Uncertainty Quantification in Deep MRI Reconstruction
Vineet Edupuganti, Morteza Mardani, Shreyas Vasanawala, John Pauly

TL;DR
This paper introduces a probabilistic deep learning framework using variational autoencoders to quantify uncertainty in MRI reconstruction, highlighting how different training strategies affect uncertainty and risk.
Contribution
It develops a VAE-based probabilistic reconstruction method for MRI, incorporating uncertainty and bias estimation, and evaluates the impact of training losses and architectures on uncertainty.
Findings
Adversarial losses increase uncertainty.
Recurrent unrolled networks reduce uncertainty.
The method provides pixel-wise variance maps for uncertainty visualization.
Abstract
Reliable MRI is crucial for accurate interpretation in therapeutic and diagnostic tasks. However, undersampling during MRI acquisition as well as the overparameterized and non-transparent nature of deep learning (DL) leaves substantial uncertainty about the accuracy of DL reconstruction. With this in mind, this study aims to quantify the uncertainty in image recovery with DL models. To this end, we first leverage variational autoencoders (VAEs) to develop a probabilistic reconstruction scheme that maps out (low-quality) short scans with aliasing artifacts to the diagnostic-quality ones. The VAE encodes the acquisition uncertainty in a latent code and naturally offers a posterior of the image from which one can generate pixel variance maps using Monte-Carlo sampling. Accurately predicting risk requires knowledge of the bias as well, for which we leverage Stein's Unbiased Risk Estimator…
Click any figure to enlarge with its caption.
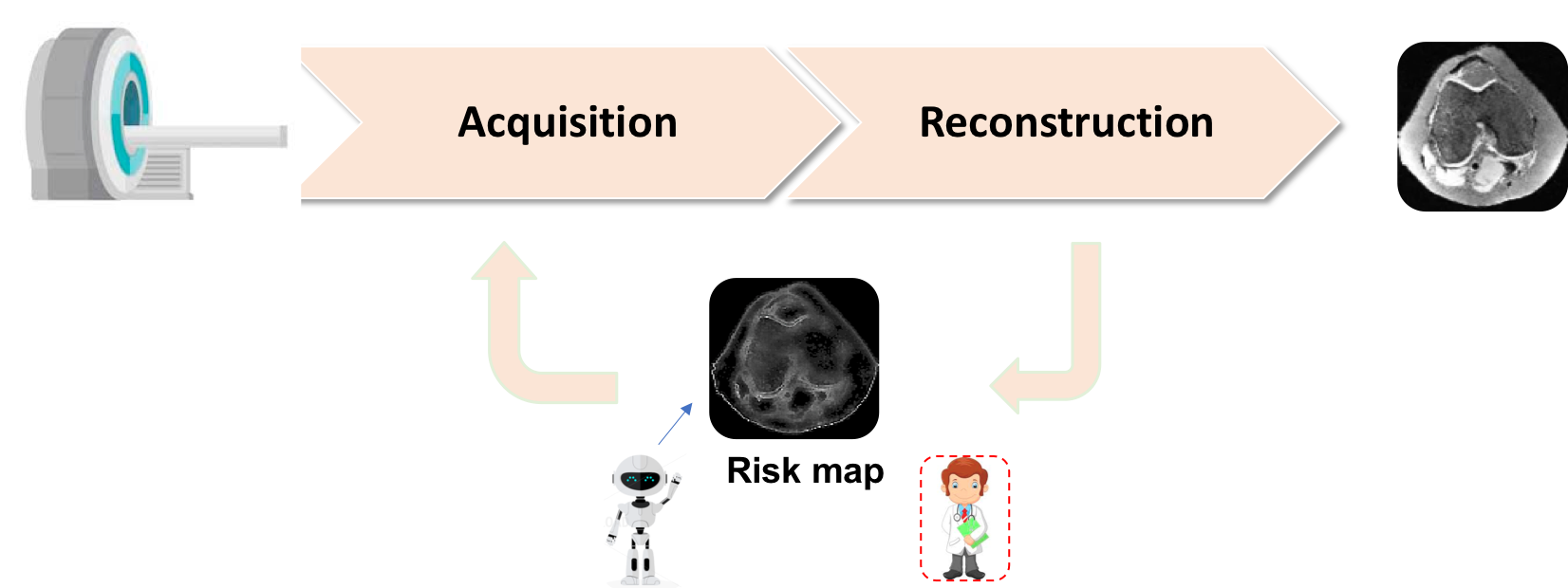 Figure 1
Figure 1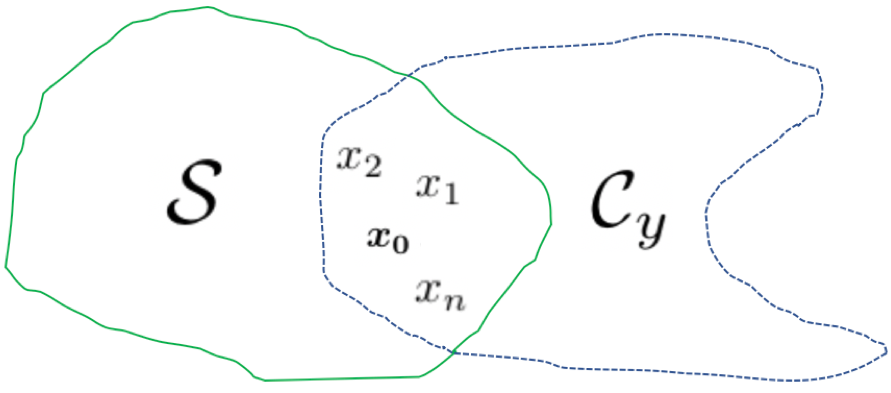 Figure 2
Figure 2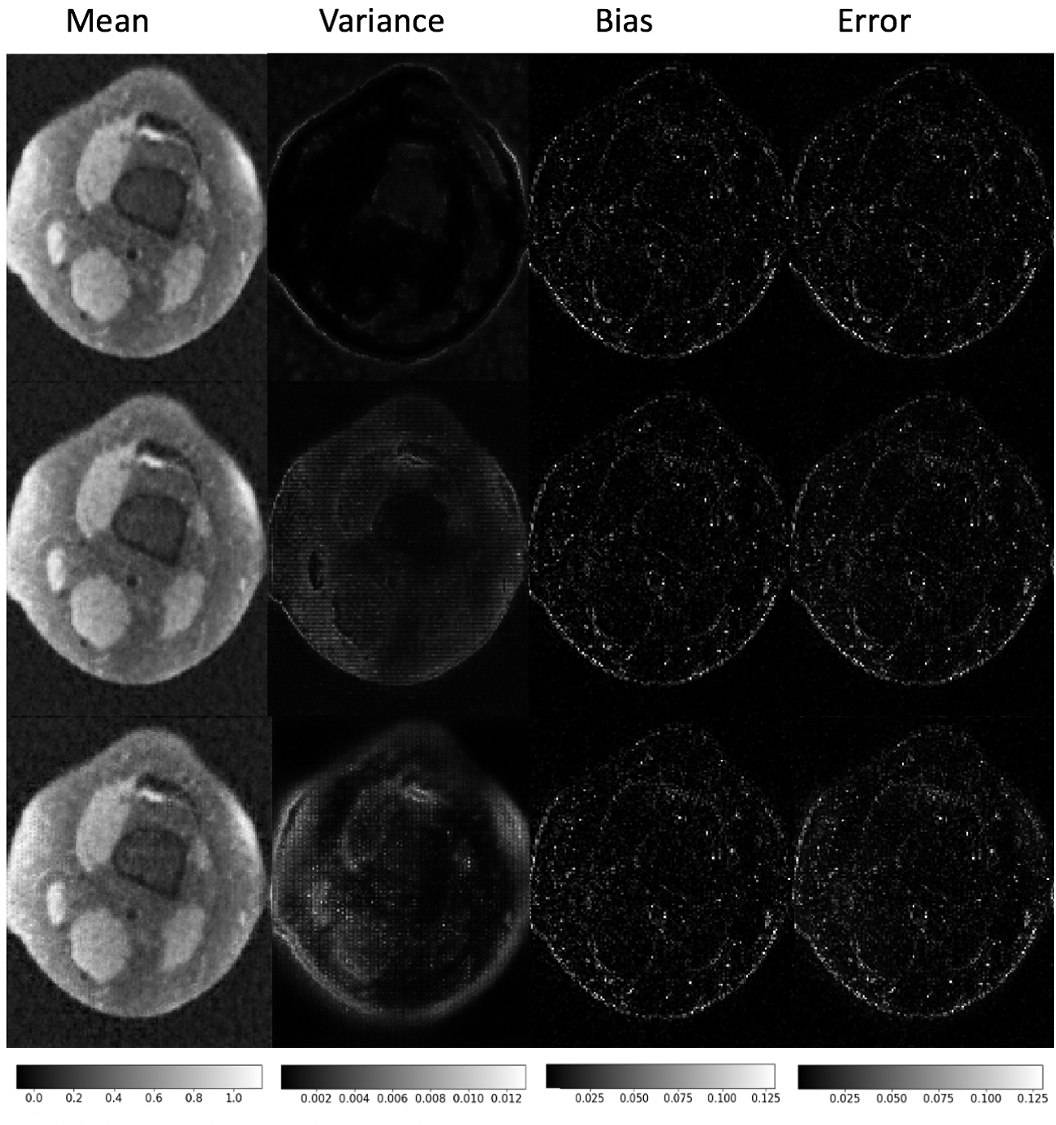 Figure 3
Figure 3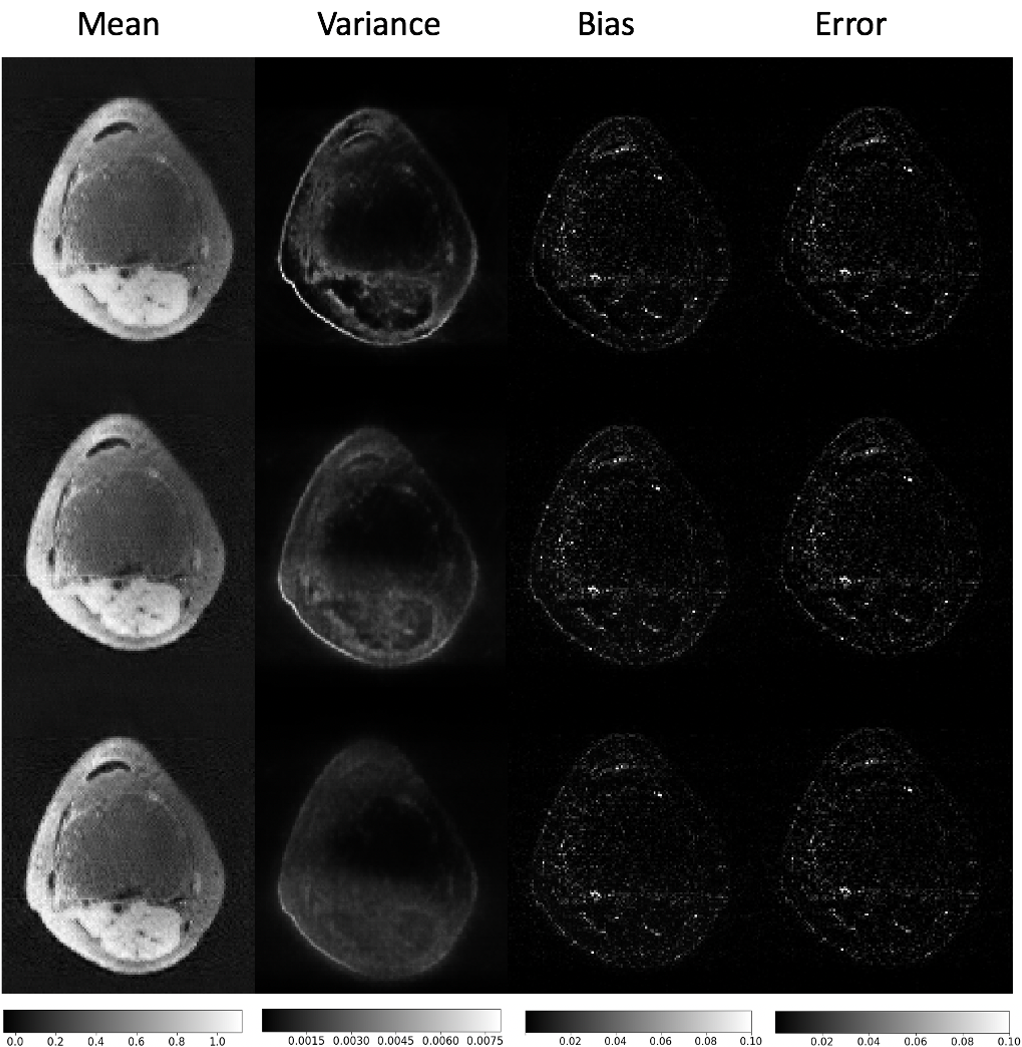 Figure 4
Figure 4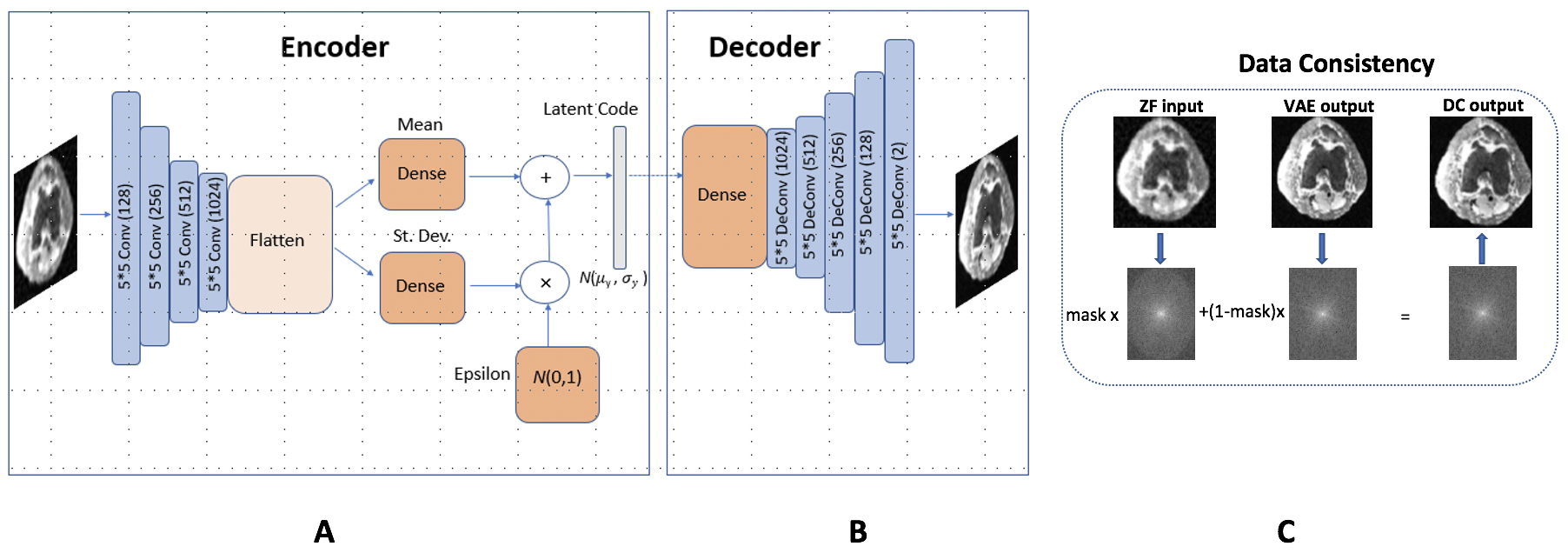 Figure 5
Figure 5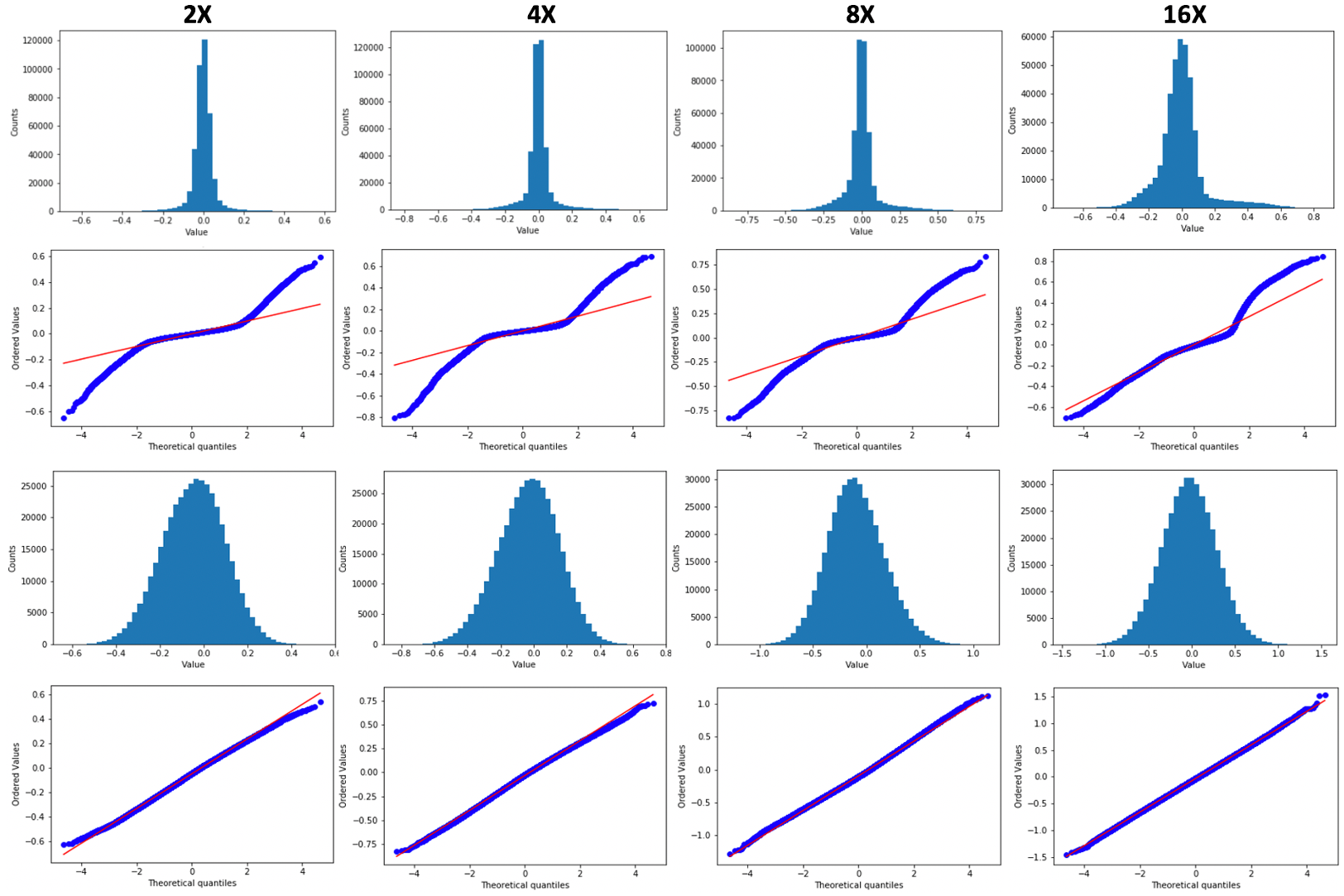 Figure 6
