CodedPrivateML: A Fast and Privacy-Preserving Framework for Distributed Machine Learning
Jinhyun So, Basak Guler, A. Salman Avestimehr

TL;DR
CodedPrivateML is a scalable framework that enables privacy-preserving distributed machine learning by ensuring data and model privacy while maintaining high training efficiency and convergence guarantees.
Contribution
It introduces CodedPrivateML, a novel approach combining information-theoretic privacy with parallel training, outperforming cryptographic methods in speed.
Findings
Achieves privacy threshold with theoretical guarantees
Demonstrates convergence for logistic and linear regression
Provides significant speedup over MPC-based approaches
Abstract
How to train a machine learning model while keeping the data private and secure? We present CodedPrivateML, a fast and scalable approach to this critical problem. CodedPrivateML keeps both the data and the model information-theoretically private, while allowing efficient parallelization of training across distributed workers. We characterize CodedPrivateML's privacy threshold and prove its convergence for logistic (and linear) regression. Furthermore, via extensive experiments on Amazon EC2, we demonstrate that CodedPrivateML provides significant speedup over cryptographic approaches based on multi-party computing (MPC).
Click any figure to enlarge with its caption.
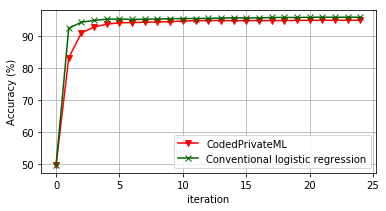 Figure 1
Figure 1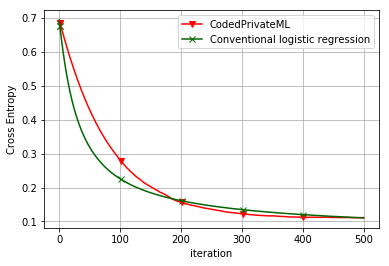 Figure 2
Figure 2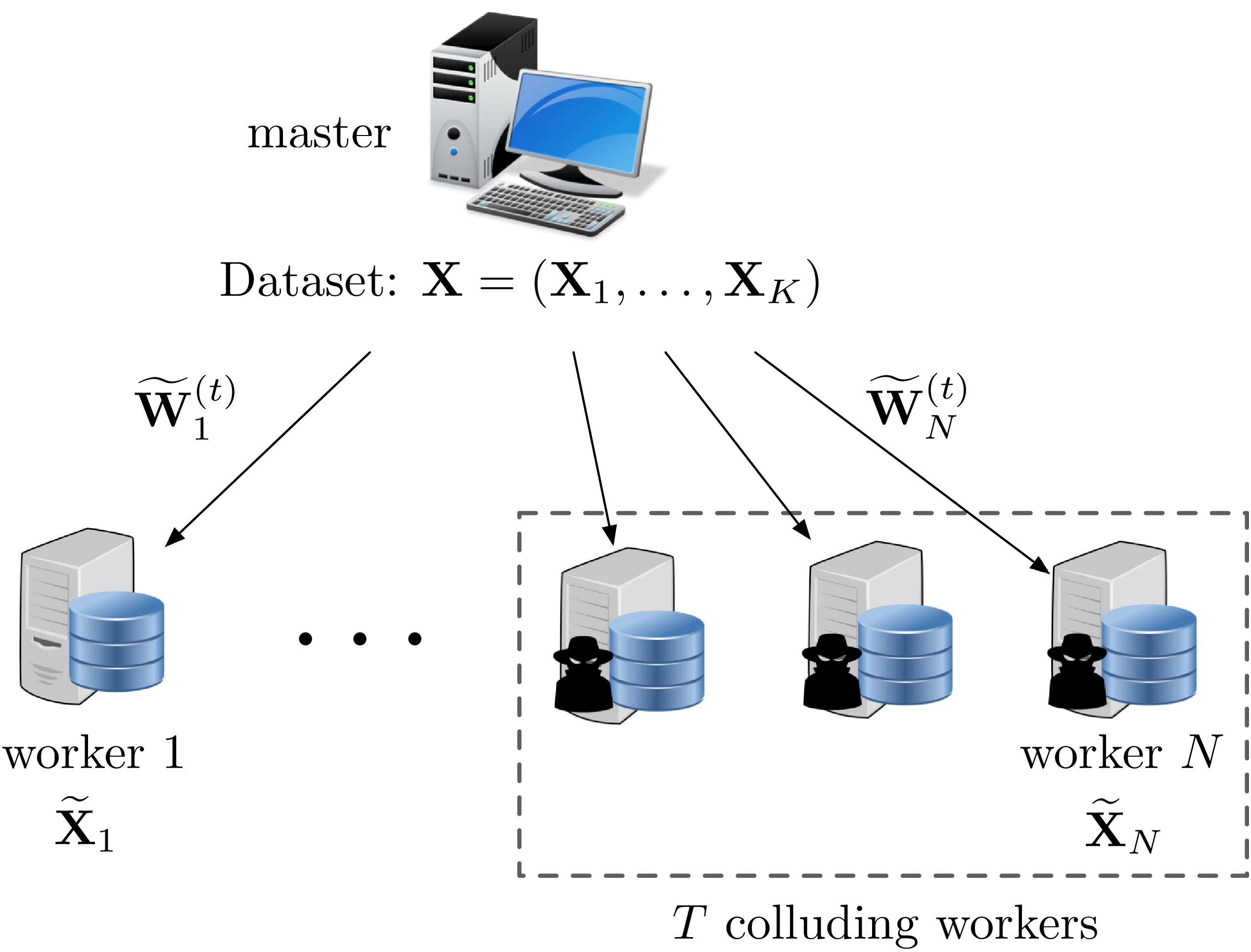 Figure 3
Figure 3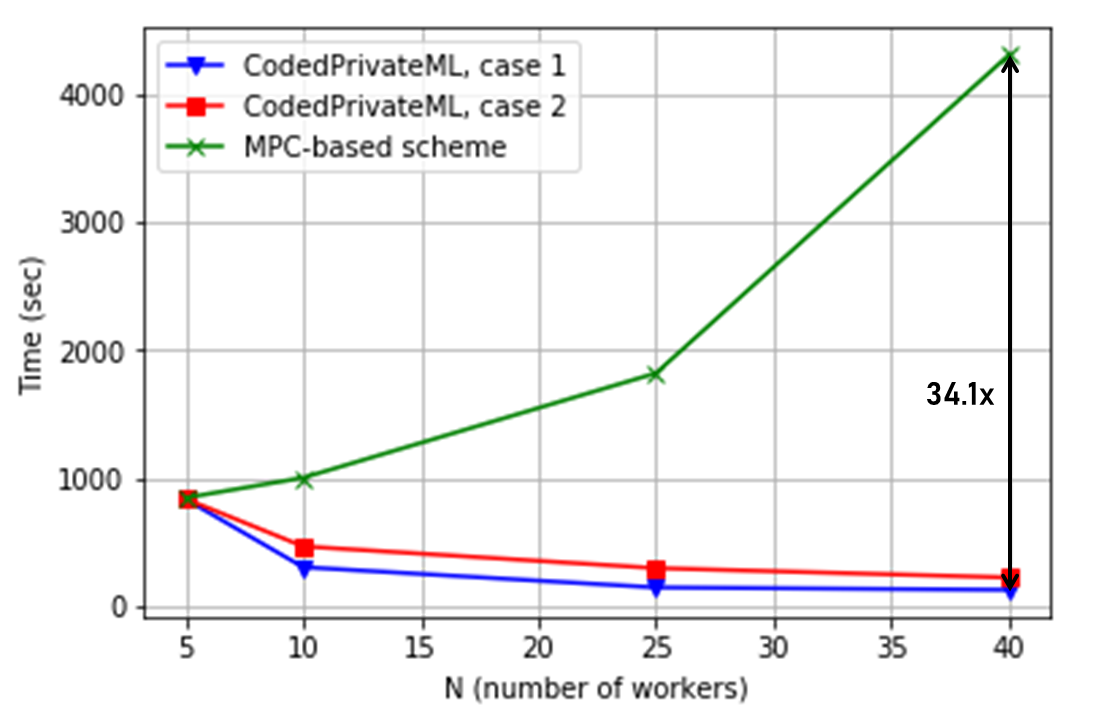 Figure 4
Figure 4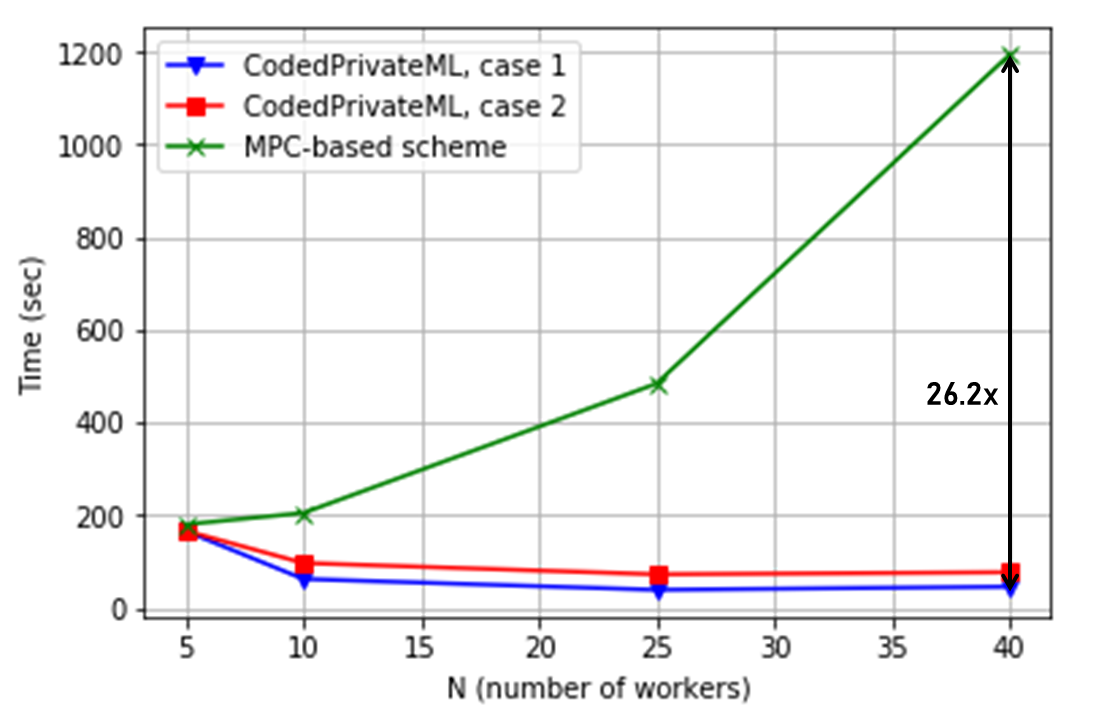 Figure 5
Figure 5| Computation | Communication | |
|---|---|---|
| Master | ||
| Worker |
| Protocol | Enc. | Comm. | Comp. | Total |
|---|---|---|---|---|
| time (s) | time (s) | time (s) | time (s) | |
| MPC using [BGW88] | 202.78 | 31.02 | 7892.42 | 8127.07 |
| MPC using [BH08] | 201.08 | 30.25 | 1326.03 | 1572.34 |
| CodedPrivateML (Case 1) | 59.93 | 4.76 | 141.72 | 229.07 |
| CodedPrivateML (Case 2) | 91.53 | 8.30 | 235.18 | 361.08 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
CodedPrivateML: A Fast and Privacy-Preserving Framework for Distributed Machine Learning
Jinhyun So1, Başak Güler1, and A. Salman Avestimehr
