Spatial Soft-Core Caching
Derya Malak, Muriel M\'edard, Edmund Yeh

TL;DR
This paper introduces a decentralized spatial soft-core cache placement policy for wireless networks that improves cache efficiency and supports proximity-based applications by balancing cache diversity and size constraints.
Contribution
The paper presents a novel spatial soft-core cache placement method that achieves high cache efficiency and can be tuned for cache size constraints in wireless networks.
Findings
SSCC provides up to 180% cache size savings compared to independent placement.
SSCC achieves over 100% savings compared to hard-core placement.
It enables effective proximity-based applications like D2D and P2P networking.
Abstract
We propose a decentralized spatial soft-core cache placement (SSCC) policy for wireless networks. SSCC yields a spatially balanced sampling via negative dependence across caches, and can be tuned to satisfy cache size constraints with high probability. Given a desired cache hit probability, we compare the 95% confidence intervals of the required cache sizes for independent placement, hard-core placement and SSCC policies. We demonstrate that in terms of the required cache storage size, SSCC can provide up to more than 180% and 100% gains with respect to the independent and hard-core placement policies, respectively. SSCC can be used to enable proximity-based applications such as device-to-device communications and peer-to-peer networking as it promotes the item diversity and reciprocation among the nodes.
Click any figure to enlarge with its caption.
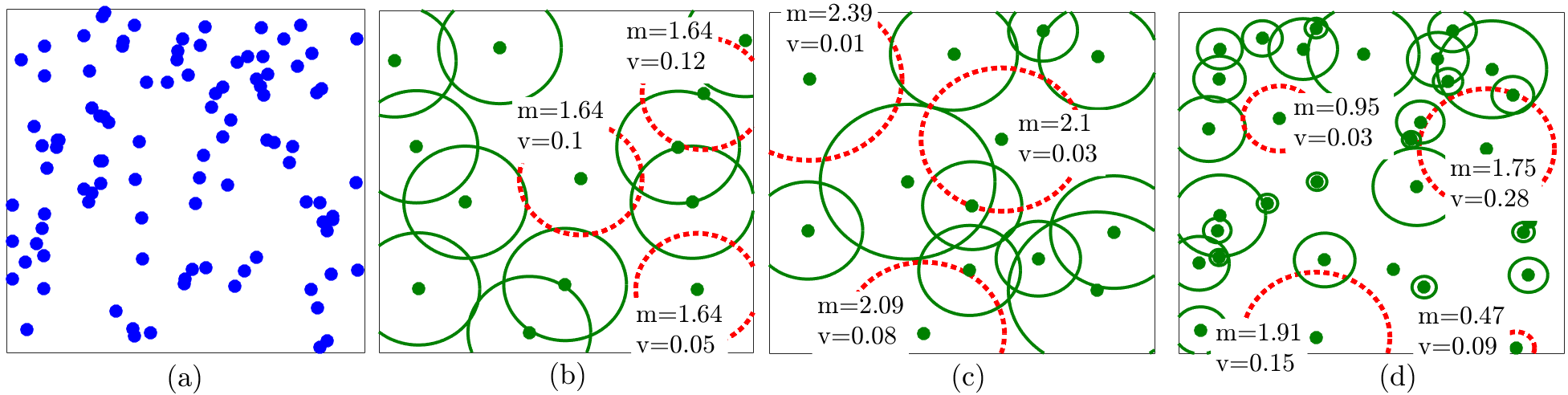 Figure 1
Figure 1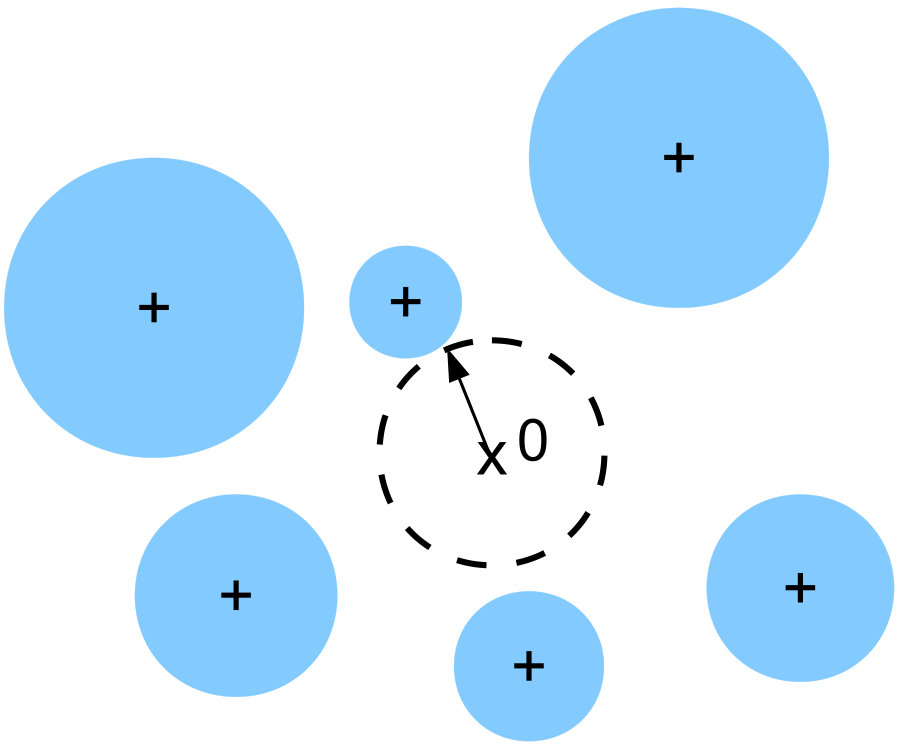 Figure 2
