Fully-functional bidirectional Burrows-Wheeler indexes
Fabio Cunial, Djamal Belazzougui

TL;DR
This paper introduces fully-functional bidirectional Burrows-Wheeler indexes supporting constant-time character addition and removal from any substring, enabling efficient, small-space, variable-order de Bruijn graph traversal.
Contribution
It presents new bidirectional BWT indexes that support both addition and removal of characters in constant or near-constant time, improving flexibility over previous structures.
Findings
Supports constant-time addition/removal from any substring
Uses space proportional to maximal repeats of T
Enables small-space, variable-order de Bruijn graph traversal
Abstract
Given a string on an alphabet of size , we describe a bidirectional Burrows-Wheeler index that takes bits of space, and that supports the addition \emph{and removal} of one character, on the left or right side of any substring of , in constant time. Previously known data structures that used the same space allowed constant-time addition to any substring of , but they could support removal only from specific substrings of . We also describe an index that supports bidirectional addition and removal in time, and that occupies a number of words proportional to the number of left and right extensions of the maximal repeats of . We use such fully-functional indexes to implement bidirectional, frequency-aware, variable-order de Bruijn graphs in small space, with no upper bound on their order, and supporting natural criteria for…
Click any figure to enlarge with its caption.
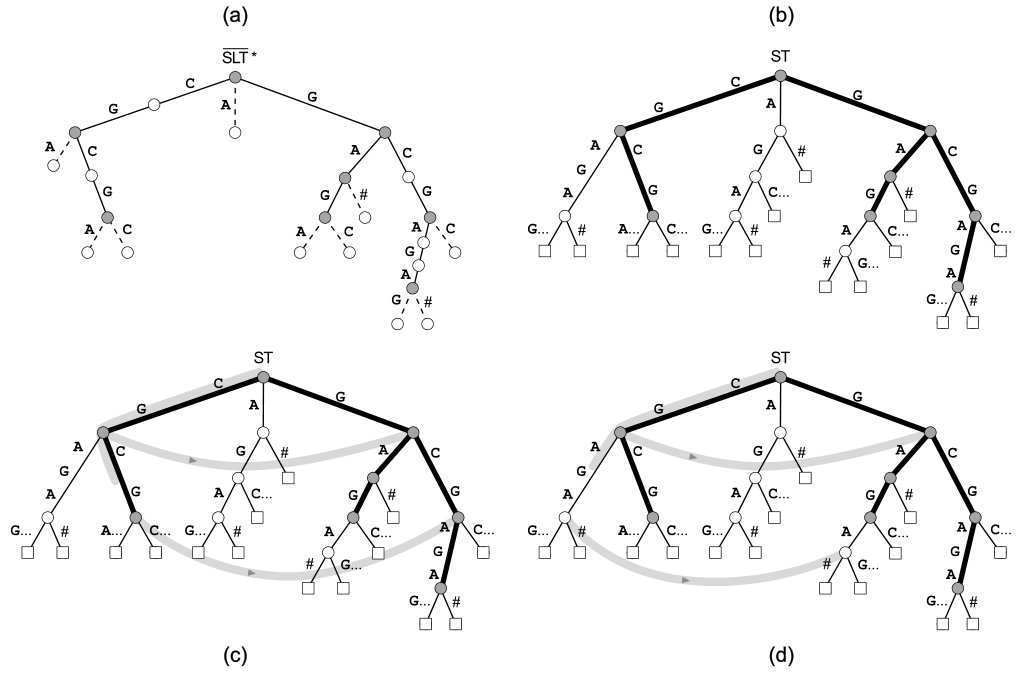 Figure 1
Figure 1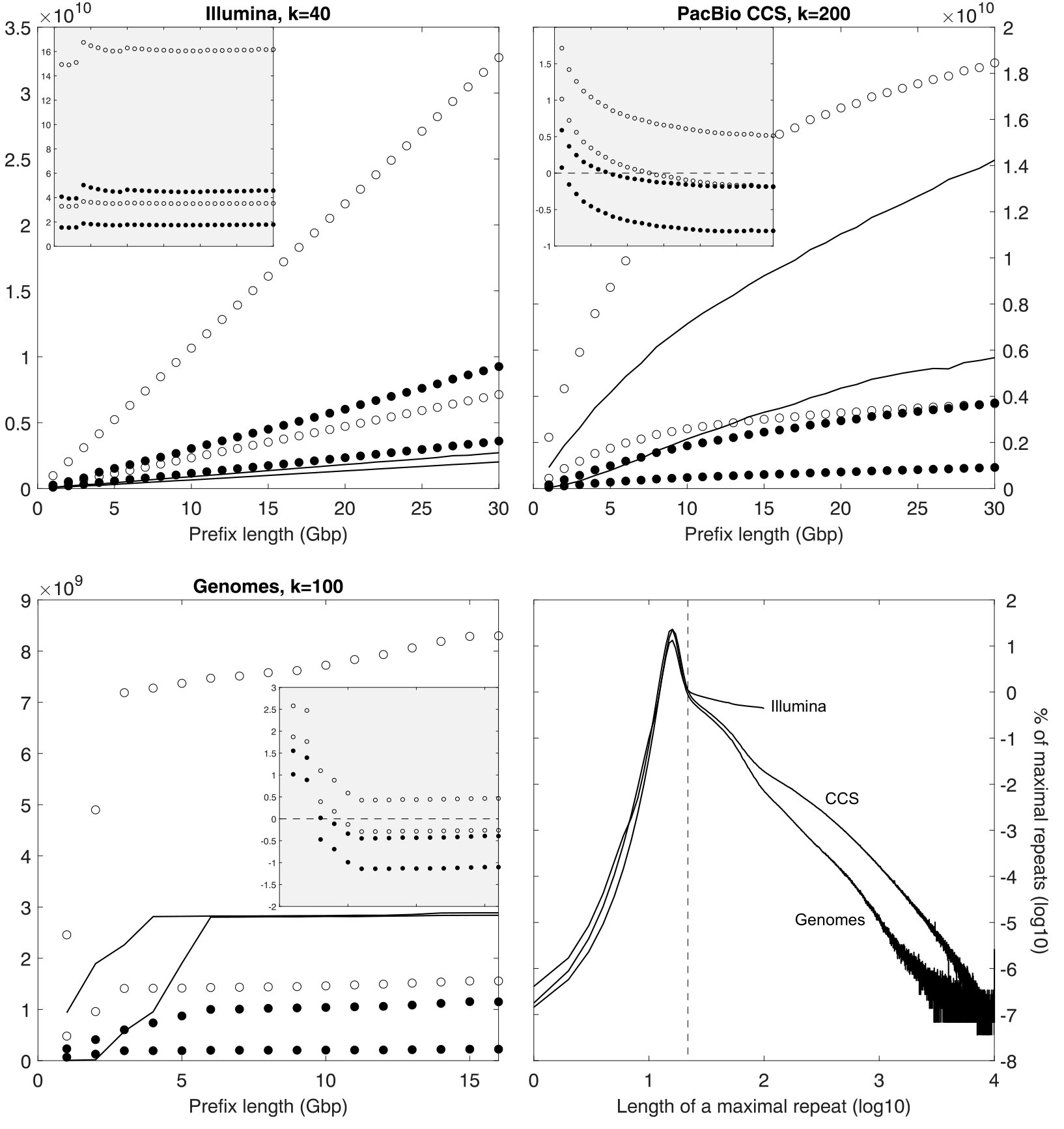 Figure 1
Figure 1Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAlgorithms and Data Compression · semigroups and automata theory · Natural Language Processing Techniques
Fully-functional bidirectional Burrows-Wheeler indexes
Djamal Belazzougui
CAPA, DTISI, Centre de Recherche sur l’Information Scientifique et Technique
Algiers, Algeria.
and
Fabio Cunial
Max Planck Institute for Molecular Cell Biology and Genetics (MPI-CBG)
Center for Systems Biology Dresden (CSBD)
Dresden, Germany.
Abstract.
