TL;DR
This paper introduces ADMM-Softmax, an efficient ADMM-based algorithm for multinomial logistic regression that improves classification performance and computational efficiency, especially for large-scale image classification tasks.
Contribution
The paper proposes a novel ADMM-based approach for multinomial logistic regression that decouples the problem into efficiently solvable steps, enabling parallelization and improved generalization.
Findings
ADMM-Softmax outperforms Newton-Krylov, quasi-Newton, and stochastic gradient methods in image classification.
The method allows for efficient parallelization and pre-computation, reducing computational costs.
Demonstrates improved generalization on two image classification datasets.
Abstract
We present ADMM-Softmax, an alternating direction method of multipliers (ADMM) for solving multinomial logistic regression (MLR) problems. Our method is geared toward supervised classification tasks with many examples and features. It decouples the nonlinear optimization problem in MLR into three steps that can be solved efficiently. In particular, each iteration of ADMM-Softmax consists of a linear least-squares problem, a set of independent small-scale smooth, convex problems, and a trivial dual variable update. Solution of the least-squares problem can be be accelerated by pre-computing a factorization or preconditioner, and the separability in the smooth, convex problem can be easily parallelized across examples. For two image classification problems, we demonstrate that ADMM-Softmax leads to improved generalization compared to a Newton-Krylov, a quasi Newton, and a stochastic…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1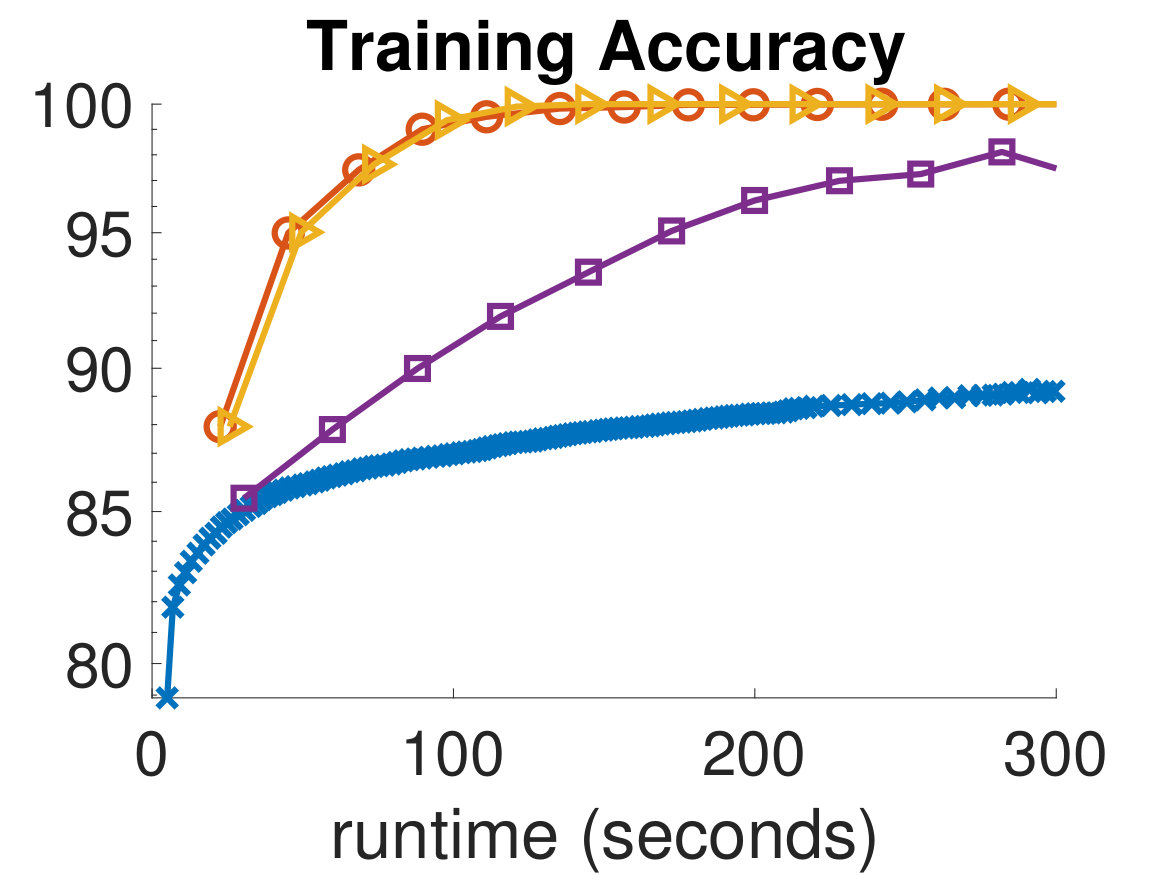 Figure 2
Figure 2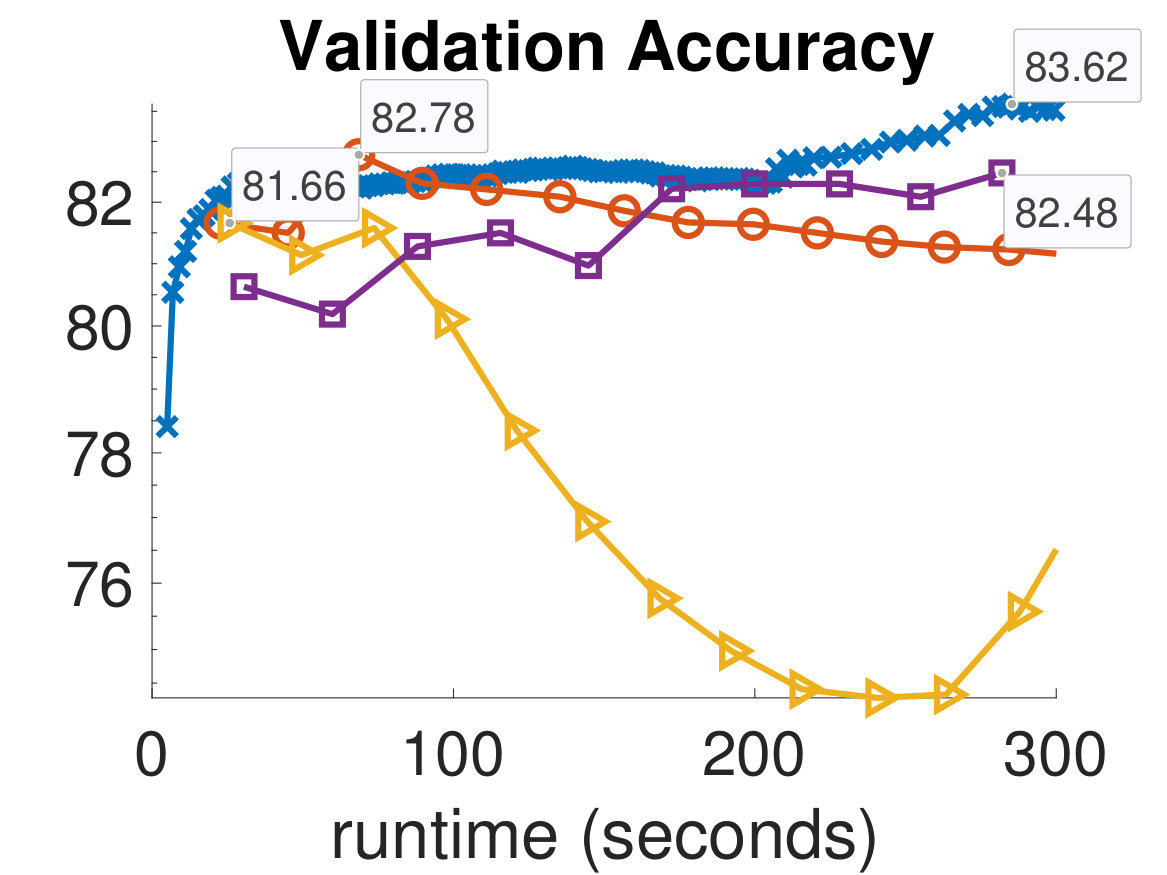 Figure 3
Figure 3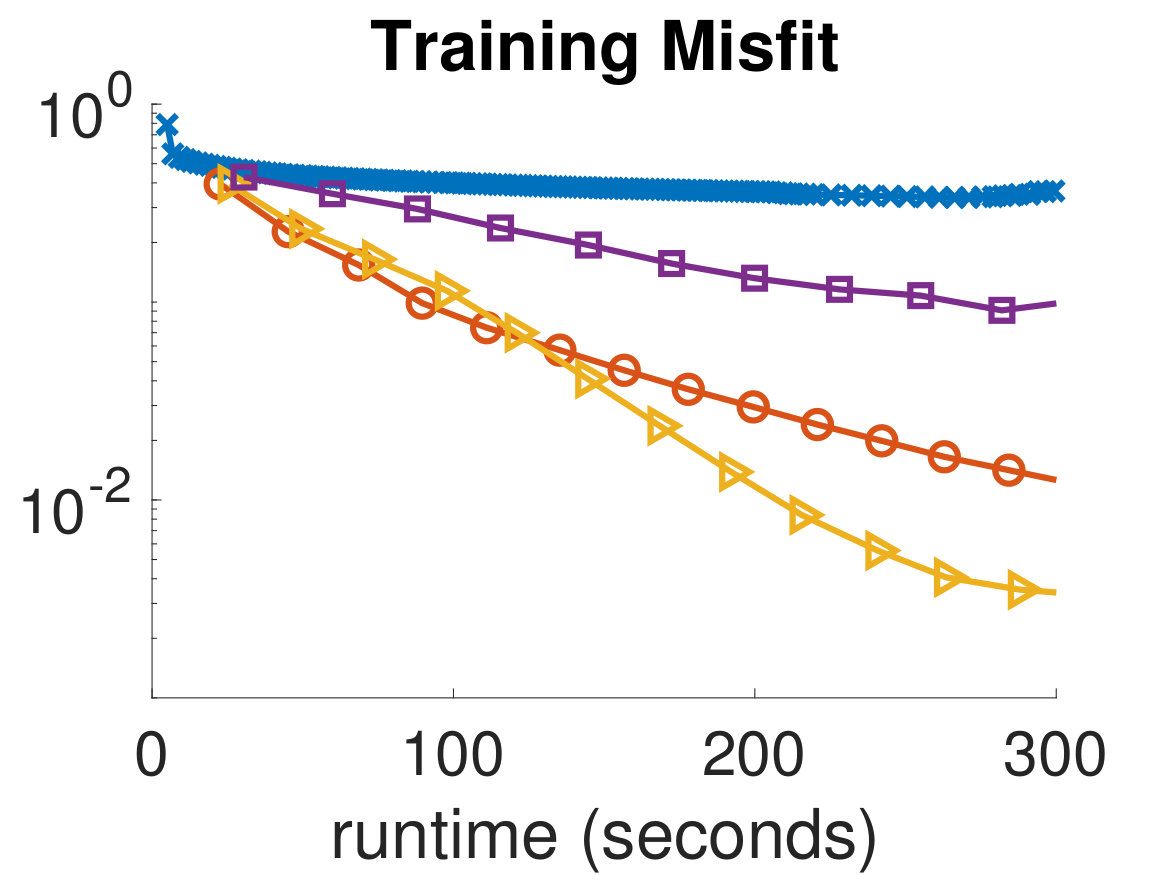 Figure 4
Figure 4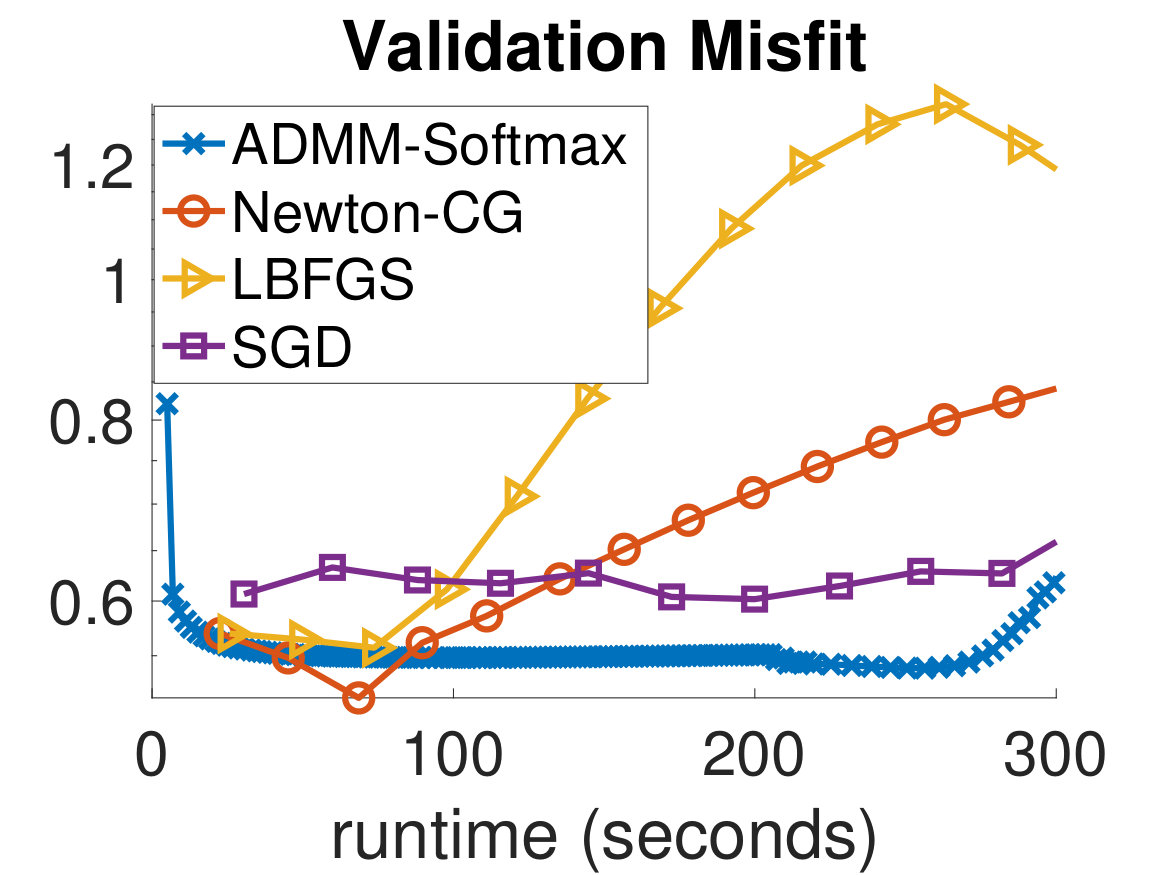 Figure 5
Figure 5 Figure 6
Figure 6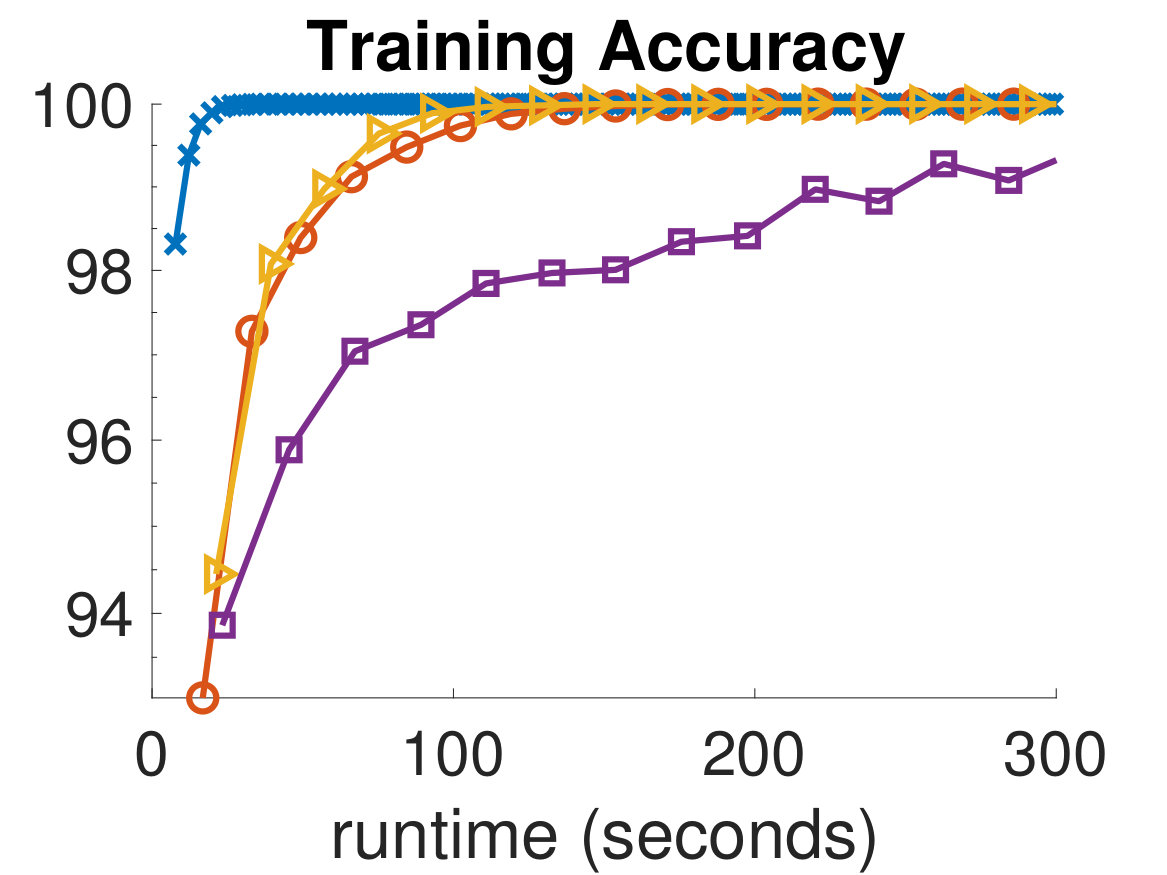 Figure 7