Figure 6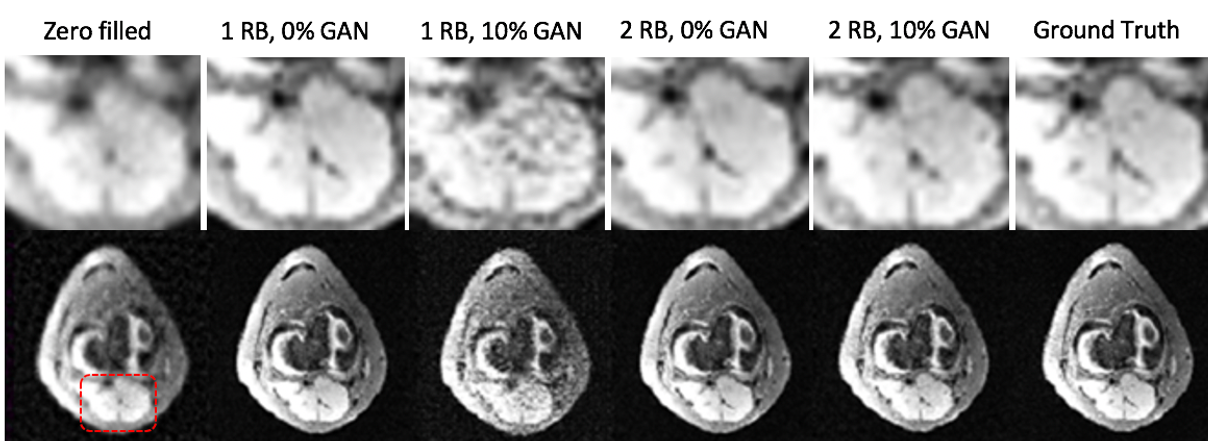 Figure 7
Figure 7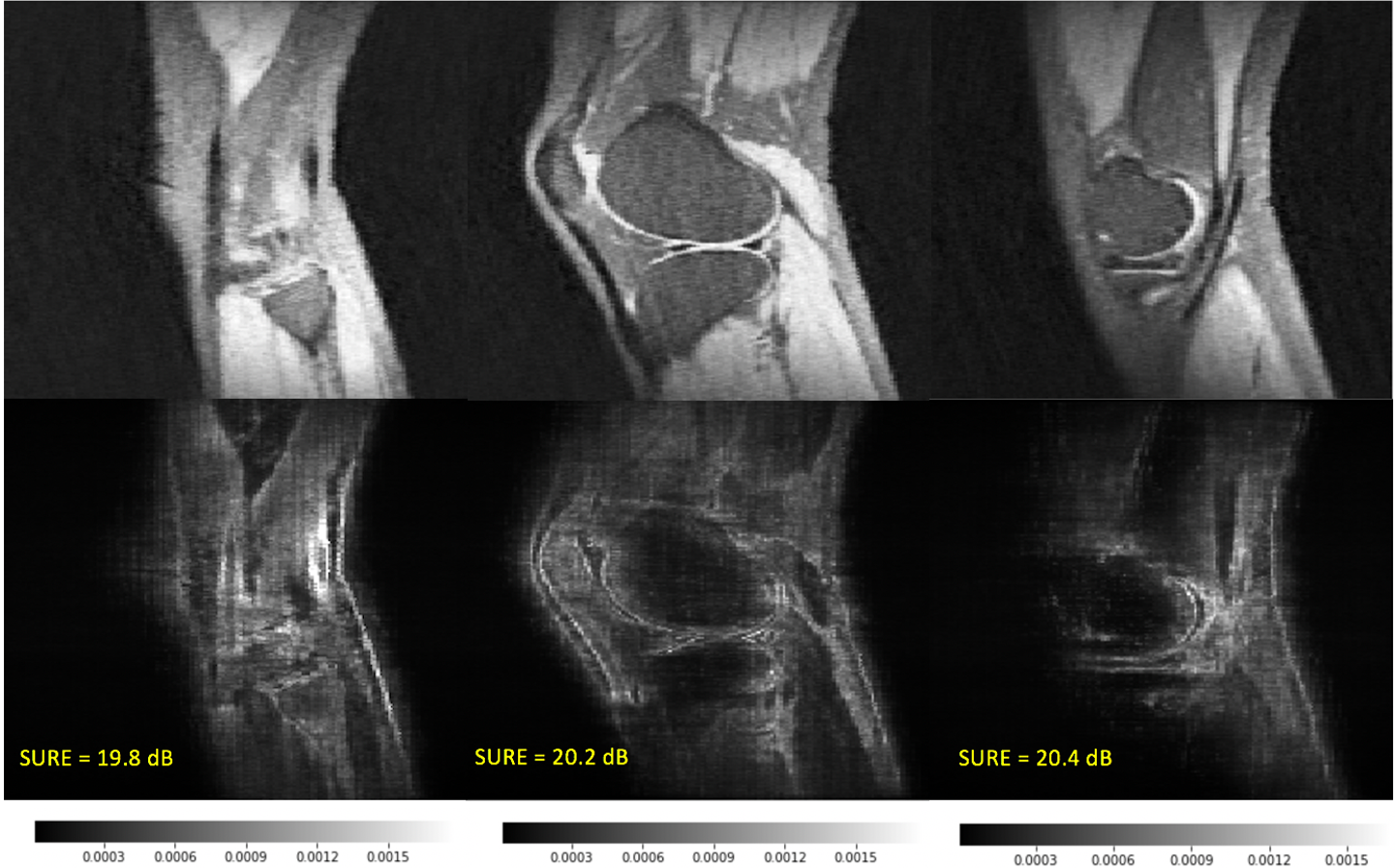 Figure 8
Figure 8 Figure 9
Figure 9Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsUSD Coin Customer Service Number +1-833-534-1729
Uncertainty Quantification in Deep MRI Reconstruction
Vineet Edupuganti, Morteza Mardani, Shreyas Vasanawala, and John Pauly V. Edupuganti, M. Mardani, and J. Pauly are with the Department of Electrical Engineering, Stanford University, Stanford, CA, 94305 USA. e-mails: *ve5, morteza, [email protected].*S. Vasanawala is with the Department of Radiology, Stanford University, Stanford, CA, 94305 USA. e-mail: [email protected].
