Implicit Diversity in Image Summarization
L. Elisa Celis, Vijay Keswani

TL;DR
This paper introduces a novel method for implicitly diversifying image search results by using a visibly diverse control set, without relying on attribute labels, to better reflect real-world diversity in the results.
Contribution
The authors propose a label-free approach that leverages a visibly diverse control set to select more representative and diverse images in search results, improving diversity without additional bias.
Findings
Significantly improves visible diversity in image search results.
Maintains high accuracy while enhancing diversity.
Effective on datasets with occupation and facial attribute diversity.
Abstract
Studies have shown that the people depicted in image search results tend to be of majority groups with respect to socially salient attributes. This skew goes beyond that which already exists in the world - e.g., Kay et al. showed that although 28% of CEOs in US are women, only 10% of the top 100 results for CEO in Google Image Search are women. Most existing approaches to correct for this kind of bias assume that the images of people include socially salient attribute labels. However, such labels are often unknown. Further, using automated techniques to infer these labels may often not be possible within acceptable accuracy ranges, and may not be desirable due to the additional biases this process could incur. We develop a novel approach that takes as input a visibly diverse control set of images and uses this set to select a set of images of people in response to a query. The goal is…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2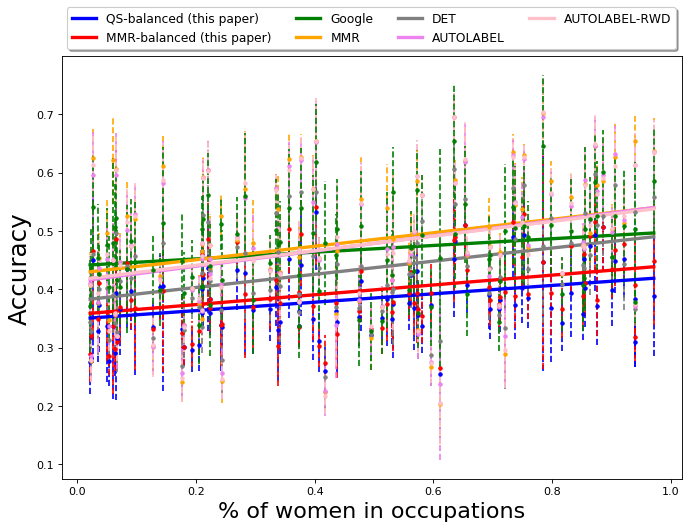 Figure 3
Figure 3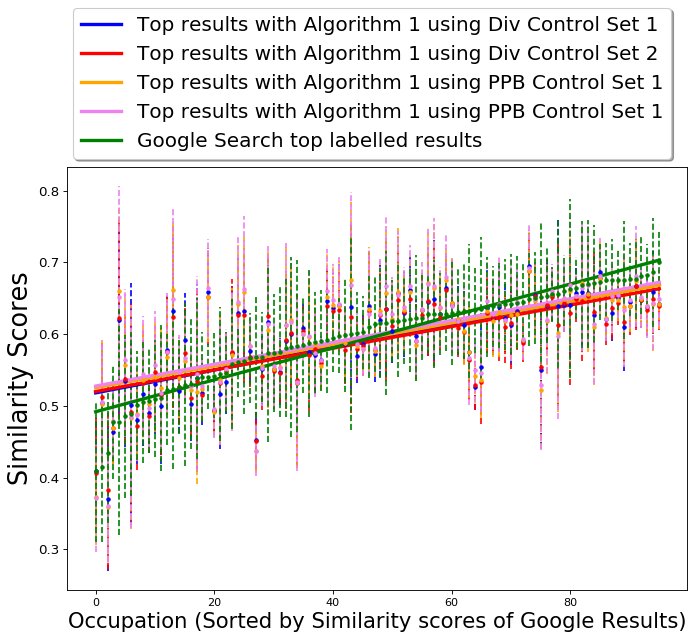 Figure 4
Figure 4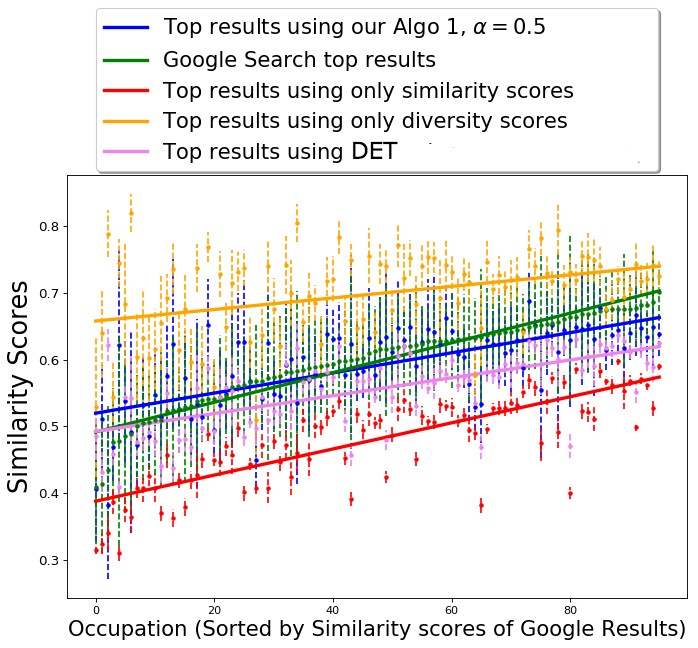 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9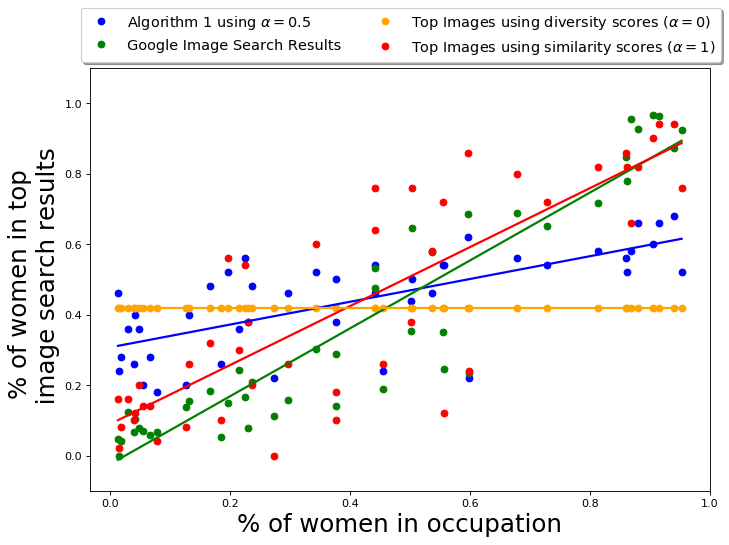 Figure 10
