TL;DR
This paper presents a hierarchical hybrid planning framework for dynamic, real-time multimodal routing that efficiently handles uncertainty and complex decision-making for autonomous agents using multiple transportation modes.
Contribution
It introduces a novel hierarchical hybrid planning approach that exploits problem structure for efficient real-time multimodal routing under uncertainty.
Findings
Framework outperforms baseline in time to reach destination.
Significantly reduces energy expenditure.
Handles large-scale, complex routing scenarios.
Abstract
We introduce the problem of Dynamic Real-time Multimodal Routing (DREAMR), which requires planning and executing routes under uncertainty for an autonomous agent. The agent has access to a time-varying transit vehicle network in which it can use multiple modes of transportation. For instance, a drone can either fly or ride on terrain vehicles for segments of their routes. DREAMR is a difficult problem of sequential decision making under uncertainty with both discrete and continuous variables. We design a novel hierarchical hybrid planning framework to solve the DREAMR problem that exploits its structural decomposability. Our framework consists of a global open-loop planning layer that invokes and monitors a local closed-loop execution layer. Additional abstractions allow efficient and seamless interleaving of planning and execution. We create a large-scale simulation for DREAMR…
Click any figure to enlarge with its caption.
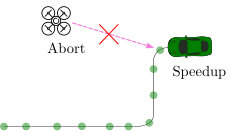 Figure 1
Figure 1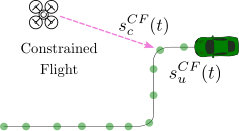 Figure 2
Figure 2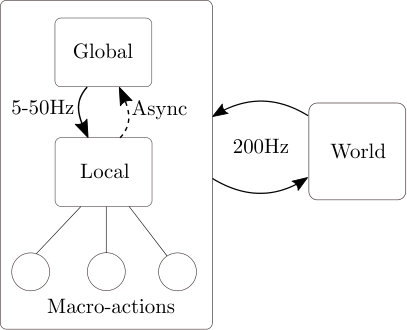 Figure 3
Figure 3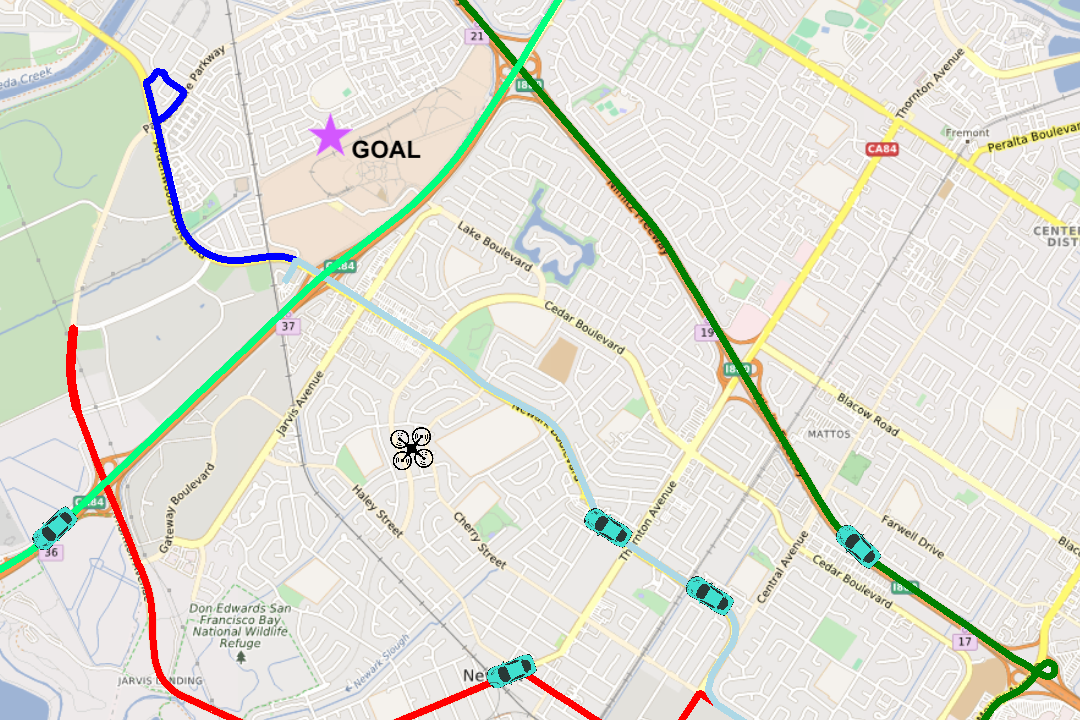 Figure 4
Figure 4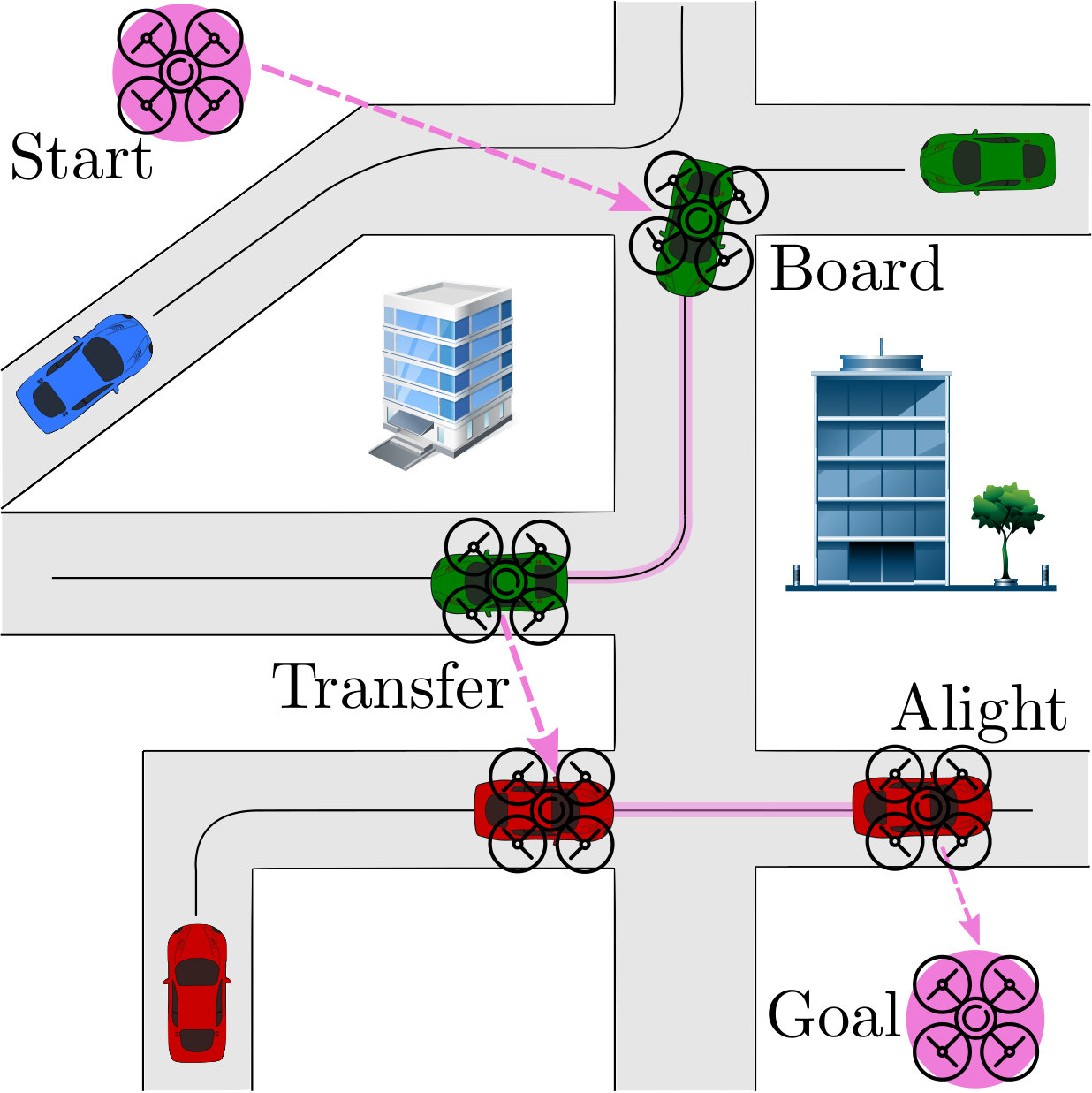 Figure 1
Figure 1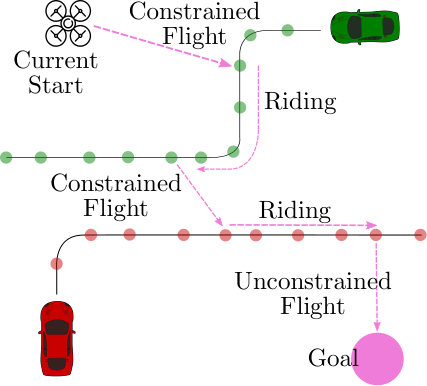 Figure 6
Figure 6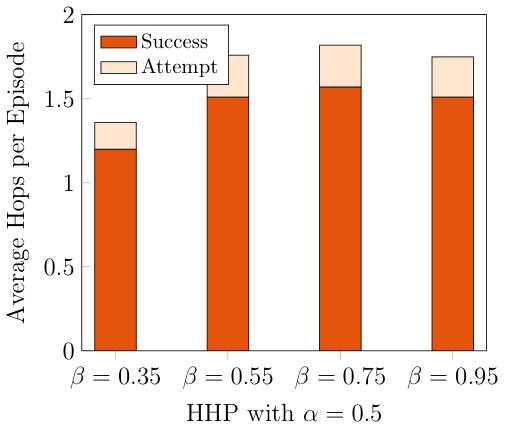 Figure 7
