A maximum principle argument for the uniform convergence of graph Laplacian regressors
Nicolas Garcia Trillos, Ryan Murray

TL;DR
This paper introduces maximum principle techniques from PDEs to prove the uniform convergence of graph Laplacian regressors in noisy, manifold-based non-parametric regression, providing new error estimates and insights.
Contribution
It develops a novel maximum principle approach for analyzing graph Laplacian regressors, enhancing theoretical understanding and parameter selection in manifold learning.
Findings
Establishes asymptotic consistency of graph Laplacian regressors.
Provides concrete error estimates for parameter tuning.
Connects Laplacian methods with kernel and k-NN techniques.
Abstract
This paper investigates the use of methods from partial differential equations and the Calculus of variations to study learning problems that are regularized using graph Laplacians. Graph Laplacians are a powerful, flexible method for capturing local and global geometry in many classes of learning problems, and the techniques developed in this paper help to broaden the methodology of studying such problems. In particular, we develop the use of maximum principle arguments to establish asymptotic consistency guarantees within the context of noise corrupted, non-parametric regression with samples living on an unknown manifold embedded in . The maximum principle arguments provide a new technical tool which informs parameter selection by giving concrete error estimates in terms of various regularization parameters. A review of learning algorithms which utilize graph Laplacians,…
Click any figure to enlarge with its caption.
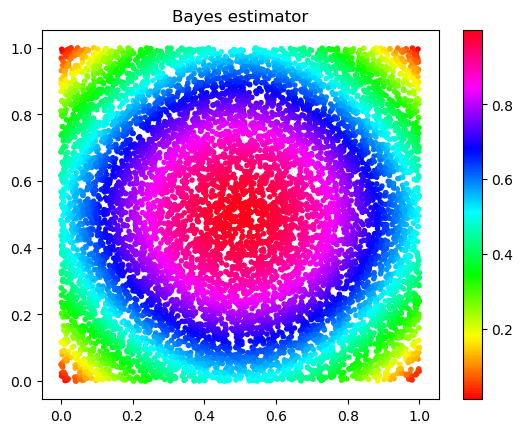 Figure 1
Figure 1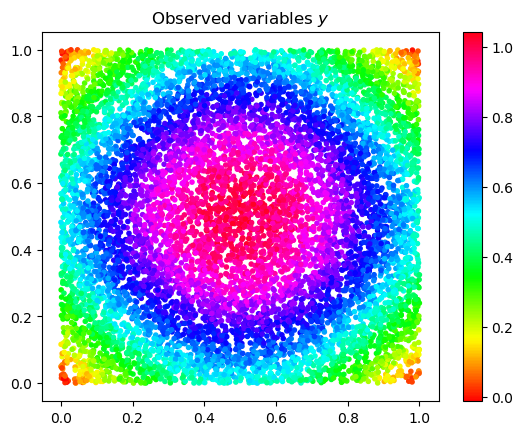 Figure 2
Figure 2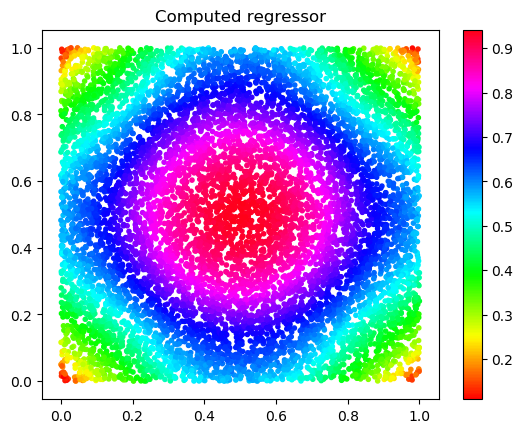 Figure 3
Figure 3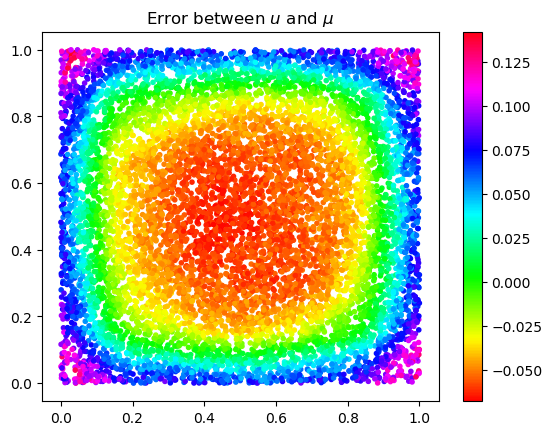 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
A maximum principle argument for the uniform convergence of graph Laplacian regressors
Nicolás García Trillos
Department of Statistics, University of Wisconsin, Madison, Wisconsin, USA
and
Ryan Murray
Department of Mathematics, North Carolina State University, Raleigh, NC, USA
Abstract.
This paper investigates the use of methods from partial differential equations and the Calculus of variations to study learning problems that are regularized using graph Laplacians. Graph Laplacians are a powerful, flexible method for capturing local and global geometry in many classes of learning problems, and the techniques developed in this paper help to broaden the methodology of studying such problems. In particular, we develop the use of maximum principle arguments to establish asymptotic consistency guarantees within the context of noise corrupted, non-parametric regression with samples living on an unknown manifold embedded in . The maximum principle arguments provide a new technical tool which informs parameter selection by giving concrete error estimates in terms of various regularization parameters. A review of learning algorithms which utilize graph Laplacians, as well as previous developments in the use of differential equation and variational techniques to study those algorithms, is given. In addition, new connections are drawn between Laplacian methods and other machine learning techniques, such as kernel regression and k-nearest neighbor methods.
Key words and phrases:
Empirical risk minimization, graph Laplacian, discrete to continuum, non-parametric regression
2010 Mathematics Subject Classification:
35J05, 49J55, 60D05, 62G08, 68R10
*To be published in SIMODS
1. Introduction
In this paper we present new theoretical results on the consistency of solutions to a family of variational problems that use graph Laplacian regularization for trend filtering and supervised learning with noisy labels, and determine scaling limits under which one can provably avoid overfitting as the number of data points grows. In addition, we draw new parallels between the methods studied here and other non-parametric regression methodologies found in the literature. Throughout the paper we highlight the analytical approach that we take in order to establish our high probability quantitative results, and that in particular allows us to study the behavior of solutions to non-linear graph-based equations. This analytical approach provides a new avenue for studying algorithms that utilize graph Laplacians; such algorithms are utilized in a wide variety of learning problems (see Section 3.1 for further discussion)
Given a data set and corresponding noisy labels , the idea in trend filtering is to reconstruct a trend function taking inputs into outputs which closely matches the observed labels. Without further constraints, finding such a function is an ill-posed problem as there are many functions that will respect the observed data, most of which should be intuitively discarded as they overfit the observations . To overcome this overfitting issue and to turn an ill-posed problem into a well-posed one, a popular idea used in applied mathematics [60] and statistics [66, 38] is to introduce a functional (a “regularizer”) which penalizes “irregular” functions, and to solve an optimization problem of the form
[TABLE]
where represents a loss function measuring empirical risk. In a classical statistical setting the loss function is dictated by the noise model, but in general, the function may simply be interpreted as a mismatch function between the observations and the regressor . On the other hand, while the choice of regularizer is largely open ended, intuitively it should be selected to enforce “smoothness” with respect to some underlying geometry (informally, one wants to force the solution to not change too much by making small perturbations of the input).
