The FFBS Estimation of High Dimensional Panel Data Factor Stochastic Volatility Models
Guobin Fang, Huimin Ma, Michelle Xia, Bo Zhang

TL;DR
This paper introduces a novel high-dimensional panel data factor stochastic volatility model with observable and unobservable factors, utilizing FFBS and MCMC methods for robust parameter estimation in financial data.
Contribution
It develops a new model combining observable and unobservable factors with a specialized estimation algorithm, enhancing analysis of financial market dynamics.
Findings
Observable factors have similar influence across company types.
Unobservable factors differ significantly between internet finance and traditional firms.
The proposed algorithm demonstrates robustness and consistency in parameter estimation.
Abstract
In this paper, We propose a new style panel data factor stochastic volatility model with observable factors and unobservable factors based on the multivariate stochastic volatility model, which is mainly composed of three parts, such as the mean equation, volatility equation and factor volatility evolution. The stochastic volatility equation is a 1-step forward prediction process with high dimensional parameters to be estimated. Using the Markov Chain Monte Carlo Simulation (MCMC) method, the Forward Filtering Backward Sampling (FFBS) algorithm of the stochastic volatility equation is mainly used to estimate the new model by Kalman Filter Recursive Algorithm (KFRA). The results of numeric simulation and latent factor estimation show that the algorithm possesses robustness and consistency for parameter estimation. This paper makes a comparative analysis of the observable and unobservable…
Click any figure to enlarge with its caption.
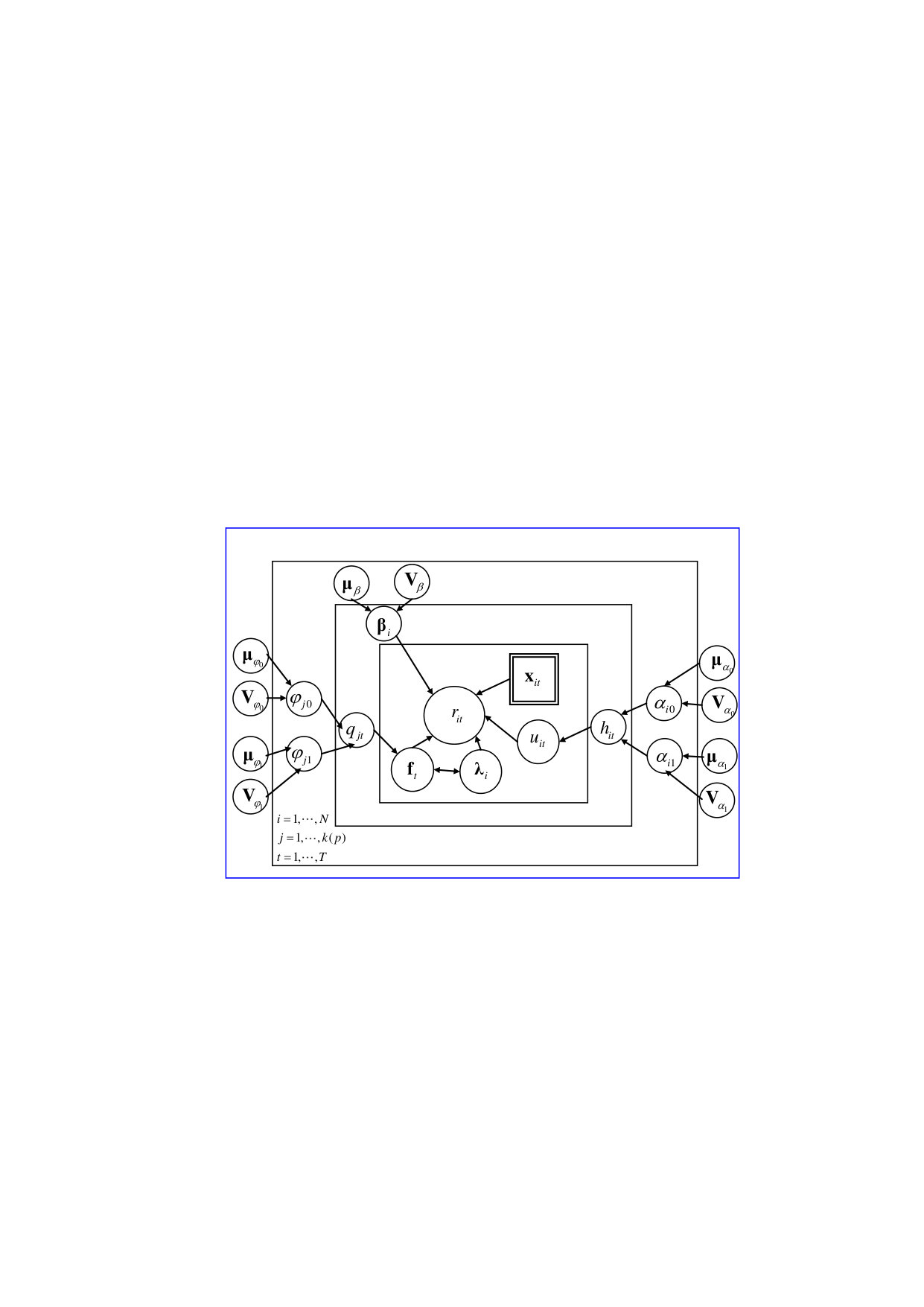 Figure 1
Figure 1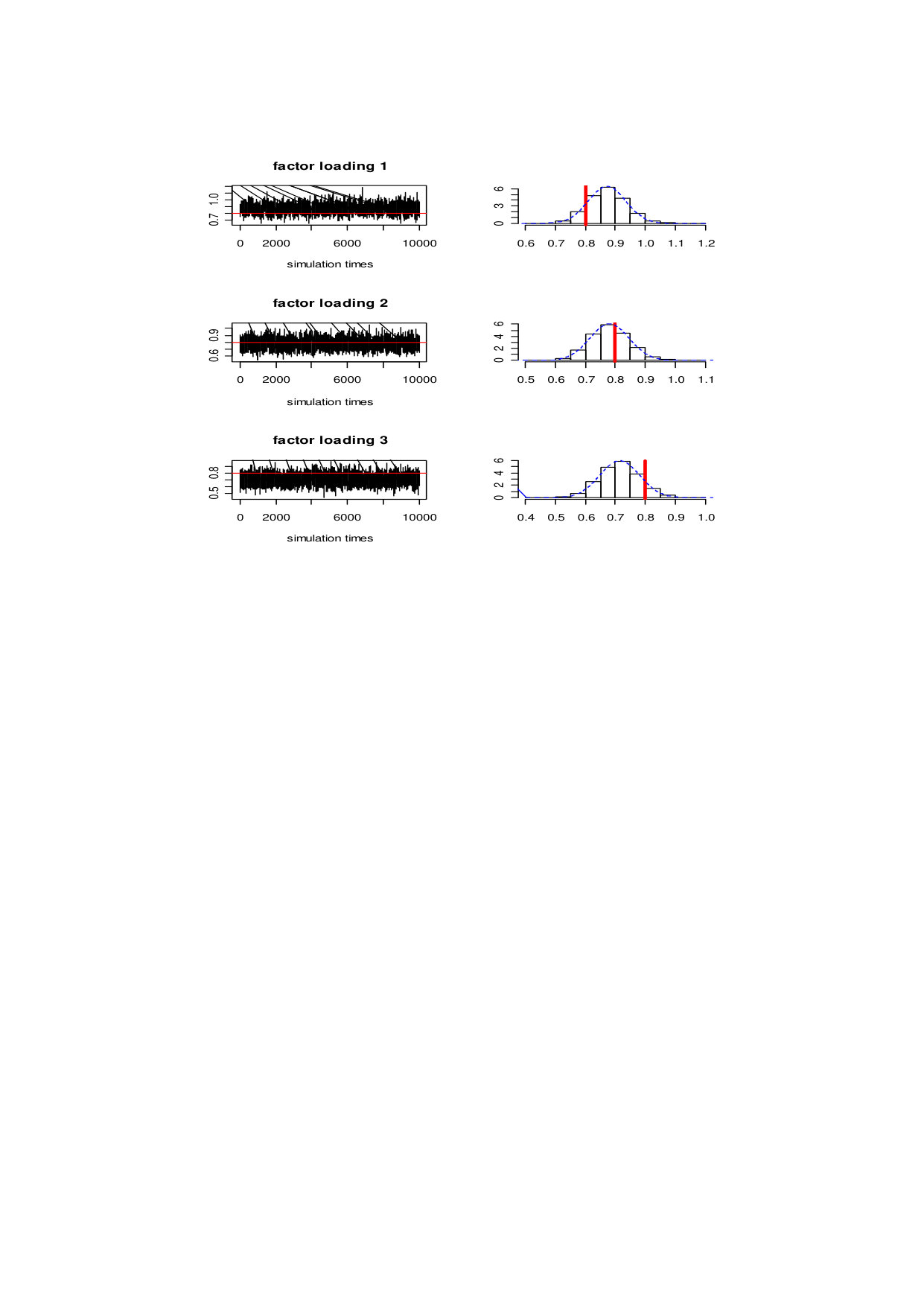 Figure 2
Figure 2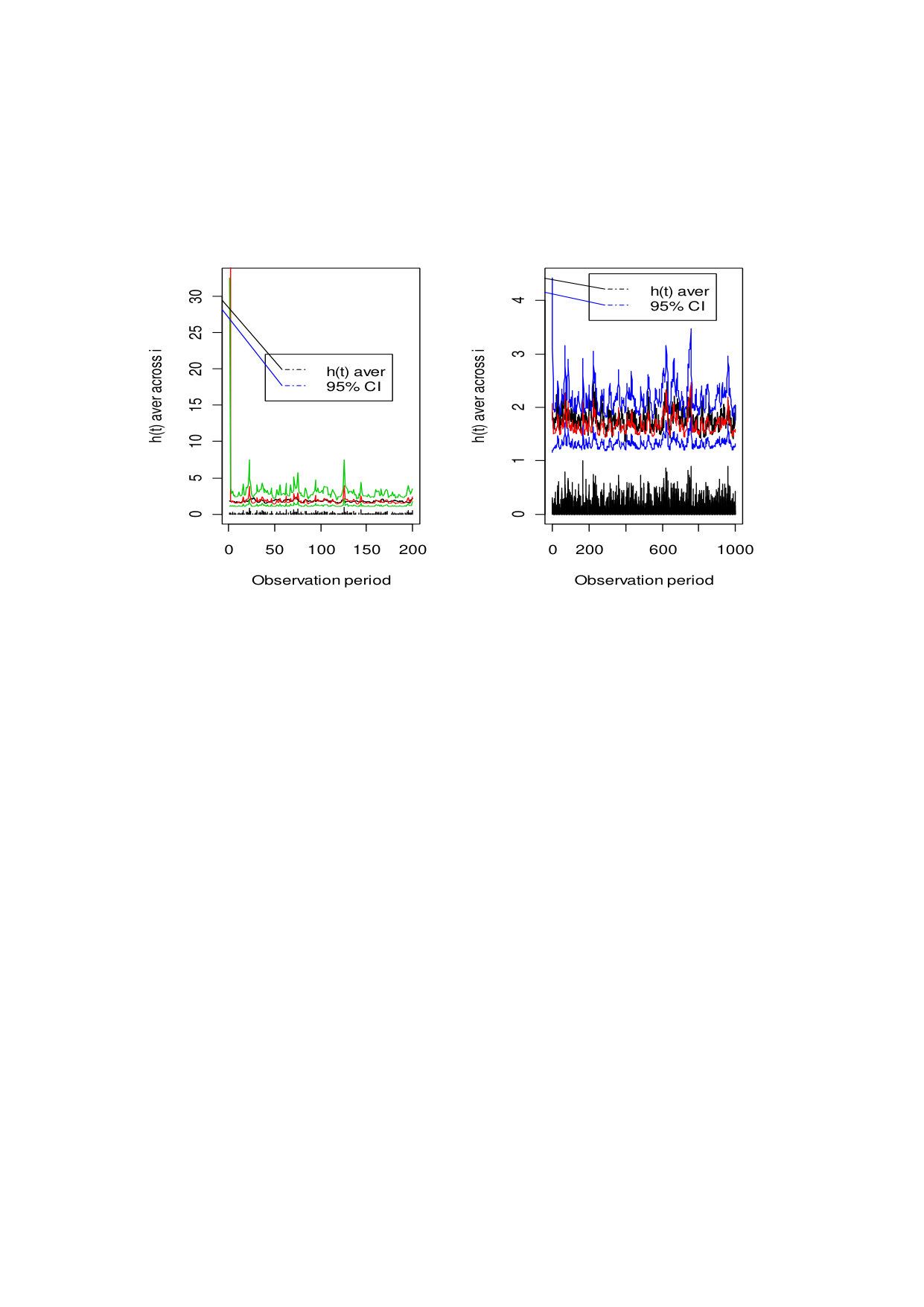 Figure 3
Figure 3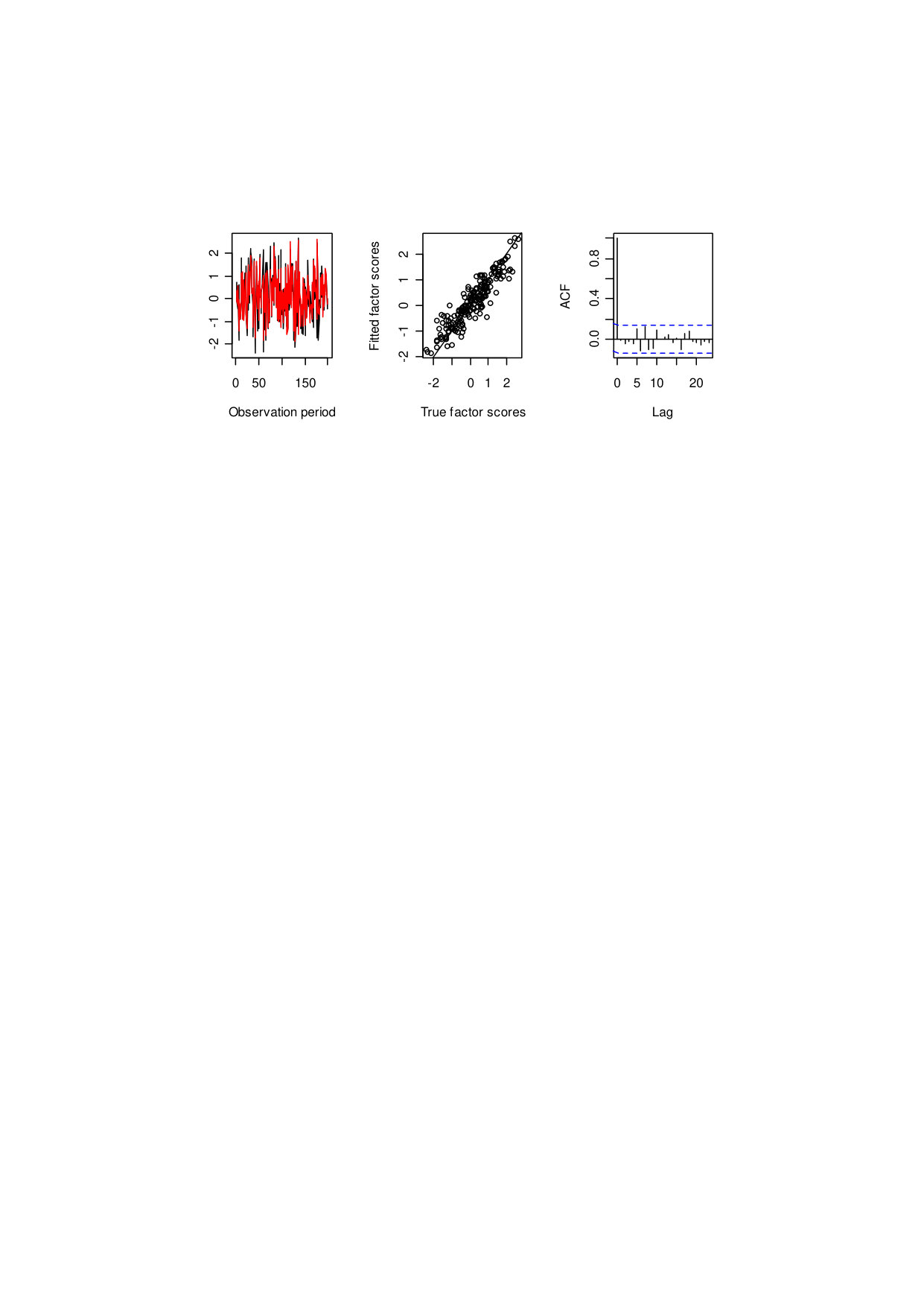 Figure 4
Figure 4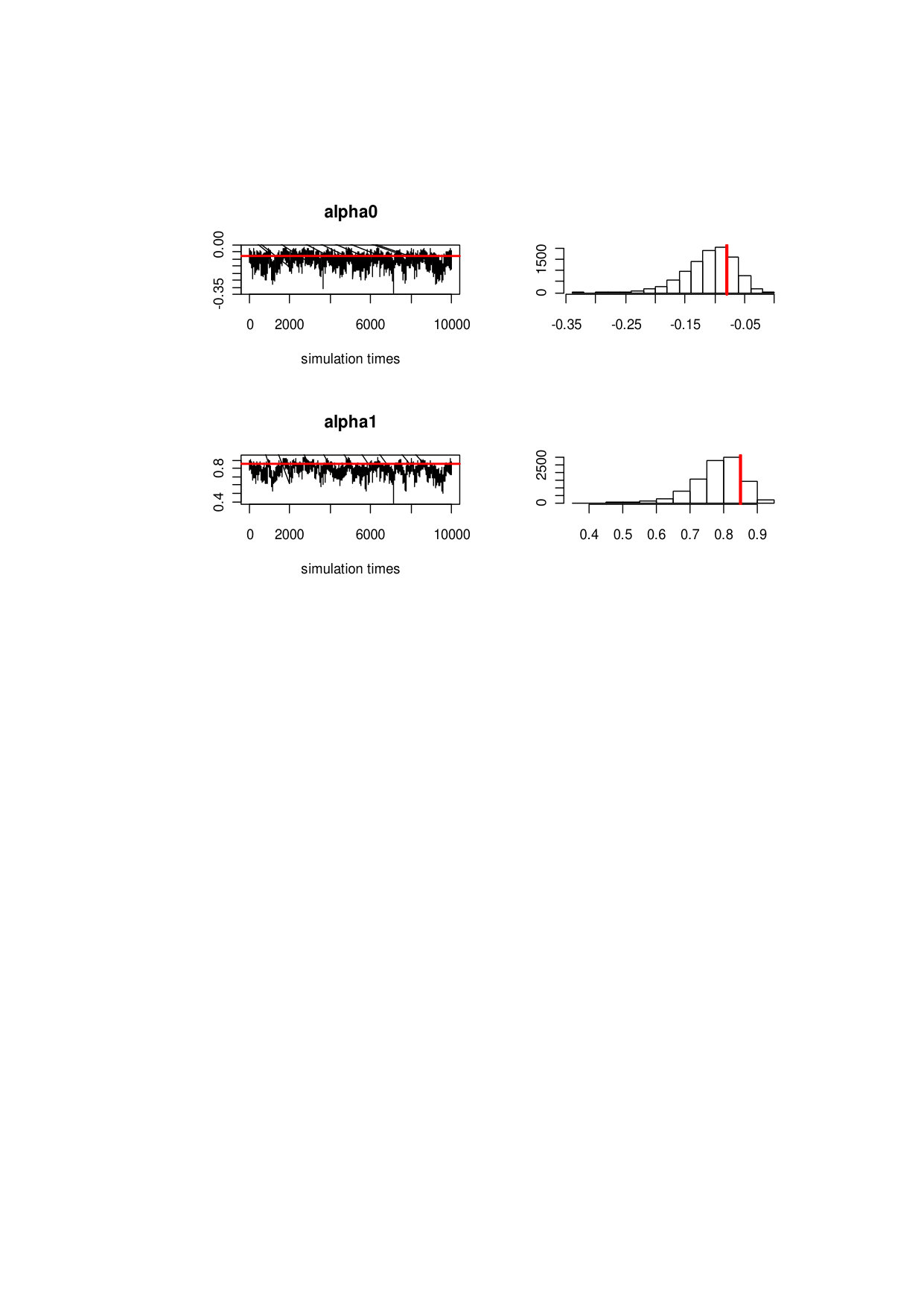 Figure 5
Figure 5| Model | No. of | Model | No. of | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Parameters | Parameters | ||||||||||
| M1 | 10 | 3 | 3 | 200 | 80 | M5 | 10 | 4 | 4 | 200 | 98 |
| M2 | 20 | 3 | 3 | 200 | 160 | M6 | 20 | 4 | 4 | 200 | 198 |
| M3 | 10 | 3 | 3 | 400 | 80 | M7 | 40 | 4 | 4 | 400 | 398 |
| M4 | 20 | 3 | 3 | 400 | 160 | M8 | 40 | 4 | 6 | 1000 | 471 |
| Model1 | ind1 | ind2 | ind3 | ind4 | ind5 | ind6 | ind7 | ind8 | ind9 | ind10 |
|---|---|---|---|---|---|---|---|---|---|---|
| const | 0.058 | 0.058 | 0.057 | 0.057 | 0.057 | 0.058 | 0.057 | 0.057 | 0.057 | 0.058 |
| t-value | 21.22 | 21.31 | 21.24 | 21.39 | 21.13 | 21.30 | 21.40 | 21.33 | 20.98 | 21.34 |
| var1 | 0.061 | 0.060 | 0.060 | 0.060 | 0.060 | 0.060 | 0.060 | 0.060 | 0.060 | 0.061 |
| t-value | 68.51 | 66.81 | 66.43 | 65.67 | 65.26 | 68.29 | 68.98 | 66.94 | 69.89 | 69.26 |
| var2 | 0.056 | 0.056 | 0.055 | 0.056 | 0.055 | 0.056 | 0.055 | 0.055 | 0.056 | 0.056 |
| t-value | 64.64 | 63.00 | 62.55 | 63.00 | 64.88 | 62.56 | 61.19 | 64.45 | 64.18 | 62.88 |
| var3 | 0.057 | 0.058 | 0.056 | 0.057 | 0.057 | 0.058 | 0.057 | 0.057 | 0.057 | 0.058 |
| t-value | 66.20 | 67.89 | 64.66 | 65.21 | 65.77 | 66.36 | 66.26 | 65.48 | 66.26 | 66.80 |
| Model5 | ind1 | ind2 | ind3 | ind4 | ind5 | ind6 | ind7 | ind8 | ind9 | ind10 |
| const | 0.059 | 0.059 | 0.059 | 0.059 | 0.059 | 0.059 | 0.059 | 0.059 | 0.059 | 0.059 |
| t-value | 24.14 | 24.09 | 24.34 | 24.16 | 24.08 | 24.15 | 24.15 | 24.30 | 24.17 | 24.28 |
| var1 | 0.055 | 0.054 | 0.053 | 0.054 | 0.054 | 0.054 | 0.054 | 0.054 | 0.054 | 0.054 |
| t-value | 61.77 | 62.37 | 59.33 | 61.13 | 61.06 | 61.25 | 62.88 | 62.12 | 62.00 | 61.24 |
| var2 | 0.058 | 0.058 | 0.058 | 0.058 | 0.058 | 0.059 | 0.058 | 0.058 | 0.058 | 0.058 |
| t-value | 66.89 | 64.90 | 64.94 | 66.40 | 67.29 | 66.22 | 66.81 | 65.17 | 66.97 | 66.27 |
| var3 | 0.058 | 0.058 | 0.057 | 0.057 | 0.057 | 0.058 | 0.058 | 0.058 | 0.057 | 0.058 |
| t-value | 65.51 | 66.85 | 65.26 | 64.48 | 66.11 | 64.77 | 64.45 | 65.20 | 64.83 | 65.88 |
| var4 | 0.058 | 0.058 | 0.057 | 0.057 | 0.057 | 0.058 | 0.057 | 0.058 | 0.057 | 0.058 |
