Simultaneous prediction of multiple outcomes using revised stacking algorithms
Li Xing, Mary Lesperance, and Xuekui Zhang

TL;DR
This paper introduces two novel stacking algorithms that improve the simultaneous prediction of multiple drug resistances in HIV using mutation data, offering flexible multivariate modeling and outperforming existing methods.
Contribution
The paper presents new stacking algorithms that leverage information among multiple prediction tasks, enhancing multivariate prediction accuracy in HIV drug resistance modeling.
Findings
Proposed methods outperform existing multivariate prediction techniques.
Algorithms are flexible, allowing use with any univariate prediction models.
Cross-validation confirms improved predictive performance.
Abstract
Motivation: HIV is difficult to treat because its virus mutates at a high rate and mutated viruses easily develop resistance to existing drugs. If the relationships between mutations and drug resistances can be determined from historical data, patients can be provided personalized treatment according to their own mutation information. The HIV Drug Resistance Database was built to investigate the relationships. Our goal is to build a model using data in this database, which simultaneously predicts the resistance of multiple drugs using mutation information from sequences of viruses for any new patient. Results: We propose two variations of a stacking algorithm which borrow information among multiple prediction tasks to improve multivariate prediction performance. The most attractive feature of our proposed methods is the flexibility with which complex multivariate prediction models can…
Click any figure to enlarge with its caption.
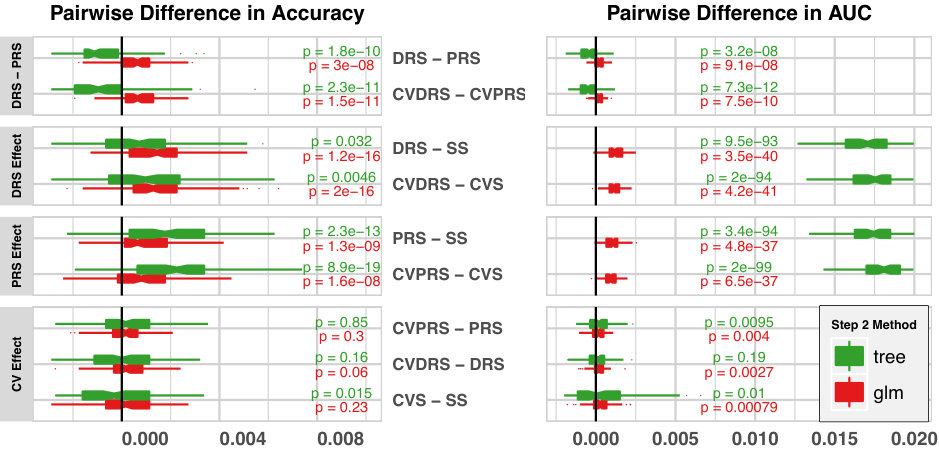 Figure 1
Figure 1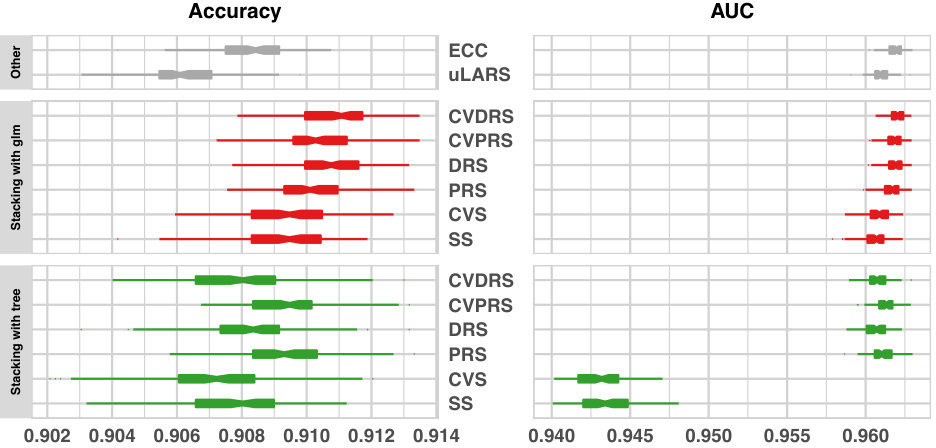 Figure 2
Figure 2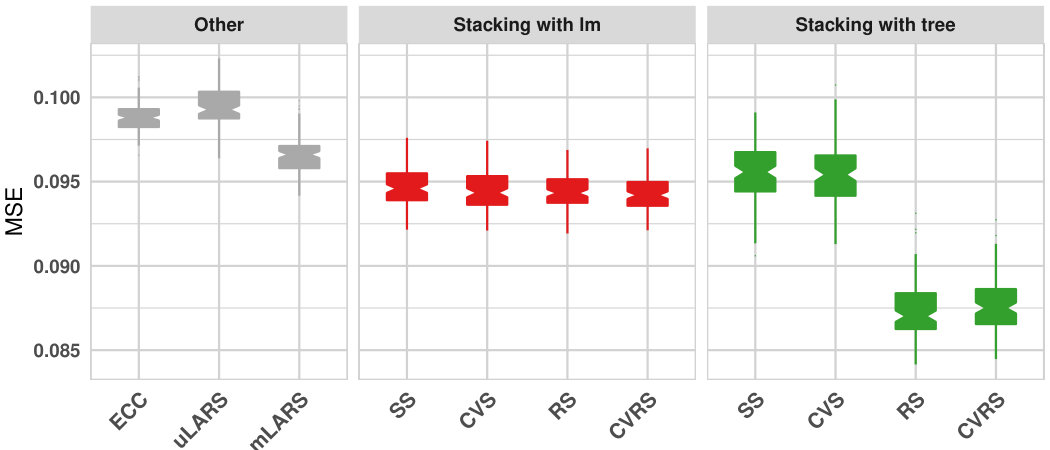 Figure 3
Figure 3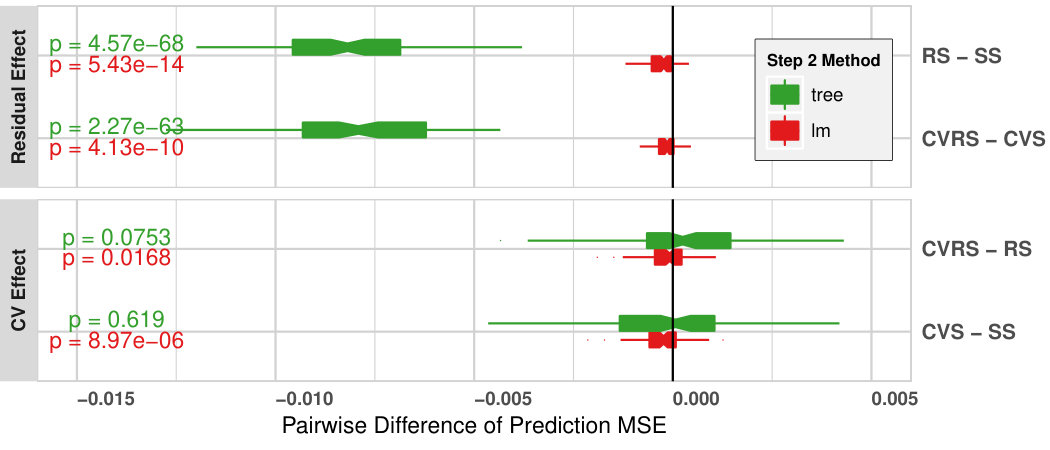 Figure 4
Figure 4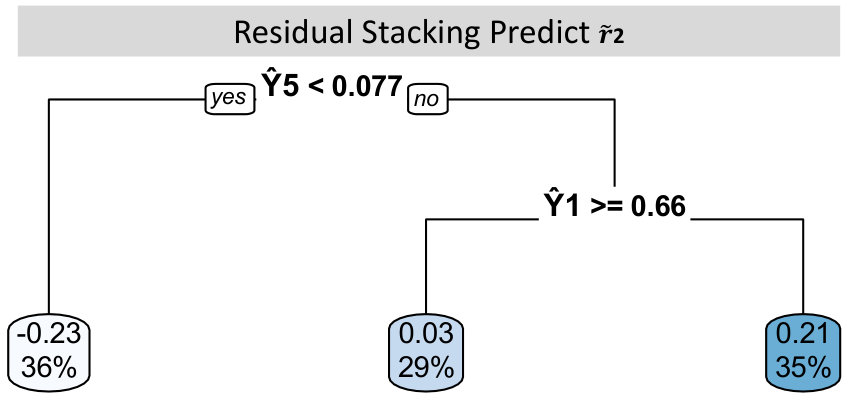 Figure 5
Figure 5| ECC: | Ensemble Classification Chain |
|---|---|
| uLARS: | Univariate LARS |
| mLARS: | Multivariate LARS |
| NNet: | Neural Network |
| SS: | Standard Stacking |
| CVS: | cross-validation Stacking |
| RS: | Residual Stacking |
| CVRS: | cross-validation + residual stacking |
| DRS: | deviance residual stacking |
| CVDRS: | cross-validation + deviance residual stacking |
| PRS: | Pearson residual stacking |
| CVPRS: | cross-validation + Pearson residual stacking |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Simultaneous prediction of multiple outcomes using revised stacking algorithms
Li Xing , Mary Lesperance , and Xuekui Zhang
Department of Mathematics and Statistics, University of Victoria, Victoria, V8N 1Y2, Canada.
