Bayesian parameter estimation for the SWIFT model of eye-movement control during reading
Stefan A. Seelig, Maximilian M. Rabe, Noa Malem-Shinitski, Sarah, Risse, Sebastian Reich, Ralf Engbert

TL;DR
This paper introduces a Bayesian parameter estimation method for the SWIFT eye-movement model during reading, enabling reliable individual data fitting and advancing process-based dynamic modeling in eye-tracking research.
Contribution
It develops an approximate likelihood function and applies Bayesian inference with MCMC, allowing for individual-level parameter estimation in the SWIFT model.
Findings
Parameters can be reliably estimated for individual subjects.
Approximate Bayesian inference advances eye-movement modeling.
Method enables process-based dynamic model fitting to individual data.
Abstract
Process-oriented theories of cognition must be evaluated against time-ordered observations. Here we present a representative example for data assimilation of the SWIFT model, a dynamical model of the control of spatial fixation position and fixation duration during reading. First, we develop and test an approximate likelihood function of the model, which is a combination of a pseudo-marginal spatial likelihood and an approximate temporal likelihood function. Second, we use a Bayesian approach to parameter inference using an adapative Markov chain Monte Carlo procedure. Our results indicate that model parameters can be estimated reliably for individual subjects. We conclude that approximative Bayesian inference represents a considerable step forward for the area of eye-movement modeling, where modelling of individual data on the basis of process-based dynamic models has not been possible…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1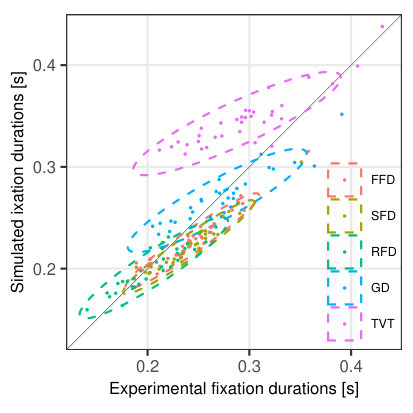 Figure 10
Figure 10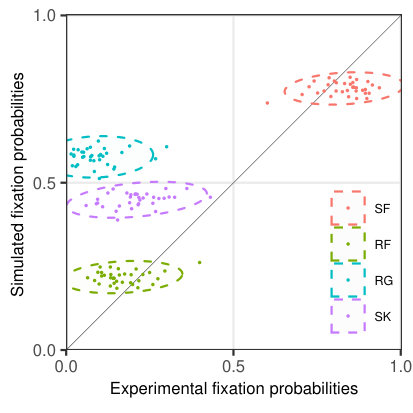 Figure 10
Figure 10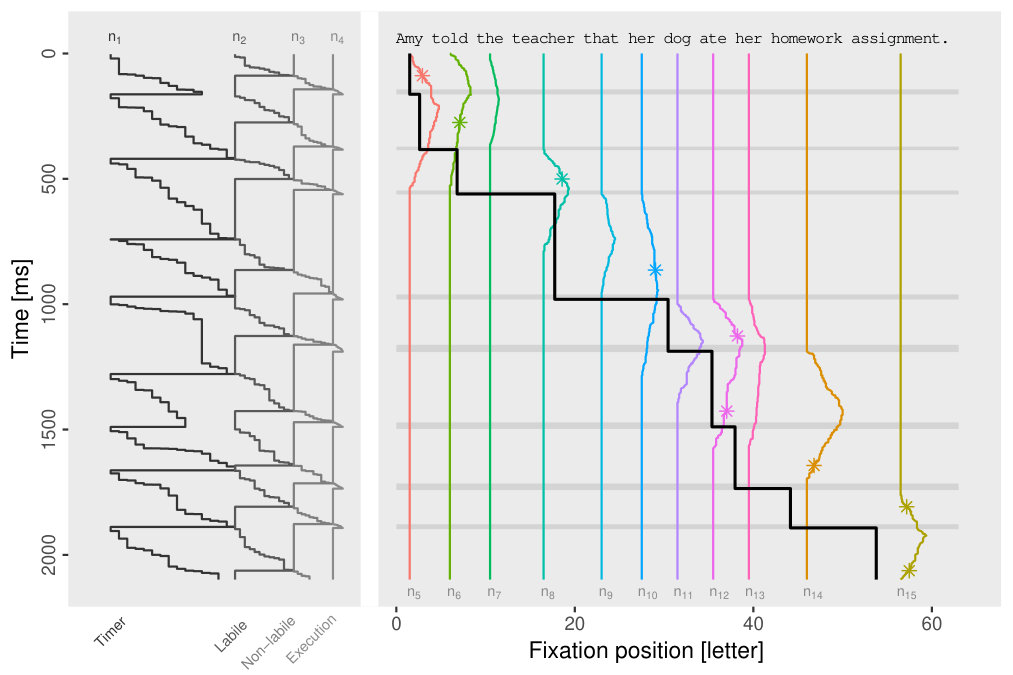 Figure 2
Figure 2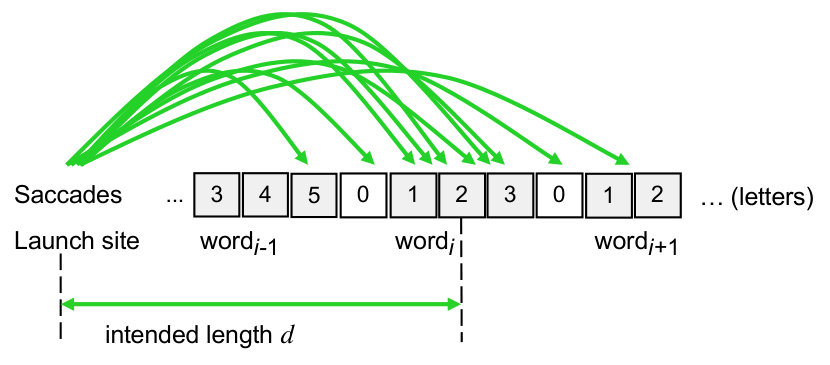 Figure 3
Figure 3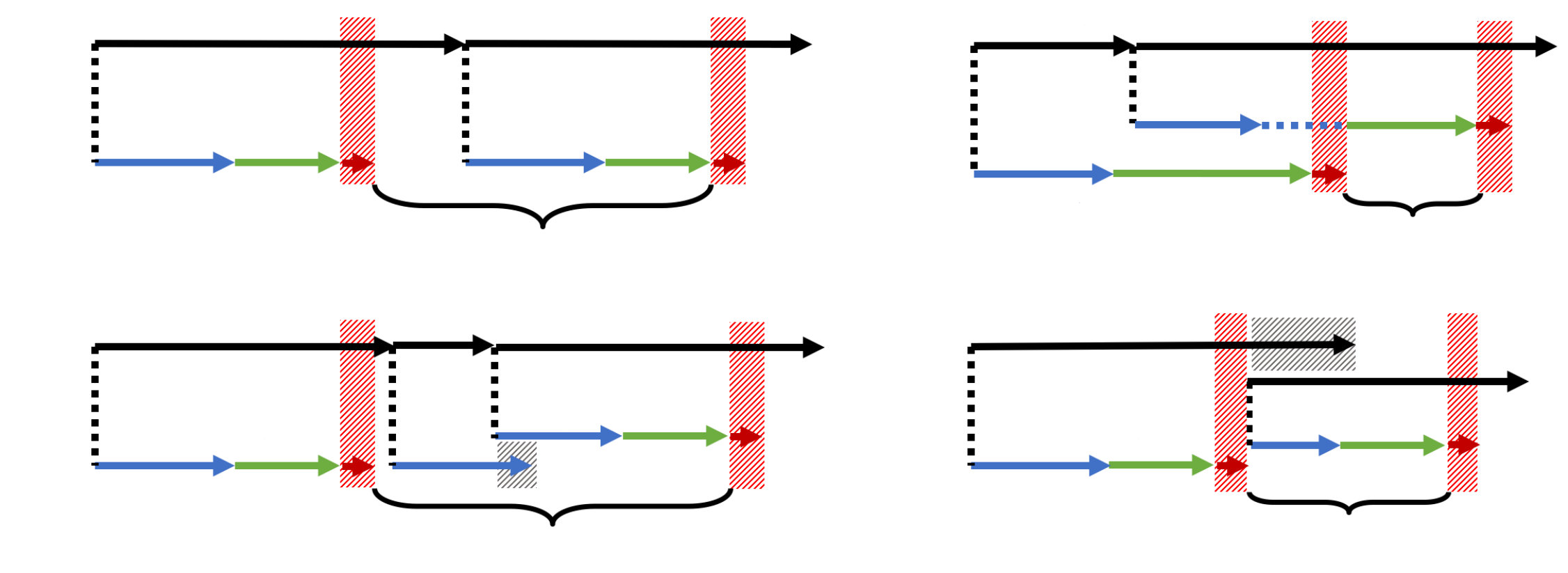 Figure 4
Figure 4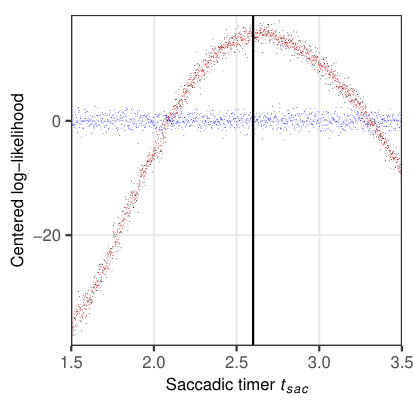 Figure 5
Figure 5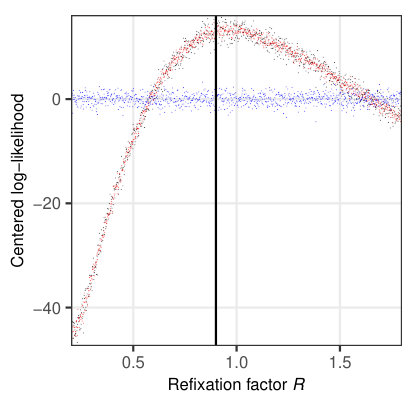 Figure 5
Figure 5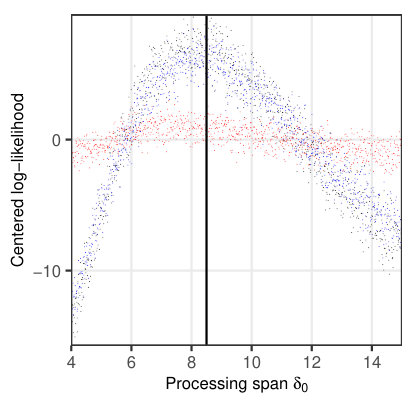 Figure 5
Figure 5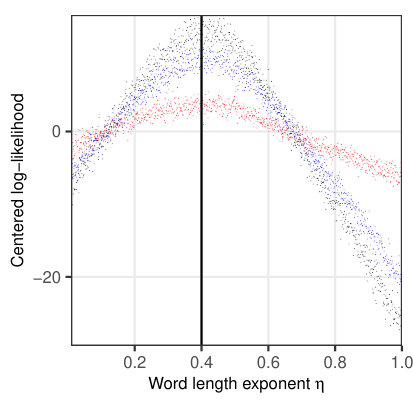 Figure 5
Figure 5 Figure 5
Figure 5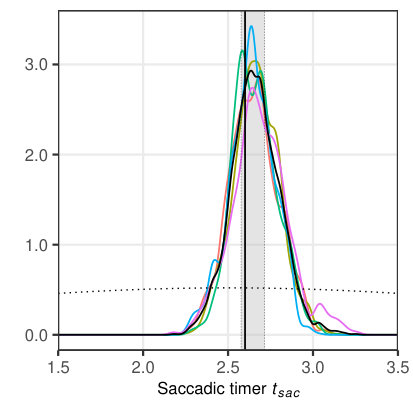 Figure 6
Figure 6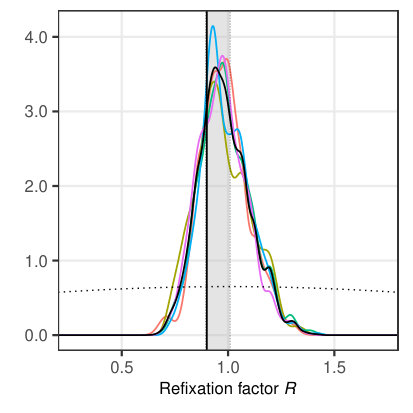 Figure 6
Figure 6| Process | Transition to … | Transition rate |
|---|---|---|
| Saccade timer | ||
| Labile program | ||
| Non-labile program | ||
| Saccade execution | ||
| Word processing | (for word ) |
| Parameter | Symbol | Typical Value | Reference |
|---|---|---|---|
| Lexical difficulty: Intercept | 50 | Eq. (13) | |
| Lexical difficulty: Slope | 0.75 | Eq. (13) | |
| Processing span | 8 | Eq. (10) | |
| Word-length exponent | 0.5 | Eq. (12) | |
| Saccade timer | 250 ms | Tab. (1) | |
| Foveal inhibition | 0.6 | Eq. (9) | |
| Labile saccade program | 120 ms | Tab. (1) | |
| Non-labile program | 80 ms | Tab. (1) | |
| Saccade execuation | 20 ms | Tab. (1) | |
| Refixation factor | 0.9 | Sec. 2.5 | |
| Mislocated fixation | 1.5 | Sec. 2.5 |
| Parameter | Symbol | Range | True value |
|---|---|---|---|
| Saccadic timer | ms | ms | |
| Refixation factor | |||
| Processing span | |||
| Word length exponent |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Bayesian parameter estimation for the SWIFT model of eye-movement control during reading
Stefan A. Seelig1, Maximilian M. Rabe1, Noa Malem-Shinitski2, Sarah Risse1,
Sebastian Reich2,3, & Ralf Engbert1,3
1Department of Psychology, 2Institute of Mathematics,
3Research Focus Cognitive Sciences,
University of Potsdam, Germany
Abstract