Figure 2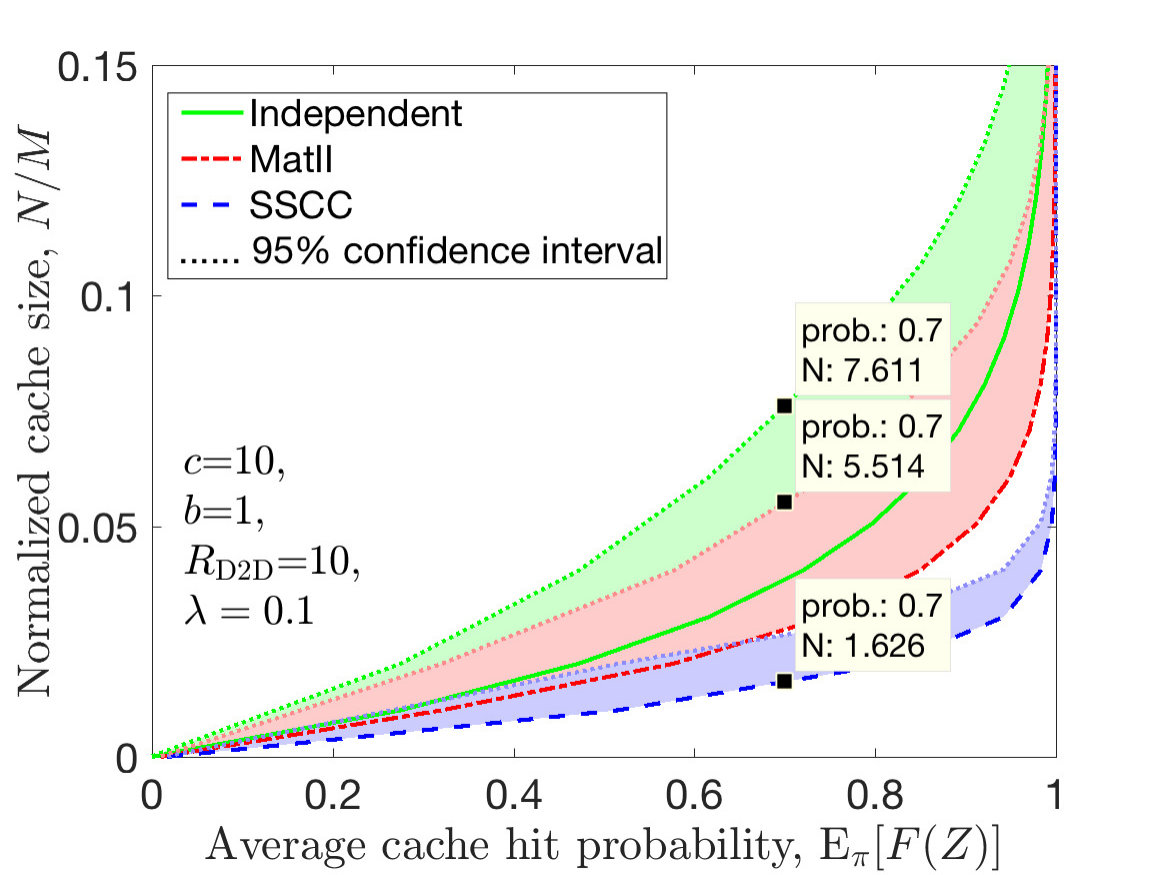 Figure 3
Figure 3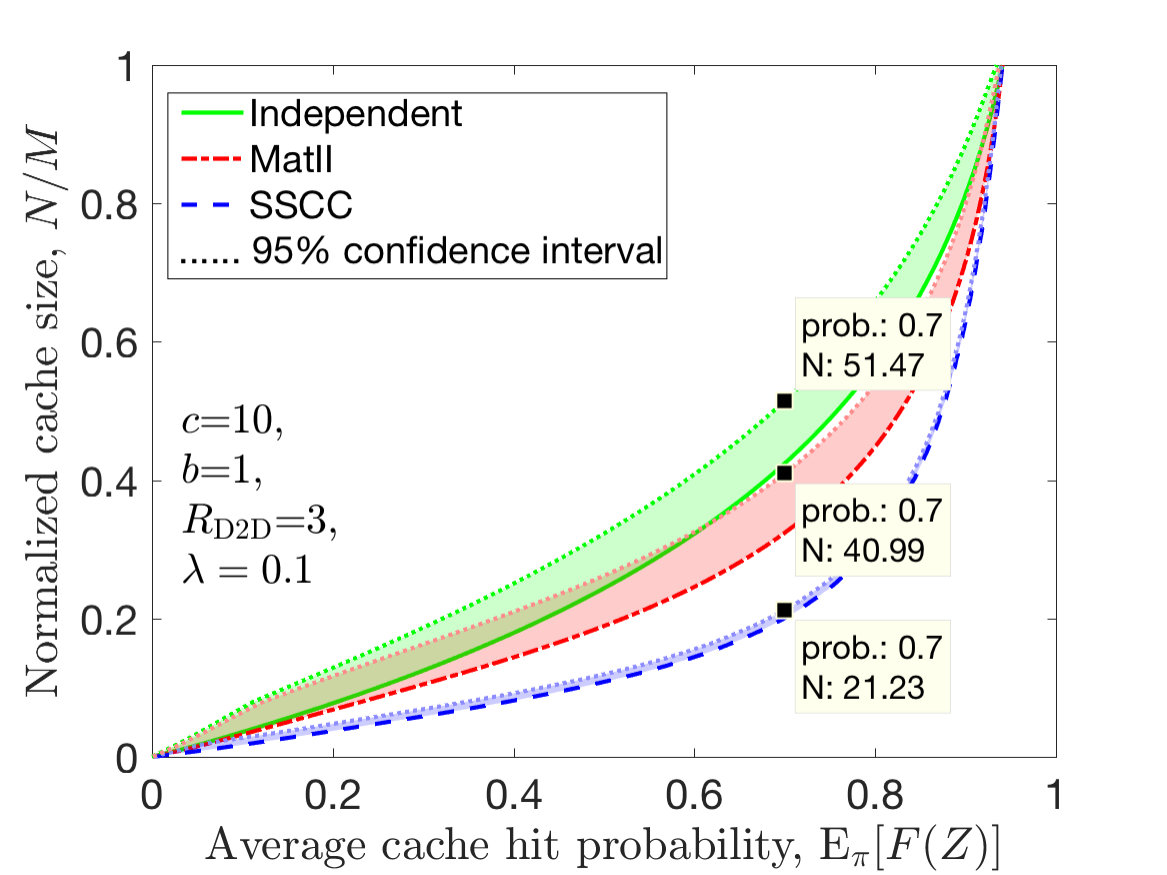 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Spatial Soft-Core Caching
Derya Malak and Muriel Médard
Research Laboratory of Electronics, MIT, Cambridge, MA, USA
Email: {deryam, medard}@mit.edu
Edmund M. Yeh
Northeastern University, Boston, MA, USA
Email: [email protected]
Abstract
We propose a decentralized spatial soft-core cache placement (SSCC) policy for wireless networks. SSCC yields a spatially balanced sampling via negative dependence across caches, and can be tuned to satisfy cache size constraints with high probability. Given a desired cache hit probability, we compare the 95% confidence intervals of the required cache sizes for independent placement, hard-core placement and SSCC policies. We demonstrate that in terms of the required cache storage size, SSCC can provide up to more than 180% and 100% gains with respect to the independent and hard-core placement policies, respectively. SSCC can be used to enable proximity-based applications such as device-to-device communications and peer-to-peer networking as it promotes the item diversity and reciprocation among the nodes.
I Introduction
Distributed caching is a powerful technique to minimize the total average delay by replacing the backhaul capacity with storage capacity at small cells [1], and to enable spectral reuse and throughput gain in networks [2]. The goal of an efficient cache placement is to maximize the hit probability, i.e. the probability of obtaining the desired item from a neighboring cache. This is affected by the demand distribution, network topology, range of communication, and cache storage size.
