initKmix -- A Novel Initial Partition Generation Algorithm for Clustering Mixed Data using k-means-based Clustering
Amir Ahmad, Shehroz S. Khan

TL;DR
This paper introduces initKmix, an innovative initialization method for k-means clustering on mixed datasets, which improves accuracy and consistency over traditional random initializations by aggregating multiple clustering runs.
Contribution
The paper presents initKmix, a new initialization algorithm that enhances k-means clustering for mixed data by combining results from multiple runs based on different attribute initializations.
Findings
initKmix outperforms random initialization in accuracy and consistency
initKmix achieves results comparable or superior to state-of-the-art methods
Experiments confirm initKmix's effectiveness on various datasets
Abstract
Mixed datasets consist of both numeric and categorical attributes. Various k-means-based clustering algorithms have been developed for these datasets. Generally, these algorithms use random partition as a starting point, which tends to produce different clustering results for different runs. In this paper, we propose, initKmix, a novel algorithm for finding an initial partition for k-means-based clustering algorithms for mixed datasets. In the initKmix algorithm, a k-means-based clustering algorithm is run many times, and in each run, one of the attributes is used to create initial clusters for that run. The clustering results of various runs are combined to produce the initial partition. This initial partition is then used as a seed to a k-means-based clustering algorithm to cluster mixed data. Experiments with various categorical and mixed datasets showed that initKmix produced…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1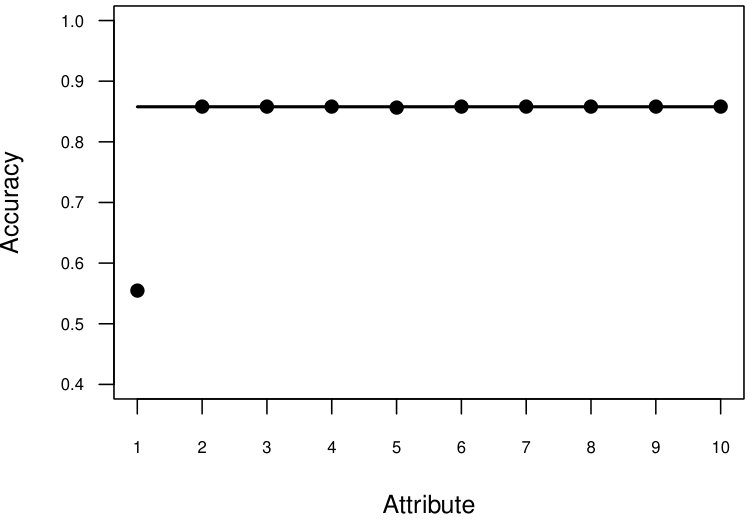 Figure 3
Figure 3 Figure 1
Figure 1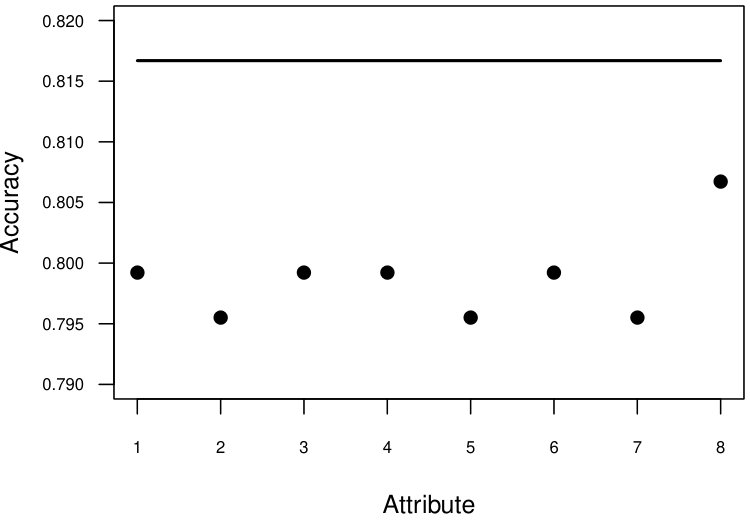 Figure 5
Figure 5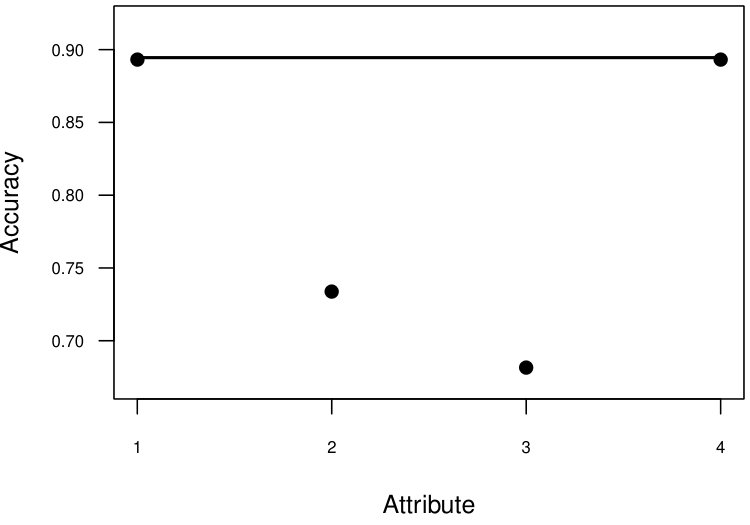 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8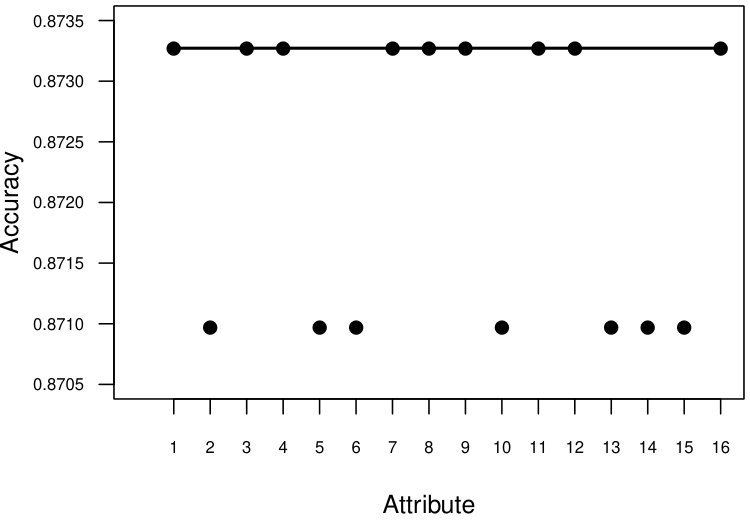 Figure 9
Figure 9| Data | First | Second | Third | Fourth |
|---|---|---|---|---|
| point | run | run | run | run |
| 1 | a | b | b | a |
| 2 | b | a | b | a |
| 3 | b | a | b | a |
| 4 | b | b | a | b |
| 5 | a | b | a | b |
| Cluster | Attributes | |||
|---|---|---|---|---|
| Categorical-1 | Categorical-2 | Numeric-1 | Numeric-2 | |
| A (90%), B (10%) | X (90%), Y (10%) | |||
| A (90%), B (10%) | X (90%), Y (10%) | |||
| A (10%), B (90%) | X (10%), Y (90%) | |||
| A (10%), B (90%) | X (90%), Y (10%) | |||
| Original cluster | Final clusters | |||
|---|---|---|---|---|
| 10 | 0 | 90 | 0 | |
| 0 | 90 | 0 | 10 | |
| 7 | 0 | 93 | 0 | |
| 0 | 90 | 0 | 10 | |
| Original cluster | Final clusters | ||
|---|---|---|---|
| 0 | 82 | 18 | |
| 18 | 82 | 0 | |
| 0 | 0 | 100 | |
| 100 | 0 | 0 | |
| Original cluster | Final clusters | |||
|---|---|---|---|---|
| 0 | 82 | 0 | 18 | |
| 11 | 0 | 89 | 0 | |
| 0 | 0 | 0 | 100 | |
| 91 | 0 | 9 | 0 | |
| Original cluster | Final clusters | |||
|---|---|---|---|---|
| 90 | 0 | 0 | 10 | |
| 0 | 89 | 11 | 0 | |
| 7 | 0 | 0 | 93 | |
| 0 | 9 | 91 | 0 | |
| Dataset | Number of | Number of | Number of |
|---|---|---|---|
| data points | attributes | classes | |
| Soybean-small | 47 | 35 | 4 |
| Vote | 435 | 16 | 2 |
| Breast cancer | 699 | 9 | 2 |
| Mushroom | 8124 | 22 | 2 |
| Dataset | The KMCMD algorithm with initKmix | The KMCMD algorithm with the random initial partition | ||
| Soybean-small | 1 | 0 | 0.967 | 0.079 |
| Vote | 0.873 | 0 | 0.871 | 0.002 |
| Breast cancer | 0.974 | 0 | 0.965 | 0.014 |
| Mushroom | 0.894 | 0 | 0.822 | 0.124 |
| Dataset | The KMCMD algorithm with initKmix | The KMCMD algorithm with the random initial partition | ||
| Soybean-small | 1 | 0 | 0.953 | 0.083 |
| Vote | 0.779 | 0 | 0.775 | 0.003 |
| Breast cancer | 0.950 | 0 | 0.931 | 0.016 |
| Mushroom | 0.811 | 0 | 0.708 | 0.147 |
| Dataset | The KMCMD algorithm with initKmix | The KMCMD algorithm with the random initial partition | ||
| Soybean-small | 1 | 0 | 0.873 | 0.091 |
| Vote | 0.557 | 0 | 0.550 | 0.004 |
| Breast cancer | 0.899 | 0 | 0.861 | 0.017 |
| Mushroom | 0.622 | 0 | 0.415 | 0.163 |
| Dataset | The KMCMD algorithm with initKmix | k-modes [Huang, 1997b] with random initialization | k-modes with Wu’s initialization [Wu et al., 2007] | k-modes with Cao’s initialization [He, 2006] | k-modes with Khan and Ahmad’s initialization [Khan and Ahmad, 2013] | k-modes with Ini_Entropy initialization [Liu et al., 2016] | CRAFTER [Lin et al., 2018] | Fuzzy k-modes clustering [Huang and Ng, 1999] |
| Soybean- small | 1 | 0.864 | 1.000 | 1.000 | 0.957 | 1.000 | 1.000 | 0.824 |
| Vote | 0.873 | 0.842 | - | - | 0.850 | 0.869 | 0.856 | 0.862 |
| Breast cancer | 0.974 | 0.836 | 0.911 | 0.911 | 0.913 | 0.933 | - | - |
