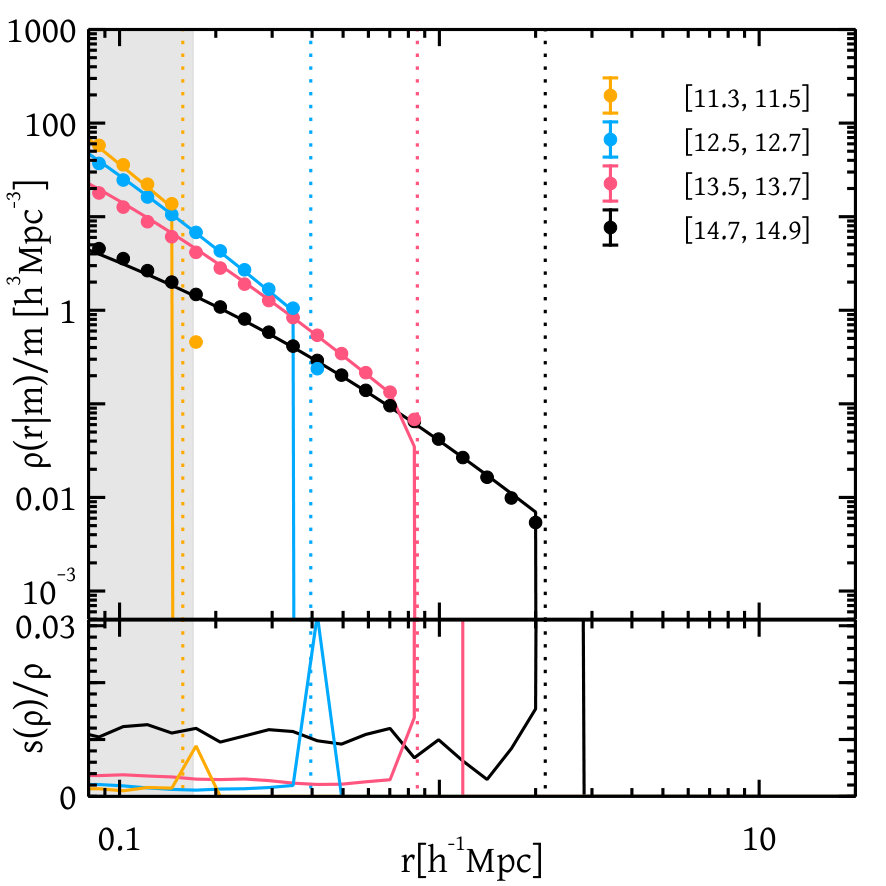 Figure 18
Figure 18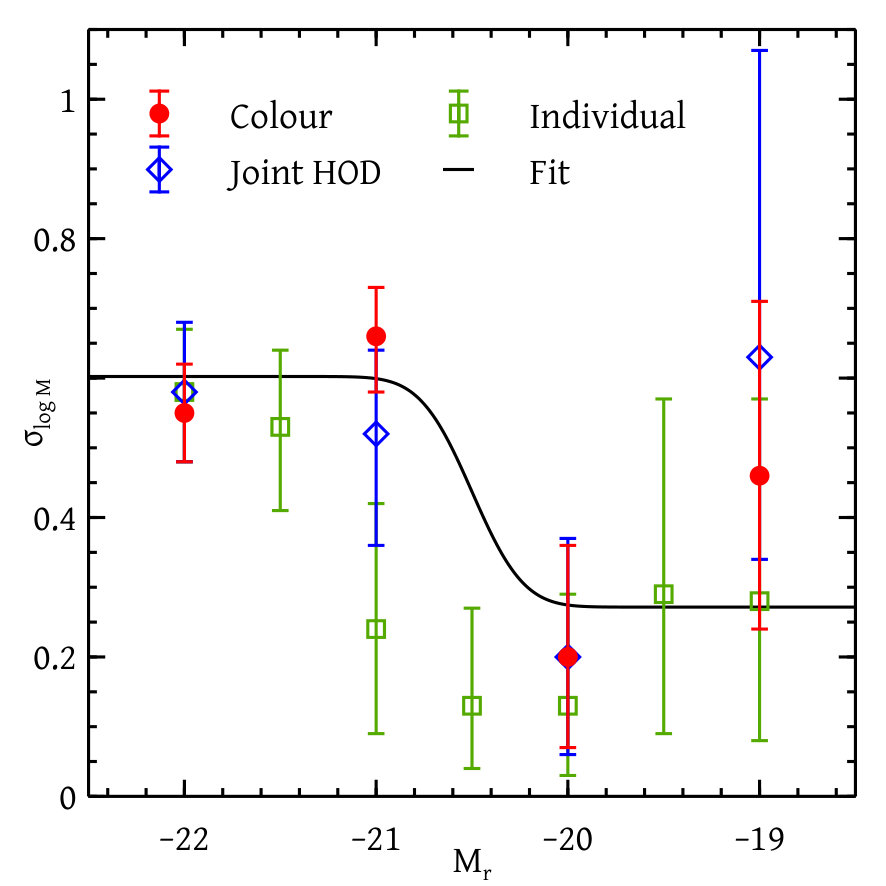 Figure 19
Figure 19 Figure 20
Figure 20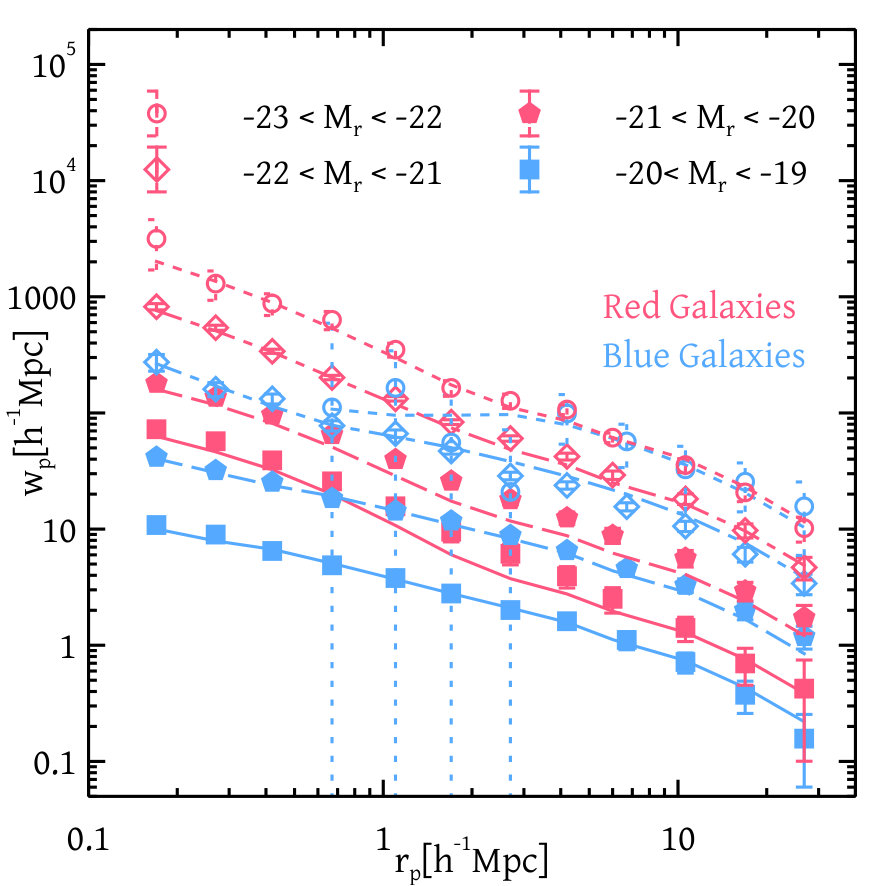 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23| bin | |
|---|---|
| -22 | |||||
|---|---|---|---|---|---|
| -21 | |||||
| -20 | |||||
| -19 |
| Parameter | Parameter values | Covariance of Paarameters |
|---|---|---|
| [, , ] = [, , ] | cov(, , ) = | |
| [, , ] = [, , ] | cov(, , ) = | |
| [, ] = [, ] | cov(, ) = | |
| [, , ] = [, , ] | cov(, , ) = | |
| [, , ] = [ , , ] | cov(, , ) = | |
| [, , ] = [, , ] | cov (, , ) = |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Global analysis of luminosity- and colour-dependent galaxy clustering in the Sloan Digital Sky Survey
Niladri Paul, Isha Pahwa & Aseem Paranjape
Inter-University Centre for Astronomy and Astrophysics, Ganeshkhind, Post Bag 4, Pune 411007, India E-mail: npaul, ipahwa & [email protected]
(draft)
Abstract
We present a Halo Occupation Distribution (HOD) analysis of the luminosity- and colour-dependent galaxy clustering in the Sloan Digital Sky Survey. A novelty of our technique is that it uses a combination of clustering measurements in luminosity bins to perform a global likelihood analysis, simultaneously constraining the HOD parameters for a range of luminosity thresholds. We present simple, smooth fitting functions which accurately describe the resulting luminosity dependence of the best-fit HOD parameters. To minimise systematic halo modelling effects, we use theoretical halo 2-point correlation functions directly measured and tabulated from a suite of -body simulations spanning a large enough dynamic range in halo mass and spatial separation. Thus, our modelling correctly accounts for non-linear and scale-dependent halo bias as well as any departure of halo profiles from universality, and we additionally account for halo exclusion using the hard sphere approximation. Using colour-dependent clustering information, we constrain the satellite galaxy red fraction in a model-independent manner which does not rely on any group-finding algorithm. We find that the resulting luminosity dependence of the satellite red fraction is significantly shallower than corresponding measurements from galaxy group catalogues, and we provide a simple fitting function to describe this dependence. Our fitting functions are readily usable in generating low-redshift mock galaxy catalogues, and we discuss some potentially interesting applications as well as possible extensions of our technique.
