Coping with Selection Effects: A Primer on Regression with Truncated Data
Adam B. Mantz (KIPAC, Stanford)

TL;DR
This paper discusses statistical methods for performing regression analysis on truncated data, common in astronomy, highlighting how to account for selection effects and improve inference accuracy.
Contribution
It provides a general framework for regression with truncated data, including computational strategies and conditions where selection effects can be ignored.
Findings
Truncation affects the estimation of variables in regression models.
Modified models can account for undetected sources in incomplete data.
Recommendations for computational approaches to truncated data regression.
Abstract
The finite sensitivity of instruments or detection methods means that data sets in many areas of astronomy, for example cosmological or exoplanet surveys, are necessarily systematically incomplete. Such data sets, where the population being investigated is of unknown size and only partially represented in the data, are called "truncated" in the statistical literature. Truncation can be accounted for through a relatively straightforward modification to the model being fitted in many circumstances, provided that the model can be extended to describe the population of undetected sources. Here I examine the problem of regression using truncated data in general terms, and use a simple example to show the impact of selecting a subset of potential data on the dependent variable, on the independent variable, and on a second dependent variable that is correlated with the variable of interest.…
Click any figure to enlarge with its caption.
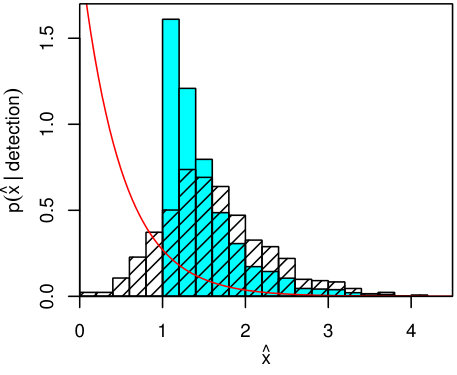 Figure 1
Figure 1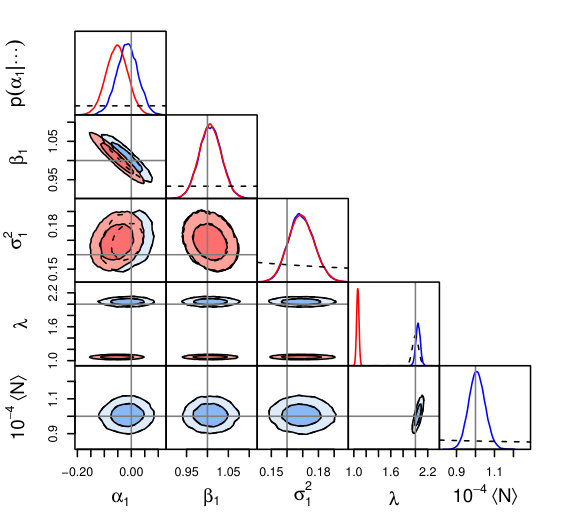 Figure 2
Figure 2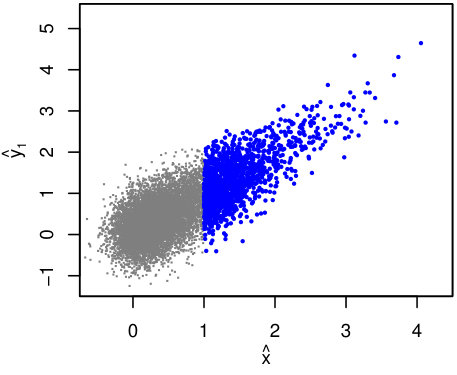 Figure 3
Figure 3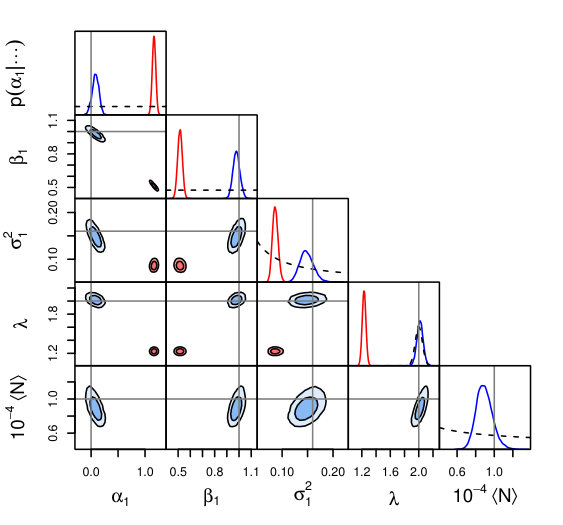 Figure 4
Figure 4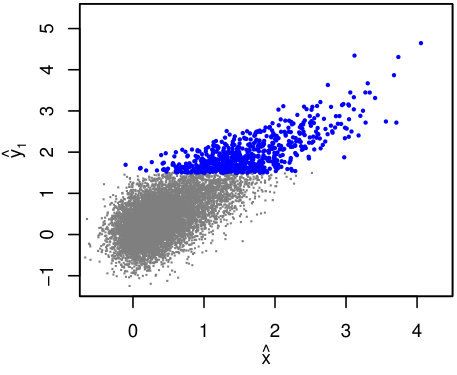 Figure 5