Process-oriented theories of cognition must be evaluated against time-ordered observations. Here we present a representative example for data assimilation of the SWIFT model, a dynamical model of the control of fixation positions and fixation durations during natural reading of single sentences. First, we develop and test an approximate likelihood function of the model, which is a combination of a spatial, pseudo-marginal likelihood and a temporal likelihood obtained by probability density approximation. Second, we implement a Bayesian approach to parameter inference using an adaptive Markov chain Monte Carlo procedure. Our results indicate that model parameters can be estimated reliably for individual subjects. We conclude that approximative Bayesian inference represents a considerable step forward for computational models of eye-movement control, where modeling of individual data on the basis of process-based dynamic models has not been possible so far.
Keywords: Dynamical models, reading, eye movements, saccades, likelihood function, Bayesian inference, MCMC, interindividual differences
1 Introduction
Dynamical models represent an important theoretical approach to cognitive systems, in particular, if we seek to explain time-ordered behavioral data such as sequences of movements. In dynamical models, sequential dependencies between observations are naturally explained by underlying dynamical principles that unfold over time when the model is simulated numerically (Van Gelder, \APACyear1998; Beer, \APACyear2000). Examples for the dynamical approach can be found in many fields of cognitive research, triggered by early examples from motor control (Haken \BOthers., \APACyear1985; Erlhagen \BBA Schöner, \APACyear2002) or decision field theory (Busemeyer \BBA Townsend, \APACyear1993).
Dynamical models generate highly specific predictions on sequential data that include statistical correlations between the subsequent observations over time. As a consequence, parameter inference for dynamical models must be carried out with the fully dynamical framework of data assimilation (Law \BOthers., \APACyear2015; Reich \BBA Cotter, \APACyear2015). Here we investigate parameter inference in the SWIFT model of saccade generation during reading (Engbert \BOthers., \APACyear2005), where the numerical computation of the model’s likelihood function will be the fundamental concept and main contribution of this work.
In the research area of eye-movements during reading, a number of competitor models has been proposed. These models implement alternative assumptions on the interaction of word recognition and saccade generation (see Reichle \BOthers., \APACyear2003; Rayner \BBA Reichle, \APACyear2010, for overviews). However, there is currently a lack of quantitative model evaluations using objective concepts. First, due to the number of different effects in experimental data, models were often compared qualitatively: Does the model reproduce an experimentally-observed effect or not? Second, in complex cognitive models, parameters were mostly hand-selected or fitted based on minimization of an arbitrary loss-function that quantifies the difference between experimental and simulated data. Third, typical models could not be fitted to data from individual subjects so far. However, explaining interindividual differences is an important aspect of model evaluation, which is precluded when fitting procedures are data hungry and require pooling of data over a large number of participants. Since model identification and model comparison are general problems in psychological and cognitive sciences, Schütt \BOthers. (\APACyear2017) recently proposed a likelihood-based, statistically well-founded Bayesian framework for parameter estimation in cognitive models. We will demonstrate the feasability of this approach in the case of the SWIFT model for eye-movement control during reading.