keywords:
galaxies: formation – cosmology: large-scale structure of the Universe – methods: numerical, analytical
††pagerange: Global analysis of luminosity- and colour-dependent galaxy clustering in the Sloan Digital Sky Survey–B
1 Introduction
Understanding the physical mechanisms at play in the formation and evolution of galaxies, and their connection to the underlying dark matter distribution and cosmology, is a problem of great interest (White & Rees, 1978; Mo et al., 2010; Somerville & Davé, 2015). To understand the large-scale distribution of the baryons, one needs to run computationally expensive full hydrodynamic large-scale simulations (Vogelsberger et al., 2014; Genel et al., 2014). There are different semi-numerical techniques to overcome these issues. One of the popular techniques is semi-analytical modelling of galaxy formation (Lacey et al., 2016; Zoldan et al., 2017; Gonzalez-Perez et al., 2018) where people use simplified mathematical formulae to understand the baryonic processes affecting galaxy evolution, happening inside halos, e.g. star formation, supernovae feedback, AGN feedback, gas cooling, tidal stripping etc.
Alternatively, one can statistically model the mapping between dark matter and galaxies assuming the halo model (Cooray & Sheth, 2002) using the halo occupation distribution (HOD) (Berlind & Weinberg, 2002) or conditional luminosity function (CLF) approaches (Yang et al., 2008; Cacciato et al., 2013). In the HOD formalism which we adopt in this work, one prescribes a statistical routine about how to populate the halos with galaxies depending on halo and galaxy properties (Seljak, 2000; Scoccimarro et al., 2001). It has been seen that it is necessary to split the galaxy population into centrals and satellites to describe both the correlation and abundance data of the galaxies accurately (Berlind et al., 2003; Yang et al., 2003; Zheng, 2004; Vale & Ostriker, 2004; Zehavi et al., 2005).