Figure 10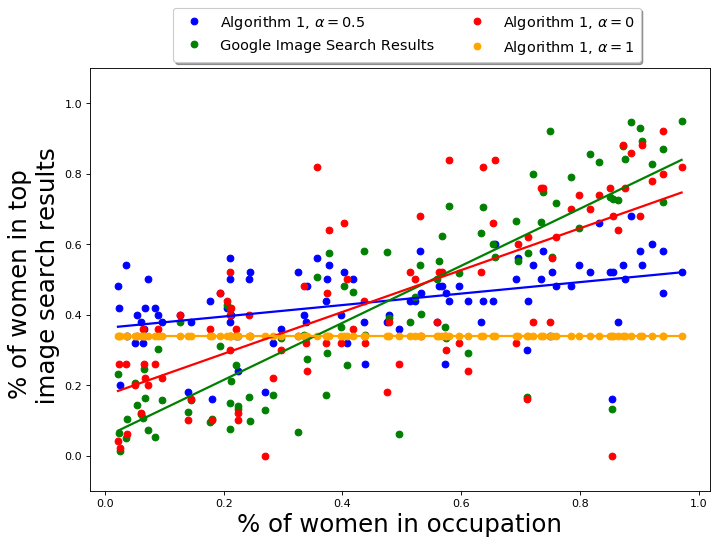 Figure 11
Figure 11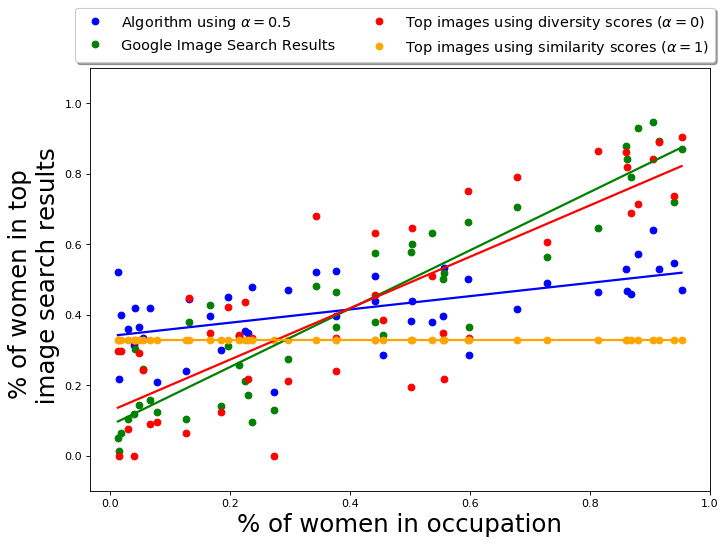 Figure 12
Figure 12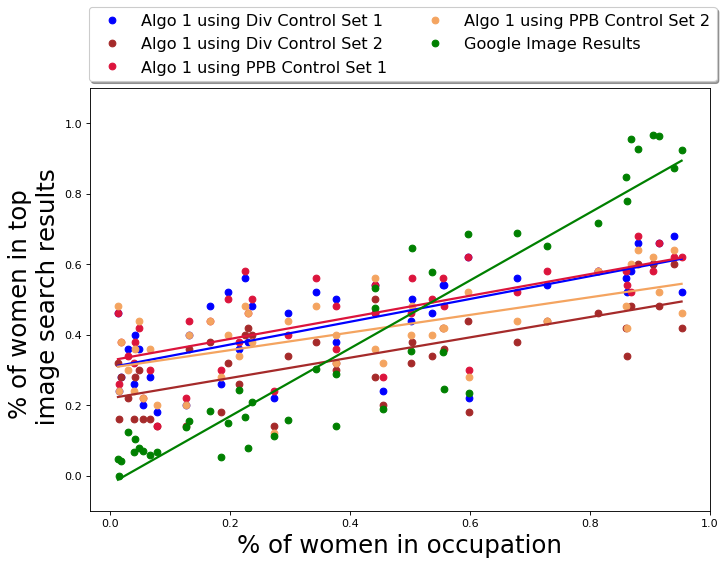 Figure 13
Figure 13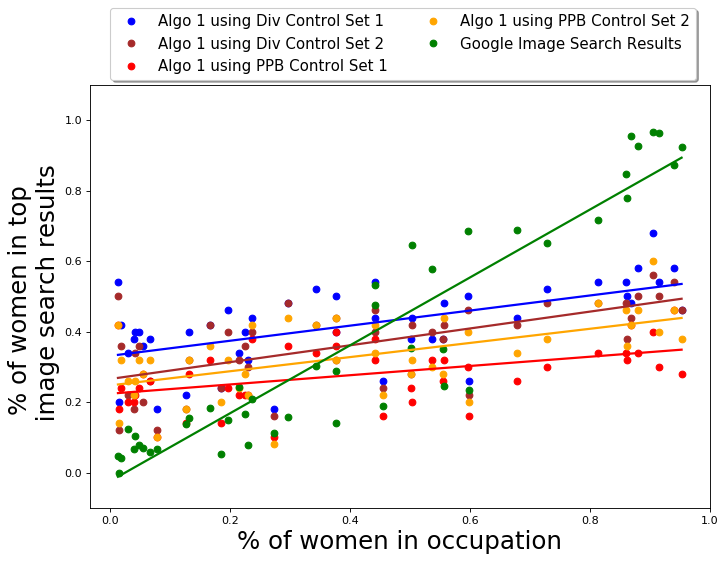 Figure 14
Figure 14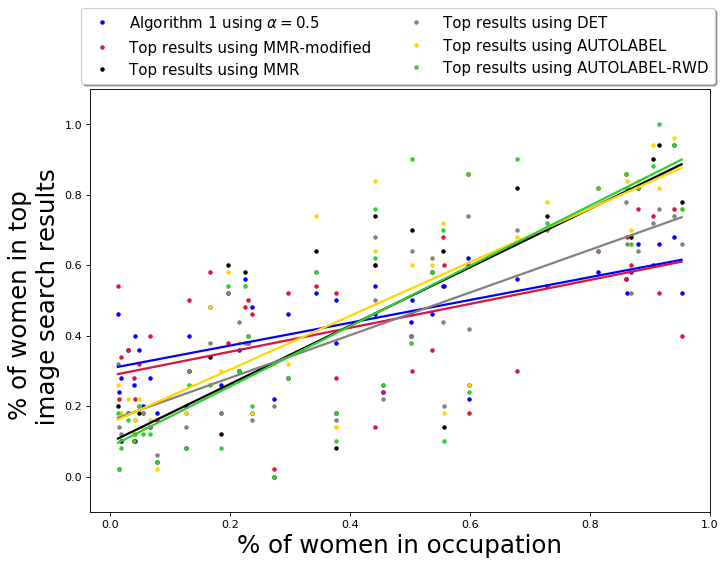 Figure 15
Figure 15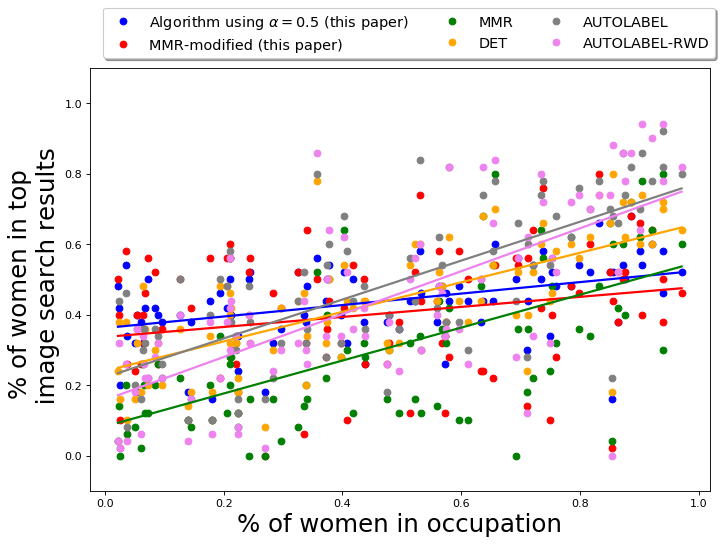 Figure 16
Figure 16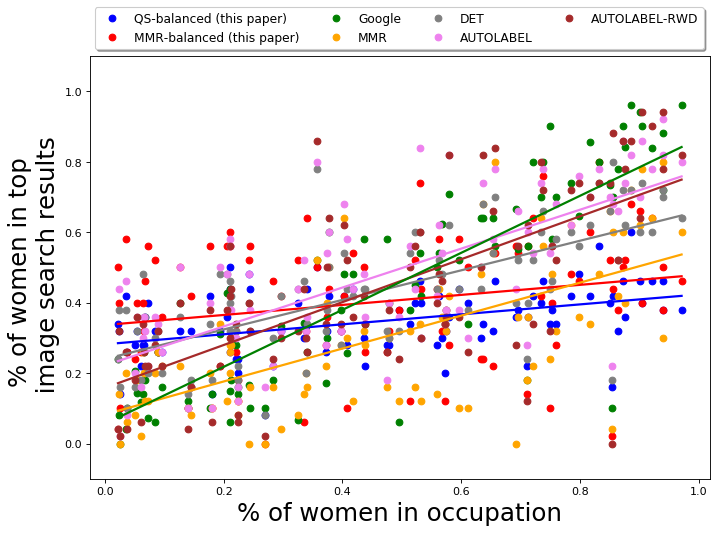 Figure 17
Figure 17 Figure 18
Figure 18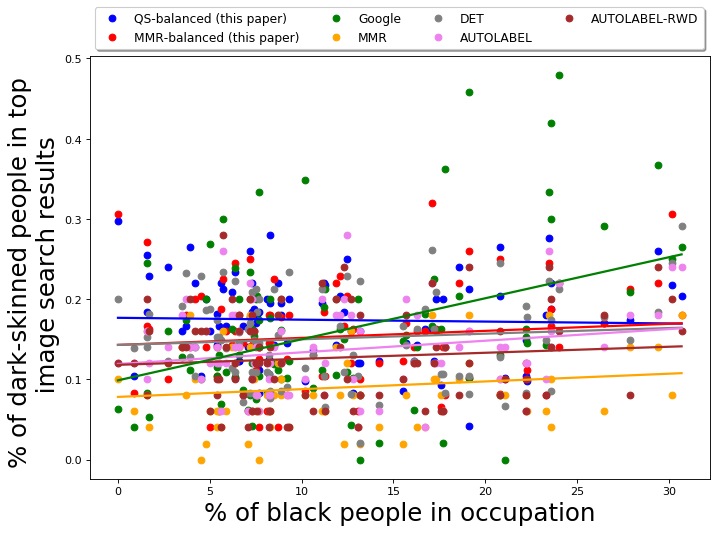 Figure 19
Figure 19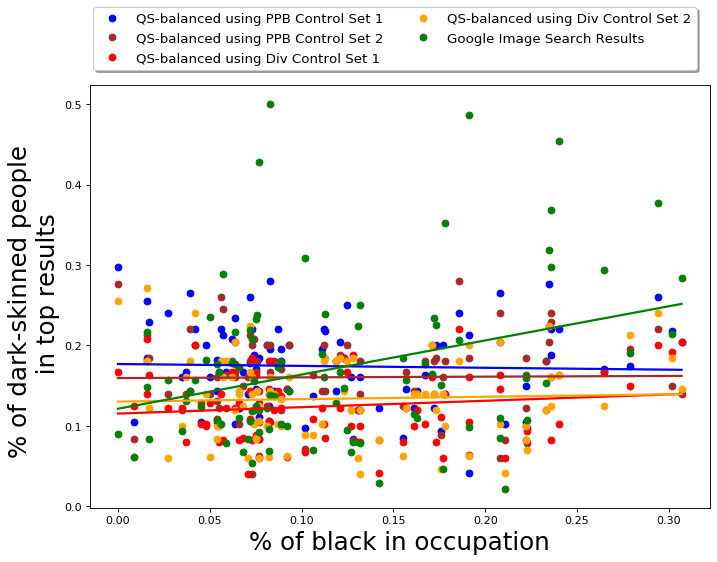 Figure 20
Figure 20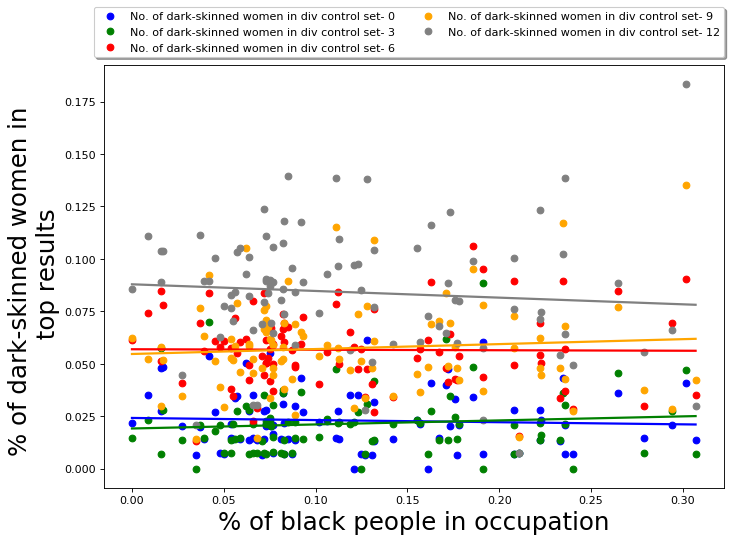 Figure 21
Figure 21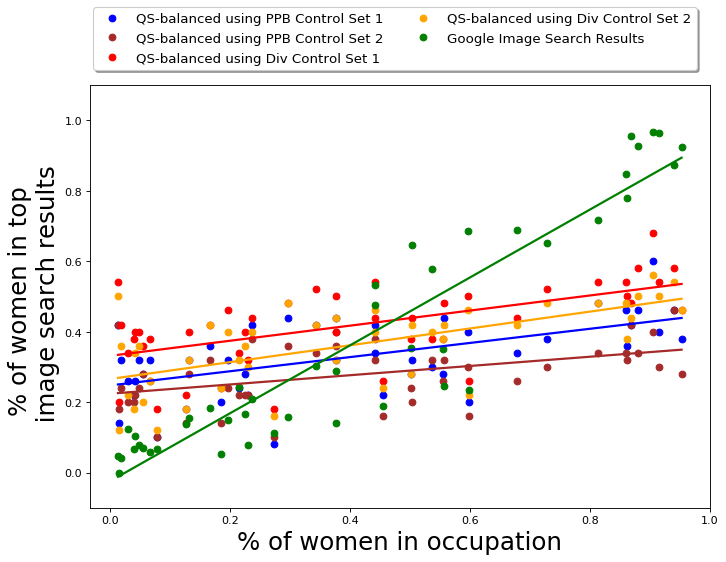 Figure 22
Figure 22 Figure 23
Figure 23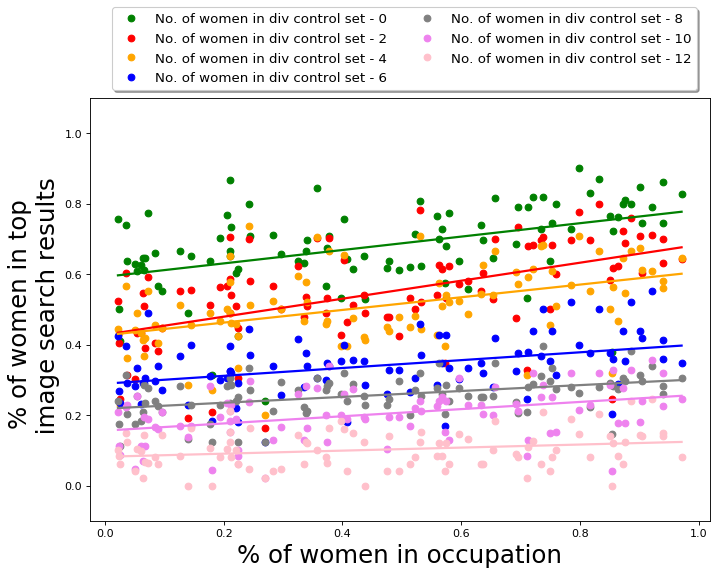 Figure 24
Figure 24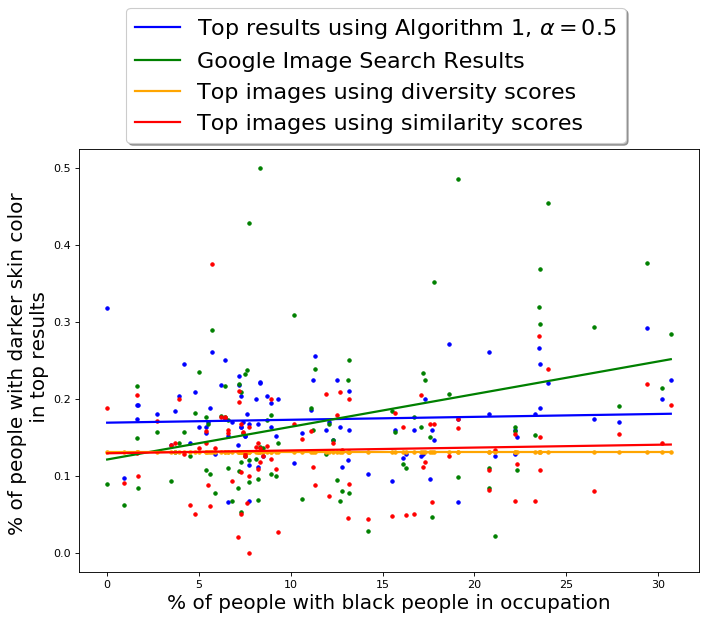 Figure 25
Figure 25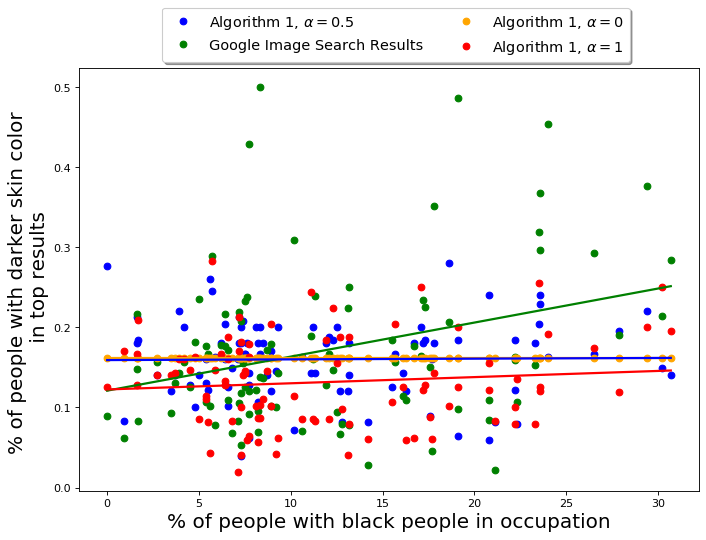 Figure 26
Figure 26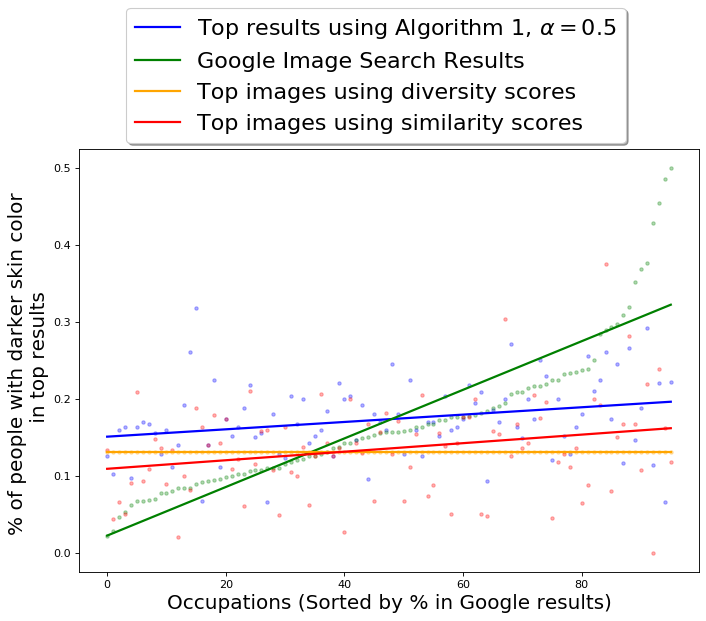 Figure 27
Figure 27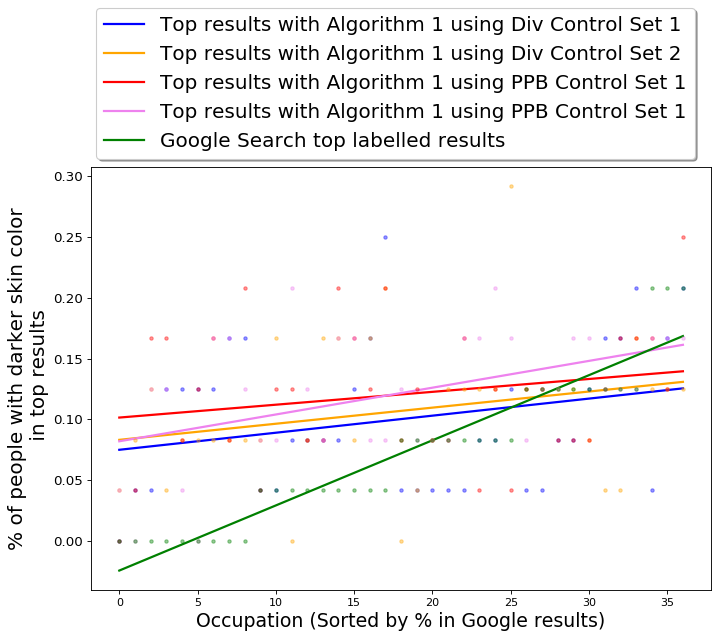 Figure 28
Figure 28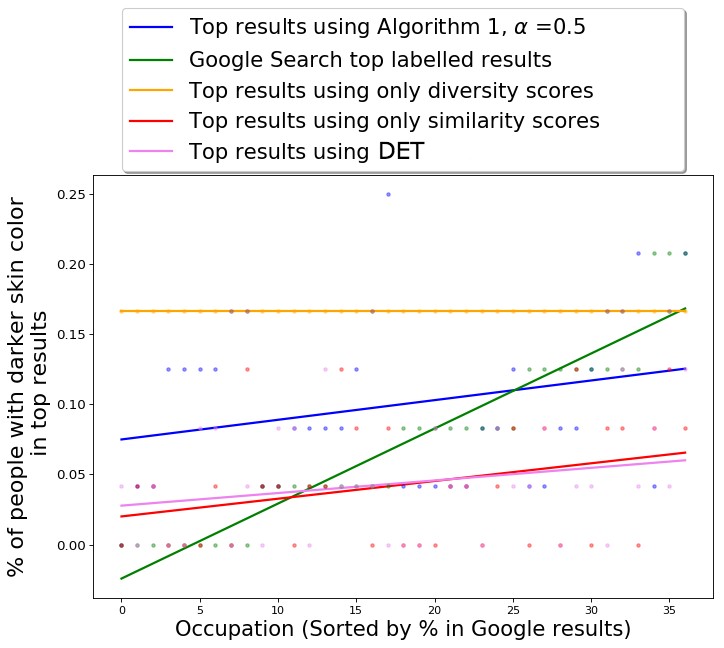 Figure 29
Figure 29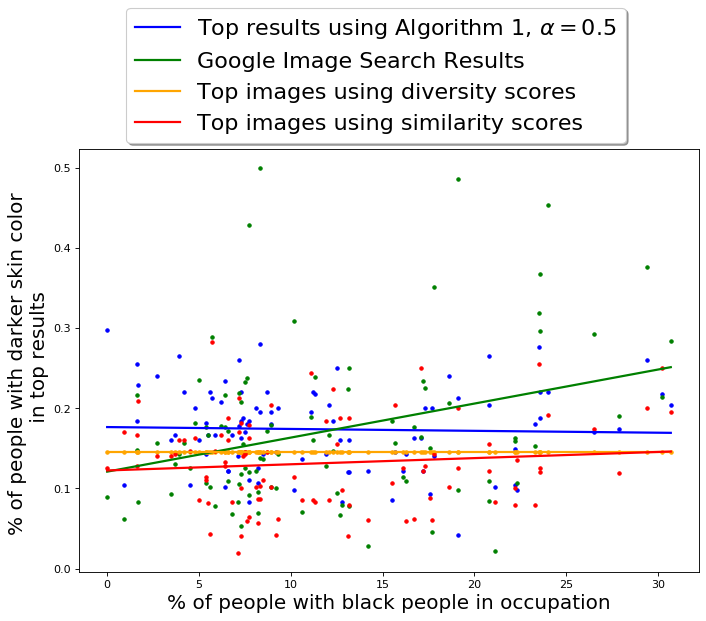 Figure 30
Figure 30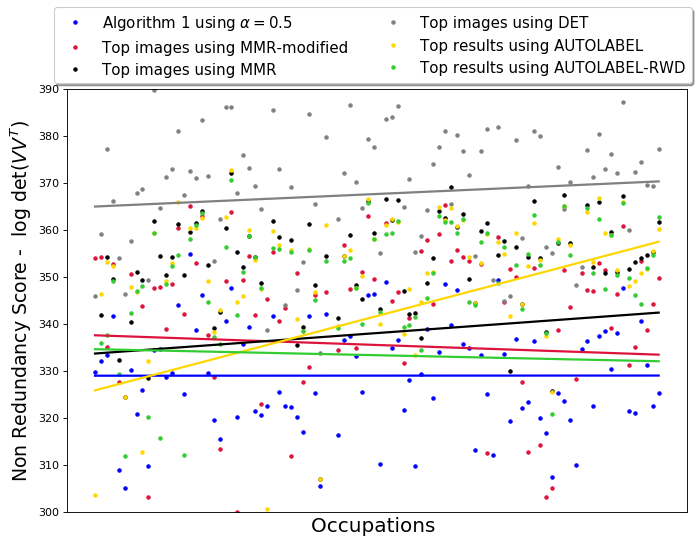 Figure 31
Figure 31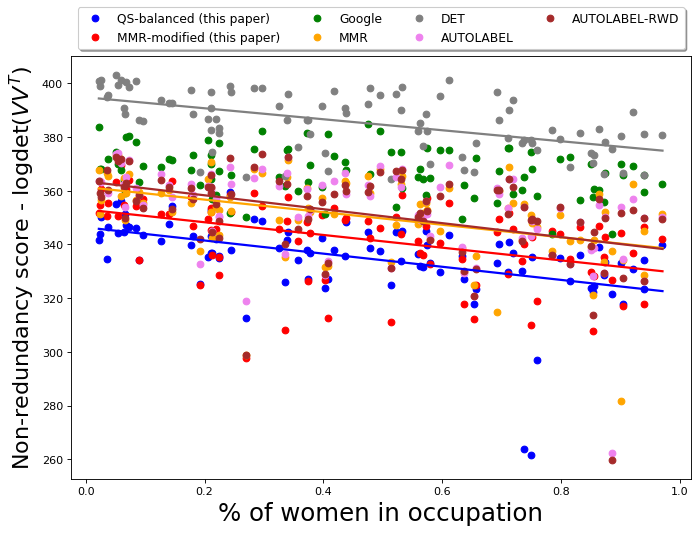 Figure 32
Figure 32 Figure 33
Figure 33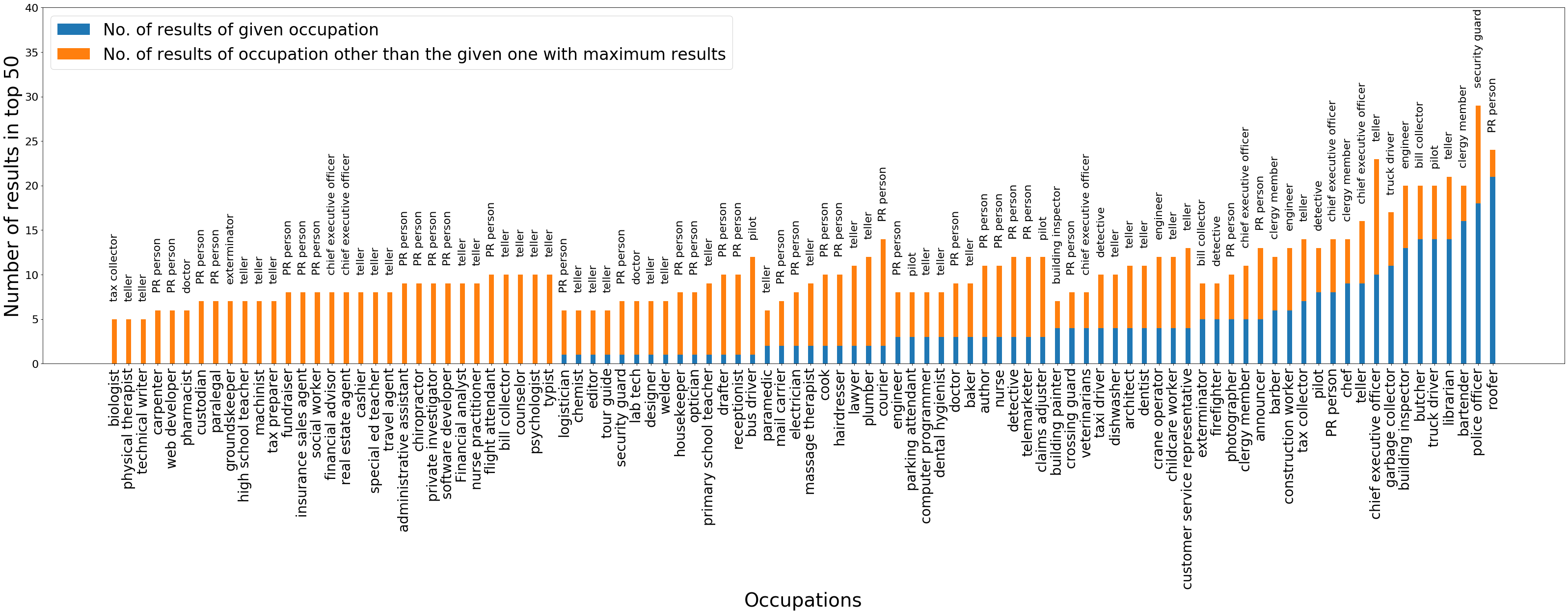 Figure 34
Figure 34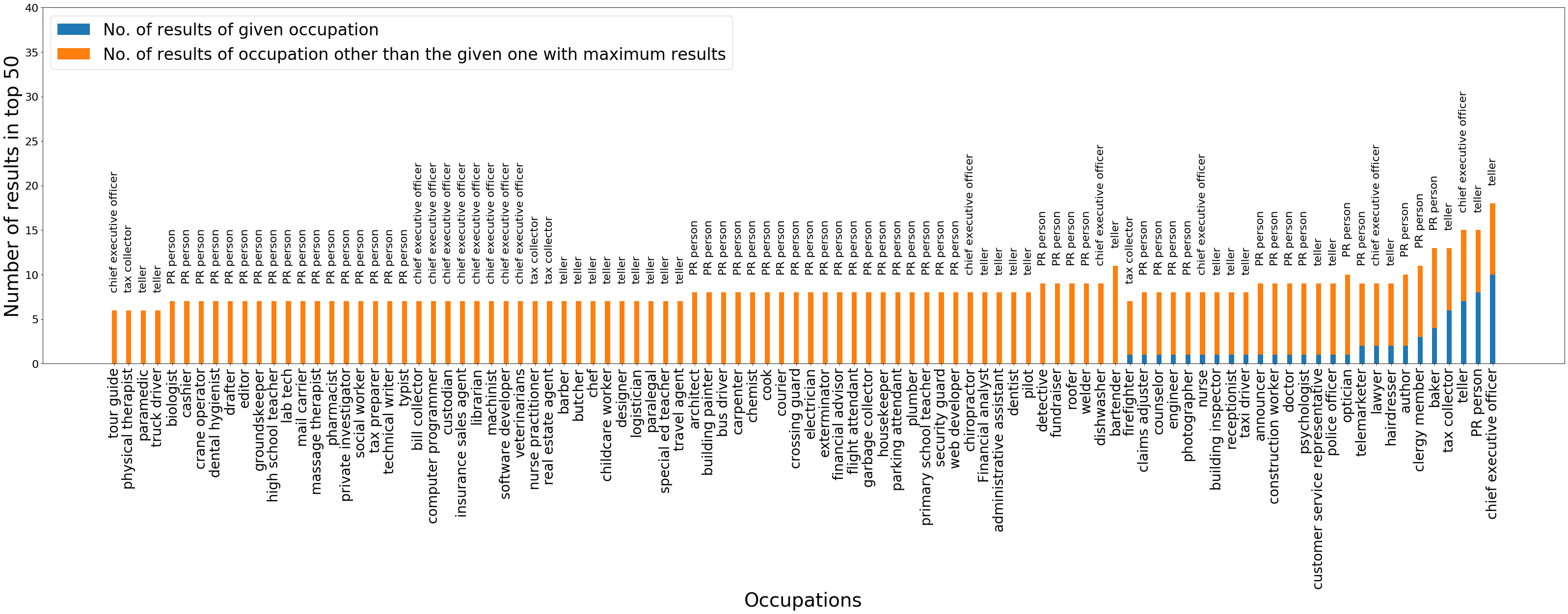 Figure 35
Figure 35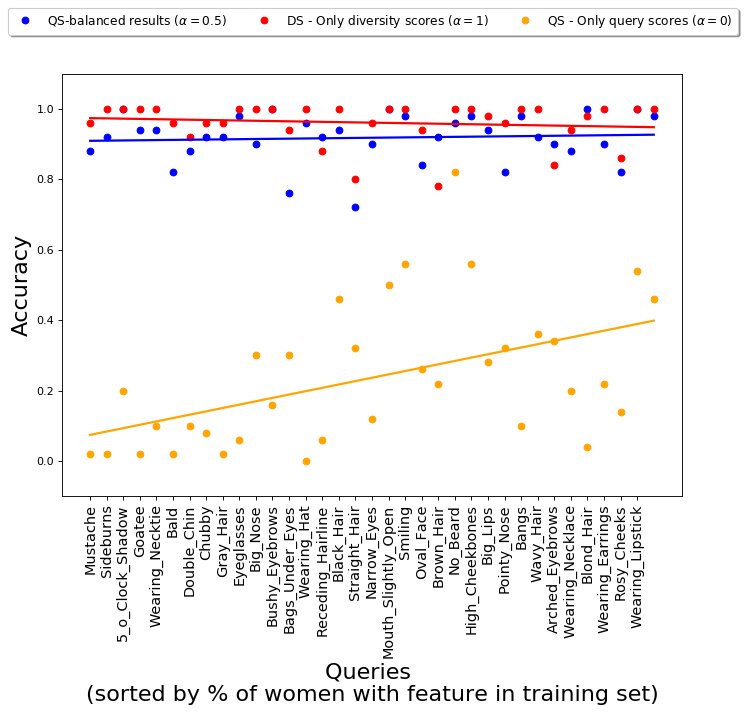 Figure 36
Figure 36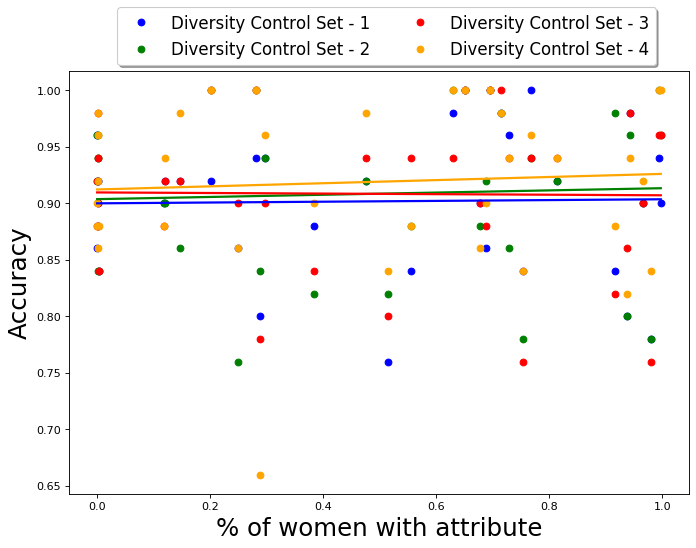 Figure 37
Figure 37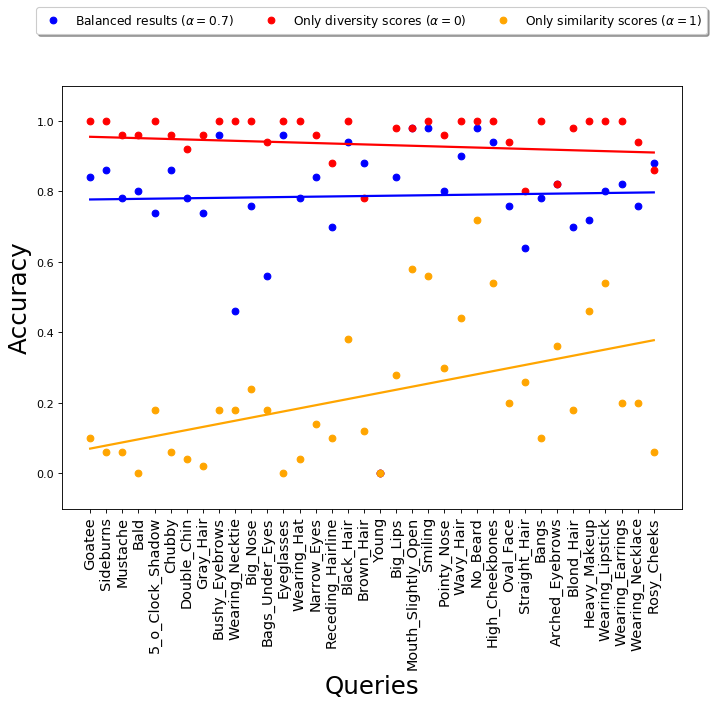 Figure 38
Figure 38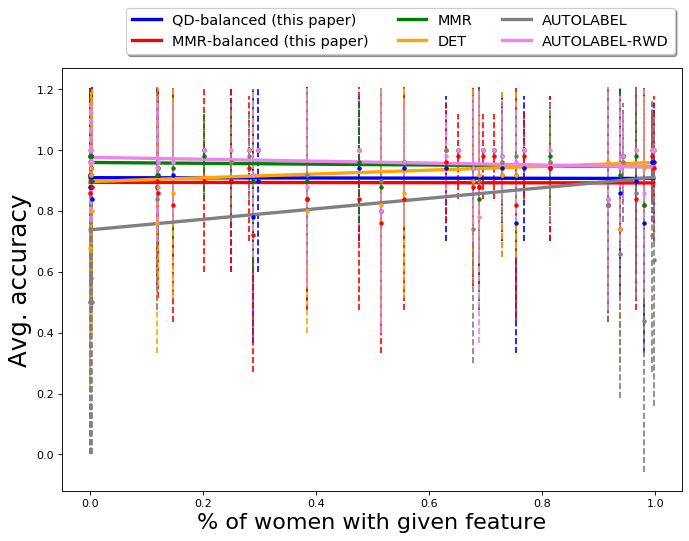 Figure 39
Figure 39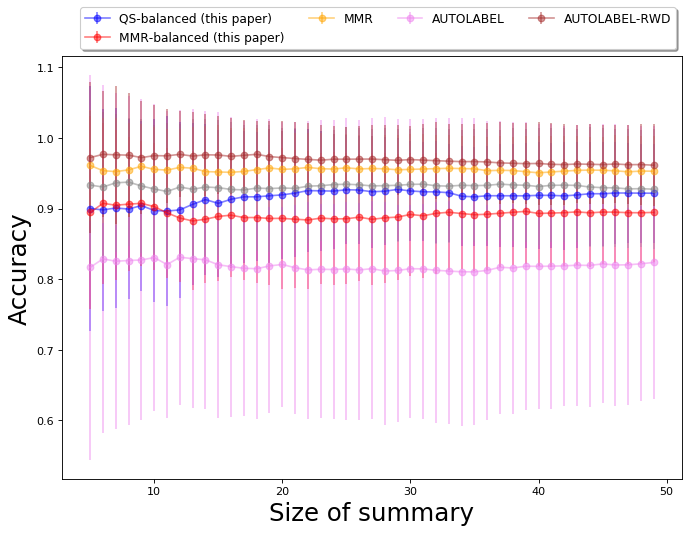 Figure 40
Figure 40| Our Algorithm | ||
| % gender stereotypical | % gender anti-stereotypical | |
| Fair skin | 0.46 (0.14) | 0.37 (0.14) |
| Dark skin | 0.09 (0.05) | 0.08 (0.05) |
| Diversity metrics | Accuracy metric | |||