| t-value | 64.26 | 65.06 | 62.15 | 64.54 | 64.31 | 65.51 | 64.10 | 63.41 | 65.68 | 65.41 |
| Internet | Fctor1 | Factor2 | Factor3 | Tradition | Fctor1 | Factor2 | Factor3 |
|---|---|---|---|---|---|---|---|
| Finance | Finance | ||||||
| 600570 | 0.48295 | 0.26396 | -0.39941 | 601229 | 0.24935 | -0.6055 | 0.34556 |
| 300468 | 0.48165 | 0.2527 | -0.33806 | 601009 | -0.35094 | -0.80025 | 0.10056 |
| 600446 | 0.53242 | 0.29306 | -0.43271 | 002142 | -0.10866 | -0.61911 | 0.21143 |
| 600588 | 0.41928 | 0.2797 | -0.27535 | 601997 | 0.15192 | -0.66763 | 0.25843 |
| 002095 | 0.40358 | 0.28249 | -0.46229 | 600919 | 0.40977 | -0.69211 | -0.18339 |
| 600599 | 0.26668 | 0.14423 | -0.16483 | 600908 | 0.45947 | -0.74334 | -0.20374 |
| 300300 | 0.34265 | 0.19878 | -0.29666 | 600926 | 0.31993 | -0.73738 | 0.13836 |
| 300295 | 0.59382 | 0.29622 | -0.28131 | 002839 | 0.35223 | -0.62106 | -0.39002 |
| 002285 | 0.44411 | 0.23941 | -0.09751 | 002807 | 0.40254 | -0.74668 | -0.34116 |
| 300178 | 0.40544 | 0.21892 | -0.31614 | 601169 | -0.01292 | -0.69512 | 0.16557 |
| Internet | Tradition | ||||||
|---|---|---|---|---|---|---|---|
| Finance | Finance | ||||||
| 600570 | 7.29E-03 | -0.00751 | 0.030701 | 601229 | -3.01E-02 | 0.032915 | -0.00375 |
| SE | 1.86E-03 | 0.001888 | 0.000227 | SE | 9.49E-03 | 0.009507 | 0.000948 |
| 300468 | -4.80E-03 | 0.011402 | 0.022815 | 601009 | 6.45E-05 | 0.000153 | 0.015969 |
| SE | 4.72E-03 | 0.004782 | 0.00155 | SE | 2.84E-03 | 0.00285 | 0.00031 |
| 600446 | 8.21E-03 | -0.00909 | 0.031296 | 002142 | 5.09E-03 | -0.00478 | 0.019807 |
| SE | 1.71E-03 | 0.00176 | 0.000439 | SE | 2.18E-03 | 0.002189 | 0.000212 |
| 600588 | 5.67E-03 | -0.0049 | 0.036145 | 601997 | 3.23E-03 | -0.00342 | 0.015774 |
| SE | 2.10E-03 | 0.002107 | 0.000429 | SE | 1.72E-03 | 0.001737 | 0.000213 |
| 002095 | 8.56E-04 | -0.00212 | 0.030323 | 600919 | -1.04E-02 | 0.009408 | 0.016956 |
| SE | 2.01E-03 | 0.002051 | 0.000403 | SE | 1.20E-02 | 0.012167 | 0.001323 |
| 600599 | 1.07E-03 | -0.00187 | 0.021443 | 600908 | 1.09E-02 | -0.0124 | 0.020783 |
| SE | 2.26E-03 | 0.002284 | 0.000378 | SE | 1.66E-03 | 0.001691 | 0.000261 |
| 300300 | -2.52E-03 | 0.005383 | 0.020595 | 600926 | 2.38E-03 | -0.00234 | 0.01458 |
| SE | 5.88E-03 | 0.005877 | 0.001016 | SE | 6.91E-04 | 0.000697 | 0.000135 |
| 300295 | 7.36E-03 | -0.00692 | 0.028783 | 002839 | -1.56E-02 | 0.0213 | 0.003849 |
| SE | 2.14E-03 | 0.002159 | 0.000429 | SE | 1.13E-02 | 0.01144 | 0.002175 |
| 002285 | 1.13E-02 | -0.01066 | 0.029251 | 002807 | 9.91E-03 | -0.00977 | 0.02229 |
| SE | 2.87E-03 | 0.002884 | 0.000697 | SE | 1.43E-03 | 0.001442 | 0.000291 |
| 300178 | -1.50E-03 | 0.000133 | 0.332127 | 601169 | 3.56E-03 | -0.00371 | 0.010487 |
| SE | 3.29E-03 | 0.000226 | 0.005708 | SE | 2.12E-03 | 0.002139 | 0.000208 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsFinancial Risk and Volatility Modeling · Complex Systems and Time Series Analysis · Monetary Policy and Economic Impact
** The FFBS Estimation of High-dimensional Panel Data Factor Stochastic Volatility Model**
Guobin Fang School of Statistics and Applied Mathematics, Anhui University of Finance and Economics, Bengbu 233030, Anhui, China
Huimin Ma School of Statistics and Applied Mathematics, Anhui University of Finance and Economics, Bengbu 233030, Anhui, China
Michelle Xia Division of Statistics, Northern Illinois University, Dekalb 60115, IL, USA
Bo Zhang Center for Applied Statistics, Institute of Probability and Statistics, School of Statistics, Renmin University of China, Beijing 100872, China
Abstract
In this paper, we propose a novel panel data factor stochastic volatility model embracing both observable factors and unobservable factors that can influence financial returns. The model is an extension of the multivariate stochastic volatility model composed of the three parts of the mean equation, the volatility equation and the factor volatility evolution. The stochastic volatility equation uses a one-step forward prediction process that simplifies parameter estimation in high-dimensional parameter spaces. In particular, Forward Filtering Backward Sampling (FFBS) based on the Kalman Filter Recursive Algorithm (KFRA) is utilized for parameter estimation of