Bootstrapped Coordinate Search for Multidimensional Scaling
Efthymios Tzinis

TL;DR
This paper introduces a bootstrapped coordinate search method for multidimensional scaling that improves efficiency by focusing on promising directions, achieving faster convergence without sacrificing accuracy.
Contribution
It proposes a novel bootstrapped coordinate search framework for gradient-free MDS that enhances speed and efficiency over existing methods.
Findings
BS CSMDS reduces function evaluations significantly.
It achieves faster convergence compared to other CSMDS methods.
Performs consistently better on synthetic and real datasets.
Abstract
In this work, a unified framework for gradient-free Multidimensional Scaling (MDS) based on Coordinate Search (CS) is proposed. This family of algorithms is an instance of General Pattern Search (GPS) methods which avoid the explicit computation of derivatives but instead evaluate the objective function while searching on coordinate steps of the embedding space. The backbone element of CSMDS framework is the corresponding probability matrix that correspond to how likely is each corresponding coordinate to be evaluated. We propose a Bootstrapped instance of CSMDS (BS CSMDS) which enhances the probability of the direction that decreases the most the objective function while also reducing the corresponding probability of all the other coordinates. BS CSMDS manages to avoid unnecessary function evaluations and result to significant speedup over other CSMDS alternatives while also obtaining…
Click any figure to enlarge with its caption.
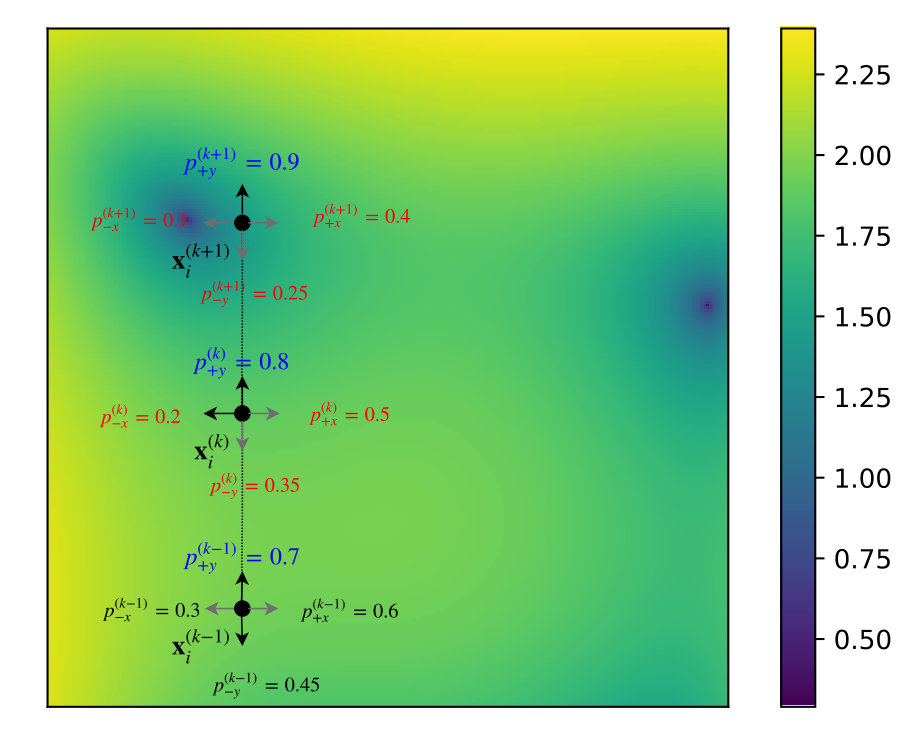 Figure 1
Figure 1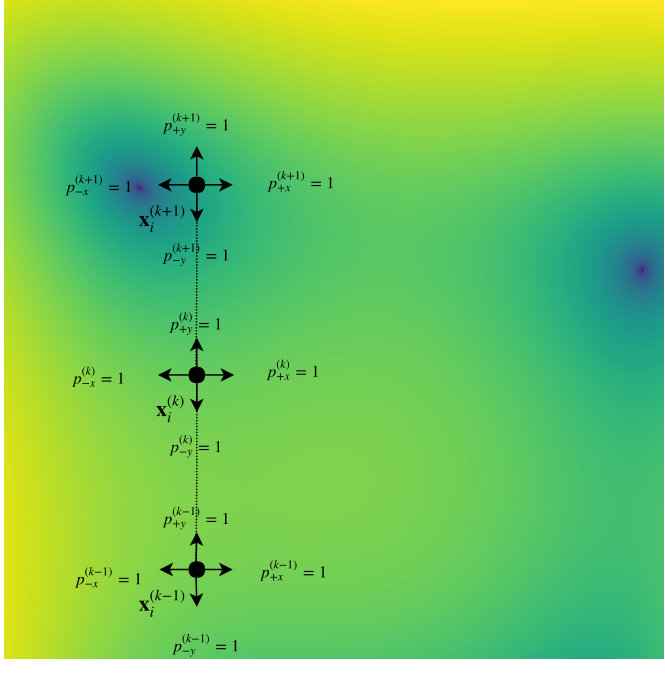 Figure 2
Figure 2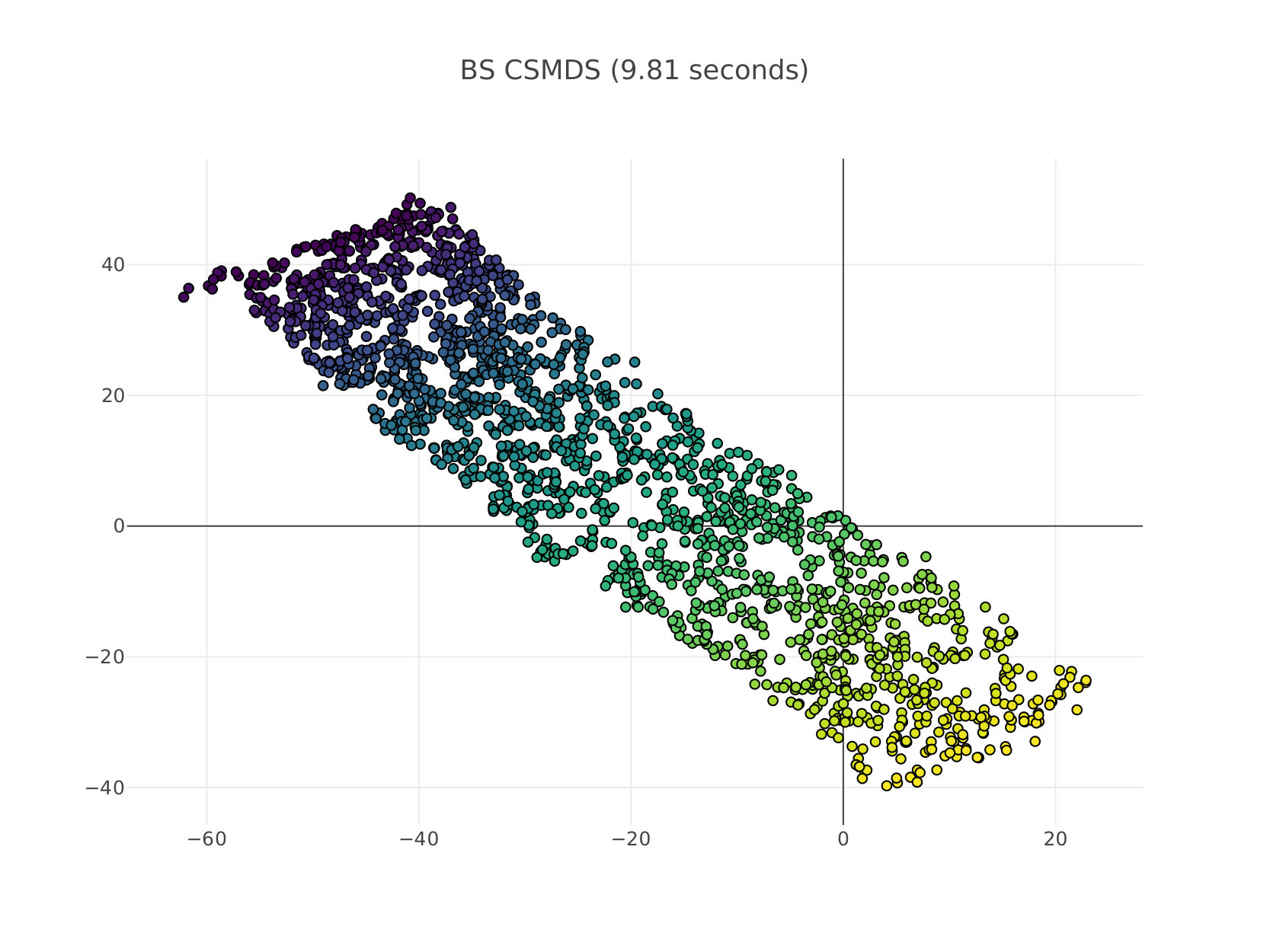 Figure 3
Figure 3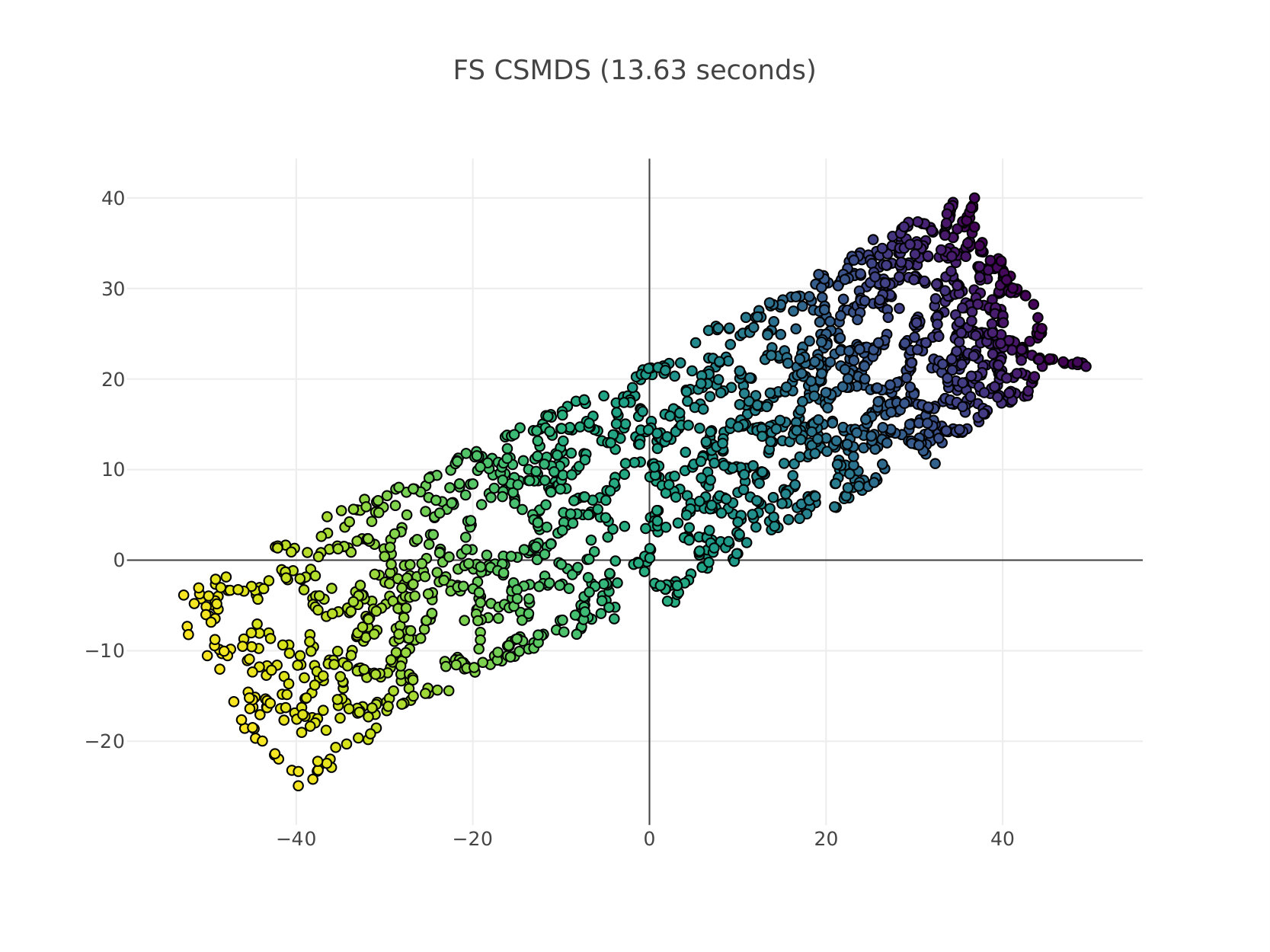 Figure 4
Figure 4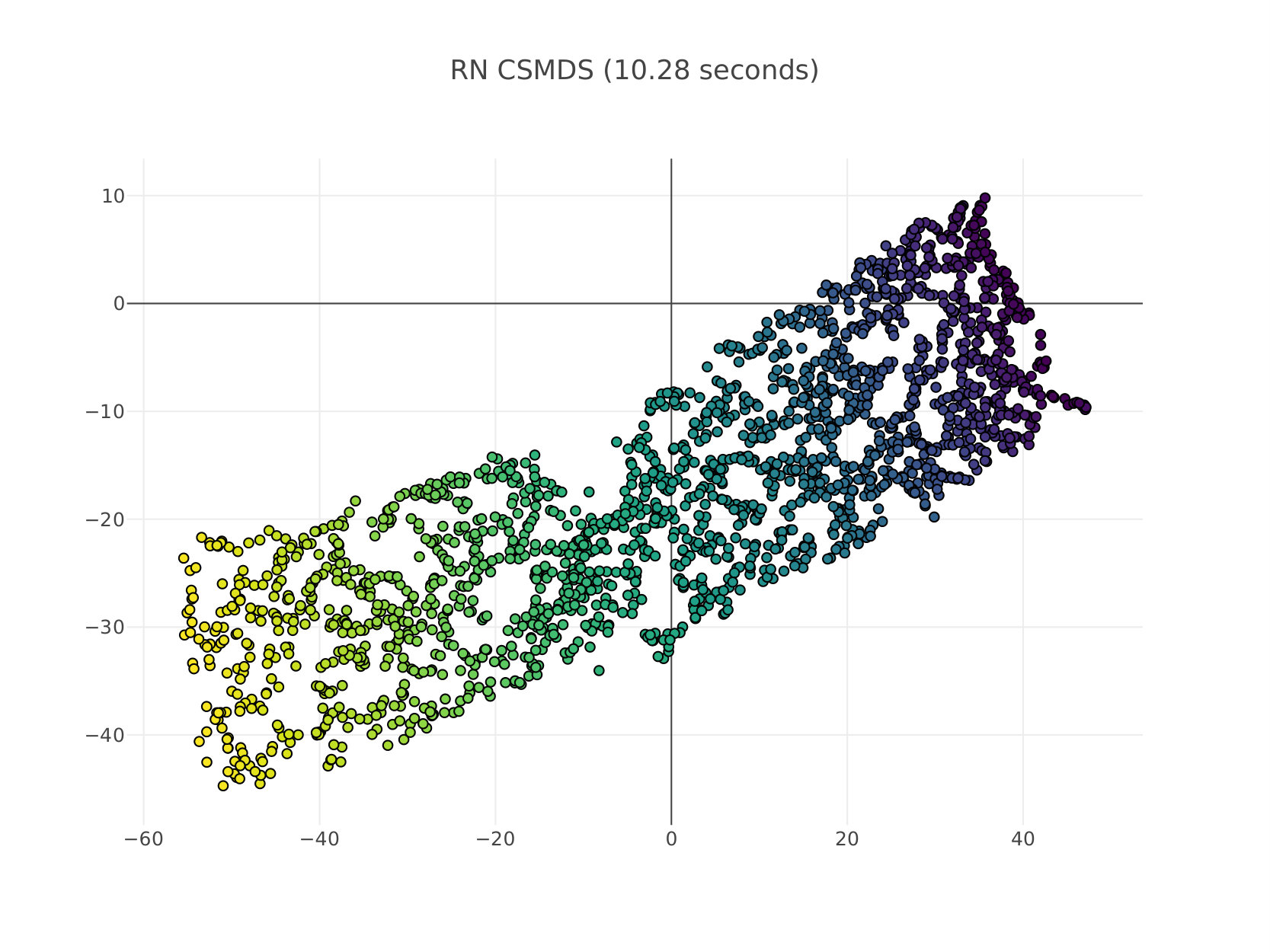 Figure 5
Figure 5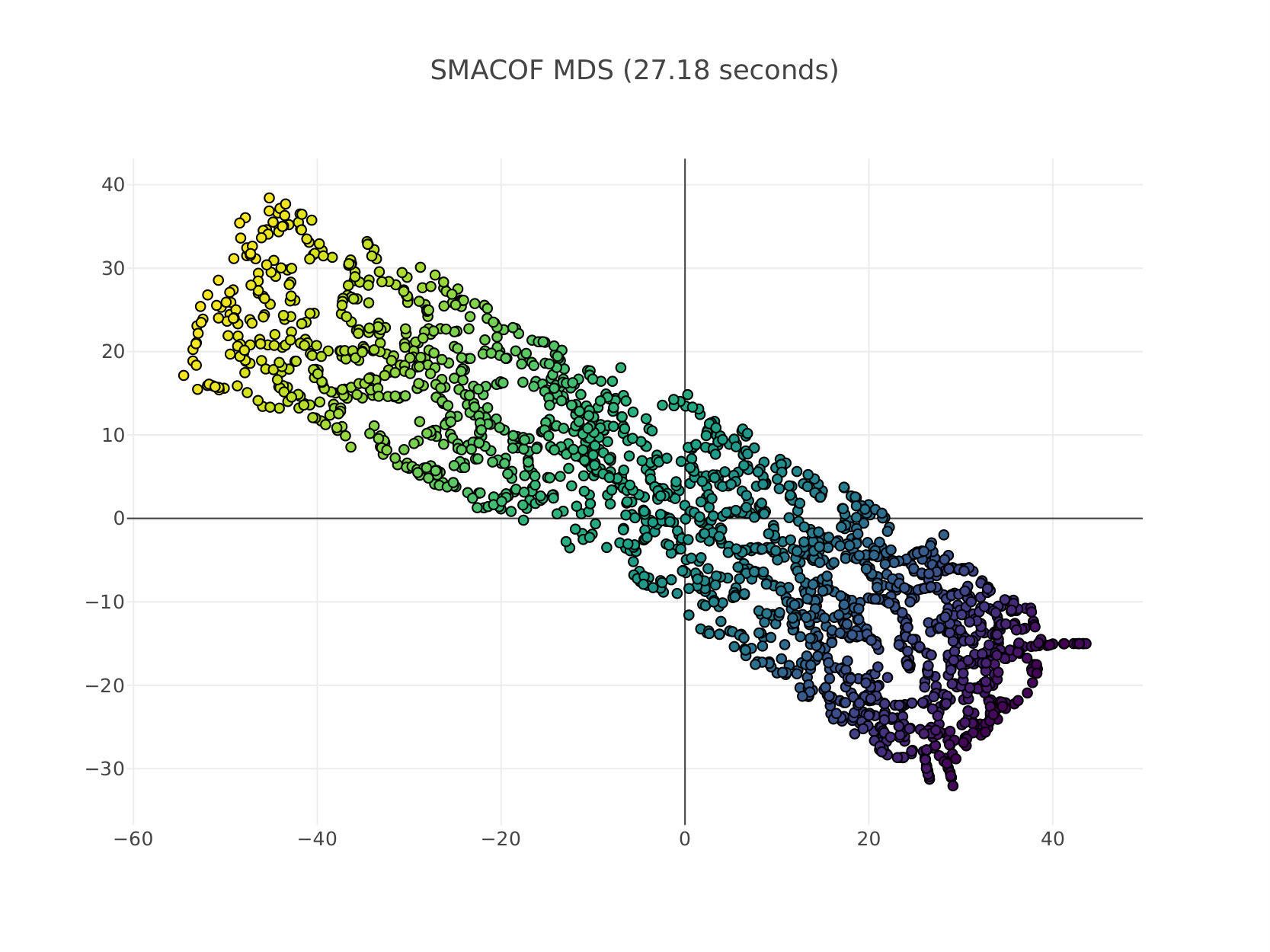 Figure 6
Figure 6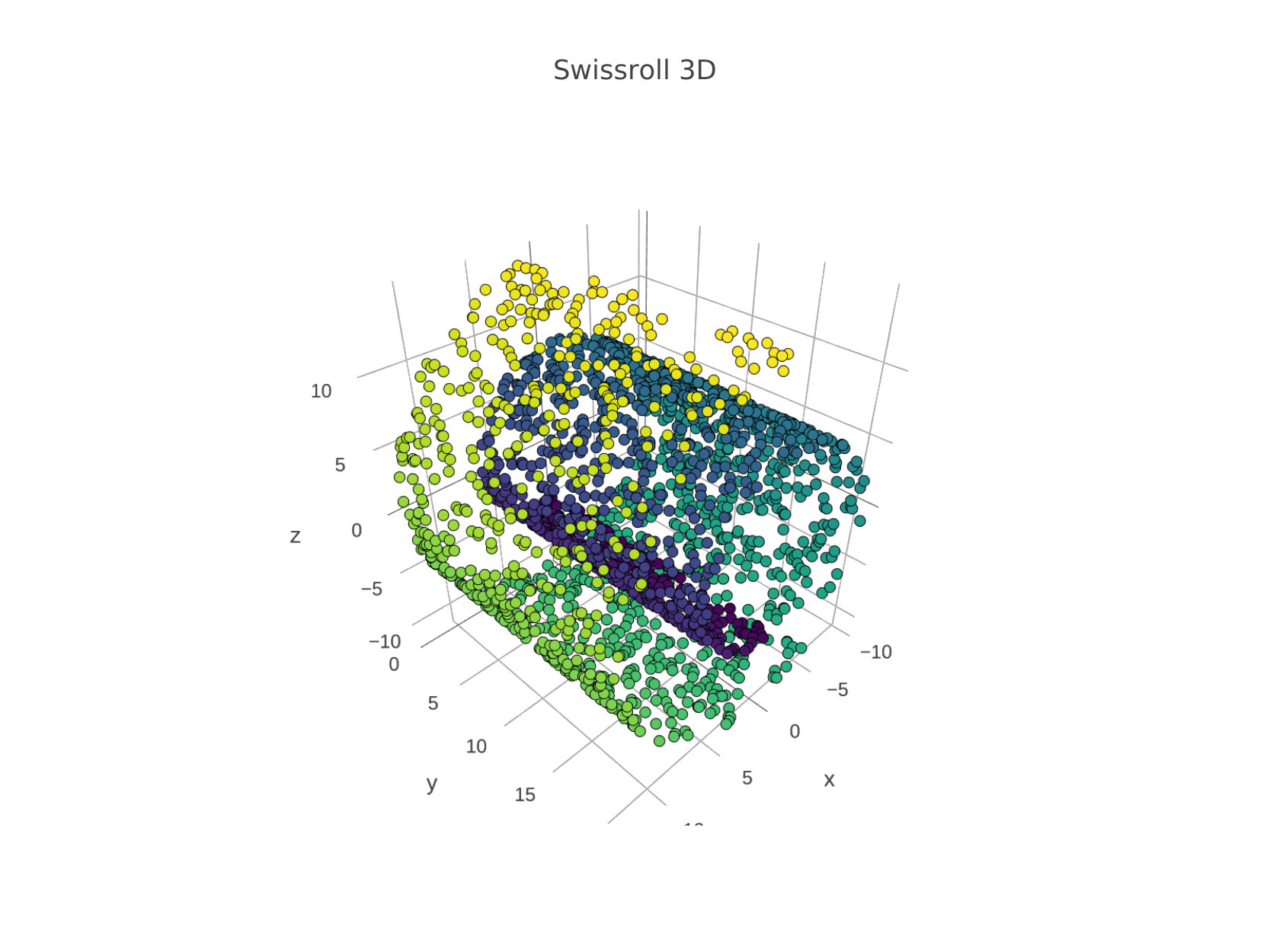 Figure 7
Figure 7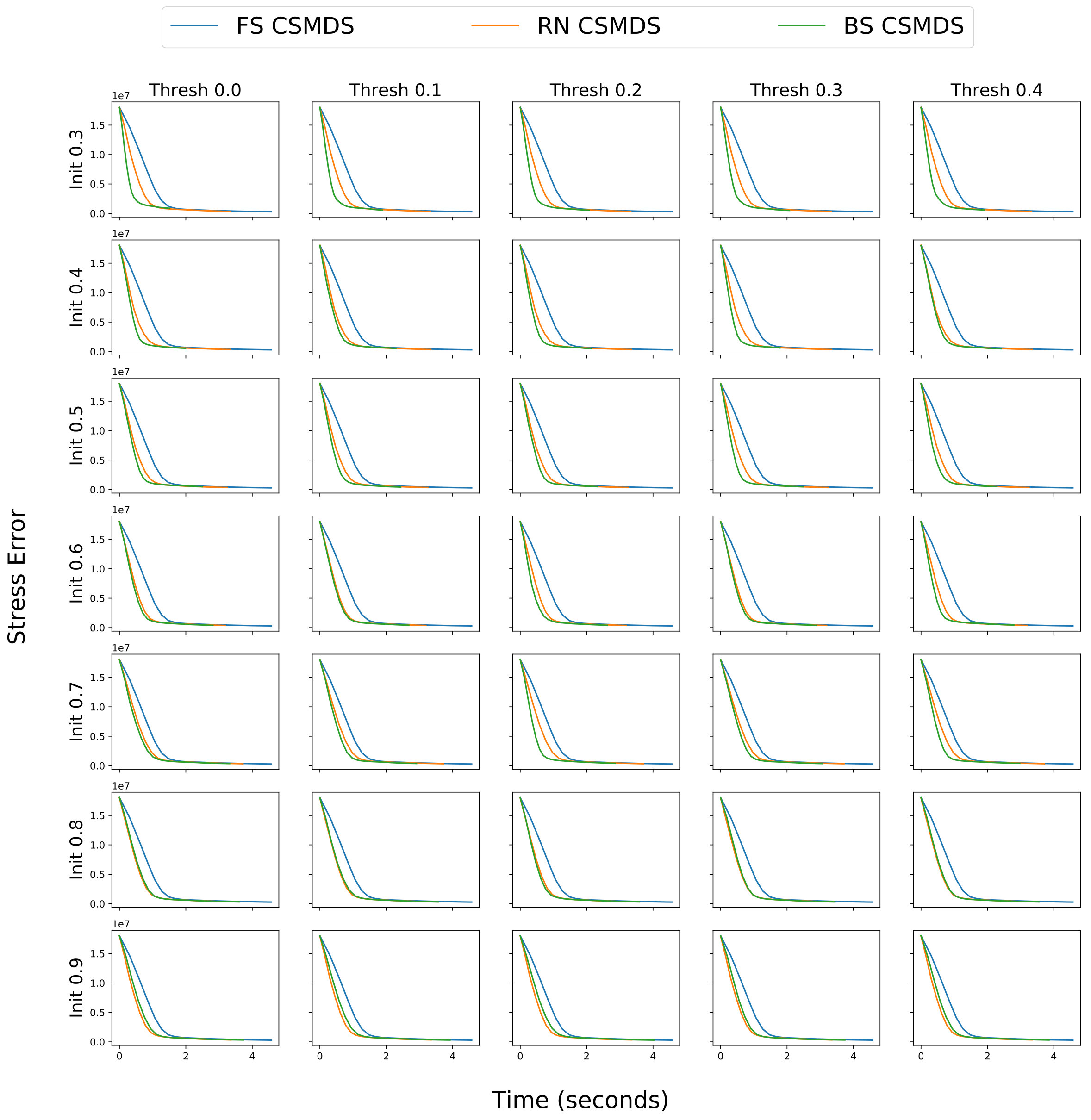 Figure 8
Figure 8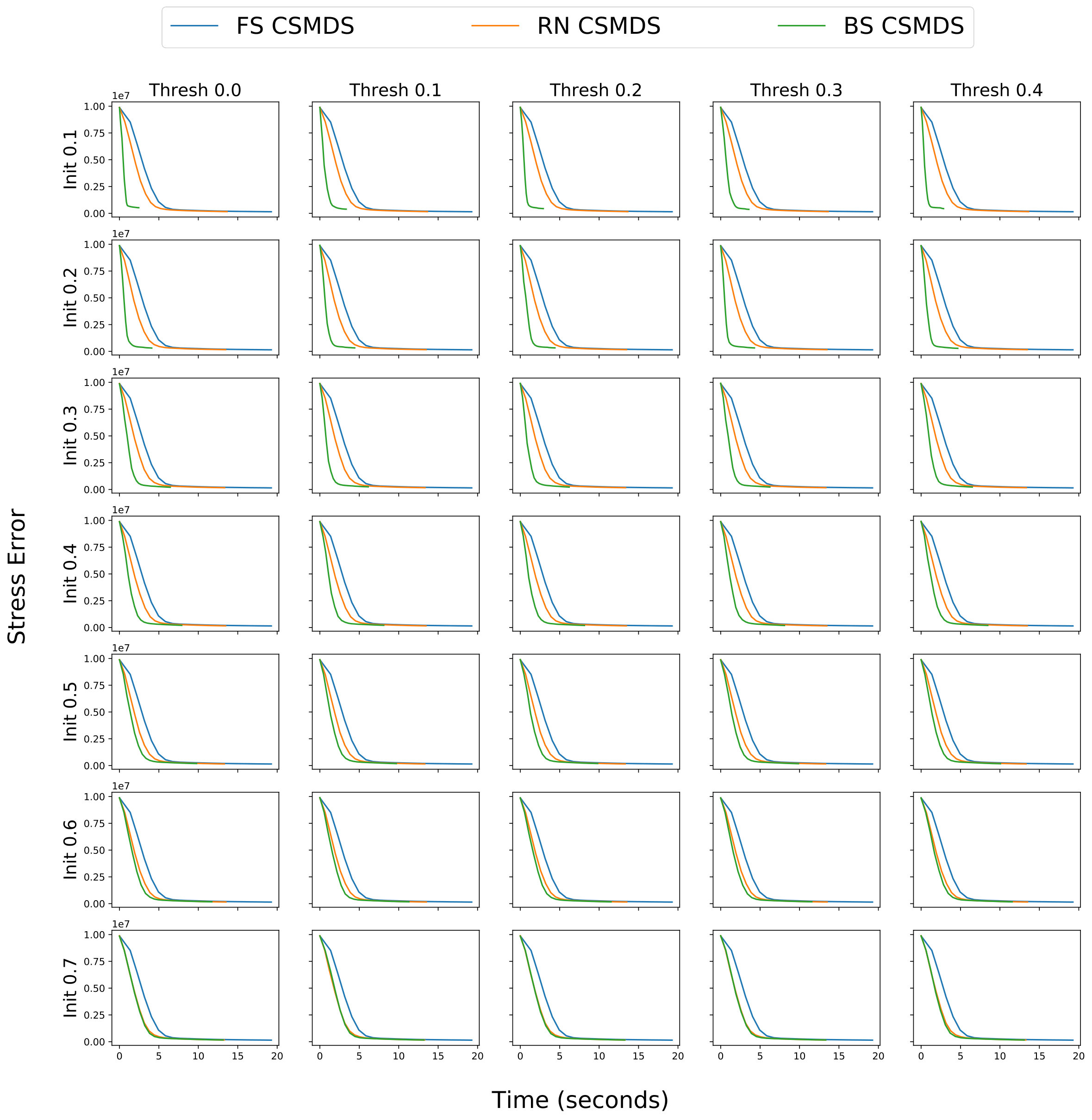 Figure 9