Given a string on an alphabet of size , we describe a bidirectional Burrows-Wheeler index that takes bits of space, and that supports the addition and removal of one character, on the left or right side of any substring of , in constant time. Previously known data structures that used the same space allowed constant-time addition to any substring of , but they could support removal only from specific substrings of . We also describe an index that supports bidirectional addition and removal in time, and that takes a number of words proportional to the number of left and right extensions of the maximal repeats of . We use such fully-functional indexes to implement bidirectional, frequency-aware, variable-order de Bruijn graphs with no upper bound on their order, and supporting natural criteria for increasing and decreasing the order during traversal.
1. Introduction
A bidirectional index on a string is a data structure that represents any substring of as a constant-size descriptor that recapitulates the set of all starting positions of in , and the set of all ending positions of in . Such a representation allows extending with a character in both directions, enumerating the distinct characters that occur after in both directions, and switching direction during extension. All existing bidirectional indexes can be seen as updating positions in the suffix tree of and in the suffix tree of the reverse of , either literally, as in the affix tree [30, 49], or in compact representations, like the affix array [50] and the bidirectional Burrows-Wheeler transform (BWT) [47]. Synchronous bidirectional indexes maintain a position in both trees at every extension step, whereas asynchronous indexes maintain a position in just one tree, and compute the position in the other only when the user needs to change direction [18]. Applications of bidirectional indexes to bioinformatics, like read mapping with mismatches and searching for RNA secondary structures, have used until now the ability of bidirectional indexes to add characters both to the left and to the right of a string (an operation called extension: see e.g. [25, 28, 34, 45, 47, 50] for a small sampler), whereas removing characters from the left and from the right (called contraction) has only been conjectured to be useful [13, 18], and it has been supported efficiently just for right-maximal and left-maximal substrings of , respectively (defined in Section 2), or for strings that occur just once in , for which the implementation is straightforward (see e.g. [11, 38]).