the stochastic volatility equation, under the Bayesian Markov Chain Monte Carlo Simulation (MCMC) framework. The results from numeric simulations demonstrate that the algorithm possesses robustness and consistency for parameter estimation and latent factor sampling. Using the new model and its estimation method, this paper makes a comparative analysis on the influence of observable and unobservable factors on Internet financial and traditional financial companies listed in the Chinese stock market. The results show that the influence of the observable factors is similar for the two types of listed companies, while that of the unobservable factors is noticeably different.
Keywords: High-dimensional; Panel Data; Factor Stochastic Volatility Model; Forward Filtering Backward Sampling
1 Introduction
In the financial markets, the return and volatility of financial assets are both sequentially correlated, with the volatility typically having time-varying characteristics. Both the stochastic volatility (SV) model and generalized autoregressive conditional heteroskedasticity (GARCH) model have been widely used to capture the dependence and the volatility clustering in financial time series. The stochastic volatility (SV) model assumes that the stochastic volatility of the return is influenced by unobservable factors, accompany with the impact from the volatility of the previous period. The stochastic volatility model is shown to perform well in modeling the realized volatility of high frequency data. From the in-depth study of the realized volatility, high frequency transaction data constantly reflect the continuous time characteristics, giving rise to the majority of the modern stochastic volatility research carried out around continuous data. In particular, the geometric Brownian motion process, the non-Gaussian O-U process, the time-varying Levy process, the Markovian switching process and other stochastic processes with jump based on continuous time have been extensively applied for stochastic volatility models.
Shephard (2005) marked the beginning of a new generation of stochastic volatility models. Whereas the early stochastic volatility models were simple stochastic differential equations based on the geometric Brownian motion, the new generation of research mainly focused on update methods for model estimation and testing. Since the late 1990s, there have been great advances in stochastic volatility models for the purposes of realized volatility prediction and high frequency modeling. In addition to traditional estimation and testing, recent research on stochastic volatility models focused more on the characterization of local characteristics, such as long memory, jump, diffusion and microstructure noise, in the modeling of high frequency transaction data. These stochastic volatility models can process both continuous and discrete data.
Although there is some controversy about who firstly proposed the stochastic volatility model (see Shephard (2005) for details), it is an indisputable fact that the stochastic volatility model have been applied to discrete time series analysis. Due to the incomparability of high frequency and relatively low frequency data in terms of means of acquisition and analysis significance, the study of univariate stochastic volatility model originated from the application of time-varying Brownian motion in financial econometrics. Taylor (1982) is regarded as one of the early pioneers of stochastic volatility model for his contributions in introducing the features of volatility clustering and time-varying volatility simultaneously. Harvey et al. (1994) first proposed the multivariate stochastic volatility model. While Diebold and Nerlove’s (1989) adopted multiple factors in their multivariate factor model, the multivariate stochastic volatility model lays more emphasis on the study of multiple financial assets. In addition to the asymmetry caused by the difference in reaction to risk, the multivariate random volatility model also considers the joint influence of multiple assets. Therefore, the multivariate factor model plays an important role in multivariate stochastic volatility modeling.
