Enabling Robots to Infer how End-Users Teach and Learn through Human-Robot Interaction
Dylan P. Losey, Marcia K. O'Malley

TL;DR
This paper proposes a Bayesian inference approach for robots to personalize understanding of human interaction strategies during HRI, improving learning and teaching by adapting to individual user behaviors.
Contribution
It introduces a method for robots to infer and adapt to individual human interaction strategies using Bayesian inference, moving beyond fixed strategy assumptions.
Findings
Personalized approach outperforms fixed strategy methods in simulations.
Robust inference of human strategies improves robot learning and teaching.
Bayesian framework effectively models diverse human interaction behaviors.
Abstract
During human-robot interaction (HRI), we want the robot to understand us, and we want to intuitively understand the robot. In order to communicate with and understand the robot, we can leverage interactions, where the human and robot observe each other's behavior. However, it is not always clear how the human and robot should interpret these actions: a given interaction might mean several different things. Within today's state-of-the-art, the robot assigns a single interaction strategy to the human, and learns from or teaches the human according to this fixed strategy. Instead, we here recognize that different users interact in different ways, and so one size does not fit all. Therefore, we argue that the robot should maintain a distribution over the possible human interaction strategies, and then infer how each individual end-user interacts during the task. We formally define learning…
Click any figure to enlarge with its caption.
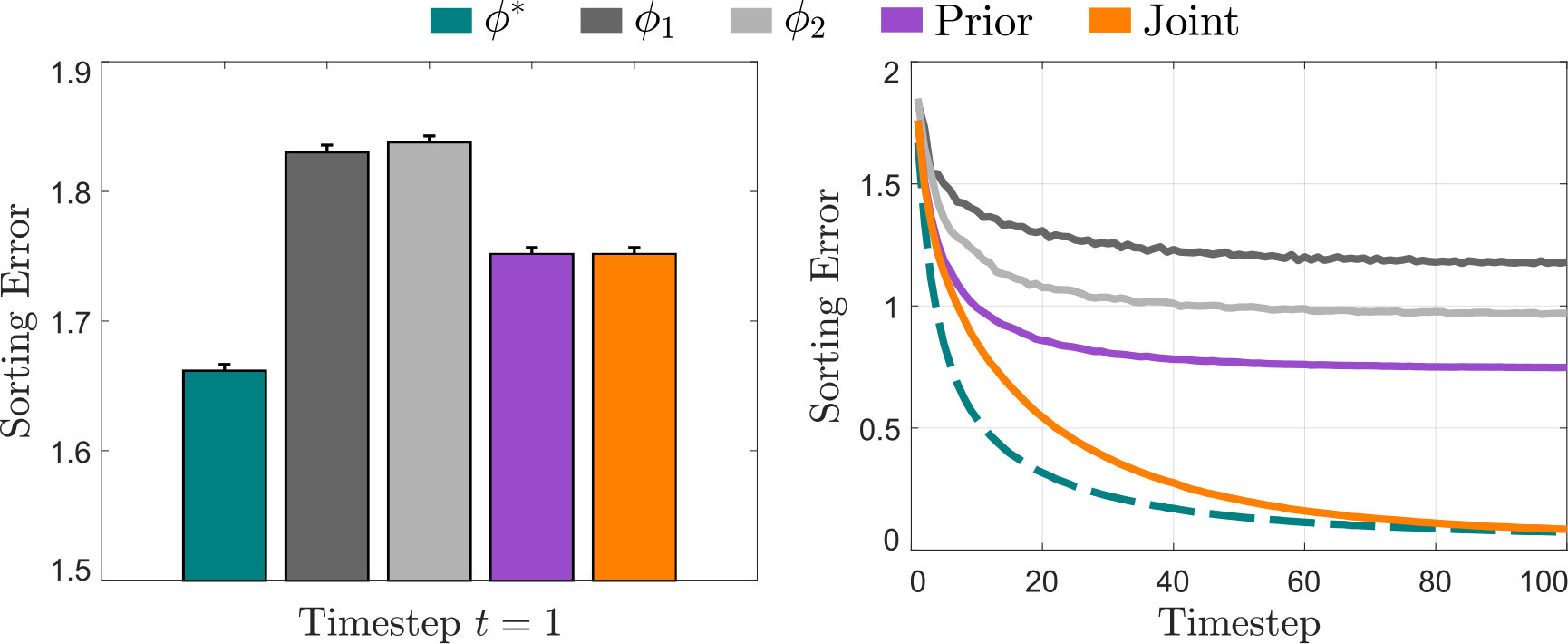 Figure 1
Figure 1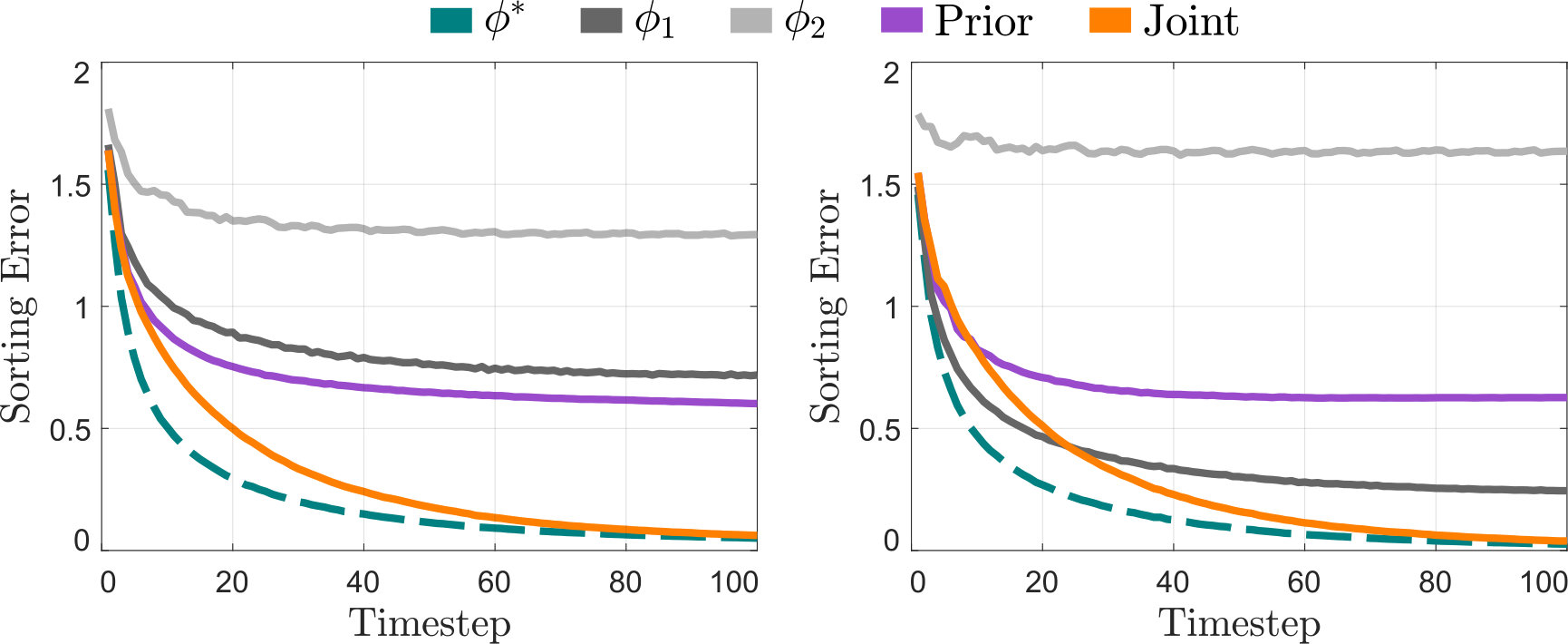 Figure 2
Figure 2 Figure 3
Figure 3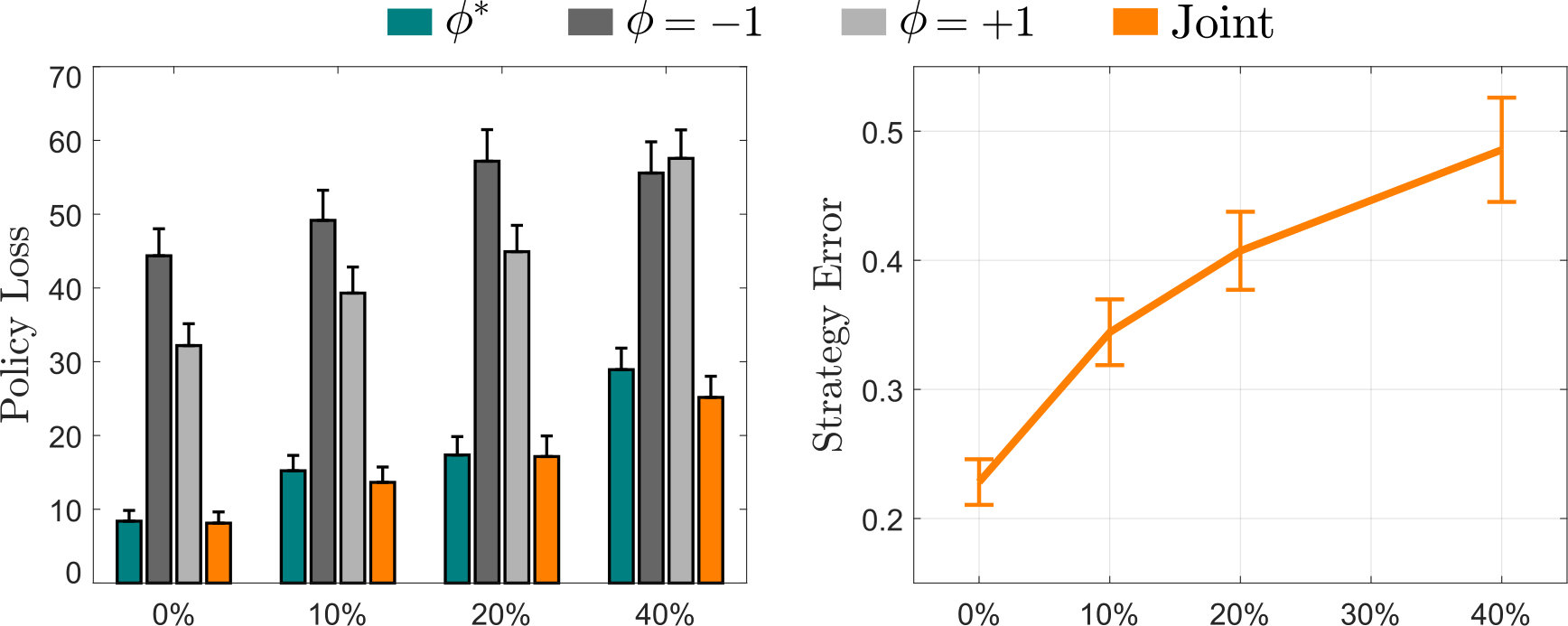 Figure 4
Figure 4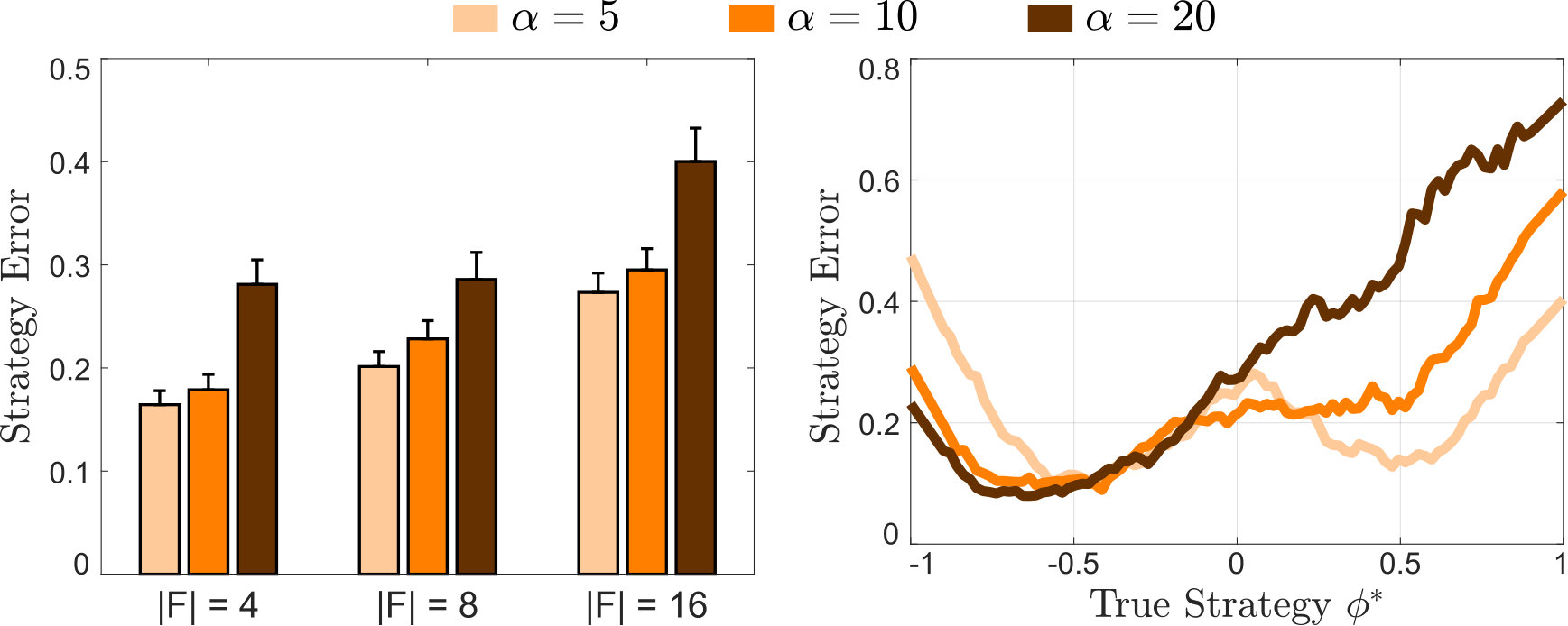 Figure 5