In this paper we describe a simple method for removing characters from the left or from the right of any substring of , based just on the ability to measure the length of the maximal repeats of (defined in Section 2). Using the recent observation that all such lengths can be represented in bits of space [7], we show that bidirectional contraction can be supported in constant time with the bidirectional BWT index described in [11], within the same space budget and without changing the complexity of its construction. Our contraction algorithm can also be implemented on top of an existing representation of the suffix tree, based on the Compact Directed Acyclic Word Graph (CDAWG), that takes a number of words proportional just to the number of left and right extensions of the maximal repeats of [8]: this yields an index that supports, in the same asymptotic space, bidirectional extension and contraction of any substring of in time.
Having both bidirectional extension and contraction enables several applications, among which a de Bruijn graph that stores the frequency of its -mers, allows for bidirectional navigation, and supports any value of , as well as increasing and decreasing the value of , with no limit on the maximum allowed. We call such a data structure an infinite-order de Bruijn graph, and we describe an implementation that takes bits of space (where is the size of the alphabet), and that supports all operations in constant time, as well as another implementation that takes a number of words proportional to the left an right extensions of the maximal repeats of , and that supports all operations in time. The latter representation establishes a connection between de Bruijn graphs and CDAWGs that was not known before. Our query times are comparable to those of the variable-order, bidirectional representation described in [13], which supports navigation and changing order in time (assuming constant ), but is frequency-oblivious and requires a maximum order to be specified during construction. This competitor has the advantage of taking just bits of space, where is the number of distinct -mers, and of allowing the user to specify by how much the order should be changed in each query (the changes in order supported by our index are detailed in Sections 3 and 4). The variable-order representation described in [22] takes constant time (assuming constant ) to implement changes in order that are similar to those supported by our index, and uses just bits of space; however, it is unidirectional, frequency-oblivious, and it requires again a maximum to be known at construction time.
We conjecture that a de Bruijn graph representation based on the CDAWG might be useful for assembling the recently introduced PacBio CCS reads, which have the same 2% error rate as Illumina short reads but an average length of 15 kilobases (see e.g. [51]). Such read sets contain long exact repeats, of length up to ten thousand, so it might be desirable to set to large values and to decrease it dynamically, down to a minimum value . Moreover, most maximal repeats are short (Figure 1, bottom right), and we can remove from the CDAWG all maximal repeats shorter than , and all arcs adjacent to them, while still being able to represent all de Bruijn graphs of order at least (see Section 4). For practical values of , the number of nodes and arcs in such a pruned CDAWG grows more slowly than the number of distinct -mers (Figure 1, top right; reads from the Genome in a Bottle consortium111ftp://ftp-trace.ncbi.nlm.nih.gov/giab/ftp/data/AshkenazimTrio/HG002_NA24385_son/
PacBio_CCS_15kb/), suggesting that our data structure might be competitive in space with the state of the art, whose size is proportional to the number of -mers for a specific value of . The same observation applies to repetitive datasets: for example, the de Bruijn graph of a set of individuals from the same species has applications in population genomics, and the de Bruijn graph of a set of genomes from related species is used in comparative genomics [35, 36]. In Figure 1, bottom left, we experiment with the concatenation of assemblies hg16, hg17, hg18, hg19 and hg38 of the human genome from the UCSC Genome Browser222http://hgdownload.soe.ucsc.edu/downloads.html#human (a benchmark dataset from [3, 36]), and we observe exact repeats of length up to 489 million. Our data structure might also be useful with noisy long reads after error correction. Even in short-read Illumina datasets, the number of maximal repeats and of their extensions after pruning is just a small multiple of the number of distinct -mers (Figure 1, top left; reads from the Illumina Platinum project333https://www.ebi.ac.uk/ena/data/view/PRJEB3381, run ERR194146, file ERR194146_1.fastq.gz, read length 101.).
Finally, recall that our de Bruijn graph representations allow access to the frequency of a node or arc: this might be useful for avoiding repetitive regions during assembly, or for reconstructing only those [26], for assembling metagenomes with non-uniform sequencing depths [29], or for inferring transcripts with different expression levels [42].
2. Preliminaries
2.1. Strings
Let be an integer alphabet, let be a separator not in , and let be a string. We denote by the reverse of a string , i.e. string written from right to left, and we call a k-mer iff . We denote by the number of (possibly overlapping) occurrences of a string in the circular version of . A repeat is a string that satisfies . We denote by the set of left-extensions of , i.e. the set of characters . Symmetrically, we denote by the set of right-extensions of , i.e. the set of characters . A repeat is right-maximal (respectively, left-maximal) iff (respectively, iff ). It is well-known that can have at most right-maximal substrings and at most left-maximal substrings. A maximal repeat of (called balanced substring in [50]) is a repeat that is both left- and right-maximal.
The unidirectional de Bruijn graph of order of is a directed graph whose node set is in one-to-one correspondence with the set of distinct -mers that occur in ; there is an arc for every distinct -mer such that both and occur in , and such arc is labelled with character . In some formulations, contains just those arcs that correspond to -mers that occur in : in this case, a -mer is right-maximal (respectively, left-maximal) in iff its corresponding node in has at at least two outgoing (respectively, incoming) arcs. The bidirectional de Bruijn graph is defined symmetrically.
