TL;DR
This paper introduces a parallel projection method that significantly accelerates solving large-scale metric-constrained optimization problems, enabling efficient handling of trillions of constraints in clustering applications.
Contribution
The paper proposes a novel parallel execution schedule for projection methods, improving convergence speed without conflicts, and demonstrates its effectiveness on large-scale correlation clustering problems.
Findings
Successfully solved problems with up to 2.9 trillion constraints
Achieved faster convergence compared to traditional projection methods
Enabled large-scale metric-constrained optimization in practical time
Abstract
Many clustering applications in machine learning and data mining rely on solving metric-constrained optimization problems. These problems are characterized by constraints that enforce triangle inequalities on distance variables associated with objects in a large dataset. Despite its usefulness, metric-constrained optimization is challenging in practice due to the cubic number of constraints and the high-memory requirements of standard optimization software. Recent work has shown that iterative projection methods are able to solve metric-constrained optimization problems on a much larger scale than was previously possible, thanks to their comparatively low memory requirement. However, the major limitation of projection methods is their slow convergence rate. In this paper we present a parallel projection method for metric-constrained optimization which allows us to speed up…
Click any figure to enlarge with its caption.
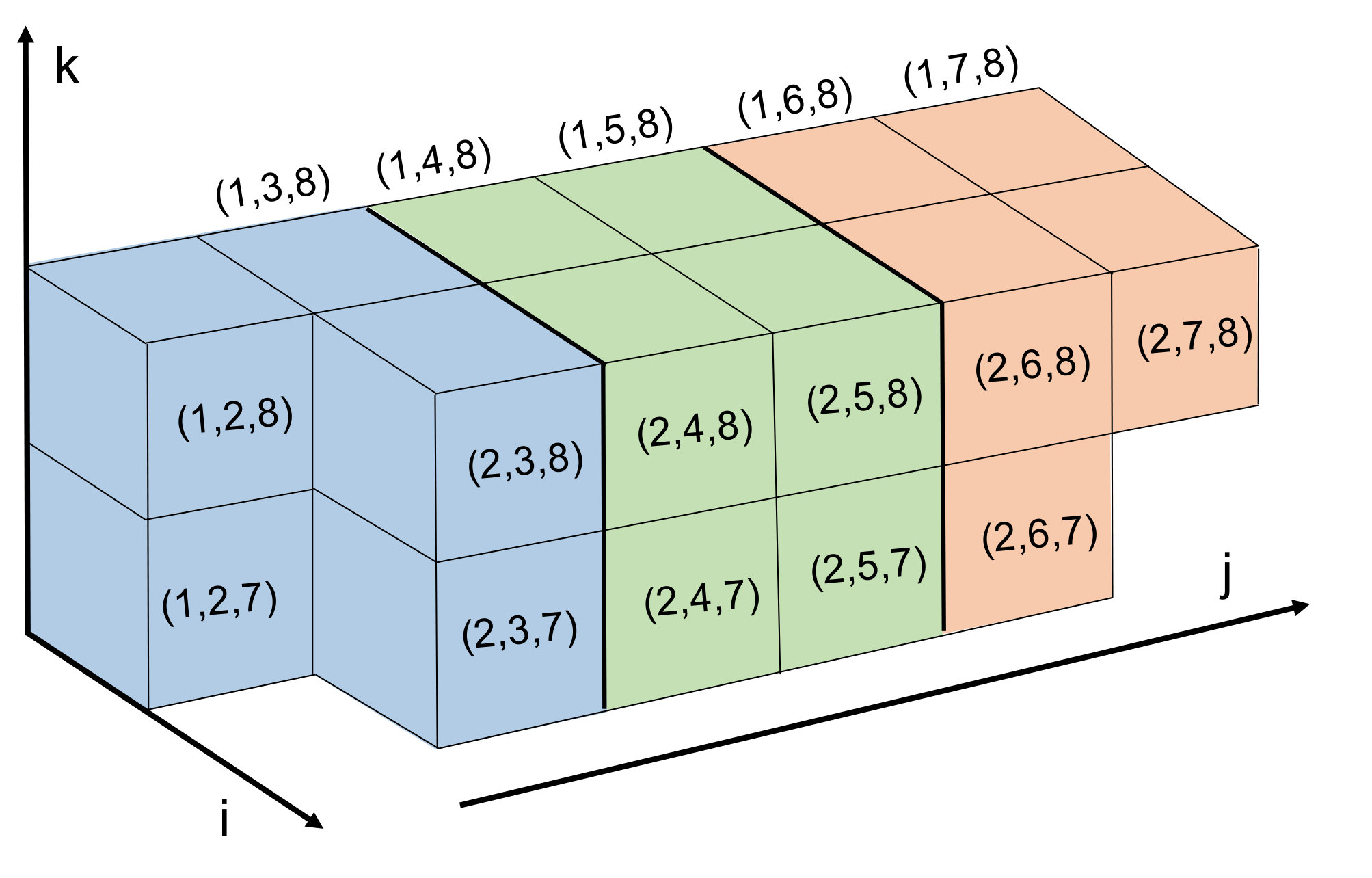 Figure 1
Figure 1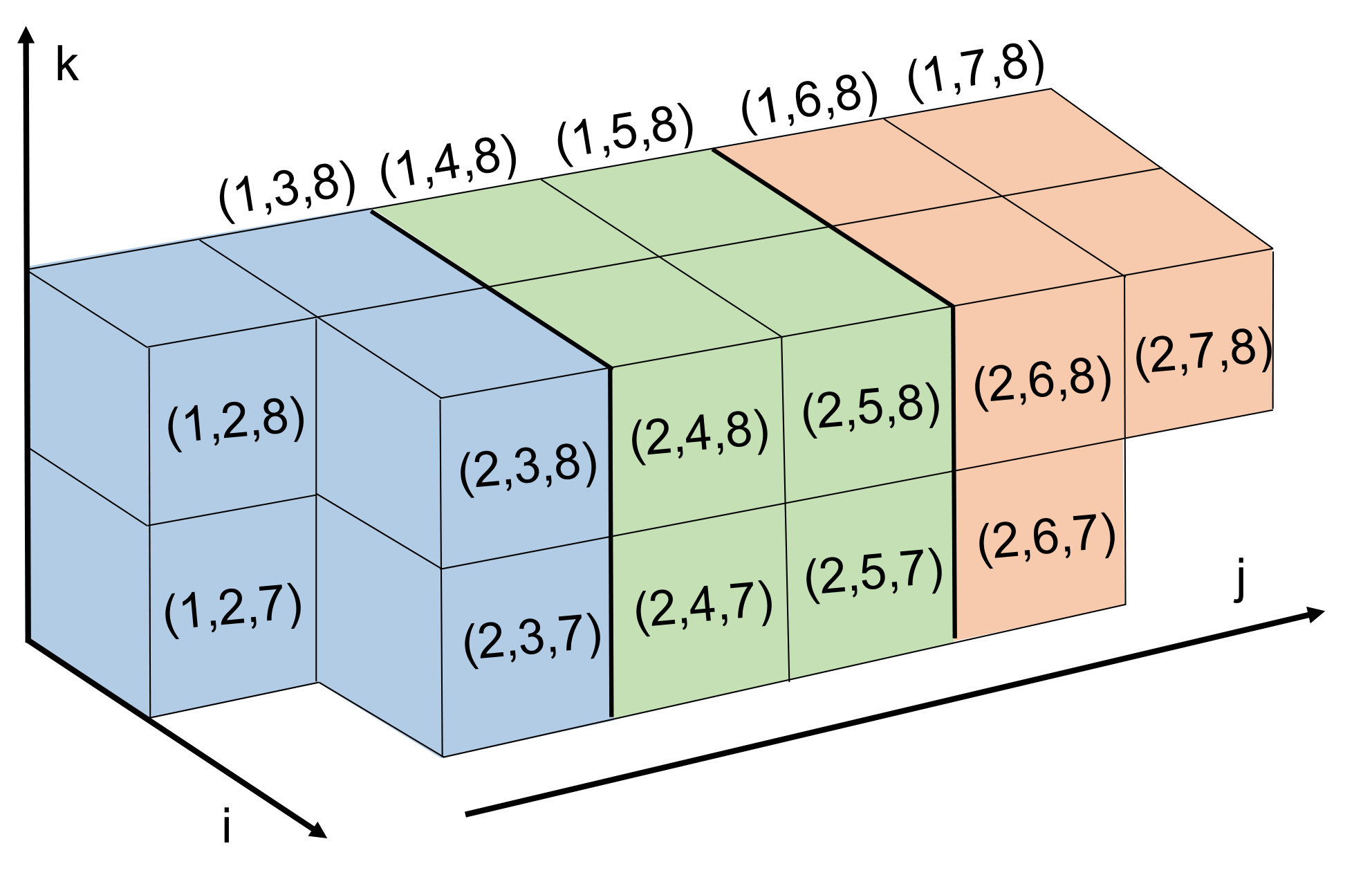 Figure 2
Figure 2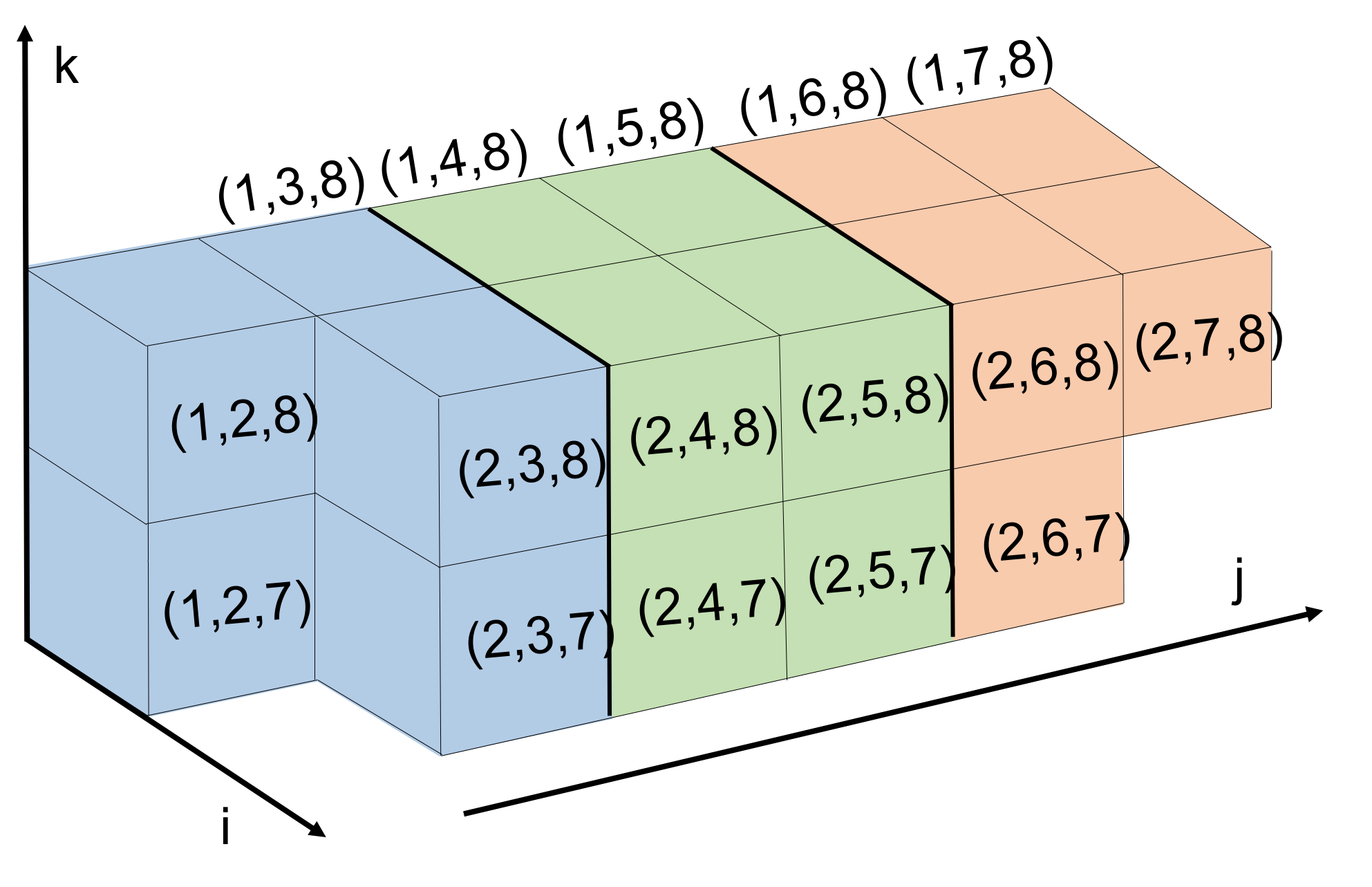 Figure 3
Figure 3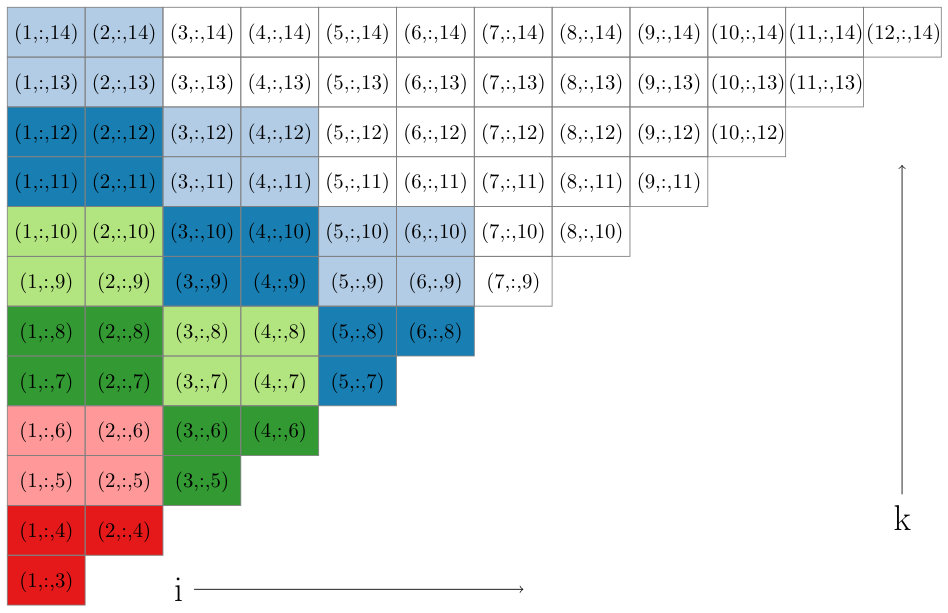 Figure 4
Figure 4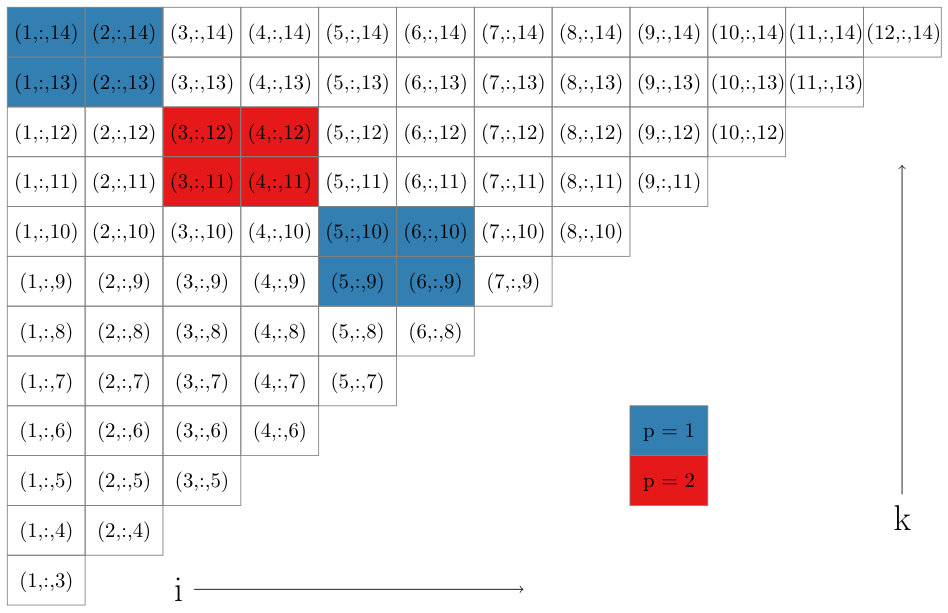 Figure 5
Figure 5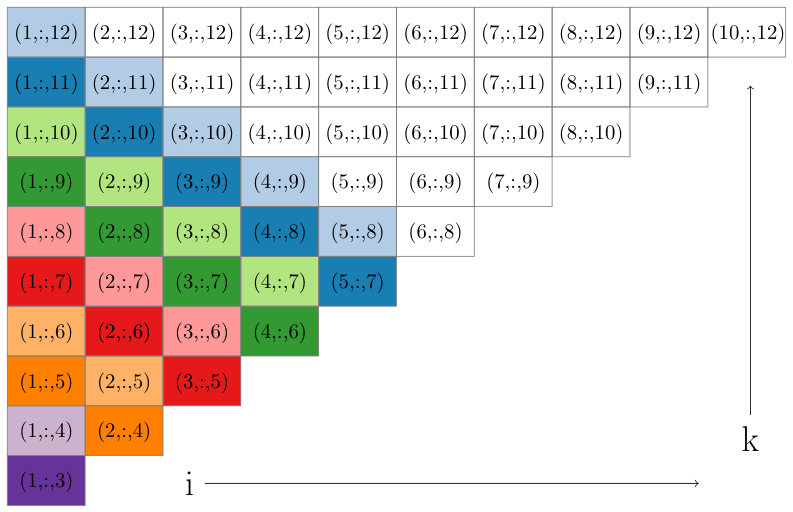 Figure 6
Figure 6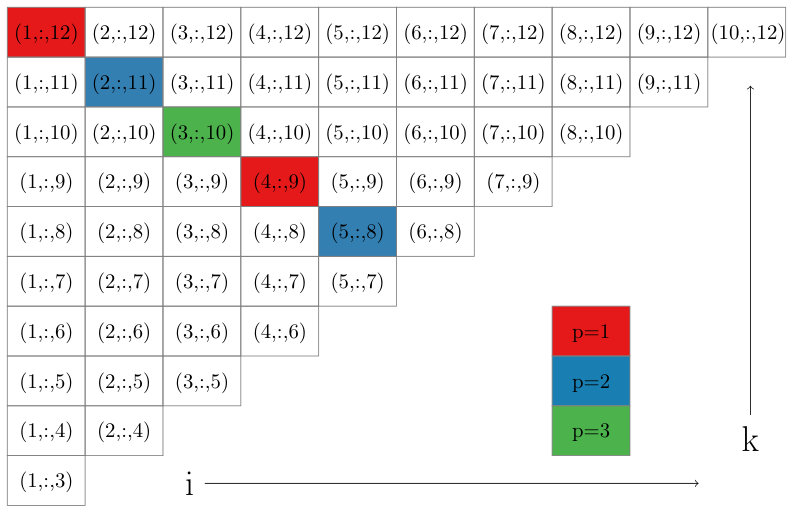 Figure 7
Figure 7 Figure 8
Figure 8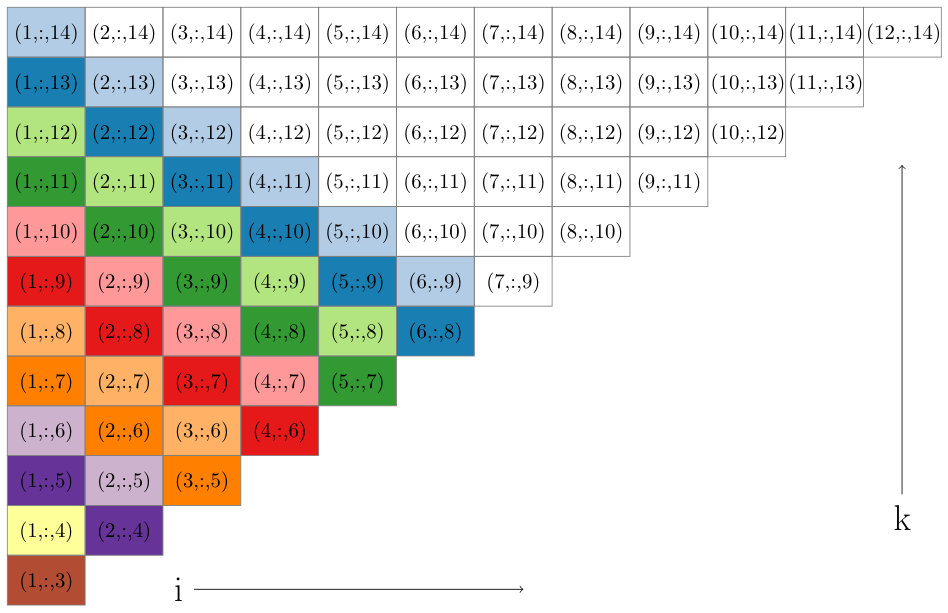 Figure 9
Figure 9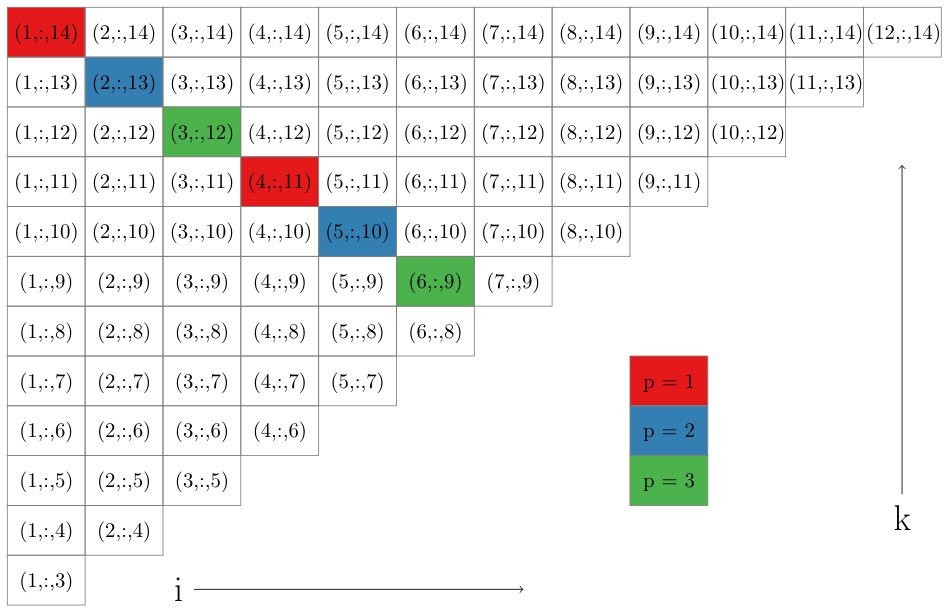 Figure 10
Figure 10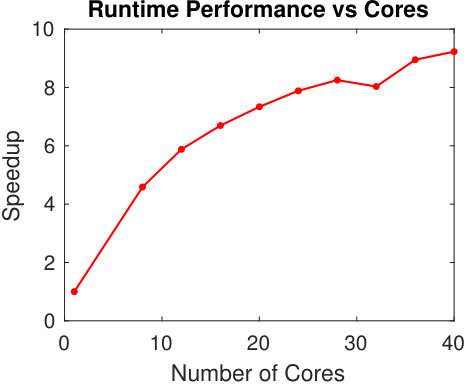 Figure 11
Figure 11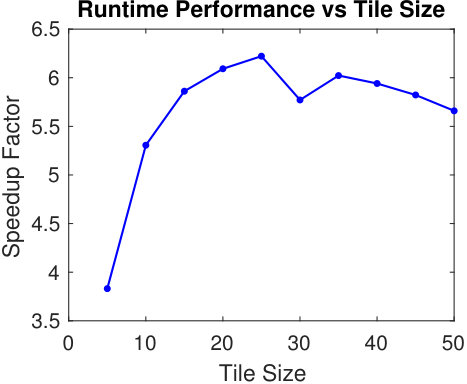 Figure 12
Figure 12| Graph | # constraints | # Cores | Times (s) | Speedup |
| ca-GrQc | 1 | 2632 | 1 | |
| 8 | 562 | 4.68 | ||
| 16 | 429 | 6.14 | ||
| 32 | 358 | 7.35 | ||
| Power | 1 | 4521 | 1 | |
| 8 | 890 | 5.08 | ||
