Particle Flow Bayes' Rule
Xinshi Chen, Hanjun Dai, Le Song

TL;DR
This paper introduces a neural ODE-based particle flow method for Bayesian inference that generalizes across different priors and observations, enabling efficient sequential Bayesian updates.
Contribution
It presents a novel neural ODE operator for particle flow Bayes' rule, capable of generalizing across various priors and observations, trained via meta-learning.
Findings
Successfully applied to high-dimensional examples
Demonstrated generalization across different priors and observations
Proved the existence of the neural ODE operator
Abstract
We present a particle flow realization of Bayes' rule, where an ODE-based neural operator is used to transport particles from a prior to its posterior after a new observation. We prove that such an ODE operator exists. Its neural parameterization can be trained in a meta-learning framework, allowing this operator to reason about the effect of an individual observation on the posterior, and thus generalize across different priors, observations and to sequential Bayesian inference. We demonstrated the generalization ability of our particle flow Bayes operator in several canonical and high dimensional examples.
Click any figure to enlarge with its caption.
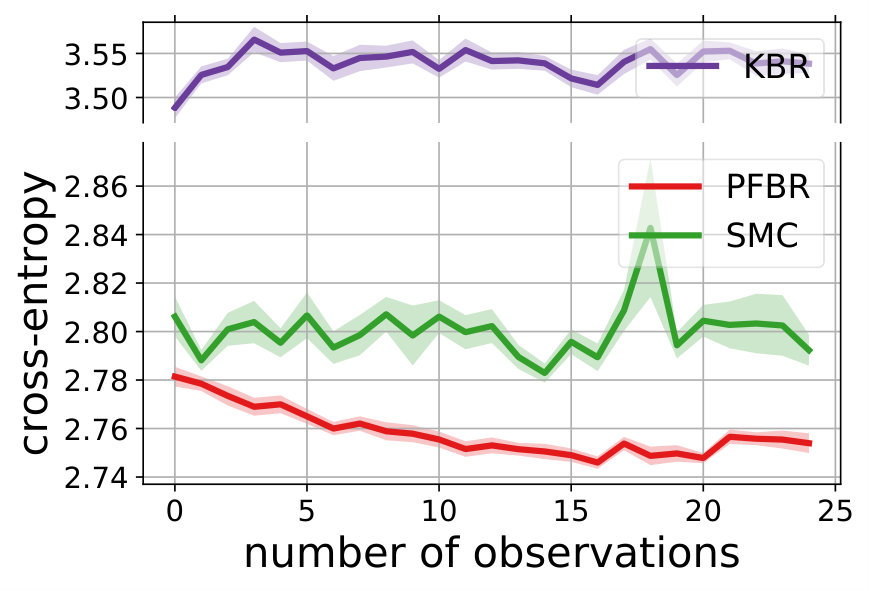 Figure 1
Figure 1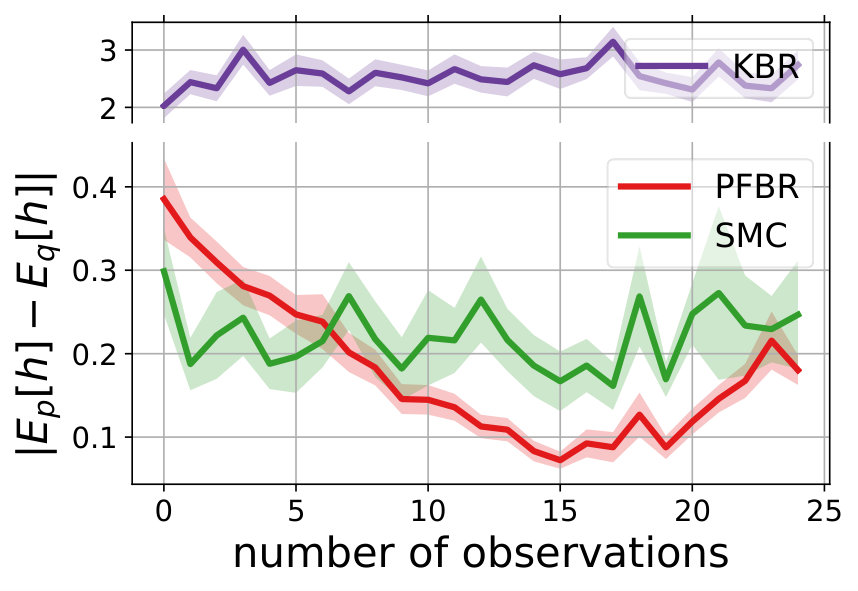 Figure 2
Figure 2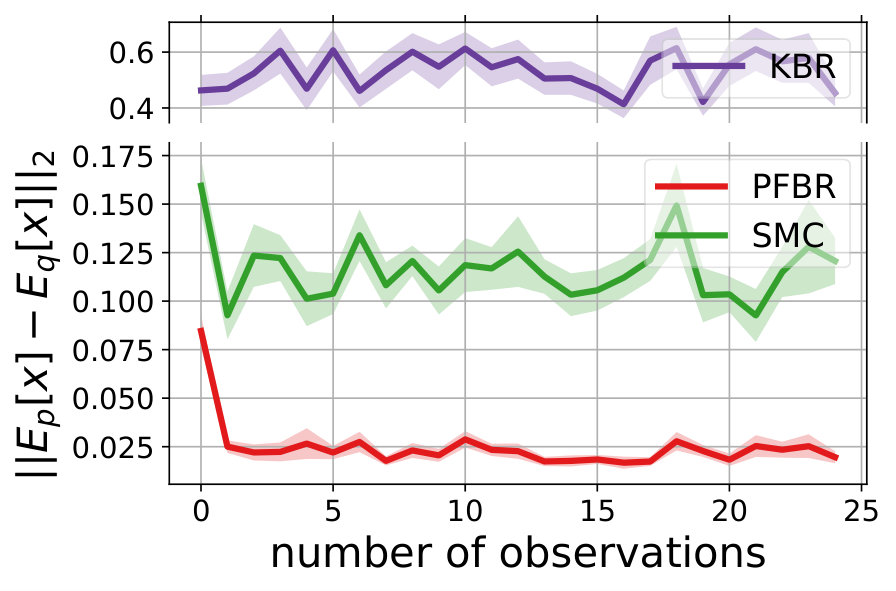 Figure 3
Figure 3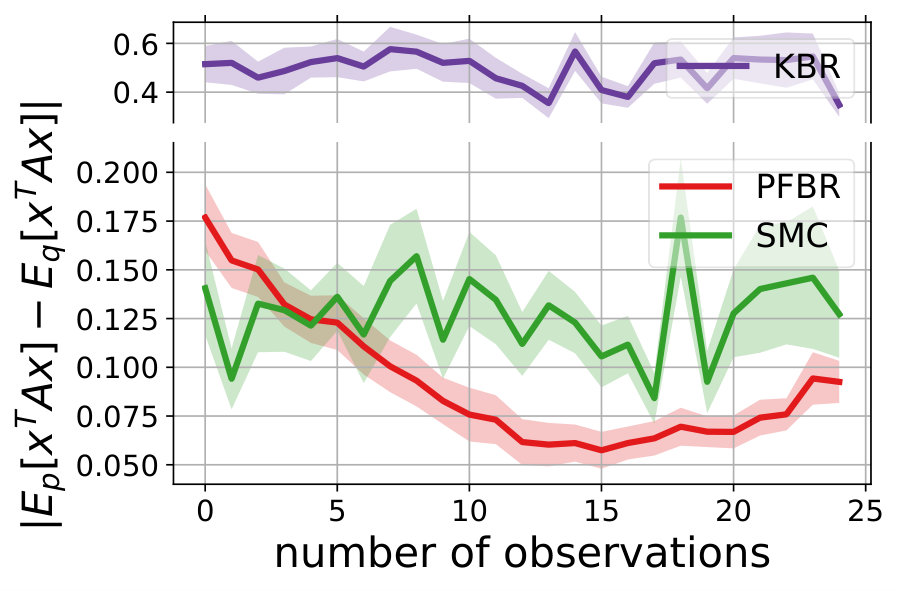 Figure 4
Figure 4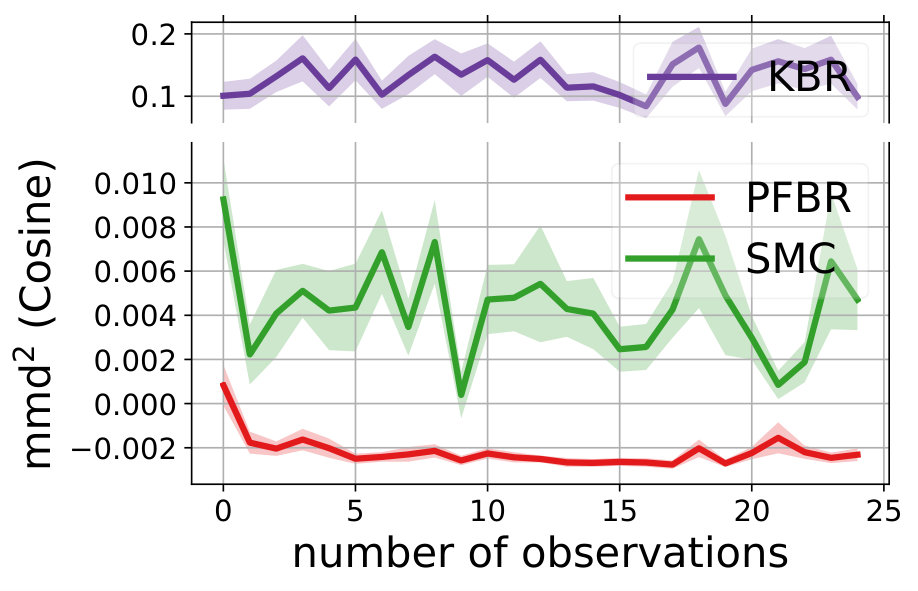 Figure 5
Figure 5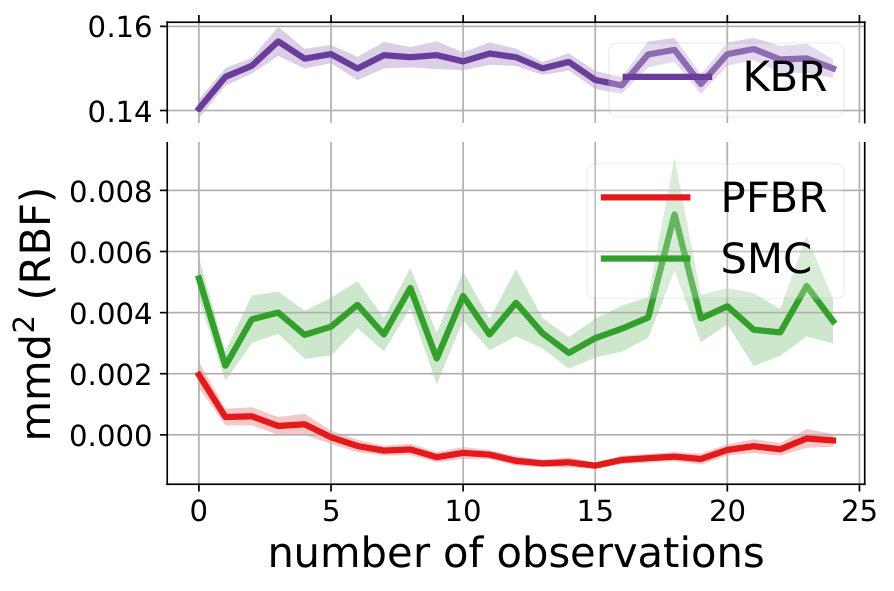 Figure 6
Figure 6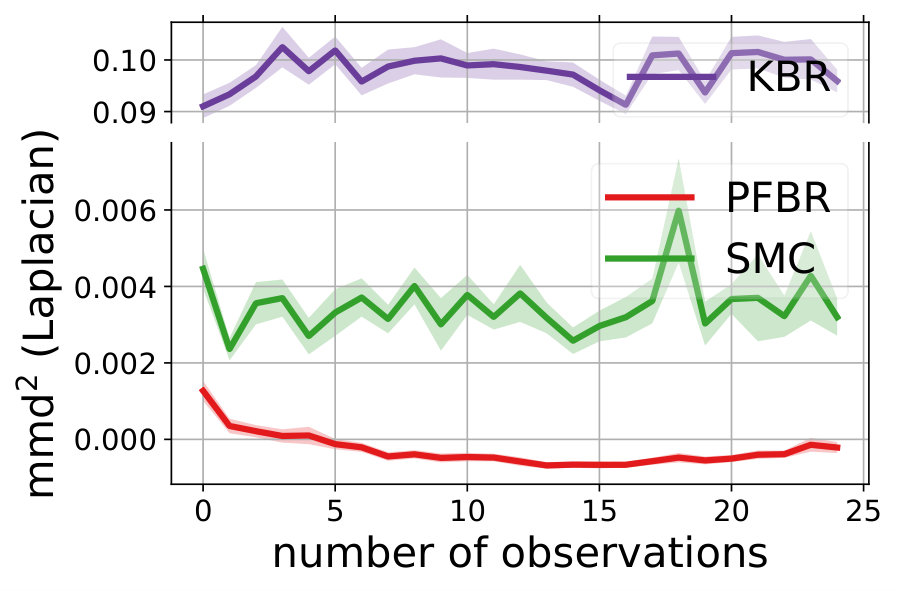 Figure 7
Figure 7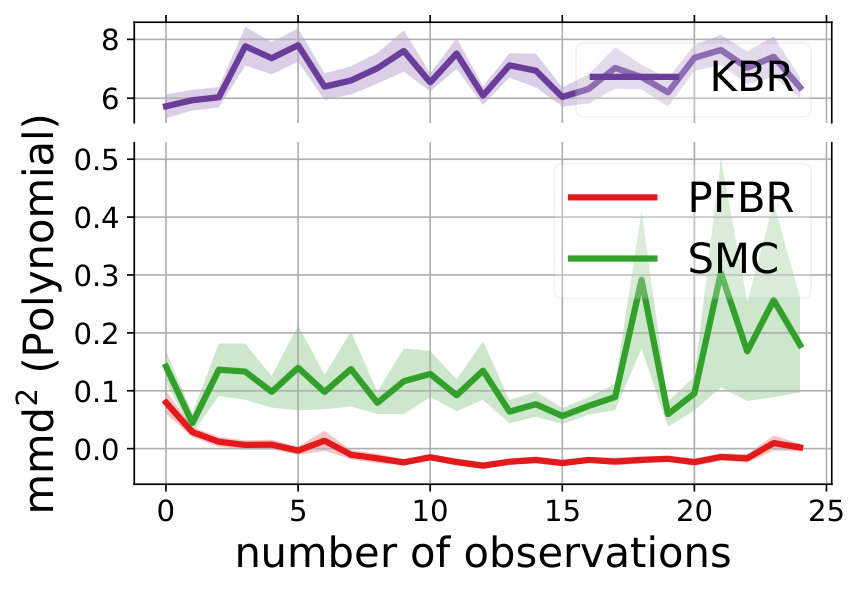 Figure 8
Figure 8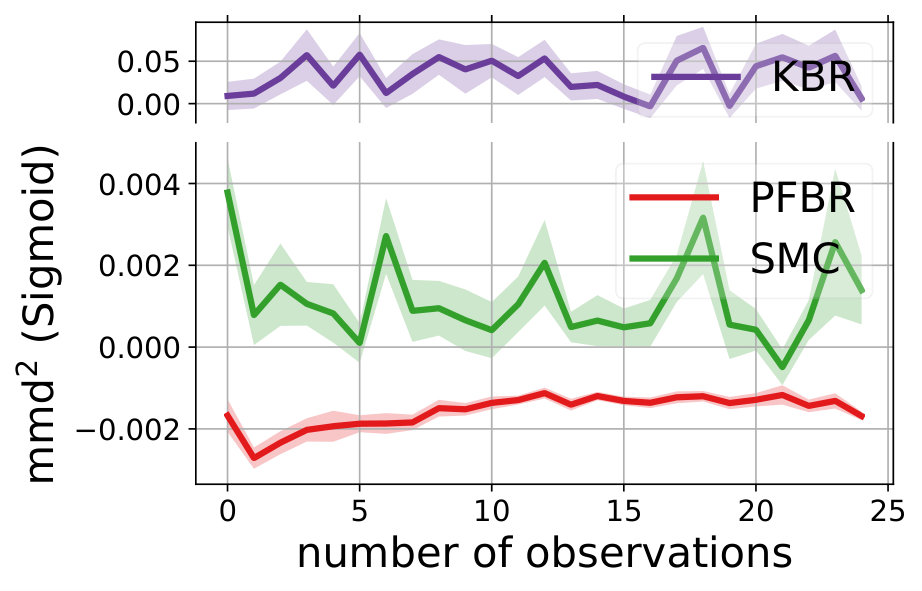 Figure 9
Figure 9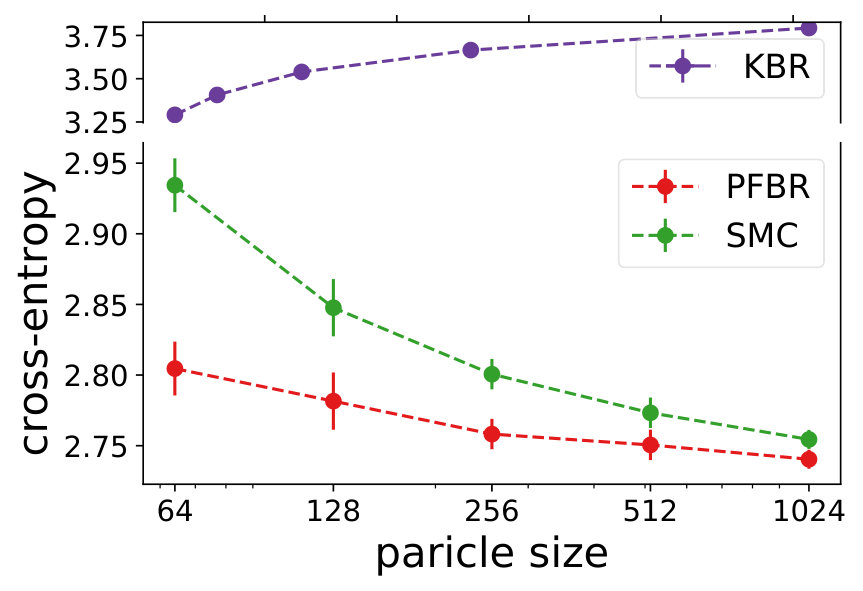 Figure 10
Figure 10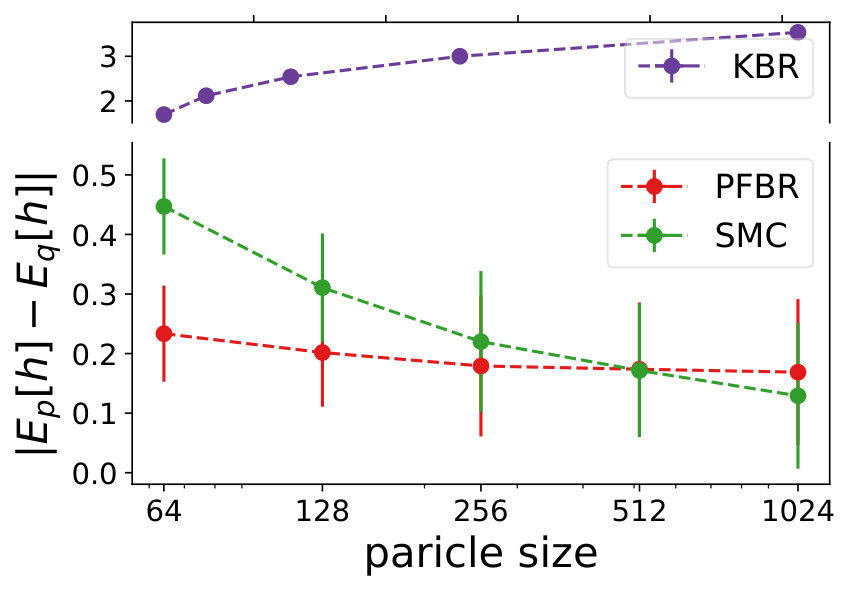 Figure 11
