Revisiting a single-stage method for face detection
Nguyen Van Quang, Hiromasa Fujihara

TL;DR
This paper introduces a fast, accurate single-stage face detection model built on ResNet-101, leveraging context information and improved decoding to outperform two-stage methods in speed while maintaining high accuracy.
Contribution
The paper proposes a novel single-stage face detection approach that reduces false positives and inference time, achieving competitive accuracy with faster runtime than existing two-stage methods.
Findings
Achieved approximately 26 ms inference time on VGA images.
Outperformed current two-stage face detectors in speed.
Maintained high detection accuracy on multiple benchmarks.
Abstract
Although accurate, two-stage face detectors usually require more inference time than single-stage detectors do. This paper proposes a simple yet effective single-stage model for real-time face detection with a prominently high accuracy. We build our single-stage model on the top of the ResNet-101 backbone and analyze some problems with the baseline single-stage detector in order to design several strategies for reducing the false positive rate. The design leverages the context information from the deeper layers in order to increase recall rate while maintaining a low false positive rate. In addition, we reduce the detection time by an improved inference procedure for decoding outputs faster. The inference time of a VGA () image was only approximately 26 ms with a Titan X GPU. The effectiveness of our proposed method was evaluated on several face detection benchmarks…
Click any figure to enlarge with its caption.
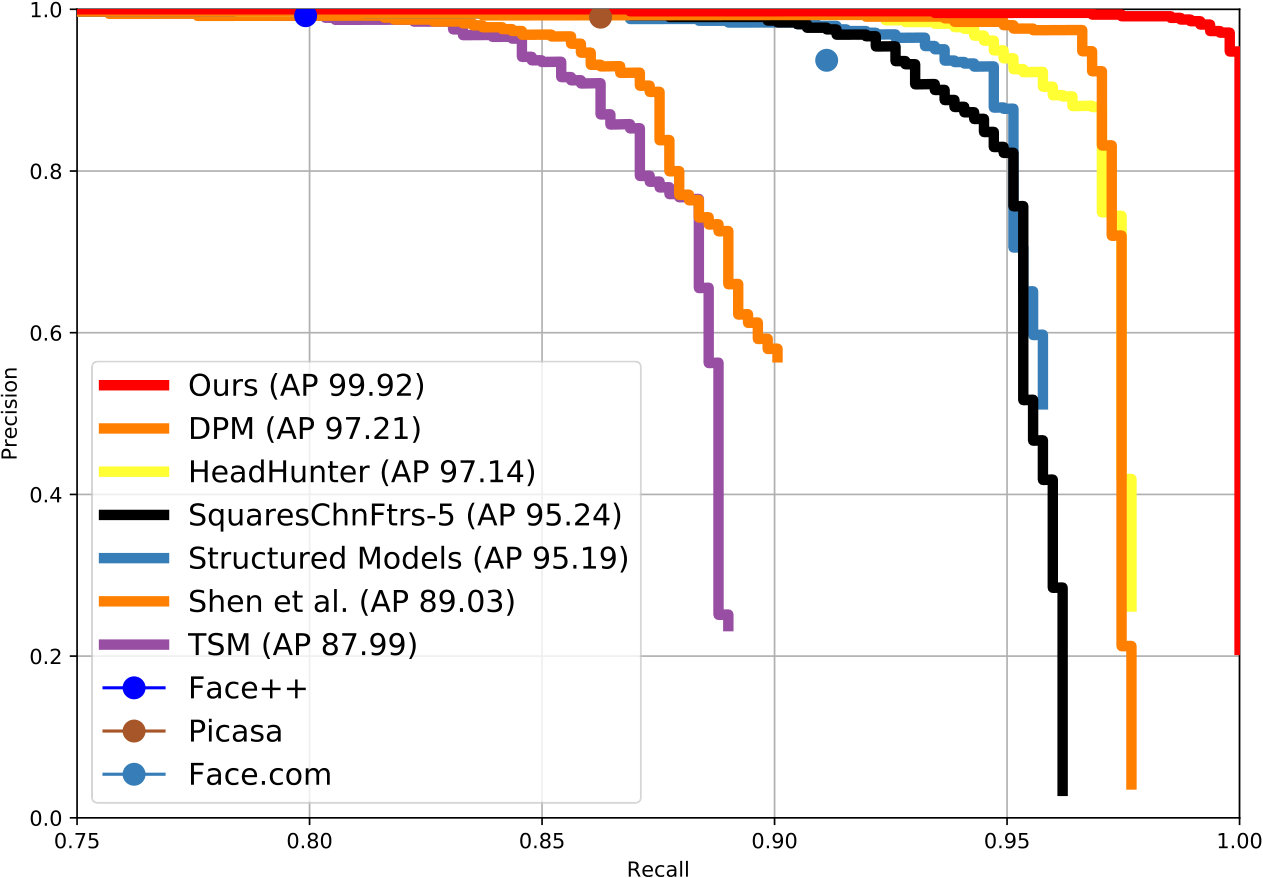 Figure 1
Figure 1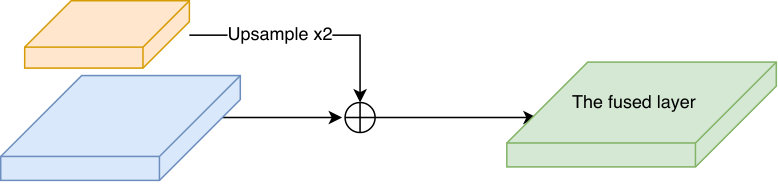 Figure 2
Figure 2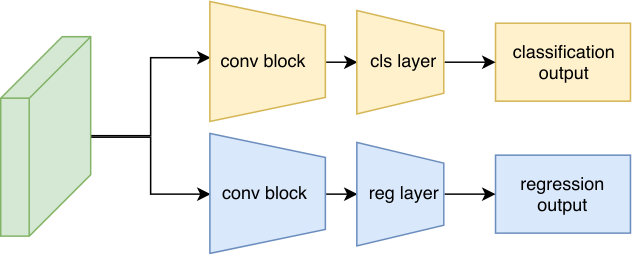 Figure 3
Figure 3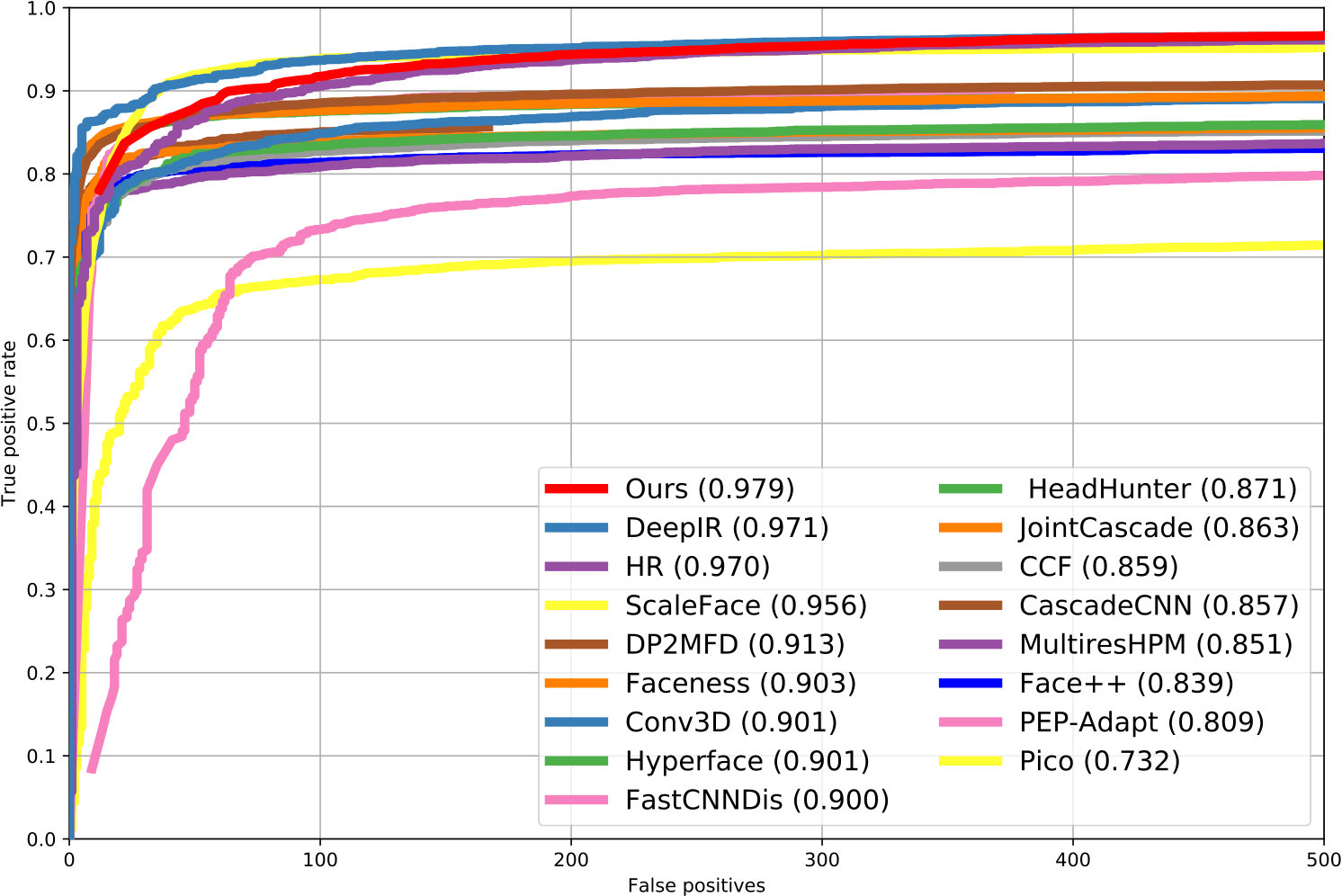 Figure 4
Figure 4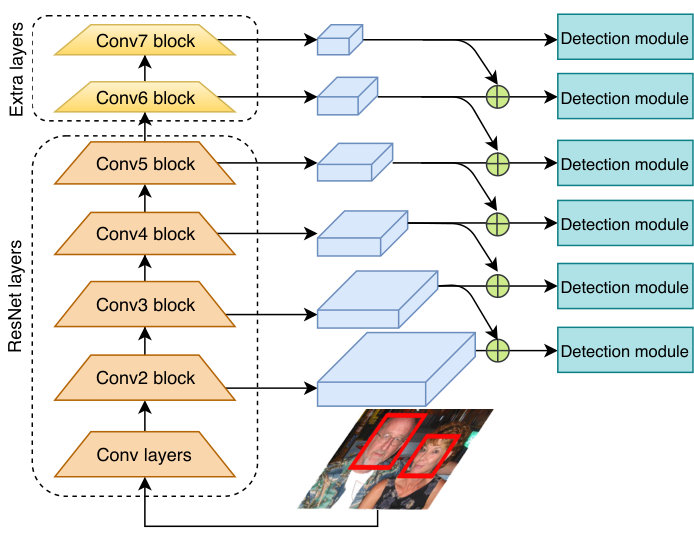 Figure 5