Figure 9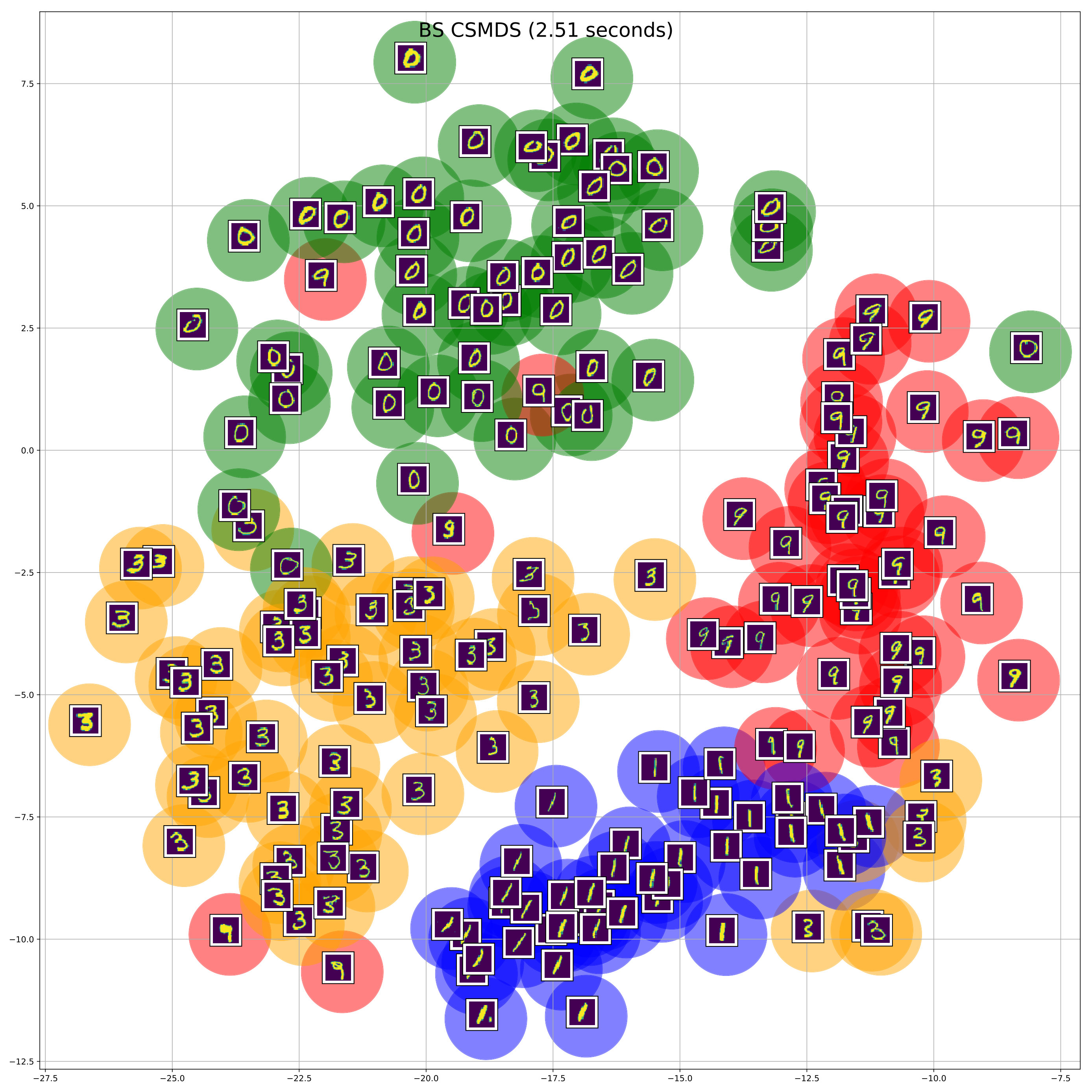 Figure 10
Figure 10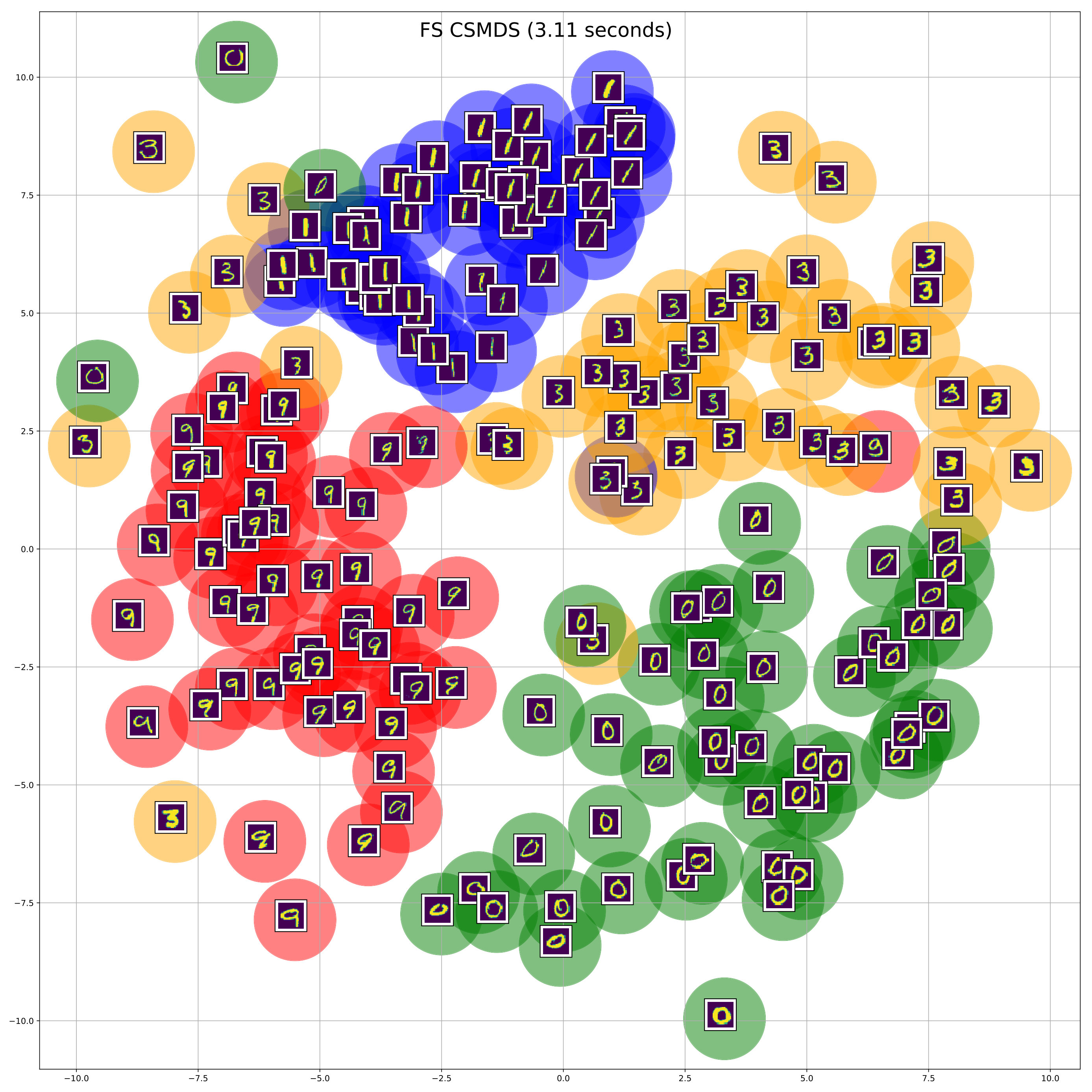 Figure 11
Figure 11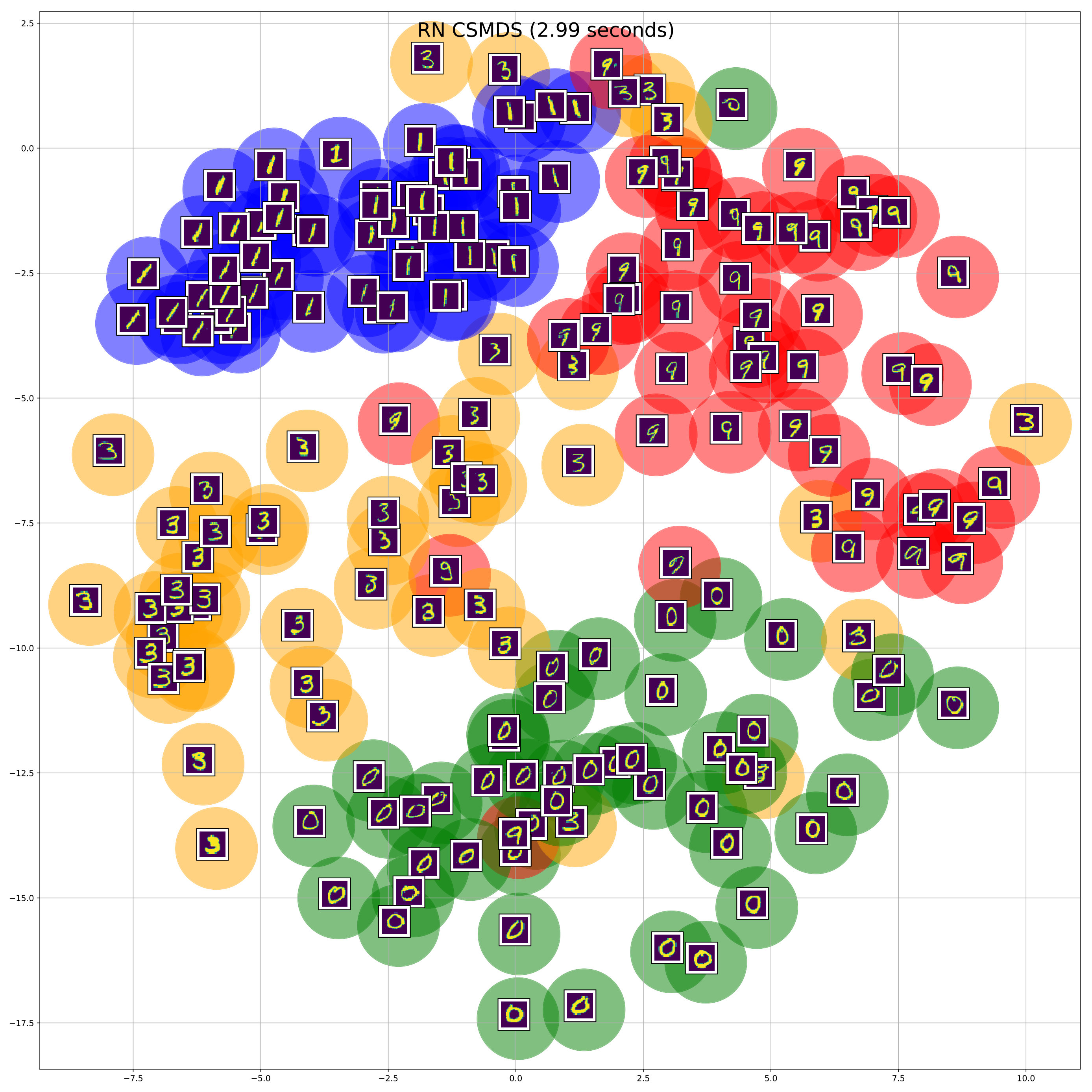 Figure 12
Figure 12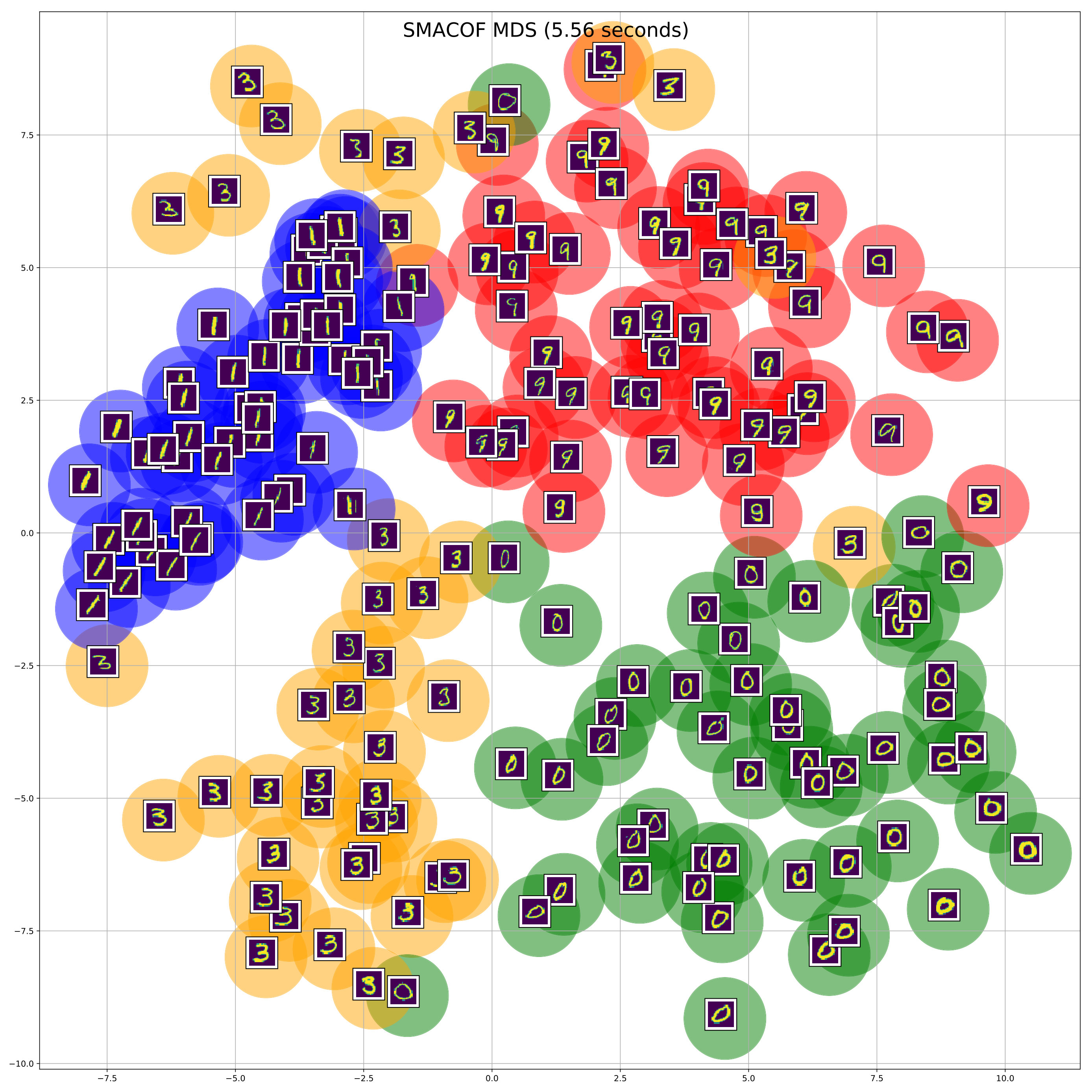 Figure 13
Figure 13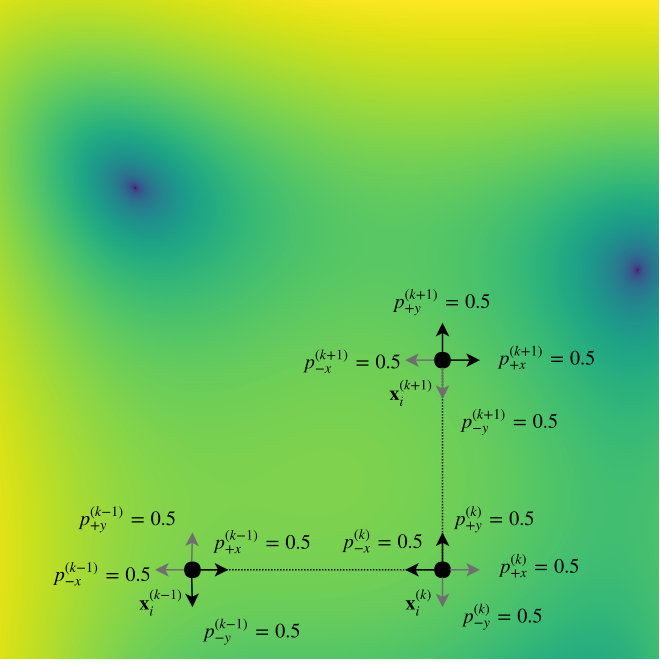 Figure 14
Figure 14| Method | Dims | Time (secs) | |||||
|---|---|---|---|---|---|---|---|
| Initial | 784 | - | 93.67 | 94.00 | 94.33 | 94.00 | 94.00 |
| SMACOF MDS | 10 | 102.64 | 84.00 | 85.00 | 86.00 | 88.00 | 86.33 |
| FS CSMDS | 10 | 185.83 | 89.33 | 90.67 | 91.33 | 90.67 | 92.33 |
| RN CSMDS | 10 | 136.31 | 89.00 | 89.67 | 91.00 | 90.67 | 91.33 |
| BS CSMDS | 10 | 85.31 | 86.67 | 88.67 | 91.67 | 91.00 | 91.33 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsFace and Expression Recognition · Advanced Image and Video Retrieval Techniques · Advanced Vision and Imaging
Bootstrapped Coordinate Search for Multidimensional Scaling
Efthymios Tzinis
Department of Computer Science
University of Illinois Urbana-Champaign
Champaign, IL 61820
Abstract
In this work, a unified framework for gradient-free Multidimensional Scaling (MDS) based on Coordinate Search (CS) is proposed. This family of algorithms is an instance of General Pattern Search (GPS) methods which avoid the explicit computation of derivatives but instead evaluate the objective function while searching on coordinate steps of the embedding space. The backbone element of CSMDS framework is the corresponding probability matrix that correspond to how likely is each corresponding coordinate to be evaluated. We propose a Bootstrapped instance of CSMDS (BS CSMDS) which enhances the probability of the direction that decreases the most the objective function while also reducing the corresponding probability of all the other coordinates. BS CSMDS manages to avoid unnecessary function evaluations and result to significant speedup over other CSMDS alternatives while also obtaining the same error rate. Experiments on both synthetic and real data reveal that BS CSMDS performs consistently better than other CSMDS alternatives under various experimental setups.