We denote by the suffix tree of , and by the suffix tree of . We assume the reader to be already familiar with the basics of suffix trees, including suffix links, which we do not further describe here. We denote by the label of a node of a suffix tree, and we say that is the locus of all substrings of where , is the parent of , and . It is well-known that a substring of is right-maximal (respectively, left-maximal) iff for some internal node of (respectively, for some internal node of ). Suffix links and internal nodes of form a tree, called the suffix-link tree of and denoted by , and inverting the direction of all suffix links yields the so-called explicit Weiner links. Given an internal node and a character , it might happen that string occurs in but is not right-maximal, i.e. it is not the label of any internal node of : all such left extensions of internal nodes that end in the middle of an edge are called implicit Weiner links. An internal node of can have more than one outgoing Weiner link, and all such Weiner links have distinct labels: in this case, is a maximal repeat, as well as the label of a node in . Maximal repeats and implicit Weiner links are related by the following simple property, which was already hinted at in [2]:
Property 1**.**
Let be an internal node of . If there is an implicit Weiner link from , then is a maximal repeat of .
It is known that the number of suffix links (or, equivalently, of explicit Weiner links) is upper-bounded by , and that the number of implicit Weiner links can be upper-bounded by as well. We call a version of augmented with implicit Weiner links and with nodes corresponding to their destinations. We say that a maximal repeat of is rightmost if no string with is left-maximal in . Symmetrically, we say that a maximal repeat of is leftmost if no string with is right-maximal in . Since left-maximality is closed under prefix operation, it is easy to see that the maximal repeats of are all and only the nodes of that lie on paths that start from the root and that end at nodes labelled by rightmost maximal repeats. We call this the maximal repeat subgraph of (Figure 2b). Clearly the maximal repeats of coincide with the branching nodes of (Figure 2a), and the rightmost maximal repeats of coincide with the leaves of . Thus, it is easy to see that (a trie) is a subdivision of the maximal repeat subgraph of (a compact trie), and that the nodes in the unary paths of are in one-to-one correspondence with the internal nodes of that are not maximal repeats (see Figures 2a and 2b for an example, and see Section 2.1 in [7] for an extended explanation). The following property is thus immediate (and symmetrical notions hold for , , and leftmost maximal repeats):
Property 2**.**
Let be an internal node of . The locus of in is such that is the reverse of a maximal repeat of .
The compact directed acyclic word graph of a string (denoted by in what follows) is the minimal compact automaton that recognizes the suffixes of [16, 20]. We denote by the CDAWG of the reverse of , by the number of arcs in , and by the number of arcs in . The CDAWG of can be seen as the minimization of , in which all leaves are merged to the same node (the sink, that represents itself), and in which all nodes except the sink are in one-to-one correspondence with the maximal repeats of [44]. Every arc of is labeled by a substring of , and the out-neighbors of every node of are sorted according to the lexicographic order of the distinct labels of arcs . Since there is a bijection between the nodes of and the maximal repeats of , the node of with is the equivalence class of the nodes of such that for all , and such that is a maximal unary path of explicit Weiner links. The subtrees of rooted at all such nodes are isomorphic. It follows that a right-maximal string can be identified by the maximal repeat it belongs to, and by the length of the corresponding suffix of (see [8] for an extended explanation).
We assume the reader to be familiar with the Burrows-Wheeler transform of , which we denote by (we use to denote the BWT of the reverse of ) and we don’t further describe here. We say that is a run iff: (1) for all ; (2) every substring such that , , and , contains at least two distinct characters. We denote by the set of all triplets such that is a run of character , and we use to denote the set of runs of . It is known that is at most equal to the number of arcs in [10].
Given a second string , the matching statistics array of with respect to is an array of length such that is the largest such that occurs in .
In the rest of the paper we drop subscripts whenever they are clear from the context.
2.2. String indexes
A bidirectional index is a data structure that, given a constant-space descriptor of a substring of , supports the following operations: if , or an error otherwise; ; iff . Operations , and are defined symmetrically. We consider bidirectional indexes based on the BWT: specifically, we denote with the function that maps a substring of to the interval of in , i.e. to the interval of all suffixes of that start with , and we use as a constant-space descriptor of . A number of bidirectional BWT indexes have been described in the literature; in this paper we are just interested in the data structure from [11], which supports all operations in linear time in the size of their output, takes bits of space, and can be built in randomized time and bits of working space.
Given a string , we call run-length encoded BWT () any representation of that takes words of space and supports the well-known rank and select operations (see e.g. [31, 32, 48]). It is easy to implement a version of that supports rank and select in time [10]. In this paper we use the representation of the suffix tree based on the CDAWG described in [8], which takes just words of space by augmenting and with the RLBWT of and . Such a data structure describes a node of as a tuple , where is the node in that corresponds to the equivalence class of , and is the interval of in . For every node of , the index stores, among other things: in a variable ; the number of right-maximal strings that belong to its equivalence class; and the interval of in . For every arc of , the index stores the first character of in a variable , and the number of characters of the right extension implied by in a variable . Finally, we add to the CDAWG all arcs such that is the equivalence class of the destination of a Weiner link from labeled by character in , as well as the reverse of all explicit Weiner link arcs. See [8] for an extended description of the data structure and of the complexity of its operations. Here we just mention that the index supports operations and in constant time, and , , in time.