Figure 7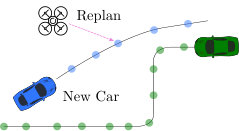 Figure 8
Figure 8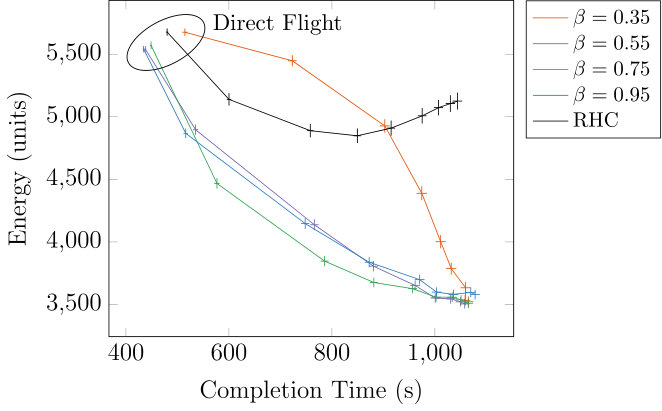 Figure 9
Figure 9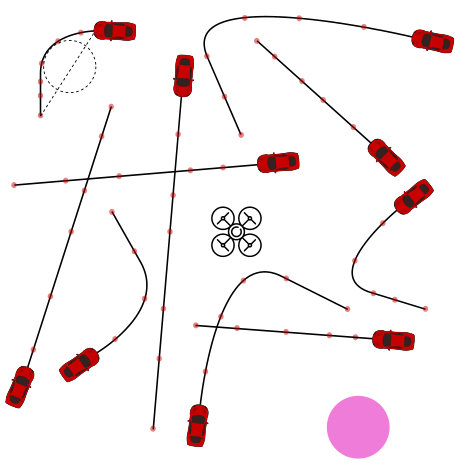 Figure 10
Figure 10| Setup | search | searches | ||
|---|---|---|---|---|
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Dynamic Real-time Multimodal Routing
with Hierarchical Hybrid Planning
Shushman Choudhury This research is funded through the Ford-Stanford Alliance. Department of Computer Science
Stanford University
Jacob P. Knickerbocker
Ford Greenfield Labs
Palo Alto
Mykel J. Kochenderfer
Department of Aeronautics and Astronautics
Stanford University
Abstract
We introduce the problem of Dynamic Real-time Multimodal Routing (DREAMR), which requires planning and executing routes under uncertainty for an autonomous agent. The agent can use multiple modes of transportation in a dynamic transit vehicle network. For instance, a drone can either fly or ride on terrain vehicles for segments of their routes. DREAMR is a difficult problem of sequential decision making under uncertainty with both discrete and continuous variables. We design a novel hierarchical hybrid planning framework to solve the DREAMR problem that exploits its structural decomposability. Our framework consists of a global open-loop planning layer that invokes and monitors a local closed-loop execution layer. Additional abstractions allow efficient and seamless interleaving of planning and execution. We create a large-scale simulation for DREAMR problems, with each scenario having hundreds of transportation routes and thousands of connection points. Our algorithmic framework significantly outperforms a receding horizon control baseline, in terms of elapsed time to reach the destination and energy expended by the agent.
I Introduction