Figure 5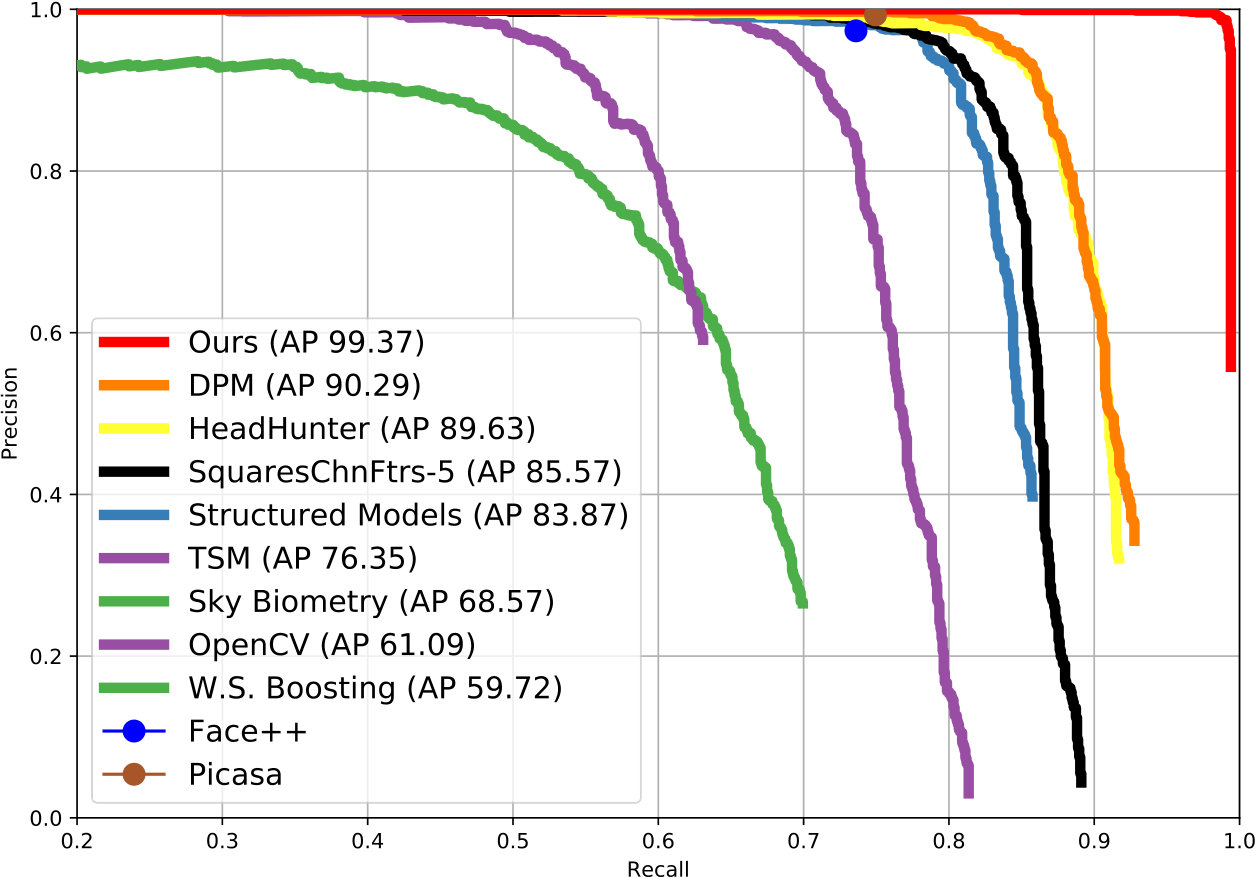 Figure 6
Figure 6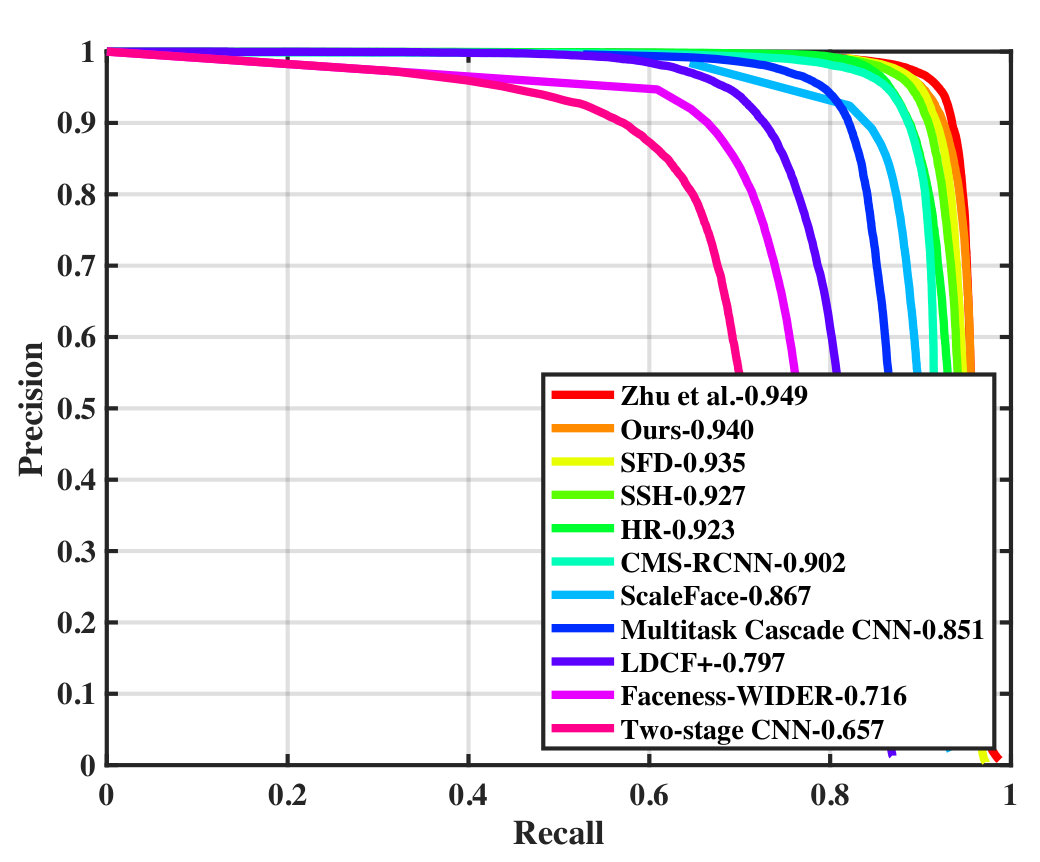 Figure 7
Figure 7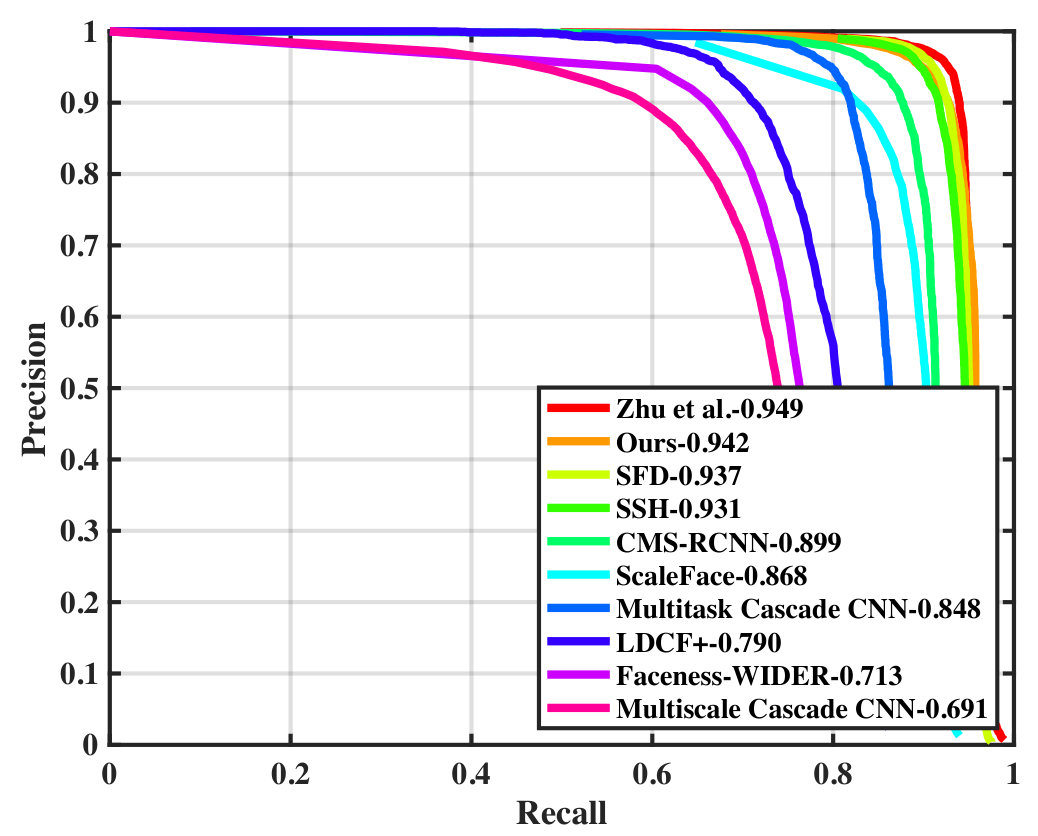 Figure 8
Figure 8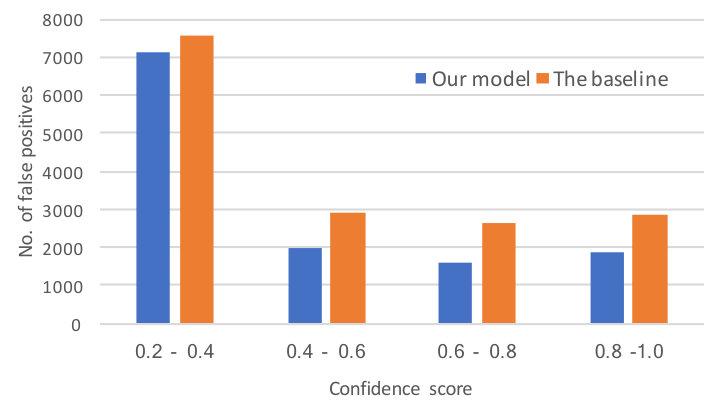 Figure 9
Figure 9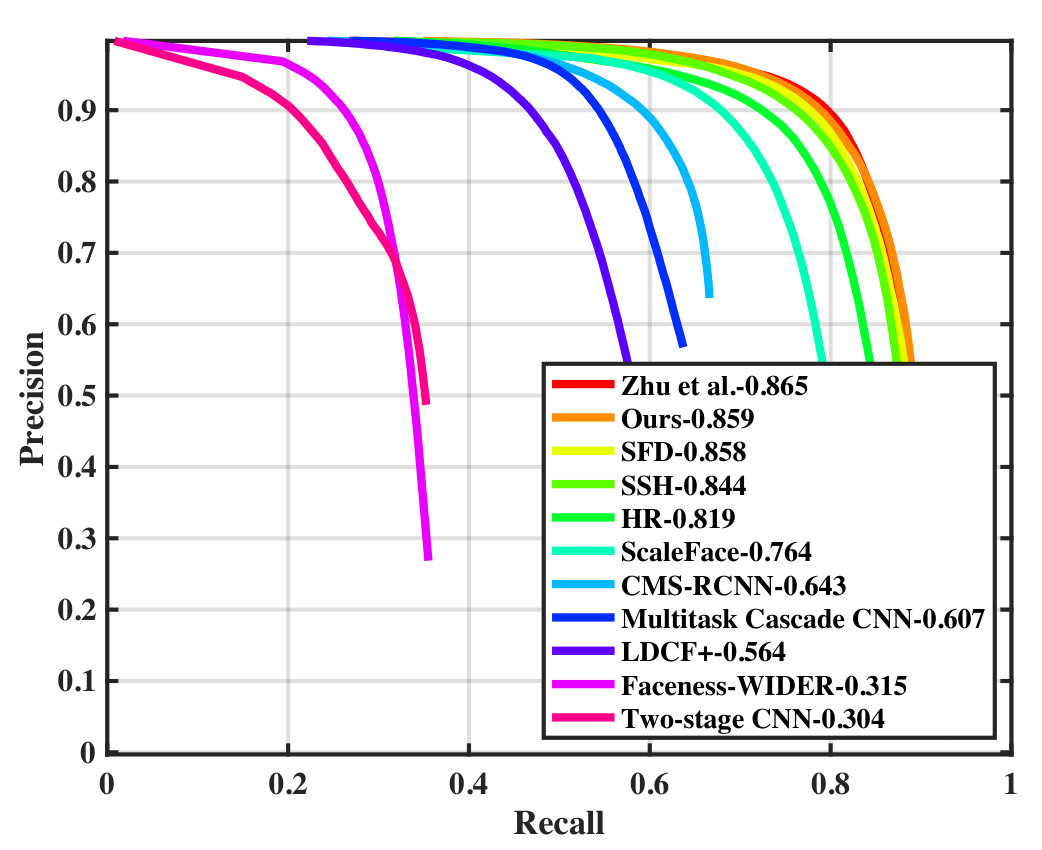 Figure 10
Figure 10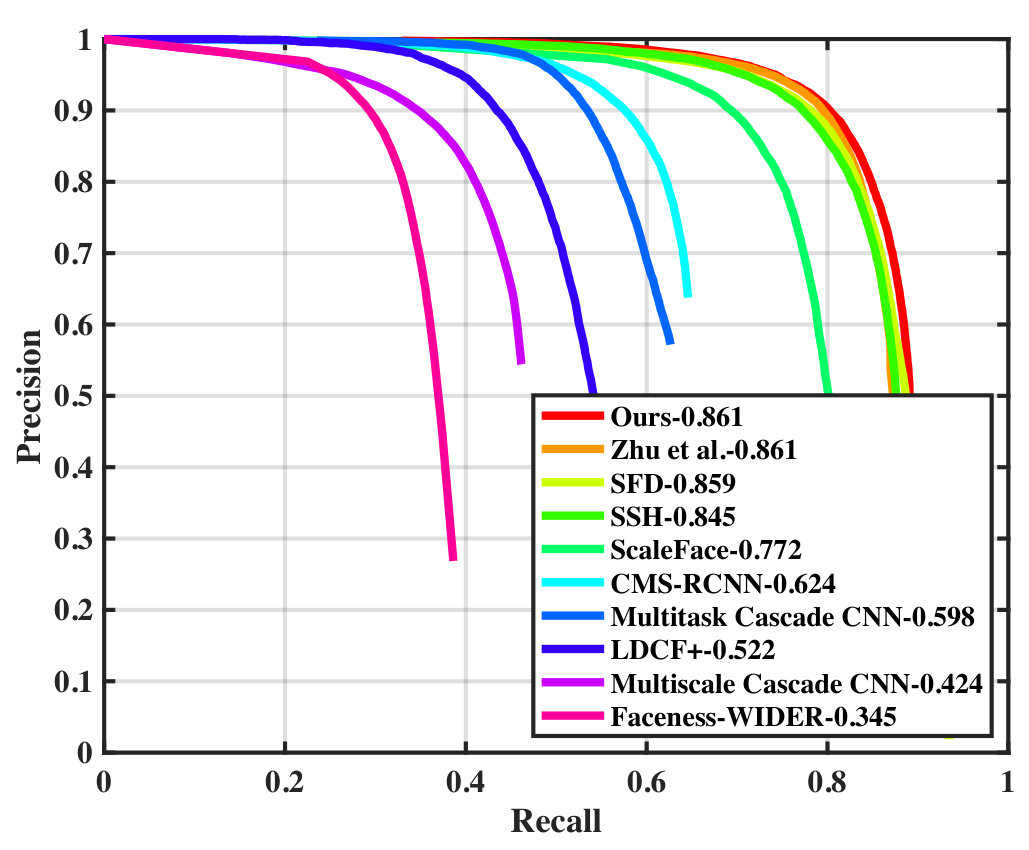 Figure 11
Figure 11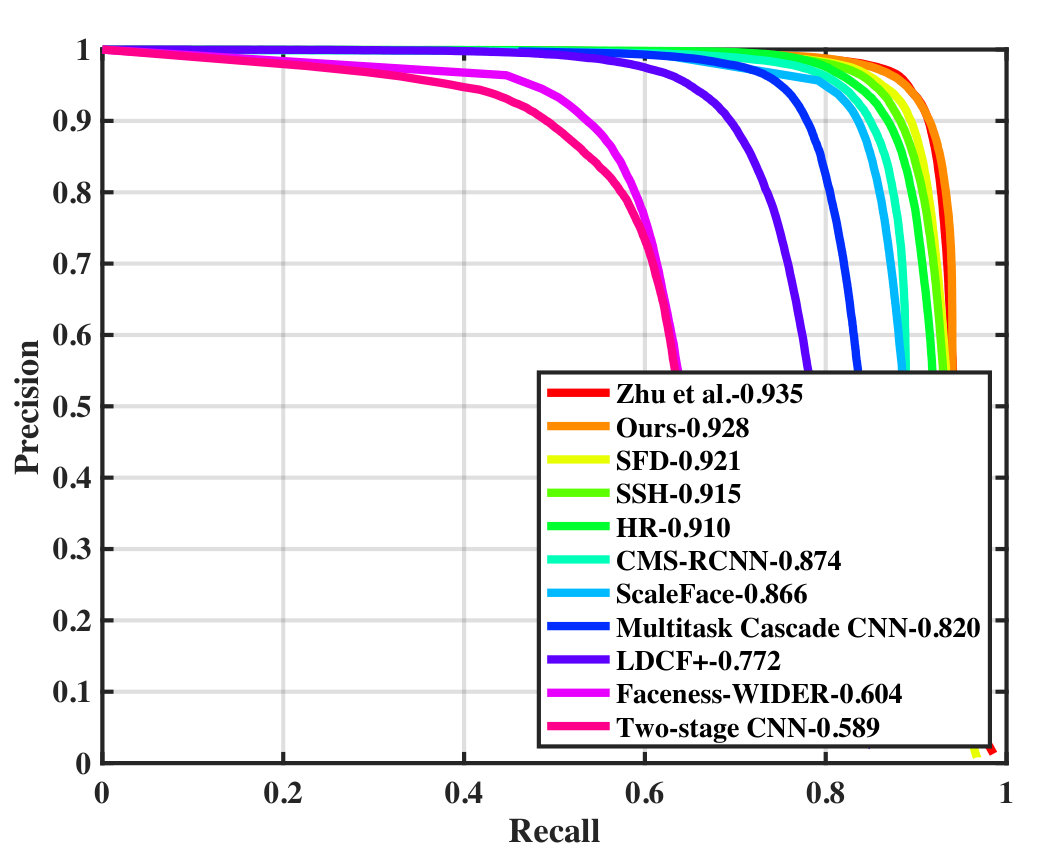 Figure 12
Figure 12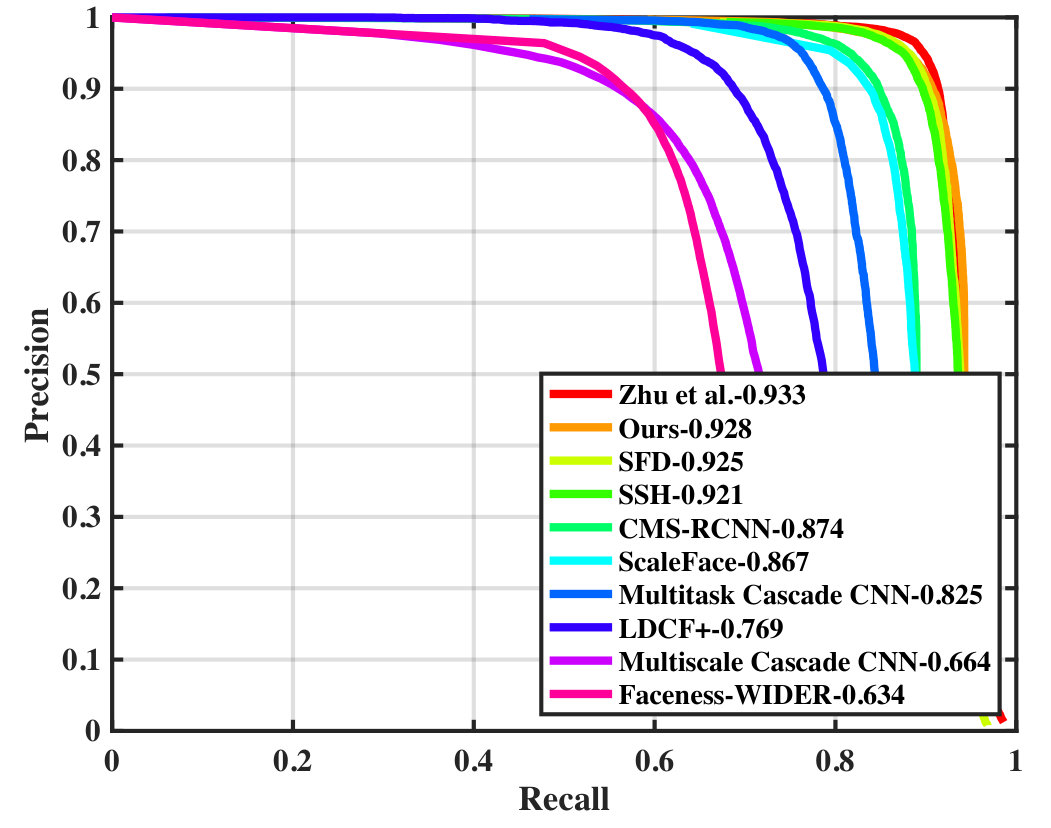 Figure 13
Figure 13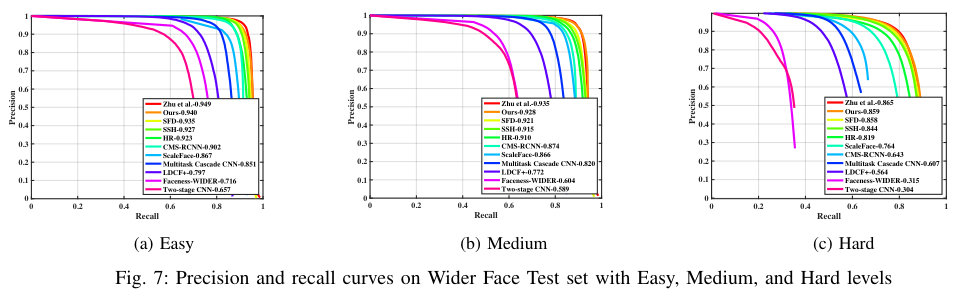 Figure 14
Figure 14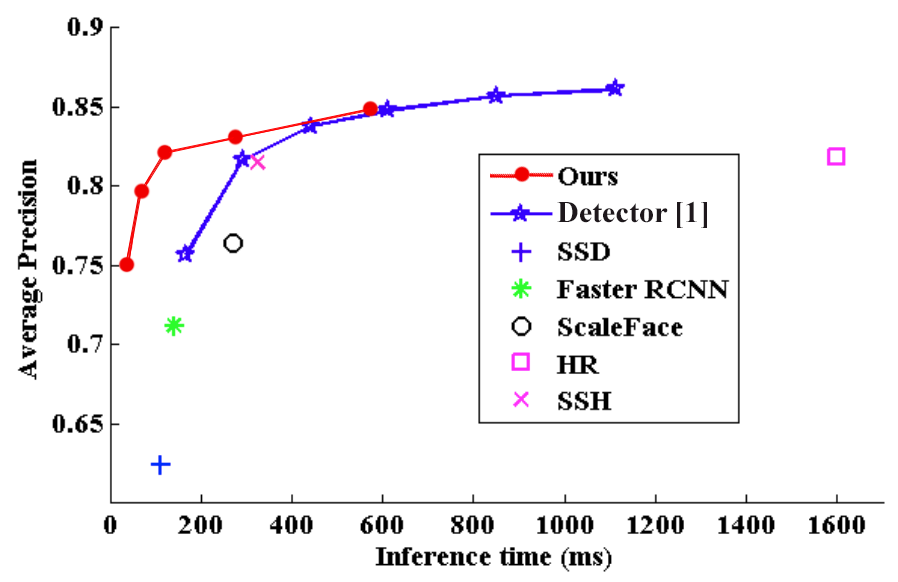 Figure 15
Figure 15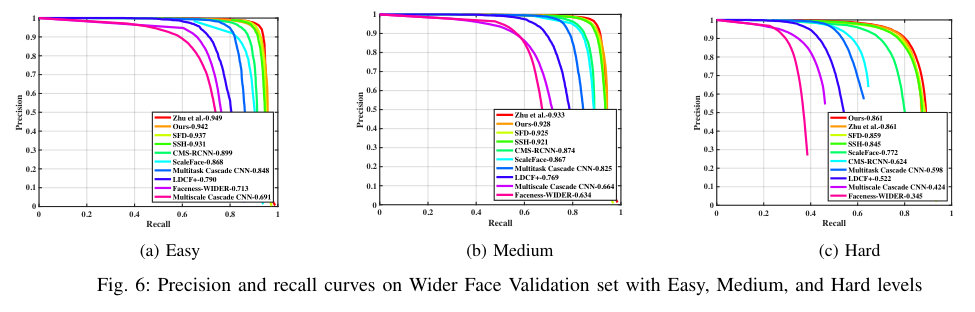 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21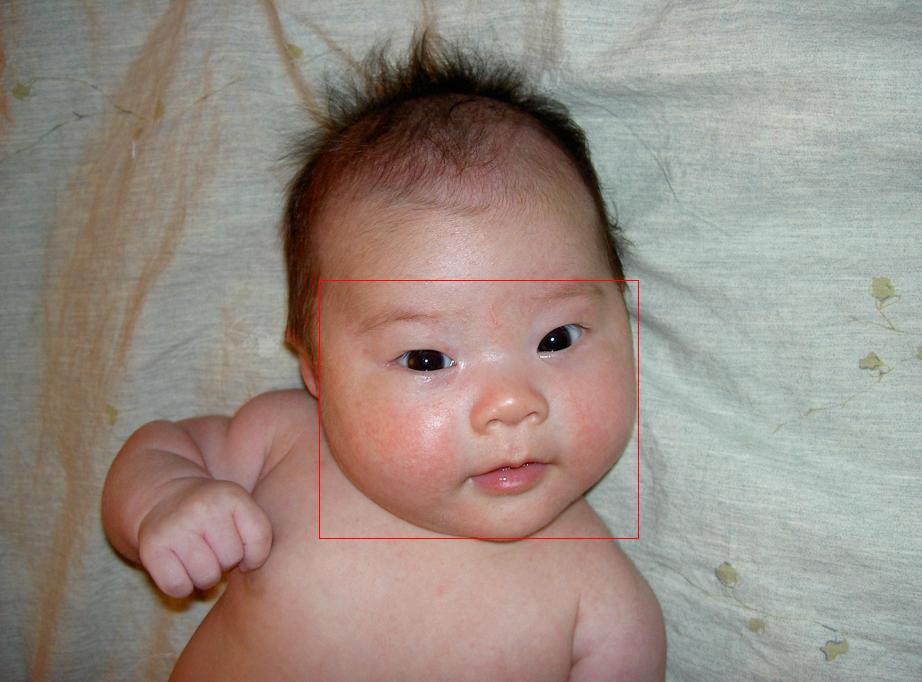 Figure 22
Figure 22 Figure 23
Figure 23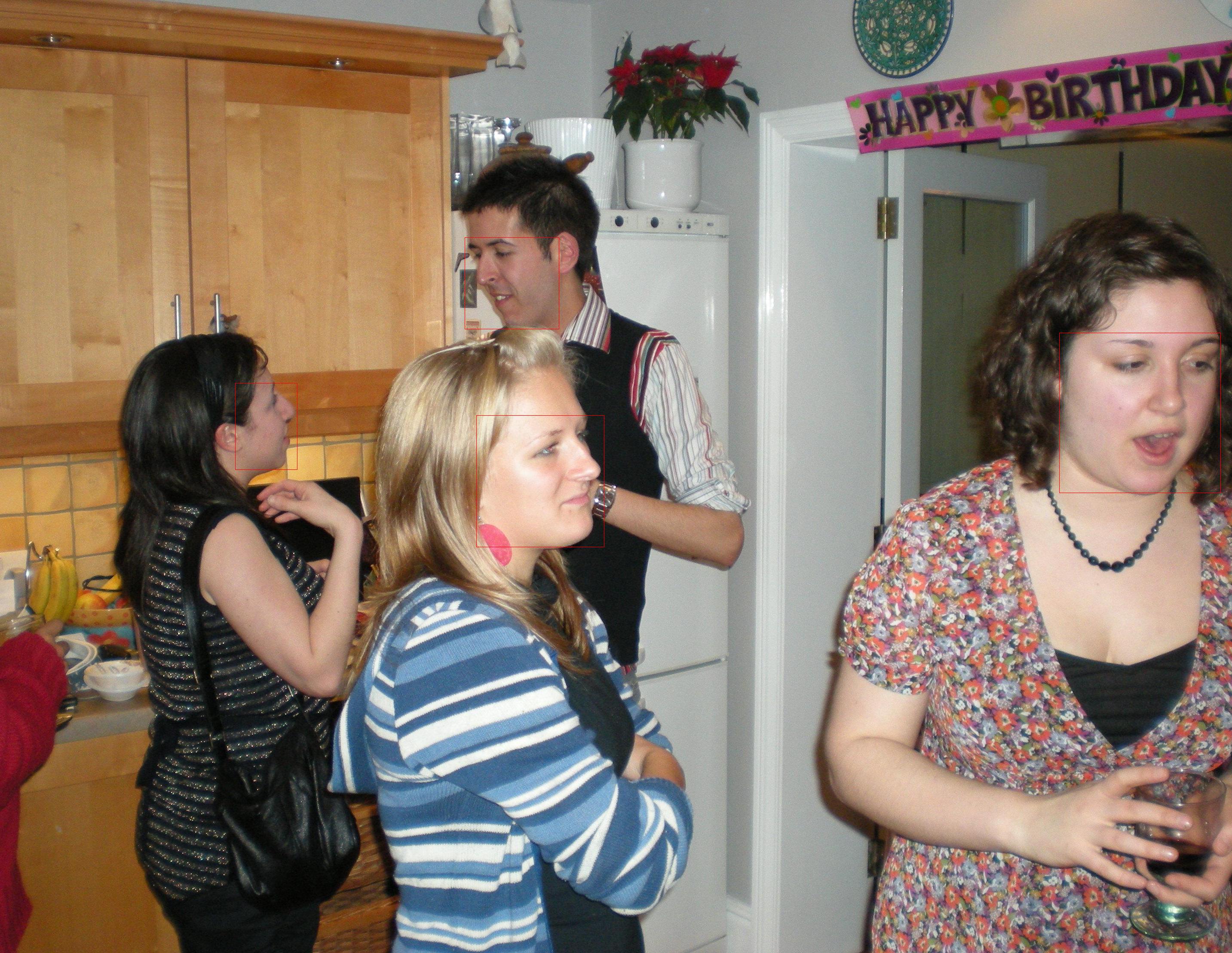 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28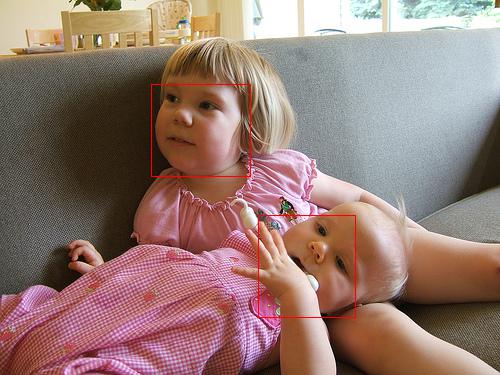 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40| Method | AP Test (Val)% | ||