| Mushroom | 0.894 | 0.875 | 0.875 | 0.875 | 0.882 | 0.888 | 0.774 | 0.723 |
| Dataset | Number of | Number of | Number of | Number of |
|---|---|---|---|---|
| data points | categorical | numeric | classes | |
| attributes | attributes | |||
| Acute Inflammations | 120 | 5 | 1 | 2 |
| Heart (Statlog) | 270 | 7 | 6 | 2 |
| Heart (Cleveland) | 303 | 6 | 7 | 2 |
| Australian credit | 690 | 8 | 6 | 2 |
| German credit | 1000 | 13 | 7 | 2 |
| Dataset | The KMCMD algorithm with initKmix | The KMCMD algorithm with the random initial partition | ||
| Acute infammation | 0.823 | 0 | 0.762 | 0.125 |
| Heart (Statlog) | 0.817 | 0 | 0.802 | 0.010 |
| Heart (Cleveland) | 0.841 | 0 | 0.834 | 0.005 |
| Australian credit | 0.858 | 0 | 0.829 | 0.118 |
| German credit | 0.683 | 0 | 0.678 | 0.004 |
| Dataset | The KMCMD algorithm with initKmix | The KMCMD algorithm with the random initial partition | ||
| Acute inflammation | 0.709 | 0 | 0.639 | 0.118 |
| Heart (Statlog) | 0.679 | 0 | 0.665 | 0.013 |
| Heart (Cleveland) | 0.728 | 0 | 0.719 | 0.005 |
| Australian credit | 0.756 | 0 | 0.716 | 0.127 |
| German credit | 0.567 | 0 | 0.563 | 0.003 |
| Dataset | The KMCMD algorithm with initKmix | The KMCMD algorithm with the random initial partition | ||
| Acute inflammation | 0.415 | 0 | 0.273 | 0.182 |
| Heart (Statlog) | 0.358 | 0 | 0.331 | 0.021 |
| Heart (Cleveland) | 0.456 | 0 | 0.438 | 0.009 |
| Australian credit | 0.512 | 0 | 0.432 | 0.217 |
| German credit | 0.0519 | 0 | 0.0415 | 0.006 |
| Dataset | The KMCMD algorithm with initKmix | k-prototypes [Huang, 1997a] with random initialization | k-prototypes [Huang, 1997a] with Ji et al. [Ji et al., 2015c] initialization method | Similarity-based Agglomerative clustering (SBAC) [Li and Biswas, 2002] | Object-cluster similarity metric (OCIL) algorithm [Cheung and Jia, 2013] | Fuzzy k-prototypes Ji et al. [2012] |
| Acute inflammation | 0.823 | 0.610 | - | 0.508 | - | 0.710 |
| Heart (Statlog) | 0.817 | 0.770 | - | - | 0.814 | - |
| Heart (Cleveland) | 0.841 | 0.772 | 0.808 | 0.752 | 0.831 | 0.835 |
| Australian credit | 0.858 | 0.738 | 0.800 | 0.600 | 0.757 | 0.838 |
| German credit | 0.683 | 0.671 | - | - | 0.695 | - |
| The KMCMD algorithm with initKmix | The KMCMD algorithm with the random initial partition | |||
| 2 | 0.858 | 0 | 0.829 | 0.118 |
| 4 | 0.849 | 0 | 0.837 | 0.010 |
| 5 | 0.852 | 0 | 0.833 | 0.009 |
| 6 | 0.823 | 0 | 0.835 | 0.011 |
| 7 | 0.839 | 0 | 0.832 | 0.025 |
| The KMCMD algorithm with initKmix | The KMCMD algorithm with the random initial partition | |||
| 2 | 0.756 | 0 | 0.716 | 0.127 |
| 4 | 0.682 | 0 | 0.651 | 0.007 |
| 5 | 0.685 | 0 | 0.648 | 0.019 |
| 6 | 0.616 | 0 | 0.612 | 0.022 |
| 7 | 0.593 | 0 | 0.584 | 0.025 |
| The KMCMD algorithm with initKmix | The KMCMD algorithm with the random initial partition | |||
| 2 | 0.512 | 0 | 0.432 | 0.217 |
| 4 | 0.368 | 0 | 0.307 | 0.014 |
| 5 | 0.372 | 0 | 0.306 | 0.038 |
| 6 | 0.237 | 0 | 0.228 | 0.044 |
| 7 | 0.216 | 0 | 0.191 | 0.049 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
initKmix-A Novel Initial Partition Generation Algorithm for Clustering Mixed Data using k-means-based Clustering
Amir Ahmad
College of Information Technology, United Arab Emirates University,Al-Ain, UAE
Shehroz Khan
KITE – Toronto Rehabilitation Institute, University Health Network, 550, University Avenue, Toronto, ON, Canada
Abstract
Mixed datasets consist of both numeric and categorical attributes. Various k-means-based clustering algorithms have been developed for these datasets. Generally, these algorithms use random partition as a starting point, which tends to produce different clustering results for different runs. In this paper, we propose, initKmix, a novel algorithm for finding an initial partition for k-means-based clustering algorithms for mixed datasets. In the initKmix algorithm, a k-means-based clustering algorithm is run many times, and in each run, one of the attributes is used to create initial clusters for that run. The clustering results of various runs are combined to produce the initial partition. This initial partition is then used as a seed to a k-means-based clustering algorithm to cluster mixed data. Experiments with various categorical and mixed datasets showed that initKmix produced accurate and consistent results, and outperformed the random initial partition method and other state-of-the-art initialization methods. Experiments also showed that k-means-based clustering for mixed datasets with initKmix performed similar to or better than many state-of-the-art clustering algorithms for categorical and mixed datasets.
keywords:
Mixed data, Clustering , K-means , Initialization , Random
MSC:
[2010] 00-01, 99-00
††journal: Expert systems with applications
1 Introduction