In the following, the data assimilation framework will be applied to the SWIFT model of eye guidance in reading. The remaining part of this section consists of a short introduction to eye movement data and the specifics of likelihood functions for models of fixation sequences. In Section 2, we describe the details of the SWIFT model. A numerical approximation of the likelihood function is proposed and tested in Section 3. In Section 4, we use data from a set of readers to estimate SWIFT parameters and to model their interindividual differences. We close with a discussion of our results in Section 5.
1.1 Eye-movement control during reading
Reading is based on successful word recognition, however, processing of words requires high-acuity vision that is confined to the center of the visual field (the fovea). Therefore, gaze shifts via fast eye movements (saccades) need to be generated to move words into the fovea for word identification. From this general behavioral pattern, reading may be looked upon as an important example of active vision (Findlay \BBA Gilchrist, \APACyear2003), which is the notion that eye movements form an essential component for almost all visual perception.
When we read texts, we perform 3 to 4 saccades per second, resulting in fixations on different words with durations between 150 and 300 ms, on average. An example is presented in Figure 1, where 11 fixations are placed on the words of a given sentence. Fixation durations range from 110 ms to 325 ms. In this example, some words are fixated more than once. In the case of an immediate second saccade to the same word as the currently fixated word, the event is called a refixation (e.g., fixations 3, a forward refixation, and 5, a backward refixation). Some words are not fixated during first-pass reading, corresponding saccades are termed skippings (e.g., word 6, the article “den”, was skipped in first-pass reading). Furthermore, it happens in roughly 5 to 10% of the fixations that a corresponding saccade returns to a previously passed region of text, which are called regressions (e.g., when word 6, the previously skipped article, receives fixation 9). Taken together, only about 50% of the saccades are moving the gaze forward from word to the next word , which generates complicated scanpaths that are difficult to reproduce and predict by theoretical models of eye guidance during reading.
Eye movement research in reading has evolved into one of the fields of cognitive psychology that is strongly driven by computational models. Most of these models are based on simplified assumptions for several cognitive subsystems (e.g., oculomotor circuitry, attention and word recognition), while the core of the models is the orchestration of the subsystems to produce purposeful saccades for reading in a psychologically plausible framework. The way to this success has been paved by the E-Z Reader model (Reichle \BOthers., \APACyear1998), a rule-based stochastic automaton model that is based on specific assumptions for the coupling of eye movements and visual attention. This model has been advanced over the years to include more and more specific assumptions (e.g., Reichle \BOthers., \APACyear2009).
One of the major differences between existing models lies in the generation of different types of saccades (forward saccades, skippings, refixations and regressions). While some models make explicit assumptions on saccade types or are built to have internal states representing saccade types, an alternative model considered here is motivated by the dynamical field theory of movement preparation (S\BHBIi. Amari, \APACyear1977; Erlhagen \BBA Schöner, \APACyear2002), which communicates the aspiration to form a general framework for human motor control. The SWIFT111Saccade Generation With Inhibition by Foveal Targets model (Engbert \BOthers., \APACyear2002, \APACyear2005; Schad \BBA Engbert, \APACyear2012) provides a coherent theoretical framework for reproducing all types of saccades that are observed during reading. Word processing maps to a distributed activation field that serves as a temporally evolving saccade targeting map. This model will be studied in detail with respect to parameter inference.
Given alternative theoretical models, model fitting and model comparisons will become an increasingly important topic in eye-movement research, as in cognitive science in general. So far, the minimization of ad-hoc statistical loss-functions has been used to obtain estimates for model parameters (e.g., Reichle \BOthers., \APACyear1998; Engbert \BOthers., \APACyear2005). For example, differences in word-frequency dependent distributions of fixation durations or skipping probabilities have been implemented as a measure of goodness-of-fit. We will replace these procedures by a Bayesian framework that exploits the likelihood function of the model.
Quantitative measures for eye movements during reading are characterized by strong interindividual differences (e.g., Risse, \APACyear2014). However, current computational models of eye-movement control could not reproduce and explain these obvious differences in human performance. It is a key message of the current work that the problem of modeling interindividual differences in reading using complex simulation models can be overcome when a likelihood-based framework of model identification, model parameter estimation, and model comparison is applied. We start with a discussion of the general concept of the likelihood function for dynamical cognitive models in the next section. The approximative computation of the likelihood function for the SWIFT model, which is the central contribution of the current work, is discussed in Section 3.
1.2 The likelihood function for dynamical cognitive models
The key theoretical concept for the current study is the likelihood function (see Myung, \APACyear2003, for a tutorial), which is a quantitative measure of the plausibility of an observation under the assumption of a specific model . We assume that the model depends on a set of parameters from parameter space . In parameter inference, we are interested in the likelihood of the model parameter values for model given the experimental data,
[TABLE]
where is the probability of the data given model with parameters .
The maximum likelihood estimator is obtained by maximization of the likelihood function, i.e.,
[TABLE]
In mathematical models of eye-movement control, a model must be evaluated against a sequence of fixations. Thus, the data is a time-ordered sequence of fixations , where each fixation is characterized by a position on the line of text, a fixation duration , and, depending on the model, also a saccade duration between fixation and fixation .
In a dynamical model, fixation is generated from the sequence of previous fixations under the control of the set of parameters and, possibly, influenced by internal degrees of freedom , which will be discussed in Section 3. Since fixations are time-ordered, we can factorize the likelihood into a product of all fixations , which are found in the experimental fixation sequence , i.e.,
[TABLE]
where is the probability of the initial fixation starting at time . In typical experimental paradigms, however, this probability is one, since the experimental procedure determines the initial fixation position.
For complex cognitive models, the likelihood function can often be computed numerically. If numerical computation of the likelihood function is possible, we must be able to evaluate the likelihood for a large number of combinations of model parameter values to find the maximum likelihood estimator, Eq. (2), based on a given fixation sequence .
For the implementation of numerical computations, it is advantageous to compute the log-likelihood, given as
[TABLE]
which prevents the addition of very small numerical values that typically occur for some of the additive terms for the fixations .
If we can compute the log-likelihood for model efficiently using numerical simulation, then it will be possible to apply Bayesian parameter inference (Marin \BBA Robert, \APACyear2007; Gelman \BOthers., \APACyear2013, for overviews). In Bayesian inference, we seek to compute the posterior distribution over the parameter vector after the observation of the fixation sequence . In addition to the likelihood that represents constraints from the experimental data, we specify a prior probability that indicates our a-priori knowledge on the model parameters. The posterior distribution is given by
[TABLE]
where the constant of proportionality, which is the normalization constant of the posterior, can be omitted, if Markov Chain Monte Carlo (MCMC) methods are used (Gilks \BOthers., \APACyear1995; Robert \BBA Casella, \APACyear2013).
So far, we discussed the structure of the likelihood function for a single experimentally observed fixation sequence . In a typical experiment, however, we obtain a set of fixation sequences from a participant who read a corpus of sentences (), i.e., the data set is composed of fixation sequences. Since fixation sequences are statistically independent observations of the reading process, the numerical computation of the likelihood can be carried out independently for each fixation sequence . This statistical independence can be exploited to accelerate computations via parallel evaluations of a large number of fixation sequences, which we will discuss in Section 4.
In summary, the likelihood function for dynamical models of sequential data factorizes as explained in Eq. (1.2), which turns out to be basis for incremental numerical computation. If we implement the computation in an efficient way numerically, then Bayesian parameter inference is available using MCMC methods. Before we discuss and apply the MCMC framework, we introduce the SWIFT model in the next section. In Section 3, we present the numerical computation of the likelihood function. The MCMC simulation for Bayesian inference will be discussed in Section 4.