In this paper we need to store the topology of and the topology of efficiently. It is well-known that the topology of an ordered tree of nodes can be represented using bits, as a sequence of balanced parentheses [39]. Let be the rank of a node in the preorder traversal of the tree. Given the balanced parentheses representation of the tree encoded in bits, it is also well-known that one can build a data structure that takes bits, and that supports several common operations in constant time [40, 41, 46], among which: , which returns , where is the parent of , or an error if is the root; , which returns , where is the lowest common ancestor of nodes and ; and , which return one plus the number of leaves that, in the preorder traversal of the tree, are visited before the first (respectively, the last) leaf that belongs to the subtree rooted at ; , which returns the distance of from the root. This data structure can be built in time and in bits of working space. Moreover, given a node and a length , a level-ancestor query asks for the ancestor of such that the path from the root to contains exactly nodes. The level ancestor data structure described in [14, 15] takes words of space and answers queries in constant time. Assuming that some nodes of the tree are marked, a lowest marked ancestor data structure allows one to move in constant time from any node, to its lowest ancestor that is marked [33].
We use the tree data structures described above to store the topology of and of . Moreover, we mark in two bitvectors the nodes of and of that are maximal repeats (in preorder), and we index such bitvectors to support constant-time rank and select queries. Since is a subdivision of the subgraph of induced by maximal repeats, the -th one in the two bitvectors correspond to the same maximal repeat. Thus, if node is a maximal repeat, and if we know its preorder position in , we can compute the length of by moving to the corresponding node in and by computing the depth of in the topology of (see [7] for an extended explanation).
The rest of the paper focuses on representations of variable-order, bidirectional de Bruijn graphs that support the following primitives (for brevity we list here just operations in one direction). Let be the current order of the de Bruijn graph. Operation , called membership, returns the identifier of the node associated with -mer , or an error if does not occur in . Operation returns the set of characters that label all arcs from node in the right direction, and operation returns the number of such arcs. Query returns the identifier of the arc that corresponds to string , if any, where is a node in the current de Bruijn graph, is the -mer that corresponds to node , and is a character; it returns an error if no such arc exists. Operation is similar, but returns the identifier of the node reached by the arc, if any. Queries and return the number of occurrences of the -mer associated with node and of the -mer associated with arc (the number of occurrences of an arc might be zero). Representations that support such queries are called frequency-aware or weighted (see e.g. [42]). Operation for returns the node associated with string in the de Bruijn graph of order , if any, or an error otherwise. Operation returns the node associated with the prefix of length of in the de Bruijn graph of order .
In addition to increasing and decreasing the order by one unit, some variable-order representations allow the user to specify the desired amount of change [13, 17]. In the rest of the paper we argue that it is more natural to change the order based on the frequency or on the extensions of -mers, as proposed in [22]. Specifically, given a node of the current de Bruijn graph, let , , be the longest string with the same frequency as in . Operation returns the node associated with in the de Bruijn graph of order , and sets to the new order . Given a node of the current de Bruijn graph, let be the longest prefix of that has a different frequency from in . Operation returns the node associated with in the de Bruijn graph of order , and sets to . Alternatively, one might want to be the longest prefix of such that the left-extensions of are a superset of the left-extensions of . A de Bruijn graph that supports such operations without returning the value of the new order is called hidden-order [22].
2.3. String indexes
A bidirectional index is a data structure that, given a constant-space descriptor of a substring of , supports the following operations: if , or error otherwise; ; iff . Operations , and are defined symmetrically. Here we consider bidirectional indexes based on the BWT: specifically, we denote with the function that maps a substring of to the interval of in , i.e. to the interval of all suffixes of that start with , and we use as a constant-space descriptor of a substring . A number of bidirectional BWT indexes have been described in the literature: here we are interested just in the data structure described in [11], which supports all operations in linear time in the size of their output, takes bits of space, and can be built in randomized time and bits of working space. See [11] for more details.
Given a string , we call run-length encoded BWT () any representation of that takes words of space, and that supports the well known rank and select operations: see for example [31, 32, 48]. It is easy to implement a version of that supports rank in time and select in time [10]. In this paper we use the representation of based on described in [8], which takes just words of space by augmenting and with the RLBWT of and of . Such data structure represents a node of as a tuple , where is the node in that corresponds to the equivalence class of , and is the interval of in . For every node of , the index stores, among other things: in a variable ; the number of right-maximal strings that belong to its equivalence class; and the interval of in . For every arc of , the index stores the first character of in a variable , and the number of characters of the right extension implied by in a variable . Finally, we add to the CDAWG all arcs such that is the equivalence class of the destination of a Weiner link from labeled by character in , and the reverse of all explicit Weiner link arcs. See [8] for a full description of the data structure and of the complexity of its operations. Here we just mention that the index supports operations and in constant time, and , , in time. It also allows reading the character at position of in time.