Fundamental limits of caching have been studied in [2], in which the content placement phase is carefully designed so that a single coded multicast transmission can satisfy different demands. Capacity scaling laws have been explored in [2], and rate-memory and storage-latency tradeoffs have been studied in [3]. Caching has been studied in the context of device-to-device (D2D) communications in [4], and interference management in [5], and in optimization of cloud and edge processing for radio access networks in [6].
Temporal caching models have been analyzed in [7] for popular cache replacement algorithms, e.g. least recently used (LRU), least-frequently used, and most recently used cache update. Decentralized spatial LRU caching strategies have been developed in [8]. These combine the temporal and spatial aspects of caching, and approach the performance of centralized policies as the coverage increases. However, they are restricted to the LRU principle. A time-to-live (TTL) policy with a stochastic capacity constraint and low variance has been proposed in [9]. The BitTorrent protocol employs the rarest first and choke algorithms to promote diversity of the pieces among peers, and foster reciprocation, respectively. These have been demonstrated in the context of peer-to-peer (P2P) file replication in the Internet [10]. A good piece replication algorithm should minimize the time spent in the transient state.
There exist studies focusing on decentralized (geographic) content placement policies such as [1], [11], [12], [13]. The main focus of the literature in this direction is to maximize the average cache hit probability subject to an average cache constraint. This optimization problem can be