Learning to Validate the Quality of Detected Landmarks
Wolfgang Fuhl, Enkelejda Kasneci

TL;DR
This paper introduces a new loss function for CNN-based landmark detection that estimates landmark accuracy, enabling exclusion of unreliable landmarks and improving overall detection quality.
Contribution
It proposes a novel validation loss function and a batch balancing method that enhances landmark detection accuracy and reliability in CNN models.
Findings
Validation loss correlates with landmark accuracy.
Batch balancing improves detection performance.
Method effective across multiple facial landmark datasets.
Abstract
We present a new loss function for the validation of image landmarks detected via Convolutional Neural Networks (CNN). The network learns to estimate how accurate its landmark estimation is. This loss function is applicable to all regression-based location estimations and allows the exclusion of unreliable landmarks from further processing. In addition, we formulate a novel batch balancing approach which weights the importance of samples based on their produced loss. This is done by computing a probability distribution mapping on an interval from which samples can be selected using a uniform random selection scheme. We conducted experiments on the 300W, AFLW, and WFLW facial landmark datasets. In the first experiments, the influence of our batch balancing approach is evaluated by comparing it against uniform sampling. In addition, we evaluated the impact of the validation loss on the…
Click any figure to enlarge with its caption.
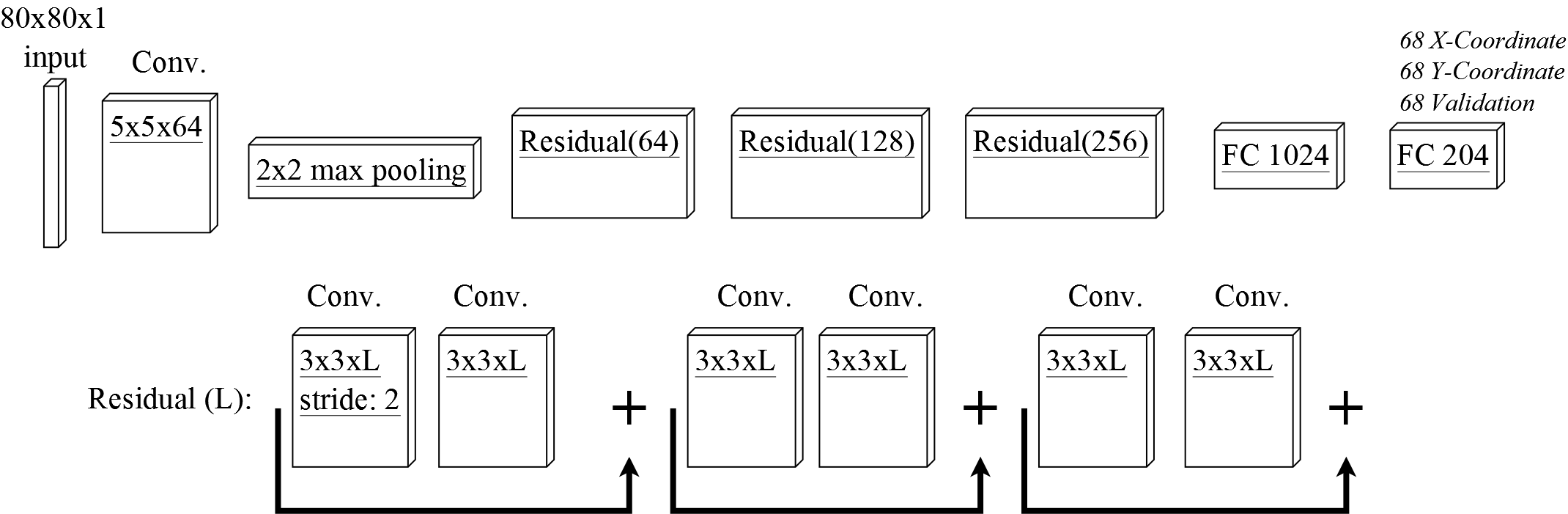 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10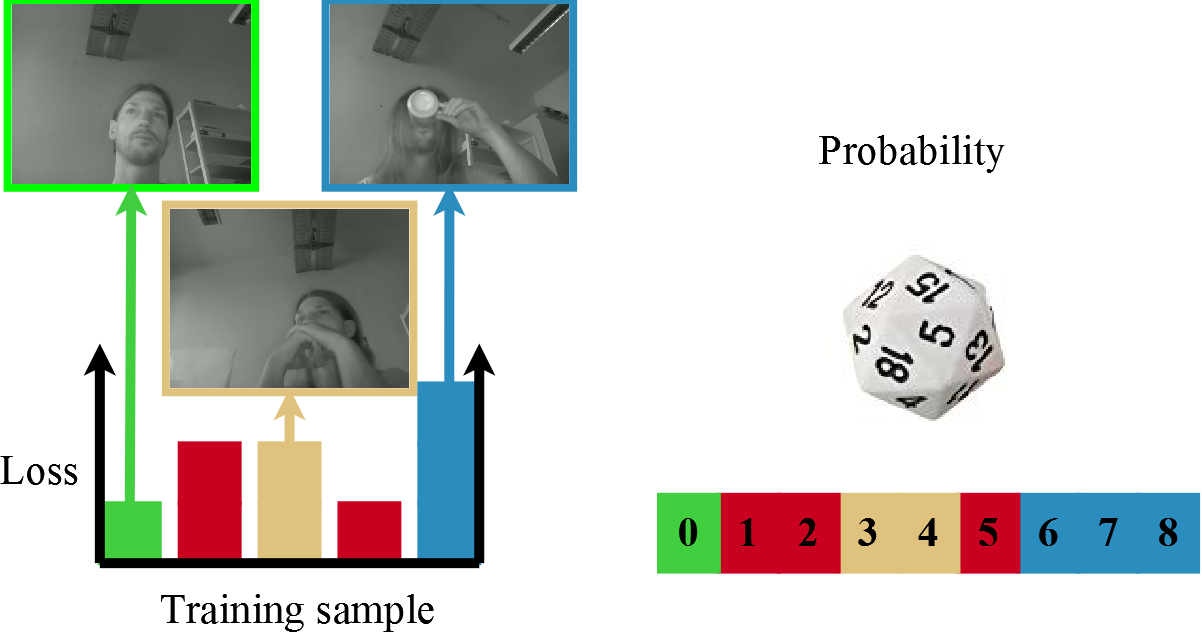 Figure 11
Figure 11 Figure 12
Figure 12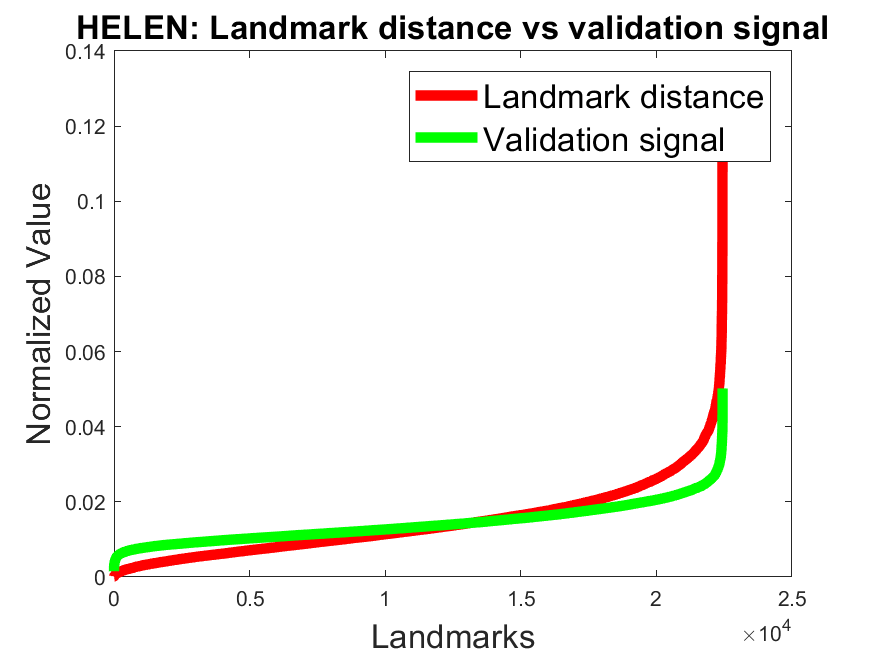 Figure 13
