Gaussian Process Regression for Derivative Portfolio Modeling and Application to CVA Computations
St\'ephane Cr\'epey, Matthew Dixon

TL;DR
This paper introduces a multi-Gaussian process regression method for efficient and accurate valuation of OTC derivative portfolios in CVA calculations, avoiding nested simulations.
Contribution
The paper develops a Gaussian process metamodel for derivative portfolios, enabling fast CVA computation without nested simulation or cash flow regression.
Findings
High accuracy in CVA estimation demonstrated
Convergence properties validated through numerical experiments
Effective modeling of risk factors with Gaussian processes
Abstract
Modeling counterparty risk is computationally challenging because it requires the simultaneous evaluation of all the trades with each counterparty under both market and credit risk. We present a multi-Gaussian process regression approach, which is well suited for OTC derivative portfolio valuation involved in CVA computation. Our approach avoids nested simulation or simulation and regression of cash flows by learning a Gaussian metamodel for the mark-to-market cube of a derivative portfolio. We model the joint posterior of the derivatives as a Gaussian process over function space, with the spatial covariance structure imposed on the risk factors. Monte-Carlo simulation is then used to simulate the dynamics of the risk factors. The uncertainty in portfolio valuation arising from the Gaussian process approximation is quantified numerically. Numerical experiments demonstrate the accuracy…
Click any figure to enlarge with its caption.
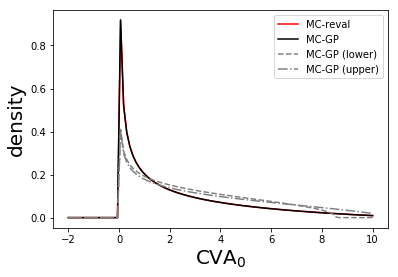 Figure 1
Figure 1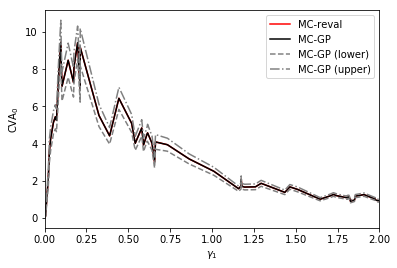 Figure 2