Figure 7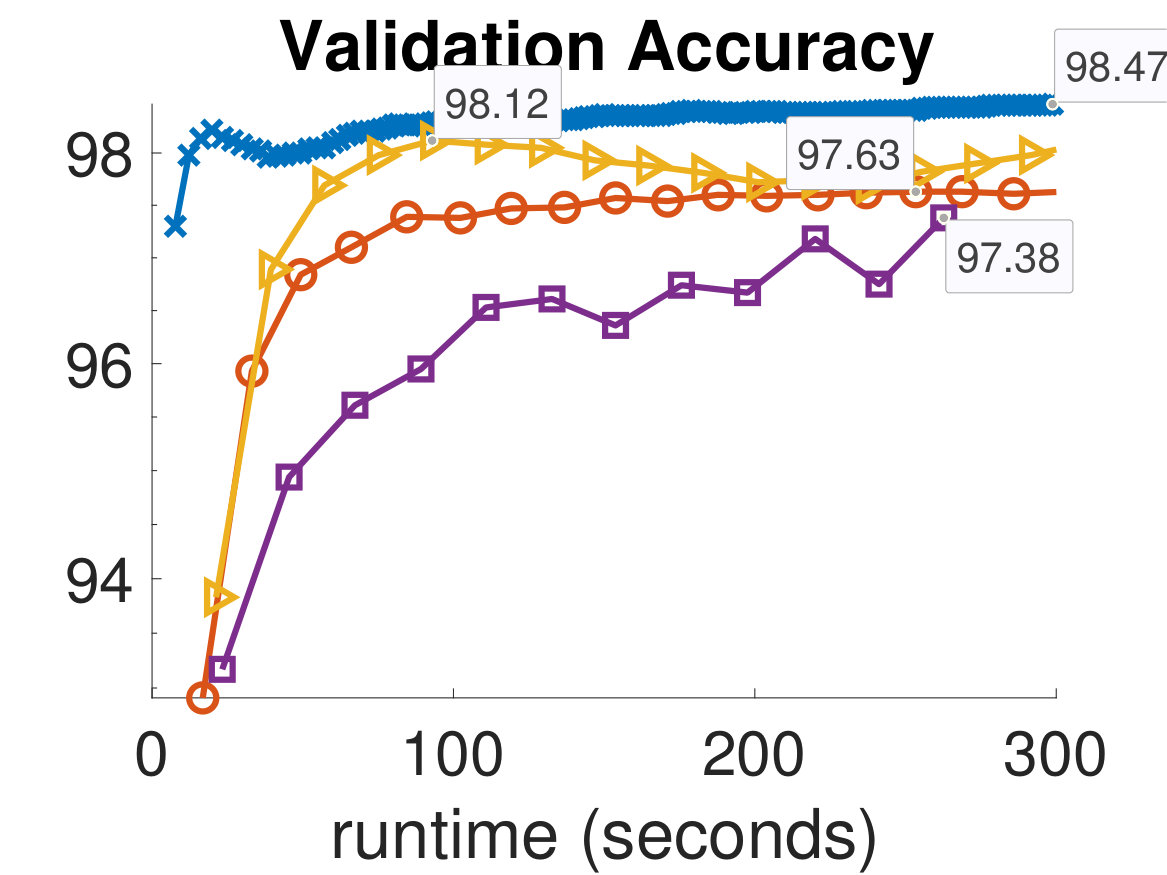 Figure 8
Figure 8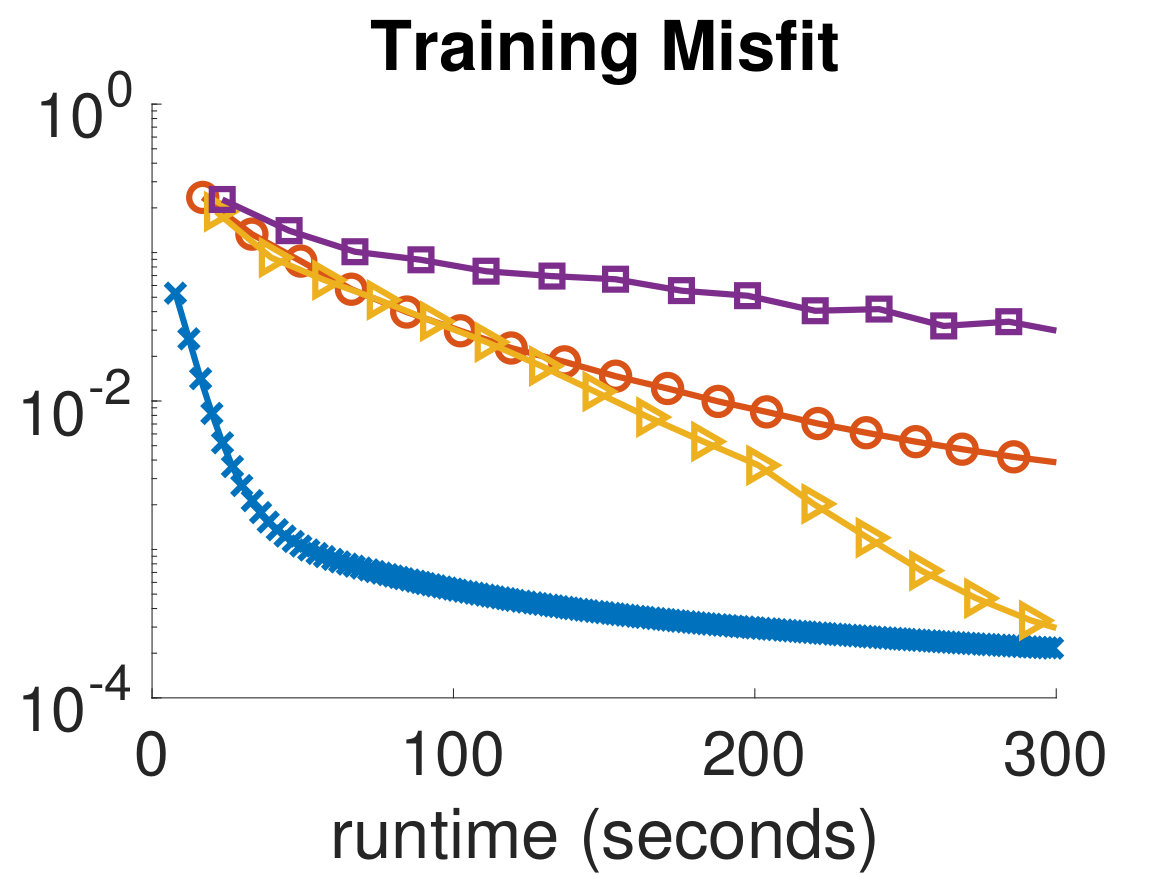 Figure 9
Figure 9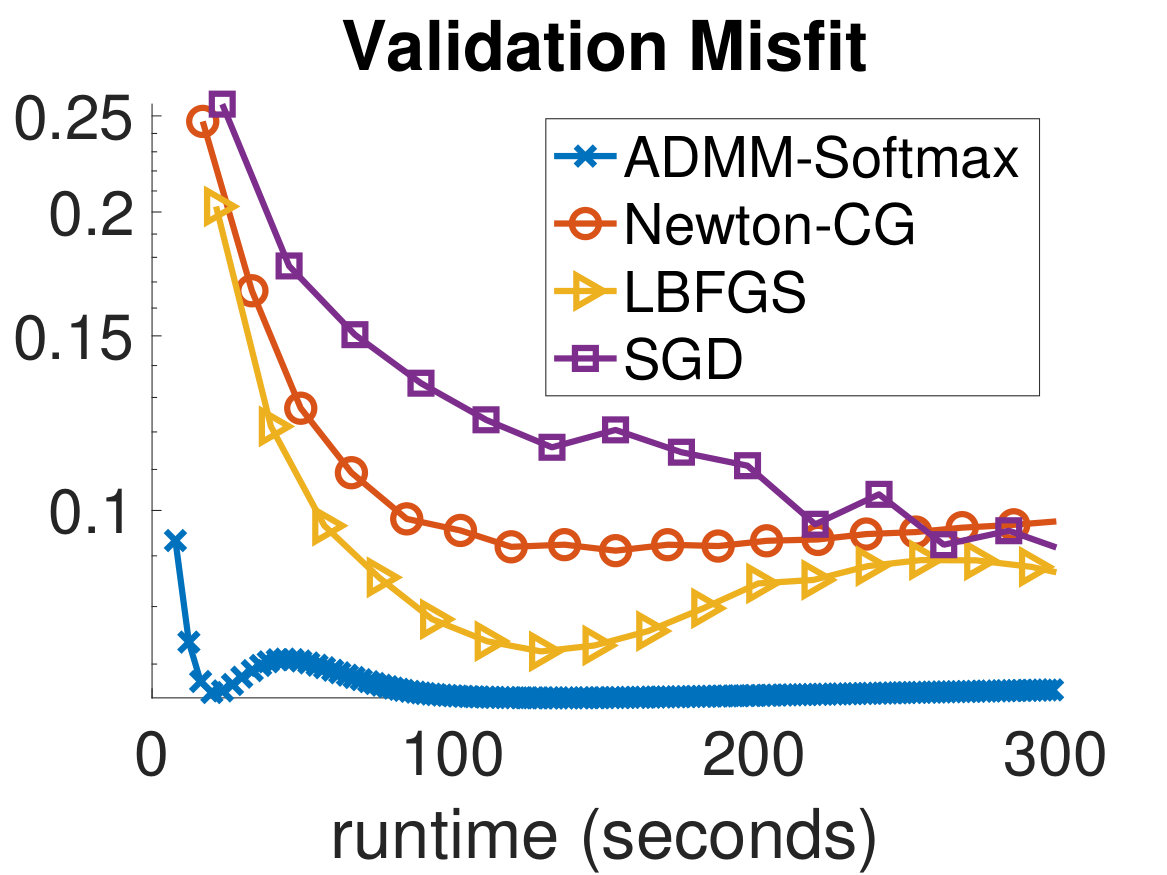 Figure 10
Figure 10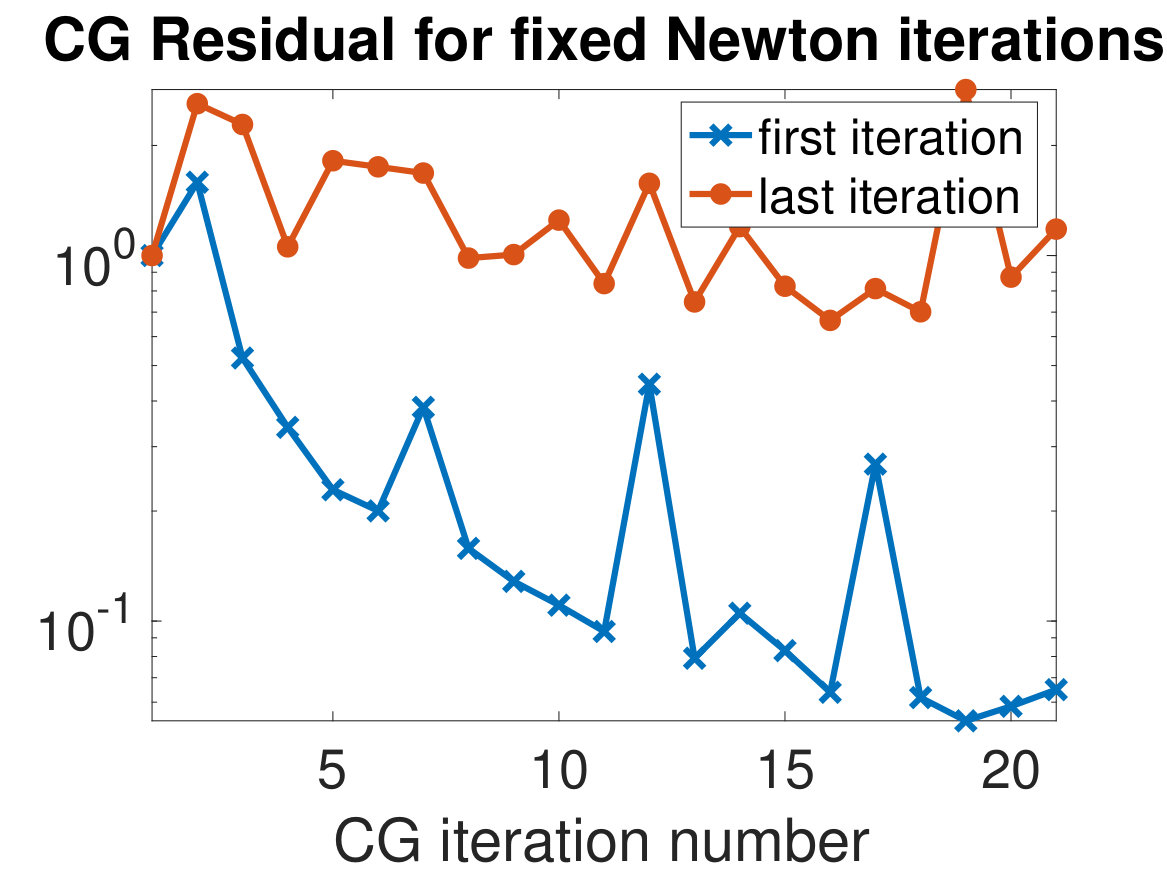 Figure 11
Figure 11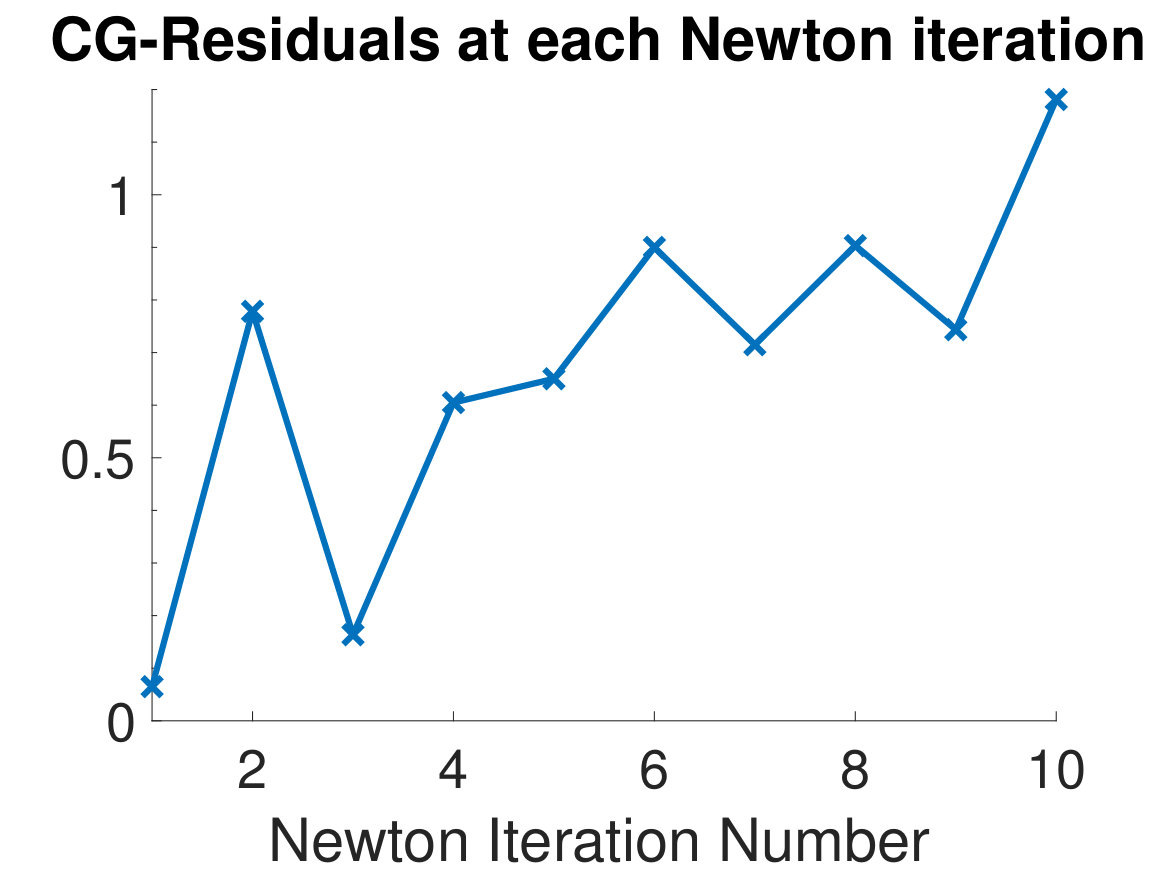 Figure 12
Figure 12 Figure 13
Figure 13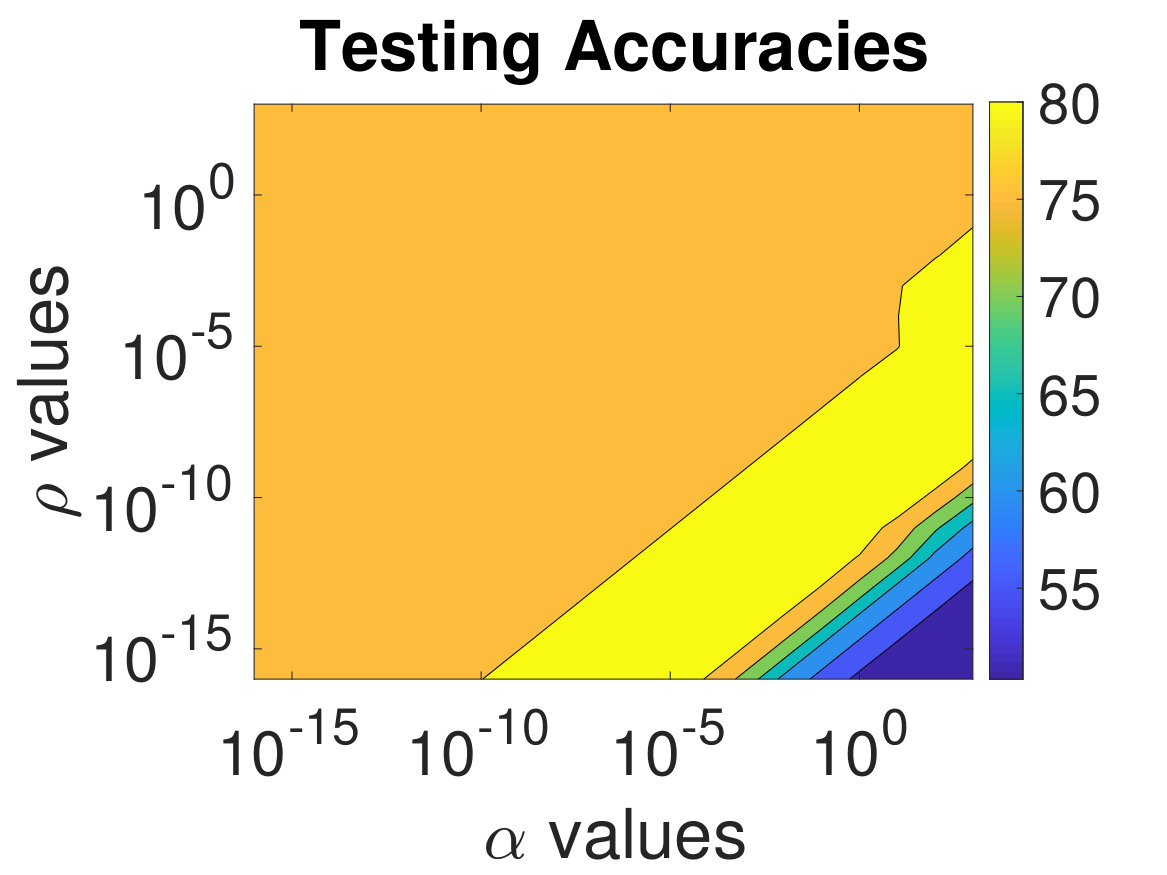 Figure 14
Figure 14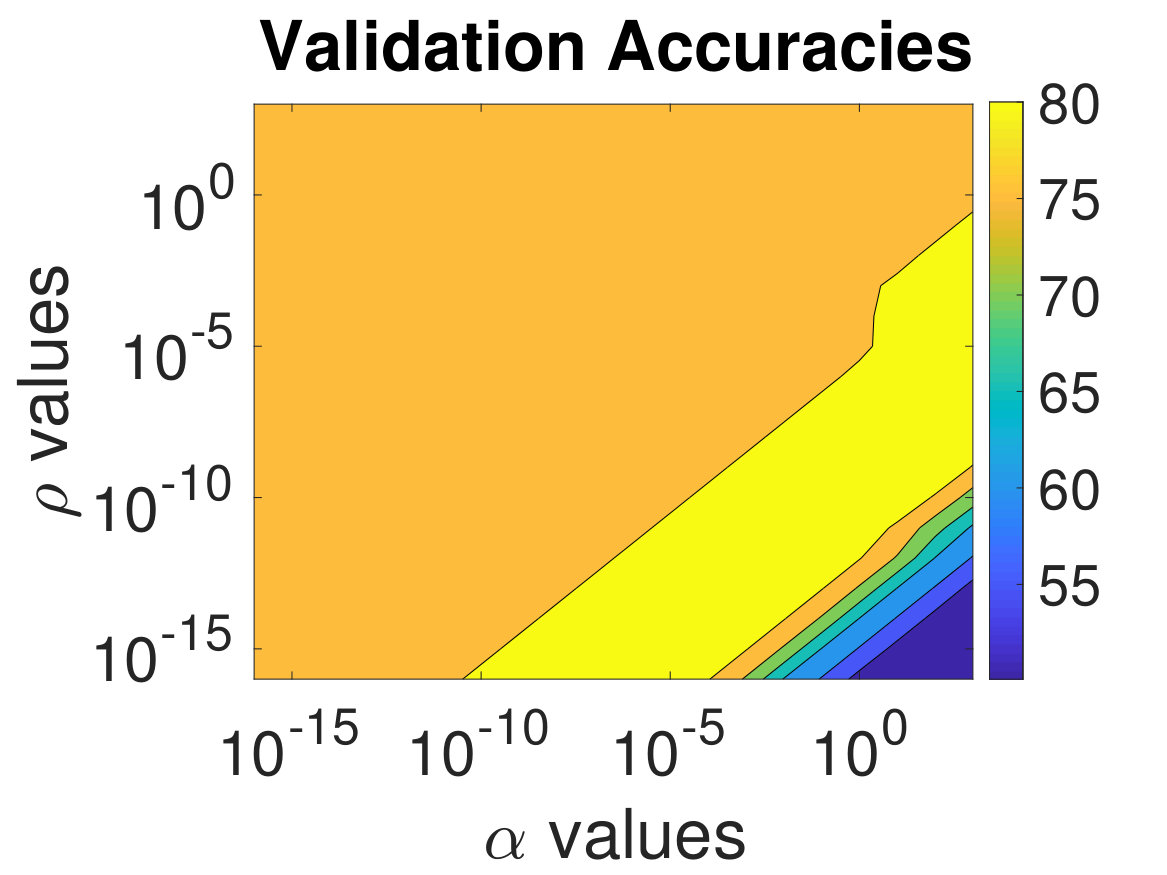 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17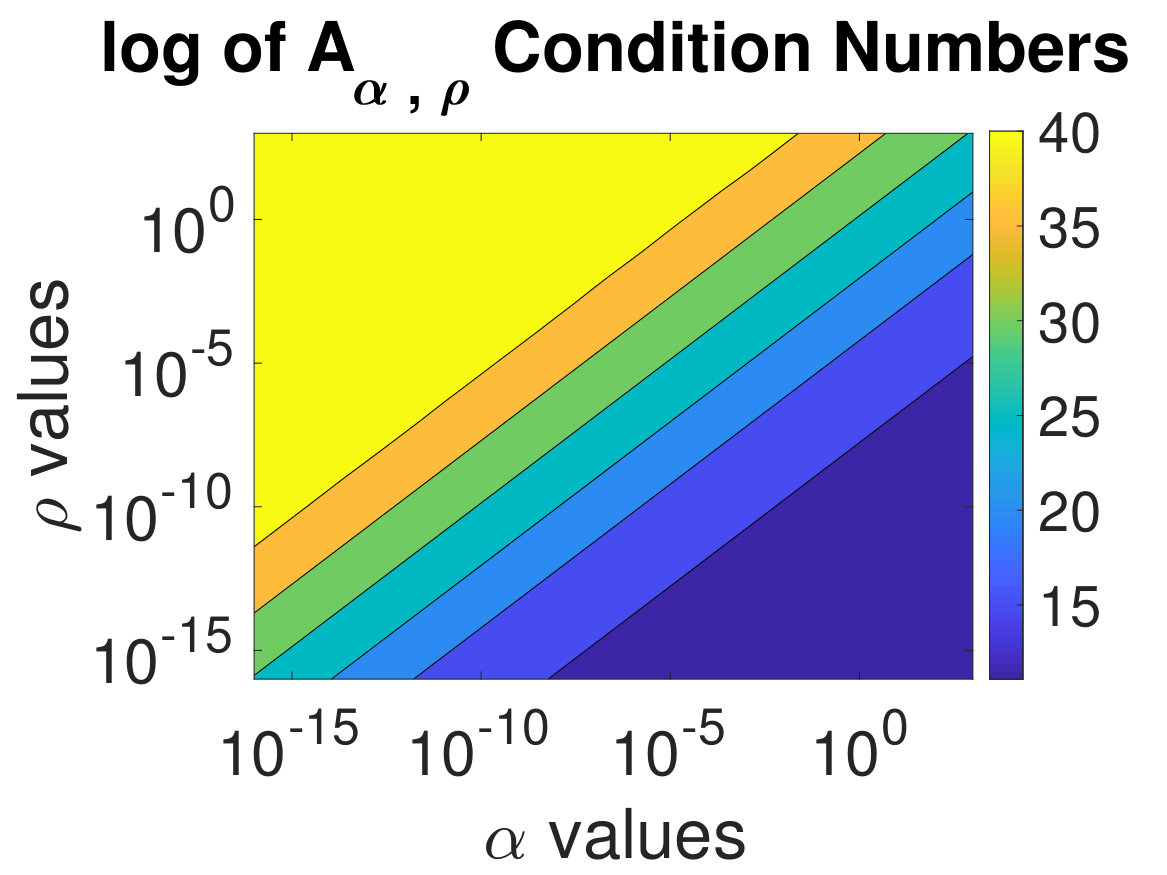 Figure 18
Figure 18| MNIST | CIFAR-10 | |||||||
|---|---|---|---|---|---|---|---|---|
| validation | testing | validation | testing | |||||
| misfit | accuracy | misfit | accuracy | misfit | accuracy | misfit | accuracy | |
| ADMM-Softmax | ||||||||
| Newton-CG | ||||||||
| -BFGS | ||||||||
| SGD | ||||||||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsLogistic Regression
ADMM-Softmax : An ADMM Approach for Multinomial Logistic Regression