Figure 13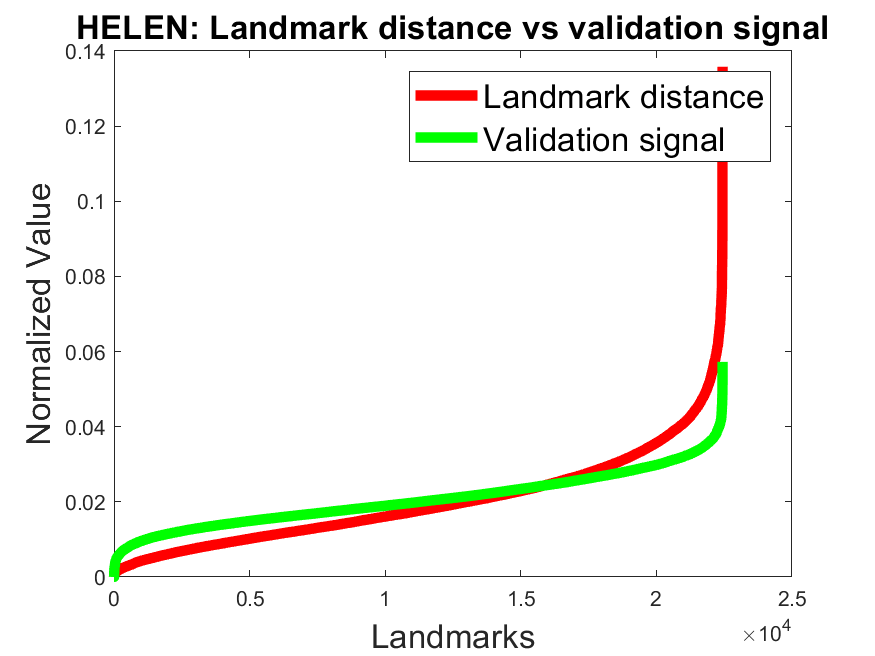 Figure 14
Figure 14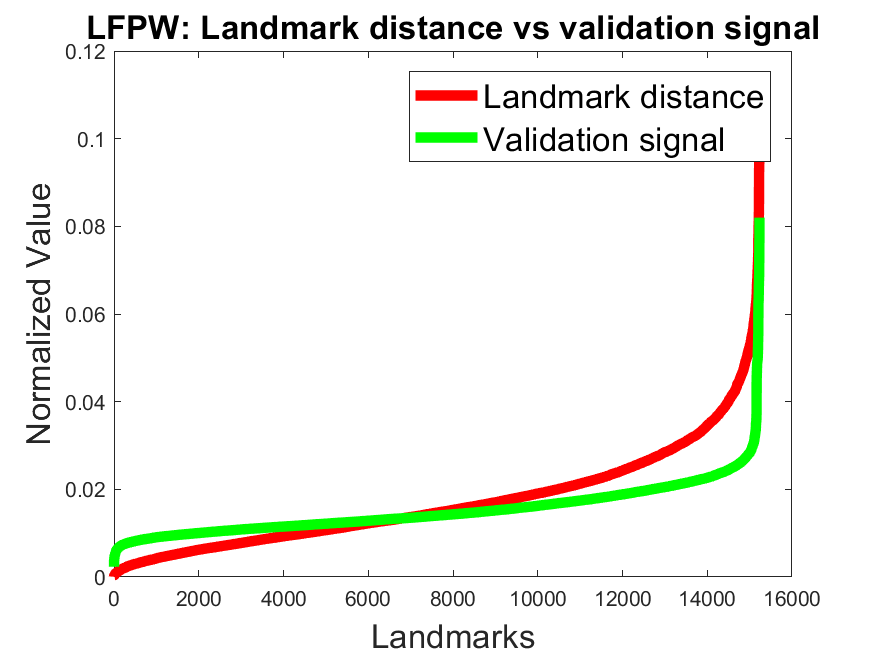 Figure 15
Figure 15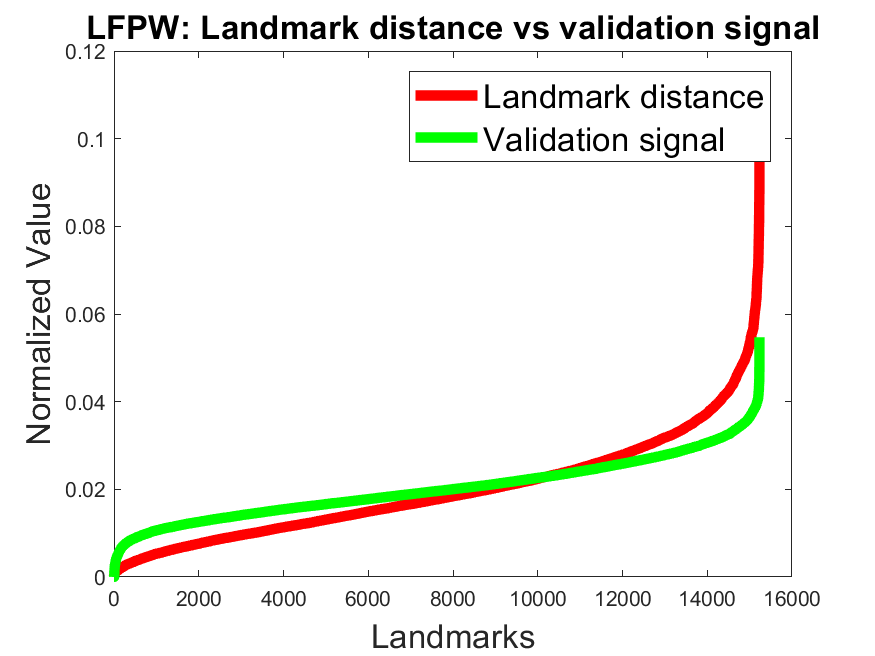 Figure 16
Figure 16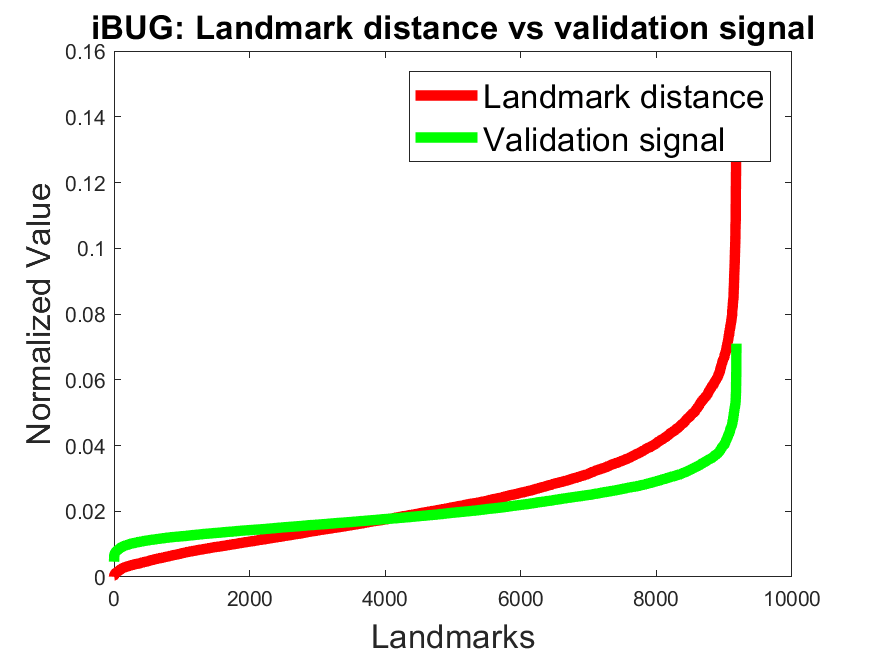 Figure 17
Figure 17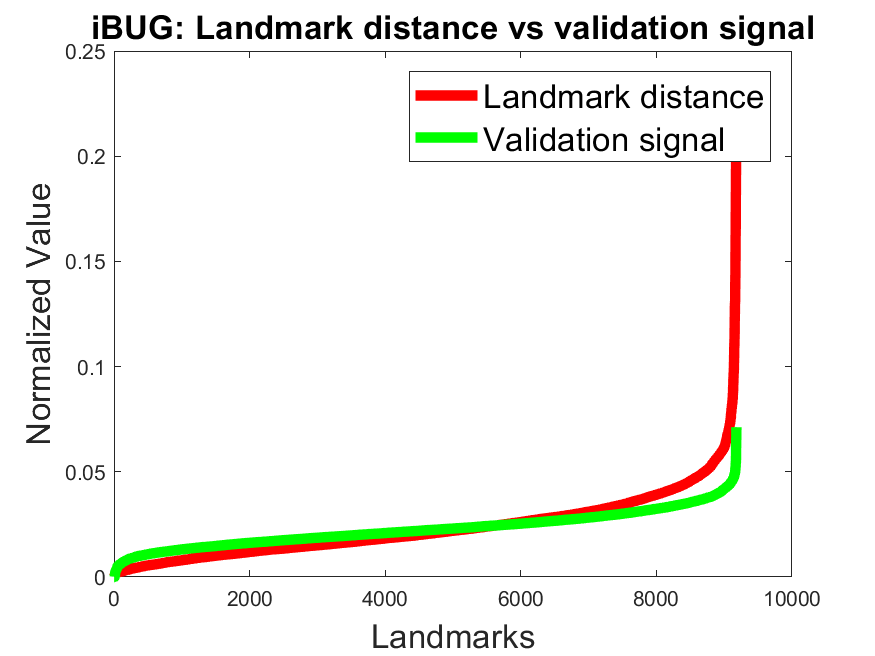 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23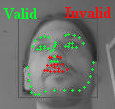 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26| Dataset | NON | NOBB |
|---|---|---|
| 300W Full | 4.35 | 4.43 |
| 300W Common | 3.67 | 3.71 |
| 300W Challenging | 7.14 | 7.38 |
| AFLW Full | 1.74 | 1.76 |
| WFLW Full | 6.62 | 6.71 |
| WFLW No challenge | 4.78 | 5.17 |
| WFLW Blur | 6.99 | 6.94 |
| WFLW Expression | 7.18 | 7.44 |
| WFLW Illumination | 6.26 | 6.36 |
| WFLW Makeup | 6.53 | 6.39 |
| WFLW Occlusion | 7.49 | 7.20 |
| WFLW Pose | 11.76 | 11.13 |
| Full | Blur | Expression | Illumination | Makeup | Occlusion | Pose | |
|---|---|---|---|---|---|---|---|
| ESR [20] | 11.13 | 12.20 | 11.47 | 10.49 | 11.05 | 13.75 | 25.88 |
| SDM [32] | 10.29 | 11.28 | 11.45 | 9.32 | 9.38 | 13.03 | 24.10 |
| CFSS [33] | 9.07 | 9.96 | 10.09 | 8.30 | 8.74 | 11.76 | 21.36 |
| DVLN [34] | 6.08 | 6.88 | 6.78 | 5.73 | 5.98 | 7.33 | 11.54 |
| LAB [24] | 5.27 | 6.32 | 5.51 | 5.23 | 5.15 | 6.79 | 10.24 |
| NON | 6.62 | 6.99 | 7.18 | 6.26 | 6.53 | 7.49 | 11.76 |
| NO | 6.71 | 6.94 | 7.44 | 6.36 | 6.39 | 7.20 | 11.13 |
| BBO | 5.86 | 6.01 | 6.28 | 5.53 | 5.68 | 6.28 | 9.67 |
| BB | 5.54 | 5.71 | 5.94 | 5.26 | 5.37 | 5.94 | 9.24 |
| Discard | Method | Common | Challenging | Full |
|---|---|---|---|---|
| 10% | NON | 3.72 | 7.23 | 4.41 |
| NOBB | 3.32 | 6.49 | 3.94 | |
| BBO | 2.91 | 6.02 | 3.52 | |
| BB | 2.72 | 5.79 | 3.32 | |
| 20% | NON | 3.72 | 7.23 | 4.40 |