Figure 2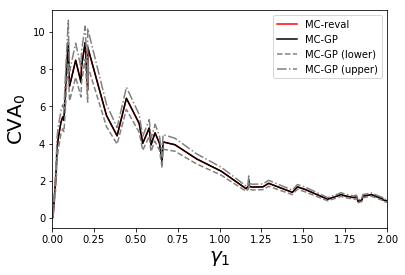 Figure 3
Figure 3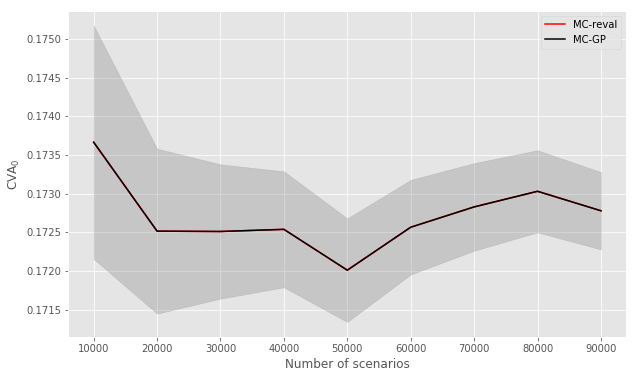 Figure 4
Figure 4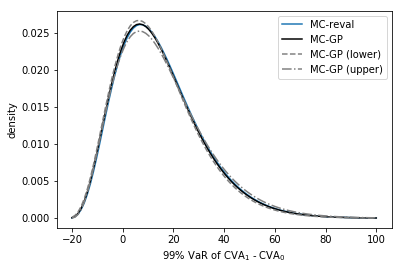 Figure 5
Figure 5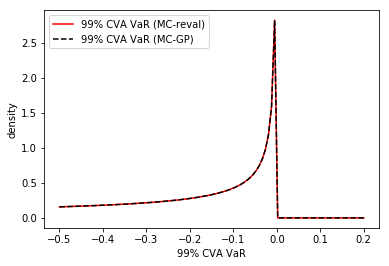 Figure 6
Figure 6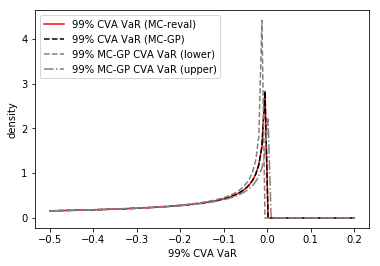 Figure 7
Figure 7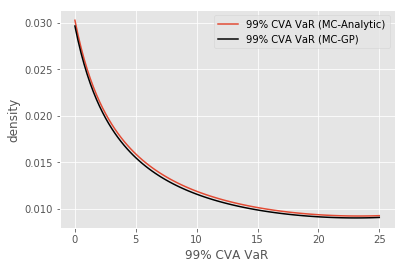 Figure 8
Figure 8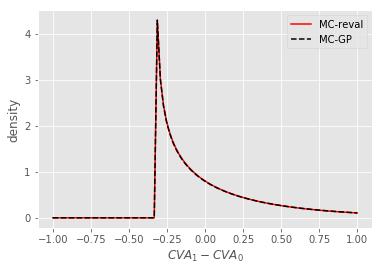 Figure 9
Figure 9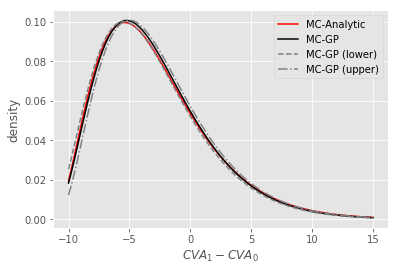 Figure 10
Figure 10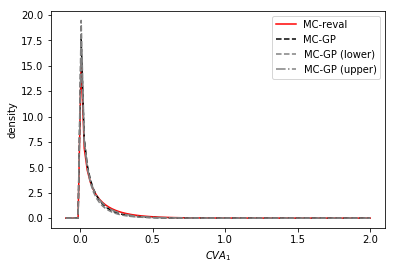 Figure 11
Figure 11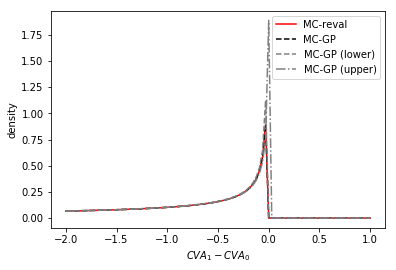 Figure 12
Figure 12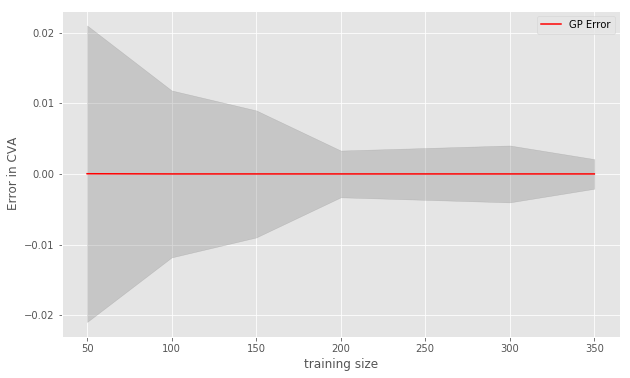 Figure 13
Figure 13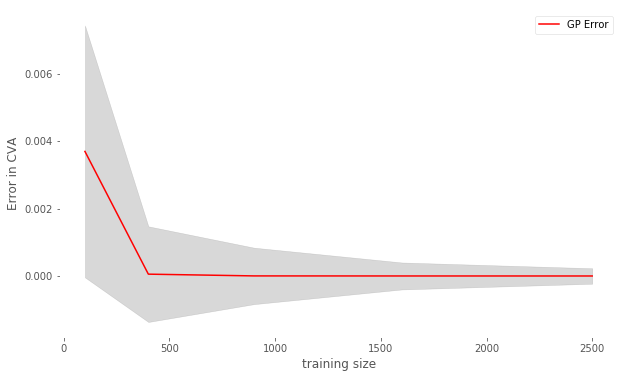 Figure 14
Figure 14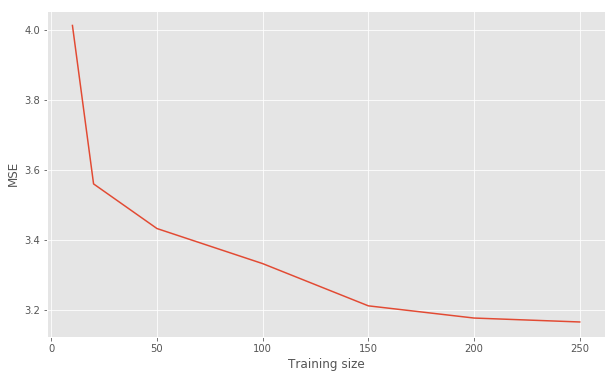 Figure 15
Figure 15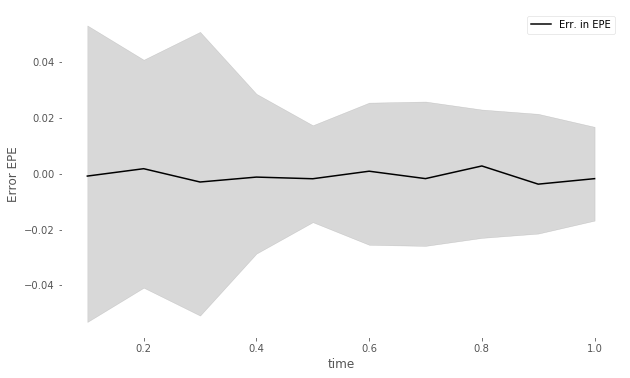 Figure 16
Figure 16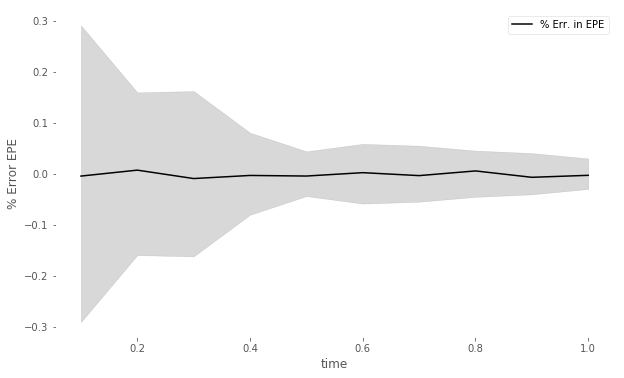 Figure 17
Figure 17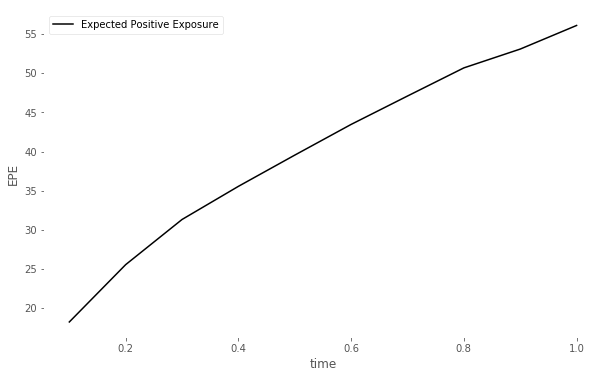 Figure 18
Figure 18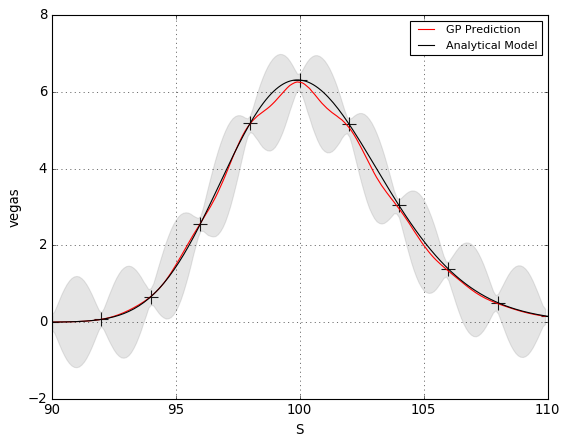 Figure 19
Figure 19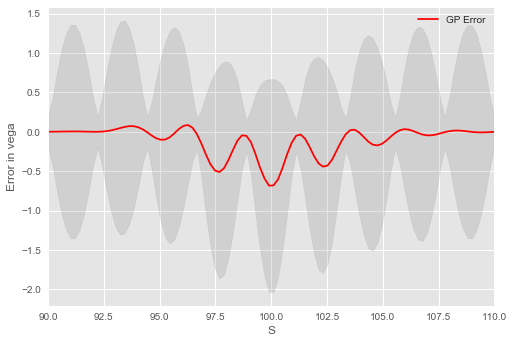 Figure 20
Figure 20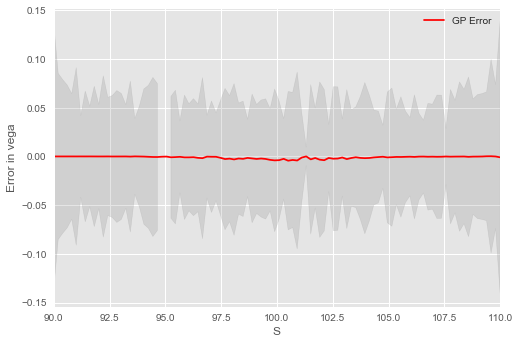 Figure 21
Figure 21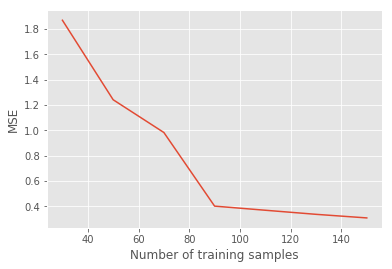 Figure 22
Figure 22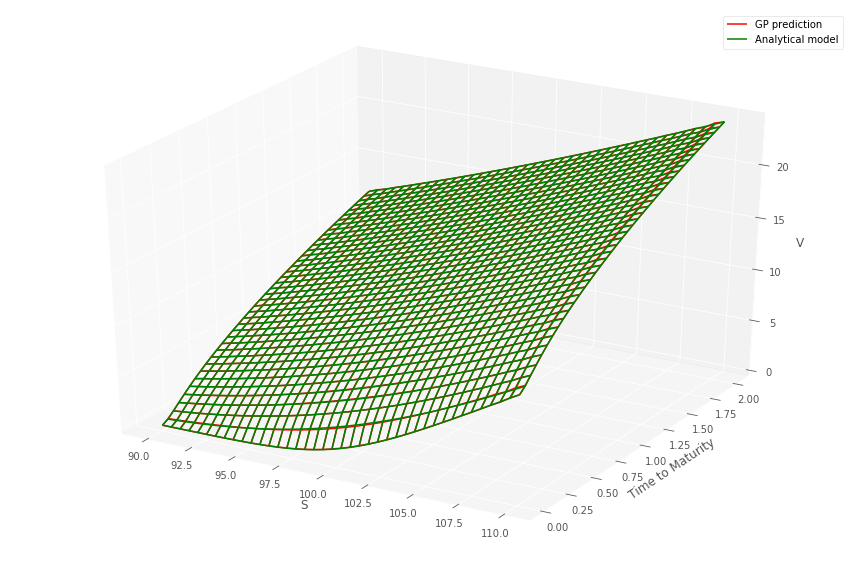 Figure 23
Figure 23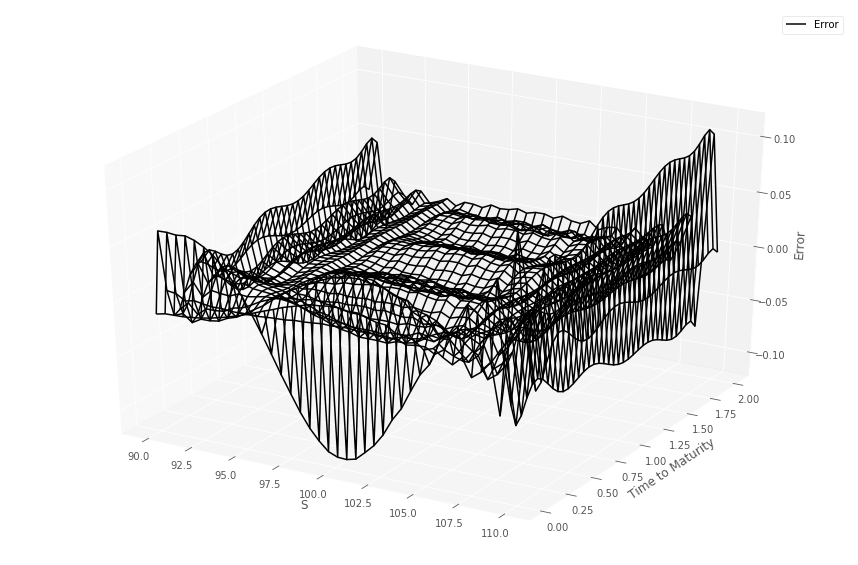 Figure 24
Figure 24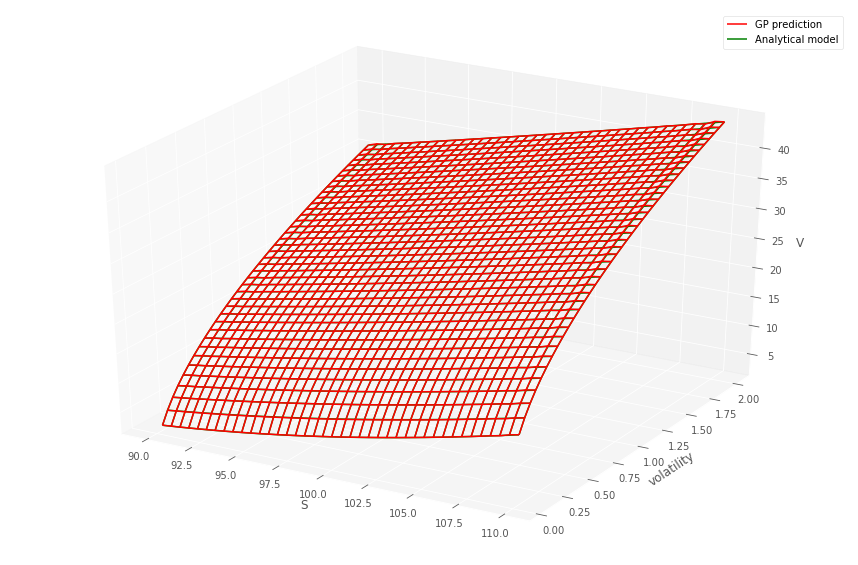 Figure 25
Figure 25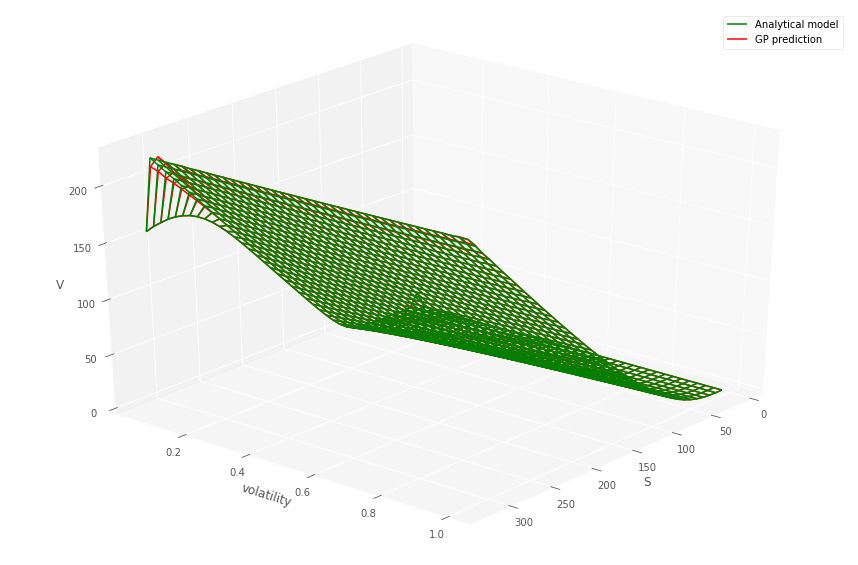 Figure 26
Figure 26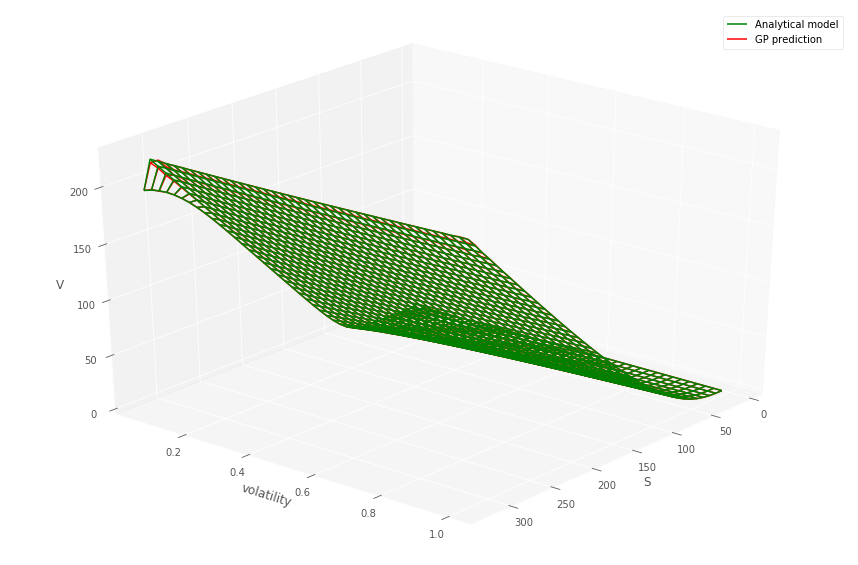 Figure 27
Figure 27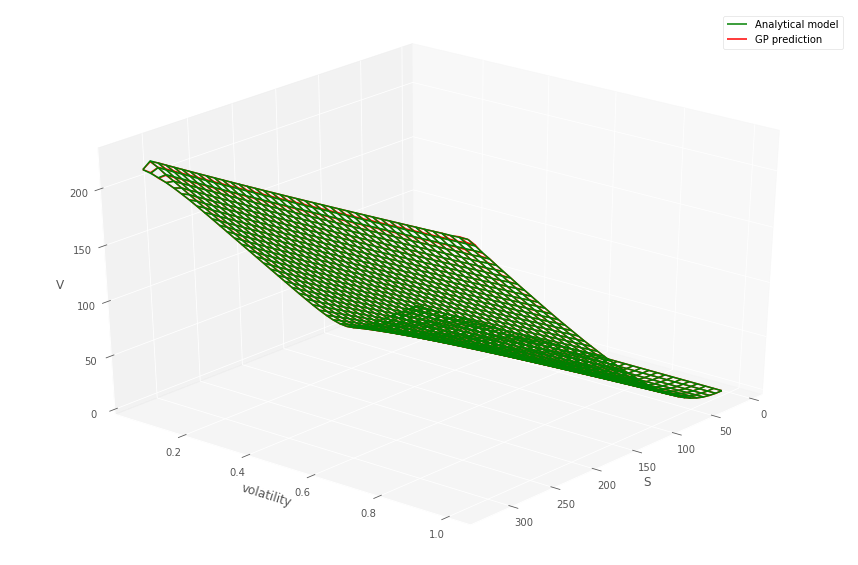 Figure 28
Figure 28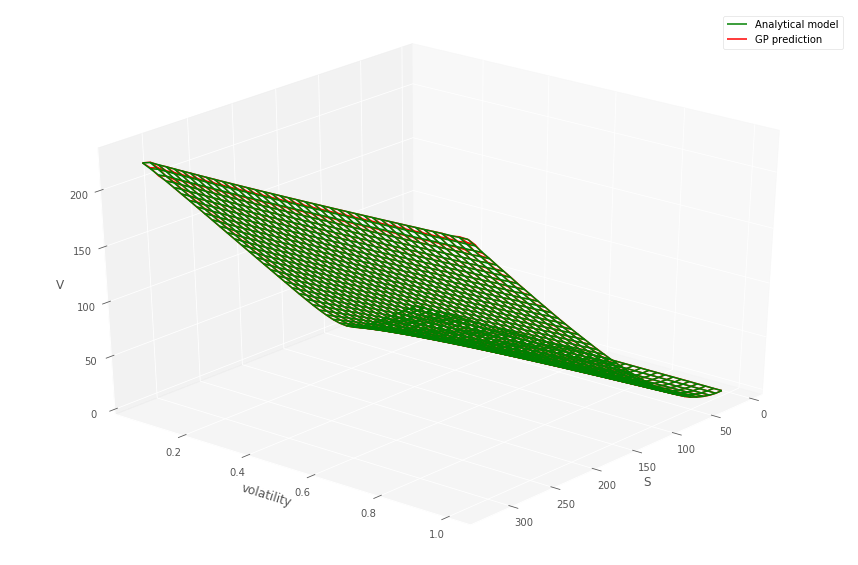 Figure 29
Figure 29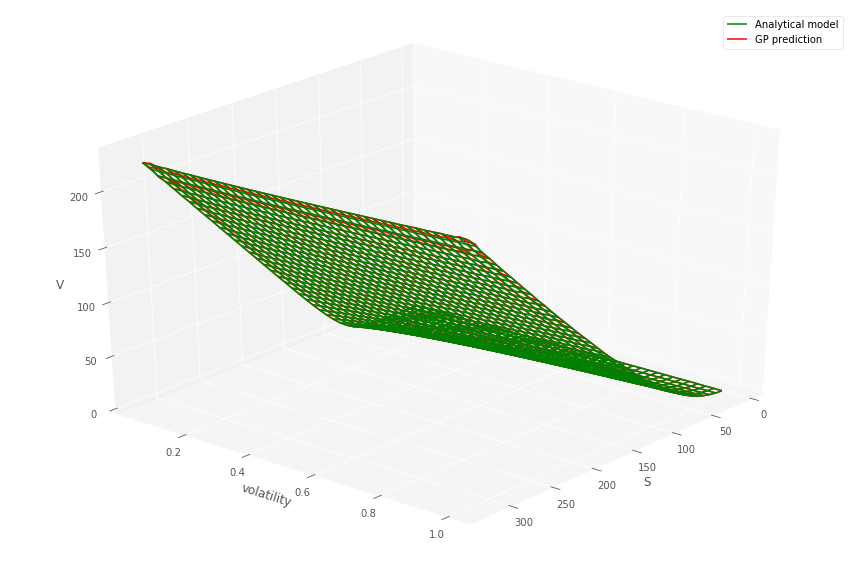 Figure 30
Figure 30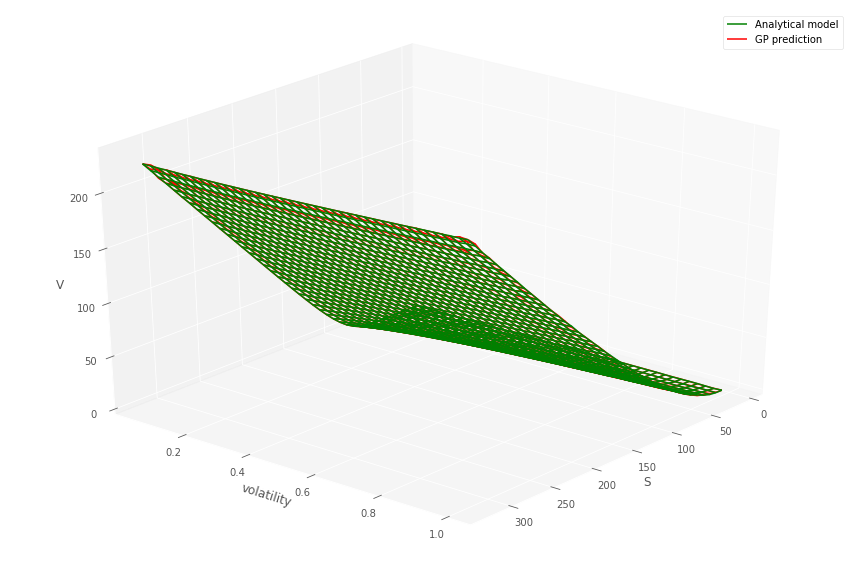 Figure 31