Abstract.
Motivation: HIV is difficult to treat because its virus mutates at a high rate and mutated viruses easily develop resistance to existing drugs. If the relationships between mutations and drug resistances can be determined from historical data, patients can be provided personalized treatment according to their own mutation information. The HIV Drug Resistance Database was built to investigate the relationships. Our goal is to build a model using data in this database, which simultaneously predicts the resistance of multiple drugs using mutation information from sequences of viruses for any new patient.
Results: We propose two variations of a stacking algorithm which borrow information among multiple prediction tasks to improve multivariate prediction performance. The most attractive feature of our proposed methods is the flexibility with which complex multivariate prediction models can be constructed using any univariate prediction models. Using cross-validation studies, we show that our proposed methods outperform other popular multivariate prediction methods.
Availability: An R package will be made available.
1. Introduction
HIV is difficult to treat because its virus mutates at a high rate and mutated viruses easily develop resistance to existing drugs. Ideally, an HIV patient should receive personalized treatment which is adapted to the mutation information of the patient’s virus. If the relationships between mutations and drug resistances can be determined from historical data, patients can be provided personalized treatment according to their own mutation information. By consistently monitoring virus mutations of patients, physicians can actively change their drugs to achieve the most efficacious treatment. The HIV Drug Resistance Database was built to investigate the relationships between HIV-1 protease and reverse transcriptase mutations to in vitro resistance to multiple antiretroviral drugs [14]. The current database contains sequences of about HIV isolates (i.e. viruses taken from infected patients) and their resistance to HIV drugs in three classes. The information for possible HIV drug resistant mutations can be extracted from the sequences of each isolate, which are used as candidate biomarkers for predicting drug resistance. The drug resistance is measured as the ratio of IC50 (the inhibitory concentration of a drug) of an isolate to the IC50 of a control [3]. Some thresholds of IC50 ratios are selected by biologists to define resistance versus susceptibility to a drug [11].
The first analysis of this HIV database [11] compared different models, including least squares regression, support vector regression, least angle regression (LARS), decision tree and neural network. None of these methods consistently outshone the others, but LARS [4] often performed better than the others. In this analysis every drug resistance response was predicted separately without borrowing information across the other drugs, even though these drugs are related with common features and they are predicted using the same mutation information. The first analysis that borrows strength across multiple prediction tasks was conducted by Heider et al [6]. The classification chain (CC) algorithm can improve classification performance over individual models, and the ensemble classification chain (ECC) can make further improvements over CC. The CC algorithm, originally proposed by Read et al [10], predicts drug resistances one by one as a chain. The resistance of a drug is predicted from not only the mutation information, but also the predicted resistance of the other drugs with positions before the current drug in the chain. Since the order of drugs in the chain may affect the prediction performance of CC, another algorithm called ECC uses different CCs of randomly ordered drugs, and the final prediction is made using voting.
In genomic studies, researchers are often interested in multivariate outcomes, as in this HIV example, motivating our investigation of algorithms that simultaneously predict multiple outcomes from a common set of predictors. In the literature, there are three major classes of multivariate outcome prediction methods. They are neural networks, multivariate outcome models extended from their corresponding univariate outcome models and stacking algorithms.
The literature about multivariate outcome learning is mostly based on neural network models, which allow multiple prediction tasks to borrow information from each other via the common hidden layers. The extension from univariate outcome neural networks to their multivariate outcome versions is trivial, since it simply requires the addition of more units in the output layer of the network. Many researchers have shown that multivariate outcome learners outperform individual learners of the same class [1], [15], [13]. Neural network models are examples of deep learning algorithms, which have been successfully applied in many areas with large data sets [7]. In a neural network, every neuron/unit is a simple model such as logistic regression model, which quickly processes input from the previous layer into input of the next layer of the network. A neural network is a network of many such neurons, which consists of many unknown weights/parameters to be learned or estimated from data. The performance of a neural network is heavily affected by its settings, that is the number of hidden layers and the number of neurons in each hidden layer. Genomic studies usually feature many predictors (e.g. genes) and small or medium sample sizes. With a limited sample size, it is not practical to build a deep neural network with many parameters to learn. It was shown that univariate outcome LARS often provides better prediction performance than univariate outcome neural networks for an HIV database [11]. In this paper, we compare the performance of the multivariate outcome version of a neural network with our proposed methods.