Starting from the simple HOD model which depends only on the mass of the halos, there have been several modifications to include ‘beyond halo mass’ effects (Wechsler et al., 2006; Hearin et al., 2015; Tinker et al., 2017; Ross & Brunner, 2009; Paranjape et al., 2015; Pahwa & Paranjape, 2017; Xu et al., 2018; Lange et al., 2018), ‘velocity bias’ effects (van den Bosch et al., 2005; Behroozi et al., 2013; Reid et al., 2014; Guo et al., 2015), the deviation of satellite density profiles from the dark matter halo profile (Yang et al., 2005; Chen, 2008; More et al., 2009; Guo et al., 2012; Watson et al., 2012) etc. These, however, lead to relatively minor contributions in the luminosity- and colour-dependent clustering when galaxies are not explicitly classified as being centrals or satellites. We will therefore ignore these effects in this work and focus on the simplest, ‘halo mass only’ flavour of HOD models. Other effects such as scale-dependent halo bias (Tinker et al., 2005), halo exclusion (Tinker et al., 2012; Leauthaud et al., 2011) and the adopted calibration of the halo concentration-mass relation (Wechsler et al., 2002; Zhao et al., 2003; Lu et al., 2006; Ludlow et al., 2013, 2014) can lead to systematic biases of order in HOD constraints and are therefore important to be modelled accurately (van den Bosch et al., 2013).
One way to take into account of all these effects consistently in one go is to directly use the measurements of halo correlation functions from -body simulations (Zheng & Guo, 2016). This way of accurate calibrations of halo model parameters has applications in understanding the redshift evolution of galaxy population inside halos (Zheng et al., 2007; White et al., 2007; Wake et al., 2008, 2011; Abbas et al., 2010; Coupon et al., 2012; de la Torre et al., 2013; Guo & White, 2014; Manera et al., 2015; Skibba et al., 2015; Contreras et al., 2017), reconstructing the initial conditions from large csale galaxy surveys etc. (Nusser & Dekel, 1992; Crocce & Scoccimarro, 2006). This is the approach we will adopt in this paper.
Additionally, in this work, we will describe a novel approach of global HOD fitting which allows us to combine clustering measurements for a wide range of galaxy luminosities in a statistically consistent manner. The resulting HOD parameters turn out to vary smoothly with luminosity threshold, and we fit them using simple, smooth functions. We will also use colour-dependent clustering information to constrain the red fraction of satellites in the data volume.
This article is organised as follows. In section 2, we describe our simulation suite and our measurements of the halo 2-point correlation function (2pcf) from it. We also describe the observational data set we use, along with a comparison of the theoretical errors in our simulation-based model with the corresponding observational errors. In section 3, we describe our global likelihood analysis of the SDSS projected clustering and abundances, along with a discussion of the data covariance matrices. In section 4, we present the results of using luminosity- and colour-dependent clustering to constrain HOD parameters and the satellite red fraction as a function of luminosity, and present our fitting functions for these quantities. We conclude in section 5. The Appendices describe some technical details of results used in our analysis.
Throughout, we will adopt a flat CDM cosmology with total matter density parameter , baryonic matter density , Hubble constant with , primordial scalar spectral index and root mean square linear fluctuations in spheres of radius , .
2 Simulations and observational data
In this section, we describe our simulation suite and the observational data set we will use in this work. We also describe our tabulated measurements of the halo 2pcf which will serve as the basis of our theoretical model and demonstrate that the corresponding statistical uncertainties are substantially smaller than the errors in the observational measurements.
2.1 Simulation details
To resolve a full dynamic range of halos ranging from to , one needs to run a box of size with approximately particles. To minimise statistical variance, one would need to run several realisations of this high-resolution simulation which requires a huge computational budget. To overcome this issue, we instead combine three simulation boxes of size , and , each run with particles. We will refer to these as the small, intermediate and large box in what follows. The dark matter particle mass in these boxes were , and , respectively. The force resolution in each case was set equal to of the mean comoving inter-particle spacing, leading to for the boxes, respectively.
All simulations used cold dark matter only and were performed using the tree-PM -body code gadget-2111http://www.mpa-garching.mpg.de/gadget/ (Springel, 2005). Initial conditions were set at a starting redshift in case of and box respectively using the code music222https://www-n.oca.eu/ohahn/MUSIC/ (Hahn & Abel, 2011) with 2nd order Lagrangian perturbation theory. By changing the random number seed for the initial conditions, we generated realisations of the large box and realisations of the intermediate box while using a single realisation of the small box. Halos were identified using the code rockstar333http://code.google.com/p/rockstar/ (Behroozi et al., 2013) which performs a Friends-of-Friends (FoF) algorithm in 6-dimensional phase space. Throughout, we will use to denote the mass of the halo in a radius that encloses a dark matter density of times the mean density of the universe. Wherever needed, we will use as the halo radius. The simulations and analysis were performed on the Perseus cluster at IUCAA.444http://hpc.iucaa.in
2.2 Calculating halo statistics from simulations
Our -body simulations allow us to accurately and self-consistently account for scale-dependent bias, halo exclusion and the nature of dark matter profiles in halos. In order to do this, we have combined measurements of the halo 2pcf over a wide range of halo mass and spatial separation, as we describe next.
The single realisation of our small box allows us to reliably obtain the mass function and the 1-halo term of the correlation function in the mass range (see Appendix A for the relevant details of halo model formalism). The realisations of the intermediate box similarly give us estimates of halo mass function for and 1-halo information for . Additionally, these realisations also allow us to measure the 2-halo term of the correlation function in the entire halo mass range which we use in this work. The realisations of the large box provide us reliable estimates of the mass function and 2-halo correlation function measurements for , as well as 1-halo information for .
We follow the simulation-based method developed in Zheng & Guo (2016) to compute the galaxy 2pcf. In this approach, we place one galaxy at the halo centre and choose halo particles as tracers of the satellite galaxies. We create tables for halo properties, including halo number density (i.e., halo mass function) and real-space 2pcf of 1-halo and 2-halo terms.
Each correlation function consists of five terms - 1-halo cen-sat, 1-halo sat-sat, 2-halo cen-cen, 2-halo cen-sat and 2-halo sat-sat. For the 1-halo terms, we use all the particles in the halo. However, in order to reduce the time taken to compute the 2-halo terms, we randomly choose particles in the halo if the halo has more than particles and suitably normalise the resulting measurements. We have checked that using particles per halo gives us sufficient precision in the resulting measurements (see also section 2.4 below). We have additionally incorporated hard-sphere exclusion by only counting halo pairs whose separation is larger than the sum of their virial radii. To generate the tables, we divide the halos into logarithmic mass bins of width dex each.