Figure 5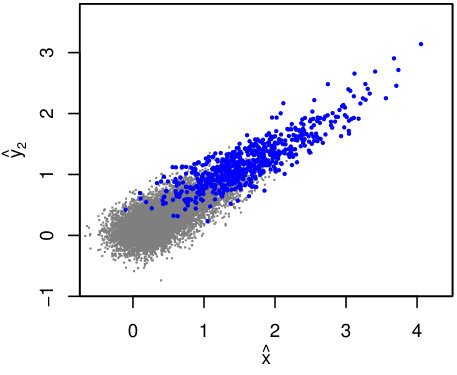 Figure 6
Figure 6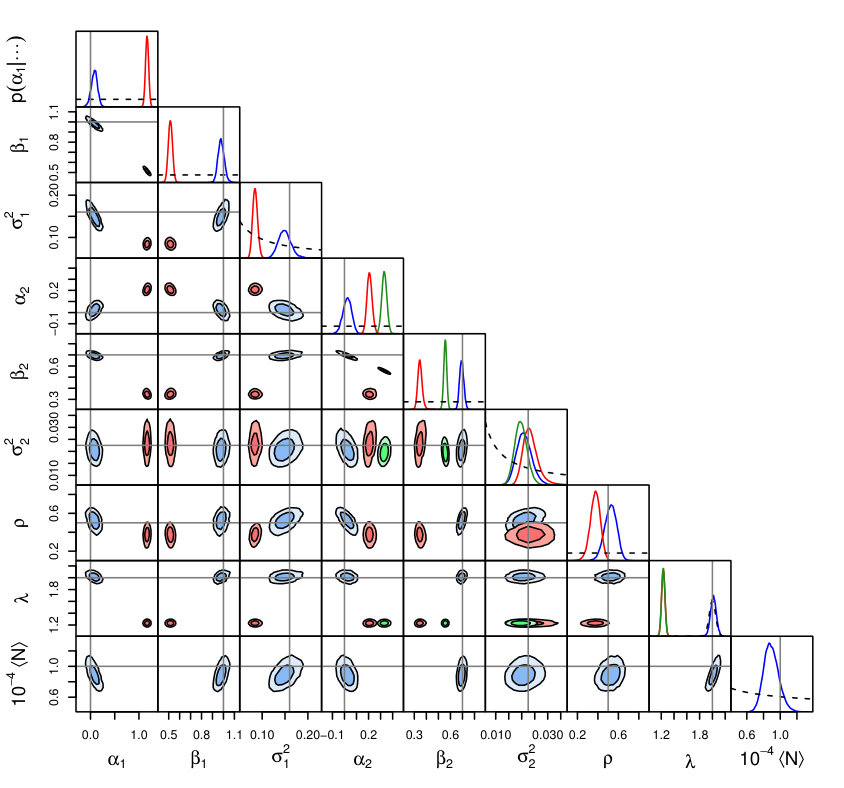 Figure 7
Figure 7| Parameter | Value | Parameter | Value |
|---|---|---|---|
| 0.4 | |||
| 2 | 0.15 | ||
| 0 | 0.5 | ||
| 0 | 0.2 | ||
| 1 | 0.05 | ||
| 0.7 | 0.1 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Coping with Selection Effects:
A Primer on Regression with Truncated Data
Adam B. Mantz1,2
1Kavli Institute for Particle Astrophysics and Cosmology, Stanford University, 452 Lomita Mall, Stanford, CA 94305, USA
2Department of Physics, Stanford University, 382 Via Pueblo Mall, Stanford, CA 94305, USA Corresponding author e-mail: [email protected]
(Submitted 24 July 2018, accepted 28 January 2019)
Abstract
The finite sensitivity of instruments or detection methods means that data sets in many areas of astronomy, for example cosmological or exoplanet surveys, are necessarily systematically incomplete. Such data sets, where the population being investigated is of unknown size and only partially represented in the data, are called “truncated” in the statistical literature. Truncation can be accounted for through a relatively straightforward modification to the model being fitted in many circumstances, provided that the model can be extended to describe the population of undetected sources. Here I examine the problem of regression using truncated data in general terms, and use a simple example to show the impact of selecting a subset of potential data on the dependent variable, on the independent variable, and on a second dependent variable that is correlated with the variable of interest. Special circumstances in which selection effects are ignorable are noted. I also comment on computational strategies for performing regression with truncated data, as an extension of methods that have become popular for the non-truncated case, and provide some general recommendations.