Samy Wu Fung222Department of Mathematics, University of California, Los Angeles, Los Angeles, CA, USA ([email protected])
Sanna Tyrväinen333Department of Mathematics, University of British Columbia, Vancouver, Canada ([email protected])
Lars Ruthotto555Department of Mathematics, Emory University, Atlanta, GA, USA ([email protected])
Eldad Haber444Department of Earth, Ocean and Atmospheric Sciences, University of British Columbia, Vancouver, Canada ([email protected] )
Abstract
We present ADMM-Softmax, an alternating direction method of multipliers (ADMM) for solving multinomial logistic regression (MLR) problems. Our method is geared toward supervised classification tasks with many examples and features. It decouples the nonlinear optimization problem in MLR into three steps that can be solved efficiently. In particular, each iteration of ADMM-Softmax consists of a linear least-squares problem, a set of independent small-scale smooth, convex problems, and a trivial dual variable update. Solution of the least-squares problem can be be accelerated by pre-computing a factorization or preconditioner, and the separability in the smooth, convex problem can be easily parallelized across examples. For two image classification problems, we demonstrate that ADMM-Softmax leads to improved generalization compared to a Newton-Krylov, a quasi Newton, and a stochastic gradient descent method.
keywords: machine learning, nonlinear optimization, alternating direction method of multipliers, classification, multinomial regression
1 Introduction
Multinomial classification seeks to assign the most likely label from a pre-defined set of three or more classes to all examples in a dataset. Classification is a key step in a wide range of applications such as data mining [31], neural signal processing [38], bioinformatics [46, 34] and text analysis [43]. The process can be described mathematically as a classifier (or hypothesis function) that maps each input feature to a vector in the unit simplex, whose components represent the predicted probabilities for each class.