For generic set of points in Euclidean space, a popular choice of regularizer is the squared norm of a reproducing kernel Hilbert space (RKHS) as discussed in [4]. This approach is analogous to the use of ridge regression in classical statistics, and in fact can actually be rigorously cast in this way after transforming the data through a map canonically induced by the reproducing property of a kernel (see [53]).
As elegant and convenient as the use of RKHSs may be, a generic choice of kernel to be used within the above regularization procedure will typically be oblivious to the specific geometric configuration of a data set . This is particularly problematic in settings like that of semi-supervised learning, where one hopes the underlying geometry of the data set reveals information that the limited number of available labels can not. Motivated by this discussion, several authors, including [70, 57, 4, 1], consider regularizers which exploit the intrinsic geometric structure of a data set. In their set-up, a data set comes with an additional weighted graph structure , where represents an similarity matrix and which intuitively captures the geometry of .
In this paper we study intrinsic regularization in the context of trend filtering and fully supervised learning. As in [57] the optimization problems we are interested in take the form
[TABLE]
where we have made the dependence of the regularizer on the graph explicit. The empirical risk that we consider here is directly linked to the log-likelihood of an assumed distribution for the noise terms in an additive model of the form
[TABLE]
where is some underlying ground-truth function. Notice that the assumed noise distribution may not be the same as the actual noise distribution which we will denote as . The standard choice for is the square loss corresponding to a Gaussian model, and we will give particular attention to this choice later on. On the other hand, the regularizer that we will focus on in this paper is the graph Dirichlet energy defined by
[TABLE]
The relevance of the graph Dirichlet energy is due to its close connection to the linear in graph Laplacian
[TABLE]
indeed, it is straightforward to show that
[TABLE]
The graph Dirichlet energy is a special choice of intrinsic regularizer with several properties that will be discussed throughout the paper. Other sensible intrinsic regularizers are the graph -Sobolev norms (obtained by changing the square in the above energy with a -th power) for some (and in particular when where is the intrinsic dimension of the data set; see [22]). The practical use of Laplacian regularization (or similar variants) was proposed some years ago [57], but has recently received new attention in the statistics and machine learning community [52, 59, 67]. Bayesian approaches to learning where graph Laplacians are used as covariance matrices in order to define Gaussian priors that exploit the intrinsic geometry of the data set have been considered in [70, 41, 5]. We notice that from a Bayesian perspective, the solution of problem (1.1) is the MAP estimator (maximum a posteriori estimator) for , in a model where the unknown variable is assumed to have a Gaussian prior distribution with mean zero and covariance matrix equal to times the graph Laplacian, and where the observations depend on according to an assumed additive noise model of the form (1.2) with noise distribution .
Going back to our problem (1.1), we notice that the graph Laplacian appears explicitly in the optimality conditions satisfied by the minimizer of (1.1), namely
[TABLE]
where . Equation (1.5) can be interpreted as an elliptic graph partial differential equation (PDE), which is linear in its highest order term, i.e. the term that involves “derivatives” of (in this case the graph Laplacian ), but that overall is not linear unless the loss function is quadratic (so that its derivative is linear). The most appropriate terminology for such an equation is semilinear equation. This graph PDE, which emerges in a fully supervised learning setting, is nothing but one of many examples in the family of graph PDE-based machine learning methodologies. Indeed, there is a large family of machine learning methodologies for supervised and unsupervised learning that, at their core, are described by a graph PDE involving the graph Laplacian, the fractional graph Laplacian (i.e. powers of the graph Laplacian), or the -graph Laplacian, followed by an extension step (in supervised settings) or a clustering step (e.g. -means after the embedding step in spectral clustering). Many of these approaches will be mentioned in section 3.1 below. This paper aims at studying the statistical properties of solutions to (1.5), with an emphasis on the analytical techniques that allow us to handle the nonlinear term in (1.5). More concretely, we aim at answering the following questions:
- i)
What is the behavior of the solution to (1.1) (alternatively solutions to the graph PDE (1.5)) as the number of data points goes to infinity, when the data set is assumed to be a collection of i.i.d. samples from a distribution supported on a -dimensional curved manifold (here we intuitively think of , although this will not be important for our analysis), the graph is obtained from the data set by giving high weights only to points that are within Euclidean distance of each other, and the labels are noisy versions of a hidden trend function ? 2. ii)
How should scale with so that the solution to (1.1) converges to the Bayes regressor (i.e. the underlying label trend) in the large data limit , and in particular so that the regression procedure does not overfit the data?
To answer these questions we exploit properties of the graph Laplacian, and in particular a maximum principle argument at the graph level to prove that the solution of (1.5) converges uniformly towards the solution of an analogous homogenized partial differential equation on with probability one (homogenized in and ). We provide explicit rates of convergence with high probability in terms of the number of samples , the parameter controlling data connectivity in the graph, and the parameter controlling the strength of regularization; our rates turn out to be essentially minimax optimal (see the discussion at the end of section 3.1.2) . The proposed maximum principle (see Proposition 2.2 below) allows us to handle any sufficiently smooth, strongly convex . We also provide a characterization for how must scale with in order to recover, in the large data limit, a modified trend which depends on and on the function . Indeed, unless the function is quadratic (i.e. is linear), in the regime , the trend may not be recovered, unless further assumptions on the distribution of the noisy labels are imposed. We provide uniform rates of convergence towards the modified trend. Stated in another way, we provide quantified asymptotic consistency estimates for this class of non-parametric regression algorithms. Our estimates will be decomposed into sample error (analogous to variance) and approximation estimates (analogous to bias). Our arguments to bound the sample error are essentially as difficult for the quadratic as for the general (and the maximum principle and monotonicity of will be key to show this). For the approximation part, we will separate the analysis for the quadratic case from the general case, as a richer set of tools is available in the quadratic case.
We would like to highlight that our results are novel with respect to the existing literature in several regards that we summarize below.
- •
We show that the solution to (1.1) (alternatively (1.5)) converges towards the solution of an analogous limiting variational problem. This contrasts with several results in the literature that establish a connection of the graph Laplacian and the negative Laplace-Beltrami operator from the point of view of pointwise convergence, where one fixes a regular enough function and establishes convergence rates for
[TABLE]
Some of these results include [3, 55, 37, 16, 31]. We remark that such results do not allow one to immediately deduce convergence of solutions to optimization problems on graphs. In this paper we show how one can bootstrap the pointwise consistency estimates to obtain convergence of solutions to optimization problems on graphs that involve the graph Laplacian, using ideas from PDE theory. In particular, the regularity of the solution to a limiting PDE will be important when using the pointwise consistency of the graph Laplacian. In addition, a very careful construction of upper and lower barrier functions for the solution of (1.5), and the use of a maximum principle at the graph level will be crucial tools in order to handle the randomness in the data points and their noisy labels. For more details see Section 2.2.
- •
While there are many recent results studying the consistency of solutions to optimization problems on graphs towards solutions to variational problems and PDEs on (see Section 3.1.1 below for a discussion), most of these results do not obtain rates of convergence. Here we use the extra structure of the graph Laplacian to obtain rates for the uniform convergence of solutions to (1.5). We emphasize that we obtain uniform (i.e. ) rates of convergence instead of -type or other type of averaged error, as it is most commonly found in the literature. We will compare our work with the few exceptions to this general absence of quantitative estimates, which are usually obtained with different assumptions from ours, particularly with regards to the next point.