Figure 5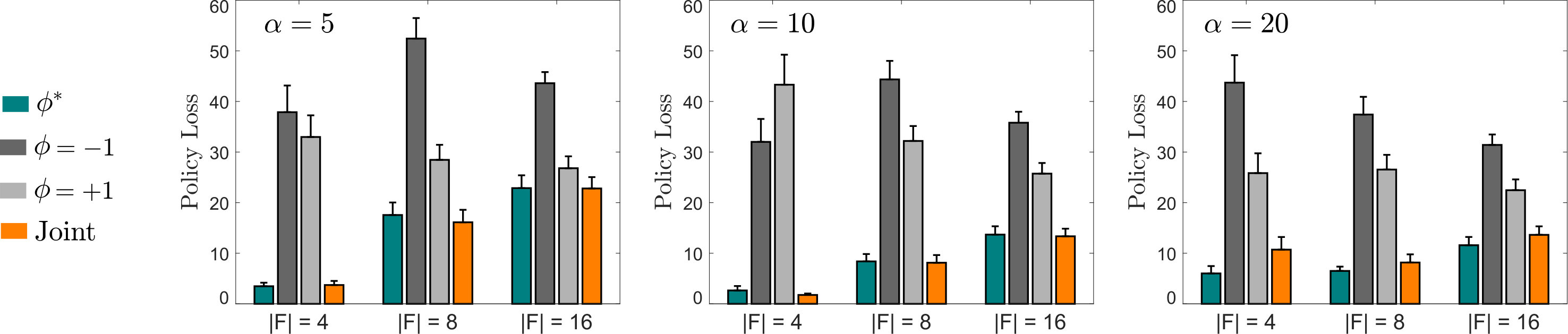 Figure 6
Figure 6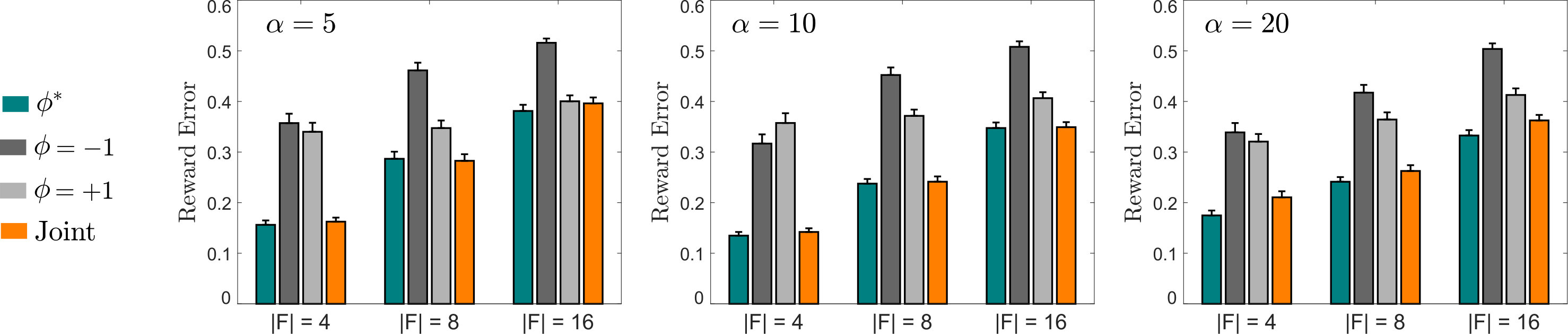 Figure 7
Figure 7 Figure 8
Figure 8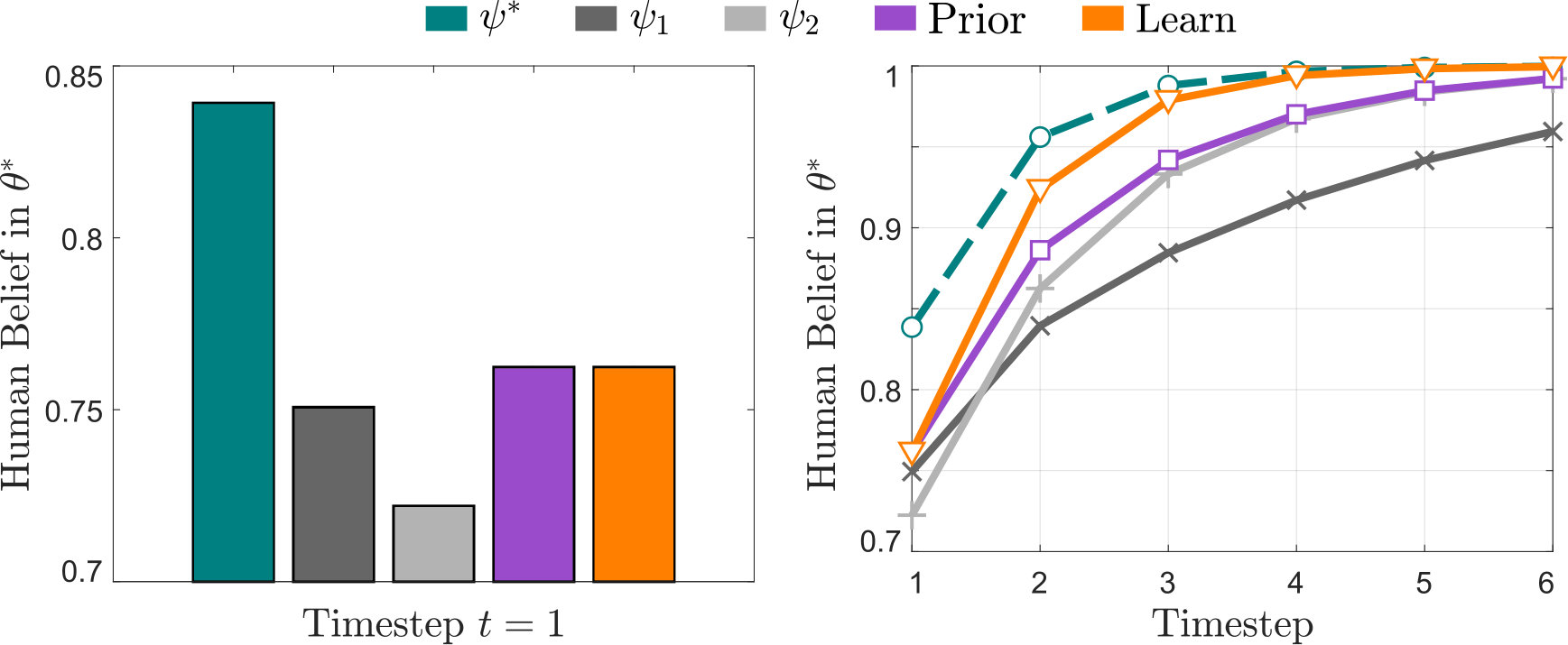 Figure 9
Figure 9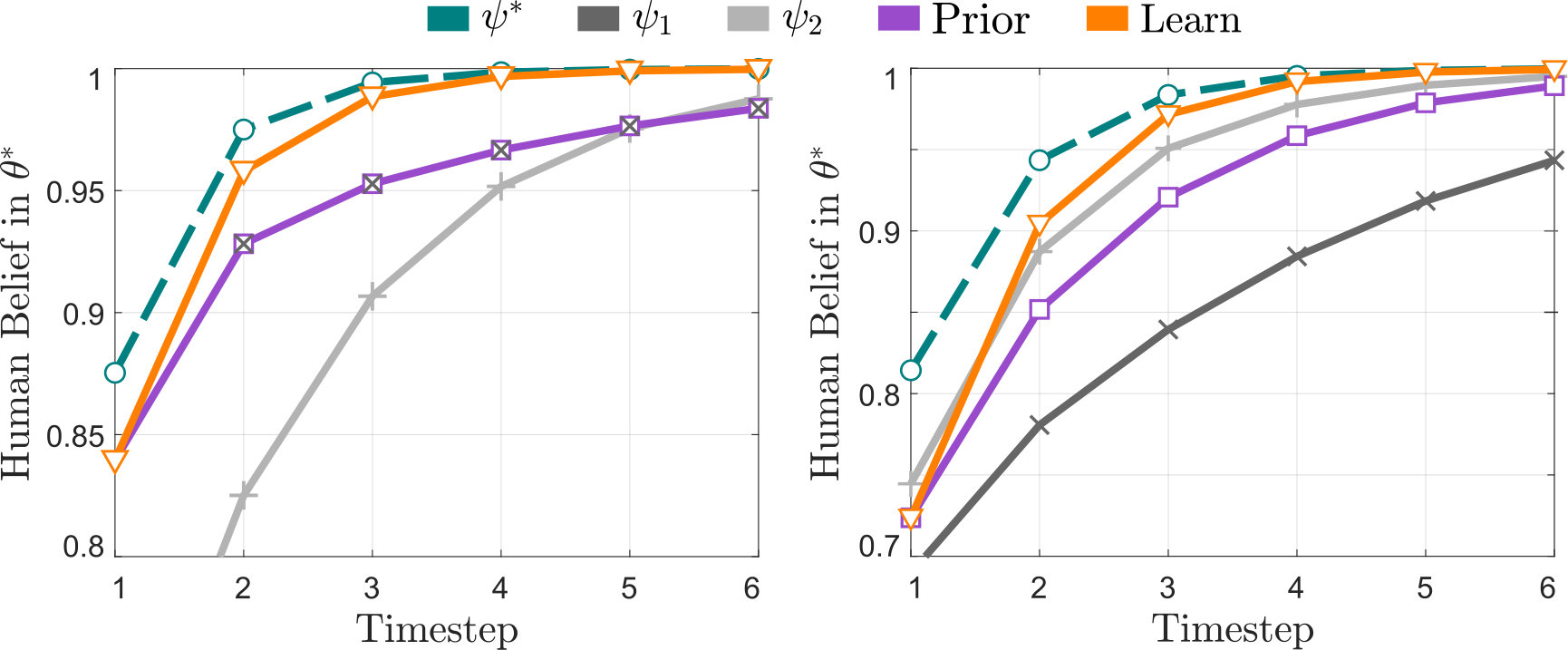 Figure 10
Figure 10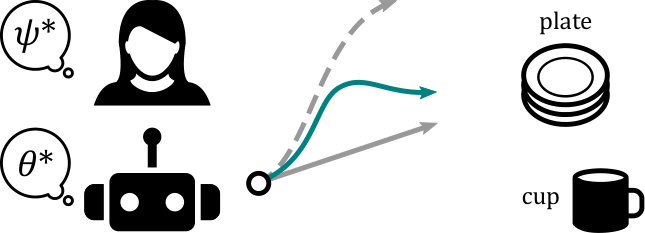 Figure 11
Figure 11Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Enabling Robots to Infer how End-Users Teach and Learn through Human-Robot Interaction
Dylan P. Losey, Student Member, IEEE, and Marcia K. O’Malley, Senior Member, IEEE This work was funded in part by the NSF GRFP-1450681.
The authors are with the Mechatronics and Haptic Interfaces Laboratory, Department of Mechanical Engineering, Rice University, Houston, TX 77005. (e-mail: [email protected])
Abstract
During human-robot interaction (HRI), we want the robot to understand us, and we want to intuitively understand the robot. In order to communicate with and understand the robot, we can leverage interactions, where the human and robot observe each other’s behavior. However, it is not always clear how the human and robot should interpret these actions: a given interaction might mean several different things. Within today’s state-of-the-art, the robot assigns a single interaction strategy to the human, and learns from or teaches the human according to this fixed strategy. Instead, we here recognize that different users interact in different ways, and so one size does not fit all. Therefore, we argue that the robot should maintain a distribution over the possible human interaction strategies, and then infer how each individual end-user interacts during the task. We formally define learning and teaching when the robot is uncertain about the human’s interaction strategy, and derive solutions to both problems using Bayesian inference. In examples and a benchmark simulation, we show that our personalized approach outperforms standard methods that maintain a fixed interaction strategy.