2 The SWIFT model of saccade generation during reading
Since word recognition is the key process driving eye movements during reading, a natural assumption is that the time-course of ongoing word processing is closely linked to target selection for saccades. In the SWIFT model, each word is represented by a separate activation variable (lexical activation) that is tracking the word’s current progress in word recognition. The resulting set of lexical activations determines the probability for saccade target selection (so-called spatial or where pathway). Whenever a saccade is prepared, the set of lexical activations provides a flexible mechanism for target selection. As time evolves, the relative activations change, so that a continuous-time representation of the next saccade target exists.
Fixation times are adjusted to the fixated (foveal) word by an inhibitory mechanism (the temporal or when pathway). According to an influential proposal (Findlay \BBA Walker, \APACyear1999) the spatial and temporal pathways of saccade generation are partially independent. The SWIFT model is compatible with this view, in the sense that control of fixation duration and saccade target selection are basically independent, however, interactions exist due to the coupling of both pathways via the set of lexical activations.
2.1 Saccade target selection and temporal evolution of activations
Each word in a sentence of words is represented by a time-dependent activation . The activation is initially increasing during lexical access (word recognition), and later decreasing during post-lexical processing. The set of activations , must be built up by parallel processing of words, which is the key assumption that distinguishes SWIFT from other models (e.g., Engbert \BBA Kliegl, \APACyear2011; Reichle \BOthers., \APACyear2003). If a saccade target has to be selected at time , then the probability for target selection of word is given by the relative activation, i.e.,
[TABLE]
which is normalized as for all . The parameter introduces a weighting of the set of lexical activations, so that switching between different selection schemes is controlled by a variation of :
[TABLE]
An example for a simulated scanpath and the full time-series of lexical activation is illustrated in Figure 2. As one can see from figure, all internal sub-processes of the model are implemented by discrete random walks. In the leftmost column, the saccade timer increases as a one-step process from up to a maximum number with transition rate . The stepping rate was chosen as , so that the mean time to reach state is the mean time inter-saccadic time of the model.
When the saccade timer terminates at state , a new saccade timer run is initiated at and, at the same time, a labile saccade program start with until its threshold is reached. If this labile program terminates, a saccade target is chosen (see asterisks in Fig. 2). After the non-labile stage, which is described by state variable , the corresponding saccade (state variable is executed.
In addition to the saccadic processes, lexical activations are also described by discrete random walks (note, however, the increasing and decreasing parts in the case of lexical activations). Thus, all sub-processes saccade timing, labile and non-labile saccade programming, saccade execution, and change of lexical activations are represented as one-step stochastic processes between discrete states.
The state of the model at time is given by the vector , where the components represent the states of the subprocesses with transition rates . Components 1 to 4 are saccade-related processes and additional stochastic variables to are keeping track of the (post-)lexical processing of words. We assume a discrete-state, continuous-time stochastic process with Markov property, so that a one-step transition table describes all possible transitions between internal states (Tab. 1). In each of the possible transitions from state to only one of the components is changes by one unit, e.g., if the saccade timer generates a transition, then the model’s internal change steps from to .
A numerical algorithm for the simulation of a trajectory of the SWIFT model can be derived easily from our assumptions. The temporal evolution of the probability over the model’s internal states is given by the master equation222The master equation can be interpreted as a conservation equation for probability (Gardiner, \APACyear1985; Van Kampen, \APACyear1992), where the temporal change of probability in state on the left side of the equation equals the gain in probability for state that is generated by transitions from neighboring states and the loss in probability generated by transitions from to neighboring states .,
[TABLE]
which is specified by the transition probabilities for transitions between state vectors shown in Table 1 with initial condition , the probability of state at time . When simulating a single trajectory, the system is in a specific state with certainty and the transition probabilities determine both the waiting time distribution for the next transition and the relative stepping probability to the adjoined states given in (Tab. 1), which will be explained below.
2.2 Temporal control of saccades and foveal inhibition
Gaze duration, defined as the sum of the durations of all immediately consecutive fixations on a word, is probably the best measure of required processing time for this word during natural reading (Rayner, \APACyear1998). Gaze durations and word recognition times depend linearly on the logarithm of the word’s frequency (printed word frequency can be estimated from the word’s occurrences in large text corpora). Since word recognition is the basis for text comprehension, an adaptive mechanism for the modulation of fixation duration by word frequency is essential for all models of eye-movement control.
In general, the required fixation duration for successful word recognition can be attained by two opposing mechanisms: The current fixation can be prolonged by inhibiting the next saccade or, alternatively, the word can be refixated to increase gaze duration. Experimentally, there is only a weak influence of word frequency on the mean first-fixation duration (Kliegl \BOthers., \APACyear2004). In contrast, we find a strong effect of word frequency on the probability for refixation. Therefore, there is a preferred strategy for extending the processing time (gaze duration) via generation of a refixation. However, saccade-inhibiting processes can be assumed to contribute a weaker effect (compared to refixation) to the increase in gaze duration by prolonging the ongoing fixation (Engbert \BOthers., \APACyear2002, \APACyear2005).
Motivated by these observations, the second central assumption in the SWIFT model is random timing of fixation duration with additional foveal inhibition (Engbert \BOthers., \APACyear2002) that delays the start of the next saccade program to extend the current fixation. We assume that foveal inhibition modulates the transition rate for transitions between elementary steps of a random-walk that implements the saccade timer (leftmost column in Fig. 2), i.e.,
[TABLE]
where is the number of states of the timer’s random walk and is the mean value of the timer; the activation of the fixated word (i.e., the word in the fovea) at time is the key variable that modulates the transition rate of the timer. Using numerical simulations of the model, it can be shown that for , foveal inhibition can produce a modulation of the fixation duration that is in good agreement with experimental data (Engbert \BOthers., \APACyear2002, \APACyear2005).
2.3 Character-based visual processing
Word recognition starts with visual processing of letters, which is done in parallel for all the letters of a given word. We define the spatial region where word activations can be influenced in the model as the processing span. Within this region, parallel processing is limited by the fact that processing rate depends on the letter’s eccentricity (i.e., the distance of the letter position from the position of the current fixation). Mathematically, we define an inverted parabolic processing span from the fovea to position on the left and to position on the right of fixation, i.e.,
[TABLE]
where is a constant given as
[TABLE]
which is necessary to normalize the total processing rate, i.e., .
Experimentally, a strong asymmetry of the perceptual span with an extension of 4 to 5 letters to the left of the fixation position and up to 15 letters to the right was found (Rayner \BOthers., \APACyear1980). Therefore, parameters and should be estimated separately from experimental data. In the following, we estimate for simplicity.
2.4 Word-based processing rate
Because of the assumption of a processing span, Eq. (10), processing rates for letters depend on spatial eccentricities. Letter of word is processed with rate , if it is located at a spatial position with eccentricity relative to gaze position at time . This letter-based processing rate must be related to the effective word-based processing rate of word at time .
Because of parallel processing of the letters of a given word, each letter contributes to word recognition. In the case of long words, some letters will have large eccentricities, so that their processing rate will be small (or zero) according to Eq. (10). To capture these opposing effects in a parametric model, we make the assumption that the word-based processing rate has the form
[TABLE]
where is the word length (i.e., number of letters) of word and is the word length exponent, with . For , long words will have a processing advantage. For , word processing rate is the arithmetic mean of the letter-based processing rates (mean over all letters of a given word); therefore, we will observe a disadvantage for long words in the case . We expect a numerical value for about 0.5.
With the assumptions on spatial aspects of letter- and word-based processing rates, the temporal aspects of word processing need to be specified. As discussed for the motivation of the SWIFT model, a time-dependent activation field will provide probabilistic control of saccadic eye movements. Word-based activations for the words of a given sentence are increasing during the initial stage of processing called lexical processing. After reaching the maximum of activation for word , the activation starts to decrease (post-lexical processing). The maximum of activation is interpreted as processing difficulty, which is a logarithmic function of word frequency , i.e.,
[TABLE]
where is the highest word frequency in a given language and parameter determines the strength of the word frequency effect.
For word processing, we assume that current activation for each word is related to the discrete state of word processing (Tab. 1), given by
[TABLE]
where is the word’s processing difficulty, Eq. (13).
Global decay of activation. Maintaining words in working memory during reading cannot be done without loss. Since word activations represent the state-of-processing, we introduce a global decay of activation. If the processing rate of a word is smaller than the constant , then we assume a decay of activation with rate .
Processing during saccades. During saccadic eye movements, lexical processing is paused because of saccadic suppression (Matin, \APACyear1974). In the SWIFT model, lexical processing is paused during saccades in the lexical processing stage (increasing activation), while post-lexical processing (decreasing activation) continues during saccades.