keywords:
methods: data analysis – methods: statistical
1 Introduction
As astronomers increasingly adopt Bayesian methods, and computational resources continue to improve, ubiquitous features of astronomical data and models that are difficult to address through classical statistical methods based on the generalized linear model are now routinely dealt with. Among these are measurement errors on the independent variables of a regression, correlation in the measurements of independent and dependent variables (hereafter called covariates and responses, respectively), and the presence of intrinsic scatter. In addition to general-purpose Markov Chain Monte Carlo tools, easy-to-use codes for specialized but reasonably generic problems have been provided to and socialized within the community. Of particular note is linmix_err (Kelly, 2007), which uses conjugate Gibbs sampling to efficiently fit a model consisting of a linear mean relation, Gaussian measurement and intrinsic scatters, and a Gaussian mixture prior distribution of the covariates. While these are strong modeling assumptions, many of them are also fairly common, irrespective of the fitting method employed. The same approach has been generalized to multivariate regression (lrgs; Mantz 2016) and applied using an off-the-shelf Gibbs sampling environment (Sereno et al., 2015).
A common and problematic feature of astronomical data that these specialized tools do not address is selection bias, resulting in truncation of the observed data set. This refers to the situation in which the data set available for analysis is not representative of the complete population that we wish to make inferences about, and furthermore that even the size of that complete population is not known. Note that this scenario is distinct from that of “censored” data, in which a subset of measurements are unavailable even though the size of the complete data set is known and fixed. Modifications of classical nonparametric estimators have been developed to address truncation (Efron & Petrosian 1992, 1999). In the Bayesian framework, the solution is to incorporate the selection mechanism into a generative model for the data; this necessitates modeling the full population, including undetected (but potentially detectable) sources. An unavoidable feature of inference on truncated data, which becomes explicit in the Bayesian formulation, is that we must have a model to describe the portion of the complete population that is not observed.
In astronomy, selection effects such as Eddington and Malmquist biases have been discussed at least since the eponymous works of Eddington (1913) and Malmquist (1922, 1925). Their importance has been recognized for cosmological surveys, especially in the context of the abundance and scaling relations of clusters of galaxies (e.g., recently, Pratt et al. 2009; Vikhlinin et al. 2009; Mantz et al. 2010a, b; Allen et al. 2011), and the distance-redshift relation of type Ia supernovae (March et al., 2018). Similar selection effects are clearly also present in, for example, exoplanet surveys (e.g. Youdin 2011; Gaidos & Mann 2013), and have been discused in the context of quasar and gamma ray burst data sets (Efron & Petrosian, 1994; Petrosian et al., 2015). The discussion below thus has applicability in many areas.111Indeed, after this work was submitted and was in revision, Mandel et al. (2018) wrote about a application of a similar framework to gravitational-wave astrophysics, with an emphasis on recovering the distribution of covariates.
The purpose of this work is twofold. First, I hope to provide an understandable overview of how truncation can be incorporated into the likelihood function in general, as well as more concretely for a few specific (and simple) selection mechanisms. This will include some discussion of the special circumstances in which selection effects are ignorable, i.e. when the likelihood need not be modified. The emphasis is on regression (that is, recovering the parameters of a linear relation), although the basic approach is more general. Second, in simple cases where selection is not ignorable, constraints on a toy model obtained using the correct likelihood will be contrasted with those from methods analogous to the codes mentioned above, which do not account for selection. This is not to impugn those codes particularly, but to emphasize that failing to account for selection in an analysis has the potential to seriously compromise the results. In the conclusions, I will comment briefly on computational strategies for performing the complete analysis. The code used to perform the fits to mock data in this work is available as an extension of the Python implementation of lrgs.222https://github.com/abmantz/lrgs
2 A Concrete Scenario
While many aspects of the model framework developed in the next section are general, it is helpful to have a specific problem in mind for illustration. Therefore, consider the closely related tasks of studying the cosmology and scaling relations of galaxy clusters. The key ingredients of the model, and the notation used in this work, are as follows.