Figure 31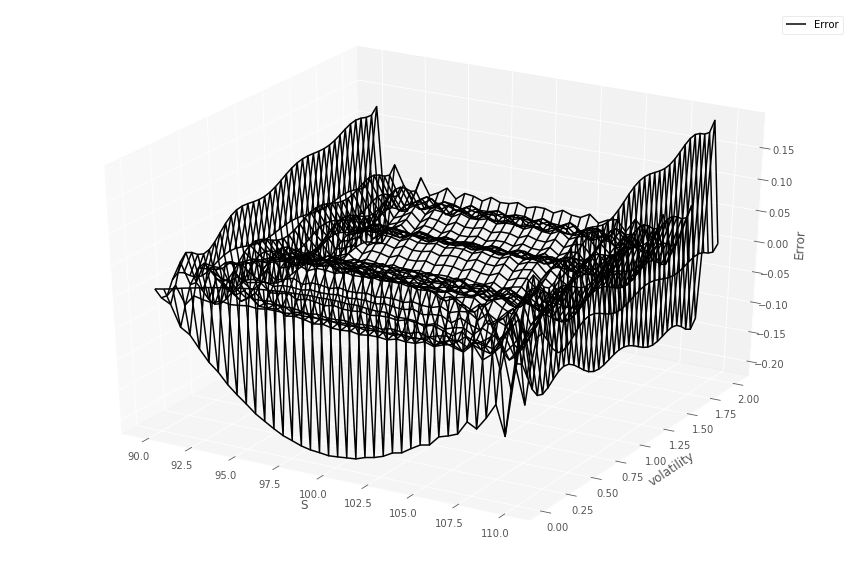 Figure 32
Figure 32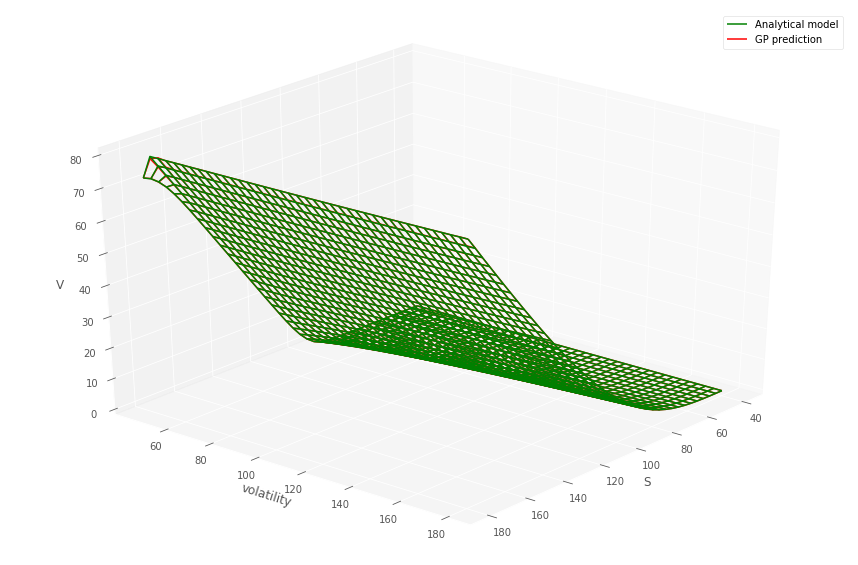 Figure 33
Figure 33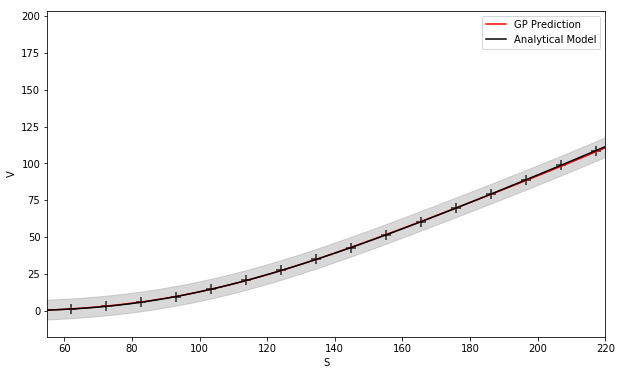 Figure 34
Figure 34 Figure 35
Figure 35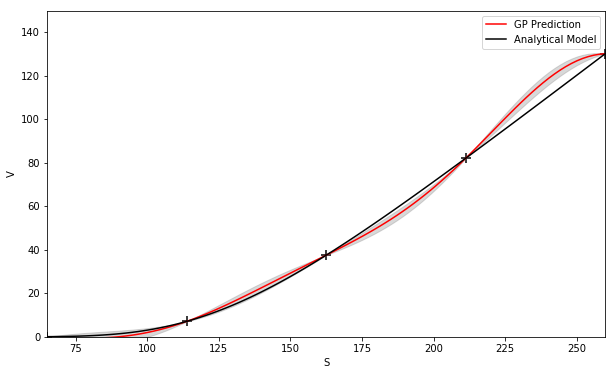 Figure 36
Figure 36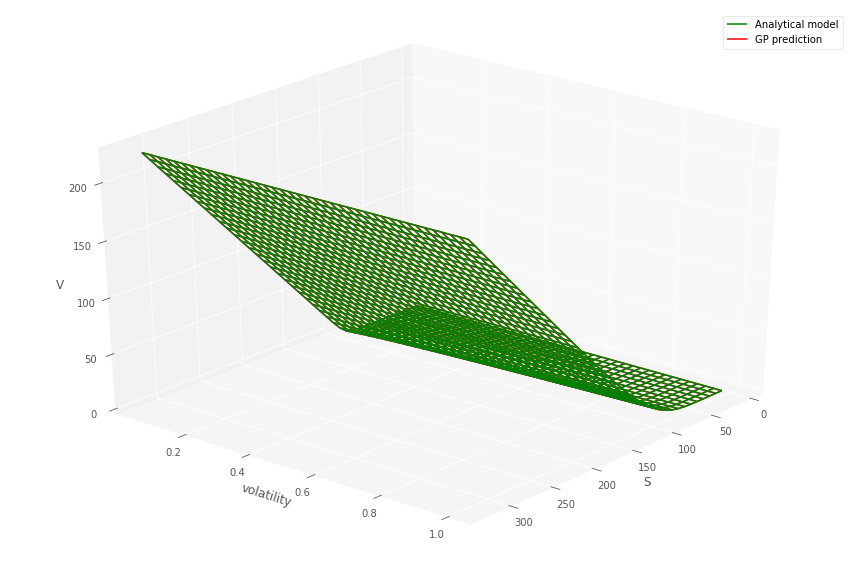 Figure 37
Figure 37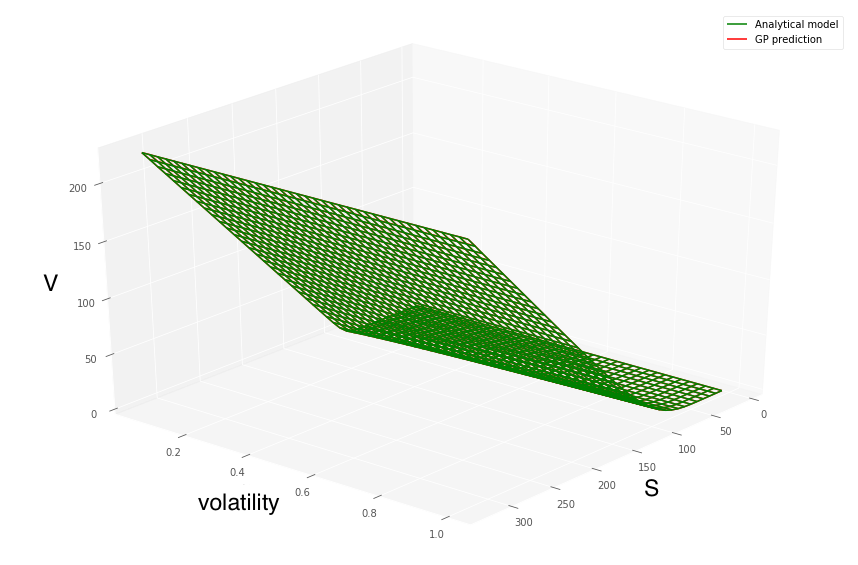 Figure 38
Figure 38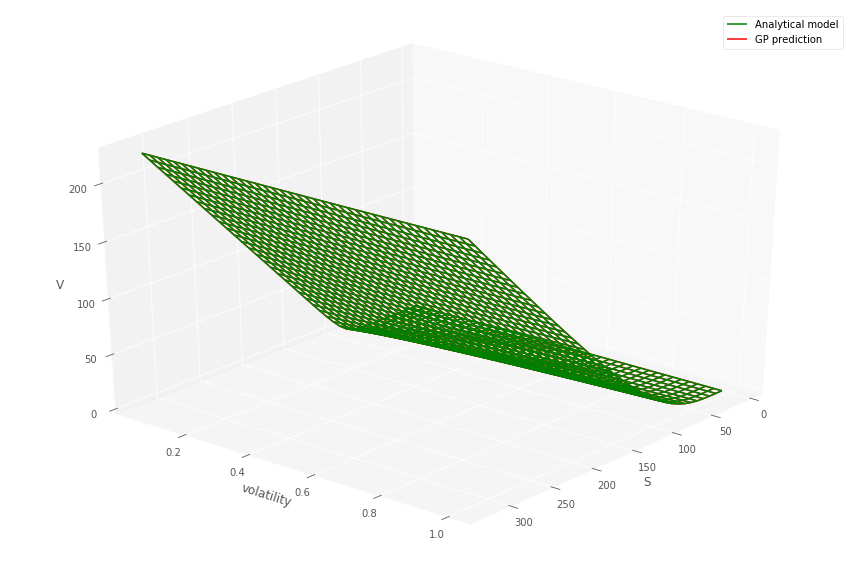 Figure 39
Figure 39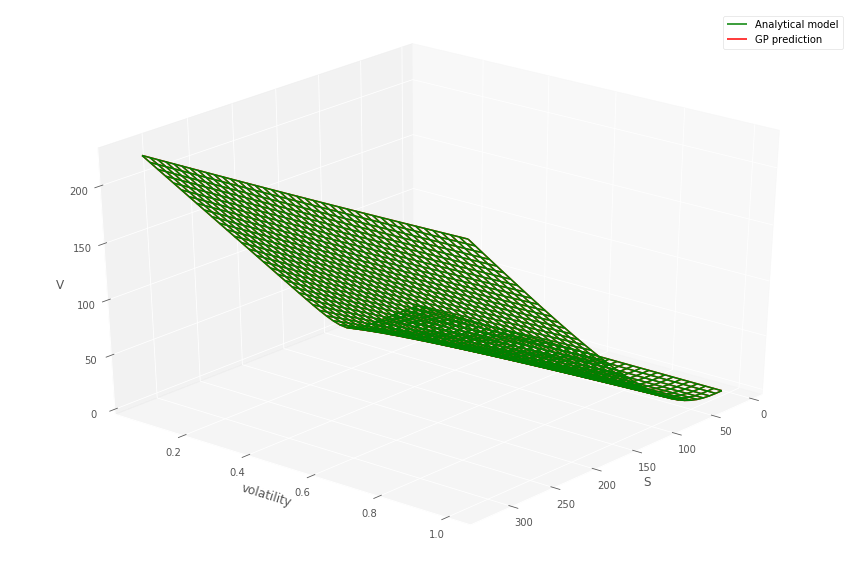 Figure 40
Figure 40| Parameter description | Symbol | Value |
|---|---|---|
| Initial stock price | 100 | |
| Initial variance | 0.1 | |
| Mean reversion rate | 0.1 | |
| Mean reversion level | 0.15 | |
| Vol. of Vol. | 0.1 | |
| Risk free rate | 0.01 | |
| Strike | 100 | |
| Maturity | 2.0 | |
| Correlation |
| Parameter description | Symbol | Value |
|---|---|---|
| Number of simulations | 1000 | |
| Number of time steps | 100 | |
| Initial stock price | 100 |
| Estimator | Mean | lower C.I. | upper C.I. |
|---|---|---|---|
| 3357.846 | 3179.715 | 3535.978 | |
| 3177.103 | 3522.072 | 3571.0287 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Gaussian Process Regression for Derivative Portfolio Modeling and Application to CVA Computations
Stéphane Crépey
LaMME, Univ Evry, CNRS, Université Paris-Saclay, 91037, Evry, France
and
Matthew F. Dixon
Department of Applied Mathematics, Illinois Institute of Technology Stéphane Crépey is a Professor in the Department of Mathematics, University of Evry, Paris Saclay. E-mail: [email protected]. The research of S. Crépey benefited from the support of the Chair Stress Test, RISK Management and Financial Steering, led by the French Ecole polytechnique