Clustering is a process in which similar data points are grouped in the same clusters whereas dissimilar data points are grouped is different clusters based on some notion of ‘similarity’ [Jain and Dubes, 1988]. Many datasets only contain numeric or categorical attributes; however, the majority of real-world datasets contain both types of attributes. These are called mixed datasets [Bishop, 2008, Witten and Frank, 2005]. Most clustering algorithms developed to handle only numeric or categorical datasets cannot be directly used to cluster mixed datasets because the calculation of ‘similarity’ is not straight forward in mixed datasets [Ahmad and Khan, 2019].
Various types of clustering algorithms have been developed to handle mixed datasets [Balaji and Lavanya, 2018]; the most prominent being the partitional, hierarchical, model-based, and neural network-based methods [Ahmad and Khan, 2019]. The partitional clustering methods are more popular among the research community because they are (i) simpler in interpretation and implementation, (ii) linear in time complexity with the number of data points, and (iii) easily adaptable to parallel architectures. The traditional k-means algorithm is a partitional clustering algorithm that was developed to cluster datasets with only numeric attributes [Khan and Ahmad, 2004]. Its objective function uses a distance metric (e.g. Euclidean distance) that can only be defined for numeric attributes. This type of clustering algorithm is further extended to develop k-means-based clustering for mixed datasets (KMD) algorithms [Huang, 1997a, Ahmad and Dey, 2007, Ahmad and Khan, 2019]. The KMD algorithms comprise of a family of algorithms that may differ in the definition of their cluster center, distance measure and objective function [Ahmad and Khan, 2019]. Most of these partitional clustering approaches perform hard clustering, i.e. a data point can belong to only one cluster. In fuzzy clustering approaches, a data point can be assigned to more than one cluster with different membership values. Approaches based on fuzzy clustering have also been applied for mixed datasets [Ji et al., 2012, D’Urso and Massari, 2019]. In this paper, we focus on hard clustering clustering algorithms.
In general, there are two type of approaches for initializing the k-means clustering algorithm. In the first approach, the random initial cluster centers, k (the number of clusters) data points are selected randomly, which act as the initial cluster centers. In the second approach, the random initial partition, first randomly assigns a cluster to each data point and then compute the centers of these clusters. The k-means based clustering algorithms may suffer from several drawbacks [Khan and Ahmad, 2004]. Prominently, the k-means optimization function can stuck in the local minima; therefore, with a different initialization, the k-means clustering algorithm may lead to different final clusters. Hence, it is difficult to obtain reliable and consistent clustering results [Khan and Ahmad, 2004].
Similar to the standard k-means clustering algorithm for numeric data, KMD algorithms also suffers from the random initialization problem. A few initialization methods have been developed for KMD algorithms [Ji et al., 2015a, b, Chen et al., 2017, Wangchamhan et al., 2017, Ahmad and Hashmi, 2016]. However, these methods are either computationally expensive (quadratic complexity with respect to the number of data points) [Ji et al., 2015b, a, Chen et al., 2017] or do not produce consistent clustering results [Wangchamhan et al., 2017, Ahmad and Hashmi, 2016]. In this paper, our baseline KMD algorithm is the one proposed by Ahmed and Dey (2007), k-means clustering for mixed datasets with a mixed distance measure (KMCMD). The reason to choose KMCMD is that it has shown superior performance in comparison to other similar partitional clustering algorithms to cluster mixed datasets [Ahmad and Dey, 2007].
In this paper, we present the initKmix algorithm, a novel algorithm to compute the initial partition for KMCMD algorithm. The initial partition is then fed to KMCMD algorithm to cluster mixed datasets. The initial clusters produced by the initKmix algorithm are stable across various runs of the algorithm or when the order of the data points is changed. This ensures consistent and reliable clustering results. Moreover, the time complexity of the initKmix algorithm is linear w.r.t. the number of data points; thus, it can be used with large datasets. The initKmix algorithm does not guarantee to find the global optima of the optimization functions of the KMCMD algorithm; however, the experiments suggest that the KMCMD algorithm with the initKmix algorithm produces superior clustering results. The choice of k is an important issue in the KMCMD algorithm [Liang et al., 2012]; however, in this paper, we focus on finding the appropriate initial partitions with given value of .