To reduce statistical noise, we took a weighted average of all the quantities weighted by the available number of particles in those measurements in each halo mass bin and in each realisation (for a detailed discussion of the weighting scheme, see Appendix B). The statistical variance on the mean value of our measurements is quite small as seen from the Figures 1 to 5, which we discuss next.
Figure 1 shows the weighted average of the halo mass function and its errors obtained from several realisations. As a comparison, in the lower panel of the figure, we have shown the ratio of the halo mass function to the fitting function of Tinker et al. (2008); this shows agreement at the level over most of the mass range. We have also shown separate contributions of several boxes towards the halo mass function.
Figure 2 shows the measurements of halo density profile and the associated errors from different simulation boxes in different halo mass bins. We see that the errors on our measurements are at all relevant scales. Figure 3 shows the convolution of the halo density profile with itself (which enters the -halo term of the 2pcf) for different halo mass bins. We see that in this case also, the errors on the measurements are . As a sanity check on our measurements, we also show the NFW analytical forms of these quantities for halos of the same mass, using the median concentration-mass relation as measured from the simulation.555The rockstar code output contains information on the NFW scale radius which can be converted into a concentration for each halo, and we take the median concentration in each halo mass bin for use in the analytical curves. We see good agreement at scales substantially larger than the force resolution of the respective simulation box. We emphasise that we only use the numerically measured and tabulated results for the halo profile in this work, not the NFW form.
Figure 4 shows the central-satellite term of the -halo correlation function coming from halos within a single halo mass bin whereas Figure 5 shows the same quantity measured from two different halo mass bins. We see from these plots that the errors on the measured quantities are also small, being over nearly the entire range of masses and separations and rising to or larger at the highest masses and largest separations. Similar trends are found for the other components of -halo correlation function e.g. and . For the sake of brevity, we do not show those plots here.
2.3 Observational data set
As observational data, we have used the projected 2pcf measurements of galaxies in the Sloan Digital Sky Survey666http://www.sdss.org (SDSS, York et al., 2000) Data Release 7 (DR7, Abazajian et al., 2009) as provided by Zehavi et al. (2011). These measurements were performed on a galaxy sample limited to an -band Petrosian magnitude cut . This galaxy sample has a redshift range covering an area of on the sky. The measurements are available for galaxies selected by absolute magnitude bins and thresholds, as well as for galaxies selected by Petrosian colour in absolute magnitude bins, split into red and blue populations in each magnitude bin using the cut
[TABLE]
where is the Petrosian magnitude in the -band, -corrected and evolution corrected to redshift .
Figure 6 shows the underlying galaxy luminosity data as a function of redshift, along with the various thresholds and bins of absolute magnitude for which 2pcf measurements are available. The tabulated measurements and associated covariance matrices have been kindly made public by I. Zehavi.777http://astroweb.cwru.edu/izehavi/dr7_covar/ Below we will describe a modification of these covariance matrices to account for the finite volume of the simulations used to build our theoretical model.
2.4 Theoretical errors
To be able to model these correlation measurements accurately, the error from our simulation-based model should ideally be substantially smaller than the error associated with the observational measurements of the projected correlation function. To know the error coming from our model we need to know the HOD, which is not known a priori. To break this circularity, we take the following approach. We first assume that the simulation errors are negligible compared to the data errors. We then determine the best-fit HOD using the global Markov Chain Monte Carlo (MCMC) procedure described in section 3 below. For running the Monte Carlo chains, we used the package EMCEE888http://dfm.io/emcee/current/ (Foreman-Mackey et al., 2013). Using this HOD, we can estimate the theoretical errors on the projected 2pcf which can be directly compared with the data errors. If these theoretical errors are smaller than the data errors, then our assumption of neglecting them is self-consistent.
The detailed procedure of calculating the errors from our model can be found in Appendix B. While computing the errors, we assume that the weighted halo mass function and the average number of galaxies in a unit comoving volume do not have any error associated with them. For the -halo term of the correlation function, in the halo mass range , we have the measurements from only one realisation of the box. So we assume a Poisson error over the measurements in that halo mass range. In the halo mass range , we take the -halo measurements from realisations of the box and in the halo mass range , we take the -halo measurements from realisations of the box. Computing the errors in the -halo term (equation 13) from several realisations of the boxes in these ranges of halo mass is straightforward. Then we add the errors coming from different ranges of halo mass in quadrature to compute the errors of the -halo term over the full halo mass range.
We take the -halo measurements over the full halo mass range only from the realisations of the box and then compute the error using our best-fit HOD and equation (14). Now we add the errors of the -halo and -halo terms to compute the error of the full projected correlation function. In this way, we neglect any correlation between the -halo and -halo terms of the correlation function, which is justified because the effect of assembly bias is expected to be small.
We see in Figure 7 that the errors from our model are indeed substantially smaller than the data errors over the entire relevant range of projected separations, thus justifying our choice of ignoring these theoretical errors in the HOD calibrations below. Along with the relative error computed using the best-fit HOD, we have also shown - error band on that computed relative error by randomly selecting HOD-s from our MCMC chains. Since the errors coming from the measurements from simulations are very small compared to the errors coming from data, we neglect this error while constraining the parameters.
3 Global analysis of projected clustering
In this section, we describe our global analysis of projected SDSS clustering and discuss the resulting constraints on the HODs and satellite red fraction.
3.1 HOD Model
The halo occupation distribution (HOD) is a statistical model to populate halos with galaxies as a function of host halo mass. To compute the galaxy correlation function accurately in the halo model framework, one needs to split the galaxy population in centrals and satellites (Zehavi et al., 2005).