solved as a convex program. However, to the best of our knowledge, the related literature does not provide guarantees in terms of (a) how far-off the average cache size is from reality, (b) how far-off the average cache hit rate is from reality, and (c) how stable the cache hit probability across the caches.
In the current paper, we provide a decentralized spatial soft-core cache placement (SSCC) policy. Since the cache storage size is finite, it is intuitive to have an exclusion range-based caching model such that the caches storing the same item are never closer to each other than some given distance (negative dependence), so as to promote diversity and reciprocation. SSCC roots in spatially balanced sampling, which is motivated by the request arrivals. For example, in P2P networking, the actual demand distribution is not known by nodes, and the cache updates in each peer are triggered by the requests. Furthermore, the traffic density in cellular networks is in general not uniform across the network, and the peak hour density can be approximated by a log-normal distribution [14]. Hence, instead of having a fixed exclusion range, it is desirable to have a variable exclusion range, depending on the popularity of the item. The SSCC policy come to the fore by putting a mark distribution on the exclusion range of an item based on its popularity. The marks may correspond to the detection ranges or the transmit powers of the nodes in heterogeneous network scenarios. Our objective is to address the issues (a)-(c) above in order to provide a better trade-off between the actual cache hit rate and the cache size violation probability. Our main contributions and use cases of SSCC are:
- i.