- •
The population of clusters in the Universe is described theoretically by a mass function, i.e. their number density as a function of mass and redshift. The mass function is determined by cosmological parameters (e.g. Press & Schechter 1974), which will be collectively denoted . Mass and redshift can be thought of as the covariates of a regression (below), and so are denoted . Thus, the mass function, apart from a normalization, can be thought of as the a priori probability for a cluster to have a given mass and redshift, . The normalization can be parametrized by , the size of the complete population of interest. The interpretation of will depend on exactly what range of is used to define the population under study; in practice, the only requirement is that all sources that could plausibly be detected are included in this definition.
- •
A given cluster generates various observable signals such as the mass, temperature, X-ray luminosity and Sunyaev-Zel’dovich signal of the intracluster gas; the number and optical/IR luminosity of its galaxies; and the gravitational lensing shear induced on background galaxies by the cluster’s mass. These depend on the cluster mass and may evolve, and so can be thought of as response variables of a regression, . Note that refers the true value of an observable quantity, not to the observed value, which is subject to measurement error. The average scaling of with is generally modeled as a power law (that is, a line if and actually refer to the logarithm of mass, etc.). In addition to this average behavior, there is an intrinsic scatter in the values of for a given . The scaling relations are thus described by a distribution , where parametrizes both the average scaling relation(s) and the intrinsic scatter.
Here I have implicitly assumed that the parameters represented by and are distinct. This need not always be true, but it is reasonably common separation, in this case reflecting a distinction between cosmological and astrophysical models.
- •
Measured (or potentially measured) values of the properties of a cluster will be denoted or ; these are related to the true values by a sampling distribution, . This notation includes the possibility of correlations in the measurement errors. For simplicity, I will assume that the sampling distribution as a function of and is known, so that no additional parameters need to appear explicitly. The measured data additionally include , the number of clusters detected in the survey.
In the galaxy cluster case, could include spectroscopic measurements of redshift. However, measurements of mass are less straightforward, and in general any measured proxy for the mass may have an intrinsic scatter which correlates at fixed true mass with one of the observables in . In practice, it therefore makes sense to include such mass proxies (including mass estimated from gravitational lensing) as response variables, with theoretical priors constraining the attendant scaling relation parameters. In practice, the same set of measurements need not be available for all detected clusters, with the exception of the survey measurement(s) used to detect them to begin with.
- •
The probability for a cluster to be detected (that is, included in the data set) as a function of measured (or potentially measured) properties is denoted . This may depend on additional parameters, , such as a completeness or a flux limit.
In practice, the detection process is generally a deterministic function of the survey data, so can be written as a function of only , and for an appropriate definition of and . In fact, it is frequently possible to express as a step function. For example, consider the scenario in which detection requires a measured flux to exceed a position-dependent threshold (corresponding to non-uniform survey depth). With position on the sky included in and flux included in , has the form of a step function, dependent on position and measured flux. However, there is no real benefit to expressing things this way, since a cluster’s position on the sky is typically both well determined (effectively without error) and not otherwise of interest. Hence, one might instead define in terms of measured flux only, with proportional to the fraction of the survey footprint where the threshold for detection is less than a given value. Conversely, a metric often used to characterize cluster surveys is the detection probability as a function of (true) mass. However, writing this way requires a marginalization over the dependent variable(s) associated with the survey detection (luminosity in the above example) as well as the corresponding scaling relation parameters. Consequently, this is not the most natural way to express in the likelihood developed in the next section.
To summarize this scenario, and determine the number density of clusters as a function of redshift and mass (); one or more response variables () for each cluster follow from its redshift, mass and the scaling relation parameters, ; potentially measured values or follow from , and the sampling distribution; and these measurements combined with the detection probability result in clusters, and their measured values, forming the available data set. This level of generality will be maintained in Section 3. In Section 4, we will specify the scenario even further in order to illustrate the impact of selection effects on a toy data set.