| Algorithm | % gender anti-stereotypical | % dark skinned | avg. accuracy | |
| This paper | QS-balanced | 0.45 (0.17) | 0.17 (0.05) | 0.38 (0.06) |
| MMR-balanced | 0.45 (0.20) | 0.15 (0.06) | 0.39 (0.06) | |
| \cdashline1-5 Baselines | QS | 0.35 (0.20) | 0.13 (0.06) | 0.47 (0.11) |
| DS | 0.48 (0.20) | 0.15 (0.00) | 0.30 (0.06) | |
| \cdashline2-5 | 0.30 (0.22) | 0.16 (0.09) | 0.48 (0.07) | |
| MMR | 0.35 (0.21) | 0.09 (0.05) | 0.48 (0.11) | |
| DET | 0.39 (0.15) | 0.15 (0.05) | 0.43 (0.08) | |
| AUTOLABEL | 0.36 (0.17) | 0.14 (0.05) | 0.47 (0.11) | |
| AUTOLABEL-RWD | 0.35 (0.21) | 0.13 (0.06) | 0.47 (0.11) | |
| Diversity metric | Accuracy metric | ||
| Algorithm | % gender anti-stereotypical | avg. accuracy | |
| This paper | QS-balanced | 0.23 (0.21) | 0.88 (0.16) |
| MMR-balanced | 0.17 (0.22) | 0.87 (0.16) | |
| \cdashline1-5 Baselines | QS | 0.08 (0.21) | 0.93 (0.16) |
| DS | 0.49 (0.12) | 0.22 (0.21) | |
| \cdashline2-4 | MMR | 0.14 (0.21) | 0.92 (0.16) |
| DET | 0.13 (0.18) | 0.90 (0.17) | |
| AUTOLABEL | 0.5 (0) | 0.80 (0.23) | |
| AUTOLABEL-RWD | 0.07 (0.24) | 0.93 (0.17) | |
| Algorithm | % gender stereotypical with fair skin | % gender anti-stereotypical with fair skin | % gender stereotypical with dark skin | % gender anti-stereotypical with dark skin |
| QS-balanced | 0.46 (0.14) | 0.37 (0.14) | 0.09 (0.05) | 0.08 (0.05) |
| MMR-balanced | 0.46 (0.17) | 0.39 (0.18) | 0.09 (0.06) | 0.06 (0.04) |
| \hdashlineGoogle | 0.60 (0.20) | 0.24 (0.21) | 0.11 (0.08) | 0.05 (0.07) |
| \hdashlineMMR | 0.57 (0.21) | 0.30 (0.21) | 0.07 (0.06) | 0.05 (0.05) |
| DET | 0.52 (0.12) | 0.33 (0.12) | 0.09 (0.05) | 0.06 (0.05) |
| AUTOLABEL | 0.54 (0.16) | 0.31 (0.16) | 0.09 (0.06) | 0.06 (0.04) |
| AUTOLABEL-RWD | 0.56 (0.19) | 0.30 (0.19) | 0.08 (0.06) | 0.05 (0.05) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Implicit Diversity in Image Summarization00footnotetext: Accepted to CSCW 2020.