2.5 Oculomotor assumptions
Our assumption of two-stage saccade programming are motivated by the experimental findings of the double-step paradigm (Becker \BBA Jürgens, \APACyear1979). A saccade program starts with a labile stage; during this stage, the saccadic gaze center is forced to prepare the next saccade (Findlay \BBA Walker, \APACyear1999), however, a new decision to start a labile saccade program during an ongoing labile stage leads to cancelation and replacement of the earlier saccade program. After the transition to the non-labile stage, the saccade can no longer be canceled or modified.
Oculomotor errors make an important contribution to eye-movement control during reading. In 1988, based on the analysis of initial fixation positions within words, McConkie and coworkers suggested that a considerable fraction of saccades landed on different words than the intended target words (McConkie \BOthers., \APACyear1988). Using an iterative oculomotor modeling approach, Engbert \BBA Nuthmann (\APACyear2008) showed that about 10% to 20% of the saccades during natural text reading are mislocated on an unintended word.
McConkie \BOthers. (\APACyear1988) showed that saccadic errors can be decomposed into a random (approximately Gaussian) error component and a systematic shift (called saccadic range error). The critical variable that determines the size of both random and systematic error components turned out to be the intended saccade length (distance from the launch site of the saccade to the center of the target word). Therefore, saccades targeting a word center at will be normally distributed with
[TABLE]
where both parameters depend linearly on the intended saccade length , i.e.,
[TABLE]
where is the physical distance between the launch site of the saccade and the word center of the target word, measured in units of character spaces. The oculomotor parameters , , , and will vary depending on the type of saccade (e.g., refixation or skipping), which is discussed in earlier papers (Engbert \BOthers., \APACyear2005; Krügel \BBA Engbert, \APACyear2010). We would like to remark that McConkie et al.’s descriptive model of saccadic errors could be replaced by a process-oriented Bayesian model (Engbert \BBA Krügel, \APACyear2010; Krügel \BBA Engbert, \APACyear2014) in perspective.
Modulation of the duration of the labile stage. An important problem is the observation of a reduced average fixation duration for refixations. As a solution, we assume that the duration of the labile stage of saccade programming is reduced by factor (), if the fixation is a refixation.
Closely related is the phenomenon of mislocated fixations (Engbert \BBA Nuthmann, \APACyear2008). If the realized fixation position (the saccadic landing position) strongly deviates from the word center, so that the landing position will fall onto the neighboring word, then a mislocated fixation will occur. In this case, the duration of the next saccade program will be reduced by factor (). Such a mechanism is a possible explanation of the inverted optimal viewing-position effect (Nuthmann \BOthers., \APACyear2005; Vitu \BOthers., \APACyear2001) of fixation durations that indicates reduced average fixation duration at word edges compared to the word center. In the SWIFT version used here, the probability of misplaced fixation is given as , where is the fixation error (distance from word center) and is the length of the fixated word.
2.6 Numerical simulation and model parameters
For numerical simulations of single trajectories of the SWIFT model, the minimal process method by Gillespie (\APACyear1976), an exact and efficient numerical algorithm, can be derived from the master equation, Eq. (8). If the model is in state at time with certainty, all other states will have zero probability, i.e., for . Therefore, the master equation, Eq. (8), reduces to
[TABLE]
where is the total transition probability from state . From Equation (18), we obtain an exponentially distributed waiting time for the next transition from state to an adjoined state . Following Gillespie (\APACyear1976), a two-step algorithm can be derived: In step 1, an exponentially-distributed random number is generated; in step 2, a transition (Tab. 1) is chosen according to relative transition probabilities, with . This algorithm is numerically efficient, since it restricts computations to the transitions when simulating the system’s trajectory.
For the simulations in this paper we used a restricted version of the SWIFT model to reduce the number of free parameters to 11 (Tab. 2; see Engbert \BOthers., \APACyear2005). Moreover, we fixed seven of these parameters to estimate four free parameters in the simulation examples. Future simulation studies will be carried out with more free parameters (see Sec. 5). The number of possible random-walk states varies between subprocesses; based on earlier simulations (Schad \BBA Engbert, \APACyear2012), we used the following numbers: (saccade timer), (labile saccade stage), (non-labile saccade stage), (saccade execution), and (word activations).
3 Likelihood function for the SWIFT model
For the parameter estimation procedure discussed in the introduction, we aim at a framework that computes the likelihood of a series of experimentally observed fixations incrementally, Eq. (1.2). For fixation , we need to compute the likelihood function given the previous fixations , the model parameters , and the internal states of model , which we not addressed in Eq. (1.2). In SWIFT each fixation event is defined by a fixation position given by the fixated word and the fixated letter within the word
, the fixation duration , and the saccade duration . The likelihood for fixation is composed of a spatial contribution and a temporal contribution. At time , fixation starts on letter of word , which is predicted by the SWIFT model with a probability determined by word activations and oculomotor assumptions. After fixation started, the model can make another prediction for the fixation duration of fixation . Next, the likelihood for fixation can be decomposed into the spatial and temporal contributions, i.e.,
[TABLE]
where we introduced to simplify the notation.
For the spatial likelihood , the dynamically evolving word activations in SWIFT determine the time-dependent probability for selecting a particular word as the next target word. Additionally, the target-selection probability is modified by oculomotor noise. Due to dynamical dependencies, we compute the likelihood of an experimentally realized fixation position based on the previous fixations. However, the internal states are given by the stochastic dynamics and are, therefore, unknown. In principle, we could integrate over many possible realizations of the internal states , which is, however, time-consuming for the numerical computations. Therefore, we compute for one realization of the internal states , which results in fluctuating numerical values for . Thus, instead of integrating out the internal degrees of freedom , we used a pseudo-marginal likelihood (Andrieu \BBA Roberts, \APACyear2009) and eliminated the dependence on for the spatial likelihood in Eq. (19).
For the temporal likelihood , SWIFT computations start with a realized fixation position on letter of word , however, with internal states . Given this fixation position, the distribution of fixation durations can be predicted by the model. The generated estimate of the likelihood of the experimentally realized fixation duration is approximated by averaging over many realizations of the internal states (e.g., the internal states of the various saccade programming stages). As a result, both and are random variables, which will be discussed in detail in the next two sections.
3.1 Spatial likelihood
In SWIFT, saccadic gaze shifts are generated in two steps: First, a target word is determined in a probabilistic selection process based on relative word activations. Second, after a short delay generated by saccade programming, the saccade is executed with oculomotor errors influenced by the saccadic landing position distribution. These oculomotor errors induce stochastic variability in the within-word fixation position and can also induce mislocated fixations (Engbert \BBA Nuthmann, \APACyear2008; Nuthmann \BOthers., \APACyear2005), where the realized fixation position is placed on a different word than the selected target.
The combination of activation-based saccadic selection and oculomotor errors generates a non-zero probability for all fixation positions (Fig. 3). The target selection probability (see. Eq. 6) is the probability of selecting word as a saccade target for a fixation starting at time . It is important to note that target selection occurs at the time of transition from the labile to the non-labile saccade program, so that the probability for selecting the next target word has to be evaluated with an average time delay . According to our oculomotor assumptions, the saccadic error generates a probability of fixating word at letter given that word is the selected target word and is the previous gaze position (or saccade launch site). Thus, the spatial likelihood of an observed saccade starting at time towards letter position of word is therefore given by
[TABLE]
where we dropped the conditional arguments to simplify the notation. Moreover, the time-dependency is now written explicitly, since for the computation of the spatial likelihood of fixation is given by the sum of fixation durations and saccade durations of the previous fixations in the sequence, .
The oculomotor system generates systematic and random errors that introduce deviations between the target word’s center and the realized fixation position. In SWIFT, we adopt McConkie et al.’s (1988) range-error framework by assuming a Gaussian distribution that is shifted with respect to the target word’s center. Thus, the probability of landing at letter of word , given a target word , is given by
[TABLE]
where is the spatial position of the target word’s center, is the spatial position of the fixated letter of word , and is the unit width of a letter. The oculomotor parameters and of the range-error model specify systematic shift (saccadic range error) and standard deviation of the random error (oculomotor noise), respectively, Eqs. (16, 17); the intended saccade length is given as the distance between the target word’s center and the fixation position before the saccade .