and its Foundation and sponsored by BNP Paribas.Matthew Dixon is an Assistant Professor in the Department of Applied Mathematics, Illinois Institute of Technology, Chicago. E-mail: [email protected]. The research of M. Dixon is supported by a grant from Intel Corp.
Acknowledgement: The authors are grateful to Marc Chataigner, Areski Cousin, Mike Ludkovski and the anonymous referees, for insights and feedback, and to Bouazza Saadeddine for the generation of the mark-to-market cube that served as a basis for the regression exercise of Section 5.5. An earlier version of this paper was presented at Quantminds 2019 in Vienna, SIAM FME 2019 in Toronto, and AMAMEF 2019 in Paris.
Abstract
Modeling counterparty risk is computationally challenging because it requires the simultaneous evaluation of all the trades with each counterparty under both market and credit risk. We present a multi-Gaussian process regression approach, which is well suited for OTC derivative portfolio valuation involved in CVA computation. Our approach avoids nested simulation or simulation and regression of cash flows by learning a Gaussian metamodel for the mark-to-market cube of a derivative portfolio. We model the joint posterior of the derivatives as a Gaussian process over function space, with the spatial covariance structure imposed on the risk factors. Monte-Carlo simulation is then used to simulate the dynamics of the risk factors. The uncertainty in portfolio valuation arising from the Gaussian process approximation is quantified numerically. Numerical experiments demonstrate the accuracy and convergence properties of our approach for CVA computations, including a counterparty portfolio of interest rate swaps.