- •
In our set-up the labels are assumed to be noisy versions of a hidden trend function so that
[TABLE]
We show that provided that the regularization parameter in (1.5) does not decay too fast to zero (and we characterize this precisely), the solution to (1.5) converges to some (modified) trend function in the limit. In particular, we show that graph Laplacian regularization is indeed capable of removing noise and prevents overfitting.
- •
We connect the Laplacian regularization stemming from (1.5) with other non-parametric methodologies for regression based on local averaging, and which adapt to the local geometry of the underlying manifold (e.g. -NN regressors). This discussion is presented in Section 3.1.2 below.
- •
We emphasize that our approach allows us to handle loss functions that are different from quadratic. As mentioned earlier, from a statistical point of view this gives us some flexibility in the assumptions made on the observations. From a technical point of view, the effect that different s have in the resulting graph PDE is the difference between having a linear PDE (in case is quadratic) and having a non-linear PDE (if is not quadratic) where in principle the analysis is more difficult.
We notice that the observed data affects the equation (1.5) in two different ways: first, the determine the graph Laplacian and in this way the “differential” operator that we study is random, and second the noisy label observations affect the right hand side of the equation. At a high level (1.5) can be thought as a numerical scheme for solving the limiting continuum PDE that we derive. However, the convergence analysis of such a numerical scheme is not standard in the literature, given the randomness in both the approximating Laplacian (in our case the graph Laplacian) and the noisy right hand side. It is precisely the presence of the regularizer that removes noise in the limit and helps to prevent overfitting. In summary, when going from (1.5) to the limiting PDE, there are two parts in the equation that get simultaneously homogenized: on the one hand the graph Laplacian behaves like a Laplacian operator on , and on the other, the noisy labels homogenize to some trend function.
We now outline the remainder of the work. In Section 2 we give a precise description of the problem and main results. In Section 3 we review related literature, comparing our results and techniques with other work. In Section 4 we then present the proofs of our results.
2. Problem set-up and Main results
2.1. Set-up
We consider an -dimensional smooth, compact, manifold embedded in with no boundary. A significant body of work studies how to estimate given a family of points (see e.g. [43]); for the purpose of this work we will treat as a priori known. Throughout the paper we will denote by the Euclidean distance in and by the geodesic distance of two points in . We will denote by the injectivity radius of the manifold . We recall that the injectivity radius of a manifold is defined as the maximum radius for which the exponential map defines a diffeomorphism for all (see [20]). In the remainder we use to denote balls in , for balls in with the geodesic distance, and finally for balls in . Finally, we will denote by the volume form of and, after rescaling as necessary, we will assume that the volume of is equal to one.
In the remainder, and unless otherwise stated, we will assume that are i.i.d. samples from the uniform distribution on . We let be an unknown trend function and assume that the labels are obtained by
[TABLE]
where the are identically distributed with distribution , are independent of each other and from the , and satisfy
[TABLE]
where is a fixed constant specifying the noise level. We have chosen to focus on the bounded noise case in order to simplify some of the technical arguments, in particular the construction and bounds of the barrier functions and in the proof of Theorem 2.1. We believe that many of the arguments and results could be modified to accommodate other noise models but we do not pursue it here.
We assume that the loss function is a smooth function which satisfies and for all ; in some references this is called strong convexity. In particular, this implies that is a strictly monotone function, and that for all and for all .
All the theorems presented in Section 2.2 are stated in the setting described above, but in Remark 2.6 we write precisely how they should be restated to cover a more general setting. No difficulties arise when extending these results, other than having to deal with more cumbersome notation and longer expressions.
By way of notation, , where is the space of continuous functions equipped with the supremum norm, and where when write the we mean that we are summing the norm of all of the mixed derivatives of order . For , space of Hölder continuous function are continuous functions equipped with the norm
[TABLE]
The space is given by the norm . For any natural number , the function space is the defined by the norm .
2.1.1. Graph construction and graph PDE
Given we construct a geometric graph as follows. We let be a non-increasing function which is only non-zero on . We further assume to be Lipschitz continuous and normalized so that
[TABLE]
We define the constant
[TABLE]
where is the first coordinate of . Between every two vertices we assign the weight
[TABLE]
Here the in the denominator is a rescaling so that the weights at each vertex sum to approximately one, while the in the denominator is chosen so that . The weighted graph is a geometric graph representing the proximity of the sample points in . We have rescaled the weights for convenience (in taking limits as ).
2.1.2. Limiting variational problem and PDE
At the continuum level, we first define an analogue of the graph regularizer . The Dirichlet energy of a function is defined as
[TABLE]
whenever is in the Sobolev space . Also, for a smooth function we define the elliptic operator as
[TABLE]
i.e. the negative of the Laplace-Beltrami operator on . It is straightforward to show (see Section 4.1) that the Euler-Lagrange equation associated to the variational problem
[TABLE]
is the PDE
[TABLE]
Equation (2.5) is the continuum “homogenized” analogue of the graph PDE (1.5). Existence and uniqueness as well as regularity properties of the solution to (2.5) are discussed in Theorem 2.3. We remind the reader that is the actual distribution function of the label noise.
When passing from the graph PDE (1.5) to the PDE (2.5), we notice that there are two terms that get homogenized. On the one hand, as more feature vectors are available, the graph gets denser, and the graph Laplacian starts behaving like . On the other hand, as more labels are acquired, we would like to obtain homogenization of the fidelity in (1.1). In the next section we present our main results relating the solutions to these two equations, i.e. (1.5) and (2.5).
2.2. Main results and discussion
Our first main result establishes probabilistic error bounds for
[TABLE]
where is the solution to the graph PDE (1.5) (with the graph as defined in Section (2.1.1)), and is the solution to (2.5). That is, we estimate the difference between the data dependent and a homogenized function .
Theorem 2.1**.**
*(Sample error)
Suppose that is the solution to the elliptic graph PDE (1.5) where is defined in (1.4) and is the solution to the PDE (2.5). Assume that . Then for any , with probability at least ,*
[TABLE]
where the constants depend only on and .
One of the implications of the above result is that for fixed, it is possible to tune in terms of appropriately to deduce asymptotic uniform convergence of solutions of (1.5) towards solutions of (2.5).
One of the main tools used to establish Theorem 2.1 is the following maximum principle at the graph level. As the proof is straightforward, we present it immediately.
Proposition 2.2**.**
(Maximum principle at the graph level) Let be a strictly increasing function and let be an arbitrary function defined on the point cloud . Suppose that the function satisfies
[TABLE]
Then,
[TABLE]
i.e. the function is non-positive.
Proof.
Notice that to prove that the function is non-positive, it is enough to show that where is the index of the point at which is maximized. Now, we notice that at the point we have
[TABLE]
It then follows that
[TABLE]
or equivalently,
[TABLE]
Since the function is strictly increasing, we conclude that , which concludes the proof.∎
This proof is an adaptation of the proof of the maximum principle in the continuum case (see e.g. [23] p. 344), with the modification that we have replaced differential operators with derivatives. We also have used the fact that we have a strictly monotone lower order term, which is often not the case in the classical setting.