Index Terms:
Cognitive Human-Robot Interaction; Learning from Demonstration; Human Factors and Human-in-the-Loop
I Introduction
Human-robot interaction (HRI) provides an opportunity for the human and robot to exchange information. The robot can learn from the human by observing their behavior [1], or teach the human through its own actions [2]. In applications such as autonomous cars, personal robots, and collaborative assembly, fluent human-robot communication is often necessary.
In order to learn from and teach with interactions, however, the human and robot must correctly interpret the meaning of each other’s behavior. Consider an autonomous car following behind a human driven car. If the human car slows down, what should the robotic car infer: is the human teaching the robot to also slow down, or signaling that the robot should pass? When learning from an end-user, the robot needs a model of that end-user’s teaching strategy, i.e., how the human’s actions relate to the information that human wants to convey. Conversely, when teaching the end-user, the robot must model that end-user’s learning strategy, i.e., how the human interprets the robot’s actions. Together, we define the end-user’s teaching and learning strategies as their interaction strategy.
In the state-of-the-art, the robot assigns a pre-programmed, fixed interaction strategy to every human; each individual end-user is assumed to teach or learn in the same way. Instead:
We here recognize that different users have different interaction strategies, and we should infer the current end-user’s interaction strategy based on their actions.
Rather than a single fixed estimate of the human’s interaction strategy, we argue that the robot should maintain a distribution (i.e., belief) over the possible human interaction strategies, and update this belief during the task. By reasoning over this belief, the robot can adapt to everyday end-users, instead of requiring each human to comply with its single pre-defined strategy.
Overall, we make the following contributions:
Learning and Teaching with Strategy Uncertainty. We introduce and formulate two novel problems in human-robot interaction, where the robot must optimally communicate with the human, but the robot is unsure about how the current end-user teaches or learns.
Solution with Bayesian Inference. We derive methods for the robot to learn and teach under strategy uncertainty. We show that—when the robot does not know the end-user’s interaction strategy—optimal solutions infer and update a belief over that interaction strategy, resulting in personalized interactions.
Simulated Comparison to Current Methods. Using didactic examples and an inverse reinforcement learning simulation, we compare our proposed approach to robots that reason over a fixed interaction strategy. We also consider practical challenges such as noisy and unmodeled interaction strategies.
II Related Work
II-A Robots Learning from Humans
When a human expert is using interactions to teach a robot, the robot can leverage learning from demonstration (LfD) to understand how it should behave [1]. Most similar to our setting is inverse reinforcement learning (IRL), an instance of LfD where the robot learns the correct reward function from human demonstrations [3, 4]. Prior works on IRL generally assume that every human has a single, fixed teaching strategy [5]: the human teaches by providing optimal demonstrations, and any sub-optimal human behavior is interpreted as noise [6, 7, 8, 9]. Alternatively, robots can also learn about the human while learning from that human. In Nikolaidis et al. [10], for instance, the robot learns about the end-user’s adaptability in addition to their reward function. Building on these works, we will infer the end-user’s teaching strategy, so that the robot can more accurately learn from human interactions.
II-B Robots Teaching Humans
Machine teaching—also known as algorithmic teaching—identifies the best way for an expert robot to teach the novice human [2]. In order to teach optimally, however, the robot must know how the human learns. Recent machine teaching works [11, 12, 13] have addressed this problem by using human feedback to resolve mismatches between the assumed human learning strategy and the user’s actual learning strategy. Most related to our research is work by Huang et al. [14], which compares the performance of different models of human learning. These authors generated the optimal teaching examples for each proposed learning strategy, and then used human feedback to identify the single best teaching strategy across all users. Like Huang et al. [14], we here reason over multiple learning strategies, but now we want to infer each user’s specific learning strategy based on their individual responses.
III Problem Statement
Consider a human who is interacting with a robot. In this setting, both the human and the robot are agents. Let us assume that one of these agents has a target model, , which they want to teach to the other agent. Here is the space of possible target models, and is particular behavior that the teacher wants to convey to the learner. For example, the teacher may want to show the learner a better way to complete the current task, or communicate how it will interact in the future. We are interested in how the robot should behave when it is (a) learning from or (b) teaching to a human agent.
III-A Notation
Let us denote the robot state as . The human takes action , and the robot takes action ; these actions and the state are observed by both the robot and the human. We use a superscript to denote the current timestep, so that is the state at time , and is the sequence of states from the start of the task to the current time . In the context of supervised learning, we can think of as the input features, and and as the output labels assigned by the human and robot, respectively [15]. Here is a hypothesis space, and defines the correct mapping from features to labels.
III-B Learning from the Human
When the human is the expert—i.e., the human knows , but the robot does not—the robot should learn from the human. The human wants to teach the robot , and has a teaching strategy , which determines what actions the human selects to convey to the robot. More formally, a teaching strategy relates the setting to the human action :
[TABLE]
Here is the probability that the human will take action given , , and . We point out that (1) is also the human’s policy when teaching the robot, and that this policy is parameterized by . In other words, if the robot knows the teaching strategy , then it can leverage (1) to correctly interpret the meaning behind the human’s actions.
In practice, however, the robot does not know what teaching strategy an end-user will employ. Hence, we argue that the robot should maintain a probability distribution over as it learns from the human. We refer to this problem of learning from the end-user when uncertain about their teaching strategy as learning with strategy uncertainty:
Definition 1
(Learning with Strategy Uncertainty). Given a discrete or continuous set of possible teaching strategies and target models , infer an optimal estimate of based on the history of states and human actions .
III-C Teaching the Human
Next we consider the opposite situation, where the robot is the expert, and is trying to teach to the human. Here the human agent has some learning strategy , which determines how the human interprets the robot’s actions . A learning strategy expresses the relationship (from the human’s perspective) between the setting and the robot action :
[TABLE]
In the above, is the human’s model of the robot’s policy—not necessarily the robot’s actual policy—and this model is parameterized by . So now, if the robot knows the user’s true learning strategy , the robot can leverage (2) to anticipate how its actions will alter the human’s understanding of .
But, when teaching an actual end-user, the robot does not know what learning strategy that specific user has. Similar to before, we therefore argue that the robot should maintain a distribution over the learning strategies when teaching the human. We refer to this problem, where the robot is teaching a user but is unsure about that end-user’s learning strategy, as teaching with strategy uncertainty:
Definition 2
(Teaching with Strategy Uncertainty). Given a discrete or continuous set of possible learning strategies and target models , select the robot action that optimally teaches based on the history of states , robot actions , and human actions .
