Path Tracking of Highly Dynamic Autonomous Vehicle Trajectories via Iterative Learning Control
Nitin R. Kapania, J. Christian Gerdes

TL;DR
This paper applies iterative learning control to autonomous racing, enabling highly dynamic vehicle path tracking over multiple laps by learning from previous runs to improve accuracy near physical limits.
Contribution
It introduces PD and Q-ILC algorithms for autonomous vehicle path tracking in racing, addressing nonlinear dynamics and repeatability for the first time.
Findings
Both algorithms effectively reduce path tracking errors.
Experimental results show improved performance over traditional control.
Algorithms maintain stability at high lateral accelerations.
Abstract
Iterative learning control has been successfully used for several decades to improve the performance of control systems that perform a single repeated task. Using information from prior control executions, learning controllers gradually determine open-loop control inputs whose reference tracking performance can exceed that of traditional feedback-feedforward control algorithms. This paper considers iterative learning control for a previously unexplored field: autonomous racing. Racecars are driven multiple laps around the same sequence of turns while operating near the physical limits of tire-road friction, where steering dynamics become highly nonlinear and transient, making accurate path tracking difficult. However, because the vehicle trajectory is identical for each lap in the case of single-car racing, the nonlinear vehicle dynamics and unmodelled road conditions are repeatable and…
Click any figure to enlarge with its caption.
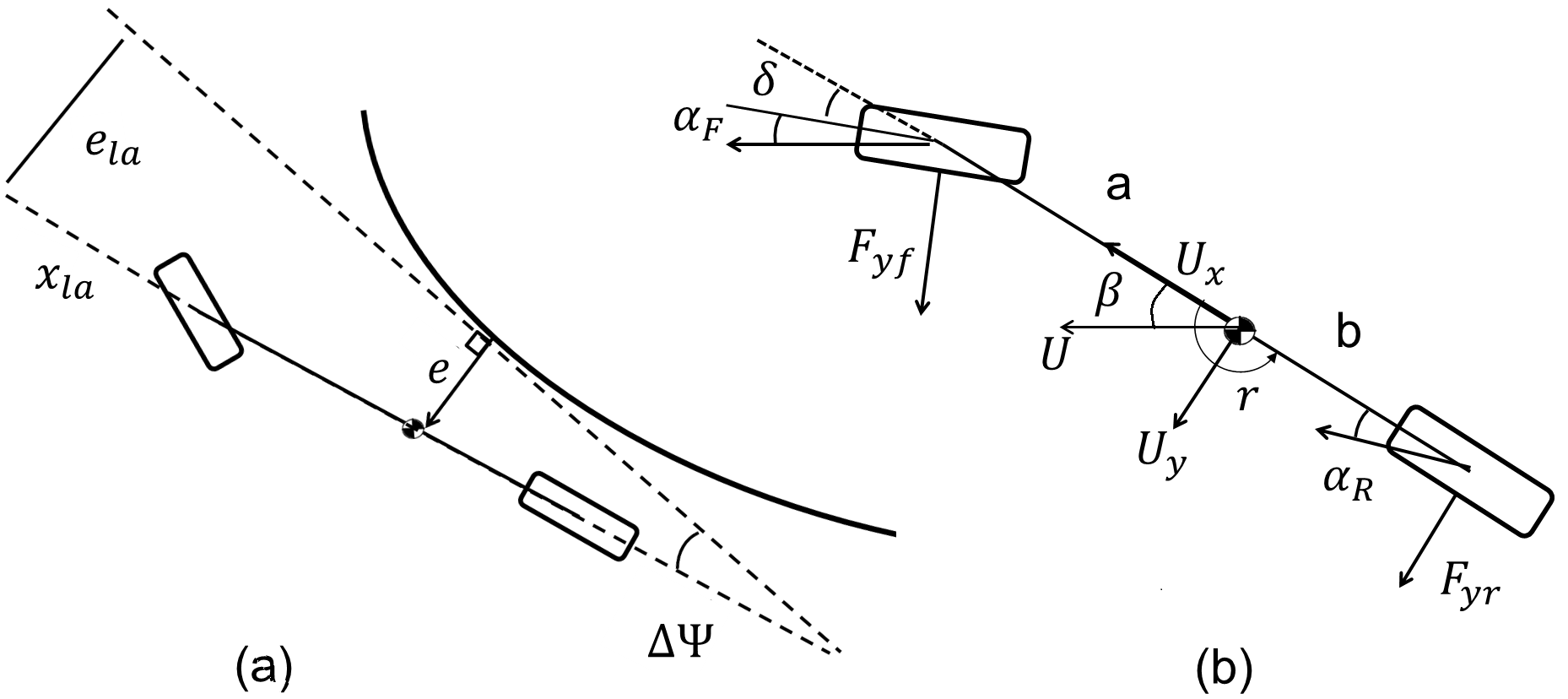 Figure 1
Figure 1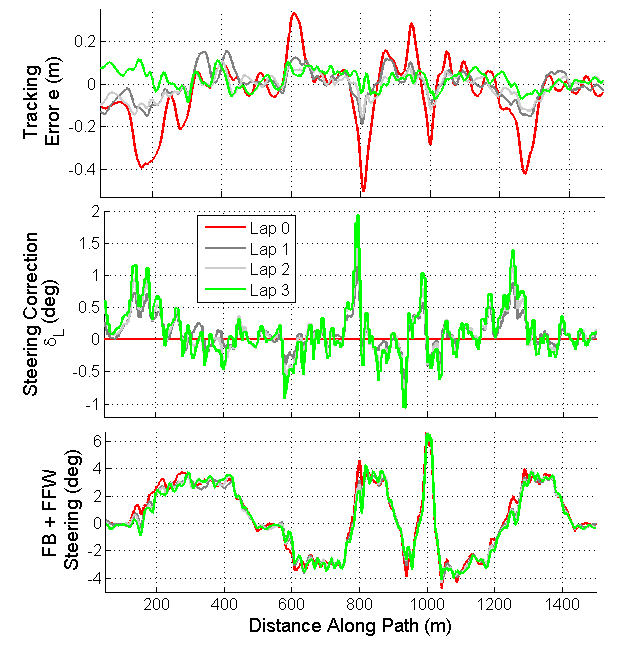 Figure 2
Figure 2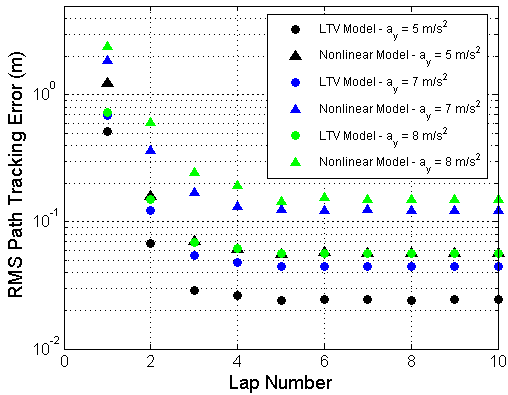 Figure 3
Figure 3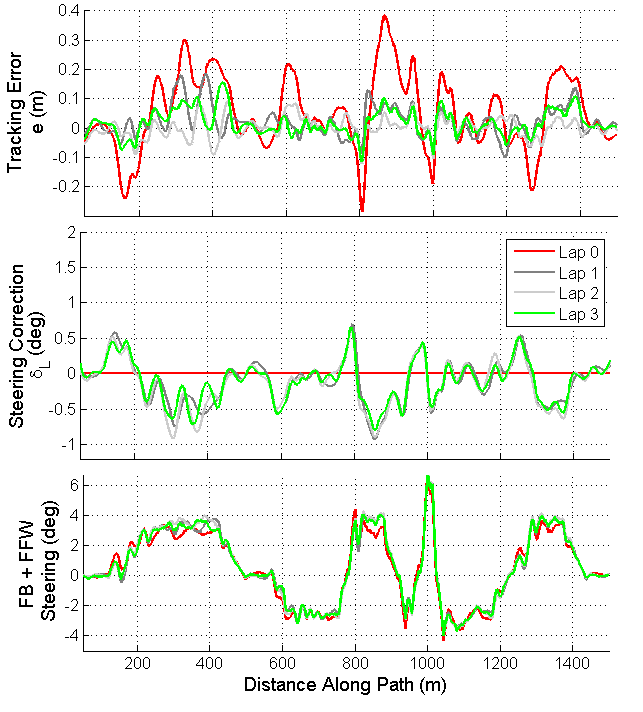 Figure 4
Figure 4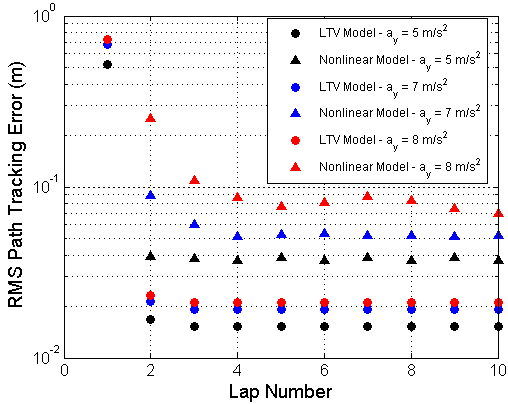 Figure 5
Figure 5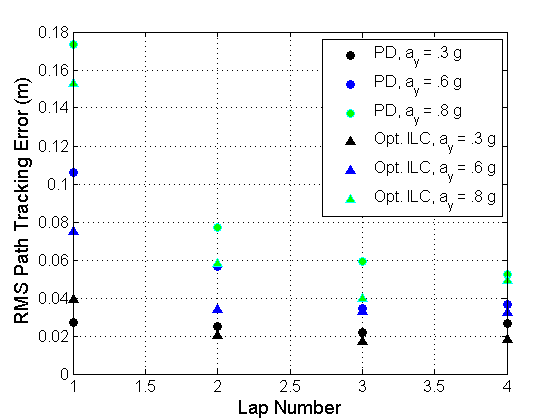 Figure 6
Figure 6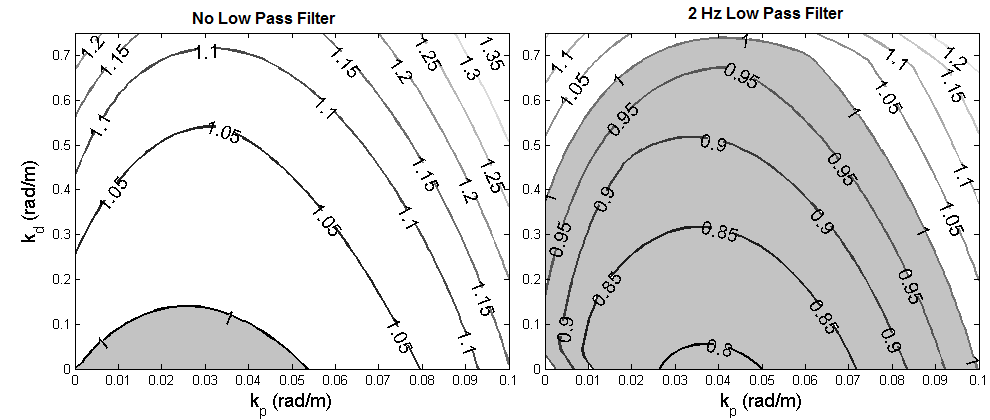 Figure 7
Figure 7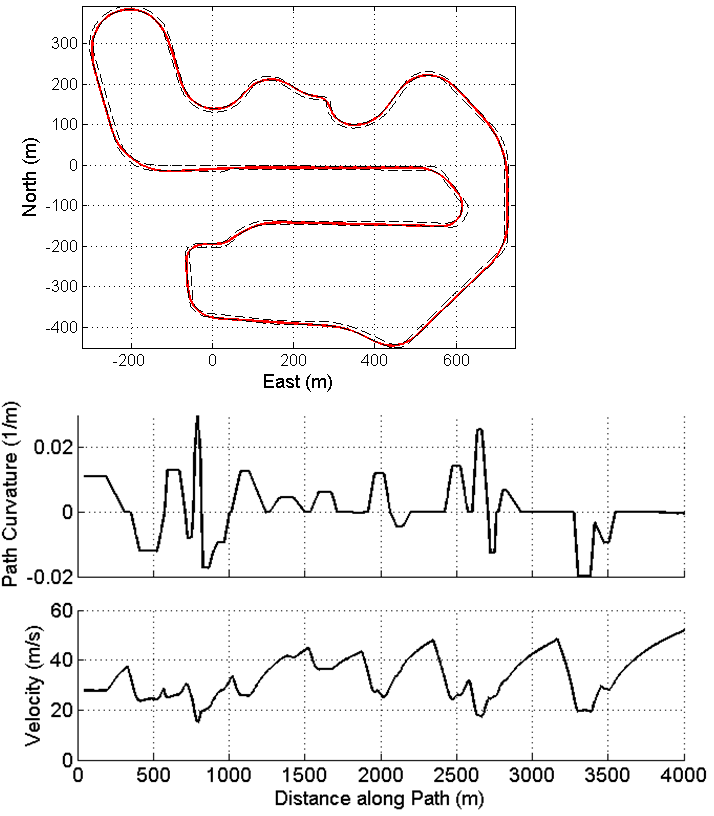 Figure 8
Figure 8 Figure 9
Figure 9| Parameter | Symbol | Value | Units |
|---|---|---|---|
| Vehicle mass | 1500 | kg | |
| Yaw moment of inertia | 2250 | ||
| Front axle to CG | 1.04 | m | |
| Rear axle to CG | 1.42 | m | |
| Front cornering stiffness | 160 | ||
| Rear cornering stiffness | 180 | ||
| Lookahead Distance | 15.2 | ||