1 Equal contribution. This material is based upon work supported by Defense Advanced Research Projects Agency (DARPA) under Contract No. HR001117C0053, ARO award W911NF1810400, NSF grants CCF-1703575 and CCF-1763673, and ONR Award No. N00014-16-1-2189, and a gift from Intel. The views, opinions, and/or findings expressed are those of the author(s) and should not be interpreted as representing the official views or policies of the Department of Defense or the U.S. Government. Jinhyun So is with the Department of Electrical and Computer Engineering, University of Southern California, Los Angeles, CA, 90089 USA (e-mail: [email protected]). Başak Güler is with the Department of Electrical and Computer Engineering, University of California, Riverside, CA, 92521 USA (email: [email protected]). A. Salman Avestimehr is with the Department of Electrical and Computer Engineering, University of Southern California, Los Angeles, CA, 90089 USA (e-mail: [email protected]). This work is published in IEEE Journal on Selected Areas in Information Theory [1].
Abstract
How to train a machine learning model while keeping the data private and secure? We present CodedPrivateML, a fast and scalable approach to this critical problem. CodedPrivateML keeps both the data and the model information-theoretically private, while allowing efficient parallelization of training across distributed workers. We characterize CodedPrivateML’s privacy threshold and prove its convergence for logistic (and linear) regression. Furthermore, via extensive experiments on Amazon EC2, we demonstrate that CodedPrivateML provides significant speedup over cryptographic approaches based on multi-party computing (MPC).
Index Terms:
Distributed training, privacy-preserving machine learning.
I Introduction
Modern machine learning models are breaking new ground by achieving unprecedented performance in various application domains [2]. Training such models, however, is a challenging task. Due to the typically large volume of data and complexity of models, training is a compute and storage intensive task. Furthermore, training should often be done on sensitive data, such as healthcare records, browsing history, or financial transactions, which raises the issues of security and privacy of the dataset. This creates a challenging dilemma. On the one hand, due to its complexity, training is often desired to be outsourced to more capable computing platforms, such as the cloud. On the other hand, the training dataset is often sensitive and particular care should be taken to protect its privacy against potential breaches in such platforms. This dilemma gives rise to the main problem that we study here: How can we offload the training task to a distributed computing platform, while maintaining the privacy of the dataset?