Following Zehavi et al. (2011); Guo et al. (2015), we consider a five parameter based HOD approach where the two main quantities to model are and . The quantity denotes the fraction of -halos (halos having mass in the range to ) which contain a central galaxy with luminosity greater than . The other quantity denotes the average number of satellites with luminosity greater than in an -halo having a central galaxy with luminosity greater than . We model these two quantities in the following way,
[TABLE]
From the above equations, it is clear that in our model, we have a total of five free parameters: the cut-off mass cale , width of the central galaxy mean function and cut-off mass scale , normalization and high mass slope of the mean occupation function of the satellite galaxies.
Once we have modelled the population of galaxies in a halo, we can convolve this with halo statistics and obtain the statistics of galaxies. The average number density of galaxies can be computed from the halo number density as,
[TABLE]
Similarly we can also compute the -halo and -halo term of the correlation function as follows,
[TABLE]
and
[TABLE]
To get a detailed discussion about this formalism please see appendix A.
While doing the global analysis of HOD-s of all magnitude bins together as discussed in the next subsection, we took the following approach to ensure that the HODs of dimmer magnitude thresholds gives a higher (or equal) number density than brighter thresholds. While running the MCMC, if for some choices of parameters, the HOD-s for a given magnitude bin which is the difference of HOD-s of two adjacent magnitude thresholds become negative in a certain halo mass range, we forcefully assign the binned HOD-s to be zero in that halo mass range. Since we are also using the data of number density of galaxies in different magnitude bins in our analysis, which has already the trend of having higher number density in case of dimmer magnitude bins, the HOD-s in our model already get constrained to follow that trend.
Additionally, while modelling colour-dependent clustering, we also include the red fraction of satellite galaxies as a free parameter. A detailed discussion on calculating colour-independent and colour-dependent 2pcfs can be found in Appendix A.
3.2 Likelihood calculation
Since the galaxy samples of different magnitude thresholds are highly correlated as seen from Figure 6, it is cleaner to use the measurements from different magnitude bins for the HOD calibration. However, the HOD parametrisation for magnitude thresholds is more well-established than the one for magnitude bins. The HODs in different luminosity bins () can be computed from HODs of adjacent luminosity thresholds ( and ) in a straight-forward way as shown below,
[TABLE]
The correlation function as a function of magnitude bin can be computed from those derived binned HODs as discussed in detail in the Appendix A.2.
The HOD of an individual magnitude threshold will contribute to the measurements of two adjacent magnitude bins. To constrain the HODs of magnitude thresholds correctly, therefore, we can construct a global likelihood using the uncorrelated measurements from a range of contiguous magnitude bins, which then allows us to simultaneously constrain the parameters corresponding to all thresholds, as we describe next.
For galaxies in a luminosity bin , we assume a Gaussian likelihood expressed as
[TABLE]
where is the vector of measurements of the projected correlation function of galaxies in this luminosity bin, is the modified inverse of the corresponding covariance matrix (see below) and is the average comoving number density of galaxies in this bin with the associated error . Quantities with carets () are measurements from observations and the ones without denote the model prediction which depends on the parameter set denoted by . We combine measurements from the available luminosity bins by summing over the corresponding log-likelihoods. Essentially, our analysis uses a Bayesian technique where the posterior probability distribution function is a product of the likelihood function and prior distribution of parameters. In each luminosity bin, we have five free parameters , , , and . For each of them we choose a flat uniform prior. In each bin, the prior range for , and was chosen to be [10.65, 15.5], the prior for was taken as and for it was taken to be .
Zehavi et al. (2011) also provide clustering measurements for red and blue galaxies separately in different luminosity bins. When including this information, we use the all-colour constraints using equation (10) as a prior, combined with the following likelihood for the luminosity bin
[TABLE]
where the superscripts (r) and (b) refer to red and blue galaxies, respectively. As before, we combine results from different luminosity bins by summing over the respective log-likelihoods. While using this extra information of colour dependent clustering, we need to incorporate one extra parameter (the satellite red fraction) in each luminosity bin to model the colour-dependent 2PCF correctly. For each parameter we choose a flat uniform prior in the range .
3.3 Data set and covariance matrices
Following Guo et al. (2015), we compute all of , and in two steps. At first, to account for the model uncertainties arising due to finite volume effect of the simulations, we multiply the covariance matrix measured from the data with the factor . For every magnitude bin, we have a below which we do not have any galaxy brighter than the bright end of that magnitude bin and a above which we do not have any galaxy fainter than the faint end of the magnitude bin. From these two redshift bounds, one can easily compute the maximum and minimum comoving distance () of the galaxies from us. So .
Since our correlation measurements for all halo mass range come mainly from the box, to be conservative, we have taken . Now to get an unbiased estimate of the inverse of this new covariance matrix we multiply its inverse with the factor of , where (Hartlap et al., 2007; Percival et al., 2014). In this expression denotes the number of data points and denotes the number of jackknife samplings used to compute the error covariance matrix. Following Zehavi et al. (2011), we have assumed a error in the measurement of .
It is worth mentioning here that while fitting colour-independent clustering and abundance data, we fit the data for the brightest magnitude threshold, i.e. and next three magnitude bins i.e. , and . While fitting the colour-dependent clustering data, on the other hand, we considered the red and blue correlation measurements from four magnitude bins and . We also assumed our HOD for the threshold to be equal to the HOD for the brightest magnitude bin. This is justified because there are few very bright galaxies with compared to those with .
We restrict our analysis to projected separations , since our simulation box volumes do not allow us to reliably probe larger projected scales due to the absence of long-wavelength modes. Following Zehavi et al. (2011), we have assumed in all the calculations in our model.
3.4 Convergence of the chains
In this section, we briefly discuss the convergence criterion for our MCMC chains. For the colour-independent HOD formalism, we ran a total of walkers with each chain run for steps. For each walker we throw away first steps as a burn-in. Then we compute the correlation length of the remaining samples using EMCEE-s default autocorr function. Then we join the chains and thin them with the proper correlation length to get independent samples of our posterior distribution. We also run the chains for steps and steps and the results were same. So we concluded that steps with walkers are sufficient enough for the walkers to converge. Traditional methods like Gelman-Rubin test etc. are not appropriate in case of EMCEE because all the walkers are correlated.