| NOBB | 2.99 | 5.76 | 3.53 | |
| BBO | 2.64 | 5.40 | 3.18 | |
| BB | 2.48 | 5.18 | 3.01 | |
| 30% | NON | 3.71 | 7.18 | 4.39 |
| NOBB | 2.72 | 5.17 | 3.20 | |
| BBO | 2.42 | 4.87 | 2.90 | |
| BB | 2.27 | 4.66 | 2.74 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Learning to Validate the Quality of Detected Landmarks
Wolfgang Fuhl
Enkelejda Kasneci \skiplinehalfEberhard Karls Universität Tübingen
72076 Tübingen
Germany
Abstract
We present a new loss function for the validation of image landmarks detected via Convolutional Neural Networks (CNN). The network learns to estimate how accurate its landmark estimation is. This loss function is applicable to all regression-based location estimations and allows the exclusion of unreliable landmarks from further processing. In addition, we formulate a novel batch balancing approach which weights the importance of samples based on their produced loss. This is done by computing a probability distribution mapping on an interval from which samples can be selected using a uniform random selection scheme. We conducted experiments on the 300W, AFLW, and WFLW facial landmark datasets. In the first experiments, the influence of our batch balancing approach is evaluated by comparing it against uniform sampling. In addition, we evaluated the impact of the validation loss on the landmark accuracy based on uniform sampling. The last experiments evaluate the correlation of the validation signal with the landmark accuracy. All experiments were performed for all three datasets.
keywords:
landmark detection, landmark validation, deep learning, batch creation
1 Introduction