3 Theory
3.1 Likelihood
At its most abstract level, the problem at hand is that of modeling the properties of some population of sources in the Universe, when a fraction of that population is systematically missing from our data set. Using the notation introduced in Section 2, our model thus divides the sources in the complete population into that are represented in the data and that are missing from the data. If we assume that sources are independent from one another both in their occurrence and detection, the likelihood of the data, marginalized over , can be written
[TABLE]
with the prior distribution for . Here is the a priori probability that a given source is not detected,
[TABLE]
which appears once for each of the undetected sources. This construction explicitly shows the integrations required to express a completeness function (or effective ) in terms of true properties and/or . Note also that this framework requires the sampling distribution, , to be defined for a generic source, at least for those observables involved in detection. That is, we need a generative model for the measurement errors involved in the survey detection process, not just error bars for the detected sources estimated from the data. is the likelihood associated with detections,
[TABLE]
where the factorization into a product relies on our assumption that the sources occur independently. The integral in this expression differs from that in Equation 2 both in the substitution and in that and are fixed by observation rather than being marginalized over. In the common case where is constant, is also a constant for all observed sources, and this factor is equivalent to the simplified likelihood (applicable in the absence of selection effects),
[TABLE]
The combinatoric factor in Equation 1, , appears because the sources are a priori exchangeable.
3.2 Prior Distributions for
Since the complete population size, , has been introduced, we will need to assign it a prior distribution. For example, Gelman et al. (2004) note that if (uniform in ), the sum in Equation 1 can be done analytically, yielding
[TABLE]
with
[TABLE]
being the a priori probability for a source to be detected. Note that has no dependence on the measured properties of the detected sources, despite the fact that it appears to the power .
While this identity makes the prior convenient, a Poisson distribution (dependent on a mean hyperparameter, ) is more appropriate in most astronomical scenarios. This is consistent with our earlier assumption of independently occurring sources. With such a prior, Equation 1 becomes
[TABLE]
where the identities and have been used, and where the last line discards a constant factor of . The same expression can be derived (perhaps more intuitively) without the need to explicitly model and marginalize over by considering the Poisson likelihood for sources in bins of the and observables, and taking the limit of infinitesimally small bins (see Mantz et al. 2010a).
In practice, may depend on further parameters of the astrophysical model (e.g. cosmological parameters in the galaxy cluster scenario of Section 2). However, for those cases where we lack a physically motivated prior for , it may be convenient to assign a gamma distribution prior, as this makes the marginalization over both and analytic. To see this, note that Equation 3.2 has the form of a gamma distribution for , with shape and rate . If we take a gamma prior on with shape and rate , then
[TABLE]
discarding constant factors that depend only on , and . In the second line above, the gamma density function has integrated to unity, provided that and .
Though not infinitely flexible, the gamma distribution provides a range of potentially useful priors. Taking , it describes power-law priors of the form . For both and (, or uniform in ), we intuitively recover Equation 5, while and is the Jeffreys prior for , . When is expected to be large, approximately Gaussian priors can be accommodated by setting and , where and are the desired mean and standard deviation. If desired, a posteriori samples of can be generated from the gamma distribution in Equation 8. A posteriori samples of could then be generated from a Poisson distribution; alternatively, if is not of interest, samples of can be drawn directly from its marginalized posterior distribution,
[TABLE]
which is the negative binomial distribution with parameters and .
3.3 Ignorability
One of the central questions for this work is under what circumstances selection effects due to truncation require us to use Equation 3.2, rather than one of the simpler likelihoods or . The latter is possible when the posterior for the parameters of interest can be written strictly in terms of the observed data. Gelman et al. (2004) refer to selection effects as ignorable in this case, and discuss the necessary conditions. To summarize, selection is ignorable if the following statements are both true:
The prior distribution for is independent of the prior distribution for all other parameters. 2. 2.
Selection does not depend on unobserved (or potentially unobserved) data.
The first condition we can assume without losing too much generality, but the second is generically violated in truncation problems. Our default expectation in these circumstances should thus be that the formalism above is necessary. We will see below that, in very special circumstances, selection effects are ignorable for the purposes of constraining the parameters of the regression, , though not necessarily (assuming that the two are indeed separable). The extreme, and intuitive, example of this occurs when data are missing completely at random with respect to the measurements and parameters of interest; in that case, is naturally a sufficient likelihood.