Abstract
Reliable MRI is crucial for accurate interpretation in therapeutic and diagnostic tasks. However, undersampling during MRI acquisition as well as the overparameterized and non-transparent nature of deep learning (DL) leaves substantial uncertainty about the accuracy of DL reconstruction. With this in mind, this study aims to quantify the uncertainty in image recovery with DL models. To this end, we first leverage variational autoencoders (VAEs) to develop a probabilistic reconstruction scheme that maps out (low-quality) short scans with aliasing artifacts to the diagnostic-quality ones. The VAE encodes the acquisition uncertainty in a latent code and naturally offers a posterior of the image from which one can generate pixel variance maps using Monte-Carlo sampling. Accurately predicting risk requires knowledge of the bias as well, for which we leverage Stein’s Unbiased Risk Estimator (SURE) as a proxy for mean-squared-error (MSE). Extensive empirical experiments are performed for Knee MRI reconstruction under different training losses (adversarial and pixel-wise) and unrolled recurrent network architectures. Our key observations indicate that: 1) adversarial losses introduce more uncertainty; and 2) recurrent unrolled nets reduce the prediction uncertainty and risk.
Index Terms:
Uncertainty Quantification, VAE, MRI reconstruction, SURE
I Introduction
Artificial intelligence (AI) has introduced a paradigm shift in medical image reconstruction in the last few years, offering significant improvements in speed and image quality [1, 2, 3, 4, 5, 6]. However, the prevailing methods for image reconstruction leverage historical patient data to train deep neural networks, and then use these models on new unseen patient data. This practice raises concerns about generalization, given that predictions can be biased towards the previously-seen training data, and consequently may struggle to detect novel pathological details in the test subjects. This is deeply problematic for both patients and physicians and can potentially alter diagnoses. It is thus crucial to ensure that reconstructions are accurate for new and unseen subjects. This well motivates developing effective and automated risk assessment tools for monitoring image reconstruction algorithms as a part of the imaging pipeline (see the clinical workflow in Fig. 1).
Despite the importance of assessing risk in medical image reconstruction, little work has explored the robustness of deep learning (DL) architectures in inverse problems. Not only is the introduction of image artifacts fairly common using such models, but there do not currently exist suitable empirical methods that enable the quantification of uncertainty [7]. Given the pernicious effects that the presence of image artifacts can have, such methods could have utility both as an evaluation metric and as a way of gaining interpretability regarding risk factors for a given model and dataset [8].
To this end, this work introduces procedures that can provide insights into the robustness of DL MR reconstruction schemes. In doing so, we develop a variational autoencoder (VAE) model for MR image recovery, which is notable for its low error and probabilistic nature which is well-suited to an exploration of model uncertainty. We first generate admissible reconstructions under an array of different model conditions. We then utilize Monte Carlo sampling methods to better understand the variations and errors in the output image distribution under various model settings [9]. Finally, because accurately assessing bias and error with the Monte Carlo approach requires access to the true (fully-sampled) image, we leverage the Stein’s Unbiased Risk Estimator (SURE) analysis of the DL model, which serves as a surrogate for mean squared error (MSE) even when the ground truth is unknown.
Extensive empirical evaluations are performed on real-world medical MR image data. Our key observations include: 1) using an adversarial loss function introduces more pixel uncertainty than a standard pixel-wise loss, while better recovering the high-frequencies; 2) a cascaded network architecture better leverages the physical constraint of the problem and results in higher confidence reconstructions 3) SURE effectively approximates MSE and serves as a valuable tool for assessing risk when the ground truth reconstruction (i.e. fully sampled image) is unavailable.
The major contributions of this paper are:
- •
A novel VAE scheme for learning inverse maps that produces pixel uncertainty maps
- •
Quantifying risk using SURE by taking into account the end-to-end network Jacobian
- •
Extensive evaluations and statistical analysis of uncertainty for various network architectures and training losses
The rest of this paper is organized as follows: Section II reviews relevant literature. Section III introduces the preliminaries on neural recovery algorithms and states the problem. Section IV details the VAE architecture. Section V explains the Monte Carlo and SURE approaches to quantifying uncertainty, including a density compensation step that makes the use of SURE more practical. Empirical evaluations are then reported in Section VI, and Section VII discusses the conclusions and future directions.
II Related Work
Medical image reconstruction methods rooted in deep learning have been widely explored. Of the various model architectures that have been used, adversarial approaches based on generative adversarial networks (GANs) are notable for high reconstruction image quality and the ability to realistically model image details. The generator function for these types of architectures is usually a U-net or ResNet [7, 10].
Variational autoencoders (VAEs) have achieved high performance in generating natural images, while also providing probabilistic interpretability of the generation process [11, 12]. However, this approach has not yet been demonstrated in the realm of medical images.
Meanwhile, a small but growing body of work has examined uncertainty in general computer vision problems. Specifically, measurements of uncertainty have been computed by finding the mean and point-wise standard deviation of test images using Monte Carlo sampling with probabilistic models [13]. With such a method, comparing the mean intensities of regions containing an artifact and the surrounding area over several cases can provide statistical insights into the types of errors made by the model [14].
Other studies have explored using invertible neural networks to learn the complete posterior of system parameters [15, 16]. Through bootstrapping, point estimate uncertainty can be obtained statistically and analyzed in a manner similar to posterior sampling. Uncertainty has also been analyzed from the standpoint of data rather than variance introduced by generative models in the context of medical imaging [17]. Techniques such as the bootstrap and jackknife can be used on the sampled input data to produce accurate error maps that provide insight into the most risky ROIs in terms of reconstructions without having access to the ground truth.
Stein’s Unbiased Risk Estimator (SURE), which this paper explores as a measure of uncertainty, has also seen some use in imaging applications. Specifically, SURE has been utilized in regularization and for image denoising, where it is explicitly minimized during the optimization step [18, 19]. However, it has not been widely used in uncertainty estimation or in the context of medical imaging.
Given that most existing approaches of quantifying uncertainty do not apply broadly or are constrained by the chosen models, developing straightforward and effective techniques is very important. Such methods have the potential to enable holistic comparison and evaluation of model architectures across a range of problems, leading to increased robustness in sensitive domains.
III Preliminaries and Problem Statement
One key application of inverse problems is to Magnetic Resonance Imaging (MRI), where significant undersampling is typically employed to accelerate acquisition, leading to challenging image recovery problems. As a result, the development of accurate and rapid MRI reconstruction methods could enable powerful applications like diagnostic-guided surgery or cost-effective pediatric scanning without anesthesia [20, 21].