3.2 Temporal likelihood
Because of two-stage saccade programming and due to the fact that fixations are bounded by two saccades in time, SWIFT’s fixation durations are given as linear combinations of realizations of random variables. For the saccade timer and saccade programming stages, resulting durations are gamma-distributed random variables, which are generated by continuous-time discrete-state random walks according to the master equation, Eq. (8).
The saccade timer controls the initiation of the saccade programming cascade with consecutive labile and nonlabile stages and a saccade execution stage. The time interval between the end point of the previous and the beginning of the next saccade execution is defined as the experimentally observed fixation duration. However, the saccade timer is continuously inhibited by word activations. As a consequence, the mean waiting times (the inverse of the transition probabilities) of the elementary steps of the saccade timer’s random walk will be time-dependent. Additionally, the mean durations of the labile stages of saccade programming depend on the type of fixation (i.e., whether it is a refixation, a mislocated fixation, or neither of these). Finally, if the saccade timer produces a short interval, then saccade cancelation will be likely, which results in a higher mean value of the predicted fixation duration.
Since each fixation duration is bounded by two saccades (i.e., the th fixation duration lies between th saccade offset and th saccade onset), each observed fixation duration is compared to the simulated realization that is given as the sum of the following terms (see Fig. 4a),
[TABLE]
where is the realized saccade timer duration, and are realized durations of the labile and non-labile saccade programming stages respectively, and is the realized saccade duration.
Our strategy for the computation of the temporal likelihood of the th fixation duration is to simulate many realizations of from Eq. (22) to numerically approximate the theoretical distribution of fixation durations with kernel density estimation333While it is possible to derive an iterative algorithm for the distribution of linear combinations of gamma-distributed random numbers (Coelho, \APACyear1998; S\BPBIV. Amari \BBA Misra, \APACyear1997), it turned out that these solutions are numerically unstable.. In the context of Bayesian analysis, this approach is termed probability density approximation (PDA) method (Turner \BBA Sederberg, \APACyear2014; Holmes, \APACyear2015; Palestro \BOthers., \APACyear2018), which falls into the broad class of likelihood-free procedures in approximate Bayesian computation (ABC; see Sisson \BBA Fan, \APACyear2011, for a review).
Since all of the terms in Eq. (22) are random realizations of stochastic variables, the order of terminations of the subprocesses shown in Fig. 4(a) can be violated. In the following, we discuss all possible cases:
Labile pausing happens if the labile saccade program terminates during an ongoing non-labile saccade program. Since we assume that there cannot be more than one non-labile saccade program active at a time, the current labile program is paused immediately before termination, thus its duration is extended until the current non-labile program and saccade execution finish (Fig. 4b). Formally, this situation is encountered if . In this case, the interval is increased and the calculation of is simplified to the duration of the non-labile saccade program, i.e.,
[TABLE]
Since the duration of the labile program is extended, however, there will be increased probability for the saccade timer to terminate during the ongoing labile program, while will cause saccade cancelation. 2. 2.
Saccade cancelation occurs if the main saccade timer realization terminates during an ongoing labile saccade programming stage , i.e., , which is illustrated in Figure 4c. In this case the labile saccade program is canceled and replaced with the new labile saccade program initiated by restarting of the saccade timer. As a result, the duration of the timer in Eq. (22) is replaced by the sum . Therefore, the corresponding distribution for saccade cancelation is given by
[TABLE]
In principle, saccade cancelation can happen repeatedly within the same fixation, depending on the choice of parameters. 3. 3.
Refixations and mislocated fixations represent another special case, where a new saccade program is triggered immediately after the fixation onset (Fig. 4d). In both cases the saccade timer realization is reset and a new labile saccade program is initiated. The mean duration of the new labile stage is modified by coefficients and for refixations and mislocated fixation, resp. (see 2.5). As a result, the observed fixation duration is given as
[TABLE]
The SWIFT model includes inhibition of fixation durations by word activation; in its simplest form, the activation of the fixated (foveal) word inhibits the fixation duration by decreasing the transition rates of the saccade timer (Eq. 9). Because of the complicated time-course of the activation field (i.e., sudden changes of activation evolution due to saccades), stochastic simulations are necessary to estimate the distribution of .
To compute the likelihood of an observed fixation duration we first simulate the activation evolution for words in the perceptual span from time until the point in time that corresponds to the end of fixation . We start simulating the stochastic contributions by initially going backwards from the time of fixation onset by sampling the saccade latencies , , and to determine the onset of the saccade timer . The previously sampled activations provide information for the simulation of the saccade timer with inhibition by foveal word activations, similar to the generative process. If , both realizations are discarded and sampled again with the same procedure (we are not interested in saccade cancelation events which do not affect the fixation duration under consideration). The offset of demarks the onset of and, following the rules of the previously discussed order violations, we can easily simulate the timer cascade until fixation offset and hence obtain a sample from the distribution of fixation durations as provided by the SWIFT framework with respect to the history of the fixation sequence.
Once fixation durations are sampled, the distribution of is approximated via KDE. Increasing the number of samples increases the accuracy of the approximation but is costly in terms of computation time. For the density estimation we use the Epanechnikov kernel (Epanechnikov, \APACyear1969) with a bandwidth setting according to Scott’s rule (Scott, \APACyear2015). The Epanechnikov kernel is computationally efficient as it only integrates samples within its limited interval given by the bandwidth. However this can result in situations where no data point is covered by the kernel. To prevent estimates with zero probability, the bandwidth of the kernel was adjusted to the 1.1-fold of the distance between and the nearest sample of , so that at least one sample will lie within the kernel.
3.3 Evaluation of the log-likelihood using single-parameter variations
A simple test of the likelihood function and its inherent stochastic contributions can be done by repeatedly evaluating the likelihood of a simulated dataset for which the parameters are known and keeping all parameters but one at their respective true values (i.e., the values used in generating the data). Systematically varying the parameter under consideration reveals its impact on the likelihood. Since the likelihood function is composed of two terms from spatial and temporal contributions (Eq. 19), separating both components can also prove insightful with regard to the strength and direction of the parameter’s influence.
To investigate the properties of the likelihood function for a relevant subset of parameters, we simulated 1624 fixations on 114 sentences (Fig. 5) from the sentence corpus of Risse \BBA Seelig (\APACyear2019). The examined parameters are given in Table 3, with the remaining parameters set according to Table 2. The likelihood was then evaluated for 1000 different, evenly spaced values within the given interval (Table 3) separately for each parameter. Since all other parameters were fixed at their true values, any systematic change in the resulting log-likelihood can only be attributed to the parameter under consideration.
Figure 5a indicates that the saccade timer influences the temporal likelihood, while there is no influence on the spatial likelihood. A similar behavior is observed for the refixation factor (Fig. 5b). In both cases, there is a clear maximum in the likelihood profile at the true parameter values, ms and , resp. A different dependence can be seen for the processing span , which clearly influences the spatial likelihood (maximum at the true value ), but exerts only a minimal influence on the temporal likelihood (Fig. 5c). For the word-length exponent , there is an influence on both spatial and temporal likelihoods (Fig. 5d), with a maximum for both likelihood profiles at the true parameter value .
Thus, our numerical implementation of the likelihood function indicates clear maxima at the true parameter values for simulated data, while stochastic fluctuations due to the approximative account for internal degrees of freedom are small. In the next section, we will apply an adaptive MCMC framework for Bayesian parameter estimation using simulated and real (experimental) data.
4 Likelihood-based parameter inference using MCMC
With the implementation of the numerical computation of the likelihood function for the SWIFT model from the previous section, we developed the critical step for adopting the Bayesian framework for parameter inference. We will discuss the Markov Chain Monte Carlo approach used for inference, discuss the efficient implementation on a digital computer, present results for parameter recovery from simulated data with known parameters, and, finally, estimate parameters for experimental data.
4.1 Markov Chain Monte Carlo simulation for the SWIFT model
As described in Section 1.2, the computability of the likelihood , Eq. (1.2), for a given set of parameters and a given fixation sequence is critical for maximum-likelihood and Bayesian inference. For the numerical procedures of Markov Chain Monte Carlo type, we use a variant of the Metropolis Hastings (MH) algorithm (Hastings, \APACyear1970). In the random-walk MH algorithm, a random walk in the parameter space is generated, where the probability of the random-walk steps depends on the ratio of the likelihoods associated with the random walk’s current and proposed new positions.