Figure 11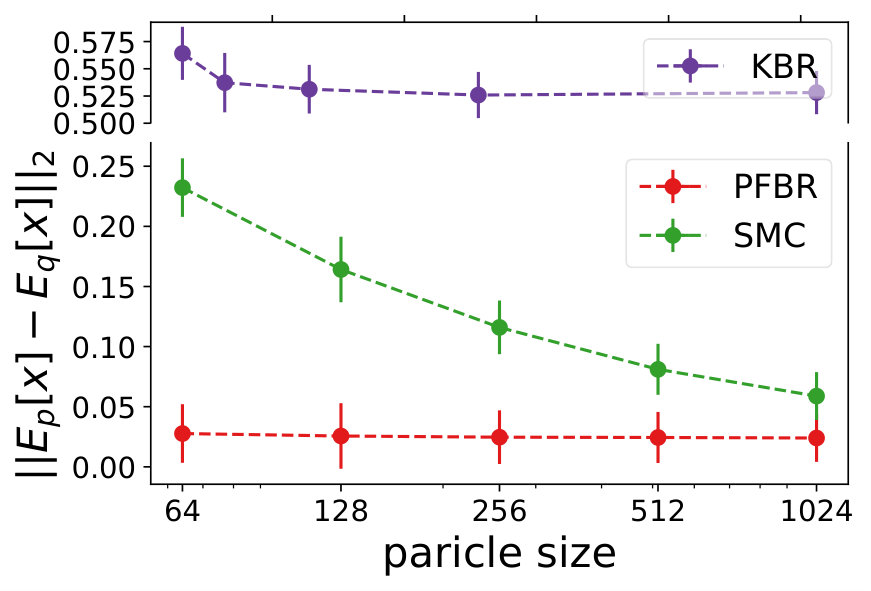 Figure 12
Figure 12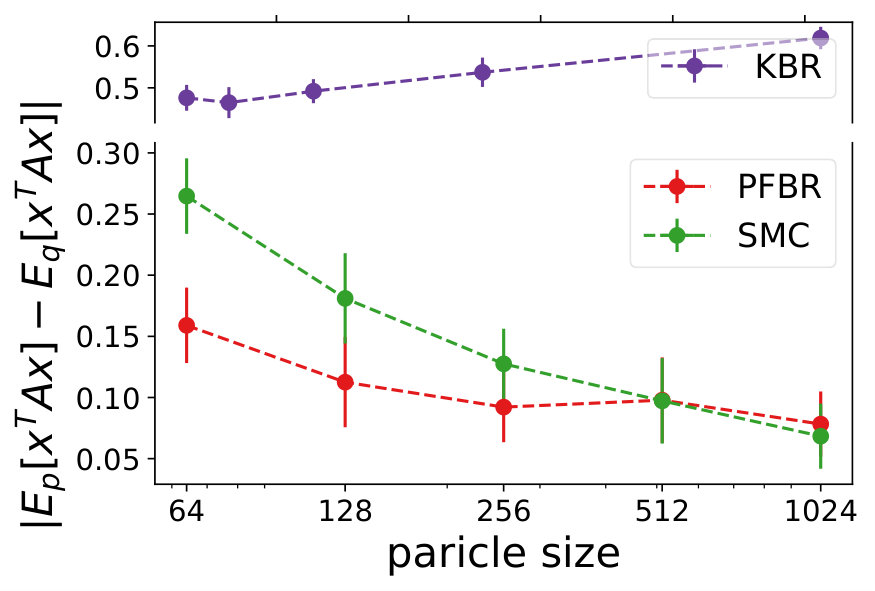 Figure 13
Figure 13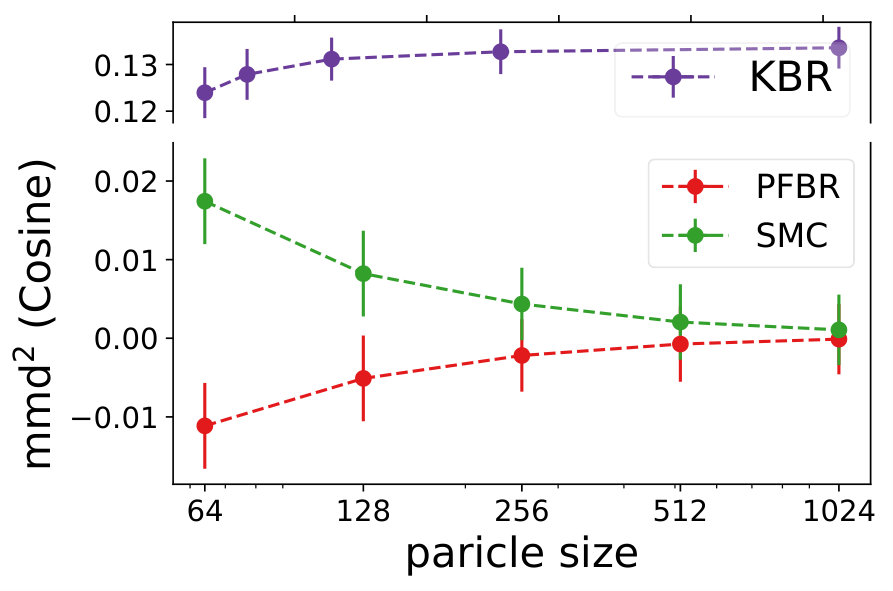 Figure 14
Figure 14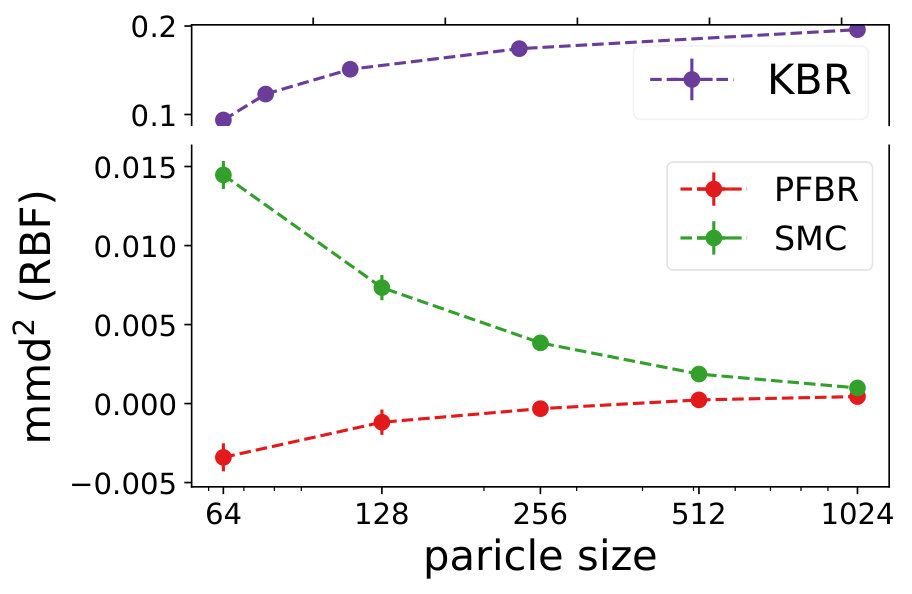 Figure 15
Figure 15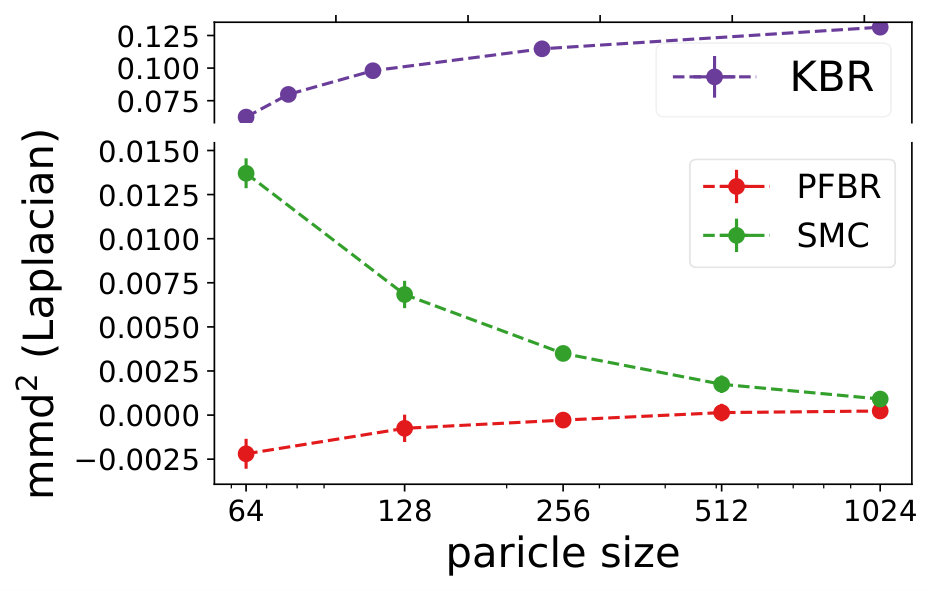 Figure 16
Figure 16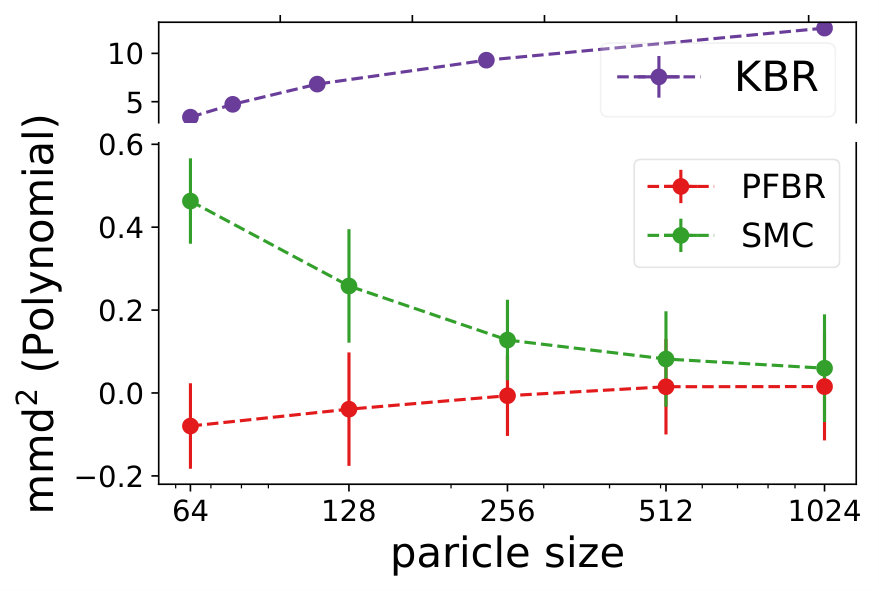 Figure 17
Figure 17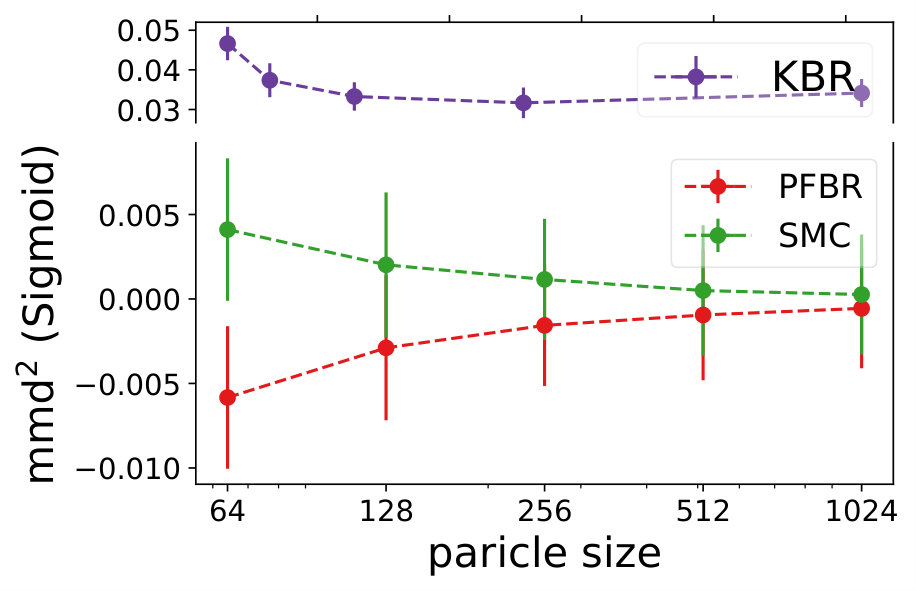 Figure 18
Figure 18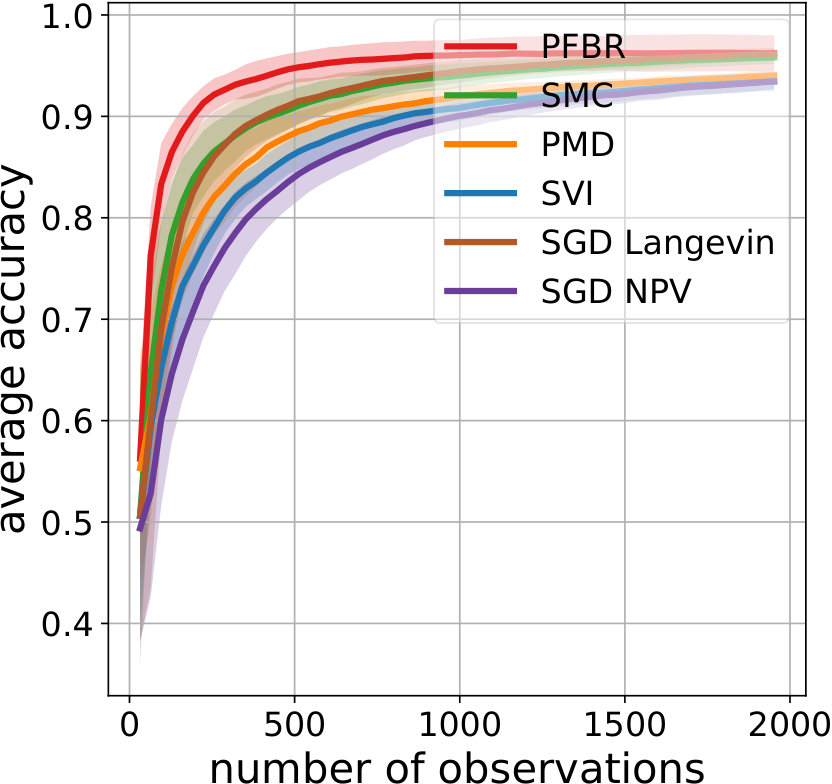 Figure 19
Figure 19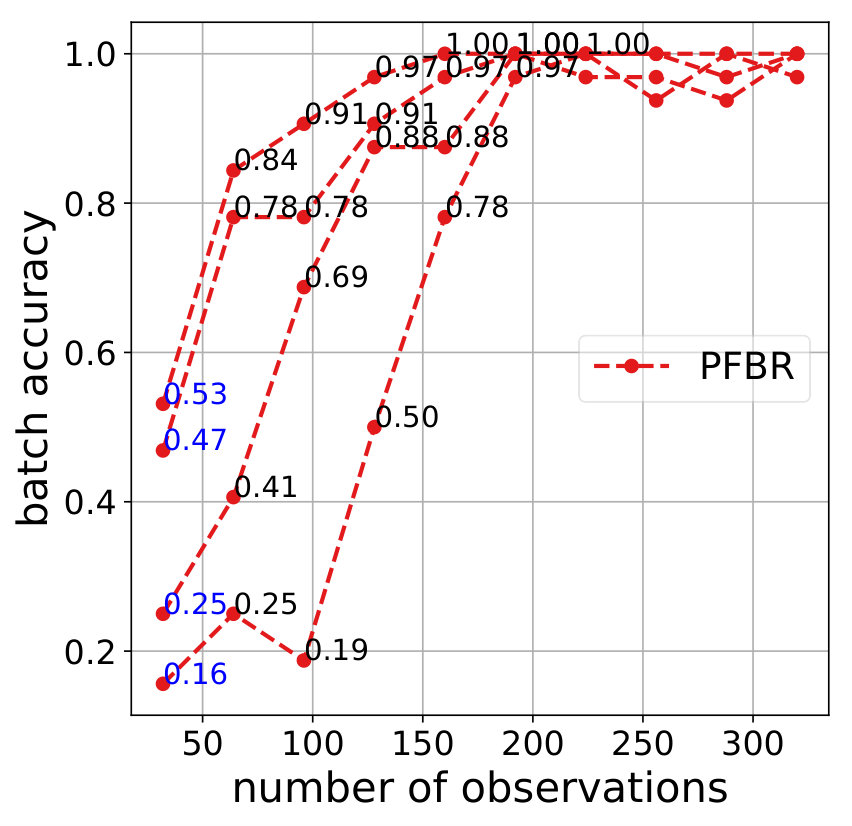 Figure 20
Figure 20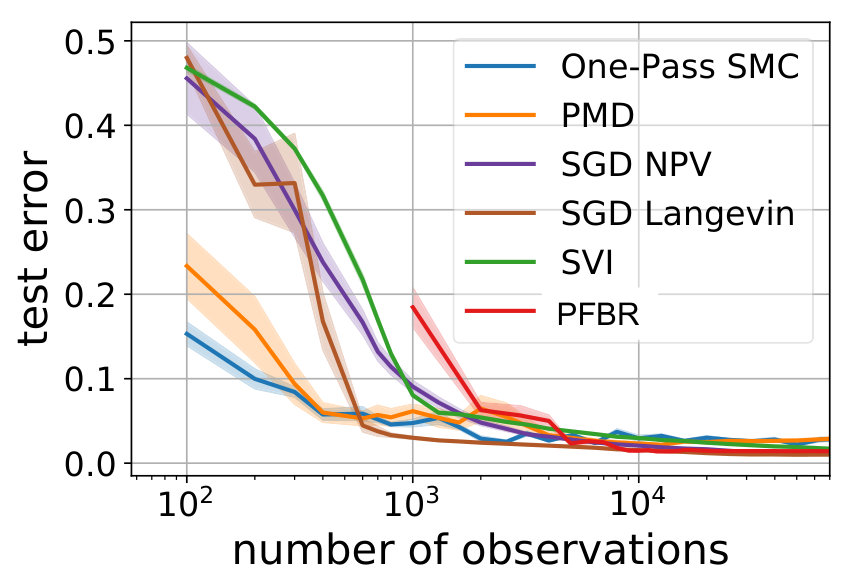 Figure 21
Figure 21 Figure 22
Figure 22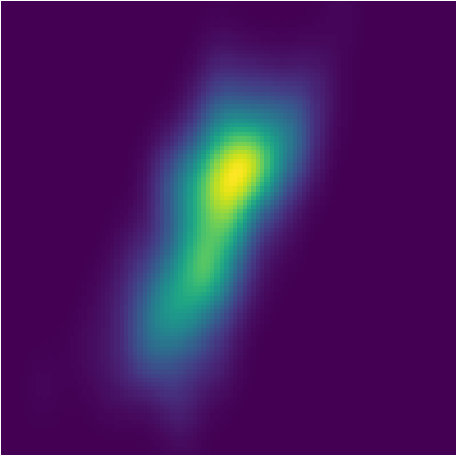 Figure 23
Figure 23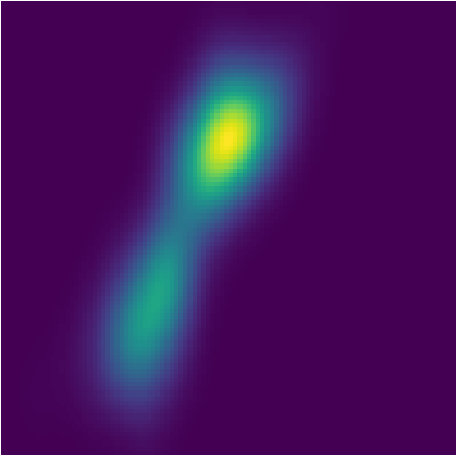 Figure 24
Figure 24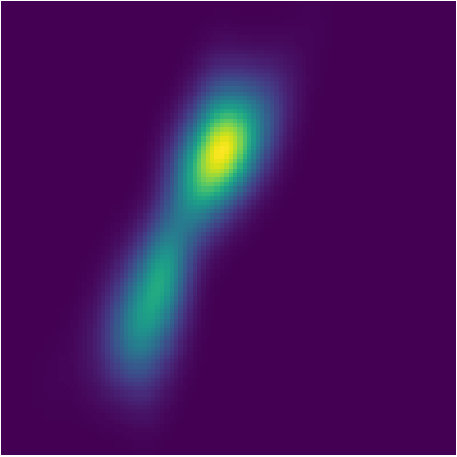 Figure 25
Figure 25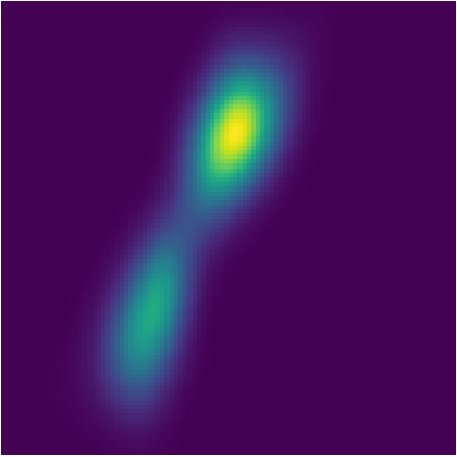 Figure 26
Figure 26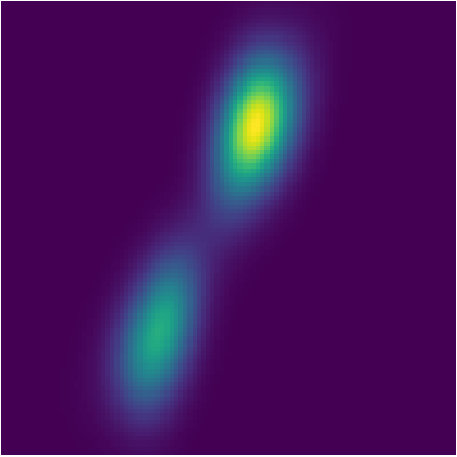 Figure 27