Cost-effective transportation often requires multiple modes of movement, such as walking or public transport. Consequently, there has been extensive work on multimodal route planning [1, 2, 3]. Prior work, even state-of-the-art [4, 5], has focused on generating static routes in public transit networks for humans, rather than real-time control for autonomous agents. This paper introduces a class of problems that we call Dynamic Real-time Multimodal Routing (DREAMR), where a controllable agent operates in a dynamic transit network.
An example of DREAMR is a drone riding on cars (fig. 1) en route to its destination. Such coordination can achieve energy efficiency and resilience for navigation, search-and-rescue missions, and terrain exploration [6]. Multimodal routing already helps humans schedule vehicle charging [7] and aerial-ground delivery systems have been developed [8].
The DREAMR problem class inherits the challenges of multimodal route planning — the combinatorial complexity of mode selection and the balancing of performance criteria like time and distance. In addition, the online transit network requires adaptivity to new information (new route options, delays and speedups). We need to make decisions at multiple time-scales by planning routes with various modes of transport, and executing them in real-time under uncertainty.
Our key insight is that DREAMR has significant underlying structure and decomposability to simpler sub-problems. We exploit this through a hierarchical hybrid planning framework. A global open-loop layer repeatedly plans (discrete) routes on the dynamic network through efficient graph search, deciding which modes of transport to use and for what duration. A local closed-loop layer executes (continuous) agent control actions in real-time under uncertainty. We design abstractions that interleave planning and execution efficiently to respond to updates in the transportation options.