Another way to put this is that using the likelihood alone is not the same as “not using information from the number of detections” – that would be most closely equivalent to marginalizing over an uninformative prior, as outlined above.
4 Simple Examples
4.1 Toy Data, Models, and Methods
To illustrate how this works in a more concrete way, we can consider a simplified version of the galaxy cluster survey case outlined in Section 2. Specifically, let represent the log-mass only (neglecting redshift), and take
[TABLE]
with . This is an approximately appropriate distribution for the log-masses of galaxy clusters (e.g. Evrard et al. 2014), apart from the unphysical restriction . We will consider two response variables, , with power-law slopes and an Gaussian intrinsic scatter covariance roughly appropriate for the log X-ray luminosity and log temperature of the intracluster gas, respectively (Allen et al., 2011; Giodini et al., 2013);
[TABLE]
where denotes the multivariate normal density function for a given mean and covariance matrix. In particular, the marginal intrinsic scatter in at fixed is relatively large, and its average scaling is relatively steep, compared with the scatter and power-law slope of , and the two scatters are moderately correlated. Measurement errors are assumed to be Gaussian, uncorrelated and identical for all sources, again with typical magnitudes, corresponding to respectably high signal-to-noise data;
[TABLE]
Specifically, measurement errors were (roughly the intrinsic scatter due to correlated structure in cluster mass estimates from weak gravitational lensing; Becker & Kravtsov 2011),333The assignment of a simple measurement error for mass contravenes the advice in Section 2, but is adopted for simplicity here. and . A complete (before truncation) mock data set of clusters was generated using these parameters, which are summarized in Table 1. To make explicit the link to the notation of Sections 2–3, we have and .
The following subsections will apply a simple selection on either or and contrast constraints obtained using the complete likelihood of Equations 3.2–8 with those obtained using only (equivalently, ; Equations 3–4). The constraints from were computed using a Python-language version of the lrgs code that was straightforwardly extended to use the exponential form of in Equation 10 rather than the usual Gaussian mixture. Constraints from the full likelihood were found by alternating lrgs conjugate-Gibbs sampling of the parameters that do not appear in ( and ) with Metropolis sampling (via the lmc code444https://github.com/abmantz/lmc) of the remaining parameters (, , , and ), a strategy implemented as a submodule of lrgs. I will therefore refer to the two methods as lrgs and lrgs.trunc, respectively.
Identical priors were applied to the parameters common to the two methods, specifically uniform priors for , and ; the Jeffreys prior for , ; and a Gaussian prior for , with mean 2 and standard deviation 0.05. For the lrgs.trunc method, I took an uninformative Gamma prior on , with and , and followed the procedure in Section 3.2 to marginalize over analytically and generate samples a posteriori. These choices for and priors mirror the typical situation in the analysis of galaxy cluster surveys, where we have prior information on the shape of the mass function, but wish to either fit for or marginalize over its normalization.
4.2 Selection on the Survey Response Variable
When the scaling relation of interest is for the dependent variable on which selection is based, it is clear that the requirements for selection to be ignorable are not met (Section 3). Consider the simple detection requirement , i.e. , with the unit step function. Figure 1 illustrates this selection on the mock data set with , for which 658 points are “detected” in this particular realization. This is a sufficiently large data set that the systematic error introduced by using an incorrect likelihood is significant compared with the width of the posterior. In the first case, consider a fit only involving and , ignoring any information about (but see Section 4.4).
For the particular scenario described above, we have
[TABLE]
where is the standard normal cumulative distribution function. More generally, selection on implies that will depend explicitly on the parameters governing the marginal scaling relations of ; hence, the correct posterior for these parameters cannot be recovered if terms in the likelihood involving are neglected. Schemes that employ only “bias corrections” of the sampling distribution, by setting to zero below and renormalizing it (e.g. Vikhlinin et al. 2009; Sereno et al. 2015), do not address this feature. Note that both the methods considered here already implicitly include this information, since for all detected sources.
The constraints obtained from lrgs and lrgs.trunc are respectively shown as red and blue contours in the right panel of Figure 1; evidently, the former disagree with the input parameter values at high significance.