SSCC has desirable properties: spatially balanced sampling across caches, concentration of the cache size, better cache over-provisioning, and multi-hop connectivity. 2. ii.
SSCC yields a better cache hit probability-cache violation probability tradeoff than the state of the art. In terms of the required cache storage size, SSCC can provide more than 180% and 100% gains with respect to independent placement [11], and hard-core placement [13], respectively. 3. iii.
SSCC is suited for enabling proximity-based applications (D2D, P2P), and offloading mobile users in networks. 4. iv.
SSCC has connections with rarest first caching as it promotes the item diversity and reciprocation among the nodes. Hence, it can be well-suited for P2P applications.
Notation. Let denote the mother point process (p.p.), and be the child p.p. obtained via the thinning of . Let be a spatial caching policy that yields a set of child p.p.’s , where is the set of retained points that cache item . Let be a given bounded convex set in containing the origin, and be its dilation by the factor . is the indicator of event . Let be a bounded Borel set. Let be the random number of points of the spatial p.p. which lie in . Any receiver can obtain the desired item if it is within a critical communication range . Assume that , where is a ball in with radius , centered at origin.
II How to Optimize the Caching Gain
The locations of the nodes (caches) in the network are modeled by a homogeneous Poisson point process (PPP) in with intensity . There are items in the network, each having the same size, and each node has the same cache storage size . Each user makes requests based on a Zipf popularity distribution over the set of the items. The probability mass function (pmf) of such requests (demand) is given by p_{r}(i)=i^{-\gamma_{r}}\big{/}\sum\nolimits_{j=1}^{M}{j^{-\gamma_{r}}}, where determines the tilt of the Zipf distribution. The demand profile is the Independent Reference Model (IRM), i.e., the standard synthetic traffic model in which the request distribution does not change over time [15]. The request distribution is uniform across the network, i.e., isotropic, and does not change over time. Hence, the intensity of the requests for item , i.e. , is proportional to its demand probability . Let be the random variable that models the demand. Each node is associated with the variables that denote whether item is available in its cache or not. There is also a cost associated with obtaining an item within the presence of nodes in the range. Given these parameters, consider the caching gain function of the following form:
[TABLE]
where (1) can be used to model multi-hop coverage scenarios as in [12], and Boolean Model coverage scenarios as in [11], [13]. Let , and , which is the probability that caches (nodes of the original p.p. ) cover the typical receiver, and is the probability of having no connection. Assume that is the first index such that a transmitter has the desired item . Then, from (1), the caching gain for item is , which is the same as probability of having at least transmitters. Equivalently, the cost of caching is .
Since both the multi-hop and Boolean coverage scenarios are equivalent up to scaling, we focus on the second scenario.
We have the following immediate observation.
Proposition 1**.**
* is convex if ’s are negatively associated (NA) [16] across , for all .*
Proof.
Exploiting (1), we have the following relation: \mathbb{E}[F(Z)]=\mathbb{E}_{\mathcal{I}}\left[\sum\nolimits_{k=0}^{\infty}w_{k}{\Big{(}1-\mathbb{E}\Big{[}\prod\nolimits_{k^{\prime}=1}^{k}\big{(}1-z_{p_{k^{\prime}}\mathcal{I}}\big{)}\Big{]}\Big{)}}\right]\overset{(a)}{\geq}\mathbb{E}_{\mathcal{I}}\left[\sum\nolimits_{k=0}^{\infty}w_{k}{\Big{(}1-\prod\nolimits_{k^{\prime}=1}^{k}\big{(}1-\mathbb{E}[z_{p_{k^{\prime}}\mathcal{I}}]\big{)}\Big{)}}\right]=F(\mathbb{E}[Z]), where is due to that \mathbb{E}\Big{[}\prod\nolimits_{k^{\prime}=1}^{k}\big{(}1-z_{p_{k^{\prime}}i}\big{)}\Big{]}\leq\prod\nolimits_{k^{\prime}=1}^{k}\big{(}1-\mathbb{E}[z_{p_{k^{\prime}}i}]\big{)} as ’s are NA across , . ∎
From Prop. 1, . The expected cache hit probability obtained via NA placement upper bounds the independent placement solution with probabilities . NA has desirable properties in terms of sampling and concentration. Some important results that hold for independent variables, e.g., the Chernoff-Hoeffding bounds, and the Kolmogorov’s inequality [16], also hold for NA variables.