Theorem 2.1 is proved by showing that the difference of the functions and (interpreting as its restriction to ) lies between two functions (referred to as barrier functions) which are uniformly close to zero, i.e.,
[TABLE]
with
[TABLE]
Up to some minor modifications, the functions take the form
[TABLE]
where is a constant conveniently chosen so as to ensure that the functions and satisfy the inequality required for the maximum principle at the graph level to apply with (which then implies (2.6)). We remind the reader that represents pointwise evaluations of the limiting PDE (2.5), are pointwise evaluations of the limiting trend function, and are the values of the noise. In order to guarantee that can be picked to be small (so that are indeed uniformly small), we need an estimate for the difference between and where is the solution to (2.5). Such pointwise estimate relies strongly on the regularity of the function . The necessary regularity for the function in turn follows from the regularity theory of solutions to elliptic PDEs (see the last part of Theorem 2.3 below). Apart from the pointwise estimates , the other probabilistic estimates that we need are used to control the expressions that appear when we apply the graph Laplacian to the functions and . After some cancellations and standard concentration inequalities, these remaining terms can be shown to be small. We emphasize that it is precisely our convenient construction of the barrier functions , and the structure of the graph Laplacian, which ultimately allows us to handle the randomness in our problem, and bootstrap basic pointwise consistency results into convergence rates for solutions to optimization problems on random geometric graphs.
After establishing error estimates for the difference between and , we obtain estimates for the difference between and a modified trend defined implicitly by
[TABLE]
The function is the solution to (2.4) when the regularizer has been turned off (i.e. when ). Notice that when the loss function has the form the modified trend coincides with . This is also the case for general when the noise distribution is assumed to be symmetric. What is more, if the actual noise distribution coincides with the assumed noise distribution then . To see this notice that in that case
[TABLE]
which implies that if we take , then indeed solves (2.7).
The following result is obtained using tools from the theory of PDE.
Theorem 2.3**.**
*(Regularity and approximation error)
Let be the solution to (2.7). Then, there exists a unique which solves the PDE (2.5). Furthermore, for sufficiently small, this function satisfies*
[TABLE]
where for . Furthermore, assuming that then
[TABLE]
where here is independent of .
We recall that the definitions of these norms is given in Section 2.1. We can combine Theorems 2.1 and 2.3 and deduce the following error estimates between our regression function constructed by solving 1.5 and the modified trend .
Theorem 2.4**.**
Under the same assumptions in Theorem 2.1 and using the same notation there as well as that in Theorem 2.3, with probability greater than , we have
[TABLE]
In particular, choosing of order one and we have that with probability larger than we have .
We note that as long as then the previous theorem gives asymptotic consistency. We emphasize that this theory provides clear asymptotic ranges of parameters for which consistency is achieved, and can be used to identify ranges of parameters where overfitting does not occur in the large limit. In particular, taking to be of order one, and for some large enough constant we obtain, with high probability, an overall error of estimation of
[TABLE]
which is known to be essentially minimax optimal for the recovery of the trend function. We will discuss more on this in section 3.1.2.
One can cast the estimates in Theorems 2.1 and 2.3 in terms of sample error and approximation error estimates in the following sense: the first theorem gives an estimate on the random variation (in an norm) one sees when comparing the solution of the (random) optimization problem (1.1) and the associated mean or homogenized problem (2.4). The second theorem gives an estimate between the solution of the homogenized problem (2.4) and the Bayes regressor, or in other words it provides an estimate on the bias induced (in the homogenized limit) by the regularizing term.
We conclude this section by making a few remarks of a technical nature.
Remark 2.5**.**
Our results can be generalized in a straightforward way to the case where the trend function is smooth everywhere except on a regular dimensional discontinuity set . In such case we can obtain similar error bounds for the difference between the solution to the graph PDE and the solution to the continuum PDE. Such error bounds are uniform away from the discontinuity set . The reason for this is that most of our estimates are local, and even those that are not, only involve averaging at the length scale . It is not clear how to utilize our techniques, which are strongly grounded in the theory of elliptic PDE, to settings where the trend function is highly irregular.
Remark 2.6**.**
[A more general statistical model] As was mentioned in Section 2.1, although we state our main results assuming the data to be uniformly distributed in and the to be identically distributed, it is completely straightforward to extend them to a more general setting. In particular, one can suppose that
[TABLE]
where are samples from a joint distribution with a smooth marginal density for denoted by , conditional distributions for the noise, which vary smoothly in , of the form
[TABLE]
which are further assumed to be centered and to have bounded support. Then, Theorems 2.1,2.3, and 2.4 continue to be true if we now let be the solution to the PDE
[TABLE]
where
[TABLE]
and if we let be the function that satisfies
[TABLE]
for all .
In this paper we have also assumed the noise in labels to be bounded. While our current proofs, in particular the construction of the barrier functions and , do not allow us directly to drop this assumption, they do serve as a basis for future improved results. In a similar way, it is likely that the assumptions we have made on the loss function can be relaxed further.
Remark 2.7**.**
[Constructing out of sample regressors] Since the regression function obtained by solving (1.5) is only defined at the data points , one needs a mechanism to extend to the whole in order to use it for prediction. A simple extension mechanism proposed in Chapter 5 in [70] is defined as follows: for an arbitrary we consider
[TABLE]
where the is the Voronoi tessellation in induced by , that is,
[TABLE]
We use the above definition for points that belong to a single Voronoi cell, and define to be the average of the associated to the cells that belongs to. In other words, is the -NN extension of .
With the bounds between and that we have derived in our main theorems one can now show that is uniformly close to when restricted to . Let us outline the argument. Take for simplicity a point which belongs only to . Then, the triangle inequality implies that
[TABLE]
*We notice that the term is controlled in Theorem 2.4. In turn the diameter of Voroni cells constructed from random samples can be controlled following [19]. *
Remark 2.8**.**
One direction of research which is worth further exploration is to study how these ideas can be used to address similar questions to the ones explored in this paper in the context of graph models different from geometric graphs. An example of such a model is the stochastic block model where points have no geometric meaning and weights are determined randomly based on a probabilistic rule. We note that large behavior of the spectra of graph Laplacians for graphs generated from a stochastic block model have been studied in [50].
3. Literature review and comparison of techniques
In this section we provide a review of relevant literature, beginning with statistical and machine learning literature related to Laplacian regularization. We then discuss recent analytical advances related to graph-based regularization. We then provide some comparison and discussion between the methods we study here and kernel and k-NN methods. Finally, we give a comparison of our analytical results with purely variational results, and demonstrate that the maximum principle method obtains more precise bounds.
3.1. Laplacians, geometry, and regularization
There is a significant literature related to the use of Laplacian in statistical problems. Here we complement (in a non-exhaustive way) the discussion started in the introduction.
The use of derivative penalties in parametric regression was advocated in the work of Wahba [66]. In that context, one seeks for a polynomial spline of specified order which interpolates observed data points, and which minimizes some derivative penalty, such as the continuum Laplacian. Around 2000, a significant body of research developed the use of Laplacians to capture intrinsic geometry in statistical tasks. Often this work was carried out with the aim of designing methods which can leverage geometry to handle settings which are not fully supervised, or where there is an active component to learning. For example, [8] investigated the use of density weighted regularizers in non-parametric regression problems. [4] uses Laplacian eigenfunctions to conduct semi-supervised learning (so does [69] and [70]). [2] uses the Laplacian to construct dimension reduction algorithms. [47] introduced spectral clustering, which uses the first non-trivial eigenvector of the Laplacian to construct meaningful clusters; theoretical consistency of these types of algorithms was studied in [65]. An algorithm linking graph cuts and spectral clustering was proposed in [40]. [17] Studies a method which uses Laplacian regularized regression to fit labeled points, and then k-NN regression on any unlabeled or new data points. [57] studies the use of the Laplacian to construct reproducing kernels on graphs. We remark that much of this work focuses on graph-based algorithms. We also remark that much of this work was developed simultaneously with kernel methods, and the two are often mixed in these works.