L. Elisa Celis
Yale University
Vijay Keswani
Yale University
Abstract
Studies have shown that the people depicted in image search results tend to be of majority groups with respect to socially salient attributes. This skew goes beyond that which already exists in the world - e.g., Kay et al. [48] showed that although 28% of CEOs in US are women, only 10% of the top 100 results for CEO in Google Image Search are women. Most existing approaches to correct for this kind of bias assume that the images of people include socially salient attribute labels. However, such labels are often unknown. Further, using automated techniques to infer these labels may often not be possible within acceptable accuracy ranges, and may not be desirable due to the additional biases this process could incur.
We develop a novel approach that takes as input a visibly diverse control set of images and uses this set to select a set of images of people in response to a query. The goal is to have a resulting set that is more visibly diverse in a manner that emulates the diversity depicted in the control set. Importantly, this approach does not require images to be labelled at any point; effectively, it gives a way to implicitly diversify the set of images selected. We provide two variants of our approach: the first is a modification of the MMR algorithm [16] to incorporate the diversity scores, and second is a more efficient variant that does not consider within-list redundancy.
We evaluate these approaches empirically on two datasets 1) a new dataset containing top Google image results for 96 occupations, for which we evaluate gender and skin-tone diversity with respect to occupations and 2) the CelebA dataset [58] for which we evaluate gender diversity with respect to facial features. Our approaches produce image sets that significantly improve the visible diversity of the results, compared to current Google search and other diverse image summarization algorithms, at a minimal cost to accuracy.
1 Introduction
Services such as Google Image Search perform the task of image summarization, namely, responding to a query with an appropriate set of images. However, for queries related to people, such algorithms are often biased with respect to socially salient attributes111Sometimes called sensitive attributes or protected attributes in the fair machine learning literature. of the data, such as the presented gender [48, 82] or skin tone [12]. In essence, the summarization algorithms over-represent the majority demographics for a given query. Kay et al. [48] show that such errors can reinforce the gender stereotypes associated with the query, underlining the need to correct such biases in image summarization results. Furthermore, the use of demographically skewed results can be propagated and reinforced by other tools; e.g., state-of-the-art image generation algorithms such as Generative Adversarial Networks (GANs), when trained on publicly available images of engineers, mostly generates images of white men wearing a hard hat [6]. Clearly, it is crucial to ensure that the algorithms used for image summarization do not propagate or exacerbate societal biases. To that end, our goal is to provide a simple and applicable image summarization algorithm which can ensure that the images correspond to the query yet are also visibly diverse.
1.1 Our Contributions
In 2013-14, Kay et al. [48] collected Google top 400 image results for each of the 96 occupations and had 10% of the images labeled by crowd workers according to presented gender. They used this dataset to infer the gender bias in the Google search results of occupations described above. In the 6 years since then Google has continually updated its image analysis algorithms [5]. Hence, the first question we address is: does bias remain an issue in Google Image Search results?
Towards this, we consider the same 96 occupations and collect the top 100 Google search results for each one in December of 2019.222http://bit.ly/2QVfM0K We have these images labeled by crowd workers using Amazon Mechanical Turk (AMT) with respect to presented gender (coded as male, female, or other) and skin-tone (coded according to Fitzpatrick skin-tone scale). This results in 60% of images containing gender labels and 63% of images containing skin-tone labels. While some improvements have been made with respect to gender (the percentage of images of women in Google 2014 results is 37% and in Google 2019 results it is 45% ), we find that the fraction of gender anti-stereotypical images 333Anti-stereotypical images refer to set of images that do not correspond to the stereotype associated with the query. For example, gender anti-stereotypical images for a male-dominated occupation (determined using ground truth) would correspond to the set of images of women in the summary generated for that occupation. is still quite low (30% in Google 2019 results and 22% in Google 2014 results).
For skin-tone, 52% of the images have a fair skin-tone label (corresponding to Type 1-3 on the Fitzpatrick scale) and 10% of the images have a dark skin-tone label (corresponding to Type 4-6 on the Fitzpatrick scale). Once again, the fraction of images of dark-skinned people in Google results is quite low. Overall 57% of the dataset has both a gender and skin-tone label; however, only 7% of these are images of dark-skinned men and 3% are images of dark-skinned women. A final statistic that captures the lack of diversity in Google results is that 35 out of 96 occupations do not have any images of dark-skinned gender anti-stereotypical people in the top 100 results. This assessment of Google Images with respect to skin-tone was not possible for the original dataset of images from 2014, as no skin tone labels were present.
Given the extent and importance of this problem, the next question we address is: are there simple and efficient methods that correct for visible diversity across socially salient attributes in image search? When considering this question, we first note that, in general, images that contain people would not have their socially salient attributes explicitly labeled. Datasets are at scales where collecting explicit labels is infeasible, and while it may be possible to learn these attributes in a pre-processing step, as we also observe this can lead to additional errors and biases [77]. Hence, we add a constraint to our main question: are there simple and efficient methods that correct for visible diversity across socially salient attributes in image search results which do not require or infer attribute labels? To the best of our knowledge, no methods with such a requirement exist for image summarization nor any other related problem in machine learning. 444
The goal of search algorithms is usually to return a ranking of images given an input query. While our approach can be extended to the case of ranking as well, in this paper, we will primarily focus on the task of fair retrieval, i.e., returning a fair summary of images corresponding to an input query and ensuring that the top results are unbiased. The reason for this simplification is to better analyze, highlight and mitigate the bias in the most visible results of image search, often characterized by images in the first or second page of the search results. However, as discussed in Remark 2.1, our algorithms can be used to a rank images in a diverse manner as well.
To address this question, we design two algorithms: MMR-balanced, a modification of the well-know MMR algorithm [16], and QS-balanced, a simpler and more efficient algorithm inspired by the former. In both cases, the method takes a blackbox image summarization algorithm and the dataset it works with and overlays the blackbox algorithm with a post-processing step that attempts to diversify the results. To do so, our method takes as input a very small control set of visibly diverse images; the control set is query-independent and should be carefully constructed to capture the kind of visible diversity desired in the output.555The size of the diversity control set can vary by application, but we show the efficacy of our method with small sets of size 8-25. On a high-level, the process is as follows (see also Figure 2): each image is given a query similarity score using the black-box algorithm, which corresponds to how well it represents the desired query. The candidate images are also given a similarity score with respect to each image in the diversity control set using a given similarity scoring tool. After adding the query similarity score to the diversity control scores, we rank the images by the combined score for each image in the control set and output the ones with the best scores. As required, this results in a method which implicitly diversifies the image sets without having to infer or obtain socially salient attribute labels.
We evaluate the effectiveness of this approach on the new Occupations dataset we collect and the CelebA dataset. The CelebA dataset contains more than 200,000 images of celebrities labeled with information about facial attributes of the person in the image. For the Occupations dataset, the queries are the occupations, while for the CelebA dataset the queries are the facial attributes.
We compare the performance of our approaches on these datasets with other state-of-the-art algorithms and relevant baselines. This includes summarization algorithms that reduce redundancy in the summary [16], diversify across the feature space [50], or use gender classification tools to compute explicit labels as a pre-processing step. For the Occupations dataset, QS-balanced and MMR-balanced return more gender-balanced results than Google Image Search results (Section 4.3) and baselines. Specifically, the percent of gender anti-stereotypical images in the output of QS-balanced and MMR-balanced is around 45% on average across occupations, while for Google Image Search this number is approximately 30%. The baseline algorithms also have a relatively lower percent of gender anti-stereotypical images in their output (35%-39%), confirming observations made in prior work which state that diversifying across feature space or using pre-trained gender classification tools do not necessarily result in diversity with respect to socially salient attributes [17, 77]. Similarly, on the CelebA dataset, our algorithms return much more gender-balanced results, compared to the results using just query similarity or other algorithms. In this case, the average fraction of gender anti-stereotypical images in the output of QS-balanced is 0.23, while using just query similarity, this number is 0.08. For example, for gender-neutral facial attributes, such as “smiling,” the 50 images obtained using top query scores are images of women while QS-balanced returns an image set with a 32% men and no loss in accuracy. On the Occupations dataset, we also show that QS-balanced and MMR-balanced increase the diversity across skin-tone as well as diversity across the intersection of skin-tone and gender.666The CelebA dataset does not contain race or skin tone labels, hence we cannot evaluate its performance with respect to these attributes. The average fraction of images of dark-skinned people in the output QS-balanced is 0.17, while for Google results the average fraction is 0.16. However, the standard deviation is higher for Google results (0.09 vs 0.05), implying that the results are relatively more unbalanced for Google. In terms of intersectional diversity, Table 1 shows that the results from QS-balanced algorithm are gender-balanced across skin-tone, unlike Google results. The average fraction of images of dark-skinned, gender anti-stereotypical people in the output of QS-balanced is 0.08, while for Google this number if 0.05.
However, the increase in diversity with respect to skin-tone is limited, perhaps due to the lack of skin-tone diversity in the dataset itself. We show that we can improve these numbers by more aggressively weighting the diversity score (computed with respect to diversity control set); this comes at an increased cost to accuracy. Importantly, our focus is on visible diversity, i.e., presented gender and skin color. We make this choice as true labels are often not only unknown but also irrelevant – e.g., a set of images of male-presenting CEOs is not sufficiently diverse to combat the problems mentioned above, regardless of the true gender identity of the people captured in the images.
The following sections are organized as follows: after briefly reviewing related work in the field of diverse image summarization, we start with a description of the setting of summarization, followed by the details of our suggested algorithms in Section 2. We next present the Occupations dataset and assess the gender and skin-tone diversity of the dataset in detail in Section 3. Following this, we state the results of the empirical analysis of our algorithm on the Occupations and CelebA dataset (Section 4). Finally, we discuss the implications and inferences from our results and address the limitations of our methods and ways to improve it in future work (Section 5).
1.2 Background and Related Work
To assess the importance of addressing bias in summarization results, we first look at prior work on the social impact of stereotypes as well as related work in the field of fair machine learning.
1.2.1 Impact of stereotypes
The study of cultivation and the impact of stereotypes has drawn serious interest in the age of digital media [69, 67], primarily due to the increased ease of information access and the possibility of stereotype propagation via sources like images on social media, search results, etc. To define briefly, stereotyping is the process of inferring common characteristics of individuals of a group. When used accurately, stereotypes associated with a group are helpful in deducing information about individuals from the group in the absence of additional information [59, 11] and also function as tools to characterize group action [42, 13, 85]. However, inaccurate or exaggerated stereotypes can be quite harmful and can inadvertently lead to biases against the individuals from the stereotyped group. Prior studies have shown that association of a negative stereotype with a group for a given task can affect the performance of the stereotyped individuals on the task [84, 89]; using the performance on such a task for any kind of future decision-making will lead to the propagation of such stereotypes and bias the results against one group. Furthermore, inaccurate stereotypes also lead to an incorrect perception of reality, especially with respect to sub-population demographics [80, 37, 48]. For example, stereotypical images of Black women as matriarchs or mammies, that are further disseminated via digital media, can lead to the normalization of such a negative stereotype [24, 41]. Given the existence of such negative social stereotypes and the possibility of their propagation via images, it is important to question the presence of stereotypes in image summary representations and explore methods to prevent the exacerbation of social biases through image search results of people.
1.2.2 Bias in existing image datasets and models:
The effect of negative stereotypes and the resulting biases have been carefully explored in television media in the form of cultivation theory [80, 37], particularly with respect to the portrayal of women, racial, and ethnic minorities. Online media has only recently been subjected to similar scrutiny and multiple studies have highlighted the presence of such biases in existing summarization tools and benchmark image datasets.
As discussed before, the study by Kay et al. [48] explored the effects of bias in Google Image Search results of occupations on the perception of people of the queried occupation.
Follow-up studies by Pew Research Center [3] and Singh et al. [82] also found evidence of gender-bias in Google Image Search results; [3] further observed that, for many occupations, images of women tend to be ranked lower than images of men in search results. Such biases extend beyond images and beyond occupations; Noble [66] highlights the inherent social biases against marginalized populations in other kinds of search results. In computer vision applications beyond search, Buolamwini and Gebru [12] found that popular facial analysis tools from IBM, Microsoft, and Face++ have a significantly larger error rate for dark-skinned women than other groups. This study led to a subsequent improvement in the accuracy of these tools with respect to images of minorities [4], and it highlights the importance of constant audit of existing models as well as the need for alternative strategies to develop unbiased models, since even improvements to existing facial analysis tools do not achieve desired diversity in their results. A case in point is the study by Scheuerman, Paul, and Brubaker [77] which showed commercial facial analysis tools do not perform well for transgender individuals and are unable to infer non-binary gender.
Even existing datasets, collected from real-world settings, can encode unwarranted biases from the data collection process. Van Miltenburg [87] provided evidence of stereotype-bias in a popular dataset of Flickr images annotated with crowdsourced descriptions. The study by Zhao et al. [97] found that datasets used for visual recognition tasks have significant gender bias.
1.2.3 Downstream propagation of biases:
As mentioned earlier, inaccurate representations of demographic groups can lead to biases against these groups, either in the form of incorrect perceptions about the groups [48, 24, 41] or in the form of bias in decision-making process based on the inaccurate representations. [69, 26, 71, 8, 46]. If a machine learning model is trained using an imbalanced or misrepresentative dataset, the biases in the dataset can edge into the output of the model as well. For example, Datta et al. [28] showed that men are more likely to be shown Google ads for high-paying jobs than women, a result of training the targeting model on gender-biased data. Similarly, Caliskan et al. [15] found that word associations learned from existing texts encode historical biases, such as gender stereotypes for occupations. Image generation algorithms, such as GANs [47], when trained on Google Images of people from certain common occupations, mostly generate stereotypical images [6]. Without any additional intervention, unconstrained models, including summarization algorithms, are bound to reflect the biases of the dataset they operate upon. Hence, to prevent the propagation of bias due to imbalanced image summaries, it is important to develop summarization algorithms that ensure the generated summaries are unbiased even when using biased datasets.
1.2.4 Algorithms for image summarization:
The rising popularity of social networks and image hosting websites has led to a growing interest in the task of image summarization. The primary goal of any image summarization algorithm is to appropriately condense a given set of images into a small representative set. This task can be divided into two parts: (a) scoring images based on their importance and (b) ensuring that the summary represents all the relevant images.
Traditional image summarization algorithms to score images on their importance have focused on using visual features, such as color or texture, to compare and rank images [39, 91]. Recently, even pretrained neural networks have been used for image feature extraction [79], which is then used to score images based on their centrality in the dataset. In the case of query-based summarization, determining the importance of an image includes quantifying the relevance of the image to the query. To find query-relevant images, search services like Google use metadata from the parent websites of images to associate keywords with them, thus simplifying the task significantly [92]. However, for the datasets we analyze, metadata or keywords for images are not available; correspondingly we need to use retrieval algorithms that use image features only. If the queries come from a pre-determined set, then supervised approaches for image classification can also be used for summarization [73, 72, 95, 33]. For example, if the queries correspond to facial features, then scores from state-of-the-art convolutional neural networks pre-trained on large image datasets with annotated facial features [58] can be employed for retrieving relevant images. We will show the efficacy of such an approach in Section 4 for the CelebA dataset. In the absence of pre-trained classification models and metadata information, one has to adopt unsupervised approaches to determine query relevance of images. Given a query image, an unsupervised approach suggested by [88] uses pre-trained models [29] to find images similar to the query image; they show that this unsupervised approach is comparable to state-of-the-art algorithms for the task of pattern spotting. We will use this approach for query-based summarization for the Occupations dataset.
Secondly, to ensure that the summary is representative of all relevant images, most prior work have used the idea of non-redundancy [16, 70, 75, 22, 56]. Once the images have been scored on their relevance, algorithms such as MMR [16], greedily select images that are not very similar to the images already present in the summary. Other efficient methods to ensure non-redundancy in the summary include the use of determinantal point processes [50] and submodular maximization models [86]. These models have also been used explicitly for the task of efficiently summarizing images of people [83]. However, reducing redundancy in the output set does not always correspond to diversity with respect to the desired features, such as gender, race, etc., as demonstrated by Celis et al. [17]. Our evaluations using redundancy-reducing algorithms also lead to this conclusion. We empirically compare our algorithm to such non-redundancy-based approaches in Section 4 and discuss them further in Section 5.