Our contributions are as follows: (i) We introduce DREAMR and formulate it as an Online Stochastic Shortest Path problem [9] of both discrete and continuous variables. (ii) We propose a novel Hierarchical Hybrid Planning (HHP) framework for DREAMR. The choices of representation and abstraction in our framework adapt techniques for multimodal routing and hierarchical stochastic planning in an efficient yet principled manner. (iii) We create a synthetic setup for a subclass of DREAMR (single controllable agent; transportation assumptions) with hundreds of vehicles and significant route variability. Our framework shows scalability to very large problems and a better tradeoff between energy and elapsed time than a receding horizon control baseline.
II Background and Related Work
We discuss a background topic and two related work areas.
II-A Markov Decision Processes
A Markov Decision Process or MDP [10] is defined by , where and are the system’s state and action spaces, is the transition function, where and , is the reward function, and the discount factor. Solving an MDP yields a closed-loop policy which maximizes the value or the expected reward-to-go from each state. An MDP can be solved by value iteration, a dynamic programming (DP) method that computes the optimal value function . We obtain a single for infinite horizon problems and ( is the maximum number of timesteps) for finite horizon or episodic problems. For large or continuous spaces, we can approximate the value function locally with multilinear interpolation [11], or globally with basis functions [12]. Our framework uses approximate DP extensively [13].
II-B Multimodal Route Planning
Route planning in transportation networks has been studied considerably [14]. DREAMR involves multimodal route planning [1], where multiple modes of transportation can be used. Multimodality can provide flexibility and resilience [15], but introduces combinatorial and multiobjective complexity [16]. Heuristic methods have tried to address this complexity [3]. Recent work has focused on real-world aspects like contingencies [2, 17], dynamic timetable updates [5] and integrating more flexible carpooling [4].
II-C Hierarchical Stochastic Planning
A powerful technique for large MDPs is to decompose it into more tractable components [18]. A hierarchical stochastic planning framework combines subproblem solutions to (approximately) solve the full MDP [19]. We use various ideas from hierarchical reinforcement learning [20]. Temporally abstract actions or macro-actions [21] are actions persisting over multiple timesteps and are viewed as local policies executed in a subset of until termination [22]. A hierarchy of abstract machines [23] is a framework with a multi-layer structure where higher-level supervisors monitor lower-level controllers and switch between them in appropriate parts of the state space. State abstraction improves tractability by ignoring aspects of the system that do not affect the current decision [24, 25].
III Problem Formulation
We use a discrete-time undiscounted episodic MDP to model DREAMR. The system state at time is
[TABLE]
where is the agent state, is the current position of vehicle , is the vehicle’s remaining route, a sequence of waypoints with estimated time of arrival (ETA), i.e. , and indicates the vehicle the agent is riding on (0 if not). Due to the time-varying number of active vehicles , the state space has nonstationary dimensionality. The action space is the union of agent control space and agent-vehicle interactions, i.e. . Both state and action spaces are a hybrid of discrete and continuous variables.
Agent: We use a 2D second-order point mass model for the agent (simplified to focus on decision-making, not physics). The state has position and bounded velocity and the control has bounded acceleration in each direction independently, subject to zero-mean Gaussian random noise,
[TABLE]
where defines the agent dynamics (an MDP can represent any general nonlinear dynamics function).
For the transition function , when the action is a control action, the agent’s next state is stochastically obtained from . The agent-vehicle interactions switch the agent from not riding to riding (Board) and vice versa (Alight). They are deterministically successful (unsuccessful) if their pre-conditions are satisfied (not satisfied). For Board, the agent needs to be sufficiently close to a vehicle and sufficiently slow, while for Alight, it needs to currently be on a vehicle.
Vehicles: The transit routes are provided as streaming information from an external process (e.g. a traffic server). At each timestep the agent observes, for each currently active vehicle, its position and estimated remaining route (waypoint locations and current ETA). New vehicles may be introduced at future timesteps arbitrarily. This online update scheme has been used previously to represent timetable delays [26], though our model can also have speedups. For this work, we make two simplifying restrictions: (i) no rerouting: route waypoint locations, once decided, are fixed and traversed in order and (ii) bounded time deviations: estimates of waypoint arrival times increase or decrease in a bounded unknown manner between timesteps, i.e. .
Objective: Our single timestep reward function penalizes elapsed time and the agent’s energy consumed (due to distance covered or hovering in place) if not riding on a vehicle:
[TABLE]
where and indicates hovering. The and coefficients encode the relative energy costs of distance and hovering, and the penalizes each timestep of unit duration (this formulation can represent the shortest distance and minimum time criteria). We vary for experiments in section V-C. The agent must go from start state to goal state . The agent’s performance criterion is the cumulative trajectory cost that depends on both discrete modes of transportation and continuous control actions. It can ride on vehicles to save on distance, potentially at the cost of time and hovering.