Landmark localization describes the process of determining the location of characteristic points of an object in an image. These points are usually characterized by a spatial relationship to each other such as the nose and eyes of a face. Under pose changes of the object, landmarks cannot change positions randomly but according to their relative positions towards each other. The problem of landmark localization is common in 2D face alignment, face reconstruction or gesture recognition [1, 2]. These are also preparatory steps for head pose estimation [3, 4], emotion estimation [5, 6] and face recognition [7, 8]. The current state of the art in this area addresses the problems of accurate and robust landmark detection in real and constrained scenarios. Deep neural networks [9, 10] are currently in the focus of attention since they outperformed any other machine learning approach for common computer vision tasks. This includes landmark detection [1, 11] with a multitude of different network architectures, including convolution neuronal networks [12], auto encoders [13], recurrent networks [14], residual networks [15, 16] and hourglass networks [1]. Recent developments emphasize the importance of the loss function as a key element for improving the accuracy and robustness of landmark localization, such as the newly proposed Wing loss [15]. Another novel architecture, a local to global context network proposed in [17], outputs heat map candidates and is therefore capable of detecting landmarks for multiple persons in an image. In this work, we address the challenge of facial landmark validation and batch balancing for training. The main contributions of this work are 1: A novel loss function that trains the network directly to estimate the accuracy alongside with landmark location. The idea behind our validation loss is that we want the network to guess the reliability in terms of distance to the ground truth position. 