1.2.5 Prior work on unbiased image summarization:
Current approaches to debias summarization algorithms often assume the existence of socially salient attribute labels for data-points. Lin et al. [56] suggest a scoring function over subsets of elements that rewards subsets that have images from different partitions. For example, Celis et al. [19] formulate the summarization problem as sampling from a Determinantal Point Process and use partition constraints on the support to ensure fairness. However, setting up the partition constraints or evaluating scores requires the knowledge of the partitions and correspondingly the socially salient attributes for all data-points. Similarly, fair classification algorithms, such as [18, 25, 32, 40, 45, 93, 94] use the gender labels during the training process. Even for language-based image recognition tasks, [97] suggest constraints-based modifications of existing models to ensure fairness of these models, but the constraints are based on the knowledge of the gender labels. Unlike these approaches, our paper aims to ensure diversity in settings where socially salient attribute labels are not available.
2 Our Model and Algorithms
In this section, we describe our approach to ensuring that the image summarization process returns visibly diverse images. Given a query from the user, we start with the goal of choosing images that correspond to the query and then incorporate an additional novel diversity check (using a diversity control set provided by the user) into the model. Let denote the large corpus of images.
**Query Score: **Suppose we are given a query and a black-box algorithm that takes the query and the dataset as input and, for each image, returns a query similarity score; the score represents how well the image corresponds to the query. The smaller the score , for a query and image , the better the image corresponds to the query. Since our framework is meant to extend an existing image retrieval model, we can assume that such a score can be efficiently computed for each query and image pair.
Image Similarity Score: Suppose that we also have a generic image similarity function sim, which takes as input a pair of images, , and calculates a score of similarity of the two images, . For the sake of consistency, here again we will assume that the smaller the score, the more similar are the images.
While the framework we propose is independent of the query matching algorithm or the image similarity function, we will present a concrete example of such algorithms and functions in a later section. We first see how we can use this score to rank our dataset.
**Diversity using a control set: ** A ranking/summary with respect to the scores returned by is unlikely to be visibly diverse without further intervention in most cases, as shown by prior studies [48]. To ensure visible diversity in the results, we use a diversity control set and a clustering approach. The diversity control set is a small set of visibly diverse images and will be used to enforce the diversity in the output; for example, if the summary is required to be gender-diverse, then the diversity control set will have equal number of images of men and women.
For each control image , using as the distance metric, we can learn the cluster of images around , by sorting for each . In other words, we can associate each image to an image in the control set to which is most similar.
**Using diversity control sets with existing redundancy-reducing algorithms: ** To ensure we take into account both the query score from the black-box and the diversity with respect to the control set , we have to combine the scores and . As mentioned earlier, a popular approach to combining query similarity and diversity is to diversify across the entire feature space, i.e., reduce the redundancy of the chosen summary. Using the maximum marginal relevance score is one of the many simple and efficient greedy selection procedures for this task [16]. The maximum marginal relevance (MMR) score of an image is a combination of the query similarity score of that image and its dis-similarity to the already chosen images; at every step, the image that optimizes this score is added to the set. However, reducing redundancy does not necessarily lead to diversification across the desired attributes, such as gender [17]. An obvious question in this respect is whether the diversity control set score can be incorporated with a non-redundancy approach to achieve diversity across gender, race, etc.
To that end, we present the MMR-balanced algorithm. Starting with an empty set , the algorithm adds one image to the subset in each iteration. The chosen image is the one that minimizes the score
[TABLE]
where . The first part of the above expression captures query relevance while the second part penalizes an image according to similarity to existing images in the summary . These two terms together constitute the maximum marginal relevance score [16]. The third term in the above expression now acts as a deterrent to choosing multiple images corresponding to the same control set image (unless there are almost equal number of images corresponding to each in ). The complete algorithm is formally presented in Algorithm 2. We will set for MMR-balanced in the following sections and empirical analysis. We also analyze this expression theoretically in Section C.
A drawback of MMR-balanced is time complexity. In particular, checking redundancy with existing images at every step is cumbersome and often necessary, if the dataset is diverse enough. Furthermore, dropping the redundancy check should not affect the diversity with respect to socially salient attributes, since we have the diversity control term for that purpose. This leads us to a more efficient algorithm.
**QS-balanced: ** Given a tradeoff parameter and a query , for each let denote the following score function:
[TABLE]
The score corresponds to a combination of similarity with and similarity with a query . Finally, for each , we sort the set and return equal number of images with the lowest scores from each set, checking for duplicates at every step. The ties are broken by choosing the image with the better query score. This gives us our final set of visibly diverse images. Algorithm 1 formally summarizes this approach. For and given a diversity control set, we will call this algorithm QS-balanced. We will also refer to the algorithm using only diversity scores, i.e., , as DS and the algorithm using only query scores, i.e., , as QS in the following sections.
**Time complexity of QS-balanced: ** Without making any assumption on the blackbox query relevance algorithm , we can upper bound the additional time to ensure diversity using the control set. The additional overhead in time complexity is , where is the time taken to compute the similarity score for any given pair of elements. This factor is due to the time taken to construct and sort the rows of the diversity-similarity matrix. The time complexity also depends linearly on the size of the control set, and hence the size of the control set should be much smaller than the size of the dataset. Note that MMR-balanced is times slower than QS-balanced, where is the size of the summary.
**Model Properties: ** An important property that many diverse summarization algorithms (including MMR) share is the diminishing returns property [16, 56, 86]. To state briefly, a function, defined over the subsets of a domain, satisfies the diminishing returns property if the change in function value on adding an element to smaller set is relatively larger. Such set functions are also called submodular functions. Due to the diminishing returns property, simple greedy algorithms can be used to approximately and efficiently optimize these functions, making them ideal for summarization over large datasets.
We can directly show that the score computed at each step of MMR-balanced satisfies the diminishing returns property (simple extension of proof for MMR). Even QS-balanced, if represented as an iterative process, can be shown to satisfy this property, implying that these algorithms share the mathematical features of common diverse summarization algorithms and that fast and greedy approaches do lead to approximately good solutions. We formalize these statements in Section C and provide mathematical proofs of submodularity of these functions.
Remark 2.1** (Ranking).**
Search algorithms usually return a ranking of images in the dataset, and ranking models also suffer from the same kind of biases as studied in the case of summarization [3, 20]. While ranking a set of images can be considered an extension of the summarization problem, we primarily focus on summarization to highlight and mitigate bias in the most visible results of image search. However, given the similarity between these problems, an obvious question is whether our approach can be used to provide a fair ranking of the images. Indeed, both QS-balanced and MMR-balanced can be used to rank images as well. Both algorithms inherently compute a score for each image which captures both the query similarity and diversity with respect to the control set (see Section C for more details). While the QS-balanced is for diverse image summarization, with slight modification the algorithm can also be used to rank the images in the dataset according to the score . We can construct a sized matrix (as shown in Figure 2) with the entry corresponding to storing the score . Next we first sort each row of this matrix according to the stored score and then sort each column. Finally we can assign a ranking, starting with the image corresponding to the first entry of the matrix and moving along the first column. Once the first column has been ranked, we move to the second column and so on, checking for duplicates at each step.
3 Datasets
3.1 Occupations Dataset
We compile and analyze a new dataset of images for different occupations. The dataset is composed of the top 100 Google Image Search results 777The images were collected in December 2019. for 96 different occupations. This dataset is an updated version of the one compiled by Kay, Matuszek, and Munson [48], which contained Google Image results from 2013 888https://github.com/mjskay/gender-in-image-search.
Since occupations are often associated with gender or race-stereotypes, empirical analysis with respect to these search terms will help better evaluate the imbalance in existing search and summarization algorithms. To compare the composition of the dataset with the ground truth of the fraction of minorities working in the occupation, we use the census data of the fraction of women and Black people working in each occupation from the Bureau of Labor and Statistics [1]. The census data shows that Black people are the racial minority in each of the considered occupations (relative to White people). In case of gender, 52 out of 96 occupations have a larger fraction of men employed and the rest have a larger fraction of women employed. In our analysis, we will often compute the fraction of gender anti-stereotypical images for different occupations, i.e., if an occupation is male-dominated we take into account the fraction of women, and if an occupation is female-dominated we take into account the fraction of men in the output set.
We used Amazon Mechanical Turk to label the gender and Fitzpatrick skin-tone of the primary person in the images. To obtain labels, we designed a survey asking participants to label the gender and skin-tone of the primary person in the images. Each survey had around 50 images and the surveys were limited to participants in US. Since some of the images had multiple primary persons or people whose features were hidden or cartoon images, “Not applicable” and “Cannot determine” were also provided for each question. For each image, we collected 3 responses and assigned the majority label to the image.
We use standard inter-rater reliability measurements to quantify the extent of consensus amongst different participants of the survey. Overall there were around 620 survey participants and each participant only labels a small subset of images (50). We compute the Cohen’s -coefficient [23] for all pairs of participants with more than 5 common images in their surveys. 999Similar techniques to evaluate interrater agreement in the setting of multiple participants rating a subset of elements has been considered in other prior work as well [54, 62]. The resulting mean -coefficient across the pairs is 0.58 (median is 0.62). Based on existing heuristic guidelines and interpretations of these coefficients [51], these results imply that, on average, there is a moderate level of agreement between survey participants.
An analysis of this dataset revealed similar diversity results to the analysis by Kay et al. [48] of Google Images from 2013. However, while their analysis was limited to gender, we are also able to assess the skin-tone diversity of the results. Furthermore, unlike Kay et al., who mainly report the fraction of images of women in top results, we focus on measuring the fraction of gender anti-stereotypical images in top images. This is because our primary goal is to provide balanced summaries and present anti-stereotypical images to effectively counter gender-stereotypes [35]. Measuring the fraction of anti-stereotypical images better quantifies the stereotype-exaggeration in current results, compared to fraction of images of women.
3.1.1 Gender Labels
Overall, approximately 61% of these images have a primary person whose gender is labelled as either Male or Female. 35% of the images are labelled Male, 26% are labelled Female, and the rest are labelled “Not applicable” and “Cannot determine”. The fraction of images of women in the results compared to the ground truth is presented in Figure 3a. The figure shows that Google Images do follow the gender stereotype associated with occupations. This was one of the main inferences of the case study by Kay et al. [48] for Google 2013 search results. While the overall fraction of women in the top 100 results seems to have increased from 2013 to 2019 (37% in 2013 to 45% in 2019), the fraction of gender anti-stereotypical images is still quite low (21% in 2013 and 30% in 2019).
3.1.2 Skin-tone Labels
For skin-tone, the options provided for labelling were the categories of Fitzpatrick skin-tone scale (Type 1-6). While there are more options in this case, choosing between consecutive options is relatively difficult. Around 15% of the images are assigned a Type-1 skin-tone label, 14% Type-2, 5% Type-3, 2% Type-4, 2% Type-5, 2% Type-6; the rest are either “Not applicable”, “Cannot determine” or have conflicting skin-tone label responses.
However, our primary skin-tone evaluation is with respect to the fraction of images of dark-skinned people. Hence we can aggregate the skin-tones into a binary feature: fair skin-tone (Type 1, Type 2, Type 3) and dark skin-tone (Type 4, Type 5, Type 6). After this aggregation, 52% of the images are have fair skin-tone label and 10% of the images have dark skin-tone label. For the rest of the paper, we will treat the skin-tone as a binary feature, unless explicitly mentioned.
3.1.3 Intersection of Gender and Skin-tone
57% of the images have both a gender and skin-tone (binary) label. Amongst these, 27% of the images are of fair-skinned men, 21% are of fair-skinned women, 6% are of dark-skinned men, and 3% are of dark-skinned women. Once again, the fraction of images of dark-skinned men and women is relatively much smaller than the fraction of fair-skinned men and women, as seen from Figure 3b. Furthermore, if we associate each occupation with its gender stereotype (for example, “Male” if the fraction of men in the occupation is larger than the fraction and women, and “Female” otherwise), then 35 out of 96 occupations do not have any images of dark-skinned gender anti-stereotypical people in the top 100 results.
Figure 3b also provides an insight into the variation of fraction of images of different groups (formed by intersection of gender and skin-tone) with respect to ground truth of fraction of Black people in occupations. For almost all occupations, a large portion of the top 100 images are of gender stereotypical fair-skinned people, further showing that current Google results for occupations do correspond to the stereotypes. Interestingly, the fraction of images of gender stereotypical fair-skinned people does not seem to be dependent on the ground truth. While this partition takes up a significant portion of top 100 images, the fraction of images from other three minority partitions seem to be partially dependent on the ground truth.
This lack of gender diversity in Google results from 2013 has also been explored in detail in the paper by Kay et al. [48]; our updated dataset shows that the current Google results still suffer from some of the gender diversity problems explored in that paper. Furthermore, our analysis also shows the Google Image results are lacking in terms of skin-tone diversity and intersectional diversity.
We test the performance of QS-balanced and MMR-balanced algorithms on this Occupations dataset and compare the results, in terms of diversity and accuracy, to top Google results.
3.2 CelebA Dataset
Another dataset we use for evaluation is CelebA. CelebA dataset [58] is a dataset with 202599 images of celebrities, along with a number of facial attributes, such as whether the person in the image has eyeglasses, smiling, etc. We use 37 of these attributes in our evaluation. One of the attributes corresponds to whether the person in the image is “Male” or not and we will use this attribute for diversity evaluation.
We divide the dataset into two parts: train and test set. The train set (containing 90% of the images) is used to train a classification model over these attributes, which is then used to compute the query similarity score. The primary dataset for summarization is the test partition of the above CelebA dataset; it contains 19962 images. The 37 facial attributes will serve as queries to the summarization algorithm and the trained classification model will be used as the blackbox query algorithm .
Some of the attributes in this dataset are gender-neutral, while other seem to be gender-specific. We consider an attribute to be gender-neutral if it is commonly associated with all genders and if the goal is to get a balanced gender representation in the results for this attribute. The dataset should also have sufficient number of images from both men and women labelled with that attribute. For example, we consider the attribute “smiling” to be gender-neutral since it is associated with both men and women, and amongst images labelled as smiling in the dataset, 34% of images that are labelled as Male and 66% are labelled as Female. 101010Despite the fact that prior studies show that there is some correlation between gender and smiling for photographs taken during public occasions [30, 27], our goal is to ensure that the summarization results do not reflect to bias of the source, i.e., when querying for a facial attribute like “smiling”, which is associated with all genders, the results should be gender-diverse to present an unbiased picture.
Similarly, the attribute “eyeglasses” can be considered gender-neutral as well. On the other hand, an attribute like “mustache” is usually associated with men and all images labelled with this attribute in the dataset are of men; hence we will consider it to be gender-specific. The fraction of images of women for other facial attributes are given in Appendix E.1. Our primary goal for this dataset is to ensure diversity with respect to such gender-neutral queries, but we present results for all the queries.
4 Setup and Observations
We empirically evaluate the performance of QS-balanced and MMR-balanced on Occupations and CelebA dataset. The complete implementation details are provided in Appendix B, including the blackbox query algorithm and the similarity function used for each of the datasets; we provide certain important details of the implementation here. In the case of Occupations dataset, the query similarity is measured by quantifying similarity to a set of images corresponding to the query, while in the case of CelebA dataset the query similarity is measured using output of a classifier pre-trained on the training partition of the dataset.
Since the choice of the diversity control set is dataset and domain-dependent, we discuss the content and construction of diversity control sets used for our simulations. A detailed discussion on the composition, social, and policy aspects of the diversity control sets is presented in Section 5.3.
4.1 Diversity Control Sets
Our criteria to choose a diversity control set can be captured by the following points: (a) the diversity control set should consist of a small number of images that belong to the same domain as the dataset and (b) the images should primarily differ with respect to the socially salient attribute and stay similar with respect to other attributes, such as background, face positioning, etc.
The domain of a dataset refers to all images that satisfy the primary visual characteristic of the dataset. For example, if the dataset contains images of faces of a few people, then images of faces of other people would still be in the domain of this dataset, where as a full body image can be considered to be outside the domain. This condition is beneficial since using images from outside the domain in the control set (i.e., visible differences between the images of the control set and the dataset) will lead to difficulty in enforcing the desired visible diversity.
For the Occupations dataset, we evaluate our approach on four different small diversity control sets. Two sets (with 12 images each) are hand-selected using images from Google results and are intended to be diverse with respect to presented gender and skin color. The reason for using Google search to construct these sets was simply to ensure that the set is comprised of images from the same domain as the dataset itself. These images are also not part of the Occupations dataset. The other two sets (with 24 images each) are generated by randomly sub-sampling from the Pilot Parliaments Benchmark (PPB) dataset [12]. We used PPB dataset to construct control sets because it contains portrait images of parliamentarians from different countries and thus ensures that the images predominantly highlight the facial features of the person. The images in the PPB dataset have gender and skin-tone labels, and we randomly select 24 images for our diversity control set, conditioned on the sampled set containing equal number of images of men and women and equal number of images of different skin-tones. These diversity control sets are presented in Section D.1.