Some specific univariate outcome models have been extended to their multivariate outcome versions, for example, elastic net for the case of multivariate normal outcomes [16]. Incorporating multivariate normal outcomes requires the estimation of their variance/covariance matrix. In high dimensional outcome data, such models contain a large number of model parameters which require estimation, or stronger model assumptions and/or sparse algorithms to reduce the number of model parameters. The largest limitation of applying such approaches to solve real problems is that not many univariate outcome models are easily extended to their multivariate outcome versions. For example, even the modeling of the correlation structure among multivariate binary variables is not trivial. Elastic net variable selection techniques using multivariate binary variables as outcomes is a complex problem and incorporating mixed outcome types, e.g. binary and continuous, can make the problem even more difficult to solve. Here, we consider a more general approach to practically model multivariate outcome data, called stacking.
Stacking is an ensemble machine learning algorithm, which was developed for univariate outcome prediction problems. Stacking first trains multiple learning algorithms to predict the same univariate outcome, and then it trains a combiner algorithm to integrate information from the step one predictions and re-predict the final outcome. Stacking often yields better performance than all single models fitted in step one [17]. The stacking algorithm was extended to handle multivariate outcome prediction problems, and applied to music tags annotation [9]. The authors suggest combining the predictions of multiple tasks instead of the traditional approach of combining predictions of the same univariate outcome from multiple algorithms, and showed it works better than fitting individual prediction tasks separately. In this paper, we use Standard Stacking (SS) to refer to this extended version for multivariate outcome predictions.
In this paper, we propose two variations of stacking algorithms and their combination, which improves the prediction performance over the standard stacking approach under certain conditions. Using cross-validation studies on real data from the HIV database, we compare prediction performance of our proposed revised stacking algorithms with methods discussed above, including univariate outcome LARS, classification chain and ECC, multivariate outcome neural network, and multivariate outcome elastic net (for continuous outcomes only). The results of the cross-validation study show our method outperforms all these methods.
2. Methods
Assume is an data matrix of outcome variables, is an matrix of predictor variables and is the sample size. For the HIV data set, is composed of IC50 ratios of drugs for the continuous outcome problem and indicators of resistance to drugs for the binary outcome problem. is the mutation information of viruses, and is the total number of mutations in the sequence of one single virus. We are interested in building a prediction model using data , so that we can predict resistance of all drugs (IC50 ratio) or (probability of binary indicator), from observed mutations of the virus for a new patient .
We first describe the standard stacking algorithm, and then propose variations of standard stacking. The proposed cross-validation stacking (CVS) and residual stacking (RS) address shortcomings of standard stacking algorithms. These two variations can be used together as cross-validation residual stacking (CVRS).
2.1. Standard stacking (SS)
Algorithm 1 describes the standard stacking algorithm for multivariate outcome problems proposed in [9]. The algorithm consists of two steps of model fitting. In Step , the individual models are fitted to predict resistance of each drug separately. In Step , the combiner models are fitted to integrate information from predictions of individual models and to make final predictions of drug resistances. Finally, the drug resistances of a new virus are predicted using models learned from the first two steps as well as mutation information of the new virus. The SS algorithm is expected to outperform individual models learned in Step 1, since Step 2 allows multiple prediction tasks to share information.
Stacking is an algorithm that can use any univariate outcome methods as Individual models in Step 1, and expect to improve their prediction performance via the Combiner models in Step 2.
2.2. Cross-Validation Stacking (CVS), a variation of step 1
In Algorithm 1, the combiner models are learned from the Step 1 ‘fitted’ values , but in formula (1), the final predictions are calculated from the Step 1 ‘predicted’ values . The two types of quantities are different because is used to learn the ’s, but is independent of the ’s. In linear regression models, it is known that predicted values have larger variance than fitted values. This discrepancy could affect the performance of stacking predictions.