| 16 | 696 | 6.50 | ||
| 32 | 576 | 7.85 | ||
| ca-HepTh | 1 | 19826 | 1 | |
| 8 | 4682 | 4.23 | ||
| 16 | 3252 | 6.10 | ||
| 32 | 2603 | 7.62 | ||
| ca-HepPh | 1 | 47309 | 1 | |
| 8 | 10313 | 4.59 | ||
| 16 | 7066 | 6.70 | ||
| 32 | 5889 | 8.03 | ||
| ca-AstroPh | 1 | 187045 | 1 | |
| 8 | 40146 | 4.66 | ||
| 16 | 35397 | 5.28 | ||
| 32 | 24374 | 7.67 | ||
| 64 | 16325 | 11.46 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsSPEED: Separable Pyramidal Pooling EncodEr-Decoder for Real-Time Monocular Depth Estimation on Low-Resource Settings
A Parallel Projection Method for Metric Constrained Optimization
††thanks: David Gleich is supported by the DARPA Simplex Program, the Sloan Foundation, and NSF awards CCF-1149756, IIS-154648, and CCF-093937. Nate Veldt is funded by NSF award IIS-154648.
Cameron Ruggles
Department of Computer Science
*Purdue University
*West Lafayette, IN
Nate Veldt
Department of Mathematics
*Purdue University
*West Lafayette, IN
David F. Gleich
Department of Computer Science
*Purdue University
*West Lafayette, IN
Abstract
Many clustering applications in machine learning and data mining rely on solving metric-constrained optimization problems. These problems are characterized by constraints that enforce triangle inequalities on distance variables associated with objects in a large dataset. Despite its usefulness, metric-constrained optimization is challenging in practice due to the cubic number of constraints and the high-memory requirements of standard optimization software. Recent work has shown that iterative projection methods are able to solve metric-constrained optimization problems on a much larger scale than was previously possible, thanks to their comparatively low memory requirement. However, the major limitation of projection methods is their slow convergence rate. In this paper we present a parallel projection method for metric-constrained optimization which allows us to speed up the convergence rate in practice. The key to our approach is a new parallel execution schedule that allows us to perform projections at multiple metric constraints simultaneously without any conflicts or locking of variables. We illustrate the effectiveness of this execution schedule by implementing and testing a parallel projection method for solving the metric-constrained linear programming relaxation of correlation clustering. We show numerous experimental results on problems involving up to 2.9 trillion constraints.