DREAMR’s underlying MDP is an online instance of Stochastic Shortest Paths (SSP) [9]. An SSP is a special case of an undiscounted episodic MDP with only negative rewards i.e. costs, where the objective is to reach a terminal absorbing state with minimum trajectory cost [13]. In online SSPs, there are two components. First, the identifiable system with known Markovian dynamics (our agent model). Second, an autonomous system which affects the optimal decision strategy but is typically external (our transit vehicle routes).
IV Approach
We use the example of drones planning over car routes for exposition, but our formulation is general and is applicable to, say, terrain vehicles moving or riding on the beds of large trucks, or vehicles coordinating segments of drafting to reduce drag. No existing methods from multimodal routing or online SSPs can be easily extended to DREAMR. The former do not consider real-time control under uncertainty while the latter are not designed for jointly optimizing discrete and continuous decisions. This motivates our novel framework.
For cars and waypoints per route, the full DREAMR state space has size . It scales exponentially (for a continuous-valued base) with the numbers of cars and waypoints. Moreover, the dimensionality is significantly time-varying in a problem instance. Therefore, to solve DREAMR realistically, we must exploit its underlying structure:
- (i)
Decomposability: Every route comprises three kinds of sub-routes: time-constrained flight to a car waypoint, riding on a car, and time-unconstrained flight. For each sub-route, at most one car is relevant. 2. (ii)
Partial Controllability: Optimal drone actions depend on the car positions and routes but cannot control them.
Our Hierarchical Hybrid Planning (HHP) framework exploits DREAMR’s structure with two layers: a global open-loop layer with efficient graph search to plan a sequence of sub-routes, each of a particular mode (either Flight or Ride), and a local closed-loop layer executing actions in real-time using policies for the sub-routes. The open-loop layer handles online updates to transit options and produces discrete decisions while the closed-loop layer handles motion uncertainty and produces control actions. Our framework balances deterministic replanning and stochastic planning.
Our specific contributions are the choices that unite techniques from multimodal routing and hierarchical stochastic planning — implicit graph search, edges as macro-actions, value functions as edge weights, terminal cost shaping, replanning as switching between macro-actions (all described subsequently). The resulting HHP framework achieves both scalability and good quality solutions to DREAMR problems. Algorithm 1 summarizes the salient aspects of HHP.
IV-A Global Open-loop Layer
Graph Model: The prevalent framework for route planning is graph search [14]. We use a time-dependent [27] directed acyclic graph (DAG) model with nonstationary edge weights. Every car waypoint is a vertex in the time-varying graph . The waypoint of the car route is , with notation from eq. 1. The waypoint ETA is updated at each timestep. By the no rerouting and bounded deviation assumptions, once a route is generated, the waypoints are guaranteed to be traversed in order. Two more vertices and represent drone goal and current drone source respectively.
The types of edges correspond to sub-routes:
- •
Constrained Flight: (drone flies to a route waypoint and executes Board).
- •
Ride: (drone executes Alight when the car reaches ).
- •
Unconstrained Flight: (drone flies to goal vertex).
Discretization is necessary to determine transfer points from a continuous route. The open-loop layer assumes that transfers can only happen at the pre-determined route waypoints. There is a tradeoff between solution quality and computation time as more transit points are considered per route, and the most suitable choice is a domain-specific decision.
Route Planning: The open-loop layer runs search [28] on (20) to obtain , the current best path (sequence of edges) from (current drone state) to (fig. 2). As the drone traverses the route and is updated (18), it replans from scratch rather than incrementally repairing , which is efficient only when few edges change [29]. Our DAG is highly dynamic, with most edges updated as vertex timestamps change. Therefore, we use an implicit graph, where edges are generated just-in-time by a successor function during the node expansion stage. Broadly speaking, the successor function enforces temporal constraints for CF edges and consistency for ride edges (the time-unconstrained goal is a potential neighbor for every expanded node). Implicit graphs have been used previously for efficient search in route planning [1, 30]. For the heuristic, we use the minimum straight line traversal time while riding (therefore no energy cost),
[TABLE]
The above heuristic is admissible, assuming the maximum speed of a car is higher than that of a drone.
Edge Weight: The edge weight function is a surrogate for eq. 3. For a ride edge, the only cost is for elapsed time,
[TABLE]
However, from a flight edge, we get only Euclidean distance and the estimated time difference. The actual cost depends on the control actions of the policy while executing the edge. Therefore, we use the negative value function of the macro-action policy, which is a better surrogate, as the corresponding edge weight; every edge encodes a state for the corresponding macro-action MDP (discussed subsequently). Consequently, we reduce average search complexity greatly by filtering out edges for infeasible or difficult connections.