Finally, in this paper we need to store the topology of and the topology of efficiently. It is well known that the topology of an ordered tree of nodes can be represented using bits, as a sequence of balanced parentheses built by opening a parenthesis, by recurring on every child of the current node in order, and by closing a parenthesis [39]. Let be the rank of a node in the preorder traversal of the tree. Given the balanced parentheses representation of the tree encoded in bits, it is also well known that one can build a data structure that takes bits, and that supports several common operations in constant time [40, 46, 41], among which: , which returns , where is the parent of , or an error if is the root; , which returns , where is the lowest common ancestor of nodes and ; and , which return one plus the number of leaves that, in the preorder traversal of the tree, are visited before the first (respectively, the last) leaf that belongs to the subtree rooted at ; , which returns , where is the -th leaf in preorder; , which returns the distance of from the root. This data structure can be built in time and in bits of working space. Moreover, given a node and a length , a level-ancestor query asks for the ancestor of such that the path from the root to contains exactly nodes. The level ancestor data structure described in [14, 15] takes words of space and it answers queries in constant time. Assuming that some nodes of the tree are marked, a lowest marked ancestor data structure [33] allows one to move in constant time from any node, to its lowest ancestor that is marked.
We use the tree data structures described above to store the topology of and of . Moreover, we mark in a bitvector the nodes of and of that are maximal repeats (in preorder), and we index such bitvectors to support constant-time rank and select queries. Since is a subdivision of the subgraph of induced by maximal repeats, the -th one in the two bitvectors correspond to the same maximal repeat. Thus, if node is a maximal repeat and if we know its position in preorder in , it is easy to see that we can compute the length of by going to the node in and by computing the depth of in the topology of : see [7] for a more thorough explanation.
3. Contracting in constant time
As mentioned, existing bidirectional BWT indexes support left-contraction just from right-maximal substrings (and symmetrically, they support right-contraction just from left-maximal substrings). Specifically, if the substring is right-maximal and labels a node of , then is the interval of node in , and since we are removing one character from the right of , the locus of in is either the same as the locus of , or it is , whichever has the same frequency as [11, 38].
To support left-contraction from a substring that is not right-maximal, it is enough to have access to the topology of :
Theorem 1**.**
Let be a string on alphabet . There is a data structure that supports operations , , and in constant time and in bits of space. Such a data structure can be built in randomized time and bits of working space.
Proof.
We use the data structures described in [11], augmented with the topology of and with a bitvector to commute between the topology of and the topology of (see [7] for details on commuting). Such data structures take bits of space, and they can be built in randomized time using the algorithms in [4, 12]. They support operations and , where . We additionally assume the knowledge of , i.e. . We only show how to support , since supporting is symmetric. Since [11] already supports for right-maximal substrings, we assume for now that is not right-maximal. Note that we can decide whether is right-maximal or not by using , and, if is right-maximal, we can just use the contraction algorithm described above. Let be the locus of in : this can be computed from using queries on . Since is not right maximal, and ends in the middle of edge of . We take in constant time the suffix link from and the suffix link from , and we decide whether is an edge or a path of by comparing to , which can be computed in constant time. If is an edge of (Figure 2c), then is the locus of and we compute in constant time. Otherwise (Figure 2d), we compute in constant time : this node is a maximal repeat by Property 1, since it is an internal node of with an implicit Weiner link whose destination falls inside . We use the data structures in Section 2.3 to measure the length of in constant time. If , the locus of is again . Otherwise, since is a maximal repeat, we move in constant time to the node of that corresponds to , we issue a constant-time level ancestor query from on with length , and, from the destination of such a level ancestor query, we move in constant time to the first branching descendant of , by using , , and queries on . Finally, we move in constant time to the node of that corresponds to , and we compute in constant time. We compute as described at the beginning of Section 3. ∎
Note that the algorithm in Theorem 1 works even when is right-maximal; moreover, if the information on whether is right maximal or not is given in input, the algorithm can decide whether is right maximal or not. In a practical implementation, once we have taken the suffix link from , we could check whether is a maximal repeat, and in the positive case we could immediately commute to and issue level ancestor queries. If is not a maximal repeat, we could move in constant time to the lowest ancestor of that is a maximal repeat, using a lowest marked ancestor data structure on , we could measure , and if , we could again issue level ancestor queries in (otherwise, the locus of is again ).
A bidirectional index on that supports extension and contraction in constant time, can be used to implement in linear time several applications that slide a window of fixed length over a query string , and that compute the frequency of every in , without the size of the window being known during construction444If the size of the window is fixed and known during construction, most such applications do not need the contract operation, and can be made to work using just one BWT and a bitvector of length that marks the boundaries of -mer intervals in the BWT.. For example, measuring the frequency of windows of fixed length for read correction [43], computing the inner product between the -mer composition vectors of and (a step in -mer kernels), estimating the probability of according to a fixed-order Markov model trained on , and checking whether is a path in the de Bruijn graph of . Our index enables also applications in which the sliding window needs to be extended or contracted during the scan, like variable-order and interpolated Markov models (see [21] for an overview). A fully-functional bidirectional index is not needed for computing the matching statistics array between and , in linear time and in bits of space, since one can use the algorithms in [5] on top of the data structures in [4]. However, achieving such bounds with our bidirectional index becomes trivial.