Another related body of work focuses on diffusion maps and manifold learning. These techniques describe the use of Laplacian eigenfunctions as a powerful parametric family which encapsulates underlying geometry. Important early works establishing theory for this topic include [15] and [16].
More recently, there has been renewed interest, especially in the statistics community, in utilizing derivative and difference-based methods on graphs in order to conduct regression tasks. In particular, trend filtering [59, 67] seeks to conduct regression tasks on a graph with an added regularization term based on function differences. This regularization term is permitted to take different forms in trend filtering, including powers of the Laplacian or TV norms. While the setup is not identical to ours, in particular due to the use of higher-order differences and -type regularizers, it is very much in the spirit of the model that we study here. The use of PDE type methods to analyze these more complicated trend filtering models is the topic of future work. In a related work, [32] studies the robustness of semi-supervised methods, and proposes using sparsity type penalties on graph derivatives similar to those from trend filtering. [24] and [34] study models for active learning which build upon the graph Laplacian framework in order to identify regions where labels should be acquired.
In addition, there has recently been a broader interest in Dirichlet (and more general derivative based regularization terms) in order to conduct learning tasks. For example, [48] studies the use of Laplacian eigenvalues on graphs in the context of Dirichlet partitions to perform generalized clustering. Bayesian inverse methods have also utilized Laplacian regularization in [26].
3.1.1. Analysis of large sample limits of variational problems on graphs
In the past few years there has been a rapid development of a body of work borrowing ideas from the calculus of variations and PDE theory to study large sample asymptotics of optimization problems on geometric graphs closely connected to machine learning tasks. The motivation is clear: to a large extent, most of the graph-based methods for learning that are in existence can be phrased as solving either a variational problem on a graph or a graph PDE. In many instances these graph PDEs involve the graph Laplacian. Said works include the study of consistency of Cheeger and ratio graph cuts on graphs [28], consistency of graph Laplacian spectrum [61], and supervised and semi-supervised learning [11, 21, 25, 26]. In the previously listed papers, the convergence of discrete solutions to continuum counterparts is studied in the -metric introduced in [27] and later further studied in [58]. The topology can be thought as convergence after suitable matching of the ground truth measure generating the data set and its empirical measure. The consistency of the optimization problems is studied using variational methods, and in particular the notion of -convergence (a.k.a. epi-convergence). This is a powerful notion used to establish asymptotic convergence of minimizers of optimization problems (especially in highly non-convex settings), but it does not offer direct ways to obtain rates of convergence.
Among the papers previously listed, the paper [25] by the authors is closely connected to this paper. There we consider an optimization problem of the form:
[TABLE]
which is the version of the problem we study here. As is well known in the image analysis community the total variation functional (the first term in the above objective function) enforces sparsity of derivatives [12] and hence the above optimization problem seems more appropriate for the purposes of classification when binary labels are available (in our notation ). In that paper we study the regimes of (and how the graph connectivity must scale with ) so as to recover in the large limit the Bayes classifier with probability one. No rates of convergence are provided.
The paper [56] is also related to our work. There, -Laplacian regularization for semi-supervised learning is studied. The optimization problem takes the form:
[TABLE]
subject to
[TABLE]
where is held fixed as . The authors are able to show that when is greater than the intrinsic dimension , solutions to the -Laplacian regularization problem converge uniformly to a continuum counterpart, as , which depends on the labels (in other words the labels are not forgotten in the limit). The uniform convergence is proved by bootstrapping the convergence obtained through variational methods by controlling the “oscillations” of the discrete minimizers at a certain convenient length-scale.
The paper [10] is very closely related to [56] and to this paper. In particular, it obtains analogue results to [56], but using a PDE approach rather than a calculus of variations one. A maximum principle at the graph level analogous to the one that we use in this paper is a crucial tool that is later used in conjunction with general and flexible results on consistency of viscosity solutions to elliptic PDEs. In this paper we take a PDE approach as in [10], and specifically use a maximum principle, to obtain rates for the uniform convergence of graph Laplacian regressors towards continuum counterparts. Whether similar results to the ones we present here can be obtained for regressors obtained using other regularization terms different from the graph Dirichlet energy is a question that we believe is worth exploring in the future.
Another very recent work which is related to ours is [54]. In that work the authors consider semi-supervised learning with Laplacian smoothing (with hard label constraints), but without any label noise (in particular, the labels are evaluations of a function). That paper establishes convergence rates which are analogous to ours, using similar technical tools (i.e. a maximum principle, but with boundary data). The semi-supervised aspect of their work is closely related to the harmonic extension problem (see [46] for additional discussion on the harmonic extension problem in machine learning). We emphasize that the noisy labels that we consider here are not covered in their analysis and are not trivial to handle: see the proof of Theorem 2.1 and the discussion in Section 3.2 for further information.
3.1.2. The linear case and connections to -NN regressors and other local averaging procedures
Here we draw a connection between the graph Laplacian regressor obtained by solving (1.5) and the classical -NN regressor. To do this, we will focus on solutions of Equation (1.5) when . As we will see, graph Laplacian regularization with squared error loss can be interpreted as a local averaging procedure, where the “locality” is defined in terms of the intrinsic geometry of the graph, which in turn approximates the geometry of the underlying manifold .
Let us first briefly recall the definition of the -NN regressor: For a , with , we define to be the set of nearest neighbors of in the data set . The -NN regressor is then defined as
[TABLE]
The use of local averages in non-parametric regression goes as far back as the work [62], -NN regression being a special case of this general idea. The book [35] presents a very complete picture of many non-parametric regression techniques and dedicates a whole chapter (Chapter 6) to -NN regression. Asymptotic properties of -NN regressors have been a topic of investigation for several decades see [35] and the paper [18] where convergence towards a trend function is proved in a very general setting. More recent results like [42] prove uniform convergence towards a trend in a quite general setting where, in particular, the intrinsic dimension of the underlying ground-truth may vary; as a byproduct -NN regression is shown to adapt to the local geometry of the underlying model. The paper [13] is closely related to [42], but studies the classification problem instead.
We now show that when is quadratic, the graph Laplacian regressor obtained by solving (1.5) can be interpreted as a local averaging procedure, where now the averaging is with respect to the heat kernel on the graph; for simplicity we take . Indeed, in this case the solution to the graph PDE (1.5) can be explicitly written as:
[TABLE]
The fact that is self-adjoint and positive semi-definite allows us to use the spectral theorem and write:
[TABLE]
Since and commute we get:
[TABLE]
where in the final step we have made a change of variables. From this formula we can conclude a couple of things. First, we notice that the function is simply the solution to the heat equation (on the graph) with initial condition evaluated at time and can be written as
[TABLE]
where is the heat kernel on the graph at time . One can then show that the function is non-negative and moreover that . From this it follows that the function is obtained by computing a local average (at length-scale ) of around each point . On the other hand, since the function is a probability density on , we conclude that the graph Laplacian regressor is nothing but an average of averages of over all length-scales . The weight given to each length-scale is naturally determined by the parameter , and in particular if is small, more relevance is given to more local length-scales, whereas if is large, more relevance is given to global length scales. Notice that the structure of (3.2) is analogous to what we would obtain if we averaged the different -NN regressors from (3.1) over the value of to produce a regression function of the form:
[TABLE]
where in the above is some p.m.f. over .