Cloud environments often operate on a shared physical infrastructure, where multiple users share the same host machine, and are separated from each other by virtual machines that act as barriers to prevent information leakage. This shared environment provides significant benefits for scaling up cloud systems, but also introduces important security and privacy challenges that may result from potentially adversarial users. For instance, it has been shown that adversarial users can compromise the host machines by disguising themselves as regular users, and access the information of other users sharing the same host machines [3, 4, 5, 6, 7, 8]. The focus of this paper is on privacy protection against such adversaries that can access a portion of the physical host machines in the cloud, and use them to spy on other users’ datasets. We focus on the semi-honest adversary setup, where the adversaries follow the protocol but may leak information in an attempt to learn the training dataset. Our goal is to develop a privacy-preserving training strategy for the honest users that will protect the privacy of their datasets even if a portion of the compute machines in the cloud are controlled by adversaries.
More specifically, we consider a scenario in which a data-owner (e.g., a hospital) wishes to train a logistic regression model by offloading the large volume of data (e.g., healthcare records) and computationally-intensive training tasks (e.g., gradient computations) to machines over a cloud platform, while ensuring that any collusions between out of workers do not leak information about the training dataset. We propose a new framework, CodedPrivateML (Coded Privacy-preserving Machine Learning), towards addressing this problem. CodedPrivateML has three salient features:
provides strong information-theoretic privacy guarantees for both the training dataset and model parameters in the presence of colluding workers, 2. 2.
enables fast training by distributing the computation load effectively across several workers, 3. 3.
leverages a new method for encoding the dataset and model parameters based on coding and information theory principles, which significantly reduces the communication overhead and the complexity for distributed training.
At a high level, CodedPrivateML can be described as follows. It secret shares the dataset and model parameters at each round of the training in two steps. First, it employs stochastic quantization to convert the dataset and the weight vector at each round into a finite domain. It then combines (or encodes) the quantized values with random matrices using Lagrange coding [9], to guarantee privacy (in an information-theoretic sense) while simultaneously distributing the workload among multiple workers. The challenge is however that Lagrange coding can only work for computations that are in the form of polynomial evaluations. The gradient computation for logistic regression, on the other hand, includes non-linearities that cannot be expressed as polynomials. CodedPrivateML handles this challenge through polynomial approximations of the non-linear sigmoid function in the training phase. Upon secret sharing of the encoded dataset and model parameters, each worker performs the gradient computations using the chosen polynomial approximation, and sends the result back to the master. The workers perform the computations over the quantized and encoded data as if they were computing over the uncoded dataset. That is, the structure of the computations are the same for computing over the uncoded dataset versus computing over the encoded dataset. Finally, the master collects the results from a subset of fastest workers and decodes the gradient over the finite field. It then converts the decoded gradients to the real domain, updates the weight vector, and secret shares it with the worker nodes for the next round. We note that since the computations are performed in a finite domain while the weights are updated in the real domain, the update process may lead to undesired behaviour as weights may not converge. Our system guarantees convergence through a stochastic quantization technique while converting between real and finite fields.
We theoretically prove that CodedPrivateML guarantees the convergence of the model parameters, while providing information-theoretic privacy for the training dataset. Our theoretical analysis also identifies a trade-off between privacy and parallelization. More specifically, each additional worker can be utilized either for more privacy, by protecting against a larger number of collusions , or more parallelization, by reducing the computation load at each worker. We characterize this trade-off for CodedPrivateML. Furthermore, we empirically demonstrate the impact of CodedPrivateML by comparing it with the cryptographic approach based on secure multi-party computing (MPC) [10, 11, 12, 13], that can also be applied to enable privacy-preserving machine learning tasks (e.g., see [14, 15, 16, 17, 18, 19]). In particular, we envision a master who secret shares its data and model among multiple workers who collectively perform the gradient computation using a multi-round MPC protocol. Given our focus on information-theoretic privacy, the most relevant MPC-based schemes for empirical comparison are the protocols from [11] and [12, 13] based on Shamir’s secret sharing [20]. While several more recent works design MPC-based learning setups with information-theoretic privacy, their constructions are limited to three or four parties [21, 22].
We run extensive experiments over the Amazon EC2 cloud platform to empirically demonstrate the performance of CodedPrivateML. We train a logistic regression model for image classification over the CIFAR-10 [23] and GISETTE [24] datasets, while the computation workload is distributed to up to machines over the cloud. We demonstrate that CodedPrivateML can provide significant speedup in the training time against the state-of-the-art MPC baseline (up to 5.2), while guaranteeing comparable levels of accuracy. This is primarily due to conventional MPC protocols’ reliance on extensive communication and coordination between the workers for private computing, and not benefiting from parallelization. They can however guarantee a higher privacy threshold (i.e., larger ) compared with CodedPrivateML.
I-A Other related works
Apart from the MPC-based schemes, one can consider two other solutions to this problem. One is based on Homomorphic Encryption (HE) [25] which allows for computations to be performed on encrypted data, and has been used for privacy-preserving machine learning solutions [26, 27, 28, 29, 30, 31, 32, 33, 34]. The privacy guarantees of HE are based on computational assumptions, whereas CodedPrivateML provides strong information-theoretic privacy. Moreover, HE requires computations to be performed on encrypted data which leads to many orders of magnitude slow down in training. For example, for image classification on the simple MNIST dataset, HE takes hours to learn a logistic regression model with accuracy [34], whereas for the same training setup, CodedPrivateML takes only seconds. This is due to the fact that, in CodedPrivateML there is no slow down in performing coded computations which allows for a faster implementation. As a trade-off, HE allows collusions between a larger number of workers whereas in CodedPrivateML this number is determined by other system parameters such as the number of workers and the computation load assigned per worker.
Another possible solution is based on differential privacy (DP), which is a noisy release mechanism that preserves the privacy of personally identifiable information, in that the removal of any single element from the dataset does not change the computation outcomes significantly [35]. In the context of machine learning, DP is mainly used for training when the model parameters are to be released for public use, to ensure that the individual data points from the dataset cannot be identified from the released model [36, 37, 38, 39, 40, 41, 42]. The main difference between these approaches and our work is that our focus is on ensuring strong information-theoretic privacy (that leaks no information about the dataset) during training, while preserving the accuracy of the model. We note, however, that if the intention is to publicly release the model after training, it is in principle possible to compose the techniques of CodedPrivateML with differential privacy to obtain the best of both worlds.
II System Model
We study the problem of training a logistic regression model. The training dataset is represented by a matrix consisting of data points with features and a label vector . The model parameters (weights) are obtained by minimizing the cross entropy function,
[TABLE]
where is the estimated probability of label being equal to , is the row of , and is the sigmoid function . The problem in (1) can be solved via gradient descent, through an iterative process that updates the model parameters in the opposite direction of the gradient. The gradient for (1) is given by . Accordingly, model parameters are updated as,
[TABLE]
where holds the estimated parameters from iteration , is the learning rate, and function operates element-wise over the vector given by .
We consider the master-worker distributed computing architecture shown in Figure 1, in which the master offloads the computationally-intensive operations to workers. For the training problem, these operations correspond to gradient computations in (2).
In doing so, the master wishes to protect the privacy of the dataset against any potential collusions between up to workers, where is the privacy parameter of the system.