The paper is organized in the following way. Section 2 presents related work focusing on the methods to calculate the initial partition for KMCMD algorithms for mixed datasets. The initKmix initial partition method is presented in Section 3. Results are presented in Section 4, followed by conclusions and future research directions in Section 5.
2 Related Work
The k-means clustering algorithm is a commonly used clustering algorithm for datasets consisting of numeric attributes because of its low computational complexity [MacQueen, 1967]. Its complexity is linear with respect to the number of data points and scales well for large datasets. The algorithm minimizes the following optimization function (Eq. (1)) iteratively,
[TABLE]
where is the number of data points in the dataset, is the nearest cluster centre to data point , is a chosen distance measure (or similarity measure) between and . Generally, the Euclidean distance is used as the distance measure.
k-means clustering algorithm computes cluster centres and data point memberships at each iteration. The algorithm starts with user-defined initial clusters. Generally, a random initial partition is selected that may produce different clustering results for different runs of the algorithm. To overcome this problem various methods have been proposed for the computation of the initial partition [Duda et al., 1973, Bradley and Fayyad, 1998, Khan and Ahmad, 2004, Arthur and Vassilvitskii, 2007]. The k-means clustering algorithm can only handle pure numeric datasets. For pure categorical datasets, k-modes clustering algorithm is proposed [Huang, 1997b], in which the cluster centre is represented by the mode of the attribute values of the data points presented in that cluster and the Hamming distance is used to compute the distance between a data point and a cluster centre. Similar to the k-means clustering algorithm, k-modes clustering algorithm can also show inconsistent clustering results due to the choice of random initial partition. Various algorithms have been proposed to find the appropriate initial partition for K-modes clustering algorithm. [Khan and Ahmad, 2013, He, 2006, Wu et al., 2007, Khan and Ahmad, 2003, Khan and Kant, 2007].
Several KMD algorithms have been developed to extend the k-means clustering algorithm to mixed datasets [Huang, 1997a, Ahmad and Dey, 2007]. In these algorithms, new definitions for cluster centres and distances are proposed to handle mixed datasets [Huang, 1997a, Ahmad and Dey, 2007]. The general steps in these algorithms algorithm are presented in Algorithm 1. A comprehensive review of these algorithms can be found in the survey paper of Ahmad and Khan [Ahmad and Khan, 2019]. Due to their similarity with k-means clustering, these algorithms also suffer from the issues of random initialization and finding appropriate number of clusters (k). The focus of this paper is to find initial partition for a KMD algorithm (the KMCMD algorithm [Ahmad and Dey, 2007]). Therefore, in this section, we restrict our literature survey to the research works that attempted to initialize KMD algorithms.
Ji et al. (2015a) suggest a method to determine initial clusters for a KMD algorithm by computing compute density and distances between data points. In another work, Ji et al. (2015b) propose the concept of centrality based on neighbouring points and combined it with the distances between data points to compute initial clusters. However, these algorithms have quadratic complexity and are therefore may not work efficiently for large mixed datasets. Using density peaks [Rodriguez and Laio, 2014], Chen et al. (2017) propose an algorithm to determine the initial cluster centres for mixed datasets. Higher density points are used to identify cluster centres. This algorithm also has quadratic complexity. Wangchamhan et al. (2017) combine a search algorithm, the League Championship algorithm [Kashan, 2009], with a KMD algorithm to identify the initial cluster centres. This algorithm has many parameters; hence, the final clustering results are dependent on parameter settings, where different parameters may lead to different clustering results. Zheng et al. (2010) combine the evolutionary algorithm (EA) with the k-prototypes clustering algorithm [Huang, 1998]. The global searching capability of EA leads the proposed algorithm to be stable to cluster initialization. However, clustering results are dependent upon the parameters and not consistent in different runs.
The k-Harmonic means clustering algorithm addresses the random initial clusters problem applying a cost function [Zhang, 2001] for numeric datasets which uses the harmonic means of the distances from each data point to the centers. This algorithm creates clusters that are more stable than those generated by k-means clustering algorithm with random initial clusters. Ahmad and Hashmi (2016) combine the distance measure and the definition of cluster centres for mixed datasets suggested by Ahmad and Dey (2007) with the k-Harmonic clustering algorithm [Zhang, 2001] to develop the k-Harmonic clustering algorithm for mixed datasets. Their method is less sensitive to the choice of the initial cluster centres. The standard deviation of the clustering accuracy of this method is small in comparison to that of the random initialization method. However, clustering results are not stable for runs with different initial partitions.
The literature review suggests that the existing initialization methods for KMD algorithms are either computationally expensive or do not produce consistent clustering results. This further limits the use of existing methods in real world situations where an algorithm’s execution time and reliability of clustering results are the key factors for their adoption. In the next section, we present our proposed algorithm initKmix to compute the initial partition for a KMD algorithm (KMCMD algorithm [Ahmad and Dey, 2007]).
3 initKmix Algorithm
The initKmix algorithm is based on following two experimental observations noted in previous research works in k-means clustering [Khan and Ahmad, 2004] and k-modes clustering [Khan and Ahmad, 2013]:
Some data points in a given dataset have similar final cluster membership irrespective of the initial partition [Khan and Ahmad, 2004, 2013]. This observation has been used to determine the initial partition for k-means clustering algorithm (for pure numeric datasets) [Khan and Ahmad, 2004] and k-modes clustering algorithm (for pure categorical datasets) [Khan and Ahmad, 2013]. We extend this approach to determine the initial partition for the KMCMD algorithm. 2. 2.
Each of the attributes of a dataset can contribute to final clustering result. Therefore, an individual attribute may be used to determine the initial partition [Khan and Ahmad, 2004, 2013].
The initKmix algorithm generates multiple instances of clustering, this aspect is similar to multiple-view clustering [Muller et al., 2012, Yang and Wang, 2018]. Multiple-view clustering manages the production of different clustering results for datasets generated from different sources or observed from different views. These clustering results are combined to generate a clustering result. The diversity of the various views is an important aspect of this clustering approach. It is suggested that multiple views should be used to present data points more comprehensively and accurately [Muller et al., 2012, Yang and Wang, 2018]. initKmix algorithm uses a similar approach as it creates multiple clustering and for each clustering a different view is used to create the initial partition.