Han (2005) and Chib et al. (2006) pushed the research of high-dimensional multivariate stochastic volatility modeling further. In their studies, the high-dimensional feature contains two aspects. On the one hand, the high dimension refers to the large number of assets, including dozens or even hundreds of financial assets. On the other hand, there are a large number of parameters that need to be estimated due to the complexity of the multivariate stochastic volatility model structure. In the Han’s study, a total of 222 parameters need to be estimated in the stochastic volatility model when there are 36 return series and 3 factors. In the Chib’s model, if the number of assets is 50 and the number of factors is 8, then the parameters to be estimated will reach 688. The estimation of such a large number of parameters requires a special computation method. The high-dimensional factor stochastic volatility models all adopted the block estimation method. The block estimation method reduces the complexity of calculation by dividing the parameters into several groups for block updating in the Gibbs sampler or the Metropolis-Hastings algorithm.
For the stochastic volatility model, the covariance structure of the model’s error components must be specified. For the error components, routine rules regarding positive definitiveness and correlation must be followed regarding the covariance matrix. Tsay (2010) considered Cholesky decomposition to re-parametrize the covariance matrix owing to its many advantages. Firstly, Cholesky decomposition ensures the positive definitiveness of a covariance matrix easily. Secondly, each element of the decomposition matrix has favorable explanatory ability. Finally, such decomposition can reflect the time-varying characteristics of volatility. Since Cholesky decomposition can run into high-dimensional problems, Lopes, McCulloch and Tsay (2012) put forward a more practical approach to estimate the Cholesky’s stochastic volatility model. Their method adopts the matrix transformation of the multivariate random error terms, and uses Cholesky decomposition to simplify the estimation of the large number of parameters for the conditional covariance matrix. Although these methods simplify the structure of random error components, corresponding estimation methods are required for processing the high-dimensional parameters. For this purpose, Kastner et al. (2017) proposed an efficient Bayesian method to estimate the factor stochastic volatility model, which they demonstrated the superior performance on the analysis of 26-dimensional exchange rate data.
In contrast to the univariate stochastic volatility model that studies the influencing factors for the rate of return on a single asset, the multivariate stochastic volatility model also captures the influences on a large number of financial assets. For both the univariate and multivariate stochastic volatility models, these influencing factors are considered to be either observable or unobservable. The influences from these factors are considered as self-driven. In fact, in addition to the influencing factors on the characteristics of volatility, the impact on the asset price changes can also be analyzed for external influencing factors. For example, some models solely consider the influence of observable factors on the change of asset return, which include the Fama and French’s three-factor model (1992) and the BARRA factor model (proposed by BARRA company).
In order to study the influence of observable factors and unobservable factors on the stochastic volatility of financial assets furtherly, this paper proposes the panel data stochastic volatility model by introducing observable factors into the multivariate stochastic volatility model. Such observable factors can include not only market factors such as industrial (stock) average return, trading volume and transaction amount, but also out of counter trade factors such as macroeconomic variables and industrial development level. Compared with the regular multivariate stochastic volatility model, the panel data stochastic volatility model considers a large number of observable factors in the market and out of the market, providing a more realistic practical application. Despite the theoretical basis and practical application significance inherited from the stochastic volatility model, add-on observable influencing factors can lead to more difficult in the model estimation and interpretation in the panel data stochastic volatility model.
This paper proposes a novel panel data factor stochastic volatility model and estimation methods for the high-dimensional parameters. The main contents are arranged as follows. The second section discusses the specification of the panel data factor stochastic volatility model, including the mean equation, volatility equation and factor equation, along with the embodiment of the stochastic effect. The third section studies model estimation methods, including the realization of joint estimation based on MCMC and FFBS algorithm. The fourth section presents simulation studies to test the validity of the proposed estimation method. The fifth section performs an application study for comparing internet financial and traditional financial companies listed in China’s stock market, based on the differences in the observable and unobservable factors that influence the two types of companies. Finally, concluding remarks and future research are given in the last section.
2 Specifications of Panel Data Factor Stochastic Volatility Model
The specification of stochastic volatility term in panel data stochastic volatility model (PDSVM) is similar to the multivariate stochastic volatility model. The factors related to the change of the rate of return are treated as explanatory variables in the model, which will influence the structure of the stochastic volatility terms. Since the multivariate factor model is difficult to explain theoretically and cannot adapt to model transformation, we only consider the additive factor structure for the panel data factor stochastic volatility model. Furthermore, the additive factors and other covariates are assumed to be independent each other. For the individual and period effects, we propose to use either the panel data random effect model where such effects are treated as random effects, or the panel data fixed effect model where they are treated as fixed effects. In both cases, the individual effect and the time effect can be included simultaneously in the model.
2.1 Panel Data Stochastic Volatility Model
In financial asset allocation and portfolio management, the excess logarithmic return rate of an investment portfolio with financial assets can be denoted by , where represents the excess logarithmic return rate of asset in time . The varying coefficient panel data random effect model can be used to capture the influence of observable and unobservable factors on the return rate of financial assets. The mean equation of panel data stochastic volatility model can be set as follows:
[TABLE]
where the vector contains the observable factors that affect the rate of return on financial assets, with its dimension being the number of influence factors that can be either internal or external factors affecting the financial market. The vectors and contain respectively the individual effects and the time effects that are both assumed to be random. The influence of the factors on the volatility of is reflected in the specification of error component terms. Here, we focus on the individual effects. Assuming that the mean of the error component at time is [math], , the conditional covariance matrix satisfies with .
Furthermore, we assume that the volatility equation of the panel data stochastic volatility model is
[TABLE]
where is a scalar, and have independent normal distributions with mean [math] and variance and respectively. The exponential transformation of guarantees the positive definiteness of the variance covariance matrix . In order to satisfy the stationarity of the time series, it is assumed that the regression parameter satisfies , otherwise, alternatively higher-order lag terms of the corresponding variable can be introduced. Models (2.1) and (2.2) constitute the basic form of a panel data stochastic volatility model. The random error term is simplified via specification of the random individual effect and random time effect in the panel data model.
2.2 Panel Data Factor Stochastic Volatility Model
The explanatory variables in panel data stochastic volatility model (2.1) only reflect observable factors, which may be internal or external market factors. In the aforementioned model, these influencing factors constitute the explanatory variables of the panel data model. The unobservable factors of the panel data model comprise of three parts: the random effect (fixed effect), random error component (stochastic volatility term), and statistical factor component. Here, panel data factor stochastic volatility model (PDFSVM) utilities the statistical factor stochastic volatility model to capture the influence of common shock on multiple assets. This common shock is represented by common factors. After introducing the common factors, the panel data factor stochastic volatility model can be written as
[TABLE]
where the random error component possesses the structure in (2.2). In the factor decomposition term , contains the factor loadings, and represents the common factors, with the number of common factors is ().
The conditional covariance structure of stochastic volatility term is the same as the panel data stochastic volatility model (2.1). In order to reflect the lag effect of common factors, i.e., the impact of continuous decay caused by the common shocks, we specify a structure similar to the multi-factor stochastic volatility model proposed by Jacquier et al. (1995) and Lopes and Carvalho (2007).
In particular, we assume that the common factors of panel data stochastic volatility model have the same evolution of stochastic volatility:
[TABLE]
where , , and the error terms are independent each other. Based on the process (2.4), for given and any , we have and . The common factors in satisfy , where is the variance-covariance matrix of the common factors . Hence, we have for the conditional variance, where is given by the AR (1) process in equation (2.4). In order to ensure the stationarity of the sequence generated by the state process (2.4), it is assumed here.
Equations (2.3), (2.2) and (2.4) compose the panel data factor stochastic volatility model. Due to some restrictions applied to the factor loadings and common factors in factor decomposition, the estimation of panel data factor stochastic volatility model is more complex than the regular panel data stochastic volatility model. The estimation of the effects of the predictive variables and latent variables in model (2.2) - (2.4) need to be carried out simultaneously, a situation difficult for obtaining a closed-form solution for the maximum likelihood estimation. For numerical optimization based on iterative algorithms, the large number of parameters gives rise to difficulty in the algorithm convergence in the high-dimensional parameter space.
In the panel data factor stochastic volatility model, the curse of dimensionality mainly comes from the large number of parameters to be estimated for the conditional covariance matrix and factor decomposition. Although the application of the factor model can help to reduce the dimensionality when the number of assets is very large, the total number of parameters generated from the estimation process can be far greater than the number of assets. For the panel data factor stochastic volatility model (2.3), is a dimensional vector, up to a total of regression coefficients. and are dimensional column vectors. Since the number of periods and individuals are and respectively, under the condition of applying identification constraints, and have and constraints respectively. With being latent factors, and there are still free parameters to be estimated. The number of coefficients in model (2.4) and is equal to the total number of financial assets . Both and in model (2.4) contain coefficients for the regression of AR (1), each of them having parameters to be estimated.
For applying identification constraints, there are parameters to be estimated in the panel data factor stochastic volatility model (2.2) - (2.4), of which are determined by factor decomposition. Thus, for a financial portfolio with assets, explanatory variables, and factors, there are 431 model parameters to be estimated without consideration the factor loading coefficients and the parameters related to random error terms. For the panel data factor stochastic volatility model, the high-dimensional problem can be caused by a large value of either , , , or . Hence, we will consider how to reasonably reduce the dimension for model computation and parameter estimation in high-dimensional scenarios.
From the above specification, we may argue that the panel data stochastic volatility model is similar to the panel data factor stochastic volatility model, despite their difference in the factor model structure. In the subsequent sections, we will focus on the panel data factor stochastic volatility model, although many of the results are also applicable to the regular panel data stochastic volatility model. From a comparative standpoint, the model specification and estimation is more complicated for the panel data factor stochastic volatility model in high-dimensional scenarios, and which will require innovative iterative algorithms and computing techniques.
3 Estimation and Computation of Panel Data Factor Stochastic Volatility Model
Model (2.3) is an extension of the panel data dynamic mixed double factor model (DMDFM) proposed by Fang, Zhang and Chen (2018). For the mean equation of the model (2.3), Bai (2009) developed the Least Squares (LS) method and the Least Squares Dummy Variable (LSDV) estimator of panel data fixed effect model based on Pesaran (2006) and Coakley, et al. (2002), he proved the consistency, asymptotic normality and other limiting properties of estimators. Similar alternative estimation methods include the Generalized Moment Method (GMM) of Ahn, Lee and Schmidt (2001) and the Quasi-Difference method (QD) of Holtz-Eakin, Newey and Rosen (1988). For the time series dynamic factor model that contains a large number of predictors, Stock and Watson (2002) proposed Nonlinear Least Square method to estimate the model parameters.