††footnotetext: Code is available at: https://github.com/etzinis/bootstrapped_mds
1 Introduction
Derivative-free optimization has been an active field of study in the past years. These methods try to optimize an objective function by searching over the input space and evaluate the function on different points. In each step, the algorithm selects the point that produces the steepest decrease on the value of the objective function. On the next iterate, the algorithm will perform the aforementioned process but starting from the point that has been produced by the previous iterate. These methods might be useful in cases where the derivative of the objective function is not available, it is extremely noisy or it is hard to compute. As a result, we can directly optimize any objective function by replacing any gradient-based method by a derivative-free one. Derivative-free optimization methods belong to the class of General Pattern Search (GPS) methods which are known to be able to converge to local minima under mild restrictions of the objective function torczon1997convergence (1). However, a harsh problem of those methods lies on their inability to scale on multiple dimensions as they scale linearly with the number of dimensions of the search space .
Multidimensional Scaling (MDS) ClassicalMDS (2) has been one of the most renowned dimensionality reduction techniques that tries to find a lower-dimensional manifold which are preserving a given similarity matrix . In essence, classical MDS tries to preserve these pairwise distances (or more general dissimilarities) between the points of the manifold by minimizing the stress objective function: , where no closed form solution is available Kruskal:a (3). Conventional methods would try to minimize the aforementioned objective function using gradient based methods. Moreover, the state-of-the-art algorithm for solving the problem is Scaling by Majorizing a Complex Function (SMACOF) Leeuw77applicationsof (4) which is minimizing the aforementioned stress by minimizing a function which is greater or equal than the objective.