Figure 27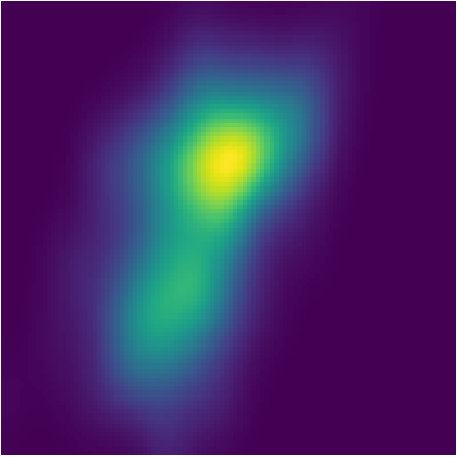 Figure 28
Figure 28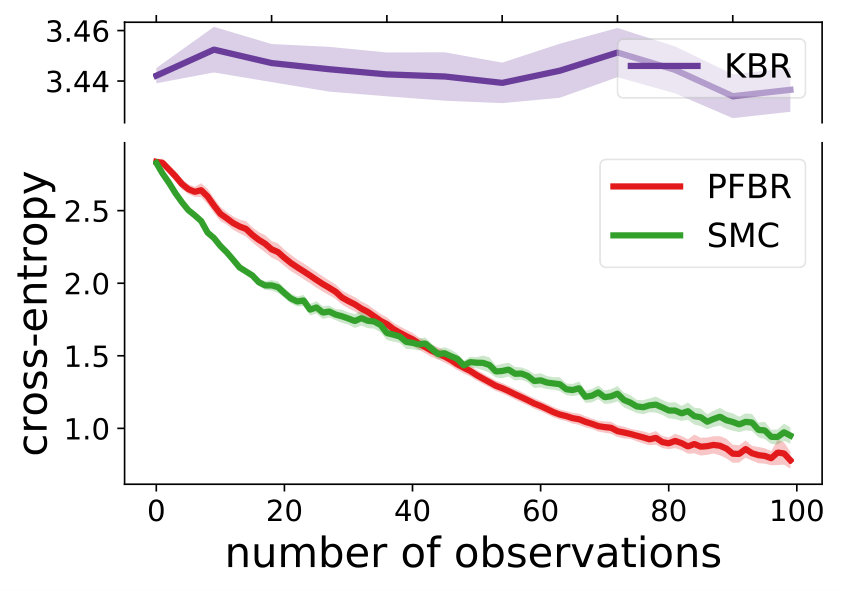 Figure 29
Figure 29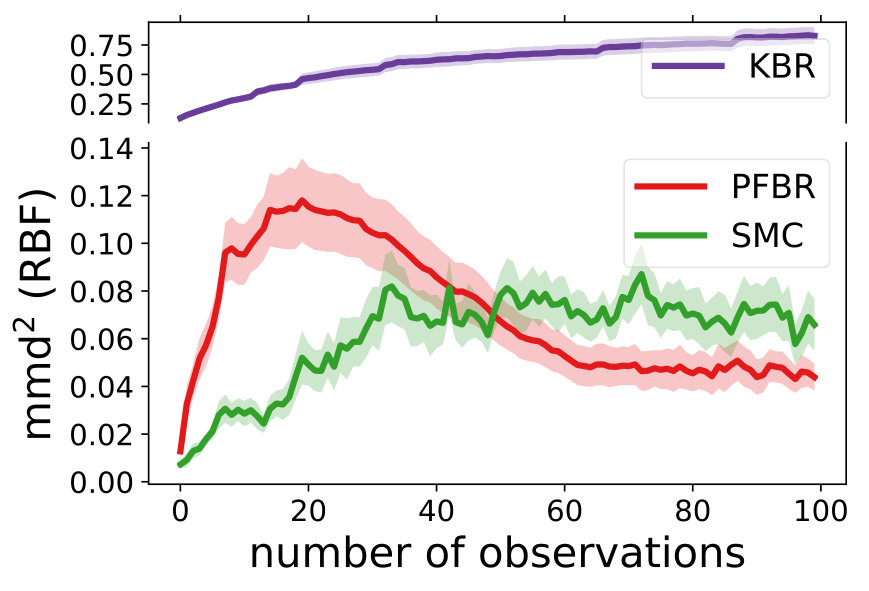 Figure 30
Figure 30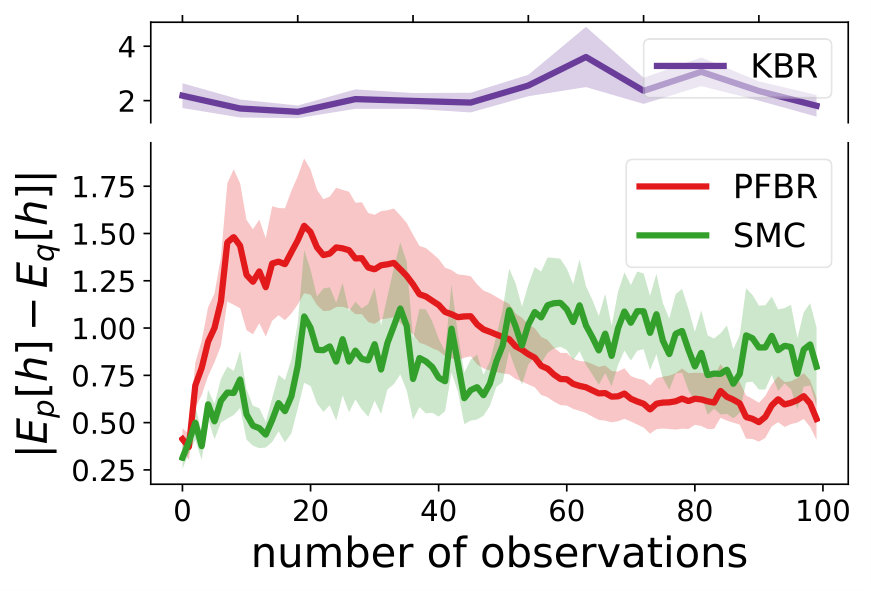 Figure 31
Figure 31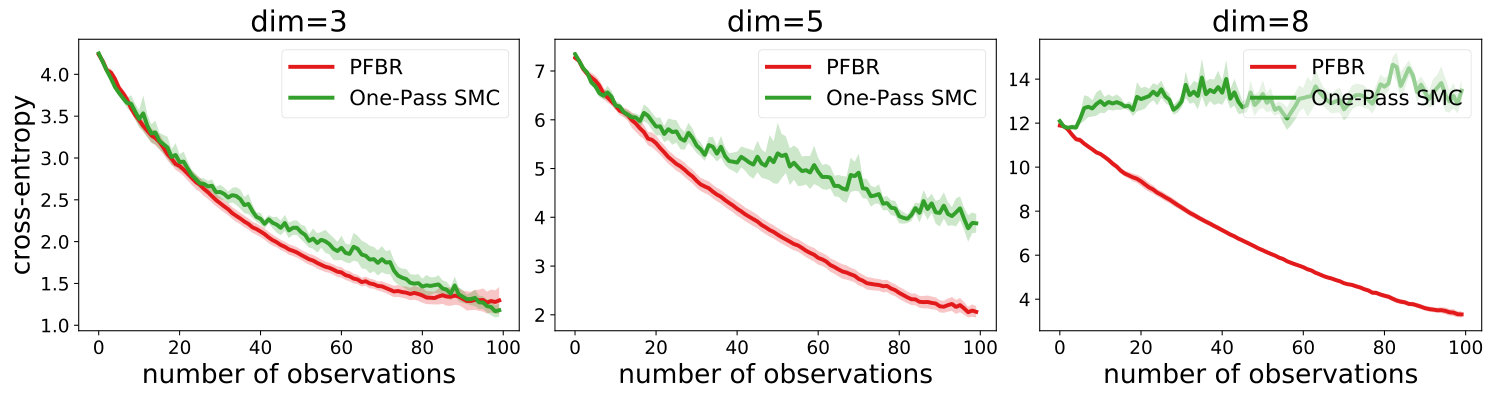 Figure 32
Figure 32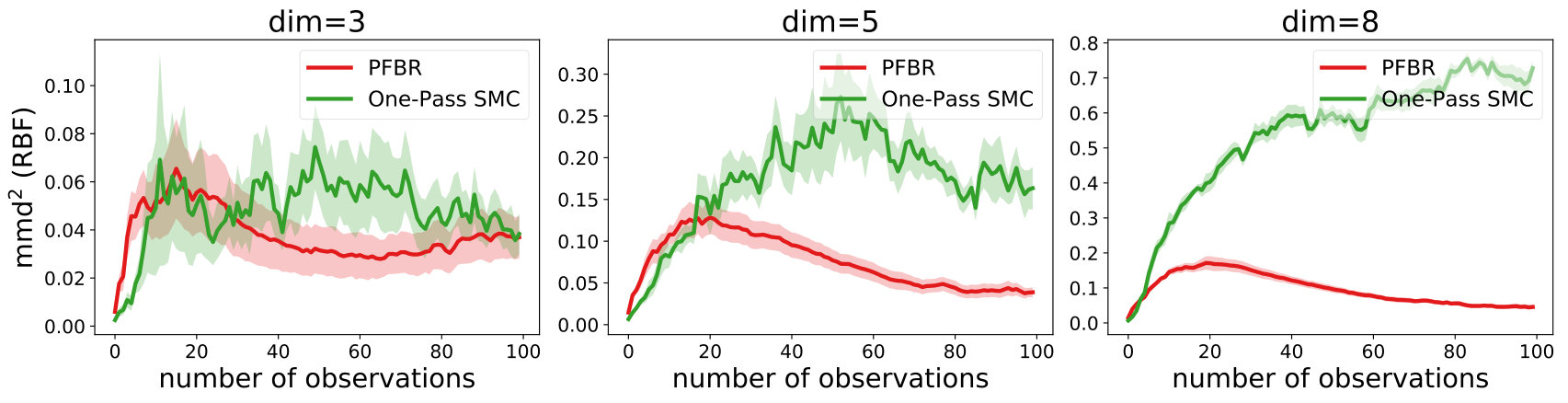 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35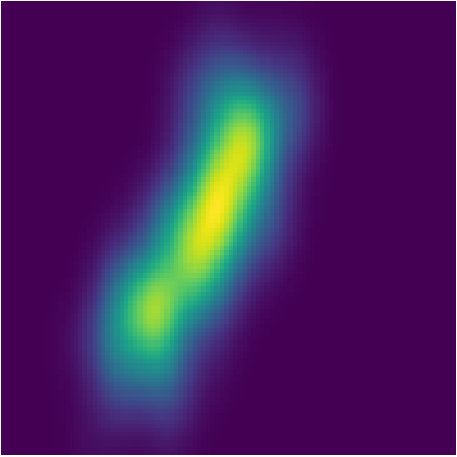 Figure 36
Figure 36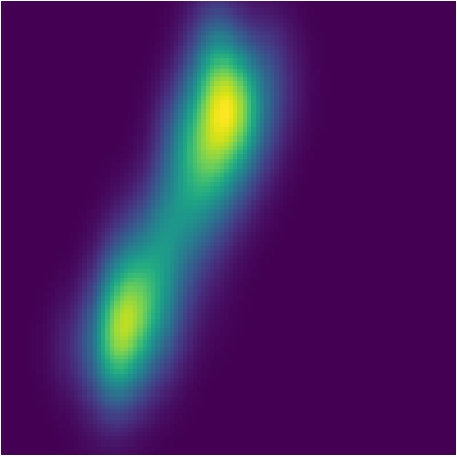 Figure 37
Figure 37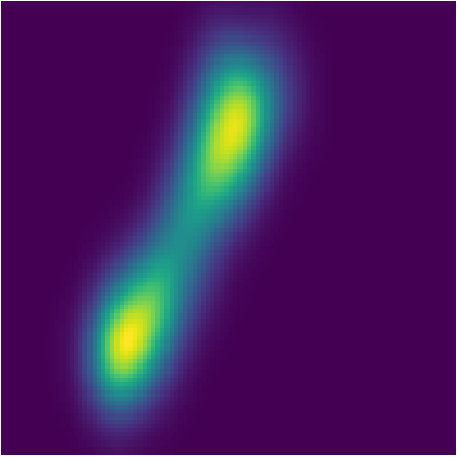 Figure 38
Figure 38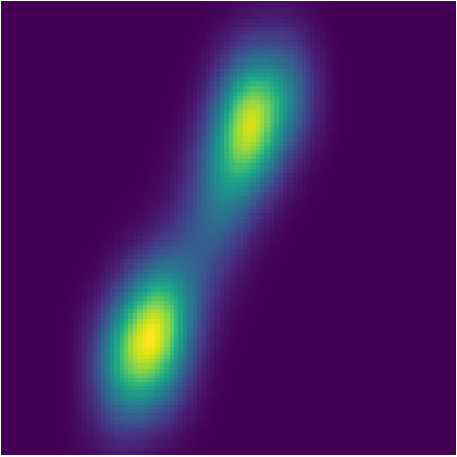 Figure 39
Figure 39 Figure 40
Figure 40| Algo | #particles | cpu time (s) | gpu time (s) | cross-entropy |
|---|---|---|---|---|
| PFBR | 256 | 0.23 | 0.26 | 16.56 |
| SMC | 256 | 0.07 | 0.02 | 26.78 |
| ASMC-mlp | 256 | 0.17 | 0.07 | 19.66 |
| ASMC-gru | 256 | 0.18 | 0.07 | 19.38 |
| ASMC-mlp | 4096 | 2.23 | 0.25 | 17.63 |
| ASMC-gru | 4096 | 2.26 | 0.26 | 17.24 |
| SMC | 8192 | 3.87 | 0.12 | 17.60 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGaussian Processes and Bayesian Inference · Markov Chains and Monte Carlo Methods · Bayesian Methods and Mixture Models
Particle Flow Bayes’ Rule
Xinshi Chen
Hanjun Dai
Le Song
Abstract
We present a particle flow realization of Bayes’ rule, where an ODE-based neural operator is used to transport particles from a prior to its posterior after a new observation. We prove that such an ODE operator exists. Its neural parameterization can be trained in a meta-learning framework, allowing this operator to reason about the effect of an individual observation on the posterior, and thus generalize across different priors, observations and to sequential Bayesian inference. We demonstrated the generalization ability of our particle flow Bayes operator in several canonical and high dimensional examples.