So far we have seen that the regressor that stems from graph Laplacian regularization with squared loss is obtained by averaging over local averages of the labels at different length-scales, and that these local averages use the intrinsic geometry of the graph (summarized in the graph heat kernel). Since in our setting the data is assumed to be sampled from a smooth manifold , it is to be expected that the graph heat kernel actually behaves like the heat kernel on , . Furthermore, for small values of one has (neglecting constants) that (see, for example, [63] or Chapter 15 in [33]), where is the geodesic distance on the manifold . In particular, for small values of the regression function is expected to behave like
[TABLE]
which can be interpreted as a bandwidth average of local regression kernels, where the local regression kernels average over geodesic distances. The bottom line is that graph Laplacian regression (at least in the linear case) is very closely related to other local averaging regression procedures like -NN regression and other methodologies that use geodesic distances to define nearest neighbors for label propagation [44, 70].
We would also like to notice that (3.2) can be written in the form
[TABLE]
Written in this form, this construction of can be seen as a modified Nadaraya-Watson regression[45, 68], also known as kernel regression. Indeed, to construct the Naradaya-Watson regressor one typically picks a kernel function , and defines . Here various choices of the kernel function are permitted, such as a sharp cutoff, or the Gaussian. One can also, in principle, permit the kernel to vary in (e.g. using the heat kernel after a fixed time on a manifold or graph [4]), and here we see that the Laplacian regression we study in this work can be cast within that framework. This can also be seen as a version of RKHS regression, without any regularization. This method is still a topic of research; for example recent works [51, 64] study kernel regression over graphs.
We also pause here to offer a comparison of performance guarantees between the regression procedure that we study and that of k-NN regression studied in [42]. In that work, under an identical regression model, it is shown that k-NN regression achieves, with high probability and ignoring logarithmic factors, the same uniform convergence rate towards the trend , with a lead constant that scales as the square of the Lipschitz constant of . It is also shown in that work that such a rate is nearly minimax optimal, in the sense that no estimator can achieve a better rate than . Given the connection between k-NN and the Laplacian regression methods discussed here, it is not surprising that the two have essentially the same convergence rate, as we rigorously show in our main result 2.4 (and the discussion below it).
It is indeed not so surprising that for small both -NN and graph Laplacian regularization (for quadratic ) are so similar. In both cases the whole idea is to average “enough” so as to remove the noise, and essentially any local averaging procedure should recover the underlying trend. However, as has been discussed throughout this paper, the Laplacian regularized supervised regression problem studied here belongs to a larger family of regularized graph-based algorithms for both supervised and unsupervised learning. One main thesis of this work is that developing tools for the fully supervised regime will facilitate the study of other, less supervised, algorithms that utilize graph Laplacians, which are currently not amenable to analysis using standard techniques for supervised methods.
3.2. PDE approach vs. Variational approach
In this section we illustrate the advantages of the PDE approach that we take in this paper and contrast it with a direct variational approach. In a variational approach one essentially uses the strong convexity of the functional to be minimized in (1.1) to derive convergence rates for minimizers. To illustrate this idea, we sketch the proof of the following proposition.
Proposition 3.1**.**
Let , and consider the variational problem
[TABLE]
Then the minimizer of (3.3) satisfies , where here we abuse notation and let represent pointwise evaluation of at the points in the data set . Furthermore, if is the minimizer of (1.1), with the same choice of , then . In turn, we have that . In particular, optimizing in we find that .
Sketch of proof.
To begin, various recent results [29, 9] allow one to show that, with high probability, as long as is sufficiently smooth. This, in turn, implies that (w.h.p.), which proves the first bound.
For the second bound, recalling the definition of in (1.1) , by using the optimality of and , summation by parts and 1.5, we compute that
[TABLE]
An identical argument, but for , yields that
[TABLE]
Adding the right hand side of (3.7), which is positive, to the inequality (3.4) then yields
[TABLE]
At this stage, one notices that the right hand side is composed of terms which are inner products between (which averages to zero at relatively small scales since and the are independent), and the functions , which enjoy of some degree of regularity. In the spirit of [25], we then use a local averaging procedure to bound these terms. In particular, given some ball , if we let be the average of over that ball, then we may write
[TABLE]
The second of these terms we may control with high probability using concentration estimates, as long as is not smaller than , introducing some error that is in the order of ( as we expect to have roughly terms in the sum). On the other hand, for the first term we may use the Poincaré inequality (which holds as long as scales appropriately with ; see [29]) to deduce that
[TABLE]
By then using the Cauchy Schwarz inequality we obtain that, w.h.p.,
[TABLE]
By using a partition of unity (details of this type of argument can be found in [25]), we may then deduce that w.h.p.
[TABLE]
An analogous bound holds for . By noting that is order one, we may deduce that . Similar logic applied to implies that . Supposing that (the smallest permissible scaling), we then have that . Strong convexity of in then implies that , which proves the desired bound.
∎
We remark that the previous proof provides an type estimate, and one would need to use the discrete maximum principle to upgrade to uniform convergence. Such techniques are well-known in the numerical analysis community, see e.g. [14]. The approach presented above is elegant and straightforward, and requires rather minimal assumptions on regimes for . However, the rates that it proves are far worse than those that we prove here using the PDE approach. In particular, the Poincaré type argument, which is used to handle the noisy labels, is overly pessimistic. In addition, the proof is elegant only when is squared loss, but the details to make a similar argument work for more general loss functions are more complicated. One of the key ideas in this paper is that by leveraging the structure of the graph Laplacian (namely the maximum principle), one is able to provide much better theoretical guarantees.
4. Proof of Main results
In this section we provide proofs of the main results. In particular, in Section 4.1 we provide a simplified proof of Theorem 2.3 for the case with quadratic loss, deferring the general argument to an appendix. In Section 4.2 we use our maximum principle at the graph level in conjunction with two technical lemmas (where our probabilistic estimates are presented) to prove Theorem 2.1.
4.1. PDE estimates
An important starting point in studying minimizers of (1.1) is to understand properties of minimizers of (2.4). The continuum problem (2.4) has a rich history: namely solutions of this variational problem are known to be highly regular. One of our goals in this work is to show that the tools used to study partial differential equations, including regularity theory, are quite helpful in analyzing regularized regression problems. However, establishing regularity estimates is a rather technical aspect of PDE theory. Hence, here we provide a simple proof for the case where the risk function is quadratic (and hence the necessary conditions are linear), and provide a more detailed proof for the non-linear case with some extended discussion in an appendix.
Proof of Theorem 2.3 in the case with quadratic loss.
In this linear case, we may express the solution of the Euler-Lagrange equation in the form
[TABLE]
which in turn can be written as:
[TABLE]
Here we are using the spectral theorem for . It follows that
[TABLE]
where is the heat kernel on (at time ). In particular,
[TABLE]
where the last inequality follows using properties of the heat kernel in , namely Gaussian upper bounds for the heat kernel on a smooth compact manifold (see, for example, [63] or Chapter 15 in [33]). The bottom line is that
[TABLE]
where is the Lipschitz constant of (which is finite since we have assumed that ; see the statements of Theorem 2.3 and Theorem 2.1).