|---|---|---|---|
| Easy | Medium | Hard | |
| Faceness [32] | 71.1 (71.3) | 60.4 (63.4) | 31.5 (34.5) |
| LDCF+ [30] | 79.7 (79.0) | 77.2 (76.9) | 56.4 (52.2) |
| MT-CNN [28] | 85.1 (84.8) | 82.0 (82.5) | 60.7 (59.8) |
| CMS-RCNN [26] | 90.2 (89.9) | 87.4 (87.4) | 64.3 (62.4) |
| ScaleFace [29] | 86.7 (86.8) | 86.6 (86.7) | 76.2 (77.2) |
| HR [5] | 92.3 (92.5) | 91.0 (91.0) | 81.9 (80.6) |
| SFD [4] | 93.5 (93.7) | 92.1 (92.5) | 85.8 (85.9) |
| SSH [3] | 92.7 (93.1) | 91.5 (92.1) | 84.4 (84.5) |
| Detector in [1] | 94.9 (94.9) | 93.5 (93.3) | 86.5 (86.1) |
| Ours | 94.0 (94.2) | 92.8 (92.8) | 85.9 (86.1) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Revisiting a single-stage method for face detection
Nguyen Van Quang1,2, Hiromasa Fujihara2
1 Faculty of Information Sciences, Tohoku University, Sendai, Japan
2 Laboro.AI Inc., Tokyo, Japan
Abstract