Previous approaches have incorporated a simple derivative-free optimization method which is called direct coordinate search or simpler Coordinate Search (CS) search Hooke:1961:DSS:321062.321069 (5) in order to minimize the stress function which is the objective function for MDS problem paraskevopoulostzinis2018MDS (6). One possible method to reduce the search space of the algorithm would be to naively random sample over the possible dimensions that the algorithm searches over. We are focused on increasing the efficiency of MDS using direct search by using a Bootstrap sampling method efron1994introduction (7) on the search space of all the possible directions. In essence, we assimilate the momentum of the optimization movement by keeping a history of the previous selected steepest descent directions and biasing towards selecting them from all the available coordinates. For each iteration we update the dictionary of the probabilities for all the directions by increasing the probability of evaluating a successful coordinate if it provided the minimum alongside all the other coordinates and we reduce the probability of selecting all the others accordingly. One can consider that we try to optimize the function by selecting only a sparse subset of all the available coordinates.
In this work, we propose a general framework of Coordinate Search (CS) optimization algorithm alternatives for solving MDS. Full-Search Coordinate Search MDS (FS CSMDS) searches over all the possible directions for each iteration and also comes with some theoretical convergence properties. On the contrary, Randomized Coordinate Search MDS (RN CSMDS) will evaluate only on a randomly selected subset of all possible coordinates for evaluating the function which seems to work faster but without any theoretical reassurance of its convergence. Finally, Bootstrapped Coordinate Search MDS (BS CSMDS) does some kind of importance sampling in order to select the subset of the available directions that the objective function would be