Keywords: Gaussian processes regression, surrogate modeling, mark-to-market cube, derivatives, credit valuation adjustment (CVA), uncertainty quantification.
Mathematics Subject Classification: 91B25, 91G20, 91G40, 62G08, 68Q32.
1 Introduction
Post the global financial crisis of 2007-2008, banks have been subject to much stricter regulation and conservative capital and liquidity requirements. Pricing, valuing and managing over-the-counter (OTC) derivatives has been substantially revised to more robustly capture counterparty credit risk. Pricing and accounting now includes valuation adjustments collectively known as XVAs ((Abbas-Turki et al., 2018; Kenyon and Green, 2014; Crépey et al., 2014)). The BCBS pointed out that 2/3 of total credit losses during the 2007-2009 crisis were CVA losses, i.e. CVA increases, where the CVA liability of a bank is its expected loss triggered by future counterparty defaults. As a consequence, a CVA capital charge has been introduced since the initial phase of the Basel III framework in December 2010.
Modeling counterparty risk is computationally challenging because it requires the evaluation of all the trades with each counterparty under market and credit simulation. For instance, CVA computation requires pathwise pricing of each counterparty portfolio under simulated market moves, with counterparty default modeled separately. The sensitivities of the CVA, with respect to all the underlying market risk buckets, are required for hedging.
The main source of computational complexity in XVA computations arises from the necessity of revaluing portfolio holdings (including path dependent or early exercise options) in numerous future dynamic scenarios. In the case of XVA (first-order) sensitivities, there has been much progress towards real-time estimation using adjoint algorithmic differentiation ((Giles and Glasserman, 2005; Capriotti et al., 2011; Capriotti, 2011; Antonov et al., 2018; Huge and Savine, 2017)). However, algorithmic differentiation is still very challenging to implement at the level of a banking derivative portfolio, and it typically comes at the cost of more or less drastic simplifications of the xVA metrics to be differentiated. Hence, bump-and-revalue sensitivities remain useful (and are in fact unavoidable regarding second-order sensitivities) and, again, multiple and fast valuation is required.
In this paper, we investigate the possible use of Gaussian processes (GP) regression as a metamodel of the mark-to-market (MtM) cube, i.e. the value of client portfolios in future time points and scenarios. Our approach consists in simulating the market risk factors forward in time and then interpolating the mark-to-market cube from a set of model generated, reference derivative prices. Such an approach is predicated on the notion that a GP model, once trained, can provide fast and reliable prices (as well as the associated, analytically differentiated Greeks).
We refer the reader to (Rasmussen and Williams, 2006) for a general introduction to Gaussian process regression, or simply Gaussian processes (GPs). As opposed to frequentist machine learning techniques, including neural networks or support vector machines, which only provide point estimates, GPs quantify the uncertainty of their predictions111Through out this paper, we will refer to ’prediction’ as out-of-sample point estimation. For avoidance of doubt, the test point need not be in the future as the terminology suggests.. A high uncertainty in a prediction might result in a GP model estimate being rejected in favor of either retraining the model or even using full model revaluation. Another motivation for using GPs is the availability of efficient training method for the model hyper-parameters. In addition to a number of favorable statistical and mathematical properties, such as universality (see (Micchelli et al., 2006)), the implementation support infrastructure is mature and provided by open source machine learning packages such as GpyTorch, scikit-learn, Edward, or STAN.
GPs have demonstrated much success in applications outside of finance and sometimes under the name of kriging. The basic theory of prediction with Gaussian processes dates back to at least as far as the time series work of Kolmogorov or Wiener in the 1940s (see (Whittle and Sargent, 1983)). Examples of applying GPs to financial time series prediction are presented in (Roberts et al., 2013). These authors helpfully note that AR processes are discrete time equivalents of GP models with a certain class of covariance functions, known as Matérn covariance functions. Hence, GPs can be viewed as a Bayesian non-parametric generalization of well known econometrics techniques. (da Barrosa et al., 2016) present a GP method for optimizing financial asset portfolios.
The adoption of kriging methods in financial derivative modeling is more recent. The underlying data to which the GP is fitted are then typically generated by the user itself in a model, rather than market data—somewhat counter the motivation for adopting machine learning, but also the case in other recent computational finance applications such as (Hernandez, 2017), (E et al., 2017), or (Bühler et al., 2018). The motivation is then fast pricing, once the prediction algorithm has been trained off-line as a pre-processing stage.
(Cousin et al., 2016) introduce shape-constrained GPs to ensure non-arbitrable and error-controlled yield-curve and CDS curve interpolation. (Ludkovski and Gramacy, 2015) and (Ludkovski, 2018)) reformulate the Bermudan option pricing problem as a response surface metamodeling problem, which they address by kriging. In the context of expected shortfall computations, (Liu and Staum, 2010) and (Ludkovski and Risk, 2018) use GPs to infer portfolio values in a given scenario, based on inner-level simulation of nearby scenarios. This significantly reduces the required computational effort by restricting inner-level simulations to few selected scenarios, while naturally taking account of the variance that arises from inner-level simulation.
(Spiegeleer et al., 2018) propose offline learning of a derivative pricing function through Gaussian process regression. Specifically, the authors configure the training set over a grid and then use the GP to interpolate at the test points. They demonstrate the speed up of GPs relative to Monte-Carlo methods and tolerable accuracy loss applied to pricing and Greek estimation with a Heston model, in addition to approximating the implied volatility surface. The increased expressibility of GPs compared to cubic spline interpolation, a popular numerical approximation techniques useful for fast point estimation, is also demonstrated.
However, the applications shown in (Spiegeleer et al., 2018) are limited to single instrument pricing, they do not consider the portfolio aspects. In particular, their study is limited to single-response GPs, as opposed to also multi-response GPs in this work (respectively referred to as single- vs. multi-GPs for brevity). In a single-GP setting, individual GPs are used to model the posterior of each predicted derivative price under the assumption that the derivative prices are independent, conditional on the training data and test input. Given that either the derivatives may share common underlyings, or the underlyings are different but correlated, this assumption is clearly violated in practice. By contrast, multi-GPs (see (Alvarez et al., 2012) for a survey) directly model the uncertainty in the prediction of a vector of derivative prices (responses) with spatial covariance matrices specified by kernel functions. Thus the amount of error in the mark-to-market cube prediction (the prediction itself does not change) can only be adequately modeled using multi-GPs.
Outline
This paper uses single- and multi-GPs for learning the posterior distribution of a mark-to-market cube, which is then used in the context of CVA computations. Section 2 reviews single-response GPs and Section 3 illustrates their use for derivative pricing and Greeking applications. Section 4 extends the setup to a multi-response generalization of GPs. Section 5 deals with CVA computations using a Monte Carlo GPs approach, whereby the GP predicted MtM cube is used for valuing the derivative portfolio of the bank at the nodes of a Monte Carlo simulation for the bank CVA. The concluding Section 6 summarizes our findings and puts GPs in perspective with either simpler or more elaborate regression alternatives. Some of the numerical examples are illustrated with Python code excerpts demonstrating the key features of our approach. All performances are based on a 2.2 GHz Intel Core i7 laptop. These and additional examples are provided in the Github repository https://github.com/mfrdixon/GP-CVA. The examples can be run using the command ipython notebook (once the required packages have been loaded).
Note that our setup involves both the randomness of financial risk factors and the Bayesian uncertainty relative to GP estimation. For clarity of exposition, we denote by and the probability and expectation with respect to a pricing measure, and by (respectively var or cov) a GP point (respectively variance or covariance) estimate. A confidence interval refers to a Monte Carlo estimate relative to the randomness of the financial risk factors, whereas an uncertainty band refers to the GP estimation procedure (both computed at the 95% probability level).
2 Single-Output Gaussian Processes
This section is a primer on (standard, single-) Gaussian processes inference, written in the classical Bayesian statistics style. Financial readers not acquainted with it may refer to (Rasmussen and Williams, 2006) (MacKay, 1998), and (Murphy, 2012, Chapter 15) for more background and detail.
Statistical inference involves learning a function of the data, . The idea of Gaussian processes (GPs) is to, without parameterizing222This is in contrast to nonlinear regressions commonly used in finance, which attempt to parameterize a non-linear function with a set of weights. , place a probabilistic prior directly on the space of functions. The GP is hence a Bayesian nonparametric model that generalizes the Gaussian distributions from finite dimensional vector spaces to infinite dimensional function spaces. GPs are an example of a more general class of supervised machine learning techniques referred to as ‘kernel learning’, which model the covariance matrix from a set of parametrized kernels over the input. GPs extend and put in a Bayesian framework spline or kernel interpolators, as well as Tikhonov regularization (see (Rasmussen and Williams, 2006) and (Alvarez et al., 2012)). (Neal, 1996) also observed that certain neural networks with one hidden layer converge to a Gaussian process in the limit of an infinite number of hidden units.
In this section we restrict ourselves to the simpler case of single-response GPs where is real-valued (multi-response GPs will be considered in Section 4).
2.1 Gaussian Processes Regression and Prediction
We say that a random function is drawn from a GP with a mean function and a covariance function, called kernel, , i.e. , if for any input points in , the corresponding vector of function values is Gaussian:
[TABLE]
for some mean vector , such that , and covariance matrix that satisfies . Unless specified otherwise, we follow the convention333This choice is not a real limitation in practice (since it only regards the prior and it does not prevent the mean of the predictor from being nonzero). in the literature of assuming .
Kernels can be any symmetric positive semidefinite function, which is the infinite-dimensional analogue of the notion of a symmetric positive semidefinite (i.e. covariance) matrix, i.e. such that
[TABLE]
Radial basis functions (RBF) are kernels that only depend on , such as the squared exponential (SE) kernel
[TABLE]
where the length-scale parameter can be interpreted as “how far you need to move in input space for the function values to become uncorrelated”, or the Matern (MA) kernel
[TABLE]
(which converges to (1) in the limit where goes to infinity), where and are non-negative parameters, is the gamma function, and is the modified Bessel function of the second kind. One advantage of GPs over interpolation methods is their expressability. In particular, one can combine the kernels by convolution (cf. (Melkumyan and Ramos, 2011)). Moreover, the regularity of the GP interpolation is controllable through the one of the kernel.
GPs can be seen as distributions over the reproducing kernel Hilbert space (RKHS) of functions which is uniquely defined by the kernel function, (see (Scholkopf and Smola, 2001)). GPs with RBF kernels are known to be universal approximators with prior support to within an arbitrarily small epsilon band of any continuous function (see (Micchelli et al., 2006)).
GPs also provide “differential regularity” — GPs are RKHSs defined in terms of differential operators, with the Hilbert norm of the latent function having the effect of penalizing the gradients. Regularity of the GP interpolation is thus controllable through the choice of the kernel and smoothing parameters (see Section 6.2 of Rasmussen and Williams (2006)).