2: An online data augmentation strategy that ranks training samples by their produced loss. This addresses the problem of pose-based data balancing [15] by not only normalizing for the occurrences of head poses but also for (a priori unknown) challenges in the dataset like occlusion and illumination.
2 Related work
State of the art methods employing deep learning for facial landmark detection is based on regression, i.e. the network estimates the correct landmark positions directly. We categorize those approaches by their employed architecture, data balancing procedure, cascading, and loss functions. Architecture: A straightforward way to use a CNN for direct 2D landmark regression was proposed in [15, 12]. The input to such a network is a face image which is extracted based on preliminary applied face detection. Novel architectures such as residual [15] and recurrent networks [14] have already improved the state of the art in regression-based landmark detection. Hourglass networks [1] have also led to an increase in both accuracy and robustness of landmark detection. However, instead of a position vector, its output is a heat map, where each pixel represents the probability to be a landmark position. Data balancing: Facial landmarks are subject to extreme pose variations. Head poses present in current datasets are however heavily biased towards frontal images; extreme orientations are rarely represented in the data. To overcome this limitation, multiview models were proposed, splitting the problem into frontal and profile faces. Those where already used in traditional approaches, such as ASM [18] and AAM [19], as well as for cascaded regression-based approaches [20, 21]. In [16], a cycle GAN was used to generate images to handle style variations.