| Lanekeeping Gain | .053 | ||
| Lanekeeping Sample Time | .005 | s | |
| ILC Sample Time | .1 | s | |
| PD Gains | and | .02 & .4 | |
| Q-ILC Matrix | and | - | |
| Q-ILC Matrix | 100 | - |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Multiple-Lap Path Tracking for an Autonomous Race Vehicle via Iterative Learning Control
Nitin R. Kapania 1,2 and J. Christian Gerdes1 1Department of Mechanical Engineering, Stanford University, Stanford, CA 94305, USA2Corresponding author: [email protected]
Abstract
Iterative learning control has been successfully used for several decades to improve the performance of control systems that perform a single repeated task. Using information from prior control executions, learning controllers gradually determine open-loop control inputs whose reference tracking performance can exceed that of traditional feedback-feedforward control algorithms. This paper considers iterative learning control for a previously unexplored field: autonomous racing. Racecars are driven multiple laps around the same sequence of turns while operating near the physical limits of tire-road friction, where steering dynamics become highly nonlinear and transient, making accurate path tracking difficult. However, because the vehicle trajectory is identical for each lap in the case of single-car racing, the nonlinear vehicle dynamics and unmodelled road conditions are repeatable and can be accounted for using iterative learning control, provided the tire force limits have not been exceeded. This paper describes the design and application of proportional-derivative (PD) and quadratically optimal (Q-ILC) learning algorithms for multiple-lap path tracking of an autonomous race vehicle. Simulation results are used to tune controller gains and test convergence, and experimental results are presented on an Audi TTS race vehicle driving several laps around Thunderhill Raceway in Willows, CA at lateral accelerations of up to 8 . Both control algorithms are able to correct transient path tracking errors and improve the performance provided by a reference feedforward controller.
I Introduction
Iterative learning control (ILC) solves the control problem of tracking a specific reference command that is repeated many times. By using tracking error information from prior attempts, ILC techniques are used to gradually determine the open-loop control inputs that cause the system output to track a desired reference with minimal tracking error.