In practical applications of matching statistics, one typically needs to maintain the intervals in both and just after every successful right extension, and, when the current match cannot be extended with in any longer, one might need both BWT intervals just for the proper suffixes such that , i.e. just for the suffixes of from which a right-extension with is attempted again. Every such suffix is a maximal repeat ancestor of in [9], thus, once we reach the locus of such a suffix in with operations, we can compute its interval in , we can measure its string length , and we can compute its interval in by issuing contract operations from the locus of in , but without updating the interval in after each contraction. Even more aggressively, we can just issue suffix links from the locus of in . Note that such a locus might correspond to the right-maximal string for some nonempty , thus taking suffix links might lead to a node of that corresponds to the right-maximal string : thus, we need to move in constant time from such a node, to its lowest ancestor in that is a maximal repeat; from there, we can then issue a level ancestor query with value . Such a lazy synchronization might be faster than issuing full contract operations in practice.
Our index can be seen as a representation of a de Bruijn graph that supports bidirectional navigation, that allows access to the frequency of every -mer and -mer, and that has no upper bound on the order: we call infinite-order such a de Bruijn graph. Note that, for a given order , we can support both the variant in which arcs must occur in (calling and then to implement and ), and the variant in which arcs do not have to occur in (calling and then ). Membership queries reduce to backward searches, and we can move from a higher to a lower order using the same algorithm as in matching statistics. Indeed, one typically wants to switch to a suffix of the current -mer whenever there is only one arc in the graph of the current order, and this arc is labelled with the terminator character [22]; or, more generally, whenever one needs to increase the number of outgoing arcs from the current -mer (for example because the existing ones have already been explored [37]), or to increase the frequency of the current right-maximal -mer. In all such cases, one wants to switch to the largest order with the desired property, and the corresponding suffix is always a maximal repeat (for example, the longest suffix, of the current right-maximal -mer, that has strictly greater frequency, is a maximal repeat). Symmetrically, when increasing the order, one may want to switch e.g. from the current -mer that is left-maximal but not right-maximal, to the maximal repeat with shortest . Clearly , we know since we can access , and we can compute by taking Weiner links from . All such Weiner links are explicit, and in practice we can just update the first position of the interval at every step.
In the next section, we describe a representation of an infinite-order de Bruijn graph in which the time to decrease or increase the order does not depend on the difference between the source and the destination order.
4. Implementing de Bruijn graphs with CDAWGs
An affix link is a map from a node of , to the locus of in (we use to denote the symmetrical map from a node of , to the locus of in ) [49, 50]. We use as a shorthand for where is the locus of . In asynchronous bidirectional indexes, affix links are used to switch direction when the user desires [50]. In this section we are more interested in their ability to extend a non-maximal repeat in a bidirectional index: for example, if is right-maximal but not left-maximal, and if it has loci in and , respectively, then its shortest left-maximal extension with , i.e. the shortest maximal repeat that contains as a (not necessarily proper) suffix, has loci ; and if is neither left- nor right-maximal, then the shortest maximal repeat with the same frequency as has loci [50]. Thus, in what follows we ignore affix links from leaves.
Rather than storing for every internal node of , it has been proposed to sample every suffix links [18]: indeed, is either , if , or it is the child of obtained by following the first character of [50]. This allows one to compute in time, paying bits of space. We briefly observe that, compared to existing sampling schemes for bidirectional indexes, we can further reduce space to bits, where is the number of maximal repeats of , since, by Property 2, is a maximal repeat of for every internal node of . In practice following Weiner links is faster than following suffix links: thus, one could sample the value of for every maximal repeat, and then sample every characters inside an edge of that connects two maximal repeats, i.e. every explicit Weiner links. If is not sampled, then is not left-maximal, so we take the only possible Weiner link from it and we repeat the search from there, returning the value of the first sampled node we find. This sampling scheme takes bits of space. One could even waive sampling the nodes of that are not maximal repeats, but to retrieve their value one would have to pay a number of Weiner links that is at most equal to the length of the longest edge of connecting two maximal repeats. Clearly, sampling just maximal repeats works also for the scheme based on suffix links.
In this section we store and explicitly, but just for maximal repeats, together with and , to implement an infinite-order de Bruijn graph in which the time to increase or decrease the order does not depend on the difference between the source and the destination order:
Theorem 2**.**
Given a string , there are a fully-functional bidirectional index, and an infinite-order representation of the de Bruijn graph of , that take space proportional to the number of left and right extensions of the maximal repeats of , and that support all queries in time.
Proof.
We represent and using CDAWGs, as described in [8] and summarized in Section 2.3 of this paper. In addition to , , and , to support Theorem 1 we store also a weighted level ancestor data structure on the maximal repeat subgraph of and , which takes space and answers queries in time [1, 24], and we store and to support changes in the order of the de Bruijn graph ( is the number of maximal repeats of ). We represent an arbitrary substring of as a triple , where is the locus of in , is the locus of in , and is the identifier of a node in the CDAWG-based representation of a suffix tree, i.e. where is a node of a CDAWG and is a BWT interval.