Although accurate, two-stage face detectors usually require more inference time than single-stage detectors do. This paper proposes a simple yet effective single-stage model for real-time face detection with a prominently high accuracy. We build our single-stage model on the top of the ResNet-101 backbone and analyze some problems with the baseline single-stage detector in order to design several strategies for reducing the false positive rate. The design leverages the context information from the deeper layers in order to increase recall rate while maintaining a low false positive rate. In addition, we reduce the detection time by an improved inference procedure for decoding outputs faster. The inference time of a VGA () image was only approximately 26 ms with a Titan X GPU. The effectiveness of our proposed method was evaluated on several face detection benchmarks (Wider Face, AFW, Pascal Face, and FDDB). The experiments show that our method achieved competitive results on these popular datasets with a faster runtime than the current best two-stage practices.
I INTRODUCTION
Face detection has attracted much attention as it constitutes the fundamental step of many common face-related tasks. Since the pioneering work of Viola-Jones [9], face detection has progressively improved [15, 16, 19], but still relying on laborious feature engineering to train the face detectors. However, in challenging datasets such as the recently introduced Wider Face [6], these approaches show the non-robustness to a wide range of facial variations. Recently, the CNN-based methods have been increasingly adopted to deal with the facial variations and have surpassed the former methods. Nevertheless, there is a trade-off between computational cost and accuracy in face detection. For instance, the HR detector [5] needs to forward an image pyramid into a shared CNN model which consumes more than 1 second for accurate results.