One limitation of the kernel is that it does not reveal any hidden representations — failing to identify the useful features for solving a particular problem. The issue of feature discovery can be addressed by GPs through imposing “spike-and-slab” mixture priors on the covariance parameters (see (Savitsky et al., 2011)).
Assuming additive Gaussian i.i.d. noise, , and a GP prior on , given training inputs and training targets , the predictive distribution of the GP evaluated at arbitrary test points is:
[TABLE]
where the moments of the posterior over are
[TABLE]
Here, , , , and are matrices that consist of the kernel, , evaluated at the corresponding points, and , and is the mean function evaluated on the test inputs .
In the context of derivative pricing applications, may correspond to a set of risk factor grid nodes, to the corresponding model prices (valued by analytical formulas or any, possibly approximate, classical numerical finance pricing schemes), to the GP regressed prices corresponding to the new value of the risk factors, and to the corresponding interpolation uncertainty. Note that the latter is only equal to 0 if and one is in the noise-free case where has been set to 0.
We emphasize that, in a least square Monte-Carlo regression approach a la (Longstaff and Schwartz, 2001) (see e.g. (Crépey, 2013, Part IV)), we train function approximators, usually as linear combinations of fixed basis functions, on simulated samples. By contrast, GPs are trained on values (not samples), on a (structured or not, deterministically or stochastically generated) grid, like a sophisticated interpolator.
2.2 Hyper-parameter Tuning
GPs are fit to the data by optimizing the evidence-the marginal probability of the data given the model with respect to the learned kernel hyperparameters.
The evidence has the form (see e.g. (Murphy, 2012, Section 15.2.4, p. 523)):
[TABLE]
where the kernel hyperparameters include in (5) and parameters of (e.g. , assuming an SE kernel as per (1) or an MA kernel for some exogenously fixed value of in (2)).
The first and second term in the brackets in (5) can be interpreted as a model fit and a complexity penalty term (see (Rasmussen and Williams, 2006, Section 5.4.1)). Maximizing the evidence with respect to the kernel hyperparameters, i.e. computing , results in an automatic Occam’s razor controlling the trade-off between the regression fit and the regularity of the interpolator (see (Alvarez et al., 2012, Section 2.3) and (Rasmussen and Ghahramani, 2001)). In practice, the negative evidence is minimized by stochastic gradient descent (SGD). The gradient of the evidence is given analytically by
[TABLE]
where , and, in the case of the SE or MA kernels,
[TABLE]
(with, in the SE case, ).
2.3 Computational Properties
Training time, required for maximizing (5) numerically, scales poorly with the number of observations . This stems from the need to solve linear systems and compute log determinants involving an symmetric positive definite covariance matrix . This task is commonly performed by computing the Cholesky decomposition of incurring complexity. Prediction, however, is faster and can be performed in with a matrix-vector multiplication for each test point, and hence the primary motivation for using GPs is real-time risk estimation performance.
If uniform grids are use, we have , where are the number of grid points per variable. However, mesh-free GPs can be used as described in Section 3.3.
In terms of storage cost, although each kernel matrix is , we only store the n-vector in (6), which brings reduced memory requirements.
Massively scalable Gaussian processes
Massively scalable Gaussian processes (MSGP) are a recent significant extension of the basic kernel interpolation framework described above. The core idea of the framework, which is detailed in (Gardner et al., 2018), is to improve scalability by combining GPs with ‘inducing point methods’. Using structured kernel interpolation (SKI), a small set of inducing points are carefully selected from the original training points. Under certain choices of the kernel, such as RBFs, a Kronecker and Toeplitz structure of the covariance matrix can be exploited by fast Fourier transform (FFT). Finally, output over the original input points is interpolated from the output at the inducing points. The interpolation complexity scales linearly with dimensionality of the input data by expressing the kernel interpolation as a product of 1D kernels. Overall, SKI gives training complexity and prediction time per test point, using the LanczOs Variance Estimates of (Pleiss et al., 2018). In this paper, we primarily use the basic interpolation approach for simplicity.
Online learning
If the option pricing model is recalibrated intra-day, then the corresponding GP model should be retrained. Online learning techniques permit performing this incrementally (see (Pillonetto et al., 2010)). To enable online learning, the training data should be augmented with the constant model parameters. Each time the parameters are updated, a new observation is generated from the option model prices under the new parameterization. The posterior at test point is then updated with the new training point following
[TABLE]
where the previous posterior becomes the prior in the update and . Hence the GP learns over time as model parameters (which are an input to the GP) are updated through pricing model recalibration.
3 Pricing and Greeking With Single-Response Gaussian Processes
3.1 Pricing
In the following example, a portfolio holds a long position in both a European call and a put option struck on the same underlying, with . We assume that the underlying follows Heston dynamics (in risk-neutral form):
[TABLE]
where the notation is defined in Table 1. We use a Fourier Cosine method by (Fang and Oosterlee, 2008) to generate the European Heston option price training and testing data for the GP. We also use this method to compare the GP Greeks, obtained by differentiating the kernel function.
Table 1 also lists the values of the Heston parameters and terms of the European call and put option contract used in our numerical experiments. Additionally, the data is generated using an Euler time stepper for (9) using 100 time steps over a two year horizon.
For each in a grid of dates (which in the context of CVA would correspond to the MtM exposure simulation times , see Section 5), we simultaneously fit numerous GPs to both gridded call and put prices over stock price and volatility (keeping time to maturity fixed). Then we fit a GP to the Heston pricing function from Heston prices computed by Fourier formulas for the gridded values of and . We emphasize that the Heston dynamics (9) are not used in the simulation mode in this procedure.
Listing 1 details how the GP and data are prepared to predict prices over the two dimensional grid, for a fixed time to maturity and strike. Figures 1 and 1 (top) show the comparison between the gridded semi-analytic and GP call and put price surfaces at various time to maturities, together with the GP estimate. Within each column in the figures, the same GP model has been simultaneously fitted to both the call and put price surfaces over a grid of stock prices and volatilities444Note that the plot uses the original coordinates and not the re-scaled co-ordinates., for a given time to maturity. The bottom panel of the figure shows the error surfaces between the GP and semi-analytic estimates. The scaling to the unit domain is not essential. However, we observed superior numerical stability when scaling.
Across each column, corresponding to different time to maturities, a different GP model has been fitted. The GP is then evaluated out-of-sample over a grid , so that many of the test samples are new to the model. This is repeated over the various dates . The option model versus GP model are observed to produce very similar values.
Extrapolation
One instance where kernel combination is useful in derivative modeling is for extrapolation—the appropriate mixture or combination of kernels can be chosen so that the GP is able to predict outside the domain of the training set. Noting that the payoff is linear when a call or put option is respectively deeply in and out-of-the money, we can configure a GP as a combination of a linear kernel and, say, a SE kernel. The linear kernel is included to ensure that prediction outside the domain preserves the linear property, whereas the SE kernel captures non-linearity. Figure 3 shows the results of using this combination of kernels to extrapolate the prices of a call struck at 110 and a put struck at 90. The linear property of the payoff function is preserved by the GP prediction and the uncertainty increases as the test point is further from the training set.
The above examples are trained on (semi)-analytic Black-Scholes and Heston prices, so the quality of the approximator can be assessed.
In a realistic application where approximators are trained on more general products in more general models, more complex, possibly approximate pricing schemes (including Monte Carlo inner simulations) could be required to find the values on the knot points.
3.2 Greeking
The GP provides analytic derivatives with respect to the input variables
[TABLE]
where and we recall from after (6) that (and in the numerical experiments we set ). Second order sensitivities are obtained by differentiating once more with respect to .
Note that is already calculated at (pricing) training time by Cholesky matrix factorization of with complexity, so there is no significant computational overhead from Greeking. Once the GP has learned the derivative prices, Equation (10) is used to evaluate the first order MtM Greeks with respect to the input variables over the test set. Example source code illustrating the implementation of this calculation is given in Listing 2.
Figure 4 shows (left) the GP estimate of a call option’s delta and (right) the error between the Black–Scholes (BS) delta and the GP estimate. We emphasize that the GP model is trained on underlying and option pricing data and not using the option’s delta. The GP delta is observed to closely track the BS formula for the delta. Figure 5 shows (left) the GP estimate of a call option’s vega , having trained on the implied volatility, and BS option model prices and not using the option’s vega. The right hand pane shows the error between the BS vega and the GP estimate. The GP vega is observed to closely track the BS formula for the vega.
3.3 Mesh-Free GPs
The above numerical examples have trained and tested GPs on uniform grids. This approach suffers from a stringent curse of dimensionality issue, as the number of training points grows exponentially with the dimensionality of the data (cf. Section 2.3). Hence, in practice, in order to estimate the MtM cube, we advocate divide-and-conquer, i.e. the use of numerous low input dimensional space, , GPs run in parallel on specific asset classes (see Section 5.5 and (Guhaniyogi et al., 2017)).
Moreover, use of fixed grids is by no means necessary. We show here how GPs can show favorable approximation properties with a relatively small number of simulated reference points (cf. (Gramacy and Apley, 2015)).
Figure 6 shows predicted Heston call prices using (left) 50 and (right) 100 simulated training points, indicated by “+”s, drawn from a uniform random distribution. The Heston call option is struck at with a maturity of years.
Figure 7 (left) shows the convergence of the GP MSE of the prediction, based on the number of Heston simulated training points.
3.4 Massively Scalable GPs
Fixing the number of simulated points to 100, but increasing the input space dimensionality, , of each observation point (i.e. including more and more Heston parameters), Figure 7 (right) shows the wall-clock time for training a GP with SKI (see Section 2.3). Note that the number of SGD iterations has been fixed to 1000.
Figure 8 shows the increase of MSGP training time and prediction time against the number of training points from a Black Scholes model. Fixing the number of inducing points to (see Section 2.3), we increase the number of observations, , in the dimensional training set.
Setting the number of SGD iterations to 1000, we observe an approximate 1.4 increase in training time for a 10x increase in the training sample. We observe an approximate 2x increase in prediction time for a 10x increase in the training sample. The reason that the prediction time grows with (instead of being constant, cf. Section 2.3) is due to memory latency in our implementation—each point prediction involves loading a new test point into memory. Fast caching approaches can be used to reduce this memory latency, but are beyond the scope of this research.
Note that training and testing times could be improved with CUDA on a GPU, but are not evaluated here.