In this work, we consider strong information-theoretic privacy, where any subset of colluding workers can not learn any information about the original dataset . Formally, for every subset of workers of size at most , we require I\big{(}\operatorname{\mathbf{X}};\mathbf{Z}_{\mathcal{T}}\big{)}=0 for any distribution on , where is the mutual information, and represents the collection of all the information received by the workers in set during training. The distribution of may be known to the workers. We refer to a protocol that guarantees privacy against colluding workers as a -private protocol. In the sequel, we present a novel protocol, CodedPrivateML, to solve (1) while preserving the information-theoretic privacy of the dataset against up to colluding workers.
Remark 1**.**
Although our presentation is based on logistic regression, CodedPrivateML can also be applied to the simpler linear regression model with minor modifications.
III The CodedPrivateML Protocol
CodedPrivateML consists of four main components: 1) quantization, 2) encoding, 3) polynomial approximation and gradient computation, and 4) decoding the gradient and model update. Figure 2 shows the flowchart of CodedPrivateML. In the first component, the master quantizes the dataset from the real domain to the domain of integers, and then embeds it in a finite field. In the second component, the master encodes the quantized dataset and sends them to the workers. At each iteration, the master also quantizes and encodes the model parameters. In the third component, given the encoded dataset and model parameters, each worker performs the gradient computations by using polynomial approximation to substitute the sigmoid function. In the last component, the master decodes the gradient computations and converts them from the finite field to real domain, and updates the model parameters in the real domain. This process is iterated until the model parameters converge.
We now provide the details of each component.
III-A Quantization
In order to guarantee information-theoretic privacy, one has to mask the dataset and weights in a finite field111We need a finite field instead of a ring as our encoding and decoding schemes based on Lagrange coding, which we explain in Sections III-B and III-D, require division (or inverse multiplication) which the ring does not have in general. using uniformly random matrices, so that the added randomness can make each data point appear equally likely. In contrast, the dataset and weights for the training task are defined in the domain of real numbers. Our solution to handle the conversion between the real and finite domains is through the use of stochastic quantization. Accordingly, in the first component of our system, master quantizes the dataset and weights from the real domain to the domain of integers, and then embeds them in a field of integers modulo a prime . The quantized version of the dataset is given by . The quantization of the weight vector , on the other hand, is represented by a matrix , where each column holds an independent stochastic quantization of . This structure will be important for the convergence of the model.
We consider an element-wise lossy quantization scheme for the dataset and weights. For quantizing the dataset , we use a simple deterministic rounding technique:
[TABLE]
where is the largest integer less than or equal to . We define the quantized dataset as
[TABLE]
where the rounding function from (3) is applied element-wise to the elements of matrix and is an integer parameter that controls the quantization loss. Function is a mapping defined to represent a negative integer in the finite field by using two’s complement representation,
[TABLE]
Note that the domain of (4) is \big{[}-\frac{p-1}{2^{(l_{x}+1)}},\frac{p-1}{2^{(l_{x}+1)}}\big{]}. To avoid a wrap-around which may lead to an overflow error, prime should be large enough, i.e., . The value of also depends on the bitwidth of the machine as well as the number of features . For instance, in our experiments presented in Section V, we select in a -bit implementation with the GISETTE dataset whose number of features is . This is the largest prime to avoid an overflow on intermediate multiplications. More specifically, we do a modular operation after the inner product of vectors instead of doing a modular operation per product of each element in order to speed up the running time of matrix-matrix multiplication. To avoid an overflow on this, should satisfy .
At each iteration , master also quantizes the weight vector from real domain to the finite field. This proves to be a challenging task as it should be performed in a way to ensure the convergence of the model. Our solution to this is a quantization technique inspired by [43, 44]. Initially, we define a stochastic quantization function:
[TABLE]
where is an integer parameter to control the quantization loss. is a stochastic rounding function:
[TABLE]
The probability of rounding to is proportional to the proximity of to so that stochastic rounding is unbiased (i.e., ).
For quantizing the weight vector , the master creates independent quantized vectors:
[TABLE]
where the quantization function (6) is applied element-wise to the vector and each denotes an independent realization of (6). To avoid a wrap-around which may lead to an overflow error, prime should be large enough, i.e., . The number of quantized vectors is equal to the degree of the polynomial approximation for the sigmoid function, which we will describe later in Section III-C. The intuition behind creating independent quantizations is to ensure that the gradient computations performed using the quantized weights are unbiased estimators of the true gradients. As detailed in Section IV, this property is fundamental for the convergence analysis of our model. The specific values of parameters and provide a trade-off between the rounding error and overflow error. In particular, a larger value reduces the rounding error while increasing the chance of an overflow. We denote the quantization of the weight vector as
[TABLE]
by arranging the quantized vectors from (7) in matrix form.
III-B Encoding the Dataset and the Model
In the second component, the master partitions the quantized dataset into submatrices and encodes them using Lagrange coding [9]. It then sends to worker a coded submatrix . This encoding enables two salient features of CodedPrivateML, parallelization and information-theoretic privacy guarantees. First, parameter is related to the computation load at each worker (i.e., what fraction of the dataset is processed at each worker) because the size of encoded dataset is -th of the size of original dataset . As we will show later, we can increase the parameter as increases, which reduces the computation overhead of each worker and communication overhead between the master and workers. This property enables our approach to scale to a significantly larger number of workers than state-of-the-art privacy preserving machine learning approaches. Second, this encoding ensures that the coded matrices do not leak any information about the original dataset even if workers collude, which will be showed in Section IV. In addition, the master has to ensure the weight estimations sent to the workers at each iteration do not leak information about the dataset. This is because the weights updated via (2) carry information about the whole training set, and sending them directly to the workers may breach privacy. In order to prevent this, at iteration , the master also quantizes the current weight vector to the finite field and encodes it again using Lagrange coding.
We now state the details of our second component. The master first partitions the quantized dataset into submatrices , where for . We assume that is divisible by . Next, the master selects distinct elements from and employs Lagrange coding [9] to encode the dataset. To do so, the master forms a polynomial of degree at most such that for , and for , where ’s are chosen uniformly at random from (the role of ’s is to mask the dataset and provide privacy against up to colluding workers). This can be accomplished by letting be the respective Lagrange interpolation polynomial,
[TABLE]
The master then selects distinct elements from such that , and encodes the dataset by letting for . By defining an encoding matrix whose element is given by , one can also represent the encoding of the dataset as
[TABLE]
At iteration , the quantized weights are also encoded using a Lagrange interpolation polynomial,
[TABLE]
where for are chosen uniformly at random from . The coefficients are the same as in (9), and we have the property for . The master then encodes the quantized weight vector by using the same evaluation points . Accordingly, the weight vector is encoded as
[TABLE]
for , using the encoding matrix from (10). The degree of the polynomials and are both .