Inherited from object detection, two main approaches have been applied successfully to face detection, namely, one-stage (single-stage) and two-stage methods. Two-stage methods follow a common pipeline: (1) produce a set of region proposals with their local features (or pixels), (2) pass them to the second network for classifying and regressing the bounding boxes of the detected faces. Though very accurate, these systems require numerous intensive computations. For example, Chenchen Zhu et al. [1] recently proposed a two-stage detector which obtains the state-of-the-art performance on face benchmarks but requires about 150ms to proceed an image of size . On the other hand, single-stage methods extract the feature maps of convolutional layers at several depths from a base network, in which each layer is associated with a set of predefined anchors. Convolutions are then performed on these feature maps for classification and regression tasks directly. Although these methods significantly improve the runtime of object detection over two-stage methods while delivering comparative performance, applying single-shot detectors (SSD) [11] directly to face detection does not yield the acceptable performance [1]. However, SFD [4] and SSH [3], the one-stage models proposed for face detection using VGG-16 [13] as a backbone framework with several improvements, could obtain very competitive results, outperforming even the top ResNet-based models.
Inspired by SSD, SFD and SSH, we build a simple single-stage model with the ResNet-101 backbone for face detection as a baseline. After investigating the baseline model, we attribute the high rate of false positives to the following causes.
Lack of context information. First, small faces appear to lack deterministic facial parts due to their low resolution. Moreover, the corresponding feature maps of small faces have less context information in the shallower anchor-associated layers than in the deeper layers. Consequently, small-scale faces are difficult to detect. According to [5], large receptive fields can increase the context information for detecting small faces.
Very large receptive field. In contrast to the above, excessively large receptive fields might provide redundant information for detection which increases the false positive rate. For a given stride, the the anchor-associated layers in ResNet-101 based networks have larger receptive fields than VGG-16 based networks do. In SFD, the anchor sizes and layouts are designed reasonably such that the anchor area matches the receptive field for each stride.
Shared feature maps for the classification and regression tasks in detection. In SSD, two conv layers are performed directly on the extracted feature maps to do both classification and regression tasks. Therefore, the network might not easily and immediately learn the mappings and balance the losses in both tasks.
Dense anchors for each ground truth box, and for each cell in the feature maps. The number of anchors assigned to small faces was increased by the matching strategy proposed elsewhere [4, 1]. Moreover, there are several anchors of different aspect ratios per cell in SSD. Although these strategies help increase the recall rate, it probably also contributes the high false positive rate.
All of the above factors lessen the capacity of the ResNet backbone in single-stage models. Herein, we propose several simple but efficient strategies that reduce the false positive rate of our single-stage model with a ResNet-101 base for face detection. Overall, reducing the false positives, especially those with high confidence scores, boosts the average precision (AP) score of the model. After implementing these strategies, our method achieved the state-of-the-art results on AFW, PASCAL face, FDDB, and also competitive results on WIDER FACE at faster runtime speed than the current best two-stage methods. We also improve the decoding procedure to make the inference faster up to about 10% with the speed of 38 fps for VGA images of size .
II RELATED WORK
II-A Face detection
In the past decades, Viola and Jones [9] pioneered a real-time face detector, using Haar-like features to train a cascade of Adaboost models. After that, face detection has continuously improved in various works from [15, 16], to deformable part models (DPM) [17, 18, 19]. Most of these methods train traditional classifiers using a selective set of hand-crafted features. Recently, CNN-based methods have significantly boosted the performance of face detection over traditional methods which struggle to deal with facial variations. These recent state-of-the-art face detectors can be divided into two main approaches: one-stage detectors and two-stage detectors. We follow the first approach to design our face detector.
II-B Single-stage networks for face detection
Several works follow the design of one-stage detection architecture, having achieved very remarkable results on common benchmarks for face detection. SFD [4] adopts the VGG-16 but tiling and assigning the anchors more tightly for small faces to increase the recall score. Mahyar Najibi et al. [3] proposed a network called SSH which removes the fully connected layers from the VGG-16 base network, and provides the context information for detection module by fusing several convolutional layers. To improve the detection of occluded faces, Wang et al. [14] proposed FAN model which employs the RetinaNet [10] using feature pyramid integrated with the attention mechanism.
III OUR PROPOSED NETWORK
III-A The network architecture
Following the SFD design, we also build a single-stage framework which is robust to face scales. We extract the feature maps of different convolutional layers from the network. Each cell in the feature map from each layer is associated with one square anchor (aspect ratio of 1:1). The anchor size from each extracted conv layer increases exponentially with the power of 2, ranging from 16 to 512 pixels. As implemented in SFD, the strides of anchors are also kept unchanged to guarantee that faces of different scales are assigned to the equally adequate number of matched anchors from the feature maps. The model consists of the feature extractor, fusion modules and detection modules. The feature extractor is constructed by several of following layers:
Base convolutional layers. We design a very deep CNN network using ResNet-101 [12] which is well known for producing highly representative features for extraction. All the layers of ResNet-101 before the first fully connected layers are retained as our feature extractor.
Extra convolutional layers. For detecting large faces, we add the extra convolutional layers to the ResNet-101 base in order. The additional and blocks are sequential blocks of two conv layers of filters, in which the latter layer with a stride of 2 is followed by ReLU activation.
Detection convolutional layers. For further detection, we extract feature maps of several layers from base convolutional layers and extra convolutional layers as anchor-associated layers for further detection. These extracted layers (, , , , , and ) are the last conv layers in their corresponding blocks. We convolve the selected layers with conv layer of 256 filters to ensure that all the extracted layers have channels if their number of channels differs from 256.
III-B Strategies for reducing the false positives
III-B1 Fusing features from the higher layer
Although the ResNet-101 backbone provides the larger receptive field for each detection convolutional layer than VGG-16 base, the shallower layers still lack context information for the detection. Fusing the features from higher layers is the common practice to enlarge the receptive fields and increase the context information for shallower layers. For instance, RetinaNet [10] designed the feature pyramid architecture which allows a layer to enjoy the flow of context information from all higher layers in the hierarchy. For face detection, the feature pyramid architecture might provide redundant context features for small face detection, increasing the false positive rate. In order to increase the context information of the feature maps in the lower layers, we fuse the current detection layer with only one consecutive higher detection layer in the hierarchical order. Therefore, we upsample the higher detection layer by factor of 2 and fuse it with the current detection layer by element-wise addition as depicted Figure 2(a). This strategy approximately doubles the receptive field of the corresponding layer approximately which provides sufficient context information for detecting small faces while reducing the risk of false positive detection.
III-B2 Shared features for detection tasks
In SFD, the detection layers are directly convolved with classification and regression filters. This makes the network harder to learn and optimize the loss of two tasks. To avoid this problem, we separate the detection tasks into two branches. Prior to the classification and regression layer, we add a sequential block including several conv layers of 256 filters for each layer on each branch as implemented in RetinaNet. For each anchor, we need to regress the 4 offsets related to its coordinates and confidence scores for classification (as we have only the background label and the face label, we set ). Therefore, we apply convolutional layers of and filters on the regression branch and classification branch, respectively. Figure 2(b) describes the detection module.
III-B3 Anchor assigning strategy
In the training phase, we need to assign a ground truth box of faces to an anchor or a set of anchors. In [4, 1], they adopt a strategy for matching which anchors to a ground truth box by decreasing the threshold of Jaccard overlap between a face bounding box and anchors. This strategy significantly increases the number of anchors per a ground truth faces, especially the small faces. Although this strategy increases the recall rate for small faces, it produces more false positives. Following the same matching strategy as SFD, we increase the number of anchors per small faces but maintaining the threshold of Jaccard overlap in the first step at . In the second step, at most 4 anchors that most overlap the hard faces (i.e., have the highest Jaccard overlap) are selected as the matched anchors. The remaining anchors are labeled as negative.