Index Terms:
triangle inequality constraints, optimization, graph clustering, projection methods, parallel computing
I Introduction
Many tasks in machine learning and data mining, in particular problems related to clustering, rely on learning pairwise distance scores between objects in a dataset of objects. One particular paradigm for learning distances, that arises in a number of different contexts, is to set up a convex optimization problem involving distance variables and metric constraints which enforce triangle inequalities on the variables. This approach has been applied to problems in sensor location [19, 20], metric learning [7, 6], metric nearness [8, 14, 15], and joint clustering of image segmentations [21, 39]. Metric-constrained optimization problems also frequently arise as convex relaxations of NP-hard graph clustering objectives. A common approach to developing approximation algorithms for these clustering objectives is to first solve a convex relaxation and then round the solution to produce a provably good output clustering [11, 28, 38].
The constraint set of metric-constrained optimization problems may differ slightly depending on the application. However, the common factor among all of these problems is that they involve a cubic number of constraints of the form where is a triplet of points in some dataset and is a distance score between two objects and . This leads to an extremely large, yet very sparse and carefully structured constraint matrix. Given the size of this constraint matrix and the corresponding memory requirement, it is often not possible to solve these problems on anything but very small datasets when using standard optimization software. In recent work [37] we showed how to overcome the memory bottleneck by applying memory-efficient iterative projection methods, which provide a way to solve these problems on a much larger scale than was previously possible. Unfortunately, although projection methods come with a significantly decreased memory footprint, they are also known to exhibit very slow convergence rates. In particular, the best known results are obtained by specifically applying Dykstra’s projection method [16], which is known to have a only a linear convergence rate [17].
Given the slow convergence rate of Dykstra’s method, a natural question to ask is whether one can improve its performance using parallelism. There does in fact already exist a parallel version of Dykstra’s method [26], which performs independent projections at all constraints of a problem simultaneously, and then averages the results to obtain the next iterate. However, this procedure is ineffective for metric-constrained optimization, since averaging over the extremely large constraint set leads to changes that are so small no meaningful progress is made from one iteration to the next. As another challenge, we note that many of the most commonly studied metric-constrained optimization problems are linear programs [1, 11, 19, 21, 39, 38]. Because linear programming is P-complete, parallelizing LP solvers is in general very hard. Thus, finding meaningful ways to solve metric-constrained optimization problems in a way that is both fast and memory efficient possess several significant challenges.
In this work we take a first step in parallelizing projection methods for metric-constrained optimization. This leads to a modest but consistent reduction in running time for solving these challenging problems on a large scale. Our approach relies on the observation that when applying projection methods to metric-constrained optimization, two projection steps can be performed simultaneously and without conflict as long as the triplets associated with different metric constraints share at most one index in common. Based on this, we develop a new parallel execution schedule which identifies large blocks of metric constraints that can be visited in parallel without locking variables or performing conflicting projection steps. Because Dykstra’s projection methods also relies on carefully updating dual variables after each projection, we also show how to keep track of dual variables in parallel and update them at each pass through the constraint set. We demonstrate the performance of our new approach by using it to solve the linear programming relaxation of correlation clustering [5]. Solving this LP is an important first step in many theoretical approximation algorithms for correlation clustering [2, 10, 11, 34, 35, 38]. In our experiments we consistently obtain a speedup of roughly a factor 5 over the serial method using even a small number cores, and achieve a speedup of over a factor of 11 for our largest problem. Our new approach allows us to handle problems containing up to nearly 3 trillion constraints in a fraction of the time it takes the serial method.
II Background
We use the term metric-constrained optimization or more simply metric optimization to refer to any convex optimization problem involving constraints of the form where represents a distance variable between two points and in a large graph or dataset. Our work builds directly on previous results for solving optimization problems of this form using projection methods [36, 8, 37]. In this section we specifically consider the metric-constrained linear programming relaxation for correlation clustering and its relationship to what is known as the metric nearness problem. We will use this LP relaxation as a special case study in this paper, although the parallel approach we develop can in principle be applied to any metric optimization problem.
II-A Metric Nearness and Correlation Clustering
One key example of metric optimization is the metric nearness problem [36, 8], in which one is given matrix of dissimilarity scores between objects in a dataset. The goal is to find the matrix whose entries satisfy the triangle inequality and for some value of minimizes
[TABLE]
where is a nonnegative weight indicating the how strongly we wish to be similar to . The problem can be cast as a linear program when , a quadratic program when , and a slightly more complicated convex optimization problem for other finite values of . One can also consider a norm version of the problem which minimizes the the maximum of over all pairs . This can also be cast as an LP.
Metric-constrained optimization is also a key ingredient in approximation algorithms for correlation clustering [5]. In correlation clustering one is given a weighted and signed graph . Each pair of nodes in defines either a positive edges or a negative edges . The goal is to partition in such a way that negative edges tend to link nodes between different clusters, and positive edges link nodes inside the same cluster. The problem also comes with weights where indicates the strength of the relationship between and . One formulation of the problem is to minimize the weight of mistakes, which can be cast as the following binary linear program:
[TABLE]
A positive mistake happens when two nodes with a positive edge are clustered apart (), and this comes with a penalty equal to the weight . A negative mistake is when two nodes sharing a negative edge are clustered together, in which case the penalty is again since in this case . We can relax (2) to a linear program by substituting with the constraint . Solving this relaxation and then rounding the solution is a general strategy that has lead to a number of approximation algorithms for different variants of correlation clustering. For arbitrary weights, there exists an approximation rounding scheme [13]. When the graph is unweighted (i.e. for all pairs ), the best rounding scheme produces an approximation ratio near 2 [11]. Several other special weighted cases also obtain their best known approximation factor by solving the relaxation of (2) and rounding [38, 35, 2].
In recent work [37] we proved that the LP relaxation of (2) can be cast equivalently as a special case of the metric nearness problem (1) when . Specifically, given an instance of correlation clustering, define a dissimilarity score if , and set otherwise. Then the metric nearness problem and the LP relaxation of correlation clustering are both equivalent to the following metric-constrained LP:
[TABLE]
II-B Projection Methods for Metric Optimization
Although solutions to problems such as (1), (3), and other metric optimization problems are desirable from a theoretical perspective, they are challenging to solve for even modest values of due to the cubic constraint set. Standard commercial optimization packages are typically unable to handle problems with even a few hundred nodes when the full constraint set is included, due to memory limitations. Sra et al. began to address this problem specifically for the metric nearness problem [36]. Their approach was to apply memory-efficient projection methods, which visit constraints cyclically and iteratively update variables in a manner that is proven to converge to the optimal solution.