In MR imaging, the goal is to recover the true image from undersampled k-space measurements with that admit
[TABLE]
Here, includes the sampling mask and the Fourier operator , as well as coil sensitivities. The noise term also accounts for measurement noise and unmodeled dynamics.
Given the ill-posed nature of this problem, it is necessary to incorporate prior information to obtain high-quality reconstructions. This prior spans across a manifold of realistic images (. However, since not all points on this manifold are consistent with the measurements, we must consider the intersection of the prior manifold with a data consistent subspace (as shown in Fig. 2). Note that there might be multiple admissible solutions at the intersection with different likelihoods.
While DL models can be effectively used for learning the projection onto the intersection , performance can be limited when seeing new data unlike the training examples. In particular, one risk is the introduction of realistic artifacts, or so-termed "hallucinations," which can prove costly in a domain as sensitive as medical imaging by misleading radiologists and resulting in incorrect diagnoses [22, 23]. Hence, analyzing the uncertainty and robustness of DL techniques in MR imaging is essential.
Thus, the objective of this work is to learn a projection onto the intersection between the real image manifold and the data consistent subspace using a DL model, and then evaluate the uncertainty of the model in producing these reconstructions.
IV VAEs for Medical Image Recovery
For image recovery, we consider a VAE architecture (, consisting of an encoder and a decoder with latent space as in Fig. 3. While VAEs have been used successfully in low-level computer vision tasks like super-resolution, they have not been applied to medical image recovery. Importantly, the VAE is capable of learning a probability distribution of realistic images that facilitates the exploration process of the manifold . By randomly sampling latent code vectors corresponding to specific images and enforcing data consistency, we can traverse the space comprising and evaluate the results visually and statistically.
The VAE functions in the following manner. First, the encoder, which takes in input , returns (an estimate of the posterior image distribution), where is an internal latent variable with low dimension. This latent variable formulation is valuable because it enables an expressive family of distributions and is also tractable from the perspective of computing maximum likelihood. Reconstruction occurs through sampling from and passing the result to the decoder. To facilitate sampling, the posterior is represented by a Gaussian distribution and constrained by a prior distribution , which for simplicity of computation is chosen to be the unit normal distribution.
In generating reconstructions, the VAE balances error with the ability to effectively draw latent code samples from the posterior. As such, the VAE loss function used in training is comprised of a mixture of pixel-wise loss and a KL-divergence term, which measures the similarity of two distributions using the expression below
[TABLE]
In the VAE loss function, the KL term (which has weight ) is designed to force the posterior (based on for a given batch) to follow the unit normal distribution of our prior [24, 25]. As increases, the integrity of the latent code (and thereby ease of sampling after training) is preserved at the expense of reconstruction quality. With reconstruction , the training cost used in updating the weights of the model is formed as
[TABLE]
At test time, latent code vectors are sampled from a normal distribution to generate new reconstructions. To ensure that these reconstructions do not deviate from physical measurement, data consistency (obtained by applying an affine projection based on the undersampling mask) is applied to all network outputs, which we find essential to obtaining high SNR [7]. Fig. 3 depicts all of the model’s components.
To deepen our analysis of robustness, we also examine the effects of a revised model architecture that is cascaded (i.e. the VAE and data consistency portions of the model repeat) for a certain number of "recurrent blocks," since prior work has shown that this can positively impact reconstruction quality [26]. In the case of a model with two recurrent blocks, for example, the zero-filled image is passed into the first VAE, the output of the first VAE is passed as the input of a second VAE, and the output of the second VAE serves as the overall model reconstruction. Data consistency is applied to each VAE in question, and the VAEs have shared weights which ensures that new model parameters are not introduced. Note that we define a model with one recurrent block as the baseline model that has no repetition.
V Uncertainty Analysis
The advantage of using a VAE model for image reconstruction is that it naturally offers the posterior of the image which can be used to draw samples and generate variance maps. While these variance maps are useful in letting radiologists understand which pixels differ the most between the model’s reconstructions, they are not sufficient since the bias (difference between reconstructions and the fully-sampled ground truth image) is unknown. Thus, methods like SURE which can assess risk without explicitly using the ground-truth are a better alternative. The following subsections introduce these ideas in more detail.
V-A Monte Carlo sampling
An effective way of analyzing the uncertainty of probabilistic models in computer vision problems is to statistically analyze output images for a given input [8]. Nonetheless, this approach has not been widely employed in inverse problems or medical image recovery.
Utilizing the probabilistic nature of the VAE model, for a given zero-filled image (i.e. the aliased input to the model), we can use our encoder function to find the mean and variance of the latent code , which we use to draw samples. We can then use our decoder function to produce reconstructions of latent code samples and then aggregate the results over samples to produce pixel-wise mean and variance maps for the reconstructions. Algorithm 1 shows the full sequence of steps in more detail.
This Monte Carlo sampling approach allows one to evaluate variance as well as higher order statistics, which can be very useful in understanding the extent and impact of model uncertainty. However, despite the information the Monte Carlo approach can provide, some important statistics such as bias are dependent on knowledge of the ground truth, which motivates the use of metrics like SURE.
V-B Denoising SURE
A useful statistical technique for risk assessment when the ground truth is unknown is Stein’s Unbiased Risk Estimator (SURE) [27]. Despite being well-established, SURE has not yet been used for uncertainty analysis in imaging or DL problems.
Given the ground truth image , the zero-filled image can be written as
[TABLE]
where is noise. Now considering reconstruction with dimension , one can expand test MSE as
[TABLE]
Since is not present in this equation, we see that SURE serves as a surrogate for MSE even when the ground truth is unknown. A key assumption behind SURE is that the noise process that relates the zero-filled image to the ground truth is normal, namely . With this assumption, we can apply Stein’s formula which approximates the covariance to obtain an estimate for the risk as
[TABLE]
Note that SURE is unbiased, namely
[TABLE]
With the risk expressed in the above form, we can separate the estimate into three terms, with the second term corresponding to residual sum of squares (RSS) and the third one corresponding to degrees of freedom (DOF). This form importantly does not depend on , and approximates the DOF with the trace of the end-to-end network Jacobian . The Jacobian represents the network sensitivity to small input perturbations and is a measure of interest when analyzing robustness in computer vision tasks [28].
