Disentangling and Learning Robust Representations with Natural Clustering
Javier Antoran, Antonio Miguel

TL;DR
This paper introduces N-VAE, a model that disentangles class-specific and shared factors of variation in data, improving generative capabilities and class-dependent factor detection.
Contribution
The paper proposes N-VAE, a novel model with a class-conditioned and shared latent space for disentangling multimodal generative factors.
Findings
Effective separation of class-specific and shared factors.
Ability to generate novel samples with unseen characteristics.
Improved detection of class-dependent generative factors.
Abstract
Learning representations that disentangle the underlying factors of variability in data is an intuitive way to achieve generalization in deep models. In this work, we address the scenario where generative factors present a multimodal distribution due to the existence of class distinction in the data. We propose N-VAE, a model which is capable of separating factors of variation which are exclusive to certain classes from factors that are shared among classes. This model implements an explicitly compositional latent variable structure by defining a class-conditioned latent space and a shared latent space. We show its usefulness for detecting and disentangling class-dependent generative factors as well as its capacity to generate artificial samples which contain characteristics unseen in the training data.
Click any figure to enlarge with its caption.
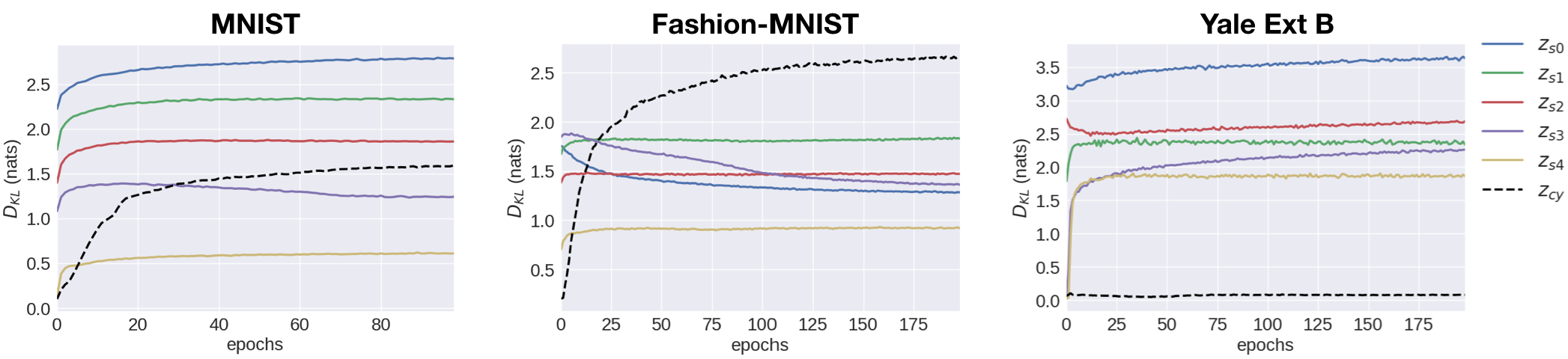 Figure 1
Figure 1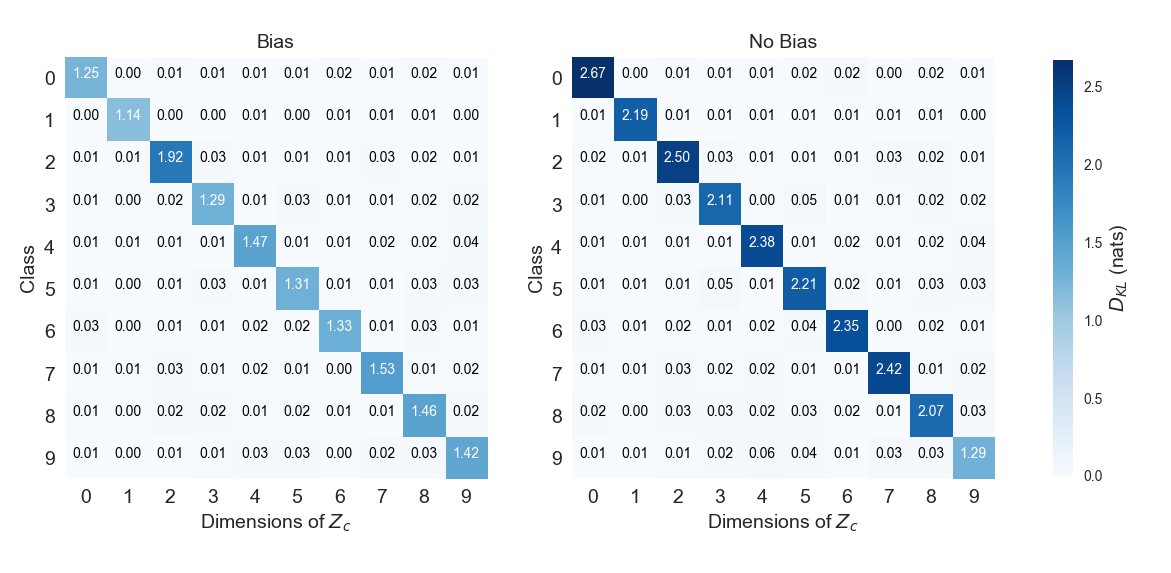 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7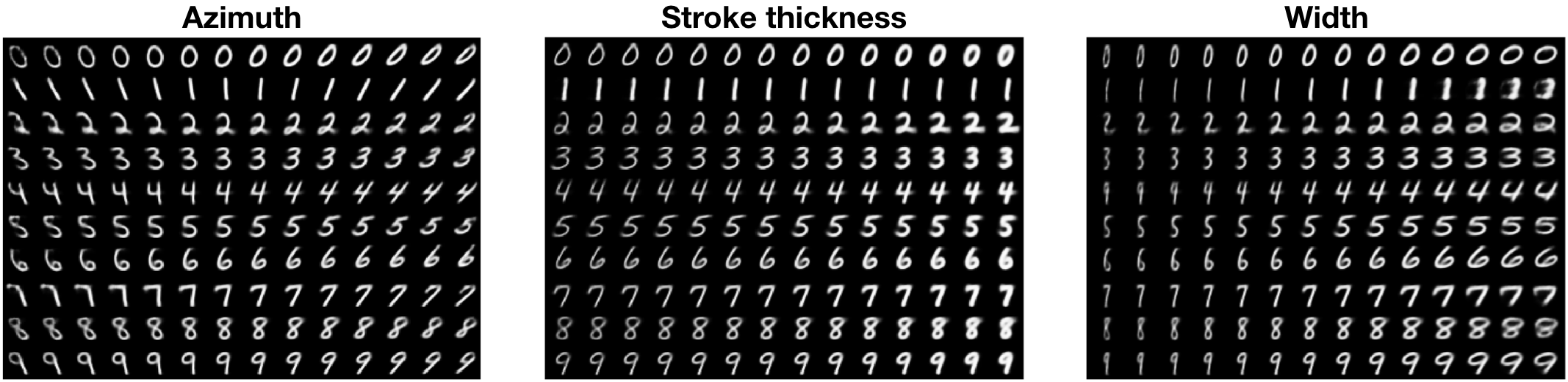 Figure 8
Figure 8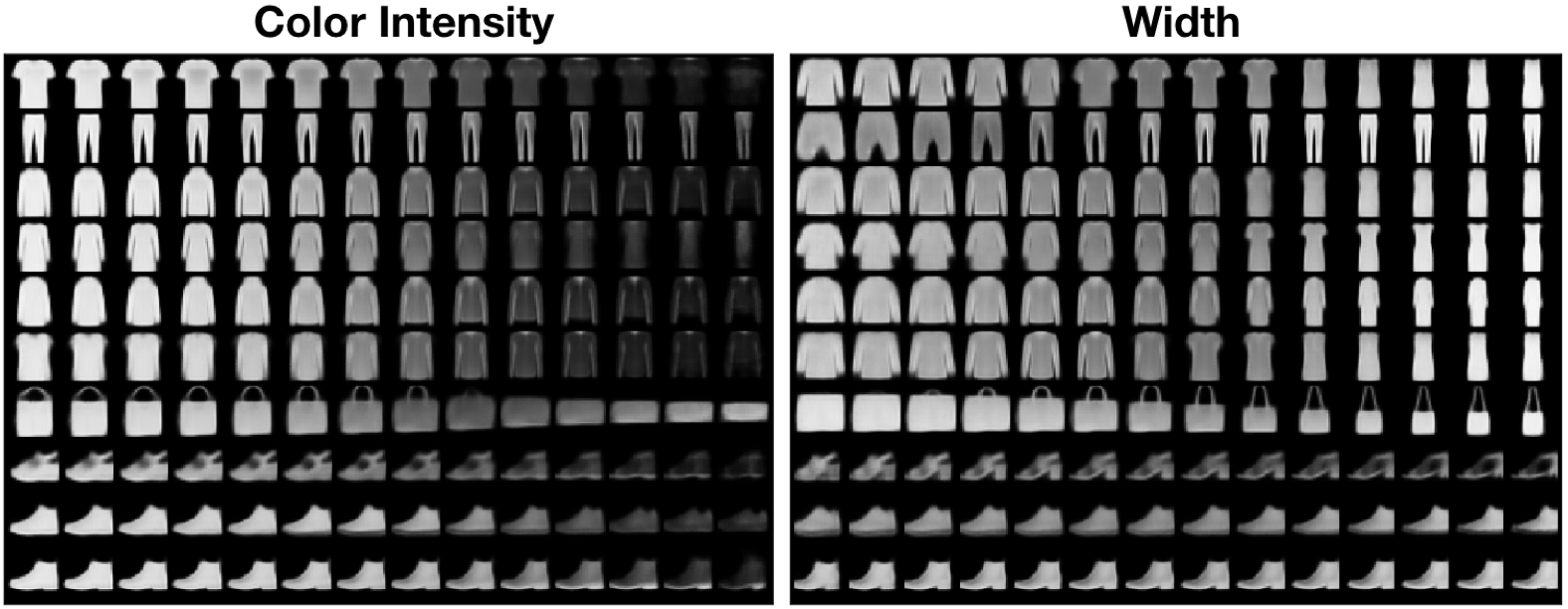 Figure 9
Figure 9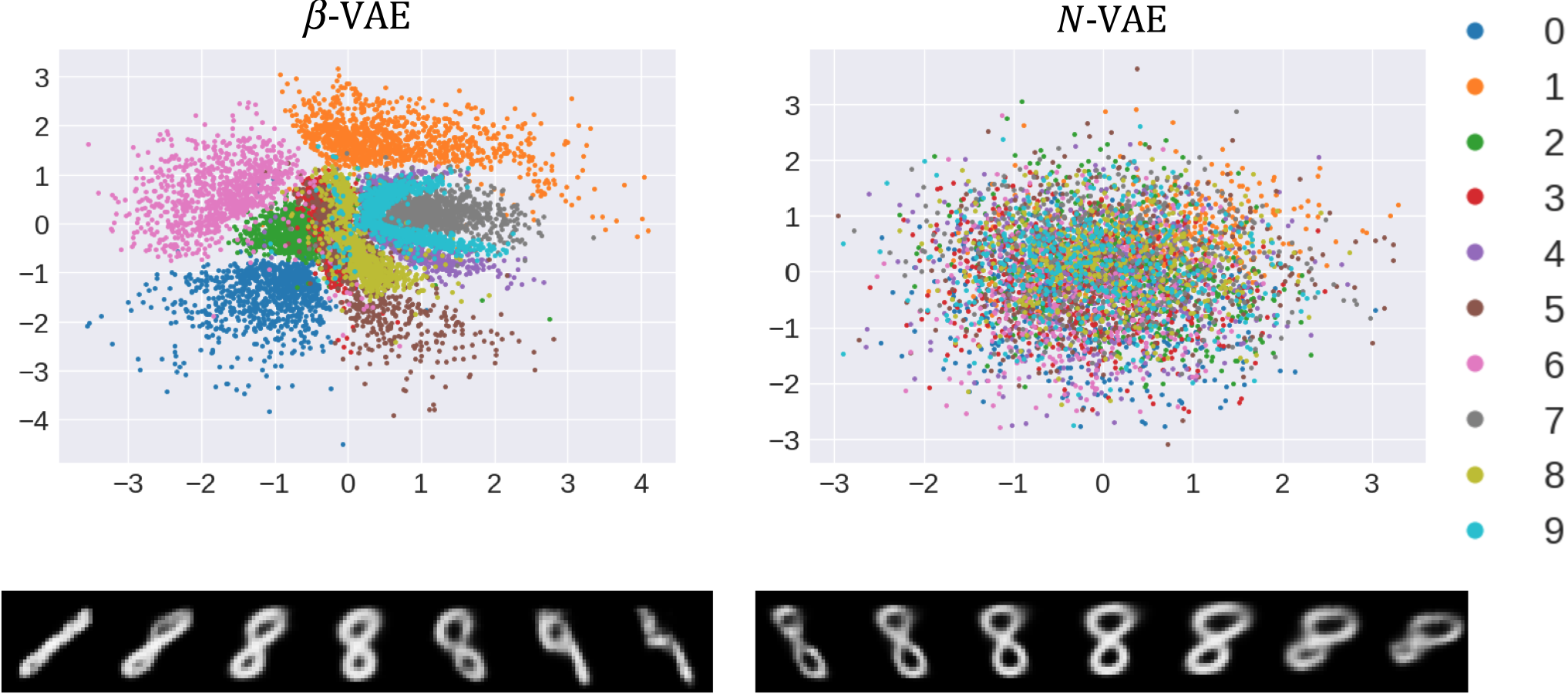 Figure 10
Figure 10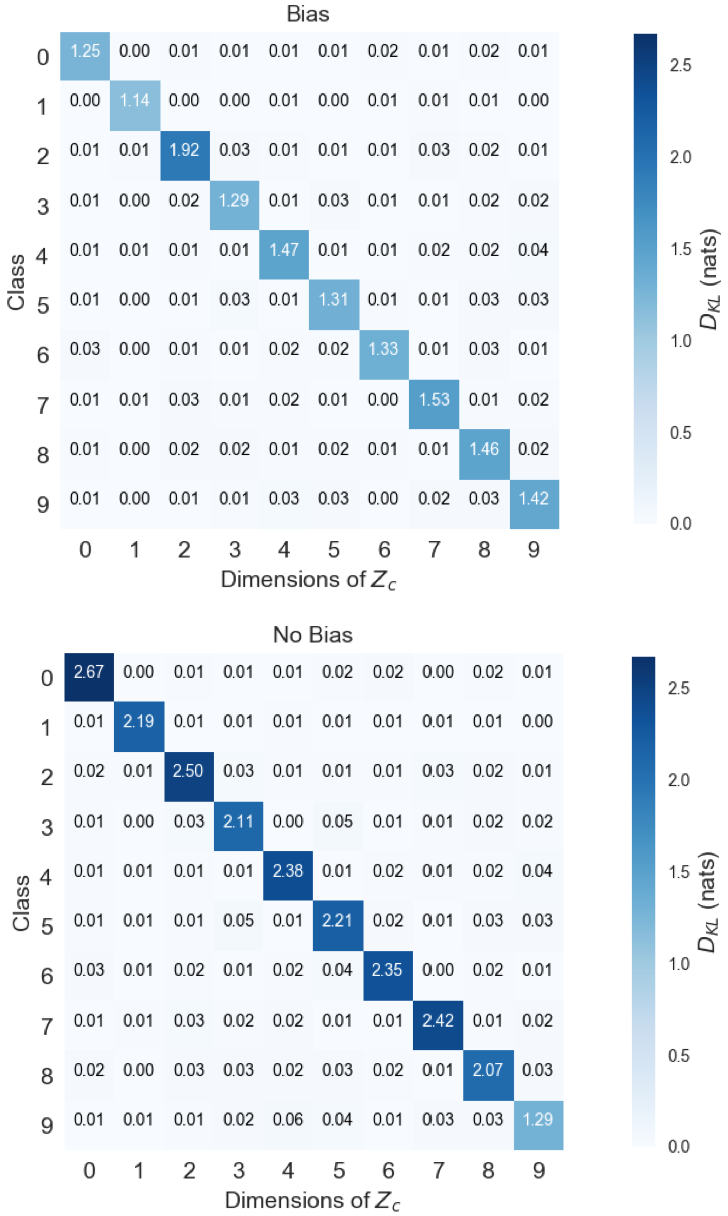 Figure 11
Figure 11Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsUSD Coin Customer Service Number +1-833-534-1729
Disentangling and Learning Robust Representations with Natural Clustering
Javier Antorán
ViVoLab, Aragón Institute for Engineering Research (I3A)
*University of Zaragoza
*Zaragoza, Spain
Antonio Miguel
*ViVoLab, Aragón Institute for Engineering Research (I3A)
University of Zaragoza
*Zaragoza, Spain
Abstract
Learning representations that disentangle the underlying factors of variability in data is an intuitive way to achieve generalization in deep models. In this work, we address the scenario where generative factors present a multimodal distribution due to the existence of class distinction in the data. We propose N-VAE, a model which is capable of