ODE, Bayesian Inference, Particle Flow, Sequential Monte Carlo, ICML
1 Introduction
In many data analysis tasks, it is important to estimate unknown quantities from observations . Given prior knowledge and likelihood functions , the essence of Bayesian inference is to compute the posterior by Bayes’ rule. For many nontrivial models, the prior might not be conjugate to the likelihood, making the posterior not in a closed form. Therefore, computing the posterior often results in intractable integration and poses significant challenges. Typically, one resorts to approximate inference methods such as sampling (e.g., MCMC) (Andrieu et al., 2003) or variational inference (Wainwright & Jordan, 2003).
In many real problems, observations arrive sequentially online, and Bayesian inference needs be performed recursively,
[TABLE]
That is the estimation of should be computed based on the estimation of obtained from the last iteration and the presence of the new observation . It therefore requires algorithms which allow for efficient online inference. In this case, both standard MCMC and variational inference become inefficient, since the former requires a complete scan of the dataset in each iteration, and the latter requires solving an optimization for every new observation. Thus, sequential Monte Carlo (SMC) (Doucet et al., 2001; Balakrishnan & Madigan, 2006) or stochastic approximations, such as stochastic gradient Langevin dynamics (Welling & Teh, 2011) and stochastic variational inference (Hoffman et al., 2012), are developed to improve the efficiency. However, SMC suffers from the path degeneracy problems in high dimensions (Daum & Huang, 2003; Snyder et al., 2008), and rejuvenation steps are designed but may violate the online sequential update requirement (Canini et al., 2009; Chopin et al., 2013). Stochastic approximation methods are prescribed algorithms that cannot exploit the structure of the problem for further improvement.
To address these challenges, the seminal work of Kernel Bayes Rule (KBR) views the Bayes update as an operator in reproducing kernel Hilbert spaces (RKHS) which can be learned and directly produce the posterior from prior after each observation (Fukumizu et al., 2012). In the KBR framework, the posterior is represented as an embedding using a feature map associated with a kernel function; then the kernel Bayes operator will take this embedding as input and produce the embedding of the updated posterior,
[TABLE]
Another novel aspect of KBR method is that it contains a training phase and a testing phase, where the structure of the problem at hand (e.g., the likelihood) is taken into account in the training phase, and in the testing phase, the learned operator will directly operate on the current posterior to produce the output. However, despite the nice concepts of KBR operator, it only works well for a limited range of problems due to its strong theoretical assumptions.
In this work, we aim to lift the limitation of KBR operator, and will design a novel continuous particle flow operator to realize the Bayes update, for which we call it particle flow Bayes’ rule (PFBR). In the PFBR framework (Fig. 1), a prior distribution , or, the current posterior is approximated by a set of equally weighted particles ; and then, given an observation , the flow operator will transport each particle to a new particle to approximate the new posterior . That is,
[TABLE]
where will be used as samples from the new posterior . Furthermore, this PFBR operator can be applied recursively to and a new observation to produce , and so on.
In a high-level, we model the PFBR operator as a continuous deterministic flow, which propagates the locations of particles and the values of their probability density simultaneously through a dynamical system described by ordinary differential equations (ODEs). A natural question is whether a fixed ODE-based Bayes operator applicable to different prior distributions and likelihood functions exists. In our paper, we resolve this important theoretical question by making a novel connection between PFBR operator and the Fokker-Planck equation of Langevin dynamics. The proof of existence also provides a basis for our parameterization of PFBR operator using DeepSet (Zaheer et al., 2017).
Similar to KBR, PFBR have a training phase and a testing phase. However, the training procedure is very different as it adopts a meta-learning framework (Andrychowicz et al., 2016), where multiple related Bayesian inference tasks with different priors and observations are created. PFBR operator will learn from these tasks how to update the posteriors given new observations. During test phase, the learned PFBR will be applied directly to new observations without either re-optimization or storing previous observations. We conduct various experiments to show that the learned PFBR operator can generalize to new Bayesian inference tasks.
Related work. There is a recent surge of interests in ODE-based Bayesian inference (Chen et al., 2018; Zhang et al., 2018; Grathwohl et al., 2018; Lei et al., 2017). These works focus on fitting a single target distribution. Consequently, the learned flow can not generalize directly to a new dataset, a new prior or to sequential setting without re-optimization.
2 Bayesian Inference as Particle Flow
We present details in this section from four aspects: (1) How to map sequential Bayes inference to particle flow? (2) What is the property of such particle flow? (3) Does a shared flow-based Bayesian operator exist? (4) How to parameterize the flow operator ?
2.1 PFBR: Particle Flow Bayes’ Rule
The problem mapping from sequential Bayesian inference to particle flow goes as follows. Initially, particles are sampled i.i.d. from a prior . Given an observation , the operator will transport the particles to to estimate the posterior . We define this transformation as the solution of an ODE. That is, ,
[TABLE]
The flow velocity takes observation as input and determines both direction and speed of the change of . In this ODE model, each particle sampled from the prior gives an initial value , and then the flow velocity will evolve the particle continuously and deterministically. At terminate time , we will take solution as the transformed particle for estimating the posterior.
Applying this ODE-based transformation sequentially as new observations arrive, we can define a recursive particle flow Bayes operator, called PFBR, as
[TABLE]
The set of obtained particles can be used to perform Bayesian inference such as estimating the mean and quantifying the uncertainty of any test function by averaging over these particles.
At this moment, we assume has a form of , and will be shared across different sequential stages. In section 2.3, a rigorous discussion on the existence of a shared flow velocity of this form will be made. Next, we will discuss further properties of this continuous particle flow which will help us study the existence of such operator for Bayesian inference, and design the parameterization and the learning for the flow velocity.
2.2 Property of Continuous Deterministic Flow
The continuous transformation of described by ODE defines a deterministic flow for each particle. Let be the probability density of the continuous random variable . The change of this density is also determined by . More specifically, follows the continuity equation (Batchelor, 2000):
[TABLE]
where is the divergence operator. Continuity equation is the mathematical expression for the law of local conservation of mass - mass can neither be created nor destroyed, nor can it ”teleport” from one place to another.
Given continuity equation, one can describe the change of log-density by another differential equation (Theorem 2.1).
Theorem 2.1**.**
If , then the change in log-density follows the differential equation (Chen et al., 2018)
[TABLE]
Since for any physical quantity , the distinguish between material derivative and partial derivative is important, we clarify the definition before the proof of this theorem.
Definition 2.1**.**
Material derivative of is defined as
[TABLE]
Note that defines the rate of change of in a given particle as it moves along its trajectory in the flow, while means the rate of change of at a particular point that is fixed in the space.
Proof of Theorem 2.1.
By continuity equation, . By chain rule, we have . ∎
Theorem 2.1 gives the same result as the Instantaneous Change of Variables Theorem stated by Chen et al. (2018). However, our statement is more accurate using the notation of material and partial derivatives. Our proof is simpler and intuitively clearer using continuity equation. This also helps us to see the connection to other physics problems such as fluid dynamics and electromagnetism.
With theorem 2.1, we can compute the log-density of the particles by integrating across for each :
[TABLE]
2.3 Existence of Flow-based Bayes’ Rule
Does a unified flow velocity exist for different Bayesian inference tasks involving different priors and observations? If it does, what is the form of this function? These questions are non-trivial even for simple Gaussian case.
For instance, let the prior and the likelihood both be one dimensional Gaussian distributions. Given an observation , the posterior distribution is . It means the ODE needs to push a zero mean Gaussian distribution with covariance to another zero mean Gaussian distribution with covariance for any . It is not clear whether such a unified flow velocity function exists and what is the form for it.
To resolve the existence issue, we will first establish a connection between the deterministic flow in Section 2.2 and the stochastic flow: Langevin dynamics. Then we will leverage the connection between closed-loop control and open-loop control to show the existence of a unified .
2.3.1 Connection to Stochastic Flow
Langevin dynamics is a stochastic process
[TABLE]
where is a standard Brownian motion. Given a fixed initial location , multiple runs of the Langevin dynamics to time will result in multiple random locations of due to the randomness of . This stochastic flow is very different in nature comparing to the deterministic flow in Section 2.2, where a fixed location will always end up with the same location .