In order to estimate the noise variance, it is reasonable to assume that error in the output reconstruction is not large, and as a result can be estimated (by setting the sum of the first two terms in the SURE expression to zero) as
[TABLE]
Our evaluations validate this assumption when the undersampling rate is not very large. With this assumption, we can rewrite our expression for SURE as follows
[TABLE]
DOF approximation. Due to the high dimension of MR images, computing the end-to-end network Jacobian for SURE can be computationally intensive. From a practical standpoint, making this computation efficient allows one to evaluate uncertainty in real time, in parallel with the reconstruction. To this end, we use an approximation for the Jacobian trace [29, 30]. In particular, given -dimensional noise vector drawn from , our trained model , the zero-filled model input , and a small value (which we define as the maximum pixel value in the zero-filled image divided by 1000), the approximation can be expressed as follows
[TABLE]
V-C Gaussian noise with density compensation
As mentioned before, the key assumption behind SURE is that the noise model is Gaussian with zero mean. However, it is not safe to assume that the undersampling noise in MRI reconstruction inherits this property. For this reason, we introduce density compensation on the input image as a way of enforcing zero-mean residuals. This approach has the added benefit of making artifacts independent of the underlying image and we find that it significantly increases residual normality (see Fig. 7 in Section 6).
More specifically, given a 2D sampling mask , we can treat each element of the mask as a Bernouli random variable with a certain probability , where (this is dependent on the sampling approach).
With this formulation, we can define a density compensated zero-filled image as follows: . We can rewrite this expression using as
[TABLE]
First, we observe that has zero mean since . In addition, the noise variance obeys
[TABLE]
Of course, in practice we do not have access to the ground truth image , and instead rely on the approximation in 5 for the noise variance. Given these main properties, the density compensation method that this work introduces represents an important step that can allow denoising SURE to be used effectively in medical imaging and other inverse problems. Algorithm 2 summarizes the steps for using density-compensated SURE in practice.
Remark 1 [Compressed Sensing SURE]. The primary assumption behind the SURE derivations is that the noise obeys an i.i.d. Gaussian distribution. Even though the density compensation in (8) enforces this property, one can also leverage the generalized SURE formulation that extends SURE derivations to colored noise distributions from the exponential family, though this is harder to compute in practice [19, 31].
VI Empirical Evaluations
In this section, we assess our model and methods on a dataset of Knee MR images. We first show reconstructions produced with the VAE model, before demonstrating representative results with the Monte Carlo and SURE methods for quantifying uncertainty.
Dataset. The Knee dataset used for all experiments was obtained from patients with a 3T GE MR750 scanner [32]. Each volume consists of 320 2D slices of dimension that were divided into training, validation, and test examples with a 70/15/15 split stratified by patient. A 5-fold variable density undersampling mask with radial view ordering (designed to preserve low-frequency structural elements) was used to produce aliased input images for the model to reconstruct [33].
VI-A Adversarial Loss
The effective modeling of high-frequency components is essential for capturing details in medical images. Thus, we train our model with adversarial loss in a GAN setup, which can better capture high-frequency details [7, 11]. In particular, we use a multi-layer CNN as the discriminator along with the VAE generator . The discriminator learns to distinguish between reconstructions and fully-sampled images, and sends feedback to the generator, which in turn adjusts the VAE’s model weights to produce more realistic reconstructions.
The training process for the VAE is identical to the case with no adversarial loss, except an extra loss term is needed to capture the discriminator feedback (with weight referred to as GAN loss)
[TABLE]
The discriminator weights are updated during training as
[TABLE]
The training process acts as a game, with the generator continuously improving its reconstructions and the discriminator distinguishing them from ground truth. As the GAN loss increases, the modeling of realistic image components is enhanced but uncertainty rises.
VI-B Network architecture
As shown in Fig. 3, the VAE encoder is composed of convolutional layers (, , , and feature maps, respectively) with kernel size and stride , with each followed by ReLU activations and batch normalization [34]. Latent space mean, , and standard deviation, , are each represented by fully connected layers with neurons. The VAE decoder has layers and utilizes transpose convolution operations (, , , , and feature maps, respectively) with kernel size and stride for upsampling [35]. Skip connections are utilized to improve gradient flow through the network [36].
The discriminator function of the GAN (when adversarial loss is used) is an 8-layer CNN. The first seven layers are convolutional (, , , , , , and feature maps, respectively) with batch normalization and ReLU activations in all but the last layer. The first five layers use kernel size , while the following two use kernel size . The first four layers use a stride of , while the next three use a stride of . The eighth and final layer averages the output of the seventh layer to form the discriminator output.
The use of multiple recurrent blocks (RB) whereby the model repeats (the output feeds into the input of another VAE with the same model parameters) is also explored [26]. Using multiple RBs does not affect the discriminator network architecture.
Training was completed over the course of 30K iterations, with loss converging over roughly 20K iterations. We utilize the Adam optimizer with a mini-batch size of 4, an initial learning rate of that was halved every 5K iterations, and a momentum parameter of 0.9. Models and experiments were developed using TensorFlow on an NVIDIA Titan X Pascal GPU with 12 GB RAM. A version of our TensorFlow source code is publicly available via GitHub [37].
VI-C Individual reconstructions
Fig. 4 shows sample model reconstructions (using the mean of the output distribution) for representative test slices with different hyperparameters. As the number of RBs increases from one to two (columns 2 and 3 versus 4 and 5), the resulting outputs improve in quality (corresponding to a roughly 1 dB gain in SNR). Additionally, progressively increasing values of GAN loss (columns 2 and 4 versus 3 and 5) introduce high-frequency artifacts to the image, while leading to sharper outputs. The highlighted ROI elucidates these effects, where the degradation in visual quality associated with poor recovery can be detrimental to radiologist diagnoses. As expected, the presence of substantial adversarial loss decreases average reconstruction SNR (and increases MSE) as Table II shows. With limited GAN loss and additional RBs, though, the SNR is close to 20 dB, indicating that the probabilistic model results in effective image recovery, in addition to facilitating uncertainty analysis.
VI-D Variance, bias, and error maps
Using the Monte Carlo method described earlier in Algorithm 1, 1K outputs corresponding to different reference slices were generated after feeding a test image into the trained model and sampling from the resulting posterior distribution. Note that for this process, only the VAE (generator portion) of the model is relevant to producing outputs, even with adversarial loss used for training.
We show the mean of the 1K reconstructed outputs for a representative slice, the pixel-wise variance, bias (difference between mean reconstruction and ground truth), and error in Figs. 5 and 6, utilizing the common relation [38]. The concept of bias and variance is important in the analysis of uncertainty because both the difference from the ground truth and the inherent variability across realizations provide information on the portions of a given image most susceptible to the introduction of realistic artifacts. Note that to compute the bias and error, we need the ground-truth which is provided here solely for validation purposes.