III-D Assumptions
Throughout this work, we will assume that the interaction strategies and for each individual user are constant, and are not affected by the robot’s behavior. Put another way, the robot cannot influence the human’s interaction strategy by selecting different actions. This assumption is consistent with prior HRI research [2, 5]: however, we can also extend our proposed approach to address cases where the human’s interaction strategy does change by incorporating a forgetting factor or transition model within the Bayesian inference.
IV Robot Learning with Strategy Uncertainty
Within this section we focus on learning from the human, where the robot does not initially know the human’s teaching strategy . Learning here is challenging, because the robot is uncertain about how to interpret the human’s actions. First, we demonstrate how the robot can learn from multiple models of the human’s teaching strategy. Second, we enable the robot to update its joint distribution over and , and simultaneously learn both the human’s teaching strategy and target model. We provide an example which compares learning this joint distribution to learning with a single fixed estimate of .
IV-A Multiple Teaching Strategies
The robot starts with a prior over what is, and updates that belief at every timestep based on the observed states and actions. The robot’s belief over target models is:
[TABLE]
In other words, is the probability that given the history of observed states and human actions up to timestep . Applying Bayes’ rule, and recalling from (1) that the human’s actions are conditionally independent, the robot’s Bayesian belief update becomes [16]:
[TABLE]
We here used a semicolon to separate the observed variables from the hidden variables. The denominator—which integrates over all possible target models—is a normalizing constant. Omitting this constant, we can more succinctly write (4) as:
[TABLE]
where is the robot’s observation model, i.e., the likelihood that the human takes action given and .
To correctly learn from the end-user, the robot needs an accurate observation model. We saw in Section III-B that the most accurate observation model is the user’s policy , which is parameterized by the true teaching strategy . Within the state-of-the-art, the robot often assumes that the user’s policy is parameterized by , where is some estimate of :
[TABLE]
Rather than a constant point estimate of the human’s teaching strategy, we argue that the robot should maintain a belief over multiple teaching strategies. In the simplest case, the robot has a prior over what is, but does not update this belief between timesteps. Here the observation model becomes:
[TABLE]
Note that (6) is a special case of (7) where . When learning with (7), the robot does not interpret human actions in the context of just one teaching strategy. Instead, the robot considers what the action implies for each possible teaching strategy, and then learns across these strategies. We can think of (7) as the best fixed learning strategy when is known.
IV-B Inferring a Joint Belief
Now that we have introduced learning with multiple teaching strategies, we can solve learning with strategy uncertainty (Definition 1). Here we not only want to learn the target model , but we also recognize that the robot is uncertain about . Let us define the robot’s joint belief over the target models and teaching strategies to be:
[TABLE]
Again leveraging Bayes’ rule and conditional independence:
[TABLE]
where is the conditional probability of human action given , , and . But this is the same as (1), so that:
[TABLE]
Using (10), we learn about both the human’s target model and the human’s teaching strategy from and .
Let us compare the observation model for this joint learning rule to the observation models from (6) and (7). If we rewrite (10) into the form of (5), we obtain the observation model:
[TABLE]
where the belief over teaching strategies given is:
[TABLE]
Intuitively, a robot implementing (11) and (12) reasons across multiple teaching strategies when learning from the end-user, and also updates its belief over these teaching strategies every timestep. We find that the observation model (7) is a special case of (11) when the robot never updates , i.e., if the robot’s belief over teaching strategies is constant. Accordingly, (6) is a special case of (11) by extension. Our analysis shows that inferring a joint belief over and both generalizes prior work and is an optimal learning rule.
IV-C Learning Example
To demonstrate how the proposed observation models affect the robot’s learning, we here provide an example simulation. Consider the sorting task in Fig. 1, where the robot is attempting to learn the right threshold classifier from the human. At each timestep , the human action indicates one screw that should be classified as short; the robot then classifies the remaining screws without additional guidance. Let be the correct decision boundary, and let the robot’s reward equal the total number of screws classified correctly. We can think of this example as an instance of inverse reinforcement learning [4], where the robot learns the true objective .
Importantly, we include two different teaching strategies that the human might use. Within the first strategy, , the human noisily indicates the short screw closest to , so that . Within the second strategy, , the user indicates a short screw uniformly at random, so that if or otherwise. Each end-user leverages one of these two teaching strategies; however, the robot does not know which.
Observation Models. We compare (6), (7), and (11). Let denote a robot that learns with (6), and assumes for all users. Similarly, is a robot that assumes . Prior denotes a robot with observation model (7), and Joint leverages our proposed approach (11). Finally, is an ideal robot that knows the teaching strategy for each individual user.
Simulation. At timestep the robot observes the action and updates its belief with (5). Next, the robot optimally sorts screws based on its current belief [8]. At timestep the task is repeated with the same end-user (who has a constant and ). The results of these simulations averaged across end-users are shown in Figs. 2 and 3.
Analysis. Using our proposed Joint observation model resulted in fewer errors than learning under , , or Prior. With Joint the robot was able to personalize its learning strategy to the current end-user across multiple iterations, and more accurately learn what the user was communicating (see Fig. 2). As expected, Prior outperformed other fixed strategies when was correct; however, if the robot did not have an accurate prior over teaching strategies, the Prior observation model (7) was less optimal than (see Fig. 3, right). We found that our proposed approach was robust to this practical challenge: despite having the wrong prior, Joint still caused the robot’s behavior to converge to the ideal learner, .
V Robot Teaching with Strategy Uncertainty
Within this section we consider the opposite problem, where the expert robot is teaching the human about , but does not know the end-user’s learning strategy . Teaching here is challenging because the robot is not certain what the user will learn from its actions. We first outline a specific instance of robot teaching, where the human learns through Bayesian inference. Next, we demonstrate how the robot can teach with multiple models of the human’s learning strategy, and derive one solution to teaching with strategy uncertainty. In a simulated example, we compare these methods to robots that teach with a constant point estimate of . We also describe how the robot can trade-off between teaching to and learning from the human via active teaching.
V-A Teaching Bayesian Humans
Similar to previous works in machine teaching [14, 17] and cognitive science [18, 19], we assume that the human learns by performing Bayesian updates. Thus, the human’s belief over the target models after robot action becomes:
[TABLE]
where we use ; to denote that the human observes but not . The denominator is again the normalizing constant:
[TABLE]
We point out that in (13) and (14) is (2), the policy that the human assigns to the robot. The human interprets the robot’s actions—and updates its belief—based on this policy, which is parameterized by the human’s true learning strategy . Here is also the state of the human at timestep , and (13) defines the state dynamics (i.e., the human’s transition function).