The initKmix algorithm has two important components, running KMCMD algorithm times ( is the number of attributes) to generate instances of clustering. Each instance of clustering creates a cluster label for each data point. instances of clustering generate a string of cluster labels for each data point (Table 1). These instances of clustering (strings of cluster labels) are combined to generate a clustering, which is then used as initial partition for the KMCMD algorithm. As discussed earlier, a mixed dataset contains two types of attributes; categorical and numeric. We use each of these attributes to create the initial partition in one of the runs of the KMCMD algorithm. These runs of the KMCMD algorithm generate clustering results. The clustering ensemble algorithm [Strehl and Ghosh, 2003] is then used to combine these results to produce final clustering that is used as the initial partition for the KMCMD algorithm. In one run, one attribute is used to create the initial partition that can be considered as one view of the data. Multiple-views of the data by using different initial partitions are used to create multiple instances of clustering. These views are diverse as they use different attributes to create the initial partition. Hence, we expect that combining these different clustering results will generate an accurate clustering that can be used as the initial partition for the KMCMD algorithm. The specific steps are presented in Algorithm 2. We will discuss each step of the proposed method in detail below.
3.1 Initial partition using numeric attributes
Each numeric attribute is used to create initial clusters for one of the runs of the KMCMD algorithm. A numeric attribute is assumed to have a normal distribution [Khan and Ahmad, 2004]. Initial clusters are created such that the probability distributions of the attribute values are equal in each cluster. For k clusters, k-1 boundaries in the normal distribution graph are created so that the area between two adjacent boundaries is . The extreme points - and + will also be used as boundaries along with the boundaries. For example, if we want to create three clusters from a numeric attribute, two points and are selected such that the area between - and , and , and and + is . The data points are distributed in three clusters depending on the range in which the attribute value of a data point lies to create initial partition. Our proposed method is different from the method proposed by Khan and Ahmad (2004) to compute the initial partition for k-means clustering algorithm as the latter computes the initial cluster centres by selecting a point in a given range such that the area under the curve in that range is divided equally. These centres are used to create the initial clusters for a run of the k-means clustering algorithm. However, as the normal distribution curve is not a straight line parallel to the horizontal axis, the probability distributions of the attribute values in the clusters are not equal. However, in the proposed method, the boundaries are computed in a way that the probability distributions of attribute values in the clusters are equal. Here, we would like to point out that we assume that all the numeric attributes are normally distributed. Previous results suggest that the assumption of numeric attributes to follow normal distribution works well, in practice, in finding initial partitions by k-means clustering [Khan and Ahmad, 2004, 2003].
The KMCMD algorithm is run on the complete mixed dataset with the initial partition created by the numeric attribute resulting in a clustering result. The algorithm for creating clusters by using the KMCMD algorithm with the initial partition yielded using a numeric attribute is presented in Algorithm 3.
3.2 Initial partition using categorical attributes
A categorical attribute consists of two or more categorical values. It has been shown that these attribute values can be used to create clusters [Iam-On et al., 2012, He et al., 2005, Khan and Ahmad, 2013]. Following a similar methodology, we use the values of a categorical attribute to create an initial partition. For example, for an attribute with three attribute values , and , the points can be clustered in the three clusters based on these attribute values; these clusters are then used as initial clusters. Each categorical attribute is used to create the initial clusters for one of the runs. Khan and Ahmad (2013) use a similar approach to identify the initial partition for pure categorical datasets. They generally only use attributes with values that are equal to or less than the number of desired clusters to prevent a large number of distinct clustering strings from being created (a clustering string is a combination of all cluster labels for a data point, see Table 1). In contrast, the proposed approach has no such constraint; all the categorical attributes all used to create the initial partition. The initKmix algorithm is for mixed datasets with two kinds of attributes, numeric and categorical. It is important that both types of attributes are treated equally. As we use each numeric attribute to create the initial partition in one of the runs of the KMCMD algorithm for mixed datasets, each categorical attribute should also be used in one of the runs of the KMCMD algorithm, which is not the case in the approach proposed by Khan and Ahmad (2013).
The KMCMD algorithm is run on the complete mixed dataset with the initial partition created by the categorical attribute to yield a clustering result. The method for creating clusters using the KMCMD algorithm for mixed datasets with initial partition created using a categorical attribute is presented in Algorithm 4.
3.3 Combining multiple clustering results
In the initKmix algorithm, the KMCMD algorithm is run times to produce clustering results. An example of clustering results for different runs is presented in Table 1. These clustering results are combined to yield the initial partition. A similar approach has been used by Khan and Ahmad (2004, 2013), however, their method to combine clustering results can be quadratic with respect to the number of data points in the worst case.
Several cluster ensemble algorithms have been developed to combine the results of multiple clustering results of a given dataset, resulting in superior clustering results [Ghosh and Acharya, 2011, Strehl and Ghosh, 2003, Topchy et al., 2005]. Strehl and Ghosh [Strehl and Ghosh, 2003] propose cluster ensemble algorithms that have a linear time complexity to the number of data points. We use the following cluster ensemble algorithms to combine the clustering results to obtain the initial clusters.
HyperGraph partitioning algorithm - In this algorithm, the clustering ensemble problem is defined as the partitioning problem of a hypergraph, where hyperedges (a hyperedge is a generalization of an edge that can connect any set of vertices) represents clusters. The complexity of this method is where is the number of runs of the clustering algorithm. 2. 2.
Meta-CLustering algorithm - In this algorithm, the cluster ensemble problem is considered to be the cluster correspondence problem. Groups of similar clusters are identified and combined. The complexity of this method is .
3.4 The KMCMD algorithm
As mentioned in Section 1, the k-means algorithm cannot directly be used to cluster mixed data because of the distance function in the objective function it optimizes. Ahmad and Dey (2007) propose KMCMD that modifies the distance function of the standard k-means algorithm. In this paper, we use this algorithm in the initKmix algorithms as a baseline to determine the initial partition. This initial partition will then be used with the KMCMD algorithm to produce the final clustering.
In this algorithm, Ahmad and Dey (2007) propose a distance measure for categorical attribute values. The weight of a numeric attribute, which represents the significance of the attribute, is also incorporated in the distance function to highlights its significance. A novel frequency-based definition of the cluster centre for categorical attributes is also proposed for a better representation of clusters. The modified distance function [Ahmad and Dey, 2007] computing the distance () between the data point () and the cluster center () is given as
[TABLE]
where is the weight of the numeric attribute and is the value of the numeric attribute of the data point. is the value of the numeric attribute of the cluster centre. is the value of the categorical attribute of the data point. is the centre representation of the centre for the categorical attribute. is the distance between a cluster centre and a data point for a categorical attribute. As shown in Eq. (2), there are two terms, one each for computing the distance for the numeric and categorical attributes. For numeric attributes, the Euclidean distance with the weight of each numeric attribute is used. For categorical attributes, the frequency based definition for centre and co-occurrence based method to compute the distance between two attribute values is used.
This distance measure does not take the distance between two attribute values of a categorical attribute as 0 or 1 (Hamming distance), rather it computes the distance between two values of an attribute from the dataset. The distance between two attribute values and with respect to the other attribute is computed by using the following formula
[TABLE]
where represents the probability for data point with attribute value having other attribute values belonging to a subset of classes , whereas represents the probability for data points with attribute value having other attribute values not belonging to . Out of many subsets of classes, a subset maximizing the value in Eq. (3) is selected. The distance between two values of an attribute is computed with respect to all the other attributes and the average is taken as the distance between these two attribute values.