III-C Polynomial Approximation and Gradient Computation
Upon receiving the encoded (and quantized) dataset and weights, workers should proceed with gradient computations. However, a major challenge is that Lagrange coding is originally designed for polynomial computations, while the gradient computations are not polynomials due to the sigmoid function. Our solution is to use a polynomial approximation of the sigmoid function,
[TABLE]
where and denotes the degree and coefficients of the polynomial, respectively. The coefficients are obtained by fitting the sigmoid function via least squares estimation. Using this polynomial approximation we can rewrite (2) as
[TABLE]
where is the quantized version of , and operates element-wise over the vector .
Another challenge is to ensure the convergence of weights. As we detail in Section IV, this necessitates the gradient estimations to be unbiased using the polynomial approximation with quantized weights. We solve this by utilizing the computation technique from Section in [44] using the quantized weights formed in Section III-A. Specifically, given a degree polynomial from (13) and independent quantizations from (8), we define a function
[TABLE]
where the product operates element-wise over the vectors for . Lastly, we note that (15) is an unbiased estimator of ,
[TABLE]
where acts element-wise over the vector , and the result follows from the independence of quantizations. Using (15), we rewrite the update equations from (14) using quantized weights,
[TABLE]
CodedPrivateML guarantees the convergence to the optimal loss function where is the cross entropy function defined in (1), even though we use the polynomial approximation to substitute the sigmoid function in the update equation (2), which will be demonstrated in Section IV.
Computations are then performed at each worker locally. At each iteration, worker locally computes ,
[TABLE]
using and and sends the result back to the master. This computation is a polynomial function evaluation in finite field arithmetic and the degree of is .
III-D Decoding the Gradient and Model Update
After receiving the evaluation results in (18) from a sufficient number of workers, master decodes \Big{\{}f\big{(}\overline{\operatorname{\mathbf{X}}}_{k},\overline{\operatorname{\mathbf{W}}}^{(t)}\big{)}\Big{\}}_{k\in[K]} over the finite field. The minimum number of workers needed for the decoding operation to be successful, which we call the recovery threshold of the protocol, is equal to as we demonstrate in Section IV.
We now proceed to the details of decoding. By construction of the Lagrange polynomials in (9) and (11), one can define a univariate polynomial h(z)=f\big{(}u(z),v(z)\big{)} such that
[TABLE]
for . On the other hand, from (18), the computation result from worker equals to
[TABLE]
The main intuition behind the decoding process is to use the computations from (20) as evaluation points to interpolate the polynomial . Specifically, the master can obtain all coefficients of from evaluation results as the degree of the polynomial is less than or equal to . After is recovered, the master can recover (19) by computing for . To do so, the master performs polynomial interpolation in a finite field. Upon receiving the local computation f\big{(}\widetilde{\operatorname{\mathbf{X}}}_{i},\widetilde{\operatorname{\mathbf{W}}}^{(t)}_{i}\big{)} in (20) from at least workers, the master computes
[TABLE]
for , where denotes the set of the first workers who send their local computations to the master. The master then aggregates the decoded computations f\big{(}\overline{\operatorname{\mathbf{X}}}_{k},\overline{\operatorname{\mathbf{W}}}^{(t)}\big{)} to compute the desired gradient as,
[TABLE]
Lastly, master converts (22) from the finite field to the real domain and updates the weights according to (17) in the real domain. This conversion is attained by the function
[TABLE]
where we let , and is defined as,
[TABLE]
The overall procedure of CodedPrivateML is given in Algorithm 1.
IV Theoretical Results
Consider the cost function (1) when the dataset is replaced with the quantized dataset . Also, denote as the optimal weight vector that minimizes (1) when , where is row of . In this section, we prove that CodedPrivateML guarantees convergence to the optimal model parameters (i.e., ) while maintaining the privacy of the dataset against colluding workers. Recall that the model update at the master follows from (17), which is
[TABLE]
We first state a lemma, which shows that the gradient estimation of CodedPrivateML is unbiased and variance bounded.
Lemma 1**.**
Let \mathbf{p}^{(t)}\triangleq\frac{1}{m}\overline{\operatorname{\mathbf{X}}}^{\top}\big{(}\bar{s}(\overline{\operatorname{\mathbf{X}}},\overline{\operatorname{\mathbf{W}}}^{(t)})-\mathbf{y}\big{)} denote the gradient computation using the quantized weights in CodedPrivateML. Then, we have
- •
(Unbiasedness) Vector is an asymptotically unbiased estimator of the true gradient. , and as where is the degree of the polynomial in (13) and the expectation is taken with respect to the quantization errors,
- •
(Variance bound) \mathbb{E}\big{[}\|\mathbf{p}^{(t)}-\mathbb{E}[\mathbf{p}^{(t)}]\|^{2}_{2}\big{]}\leq\frac{1}{2^{-2l_{w}}m^{2}}\|\operatorname{\overline{\mathbf{X}}}\|_{F}^{2}\triangleq\sigma^{2} where and are the and Frobenius norms, respectively.
Proof.
The proof of Lemma 1 is presented in Appendix A. ∎
We also need the following basic lemma, which describes the -Lipschitz property of the gradient of the cost function.
Lemma 2**.**
*The gradient of the cost function from (1) evaluated on the quantized dataset is -Lipschitz with , that is, for all . *
Proof.
The proof of Lemma 2 is presented in Appendix B. ∎
We now state our main result for the theoretical performance guarantees of CodedPrivateML.
Theorem 1**.**
Consider the training of a logistic regression model in a distributed system with workers using CodedPrivateML with the dataset , initial weight vector , and constant step size (where is defined in Lemma 2). Then, CodedPrivateML guarantees,
- •
(Convergence) \mathbb{E}\big{[}C\big{(}\frac{1}{J}\sum_{t=0}^{J}\operatorname{\mathbf{w}}^{(t)}\big{)}\big{]}-C(\operatorname{\mathbf{w}}^{*})\leq\frac{{\|\operatorname{\mathbf{w}}^{(0)}-\operatorname{\mathbf{w}}^{*}\|}^{2}}{2\eta J}+\eta\sigma^{2} in iterations, where is given in Lemma 1,
- •
(Privacy) remains information-theoretically private against any colluding workers, i.e., I\big{(}\operatorname{\mathbf{X}};\widetilde{\mathbf{X}}_{\mathcal{T}},\{\widetilde{\mathbf{W}}^{(t)}_{\mathcal{T}}\}_{t\in[J]}\big{)}=0 for any distribution on and any set with ,
for any , where is the degree of the polynomial from (13).
Remark 2**.**
Theorem 1 reveals an important trade-off between privacy and parallelization in CodedPrivateML. Parameter reflects the amount of parallelization in CodedPrivateML, since the computation load at each worker node is proportional to -th of the dataset. Parameter reflects the privacy threshold in CodedPrivateML. Theorem 1 shows that, in a cluster with workers, we can achieve any and as long as . This condition further implies that, as the number of workers increases, the parallelization () and privacy threshold () of CodedPrivateML can also increase linearly, leading to a scalable solution.