3 Batch balancing
Existing pose-based data balancing approaches [15] are a valuable and effective procedure but have one major drawback: the data is balanced only based on the underrepresentation of some head poses with regard to a parameter of histogram bins. Figure 1 shows an example where data is already balanced based on the head pose. But additional challenges, such as reflections (top right) and three different types of occlusions are only represented by one sample each. Our idea is to use the produced loss of a training image to compute the probability of an image being included in the next training batch. Thereby, we can make the network learn especially the challenging cases, even if they are not annotated as such.
Figure 1 shows such a training set. Each sample, therefore, has an assigned value range which allows to create a new batch using a uniform random sampling.
[TABLE]
Equation 1 describes our Loss Probability based Batch Balancing (LPBB). For the selection of the training sample () in our batch () we first select a value in the range using the uniform distribution . is the amount of all samples in our training set. Afterward, we search for the th sample which has a greater or equal sum of the loss values as our randomly selected value. For completeness, it should also be required that k is the smallest sum that satisfies this condition (Not integrated into the formula for simplification). This sample is than included in the batch. This also means that samples can be assigned twice in a batch but since we use online data augmentation, there is no limitation (Section 5). Figure 2 shows the sample selection. First the sum is computed based on which the range for the uniform distribution is computed. Afterwards, the sample three is selected since it has a greater sum of loss values. For an exact determination of the probability based on the loss value, all data must be evaluated after each training batch. Since this represents a considerable effort, two different uses were considered in our evaluation (Section 6). An exact description can be found in Section 5.
4 Validation loss formulation
The idea behind our validation loss is that we want the network to guess the expected distance between its prediction and the ground truth position as a proxy of the reliability of the prediction. This means that the network not only estimates the landmark position, it also evaluates its accuracy and provides this information in the additional output. Therefore, we compute the distance between the estimated and annotated position (L2, L1, or any task-specific distance metric) and use this as a training label for the next training iteration. For landmarks the convetional loss formulation is for the th index of the output neuron where is the ground truth and the estimated value. The derivative and therefore the gradient is . Each landmark position is estimated using two neurons from the last layer as shown in Equation 2.
[TABLE]
in Equation 2 is the gradient for the x coordinate of the th landmark and the gradient for the y coordinate which are represented by neuron and respectively. We extended this formulation by a third value which is the validation signal. As metric between the ground truth position and the estimated value we used the Manhattan distance. The computation of the gradients for one landmark position using the validation loss is shown in Equation 3.
[TABLE]
As can be seen each landmark receives an additional neuron () which learns to evaluate the quality of the position estimation of the landmark. The higher this signal is, the less accurate is the landmark estimation. The advantages of this formulation are first than the CNN can learn to estimate the landmark quality end to end and that our formulation is not bound to a distance metric. The Manhattan distance () can also be replaced by the Euclidean distance () or any other distance metric.
5 System, training, and augmentation parameters
For the training of our network, we used DLIB [22]. The training was performed on a POWER8 server from IBM with four Nvidia Tesla P100 GPUs and 1TB of RAM. For the evaluation and measuring the inference runtime, we used a desktop computer with an NVIDIA GeForce GTX 1050ti, 16GB of RAM and an Intel i5-4570 CPU. The network architecture itself is shown in Figure 3 and consists of an initial convolution layer followed by a max pooling. Afterward, three residual blocks are used with 64, 128 and 256 layers, respectively. After each convolution, we used a batch normalization layer followed by a rectifier linear unit. The end of our architecture consists of two fully connected layers, wherein the last layer has outputs with the validation loss and without. represents the number of landmarks. This means that for the 300W [3] dataset with 68 landmarks our output layer has neurons using the validation loss. These three values represent the x and y coordinate as well as the validation signal per landmark.
Naming convention: For our evaluation we trained four CNNs for each data set (300W [3], AFLW [23], and WFLW [24]). All CNNs follow the same architecture as shown in Figure 3. NON: CNN using no validation signal and no batch balancing. NOBB: CNN using the validation signal and no batch balancing. BBO: CNN using the validation signal and batch balancing (PLBB) with an online update. BB: CNN using the validation signal and batch balancing (PLBB) with an update of the loss value for all training samples every 10% of an epoch.
Data augmentation: For data augmentation, we used randomly added noise of up to 20%. The face bounding box was randomly shifted by up to 20% of the image in any direction (corners or between) and rotated between in the range [-1, 1] radian. Gaussian blur was added to the image in the range σ=[1.0, 1.3]. Additionally, we added occlusions which could cover up to 50% of the image. The gray value of the occlusion was also randomly chosen in the range [0, 30] (dark), [200, 255] (bright) or randomly between [0, 255]. The last data augmentation was the contrast which was adjusted with a randomly selected value between [-30, 30].