The distance algorithm does not take the significance of the numeric attributes as equal but computes the significance of a numeric attribute from the dataset. A numeric attribute is discretized; the new attribute is treated as a categorical attribute. The average of the distances of all the pairs of attribute values is taken as the weight of the numeric attribute. The discretization of numeric attributes is undertaken only to compute the weight of the numeric attributes. The clustering is performed with numeric attributes. The complete clustering algorithm is presented in Algorithm 5.
3.5 Computational complexity
The initKmeans algorithm run the KMCMD algorithm [Ahmad and Dey, 2007] times for a dataset (with data points) to create clustering results corresponding to each attributes. The complexity of the KMCMD algorithm is where is the number of iterations and is the average number of distinct categorical values. Hence, for number of runs, the complexity is . Then these clustering results are combined to obtain a clustering result. These results are combined using HyperGraph partitioning algorithm (complexity ) or Meta-CLustering algorithm (complexity ) [Strehl and Ghosh, 2003]. This clustering result is used as an initial partition to run the KMCMD algorithm. Hence, the total complexity when clustering results are combined with:
HyperGraph partitioning algorithm is
[TABLE]
Meta-CLustering algorithm is
[TABLE]
In both the cases, the time complexity is linear to the number of data points. In the experiment, both ensemble algorithms are run and the clustering results with better normalized mutual information is selected. As both the ensemble algorithms are linear to the number of data points, the total complexity of the clustering algorithm will remain linear to the number of data points.
4 Experiments and Results
We implemented the initKmix and the KMCMD algorithm [Ahmad and Dey, 2007] using Java JDK 1.8. To perform cluster ensemble step, the Octave implementations of the cluster ensemble algorithms were used [Strehl, 2011]. A minor modification was made to the clustering ensemble implementation such that the method only considered HyperGraph Partitioning Algorithm and Meta-CLustering Algorithm based on the maximum average normalized mutual information [Strehl and Ghosh, 2003]. The initKmix algorithm was first tested on a simulated mixed dataset, then on four pure categorical datasets and five mixed datasets downloaded from UCI repository [Dua and Graff, 2017]. All these datasets have predefined class and class labels, which were taken as ground truth. The number of the desired clusters was set to the number of the classes. The clustering accuracy was computed against the ground truth. Each cluster was mapped to a distinct class so that the following measure [Ahmad and Dey, 2007] had the maximum value;
[TABLE]
Where is the number of data points correctly assigned to a class.
This measure is called clustering accuracy () and has been used to compare the clustering results [Ahmad and Dey, 2007]. Two measures derived from , (for the average clustering accuracy) and (for the standard deviation of clustering accuracy), were also used to present the results of clustering methods with random initial clusters; The average clustering accuracy for runs is defined in the following way;
[TABLE]
where is the clustering accuracy in the run.
The standard deviation of the clustering accuracy for runs is computed in the following way;
[TABLE]
Where is the clustering accuracy in the run.
Two other clustering performance measures, Rand index () and Adjusted Rand index () [Rand, 1971] were also employed to compute the clustering performance. represents the frequency of occurrence of agreements between two clustering over the total pairs of data points. is defined by following expression;
[TABLE]
where in the the number of pairs of data points belong to the same cluster across two different clustering results and the is the number of pairs of data points are in different clusters across two different clustering results. Classes were taken as one clustering and the clustering is compared with it.
is the corrected-for-chance version of the Rand index. is defined by following expression;
[TABLE]
denotes the number of data points common between cluster of clustering and class, refers the number of data points in cluster and denotes the number of data points in class.
Similar to , for many runs of the KMCMD algorithm, the average values of () and () were computed. Standard deviation of () and () were also used to compute the performance of clustering algorithms.
The higher values of performance measures (, and ) suggest better clustering results. The maximum possible value for these performance measures is that represents that the data clustering and data classes are exactly the same. Similarly, for the KMCMD algorithm with random initial partitions, high values of (, and ) are desired. represents the inconsistency of clustering results with a different initialization in each run of the KMCMD algorithm. The low values of (, and ) point to the robustness of the algorithm for different initial partitions.
We carried out the two types of experiments. First, we compared the initKmix algorithm against the random initial partition method. The KMCMD algorithm [Ahmad and Dey, 2007] was run 50 times with a random initial partition method and average clustering performances are presented. We ran the initKmix algorithm just once for a dataset to obtain the initial partition, and then the KMCMD algorithm [Ahmad and Dey, 2007] was applied with this initial partition to yield the clustering result. As this approach yields identical results every time, the of clustering results for the initKmix algorithm is [math] for any dataset.
Second, the KMCMD algorithm [Ahmad and Dey, 2007] with initKmix algorithm was also compared with other clustering algorithms using performance measure. Results for these clustering algorithms were taken from the published papers. Majority of papers on mixed data clustering methods use similar datasets and performance measure (). Therefore, we also use those frequently used datasets and the performance measure to facilitate comparison of various clustering algorithms with the KMCMD algorithm with the initKmix algorithm.
Now, we show the results on a mixed simulated dataset, followed by results on pure categorical and mixed datasets.
4.1 Simulated mixed data
We compared the performance of initKmix algorithm against random initial partition on a simulated mixed dataset. Following clustMixType package [Szepannek and Aschenbruck, 2020] of R [R Core Team, 2013], a mixed dataset was generated. The dataset had four attributes, two of them were categorical, whereas the other two were numeric. Each categorical attribute had two categories, and for the first categorical attribute and and for the second attribute. The numeric attributes were created using normal distribution. There were 400 data points divided equally into four clusters. First attribute values of cluster, , were created by selecting attribute categories and randomly with 0.9 and 0.1 probability respectively. Similarly the second attribute values of , were created by selecting attribute categories and . Third attribute values were created using normal distribution with = -5 and = 1. The fourth attribute values generated using the same method as of attribute three. All the remaining three clusters (, , ) were created with similar procedures but with different parameters. The properties of each cluster are presented in Table 2. We ran KMCMD algorithm with random initial partition 50 times and studied the final clustering results. Final clustering results were inconsistent in different runs. Mostly, data points were clustered in two, three or four clusters. Examples of these clustering results are given in Tables 3 - 5. It is to be noted that in two different clustering runs there is no direct correspondence between final cluster labels. For example, (cluster label) in one instance of clustering may not be (cluster label) in the other instance of clustering.
Clustering results (Table 6) demonstrate that in contrast to KMCMD with the random partition, KMCMD with the initKmix algorithm was able to identify four clusters for the dataset accurately ( = 0.908, = 0.916 and = 0.775). We would like to emphasise that initKmix algorithm generates only one clustering result. This further highlights that that application of initKmix algorithm produces accurate and consistent clustering results.