How can we intuitively understand this? First, it’s worth noting that prior information about the form of in has nothing to do with the bias in the constraints from lrgs. In fact, fixing (which lrgs gets spectacularly wrong, in spite of the informative prior) to the true value does not significantly change the constraints on the scaling parameters. More formally, if we take the limit of zero measurement errors on , the likelihood (or ) provides no mechanism to produce covariance between and the scaling parameters. We should therefore expect the bias produced by neglecting terms with in the likelihood to persist, even with perfect prior information on , despite the fact that the true clearly implies that a substantial number of objects must be missing at x\ {\raise-3.22916pt\hbox{\buildrel<\over{\sim}}}\ 2.
The reason that cannot recover the input scaling relation, even with accurate prior information about , is that it fails to capture the systematic way in which sources with small are missing, specifically the dependence on their value of . The practice of truncating the sampling distribution for at is of no help here; while it may prevent the cluster of observed points just above at small from significantly penalizing models near the truth, models with shallower slopes that pass closer to these points will still be preferred. This is exactly what we see in the constraints from lrgs.
In contrast, the lrgs.trunc method, when provided with the same prior information, recovers the true parameter values. In this case, the highly biased points detected at small do carry significant information. Their particular values of are not very informative for models near the truth – is so far from the mean scaling relation that detected points must lie just above the threshold. But the number of sources that exceed , combined with knowledge of , constrains the scaling relation and its scatter. In this example, there are 100 detections with , implying (for ) that exceeds the mean relation by – in this regime. This dependence of the interpretation of the data on is illustrated by the degeneracies between and the other parameters of interest in Figure 1.
4.3 Selection on the Covariate
At the other extreme, consider selection on instead of , , again ignoring for the moment. In this case, has an analogous form to Equation 38,
[TABLE]
Intuitively, the detected fraction is now independent of the scaling relation parameters, . It follows that:
- •
If our model for is fixed a priori, then is a constant and selection effects are ignorable. This holds regardless of whether there are non-zero measurement errors. If is a free parameter, selection is still ignorable for inferences about because the likelihood factors into one part that depends on and another that depends on , with no free parameters appearing in both.
- •
If measurement errors on are zero (the latent parameters are effectively fixed), then selection is ignorable for inferences about (only). This is because the observed data are always complete and therefore unbiased for every that is represented in the data set.
The above are special cases, however. In general, when there are non-zero measurement errors on and the model for is not fixed, selection must be accounted for. Note that even these exceptions depend on the parameters governing and the scaling relation ( and ) being distinct, which was an assumption in this application (Section 2), but is not true of all possible applications.
The mock data selection for () and the resulting constraints appear in Figure 2. As one might guess from the discussion above, the constraints from lrgs are less biased than before, although the joint posterior for and is still inconsistent with the input parameters at high significance. Again, fixing the value of would not eliminate the bias on the other parameters (see above).
4.4 Selection on a Correlated Response Variable
Next, consider the case where we are interested in the scaling of with when the data set is selected on a different response variable, . The key question here is whether and are correlated at fixed , either due to correlation of their measurement errors or due to an intrinsic covariance of and at fixed . If no such correlation is possible, then selection on is equivalent to a (possibly noisy) selection on , and the comments in Section 4.3 apply.
For illustration, Equation 21 can be rewritten as
[TABLE]
This factorization demonstrates how our interpretation of may depend on information about , such as satisfaction of a selection criterion, for . Specifically, the difference between and its mean value predicted by the scaling relation, , impacts our interpretation of the analogous displacement of from its mean scaling law. Thus, for a positive correlation, at low masses () we expect a selection on luminosity () to bias the observed data high in both luminosity and temperature (). The detected fraction for selection on is given by Equation 38.
As in Section 4.3, we can see that selection effects are ignorable for inference of , and only in very special circumstances, namely if
the marginal scaling relation for (i.e. the values of , and ) and the intrinsic correlation coefficient, , are fixed a priori; and 2. 2.
the model for is fixed or the measurement errors for are zero.
Note that the second condition is identical to the requirement for selection on to be ignorable. The requirements of the first condition above are exactly those that make selection on equivalent to a noisy selection on , with the nature of that stochasticity fully understood.
Using the same selection as in Section 4.2 (), Figure 3 shows the complete and observed mock data set in terms of and . Due to the modest intrinsic correlation () and relatively smaller marginal scatter compared with , selection effects on the observed data are less visually dramatic than in Figures 1–2. Nevertheless, we will see below that neglecting to model the truncation results in biased inferences.