From Prop. 1, it is clear that in terms of average cache hit performance, NA placement performs better than independent placement. Therefore, our main focus is on a class of placement policies that are NA. We also demonstrate that NA placement policies have lower variance across the nodes, hence are more stable than independent placement policies.
III A Soft-Core Caching Model
The spatial soft-core caching (SSCC) policy is constructed from the underlying PPP by removing certain nodes depending on the positions of the neighboring nodes, and on the marks and weights attached to them. It generalizes the Matérn II hard-core p.p. (MatII) such that there is a distinct distribution modeling the exclusion radius of each item.
For each item , let be a homogeneous independently marked PPP with intensity , and i.i.d. -valued marks, where , and is the random bivariate mark. The first component of the bivariate mark is referred to as mark, and has distribution . The mark of item , i.e., , denotes its exclusion radius, and depends on its popularity in the network. If item is more popular than item , then is stochastically dominated111 is stochastically dominated by , which is denoted by , if for all increasing functions , we have . by . The second component of the bivariate mark is weight, which serves as a weight in the thinning procedure, and has distribution which might depend on .
Let be a soft-core p.p. that denotes the set of points that cache item . The cache placement model is such that item is stored in cache if and only if cache is kept as a point of . Equivalently, we have
[TABLE]
Node is retained as a point of with probability . The weights are i.i.d. and uniformly distributed, i.e. , for each node and item . The marks are distributed according to for each , and . For the special case of MatII, i.e., when the marks are fixed, we optimized the exclusion radii in [13].
The number of items in cache is the sum of the individual items’ indicator functions . The cache size constraint has to be satisfied on average, i.e.
[TABLE]
We next detail the dependent thinning procedure, and investigate the relationship between and , .
III-A Dependent Sampling of Nodes for Placement
In this section and onwards, for brevity of notation, we omit the index , and consider the generic thinned process , which is derived from by applying the following probabilistic dependent thinning rule. Assume that mark has a distribution , and is the set of marks for all points in , where and . Assume that weight does not depend on the mark . The marked point is retained as a point of with probability
[TABLE]
independently from deleting or retaining other points of . In other words, a node is retained to cache item with probability , if it has the lowest weight among all the points within its exclusion range. In (4), , is a deterministic function satisfying for all . This means that if two points with marks and , and weights are a distance apart, then the point with weight is deleted by the other point with probability . Additionally, each surviving point is then again independently -thinned. The function in (4) should be determined according to (3). Inspired from [17], assume that satisfies
[TABLE]
Denote by SSCC the distribution of . We next give its intensity, i.e., .
Theorem 1**.**
[17, Theorem 12]** The intensity of the process SSCC is given by
[TABLE]
where is the cumulative distribution function of .
Proof.
The probability generating functional (PGFL) [18] of the PPP states for function that \mathbb{E}\left[\prod\nolimits_{x\in\Phi}f(x)\right]=\exp\big{(}-\lambda\int\nolimits_{\mathbb{R}^{2}}(1-f(x)){\rm d}x\big{)}. We obtain using the PGFL and , along with (4). ∎
In Fig. 1, we plot different realizations of SSCC formed by thinning . As the mark variance increases, the packing is denser, which is desired for spatially balanced caching.