Nonetheless, while Langevin dynamics is a stochastic flow of a continuous random variable , the probability density of follows a deterministic evolution according to the associated Fokker-Planck equation (Jordan et al., 1998)
[TABLE]
where is the Laplace operator. Furthermore, if the so-called potential function is smooth and , the Fokker-Planck equation has a unique stationary solution in the form of a Gibbs distribution (Jordan et al., 1998),
[TABLE]
Clearly, this stationary solution is the posterior distribution .
Now we will rewrite the Fokker-Planck equation in Eq. (2.3.1) into the form of the deterministic flow in Eq. (5) from Section 2.2, and hence identify the corresponding flow velocity.
Theorem 2.2**.**
Assume the deterministic transformation of a continuous random variable is , where
[TABLE]
and is the probability density of . If the potential function is smooth and , then converges to as .
Proof.
By continuity equation in Eq. (5), the probability density of satisfies {\partial q}/{\partial t}=-\nabla_{x}\cdot\big{(}q\big{(}-\nabla_{x}\Psi({\bm{x}})-\nabla_{x}\log q({\bm{x}},t)\big{)}\big{)}. It is easy to see this equation is the same as the Fokker-Planck equation in Eq. (2.3.1), by decomposing the Laplace as . Under the conditions for the potential function , since Fokker-Planck equation has a unique stationary distribution equal to the posterior distribution , the deterministic flow in Eq. (12) will also converge to .
∎
The implication of Theorem 2.2 is that we can construct a deterministic flow of particles to obtain the posterior and hence establish the existence. However, the flow velocity in Eq. (12) depends on the intermediate density which changes over time. This seemingly suggests that can not be expressed as a fixed function of and . In the next section, we show that this dependence on can be removed using theory of optimal control for deterministic systems.
2.3.2 Closed-loop to Open-loop Conversion
Now the question is: whether the term in Eq. (12) can be made independent of , or whether there is a equivalent form which can achieve the same flow. To investigate this question, we consider the the following deterministic optimal control problem
[TABLE]
where can be any metric defined on the set of densities over . In Eq. (13), we are optimizing over , which is usually called the control. By Theorem 2.2, is apparently an optimal solution. Furthermore, the corresponding flow velocity derived by Fokker-Planck equation can be regarded as the continuous steepest descent of KL under Wasserstein distance (Jordan et al., 1998). We are seeking an alternative expression to the above optimal solution which only depends on and . First, we introduce the terminology below from optimal control literature.
Definition 2.2**.**
In optimal control literature, a control in a feed-back form is called closed-loop. In contrast, another type of control is called open-loop. An open-loop control is determined when the initial state is observed, whereas, a closed-loop control can adapt to the encountered states .
Theorem 2.3**.**
For the optimal control problem in Eq. (13) and Eq. (14), there exists an open-loop control such that the induced state satisfies . Moreover, has a fixed expression with respect to and across different .
Proof.
By Theorem 2.2, can induce the optimal state and achieve a zero loss, . Hence, is an optimal closed-loop control for this problem.
Although in general closed-loop control has a stronger characterization to the solution, in a deterministic system like Eq. (14), the optimal closed-loop control and the optimal open-loop control will give the same control law and achieve the same optimal loss (Dreyfus, 1964). Hence, there exists an optimal open-loop control such that the induced state also gives a zero loss and thus . More details are provided in Appendix A to express as a fixed function of , , and . ∎
Conclusion of a unified . In sequential Bayesian inference, we will set as . Therefore, Theorem 2.3 shows that there exists a fixed and deterministic flow velocity of the form
[TABLE]
which can transform to and in turns define a unified particle flow Bayes operator .
2.4 Parametrization
We design a practical parameterization of based on the expression of the unified flow in Eq. (15).
(i) : Since we do not have full access to the density but have samples from it, we can use these samples as surrogates for . A related example is feature space embedding of distributions (Smola et al., 2007), . Ideally, if is an injective mapping from the space of probability measures over to the feature space, the resulting embedding can be treated as a sufficient statistic of the density and any information we need from can be preserved. Hence, we represent by , where is a nonlinear feature mapping to be learned. Since we use a neural version of , this representation can also be regarded as a DeepSet (Zaheer et al., 2017).
(ii) : In both Langevin dynamics and Eq. (15), the only term containing the likelihood is . Consequently, we can use this term as an input to . In the case when the likelihood function is fixed, we can also simply use the observation , which results in similar performance in our experiments.
Overall we parameterize the flow velocity as
[TABLE]
where and are neural networks (See specific architecture we use in Appendix C.1). Let be their parameters which are independent of . From now on, we write . In the next section, we will propose a meta learning framework for learning these parameters.
3 Learning Algorithm
Since we aim to learn a generalizable Bayesian operator, we need to create multiple inference tasks as the training set and design the corresponding learning algorithm.
Multi-task Framework. The training set contains multiple inference tasks. Each task is a tuple
[TABLE]
which consists of a prior distribution, a likelihood function and a sequence of observations. A task with sequential observations can also be interpreted as a sequence of sub-tasks with 1 observation:
[TABLE]
Therefore, each task is a sequential Bayesian inference and each sub-task corresponds to one step Bayesian update.
Cumulative Loss Function. For each sub-task we define a loss , where is the distribution transported by at -th stage and is the target posterior (see Fig. 1 for illustration). Meanwhile, the loss for the corresponding sequential task will be , which sums up the losses of all intermediate stages. Since its optimality is independent of normalizing constants, it is equivalent to minimize the negative evidence lower bound (ELBO)
[TABLE]
The above expression is an empirical estimation using particles . In each iteration during training phase, we will randomly sample a task from and update the PFBR operator by the loss gradient.
3.1 Training Tasks Creation
Similar to some meta learning problems, the distribution of training tasks will essentially affect learner’s performance on testing tasks (Dai et al., 2017). Depending on the nature of the Bayesian problem, we propose two approaches to construct the multitask training set: one is data driven, and the other is based on generative models. The general principle is that the collection of training priors have to be diverse enough or representative of those may be seen in testing time.
Data-Driven Approach. We can use the posterior distribution obtained from last Bayesian inference step as the new prior distribution. If the posterior distribution has an analytical (but unnormalized) expression, we will directly use this expression.
More precisely, since each Bayesian inference step will generate a set of particles, , corresponding to the posterior distribution , we can apply a kernel density estimator on top of these samples to obtain an empirical density function
[TABLE]
where is the kernel bandwidth. Then this density function with a set of samples from it will be used as the new prior for the next training task. This approach has two attractive properties. First, it does not require any prior knowledge of the model and thus is generally applicable to most problems. Second, it provides us a way of breaking a long sequence with large into multiple tasks with shorter sequences
[TABLE]
This will help make the training procedure more efficient. This approach will be particularly suited to sequential Bayesian inference and is used in later experiments.
Generative Model Approach. Another possibility is to sample priors from a flexible generative model, such as a Dirichlet process Gaussian mixture model (Antoniak, 1974). We will leave the experimental evaluation of this approach for future investigation.
3.2 Overall Learning Algorithm
Learning the PFBR operator is learning the parameters of to minimize the following loss for multiple tasks
[TABLE]
where is the loss for a single task defined in Eq. (17). Both the particle location and its density value in are results of forward propagation determined by according to ODEs in Eq. (4) and Eq. (8). The training procedure is similar to other deep learning optimizations, except that an ODE technique called adjoint method (Chen et al., 2018) is used to compute the gradient with very low memory cost. The overall algorithm under a meta-learning framework is summarized in Algorithm 1.
3.3 Efficient Learning Tricks
We introduce two techniques to improve training efficiency for large scale problems. Its application to an experiment which contains millions of data points is demonstrated in Section 4. These two techniques can be summarized as mini-batch embedding and sequence-segmentation.
The loss function in Eq. (17) contains a summation from to and also a hidden inner-loop summation
[TABLE]
Thus the evaluation cost of is quadratic with respect to the length of the observation sequences. Therefore, we need to reduce the length for large scale problems.
Mini-batch embedding. Previously we defined as a single observation. However, we can also view it as a batch of observations, i.e., . Each Bayesian update corresponding to this mini-batch will become . If we rewrite , this is essentially the same as our previous expression. Therefore, we can replace by and input these samples simultaneously as a set to the flow . To reduce the input dimension, we resort to a set-embedding , where is a neuralized nonlinear function to be learned. Depending on the structure of the model, one define the embedding as a Deepset (Zaheer et al., 2017), or, if the posterior is not invariant with respect to the order of the observations (e.g., hidden Markov models), one need to use a set-embedding that is not order invariant. To conclude, for a mini-batch Bayesian update, the parameterization of flow velocity can be modified as
[TABLE]
Sequence-segmentation. We will use the approach in Eq. (19) to break a long sequence into short ones. More precisely, suppose we have particles at -th stage. We can cut the sequence at position and generate a new task using the second half. The prior for the new sequence will be an empirical density estimation as defined in Eq. (18). Then, for all stages , the terms in Eq. (20) becomes
[TABLE]
We can apply this technique for multiple times to split a long sequence into multiple segments.
4 Experiments
We conduct experiments on multivariate Gaussian model, hidden Markov model and Bayesian logistic regression to demonstrate the generalization ability of PFBR and also its accuracy for posterior estimation.
Evaluation metric. For multivariate Gaussian model and Gaussian linear dynamical system, we could calculate the true posterior. Therefore, we can evaluate:
- (i)
Cross-entropy ;
- (ii)
Maximum mean discrepancy (Gretton et al., 2012)
[TABLE]
- (iii)
Integral evaluation discrepancy ;
where we use Monte Carlo method to compute for the first two metrics. For the integral evaluation, we choose some test functions where the exact value of has a closed-form expression. For the experiments on real-world dataset, we estimate the commonly used prediction accuracy due to the intractability of the posterior.
Multivariate Gaussian Model. The prior , the observation conditioned on prior and the posterior all follow Gaussian distributions. In our experiment, we use and . We test the learned PFBR on different sequences of 100 observations , while the training set only contains sequences of 10 observations, which are ten times shorter than sequences in the testing set. However, since we construct a set of different prior distributions to train the operator, the diversity of the prior distributions allows the learned to generalize to compute posterior distributions in a longer sequence.
We compare the performances with KBR (Fukumizu et al., 2012) and one-pass SMC (Balakrishnan & Madigan, 2006). Both PFBR and KBR are learned from the training set and then used as algorithms on the testing set, which consists of 25 sequences of 100 observations conditioned on 25 different sampled from . We compare estimations of across stages from to 100 and the results are plotted in Fig. 2. Since KBR’s performance reveals to be less comparable in this case, we leave its results to Appendix D. We can see from Fig. 2 that as the dimension of the model increases, our PFBR has more advantages over one-pass SMC.