On a heuristic level, one can argue for the remaining bounds simply using the PDE: As , and as , we can then deduce that . Similarly, we formally have that , and hence . Classical theory, as discussed in the appendix, can be used to infer a bound from a bound on and a bound from a bound on . An interpolation argument gives the desired bound of order . Rigorously justifying these types of arguments requires that the PDE hold in a classical sense, which is often not clear a priori. More details on how one infers classical regularity of the solutions of variational problems is given in the appendix.
∎
We note that if the heat kernel were given by a convolution, then we could pass derivatives directly to and from formula (4.1) one could immediately argue that . It’s likely that such bounds still hold in our case, but they were not necessary for our purposes and so we do not pursue them further.
4.2. Probabilistic estimates
In order to show the sample error bounds from Theorem 2.1 we start by making some computations based on standard concentration inequalities (see, e.g., [6]).
Proposition 4.1** (Hoeffding and Bernstein inequalities).**
Suppose are independent real valued random variables, with mean zero, and for which for all . Suppose that
[TABLE]
for some . Then,
- •
(Hoeffding) For every
[TABLE]
- •
(Bernstein) For every
[TABLE]
Remark 4.2**.**
In most applications these inequalities are used to prove that the empirical average is small with high probability, so that in particular one is typically interested in choosing . When the estimate on the average of variances is not significantly smaller than , Bernstein’s inequality does not produce any improvement over Hoeffding’s.
Our first probabilistic estimates are concerned with the pointwise convergence of towards for a fixed regular enough function . Such estimates have been obtained in the literature before (see, for example, [36, 9, 10]), but here we present them again emphasizing the dependence of constants on the regularity of the function . In particular, we will need this explicit dependence in order to quantify the error between and in terms of the regularity estimates obtained in Theorem 2.3 for the function .
Proposition 4.3**.**
(Pointwise consistency of graph Laplacian) Let . Then, for every , with probability at least , we have
[TABLE]
where the last constant depends at most linearly on .
We remind the reader that is the kernel describing the connectivity of our graph, is the dimension of the manifold , and the norm measures size of the first derivatives of a function.
Proof.
Associated to the function we define a function
[TABLE]
This function can be interpreted as a non-local Laplacian of .
Fix and denote by the variables
[TABLE]
Notice that given , we have
[TABLE]
Also, using the bound on the support of ,
[TABLE]
[TABLE]
It is simple to see that for all and all we have
[TABLE]
where is a positive constant. In particular it follows that
[TABLE]
We notice that neither nor depend on , and that the are independent random variables. We may now use Bernstein’s inequality (Proposition 4.1), along with the definition of and Equations (4.3) and (4.4), to obtain
[TABLE]
and by the law of iterated expectation get
[TABLE]
A simple union bound implies that
[TABLE]
Now we claim that for all and all
[TABLE]
We first replace with a version of it that uses the geodesic distance on rather than the Euclidean distance. More precisely, we set
[TABLE]
where is the geodesic distance between two points in . Now, as long as for some small enough (that only depends on ) we have that
[TABLE]
where is a constant that depends on ; see for example Proposition 2 in [29].
From this and the Lipschitz continuity of we can conclude that if then,
[TABLE]
On the other hand, if , we must also have . Therefore, in all cases we have
[TABLE]
from where it follows that for all ,
[TABLE]
Let us now compare with . For that purpose we use the exponential map at the point ,
[TABLE]
which takes tangent vectors at with norm less than into points in that are within geodesic distance of . Let be the composition , i.e. the function written in normal coordinates around . The regularity of and implies that is also regular, and using a Taylor expansion around the origin we get
[TABLE]
where the remainder is a function that satisfies:
[TABLE]
The constant depends on and the third derivatives of . We emphasize that, by the integral form of the Taylor remainder theorem, the constant in this expression scales at most linearly in the third derivatives of . In normal coordinates we can then write
[TABLE]
We know that the Jacobian of the exponential map satisfies
[TABLE]
(see Section 2.2. in [9]) so we can actually write
[TABLE]
where , with the constant depending at most linearly in . We notice that the first term on the right hand side of the above expression drops due to the radial symmetry of the kernel, and also that the second term is equal to
[TABLE]
The bottom line is that, as anticipated in (4.6),
[TABLE]
Combining (4.5) and (4.6) we deduce that with probability greater than ,
[TABLE]
∎
Our next result will allow us to show that the functions and mentioned in (2.6) and defined explicitly in (4.10), are uniformly small.
Lemma 4.4**.**
Let be a smooth function. For each let be defined as
[TABLE]
where
[TABLE]
Let . Then with probability greater than ,
[TABLE]
Proof.
Fix and let be the random variables
[TABLE]
Conditioned on , the variables are independent and satisfy
[TABLE]
where
[TABLE]
and where
[TABLE]
Moreover,
[TABLE]
and
[TABLE]
where
[TABLE]
Bernstein’s inequality (Proposition 4.1) then implies that:
[TABLE]
Using a simple union bound we deduce that
[TABLE]
and by the law of iterated expectation we obtain
[TABLE]
Now, the only terms in the above expression that depend on are and . These however can be showed to be bounded below and above by positive constants with very high probability. Indeed, we first notice that for all and all we have
[TABLE]
for some positive constant . On the other hand, using Hoeffding’s inequality we get that
[TABLE]
from where it follows that except on a set with probability less than , we have
[TABLE]
Therefore,
[TABLE]
∎
We are ready to prove Theorem 2.1.
Proof of Theorem 2.1.
Let us first introduce some notation. For a function we denote by the value of the function at , i.e. . Also, we will restrict the solution of (2.5) and its Laplacian to the point cloud , so in particular we will treat and as functions defined on .
First, we notice that, by (2.5)
[TABLE]
at all points in . Let us denote by the right hand side of the above expression (i.e. times the difference between and ). By Proposition 4.3 and Theorem 2.3 we know that with probability at least we have that
[TABLE]
Now, let . Then, by (1.5) and (2.5) ,
[TABLE]
Let us define the functions and on respectively by
[TABLE]
where is as defined in Lemma 4.4 and is a constant that will be chosen later on. Indeed, we will show that with the appropriate choice of , the following holds at all point in :
[TABLE]
We focus on showing , the other inequality obtained in a completely analogous way. To see that , we will actually show that for an appropriate (small) value of , the function
[TABLE]
satisfies the inequality
[TABLE]
from where it follows, thanks to the maximum principle (Proposition 2.2), that . Let us then focus on showing (4.11). First, a direct computation shows that
[TABLE]
where in the above we are using as defined in Lemma 4.4. It follows that
[TABLE]
Since is a bounded function (in particular thanks to their regularity as it follows from Theorem 2.3 and by the assumptions on ), Lemma 4.4 implies that, with probability at least we have
[TABLE]
Hence, by using (4.8), with probability at least , for all we have:
[TABLE]
which can be rewritten as
[TABLE]
Now, notice that can be chosen in such a way that
[TABLE]
Indeed, since we have assumed that the noise is bounded, we can conclude that for some constant , from where it follows that if is chosen to be larger than we can conclude that . In particular, for such choice of we have and thus by the fundamental theorem of Calculus:
[TABLE]
for some constant (using the assumed strict monotonicity of ) and where
[TABLE]
Plugging this back into (4.14) we deduce that (with probability at least )
[TABLE]
Hence if we let be defined according to
[TABLE]
we conclude that, with probability at least
[TABLE]
as we wanted to show. Repeating this argument for , and using a union bound completes the proof.