In machine learning, the classifier is modeled as a fairly general parameterized function whose parameters (also called weights) are trained using a number of examples. Depending on the availability of labels for this data, one distinguishes between supervised learning, where labels are available for all examples, unsupervised learning, where only input features are provided, and semi-supervised learning, where only parts of the examples are labeled. Some well-known optimization problems arising in multinomial classification include multinomial logistic regression (MLR) [13] and support vector machines (SVMs) [36] for supervised learning, and k-nearest neighbors [23] for unsupervised learning. In this paper, we are primarily concerned with the efficient solution of the supervised learning problem arising in MLR.
When the dimensionality of the feature vector and the number of examples are large, a key challenge in MLR is the computational expense associated with solving a convex, smooth optimization problem. In short, the MLR problem consists of minimizing a (regularized) cross-entropy loss function used to compare the classifier’s outputs to the given class probabilities. The classifier concatenates a softmax function, which maps a vector to the unit simplex, and an affine transformation whose weights are to be learned. Since the problem is smooth and convex, many standard optimization algorithms can be used to train the classifier, e.g., steepest descent [35], inexact-Newton or quasi-Newton methods [47], and perhaps the most commonly used in the machine learning community, stochastic gradient descent (SGD) [52, 30]. In practice, the performance of these methods can deteriorate close to the minimizer (manifesting, e.g., in a larger number of Conjugate Gradient (CG) steps in Newton-CG shown in Fig. 7) and, particularly in the case of SGD, the limited potential for parallelization.
It is important to note that MLR is not equivalent to solving the optimization problem since an effective classifier must generalize well, i.e., it must assign accurate labels to instances not used during training. A known problem is overfitting, which occurs when the optimal weights fail to generalize. Hence, the optimization problem is not equivalent to the learning problem. To gauge the risk of overfitting, we partition the available training set into three subsets: the training set, which is used in the optimization, the validation set, which is used to gauge the generalization of the classifier and tune regularization and other parameters through cross-validation, and the test set, which is not used at all during training but used for the final assessment. As we will also demonstrate in our numerical experiments, the effect of overfitting in MLR is similar to the well-known semi-convergence in ill-posed inverse problems. This motivates the use of iterative regularization methods that have been very successful in inverse problems; see, e.g., [25, 37, 21, 8, 15].
Our contribution consists of a reformulation of the MLR optimization problem into a constrained problem and its approximate solution through the alternating direction method of multipliers (ADMM). Each iteration of the scheme requires the solution of a linear least-squares (LS) problem, a separable convex, smooth optimization problem, and a trivial dual update variable; see Sec. 3. The LS problem arising from the weights can be efficiently solved using direct or iterative solvers [18, 41]. Due to its separability, the smooth and convex problem arising from the second step can be solved in parallel for each example from the training set. We also provide all codes and examples used in this paper at https://github.com/swufung/ADMMSoftmax.
We test our method on two popular image classification problems: MNIST [33], a collection of hand-written digits, and CIFAR-10 [28], a collection of color images divided into 10 classes. As is common in machine learning, we embed the original data into a higher-dimensional space before beginning the training process to improve the accuracy and generalization of the classifier. In particular, we propagate the MNIST dataset through a convolution layer with randomly chosen weights, which is also known as extreme learning machines (ELM); see Sec. 4.1.1 and [24]. For the CIFAR-10 dataset, we propagate the input data through a neural network which was previously trained on a similar dataset (also known as transfer learning). The pre-trained network we choose to use is AlexNet [28], which was trained on the ImageNet dataset [9], a dataset similar to CIFAR-10.
Our paper is organized as follows. In Sec. 2, we phrase MLR as an optimization problem and briefly review existing approaches for its solution. In Sec. 3, we present the mathematical formulation of the proposed ADMM-Softmax algorithm and discuss its computational costs and convergence properties. In Sec. 4, we compare our method to SGD and Newton-CG on the MNIST and CIFAR-10 dataset. Finally, we conclude our paper with a discussion in Sec. 5.
2 Multinomial logistic regression
In this section, we review the mathematical formulation of multinomial logistic regression and discuss some related works. In training, we are given labeled data sampled from a typically unknown probability distribution. Here, is the feature vector, is the number of features (e.g., number of pixels in an image), is the class label, and denotes the unit simplex in where is the number of classes. Since the class vector, , belongs to the unit simplex, we can interpret it as a discrete probability distribution.
The softmax classifier used to predict the class labels is given by
[TABLE]
Here, is the predicted class label, is a weight matrix, is a vector of all ones, and the exponential function is applied component-wise. To simplify our notation, we assume that (1) already contains a bias term that applies a constant shift to all transformed features and leads to an affine model. A simple way to incorporate the bias term is by appending the feature vector with a one and adding a new column to the weight matrix.
In the training, we seek to estimate weights such that and that the predicted label (i.e. the index of the largest component of ) matches the true label for all pairs . To quantify this, we use the expected cross-entropy loss function to measure the discrepancy between the true probabilities, , and the predicted probabilities, . In particular, we write the expected loss function as
[TABLE]
where the we use the fact that since . The expected loss function consists of a linear term and log-sum-exp term and thus is convex and smooth [5]. In general, the loss couples all components of , which we will address with our proposed method.
To further aid generalization and avoid overfitting, it is common to add a Tikhonov regularization term and consider the following stochastic optimization problem of multinomial logistic regression
[TABLE]
where is a regularization operator that may enforce, e.g., smoothness, and is a regularization parameter that balances the minimization of the loss and the regularity of the solution. Note here that has dimensions so that each row of corresponds to the features of each class. Therefore, we transpose the weights in the regularization term so that we regularize the features rather than the classes of the weights. The matrix is a reference solution around which the regularizer is centered and needs to be chosen by the user. During the training process, we monitor the effectiveness of the weights for instances in the validation set to calibrate the regularization parameter and other hyperparameters using cross validation. After the training, we apply the classifier to the test dataset to quantify its potential to generalize.
Since we are primarily concerned with the splitting schemes, we focus the discussion to the quadratic regularizer. This choice also leads to a linear least-squares problem in our proposed scheme. A common alternative to the quadratic regularizer is regularization, which is used to enforce sparsity of the weight matrix and identify and extract the essential features in the data. Efficient approaches exist to address the non-smoothness introduced by this regularizer, e.g., interior-point methods [27], iterative shrinkage [20], and hybrid algorithms [42]; see also the survey by Yuan et al. [50]. These schemes can be incorporated into ADMM-Softmax.
Optimization methods for soving (3) can be broadly divided into two classes. Stochastic approximation (SA) methods such as stochastic gradient descent (SGD) and its variants, iteratively update using gradient information computed with a single pair (or a small batch of pairs) randomly chosen from the training set [40]. Upon a suitable choice of the step size (also called learning rate) these methods can decrease the expected loss. In contrast, stochastic average approximation (SAA) schemes [26] approximate the expected loss with an empirical mean computed for a large batch containing randomly chosen examples , which leads to the deterministic optimization problem
[TABLE]
Since the objective function is convex and differentiable, many standard gradient-based iterative optimization algorithms are applicable. The method proposed in this work is an SAA method, and our numerical experiments consider both SGD (an SA method) and several standard SAA methods for comparison. For an excellent review and discussion about the advantages and disadvantages of both approaches, we refer to [3].
In general, the objective functions in (3) and (4) are not separable, i.e., they couple all the components in . Due to the coupling, the Hessian cannot be partitioned and also changes in each iteration dependent due to the nonlinearity of the problem. The above reasons can render their solution computationally challenging, especially for high-dimensional data, and in the case of SAA methods, a large number of samples, .
2.1 Related work
The wide-spread use of MLR in classification problems has led to the development of many numerical methods for its solution. A common thread is efforts to decouple the optimization problems (3) and (4) into several subproblems that can be solved efficiently and in parallel.