Gaussian Mixture Model. Following the same setting as Welling & Teh (2011), we conduct an experiment on an interesting mixture model, where the observations o\sim\frac{1}{2}\big{(}{\mathcal{N}}(x_{1},1.0)+{\mathcal{N}}(x_{1}+x_{2},1.0)\big{)} and the prior . The same as Dai et al. (2016), we set so that the resulting posterior will have two modes: and . During training, multiple sequences are generated, each of which consists of 30 observations.
Compared to Welling & Teh (2011) and Dai et al. (2016), our experiment is more challenging. First, they are only fitting one posterior given one sequence of observations via optimization, while PFBR will operate on sequences that are NOT observed during training without re-optimization. Second, they are only estimating the final posterior, while we aim at fitting every intermediate posteriors. Even for one fixed sequence, it is not easy to fit the posterior and capture both two modes, which can be seem from the results reported by Dai et al. (2016). However, our learned PFBR can operate on testing sequences and the resulting posteriors look closed enough to true posterior (See Fig. 3).
Hidden Markov Model — LDS. Our PFBR method can be easily adapted to hidden Markov models, where we will estimate the marginal posterior distribution . For instance, consider a Gaussian linear dynamical system (LDS):
[TABLE]
where and . The particles can be updated by recursively applying two steps:
[TABLE]
where . The second step is a Bayesian update from to given the likelihood . The only tricky part is we do not have a tractable loss function in this case because of the integration . Hence, at each stage , we use the particles to construct an empirical density estimation as defined in Eq. (18) and then define the loss at each stage as
[TABLE]
where we replace the intractable density by . Given this loss, the PFBR operator can be learned.
In the experiment, we sample a pair of 2 dimensional random matrices and for the LDS model. We learn both PFBR and KBR from a training set containing multiple different sequences of observations. For KBR, we use an adapted version called Kernel Monte Carlo Filter (Kanagawa et al., 2013), which is designed for state-space models. We use Kalman filter (Welch & Bishop, 2006) to compute the true marginal posterior for evaluation purpose.
Fig. 4 compares our method with KBR and SMC (importance sampling with resampling) on a testing set containing 25 new sequences of ordered observations. We see that our learned PFBR can generalize to test sequences and achieve better and stabler performances.
Comparison to Variational SMC. Autoencoding SMC (AESMC), Filtering Variational Objectives, and Variational SMC are three recent variational inference approaches that approximate the posterior based on SMC and a neural proposal (Le et al., 2018; Maddison et al., 2017; Naesseth et al., 2018). Since they share similar ideas, we implemented AESMC as a representative. We tried both MLP and GRU as mentioned in these papers. A comparison is made for 10-dimensional LDS (Table 1), which shows PFBR is better even with much fewer particles.
Inference Time Comparison. Table 1 also shows the inference time for updating posterior given one new observation. Though PFBR takes more time for the same #particles (e.g., 256), to get closer to PFBR’s performance, others need to use much more particles (e.g., 4096).
Bayesian Logistic Regression (BLR). We consider logistic regression for digits classification on the MNIST8M 8 vs. 6 dataset which contains about 1.6M training samples and 1932 testing samples. We reduce the dimension of the images to 50 by PCA, following the same setting as Dai et al. (2016). Two experiments are conducted on this dataset. For both experiments, we compare our method with SMC, SVI (stochastic variational inference (Hoffman et al., 2012)), PMD (particle mirror descent (Dai et al., 2016)), SGD Langevin (stochastic gradient Langevin dynamics (Welling & Teh, 2011)) and SGD NPV (stochastic version of nonparametric variational inference (Gershman et al., 2012)). This is a large dataset, so we use the techniques discussed in Section 3.3 to facilitate training efficiency.
BLR-Meta Learning. In the first experiment, we create a multi-task environment by rotating the first and second components of the features reduced by PCA through an angle uniformly sampled from . Note that the first two components account for more variability in the data. With a different rotation angle , the classification boundary will change and thus a different classification task will be created. Also, a different sequence of image samples will result in different posterior distributions and thus corresponds to a different inference task.
We learn the operator from a set of training tasks, where each task corresponds to a different rotation angle . After that, we use as Bayes’ Rule for testing tasks and compare its performances with other stochastic methods or sampling methods. Test is done in an online fashion: all algorithms start with a set of particles sampled from the prior (hence the prediction accuracy at 0-th step is around 0.5). Each algorithm will make a prediction to the encountered batch of 32 images, and then observe their true labels. After that, each algorithm will update the particles and make a prediction to the next batch of images. Ideally we should compare the estimation of posteriors. However, since it is intractable, we evaluate the average prediction accuracy at each stage. Results are shown in Fig. 5.
Note that we have conducted a sanity check to confirm the learned operator does not ignore the first 2 rotated dimensions and use the rest 48 components to make predictions. More precisely, if we zero out the first two components of the data and learn on them. The accuracy of the particles dropps to around 65%. This further verifies that the learned PFBR indeed can generalize across different tasks.
BLR-Variational Inference. For the second experiment on MNIST, we use PFBR as a variational inference method. That is to say, instead of accurately learning a generalizable Bayesian operator, the estimation of the posterior is of more importance. Thus here we do not use the loss function in Eq. (17) summing over all intermediate states, but emphasize more on the final error . After the training is finished, we only use the transported particles to perform classification on the test set but do not further use the operator . The result is shown in Fig. 6, where -axis shows number of visited samples during training. Since we use a batch size of 128 and consider 10 stages, the first gradient step of our method starts after around samples are visited.
5 Conclusion and Future Work
In this paper, we have explored the possibility of learning an ODE-based Bayesian operator that can perform online Bayesian inference in testing phase and verified its generalization ability through both synthetic and real-world experiments. Further investigation on the parameterization of flow velocity (e.g., use a stable neural architecture (Haber & Ruthotto, 2018) with HyperNetwork (Ha et al., 2017)) and generating diverse prior distributions through a Dirichlet process can be made to explore a potentially better solution to this challenging problem.
Acknowledgements
This project was supported in part by NSF IIS-1218749, NIH BIGDATA 1R01GM108341, NSF CAREER IIS-1350983, NSF IIS-1639792 EAGER, NSF IIS-1841351 EAGER, NSF CNS-1704701, ONR N00014-15-1-2340, Intel ISTC, NVIDIA, Google and Amazon AWS.
Appendix A Existence of Unified Flow Operator
See 2.3
Proof.
By Theorem 2.2, can induce the optimal state and achieve a zero loss, . Hence, is an optimal closed-loop control for this problem.
Although in general closed-loop control has a stronger characterization to the solution, in a deterministic system like Eq. (14), the optimal closed-loop control and the optimal open-loop control will give the same control law and thus the same optimality to the loss function(Dreyfus, 1964). Hence, there exists an optimal open-loop control such that the induced optimal state also gives a zero loss and thus .
More specifically, when the system is deterministic, a state is just a deterministic result of the initial state and the dynamics. The optimal flow determined by is
[TABLE]
The continuity equation gives
[TABLE]
Hence, for any ,
[TABLE]
The dynamcis is a fixed function of , and , so the solution of this initial value problem(IVP) is a fixed function of , , and , which can be written as
[TABLE]
Finally, we can write the optimal open-loop control as
[TABLE]
Hence, has a fixed form across different .
∎
Appendix B Adjoint Method
To explain it more clearly, let us denote the evolution of the -th particles at the -th stage by for . Note that . (Then the notation in the main text will become .)
Recall the loss for each task:
[TABLE]
The loss of one particle is
[TABLE]
where
[TABLE]
and .
First, an adjoint process is defined as
[TABLE]
Denote . During the -th stage, the adjoint process follows the following differential equation
[TABLE]
Note that
[TABLE]
Claim: The gradient of the loss is the solution of a backward ODE. That is to say, , if and
[TABLE]
and , for .
Proof.
First, we can compute :
[TABLE]
Next, we have
[TABLE]
Hence, if . ∎
An algorithm for computing is summarized in Algorithm 2. A nice python package of realizing this algorithm is provided by Chen et al. (2018).
Appendix C Experiment Details
C.1 Parameterization
Overall we parameterize the flow velocity as
[TABLE]
where both and are neural networks. For instance, let be the context of this conditional flow, where is a dense feed-forward neural network, a specific neural architecture we use in the experiment is
[TABLE]
where is element-wise multiplication. The number of layers can be tuned, but in general is a shallow network.
C.2 Evaluation Metric
MMD2
The maximum mean discrepancy (MMD) of the true posterior and the estimated posterior is defined as
[TABLE]
When is a unit ball in a characteristic RKHS, Gretton et al. (2012) showed that the squared MMD is
[TABLE]
where and .
Cross-entropy
Evaluating the KL divergence is equivalent to evaluating the cross-entropy.
[TABLE]
where is approximated by kernel density estimation on the set of particles obtained from different sampling methods.
Integral Evaluation
When the true posterior is a Gaussian distribution , the expectation of the following test functions have closed-form expressions.
- •
- •
- •
Appendix D More Experimental Results
D.1 Multivariate Guassian Model
D.2 LDS Model
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Andrieu et al. (2003) Andrieu, C., de Freitas, N., Doucet, A., and Jordan, M. I. An introduction to mcmc for machine learning. Machine Learning , 50:5–43, 2003.
- 2Andrychowicz et al. (2016) Andrychowicz, M., Denil, M., Gomez, S., Hoffman, M. W., Pfau, D., Schaul, T., and de Freitas, N. Learning to learn by gradient descent by gradient descent. In Advances in Neural Information Processing Systems , pp. 3981–3989, 2016.
- 3Antoniak (1974) Antoniak, C. Mixtures of Dirichlet processes with applications to Bayesian nonparametric problems. Annals of Statistics , 2:1152–1174, 1974.
- 4Balakrishnan & Madigan (2006) Balakrishnan, S. and Madigan, D. A one-pass sequential monte carlo method for bayesian analysis of massive datasets. Bayesian Analysis , 1(2):345–361, 06 2006.
- 5Batchelor (2000) Batchelor, G. Kinematics of the Flow Field , pp. 71–130. Cambridge Mathematical Library. Cambridge University Press, 2000.
- 6Canini et al. (2009) Canini, K. R., Shi, L., and Griff iths, T. L. Online inference of topics with latent dirichlet allocation. In Proceedings of the Twelfth International Conference on Artificial Intelligence and Statistics (AISTATS) , 2009.
- 7Chen et al. (2018) Chen, T. Q., Rubanova, Y., Bettencourt, J., and Duvenaud, D. K. Neural ordinary differential equations. In Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., and Garnett, R. (eds.), Advances in Neural Information Processing Systems 31 , pp. 6572–6583. Curran Associates, Inc., 2018.
- 8Chopin et al. (2013) Chopin, N., Jacob, P. E., and Papaspiliopoulos, O. Smc 2: an efficient algorithm for sequential analysis of state space models. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , 75(3):397–426, 2013.