The results indicate that variance, bias, and error increase as the GAN loss weight increases (Fig. 5) and as the number of RBs decreases (Fig. 6). Furthermore in all cases with GAN loss, the variance extends to structural components of the image, which poses the most danger in terms of diagnosis. Nevertheless, with a reasonably conservative choice of GAN weight, the risk is substantially lower. More RBs can lower variance as well as error, and can be a useful tweak to improve robustness. Although only a few representative examples are shown here, similar trends were observed with all examined reference slices.
VI-E Noise distribution with density compensation
As described earlier, denoising SURE builds on the Gaussian noise assumption for the residuals . To validate this assumption, we produce histograms and Q-Q plots of the residuals at various undersampling rates, by considering the differences for individual pixels across test images. From the top two rows of Fig. 7 one can observe the quantiles closer to the center of the distribution are aligned with those of the normal distribution for all undersampling rates. The noise distribution is not perfectly normal in any of the cases, however, which can limit the effectiveness and accuracy of SURE.
To overcome the lack of normality in the residuals, we apply our density compensation method (section V.C). For a given undersampling rate, 100 variable-density random sampling masks are generated and then averaged to obtain the sampling density . The element-wise inverse of this density can then be multiplied with any given mask to produce a density-adjusted mask . This adjusted mask can be used to generate new zero-filled images as input to the network.
As Fig. 7 (bottom two rows) shows, the distribution of residuals (for various undersampling rates) better matches the normal distribution, and the mean of the distribution lies very close to zero. This observation indicates density compensation is a valuable preprocessing step that enables the use of denoising SURE for quantifying the uncertainty in MRI reconstruction.
VI-F SURE results
To evaluate the effectiveness of the density-compensated SURE approach, we produce correlations of SURE versus MSE (which depends on the ground truth and is a standard metric for assessing model error) using the results from our test images. Fig. 8 shows the strong linearity of the correlations under all conditions. The linear relationship is strongest for lower undersampling rates ( for 2-fold while for 16-fold). Nonetheless, the results show that even with relatively high undersampling, SURE can be used to effectively estimate risk in medical image reconstructions.
In addition, the average reconstruction SURE, RSS, and DOF values for different hyperparameters are shown in Table I and Table II. Increased GAN loss results in decreased SURE values (note the units of dB) and increased RSS and DOF. Meanwhile, more RBs result in higher SURE values and lower RSS and DOF, demonstrating a simple way of improving reconstruction quality while reducing uncertainty. Note that these results align closely with the Monte Carlo analysis from before, thereby reinforcing the effectiveness of the SURE approach in quantifying risk.
Furthermore, the uncertainty analysis of the sample reconstructions in Fig. 9 indicates that there is a relationship between SURE values and variance magnitude. As overall variance decreases from left to right, the SURE values (again, in dB) increase correspondingly. In practice, these two methods need to be used in conjunction, with the variance maps illustrating the localization of uncertainty and SURE providing a more statistically sound global metric.
VII Conclusions
This paper introduces methods to analyze uncertainty in deep-learning based compressive MR image recovery. To thoroughly explore realistic and data-consistent images, we develop a probabilistic VAE model with low-error. A Monte Carlo approach is used to quantify the pixel variance and obtain uncertainty maps in parallel with reconstruction. Moreover, to fully assess the reconstruction risk (which requires the bias and thus fully sampled data), we leverage Stein’s Unbiased Risk Estimator on density-compensated zero-filled images where the noise obeys zero-mean Gaussian. We validate the utility of these tools with evaluations on a dataset of Knee MR images.
In particular, our observations demonstrate that increased adversarial loss leads to larger uncertainty, indicating a trade-off when using adversarial loss to better retrieve high-frequencies. On the other hand, using multiple recurrent blocks (cascaded VAE and data consistency layers), decreases uncertainty, which suggests an effective way of promoting robustness.
There are still important future directions to explore. While we focus on model uncertainty in this work, there are other sources of uncertainty (pertaining to data and knowledge) that should be taken into account. As such, next steps involve extensive evaluations with different MRI datasets and acquisition strategies to assess the effects of data uncertainty on model reconstructions. Additionally, it would be useful to perform uncertainty analysis for pathological cases. Quantifying the likelihood of a diagnosis being altered by hallucinated artifacts, and finding regularization schemes to limit this, will improve the effectiveness of DL methods for MRI reconstruction.
Finally, it would be valuable to extend SURE to obtain local, pixel-wise risk in addition to a global measure pertaining to the overall image. The pixel-wise SURE could then be used to generate uncertainty maps that incorporate valuable spatial information, similar to Monte-Carlo variance maps.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] A. Radford, L. Metz, and S. Chintala, “Unsupervised representation learning with deep convolutional generative adversarial networks,” ar Xiv preprint ar Xiv:1511.06434 , 2015.
- 2[2] T. M. Quan, T. Nguyen-Duc, and W.-K. Jeong, “Compressed sensing MRI reconstruction with cyclic loss in generative adversarial networks,” ar Xiv preprint ar Xiv:1709.00753 , 2017.
- 3[3] B. Zhu, J. Z. Liu, S. F. Cauley, B. R. Rosen, and M. S. Rosen, “Image reconstruction by domain-transform manifold learning,” Nature , vol. 555, no. 7697, p. 487, 2018.
- 4[4] D. Lee, J. Yoo, and J. C. Ye, “Deep residual learning for compressed sensing MRI,” in Biomedical Imaging (ISBI 2017), 2017 IEEE 14th International Symposium on . IEEE, 2017, pp. 15–18.
- 5[5] A. Bora, A. Jalal, E. Price, and A. G. Dimakis, “Compressed sensing using generative models,” ar Xiv preprint ar Xiv:1703.03208 , 2017.
- 6[6] A. Mousavi, A. B. Patel, and R. G. Baraniuk, “A deep learning approach to structured signal recovery,” in Communication, Control, and Computing (Allerton), 2015 53rd Annual Allerton Conference on . IEEE, 2015, pp. 1336–1343.
- 7[7] M. Mardani, E. Gong, J. Y. Cheng, S. S. Vasanawala, G. Zaharchuk, L. Xing, and J. M. Pauly, “Deep generative adversarial neural networks for compressive sensing (GANCS) MRI,” IEEE Transactions on Medical Imaging , 2018.
- 8[8] A. Kendall and Y. Gal, “What uncertainties do we need in bayesian deep learning for computer vision?” in Advances in neural information processing systems , 2017, pp. 5574–5584.