ILC algorithms work best when the exogenous system signals (i.e. disturbances and reference inputs) are constant from iteration-to-iteration. As a result, iterative learning controllers have frequently been applied in relatively structured robotics and automation environments, with recent publications considering piezolectric positioning [1], robotic arm tracking [2], and microdeposition [3]. However, iterative learning control has recently expanded into applications outside of the traditional automation and process control setting. Chen and Moore [4] proposed a simple iterative learning scheme in 2006 to improve path-following of a ground vehicle with omni-directional wheels, where double integration of the previous feedback input was used to improve the feedforward signal. In 2013, Sun et al. proposed an iterative learning controller for overspeed proctection of high-speed trains [5]. Purwin and Andrea synthesized an iterative controller using least-squares methods to aggressively maneuver a quadrotor unmanned aerial vehicle from one state to another [6]. Iterative learning control has also extended into the neuromuscular and biological domains, with Rogers et al. [7] developing an ILC algorithm for robotically assisted stroke rehabilitation.
This paper presents autonomous race car piloting as a previously unexplored application area for iterative learning control. Race car drivers must drive multiple laps around the same sequence of turns on a closed track, while operating near the physical limits of tire-road friction to minimize lap times. At the limits of tire friction, the steering dynamics associated with lateral tracking of the desired path become highly nonlinear, and difficult-to-measure disturbances such as bank, grade and local friction variation of the road surface have a large effect on the transient dynamics of the vehicle. These factors make development of a suitable feedforward steering controller challenging. However, because operation of the race vehicle occurs over multiple laps, with the reference road curvature unchanging from lap-to-lap, the unknown transient disturbances and vehicle dynamics tend be constant from lap to lap and can therefore be accounted for via iterative learning control. A notable exception occurs when the vehicle has significantly understeered due to lack of front tire force availability. In this case, additional steering will have no impact on path tracking.
This paper is further divided as follows. Section II introduces a linear model for the planar vehicle dynamics of a race car following a fixed reference path. Because the transfer function between the steering wheel input and the vehicle’s path deviation is open-loop unstable, a stabilizing lanekeeping controller is added to the steering system and the closed loop dynamics are represented in the commonly used “lifted domain”. Section III presents a PD-type iterative learning controller with a low-pass filter used to speed up convergence. Gain tuning and stability at low lateral accelerations are shown using lifted domain techniques, while nonlinear simulations are used to predict a desirable tracking response in the presence of high lateral acceleration. Section IV presents a quadratically optimal (Q-ILC) iterative learning controller, which has the benefit of explicitly accounting for changes in vehicle speed along the race track. Section V presents experimental data of both controllers implemented on an Audi TTS race vehicle at combined lateral/longitudinal accelerations of up to 8 .
II Vehicle Dynamics and Problem Overview
For this paper, the objective of piloting an autonomous vehicle along a fixed race track in minimum time is divided into separate lateral and longitudinal vehicle control problems. The lateral controller uses the the steering wheel input to track a desired “racing-line”, shown in Fig. 1a. The racing line is frequently represented by a path curvature function parametrized by distance along the track (Fig. 1)b. The longitudinal controller tracks a desired speed profile that keeps the vehicle at a specified lateral-longitudinal acceleration magnitude, typically near the limits of tire-road friction (Fig. 1)c. This paper focuses on learning the desired steer angle command over multiple laps in order to accurately track the reference path at high speeds, and we therefore assume minimum time velocity and curvature profiles have been computed using methods published in [8], and that tracking of the velocity profile is handled by a separate controller [9].
II-A Lateral Vehicle Dynamics
Fig. 2 shows a schematic of a vehicle following a path with curvature profile . The lateral deviation of the vehicle from the desired path () is the measured output for the ILC algorithms. Since iterative learning controllers determine appropriate feedforward control inputs over several iterations, it is necessary for the open-loop dynamics between the control input and control output to be asymptotally stable. For the case of active steering control, the transfer function between the vehicle steer angle () and the lateral path error is characterized by two poles at the origin, requiring the addition of a stabilizing feedback controller.