Recently, we showed how the techniques of Sra et al. can be adapted and improved to apply more broadly to a wider range of linear and quadratic metric-constrained optimization problems [37]. These results come with new approximation guarantees for specific graph clustering objectives, and are designed to produce output solutions with better constraint satisfaction and convergence guarantees. Here we review the main background for applying Dykstra’s method to metric-constrained linear programming. For details on how to apply projection methods to metric-constrained convex optimization problems that are not linear programs, we refer to the reader to other work [8, 36].
Metric-Constrained Linear Programming
Consider a general linear program of the form
[TABLE]
Encoding a metric-constrained LP in this format can be accomplished by letting x encode a linearization of the distance variables and potentially other variables depending on the specific optimization problem. The constraint matrix will encode metric constraints and other problem specific constraints, (e.g. the non-metric constraints in (3)). Because of the metric constraints, will be large, sparse, and very structured.
Projection methods do not apply directly to solving linear programs, so we first consider a regularized linear program
[TABLE]
where is a positive constant and is a positive definite diagonal matrix of weights. Both and are viewed as parameters that can be chosen to control the relationship between (4) and (5). When is the identity matrix, solving (5) for a small enough value of will output the smallest norm solution to the LP (4) [31]. Furthermore, our recent work provides specific details for how to set and to bound the difference between the original linear program and the related quadratic program (5) for specific graph clustering relaxations [37].
Applying Projection Methods
The quadratic program (5) can be solved using memory-efficient projection methods, which iteratively visit constraints and perform correction and projection steps that slowly fix constraint violations, update dual variables, and eventually converge to the unique optimal solution. Following previous work [36, 37], we specifically consider Dykstra’s method, which for quadratic programs is equivalent to Hildreth’s method [23] and Han’s method [22]. We provide pseudocode for applying this method to (5) in Algorithm 1.
Localized Metric Projections
For a more in-depth explanation of the algorithm, we refer to our previous work [37]. The key thing to realize is that Algorithm 1 is simply Dykstra’s method applied specifically to solve (5). Most importantly, updates of the form for a constant can be performed very quickly for metric constraints, since in this case (the th row of constraint matrix ) has only three nonzero entries.
For illustration, we show how to perform the projection step in Algorithm 1 when is a linearization of the distance variables, and is the identity matrix (note that the projection step is unaffected by the value of , so we do not specify its value here). Row a of and entry of b encode the constraint . For this constraint, a has three nonzero entries: 1, , and , corresponding to the locations of , , and in x. If , then the constraint is already satisfied, and , thus there is no update to the vector x. If , then , and . The projection step in Algorithm 1 updates only three entries of x:
[TABLE]
The correction step in Algorithm 1, which is necessary to guarantee convergence, can be performed in a similar localized manner.
Slow Convergence Rate
The decreased memory footprint of Dykstra’s method makes it possible to solve metric constrained problems on a much larger scale than was previously possible [37]. However, this method converges very slowly, given that the convergence rate for Dykstra’s method applied to quadratic programs is only linear [17].
III Parallel Metric Constrained Optimization
The primary contribution of our work is to show how to parallelize projection methods specifically for metric-constrained optimization problems. We accomplish this by showing how to visit multiple metric constraints at once and perform a large number of projections simultaneously without conflicts or locking variables.
III-A Performing Two Simultaneous Projections
To develop intuition for our approach, we consider two sets of triplets and , where the indices within each triplet are distinct, but some indices may be the same across both triplets. Each of these triplets is associated with three metric constraints, thus three projection steps that must be performed during one pass through the constraint set using Dykstra’s method.
Performing projections associate with triplet involves variables . Similarly, triplet is associated with variables . Note that if these triplets share two indices (e.g. and ), then we cannot perform projections at both constrains in parallel without conflict, since one variable (e.g. ) would be updated by both projections. However, if and share at most one index in common, then are all distinct and we can perform projection steps in Dykstra’s iteration at and at the same time. Our goal is to use this observation to develop a parallel execution schedule that will allow us to visit a large number of metric constraints at once and perform simultaneous projection steps without conflicts. Because this amounts simply to a re-ordering of constraints in a way that is more easily parallelizable, this will not affect the convergence guarantees of Dykstra’s method.
III-B New Ordering for Visiting Triplets
We abstract the process of visiting metric constraints to the process of enumerating triplets of the form where . Let denote this set of ordered triplets. Each fixed ordered triplet will be associated with three different metric constraints, and hence three different projection steps, that we assume will be handled by the same processor in a parallelized projection method.
Based on our intuitive observation in the previous section, we wish to group the triplets in into subsets in such a way that , , and such that any two triplets in different sets will share at most one index in common. If we can accomplish this, then we can assign each set to a different thread or processor. The work done at each processor (i.e. each set of triplets) will be then completely independent of work performed at other sets by different processors.
To accomplish this we define sets of triplets in which the smallest and largest indices are fixed values such that . We specifically define
[TABLE]
which includes all triplets with as the smallest index and as the largest index. In Figure 2 we show a grid of pairs associated with sets. Observe that drawing lines along downward-sloping diagonals of this grid highlights a large number of sets that can be processed simultaneously, i.e any two triplets taken from different sets along the diagonal will share at most one common index. Note that for a fixed satisfying , the diagonals in Figure 2 are made up of sets of the form for . The upper bound is chosen to guarantee that , implying that contains at least one ordered triplet from . Based on this observation, in Figure 1 we show how to loop through all triplets in in such a way that the inner loop iterates through sets that can be processed simultaneously. The code in Figure 1 contains two double loops for visiting sets. The first double loop handles the main diagonal of sets in Figure 2 and everything above below it, and the second double loop iterates through the sets above the main diagonal. Equivalently, for the first double loop we set and , and then in the outer loop decrement by one at each step. The second double loop fixes and iterates through all possibilities in the outer loop.