For example, [4, 19], use an upper bound based on the first-order concavity property of the log-function to decouple (4) into subproblems associated with the different classes. The new optimization problem, however, is no longer convex. Other possible upper bounds that allow for a separable reformulation of MLR include quadratic upper bounds and a product of sigmoids. Detailed comparison of these and analytical solutions in a Bayesian setting can be found in [4]. In [19], Gopal and Yang use the concavity bound to solve multinomial logistic regression in parallel and show that their iterative optimization of the bounded objective converges to the same optimal solution as the unbounded original model. Related to the concavity bound, Fagan & Iyengar [12] and Raman et al. [39] use convex conjugate of the negative log to reformulate the problem as a double-sum that can be solved iteratively with SA methods like SGD.
A method closely related to ours is [19], which reformulates the MLR problem (4) as a constrained optimization problem that decouples the linear and nonlinear terms of the cross-entropy loss and approximately solves the problem using an ADMM approach. Our method uses a similar splitting and parallelization scheme. As in [19], the existing optimization methods slightly outperform our scheme in terms of minimizing the expected loss over the training set; however, the obtained solutions of our scheme generalize better. Both approaches are inspired by the work of Boyd et al. [5], who solve sparse logistic regression problems parallel by splitting it across features with ADMM.
Splitting techniques have also been applied to non-convex classification problems, e.g., the training of neural networks [44]. Here, the examples concentrate on binomial regression, which allows one to use a quadratic loss function and closed-form solutions for each iteration steps. Another related approach to train neural networks is the method of auxiliary coordinates (MAC) [6]. In MAC, new variables are introduced to decouple the problem. Unlike ADMM, however, MAC breaks the deep nesting (i.e., function compositions) in the objective function with the new parameters.
3 ADMM-Softmax
In this section, we derive ADMM-Softmax, which is an SAA method for MLR. The main idea of our method is to introduce an auxiliary variable and associated constraint in (4) to obtain a separable objective function and then solve the problem approximately using an ADMM method. As common, the iterations of the ADMM method break down into easy-to-solve subproblems; see [5] for an excellent introduction to ADMM. In our case, we obtain a regularized linear least-squares problem, a separable convex, smooth optimization problem, and a trivial dual variable update. Efficient solvers exist for the first two subproblems.
By introducing global auxiliary variables , we reformulate (4) as
[TABLE]
Note that this problem is equivalent to the SAA version of MLR in (4).
To solve (5) using ADMM-Softmax, we first consider the augmented Lagrangian
[TABLE]
where is the Lagrange multiplier associated with the th constraint, and is a penalty parameter. The ADMM algorithm aims at finding the saddle point of the by performing alternating updates. Denoting the values of the primal and dual variables at the th iteration by , respectively, the scheme consists of the following three steps
[TABLE]
Note that in the second step we have used the fact that the Lagrangian does not couple the variables and for to obtain independent subproblems that can be solved can be solved in parallel. By introducing the scaled Lagrange multiplier and dropping constant terms in the respective optimization problems, the steps simplify to
[TABLE]
The first subproblem (6) is a linear least-squares problem whose coefficient matrix is independent of (see Sec. 3.1), and the second subproblem (7) decouples into independent problems, each of which is a convex, smooth optimization problem and involves variables; see Sec. 3.2.
Let us note in passing that a different regularization in the original optimization problem (4) would only impact the least-squares subproblem in (6), and the formulation of the -steps in (7) would remain unchanged. Therefore, one can use any existing algorithms to efficiently solve least-square problems with different types of regularizations terms.
To terminate the ADMM iteration, a common stopping criteria is described in [5], where the norms of the primal and dual residuals are defined as
[TABLE]
respectively, where for any matrix , the operator vec() returns its vectorized form. The stopping criterion is satisfied when
[TABLE]
where and are the relative and absolute tolerances chosen by the user. For a summary of the proposed scheme, we refer to Alg. 1.
3.1 -update
Letting
[TABLE]
we can rewrite the -update (6) as
[TABLE]
which amounts to solving independent linear least-squares (i.e., one for each row in ). This is equivalent to solving normal equations
[TABLE]
where . Noting that the coefficient matrix in (12) is not iteration-dependent, depending on the number of features, the matrix can be factorized once (e.g., using Cholesky applied to the normal equations or a thin-QR applied to the original least-squares problem [18]) and its inverse can be quickly applied, leading to trivial solves throughout the optimization. We also note that this is only one possible approach for solving (12), and that large-scale problems can be addressed using iterative methods; see, e.g., [18, 41, 2, 16, 17, 1, 14]. As the performance of most iterative methods can be improved using pre-conditioning, we can compute a preconditioner (e.g., incomplete Cholesky factorization) in an offline phase and re-use it in the ADMM iterations.
3.2 -update
Each of the objective functions in the -updates in (7) can be written as
[TABLE]
where , and . In our numerical experiments, we solve these -dimensional convex, smooth optimization problems using a Newton method. The gradient and Hessian of the objective are
[TABLE]
and
[TABLE]
respectively. Here, for a generic vector , the operator returns a diagonal matrix with along its diagonal. For examples with many classes, the Newton direction can be approximated using an iterative solver, e.g., the preconditioned conjugate gradient method (PCG). In this case, we do not build the Hessian in (14) explicitly; instead, we implement its action on a vector in order to save memory.
3.3 Computational costs and convergence
A computationally challenging step in ADMM-Softmax is solving the least-squares problem (6), for which there is a myriad of efficient solvers; see, e.g., [18] for an extensive review. Noting that the coefficient matrix, in (12) is iteration-independent, it could be factorized in the off-line phase with, e.g., Cholesky or thin QR, and we can trivially solve least-squares throughout the optimization.
The -updates in (7) can be solved in independently and in parallel for each . In our experiments, we solve the -updates using Newton-CG. Assuming workers are available, the cost for each Hessian matrix-vector product from (14) is in the order of about FLOPS per worker, leading to very fast computations of the global variable update. If , that is, if we have a worker for each example, the cost per worker is in the order of FLOPS. We note that the number of class labels is usually relatively small compared to the number of features (in our experiments, for instance, ), making (7) negligible when solved in parallel.
As for convergence, it has been shown that the ADMM algorithm converges linearly for convex problems with an existing solution regardless of the choice [11]. If the subproblems (6) or (7) are solved inexactly, ADMM still converges under additional conditions. In particular, the sequences
[TABLE]
must be summable. This allows us to solve the subproblems iteratively, especially for large-scale problems. More details can be found in [11].
4 Numerical experiments
In this section, we demonstrate the potential of our proposed ADMM-Softmax method using the MNIST and CIFAR-10 datasets. For both datasets, we first compare three algorithms: The SAA methods ADMM-Softmax, Newton-CG, and -BFGS and the SA method SGD. We then study the behavior of ADMM-Softmax and its dependence on the penalty and regularization parameter. We illustrate the challenges of Newton-CG in MLR by a comparison of the PCG performance at the first and final nonlinear iteration. We perform our experiments in MATLAB using the Meganet deep learning package [48] and we provide our code at https://github.com/swufung/ADMMSoftmax. We perform all of our experiments on a shared memory computer operating Ubuntu 14.04 with 2 Intel Xeon E5-2670 v3 2.3 GHz CPUs using 12 cores each, and a total of 128 GB of RAM.
4.1 Setup
4.1.1 MNIST
The MNIST database consists of 60,000 grey-scale hand-written images of digits ranging from 0 to 9; see [32, 33]. Here, we set 40,000 examples for training our digit-recognition system, 10,000 are used for validation, and the remaining 10,000 is used as testing data. Each image has pixels. A few randomly chosen examples are shown in Fig. 1.
To improve the capacity of our multinomial regression model, we embed the original features into a higher-dimensional space obtained by a nonlinear transformation to the original variables; this procedure is also known as extreme learning machines [24]. In particular, for each image, we obtain nine transformed images by using a convolution layer with randomly chosen filters, i.e.,
[TABLE]
where all 9 vertical blocks of are 2D convolution operators. Here, we assume periodic boundary conditions which render each block to be a block-circulant matrix with circulant blocks (BCCB) [22]. The transformed features have dimensions . Expanding the features increases the effective rank of the feature matrix and increase the capacity of the classifier. An illustration of the propagated features is shown in Fig. 3.
We compare four algorithms: our proposed ADMM-Softmax, Newton-CG, -BFGS, and SGD. In SGD, we use Nesterov momentum with minibatch size , and learning rate . Here, we choose the learning rate and minibatch sizes by performing a grid-search on and to maximize the performance on the validation set, respectively. The initial learning rate grid-search is done logarithmically, whereas the minibatch sizes are uniformly spaced. In Newton-CG, we set a maximum number of inner CG iterations per Newton iteration, with CG tolerance of . In -BFGS, we store the most recent vectors used to approximate the action of the Hessian on a vector at each iteration, and solve the inner system with the same settings as in Newton-CG.
For the ADMM-Softmax, we perform a grid-search on and report the that led to the best validation accuracy - in this case, . To solve the LS system, we compute a QR factorization in the off-line phase, which for this experiment took about seconds. To solve (7), we use the Newton-CG method from the Meganet package using a maximum of iterations with gradient norm stopping tolerance of , and initial condition (i.e., warm start). Since we do not parallelize step (7) in our implementation, our input for (7) is given by , and the resulting Hessian is block diagonal. As a result, we solve the inner Newton system using a maximum of inner iterations and stopping tolerance of . Note that if we solved (7) in parallel using workers, we would not need more than CG iterations, as each individual Hessian would have size .