For the colour-dependent clustering analysis, we drew the priors from the posteriors of the previous colour-independent analysis. In this sampling, we ran walkers with steps each. We followed same procedure as discussed above for computing the correlation length and then thin the samples by the correlation length. We also did the same analysis with steps for each walker and again for steps per walker. The results were very similar. So we concluded then that walkers with steps each was good enough to achieve the convergence.
4 Results
In this section, we present the results of our MCMC fitting exercise along with fitting functions for the HOD parameters and satellite red fraction as a function of luminosity and discuss a few potential applications.
4.1 Luminosity-dependent clustering
We have initially performed our analysis for luminosity-dependent clustering without accounting for any colour information. Using the results of this analysis as a prior, we then analyse colour-dependent clustering, including the red satellite fractions in various luminosity bins as additional free parameters. The latter analysis also simultaneously updates the constraints on the parameters of the luminosity-dependent clustering analysis.
We find that imposing the extra information of colour-dependent clustering does not change the constraints on the HOD parameters much but improves the overall reduced chi-square significantly due to the use of extra data points ( when including colour information compared to without colour information). In the following, therefore, we will only quote the results of our full analysis which included colour information. Below we will also compare our results with those of a more traditional luminosity dependent analysis which considers luminosity thresholded samples one at a time.
Figure 8 shows the correlation function of galaxies of all colour for the brightest magnitude threshold and the three magnitude bins used in our analysis. The solid circles with error-bars show the measurements from (Zehavi et al., 2011); the solid curves show our best-fit model for galaxies of all colour after the colour- dependent clustering information was given. The dotted curve with error-band shows the median and - error from our model. The data points and model curves below the magnitude bin are separated by dex.
Figure 9 shows the corresponding HODs, i.e. population of galaxies of all colour as a function of halo mass in different magnitude thresholds and bins. This is clear from this figure that brighter galaxies tend to live in massive halos as also seen from previous HOD analysis (Zehavi et al., 2011; Guo et al., 2015).
4.2 Colour-dependent clustering
Figure 10 shows the correlation function of red and blue galaxies separately from our analysis. We see that in a given magnitude bin, red galaxies are always more clustered compared to the blue ones. Figure 11 shows the population of red and blue galaxies separately as a function of halo mass coming from our analysis in different magnitude bins.
Figure 15 in the Appendix shows the contour plots of the HOD parameters of four magnitude bins discussed above and the satellite red fractions for those four magnitude bins. These and contours were obtained by fitting colour-dependent clustering data with parameter priors taken as the posterior from the colour-independent analysis. The marginal distributions of the parameters are shown in the top panels of the figure. A detailed list of the constrained values of the satellite red fraction and HOD parameters is shown in Tables 1 and 2, respectively. Figure 16 focuses on the joint distributions of parameter pairs which show the largest correlations.
Figures 12 and 13 together show our constraints on different HOD parameters with and without colour information and for the analysis of individual magnitude thresholds. We see that the constraints on the HOD parameters with or without colour-dependent clustering information agrees well with one another. The constraints due to the analysis of individual magnitude thresholds match with the global analysis except for the two parameters and . These differences are very likely due to the coupling between parameters for different thresholds introduced by our global likelihood calculation. The fact that these are especially pronounced for could be due to the fact that the total number of galaxies in this bin is substantially smaller than in neighbouring bins due to our choice of redshift ranges (see Figure 6).
The right panel of Figure 13 shows the red fraction of the satellite galaxies as a function of magnitudes both from our model and other calibrations. We find that the resulting luminosity dependence of the satellite red fraction is significantly shallower than corresponding measurements from the galaxy group catalogue of Yang et al. (2007). In part, this could be due to the known systematic errors in the group finding algorithm, which are at the level of - (Campbell et al., 2015); our clustering-based determination is free from such systematics. However, considering the importance of this variable for galaxy evolution studies (see, e.g., van den Bosch et al., 2008), it will still be interesting to understand these differences in greater detail. We leave this exercise for future work.
4.3 Fitting functions and applications
One of the useful applications of the HOD approach is generating mock galaxy catalogues. To generate mock catalogues of galaxies as a function of magnitudes, one needs to make smooth fitting formulae for the HOD parameters as a function of magnitude (Skibba & Sheth, 2009).
We prescribe different types of smooth fitting functions to the set of HOD parameters coming from the colour-dependent global analysis. The analytical form of the fitting functions and the best-fit values and uncertainties of the corresponding parameters are shown in Table 3. Figures 12 and 13 show the comparison of our fitting functions with the measured parameter values.
The left panel of Figure 14 shows the correlation function of all the galaxies for different magnitude thresholds. The solid points with error bars show the measurements from SDSS data taken from Zehavi et al. (2011). The solid curves show the 2pcf calculated using the fitting functions of the HODs from Table 3 combined with the simulation-based tabulated halo correlation functions. The right panel of the Figure shows the cumulative luminosity function as a function of luminosity. We see that our fitting functions, when combined with the simulation-based tabulated theoretical 2pcf, accurately describe the 2pcf and luminosity function of galaxies at all available magnitude thresholds.
Mock catalogues based on these fitting functions could be useful, e.g., in setting up null hypotheses for testing a variety of ‘beyond halo mass’ effects in galaxy evolution studies, such as assessing the magnitude of assembly bias (Zentner et al., 2014, 2019) and conformity effects at large scales (Paranjape et al., 2015), the role of the cosmic tidal environment in determining galaxy properties (Paranjape et al., 2018; Alam et al., 2019), etc. Our parameter constraints are consistent to those obtained with the decorated HOD in Zentner et al. (2019).
For example, Paranjape et al. (2018) showed that a ‘halo mass only’ flavour of HOD parametrisation was sufficient to qualitatively describe the dependence of galaxy clustering in the SDSS on the cosmic tidal environment, but also found some intriguing quantitative differences between the mocks and data in the most anisotropic environments. Since the mocks used by those authors were based on less accurate HOD interpolations than ours, it will be very interesting to revisit that analysis with the more accurate mock catalogues that our fitting functions would allow for.