III-C Load Balancing and Tiled Triplet Assignment
One issue we must address with our listing of triplets in Figure 1 is the load balance. There is variability in both the number of triplet sets in the parallelized inner loop (i.e. the number of entries along a given diagonal in Figure 2), as well as the size of each triplet set within the same inner loop (i.e. different entries in the same diagonal of the grid in Figure 2). For example, when and for a fixed , there are sets, and these sets have variable size for different values of ranging from [math] to . We begin by noting that the vast majority of the triplets are visited for values of . Secondly, we assume that the number of threads or processors we use when iterating over sets is significantly smaller than the problems size , and we can assign sets of triplets to processors in a way that will not be too imbalanced. For a diagonal defined by fixed values, there are sets of triplets. If we assigned the first group of triplet sets to the first processor, and in general assigned the th group of triplet sets to the th processor, this would indeed lead to a significant imbalance. However, in practice, we balance the load much more effectively by assigning the th set to processor . In this way each processor is responsible for different triplet sets with a range of different sizes, for an overall load that is roughly balanced. We illustrate this load balanced assignment in Figure 3.
We also improve our parallel execution schedule by implementing a tiled approach to triplet set assignment for better cache efficiency when accessing distance variable in the matrix . This is inspired by previous work on tiled matrix multiplication, though it differs slightly in order to apply to enumerating triplets specifically for metric constrained projection methods. In short, this tiled strategy corresponds to substituting the diagonal pattern in Figure 2 with the block diagonal pattern shown in Figure 4. In more detail, for a tile size , each tile is defined by a fixed pair, and is made up of all sets where and . Much like in the untiled case, we note that different tiles of the same color in Figure 4 can be visited by different processors at the same time without conflict. That is, different processors will access completely independent parts of the matrix . When assigning processors to tiles along a block diagonal, we assign the th tile to processor , generalizing the strategy outlined in Figure 3 for the untiled case.
Each tile, which is defined by a fixed pair and a tile size , is associated with choices for the smallest index and choices for the largest index . The processor assigned to this tile must then iterate through all valid middle indices and perform projections corresponding to triplets of the form . One approach for doing this would be to consider each pair in turn and iterate through all values of from to . However, for better cache efficiency, we instead split the full range of possible values from to into subintervals that are also of length . This gives us a sequence of cubes of values, each associated with entries , , and from . Within each of these cubes, we iterate through triplets in a way that maximizes column locality (assuming is stored in column major format), before moving on to the next cube. We give a simple illustration of this in Figure LABEL:fig:tiles2. Depending on the values of ,, and , we will of course not be able to organize all triplets into perfect cubes of triplets satisfying . In practice however for large values of and , this approach will still provide a balanced and cache efficient way to access variables in .
III-D Storing Dual Variables for Parallel Computations
In addition to updating primal variables , Dykstra’s method requires we keep track of dual variables as a part of correction step (line 7 in Algorithm 1) that is necessary to guarantee convergence to the optimal solution. Specifically, for each metric constraint associated with a triplet , there is a corresponding dual variable that is updated during each visit to a constraint. This variable is only nonzero if in the previous pass through the constraints, there was a non-trivial projection step (i.e. the entries , , changed). For serial projection methods for metric optimization, the metric constraints are visited in the same order in every pass through the constraint set [37]. This makes it possible to effectively query dual variables from an array that stores tuples of the form where is a unique index associated with a metric constraint and is the dual variable. For memory-efficiency, these tuples are only stored for nonzero dual variables: . Because the serial version visits constraints in the same order each round, the array is always traversed in the same order. At each step, the method can access each necessary dual variable in time by maintaining a pointer in the array to the next known triplet associated with a nonzero dual variable. In this way the method can access the necessary dual variables in time.
Using our new parallel execution schedule, the triplets are no longer visited in a deterministic fashion, so a new approach is necessary. Fortunately, our approach is designed in such a way that each triplet is always visited by the same processor during each different pass through the constraints. Furthermore, even though globally the triplets are not visited in a deterministic fashion, each individual processor visits its assigned triplets in the same deterministic order at every iteration. Therefore, we can maintain dual variables efficiently by assigning an array to each processor, allowing the processor to keep track of the next triplet it will visit that will require a non-trivial correction step. Thus the main difference between the serial and parallel versions is simply that the latter requires we maintain an array for each processor rather than a single array for storing all dual variables. Accessing dual variables is therefore still performed in time at each projection step and the theoretical memory complexity is the same.
IV Experiments
We demonstrate the power of our new parallel approach to metric-constrained optimization by using it to solve the linear programming relaxation of correlation clustering on several large instances. We find that using even a modest number of cores consistently leads to a speed up of roughly a factor 5, and up to a speedup over a factor 10 on the largest problem, which involves nearly 3 trillion constraints.
IV-A Implementation Details
We implement a solver for the metric-constrained LP relaxation of correlation clustering by incorporating our new parallel execution schedule into our previous serial framework [37]. We use the Julia programming language, using its support for threaded computations to parallelize the inner loops of our new approach to iterating through index triplets. Our code is available publicly online at https://github.com/camruggles/ParallelDykstras. In our experiments we compare against our previous serial projection methods, available at at https://github.com/nveldt/MetricOptimization.
IV-B Problem Construction and Datasets
To test our parallel solver we construct several large instances of correlation clustering from undirected graphs following the approach of Wang et al. [40], and including a slight modification applied in previous work [37]. In short, given a graph , we compute a signed and weighted edge between each pair of nodes by computing the Jaccard index between the nodes (which is always nonnegative) and applying a non-linear function to obtain a signed value that either represents similarity or dissimilarity between the nodes. We then offset these scores by for a small . This last step ensures the result will be an instance of correlation clustering in which each pair of nodes possesses a nonzero weight and a sign. Partitioning the original graph using the correlation clustering objective can be used as a way to perform community detection on . For our purposes, this construction leads to a dense instance of correlation clustering that serves as a good benchmark for solving the LP relaxation of correlation clustering on a large scale.
We apply this procedure to five undirected and unsigned graphs: the graph power from the Newman group of matrices in the SuiteSparse Matrix Collection [41, 12], and four collaboration networks available from the SNAP repository [30, 29]: ca-GrQc, ca-HepTh, ca-HepPh, and ca-AstroPh. We take the largest connected component of each graph before converting it into an instance of correlation clustering. The LP relaxation of the correlation clustering instance corresponding to the largest graph (ca-AstroPh) has over 160 million variables and 2.9 trillion constraints.
IV-C Machine Specifications and Computing Environment
Our experiments were almost exclusively performed on a computer with 4 16-core Intel Xeon E7-8867 v3 processors. For one experiment on the largest graph, in which we wanted to run a large number of cores, we used a machine with 8 24-core 2.7 GHz Intel Xeon Platinum 8168 processors. For our experiments we did not utilize exclusive access to the computers. Thus, the reported runtimes vary depending on whether there were other users simultaneously using the machine at the same time as our experiments. This emulates the natural and realistic performance that may be expected in settings such as Amazon EC2, with multiple shared VMs on a single machine.