4 Multi-response Gaussian Processes
A multi-response Gaussian process is a collection of random vectors, any finite number of which have matrix-variate Gaussian distribution. We borrow from (Chen et al., 2017) the following formulation of a separable noise-free multi-response kernel specification as per (Alvarez et al., 2012, Eq. (9)):
By definition, is a variate Gaussian process on with vector-valued mean function , kernel , and positive semi-definite parameter covariance matrix , if the vectorization of any finite collection of vectors have a joint multi-variate Gaussian distribution,
[TABLE]
where is a column vector whose components are the functions , is a matrix in with , is a matrix in with , and is the Kronecker product
[TABLE]
Sometimes is called the column covariance matrix while is the row (or task) covariance matrix. We denote . As explained after Eq. (10) in (Alvarez et al., 2012), the matrices and encode dependencies among the inputs, respectively outputs.
4.1 Multi-Output Gaussian Process Regression and Prediction with Noisy Observations
In practice, the observations are not drawn from a function but exhibit noise. Given pairs of noisy observations , we assume the model , where with , in which is the variance of an additive Gaussian i.i.d. noise, . The vectorization of the collection of functions therefore follows a multivariate Gaussian distribution
[TABLE]
where is the covariance matrix of which the -th element .
To predict a new variable at the test locations , the joint distribution of the training observations and the predictive targets are given by
[TABLE]
where is an matrix of which the -th element , is an matrix of which the -th element , and is an matrix with the -th element . Thus, taking advantage of the conditional distribution of the multivariate Gaussian process, the predictive distribution is:
[TABLE]
where
[TABLE]
The hyperparameters and elements of the covariance matrix are found by minimizing over the negative log marginal likelihood of observations:
[TABLE]
Further details of the multi-GP are given in (Bonilla et al., 2007), (Alvarez et al., 2012), and (Chen et al., 2017). The computational remarks made in Section 2.3 also apply here, with the additional comment that the training and prediction time also scale linearly (proportionally) with the number of dimensions . Note that the task covariance matrix is estimated via a vector factor by (where the component corresponds to a standard white noise term). An alternative computational approach, which exploits separability of the kernel, is described in Section 6.1 of (Alvarez et al., 2012), with complexity .
4.2 Portfolio Value and Market Risk Estimation
The value of a portfolio of financial derivatives can typically be expressed as a linear combination of the components of a d-vector of a set of underlying risk factors , i.e.
[TABLE]
We estimate the moments of the predictive distribution by
[TABLE]
where
[TABLE]
In particular, (19) yields an expression for estimating the GP uncertainty in the point estimate of a portfolio, given the underlying risk factors, which accounts for the dependence between the financial derivative contracts. In general financial derivative contracts in the portfolio share common risk factors and the risk factors are correlated. Hence, a multi-GP approach, if not too demanding computationally, should be the meta-modelling method of choice for the .
Once the vector-function in (17) has been learned, evaluating any portfolio spanned by becomes very fast. Hence the practical utility of a multi-GP approach is the ability to quickly predict portfolio values, together with an error estimate which also accounts for covariance of the derivative prices over the test points (conditional on the training points).
Note that the meta-model only refers to (as opposed to the portfolio weights). Thus the predictive distribution of the portfolio remains valid even when the portfolio composition changes (e.g. in the context of trade incremental XVA computations, see (Albanese et al., 2019, Section 5)). Note that, if a new derivative is added to the portfolio, we need not necessarily retrain all the GPs—the mean posterior estimate of the original portfolio value remains valid. However, the kernels must be relearned to update the covariance estimate. By construction, a derivative can be subtracted from the portfolio by simply setting the weight to zero—no retraining is required.
GP divide-and-conquer strategies
We reiterate that the benefit of using GPs is primarily for fast real-time computation.
Since different GPs involved in the MtM cube computation are independent (cf. Section 3.3), they can be trained in parallel over a grid of compute nodes such as a GPU or many-core CPU. In the case single-GPs are used, typically the number of input variables per model is small, and hence the training set consists of relatively few observations. The training of multi-GPs is more challenging since it involves fitting several instruments in the portfolio.
In practice, we can identify the subset of derivatives sharing common risk factors and fit a multi-GP to each subset. The computational overhead of multi-GP is justified by more accurate uncertainty estimates.
Instead of fitting a GP component (correlated with the others or not) to each derivative in a sub-portfolio as suggested above, an alternative can be to fit one single-GP per overall sub-portfolio value. However, if the weights of the portfolio are changed, then the corresponding GP must be re-trained. We mention these pros and cons so that the most suitable approach can be assessed for each risk application.
4.3 Numerical Illustration
The above concepts are illustrated in Figures 9 and 10 for a portfolio holding two long positions in a call option struck at 110 (left) and a short position in a put option struck at 90 (center), where . Recall there is one risk factor which is common to both options—the underlying instrument —and the maturity of each option is 2 years.
To illustrate the uncertainty band under multi-GP regression, a bivariate-GP with a MA kernel (with fixed to 2.5) is trained to a Black-Scholes model as a function of on fifty training points, with additive Gaussian i.i.d. noise, as displayed in Listing 3. Typically, one would use hundreds of training points. After 300 iterations the fitted kernel lengthscale and noise is , and the fitted task covariance matrix is
[TABLE]
The bivariate-GP subsequently estimates the values of the options and the portfolio at a number of test points. Some of these test points have been chosen to coincide with the training set and others are not in the set. The uncertainty in the point estimates is shown by the grey bands, denoting the 95% GP uncertainty. In the portfolio case this uncertainty is a weighted combination of the uncertainty in the point estimate of each option price and the cross-terms in the covariance matrix in Equation (19). If, instead, single GPs were used separately for the put and the call price, then the uncertainty in the point estimate of the portfolio would neglect the cross-terms in the covariance matrix.
To gain more insight into the components of the uncertainty, Figure 10 shows the distribution of uncertainty in the point estimates of over 100 testing points. Two experiments, with 5 and 50 training samples, are chosen to illustrate various properties in the multi-GP setting. The former experiment (left plot in figure) is chosen to highlight the importance of the cross-term in the posterior covariance , which is negative in this example. We reiterate that such a term is only represented in the multi-GP setting. In the case of noisy data or for a large portfolio, it may yield a non-negligible contribution to the portfolio value uncertainty.
5 CVA Computations
In this section, as an example of a portfolio risk application, we consider the estimation of counterparty credit risk on a client portfolio. The expected loss to the bank associated with the counterparty defaulting is given by the (unilateral, see (Albanese et al., 2019, Section 4.3)) CVA. Taking discounted expectation of the losses triggered by the client default with respect to a pricing measure and the related discount process , we obtain (assuming no collateral for simplicity)
[TABLE]
where is a Dirac measure at the client default time and is the client recovery rate.
Assuming endowed with a stochastic intensity process and a basic immersion setup between the market filtration and the filtration progressively enlarged with (see Albanese and Crépey (2019, Section 8.1)), we have
[TABLE]
Under Markovian specifications, is a deterministic function of time and suitable risk factors , i.e. ; likewise, in the case of intensity models, . Factors common to and allow modeling wrong way risk555Or, at least, soft wrong way risk, whereas hard wrong way risk may be rendered through common jump specifications (see (Crépey and Song, 2016))., i.e. the risk of adverse dependence between the risk of default of the client and the corresponding market exposure.
In the special case where the default is independent of the portfolio value expressed in numeraire units, then the expression (22) simplifies to
[TABLE]
where is the probability density function of . To compute the CVA numerically based on (24) in this independent case, a set of dates is chosen over which to evaluate the so-called expected positive exposure . The probabilities can be bootstrapped from the CDS curve of the client (or some proxy if such curve is not directly available).
In stochastic default intensity models, one can evaluate likewise the and compute the CVA based on (23), or simulate and compute the CVA based on (22).
Note that the portfolio weights in (17) are all 0 or 1 in the context of trade incremental XVA computations (cf. (Albanese et al., 2019, Section 5)).
The above approximation uses Gaussian process regression to provide a fast approximation for valuation. A metamodel for is fitted to model generated data, assuming a data generation process for the risk factors. Our GP regression provides an estimation of the GP error in the point estimate of the portfolio value (also accounting for the dependence between the portfolio ingredients, i.e. between the in (17), provided multi-GP is used).
Hence, we use machine learning to learn the component derivative exposures as a function of the underlying and other parameters, including (by slicing in time) time to maturity. The ensuing CVA computations are then done by Monte Carlo simulation based on this metamodel for . This procedure is referred to as MC-GP CVA computational approach hereafter. It saves one level of nested (such as inner Monte-Carlo) full revaluation (referred to as MC-reval hereafter), while avoiding parametric regression schemes for (at each ), which have little adaptivity and error control.
5.1 MC-GP Estimation of CVA
First we consider the independent case (24), which entails the following Monte-Carlo estimate of the CVA over M paths, along which the market risk factors are sampled:
[TABLE]
where the exact portfolio value is evaluated for simulated risk factor in path at time .
Then we replace the exact portfolio value by the mean of the posterior function conditioned on the simulated market risk factors , which results in the following CVA estimate (assuming a uniform time-grid with step ):
[TABLE]
In the stochastic intensity case (23), the above formulas become
[TABLE]
and
[TABLE]
The MC sampling error in the GP-MC estimate of the CVA is given by
[TABLE]
In the context of CVA on equity or commodity derivatives, structural default models may be found more suitable than default intensity models (see e.g. (Ballotta and Fusai, 2015)). A Monte Carlo GP approach is then still workable, by relying on the native formulation (22) of the CVA. The latter can be implemented based on client default simulation, which does not require that the client default time has an intensity.
5.2 Expected Positive Exposure Profile and Time 0 CVA
We continue with the same portfolio and option model (for data generation) as in the example of Section 4.3 (of course, in practice XVAs are mainly for OTC derivatives, instead of exchange tradeable options in this example, but our purpose is purely expository). Table 2 shows the values for the Euler time stepper used for simulating Black-Scholes dynamics over a two year horizon.
Figure 11 compares the (left) MC-reval (i.e., with full reevaluation of the portfolio, in this case by the Black Scholes formula) and MC-GP estimate of , the expected positive exposure (EPE) of the portfolio, over time. The error in the MC-GP estimate and 95% uncertainty band, exclusive of the MC sampling error, is also shown against time (right).
In order to illustrate CVA estimation using both credit and market simulation, we introduce the following dynamic pre-default intensity (cf. (Bielecki et al., 2011)):
[TABLE]
where . The time 0 CVA is then computed based on (27) as displayed in Listing 4.
Setting hereafter, Figure 12 shows how the standard error in the MC-GP CVA0 estimate versus MC-reval decays against the number of training samples used for each GP model. The 95% uncertainty band of the GP prediction is also shown.
5.3 Incremental One-Year CVA VaR
In this section, we demonstrate the application of GPs to the estimation of the Value-at-risk (VaR, i.e. quantile) of level of the one year incremental CVA. The purpose of the calculation is to estimate, at the confidence level , the extent to which to CVA liability of a bank may increase over the next year. For this purpose, we estimate the distribution of the incremental CVA over one year, i.e. of the random variable ().