Starting from an arbitrary initial point in parameter space, every move is determined by two steps:
A proposal is generated by a random-walk step from position ,
[TABLE]
where . Both the shape matrix and the width of the proposal distribution must be chosen beforehand and kept constant during a run of the algorithm. 2. 2.
The proposal is then accepted with the probability
[TABLE]
in which case , i.e. the walker moves to the proposed position. If the proposal is rejected, then the random walk remains at the current position .
By recursively following these rules the chain of accepted samples of the algorithm asymptotically converges to the true distribution of . However, the speed of convergence greatly depends on an optimal choice of both the shape matrix and the width parameter of the proposal distribution. Poor choices lead to abundant rejections (i.e. the chain is stationary most of the time if is chosen badly or is too large) or strong autocorrelations of the samples (i.e., movements are very small if is chosen too small, even if is optimal). Both parameters are however not known in advance and cannot be obtained due to analytical intractability of SWIFT model’s likelihood function.
Therefore, we used the Robust Adaptive Metropolis (RAM) algorithm by Vihola (\APACyear2012) which progressively captures the parameters’ covariance structure shape and at the same time attains a predefined acceptance rate (see Roberts \BOthers., \APACyear1997). The speed of the adaptation can also be specified parametrically. Although the RAM algorithm is a good strategy for parameter estimation, it is still computationally expensive, as exploration is naturally slow, if subsequent samples are dependent. Furthermore, it is necessary to use several independent chains with randomly dispersed initial values, each requiring a burn-in phase necessary for the sampler to progress to the vicinity of the stationary distribution.
An additional modification of the MCMC algorithm is necessary because of the stochastic pseudo-likelihood function of the SWIFT model. If, by chance, an exceptionally high log-likelihood value is obtained for a proposal, the acceptance rate for the subsequent proposal will be very low, which might stall the chain (Holmes, \APACyear2015). Therefore we re-evaluate for every iteration of the algorithm, which, however, doubles the computation time of the sampling.
To increase computational efficiency, we introduced parallel computation at two levels. First, while the likelihood of a fixation is dependent on all preceding fixations in the respective fixation sequence, likelihoods of whole fixation sequences can be computed independently from each other and added up later. This procedure enables computing the log-likelihood for independent fixation sequences in in parallel using a multi-core compute cluster. Second, different chains are independent of each other and can therefore be calculated in parallel as well.
4.2 Parameter recovery using simulated data
Before we demonstrate the application of the MCMC framework for the SWIFT model to experimental data, we investigate its performance for simulated data with known parameters. While we tested the likelihood function using single-parameter variation around the true value in Section 3.3, we now estimate all four selected parameters (Tab. 3) simultaneously using the MCMC procedure for the same dataset. We specified truncated normal distributions centered at parameter ranges (see Tab. 3). The standard deviation was set to one half of the estimation range in order to obtain an uninformative prior. We ran 5 independent chains with iterations each and the default adaptation parameter value of . The resulting marginal posterior distributions are given in Figure 6, where all true parameter values lie within the 40% highest posterior density interval (HPDI). The results suggest that the likelihood-based MCMC framework is very promising for parameter estimation based on data from single participants.
4.3 Estimation of parameters based on experimental data
In the next step, we estimated the same parameters for data from an eye tracking experiment. We used the control condition from a larger experimental study on parafoveal processing using the boundary paradigm (see Risse \BBA Seelig, \APACyear2019, for a detailed description of the boundary paradigm). We ran 10 chains per participant, each with 4,000 iterations. We used the last 2,000 samples (50%) after the burn-in to estimate the posterior density. The resulting marginal posterior densities for a single participant are plotted in Figure 8. While there is an increased variance in the posterior densities for the estimation using experimental data compared to the simulated data (Fig. 6), we observe clear convergence of the independent chains to a common posterior estimate. Since there is qualitative agreement for the results on simulated and experimental data, the method seems promising to investigate interindividual differences via parameter estimation, which is discussed in the next section.
4.4 Interindividual differences and model parameters
In this section we study interindividual differences in model parameters across 34 subjects that served as participants in the experiment by Risse \BBA Seelig (\APACyear2019). Figure 8 shows the posterior densities for all subjects, demonstrating considerable interindividual differences over the model parameters , , and , whereas estimates of fall close to zero.
A critical question is how much of the differences in reading behavior could be explained by the estimated differences in model parameters. Therefore, we used the maximum a posteriori (MAP) estimator (i.e. the mode) of the pooled chains for each subject as input parameters for the generative model and created a simulated data set that corresponds to the experimental data.
Fixation durations. For both the experimental and the artificial data, we calculated participant-wise averages in different measures of fixation durations. Specifically we compared durations of single fixations (SFD; when the word was fixated only once in first-pass), first fixations (FFD; when the word was fixated once or more in first-pass), refixations (RFD; the second fixation on words, which were fixated more than once consecutively in first-pass), gaze durations (GD; the total time spent on a word in first-pass) and total viewing time (TVT; the total time spent on a word regardless of first, second or more passes). The results (Fig. 10a) indicate a remarkably good fit between the experimental data and model predictions for individual participants for RFD and GD. Mean FFD and SFD generated by the model tend to be slightly underestimated for participants with longer initial fixations. Mean TVT, however, is higher in the model predictions than in the experiment. It is important to note that the TVT measure captures more complex gaze behavior, since it also incorporates additional fixation time due to regressions.
Fixation probabilities. Similar to the analysis of fixation durations, we calculated word-based probabilities for single fixations (SF), refixations (RF), regressions (RG), and word skipping (SK) (Fig. 10b). While in the experiment words are more likely to receive single fixations as compared to the simulated data, they consequently have a lower probability of receiving refixations. Additionally, the model predicts higher skipping probabilities and also higher probabilities of serving as regression target. It should be noted that the mismatch between experimental and simulated regression probabilities and experimental and simulated TVT (discussed above) is closely related. In general, part of the regressions might be looked upon as a more complicated psycholinguistic measure related to various aspects of post-lexical processing (Rayner, \APACyear1998) that cannot be captured in the SWIFT model, while another portion of the regressions might be of oculomotor origin and can be found even in scanning tasks (Nuthmann \BBA Engbert, \APACyear2009).
In summary, our results indicate that estimated parameters can explain some of the interindividual differences in fixation durations and fixation probabilities. Thus, the likelihood-based MCMC approach to parameter inference could be applied successfully to estimate model parameters from individual behavioral data.
5 Discussion
Current approaches to parameter inference and model comparison (e.g., Reichle \BOthers., \APACyear2003) for dynamical cognitive models are insufficient in at least three ways: First, dynamical models need to be tested against time-ordered observations. Second, a likelihood-based procedure is necessary for statistical inference. Third, parameter estimates are needed for individual subjects to explain interindividual differences based on specific model assumptions or components. We set out to solve these three issues in current modeling in computational cognitive science using the SWIFT model of eye-movement control during reading (Engbert \BOthers., \APACyear2005) as a case study.
The approach discussed here is fundamentally based on the likelihood function of the model. Therefore, we proposed and investigated the numerical likelihood computation of the SWIFT model. This approach is based on the observation that incremental prediction of fixation positions and fixation durations by the generative model can be exploited to determine the likelihood of the next fixation.
Since the likelihood can be decomposed into a spatial (i.e., fixation position) and a temporal part (i.e., fixation duration), we tried to find separate solutions to both problems. In the spatial part of the likelihood function, internal degrees of freedom (stochastic internal states) could not be integrated out due to numerical efficiency considerations; therefore, we computed a (stochastic) pseudo-likelihood (see Andrieu \BBA Roberts, \APACyear2009). In the temporal part, the theoretical likelihood function was unavailable. Therefore, we constructed an approximate likelihood function using a sufficient number of predicted fixation durations from the SWIFT model and KDE for the approximation of the likelihood. In sum, we combined a pseudo-marginal spatial likelihood and an approximated pseudo-likelihood (see Holmes, \APACyear2015, for nomenclature) function to obtain the likelihood function of the model (Sisson \BBA Fan, \APACyear2011).