Training parameters: Weight decay was set to and momentum to 0.9 with a batch size of 10. All images during training and evaluation were converted to grayscale. For the training of the NOBB, BBO, and BB networks we used the Manhattan distance for the validation loss as shown in Equation 3. All models were initialized with random values and trained in three steps. The first step used the L2 loss formulation for the x and y coordinate with a learning rate of . Each model was trained for epochs with this configuration. This was done since DLIB ends up in a loss of NaN for random initialization networks if the initial learning rate is set too high. Afterward, the learning rate was increased to for additional epochs. For the second training step, we changed the loss formulation from L2 to L1 for the coordinate regression. The training was conducted for an additional epochs. Afterward, the learning rate was increased to for all models with the exception of those trained on the WFLW [24] dataset. For the WFLW [24] dataset the learning rate was kept at . The training of all models was continued for an additional epochs also the models which are trained on WFLW. For the last and third part of our training, we changed the loss function to the wing loss [15] for the coordinate regression. The wing loss function is a combination of a log loss and an L1 loss function. For large errors () it behaves like the L1 loss function and for small errors () like a log loss function. We used the parameters as in the original paper [15] where is used to limit the curvature of the log function. The training was continued for an additional epochs where after each epochs the learning rate was decreased by to a minimum of . For the models trained on the WFLW [24] dataset the learning rate was decreased to after the first epochs and kept at this value for the remaining epochs.
6 Evaluation
In this section, we evaluate the proposed methodology and compare the resulting networks with the state of the art on the data sets 300W [3], AFLW [23], and WFLW [24]. First, the datasets are described. For the evaluation of our batch balancing approach and the comparison to the state of the art we used the 300W [3], AFLW [23], and WFLW [24] facial landmark dataset [3]. All values are reported with a factor of . The datasets are described in the following. 300W: The dataset is an aggregation of multiple face datasets, namely LFPW [25], HELEN [26], AFW [3] and XM2VTS [27]. 68 landmarks are annotated semi automatically [28]. The evaluation procedure is identical to [15, 16, 29]. The training set consists of the annotated images from AFW and the training subset of LFPW and HELEN (3,148 images in total). For evaluation three test sets are considered. The common test set from LFPW and HELEN (554 images). A challenging test set consisting of 135 collected iBUG face images. All images together form the full test set (689 images). We report our results in normalized mean errors (NME). This corresponds to the pixel distance between detected and annotated landmark, normalized by the pixel distance between both eye centers (equal to the inter-pupillary distance if pupils are not annotated [15, 16, 29]). AFLW: In our experiments, we used the AFLWFull protocol [30]. The dataset consists of 20,000 training and 4,386 test images. Each image has 19 manually annotated landmarks and has been widely used for facial landmark localization benchmarking since it contains high pose variations(-90∘-90∘). We report our results in normalized mean errors (NME) which corresponds to the pixel distance between detected and annotated landmark, normalized by the width or height of the squared face bounding box. WFLW: The dataset consists of 7,500 images for training and 2,500 images for testing. Each image has 98 manually annotated facial landmarks. In addition, the test set is split up in different challenges e.g. occlusion, pose, make-up, illumination, blur, and expression. We followed the original protocol [24] and evaluated each challenge separately. The results are reported as normalized mean errors (NME). For the original protocol, the pixel distance between detected and annotated landmark is normalized using the inter-ocular distance.
Impact of validation loss on the accuracy: Table 1 shows the comparison of the models NON and NOBB. Both do not use the batch balancing but the model NOBB uses the proposed validation signal regression. As can be seen for the datasets 300W and AFLW the validation signal reduces the accuracy of the landmark regression. This due to the competition between the landmark position and its inaccuracy. For the dataset WFLW this is slightly different. Overall the model NON is more accurate but not for all challenges. For blur, makeup, occlusion, and pose the model NOBB outperforms NON.
Impact of PLBB: Table 2 shows the results on the 300W dataset. Comparing the results of NOBB to BBO and BB it can be seen that our batch balancing approach improves the results further. For BBO the results are slightly worse compared to BB because the loss distribution is less accurate. However, the computational effort for BBO is only one fifth. Comparing both (BB and BBO) to the state-of the art it can be seen that they are equally or more accurate. The models CNN-6 [24] and CNN-6/7 [24] where proposed together with the wing loss which we are using too. The authors additionally proposed a dataset balancing strategy (PDB) which shows to be effective by comparing these two networks to our NON and NOBB models which do not use any batch balancing strategy. The comparison of the CNN-6/7 [24] to our BBO model it can be seen that the main improvement of our batch balancing strategy is in the challenging part of the 300W dataset. This is due to similar images in the training set produce higher loss values and are more likely to be in a batch. For the LAB [31] landmark detection, there are also results using the ground truth boundary information on the 300W dataset. This combination together with the pretrained ResNet-50 [24] is compared to our approach in Table 6 where our model uses the validity signal to rule out inaccurate landmarks. Table 3 shows the comparison of our approch on the AFLW dataset. As in Table 2 it can be seen that the batch balancing approach used for CNN-6/7 [15] is effective in comparison to our models NON and NOBB. The proposed batch balancing approach used in our models BBO and BB further improves the results on the AFLW dataset wherein compared to Table 2, BBO is slightly more accurate than the network CNN-6/7 [15]. The results for LAB [24] with boundary information on the AFLW dataset will be shown in Table 6 as well as the results for the pretrained ResNet-50 [15].