To accommodate the extra variation of prediction, we replace in Algorithm 1 by the cross-validation predicted values . To obtain , we randomly partition the data into subsets. For every subset , we fit Step 1 models using all data outside of this subset, denoted as . Using the predictor data as new data in models fitted outside of subset , we obtain predicted outcomes, . Combining predictions from all subsets, we obtain predicted values, denoted as . Note there are models learned for each drug in Step 1, but the final prediction only allows one output, so we use the average of outputs ( for continuous outcomes, and for binary outcomes) from all models in formula (1). We name this algorithm Cross-Validation Stacking (CVS), since are cross-validation predictions. The detailed algorithm is described in Algorithm 2.
2.3. Residual Stacking (RS), a variation of step 2
In the standard stacking algorithm, the Step 1 models learn the relationship between the predictors and every individual outcome, while the Step 2 models use the relationship among outcome variables to revise the Step 1 predictions. In the case where Step 2 models are ordinary linear regressions, stacking produces weighted averages of the Step 1 predictions as final predictions. To predict the -th outcome, the stacking algorithm revises the Step 1 contribution of from to a new weight learned from the Step 2 combiner models. Sometimes Step 1 already provides accurate predictions, but the results of Step 2 models are not accurate due to data noise or unstable model fitting, hence the Step 1 prediction accuracy may be compromised by stacking. This argument can also be extended to stacking algorithms using other Step 2 models.
To ameliorate the problem above, we retain all information learned from the Step 1 models, and use the relationship among the outcomes to explain the variation that cannot be explained by the Step 1 models. We call this revised stacking algorithm Residual Stacking (RS), and provide the steps in Algorithm 3. In RS algorithm, the Step 2 model for the -th outcome is learned using the Step 1 residual as outcome, and using the Step 1 fitted value excluding as predictors. The formulas for the final predictions are revised using the residuals, which are given in formula (2).
2.4. Stacking algorithms for binary outcomes
For binary outcomes, , we denote the predicted probability of the -th outcome for the -th sample in the Step 1 model as . Algorithms 1 and 2 can accommodate binary outcomes simply by replacing with . Algorithm 3, residual stacking, requires additional changes to handle binary regression residual types. Instead of raw residuals , two alternative types of residuals are more appropriate for binary outcomes. We consider Pearson Residual Stacking (PRS) and Deviance Residual Stacking (DRS), which are described below.
The Pearson residual is defined as
[TABLE]
and the prediction formula (2) becomes
[TABLE]
The Deviance residual is defined as
[TABLE]
Formula (3) cannot be inverted explicitly to derive . Instead, we predict using the distance between the Step 2 predicted residuals and the two conditional residuals calculated using formula (3) and the Step 1 predicted probabilities . The prediction formula (2) becomes the proportion of the inverted distance,
[TABLE]
Note that predicted probabilities using deviance residuals are guaranteed to be in the range of , but this is not true for the Pearson residual. For Pearson residuals, we truncate the predicted probability onto the range when necessary.
2.5. Comparison of prediction performance of methods
Data
Following both [6] and [11], we compare the performance of the methods using cross-validation on the real HIV data. Cross-validation is a popular alternative to simulation studies for the comparison of methods, especially in the community of machine learning researchers [8]. When the true data generation mechanism is unknown or too complex, it is preferable to evaluate the performance of methods by cross-validation on real data.
In the HIV database, the resistance of five Nucleoside RT Inhibitor (NRTI) drugs were used as multivariate outcomes by [6], including Lamivudine (3TC), Abacavir (ABC), Zidovudine (AZT), Stavudine (D4T), Didanosine (DDI). We use the same five drugs as multivariate outcomes in our study. At the time of our analysis, the database contains samples, with the measurements of their resistance to NRTI drugs and mutation variables. The sample size is reduced to after we remove samples with missing values. We removed mutation variables, since they do not contain enough variation (i.e. fewer than samples are mutated in these variables). The final outcome data is a matrix of size , and the predictor data is a matrix of values.
The ratios are used as the outcomes of drug resistance to compare the prediction performance of methods for continuous multivariate outcomes. HIV scientists define threshold values to convert the ratio into categorical outcomes, “susceptive”, “low resistance”, and “high resistance”. Following [6], we combine “low resistance” and “high resistance” into one category, and use the binary outcome to compare the classification performance of the methods. At the time of our analysis, the HIV database website recommended cutoff values to convert ratios to binary outcomes are 3TC, ABC, AZT, D4T, and DDI. Since the database is actively expanded by new data submissions from researchers, we provide a snapshot of the data used in this paper as supplementary material for this paper.