Before we applied our framework to real data, we demonstrated that, in a simplified model version with 4 free parameters, we could reconstruct the true parameter values from simulated data. We used a Bayesian approach using MCMC sampling from the posterior distribution based on an adaptive sampling algorithm (Vihola, \APACyear2012). The size of the simulated data-set was comparable to a typical experimental data set that is recorded from an individual participant during a one-hour session of eye-tracking experimentation. Next, the same procedure was applied to experimental data. Motivated by the results from simulated data, we estimated model parameters independently for 34 subjects.
Finally, our results indicate that it is possible to relate interindividual differences in reading behavior (characterized by 5 different measures of fixation durations and 4 different measures of fixation probabilities) to differences in the estimated model parameters. Given the typical state-of-the-art models of eye-movement control in reading, this is a major step for generating hypotheses on the observed interindividual differences in a task as complex as reading.
Throughout the current work, we focused on the numerical implementation of the likelihood function for the SWIFT model. Since likelihood-based Bayesian inference turned out to be a viable and sound alternative to ad-hoc parameter estimation procedures, we expect that our approach can be further advanced for both theory building and modeling of interindividual differences. For example, for higher dimensional parameter spaces Differential Evolution MCMC algorithms (see, e.g., ter Braak, \APACyear2006; ter Braak \BBA Vrugt, \APACyear2008; Laloy \BBA Vrugt, \APACyear2012) might be more adequate. Additionally, we expect that a hierarchical Bayesian design will help to increase the stability of the posterior estimates for individual subjects—even if we apply our methods to data sets smaller than used in the current work.
Acknowledgments
This work was supported by grants from Deutsche Forschungsgemeinschaft (SFB 1294, project B03 to R.E. and S.Re.; SFB 1287, project B03 to R.E. and Shravan Vasishth; grant RI 2504/1-1 to S.Ri.). We acknowledge a grant for computing time from Norddeutscher Verbund für Hoch- und Höchstleistungsrechnen (HLRN, grant bbx00001).
Appendix: Experimental data and sentence material
All eye-tracking data used in our simulation studies originate from Risse \BBA Seelig (\APACyear2019), who collected data for an experiment that was a version of the boundary paradigm (Rayner, \APACyear1975) to investigate effects of parafoveal word difficulty on fixation durations and distinguish them from preview benefit effects (see Vasilev \BBA Angele, \APACyear2017, for a comprehensive review). Their data is available online at 10.17605/OSF.IO/KZ483.
In the experiment, 34 participants, mostly students of psychology at the University of Potsdam, read 114 single sentences presented on a computer screen while their eyes were being tracked. The simple structured German sentences consisted of six to 12 words with an average length of 9 words. Every sentence contained a gaze contingent invisible boundary before a specific target word. Before the eyes crossed the boundary, the preview of the target word could either be of low, high or medium frequency (i.e. high, low or medium difficulty respectively). During the saccade in which the boundary was crossed, the target word was always exchanged with the medium frequency word. Word frequencies were taken from the dlexDB database (Heister \BOthers., \APACyear2011) based on The DWDS corpus: A reference corpus for the German language of the 20th century (Geyken, \APACyear2007).
Data treatment and preprocessing. The data were collected using an Eyelink II System (SR Research, Osgoode/Ontario, Canada) with a temporal resolution of 1,000 Hz. Since spatial resolution was preprocessed to letter accuracy. Within-letter position was randomized by added small random numbers to avoid artifacts from discretization. Basically, the data used here were treated by the same preprocessing as reported in the statistical analysis of the experiment. Additionally, fixation durations smaller than 25 ms were discarded (550 fixations in 338 trials). Trials that included fixation durations larger than 1,000 ms were discarded (45). Trials consisting of less than three fixations were also removed from the data-set. Additionally, re-readings signaled by regressions starting from the second last or last word of the sentence and all subsequent fixations were discarded (5,773 fixations). After preprocessing, 30,639 fixations from 3,422 trials were included in the data-set for estimation. The implementations of the model, the estimation algorithm, and scripts for analyses and plots, along with the corpus data and fixation sequences are available at 10.17605/OSF.IO/XDKWQ.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1S \BHBI i. Amari ( \APA Cyear 1977) \APA Cinsertmetastar Amari 1977 {APA Crefauthors} Amari, S \BHBI i. \APA Cref Year Month Day 1977. \BBOQ \APA Crefatitle Dynamics of pattern formation in lateral-inhibition type neural fields Dynamics of pattern formation in lateral-inhibition type neural fields. \BBCQ \APA Cjournal Vol Num Pages Biological Cybernetics 27277–87. \Print Back Refs \Current Bib
- 2S \BPBI V. Amari \BBA Misra ( \APA Cyear 1997) \APA Cinsertmetastar Amari 1997 {APA Crefauthors} Amari, S \BPBI V. \BCBT \BBA Misra, R \BPBI B. \APA Cref Year Month Day 1997. \BBOQ \APA Crefatitle Closed-form expressions for distribution of sum of exponential random variables Closed-form expressions for distribution of sum of exponential random variables. \BBCQ \APA Cjournal Vol Num Pages IEEE Transactions on Reliability 464519–522. \Print Back Refs \Current Bib
- 3Andrieu \BBA Roberts ( \APA Cyear 2009) \APA Cinsertmetastar Andrieu 2009 {APA Crefauthors} Andrieu, C. \BCBT \BBA Roberts, G \BPBI O. \APA Cref Year Month Day 20094. \BBOQ \APA Crefatitle The pseudo-marginal approach for efficient Monte Carlo computations The pseudo-marginal approach for efficient monte carlo computations. \BBCQ \APA Cjournal Vol Num Pages The Annals of Statistics 372697–725. {APA Cref URL} https://doi.org/10.1214/07-AOS 574 {APA Cref DOI} \doi 10.1214/07-AOS 57 · doi ↗
- 4Becker \BBA Jürgens ( \APA Cyear 1979) \APA Cinsertmetastar Becker 1979 {APA Crefauthors} Becker, W. \BCBT \BBA Jürgens, R. \APA Cref Year Month Day 1979. \BBOQ \APA Crefatitle An analysis of the saccadic system by means of double step stimuli An analysis of the saccadic system by means of double step stimuli. \BBCQ \APA Cjournal Vol Num Pages Vision Research 199967–983. \Print Back Refs \Current Bib
- 5Beer ( \APA Cyear 2000) \APA Cinsertmetastar Beer 2000 {APA Crefauthors} Beer, R \BPBI D. \APA Cref Year Month Day 2000. \BBOQ \APA Crefatitle Dynamical approaches to cognitive science Dynamical approaches to cognitive science. \BBCQ \APA Cjournal Vol Num Pages Trends in Cognitive Sciences 4391–99. \Print Back Refs \Current Bib
- 6Busemeyer \BBA Townsend ( \APA Cyear 1993) \APA Cinsertmetastar Busemeyer 1993 {APA Crefauthors} Busemeyer, J \BPBI R. \BCBT \BBA Townsend, J \BPBI T. \APA Cref Year Month Day 1993. \BBOQ \APA Crefatitle Decision field theory: a dynamic-cognitive approach to decision making in an uncertain environment. Decision field theory: a dynamic-cognitive approach to decision making in an uncertain environment. \BBCQ \APA Cjournal Vol Num Pages Psychological Review 1003432. \Print Back Refs \Current
- 7Coelho ( \APA Cyear 1998) \APA Cinsertmetastar Coelho 1998 {APA Crefauthors} Coelho, C \BPBI A. \APA Cref Year Month Day 1998. \BBOQ \APA Crefatitle The generalized integer Gamma distribution—a basis for distributions in multivariate statistics The generalized integer gamma distribution—a basis for distributions in multivariate statistics. \BBCQ \APA Cjournal Vol Num Pages Journal of Multivariate Analysis 64186–102. \Print Back Refs \Current Bib
- 8Engbert \BBA Kliegl ( \APA Cyear 2011) \APA Cinsertmetastar Engbert 2011 {APA Crefauthors} Engbert, R. \BCBT \BBA Kliegl, R. \APA Cref Year Month Day 2011. \BBOQ \APA Crefatitle Parallel graded attention models of reading Parallel graded attention models of reading. \BBCQ \B In S \BPBI P. Liversedge, I \BPBI D. Gilchrist \BCBL \BBA S. Everling ( \BEDS ), \APA Crefbtitle Oxford Handbook of Eye Movements Oxford Handbook of Eye Movements ( \BPGS 787–800). \APA Caddress Publisher