For the purpose of illustration, we again use the dynamic pre-default intensity in (29), for fixed parameters and in (29), and the same market portfolio as before. However, we now model the (pre-default) CVA process such that (with zero interest rates)
[TABLE]
We fix the pre-default intensity model parameters. Overall, the MC-GP estimation of VaR is implemented as a nested simulation, with an outer loop over the simulation of the underlying out to one year, and a nested MC simulation for the point estimation of the one year CVA along each path. The CVA0, by contrast, is estimated with only an outer simulation loop and is a non-negative scalar.
Figure 13 (left) shows the distribution of CVA1, as estimated with a MC-reval (i.e. using Black-Scholes formulas at time 1) or a MC-GP method. Also, not shown, CVA, and hence the random variable () can be negative. In order to isolate the effect of the GP approximation, we use identical random numbers for each method.
The MC-GP and MC-reval graphs are practically indistinguishable from each other. The reason for sharp approximation is three-fold: (i) the dimension (in the sense of the number of risk factors) is only 1, (ii) the statistical experiment has been configured as an interpolation problem, with many of the gridded training points close to the gridded test points; and (iii) the training sample size of 200 is relatively large to approximate smooth surfaces (with no outliers). The right hand plot shows the distribution of at various times over the simulation horizon.
5.4 CVA Uncertainty Quantification
In this section, we demonstrate the application of GPs to the uncertainty quantification of CVA computations, given a prior on the credit risk model parameters.
Namely, the parameters, , of the dynamic intensity model (29) are now in one-to-one correspondence through the constraint
[TABLE]
in which the right-hand side is a given target value extracted from the client CDS curve (or a suitable proxy for the latter). Instead of fixing , we now place a chi-squared prior over , which is centered at . For each sample of , the corresponding value of is determined by time discretization and numerical root finding through (31)).
Figure 14 shows the density of the time 0 CVA posterior, as estimated by MC-reval (MC with full repricing using Black-Scholes formulas) versus MC-GP.
Next we show the estimation of the one year CVA VaR with uncertainty quantification. As displayed in Listing 5, the MC-GP estimation is implemented as a doubly nested simulation, with an outer loop for the sampling from the prior distribution on , a middle nested loop for simulation of the underlying out to one year, and an inner nested MC simulation for the point estimation of the one year CVA along each path.
Figure 15 shows the distribution of the 99% VaR of () under a chi-squared prior on the parameter and the corresponding value of is found from solving (31) with . The MC-GP and MC-reval 99% CVA VaRs are observed to be practically identical under the same random numbers.
5.5 Scalability of the Approach
We demonstrate the application of our GP meta-model to the CVA estimation on a counterparty portfolio of interest rate swaps (IRSs). The portfolio holds both short and long positions in 20 IRSs on a total of eleven interest rates and 10 FX rates. The contracts range from 5 to 10 years in maturity.
The short interest and FX rates data are generated from mean reverting processes with a quasi-homogeneous correlation structure between the driving Brownian motions of our factors. Specifically, we set the correlation between interest rates to 0.45, between interest rates & FX to 0.3 and 0.15 between FX rates. In our experiment, , giving a total of 21 factors.
We use the multi-factor Hull-White model for the short rates. For completeness the details of the models are given in Appendix A.
These models are simulated under a Euler scheme with a time step of 0.01. Every ten time steps, i.e. for a coarse , we store the simulated rates and evaluate the IRS prices.
The IRS contracts are spot-starting, with the first reset at time and subsequent resets every years at times . To price the swap, let’s denote by the simple rate prevailing at time t for a maturity T, which is deterministic function of the short rate given by the Hull-White model. Then the foreign price of the IRS at reset dates to the party receiving floating and paying fixed is given in units of notional denominated in the foreign currency as:
[TABLE]
and
[TABLE]
For non-reset dates, i.e. any we have:
[TABLE]
Except for , we note that the price is always a function of both the short rate at and at the previous reset date.
Each GP model therefore uses up to three inputs to learn the swap price: the domestic or foreign short rate, the same rate at the latest reset date, and if foreign the FX rate into Euros. Hence a GP model for a domestic interest rate swap price has two input variables and a foreign interest rate has three.
To train each GP model, we use 1000 paths of short and FX rates and Euro denominated mark-to-market IRS prices at the coarse time step . Each GP model is trained as a surrogate of each IRS contract in the portfolio. With ten periods, there are therefore 200 GP models trained.
The above numerical examples have trained and tested GPs on uniform grids. This approach suffers from a stringent curse of dimensionality issue, as the number of training points grows exponentially with the dimensionality of the data (cf. Section 2.3). Hence, in practice, in order to estimate the MtM cube, we advocate divide-and-conquer, i.e. the use of numerous low input dimensional space, , GPs run in parallel on specific asset classes (see Section 4.2). In the present example, we even train one GP per instrument. As seen in the end of Section 4.2, the advantage of this extreme case of a divide-and-conquer approach is that the portfolio can then be rebalanced without the need to retrain the GP.
All variables, including the prices, are rescaled to the unit interval to resolve potential scaling issues. The GP is configured to use Matern kernels with . See Example-5-MC-GP-IRS-CVA.ipynb in Github for further details.
The EPE profile (cf. Section 5.2) of the IRS portfolio evaluated using the pricing formula (MC-reval) versus the MC-GP is shown in Figure 16. The using the MC-GP or MC-reval model is given in Table 3. The mean of GP model estimate is found to be within of the GP-reval estimate . The 95% upper and lower confidence intervals for the MC sampling are also given.
6 Conclusion
This paper introduces a Gaussian process regression and Monte Carlo simulation (MC-GP) approach for fast evaluation of derivative portfolios, their sensitivities, and related counterparty credit risk metrics such as the EPE and the CVA. The approach is demonstrated by estimating the CVA on a simple portfolio with numerical studies of accuracy and convergence (in terms of both the numbers of training points and of sample paths) of our MC-GP estimates. Once the kernels have been learned, there is no need to use expensive derivative pricing or Greeking functions. The kernels permit a closed form approximation for the sensitivity of the portfolio to the risk factors and the approach preserves the flexibility to rebalance the portfolio. Efficient hyper-parameter optimization procedures are available. Moreover, the advantage is not just computational: The risk estimation approach is Bayesian—the uncertainty in a point estimate which the model hasn’t seen in the training data is quantified. The approach is scalable through a divide-and-conquer approach, possibly implemented in parallel, where a different GP is used for each sub-portfolio of assets depending on the same (few) risk factors.
Compared with simpler alternatives such as splines or kernel smoothers, GP regressions offer a metamodeling framework with a probabilistic Bayesian interpretation and a quantification of the associated numerical uncertainty. Marginal likelihood maximization yields a convenient way of setting the hyperparameters. GPs can cope with noisy data but they are also interpolating in the noise-free limit. As opposed to Chebyshev interpolation, which uses a deterministic node location imposed by the scheme (in conjunction with suitable interpolation weights, see (Gaß et al., 2017)), GPs can use an arbitrary, possibly unstructured (e.g. stochastically simulated) grid of observations.
Compared with richer alternatives such as deep neural networks (DNN), GPs typically require much less data to train. They also inherently provide “differential regularization” without the need to adopt cumbersome cross-validation techniques to tune regularization hyper-parameters, as in DNNs. Also, despite recent Bayesian deep learning developments meant to enable deep learning in small data domains, DNNs are still difficult to cast in a Bayesian framework. However, unlike DNNs, a kernel view does not give any hidden representations, failing to identify the useful features for solving a particular problem. More elaborate choice of priors can be used to address this issue.
Our usage of “uncertainty” in this paper refers to the GP regression error estimate. However, GPs could also potentially be used for uncertainty quantification in the sense of quantifying model risk. Model risk is, in particular, an important and widely open XVA issue, which we leave for future research.
Appendix A Multi-Factor Rates Model
We consider a correlation matrix . For every currency , we consider a vector of independent Brownian motions , where the superscript indicates that the process is a Brownian motion in the world, which in turn is where cash-flows in the currency are priced. Also, denotes the vector with coordinate equal to 1 and all other components equal to 0.
The Hull-White model for short rates is given by
[TABLE]
with an exogenous deterministic function to be able to fit the forward curve at time [math].
Or equivalenty, we may write with being a deterministic function and:
[TABLE]
If is the time-[math] instantaneous forward curve for rate , then:
[TABLE]
The FX rates are given by a mean-reverting process as follows. Consider, for ease of exposition to case when ,
[TABLE]
where and . By comparing with the dynamics obtained by FX inversion, one can deduce the following Brownian motion change between the and the worlds:
[TABLE]
or equivalently:
[TABLE]
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Abbas-Turki et al. (2018) Abbas-Turki, L. A., S. Crépey, and B. Diallo (2018). XVA Principles, Nested Monte Carlo Strategies, and GPU Optimizations. International Journal of Theoretical and Applied Finance 21 , 1850030.
- 2Albanese et al. (2019) Albanese, C., M. Chataigner, and S. Crépey (2019). Wealth transfers, indifference pricing, and XVA compression schemes. In Y. Jiao (Ed.), From Probability to Finance—Lecture note of BICMR summer school on financial mathematics , Mathematical Lectures from Peking University Series. Springer. Forthcoming.
- 3Albanese and Crépey (2019) Albanese, C. and S. Crépey (2019). XVA analysis from the balance sheet. Working paper available at https://math.maths.univ-evry.fr/crepey.
- 4Alvarez et al. (2012) Alvarez, M., L. Rosasco, and N. Lawrence (2012). Kernels for vector-valued functions: A review. Foundations and Trends in Machine Learning 4 (3), 195–266.
- 5Antonov et al. (2018) Antonov, A., S. Issakov, A. Mc Clelland, and S. Mechkov (2018). Pathwise XVA Greeks for early-exercise products. Risk Magazine (January).
- 6Ballotta and Fusai (2015) Ballotta, L. and G. Fusai (2015). Counterparty credit risk in a multivariate structural model with jumps. Finance 36 , 39–74.
- 7Bielecki et al. (2011) Bielecki, T. R., S. Crépey, M. Jeanblanc, and M. Rutkowski (2011). Convertible bonds in a defaultable diffusion model. In A. Kohatsu-Higa, N. Privault, and S.-J. Sheu (Eds.), Stochastic Analysis with Financial Applications , Basel, pp. 255–298. Springer Basel.
- 8Bonilla et al. (2007) Bonilla, E. V., K. M. A. Chai, and C. K. I. Williams (2007). Multi-task gaussian process prediction. In Proceedings of the 20th International Conference on Neural Information Processing Systems , NIPS’07, USA, pp. 153–160. Curran Associates Inc.