The robot should select actions so that this state transitions to . Let us define the ideal robot action as:
[TABLE]
where will greedily maximize the human’s belief in at the subsequent timestep. The human takes an action based on what they have previously learned; the human actions are therefore observations on the human’s state, i.e., . For example, the human’s action could be completing a test about the target models, or performing the task themselves. Here we consider the simplest case, where:
[TABLE]
Hence, the human feedback provides their actual belief over the target models at the current timestep. The robot observes the human state from (16), and selects action with (15) to shift the human towards the desired state .
V-B Multiple Learning Strategies
Consider cases where the robot is teaching this Bayesian human, but does not know the human’s learning strategy . When (and therefore the future state ) is unknown, teaching is analogous to controlling an agent with unknown state dynamics [20]. Define as the robot’s prediction of the human’s state given the history of actions and world states:
[TABLE]
Since the human performs Bayesian inference (13), and recalling that the robot observes , we equivalently have:
[TABLE]
Within the above, is the robot’s belief over the human’s learning strategies. For the state-of-the-art, the robot estimates the human’s learning strategy as , so that (18) reduces to:
[TABLE]
Instead, we here argue that the robot should teach with a belief over multiple learning strategies. Let be the prior over what is. If the robot never updates this initial belief, then the predicted human state after action becomes:
[TABLE]
Comparing (20) to (19), now the robot reasons about how its actions are interpreted by each learning strategy. When selecting the action with (15)—where we replace with prediction —this robot teaches across multiple strategies.
V-C Inferring the Learning Strategy
Because the robot is getting feedback from the user, however, we can also infer that specific user’s learning strategy, . Learning about provides a solution to teaching with strategy uncertainty (Definition 2), and results in robots that adapt their teaching to match the human. Let us formally define the robot’s belief over learning strategies as:
[TABLE]
We use the subscript instead of since does not actually depend on , as we will show. Applying Bayes’ rule:
[TABLE]
Recalling that the human’s learning strategy is not altered by the robot, . Moreover, because the human is a Bayesian learner, and , here depends on , , , and (13). Hence, (22) simplifies to:
[TABLE]
Intuitively, (23) claims that the belief over learning strategies is updated based on the differences between the human’s actual state (left side of the likelihood function) and the predicted human state given (right side of the likelihood function)111We used Kullback-Leibler (KL) divergence [21] to define the likelihood of given the right side of (23), but other options are possible.. By observing , we can use (23) to infer the human’s learning strategy. By then substituting (23) back into (18), the robot learns about while teaching the human : thus, using (18) with (23) addresses teaching with strategy uncertainty.
V-D Teaching Example
Here we provide an illustration of how reasoning over multiple learning models can improve teaching with uncertainty. As shown in Fig. 4, the robot is moving towards goal position , and wants to teach that goal to the nearby human. At each timestep , the robot’s action is an incomplete trajectory (e.g., see the three trajectory segments in Fig. 4). After observing this robot trajectory, the human updates their belief over ; specifically, the human applies Bayesian inference to determine whether the robot’s goal is the cup or the plate. The robot uses (15) with prediction to select the trajectory which will teach the human the most about .
We consider two possible learning strategies for the simulated end-users. Humans with learn best from legible (i.e., exaggerated) trajectories [22]: if the robot moves directly towards , slightly exaggerates, or fully exaggerates, respectively. By contrast, under the user learns best from predictable (i.e., goal-directed) trajectories, such that if the robot moves directly towards , slightly exaggerates, or exaggerates, respectively. The robot does not know which strategy a given user selects.
Prediction Method. We compare (18), (19), and (20). Let denote a robot which predicts that every user learns with (19), where . Likewise, is a robot that estimates . The Prior robot reasons over both learning strategies using (20), and our proposed Learn robot solves teaching with strategy uncertainty by leveraging (18) with (23).
Simulation. The robot observes the human action —i.e., the human’s current belief—and selects an action using (15) and its prediction method. The robot can select between different legible or goal-directed trajectory segments ( for each goal ). The human is a Bayesian learner. Our results (averaged across simulated users) are depicted in Figs. 5 and 6.
Analysis. Robots using our proposed Learn approach more quickly taught than with the fixed teaching methods , , or Prior. Reasoning over human learning strategies led to better teaching during a single interaction (see Fig. 5). For multiple iterations, we tested practical scenarios where the robot has the wrong prior: in every case, Learn yielded the fastest convergence, and taught as well as the ideal teacher after timesteps (see Fig. 6). Intuitively, the Learn robot gradually shifted to teaching with either legible or predictable trajectories, while the Prior robot continued to compromise between both strategies instead of adapting to the specific user.
V-E Active Teaching
Like we saw in the previous example, learning about the human’s learning strategy can improve the robot’s teaching. Hence, we here focus on selecting robot actions which actively gather information about , so that the robot more quickly adapts its teaching to the end-user. Let us formulate teaching with strategy uncertainty as a partially observable Markov decision process (POMDP) [16]: the state is \big{(}b^{t}({\theta}),\theta^{*},\psi^{*}\big{)}, the action is , the observation is , the state transitions with (13)—where and are constant—the observation model is (23), and the reward is . Solving this POMDP causes the robot to optimally trade-off between exploring for more information about and exploiting that information to maximize the human’s belief in . When solving this POMDP is intractable, we can more simply perform active teaching by favoring actions that gather information about [23]:
[TABLE]
In the above, , and is the Shannon entropy. Comparing (24) to (15), now the robot selects actions to disambiguate between the possible learning strategies (i.e., reduce the entropy of the robot’s belief over ). Intuitively, we expect a robot that is actively teaching with (24) to select actions, , which cause users with different learning strategies to respond in different ways, allowing that robot to more easily infer .
VI Robot Learning Simulations
To compare our learning with strategy uncertainty against the state-of-the-art in a realistic problem setting, we performed a simulated user study. We here consider an instance of inverse reinforcement learning (IRL): the human demonstrates a policy, and the robot attempts to infer the human’s reward function from that demonstrated policy [3, 4, 5]. Unlike the example in Section IV-C, now (the human’s reward parameters) and (the human’s demonstration strategy) lie in continuous spaces. We compared robots that learn with a constant point estimate of to our proposed method, where the robot learns about both and from the human. To test the robustness of our method within more complex and challenging scenarios, we also introduced noisy end-users, who did not follow any of the modeled teaching strategies.
VI-A Setup and Simulated Users
Within each simulation the human and robot were given an 8-by-8 gridworld (64 states). The state reward, , is the linear combination of state features weighted by , so that . The human knows , and provides a demonstration . This demonstration is a policy, where the human labels each state with action ; actions deterministically move in one of the four cardinal directions. The discount factor—which defines the relative importance of future and current rewards—was fixed at .