For the CelebA dataset, once again we use four different diversity control sets for our evaluation, two sets have 8 images and the other two have 24 images; the exact images are provided in Section E.2. The diversity control sets are constructed by randomly sampling equal number of images with and without the “Male” attribute from the train set. Once again, we use the training part of the dataset to construct diversity control sets because, if possible, the images in the diversity control sets should be from the same domain as the dataset itself. Since the domain, in this case, is images of celebrities, using images from the training partition leads to better results (in terms of accuracy and diversity) than using images from Google search.
The results presented here compare the best performance using one of the diversity control sets, and the comparison of different diversity control sets is presented in the Appendix.
4.2 Baselines
To better judge the results of our algorithms, we compare them to multiple other approaches as well as relevant baselines. We first consider two baselines that give the range of our options – simply considering query accuracy (QS) or simply considering the diversity of the set (DS). We also compare our results to the existing top Google results in the dataset.
For other baselines, we consider natural and effective approaches that have been proposed in prior image summarization literature. To score images on query relevance, all algorithms once again either measure similarity using query images, in case of the Occupations dataset, or use output of the trained classifier, in case of the CelebA dataset. To ensure diversity in the summary, prior work can be divided into two categories: algorithms that aim to reduce redundancy in the summary and algorithms that use socially salient attribute labels inferred using pre-trained classification tools. We compare against both kinds of algorithms and also discuss the potential drawbacks of these approaches below.
4.2.1 Algorithms that ensure non-redundancy
Reducing redundancy is a common approach for achieving diversity in the output summary. Essentially, algorithms that aim to maximize non-redundancy try to choose a summary which has images that are maximally-representative of all the relevant images. However, as shown by prior work [17] and our empirical results, this approach does not always effectively diversify across socially salient attributes, such as gender, and instead results in a summary that is diverse with respect to other attributes, such as background, body position, etc. We compare our algorithms against two approaches that fall under the category of reducing redundancy in the output summary.
- •
DET: Determinant-based diversification [50, 19]. This approach first filters images according to their query relevance. Then it uses a geometric measure (determinant) on the features of a given subset of relevant images to quantify the diversity of the subset and aims to select the subset that maximizes this measure of diversity. However, without any constraints on the subset, DET returns a summary that is diverse across all features, including irrelevant features such as background color, and hence can be unsuitable for the task of diversifying across the given socially salient attributes.
- •
MMR: This algorithm is an iterative greedy algorithm that starts with an empty set and, in each iteration, adds an image that has maximum marginal relevance, a score which combines both query relevance and extent of similarity to the images already chosen for the summary [16]. Similar to DET, we compare against this method to show that greedily choosing non-redundant images does not explicitly lead to diversity across socially salient attribute values.
4.2.2 Algorithms that use label-inference tools
Many existing fair summarization algorithms assume the presence of socially salient attribute labels to generate fair summaries [56, 19] by using the labels to enforce fairness constraints on the output summary. In the absence of labels, one way to employ these algorithms is to use pre-trained classification tools to infer the socially salient attribute labels for all images in the dataset. For example, one can use pre-trained gender classification tools to obtain gender labels for the images and then enforce constraints using these inferred labels. However, this approach can be problematic if the classification model has been trained on biased data (as seen in [12]) or has a relatively low accuracy for the given dataset. In both cases, the use of a pre-trained gender classification model can further exacerbate the bias in the summary (as will be evident from empirical results on the Occupations dataset). For comparison of our approach against these kinds of methods, we use a pre-trained gender classification model [53] and the following two approaches for generating summaries using query similarity scores and inferred labels.
- •
**AUTOLABEL: ** Using a pre-trained gender classification model [53] 111111https://github.com/dpressel/rude-carnie, this approach first divides the dataset into two partitions: images labelled “male” and images labelled “female”. Then it sorts images in each partition by query relevance score and selects equal number of top images labelled “male” and “female” for the summary.
- •
AUTOLABEL-RWD: This approach uses a pre-trained gender classification model as well, but along with a more effective scoring function suggested by Lin et al. [56]; it rewards a subset for having images from multiple partitions instead of penalizing it for having images from the same partition.
Empirical comparison with these baselines show that the bias or errors in pre-trained classification models can often exacerbate the bias of generated summaries or adversely affect their accuracy.
Additional mathematical details and descriptions of all the baselines are provided in Appendix A. Each algorithm, including the baselines, is used to create a summary of 50 images, corresponding to each query occupation. The comparison of our algorithms and baselines on smaller summary sizes is also presented in Appendix D.6 and E.8. For the Occupations dataset, we compare our algorithm and the baselines on metrics of gender diversity, skin color diversity, and accuracy. For the CelebA dataset, we compare our algorithm and the baselines on metrics of gender diversity and accuracy.
4.3 Observations - Gender Diversity
4.3.1 Occupations Dataset
As reported earlier, 52 out of 96 occupations have a larger fraction of men employed, while the rest have a larger fraction of women employed (inferred using the BLS data [1]). We first report the fraction of gender anti-stereotypical images in the output for each query occupation, i.e., if an occupation is male-dominated, we take into account the fraction of women and if an occupation is female-dominated, we take into account the fraction of men in the output set. The results are presented in Table 2. Algorithm QS-balanced, using PPB Control Set-1 returns a set for which the average fraction of gender-anti-stereotypical images is 0.45 with a standard deviation of 0.17. In comparison, for Google Image Search, the average fraction of gender-anti-stereotypical images in top results is 0.30 with a standard deviation of 0.22. The table shows that QS-balanced algorithm returns a larger fraction of images that do not correspond to the gender-stereotype associated with the occupation.
In terms of raw gender numbers, the average fraction of women in the top results of QS-balanced for any occupation is 0.35 with a standard deviation of 0.10. The results for performance of QS-balanced using other control sets is presented in the Appendix D.3. Using Diversity Control Set-1 leads to a slightly larger average fraction of women; however, using PPB Control Set-1 leads to better performance with respect to both gender and skin-tone, which is why we present our main results using this control set.
The gender diversity of the results of MMR-balanced is similar to those of QS-balanced, and much better than Google results and baselines. The average fraction of gender anti-stereotypical images in the MMR-balanced is 0.45, with a standard deviation of 0.20, which is slightly worse than QS-balanced results. The average fraction of women in top results of any occupation for MMR-balanced is 0.40 with a standard deviation of 0.17. The results empirically show that the use of diversity control set appropriately, either in QS-balanced or MMR-balanced, leads to better diversification across gender.
The variation of the percentage of women in the output of different algorithms is presented in Figure 4(a). The -axis in Fig 4(a) is the actual percentage (ground truth) of women in occupations, obtained using data from BLS [1]. The figure primarily shows the results from MMR-balanced and QS-balanced are relatively more gender-balanced. On the other hand, MMR and DET have a relatively smaller fraction of gender anti-stereotypical images in their output, showing algorithms that aim to diversify across feature space (like MMR and DET) cannot always achieve desired diversity with respect to socially salient attributes, such as gender. The fraction of gender anti-stereotypical is, however, better than Google results, illustrating that it does diversify across gender to an extent.
The performance of gender anti-stereotypical images in the output of AUTOLABEL and AUTOLABEL-RWD is relatively lower as well (around 0.35); this is likely due to the low accuracy of the pre-trained gender classification tool (error rate 30%). The performance of these algorithms demonstrate that one cannot rely on automatic classification tools, for gender or other socially salient attributes, to ensure constraint-based diversification. Hence, an intervention, in the form of a diversity control set, can help target the necessary attributes appropriately.
4.3.2 CelebA Dataset
Table 3 shows that the output image set from the QS-balanced algorithm contains a larger fraction of gender anti-stereotypical images (0.23) than MMR-balanced, MMR, DET, and AUTOLABEL-RWD. The average loss in accuracy is also small (0.05) for QS-balanced.
On the other hand, the output set from the AUTOLABEL algorithm is always perfectly balanced. In this case the auto-gender classification tool used for CelebA dataset has better accuracy (95%), and hence we are always able to choose a perfectly gender-balanced set. However, the accuracy of this algorithm is much worse than the other algorithms, showing that enforcing hard fairness constraints does not always lead to the best results.
Even for image sets from QS-balanced and MMR-balanced, the overall fraction of gender anti-stereotypical images is not close to 50%, as desired. This is primarily because many queries correspond to a particular gender- tereotype; for example, most of the images satisfying the attribute “wearing necklace” correspond to female celebrities, and hence the algorithm cannot diversify with respect to this feature, due to lack of images of men satisfying this attribute. Similarly, most of the images satisfying the attribute “bald” correspond to male celebrities, and hence the images in the output for this query mostly contain men.
On the other hand, our framework does lead to more gender-balanced results for queries that do not have an associated gender stereotype. For example, for the query “smiling”, the top 50 images with the best query scores contain only images of women, whereas the results from QS-balanced contain around 36% images of men and 64% images of women. Similarly, for the query “receding hairline”, the top 50 images with the best query scores contains 12% women, whereas QS-balanced returns an image set with 38% women. Hence, for queries which are gender-neutral, using our framework leads to results that are relatively more gender-balanced.
4.4 Observations - Skin-tone Diversity
4.4.1 Occupations Dataset
Unlike gender, for skin-tone dark-skinned people are the minority group for all occupations considered in this dataset. Hence, in this case the fraction of anti-stereotypical images just corresponds to the fraction of images of dark-skinned people.
Using the QS-balanced algorithm, with PPB Control Set-1, the average fraction of people with dark skin-tone in top results of any occupation is 0.17 with a standard deviation of 0.05; for Google Image Search, the average fraction of women in top 50 results for any occupation is 0.16 with a standard deviation of 0.09. The high standard deviation shows that Google results are relatively more imbalanced with respect to gender, i.e., for many occupations, the fraction of images of dark-skinned people is much smaller or larger than the average. The skin-tone diversity of the results of MMR-balanced is also relatively better than baselines; the average fraction of women in top results of any occupation is 0.15 with a standard deviation of 0.06.
We also compare the skin-tone diversity of results of QS-balanced with other baseline algorithms; the results are presented in Table 2 and Figure 4(b). The -axis in Fig 4(b) is the actual percentage (ground truth) of Black people in occupations, once again obtained using data from Bureau of Labor and Statistics [1].
Once again MMR is unable to diversify across the desired attributes. For the results obtained using MMR, the average fraction of people with dark skin-tone in top results is 0.09, with a standard deviation of 0.05. The skin-tone diversity of results of DET is relatively better, the average fraction of people with dark skin-tone in top results is 0.15, with a standard deviation of 0.05.
Note that for all algorithms, the top results still have a very small fraction of people with dark skin-tone (despite using a diversity control set that is balanced with respect to skin-tone). This is primarily because, for most occupations, there are very few images of people with dark skin-tone in the dataset. We expect that summarization over a more robust dataset (such as one accessible to Google for search results) can lead to better results.
4.5 Observations - Intersectional Diversity
In the presence of multiple socially salient attributes, intersectional diversity would imply that the results are diverse with respect to combination of different socially salient attributes.
4.5.1 Occupations Dataset
We evaluate the performance of QS-balanced algorithm on the basis of intersectional diversity with respect to gender and skin-tone attributes. In other words, we check how the output set is distributed across the following four partitions: gender stereotypical fair skin-tone images, gender anti-stereotypical fair skin-tone images, gender stereotypical dark skin-tone images, and gender anti-stereotypical dark skin-tone images. The results are presented in Table 1. The diversity control set used here is PPB Control Set-1.
As discussed earlier, Google Images tend to favor the gender and skin-tone associated with the stereotype of the occupation; the table shows that the fraction for gender-stereotypical fair skin-tone images is much larger than the fraction for other partitions. In comparison, the results from QS-balanced are relatively more balanced; the difference between the fraction of gender-stereotypical and gender anti-stereotypical images is smaller, for both fair skin-tone and dark-skin tone. Furthermore, the fraction of gender anti-stereotypical dark skin-tone images in the output of QS-balanced is also larger than the corresponding fraction in Google Images. The comparison with other baselines is also presented in Table 4 in the Appendix.
Overall, the fraction of gender anti-stereotypical, dark skinned images is still low in the output of QS-balanced. Once again, the primary reason for this is the lack of robustness of the dataset itself. As noted earlier, for 35 occupations, the dataset does not contain any gender anti-stereotypical dark skinned images; to choose such images for these queries, the algorithm has to look for similarity with images from other occupations, which leads to a small fraction of gender anti-stereotypical dark skinned images and also affects accuracy.
4.6 Observations - Accuracy
4.6.1 Occupations Dataset
For the Occupations dataset, we compute accuracy by measuring similarity to the query in the following manner: for every query occupation , we have a small set of images for reference; for example, for query “doctor”, 10 images of doctors are provided. 121212These images are hand-verified and are not present in the primary evaluation dataset .. Then using the sim function, for the reference set and for each image in summary, we can calculate the score . The score gives us a quantification of how similar the image is to all other images in set , and correspondingly how similar it is to query .131313This is similar to the ROUGE score [55] employed to measure the utility of text summaries against reference summaries and has been shown to correlate well with human judgment. The query similarity of different algorithms and baselines is presented in Table 2. 141414For Occupations dataset, we can also alternately define accuracy as the fraction of images in the summary that belong to the query occupation. However, this measure is problematic since many occupations have similar looking images, for example, “doctor” and “chemist”, or “insurance sales agent” and “financial advisor”. Hence, similarity with reference images is a better measure of accuracy in this case; nevertheless, we also present the accuracy with respect to query occupation in Appendix D.8.
From the figure, we can see that the accuracy of the top images of QS-balanced (0.38) and MMR-balanced is relatively lower than the top images of Google Image Search (0.48). The average accuracy of other baselines is slightly better than our primary algorithms (greater than 0.42). Hence the loss in accuracy, due to the incorporation of the diversity control matrix, is not very large.
Note that query similarity does not imply that most of the output images belong to the query occupation. There will be images from other occupations that are matched to the query occupation, since multiple occupations can have similar images (for example, doctors and pharmacists, or CEOs and financial analysts). The plot presented here simply checks whether the average query scores of the output images of QS-balanced and MMR-balanced are close to the Google search results and other baselines. To further check the number of images in the output set that belong to the query occupation, we plot a bar graph of number of images belonging to the query occupation and the results are presented in in Figure 14 in the Appendix.
4.6.2 CelebA Dataset
Table 3 also shows the accuracy comparison of our algorithm on the CelebA dataset against baselines. Here the accuracy is measured as the fraction of images that satisfied the query facial attribute. As expected, the accuracy of the results from QS-balanced (88%) is worse than the accuracy of QS (93%), but better than the average accuracy of DS (22%), MMR-balanced (87%), and AUTOLABEL (80%). The relatively lower accuracy of MMR-balanced is primarily because it aims to reduce non-redundancy in the summary as well.
For some queries, such as “smiling” or “eyeglasses,” the loss in accuracy is small (2%), while for other queries, such as “straight hair,” even though the accuracy is small (72%), the images do visually correspond to the query. For these kinds of queries, the performance of our algorithm (in terms of accuracy and diversity) seems to be as desired. For some other queries, such “mustache” or “wearing lipstick,” the use of diversity control scores with does not seem to have an impact on gender diversity (0% gender anti-stereotypical images for both). This is primarily because these queries are associated with a gender-stereotype, in which case forced diversification will affect accuracy.
4.7 Observations - Other Diversity Metrics
We also evaluate the performance of QS-balanced, MMR-balanced, and baselines with respect to other standard diversity metrics from literature, such as non-redundancy scores (measured using log-determinant of the kernel matrix). The details and results of this comparison are presented in Appendix D.7. To state the observations briefly, the non-redundancy scores of the output generated by DET are observed to be better than non-redundancy scores of other algorithms. This is expected since DET optimizes the determinant-metric being measured. However, as noted before, maximizing non-redundancy does not necessarily ensure diversity with respect to gender and skin-tone. Amongst the algorithms from this paper, MMR-balanced has relatively better non-redundancy scores than QS-balanced. This is primarily because MMR-balanced has a non-redundancy component already built into it (at the cost of efficiency); QS-balanced, on the other hand, is faster since it only aims to ensure diversity with respect to attributes represented in the control set.
5 Discussion, Limitations and Future Work
The algorithms presented here are prototypes that aim to improve diversity in image summarization. A crucial feature of our framework is that it is built to extend existing image summarization algorithms (represented using the blackbox ). Summarization algorithms can be designed in a manner very specific to the domain; for example, Google Image Search uses metadata of the images (such as parent website, website metadata, etc.) to return images that correspond to the query. Designing a new fair summarization from scratch is unreasonable, and a post-processing approach to ensuring fairness is more likely to be adopted. However, there are certain limitations to this approach which we examine in connection to potential future work in this section.
5.1 Discussion on the Observations
The empirical results show that using the diversity control set has a positive impact on the gender and skin-tone diversity of the summary, either in the form of QS-balanced or MMR-balanced. The average fraction of gender anti-stereotypical images in the output of both algorithms is close to 0.45 for the Occupations dataset. In comparison, the average fraction of gender anti-stereotypical images in Google Image results is around 0.30. Even the algorithms that aim to just reduce non-redundancy are unable to diversify across gender and skin-tone to the extent that QS-balanced or MMR-balanced does.