IV-B Local Closed-loop Layer
For the three kinds of edges, at most one car is relevant. This motivates state abstraction by treating edges as macro-actions with corresponding MDPs of smaller and fixed dimensionality [25, 24]. A closed-loop policy for each MDP is obtained offline (1–4) and used by the local layer to execute the corresponding edge in real-time (23–28). Each macro-action policy only uses local information about the currently executing edge [22].
IV-B1 Constrained Flight (CF)
The source is the drone vertex, , and the target is the connection point chosen by the global layer. Here, is the position and the current ETA of the car at its waypoint.
The constrained flight (CF) macro-action policy must control the drone from to and slow down to a hover before the car arrives to execute Board successfully. It also needs to adapt to changes in . The CF problem is partially controlled as the drone action does not affect the car’s ETA. Therefore, we build upon a partially controllable finite-horizon MDP approach originally applied to collision avoidance [31]. It decomposes the problem into controlled and uncontrolled subproblems, solved separately offline and combined online to obtain the approximately optimal action ([13], Sec. 1.4).
For CF, the state is where
[TABLE]
represents relative drone state and time to car ETA respectively. The MDP episode terminates when , where is a small time threshold for the car ETA.
The action space is for drone control, i.e. . The transition function uses drone dynamics from eq. 2. For non-terminal states, the reward function is the same as eq. 3. A constrained flight edge encodes a state of the CF MDP, so the edge weight for the global graph search is set to the negative value of the encoded state. We use terminal cost shaping (discussed subsequently) such that the value function approximates the drone dynamics cost.
The partial control method computes a horizon-dependent action-value function for the controlled subproblem ( and for out-of-horizon, denoted with ), assuming a distribution over episode termination time. The uncontrolled subproblem dynamics define probability distributions over termination time for the uncontrolled states ( and ), where is the probability that terminates in steps. The and values are computed offline and used together online to determine the (approximately) optimal action for the state ,
[TABLE]
The partial control decomposition stores compactly in over [31].
We compute (and value function and policy ) offline. Our uncontrolled state is just the time to the car’s ETA, i.e. the CF termination time. If is provided as a distribution over ETA, we obtain directly from . Otherwise, if it is a scalar estimate , we construct a normal distribution , where is the standard deviation of the observed ETAs so far, and sample from it to compute .
Terminal Cost Shaping: A CF episode terminates when , i.e. at horizon [math]. Let be the set of successful terminal states, where relative position and velocity are close enough to [math] to Board. Typically, successful terminal states for a finite-horizon MDP are given some positive reward to encourage reaching them. However, there is no positive reward in eq. 3 (recall DREAMR is an SSP). Therefore, rewarding a hop will make an unsuitable surrogate of the true cost and a poor edge weight function; the open-loop layer will prefer constrained flight edges likely to succeed whether or not they advance the drone to the goal. Instead, we have a sufficiently high cost penalty for unsuccessful terminal states to avoid choosing risky CF edges. Any terminal state not in is penalized with lower bounded by the maximum difference between any two -length control sequences and ,
[TABLE]
such that any high-cost successful trajectory is preferred to a lower-cost unsuccessful one. The value can be computed in one pass offline. This terminal pseudo-reward makes reusable for all CF edges (c.f [25], pages ).
IV-B2 Riding and Unconstrained Flight
We discuss these simpler macro-actions briefly. A riding edge is between two waypoints, after the successful execution of Board and up to the execution of Alight. This is an uncontrolled problem where the (deterministic) policy is: do nothing until the car reaches the waypoint and then Alight. An unconstrained flight (UF) edge represents controlling the drone from the current waypoint to the goal, which is a time-unconstrained drone state. Therefore, we use an infinite horizon MDP, and run value iteration until convergence to obtain the control policy for unconstrained flight (we could also have used an open-loop controller here). The value function for the unconstrained flight MDP is used for the edge weight.
For both CF and UF, we discretized the drone state space with a multilinear grid evenly spaced along a cubic scale, and used interpolation for local value function approximation. The cubic scale has variable resolution discretization [32] and better approximates the value function near the origin, where it is more sensitive. The discretization limits were based on the velocity and acceleration bounds.
IV-C Interleaving Planning and Execution Layers
The car route updates require significant adaptivity. New cars may improve options, a delay may require Alight, and a speedup may invalidate the CF edge. The global open-loop layer keeps replanning as the car routes are updated, to obtain the current best path . The local closed-loop layer is (somewhat) robust to uncertainty within the macro-action but is unaware of the global plan, and may need interrupting so a new can be executed. Figure 3 depicts scenarios that motivate interleaved planning and execution.
IV-C1 Open-Loop Replanning
HHP uses periodic and event-driven replanning, which effectively obtains high-quality schedules [33]. The period is the ratio of layer frequencies and the events are aborting constrained flight or mode switches (25 and 33). If the first edge of the new path is different than the current one, the correspondingly different macro-action policy is invoked. This switching between macro-actions is seamlessly achieved by switching between paths in our framework since edge weights are based on macro-action value functions and edges are equivalent to macro-action states. For hierarchical stochastic planning, switching between macro-actions rather than committing to one until it terminates guarantees improvement (c.f. [34] for proof).