Figure 4 compares constraints from lrgs and lrgs.trunc in the usual way, where both codes are now fitting joint scaling relations and scatter for and as a function of . In addition, constraints are shown from an lrgs analysis where is disregarded completely, i.e. simply fitting against without accounting for selection effects. In this particular case, both lrgs analyses are consistent with the input value of , as one might guess by inspection of Figure 3, but produce biased constraints (to differing degrees) on and .
Note that a non-zero correlation in the measurement errors of and would play essentially the same role as the intrinsic correlation, , in the discussion above.
5 Discussion and Conclusions
Although the examples explored above are far from exhaustive, hopefully it’s clear that selection effects have the potential to dramatically bias the results of otherwise straightforward model fitting if not taken into account. Exactly how important this systematic effect is compared with the statistical uncertainties is not a simple question to answer in general, as it will depend not just on the number of observed data points and their error bars, but also on the selection mechanism and the true, underlying model. One could always straightforwardly test whether simple fitting methods are able to recover the correct parameter values by running them on mock data appropriate for a given situation, along the lines of the examples above. A better option, whenever feasible, would be to properly include selection in the model being fit.
An unfortunate feature of models that account for selection is that they lack the full conjugacy that allows all of the parameters in models like those used by lrgs and linmix_err to be efficiently Gibbs sampled, even for simple selection mechanisms like those considered here. Specifically, conjugacy will generally be lost for any parameters appearing in . It is, however, still possible to efficiently Gibbs sample the remaining parameters, in particular and , under the assumptions made by these codes, namely Gaussian (or similarly convenient) forms of the measurement errors, intrinsic scatter, and . Since and normally account for the great majority of the free parameters in such models, mixing conjugate Gibbs sampling of with some other method of sampling the remaining parameters, as outlined in Section 4.1, is a viable strategy for these cases (though I by no means claim it to be the most efficient strategy). Note that this strategy is not without its pitfalls; in particular, when using mixture models, the potentially large number of parameters and the exchangeability of the mixture components can make sampling challenging (this is a generic feature, not specific to truncation problems). In addition, it’s potentially helpful that can be marginalized analytically for a wide range of approximately power-law and Gaussian priors.
A basic and intuitive feature of truncation is that our interpretation of the data relies to some extent on a model for the population of sources that were not observed. There are two immediate consequences of this. Firstly, we can expect our results in general to be sensitive to prior information about , including the form of . Thus, the Gaussian mixture models employed by some “out of the box” codes, while convenient and flexible, are no substitute for accurate modeling of . Inspection of the distributions of selected from the mock data sets analyzed above (Figure 5) makes clear that no amount of flexible but uninformed modeling of the observed data is likely to recover or even be consistent with the underlying, non-Gaussian form of . While we may not need precise knowledge of the true a priori to obtain correct results in this example, we would likely at least need the prior that is monotonically decreasing. Secondly, the amount of data required for our results to be data-dominated rather than prior-dominated will generally be greater than in problems without truncation, and may not be particularly obvious. Analysis of mock data sets is probably the best way to get a handle on this.
Despite these complicating aspects, the general solution for fitting truncated data is relatively straightforward. This is encouraging, given that truncation is such a common feature of astrophysical data.
Acknowledgments
This work was supported by the National Aeronautics and Space Administration under Grant No. NNX15AE12G issued through the ROSES 2014 Astrophysics Data Analysis Program. I thank Gus Evrard and Arya Farahi for interesting discussions, and the anonymous referee for very good suggestions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Allen et al. (2011) Allen S. W., Evrard A. E., Mantz A. B., 2011, ARA&A , 49, 409 · doi ↗
- 2Becker & Kravtsov (2011) Becker M. R., Kravtsov A. V., 2011, Ap J , 740, 25 · doi ↗
- 3Eddington (1913) Eddington A. S., 1913, MNRAS , 73, 359 · doi ↗
- 4Efron & Petrosian (1992) Efron B., Petrosian V., 1992, Ap J , 399, 345 · doi ↗
- 5Efron & Petrosian (1994) Efron B., Petrosian V., 1994, J. Am. Stat. Assoc., 89, 452
- 6Efron & Petrosian (1999) Efron B., Petrosian V., 1999, J. Am. Stat. Assoc., 94, 824
- 7Evrard et al. (2014) Evrard A. E., Arnault P., Huterer D., Farahi A., 2014, MNRAS , 441, 3562 · doi ↗
- 8Gaidos & Mann (2013) Gaidos E., Mann A. W., 2013, Ap J , 762, 41 · doi ↗