evaluated and can also be presented in the same general framework like the latter two alternatives. We experiment using synthetic data and we qualitatively inspect how well MDS can create low-dimensional manifolds able to preserve the input dissimilarities for multiple cases of the randomized selection of the optimization coordinate directions. We also provide the same results when trying to reconstruct a nonlinear manifold by using as input the geodesic distances of the input data instead of the euclidean ones. By the latter approach, we effectively resemble the functionality of Isometric Mapping (ISOMAP) tenenbaum_global_2000 (8). Furthermore, we try to give a quantitative performance measure using real data from MNIST images lecun1998mnist (9) in order to evaluate the efficacy of these low dimensional embeddings under a K-Nearest Neighbor (KNN) classification scheme. This would give us a deeper insight on how well the intrinsic geometry of the data is preserved when we perform dimensionality reduction. All the above would be consistently evaluated for all the cases of: 1) FS CSMDS, 2) RN CSMDS and 3) BS CSMDS. Finally, we compare these three alternatives of CSMDS framework under different configurations in order to assess the efficacy of the proposed Bootstraped Coordinate Search MDS (BS CSMDS).
2 Preliminaries
2.1 Multidimensional Scaling (MDS)
2.1.1 Classical MDS
Classical MDS was first introduced in ClassicalMDS (2). MDS can be formalized as: given the matrix consisting of pairwise distances or dissimilarities between points in a high dimensional space, we seek to find a set of points which lie on the manifold and their pairwise distances are preserve the given dissimilarities as truthfully as possible. corresponds to the data array contains all points as its columns. Ideally, we would like to obtain an embedding dimension as small as possible in order to reduce as much as possible the dimensionality of the produced manifold but not to deviate much from the given dissimilarities . Usually, euclidean distances are considered in the embedded space .