The parameter estimation of the panel data factor stochastic volatility model becomes relatively complex after adding the stochastic equation (2.2) and (2.4). In particular, the likelihood function associated with the model is intractable. Since models (2.2), (2.3) and (2.4) are nested with each other, it is natural to perform estimation based on the profile likelihood given the estimates of the nested parameters. This paper uses MCMC method based on Gibbs sampling and Metropolis-Hastings Algorithm that allows block updating in posterior sampling.
3.1 Preliminary Tact
The observable information of the panel data factor stochastic volatility model can be divided into two parts. The first part comes from the predictors (independent variables) , and the other part comes from the response (dependent) variable . Denoting the information set composed of observable historical records, the parameters of the model are , and the conditional density function of the latent variables is . The conditional probability function of the observed variables (i.e., the conditional likelihood function with respect to the parameters) can be written as:
[TABLE]
where, denotes the multivariate normal distribution, is the conditional mean of , and is its marginal condition covariance matrix that can be written as:
[TABLE]
Although the density function of the multivariate normal distribution has an explicit form, the above integral in (3.1) does not have an analytical solution. For the proposed model, the conditional density function of latent variables can’t be written analytically. Thus, the likelihood function given in equation (3.1) in tractable, making it difficult to estimate the panel data factors stochastic volatility model via maximum likelihood estimation.
Here, we will use the Markov Chain Monte Carlo Simulation (MCMC) method to implement the panel data factor stochastic volatility model (2.1) - (2.4). This method constructs aperiodic and irreducible Markov chains to obtain the invariant-distribution of posterior distribution of the target parameters. For the proposed model, the latent variables and parameters can be sampled simultaneously based on Markov chains. In particular, the joint posterior distribution can be denoted as follows:
[TABLE]
The invariant-distribution of all latent variables and parameters will contain a huge number of distributional components that can be decomposed for computational purposes. For the Bayesian implementation, we will resort to hierarchical Bayesian methods for which the effectiveness and consistency of estimation depends on the prior specification and other posterior settings. Because of the dynamic features of the parameters and the similarity in the structure of the AR (1) process in (2.2) and (2.4), the dynamic correlation of the latent variables will be estimated via the processing method of the Dynamic Linear Model (DLM).
With adaption to the high-dimensional characteristics of the multivariate stochastic volatility model, Chib (2001) summarized the Bayesian inference method based on MCMC techniques. Chib, Nardari and Shephard (2006) discussed the estimation and comparison of high-dimensional latent factor stochastic volatility models with jumps and alternative specifications. Han (2005) studied the portfolio construction and risk control of a large number of financial assets by using the dynamic factor multivariate stochastic volatility model, and achieved favorable prediction performance. For the high-dimensional multivariate stochastic volatility model and the panel data stochastic volatility model, estimation of a large number of parameters in the presence of latent variables is a challenging problem in Bayesian inference. Lopes, McCulloch and Tsay (2012) used parallel computing techniques. In order to obtain computational efficiency, they performed parallel estimation of multiple assets via recursive conditional regression, after partition the assets into several smaller portfolios. The parallel computing technique is appropriate for the multivariate factor decomposition model. For the panel data stochastic volatility model, however, the explanatory variables exhibit both temporal and spatial correlation, resulting in cross-sectional dependence among individuals that needs to be captured using alternative algorithms.
In the Bayesian estimation of the panel data stochastic volatility model, Chib et al. (2006) proposed the blocking method to improve the computing speed. The method divides the parameters and latent variables into separate blocks (groups) so that they can be updated sequentially within each iteration of the MCMC algorithm. The blocking algorithm design requires consideration of factors such as the blocking strategy, the form of the likelihood function, the prior distribution specification, and the form of the joint posterior distribution of the parameters.
For designing a blocking MCMC algorithm, it is natural to divide the parameters and latent variables in (3.1) into three parts according to the three equations of the panel data factor stochastic volatility model. The three parts are the parameters and variables in model (2.3); , the mean and variance of the random terms in model (2.2); in model (2.4) and the estimation of mean and variance of its random term. When subdivided further, , , and can be sampled in blocks. For posterior sampling, the conditional posterior distribution of each parameter or latent variable must be considered. When using the hierarchical Bayesian method, both the specific form and parameters of the distribution needs to be studied. In the subsequent paragraphs, we will focus on the algorithm implementation, after specifying the posterior parameters. In order to reduce computational time, each iteration of the MCMC algorithm will be divided into three blocks corresponding to the estimation of regression coefficients, factor decomposition and the dynamic linear model. The relationship between these three parts is shown in the simplified directed graphical structure given in Figure 1.
3.2 Prior and Posterior Specification for Latent Variables and Model Parameters
The key step in Bayesian block sampling techniques is the specification of the ”blocks”, and the conditional posterior distribution of each block whilst the others are given. For the panel data factor stochastic volatility model, the parameters and latent variables can be divided into four parts: the regression coefficients , factor loadings , the common factors , and the latent variables and for the evolution of stochastic volatility. The four parts are dependent a posteriori. The conditional posterior distribution is specified for each block, given the samples from the other blocks. The detailed process of prior and posterior specification can be seen in Fang & Zhang (2014).
3.2.1 Prior and posterior specification for
The joint prior distribution of can be specified as a multivariate normal distribution given as
[TABLE]
with the hyper-parameters of its mean and inverse covariance matrix having prior distributions given by:
[TABLE]
[TABLE]
Correspondingly, the joint posterior distribution of have the multivariate normal form:
[TABLE]
where , , and is the model error accuracy that can directly affect the posteriors.
3.2.2 Prior and posterior specification for
To ensure the identification of parameters, assume that the factor loading parameters form a lower triangular matrix, i. e. ( ; ; ). The prior distribution of can be set as follows:
[TABLE]
where is the indicator function, is variance of the prior distribution.
When , the posterior distribution of is
[TABLE]
When , the posterior distribution of is
[TABLE]
It should be noted that the factor loading parameters need to be specified jointly with the as follows. The algorithm is given in the appendix.
3.2.3 Prior and posterior specification for
The common factors and factor loadings need to be sampled simultaneously based on their joint posterior distributions. Compared with the factor loadings, the specification of the common factors is relatively simple. The joint posterior distribution of in the panel data factor stochastic volatility model is related to the fixed effect parameters and the terms in the volatility equation. Its conditional posterior distribution () still has a multivariate normal distribution. Given the factor loadings, is assumed to follow the - dimensional normal distribution:
[TABLE]
In particularly, given the factor loadings , the posterior distribution of is given by
[TABLE]
where
[TABLE]
and is determined by the identification conditional constraints by choosing an appropriate to make .
3.2.4 Prior and posterior specification for and
The conditional distribution of the logarithmic error volatility vector can be specified as an -dimensional normal distribution. In particular, we set
[TABLE]
where is the variance-covariance matrix of the volatility equation. Since we assume that and are both diagonal matrices, that is, there is no correlation between error terms and volatility terms. The volatility equation can be simplified as independent univariate autoregressive processes conditions (Pitt and Shephard (1999), Migon, Gamerman, Lopes and Ferreira (2005)). It could be decomposed into independent dynamic linear models. If these dynamic linear models are regarded as the evolution process, the prior, prediction and posterior conditional distribution of the volatility term at time can be expressed respectively as:
[TABLE]
where the information set is composed of the data set and the derived parameter set , which can be denoted as:
[TABLE]
Since the volatility equation can be decomposed into independent components, the prior distribution of the logarithmic volatility can be specified as follow:
[TABLE]
The blocking movement method proposed by Chib et al. (2006) is adopted to the panel data factor stochastic volatility model. Denote . Both the coefficient block and the logarithmic fluctuation block are required to specify the posterior conditional distribution in the blocking movement sampling method.
Given prior distribution (3.11), for coefficient and volatility variance , the corresponding posterior distribution is also normal - inverse Gamma distribution. In a hierarchical form, it can be expressed as follows:
[TABLE]
The relationship between the prior distribution and the conjugate posterior distribution of in equation (3.10) can be obtained via the Bayesian law.
3.3 MCMC Algorithm for Joint Parameter Estimation
For convenience in algorithm design, we divide the parameters of the panel data factor stochastic volatility model into several blocks for MCMC sampling. Based on the structure of the model, it is divided into three blocks. The first block contains the regression coefficients of the explanatory variables, which we refer to as the joint parameters. The second block contains the factor decomposition terms, including the common factors and factor loadings. The third block contains the random errors and the other terms from the corresponding stochastic volatility equation. The major advantage of Bayesian inference is its ability to incorporate prior information through MCMC. Equations (3.4) - (3.7) provide the foundations for specifying the joint hierarchical posterior distribution of the regression coefficients of explanatory variables. In order to sample the joint parameters via Gibbs sampling and the Metropolis-Hastings (M-H) algorithm, some assumptions must be made about the error accuracy involving factorization. In algorithm design for the factor decomposition and error terms, the assumption on the error accuracy is closely related to the sampling of the joint parameters .
Previously, it has been assumed that the variance-covariance matrix of the error terms (including the factorization part) of the panel data stochastic volatility model is . This is due to the fact that the error terms of stochastic volatility model are subject to both heteroscedasticity and sequential correlation. In order to facilitate the estimation of the joint parameters , combining Basu & Chib (2003) and Chib & Greenberg (1994) , we assume that the variance-covariance matrix is on the premise of heteroscedasticity and temporal correlation. Here, has the following hierarchical form:
[TABLE]
where and have inverse Gamma and Gamma prior distributions, respectively. The parameters of , and are scale constants. Furthermore, it is assumed that the prior distribution of is
[TABLE]
The aforementioned covariance matrix specification captures the heteroscedasticity of the error terms very well. The sequential correlation is also determined by the parameters and of the volatility equation, with the autocorrelation parameters denoted as . Posterior sampling can be performed based on the following algorithm:
(1) Sampling the joint parameters from their conditional posterior given by
[TABLE]
(2) Sampling the scale parameter of the variance covariance matrix from
[TABLE]
(3) Sampling the variance parameter from its conditional posterior distribution given by
[TABLE]
(4) Sampling the autocorrelation parameter according to
[TABLE]
(5) Gibbs sampling and M-H algorithm are used to iterate until convergence. Given the posterior samples from the above algorithm, the posterior samples of and can be obtained from
[TABLE]
The conditional posterior density function of can be approximated as the multivariate distribution.
[TABLE]
where , and are the location (vector) parameters, scale (matrix) parameters and degrees of freedom respectively. The degree of freedom can be set to any constant greater than 1. The other two parameters and will be sampled using the Forward Filtering Backward Sampling (FFBS) algorithm in section 3.5 below.
In the MCMC algorithm of joint parameters , the parameters , and depend on the factorization results and the settings of volatility equation. Here, is a parameter that reflects heteroscedasticity, and and are autocorrelation parameters. Therefore, in the M-H algorithm for these parameters, it is necessary to combine the volatility equation and factor decomposition results within each iteration. This is the main difference between the panel data factor stochastic volatility model and the individual random effect panel data model in parameter estimation.