Remark 3**.**
There are two terms in the bound on the distance between the loss function to the optimum in the first equation of Theorem 1, i.e., \mathbb{E}\big{[}C\big{(}\frac{1}{J}\sum_{t=0}^{J}\operatorname{\mathbf{w}}^{(t)}\big{)}\big{]}-C(\operatorname{\mathbf{w}}^{*})\leq\frac{{\|\operatorname{\mathbf{w}}^{(0)}-\operatorname{\mathbf{w}}^{*}\|}^{2}}{2\eta J}+\eta\sigma^{2}. When we use a constant learning rate , the first term goes to zero as the number of iterations increases, hence CodedPrivateML has the convergence rate of . The second term is a residual error in the training as it does not go to zero as increases. By using an adaptive (decreasing) learning rate, this term can be made arbitrarily small.
Remark 4**.**
The convergence rate of CodedPrivateML is the same as that of conventional logistic regression. This follows from Theorem where the convergence rate of CodedPrivateML is found as where is the iteration index, which is the same as the convergence rate of conventional logistic regression, which follows from [45, Section 9.3] and [45, Section 7.1.1].
Remark 5**.**
Theorem 1 applies also to (simpler) linear regression. The proof follows the same steps.
Proof.
The proof of Theorem 1 is presented in Appendix C.
∎
IV-A Complexity Analysis
In this section, we analyze the asymptotic complexity of CodedPrivateML with respect to the number of workers , parallelization parameter , privacy parameter , number of samples , number of features , and number of iterations .
Complexity Analysis of the Master Node: Computation cost of the master node can be broken into three parts: 1) encoding the dataset by using from (9) for , 2) encoding the weight vector by using from (11) for , and 3) decoding the gradient by recovering in (19) for . For the first part, the encoded dataset () from (9) is a weighted sum of matrices where the size of each matrix is . The Lagrangian coefficients can be calculated offline since the sets of and are public. Each encoding requires O\big{(}\frac{md(K+T)}{K}\big{)} multiplications and we must perform encodings, resulting in a total computational cost of O\big{(}\frac{mdN(K+T)}{K}\big{)}. Decoding the gradient computations from (21) can be performed via a weighted sum of vectors where the size of each vector is . Each decoding requires multiplications and we require decoded gradients, resulting in a total computational cost of . Communication cost of the master node to send the encoded dataset and the encoded weight vector to worker is and , respectively. Communication cost of the master to receive the local computation from worker for is .
Complexity Analysis of the Workers: Computation cost of worker to compute , the dominant part of the local computation in (18), is . This corresponds to of the computation cost of conventional logistic regression, which requires the computation of in (2). This is due to the fact that the size of the encoded dataset and original dataset are and , respectively. Communication cost of worker to receive the encoded dataset and the encoded weight vector for is and , respectively. Communication cost of worker to send the local computation to the master for is .
We summarize the asymptotic complexity of CodedPrivateML in Table I.
V Experiments
We now experimentally demonstrate the performance of CodedPrivateML compared to conventional MPC baselines. Our focus is on training a logistic regression model for image classification, while the computation load is distributed to multiple machines on the Amazon EC2 Cloud Platform.
Experiment setup. We train the logistic regression model from (1) for binary image classification on the CIFAR-10 [23] and GISETTE [24] datasets to experimentally examine two things: the accuracy of CodedPrivateML and the performance gain in terms of training time. The size of the CIFAR-10 and GISETTE datasets are 222We select images with the label of ”plane” and ”car”, and the number of these images in training samples is . For the number of features, we added a bias term, hence, we have features. and , respectively. We implement the communication phase using the MPI4Py [46] message passing interface on Python. Computations are performed in a distributed manner on Amazon EC2 clusters using m3.xlarge machine instances.
We then compare CodedPrivateML with two MPC-based benchmarks that we apply to our problem. In particular, we implement two MPC constructions. The first one is based on the well-known BGW protocol [11], whereas the second one is a more recent protocol from [12, 13] that trade-offs offline calculations for a more efficient implementation. Our choice of these MPC benchmarks is due to their ability to be applied to a large number of workers. While several more recent works exist that have developed MPC-based training protocols with information-theoretic privacy guarantees, their constructions are limited to three or four parties [16, 21, 22]. For instance, [16] is a two-party protocol that requires two non-colluding workers.
Both baselines utilize Shamir’s secret sharing scheme [20] where the dataset is secret shared among the workers. For the (quantized) dataset , this is achieved by creating a random polynomial , where for are i.i.d. uniformly distributed random matrices. This guarantees privacy against colluding workers [11, 12, 13], but requires a computation load at each worker that is as large as processing the whole dataset at a single worker, leading to slow training. Hence, in order to provide a fair comparison with CodedPrivateML, we optimize (speed up) the benchmark protocols by partitioning the users into subgroups of size . Then, we let each group compute the gradient over the partitioned dataset , where and is the number of subgroups. For group , each worker receives a share of the partitioned dataset by using a random polynomial , where for and are i.i.d. uniformly distributed random matrices. Workers then proceed with a multiround protocol to compute the sub-gradient. We further incorporate our quantization and approximation techniques in our benchmark implementations as conventional MPC protocols are also bound to arithmetic operations over a finite field. In our experiments, we set , hence the total amount of data stored at each worker is equal to one third of the size of the dataset , which significantly reduces the total training time of the two benchmarks, while providing a privacy threshold of . The implementation details of the MPC operations are provided in Appendix D.
CodedPrivateML parameters. There are several system parameters in CodedPrivateML that should be set. Given that we have a -bit implementation, we select the field size to be , which is the largest prime with bits to avoid an overflow on intermediate multiplications. We then optimize the quantization parameters, in (4) and in (7), by taking into account the trade-off between the rounding and overflow error. In particular, we choose and for the CIFAR-10 and GISETTE datasets, respectively. We also need to set the parameter , the degree of the polynomial for approximating the sigmoid function. We consider both and and as shown later empirically we observe that the degree one approximation achieves good accuracy. We finally need to select (privacy threshold) and (amount of parallelization) in CodedPrivateML. As stated in Theorem 1, these parameters should satisfy . Given our choice of , we consider two cases:
- •
Case 1 (maximum parallelization). All resources allocated for parallelization (faster training) by setting , ,
- •
Case 2 (equal parallelization & privacy). Resources split almost equally between parallelization & privacy, i.e., .
Training time. Initially, we measure the training time while increasing the number of workers gradually. Our results are demonstrated in Figure 3, which shows the comparison of CodedPrivateML with the [BH08] protocol from [12], as we have found it to be the faster of the two benchmarks. In particular, we make the following observations.333For , all schemes have similar performance because the total amount of data stored at each worker is one third of the size of whole dataset ( for CodedPrivateML and for the benchmark).
- •
CodedPrivateML provides substantial speedup over the MPC baselines, in particular, up to and with the CIFAR-10 and GISETTE datasets, respectively, while providing the same privacy threshold as the benchmarks ( for Case 2). Table II demonstrates the breakdown of the total runtime with the CIFAR-10 dataset for workers. In this scenario, CodedPrivateML provides significant improvement in all three categories of dataset encoding and secret sharing; communication time between the workers and the master; and the computation time. Main reason for this is that, in the MPC baselines, the size of the data processed at each worker is one third of the original dataset, while in CodedPrivateML it is -th of the dataset. This reduces the computational overhead of each worker while computing matrix multiplications as well as the communication overhead between the master and workers. We also observe that a higher amount of speedup is achieved as the dimension of the dataset becomes larger (CIFAR-10 vs. GISETTE datasets), suggesting CodedPrivateML to be well-suited for data-intensive training tasks where parallelization is essential.