A lookahead controller provides the stabilizing feedback command for this paper. The “lookahead error” is defined by
[TABLE]
Where is the vehicle heading error and is the lookahead distance, typically 5-20 meters for autonomous driving. The resulting feedback control law is
[TABLE]
with proportional gain . The control law (2) is a natural extension of potential field lanekeeping, as described by Rossetter et al. in [10], which also provides heuristics for selecting and . Desirable stability properties over significant tire saturation levels are demonstrated in [11].
With the feedback controller added, closed loop dynamics of the lateral path deviation are dependent on three other states: vehicle sideslip , yaw rate and heading error . For controller development and testing, these dynamics are given by the planar bicycle model:
[TABLE]
Where is the vehicle forward velocity and and the front and rear lateral tire forces. The vehicle mass and yaw inertia are denoted by and , while the geometric parameters and are shown in Fig. 2.
As automotive racing frequently occurs near the limits of tire force saturation, lateral tire force is modeled using the nonlinear Fiala brush tire model, assuming a single coefficient of friction and a parabolic force distribution [12]. The lateral tire forces are functions of the front and rear tire slip angles and .
[TABLE]
where is the surface coefficient of friction, is the normal load, and is the tire cornering stiffness. The linearized tire slip angles are given by
[TABLE]
II-B Linear Time Varying Model in the Lifted Domain
While the nonlinear tire model presented in (II-A) captures the effect of tire saturation at the limits of handling, established methods for design and analysis of iterative learning controllers requires a linear system description. With the assumption of low lateral acceleration, a simple linear tire model is given by,
[TABLE]
The lateral error dynamics of the vehicle in response to a feedforward steer angle input (recall that there is also a feedback steer angle in the loop) can then be represented by the continuous, linear time varying (LTV) state space model,
[TABLE]
Where is the learned steering input. The LTV framework is chosen to account for the variation in vehicle velocity along the track (Fig. 1). While the longitudinal dynamics are not explicitly accounted for in (3a), allowing for the state matrices to vary with measured values of enables more accurate controllers and analysis. The time-varying matrices , , and are given by
[TABLE]
[TABLE]
[TABLE]
The disturbance , is assumed constant from lap to lap and is given by
[TABLE]
The next step is to discretize (7) by the controller sample time , resulting in the discrete time system,
[TABLE]
Where is the time sample index, and is the number of iterations (i.e. the number of laps around the track). Development and analysis of the iterative learning controllers in the next section will be made easier by representing the system dynamics in the “lifted-domain”, where the inputs and outputs are stacked into arrays and related by matrix multiplication, as follows:
[TABLE]
Where the elements of the matrix are given by,
[TABLE]
Note that for the case where is constant, we have a linear time invariant (LTI) system given by only elements, with , and the resulting lifted-domain matrix is Toeplitz.
III Controller Design
With the representation of the steering dynamics for a given lap represented by (14), the next step is to design algorithms that determine the learned steering input for the next lap, given the error response from the completed lap . A common framework for iterative learning algorithms is to choose as follows [13],
[TABLE]
Where is the filter matrix, and is the learning matrix. In following sections, the matrices and will be obtained by designing a PD type iterative learning controller as well as a quadratically optimal (Q-ILC) learning controller.
III-A Proportional-Derivative Controller
The proportional-derivative iterative learning controller computes the steering addition at a given time index based on the error and the change in error at the same time index from the previous lap,
[TABLE]
Where and are the proportional and derivative gains. In the lifted domain representation from (16), the resulting learning matrix is given by
[TABLE]
An important consideration in choosing the gains and is achieving a monotonic decrease in the path tracking error on every lap. This property, known as monotonic convergence, occurs if the following condition is met [13]:
[TABLE]
Where is the maximum singular value. In this case, the value of provides an upper bound on the decrease in the tracking error norm from lap to lap, i.e.
[TABLE]
where is the converged path tracking error. The monotonic stability condition differs from its weaker counterpart of asymptotic stability in that we are guaranteed that the path tracking error on the first lap (i.e. with no added learning input) is the worst case performance.