3.4 MCMC Algorithm for Factor Decomposition
The conditional posterior distributions of the factor loadings and common factors (factor scores) are specified as normal distributions. Based on the Bayesian law, the Gibbs sampler is used to sample the parameters with conjugate priors. The conditional posterior distribution of the factor loadings is
[TABLE]
where is given by Equation (3.2), and . The decomposition of common factors can be carried out simultaneously with the sampling of the joint parameters, with the remaining part of consisting of the factorization terms and the stochastic volatility terms. When the identification constraints are applied, the number of factor loadings is . This causes a rather high-dimensional issue for parameter estimation, especially when the sample size is very large.
Chib, Nardari and Shephard (2006) proposed to use the t-distribution as the approximate distribution of as alternative distributions of the factor loadings. This method is simpler than the normal distribution approach and is easier to deal with in high-dimensional problems. The influence of the fixed effects on the parameter estimation needs to be considered in the estimation of factor loadings of the panel factor stochastic volatility. Here, we assume that the factor loadings are subject to the multivariate t-distribution.
[TABLE]
Denote . The location parameter in the multivariate t-distribution is generally obtained by empirical approximation on the mode of logarithms of multivariate densities. The degree of freedom can be set to any constant. The scale parameter is the inverse of the second derivative of , i.e., . Theoretically, approximation using the multivariate t-distribution works well with the multivariate normal distribution. Such approximation makes it easy to design relevant algorithms. The Newton-Raphson algorithm is usually used in the calculation of and . When dealing with higher dimensional problems, the operation time can be increased. The MCMC algorithm of factor loadings assumes subject to the multivariate normal distribution form. Since the M-H algorithm does not require symmetry in its jumping distribution in here, the multivariate t-distributions are used as the jumping distribution.
The sampling process of the common factors is very similar to that for factor loadings. Based on a multiplicative relation among them, the factor decomposition process of the factor stochastic volatility model captures the unobservable factors of the response variables. The process combines the sampling of the joint and the influence of the volatility equation on the specification of the random error components. The idiosyncratic variance part of factor decomposition is the filtering of stochastic volatility terms.
When , the algorithm of free elements in the factor loading matrix and the corresponding common factors (scores) is based on the following steps of sampling steps.
(1) Sampling according to the conditional posterior distribution
[TABLE]
(2) Sampling from
[TABLE]
(3) The M-H algorithm is used to sample the free elements of , based either on the multivariate normal distribution or the approximate multivariate t-distribution given samples of the other parameters. The current value is chose by the following rules:
[TABLE]
with the new free elements generated based on above probability. If the value is rejected, the current value is accepted as a node element of the Markov chain, iterating until the stationary distribution of each is obtained.
(4) According to the multiplicative form of the factor decomposition, the common factors are sampled from the following distribution:
[TABLE]
(5) The algorithm iterates through the above steps until the Markov chain converges.
When , sampling algorithms for factor loading and common factor can be set similarly. Compared with , the sampling distribution dimension of factor loading and common factor are different. For the high-dimensional factor model, the dimension of factor decomposition is decided by the purpose of dimensionality reduction.
Here, we focus on the dimension reduction regarding the number of individuals. How to reduce the dimension of individuals to an appropriate number of common factors and factor loadings depends not only on the criteria for the selection, but also on the real application of concern. Note that the selection of the number of common factors can also impact the performance of the algorithm.
3.5 FFBS Estimation of Dynamic Stochastic Volatility Equation
The panel data factor stochastic volatility model includes two volatility equations, namely the factor volatility equation and error volatility equation. Unlike the specification of major multivariate stochastic volatility models, the random disturbance terms of these two volatility equations are assumed to have no individual correlation. Hence, they are not expressed as the product of two independent components. In a stochastic volatility model without considering the leverage effect and jump, the volatility equation can be regarded as the state-space equation. The logarithmic distribution can be converted into seven normal distributions of independent components. The volatility equation can be expressed as a Gaussian state-space model. The Kalman filtering algorithm of state-space model can be used for one-step forward prediction. Here, we mainly consider the Gibbs sampling algorithm proposed by Carter and Kohn (1994) and the Forward Filtering Backward Sampling (FFBS) method proposed by Fruhwirth-Schnatter (1994). The two volatility equations are both AR (1) processes of volatility terms. For the joint sampling of the two blocks, we will reform models (2.2)-(2.4) into an alternative form involving the following two steps. Firstly, after getting the joint parameter sampling according to (3.14) in Section 3.3, , the observable fixed design part at the right side of model (2.3) can be moved to the left side for performing logarithmic transformations. Secondly, combining models (2.2) and (2.3) into one model. In order to differentiate its different sources, the first terms represent error disturbance terms, and the last terms represent factor volatility terms. Let , be an vector with dimension. We can write
[TABLE]
where equation (3.17) is a transformation of equation (2.3), equation (3.18) is combined from equations (2.2) and (2.4), is the drift term, and . According to the seven-component decomposition from Chib et al. (2002), . Amongst the volatility equation (3.18), the dynamic coefficients are , .
Models (3.17) and (3.18) convert the factor panel stochastic volatility model into the special Gaussian dynamic linear model. In addition to the observable part , we sample the volatility coefficients through the particle filtering algorithm so as to extrapolate the prediction of the latent variables . The FFBS block sampling algorithm needs to construct Markov chains to extract discrete samples from a block which has been set beforehand. Here, is the information set up to time plus the observation values of the explanatory variables and the response variable at time . These values are generally observable. contains the full observable information set and the unobservable information set at time . Given the other parameters and sample data, is denoted as an implied volatility block, of which the joint full conditional posterior distribution is . The conditional distribution is characterized by the volatility equation and the generation process of the latent variables:
[TABLE]
The joint posterior distribution of the implied volatility blocks are determined by the conditional distribution at time . Therefore, the conditional distribution can be described as:
[TABLE]
The last step of equation (3.20) is obtained from the backward property of the Markov chain. Here, is conditionally independent of .
According to Bayesian law, the conditional distribution of in formula (3.20) can be acquired from the conditional transition probability function and the conditional probability function . Denote and . We have
[TABLE]
where
[TABLE]
The joint sampling of consists of two steps: backward sampling and forward Kalman filtering. Note that is subject to the normal distributions. Using the Kalman filtering algorithm, the estimation of the mean and variance of can be obtained. Since and are independent to each other, from Markov chain , we have
[TABLE]
where can be sampled from the information set via the mean equation and the volatility equation. The implied volatility block is sampled in MCMC. The sampling algorithm of the implied volatility blocks of the panel data factor stochastic volatility model can constructed via the multivariate FFBS as follows:
(1) Using Kalman filtering to filter from the conditional probability density , forming a series of parameters and the probability density function of ( ).
(2) The current value of the state vector is sampled from the distribution given by the marginal density (3.21).
(3) The previous value is sampled from the conditional probability by backward sampling. Return to step (2) until and complete the backward sampling process.
In all, the FFBS method includes two steps: forward filtering and backward sampling. The algorithm we propose can take the advantage of the information until time to predict . The unobservable volatility terms have sequential correlation, a situation for which the two-step algorithm is more effective. The multivariate sampling algorithm is also favorable for capturing the correlation between individuals and for simultaneously accounting for the pairwise correlations of the panel data sequence and the cross sectional characteristics. In the multivariate FFBS, both the conditional probability density and marginal probability density of latent variables satisfy the multivariate normal distribution. In the joint sampling for the volatility equation with multiple individuals, the correlation between individuals is captured by the parameters of multivariate normal distribution given in equation (3.18).
4 Simulation Studies
The posterior estimation of PDFSVM is a joint estimation process. The three-block sampling method proposed in here captures the aforementioned structural characteristics of each component. As mentioned earlier, the full model is divided into three blocks in the prior and posterior specification: the joint parameters, factor decomposition and volatility equation whilst determining the posterior distributions for constructing the MCMC algorithm. In the actual sampling process, these three blocks of parameters are sampled sequentially and cannot be separated completely. From the joint parameter estimation, the influence of the observable factors on the response variables can be assessed according to the estimation of regression coefficients. The factorization results of unobservable factors can be used to explain the unobservable stochastic volatility factors. Thus, the factorization process should be combined with the estimation of the stochastic equation. In order to validate the effectiveness of the joint estimation method designed in the previous section, we consider the influence of unobservable factors firstly, then add the observable variables to estimate the mean equation.
From the perspective of model fitting and efficiency, we mainly discuss four aspects: the estimation accuracy, the robustness of the estimation results, the prior distribution, and the influence of the initial values on the estimation results. In the simulation study, a set of models are constructed to mimic real application problems. For example, we consider a large portfolio consisting of 20 to 40 financial assets. It includes not only observable factors but also unobservable factors on the price changes of financial assets. In order to study the estimation efficiency of joint estimation based on MCMC, the data generation process is designed according to models (2.2) - (2.4). The high-dimensional property of the panel data factor stochastic volatility model are characterized by the number of individuals , the period length , the number of covariates , and the number of common factors . In the simulation study, we consider eight different models to reflect the impact of these numbers on the estimation results. The model dimension settings are shown in table 1.
The generation process of the response variable is determined by the high-dimensional parameters involved in each of model elements. After specifying the numbers of individuals, periods, covariates and common factors, we randomly generate the parameters and data sets including each free element of the factor loading matrix , covariates , regression coefficients , factor volatility coefficients , stochastic volatility coefficients , random error terms and . It is assumed that the parameters are independent of each other except for the correlations inherited from the model setting.
The data generation process (DGP) for the scenarios in table 1 are set as follows:
(1) Generate (a total of variables in addition to the constant terms), assuming that the observable factors , , and all come from different normal distributions. For example, the -th explanatory variable is generated by a normal distribution with mean and variance ( ).
(2) Generate for the random intercept model where the coefficient of each explanatory variable changes with the individual. For individual , for example, the coefficients , , and are obtained from the normal distribution. Without loss of generality, its mean and variance are assumed to be 0.06 and 0.009.
(3) Generate from normal distributions. For any ; , we assumed .
(4) Generate . For any , we assume , with generated from a rescaled Beta distribution with mean 0.85 and variance 0.25.
(5) Generate . For any , we assume , with generated from a rescaled Beta distribution with mean 0.95 and variance 0.3.
(6) Generate from the standard normal distribution , assuming the error term is white noise.
(7) Generate from the standard normal distribution , assuming the error term is white noise.
(8) Set the initial value of to 0.0.
(9) Set the initial value of to 0.0.
Note that the generation process of the random disturbance terms and factor volatility terms depends not only on and that are generated by volatility equation (2.2) and (2.3), but also on its hierarchical form.
(10) Generate according to the setting of random error terms, with , where .
(11) Generate the factor volatility terms with , where .