- •
The total runtime of CodedPrivateML decreases as the number of workers increases. This is again due to the parallelization gain of CodedPrivateML (i.e., increasing while increases). This is not achievable in conventional MPC baselines, since the size of data processed at each worker is constant for all .
- •
Increasing in CodedPrivateML has two major impacts on the total training time. The first one is reducing the computation load per worker, as each new worker can be used to increase the parameter . This in turn reduces the computation load per worker as the amount of work done by each worker is scaled with respect to . The second one is that increasing the number of workers increases the encoding time at the master node. Hence, the gain from increasing the number of workers beyond a certain point may be minimal and the system may saturate. In those cases, increasing the number of workers cannot further reduce the training time, as the computation will be dominated by the encoding overhead.
- •
CodedPrivateML provides up to speedup over the BGW protocol [11], as shown in Table II for the CIFAR-10 dataset with workers. This is due to the fact that BGW requires additional communication between the workers to execute a degree reduction phase for every multiplication operation.
Accuracy. We also examine the accuracy and convergence of CodedPrivateML. Figure 4(a) illustrates the test accuracy of the binary classification problem between plane and car images for the CIFAR-10 dataset. With 50 iterations, the accuracy of CodedPrivateML with degree one polynomial approximation and conventional logistic regression are and , respectively. Figure 4(b) shows the test accuracy for binary classification between digits 4 and 9 for the GISETTE dataset. With 50 iterations, the accuracy of CodedPrivateML with degree one polynomial approximation and conventional logistic regression has the same value of . Hence, CodedPrivateML has comparable accuracy to conventional logistic regression while being privacy preserving.
Figure 5 presents the cross entropy loss for CodedPrivateML versus the conventional logistic regression model for the GISETTE dataset. The latter setup uses the sigmoid function and no polynomial approximation, in addition, no quantization is applied to the dataset or the weight vectors. We observe that CodedPrivateML achieves convergence with comparable rate to conventional logistic regression, while being privacy preserving.
VI Conclusion and Discussion
In this paper, we considered a distributed training scenario in which a data-owner wants to train a logistic regression model by off-loading the computationally-intensive gradient computations to multiple workers, while preserving the privacy of the dataset. We proposed a privacy-preserving training framework, CodedPrivateML, that distributes the computation load effectively across multiple workers, and reduces the per-worker computation load as more and more workers become available. We demonstrated the theoretical convergence guarantees and the fundamental trade-offs of our framework, in terms of the number of workers, privacy protection, and scalability. Our experiment results demonstrate significant speed-up in the training time compared to conventional baseline protocols.
This work focuses on a logistic regression model mainly with the goal of demonstrating how CodedPrivateML can be utilized to scale and speed up logistic regression training under privacy and convergence guarantees, which is a first step towards more complex models. To the best of our knowledge, even for this setup, no other system has been able to efficiently scale beyond workers while achieving information-theoretic privacy. Our work is the first privacy-preserving machine learning approach that reduces the communication and computation load per worker as the number of workers increases, which we hope will open up further research. Future directions include extending CodedPrivateML to deeper neural networks by leveraging an MPC-friendly (i.e., polynomial) activation function or extending CodedPrivateML to collaborative learning setting such as [47].
In this paper, in order to provide information-theoretic privacy, we utilize quantization to convert the dataset and model to the finite field . Doing so has two inherent challenges: 1) determining a proper value for and 2) potential performance degradation caused by quantization or overflow error. This has inspired a new line of works, such as analog coded computing [48, 49], which uses floating-point numbers instead of fixed-point numbers to represent the finite field and provides a fundamental trade-off between the accuracy and privacy level. Leveraging such techniques to address these challenges is another interesting future direction.
Acknowledgement
Authors would like to thank helpful comments and discussions with Dr. Payman Mohassel on this problem.
-A Proof of Lemma 1
(Unbiasedness) Given , we have
[TABLE]
where (26) follows from the unbiasedness of the quantization strategy, , and expectation is taken with respect to the quantization noise at iteration . Then, we obtain
[TABLE]
Assume is constrained such that for some real value [44, 50]. Then, from the Weierstrass approximation theorem [51, 52], for every , there exists a polynomial that approximates the sigmoid arbitrarily well, i.e., for all in the constrained interval. Therefore, given , there exists a polynomial making the norm of (27) arbitrarily small.
(Variance bound) The variance of satisfies,
[TABLE]
where denotes the trace of a matrix, and we let . From Lemma 4 of [44], we have that
[TABLE]
where denotes the element of . Combining equations (28) and (29) with the fact that \Big{(}\sum_{k=0}^{r}c_{k}\big{(}\operatorname{\overline{\mathbf{x}}}_{i}\operatorname{\mathbf{w}}^{(t)}\big{)}^{k}\Big{)}^{2}\approx\big{(}{s}(\operatorname{\overline{\mathbf{x}}}_{i}\cdot\operatorname{\mathbf{w}}^{(t)})\big{)}^{2}\leq 1 for all , we obtain
[TABLE]
-B Proof of Lemma 2
For the logistic regression cost function , the Lipschitz constant is less than or equal to the largest eigenvalue of the Hessian for all and is given by
[TABLE]
-C Proof of Theorem 1
(Convergence) First, we show that the master can decode over the finite field as long as . As described in Section III, given the polynomial approximation of the sigmoid function in (13), the degree of in (19) is at most . The decoding process uses the computations from the workers as evaluation points to interpolate the polynomial . The master can obtain all of the coefficients of as long as it collects at least \text{deg}\big{(}h(z)\big{)}+1\leq(2r+1)(K+T-1)+1 evaluation results of . After is recovered, the master can decode the sub-gradient by computing for . Hence, the recovery threshold is given by to decode .
Next, we consider the update equation in CodedPrivateML (see (25)) and prove its convergence to . From the -Lipschitz continuity of stated in Lemma 2, we have
[TABLE]
where is the inner product [45].By taking the expectation with respect to the quantization noise on both sides,
[TABLE]
where (31) follows from , (32) from the convexity of , and (33) holds since and \mathbb{E}\big{[}\|\mathbf{p}^{(t)})\|^{2}\big{]}-\|\operatorname{\nabla C}(\operatorname{\mathbf{w}}^{(t)})\|^{2}\leq\sigma^{2} from Lemma 1 by assuming an arbitrarily large . Summing the above equations for , we have
[TABLE]
Finally, since is convex, we observe that,
[TABLE]
which completes the proof of convergence.
(Privacy) Let and are the top and bottom submatrix of the encoding matrix constructed in Section III, respectively. From Lemma 2 of [9], is an MDS matrix. Therefore, every submatrix of is invertible.