IV-C2 Aborting Constrained Flight
Aborting the CF macro-action is useful when the target car speeds up and the drone might miss the connection. For , we compute (offline) the worst value of any controlled state (least likely to succeed from horizon ), \underaccent{\bar}{V}^{CF}(k)=\min_{s^{CF}_{c},a}Q^{CF}_{k}(s^{CF}_{c},a). During macro-action execution (online),
[TABLE]
where is a risk factor. The graph search successor function also uses eq. 9 to reject edges that are unlikely to yield successful connections. The closer is set to 1, the greater the risk we take for the connection. For , the CF macro-action never aborts (but may still be interrupted by the global layer replanning). By incorporating abort into , we can reason about it at the higher closed-loop frequency. We evaluate the effect of in fig. 7, but the framework could adaptively use multiple -policies at the same time.
V Experiments
We used Julia and the POMDPs.jl framework [35]. Figure 4 shows a simplified architecture. Simulations were done with RAM and a -core CPU. Table I summarizes HHP’s scalability to network size through the open-loop query time, which is competitive with state-of-the-art multimodal journey planning [5] (c.f. Table 7 in their Appendix). A perfect comparison is not feasible as they have different technical specifications and use a public transit network with explicit edges, while we use an implicit dynamic graph. Still, their Berlin graph (4.3\text{\times}{10}^{6}$$, c.f. their table 2) is comparable in size to row 2 of our table I. Their MDTM-QH algorithm with Bus and Train (2 modes like ours) without the ALT preprocessing (inapplicable for dynamic graphs) takes per query while ours takes for the most expensive first search. The average computation time for our local layer is (independent of network size).
V-A Baseline
To baseline our HHP framework, we used receding horizon control (RHC), which repeatedly does open-loop planning. The baseline uses HHP’s graph search to choose routes, with a nominal edge weight for flight distance and time. Flight edges are traversed by repeated non-linear trajectory optimization:
[TABLE]
with shared symbols from eq. 2 and eq. 3. The RHC horizon is adjusted depending on car ETA for CF, and fixed for UF, and is the set of successful terminal states (e.g. for constrained flight). We attempt Board at the waypoint if the pre-conditions are satisfied, or else we replan. Ride edges use the same strategy as in HHP.
V-B Problem Scenarios
We are evaluating a higher-level decision-making framework so we abstract away physical aspects of obstacles, collisions, and drone landing. We also mention only illustrative experimental parameters in the interest of space. The spatiotemporal scale is chosen to reflect real-world settings of interest. We simulate routes on a grid representing (approximately the size of north San Francisco). We have scaled velocity and acceleration limits for the drone. Each episode lasts for minutes (), with timesteps or epochs of each. An episode starts with between to cars (unlike the fixed-size settings for scalability analysis in table I) and more are added randomly at each subsequent epoch (up to twice the initial number).
A new car route is generated by first choosing two endpoints more than apart. We choose a number of route waypoints from a uniform distribution of to , denoted , and a route duration from s. Each route is either a straight line or an L-shaped curve. The waypoints are placed along the route with an initial ETA based on an average car speed of up to . See fig. 5 for a simplified illustration.
The scheme for updating route schedules is based on previous work [26] but is simulated to be more adversarial. At each epoch, the car position is propagated along the route and the ETA at each remaining waypoint is perturbed with within \pm$$5\text{\,}\mathrm{s} (highly dynamic). The route geometry is simple for implementation, but we represent routes as a sequence of waypoints. This is agnostic to route geometry or topology and can accommodate structured and unstructured scenarios. For instance, the urban street-map scenario shown in fig. 6 can be seamlessly represented by our setup.
In addition to transit routes, we have a simulator for the agent dynamics model (we use a double integrator) and agent-transportation interactions (29). The updated route information at each epoch is provided with the current MDP state, formatted as in eq. 1. The drone starts at the grid center, while the goal is near a corner. The code repository111The Julia code is at https://github.com/sisl/DreamrHHPhas a video for two scenarios that illustrate HHP’s behavior.
V-C Results
We compared RHC against four variants of HHP using different values (the risk parameter in section IV-C). We used 9 values of the energy-time tradeoff parameter from eq. 3, linearly spaced from [math] to . For each corresponding , we evaluated the two approaches over 1000 simulated episodes (different from table I episodes) and plotted in fig. 7 their average performance with the two components of , the energy consumed and time to reach the goal.
For (left-most), the objective is to minimize time by typically flying directly to goal at full speed without riding. Subsequent points (increasing ) correspond to prioritizing lower energy consumption by more riding, typically taking more time, although sometimes riding may save both time and energy. HHP significantly dominates RHC on both metrics, with RHC requiring up to more energy. Compared to HHP, flying directly to the goal (the top-left-most point) requires up to more energy.