III-B Spherical Contact Distribution Function
Our goal in this section is to relate the cache hit probability distribution to the (spherical) contact distribution function.
Definition 1**.**
The spherical contact distribution function (SCDF) of the p.p. is the conditional distribution function of the distance from a point chosen randomly outside (i.e. [math]), to the nearest point of given [18]. It is given by
[TABLE]
where , where , and is the dilation of the set by the factor .
As an example, in Fig. 2 we show the SCDF for the Boolean model with random spherical grains in [19, Ch. 3.1].
Theorem 2**.**
The average cache hit probability of policy is
[TABLE]
where is the SCDF of the thinned p.p. for .
Proof.
Let and be the number of transmitters containing item within a circular region of radius around the origin. Then we have
[TABLE]
The average cache hit probability is given by , where defining , given we have that
[TABLE]
which is the SCDF of evaluated at . ∎
The variance of across the nodes satisfies
[TABLE]
since the spatial thinning processes across different items are independent of each other. Under the IRM and a Zipf popularity model, decreases with increasing variance of marks when is held constant. A spatially balanced sampling yields a low as expected.
III-C Migration to the Child Process: Effective Thinning
Consider the pair of mother and child p.p.’s. The spherical contact distance denotes the distance between a typical point in and its nearest neighbor from .
Using (7), the SCDF for the p.p. can be written as:
[TABLE]
where is the conditional thinning Palm-probability (CTPP), i.e. the probability of the point migrating to under policy , with a fixed (exclusion) radius . It equals
[TABLE]
Remark 1**.**
An effective thinning policy yields a larger CTPP . The more effective the thinning is, the larger (11) is. From Theorem 2, is improved if is more effective.
We next compute the CTPP for the SSCC policy.
Proposition 2**.**
The CTPP for PPP-SSCC is given as
[TABLE]
where given radius marks , satisfies the relation , where is the area of the intersection of and .
Proof.
The proof follows from generalizing [20, Eq. (15)]. ∎
Corollary 1**.**
The CTPP for PPP-MatII is given as
[TABLE]
The next Theorem shows that having a distribution on the marks yields a more effective thinning than MatII does.
Theorem 3**.**
The CTPPs satisfy , where is the set of marks in , with , .
Proof.
From Prop. 2, we have that
[TABLE]
where , and q(\lambda,r,m)=\lambda\pi\big{(}m^{2}+2m\bar{m}_{2}\big{)}+\lambda\mathbb{E}_{m_{2}}\big{[}\pi m_{2}^{2}-l_{2}(r,m_{2})\big{]}. Let , . We have, , with . Then , . Hence, . ∎
Exploiting Theorem 3, can be improved using a mixture of marks. The variable exclusion range model can suit to the case of cellular networks where demand is not uniform across the network [14], which we left as future work.
III-D Cache Over-Utilization
The cache placement requires , for all , where is finite. The storage constraint is satisfied on average, i.e. , . However, the set of child p.p.’s , might overlap. We need to make sure that the cache capacities are not over-utilized. Hence, the intersection of the sampled processes, i.e. , should not include any more than times with high probability. We next provide an upper bound for the violation probability of the cache size for SSCC.
Proposition 3**.**
Bernstein bound for cache size.* The cache violation probability is upper bounded as*
[TABLE]
where since the placement is independent across items, where , for , .
Proof.
It follows from employing Bernstein inequality since are independent -[math] random variables across . ∎
As drops, the bound in (13) becomes lower. Hence, the cache violation probability is negligible if the cache placement strategy has very low-variance. In Sect. IV, we demonstrate that SSCC has very small violation probability.
For the spatially independent placement policy in [11], where nodes are sampled i.i.d., authors have proposed a probabilistic placement technique to guarantee that the cache constraint is satisfied with equality. However, in SSCC, nodes are not sampled independently. Because the placement policy is NA across the nodes, it is nontrivial to design probabilistic placement techniques to satisfy the cache size constraint. In this section, we discuss how to bound the violation probability, and demonstrate in Sect. IV that for SSCC the cache violation probability can be made negligibly small.