However, the skin-tone and intersectional diversity in the output from QS-balanced and MMR-balanced on the Occupations dataset is still lower than the desired level of diversity (close to the fraction in the control set). Even though this is because of the lack of images of people with darker skin-tone in the Occupations dataset, it will be to important to empirically evaluate the performance of the framework on more robust datasets.
In case of CelebA dataset, while the overall average fraction of gender anti-stereotypical images is not very high (0.23), we do observe that for certain queries the fraction of gender anti-stereotypical images is higher than those obtained using just query scores (for example, “smiling”). These queries mostly correspond to gender-neutral facial attributes, for which there are sufficient images in the dataset.
5.2 Comparison with Baselines
From the performance of DET and MMR, we see that diversifying across feature space does not necessarily diversify across the socially salient attributes, an observation also made in [17]. Furthermore, imposing hard fairness constraints (such as using AUTOLABEL when the pre-trained gender classifier has high accuracy) is not ideal since this can lead to undesirably high loss of accuracy. Hence diversity control sets can serve as a medium of soft fairness constraints.
5.3 Diversity Control Sets
While diversity control sets, when appropriately chosen, do seem to improve the diversity of the output, the choice of the composition of the diversity control set is context-dependent. It is obvious that the diversity control set images should be chosen keeping in mind the domain of the images of the dataset, to ensure that image similarity comparison is not redundant. For example, a visible age gap between the people in the images in the dataset and the control-set can only lead to more inaccurate results. Even the diversity control sets used for the Occupations dataset do not perform well for the CelebA dataset, demonstrating that the choice of control set has to be dataset-specific.
But what should be the fraction of images of women or dark-skinned people in the diversity control set? We observe that changing the composition of the diversity control set changes the composition of the output similarly. We infer this by empirically evaluating the performance of QS-balanced algorithm for diversity control sets with different fractions of images of minorities and observe that as the fraction increases the representation of images of these minorities in the output set also increases. The diversity control sets are randomly chosen from the PPB dataset. The results for this analysis are presented in Appendix D.4. Hence, the composition of the diversity control set does seem to have an impact on the composition of the output summary.
The size of the control set is intentionally kept to be very small (recall that the time complexity depends linearly on the size of the control set). Indeed it is a key advantage of our approach that it performs well even with small control sets. Larger control sets could be used, but constructing them could be considerably more difficult, especially considering that determining the control set is context-specific and could/should require input from multiple parties. Empirically, we did not observe any statistically significant advantage in using control sets of sizes 100-200.
There are many other context-specific and policy-related questions about the diversity control set that cannot be answered through the above empirical analysis. Typically for an application, the range of composition of the control set should be decided after a thorough research of the user demographics and requires input from all the affected parties/communities to ensure that there is appropriate representation of all groups. Once the control set is created and deployed, ideally the company responsible for the application of the framework should also provide opportunities for public audit/examination of the decision criteria and the diversity control sets to ensure transparency in the diversification process. Transparency is crucial in this process as using misrepresentative, non-diverse, or adversarially-chosen control sets can lead to more harm than good, in terms of both accuracy and fairness. Similar to the process adopted in other settings such as voting [2], or according to distributive justice principles, it should be up to the user-base to determine whether a diversity control set is, in fact, diverse.
5.4 Choice of Tradeoff Parameter
The hyper-parameter represents the fairness-accuracy tradeoff in this algorithm. Once again, the choice is application-oriented and depends on how much loss in accuracy is acceptable to achieve the required amount of fairness in the output. We empirically evaluate the performance of QS-balanced and MMR-balanced for different values, and the results are presented in Appendix D.5 and E.7. As expected, as increases from 0 to 1, the fraction of gender anti-stereotypical images (for both Occupations and CelebA datasets) increases. At the same time, the similarity to the query or accuracy decreases. In our case, the figures show that a balanced choice of is reasonable.
The choice of hyper-parameters, such as diversity control set and value, are context-dependent, and we expect the use of this algorithm to be preceded by a similar thorough evaluation and analysis using different control sets with different composition, and different values.
5.5 Socially Salient Attributes
It is important to state that the primary evaluation of our method was with respect to gender. This evaluation made use of labelled data where gender was primarily treated as binary, which is unnecessarily and problematically restrictive [44], not an accurate representation of the gender diversity in humanity [38], and can be used in a discriminative manner [9, 43]. It would be important to evaluate this work in light of other socially salient attributes and broader label classes.
The lack of analysis and evaluation with respect to non-binary gender attribute is a limitation of many existing gender-classification tools as well. A study conducted by Scheuerman, Paul and Brubaker [77] showed that existing commercial facial analysis tools do not perform well for transgender individuals and are unable to infer non-binary gender, primarily because of focus of training on recognizing gender-stereotypical facial features. Such studies further highlight the importance of not relying on the pre-defined notion of gender, as considered by existing gender classification tools.
5.6 Better Implementation Techniques
Despite the fact that the diversity control sets used are balanced across male/female presented genders, the results from QS-balanced do not match these ratios exactly, and there is scope for improvement, perhaps with better diversity sets or similarity functions. Our current query matching algorithm for the Occupations dataset is based only on similarity with the query control set images and can be improved given additional information about the image. Once again, for a model similar to Google Image Search, one would have access to the metadata of the image which will help better quantify query similarity or the similarity of two images. Other transfer learning techniques, like retraining a small part or a single layer of the CNN, could also be employed for better feature extraction, although we did not see any improvement on an initial approach in this direction.
Just like other aspects of our algorithms, the implementation will also be context-specific. For example, in case of CelebA dataset, we had a highly-accurate multi-class classifier to determine query similarity. Hence, in this case the accuracy of the output summaries was quite high (in the range of 85% to 90%). On the other hand, for Occupations dataset, we had to use a generic similarity measure (average similarity with query images), which cannot be expected to have the best performance for every dataset.
An important part of our framework is the function employed to quantify the similarity between a pair of images. We use the standard cosine-distance to measure pairwise-similarity since it takes into account how similarly oriented two vectors are, independent of their sizes. With images from possibly different sources in the dataset, this property makes the cosine-distance more useful for our framework than other metrics such as Euclidean distance. However, just like the other variables and parameters in any framework, an inappropriate choice of similarity function can be a source of potential bias(for example, -norm is observed to be quite inefficient for our framework; see Section D.8). While cosine distance is considered appropriate for measuring similarity between images [65], in general, identifying the appropriate metric to quantify pairwise similarity between two individuals is another active topic of research and we refer the readers to [61, 90] for further discussion in this direction.
5.7 Evaluation in the Absence of Labels
Another challenge of using this approach is the difficulty in evaluating its success. Its main strength – that it can diversify without needing class labels in the training data – is also an important weakness because we may not always have labelled data with which to evaluate the results. One approach would be to predict labels using, e.g., gender classification tools [53]. However, we do not recommend using predicted labels in general as such classification tools can themselves introduce biases (as seen with the baseline AUTOLABEL for Occupations dataset) and are currently not designed with broader label classes or non-binary gender in mind, and hence do not address the core problem. Perhaps a better approach would be to use human evaluators to rate or define the visible diversity of the images selected by the algorithm.
The absence of labels also limits our analysis to relatively smaller datasets. Real-world image datasets handled by applications like Google Search are considerably larger than the ones used in this paper and are often handled as data streams [60, 34]. However, without socially salient attribute labels, the diversity of summaries for large datasets cannot be evaluated. At the same time, since the application of our framework is independent of labels, the performance reported in this paper should extend to larger datasets as well, and, as part of future work, exploration of techniques to evaluate performance on larger datasets will help establish the scalability of our approach.
5.8 Community-driven Application of the Framework
Our work can also be seen in light of the push towards participatory technologies in machine learning. Uninformed application of any technology that aims to ensure fairness can inadvertently cause more harm than good [57, 96, 10]. Recent studies exploring the current and future applicability of research in fairness have correspondingly emphasized on the importance of participation of all stakeholders in the design process of an application [76, 21, 63, 31]. Such a design process is especially important for summarization models since the results of these models can shape the perceptions of the users. Participatory design encourages the practitioners to engage with the users of the application to obtain valuable feedback on the possible disparate impacts of the application and ensures that there is a balanced power relation between the user and the engineer designing an application [74, 63, 36, 52].
An important aspect of our framework is that it requires community participation to ensure its success. As discussed in Section 5.3, the selection of a diversity control set should regularly take user feedback into account to guarantee that it is sufficiently representative of the user demographics. Encouraging community participation also ensures that the decisions regarding key aspects of the summarization framework are not entirely made by engineers. Crucially this shifts the power of the design process away from organizations and applications like Google Search and towards the users affected by the search results.
Furthermore, a crucial advantage of our framework is its post-processing nature; given any existing blackbox summarization or ranking algorithm, our framework adds a diversification component above the blackbox algorithm to ensure that the summary is fair. Hence the implementation of the framework can be independent of the organization responsible for the blackbox algorithm. This advantage can be exploited in settings where the blackbox algorithm cannot be modified. For example, our framework can possibly be implemented as a browser extension or a separate web application created by a third party that uses results from Google Image Search API and maintains a diversity control set. However, the absence of participation of the organization that designed the blackbox summarization algorithm may not be ideal either. The engineers who design the summarization algorithm would have considerably more knowledge of the domain of the datasets and can better decide the feasibility of any control set as well as its impact on the accuracy of the results. As discussed earlier, an inappropriately chosen control set can lead to exacerbation of biases in the output generated by the framework, and to prevent this one has to make sure the control set images belong to the same domain as the dataset. Given that the users only see a fraction of the dataset at any point of time, they cannot be expected to accurately judge the feasibility of any control set. The ideal use of diversity control sets would, therefore, need involvement and discussion from all parties. Importantly, our framework provides an opportunity for such a discussion and can help create a balanced power dynamic between the designers of search algorithms and the users of these algorithms when deciding how well the results should represent the user demographics.
6 Conclusion
The approaches presented in this paper (QS-balanced and MMR-balanced) aim to ensure fairness in summarization algorithms in the absence of (explicitly or inferred) labelled data in either training or deployment in order to decrease bias. As a post-processing approach, it is also flexible in that it can be applied post-hoc to an existing system where the only additional input necessary is a small set of “diverse” images. We show its efficacy on two datasets: an image dataset of occupations where it can significantly improve the diversity of the images selected with little cost to accuracy as compared to images selected by Google and an image dataset of celebrities where it can selects significantly more diverse images for gender-neutral facial attributes. Due to the generality and simplicity of the approach, we expect our algorithm to perform well for a variety of domains, and it would be interesting to see to what extent it can be applied in areas beyond image summarization.
Acknowledgments
We thank the anonymous area-chairs and reviewers of CSCW’20 for their thorough and helpful feedback.
Appendix A Details of baselines
In this section, we provide the details of the baselines that we compare our algorithms against. The first is determinant-based diversification [50, 19], DET. This approach effectively diversifies the selected images across their feature space. Suppose that we need to return images corresponding to the query . Given the query similarity scores , we can sort the list in ascending order and extract the first images from the list, where (we use in our experiments), denoted by . We can then employ the following standard diversification technique to find the most diverse images in the set . For any , such that , let denote the matrix with the feature vectors of images in as rows. Then return the set
[TABLE]
If the number of subsets is large (can be exponential), we use greedy approximate algorithms for this task [64].
Next we compare with respect to another algorithm that aims to reduce redundancy in the final set, MMR. The algorithm is an iterative algorithm that starts with an empty set and adds one image to in each iteration. The chosen image is the one that minimizes the score
[TABLE]
The first part of the above expression captures query relevance while the second part penalizes an image according to similarity to existing images in the summary . This algorithm (also referred to as maximum marginal relevance) is a popular document summarization algorithm to reduce redundancy [16]. We will use .
The baselines DET and MMR aim to show the importance of having a diversity control set. In the absence of any attribute information with respect to which the results are expected to be diverse (for example, say gender), directly diversifying the output images will results in images that are diverse in unimportant features like background etc. The diversity control set helps us identify the features for which diversity should be ensured.
For the third and fourth baseline, we will use automatic gender classification tools. Using existing pre-trained gender classification models, in particular [53] 151515https://github.com/dpressel/rude-carnie, we derive the gender labels for the images in the small dataset.
The third baseline, AUTOLABEL, is the following: we select images labelled male (by the classification tool) with the best query relevance score and images labelled female with the best query relevance score . For evaluation, however, we use the true gender labels of the images. The purpose of this baseline is to show that using existing imperfect auto-labelling tools to set constraints for diversification can lead to magnifying the biases already present in the pre-trained classification model used.
For the fourth baseline AUTOLABEL-RWD, we use the monotone submodular function proposed by [56]. They suggest that instead of penalizing a subset for having redundant images, one should reward a subset for being diverse. The scoring function to measure the quality of a set is then the following (adapted for our domain):
[TABLE]
where are the partitions of the domain based on the socially salient attribute. For the case of gender, we will have two partitions. The second part of the expression ensures that adding images from different partitions has a higher diversity score than adding images from same partition. Once again, we will create the partitions according to the gender labels obtained using the classification tool. We will use a greedy algorithm to obtain an approximately optimal subset for this case, since finding the optimal solution directly has a large time complexity. The greedy algorithm will simply add the image at every step, where is the subset chosen so far.
Appendix B Implementation details
In this section, we provide the complete implementation details, starting with the query matching algorithm and the similarity function used in our empirical analysis.
B.1 Image similarity
To obtain the similarity score for two given images, we can utilize a pre-trained convolutional neural network. We use the VGG-16 network [81], a 16-layer CNN, pre-trained on Imagenet [29] dataset, for generating the feature vectors161616other networks such as [78] could similarly be used instead.. We take the weights of the edges from the last fully-connected layer as the feature vector for the image. The process can be summarized in the following steps 171717Similar to one-shot learning using Siamese Networks [49]. 181818Cosine distance has been used in document summarization literature to calculate similarity [56] as well. The cosine distance metric also outperformed other norm-based metrics (see Fig 15 in the Appendix).: (1) feed the image into the VGG-16 network and obtain the feature vectors of dimension 4096, (2) perform Principal Component Analysis to reduce the feature vector size, (3) return the cosine distance as similarity score, i.e.,
[TABLE]
This method of using pre-trained models for other tasks is also called “transfer learning”. This technique has been succesfully employed in many other image-related tasks [68].
B.2 Query matching
QS-balanced (Algorithm 1) and MMR-balanced use a black-box querying algorithm to rank images according to similarity to a query. For evaluation purposes, we describe an algorithm for query matching algorithm in case of Occupations and CelebA datasets.
Query matching algorithm for Occupations dataset: Suppose that for every , we are provided a small set of images ; for example, for query “doctor”, 10 images of doctors (that can be hand-verified). Then using sim function, for the query set and for each image , we can calculate the score The score gives us a quantification of how similar the image is to all other images in set , and correspondingly how similar it is to query . Before using this score further, we can normalize it by subtracting the mean and dividing by standard deviation. Therefore given a set , for each , the query similarity score can be defined as
[TABLE]
We will use this score to compute .
For each query occupation , we use the top 10 images from Google results of that occupation in the dataset as the similarity control set . Note that we use this query relevance algorithm for other baselines which employ score as well.
When we have to report accuracy for results over Occupations dataset, we will use the measure of query similarity. While the above score is a measure of query similarity, is represents high similarity if the value is lower. To avoid confusion, and maintain the convention that high value is high accuracy, when measuring accuracy we will use and then similarity calculate average similarity with respect to all query images.
Query matching algorithm for CelebA dataset: For the CelebA dataset, recall that we divide the dataset into train and test partitions. The train partition is used to train a multi-class classification model, with the facial attributes as the labels.
The classification model, given an input image, returns a vector of length 37, where each entry () represents the probability that the input image satisfies the corresponding attribute; let denote the classifier. We use the MobileNetV2 architecture and a transfer learning approach suggested by Anzalone et al. [7] for the classifier, which achieves a training accuracy of around 90%.
Since we follow the convention that the smaller the score the better the image corresponds to the query, we will use the negative of the classifier output as the query-similarity score, i.e., , where denotes the output of classifier for image and denotes the entry corresponding to the attribute .
For the image-similarity scoring function, we will use the pre-trained VGG-16 network to extract the features of the images and return the cosine distance between the features as the similarity score between the images.
B.3 Diversity Control Matrix
Finally, to efficiently implement QS-balanced, we can construct a diversity control matrix of size using the image-similarity scores between the images in and images in . Before using this matrix to compute the scores, we will normalize each column of this matrix, i.e., we compute . Therefore the final score is evaluated as
[TABLE]
To implement this approach efficiently, we calculate the scores as a pre-processing step and store them in the diversity control matrix. Then given a query, we calculate the scores and combine the diversity control matrix and query similarity score list to get a matrix of size , where the element corresponding to and has the value .