Additionally, our fitting functions for the HOD parameters can also be directly used in analyses which combine optical properties of galaxies with other properties such as neutral hydrogen (HI) mass. Recently, Paul et al. (2018) presented an analysis of galaxy clustering as a function of HI mass by using optical HODs calibrated on SDSS (the same set used by Paranjape et al., 2018) with an assumed optical-HI scaling relation which was constrained using MCMC techniques applied to clustering data from the ALFALFA survey (Guo et al., 2017). Our HOD fitting functions would be useful in making the resulting best-fit scaling relations more robust and accurate.
5 Conclusion
In this work, we have revisited the Halo Occupation Distribution (HOD) method of describing the luminosity- and colour-dependence of clustering of SDSS galaxies with the goal of obtaining accurate and self-consistent HOD prescriptions parametrised using convenient fitting functions. Our analysis has combined two techniques that have allowed us to minimise systematic modelling uncertainties while maximising the information content available in the data for parameter estimation.
Firstly, we have calibrated the HOD parameters by using direct measurements of halo correlation functions from -body simulations (section 2.2). This way of modelling the HOD accurately accounts for the scale-dependence and nonlinearity of halo bias, as well as potential departures of the halo density profile from the universal NFW form. We have also accounted for halo exclusion by modelling halos as hard spheres. Our measurements rely on a suite of dark matter simulations which span the entire range of halo mass and spatial separation required for modelling SDSS projected clustering. We have used multiple independent realisations of our simulation boxes to obtain reliable estimates of the halo correlation functions.
Secondly, we have used a novel global analysis of SDSS clustering measurements. By modelling the projected clustering in a given luminosity bin using HOD parameters for a pair of luminosity thresholds, we were able to self-consistently combine measurements from a range of luminosity bins into a single, global likelihood which simultaneously constrains the HOD parameters for all luminosity thresholds of interest (section 3). This global analysis thus uses all the available information from the data while correctly accounting for correlations between parameter estimates.
In addition to luminosity dependence, we have also included the colour dependence of clustering in our analysis. This substantially improves the quality of our fit (Table 2) while also allowing us to place essentially model-independent constraints on the red fraction of satellites (section 4.2, Table 1). The resulting luminosity dependence of (right panel of Figure 13) shows interesting differences from previous calibrations from analyses of galaxy group catalogues, which we will follow up in future work.
We have produced simple and accurate fitting functions for the luminosity dependence of all HOD parameters, as well as the satellite red fraction (Table 3). We have demonstrated that these correctly describe the clustering of samples defined using thresholds which were not included in the analysis (Figure 14). We expect these fitting functions to be very useful in making mock catalogues of galaxies at low redshift.
Our technique can be easily extended to include halo properties other than halo mass (such as concentration or asphericity) when constructing our tabulated theoretical 2pcfs. The resulting models can then serve, e.g., to calibrate the level of galaxy assembly bias or galactic conformity in the clustering and abundance data. Our mass-only calibrations can themselves also be improved further by considering the possible deviation of the spatial distribution of the satellites from the underlying dark matter distributions, as well as allowing for colour-dependent differences in these distributions. Overall, we do not find strong correlations between the parameters of different magnitude thresholds (Figure 15, see also Figure 16). The constraints on HOD parameters can be further improved if one uses the measurements of anisotropic galaxy correlations (Guo et al., 2015). Incorporating these improvements is the subject of work in progress.
Acknowledgments
We thank R. Srianand, K. Subramanian and T. R. Choudhury for useful discussions. This work has used the open source computing packages NumPy (Van Der Walt et al., 2011, http://www.numpy.org), SciPy (Jones et al., 01) and the plotting softwares Veusz (https://veusz.github.io/) and corner.py (Foreman-Mackey, 2016). The research of AP is supported by the Associateship Scheme of ICTP, Trieste and the Ramanujan Fellowship awarded by the Department of Science and Technology, Government of India. NP acknowledges the financial support from the Council of Scientific and Industrial Research (CSIR), India as a Shyama Prasad Mukherjee Fellow. IP acknowledges the hospitality and facilities provided by the Korea Institute for Advanced Study and School of Liberal Arts, Seoul-Tech, South Korea where part of this work was completed. We gratefully acknowledge the use of high performance computing facilities at IUCAA, Pune. We sincerely thank the anonymous referee for the valuable comments which led to the significant improvement of the draft.
Appendix A Simulation-based halo model
In this section, we discuss how to compute the 2pcf of galaxies using measurements of different quantities from sinulations. In the first subsection, we describe how to compute the 2pcf and abundance for magnitude thresholds, then in the next subsection, we discuss how to compute those quantites in binned measurements using the thresholded HOD. Finally, in the next subsection, we discuss how to compute the 2pcf for red and blue galaxies.
A.1 Computation of abundance and clustering for individual magnitude threshold
If we have a total of bins of halo mass and in a given halo mass bin , we have HODs and cf. equation (2), (3), then the average comoving number density of galaxies can be written as,
[TABLE]
It is worth to note that all the HOD quantities and the ones derived from it depends on the properties of the galaxies, in this case luminosity , which we have not written explicitly. In equation (12), is the comoving number-density of halos per unit logarithmic mass in the halo mass-range and . If the density profile of the galaxies inside dark matter halos in the -th mass bin be and the convolution of the density profile with itself be , then the -halo correlation function of the galaxies can be written as,
[TABLE]
The 2-halo term of the correlation function of the galaxies can be similarly computed as,
[TABLE]
where , and -s are two-point correlations between central-central, central-satellite and satellite-satellite pairs respectively in two different halos. The above equations are just generalisations of the analytical 2pcf formulae in HOD prescriptions (Cooray & Sheth, 2002; Zheng & Guo, 2016). Once we have these two terms we can compute total correlation function and then compute the projected 2pcf using (Davis & Peebles, 1983),
[TABLE]
The upper limit in the above integration is practically not , rather it is , where the two quantities and are the separation between two galaxies perpendicular and parallel to the line of sight respectively.