IV-D The Effect of Reordering Constraints
Dykstra’s method is guaranteed to converge regardless of the order in which the constraints are visited. However, we found that in practice the number of iterations required to solve a problem to within a fixed tolerance for constraint satisfaction and duality gap did vary depending on the constraint ordering. In some cases, the standard serial ordering led to a smaller overall iteration count, though in many other cases the iteration count was lower for our new approach for visiting triplets. Given the variability between problem instances, in our experiments we focus simply on the time it takes to complete a fixed number of iterations of Dykstra’s method. In this way, we are always comparing the time it takes to visit and perform a step of Dykstra’s method at each individual constraint exactly times for some fixed integer .
IV-E Results
In Table I, we report results for running our parallel code on all five graphs using 8, 16, and 32 cores. The runtime for 1 core comes from applying the previous serial version of the algorithm [37]. For the largest graph we additionally run our new algorithm using 64 cores, which is the only experiment for which we used the machine with 8 24-core processors. For each graph we report the time it took in seconds to run Dykstra’s method for 20 iterations, using a tile size of . Running our method with 8 cores is consistently 4-5 times faster than the serial implementation. We continue to see performance gains as we increase the number of cores used, leading to a speedup of over a factor ten on our largest graph.
In Figure 6 we display results specifically on ca-HepPh using a wider range of core counts. We see the performance of our method increase sharply at first and slowly level off as we increase the number of cores.
Finally, we observe what happens as we vary the tile size and keep the number of cores fixed. Figure 7 illustrates the algorithm’s performance on ca-GrQc as we vary tile size from 5 to 50 and keep the number of cores fixed at 16. The curve in the figure shows the speedup over the serial implementation, which is above a factor 5 for all tile sizes except 5. The performance peaks just above a factor 6 speedup for a tile size of 25, and slowly begins to decrease after this point.
V Related Work
Our work is related to a number of different areas in machine learning, optimization, graph theory, and matrix computations.
Metric-Optimization and Projection Methods
The parallel algorithms we have develop build directly on previous serial techniques for metric constrained optimization. These optimization problems arise in algorithm design for graph clustering problems [10, 28, 1, 38], image segmentation [21, 39], sensor location [19, 20], metric nearness [8], and metric learning [7, 6]. Sra et al. [36] were the first to apply projection methods for metric-constrained optimization, by using Dykstra’s method [16] to solve different variants of metric nearness. In recent work [37], we developed improved techniques for applying this method more broadly to linear programming relaxations of graph clustering objectives.
Graph Coloring
The parallel execution schedule we have develop in this paper is related to a number of different graph coloring problems. Consider a graph in which every node corresponds to a triplet , and edges connect nodes (i.e. triplets) if they share two indices in common. Coloring the nodes in this graph in such a way that no adjacent nodes share the same color is equivalent to partitioning all triplets into disjoint sets such that triplets within the same set can be processed simultaneously by our projection methods. Another approach would be to instead assign each pair (i.e. each entry in the distance matrix ) to a node in a hypergraph, and for every triplet of indices define a hyperedge of the form . Then the problem of finding sets of triplets to process simultaneous is equivalent to edge coloring in 3-uniform hypergraphs [32]. In general, graph coloring arises frequently as a way to determine potential areas for concurrency when completing a given task in parallel. We refer to several helpful resources on coloring algorithms for parallel and multithreaded computations [33, 9, 18].
Block Matrix Multiplication
Our tiled approach to triplet enumeration is inspired by techniques for block matrix multiplication, which also involves doubly indexed blocks of data and computational steps corresponding to a triplet of indices. Specifically, multiplying the block of a matrix with the block of another matrix is a step in block matrix-matrix multiplication (), that can be indexed by a triplet . Our tiled triplet enumeration procedure is related to research on communication bounds for dense matrix multiplication. The pioneering work of Hong and Kung [24] proved a lower bound on the communication necessary to move data between slow and fast memory in matrix multiplication. Irony, Toledo, and Tiskin [25] later extended this result to distributed parallel computations. The state of the art numerical linear algebra software package LAPACK [3] determines block sizes automatically for efficient matrix-matrix computations. For an in-depth overview of communication-avoiding and cache efficient algorithms for numerical linear algebra, we refer to the work of Ballard et al. [4] and Knight [27] (see in particular Section 5.5).
VI Discussion and Future Work
In our work we have taken a first step in developing parallel algorithms for metric-constrained optimization. These problems are very challenging to solve in practice due to their extremely large constraint set, involving constraints for a dataset of size . Furthermore, parallelizing solvers for these problems possess several very significant challenges, including the P-completeness of linear programming and the downsides of applying existing parallel versions of projection methods. Despite this, we have demonstrated that exploiting the special structure of the constraint matrix can lead to noticeable performance improvements, in particular when applying projection methods such as Dykstra’s method. Our work demonstrates that metric-constrained optimization problems are challenging to solve, but also serve as good benchmarks for testing parallel design techniques. In future work we will continue to explore other even more effective ways to visit metric constraints in parallel, as well as other possible ways to exploit the special structure of the constraint matrix in order to solve these problems more effectively in practice.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] G. Agarwal and D. Kempe. Modularity-maximizing graph communities via mathematical programming. The European Physical Journal B , 66(3):409–418, Dec 2008.
- 2[2] Nir Ailon, Moses Charikar, and Alantha Newman. Aggregating inconsistent information: ranking and clustering. Journal of the ACM (JACM) , 55(5):23, 2008.
- 3[3] E. Anderson, Z. Bai, C. Bischof, S. Blackford, J. Demmel, J. Dongarra, J. Du Croz, A. Greenbaum, S. Hammarling, A. Mc Kenney, and D. Sorensen. LAPACK Users’ Guide . Society for Industrial and Applied Mathematics, Philadelphia, PA, third edition, 1999.
- 4[4] Grey Ballard, Erin Carson, James Demmel, Mark Hoemmen, Nicholas Knight, and Oded Schwartz. Communication lower bounds and optimal algorithms for numerical linear algebra. Acta Numerica , 23:1–155, 2014.
- 5[5] Nikhil Bansal, Avrim Blum, and Shuchi Chawla. Correlation clustering. Machine Learning , 56:89–113, 2004.
- 6[6] D. Batra, R. Sukthankar, and T. Chen. Semi-supervised clustering via learnt codeword distances. In Proceedings of the British Machine Vision Conference , BMVA 2008, pages 90.1–90.10. BMVA Press, 2008. doi:10.5244/C.22.90.
- 7[7] Arijit Biswas. Semi-supervised and Active Image Clustering with Pairwise Constraints from Humans . Ph D thesis, University of Maryland, College Park, 2014.
- 8[8] Justin Brickell, Inderjit S. Dhillon, Suvrit Sra, and Joel A. Tropp. The metric nearness problem. SIAM Journal on Matrix Analysis and Applications , 30(1):375–396, 2008.