Our setting is based upon previous IRL works [5], where this problem is more formally introduced as a Markov decision process (MDP). These prior works typically assume that the human’s demonstrated policy approximately solves the MDP, i.e., maximizes the expected sum of discounted rewards [8, 9]. By contrast, we here considered users with a spectrum of demonstration strategies. Let be the reward for taking action in state , and then following the optimal policy for reward parameters . We define the probability that the simulated user takes action given , , and as:
[TABLE]
where , and is the state reached after taking action in state . When , (25) is the same as the observation model from [8, 9]. As , the human biases their demonstration towards states that have locally higher rewards; conversely, when , the human favors states with lower rewards. Sample user demonstrations with different teaching strategies are shown in Fig. 7.
VI-B Independent Variables
We compared four different approaches for learning from the user’s demonstration: , , , and Joint. Under the ideal robot knows the human’s true teaching strategy, while and indicate robots which assume that the human’s demonstration is biased towards low-reward or high-reward states, respectively. Joint refers to a robot which attempts to learn both and from the human’s demonstration, as discussed in Section IV-B.
To see how these approaches scale with the length of the feature vector, , we performed simulations with , , and features. In practice, each state was randomly assigned a feature vector with binary values, indicating which features were present in that particular gridworld state.
Finally, to test how well the robot learned when the human demonstrations were imperfect, we varied the value of in (25). Parameter represents how close to optimal the human is: as , the human becomes increasingly random, while the human always chooses the best action when .
We simulated users for each combination of and , where the users’ teaching strategies were uniformly distributed in the continuous interval . The gridworld and were randomly generated for each individual user.
VI-C Dependent Measures
For each simulation we measured the robot’s learning performance in terms of Reward Error, Strategy Error, and Policy Loss. Reward Error is the difference between the robot’s mean estimate of and the correct reward parameters: . Similarly, Strategy Error is the error between the robot’s mean estimate of and the user’s actual teaching strategy: . Policy Loss measures how much reward is lost by following the robot’s learned policy (which maximizes reward under ) as compared to the optimal policy for [8]. The code for our examples and simulations can be found at https://github.com/dylanplosey/iact_strategy_learning.
VI-D Results and Discussion
We performed a mixed ANOVA with the number of features and value of as between-subjects factors, and the learning approach as a within-subjects factor, for both Policy Loss and Reward Error (see Figs. 8 and 9). Since we found a statistically significant interaction for both dependent measures (), we next determined the simple main effects.
Simple main effects analysis showed that Joint resulted in significantly less Policy Loss than either or for each different combination of and (). We similarly found that Joint resulted in significantly less Reward Error () for every case except , ; here there was no statistically significant difference between Joint and (). These results from Figs. 8 and 9 suggest that learning while maintaining a distribution over results in objectively better performance than learning with a fixed point estimate of .
Next, we investigated how well the Joint method learned the individual users’ teaching strategies. We performed a two-way ANOVA to find the effects of and on the Joint robot’s Strategy Error (see Fig. 10). We found that the number of features () and the human’s () had a significant main effect. Post-hoc analysis with Tukey HSD revealed that and led to significantly higher Strategy Error than the other values of and , respectively. As shown in Fig. 10, the robot had larger Strategy Error for higher values of because it was unable to distinguish between teachers with ; i.e., these different teachers provided similar policy demonstrations when .
Finally, we conducted a followup simulation in which we introduced unmodeled noise (see Fig. 11). Here and , but we now increased the ratio of the human taking completely random actions, which were not modeled in (25). Joint resulted in significantly less Policy Loss than or , even as the ratio of unmodeled user noise increased. Hence, reasoning over multiple strategies still improved performance for cases where the noisy end-user did not comply with any of the modeled teaching strategies.
VI-E Challenges and Limitations
Although this simulated user-study supports learning with strategy uncertainty, there are still practical challenges that may limit our proposed approach. In particular, the end-user’s actual interactions may not match any of the learning or teaching models, such that or . Having the wrong hypothesis space is often unavoidable when using models to learn from humans: but, as we show in Fig. 11, our proposed approach does remain robust to some errors in the hypothesis space (such as noisy users, that do not follow any of the included models). In practice, designers could leverage data from previous trials to construct a richer space of possible interaction strategies, so that is updated to include .
VII Conclusion
Because the human’s interaction strategy during HRI varies from end-user to end-user, robots that assume a fixed, pre-defined interaction strategy may result in inefficient, confusing interactions. Thus, we proposed that the robot should maintain a distribution over the human interaction strategies, and exchange information while reasoning over this distribution. We here introduced robot (a) learning with strategy uncertainty and (b) teaching with strategy uncertainty, and derived solutions to both novel problems. We performed learning and teaching examples—as well as learning simulations—and compared our approach to the state-of-the-art. Unlike standard approaches that assume every user interacts in the same way, we found that attempting to infer each individual end-user’s interaction strategy led to improved robot learning and teaching, while remaining robust to unmodeled strategies.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] B. D. Argall, S. Chernova, M. Veloso, and B. Browning, “A survey of robot learning from demonstration,” Robotics and Autonomous Systems , vol. 57, no. 5, pp. 469–483, 2009.
- 2[2] X. Zhu, “Machine teaching: An inverse problem to machine learning and an approach toward optimal education.” in AAAI , 2015, pp. 4083–4087.
- 3[3] A. Y. Ng, S. J. Russell et al. , “Algorithms for inverse reinforcement learning.” in Int. Conf. Machine Learning (ICML) , 2000, pp. 663–670.
- 4[4] P. Abbeel and A. Y. Ng, “Apprenticeship learning via inverse reinforcement learning,” in Int. Conf. Machine Learning (ICML) , 2004.
- 5[5] T. Osa, J. Pajarinen, G. Neumann, J. A. Bagnell, P. Abbeel, and J. Peters, “An algorithmic perspective on imitation learning,” Foundations and Trends in Robotics , vol. 7, no. 1-2, pp. 1–179, 2018.
- 6[6] J. Choi and K.-E. Kim, “MAP inference for Bayesian inverse reinforcement learning,” in NIPS , 2011, pp. 1989–1997.
- 7[7] D. P. Losey and M. K. O’Malley, “Including uncertainty when learning from human corrections,” in Conf. on Robot Learning (Co RL) , 2018, pp. 123–132.
- 8[8] D. Ramachandran and E. Amir, “Bayesian inverse reinforcement learning,” Urbana , vol. 51, no. 61801, pp. 1–4, 2007.