IV Numerical Simulations
The nodes live in a square region of the Euclidean plane with area where . To avoid edge effects, we evaluate the performance only for the middle square region with area . The network parameters are and . The request process is isotropic and Zipf distributed with parameter over items.
For MatII, there is a fixed exclusion range for a given item, and we have derived the optimal exclusion radii in [13]. Let be the optimized exclusion range for item for MatII. For SSCC, we assume that the marks for item (exclusion radii) are distributed according to a gamma distribution for each , and all items , where we choose its parameters such that the average value of the radius mark for item equals . Hence, SSCC. We can observe that the SSCC model can be used to optimize the cache hit probability-cache violation probability tradeoff. As variance of exclusion range increases, the violation probability might also increase for a desired cache hit probability. Note that we do not optimize the distributions of the marks across all over a class of distributions. We leave the study of the fundamental performance limits of SSCC as future work.
We numerically investigate how much cache over-provisioning is required for different spatial cache placement policies: spatially independent [11], MatII [13], and SSCC cache placement. In Fig. 3, we investigate the required cache size (normalized) of each policy given that the probability of cache violation is small such that in order to characterize the required cache size for a given average cache hit probability. We also illustrate the confidence intervals represented by the shaded regions, and mark the cache sizes for different policies when the average cache hit probability is . For example, when , for the confidence interval, the excess cache ratio for independent placement in [11], and MatII placement in [13] with respect to the SSCC policy is , and , respectively. When we have , the respective excess ratios for the independent and MatII placement policies are , and , which are illustrated on the plots. SSCC yields a better concentration of the required cache size, which is desired. Hence, policies like SSCC can be exploited so that the cache does not overrun or underrun its capacity constraint.
SSCC gives insights into not only how to cache the content, but also how to effectively sample in spatial settings. SSCC is suited for enabling applications such as D2D and P2P as it promotes the item diversity and reciprocation. Extensions include the incorporation of the spatial variation of the demand. They also include employing the exclusion based models to optimize the performance of time-to-live (TTL) caches.
Acknowledgment
We thank Salman Salamatian for helpful discussions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] N. G. K. Shanmugam, A. G. Dimakis, A. F. Molisch, and G. Caire, “Femto Caching: Wireless content delivery through distributed caching helpers,” IEEE Trans. Inf. Theory , vol. 59, no. 12, pp. 8402–13, Dec. 2013.
- 2[2] M. A. Maddah-Ali and U. Niesen, “Fundamental limits of caching,” IEEE Trans. Inf. Theory , vol. 60, no. 5, pp. 2856–67, May 2014.
- 3[3] Q. Yu, M. A. Maddah-Ali, and A. S. Avestimehr, “The exact rate-memory tradeoff for caching with uncoded prefetching,” IEEE Trans. Inf. Theory , vol. 64, no. 2, pp. 1281–1296, 2018.
- 4[4] M. Ji, G. Caire, and A. F. Molisch, “Fundamental limits of caching in wireless D 2D networks,” IEEE Trans. Inf. Theory , vol. 62, no. 2, pp. 849–869, Feb. 2016.
- 5[5] M. A. Maddah-Ali and U. Niesen, “Cache-aided interference channels,” in Proc., IEEE Int. Sym. Inf. Theory . IEEE, 2015, pp. 809–813.
- 6[6] S.-H. Park, O. Simeone, and S. Shamai, “Joint optimization of cloud and edge processing for fog radio access networks,” in Proc., IEEE Int. Sym. Inf. Theory , 2016, pp. 315–319.
- 7[7] H. Che, Y. Tung, and Z. Wang, “Hierarchical web caching systems: Modeling, design and experimental results,” IEEE J. Sel. Areas Commun. , vol. 20, no. 7, pp. 1305–14, Sep. 2002.
- 8[8] A. Giovanidis and A. Avranas, “Spatial multi-LRU caching for wireless networks with coverage overlaps,” in Proc., ACM Sigmetrics/IFIP Performance , Antibes, France, Jun. 2016, pp. 403–405.