Methods compared
In the analysis of [11], LARS performs better than the other methods, and we use LARS as the base model in CC and the stacking algorithms. The models compared are (i) univariate outcome LARS models (uLARS) fitted separately for each outcome, (ii) Ensemble Classification Chain (ECC), with LARS as each model in the chain. In [6], CC’s of randomly ordered chains were built, and the most frequently predicted outcomes were used as final predictions for the ECC method. We follow the same procedure for binary multivariate classifications, and extend their idea to predict continuous outcomes as the average predictions of continuous multivariate outcome prediction chains. (iii) Multivariate outcome neural network (NNet), which has one hidden layer with neurons, and units on the outcome layer corresponding to the drugs to be predicted. This network structure has weights/parameters to be estimated from data. We also tried NNet with neurons in the hidden layer, (i.e. weights/parameters), which has the same network structure as stacking. The result of this network is much worse than using neurons, so we did not include it in this paper. (iv) Stacking algorithms and their variations. (v) The multivariate normal outcome LARS (mLARS), which is only used for continuous multivariate outcome problems.
For the stacking algorithms, we compare various models in combination with standard stacking (SS), cross-validation stacking (CVS), residual stacking (RS), and cross-validation residual stacking (CVRS). LARS is used as the Step 1 model in all stacking algorithms applied here. For Step 2 models, we compared linear regression (for continuous outcomes), logistic regression (for binary outcomes), and decision trees. For binary outcome RS, we also compared deviance residuals and Pearson residuals. The methods compared and their abbreviations are listed in Table 1.
The LARS models are fitted using the R package ‘glmnet’ [5]. Decision trees are fitted using the recursive partition implementation in the R package ‘rpart’ [2]. The neural network models are fitted using the R package ‘nnet’ [12].
Evaluation criteria
We use -fold cross-validation to compare the methods. One subset, in turn, is held out and the remaining subsets are used to fit models, and the model predictions are made on the holdout subset. The -fold cross-validation predictions are compared against the observed outcome data to evaluate each method we applied. The average mean squared error (MSE) across the 5 drugs is used as comparison criteria for continuous outcome problems. Smaller MSE indicates better prediction performance. For binary outcome predictions of drug resistance versus susceptive, we consider two criteria, average accuracy and AUC statistics. Average accuracy is the proportion of correctly classified samples, which is computed using the cut-off predicted probability of to predict the binary outcome for . The AUC statistic is the area under ROC curve, and the predicted probabilities are used directly to compute it. Larger accuracy or AUC indicates better classification performance.
Since the results can be affected by how the data are randomly split into cross-validation subsets, we repeat the comparison times with different folds generated using different random seeds.
3. Results
3.1. Comparison of continuous outcome methods
Comparison of all methods
Figure 1 shows average Mean Squared Errors (MSEs) of -fold cross-validation predictions of all methods (except for neural network) compared in this paper. Each box displays the distribution of prediction MSEs of a method over different random splits of data. The performance of the Neural networks is much worse than all other models in our comparison and we exclude NNet from Figure 1 for reasons of aesthetics. The same figure with NNet is in supplementary Figure 1. The multivariate outcome neural network is the only method in the study that is not based on LARS. In the analysis of [11], binary prediction performance of univariate LARS is much better than univariate neural networks for the four drugs we consider here, and slightly worse for the drug 3TC. The multivariate outcome version of the neural network model does not outperform LARS in our study.
The methods with the best performance are RS and CVRS with regression trees in the Step 2 models. It is not a surprise that the individual univariate LARS performs worst among them, since uLARS does not borrow information across multiple prediction tasks. RS and CVRS performance is considerably reduced if we replace regression trees by linear regression in the Step 2 models. This is because the relationships in Step 2 of RS or CVRS may contain strong interaction/nonlinear effects. Figure 2 shows a sample residual stacking fitted Step 2 regression tree for drug two. The second drug residual is predicted by the interaction of the fifth and first drugs (, ) in the residual stacking tree. Adding this interaction term to the linear regression model version of Step 2, results in a p-value of for the likelihood ratio test, suggesting that the interaction term significantly improves model fit. In addition, prediction performance is reduced substantially if we replace RS by SS or replace CVRS by CVS for the Step 2 tree models.
Evaluation of residual and cross-validation effects
In this paper we propose two variations of standard stacking, residual stacking and cross-validation stacking. Next we evaluate whether our proposed variations improve prediction performance over standard stacking.