To implement , where is assumed to occur in , we first check whether is right-maximal, by comparing to : if is not right-maximal, then the representation of is . Otherwise, the representation is . If we assume that procedure can be called with an invalid , we first have to check whether occurs in using the interval of in . To implement , we first check whether is right-maximal, by comparing to : if so, the representation of is , where is either the parent of or itself, depending on which one of them has the same frequency as the locus of in . If is not right-maximal, we run the algorithm in Theorem 1 using the and operations provided by the CDAWG-based representation of , and issuing weighted level ancestor queries on the maximal repeat subgraph of rather than level ancestor queries on the topology of .
To implement and in the de Bruijn graph, we proceed as follows. If the current -mer is right-maximal, the representation of the longest suffix of that is a maximal repeat is clearly , where is the maximal repeat reached by taking a suffix link arc from the node of the CDAWG pointed by . One could further move to a suitable ancestor of such a maximal repeat, by marking the topology of the maximal repeat subgraph of . If the current is left-maximal but not right-maximal, the representation of the shortest maximal repeat of the form for some nonempty is , where is the node of the CDAWG pointed by . The same holds if is neither left- nor right-maximal, and if we want to move to the shortest -mer that contains and is both left- and right-maximal. Implementing the other operations of a bidirectional de Bruijn graph is straightforward and is left to the reader. We use data structures from [6] to answer the membership query in time. ∎
Our construction based on two CDAWGs is reminiscent of the symmetric compact DAWG described in [16], which was used however just for bidirectional extension. Theorem 2 could be simplified in several ways for a practical implementation. For example, as noted already in [16], since and share the same set of nodes, every such node could be stored only once, in which case and would not need to be represented explicitly. If the descriptor of a substring is with and , then and would become pointers to the same node, could be derived from , and rather than storing and , we could just store . Our representation collapses to the sink of a CDAWG all -mers that occur just once in the dataset, which are likely induced by sequencing errors and are thus not useful for most applications: in this case, we don’t even need to store left and right extensions of maximal repeats directed to the sink. If the target application never uses orders smaller than a threshold , we could remove from the index all maximal repeats of length smaller than and prune the top part of the corresponding tree data structures, as described in [22]. We could proceed in a similar way when the user specifies a lower bound on the frequency of -mers (called solid, see e.g. [29, 37]).
5. Discussion and extensions
Our CDAWG-based representation of the de Bruijn graph might be practical: a full experimental study and a careful implementation of each primitive would be an interesting research direction. Given a node in the de Bruijn graph, it would also be interesting to know if we can traverse an entire maximal non-branching path, i.e. a path in which no -mer except for and the destination has more than one arc to the left and to the right, without taking time proportional to the length of such a path: this would provide a fast implementation of the compacted de Bruijn graph (see e.g. [19, 36] and references therein). It is natural to wonder whether one can support the operations of an infinite-order de Bruijn graph in less space than our indexes. Another open question is whether the CDAWG can be used as a substrate for implementing the string graph as well, and whether we can design a single compact index, as wished by [23], that supports both the primitives of a string graph and of an infinite-order de Bruijn graph efficiently, allowing the user to take advantage of both approaches in genome assembly.
6. Acknowledgements
We thank Martin Bundgaard for motivating the contract operation, Rodrigo Canovas for discussions about bidirectional indexes, Gene Myers for discussions about PacBio CCS reads, and German Tischler for help with -mer counting.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Amihood Amir, Gad M Landau, Moshe Lewenstein, and Dina Sokol. Dynamic text and static pattern matching. ACM Transactions on Algorithms (TALG) , 3(2):19, 2007.
- 2[2] Alberto Apostolico and Gill Bejerano. Optimal amnesic probabilistic automata or how to learn and classify proteins in linear time and space. Journal of Computational Biology , 7(3-4):381–393, 2000.
- 3[3] Uwe Baier, Timo Beller, and Enno Ohlebusch. Graphical pan-genome analysis with compressed suffix trees and the Burrows–Wheeler transform. Bioinformatics , 32(4):497–504, 2015.
- 4[4] Djamal Belazzougui. Linear time construction of compressed text indices in compact space. In Proceedings of the forty-sixth Annual ACM Symposium on Theory of Computing , pages 148–193. ACM, 2014.
- 5[5] Djamal Belazzougui and Fabio Cunial. Indexed matching statistics and shortest unique substrings. In International Symposium on String Processing and Information Retrieval , pages 179–190. Springer, 2014.
- 6[6] Djamal Belazzougui and Fabio Cunial. Fast label extraction in the CDAWG. In International Symposium on String Processing and Information Retrieval , pages 161–175. Springer, 2017.
- 7[7] Djamal Belazzougui and Fabio Cunial. A framework for space-efficient string kernels. Algorithmica , 79(3):857–883, 2017.
- 8[8] Djamal Belazzougui and Fabio Cunial. Representing the suffix tree with the CDAWG. In LIP Ics-Leibniz International Proceedings in Informatics , volume 78. Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik, 2017.