4.2 Categorical datasets
We carried out an experiment with four categorical datasets; Soybean-small, Vote, Breast cancer and Mushroom [Dua and Graff, 2017]. Information on these datasets is provided in Table 7. We apply the KMCMD algorithm on those datasets. The numeric part of the distance measure presented in Eq. (2) will be zero in this case. The clustering results of the KMCMD algorithm with initKmix and the KMCMD algorithm with the random partition method using different measures (, and ) using are presented in Tables 8 - 10. Unpaired t-test with 95% confidence interval [Freedman et al., 2007] was carried out to compare the performance of the KMCMD algorithm with the initKmix algorithm and the KMCMD algorithm with the random partition method. The calculations indicated that for all categorical datasets the initKmix algorithm performed statistically better than the random partition method.
The performance () of the KMCMD algorithm with initKmix algorithm was also compared with k-modes algorithm with different state-of-the-art initialization methods; including Wu’s initialization [Wu et al., 2007], Cao’s initialization [He, 2006], Khan and Ahmad’s initialization[Khan and Ahmad, 2013] and Ini_Entropy [Liu et al., 2016]. The KMCMD algorithm with the initKmix algorithm was also compared with the Fuzzy k-modes clustering algorithm [Huang and Ng, 1999] and CRAFTER [Lin et al., 2018] algorithm. The results of various clustering methods are presented in Table 11. The results for the other clustering algorithms were taken from existing papers [Khan and Ahmad, 2013, Liu et al., 2016, Lin et al., 2018, Zhu and Xu, 2018]. Except for the Soybean-small dataset, the combination of the KMCMD algorithm and initKmix outperformed the other clustering methods. For the Soybean-small dataset, the KMCMD algorithm with the initKmix algorithm performed similarly or better than the other clustering methods.
4.3 Mixed datasets
The following five mixed datasets [Dua and Graff, 2017] were used in the experiments: Acute Inflammations, Heart (Statlog), Heart (Cleveland), Australian credit and German credit. Table 12 displays information on these datasets. The clustering results by the KMCMD algorithm with the initKmix algorithm and the KMCMD algorithm with the random partition method using different measures (, and ) using are presented in Tables 13 - 15. Unpaired t-test with 95% confidence interval (sample sizes were 50) was carried out to compare the performance of KMCMD algorithm with initKmix and the KMCMD algorithm with random inital partition. Results suggest that except Australian credit dataset for performance measure (Table 13), the initKmix algorithm performed statistically better than the random partition method for all other datasets on all the performance measures. For Australian credit dataset, there is no statistically significant difference initKmix between the performances of two methods. However, initKmix algorithm produced consistent clustering.
The performance of the KMCMD algorithm with the initKmix algorithm was also compared using performance measure with k-prototypes [Huang, 1997a] with random initialization, k-prototypes [Huang, 1997a] with the Ji et al. [Ji et al., 2015c] initialization method, Similarity-based Agglomerative clustering (SBAC) [Li and Biswas, 2002], Object-cluster similarity metric (OCIL) algorithm [Cheung and Jia, 2013] and fuzzy k-prototypes clustering [Ji et al., 2012]. The results of various clustering methods are presented in Table 16. The results for the other clustering algorithms were taken from published papers [Ji et al., 2012, Cheung and Jia, 2013, Du et al., 2017]. Except for the German credit dataset, the KMCMD algorithm with initKmix performed better than the other clustering algorithms. For the German credit dataset, the OCIL algorithm performed better than the KMCMD algorithm with initKmix.
4.4 Discussion
Wilcoxon Signed-Ranks test [Wilcoxon, 1945] with 95% confidence level was carried out to compare the performance of the KMCMD algorithm with the initKmix algorithm against KMCMD algorithm with random initial partition over all the nine datasets. The test suggests that the KMCMD algorithm with the initKmix algorithm significantly better than KMCMD algorithm with the random initial partition method.
The KMCMD algorithm with initKmix perform similar to or better than the other state-of-the-art clustering algorithms for categorical datasets. Some of these clustering methods use different initialization methods [Khan and Ahmad, 2013, Wu et al., 2007, He, 2006], and the better clustering results with the initKmix algorithm suggests that the it produces good initial partition. The similar behaviour is observed for mixed datasets. The proposed approach has the best performance across clustering methods for mixed datasets for four out of five datasets. One of these clustering methods [Ji et al., 2015c] uses an initialization method, but the better clustering results point to the superiority of the initKmix algorithm in creating an initial partition.
In initKmix algorithm, we get initial partition of a dataset for the KMCMD algorithm after combining many clustering results. It is possible that this initial partition can be used as the final clustering result. However, the goal of this paper is to study the performance of a KMCMD algorithm with initial partition created by initKmix algorithm.
The results suggest that the KMCMD algorithm with the initKmix algorithm produces accurate clustering for both categorical and mixed datasets. The initKmix algorithm generates the accurate initial partition, which in turn improves the performance of KMCMD in comparison to random initial partition. The accurate and diverse clustering results are the key for an accurate cluster ensemble [Strehl and Ghosh, 2003]. Accurate initial partition suggests that the initKmix algorithm is able to create accurate and diverse clustering results in different runs. Using each attribute for creating initial clusters in different runs of the KMCMD algorithm could be the reason for it.
4.5 Effect of k on the performance of the KMCMD algorithm with the initKmix algorithm
In the experiments (Section 4.1 - Section 4.3) for each dataset, the number of the desired clusters () was equal to the number of the actual classes. We also carried out experiments to observe the performance of the KMCMD algorithm with the initKmix algorithm when the number of desired clusters was not equal to the number of actual classes. We selected a mixed dataset, Australian credit, for our experiment. The number of the actual classes was two for the dataset. We carried out experiments with = 4, 5, 6 and 7. The results are presented in Tables 17 - 19. For performance measures, we did not observe huge variation as the difference between maximum (0.858 for = 2) and minimum (0.823, for = 6) is 0.035, which is around 4% of the maximum value (as shown in Table 17). The results demonstrate that the performance of KMCMD with the initKmix algorithm is robust to the value of .
However, the differences between maximum and minimum values are quite large for measure (21.56% of the maximum value) and measure (57.18% of the maximum value). That was expected as the number of the clusters increases, the data points in a original class tend to be in different clusters, which leads to lower values of these performance measures.
We also compared the initKmix algorithm against the random initial partition for different values of . Experimental set up was the same as discussed at the start of Section 4. The average and standard deviation of various performance measures are presented in Tables 17 - 19. Expect in one case ( = 6 and performance measure), KMCMD with the initKmix algorithm outperformed KMCMD with the random initial partition in all the cases.
The results show that initKmix initialization is effective even if is not equal to the actual number of clusters.