Our procedure of convolving the HOD-s wit halo statistics is a robust and fast technique. But it has its own drawback. We have assumed that the central galaxy always live at the center of the halos and the density profile of the galaxies trace the underlying density profile of dark matter halos. These assumptions are not always true and can have sub-percent level effect at small scale correlation functions. An alternative approach where one obtain the galaxy population by directly populating the halos with HOD-s has the potential to overcome these issues.
A.2 Computation of abundance and clustering in a magnitude bin
Now we will see how to compute the correlation and abundance of galaxies in a given magnitude bin using the HODs of two adjacent magnitude thresholds. Let’s denote by the fraction of -halos having a central galaxy with luminosity in the range . We also define to be the average number of satellite galaxies of luminosity residing in -halos which have a central galaxy with luminosity . Then the binned-HODs can be computed in the following way (Paranjape et al., 2015; Pahwa & Paranjape, 2017),
[TABLE]
Having defined these binned HODs, the calculation of the abundance and the 2-halo term of the correlation function is straighforward. One just needs to replace and with and in equation (12) and (14). But for the 1-halo correlation function, we need to keep in mind that the first term of the correlation function will be the correlation between a central galaxy of luminosity and satellites of luminosity residing in a -halo having a central of luminosity . The second term will be the correlation between satellites of luminosity living inside a halo having a central galaxy of luminosity . Therefore, then modified 1-halo correlation function will be,
[TABLE]
A.3 Computation of red and blue clustering in a given magnitude bin
Once we know how to compute the 2pcf of galaxies in a given magnitude bin, we can proceed to model the colour-dependent clustering. We need the following red and blue HODs to compute the colour-dependent correlation function,
[TABLE]
Here is the galaxy type, either central or satellite. In the above equations we have assumed that red (or blue) fractions of the galaxies are independent of their halo mass. In the following, let’s derive the working equations for the red fraction first. The corresponding equations for blue galaxies will follow. In our model, we will keep the red fraction of satellite galaxies, as a free parameter. Then the red fraction of the centrals can be computed very easily in the following way,
[TABLE]
In the previous expression, is the fraction of galaxies which are central (satellite) in a given magnitude bin. This can be computed from the HOD in the following way,
[TABLE]
We are now only left with the quantity , i.e. the red fraction of all galaxies in a given magnitude bin. This we can get directly from SDSS data using Zehavi et al. (2011) definition of red and blue galaxies. For the blue galaxies, we can write,
[TABLE]
Thus having obtained the HODs for red and blue galaxies separately we can use the formalism defined in the previous subsection to compute the correlation function of red and blue galaxies in a given magnitude bin.
Appendix B Weighting Scheme for simulation measurements and their errors
If a given quantity is measured from different realisations as a set with corresponding uncertainties , then the weighted average which maximises the joint likelihood function over all realisations has the following expression,
[TABLE]
For our work, we assume a Poisson distribution of the quantities, so the relative error on the mean value of the measured quantities in each realisation and in each halo mass bin scales as the inverse of the square root of the number of particles associated with each component measured. So with the approximation that the mean of the quantities measured in each realisation and in each halo mass bin is same, we can define the unnormalized weights to be equal to the number of particles in that halo mass bin and in that realisation which has been used to measure the quantity. It is important to note that throughout this discussion, by ‘realisation’, we mean all available realisations from all the boxes.
Therefore, for the halo mass function , weight is , where is the number of available halos in the realisation in the halo mass bin . For , the weight will be . Here is the number of available dark matter particles in the realisation and in the halo mass bin . Now , where , the mass of each dark matter particle in the realisation, is computed as . In this expression, is the total number of dark-matter particles in the realisation of the box. Similarly, for the quantity the weight will be . For simplicity, we assume the weights of the normalized quntities and to be same as their unnormalized counterparts. Furthermore, wherever the two quantities and appear, we will take them to be the weighted average over all the realizations. So in case of error estimation, we neglect the errors coming from them. Similarly, the weights for the 2-halo quantities will be following,
[TABLE]
[TABLE]
[TABLE]
The weights for the term is very similar to that of . Once we know the weights to assign to each of the components, we can find the error associated to their weighted mean. The standard error on the mean has the following expression,
[TABLE]
where . This is just a schematic equation which will change the exact form depending on whether we are calculating the errors on the 1-halo or 2-halo terms of the correlation function.
Once we have the mean and error on that mean of the quantities in each halo mass bin, we can compute the mean of the quantites and error on that mean for a given thick halo mass range . If the schematic quantity is with mean and error of the mean in each halo mass bin, then the weighted average of that quantity in the halo mass range will be,
[TABLE]
and the error on this mean quantity will be,
[TABLE]
Formulae from equation (24) to (30) have been used to compute errors in different components of the correlation function in different thick halo mass bins as shown in Figures 1 to 5.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Abazajian et al. (2009) Abazajian K. N., et al., 2009, Ap JS , 182, 543 · doi ↗
- 2Abbas et al. (2010) Abbas U., et al., 2010, MNRAS , 406, 1306 · doi ↗
- 3Alam et al. (2019) Alam S., Zu Y., Peacock J. A., Mandelbaum R., 2019, MNRAS , 483, 4501 · doi ↗
- 4Behroozi et al. (2013) Behroozi P. S., Wechsler R. H., Wu H.-Y., 2013, Ap J , 762, 109 · doi ↗
- 5Berlind & Weinberg (2002) Berlind A. A., Weinberg D. H., 2002, Ap J , 575, 587 · doi ↗
- 6Berlind et al. (2003) Berlind A. A., et al., 2003, Ap J , 593, 1 · doi ↗
- 7Cacciato et al. (2013) Cacciato M., van den Bosch F. C., More S., Mo H., Yang X., 2013, MNRAS , 430, 767 · doi ↗
- 8Campbell et al. (2015) Campbell D., van den Bosch F. C., Hearin A., Padmanabhan N., Berlind A., Mo H. J., Tinker J., Yang X., 2015, MNRAS , 452, 444 · doi ↗