III-C Improved decoding strategy
We adopt an efficient decoding strategy during the inference although single-stage models like SSD enjoy very fast detection speed. During the inference, transfering raw outputs of detection modules from the GPU to CPU also incurs a time burden. For an image with the size of , we need to transfer the output tensor with size of which corresponds to the number of generated anchors, in which only few of the anchors are associated with the detected faces. Hence, we compute the classification scores for all the anchors, and keep only the feature maps corresponding to anchors with confidence scores greater than a threshold . Then, we regress the offsets for coordinates of bounding boxes corresponding to these anchors and transfer them to the CPU for further steps. The overlapped bounding boxes are filtered by non-maximum suppression with a threshold of . The improved strategy decreases the inference time by approximately 10%, improving the runtime to fps on VGA images.
IV EXPERIMENTS AND RESULTS
IV-A Experimental setup
Training dataset. The Wider Face dataset [6] comprises 32,203 images of 393,703 annotated faces with widely varying scales, light conditions, expressions, poses and occlusions. The dataset is divided into train set, validation set, and test set (ratio 40:10:50). The validation and test sets are split into three subsets with varying detection-difficulty levels: easy, medium, and hard. We trained our model on the Wider Face train set, and evaluated on the Wider Face validation and test sets. Following [4], we performed color jittering and selected a random square crop with a size ratio from to (relative to the original image’s shortest side). The cropped patch was resized into to , along with random horizontal flip.
Loss function. The multi-task loss was formulated as follows:
[TABLE]
where is the index of an anchor and denotes the predicted probability that anchor is a face, denotes the vector of predicted offsets for anchor while , are the ground truth label and offsets, respectively.
We computed the cross entropy loss for the classification task over two classes (background and face), and divided it by the number of anchors taken account into the loss. During the training process, the number ratio of negative examples (background) to positive examples (faces) was maintained at via online negative hard mining procedure. The regression loss is a smooth loss, and is the number of anchors assigned to the ground truth (). We set as to optimally balance the two losses.
Training settings. We train our model with the ResNet module pre-trained on Imagenet dataset [12] with the batch size of 6 on 1 GPU. SGD with momentum of and weight decay of is used as our optimizer. The model was trained in 300 full epochs with the initial learning rate at which was divided by when the multi-task loss plateaued. Meanwhile, the ResNet-101 based single-stage baseline was constructed with the same feature extractor as our model and the same training settings but not applied some proposed strategies. The details of the baseline will be presented in the supplementary part.
IV-B Results on Common benchmarks
Wider Face To demonstrate the effectiveness of our proposal, Figure 3 compares the false positves of our proposed model and the ResNet baseline. The detection result was divided into three subsets with different image size thresholds. Our model is evaluated on the Wider Face validation and test sets following the standard evaluation protocol. Table I compares the average precision scores (AP) obtained by our model and several face detectors in [1], SFD [4], SSH [3], ScaleFace [29], HR [5], CMS-RCNN [26], Multitask Cascade CNN [28], LDCF+ [30], and Faceness [32] on Wider Face test and validation sets. Among the compared methods, our detector achieved the second best AP scores on all face cases.
To show the consistency of our model’s performance, we evaluated the model on other common dataset benchmarks FDDB [7], AFW [8], and Pascal Faces [2]. Following [3], we resize one side of images to 640 and keep the image aspect ratio unchanged. Interestingly, our model achieved state-of-the-art results on small resized images of these datasets without constructing an image pyramid.
AFW The dataset comprises 205 images in which 473 faces are annotated. We compared our model with several popular methods [17, 24, 19, 25] and commercial face detectors (Face.com, Picasa and Face++). Our model achieved a state-of-the-art result with an AP score of 99.92%. Figure 4(a) depicts the comparisons.
Pascal Face This dataset comprises 851 images in which 1,335 faces are annotated. We compared our model with some popular methods [17, 24, 19] and commercial face detectors (Picasa, Face++). Again, our model outperformed the other detectors by a large margin with an AP score of 99.37% (Figure 4(b)).
FDDB This dataset comprises of 2,845 images in which 5,171 faces are annotated in elliptic bounding boxes. Rather than learning an elliptic regressor, we directly regressed the rectangular boxes for faces, and compared our method with other methods [27, 5, 29, 28, 30, 31, 32, 33, 34, 35, 17, 36, 37, 38, 39, 40, 41, 42, 43, 44] which use no additional self-annotations. Our detector also achieves the top AP score of 97.9% (depicted in Figure 4(c)).
IV-C Runtime analysis
Finally, we evaluated the inference time of our model. Following [1], we recorded the AP scores and the corresponding inference times of variously sized images with the same hardware configuration (a single NVIDIA Titan X GPU with a batch size of 1). Figure 5 shows that our model achieved very fast inference time with competitive accuracy compared with the detector in [1]. In fact, the AP-versus-runtime curve of our model enveloped those of the others except that of [1]. On the Wider Face Validation hard set, our detector forwarded one image within 36 ms and achieved 75.0% AP score. Meanwhile, the detector in [1] needs more than 150ms to process an image to obtain 75.7% AP score. Our speed advantage is mainly gained from the single-stage design with one predefined anchor per cell whereas the detector in [1] adopts a two-stage design with several predefined anchors per cell.
V CONCLUSIONS
This work introduced a simple single-stage model for face detection which reasonably handles the speed-accuracy trade-off. Understanding the causes of the high false positive rate in single-stage methods was important for designing an effective, accuracy face detection framework. With SSD fashion, our model uses ResNet-101 as the feature extractor and incorporates several effective strategies that lower the rate of false positive together with fast inference time. Our model consistently achieved competitive results on common benchmarks for face detection with superiorly real-time inference.
VI Supplementary Materials
VI-A The details of our baseline
To avoid cluttering, we describe some details of our baseline here. The feature extractor of our baseline has the same architecture like that of our proposed model with the convolutional layers (ResNet-101), and extra convolutional layers. The detection layers extracted from the feature extractor are convolved directly with classification and regression conv layers. The anchor assigning and training on the model are followed that of the single shot detector (SSD).
VI-B Precision-recall curves on Wider Face dataset
In this section, we present the precision-recall curves on Wider Face validation and test set which are omitted in our paper. The results were obtained using the standard evaluation protocol (validation set) and from the test server (test set). The precision-recall curves on Wider Face validation set is shown in Figure 6 while the precision-recall curves on Wider Face test set is shown in Figure 7.
VI-C Some qualitative results
In this section, we show some qualitative results on several benchmark datasets (see in the next pages) in Figure VI.6 and Figure VI.7. We denote the red bounding boxes as the detected faces by our models. Best view the results in color.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Chenchen Zhu, Ran Tao, Khoa Luu, Marios Savvides. Seeing Small Faces from Robust Anchor’s Perspective. In Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
- 2[2] B. Yang, J. Yan, Z. Lei, and S. Z. Li. Fine-grained evaluation on face detection in the wild. In Automatic Face and Gesture Recognition (FG), 11th IEEE International Conference on. IEEE, 2015.
- 3[3] M. Najibi, P. Samangouei, R. Chellappa, and L. S. Davis. Ssh: Single stage headless face detector. In The IEEE International Conference on Computer Vision (ICCV), Oct 2017.
- 4[4] S. Zhang, X. Zhu, Z. Lei, H. Shi, X. Wang, and S. Z. Li. S 3fd: Single shot scale-invariant face detector. In The IEEE International Conference on Computer Vision (ICCV), Oct 2017.
- 5[5] P.Hu and D.Ramanan. Finding tiny faces. In Proceedings of the IEEE Conference Computer Vision and Pattern Recognition (CVPR), 2017.
- 6[6] S. Yang, P. Luo, C.-C. Loy, and X. Tang. Wider face: A face detection benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5525-5533, 2016.
- 7[7] V. Jain and E. Learned-Miller. Fddb: A benchmark for face detection in unconstrained settings. Technical Report UM- CS-2010-009, University of Massachusetts, Amherst, 2010.
- 8[8] P. M. R. M. Koestinger, P. Wohlhart and H. Bischof. Annotated facial landmarks in the wild: A large-scale, real-world database for facial landmark localization. 2011.