For all three methods, we use a discrete Laplace operator as the regularization operator with to enforce smoothness of the images, and set reference weights to . In this case, we chose the that led to the best validation accuracy for the Newton-CG method.
4.1.2 CIFAR-10
The CIFAR-10 dataset [28] consists of 60,000 RGB images of size that are divided into 10 classes. As in MNIST, we split the data as follows: for training, as validation, and as testing data. The images belong to one of the following 10 classes: airplane, automobile, bird, cat, deer, dog, frog, horse, ship, and truck.
For this dataset, we increase the feature space by propagating the input features through a neural network (AlexNet [29]), which was trained on the ImageNet dataset [9] using MATLAB’s deep neural networks toolbox - this procedure is also known as transfer learning. The main goal apart from increasing the dimensionality of the dataset is to embed the features in a way that renders them linearly separable, which is the assumption on MLR. The main difference to the extreme learning machine that we used for MNIST is that instead of propagating through a random hidden layer as in (15), we propagate through a network whose layers have already been trained on a similar dataset to that of CIFAR-10. In this case, we extract the features from the pool5 layer in AlexNet. For this dataset, each example is an RGB image of dimension and the propagated data has dimension .
As for the optimization, we maintain the same parameter choice as in the MNIST dataset except for the following. For SGD, we repeat our grid-search for the learning rate and minibatch sizes as in MNIST and report the parameters that led to the best results. This leads to a smaller learning rate of but the same minibatch size of . For ADMM-Softmax, we choose the penalty parameter as in the same manner as in Sec. 4.1.1. In this case, the propagated features no longer correspond to RGB images. As before, we use the Laplace operator as the regularization operator with and chose the that led to the best results for Newton-CG, in this case, .
4.2 Comparison
In Fig. 4 and Fig. 5, we show the training and validation accuracies and misfits for all algorithms on the MNIST dataset and CIFAR-10 dataset, respectively. The former demonstrate the effectiveness of the optimization scheme, while the latter gauges the classifier’s ability to generalize, which is the main concern in MLR. Since the computational work required for each algorithm per iteration is different, we report the runtimes of each algorithm and provide an equal computational budget of 300 seconds to all methods and instances. As can be seen, we are able to afford many more ADMM-Softmax iterations than the other algorithms within the 300-second budget (noting again that the off-line factorizations took about 20 seconds). This is because the LS-problem and -updates took on average and seconds, respectively, per iteration for the MNIST dataset (despite not using any parallelization). Similarly, they took and seconds on average, respectively, per iteration for the CIFAR-10 dataset. This is dependent on the computational platform and implementation, but we conducted a serious effort to optimize the standard methods, while not realizing the parallelization potential of ADMM-Softmax. We also provide all codes needed to replicate our experiment. To compare the performance of each algorithm, we pick the weights in the iteration containing the highest validation accuracy for each respective algorithm and use them to classify the testing dataset. We show these results in Tab. 1.
It is important to note that although the training process is formulated as an optimization problem, we are not necessarily solving an optimization problem, since this may not mean better generalization. Instead, we wish for an algorithm that leads to the best validation dataset. For instance, in Fig. 5, the Newton-CG method is the most effective algorithm at reducing the training misfit, however, this makes the algorithm overfit to the training set, leading to worse performance on the validation dataset. This can be seen in the semi-convergence behavior of the validation misfits in Fig. 5, and is a reason for which SGD and ADMM are popular methods in the machine learning community. This situation is analogous to that of solving ill-posed inverse problems iteratively, where the objective is not necessarily choosing the parameters that best fit the (potentially noisy) data. Finally, we note that we did not use any parallelization in any of these experiments; however, we expect that further speedups of the ADMM-Softmax method can be achieved by computing the -update (7) in parallel, particularly for larger datasets.
4.3 Parameter dependence
We study the dependence of ADMM-Softmax on the penalty and regularization parameters and , where for brevity, we use only the CIFAR-10 dataset since it is the more challenging dataset; as can be seen in Sec. 4.2. In Fig. 6, we show the validation and testing accuracies for different values of and sampled from . As in Sec. 4.2, the weights that led to the highest validation accuracy were chosen to classify the testing dataset. The accuracy behavior is similar for the testing and validation datasets; thus, the validation dataset gives us a good indication of the generalizability of our classifier during the optimization. On the right, we show the condition numbers of (see (12)). As expected, smaller values of lead a more ill-conditioned , however, this can be remedied with sufficiently small .
4.4 Deterioration of Newton-CG Performance
As a final experiment, we exemplarily show that the performance of the inner iteration of Newton-CG deteriorates as we approach the global minimum. We have observed this phenomenon in many numerical experiments. Recall that the performance of CG depends mainly on the clustering of the eigenvalues of the Hessian of the objective function in (4), which is iteration-dependent; for an excellent discussion of CG, see [41]. We note that the Hessians are too large for us to reliably compute a full spectral decomposition in a reasonable amount of time, so as one indicator, we plot the residuals of the CG-solver after each Newton iteration on the left of Fig. 7. The plot shows that CG is less effective in later Newton-CG iterations. We also show the relative residuals for each inner CG iteration at the first and last Newton-CG iteration. Here, a decrease in performance is also evident as the last Newton iteration is quicker to stall than the first Newton iteration. ADMM-Softmax circumvents this problem as the Hessians in the -update are much smaller and easier to solve.
5 Conclusion
In this paper, we present ADMM-Softmax, a simple and efficient algorithm for solving multinomial logistic regression (MLR) problems arising in classification. To this end, we reformulate the traditional MLR problem consisting of an unconstrained optimization into a constrained optimization problem with a separable objective function. The new problem is solved by the alternating direction method of multipliers (ADMM), whose iteration consists of three simpler steps, i.e., a linear least-squares, a large number of independent convex, smooth optimization problems, and a trivial dual variable update. ADMM-Softmax allows the use of standard method for each of these substeps. In our experiments, we solve the resulting least-squares problems using a direct solver with a pre-computed factorization, and the nonlinear problems using a Newton method; see Sec. 3.
Our method is also inspired by the successful applications of ADMM to -regularized linear inverse problems, also known as lasso [45, 51] and basis pursuit [7]. Here, ADMM breaks the lasso problem into two subproblems: one containing a linear least-squares problem, and the other containing a decoupled nonlinear, non-smooth term, which amends a closed-form solution given by soft thresholding [10]. Our problem can be similarly divided into a linear least-squares problem and a set of decoupled smaller problems involving a nonlinear cross-entropy loss minimization. One distinction is that our second substep is solved using a Newton scheme.
Our numerical results show improved generalization when compared to Newton-CG and SGD for the MNIST and CIFAR-10 datasets. Further benefits are to be expected for large datasets where parallelization is necessary. We note that better accuracies, especially for the CIFAR-10 dataset, could be achieved if we re-train the parameters of pre-trained AlexNet [49] (rather than keeping them fixed). To this end, our method can accelerate block-coordinate algorithms that alternate between updating the network weights and the classifier. This is a direction of our future work. Our results can be reproduced using the codes provided at https://github.com/swufung/ADMMSoftmax.
Acknowledgments
This material is supported by the U.S. National Science Foundation (NSF) through awards DMS 1522599 and DMS 1751636. We also thank the Isaac Newton Institute (INI) for Mathematical Sciences for the support and hospitality during the programme on generative models, parameter learning, and sparsity.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] M. Benzi , Preconditioning techniques for large linear systems: a survey , Journal of computational Physics, 182 (2002), pp. 418–477.
- 2[2] M. Benzi and M. T u ma , A robust incomplete factorization preconditioner for positive definite matrices , Numerical Linear Algebra with Applications, 10 (2003), pp. 385–400.
- 3[3] L. Bottou, F. E. Curtis, and J. Nocedal , Optimization methods for large-scale machine learning , SIAM Review, 60 (2018), pp. 223–311.
- 4[4] G. Bouchard , Efficient bounds for the softmax function, applications to inference in hybrid models , in NIPS, Whistler, Canada, Dec 2007.
- 5[5] S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein , Distributed optimization and statistical learning via the alternating direction method of multipliers , Foundations and Trends® in Machine Learning, 3 (2011), pp. 1–122.
- 6[6] M. Á. Carreira-Perpiñán and W. Wang , Distributed optimization of deeply nested systems , in Proceedings of the Seventeenth International Conference on Artificial Intelligence and Statistics, S. Kaski and J. Corander, eds., vol. 33 of Proceedings of Machine Learning Research, PMLR, Reykjavik, Iceland, Apr 2014, pp. 10–19.
- 7[7] S. S. Chen, D. L. Donoho, and M. A. Saunders , Atomic decomposition by basis pursuit , SIAM Rev., 43 (2001), pp. 129–159.
- 8[8] J. Chung, J. G. Nagy, and D. P. O’Leary , A weighted GCV method for Lanczos hybrid regularization , Electronic Transactions on Numerical Analysis, 28 (2008).