Classical MDS uses a centering matrix which is effectively a way to subtract the mean of the columns and the rows for each element. Where is a vector of ones in space. By applying the double centering to the Hadamard product of the given dissimilarities, the Gram matrix is constructed as follows:
[TABLE]
As shown in Ch. 12 borg_groenen_2005 (10), Classical MDS minimizes the Strain algebraic criterion, namely:
[TABLE]
is a symmetric matrix. The embedded points in are given by the first positive eigenvalues of , namely . As shown in doi:10.1093/biomet/53.3-4.325 (11) the solution to Classical MDS provides the same result as Principal Component Analysis (PCA) if the latter is applied on the vector in the high dimensional space. Classical MDS was originally proposed for dissimilarity matrices which can be embedded with good approximation accuracy in a low-dimensional Euclidean space as we also consider in this work. However, matrices which correspond to different spaces such as: Euclidean sub-spaces 10.1007/978-3-642-46900-8_44 (12), Poincare disks Poincare:MDS (13) and constant-curvature Riemannian spaces lindman1978constant (14) have also been studied.
2.1.2 Metric MDS
Metric MDS describes contains Classical MDS. Shepard has introduced heuristic methods to enable transformations of the given dissimilarities Shepard1962 (15), Shepard1962b (16) but did not provide any loss function in order to model them groenen2014past (17). Kruskal in Kruskal:a (3) and Kruskal:b (18) formalized the metric MDS as a least squares optimization problem of minimizing the non-convex Stress-1 function defined below:
[TABLE]
where matrix with elements represents all the pairs of the transformed dissimilarities that are used to fit the embedded distance pairs .
A weighted MDS raw Stress function is defined as:
[TABLE]
where the weights are restricted to be non-negative; for missing data the weights are set equal to zero. In our work, we consider always where we assume an equal contribution to the Metric-MDS solution for all the elements.
2.1.3 SMACOF
A state-of-the-art algorithm for solving metric MDS is SMACOF stands for Scaling by Majorizing a Complex Function Leeuw77applicationsof (4). By setting in raw stress function defined in Equation 4, SMACOF minimizes the resulting stress function .
[TABLE]
The algorithm proceeds iteratively and decreases stress monotonically by optimizing a convex function which serves as an upper bound for the non-convex stress function in Equation 5. SMACOF has been extensively described in borg_groenen_2005 (10) while its convergence for a Euclidean embedded space has been proven in deLeeuw1988 (19).
Let matrices and be defined element-wise as follows:
[TABLE]
[TABLE]
An alternative view of Equation 5 is the equivalent quadratic form:
[TABLE]
The quadratic is minimized iteratively as follows:
[TABLE]
Now, for -th iteration we obtain the next optimal point:
[TABLE]
where is the estimate of the embedding data matrix at the th iteration and is Moore-Penrose pseudo-inverse of . Noticeably, is constant for all data matrices estimations for each iteration. At th iteration, the convex majorizing convex function touches the surface of at the point . By minimizing the quadratic problem in Equation 9 we find the next update which serves as a starting point for the next iteration . The solution to the minimization problem is shown in Equation 10. The algorithm stops when the new update yields a decrease that is smaller than a threshold value.
2.2 General Pattern Search (GPS) methods
A wide class of derivative-free algorithms for nonlinear optimization has been studied and analyzed in Rios2013 (20) and avriel2003nonlinear (21). GPS methods are a subset of these algorithms which do not require the explicit computation of the gradient in each iteration-step. Some GPS algorithms are: the original Hooke and Jeeves direct coordinate search algorithm Hooke:1961:DSS:321062.321069 (5), the evolutionary operation by utilizing factorial design box1957evolutionary (22) and the multi-directional search algorithm torczon1989multidirectional (23), doi:10.1137/0801027 (24). In torczon1997convergence (1), a unified theoretical formulation of GPS algorithms under a common notation model has been presented as well as an extensive analysis of their global convergence properties.
2.2.1 GPS formulation
GPS methods optimize an objective :
[TABLE]
GPS try to minimize Equation 11. The general framework for all pattern search methods also contains Coordinate Search methods. A full formalization of the general framework of all GPS methods is given in torczon1997convergence (1, 25). Firstly, we define the following components:
- •
A basis matrix that could be any nonsingular matrix .
- •
A matrix for generating all the possible direction for the th iteration of the GPS minimization algorithm
[TABLE]
where the columns of form a positive span of and contains at least the zero column of the search space .
- •
A pattern matrix defined as
[TABLE]
where the submatrix forms a basis of .
In each iteration , the set of steps are generated by the pattern matrix :
[TABLE]
where is the th column of defines the direction of the new step, while configures the length towards this direction. If pattern matrix contains columns, then in order to positively span the search space . A new trial point of GPS algorithm would be where we evaluate the value of the function which we seek to minimize. A successful step would mean a further minimization of the objective function would mean , i.e., . A pseudo-code for all GPS methods is presented in Algorithm 1.
Initially, we select and a positive step length parameter . In each iteration , we explore a set of possible steps defined by the subroutine at line 5 of the algorithm. Pattern search methods mainly differ on the heuristics used for the selection of exploratory moves that they evaluate the function on. If a new exploratory point lowers the value of the function , iteration is considered successful and the starting point of the next iteration is updated . Otherwise, if at a certain iteration we cannot obtain any successful step then the algorithm can produce the zero-step point. The step length parameter is modified by the subroutine. For successful iterations, i.e., , the step length is forced to increase in a way that can be described as follows:
[TABLE]
where and are predefined constants that are used for the th successive successful iteration. For unsuccessful iterations the step length parameter is decreased, i.e., as follows:
[TABLE]
where and the negative integer determine the fixed ratio of step reduction. Generating matrix could be also updated for unsuccessful/successful iterations in order to contain more/less search directions, respectively.
2.2.2 GPS Convergence
Important convergence properties have been shown in torczon1997convergence (1, 25, 26, 27, 28) for any GPS method that can be described by the previously defined framework.
Hypothesis 1** (Weak Hypothesis on Exploratory Moves)**
The subroutine as defined in Algorithm 1, line 5 guarantees the following:
- •
The exploratory step direction for iteration is selected from the columns of the pattern matrix as defined in Equation 14 and the exploratory step length is as defined in Equations 15, 16.
- •
If among the exploratory moves at iteration selected from the columns of the matrix exist at least one move that leads to a successful iteration, i.e., , then the subroutine will return a move such that .
Hypothesis 1 enforces some mild constraints on how the exploratory moves would be produced by Algorithm 1, line 5. Essentially, the suggested step must be derived from the pattern matrix . Moreover, the algorithm needs to provide a simple decrease for the objective function at every step. Specifically, the only way to accept an unsuccessful iteration would be if none of the steps from the columns of the matrix lead to a decrease of the objective function .
Based on the aforementioned Hypothesis, a GPS method can enjoy some theoretical convergence guarantees which are stated rigorously in Theorem. 1 as follows:
Theorem 1
Let be closed and bounded and continuously differentiable on a neighborhood of , namely on the union of the open balls where . If a GPS method is formulated as described in Section 2.2.1 and Hypothesis 1 holds then for the sequence of iterations produced by Algorithm 1
[TABLE]
For the proof of this Theorem we refer the reader to torczon1997convergence (1).
However, as shown in Audet2004 (29) one can construct a continuously differentiable objective function and a GPS method with infinite many limit points with non-zero gradients and thus even Theorem. 1 holds, the convergence of is not assured.
3 Coordinate Search Multidimensional Scaling (CSMDS)
Coordinate search is a specific case of GPS methods that have been described before and thus it can be formulated under the aforementioned GPS framework (see Section 2.2.1). In this section we try to unify the three alternatives of CSMDS: 1) Full-Search Coordinate Search MDS (FS CSMDS), 2) Randomized Coordinate Search MDS (RN CSMDS) and 3) Bootstrapped Coordinate Search MDS (BS CSMDS) under a common family of algorithms which encapsulate a probability of selecting one dimension in order to evaluate the objective function. this family of algorithms can be directly restated as specific examples of GPS methods. Moreover, we discuss about the complexity of these algorithms in each case and we restate the convergence reassurance of FS CSMDS as firstly introduced in paraskevopoulostzinis2018MDS (6).
3.1 Unified CSMDS Algorithm
In accordance with paraskevopoulostzinis2018MDS (6), we consider a derivative-free optimization method for MDS. The input to CSMDS is a target dissimilarity matrix and the target dimension of the embedding space. The algorithm of the unified CSMDS algorithms is shown in Algorithm 2.
First of all, we initialize randomly and we compute the euclidean distance matrix of the embedded space. Thus, represents the Euclidean distance between vectors and of . The approximation error is the element-wise mean squared error (MSE) between the two matrices. The objective function which is optimized for all CSMDS variants is shown below and is the stress function for MDS:
[TABLE]
We introduce the notation of matrix that contains the probabilities of all the possible coordinates to be searched for th iteration. Specifically, , ( and ) is the probability of evaluating the objective function for point towards coordinate with index at th iteration. Because we consider dimensions of the embedding space we search over all positive and negative coordinates of this space on a certain radius . For example in the case of Full-Search CSMDS we will have because we always evaluate the function over all the possible directions for every iteration. Consequently, this probability matrix will not be updated over different epochs in both cases of Full-Search (FS) and Randomized (RN) CSMDS. We also introduce two more variables and which would be the threshold of the probability for all the values of matrix and the step of the update towards the probabilities for all the coordinates when the matrix is updated, respectively. So in any case we will have . In the case of the proposed BS CSMDS, when a successful coordinate step is evaluated for point (the coordinate that produces the maximum minimization of the objective function) we would enhance the probability of this coordinate for the next iterates by and we will reduce the probabilities of selecting any of the other non-optimal coordinates by the same amount.
In other words, Algorithm 2 minimizes the objective function by iterating over all the points for each epoch and searches over some coordinates. For the given set of all the coordinates, the optimal direction (the coordinate that yields the steepest descent for the objective function) is taken and then this point on the embedding space is updated. The resulting error is computed after performing the optimal move for each point of the data matrix . If the error does not relatively decrease more than a specified constant , namely, , we halve the search radius and proceed to the next epoch. The process stops when the search radius becomes smaller than another positive constant . Depending on the variant of CSMDS framework we might need to update the probability matrix by favoring the probability of a successful step over all the other coordinates. In the next sections we describe all these procedures extensively.
3.2 Searching Coordinates
Following the initialization steps, in each epoch (iteration), we consider the surface of a hypersphere of radius around each point x. The possible search directions lie on the surface of a hypersphere along the orthogonal basis of the space, e.g., in the case of -dimensional space along the directions on the sphere. Moreover, the no movement would also be considered a possible direction in the case that no other directions are actually producing a decrease for the objective function. This would create the set of all possible search coordinates . Where denotes that vector s is a column of matrix . Now we create the actual set of all the coordinates that would be evaluated for point x, namely by appending any direction s on the final set with probability . This process is summarized in Algorithm 3:
3.3 Move Alongside the Coordinate that Produces the Maximum Decrease
Each point is moved greedily along the dimension that produces the minimum error or no error at all considering the zero step direction . Algorithm 4 finds the optimal step from the set of coordinates that minimizes the most the error function for each point . The data matrix is updated by updating only the corresponding point (which is a row vector of the data matrix). We denote by the row of the data matrix which corresponds to the point a. Similarly, when we evaluate a specific coordinate movement s out of the set of possible directions then would denote the subscript of this coordinate.