Fig. 3 shows values of for both an unfiltered PD controller (), and for a PD controller with a 2 Hz low pass filter. The values are plotted as a contour map against the controller gains and . Addition of the low-pass filter assists in achieving controller monotonic stability by removing oscillations that are frequently generated by iterative learning controllers when trying to remove small reference tracking errors after several iterations. Since the filtering occurs when generating a control signal for the next lap, the filter can be zero-phase.
However, testing for linear stability is insufficient controller design given that racing frequently occurs near the limits of vehicle handling, when the vehicle dynamics are described by the nonlinear equations of motion presented in Section II. To test the PD controller feasibility, the vehicle tracking performance over multiple laps is simulated using the path curvature and speed profile shown in Fig. 1. Simulated results for the root-mean-square (RMS) tracking error are shown in Fig. 4 for both the linear state dynamics prescribed by (13) and the nonlinear dynamics model given by (3) and (II-A). The results indicate that as the vehicle corners closer to the limits of handling, the tracking performance of the ILC degrades relative to the expected performance given by the linear model, but can still be expected to converge over relatively few iterations.
III-B Quadratically Optimal Controller
An alternate approach to determining the learned steering input is to minimize a quadratic cost function for the next lap:
[TABLE]
Where and the matrices , , and are weighting matrices. This formulation allows the control designer to weight the competing objectives of minimizing tracking error, control effort, and change in the control signal from lap to lap. While constraints can be added to the optimization problem, the unconstrained problem in (21) can be solved analytically [13] to obtain desired controller and filter matrices:
[TABLE]
An advantage to the quadratically optimal control design over the simple PD controller is that the controller matrices and take the linear time-varying dynamics into account. This allows the iterative learning algorithm to take into account changes in the steering dynamics due to changes in vehicle velocity. However, a disadvantage is that determining new and matrices every lap requires resolving (22), which can be computationally expensive for fast sampling rates.
Fig. 5 shows simulated results for the quadratically optimal ILC controller. The results are similar to those in Fig. 4 in that the predicted controller performance is worse when the simulation accounts for nonlinear tire dynamics. However, the simulation still shows a rapid decrease in path tracking error over the first ten laps, with RMS errors on the order of 8-9 cm at lateral accelerations of .8 .
IV Experimental Results
Experimental data for both controllers was collected over multiple laps at Thunderhill Raceway, a 3 mile paved racetrack in Willows, CA, with track boundaries shown in Fig. 1a. The experimental testbed is an autonomous Audi TTS equipped with an electronic power steering motor, active brake booster, and throttle by wire Fig. 6. Vehicle and controller parameters are shown in Table 1.
An integrated Differential Global Positioning System (DGPS) and Inertial Measurement Unit (IMU) is used to obtain vehicle state information, and a localization algorithm determines the lateral path tracking error , heading error , and distance along the desired racing line. The steering controller updates at 200 Hz, and the iterative steering corrections are calculated after each lap from data downsampled to 10 Hz. The corrections are then applied as a function of distance along the track using an interpolated lookup table. For safety reasons, a steady-state feedforward steering algorithm [14] is also applied to keep the tracking error on the first lap below 1 m.
Fig. 7 shows the applied iterative learning signals and resulting path tracking error over four laps using the PD learning algorithm. The car is driven aggressively at peak lateral/longitudinal accelerations of 8 . On the first lap, despite the incorporation of a feedforward-feedback controller operating at a high sampling rate, several transient spikes in tracking error are visible due to the underdamped tire dynamics near the limits of handling. However, the iterative learning algorithm is able to significantly attenuate these transient spikes over just two or three laps. Similar qualitative results occur for the quadratically optimal ILC.