Table 4 shows the results of our models in comparison to the state of the art. It can be seen that overall the LAB [24] model performs best on the WFLW dataset with which it was published together. It has to be mentioned that the landmarks on this dataset were annotated so that they always lie on the boundary of the face. This makes the LAB [24] model especially effective on this dataset. In comparison to our models it can be seen that our batch balancing approach proof to be effective especially for the challenging pose dataset. Both models BB and BBO outperform the LAB [24] approach on this challenge. In addition, blur as well as occlusions show to be more accurate using our batch balancing. This has the same reason as for the challenging iBUG images from the 300W dataset. For all approaches in the Table 4 it can be seen that blur, occlusion and pose are the most inaccurate which means that similar images produce the highest loss values.
Validation signal accuracy: Figure 4 shows the normalized error (red) against the normalized validation signal (green) for all landmarks on the datasets 300W, AFLW, and WFLW. We sorted the values ascending based on the normalized error (red) for a better visualization. For the models BBO and BB it can be seen that the validation signal correlates with the error on all datasets. To show the effectiveness of the validity signal to remove inaccurate landmarks, we made an additional experiment on the 300W and AFLW datasets. Table 5 shows the results for our networks by discarding different amounts of landmarks based on the validation signal. This was done by ignoring the landmarks per face with the highest validation signal values. As a baseline we also included the NON model which has no validation signal. Therefore, we selected the 10%, 20%, and 30% of the landmarks per face randomly using a uniform distribution. As can be seen in Table 5 the model NON has only a slight improvment by discarding 30% of the landmarks. The comparison to the models NOBB, BBO, and BB, which improve significantly, shows the efficiency of our validation loss.
Runtime comparison: Table 6 shows the results on the 300W and AFLW dataset together with runtime. For our models the runtime was obtained on a NVIDIA GeForce GTX 1050ti, for LAB [24], ResNet-50 [15], CNN-6 [15] and CNN-6/7 [15] on a NVIDIA GeForce GTX Titan X. As can be seen in Table 6 the fastest model is the CNN-6 [15] with 400fps directly followed by our architecture (333fps). The best results are optained by the model BB discarding 30% of the landmarks per face by using the validation signal. For all landmarks the best result is obtained by LAB [24] with the usage of the ground truth boundary.
7 Conclusion
We proposed a novel loss formulation that allows regression based point estimation alongside with a reliability estimate of the result. This improves the usability of the signal as well as the accuracy of subsequent steps that rely on it. Additionally, the signal can be used for a secondary validation of face detection. To tackle the problem of unbalanced training data in available datasets, we proposed an approach to automatically balance the training data based on the produced loss of samples. The advantage of this approach is that it does not account only for the head pose but also for other challenges and imbalances in the data.
Acknowledgments:
Work of the authors is supported by the Institutional Strategy of the University of Tübingen (Deutsche Forschungsgemeinschaft, ZUK 63). This research was supported by an IBM Shared University Research Grant including an IBM PowerAI environment. We especially thank our partners Benedikt Rombach, Martin Mähler and Hildegard Gerhardy from IBM for their expertise and support.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] A. Bulat and G. Tzimiropoulos, “How far are we from solving the 2d & 3d face alignment problem?(and a dataset of 230,000 3d facial landmarks),” in ICCV , 1 , 4, IEEE (2017).
- 2[2] P. Koppen, Z.-H. Feng, J. Kittler, M. Awais, W. Christmas, X.-J. Wu, and H.-F. Yin, “Gaussian mixture 3d morphable face model,” Pattern Recognition 74 , 617–628 (2018).
- 3[3] X. Zhu and D. Ramanan, “Face detection, pose estimation, and landmark localization in the wild,” in CVPR , IEEE (2012).
- 4[4] J. Wu and M. M. Trivedi, “A two-stage head pose estimation framework and evaluation,” Pattern Recognition 41 (3) (2008).
- 5[5] R. Walecki, O. Rudovic, V. Pavlovic, and M. Pantic, “Copula ordinal regression for joint estimation of facial action unit intensity,” in CVPR , 4902–4910, IEEE (2016).
- 6[6] S. Li, W. Deng, and J. Du, “Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild,” in CVPR , 2584–2593, IEEE (2017).
- 7[7] J. Yang, P. Ren, D. Zhang, D. Chen, F. Wen, H. Li, and G. Hua, “Neural aggregation network for video face recognition.,” in CVPR , 4 , 7, IEEE (2017).
- 8[8] W. Liu, Y. Wen, Z. Yu, M. Li, B. Raj, and L. Song, “Sphereface: Deep hypersphere embedding for face recognition,” in CVPR , 1 , 1, IEEE (2017).