For a colluding set of workers of size , their received dataset satisfies,
[TABLE]
where \mathbf{R}=\big{(}\mathbf{R}_{K},\ldots,\mathbf{R}_{K+T}\big{)}, and and are the top and bottom submatrices which correspond to the columns in that are indexed by . All elements of are independent and uniformly distributed over the finite field .
Similarly, can be represented as
[TABLE]
where and all elements of are independent and uniformly distributed over the finite field , for all . We first show that =0 as follows.
[TABLE]
where (36) follows from (34), (37) holds since we can drop given as the former is a deterministic function of the latter. Equation (38) holds since and are independent and is invertible. Equation (39) holds from the observation that is a uniformly distributed random matrix, hence it has the maximum entropy in the finite field , combined with the fact that mutual information is always non-negative. Next, we prove I\big{(}\overline{\operatorname{\mathbf{X}}};\widetilde{\mathbf{X}}_{\mathcal{T}},\{\operatorname{\widetilde{\mathbf{W}}^{(t)}_{\mathcal{T}}}\}_{t\in[J]}\big{)}=0. We first obtain
[TABLE]
where (40) follows from (39), and (41) from the chain rule of entropy. From the second term of (41), we derive
[TABLE]
where (42) holds since conditioning cannot increase entropy. Equation (43) holds since and \big{(}\{\operatorname{\widetilde{\mathbf{W}}^{(t)}_{\mathcal{T}}}\}_{t\in[j-1]},\overline{\operatorname{\mathbf{X}}},\operatorname{\widetilde{\mathbf{X}}_{\mathcal{T}}}\big{)} are conditionally independent given . Equation (44) follows from (35), and (45) follows from the same steps (36)-(38). From (41) and (45) we obtain
[TABLE]
where (46) holds since is a uniformly distributed random matrix, and therefore has the maximum entropy in the finite field , H\big{(}\mathbf{V}^{(j)}\big{)}\geq H\Big{(}\widetilde{\mathbf{W}}^{(j)}_{\mathcal{T}}\big{|}\{\operatorname{\widetilde{\mathbf{W}}^{(t)}_{\mathcal{T}}}\}_{t\in[j-1]},\operatorname{\widetilde{\mathbf{X}}_{\mathcal{T}}}\Big{)}, combined with the fact that mutual information is always non-negative, I\big{(}\overline{\operatorname{\mathbf{X}}};\operatorname{\widetilde{\mathbf{X}}_{\mathcal{T}}},\{\operatorname{\widetilde{\mathbf{W}}^{(t)}_{\mathcal{T}}}\}_{t\in[J]}\big{)}\geq 0. Finally, from the data-processing inequality [53],
[TABLE]
Therefore, I\big{(}{\operatorname{\mathbf{X}}};\widetilde{\mathbf{X}}_{\mathcal{T}},\{\widetilde{\mathbf{W}}^{(t)}_{\mathcal{T}}\}_{t\in[J]}\big{)}=0 and the original dataset remains information-theoretically private against colluding workers.
-D Details of the Secure Multi-Party Computation (MPC) Implementation
Our benchmarks are based on two well-known MPC protocols, the notable BGW protocol from [11], and the more recent MPC protocol from [12, 13]. Both protocols allow computations of polynomial functions, which consists of addition and multiplication operations, in a privacy preserving manner by untrusted workers. At the end of the computation, any collusion between out of workers does not reveal any information (in an information-theoretic sense) about the input variables while workers only learn a secret share of the actual result. The former protocol is more communication-intensive than the latter, as it incurs a communication cost that is quadratic in the number of workers. The latter protocol enables the communication cost to scale linearly with respect to the number of workers, however, as a trade-off, it requires a significant amount of offline computations as well as storage load at each worker.
For constructing the secret shares, we use Shamir’s secret sharing protocol [20], which protects the privacy of secret variables against any collisions between up to workers. This is done by embedding a given secret in a degree polynomial where , are uniformly random variables. The secret share of at worker is represented by . Then, addition and multiplication operations are computed as follows.
**Addition. ** To compute a secure addition , workers locally add their secret shares and perform a modulo operation.
**Multiplication. ** To compute a secure multiplication , the two protocols differ in their approaches. In the BGW protocol from [11], each worker first multiplies its secret shares and locally. The resulting value is a secret share of , however, the corresponding polynomial has degree , twice the degree of the original polynomial. This causes the degree to grow excessively as more multiplication gates are executed. To alleviate this problem, workers perform a degree-reduction step by creating new shares corresponding to a polynomial of degree , reducing the degree from . The communication overhead of this protocol is . The protocol from [12, 13] utilizes offline computations to reduce the communication overhead. In the offline phase, this protocol creates a random variable and two secret shares corresponding to random polynomials with degree and , which are denoted by and , respectively, for worker . In the online phase, worker locally the multiplies with . Each worker now holds a secret share of , however, the corresponding polynomial for the secret shares has degree . Worker then locally computes . Next, workers broadcast their local computations to others, after which each worker decodes . Note that the privacy of is still protected since it is masked by the random value . Finally, each worker locally computes . As a result, cancels out and workers obtain a secret share of embedded in a degree polynomial. The communication overhead of this protocol is . For the details, we refer to [54].
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Jinhyun So, Başak Güler, and A Salman Avestimehr. Codedprivateml: A fast and privacy-preserving framework for distributed machine learning. IEEE Journal on Selected Areas in Information Theory , 2021.
- 2[2] Tiago Koketsu Rodrigues, Katsuya Suto, Hiroki Nishiyama, Jiajia Liu, and Nei Kato. Machine learning meets computation and communication control in evolving edge and cloud: Challenges and future perspective. IEEE Communications Surveys & Tutorials , 22(1):38–67, 2019.
- 3[3] Thomas Ristenpart, Eran Tromer, Hovav Shacham, and Stefan Savage. Hey, you, get off of my cloud: exploring information leakage in third-party compute clouds. In ACM Conf. on Comp. and Comm. Security , pages 199–212, 2009.
- 4[4] Yinqian Zhang, Ari Juels, Michael K Reiter, and Thomas Ristenpart. Cross-vm side channels and their use to extract private keys. In ACM Conf. on Comp. and Comm. Security , pages 305–316. ACM, 2012.
- 5[5] Yinqian Zhang, Ari Juels, Michael K Reiter, and Thomas Ristenpart. Cross-tenant side-channel attacks in paas clouds. In ACM Conf. on Comp. and Comm. Security , pages 990–1003, 2014.
- 6[6] Zhenyu Wu, Zhang Xu, and Haining Wang. Whispers in the hyper-space: high-bandwidth and reliable covert channel attacks inside the cloud. IEEE/ACM Transactions on Networking , 23(2):603–615, 2014.
- 7[7] Venkatanathan Varadarajan, Yinqian Zhang, Thomas Ristenpart, and Michael Swift. A placement vulnerability study in multi-tenant public clouds. In 24th USENIX Security Symposium , pages 913–928, 2015.
- 8[8] Kaveh Razavi, Ben Gras, Erik Bosman, Bart Preneel, Cristiano Giuffrida, and Herbert Bos. Flip feng shui: Hammering a needle in the software stack. In 25th USENIX Security Symposium , pages 1–18, 2016.