4.6 Effect of n and k on the running time
We carried out experiments with different datasets to study the effect of n and k on the running time of the KMCMD algorithm with the initKmix algorithm. The experiments were done on a computer with Intel Core i7 1.80 GHz and 16 GB RAM. To study the effect of on the running time, 5 artificial datasets of different sizes (5000, 10000, 20000, 50000 and 100000) were generated (by clustMixType package [Szepannek and Aschenbruck, 2020]) using the same procedure as discussed in Section 4.1. These datasets had four attributes and the value of was set to four. As there were two different parts of the initKmix algorithm (different runs of KMCMD algorithm and cluster ensemble algorithms) and their implementation is in different programming platforms, we present their results in different figures for better understanding. The results presented in Figure 1(a) and Figure 1(b) demonstrate that the running times of both parts of the initKmix algorithm are linear with respect to .
We also carried experiments to study the effect of the value of on the running time of initKmix algorithm. We selected the dataset with 100,000 data points for the experiment. Four different values of (2, 4, 6 and 8) were used in the experiment. The running times for KMCMD algorithm (for all runs) and cluster ensemble algorithm are presented in Figure 2(a) and Figure 2(b). The results suggest that there is a increase in the running time of KMCMD algorithm; however, no significant changes were observed for cluster ensemble algorithms. We can infer from these running times that the total time of initKmix algorithm increases with the value of . It is to be noted that we run KMCMD algorithm time using each attribute as initial clusters, the value of desired clusters in a run with a categorical attribute is set to the number of unique attribute values. Therefore, it is independent of the value of . In the present case, two out of four instances of clustering results are the same for all the values of .
4.7 Analysis of individual clustering results
Regarding the KMCMD algorithm with the initKmix algorithm, we run the KMCMD algorithm times to produce clustering results. These results are combined to yield the initial partition and then the KMCMD algorithm is run with this initial partition to obtain the final clustering results. Therefore, we perform an analysis to compare the accuracy of individual clustering results and the final clustering result using the performance measure.
For this analysis, we selected two categorical datasets, Vote and Mushroom, and two mixed datasets, Heart (Statlog) and Australian credit, for this analysis. For better comparative study, for categorical datasets, we selected these datasets with some attributes having the same number of values as the number of desired clusters. Similarly, for mixed datasets, we selected these datasets with some categorical attributes having the same number of values as the number of desired clusters. Using categorical attributes, with the numbers of attribute values not equal to the desired clusters, to create the initial clusters does not produce the desired number of clusters. Therefore, clustering results when those attributes were used as initial clusters were not selected for the comparative study.
For Vote dataset, the individual clustering results for categorical attributes as initial clusters in different runs are presented in Figure 3(a). We did not observe large differences in individual clustering results (the minimum - and the maximum - ). The final () was equal to the maximum . For the Mushroom dataset, only four attributes had two values (same as the number of desired clusters). The results for these four attributes are presented in Figure 3(b). There was a large variation in individual clustering results (the minimum - , the maximum - ). The final clustering result () was slightly better than the best individual clustering (). Figure 3(c) has individual clustering results for the Heart (Statlog) dataset (the minimum - , the maximum - ), the final clustering accuracy was , which was slightly better than the best individual accuracy (0.807). The individual clustering results for Australia credit dataset (for six numeric and four categorical) are presented in Figure 3(d) (the minimum - , the maximum - ). There was a large variation in individual clustering results. The final clustering result () was equal to the best individual clustering result.
The analysis suggests that individual clustering results for various datasets had small or large variations; however, the final clustering results were equal to or better than the best individual clustering results. This shows that combining clustering results is a good approach to obtain better initial clusters, and when feeding these to the KMCMD algorithm results in better clustering accuracy for the studied categorical and mixed datasets.
5 Conclusion and Future Work
KMD algorithms suffer from the random initial partition problem that can lead to different clustering results in different runs thereby undermining the reliability of results. In this paper, we presented initKmix, an algorithm to find the initial partition for the KMCMD algorithm [Ahmad and Dey, 2007]. The algorithm uses an individual attribute to create the initial partition when running the KMCMD algorithm. Multiple clustering results created by this procedure are combined to obtain the initial partition. The clustering results obtained using the KMCMD algorithm with the initial partition created by initKmix were accurate and consistent. The KMCMD algorithm with initKmix algorithm outperformed KMCMD algorithm with the random initial partition method on multiple categorical and mixed datasets. The KMCMD algorithm with initKmix algorithm also performed similar to or better than other state-of-the-art clustering algorithms on multiple categorical and mixed datasets. Computational complexity analysis and running time results suggest that the running time of the KMCMD algorithm with initKmix is linear with respect to number of data points. Therefore, this clustering algorithm scales well with the number of data points. Results also demonstrated that the performance of the KMCMD algorithm with the initKmix algorithm is robust to the choice of the .
In future, other KMD algorithms [Huang, 1997a, Huang et al., 2005, Modha and Spangler, 2003] with initKmix will also be studied. KMD algorithms have been suggested for fuzzy clustering [Ji et al., 2012, Du et al., 2017] and subspace clustering [Ahmad and Dey, 2011], in future, we will consider applying the initKmix algorithm to these clustering algorithms. We will also investigate possible extension of initKmix to find the value of k for KMD algorithms.
Funding
This research was funded by a UAE university Start-up grant (grant number G00002668; fund number 31T101).
Conflicts of interest
The authors declare no conflict of interest.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ahmad and Dey [2007] Ahmad, A., Dey, L., 2007. A k-mean clustering algorithm for mixed numeric and categorical data. Data and Knowledge Engineering 63, 503–527.
- 2Ahmad and Dey [2011] Ahmad, A., Dey, L., 2011. A k-means type clustering algorithm for subspace clustering of mixed numeric and categorical datasets. Pattern Recognition Letters 32, 1062–1069.
- 3Ahmad and Hashmi [2016] Ahmad, A., Hashmi, S., 2016. K-harmonic means type clustering algorithm for mixed datasets. Applied Soft Computing 48, 39–49.
- 4Ahmad and Khan [2019] Ahmad, A., Khan, S.S., 2019. Survey of state-of-the-art mixed data clustering algorithms. IEEE Access 7, 31883–31902.
- 5Arthur and Vassilvitskii [2007] Arthur, D., Vassilvitskii, S., 2007. K-means++: The advantages of careful seeding, in: Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA. pp. 1027–1035.
- 6Balaji and Lavanya [2018] Balaji, K., Lavanya, K., 2018. Clustering algorithms for mixed datasets: A review. International Journal of Pure and Applied Mathematics 18, 547–556.
- 7Bishop [2008] Bishop, C.M., 2008. Pattern Recognition and Machine Learning. Springer-Verlag New York Inc.
- 8Bradley and Fayyad [1998] Bradley, P.S., Fayyad, U.M., 1998. Refining initial points for k-means clustering, in: ICML 1998 Proceedings of the Fifteenth International Conference on Machine Learning, Morgan kaufmann. pp. 91–99.