From steps (1) - (11) of the DGP, multivariate time series with length can be generated. Our purpose is to establish the panel data factor stochastic volatility model for applying the aforementioned MCMC algorithm for model esitmation, and validate the estimation efficiency and performance. For the prior specification of the high-dimensional factor model, we assume independent prior distributions, in order to improve the algorithm performance. The prior specifications are as follows:
The prior distribution of the joint parameters is . We neglect the difference between sampling by column and sampling by row here. The free elements of factor loadings . and are assumed to have the normal distribution . From Chib et al. (2006), it is assumed that and , where and . For cases involving degrees of freedom, we assume that the degrees of freedom come from the uniform distribution of lattice points (7,10,13,16,19,22,25,30). Prior and posterior specification of the other parameters are given in equations (2.2) - (2.3).
In posterior sampling, we consider how to combine the factor decomposition and FFBS algorithm, after considering the interaction of each system of equations and the others. Whereas the factorization process is an in-depth analysis of unobservable factors, the FFBS algorithm takes into account the generation process of the latent variables. Hence, the filtering process in the forward prediction is closely related to the factor decomposition process. Furthermore, there is a nesting structure between the potential fluctuation terms , the factor fluctuation terms and the estimation of the joint parameters. Based on the relationships between the three, the follow steps must be obeyed: (1) sampling observable factors before the non-observable factors and (2) carrying out component decomposition before dynamic linear model estimation. Due to various factors that need to be considered, the overall process of model implementation is very complex. Here, we mainly focus on the estimation of the regression coefficients and other parameters that can describe the fluctuation characteristics of explanatory variables. Without loss of generity, we generate 12,000 posterior samples for each parameter, with the first 2,000 samples are discarded as burn-in and the last 10,000 samples are retained for inference.
The three blocks of parameters from the panel data factor stochastic volatility model need to be sampled jointly in each iteration, as the posterior distribution of each block depends on the current values of the other two blocks. In order to verify the estimation performance of the proposed algorithm, we consider the four parts of parameters and random terms: the factor loadings, the implied volatility terms, the scores of the common factors, and the regression coefficients of the covariates. The implied volatility terms include the factor volatility and random volatility terms. In what as follows, we only report the simulation results from model . The results of other models are similar, and will be reported only when a comparison needs to be done between the models.
The sampling of the factor loadings depends on the choice of the number of factors. In simulation model , the number of individuals is 10 and the observation period is 200. According to the ICp criterion proposed by Bai and Ng (2002), the number of common factors is 3, so the factor loading matrix contains 10 rows and 3 columns. Based on the 10,000 posterior samples, the average factor loading corresponding to the three common factors are calculated respectively. From figure 2, after 2000 simulations, the distribution of the posterior samples of the factor loading tends to be stationary, with the posterior distribution covering the mean of the initial distribution. The histograms show that the posterior distributions are approximately normal. Compared with the initial value used in the data generation process, the location parameter has some deviation. Such deviation can be explored in the future research. The posterior samples of the factor loadings can be generated simultaneously from the above MCMC algorithm.
With the generation mechanism, the sampling of the stochastic volatility terms and factor volatility terms are related to the factor decomposition process and the state transition rule of the volatility equation at the same time. In the FFBS algorithm, the filtering and sampling the two groups of latent state variables are apparently different due to the structural difference in the models. The estimates of the stochastic volatility terms describe the heteroscedasticity and stochastic volatility of the model, while the possible correlation in the sequence of error terms reflects the error structures of the mean equation. The estimates of the factor volatility terms describe the structure characteristics of the common factors. The common factors obtained by factorization are latent variables, with the estimate reflecting the impact of each common factor. For the simulation study, the estimates and the true values of the factor scores can be compared for assessing the effectiveness of factor volatility model and factor decomposition process.
The sampling process is similar to the two types of latent factors. Figure 3 shows the posterior samples of the latent factors of random error terms. In order to reflect the change of latent factors over time, we average the latent factors for each individual. The observation period in the left figure is , and the right figure is 1000. Obviously, with the growth of observation period, the posterior samples of the latent factors tend to stationary distributions. This shows that the FFBS method for the panel data factor stochastic volatility model works better for data with a long observation period. This is consistent with the requirement of a long observation period by the mixed double factor model and the discrete panel data dynamic factor model, according with the large number of outliers at the beginning of initial observation periods. When the forward filtering and backward sampling algorithm is adopted, the outliers in the initial stage are effectively accounted for later in the observation period. This is the reason that the performance of the model seems well in the left and right panels of the figure. The posterior mean of the latent factors (represented by “” in the figure) almost coincides with the true value, both falling within the 95 confidence interval, which shows the joint sampling based on FFBS captures the transfer rule of the potential factors better. In figure 3, the scatter plots below the two graphs are based on the posterior samples of the variance of the latent factors. For the convenience of comparison, we used a different scale (raised by one unit) for the posterior samples of the mean of the latent factors. It can be seen that the errors of the latent factors have apparent clustering characteristics, revealing the heteroscedasticity of the stochastic volatility model.
For the latent factor terms, the scores of common factors and the random error components of the mean equation can be obtained through the relationship between the generation process of common factors and latent factors expressed as follows:
[TABLE]
In order to compare the true factor scores and their estimates, the individual average method is used to obtain the estimates of the common factor scores. Let represents the common factor individual average score. We can write
[TABLE]
The individual average of the true factor scores is calculated in the same way as that for the posterior estimates, with the comparison, the two results are given in figure 4. The left panel of figure 4 shows the fitting performance based on the true factor scores and estimated scores based on 200 observations. The middle panel gives the scatter plot of the true factor scores (x-axis) versus the fitted (y-axis). In the middle panel, the observations closely scattered around the diagonal line, which indicates favorable fitting performance. The right panel shows the autocorrelogram of the posterior samples of the factor scores. With the AR (1) process added to the stochastic volatility effect, there is no obvious high-order autocorrelation of the factor score items. Overall, the results of figure 4 shows that the joint method of filtering and sampling is effective in estimation the latent factor volatility.
The favorable performance of the joint algorithm is reflected not only through the fitting of the latent fluctuation terms and factor error terms but also through the fitting of the interception term and coefficients of the autoregressive terms of the AR (1) process in the volatility equation. For the data generation processes, the constant term and slope term of factor volatility equation are set to 0.08 and 0.85, respectively. From the simulation study, we observe that gets closer to 1 as soon as gets closer to 0, showing the goodness of fit resulting from the assumption . Combined with other conditions, the assumption help guarantee the unique identification of the factorization results. The left panel of figure 5 presents the individual average of the interception and the slope term . The right penal presents the frequency based on the posterior samples, showing that the posterior samples oscillate around the true values and the posterior mean gradually tends to the true values of 0.08 and 0.85 after a burn-in of 2000 samples. The frequency figure validates that the mode is very close to the true value. With the increase of the chain length and observation period, the posterior samples of the coefficients converges to the true values very well.
Furthermore, we verify the estimation accuracy of the regression coefficients . Compared with the simple stochastic volatility model and the multivariate stochastic volatility model, the regression coefficients of the factor panel data model has specific real implications. Based on such implications, we can further analyze estimation results of . Here, we verify the performance of joint algorithm with the FFBS algorithm for the latent fluctuation terms and hierarchical Bayesian factor decomposition. Based on the data generation process designed earlier, we use the joint algorithm to implement Models - in table 1. Here, we only report the estimation results of models and model . The number of individuals in model and model is 10, and the number of covariates is 3 and 4 respectively. Both models include interception terms. The regression coefficients are generated by a normal distribution with mean 0.6 and variance 0.009.
In the panel data factor stochastic volatility model, the influence of various observable factors on the response variables is captured by the covariates and individual effects. In the joint algorithm, the regression coefficients are estimated by the hierarchical Bayesian method of the panel data random coefficient model, with each model assumed to have interception terms. In the MCMC algorithm, a total of 10,000 posterior samples are taken after the burn-in period. The simulation was repeated 1000 times to obtain the estimates of coefficients of each individual variable, according to the new data generated process. The estimated standard error of each coefficient and the root-mean-square error (RMSE) are very small, so we only report the average of the estimated coefficient and the -statistic. The estimates and -statistics are presented in table 2.
In table 2, represents individuals and represents variables. And represents the interception term of the model. The estimation of each coefficient is the average of the 1000 repeated simulations. The -statistic value under the estimated coefficient is computed based on the average of the estimated standard error. The estimated values of coefficients from the two models are very close to the mean of the normal distribution, with the all -tests all are highly significant. This shows the super performance goodness of fit. The results of numerical simulations show that the deviation between the estimated value and the true value depends on the estimation method and the initial data generation process. The estimates’ result will be more accurate when we reduce the variance of the normal distribution of in the data generation process.
The simulation results demonstrate that the proposed algorithm is effective for the panel data factor stochastic volatility model. The estimated coefficient of the mean equation or stochastic equation and the extraction of latent factors and random error components both have good fitting performance on simulated data. The estimates of the observable factors are reflected in the individual random coefficients, while the unobservable factors are determined by the volatility equation and factor decomposition. From the simulation studies, we can study that each part can reflect the distribution features observed in real data. The estimates from the proposed algorithm are accurate in overall, with the mean structure of being estimated more precisely. Hence, the panel data factor stochastic volatility model implemented with FFBS has the capacity of capturing the influence of observable factors and unobservable factors very well.
5 Comparative Analysis on Internet and Traditional Financial Listed companies in China
Compared with other stochastic volatility models, the main advantage of the factor panel stochastic volatility model is its ability to simultaneously capture the influence of observable and unobservable factors on the investment return of financial assets. The observable and unobservable factors can be represented by influencing factors from the real world. Explanatory variables in the panel data stochastic volatility model represent influencing factors that are observable, whereas the unobservable factors are represented by latent factors and random error terms. In research concerning the stock market, observable factors can include market factors, over-the-counter market factors, and industrial factors related to the company. Unobservable factors can have the same sources as observable factors but are not observable or captured in the available data. By analyzing various factors, companies may be able to minimize the risk of financial assets, optimize the allocation of financial assets, as well improve the investment return.
In recent years, internet finance started booming in China’s financial market, the concept of internet finance attract great attention in the capital market. Many listed companies have incorporated internet finance into their main businesses. Internet financial companies take advantage of modern information technology and take traditional financial businesses from the counter to the network. Here, we use the term ’internet financial company’ for a listed company with main businesses including internet financial technologies, internet financial services, direct or indirect control a P2P online lending platforms fully. Traditional financial companies are those that rely on banking as the main businesses solely. P2P lending platform and crowd funding are regarded as newcomer Internet-based financial businesses in China. Many listed companies have paid great interesting in investing in internet finance. Therefore, we will compare influence of the observable and unobservable factors on the stock returns of internet financial companies and traditional financial listed companies in the Chinese stock market.