A higher for makes HHP optimistically attempt constrained flight (CF) connections. Lower values are more sensitive; has the poorest energy-time tradeoff due to being risk-averse to potentially useful connections. Figure 8 further analyzes the effect of on CF connections. Increased optimism can affect success rates for the attempts.
The difference between HHP and RHC varies with . For they both fly straight to goal and any small differences are due to the underlying control method. However, the performance gap widens with increasing as more riding is considered to save energy. For CF edges, RHC’s nominal edge weight only accounts for time difference and flight distance, but not hovering or control action costs. The negative value function of the encoded state better estimates the traversal cost and penalizes the CF edge if failure is likely. HHP is thus less likely to commit to difficult connections (depending on ). Furthermore, RHC’s underestimation of the true energy cost is exacerbated as energy consumption is prioritized, which accounts for the greater deviation in RHC’s tradeoff curve as approaches 1 on the right.
We provide an illustrative example about the edge weights. Consider two CF edges for which HHP succeeds on the first but aborts on the second. For the success, the nominal edge weight was and the value function cost was ; the actual execution trace until Board incurred units of cost. In the abort case, the nominal edge weight estimate was and the value function estimate was . For edges likely to succeed, HHP’s cost estimate is more accurate, while for likely failures, HHP’s cost estimate is higher and the edges less preferred. This example is anecdotal but this effect cumulatively contributes to the performance gap.
VI Conclusion
We introduced Dynamic Real-time Multimodal Routing (DREAMR) and formulated it as an online discrete-continuous SSP. Our hierarchical hybrid planning framework exploits DREAMR’s decomposability, with a global open-loop layer using efficient graph-based planning for discrete decisions and a local closed-loop policy layer executing continuous actions in real-time. Our framework scales to large problems, and interleaves planning and execution in a principled manner by switching macro-actions. Empirically, we are competitive with state-of-the-art multimodal routing for high-level plans. We also greatly outperform a receding horizon control baseline for the energy-time tradeoff.
Limitations and Future Work: This paper summarizes initial work introducing DREAMR and designing an HHP framework. There are several limitations motivating future research. The algorithmic choices we made for our framework work well but a comparative study with other components would be valuable. Our design and analysis is empirical; theoretical analysis of optimality for continuous-space online stochastic sequential problems requires several restrictive modeling assumptions. There is a taxonomy of DREAMR problems, depending on single or multiple controllable agents, control over transportation, and performance criteria. Solving them will require extensions and modifications to our current framework. The underlying MDP model will be explored in the context of other hybrid stochastic decision making problems. The grid scenarios are sufficient to evaluate scalability and decision-making, but we will create city-scale datasets as well. On the engineering side, a more sophisticated simulator is also of interest.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Pajor [2009] T. Pajor, “Multimodal Route Planning,” Master’s thesis, Universität Karlsruhe, 2009.
- 2Botea et al. [2013] A. Botea, E. Nikolova, and M. Berlingerio, “Multimodal Journey Planning in the Presence of Uncertainty,” in International Conference on Automated Planning and Scheduling (ICAPS) . AAAI Press, 2013, pp. 20–28.
- 3Delling et al. [2013] D. Delling, J. Dibbelt, T. Pajor, D. Wagner, and R. F. Werneck, “Computing Multimodal Journeys in Practice,” in International Symposium on Experimental Algorithms . Springer, 2013, pp. 260–271.
- 4Huang et al. [2018] H. Huang, D. Bucher, J. Kissling, R. Weibel, and M. Raubal, “Multimodal Route Planning with Public Transport and Carpooling,” IEEE Transactions on Intelligent Transportation Systems , 2018.
- 5Giannakopoulou et al. [2018] K. Giannakopoulou, A. Paraskevopoulos, and C. Zaroliagis, “Multimodal Dynamic Journey Planning,” ar Xiv:1804.05644 , 2018.
- 6Ponda et al. [2015] S. S. Ponda, L. B. Johnson, A. Geramifard, and J. P. How, “Cooperative Mission Planning for Multi-UAV Teams,” in Handbook of Unmanned Aerial Vehicles . Springer, 2015, pp. 1447–1490.
- 7Schuster et al. [2012] A. Schuster, S. Bessler, and J. Grønbæk, “Multimodal Routing and Energy Scheduling for Optimized Charging of Electric Vehicles,” Electrical Engineering and Information Technology , vol. 129, no. 3, pp. 141–149, 2012.
- 8Arbanas et al. [2016] B. Arbanas, A. Ivanovic, M. Car, T. Haus, M. Orsag, T. Petrovic, and S. Bogdan, “Aerial-ground Robotic System for Autonomous Delivery Tasks,” in IEEE International Conference on Robotics and Automation (ICRA) . IEEE, 2016, pp. 5463–5468.