3.4 Updating the Probability Matrix
The step for each point is being selected greedily along the dimension that produces the minimum error or no error at all considering the zero step direction . Algorithm 4 finds the optimal step from the set of coordinates that minimizes the most the error function for each point . The data matrix is updated by updating only the corresponding point (which is a row vector of the data matrix). We denote by the row of the data matrix which corresponds to the point a. Similarly, when we evaluate a specific coordinate movement s out of the set of possible directions then would denote the subscript of this coordinate.
3.5 GPS Formulation of CSMDS
CSMDS can be expressed by using the unified GPS formulation introduced in Section 2.2. In accordance with the authors in paraskevopoulostzinis2018MDS (6), who managed to express the specific case of Full-Search CSMDS as an instance of GPS methods, we do the same for the general framework of CSMDS.
To begin with, the problem of MDS is restated in a vectorized form which spans all the possible coordinates considered for all points. We use matrix with elements as the dissimilarities between points in the high dimensional space. The set of points lie on the low dimensional manifold and form the column set of matrix . The embedded data matrix will be now vectorized as an one column vector as shown next:
[TABLE]
Now our new variable lies in the search space . The distance between any two points and of the manifold remains the same but is now expressed as a function of the vectorized variable . Namely, . The equivalent objective function to minimize is the MSE between the given dissimilarities and the euclidean distances in the low dimensional manifold as defined next:
[TABLE]
Consequently, the initial MDS is now expressed as an unconstrained non-convex optimization problem which that tries to mimize the objective function over the search space of (Equation 20). Thus, the degrees of freedom for our solution are corresponding to the coordinates for all points on the manifold .
[TABLE]
CSMDS is now expressed in an equivalent way by utilizing the auxiliary variable . Next, we match each epoch of our initial algorithm with an iteration of a GPS method. Therefore, the steps which are produced by CSMDS would form a sequence of points in the new search space . Moreover, we define the matrices for the general framework of CSMDS in an equivalent way to Equations 12, 13. The choice of our basis matrix is the corresponding identity matrix of our search space as shown in Equation 22.
[TABLE]
[TABLE]
Because the columns of identity matrix span positively the search space , we consider as the matrix which is constructed by all the available positive coordinate directions but with respect to the probability matrix . Because there is one to one mapping from the auxiliary variable to any point of the initial data matrix we can construct the set of all the considered directions using the subscript of each point and all available positive coordinates of the embedding space. Formally, we can construct the set of all the coordinate directions that would be considered on th epoch as:
[TABLE]
where denotes the subscript of a specific positive coordinate of the space and is the subscript that corresponds to the point or equivalently the th row of the data matrix X. The subscript would correspond to the entry of the probability matrix . Similarly, for the case of negative coordinates we would have that the corresponding probabilities would lie on the second half of the columns of the probability matrix and this is why we need the notation for the th negative coordinate direction. Now the matrices and are constructed by concatenating all the vectors of the sets and , respectively. This means that we get all the possible coordinate steps alongside the unit coordinate vectors of . In Equation 24 matrix concatenates the aforementioned matrices in order to incorporate both negative and positive coordinate steps. Nevertheless, our generating matrix also comprises the zero step vector which would be a constant vector-matrix .
[TABLE]
[TABLE]
According to Equations 24, 25, we construct the full pattern matrix in Equation 26 in a similar way to Equation 13. For our algorithm the pattern matrix is identical to our generating matrix . Conceptually, the generating matrix contains all the possible exploratory moves which would be considered in order to evaluate the objective function on but always with respect to the probability matrix which controls how probable is each coordinate to be evaluated for a certain epoch.
[TABLE]
Recalling the notation of Section 2.2.1, is the step which is returned from our exploratory moves subroutine at th iteration. For successful iterates that produce a decrease on the objective function we do not further increase the length of our moves by limiting as follows:
[TABLE]
On the other side, for unsuccessful iterations we halve the distance by a factor of by setting as it is shown next:
[TABLE]
Another way to understand CSMDS under GPS methods formulation is the following: In each iteration, we acquire all the possible coordinate directions with respect to the probability matrix . Each entry of this matrix specifies the probability of a Bernoulli random variable to be successful and this is equal to the probability that a specific coordinate of the search space to be considered for evaluation. After that, the algorithm proceeds by moving towards this direction and updates the probability matrix by increasing the probability of this coordinate for the next iterates and reduces the probabilities of all the other coordinates. Otherwise, if no direction produces there is no update in the embedding data matrix X and the radius of the search is reduced in half. This approach provides a potential one-hot vector as described in Equation 21 if the iterate is successful or otherwise, the zero vector as the step update. The final direction vector for th iteration is computed by summing these one-hot or zero vectors for all the point updates. At the th iteration, the movement would be given by a scalar multiplication of the step length parameter with the final direction vector in a similar way as defined in Equation 14. A one-hot vector that corresponds to a specific point would correspond to a simple decrease for the objective function or in the worst case it would represent a zero movement in the search space . The movement alongside the optimal coordinate from all points is an associative operation and thus the summation of all these vectors would result in an equivalent update for the auxiliary variable z. In other words, accumulating all best coordinate steps for each point and performing the movement at the end of the th iteration (as GPS method formulation requires) produces the same result as taking each coordinate step individually. Finally, this process is repeated until convergence.
3.6 CSMDS Alternatives
We will distinguish three different cases of the CSMDS general framework that was described earlier where each case can be configured by giving different configurations of the initial probability matrix , the threshold for each entry of the latter probability matrix and the probability update step which are the calling parameters of Algorithm 2. For the cases of Full-Search (FS) and Randomized (RN) CSMDS the probability matrix would not be updated across epochs but they would be specified by the given probability matrix . Thus, each positive or negative coordinate would correspond to a Bernoulli random variable with a constant probability. On the contrary, would be updated for each epoch by increasing the probability of the coordinates that produce the optimal decrease and by reducing all the other. In Figure 1 we provide a visualization of how the algorithm proceeds for the three different alternatives of CSMDS.
3.6.1 Full-Search CSMDS (FS CSMDS)
FS CSMDS can be configured as an instance of the unified CSMDS framework (see Algorithm 2) with an initial probability matrix which has one in all of its entries and with no updates on this matrix which is equivalent to specifying the argument . Of course this configuration would always give the best results from all kind of randomized alternatives that can be modeled using CSMDS framework but this comes with a huge computational cost because in every epoch we will consider all possible directions even if some of them have a history of being completely useless towards the minimization of the objective function (see example in Figure 1(a)). The complexity of FS CSMDS is . Because for each epoch we search across dimensions for points while we also need operations to update the distance matrix as we move all points independently for each epoch.
On the contrary, this variant of CSMDS framework comes with a theoretical convergence property because in each epoch we search all over the possible coordinates. In paraskevopoulostzinis2018MDS (6) this has been proven because FS CSMDS is an instance of GPS methods as we have already shown for the general CSMDS framework in Section 3.5. The core idea of the proof is that because FS CSMDS is an instance of GPS methods the we can use Theorem 1 because the following are true:
The stress objective function (see Equation 19) is continuously differentiable around all points of the search space as it is a sum of norms except of the points where we have the minimization . Thus, we can relax the initial requirements of the theorem on the set of open balls where by alternating the set of minimizers in order to include the points of where torczon1991convergence (30). 2. 2.
Pattern matrix in Equation 26 contains all the possible coordinate step vectors (which are also defined by Equation 14) which are evaluated with probability vector for each point and epoch. Thus, if there exists a simple decrease when moving towards any of the directions provided by the columns of then our algorithm also provides a simple decrease. As a result, Hypothesis 1 holds for the exploratory coordinates.
By combining the latter two intermediate results, Theorem 1 holds for FS CSMDS and thus, is guaranteed.
3.6.2 Randomized CSMDS (RN CSMDS)
In this case, Algorithm 2 is configured with an constant probability matrix which has the same value for all of its entries but it should be less than one in order to avoid evaluating every time all possible coordinates. Moreover, because there is no update on the probability matrix . Intuitively, RN CSMDS takes advantage of some directions that might not be needed to taken into consideration when trying to infer the optimal movement mainly because another direction could also produce a reasonably good decrease. In paraskevopoulostzinis2018MDS (6) authors have noted this method as an optimization over FS CSMDS because they have empirically seen that this produces faster convergence. However, they have not explicitly taken into consideration its proper formalization under a general framework. Now the complexity of RN CSMDS is where is the expected number of search coordinates that the algorithm would evaluate with . The problem is that by just random sampling over the possible coordinates does not always perform favorably as sometimes we might need to keep moving towards a specific direction for multiple epochs but there is no structure of history tracking. This might result to unwanted behavior where all coordinates are equally probable to be evaluated and thus, a wrong step is the same probable to happen as the best one (see Figure 1(b)).
3.6.3 Proposed Bootstrapped CSMDS (BS CSMDS)
In the proposed Bootstrapped (BS) CSMDS we try to incorporate an importance sampling scheme in order to favor the coordinates that have previously produced optimal decrease of the loss function over all the other coordinates. This method would presumably help in certain cases where we only need to move along specific directions for certain epochs (see example in Figure 1(c)). BS CSMDS inherently adds an equivalent inertia term for the coordinate search algorithm as more contemporary gradient-based optimizers also do, e.g. Nadam optimizer nadamOptimizer (31). For the configuration of BS CSMDS we also need probability matrix which would be updated over time, a threshold probability and a non-zero update probability step .
The number of the coordinates that would be evaluated for each point would decrease over time. Let us assume without loss of generality that all values of the initial probability matrix are set to and a given threshold probability that we cannot reduce any probability entry below that . Omitting the zero-step epochs for certain points that do not produce any update on the probability matrix, in every epoch we only increase the probability of the optimal direction by and for all the other we reduce it by the same amount. So for each successful iteration of a certain point the number of coordinates would be reduced by . So as epochs goes to infinity, the probability of evaluating any coordinate would reduce to the threshold value. Thus, the number of the coordinates to be evaluated would be equal to . This yields the problem that if the threshold is set extremely low this saturation happens very fast then we might end up with not being able to search over any coordinate that would actually provide a decrease of the objective function. So one might consider that it would be wise to select a threshold which would enable the algorithm to search over coordinates even when it trespasses over the saturation phase. Notably, BS CSMDS is able to self-regulate even in saturation-phase if there is a decrease over a certain coordinate. In essence, BSMDS will evaluate this coordinate with probability (in the worst case) and it will iteratively increase this probability by for each successful iteration.
3.7 Implementation Details
We provide a highly efficient Python code for CSMDS which runs C and Cython routines which are computationally intense. Moreover, our implementation is highly parallelizable as each evaluation across a possible coordinate can run on a different thread and it is completely independent from all the other coordinates.
4 Experiments
We assess the performance of the proposed BS CSMDS using both synthetic and real image data. We compare with the state-of-the-art SMACOF MDS but also for the other two alternatives of CSMDS framework as described in the previous section. For the configuration of the starting radius parameter we select the value of empirically as it is self-regulating in all of the cases because if it does not produce a relative error decrease better than between two consecutive epochs then radius will be reduced by . The parameter for checking the convergence threshold or equivalently the threshold of how small the searching radius would be is set to .