In Fig. 8, results are shown for versions of the velocity profile in Fig. 1 that are scaled to achieve different vehicle accelerations. The results show that at low vehicle accelerations, when vehicle dynamics are accurately prescribed by a linear tire model, the feedback-feedforward controller is able to keep the vehicle close to the desired path, leaving little room for improvement through iterative learning control. However, as the speed profile becomes more aggressive, the path tracking degrades in the presence of highly transient tire dynamics, and iterative learning control can be effectively used to obtain tight path tracking path over two or three laps of racing. In practice, the performance of both the PD algorithm and quadratically optimal algorithms are similar, and an important observation is that the RMS tracking error increases slightly from lap-to-lap at the end of some tests. While not predicted in simulation, this behavior is not unreasonable given unmodelled sensor noise and disturbances that vary from lap to lap. More refined tuning of the gain matrices may be able to prevent this RMS error increase, or the ILC algorithm can be stopped after several iterations once the tracking performance is acceptable.
V Conclusion
This paper demonstrates the application of iterative learning control (ILC) methods to achieve accurate steering control of an autonomous race car over multiple laps. Two different algorithms, proportional-derivative (PD) and quadratically optimal (Q-ILC) learning control are tested in simulation and then used to experimentally eliminate path tracking errors caused by the highly transient nature of the vehicle lateral dynamics near the limits of tire-road friction. Both learning algorithms provide comparable lap-to-lap tracking performance, although the PD method is computationally fast enough to run in real time. Two clear limitations of the presented iterative learning controllers present avenues for future work. While representing the vehicle dynamics with a linear, time-varying model allows for the quadratically optimal ILC algorithm to account for varying longitudinal speed, a better approach is to linearize the vehicle dynamics at each point on the track and create an affine time-varying model whose path tracking error can be minimized. Furthermore, applying a steering wheel input to eliminate lateral errors will work only if the vehicle is near the limits of handling, but has not fully saturated the available tire force and entered a limit understeer condition. In this case, a separate controller must be developed to modify the racing line and velocity profile for future laps in order to reduce the vehicle cornering forces.
ACKNOWLEDGMENT
This research is supported by the National Science Foundation Graduate Research Fellowship Program (GRFP). The authors would like to thank the members of the Dynamic Design Lab at Stanford University and the Audi Electronics Research Lab.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] D. Huang, J.-X. Xu, V. Venkataramanan, and T. Huynh, “High-performance tracking of piezoelectric positioning stage using current-cycle iterative learning control with gain scheduling,” IEEE Trans. on Industrial Electronics , vol. 61, no. 2, pp. 1085–1098, 2014.
- 2[2] C. T. Freeman and Y. Tan, “Iterative learning control with mixed constraints for point-to-point tracking,” IEEE Trans. on Control Systems Technology , vol. 21, no. 3, pp. 604–616, 2013.
- 3[3] D. J. Hoelzle, A. G. Alleyne, and A. J. W. Johnson, “Basis task approach to iterative learning control with applications to micro-robotic deposition,” IEEE Trans. on Control Systems Technology , vol. 19, no. 5, pp. 1138–1148, 2011.
- 4[4] Y. Q. Chen and K. L. Moore, “A practical iterative learning path-following control of an omni-directional vehicle,” Asian Journal of Control , vol. 4, no. 1, pp. 90–98, 2002.
- 5[5] H. Sun, Z. Hou, and D. Li, “Coordinated iterative learning control schemes for train trajectory tracking with overspeed protection,” IEEE Trans. on Automation Science and Engineering , vol. 10, no. 2, pp. 323–333, 2013.
- 6[6] O. Purwin and R. D’Andrea, “Performing and extending aggressive maneuvers using iterative learning control,” Robotics and Autonomous Systems , vol. 59, no. 1, pp. 1–11, 2011.
- 7[7] E. Rogers, D. H. Owens, H. Werner, C. T. Freeman, P. L. Lewin, S. Kichhoff, C. Schmidt, and G. Lichtenberg, “Norm-optimal iterative learning control with application to problems in accelerator-based free electron lasers and rehabilitation robotics,” European Journal of Control , vol. 16, no. 5, pp. 497–522, 2010.
- 8[8] P. A. Theodosis and J. C. Gerdes, “Generating a racing line for an autonomous racecar using professional driving techniques,” in Dynamic Systems and Control Conference , 2011, pp. 853–860.