Visual inspection of the boxplots in Figure 1 provides some information about the relative performance of our proposed methods versus standard stacking, however, a more powerful approach is to compare the within-replicate differences of average MSE’s for relevant pairs of methods. Figure 3 shows boxplots and paired t-test p-values for pairs which evaluate the effect of our variations.
The top panel in Figure 3 compares RS versus SS and CVRS versus CVS, which estimates the effect of the ‘residual’ method in the stacking algorithm. We found that all stacking algorithms incorporating residuals have smaller median MSE’s than their corresponding non-residual versions of the algorithms. The visual trend is supported by significant p-values for the paired t-tests. This indicates that residual stacking significantly improves prediction performance consistently in all settings we considered.
The bottom panel in Figure 3 compares CVS versus SS and CVRS versus RS, which estimates the effect of ‘cross-validation’ on stacking prediction performance. CV stacking significantly reduces MSE’s over the non-CV version, only when the Step 2 model is linear regression. In interpreting this result, we note that fitted values have smaller variance than predicted values, which motivated us to propose the use of CVS. For Step 2 linear regression, all changes of predictor values will be linearly passed to the final output. Hence CV stacking is helpful in this situation. However, a regression tree is more robust to small errors, since each node of a regression tree is a binary decision. Small changes of predictor values will not affect the results of regression trees, as long as the changes do not pass the threshold and cause change in the binary decision at the nodes. In fact, if all values of the predictors are consistently scaled, the structure of the decision tree will not change, only the threshold of each decision node will be scaled accordingly. This explains why CV stacking is not helpful when the Step 2 model is regression tree.
3.2. Comparison of binary outcome classification methods
Comparison of all methods Figure 4 shows the prediction performance of all methods we evaluated, except the neural network. The left panel shows boxplots of accuracy, the proportion of correct predictions, while the right panel shows boxplots of the Area Under ROC curve (AUC) statistics. Each boxplot represents the distribution for 100 replicates of random split cross-validation folds. The Neural network is still the worst performer, for both accuracy and AUC, among the models in our comparison and it isn’t shown here. The same figure including NNet is in supplementary Figure 2.
In Figure 4, ECC and all stacking models show improved accuracy over the individual univariate LARS model. The majority ( of ) of stacking models have better accuracy than ECC with significant paired t-test p-values. The visual trends of comparisons of AUC are consistent with the trends of accuracy, except the order of stacking and ECC. For AUC, ECC is the second best model among all models we compared. ECC is slightly worse than CVDRS that uses logistic regression as the Step 2 combiner model, with a paired t-test p-value of . This result can be explained by the shared property of ensemble methods and AUC statistics. Accuracy measures the prediction performance of one decision rule corresponding to a specific threshold value, here. AUC measures the weighted average of prediction performance across multiple decision rules corresponding to all possible threshold values. Each classification chain works well at some specific threshold value. ECC makes decisions by voting of multiple CC’s, so it is not surprising that ECC makes “smoothed” improvement across many different threshold values of choice, hence shows better performance in terms of AUC.
Evaluation of residual and cross-validation effects
Figure 5 evaluates the residual and cross-validation effects for the various stacking algorithms. The left panel shows paired differences of accuracy, while the right panel shows the paired differences of AUC statistics.
The top three panels in Figure 5 show results for the evaluation of residual effects. Both deviance residual and Pearson residual stacking algorithms consistently show larger accuracy and larger AUC than their corresponding non-residual versions. The visual trend is supported by significant p-values of all paired t-tests. This indicates that residual stacking consistently improves performance of multivariate binary classification problems. We also found that the deviance residual is preferred when the Step 2 model is logistic regression, and the Pearson residual is preferred when the Step 2 model is a regression tree.
The bottom panel in Figure 5 shows results for the evaluation of cross-validation effects. There are no strong visual trends to support that cross-validation can improve classification performance in most settings. This result is not surprising, since small bias (between fitted probability and predicted probability in the Step 1 models) may not be large enough to pass threshold values and change final binary decisions of classification. In addition, unlike continuous outcome problems, the exact relationship between predicted probability and fitted probability is unclear.
The paired t-test p-values suggest significant AUC prediction improvement when the Step 2 model is logistic regression. Unlike accuracy, AUC is an averaged summary of classification performance over all possible threshold values. When small improvements in predicted probabilities can affect binary classifications based on some (but not all) threshold values, the AUC will be affected. This result suggests cross-validation stacking is preferred for classification problems, only if the Step 2 model is logistic regression and if the prediction problem requires soft decisions (decisions based on multiple threshold values).