For MMR-balanced, we use the greedy approach and add the diversity score of an image to its relevance score at every step.
Appendix C Model Properties
As mentioned earlier in the Related Work section, query-based diverse summarization has been a major area of research in many sub-domains within information retrieval. For diverse document and image summarization, multiple models have been considered and evaluated rigorously [16, 56, 86]. Some of the models we consider as baselines are derived from models that are popular and commonly used in diverse document summarization literature (MMR, DET and AUTOLABEL-RWD). One of the properties that a lot of diversity-ensuring summarization models share is the property of submodularity, defined formally below.
Definition C.1** (Submodular function).**
Given a set of elements and a function , the function is called submodular if it satisfies the property that for any and any element ,
[TABLE]
Submodular functions quantify the property of diminishing returns, and in many settings, a simple greedy approach can return a good approximation of the optimal solution for maximizing a submodular function. In case of maximizing monotone submodular functions subject to cardinality/matroid constraints, a greedy algorithm returns a 0.632-factor approximation to the optimal subset in the worst case [64, 14], and in many cases, performs much better than the worst-case bound.
Submodular functions occur naturally when the task is to ensure that the output summary is representative of a particular subdomain of the population. For example, in case of image summarization tasks that aim to reduce redundancy or ensure representativeness in the final set, Tschiatschek et al. [86] argued that many models in existing literature are cases of submodular maximization. Even algorithms based on determinantal point processes, such as [19, 50] satisfy this property, since the determinant-based objective function is log-submodular.
In this section, we show that the scoring mechanisms considered in Section 4 satisfy the diminishing returns property and are in-line with the submodularity property common to the diverse summarization literature. The submodularity of MMR, AUTOLABEL-RWD [56] and DET [50] has been already discussed and proved in multiple prior works. We primarily focus on the main algorithms introduced in this paper: QS-balanced and the MMR-balanced algorithm.
**Reducing Redundancy: **
A simple algorithm to reduce redundancy in the output summary is the following: let denote summary; at each step add the image which minimizes the following score
[TABLE]
where . We use this expression, called the maximum marginal relevance, as a baseline in our experiments as well, and it is common in document summarization algorithm [16, 56].
While this expression ensures the images are visibly diverse, it cannot focus on the features with respect to which diversity is desired by the user (as seen in Section 4.3). For example, it may ensure that the images in the summary have very different backgrounds, but cannot ensure the gender proportion of the people in the image summary is equal. This leads us to using a diversity control set.
**Diversity using a control set: ** To ensure visible diversity in the results we use a diversity control set .
Adding the control set similarity score to expression (1), we get the following relevance score for adding an image to a set ,
[TABLE]
where . The second term in the above expression now also aims to find the image in the control set most similar to . If an image corresponding to has already been chosen, call it , and has large similarity with as well, then we don’t want to choose . In this case values and will be close and partially cancel each other, ensuring that the overall expression doesn’t have the minimum value.
Recall that we use this scoring function as a baseline in our experiments as well. Furthermore, the expression (2) satisfies the diminishing-returns property.
Lemma C.1** (Submodularity of (2)).**
Let be a function such that Then is submodular.
Proof.
For each , is constant and independent of the set . Consider two subsets . Then
[TABLE]
since the chance of an image in being similar to is larger than that for . Correspondingly, this score satisfies the diminishing-returns property. ∎
**Alternate summarization relevance expression: ** Note that while the above algorithm can ensure diversity and non-redundancy, it has two major problems.
The first problem is that in the presence of a diversity control set, the primary aim is to ensure that diversity in the output set of images with respect to the features in the control set, and not the overall feature space. For such a task, the score may not ensure complete diversity with respect to the features of the diversity control set due to the additional goal of reducing redundancy. This was also observed in the empirical results presented in Section 4.3; the standard deviation of the fraction of women in top results was higher for MMR-balanced results compared to QS-balanced results. Hence we can try to slightly relax the goal of reducing redundancy to ensure better diversity with respect to diversity control set features.
The second problem is the time complexity. The iterative algorithm, based on choosing the image with the lowest score according to (2), is very slow. This is due to the fact that it has to evaluate the non-redundancy score at each step of the algorithm. Once again, we can instead use directly to ensure diversity and reduce the time complexity.
This leads us to our main algorithm, which addresses both these issues. Given the parameter and a query , for each , our primary scoring function is the following:
[TABLE]
We can show that this algorithm also corresponds to the diminishing returns property. Furthermore, since it does not include any term to reduce redundancy by checking already chosen elements, using appropriate pre-processing (as mentioned in Section 4) it is much faster than MMR-balanced.
Diminishing-returns property of QS-balanced (Algorithm 1): To show that QS-balanced also satisfies the diminishing returns property, we will present an alternative iterative algorithm which outputs the same set as QS-balanced (Algorithm 1). For simplicity, assume that the size of the desired summary is a multiple of . Let , be the following function Consider an iterative algorithm that adds one image to the final subset in each iteration. The image is chosen according to the following score function:
[TABLE]
where is as defined earlier and are numbers such that . Then we can prove the following theorems about the expression and its relation to (3).
Theorem C.2**.**
Given a dataset , diversity control set , query , query relevance algorithm and numbers , such that , the set returned by Algorithm 1 is the same as the set returned by the iterative algorithm using the scoring function (3).
Proof.
As mentioned earlier (Figure 2), Algorithm 1 is based on the constructing a matrix using scores , and then sorting each row of the matrix. The images are finally chosen by taking images first from the first column, then second column and so on. DDS score creates a similar ordering.
The first image chosen for any , since for all of them . The image chosen will be the image will have the best score with respect to , i.e., . This corresponds to Step 9 of Algorithm 1. Now and for all other , , the iterative algorithm will next choose an image corresponding to a different (since ), thus enforcing the loop in Step 8 of Algorithm 1.
Once one image is chosen for each , the counter will increase and the same process will be repeated. Since we assumed that the size of the chosen subset is a multiple of , the ordering in which each is addressed does not matter. ∎
Note that the above expression can be modified for the case when the size of the desired summary is not a multiple of . To do so, one just has to fix an ordering for according to the scores .
Having established the above equivalence, we can also show that the expression satisfies the diminishing-returns property.
Lemma C.3** (Submodularity of (3)).**
Let be a function such that Then is submodular.
The fact that the above function is submodular is in line with other functions considered for diverse image summarization, for example [19, 86].
Proof.
Consider two subsets . Let and . Assume that . There are two cases that we need to address.
Case 1, . In this case, if , then . If does not satisfy this condition and is not the image with the best score for in this iteration, then . For both cases, the score of is equal for and .
Case 2, . In this case, there are two sub-cases. Either and . Then and . Since , we have that
[TABLE]
The other sub-case is that and . Then
and . Since and , we have that
[TABLE]
Hence the score DDS follows the diminishing returns property for all cases. ∎
Appendix D Additional Empirical Results on Occupations Dataset
In this section, we presents additional details and empirical results for Occupations dataset. While the results in the main paper represent the best choice of parameters for the algorithm, such as value or the diversity control set, we also present here the empirical results corresponding to varying parameters so as to motivate the choices made for the simulations in the main paper.
D.1 Diversity Control Sets
For Occupations dataset, we evaluate our approach on four different small (10-30 image) diversity control sets in order to evaluate the effect of the diversity control set on the end result. Two sets (Diversity Control Set-1 and Diversity Control Set-2) are hand selected by the authors using images from Google results, and are intended to be diverse with respect to presented gender and skin color. The other two sets (PPB Control Set-1 and PPB Control Set-2) are generated by randomly sub-sampling from the Pilot Parliaments Benchmark Dataset [12]. This dataset has gender and skin-tone labelled images, and we select images uniformly at random conditioned on selecting equal number of men and women and equal number of people from all skin-tones. The diversity control sets are presented in Figure 5.
D.2 Intersectionality Results for all algorithms
We present the detailed intersectionality comparison with all baselines in the following table. This is an extension of Table 1. The performance of QS-balanced algorithm can be observed to be better than other baselines in terms of intersectional diversity.
D.3 Results for different diversity control sets
As noted earlier, we use 4 different diversity control sets in our empirical evaluations. The results presented in the paper correspond to evaluation using PPB-control set 1. We provide the diversity comparison for different diversity control sets in Figure 6.
D.4 Results for different compositions of diversity control sets
To explicitly see the impact of diversity control on the diversity of the output of the algorithm, we can vary the content of the diversity control set and observe the corresponding changes in the results. We first vary the fraction of women in the diversity control set. The diversity control sets are randomly chosen for the PPB-dataset, while maintaining the desired gender ratio. The results for different diversity control sets are presented in Figure 7a. The figure shows that increasing the fraction of women in the diversity control set leads to an increase in the fraction of women in the output set.
Similarly, increasing the fraction of images of dark-skinned people in the diversity control set leads to an increase in fraction of images of dark-skinned people in the output; this is shown in Figure 7b. Finally, Figure 7c shows the impact of variation of images of dark-skinned women in the control set on the output. While the fraction of dark-skinned women still increases, it seems to be upper bounded by the fraction of images of dark-skinned women in the dataset.
D.5 Results for different values
We vary the quality-fairness parameter and look at its impact on the performance of our algorithms. The diversity results are presented in Figure 8, while Figure 9 expands on the accuracy for different alphas.
For both QS-balanced and MMR-balanced, the fraction of gender anti-stereotypical images increases as the value increases. With an increase in fairness, a loss in accuracy is expected. While the figure shows a small change in average query scores, the standard deviation of the scores seem to be decreasing as well, showing that as increases, the dependence on the query decreases. Hence a balance between query similarity and diversity score has to be maintained by choosing an appropriate value of , such as 0.5.
D.6 Results for different summary sizes
While the results we have presented so have been with respect to a summary of size 50. However, the size of the summary can depend on the application and the results in the first page of any web-search application will depend on the size of the screen or the device being used. Correspondingly, it is important to analyze the results for different summary sizes as well.
For QS-balanced, MMR-balanced and the baselines, we look at the average fraction of images of gender anti-stereotypical and dark-skinned people in the top results, where ranges from 2 to 50; the average is taken over all occupations. The results are presented in Figure 10. We also present the gender and skintone-diversity comparison of our method vs baselines for summary sizes 10 and 20 in Figure 11 and Figure 12.
The figures shows that QS-balanced and MMR-balanced return a larger fraction of gender anti-stereotypical images for all summary sizes. With respect to skin-type, Google results seem to have a larger value for average fraction of dark-skinned people for smaller summary sizes; however, the performance of QS-balanced in this respect is similar to better for larger summary sizes. Furthermore, Google results also have a significantly larger standard deviation, implying that the fraction of dark-skinned people is also much lower than average for some occupations.
D.7 Similarity and Non-redundancy comparison for Occupations dataset
As mentioned earlier, the accuracy for Occupations dataset is measured using average query similarity, i.e., similarity to the set of images corresponding to the given query. We present the accuracy comparison for our methods and baselines in Figure 13. The accuracy score of results of all algorithms are close to each other, showing that using diversity control set does not adversely impact the accuracy.
The second figure also presents the non-redundancy comparison of our methods and baselines. The non-redundancy measure used is the log of the determinant of the feature kernel matrix, i.e., if for a summary , if is the matrix with columns representing the feature vectors of the images in , then the non-redundancy is measured as (the determinant can be pretty large and computationally more difficult to calculate, hence the logarithm). As expected, the results from DET have the largest non-redundancy score. The non-redundancy scores of QS-balanced and MMR-balanced are the lowest, perhaps due to enforcing fairness constraints using the diversity control set. However, as we saw earlier, non-redundancy does not imply diversity with respect to the socially salient attributes.
D.8 Occupation accuracy of QS-balanced algorithm
Finally, we also present the accuracy of the results of QS-balanced algorithm. The accuracy is measured as the number of images in the summary belonging to the queried occupation. The results for this accuracy are presented in Figure 14. Note that accuracy is not a good measure of quality in this case; this is because a lot of occupations have similar looking images. For example, images of lawyers and financial analysts are very similar, images of doctors and pharmacists are very similar. Hence when using image similarity as a method of query matching, one cannot expect the matched images to always belong to the same query. This problem is relatively less visible for CelebA dataset, since in that case the query similarity algorithm is more specialized to the dataset.
We also present the bar graph for when 1-norm is used, instead of cosine distance for similarity. In this case, the accuracy is much worse and this is reason for using cosine-distance over 1-norm distance for all our simulations.
Appendix E Additional Results on CelebA Dataset
In this section, we present additional details and empirical results for CelebA dataset. The additional results correspond to varying different parameters in the algorithm, such as value or the diversity control set.
E.1 Attributes of the dataset
We first present the list of facial attributes in the dataset and the fraction of images with a given attribute that are also labelled “Female”.
[TABLE]
E.2 Diversity Control Sets
Once again, we will use four different diversity control sets for our evaluation, two of them have 8 images and the other two have 24 images; the exact images are provided in Section E.2. The diversity control sets are constructed by randomly sampling equal number of images with and without the “Male” attribute from the train set. The diversity control sets are presented in Figure 16.
E.3 Results by features
We first present the exact gender and accuracy results by features in Figure 17.
E.4 Results for different diversity control sets
As noted earlier, we use 4 different diversity control sets in our empirical evaluations. The results presented in the paper correspond to evaluation using Diversity Control Set-4. We provide the accuracy and diversity comparison for different diversity control sets in Figure 18.
E.5 Results for different compositions of diversity control sets
To explicitly see the impact of diversity control on the diversity of the output of the algorithm, we once again vary the content of the diversity control set and observe the corresponding changes in the results. In this case, we only vary the fraction of women in the diversity control set. The diversity control sets are randomly chosen from the training dataset, while maintaining the desired gender ratio. The results for different diversity control sets are presented in Figure 19. The figure shows that increasing the fraction of women in the diversity control set leads to an increase in the fraction of women in the output set.
E.6 Non-redundancy comparison
Figure 20 presents the non-redundancy comparison of our methods and baselines. Recall that the non-redundancy measure used is the log of the determinant of the feature kernel matrix, i.e., if for a summary , if is the matrix with columns representing the feature vectors of the images in , then the non-redundancy is measured as . As expected, the results from DET have the largest non-redundancy score for most attributes. However, once again, non-redundancy does not imply diversity with respect to the socially salient attributes.
E.7 Results for different values
We vary the quality-fairness parameter and look at its impact on the performance of our algorithms. The results are presented in Figure 21.
For both QS-balanced and MMR-balanced, the fraction of gender anti-stereotypical images increases as the value increases. However, increasing the value results in a corresponding decrease in the accuracy, which is much more significant for MMR-balanced results.
E.8 Results for different summary sizes
Once again, we provide the performance of our algorithms and baselines for different summary sizes. For QS-balanced, MMR-balanced and the baselines, we look at the average fraction of images of gender anti-stereotypical and dark-skinned people in the top results, where ranges from 2 to 50; the average is taken over all occupations. The results are presented in Figure 22. The figures shows that QS-balanced returns a larger fraction of gender anti-stereotypical images for all summary sizes, compared to all baselines, other than AUTOLABEL. While AUTOLABEL is able to achieve better gender diversity, in this case, due to the good performance of the auto-gender classifier, simply using the partitions has an impact on accuracy of the summaries generated by AUTOLABEL. The second figure shows that the accuracy of AUTOLABEL is the worst amongst all algorithms.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Bureau of labor statistics. labor force statistics from the current population survey. https://www.bls.gov/cps/aa 2012/cpsaat 11.htm , 2013.
- 2[2] Appel citoyen. https://appelcitoyen.ch/on-ouvre-les-urnes-donnees-brutes-de-la-primaire/ , 2018.
- 3[3] Gender and jobs in online image searches. https://www.pewsocialtrends.org/2018/12/17/gender-and-jobs-in-online-image-searches/ , 2018.
- 4[4] Ibm response to “gender shades: Intersectional accuracy disparities in commercial gender classification”. http://gendershades.org/docs/ibm.pdf , 2018.
- 5[5] When it comes to gorillas, google photos remains blind. https://www.wired.com/story/when-it-comes-to-gorillas-google-photos-remains-blind/ , 2018.
- 6[6] Ai reveals misrepresentation of engineers online. https://www.raeng.org.uk/news/news-releases/2019/november/ai-reveals-misrepresentation-of-engineers-online , 2019.
- 7[7] Luca Anzalone, Paola Barra, Silvio Barra, Fabio Narducci, and Michele Nappi. Transfer learning for facial attributes prediction and clustering. In International Conference on Smart City and Informatization , pages 105–117. Springer, 2019.
- 8[8] Julia B Bear, Lily Cushenbery, Manuel London, and Gary D Sherman. Performance feedback, power retention, and the gender gap in leadership. The Leadership Quarterly , 28(6):721–740, 2017.