∎
Appendix A Proof of theorem 2.3
Here we give an outline of the proof of Theorem 2.3 in the case with general loss function. We attempt to offer some additional discussion and pointers to important inequalities that are used in this process, but do not attempt to provide all the details (see e.g. the reference [30] for complete details).
Proof.
Given the continuum variational problem (2.4), the first question is whether a unique minimizer exists. A typical modern approach is to consider minimizing this functional over a wide class of functions (e.g. , the broadest class of functions for which the Dirichlet energy is finite). Since the functional is convex and coercive, one can generally infer the existence of a solution using “soft” (i.e. non-constructive) methods. This is done by using, e.g., weak compactness of bounded sets in along with weak lower semi-continuity of the functional. Alternatively, in the cases we’re considering one can use other non-constructive methods, such as Lax-Milgram or Browder-Minty (see Chapter 6, Theorem 3 in [23] and [49] Section 10.3), to infer the existence of minimizers. Uniqueness usually follows directly from strong convexity of the functional. Directly using these methods, we may infer the existence and uniqueness of an function minimizing (2.4).
Once one has assured the existence and uniqueness of a () solution to the problem, we would like to study finer properties of the solutions. To do this, we first notice that by taking variations in (2.4), that is by letting , and then considering , we have for any
[TABLE]
where is the minimizer of (2.4). Note that if were sufficiently regular (e.g. ) then we could use integration by parts in the first term and the fundamental theorem of the calculus of variations to infer (2.5). At the moment, given only that , we simply can say that is a weak solution of the PDE (2.5).
Several avenues are available at this stage to demonstrate that the optimizer is more regular. First, we notice, in our case, that truncating at any value above and below (we recall that is supported in ) will decrease the objective value in (2.4). This implies that
[TABLE]
Next, various tools are available for establishing regularity of elliptic equations. For example, Theorem 2 in Chapter 6 in [23] states that any weak solution of (for an arbitrary ) will satisfy
[TABLE]
where the inequality is only meaningful when belongs to the Sobolev space (i.e. the largest space of functions where one can make sense of -th order “weak” derivatives which are squared integrable). This is proved by using the weak elliptic equation to provide a priori bounds on difference quotients of the function . Using a version of the chain rule in higher-order Sobolev spaces (namely that , see e.g. [7] or [39]), and using the fact that and are smooth, we can take and rewrite this estimate in the following way:
[TABLE]
where here we remark that the constants in the previous line will depend on and . Iterating this inequality then gives that for any positive integer .
Once one has established Sobolev regularity, we may use Morrey’s inequality (see, e.g., Theorem 6 in Chapter 5 of [23]), which allows one to infer that for any there exists an so that . This then implies that the minimizer of the problem (2.4) is in fact infinitely differentiable, and is a classical solution of (2.5).
Once one has a more regular solution, a variety of techniques are available to demonstrate a priori-bounds on different derivatives (such as the bounds (2.8) and (2.9) ). For example, the classical maximum principle (see e.g. Theorem 2 in Chapter 6 of [23]) states that, given a function , if on a set then attains its maximum on the boundary of . We may use this to prove the estimate (2.8) as follows: we note that for any point where we have
[TABLE]
where in the second equality we have used the definition of in (2.7), and in the inequality we have used (A.1) and the fact that on a bounded interval we have for some constant (which follows from the strict monotonicity of ). Now, suppose for the sake of contradiction that the set
[TABLE]
is non-empty. Notice that this is an open set given that both and are continuous. From the above computations it follows that on we have that
[TABLE]
This implies (by the classical maximum principle) that when restricted to attains its maximum on the boundary of . However, since is a manifold without boundary, takes the form , and we conclude that the maximum value that can take in is . However, this contradicts the fact that was nonempty (where in theory achieves values higher than ). This provides the desired upper bound. The lower bound is deduced analogously. This proves (2.8) and by directly using the Euler-Lagrange equation (2.5), we then have that .
Now, to prove further bounds, we need a priori estimates in stronger norms. Many types of estimates are available, but we focus on two: Hölder type estimates (due to De Giorgi, Nash and Moser), and Schauder estimates. The classical Hölder estimates state that any solution of will satisfy (see Theorem 8.24 in [30])
[TABLE]
for some appropriately chosen (here denotes the space of -Hölder continuous functions). We can use this to infer that , with independent of . On the other hand, the classical Schauder estimates (see Theorem 6.6 in [30]) state that for a solution of we have the bound
[TABLE]
where here is the space of functions with -Hölder continuous second derivatives. By applying this to , and noting that by the smoothness of we have that , we may then apply these estimates to infer that , independent of . In turn, by considering , we may again apply the Schauder estimate to conclude that . Since we have that and , we may use interpolation inequalities (see e.g. Lemma 6.32 in [30]) to deduce that . These arguments then conclude the proof of Theorem 2.3.
∎
We remind the reader here that convergence of as is towards , not . One can only guarantee convergence towards if one makes more specific assumptions upon the label error distribution or on the empirical risk function . We remark that the references in the previous proof referred to the Euclidean case, but can be extracted to the manifold case we consider here via standard localization arguments. We also emphasize that there are many other techniques and technical challenges associated with elliptic regularity (especially associated with boundary values), which were not relevant in this context, a standard reference is [30].
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] R. K. Ando and T. Zhang , Learning on graph with laplacian regularization , in Proceedings of the 19th International Conference on Neural Information Processing Systems, NIPS’06, Cambridge, MA, USA, 2006, MIT Press, pp. 25–32.
- 2[2] M. Belkin and P. Niyogi , Laplacian eigenmaps for dimensionality reduction and data representation , Neural computation, 15 (2003), pp. 1373–1396.
- 3[3] , Towards a theoretical foundation for laplacian-based manifold methods , in Proceedings of the 18th Annual Conference on Learning Theory, COLT’05, Berlin, Heidelberg, 2005, Springer-Verlag, pp. 486–500.
- 4[4] M. Belkin, P. Niyogi, and V. Sindhwani , Manifold regularization: A geometric framework for learning from labeled and unlabeled examples , Journal of machine learning research, 7 (2006), pp. 2399–2434.
- 5[5] A. Bertozzi, X. Luo, A. Stuart, and K. Zygalakis , Uncertainty quantification in graph-based classification of high dimensional data , SIAM/ASA Journal on Uncertainty Quantification, 6 (2018), pp. 568–595.
- 6[6] S. Boucheron, G. Lugosi, and P. Massart , Concentration inequalities , Oxford University Press, Oxford, 2013. A nonasymptotic theory of independence, With a foreword by Michel Ledoux.
- 7[7] G. Bourdaud , Le calcul fonctionnel dans les espaces de Sobolev , in Séminaire sur les Équations aux Dérivées Partielles, 1990–1991, École Polytech., Palaiseau, 1991, pp. Exp. No. IV, 4.
- 8[8] O. Bousquet, O. Chapelle, and M. Hein , Measure based regularization , in Advances in Neural Information Processing Systems, 2004, pp. 1221–1228.