The internet financial companies have been growing rapidly in recent years in China. For comparative analysis purposes, we select 10 listed companies from the three classes of internet financial companies defined above. Because the state-owned commercial banks in China are very large, we select 10 regional commercial banks from the public banking sector. In China, regional commercial banks refer to banking financial institutions whose business area is subject to regional restrictions. All of these listed companies come from the stock markets of Shenzhen A-shares, Shanghai A-shares and the Growth Enterprise Market (GEM). For simplicity, the stock code is used to represent the name of the listed company. The trade data of the listed companies come from the CSMAR China Stock Market Trading Database. We apply the panel data factor stochastic volatility model based on the company trading records. For the model, we assume that the mean equation and common factors have volatility evolution, with both the excess logarithmic rate of return sequence and the factor component assumed to have lag effects. Due to such assumptions, the continuity of data period must be ensured. For the analysis, we use the trading records of the aforementioned 10 listed companies of internet finance and regional banks from November 1, 2017 to October 12, 2018 for a total of 231 consecutive trading days. It is assumed that the observable information and unobservable information of the listed companies has been reflected in the changes of stock price, stock transaction amount and trading volume. For the daily trading data, price fluctuation is revealed from the close price, which reflects the change of one day return. The direct related factor of daily stock price is the trading volume and trading amount on that day. In addition, the amount of the circulation market value reflects the scale and value of the listed company, which is a comprehensive evaluation of the company’s operating status by the market.
In model (2.3), daily per stock return () (including dividend) is selected as the dependent variable. Daily per stock trading volume (), daily per stock transaction amount () and daily per stock circulation market value () are selected as the explanatory variables. In order to increase the comparability between companies of different scales and market values, the three explanatory variables were standardized. Thus, the individual random effect panel data model without constant terms can be rewritten as:
[TABLE]
The proposed algorithm is used to implement the model (5.1) together with the factor panel stochastic volatility model (2.2) - (2.4). According to number of factors choice the method proposed by Bai and Ng (2002), three common factors are selected. The estimates of the factor loadings and individual random effects are shown in table 3 and table 4 respectively.
From table 3, internet financial companies and traditional financial companies have obvious differences in estimated factor loadings. Among them, internet financial listed companies have generally higher loadings on the first common factor, while traditional financial listed companies have higher loadings on the second common factor. Since the common factors represent the common shocks or the common influencing factors on a group of stocks, it reveals that the influencing factors of these two classes of financial companies are completely different, or they are from different sources. On the other hand, traditional financial listed companies have both positive and negative factor loadings on the three factor loadings, indicating that their directions of impact are not consistent. However, for listed internet financial companies, the signs are all positive for the first factor loading and the second factor loading, and all negative for the third factor load, showing a consistent pattern. In conclusion, these two classes of financial listed companies show obvious difference behavioral from their transactions, which verifies that there is indeed a noticeable difference between their internal and external influential factors.
While the factor loading analysis only reveals influence of unobservable factors, in the factor panel data stochastic fluctuation model, we can assess the influence of observable factors such as trading volume, transaction amount and current market value and their lag terms on the current stock return from the estimated regression coefficients. Using the Chinese stock market data, the estimates of model (5.1) from the FFBS method are presented in table 4. Since all explanatory variables have been standardized, the coefficient of each explanatory variable is comparable for the two types of listed companies. As shown from table 4, the estimated coefficients of the stock circulation market value have relatively smaller standard errors, and all of them are significance at the significance level of 10. The estimated coefficients of these observable factors show no obvious difference in patterns for the two types of companies. Except for the bank of Shanghai (601229), there is a significant positive correlation between the current market value and the stock return. It shows that listed companies with larger current market values have a higher expected positive return during the observation period. The results do not seem to be consistent regarding the influence of trading volume and trading amount on the return for the two types of companies. However, except for the bank of Nanjing (601009), most stock trading volume and transaction amount are negatively correlated with the stock return. It shows that the market performance seems to differ between the high price stocks and the low price stocks.
From the comparative analysis, Internet financial companies and traditional financial companies of concern are affected by various observable and unobservable factors. There seems to be similarity and dissimilarity with regard to the influential patterns with these factors. The effects of the observable factors seems to be similar for the market performance of the two types of companies, while the unobservable influence seems to different upon individual stocks.
Regarding the observable factors, the current market value of the company has a positive correlation with the stock return. Since the period from the end of 2017 to the end of 2018 selected here are stock price associated with a downward trend in China’s stock market, the increase in trading volume or transaction amount maybe simply reflect the decline on the stock returns. From table 4, the estimated coefficients of individual random effects is negative, indicating a negative correlation between the return and the trading volume/trasaction amount. This demonstrates the potential purpose of using the factor panel data stochastic volatility model to predict the trend of company’s stock return based on observable factors.
On the other hand, the influence of unobservable factors on the two types of listed companies seems to be noticeably different. Based on the estimates from factor decomposition for the unobservable factors, we may obtain practical implications of each common factor or a group of common factors and their associated influences. The results can be used to classify the company in order to help individual and institutional investors make reasonable investment decisions. Compared with other stochastic volatility models, the panel data factor stochastic volatility model containing both unobservable and observable factors provides an alternative tactic to analyze the investment value and market performance of a listed company.
6 Conclusions and Further Research
In this paper, we proposed the panel data factor stochastic volatility model and discussed its estimation using the multivariate FFBS algorithm based on block sampling. Potential alternative methods for model implementation include the generalized moment method which has been widely used for the multivariate stochastic volatility model, quasi-maximum likelihood estimation, simulated maximum likelihood, important sampling technique, as well as other estimation methods which have been successfully applied to univariate and multivariate stochastic volatility models. Other filtering algorithms combining MCMC with Kalman filtering and particle filtering also can be considered. For high-frequency data, the reflection of jump, microstructure noise and realized volatility can also be considered when constructing estimation method.
For the empirical study, the Forward Filtering Backward Sampling algorithm is used to implement the new panel data model. The empirical study shows that the panel data factor stochastic volatility model, which considers the observable factors inside the market and the unobservable factors outside the market, can not only capture the impact of common shocks on the same type of stocks, but also differences between different types of stocks. Based on factor analysis in the literature shows that stock returns are main determined by macroeconomic factors, industrial factors and individual factors, we study the effects of observable factors including macroeconomic factor and industrial factors and unobservable factors representing individual factors. From the empirical analysis, we observe that the influence of observable factors and unobservable factors on stock returns shows different patterns. The observable factors seem to have similar effects on the two types of stocks from internet financial and traditional financial companies, while the unobservable individual factors seem to have different patterns of effects.
In addition to estimates of parameters and standard errors, future research can be done on model diagnosis for the panel data factor stochastic volatility model. Pitt and Shephard (1999) proposed four methods for the stochastic volatility model diagnostic, including the methods of logarithmic likelihood, standardized logarithmic likelihood, consistency residual, and distance measurement. Due to the large number of free parameters including latent factors included in the model, traditional methods such as AIC and BIC are not suitable for selection model estimated by MCMC method. For a complex model such as the factor model, the deviation information criterion (DIC) proposed by Spiegelhalter et al. (2002) can be difficult to computing. In future studies, the distance measurement method or an improved DIC can be considered. In addition, the model selection methods for spatial and temporal two-dimensional panel data models can be used for alternative Bayesian models.
Appendix:
The FFBS Algorithm for Panel Data Factor Stochastic Volatility Model
The Forward Filtering and Backward Sampling (FFBS) algorithm was proposed by Carter & Cohen (1994) and Frühwirth-Schnatter (1994) separately. Hore et al. (2010) documented the FFBS algorithm in a nonlinear state space model in detail. This paper mainly discusses the panel data factor stochastic volatility model estimation based on the multivariate FFBS algorithm.
For model (2.1), the observable response and explanatory variables items (including the coefficients obtained by the joint estimate) can be merged and moved to the left hand, while the unobservable factors, the factor loadings and error components can be moved to the right hand of the model. After the re-parametrization and rearrangemeng, the model can be written as:
[TABLE]
Let , and assume that . Since the unobservable factors are uncorrelated with the time variable, we can obtain model (3.18) and (3.19). To predict the implicit volatility block, in model (3.20), neglecting the known parameters and data information gives the conditional probability density:
[TABLE]
with the Information set and defined earlier.
Since
[TABLE]
the backward sampling process of (6.2) can be written as:
[TABLE]
The estimation of high-dimensional implicit volatility terms can be done in two steps: forward filtering and backward sampling.
6.0.1 Forward Filtering
To use the information collected at timing to predict the state of future timing, we can add the state variables at timing to the state equation (6.3), and obtain the full conditional density of joint states as:
[TABLE]
The includes the full information of model parameters and data . From the property of Markov chains, we have
[TABLE]
The first term at the RHS of equation (6.5) can be written as
[TABLE]
where
[TABLE]
The last step of (6.8) is true since and are conditionally independent. Combining (6.5)-(6.8), we have
[TABLE]
After introducing the information of parameters and data at timing , (6.9) evolved into a renewal process. At this point, the forward filtering algorithm of state equation (3.19) is realized by transfer rule (3.20), where
[TABLE]
Moreover, the Kalman filtering algorithm of the nonlinear state equation is given by
[TABLE]
where represents the state transition equations, the corresponding and terms are conditional expectation and conditional variance-covariance matrices. Filtered by equation (6.3), the posterior samples of the implied volatility can be obtain in sequence.
6.0.2 Backward Sampling
The backward sampling process of equation (6.4) is designed to smooth the state variables. From the property of Markov chains, we have
[TABLE]
On the other hand, we can obtain
[TABLE]
In order to realize the posterior joint sampling, assuming that the joint distribution of is the multivariate normal distribution, the block samples of the implied volatility terms can be extracted from the distribution of (6.11).
Compliance with Ethical Standards: This article does not contain any study on human subjects or animals.
Funding: This research was funded by National Natural Science Foundation of China ( 714711730 , 71873137 , 71271210); Fang’s study was funded by The Philosophy and Social Science Fund of Anhui (AHSKY2015D53).
Disclosure of potential conflicts of interest: None
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Ahn, S. G., Lee, Y. H., and Schmidt, P. 2001. GMM estimation of linear panel data models with time-varying individual effects. Journal of Econometrics, 101(2), 219-255.
- 2[2] Bai, J., and Ng, S. 2002. Determining the number of factors in approximate factor models. Econometrica, 70(1), 191-221.
- 3[3] Bai, J. 2009. Panel data models with interactive fixed effects. Econometrica, 77(4), 1229-1279.
- 4[4] Basu, S., and Chib, S. 2003. Marginal likelihood and Bayes factors for Dirichlet process mixture models. Journal of the American Statistical Association, 98(461), 224-235.
- 5[5] Carter, C. K., and Kohn, R. 1994. On Gibbs sampling for state space models. Biometrika, 81(3), 541-553.
- 6[6] Chib, S. 2001. Markov chain Monte Carlo methods: computation and inference. In: Heckman, J. J., Leamer, E., eds. Handbook of Econometrics. Vol. 5. North-Holland, pp. 3569-3649.
- 7[7] Chib, S., and Greenberg, E. 1994, Bayes inference for regression models with ARMA(p,q) errors. Journal of Econometrics, 64(1), 183-206.
- 8[8] Chib, S., Nardari, F., and Shephard, N. 2002. Markov Chain Monte Carlo methods for stochastic volatility models. Journal of Econometrics, 108(2), 281-316.