4.1 Experiments with Synthetic Data
In this experimental setup we perform non-linear dimensionality reduction using MDS. This can be done in the same way as ISOMAP tenenbaum_global_2000 (8) first extracts the geodesic distance matrix by considering high-dimensional points as graph nodes and then connecting each node with a number of nearest neighbors and the value of the edge is the corresponding Euclidean distance. The assumption here is that data lie on a manifold which is locally Euclidean and thus geodesic distances would preserve the true structure of the data when performing MDS. In Figure 2 we compare BS CSMDS with the FS and RN variants as well as SMACOF MDS which is considered the state-of-the-art algorithm for MDS when generating data points which are drawn from a Swissroll distribution. All algorithms run for epochs and converged to same level of Stress errors, while SMACOF yielded a higher error compared to all other CSMDS variants. RN CSMDS and BS CSMDS are configured with , while the latter uses the extra arguments: and . Experimentally, we noticed that when using a much higher probability update we very quickly force the algorithm to enter the saturating phase which produces weird error rates.
It is very important to notice that all algorithms aptly capture the intrinsic geometry of the data (which is actually -dimensional and thus, it can be visualized perfectly when unfolding Swissroll using only dimensions) when the target matrix includes the geodesic distances between each pair of local neighborhood points. Moreover, we can clearly see that from the structure of the low-dimensional representations all MDS algorithms under comparison are converging to similar solutions besides the way we choose to optimize the Stress function by Coordinate Search that CSMDS variants use or either minimization by majorization that SMACOF uses. Another important conclusion that we draw is that when using a small number of dimensions in order to describe our data, CSMDS converge way faster than SMACOF to an acceptable error. This certainly would not be the case when one uses much more dimensions because the computational time of all CSMDS variants scale linearly with the number of dimensions which are used (CSMDS variants would have different constants depending on the expected number of dimensions that we evaluate for each epoch). On the contrary, complexity of SMACOF does not depend on the number of dimensions but generally need a number of runs larger than one in order to find a good solution de2011multidimensional (32), in this case we only use one run that produces an acceptable solution in order to be fair in time-comparison. Having all that said, we can clearly see that CSMDS variants are extremely wants to perform MDS with a small number of dimensions. Finally, the proposed CSMDS is able to outperform all other variants even in this case with -dimensions which is somewhat unintuitive because one would expect to see an unwanted behavior when we only have coordinates to move for each point (all of them might be needed).
4.2 Experiments with MNIST
In this experimental setup we perform linear dimensionality reduction using as target dissimilarity matrices the Euclidean ones from the high-dimensional pixel space of MNIST dataset lecun1998mnist (9).
4.2.1 Visualizing Linear Embeddings
We use only out of the available handwritten digits, namely: and we select randomly images from all the selected classes of digits. Moreover, we compute the Euclidean distance matrix between all the images on the pixel space. After that, we perform MDS using SMACOF and all variants of CSMDS using only -dimensions. All algorithms run for epochs and converged to same level of Stress errors. RN CSMDS and BS CSMDS are configured with , while the latter uses the extra arguments: and . The resulting embeddings after some random sampling on the constructed low-dimensional space (for visualization purposes) are displayed in Figure 3. Different colors correspond to the classes of different handwritten-digits which are mapped to green, blue, orange, red, correspondingly.
From the visualization of the embeddings we can clearly see that all MDS algorithms are able to preserve the geometry of the hand-written digits in a way that all digits of the same class would lie on compact Euclidean subspaces. Although, RN CSMDS provides a good embedding, it performs poorly for the class of digit which has the most variance among all algorithms. On the contrary, again we see that we get a similar result with the experiments on synthetic data (see Section 4.1) where BS CSMDS provides a very good solution by outperforming SMACOF and the other CSMDS variants in terms of computational efficiency. Noticeably, BS CSMDS constructs a very dense and center-based cluster representation even for the class of digit which makes this representation amenable for center-based clustering and classification.
4.2.2 Image Classification on the Low-Dimensional Space
We steer our focus on how the embeddings of the different MDS algorithms behave under a true classification experimental setup. For this experiment all classes of handwritten digits have been used and images have been drawn randomly from all these classes which have a very similar prior distribution on the initial dataset. We first perform linear-dimensionality reduction using MDS with target dissimilarity matrix the euclidean distances on the pixel space in order to obtain -dimensional embeddings. We randomly spit the embeddings in two sets where the labels of of the images () would be considered known and used in order to infer the class-labels of the remaining . On the produced embeddings a K-Nearest Neighbor (KNN) classification is performed using different parameters of nearest neighbors which are taken into consideration for the inference of a sample which comes from the test set. The evaluation metric which is considered is the total classification accuracy which is the percentage of true predictions across all classes divided by the number of total predictions. In order to get a better insight of the accuracy which is obtained by these embedding representations we also perform KNN on the orignal space without performing any dimensionality reduction (and possibly loose some information which is crucial for classification). RN CSMDS is configured with , while the BS CSMDS is configured with: , and . The results for both the computational time which was needed in order to obtain the embeddings and the final accuracy from KNN classification is shown in Table 1.
Even now that we have increased significantly the number of dimensions of the embedding space again we see that BS CSMDS outperforms all other alternatives and SMACOF in terms of computational efficiency but without having a significant performance drop in terms of classification accuracy on the embedded space. Compared to FS CSMDS which obtains the best results under most configurations but also is the most computationally intensive task, BS CSMDS manages to obtain similar classification accuracy in all of the cases while sometimes even surpassing FS alternative. Moreover, RN CSMDS always has a higher probability of searching a possible coordinate to optimize compared to proposed BS CSMDS () but does not yield any better results in terms of classification accuracy and of course it is much more computationally intensive. This indicates that only a random sampling across the dimensions we want to optimize is not sufficient in order to significantly reduce the computational time of CSMDS algorithms and also obtain a “good" embedding representation which is amenable to classification and clustering. Presumably, only a small number of all the available coordinates to be searched is needed even in the case of possible directions.
4.2.3 Head-to-Head Convergence Comparison for CSMDS Alternatives
In this section we aim to extensively evaluate all variants of CSMDS when performing dimensionality reduction using a much higher number of embedding dimensions. We also focus on understanding how the proposed BS CSMDS behaves under different configurations of the initial probability and the probability threshold which defines the behavior of the bootstrapped version on the saturating phase. In order to do so, we randomly select MNIST images from all the available digit-classes and we set the target embedding dimension to be . We keep the same configuration for the probability update step . We measure how the Stress error function (see Equation 20) decreases across time for FS CSMDS, RN CSMDS and proposed BS CSMDS under the aforementioned setup. In Figure 4, we plot the value of Stress error function across time for all CSMDS variants under different configurations of (shared for the configuration of RN and BS alternatives) and (behavior changes only for BS CSMDS). Also, FS CSMDS is not configured by neither of the parameters and . Consequently, FS CSMDS is the same for all plots and RN CSMDS changes only across rows. However, we plot every time all alternatives in order to provide a much easier inspection for the comparison of the performance.
It is evident that the proposed variant of BS CSMDS yields the best convergence results across all configurations and surpasses RN and FS but with a different margin. That means that BS CSMDS is quite robust and can self-regulate under different configurations. RN CSMDS also converges to approximately the same level as FS CSMDS but faster in all of the cases which is in accordance with the empirical conclusion authors state in paraskevopoulostzinis2018MDS (6). It is important to notice that the latter holds irregardless of the initial probability that is set. This can be explained because in RN alternative the sampling of the searching directions is completely random and thus when we decrease the time that we spend for the evaluation of the objective function on each epoch but more epochs are needed in order to converge. On the contrary, BS CSMDS enhances the probability of evaluating directions that yield steepest descent of the objective function and thus it manages to converge much faster than all the other alternatives. This fact becomes much more apparent when configuring BS CSMDS with lower initial probability or . In these cases BS CSMDS manages to find these optimal directions, enhances the probability of selecting them in later evaluations and thus very quickly manages to reduce the error to the same level as RN and FS alternatives around times faster. As we increase the initial probability BS CSMDS becomes very similar to the behavior of RN alternative as the initial probability dominates and in the first epochs that we run, all coordinates have an equal probability of being evaluated. Thus, BS CSMDS cannot properly enhance the probability of the steepest direction and it has much more random behavior because all directions have approximately the same probability to be evaluated. Finally, we have to identify that CSMDS alternatives irregardless of how quick the converge to a good solution when we want to do smaller movements around a local minima then the computational time which is needed is extremely expensive and consequently, gradient-based solvers are would be much more efficient. However, with BS CSMDS we are able to converge extremely fast (compared to the other CSMDS alternatives) around a local minimizer that could potentially serve as an initialization for a much faster gradient-based optimizer.
5 Conclusions
In this work, we have proposed a unified framework for gradient-free Multidimensional Scaling (MDS) based on Coordinate Search (CS) over the embedding space, namely, CSMDS. We have formally described CSMDS framework as an instance of General Pattern Search (GPS) methods that can be used in order to provide theoretical convergence properties of the deterministic Full-Search CSMDS (FS CSMDS) alternative. We propose a Bootstrapped alternative of CSMDS (BS CSMDS) which enhances the probability of the direction that yields the best decrease of the objective function while also reducing the corresponding probability of all the other coordinates. In this way, BS CSMDS manages to quickly identify the directions that are needed towards minimization and avoids evaluating coordinates that might not produce a simple decrease resulting on significant speedup over other deterministic and randomized CSMDS alternatives under experiments on both synthetic and real data. Because BS CSMDS converges very fast to a local minima, we consider a potential future direction to utilize it as an initialization step for gradient-based solvers.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1) Virginia Torczon “On the convergence of pattern search algorithms” In SIAM Journal on optimization 7.1 SIAM, 1997, pp. 1–25
- 2(2) Warren S. Torgerson “Multidimensional scaling: I. Theory and method” In Psychometrika 17.4 , 1952, pp. 401–419
- 3(3) J. B. Kruskal “Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis” In Psychometrika 29.1 , 1964, pp. 1–27
- 4(4) Jan De Leeuw et al. “Applications of convex analysis to multidimensional scaling” In Recent Developments in Statistics North Holland Publishing Company, 1977, pp. 133–146
- 5(5) Robert Hooke and T. A. Jeeves ““ Direct Search” Solution of Numerical and Statistical Problems” In J. ACM 8.2 New York, NY, USA: ACM, 1961, pp. 212–229
- 6(6) Georgios Paraskevopoulos, Efthymios Tzinis, Emmanuel-Vasileios Vlatakis-Gkaragkounis and Alexandros Potamianos “Pattern Search Multidimensional Scaling” In ar Xiv:1806.00416 , 2018 ar Xiv: 1806.00416 [quant-ph]
- 7(7) Bradley Efron and Robert J Tibshirani “An introduction to the bootstrap” CRC press, 1994
- 8(8) Joshua B. Tenenbaum, Vin de Silva and John C. Langford “A Global Geometric Framework for Nonlinear Dimensionality Reduction” In Science 290.5500 American Association for the Advancement of Science, 2000, pp. 2319–2323