4. Discussion
The most attractive property of the stacking algorithm is its flexibility. Complex multivariate outcome prediction models can be easily constructed using models for univariate outcome prediction problems. The models used to construct stacking algorithms can be any model of the user’s choice, from simple linear regressions to very complex Bayesian hierarchical models.
Different models can be used in the same step, to handle mixed types of multivariate outcomes. For example, bivariate outcomes which contain a binary variable (e.g. disease status) and a continuous variable (e.g. blood pressure)can be accommodated. In each step, a linear regression models could predict the blood pressure and logistic regression could predict the binary disease status.
Stacking algorithms can be considered as revised versions of three-layer neural networks, which can be more effective on smaller sample size problem where fitting deep neural networks is not practical. Stacking is different from standard neural networks in 3 ways. (1) Its hidden layer (Step 1 models) must have the same number of neurons as the output layer (2) The learning of parameters of the hidden layer is directly supervised by the observed outcome data, while standard neural networks learn parameters in hidden layers indirectly supervised through their connection to outcome data in the output layer. (3) Stacking algorithms can use complex models in the neurons on a fixed network structure, which contains limited number of model parameters to learn. In contrast, deep neural networks (DNN) build complex network structures of many hidden layers and many neurons, but each neuron is often a simple function. DNN usually has a large number of parameters to learn from data. The difference between stacking algorithms and neural networks makes stacking more suitable for data sets with smaller sample sizes. This explains why neural networks do not show superior performance in our study.
The computational complexity of classification chains is similar to Step 1 models of the stacking algorithms. Extra time used to fit Step 2 models makes stacking slower than CC, but ECC needs to fit multiple CC models, which is slower than stacking. In CC algorithms, predictor and outcome information are used equivalently in a single model, while stacking algorithms use two separate models to describe the two types of information. This difference makes stacking more flexible and more powerful when the relation between predictors and outcome and the relation among outcomes are too different to be modelled by the same model. This explains why in our study stacking algorithms often outperform ECC.
In the comparison, we found the performance rank of ECC is much higher when using AUC as the comparison criteria. This suggests that ensemble algorithms are helpful in applications where a hard binary decision is not required.
5. Conclusion
Based on results of this study, we recommend residual stacking algorithms. Cross-validation stacking can be used together with residual stacking if the Step 2 models are linear models but not trees. This algorithm outperforms all other algorithms that we considered in this study.
Any model can be used to construct a stacking algorithm. When a new model is used to replace LARS or regression trees in our study, we suggest the use of the cross-validation approach illustrated in this paper, to compare different models of choice and compare combinations of residual stacking and cross-validation stacking. This ensures that the best model is used in data analysis.
Acknowledgements
Authors thank Professor Dominik Heider (University of Marburg) for his helpful discussion about pre-processing data from HIV data base.
Funding
This work was supported by the Natural Sciences and Engineering Research Council Discovery Grants (XZ, ML), Natural Sciences and Engineering Research Council Post Doctoral Fellowship (LX), and the Canada Research Chair (XZ).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] J Baxter. A Model of Inductive Bias Learning. Journal of Artificial Intelligence Research , 12:149–198, March 2000.
- 2[2] Leo Breiman. Classification and Regression Trees. In Classification And Regression Trees . Routledge, 1984.
- 3[3] Dana S Clutter, Michael R Jordan, Silvia Bertagnolio, and Robert W Shafer. HIV-1 drug resistance and resistance testing. Infection, Genetics and Evolution , 46:292–307, December 2016.
- 4[4] B Efron, T Hastie, I Johnstone, and R Tibshirani. Least angle regression. The annals of statistics , 32(2):407–451, April 2004.
- 5[5] Jerome Friedman, Trevor Hastie, and Robert Tibshirani. Regularization Paths for Generalized Linear Models via Coordinate Descent. Journal of Statistical Software , 33(1):1–22, 2010.
- 6[6] Dominik Heider, Robin Senge, Weiwei Cheng, and Eyke Hüllermeier. Multilabel classification for exploiting cross-resistance information in HIV-1 drug resistance prediction. Bioinformatics (Oxford, England) , 29(16):1946–1952, June 2013.
- 7[7] Yann Le Cun, Yoshua Bengio, and Geoffrey Hinton. Deep learning. Nature , 521(7553):436–444, May 2015.
- 8[8] F Leisch and E Dimitriadou URL http CRAN R-project org package mlbench. mlbench: machine learning benchmark problems. R package version 2.1-1, 2010.