separating factors of variation which are exclusive to certain classes from factors that are shared among classes. This model implements an explicitly compositional latent variable structure by defining a class-conditioned latent space and a shared latent space. We show its usefulness for detecting and disentangling class-dependent generative factors as well as its capacity to generate artificial samples which contain characteristics unseen in the training data.
Index Terms:
Representation Learning, Dimensionality reduction, Disentangling, Natural Clustering, Variational Autoencoders
I Introduction
Disentangled representations, defined as those where each latent variable is responsible for only one generative factor in the data while being relatively invariant to other factors [1], allow for more easily interpretable models, [2], and facilitate generalization to previously unseen combinations of features, [3]. They also generalize to new domains that share underlying factors of variation, [4].
Typically, variational autoencoder (VAE) [5] based disentanglement methods impose an isotropic Gaussian prior on their latent space. However, any dataset that can be separated into classes will present some form of multimodality. Despite the unimodal prior, in these scenarios, the inferred posterior is often multimodal. This creates dependencies between latent dimensions and reduces reconstruction accuracy, [6].
Moreover, there can exist underlying factors of variation in data that are exclusive to certain classes. An example of this phenomenon is found in the MNIST dataset. The number seven can be drawn with a horizontal line crossing its stem or without it. The number two can have a flat base or one with a loop. We show how these class-exclusive factors are disentangled by our proposed model in fig. 1. Other factors of variability, such as stroke thickness or azimuth, are shared among all classes, as can be seen in fig. 2.
The natural clustering prior [1] states that probability mass concentrates on a set of low dimensional manifolds. Each manifold is associated with a possible outcome of categorically distributed phenomena in the data, such as class membership. Our model, natural clustering VAE (N-VAE), conditions some of its latent variables on samples from a categorical distribution. By incorporating inductive biases about compositional structure in the data, it is able to capture class-dependent factors of variation which are usually ignored by other generative modelling techniques.
Our main contributions are the following: 1) We formulate a lower bound on the joint log-likelihood of inputs and class labels. It can be optimized approximately by simply adding a classification objective to the standard VAE cost function. 2) We propose N-VAE, a model that is capable of capturing both generative factors which are class-dependent and ones that are shared among classes. To the best of our knowledge, we are the first to disentangle these two types of factors. 3) We show how N-VAE can be used for detection and disentanglement of mode-dependent factors of variation. We also evaluate the expressivity111We understand expressivity as the number of possible input configurations that are explained by a model, [1]. of N-VAE relative to other class-conditioned generative models by comparing the usefulness of their generated samples for dataset augmentation.
II Preliminaries
We first give a brief overview of the variational autoencoder, as N-VAE builds upon this model. We then give a recap of some recent techniques for disentangling in VAEs. We show that, despite the popularity of these models, they are not well equipped to disentangle multimodally distributed generative factors.
II-A The Variational Autoencoder
The VAE approximates the intractable posterior over a set of latent variables with an approximate distribution . is minimized by optimizing the Evidence Lower Bound (ELBO) :
[TABLE]
becomes equal to when . The VAE framework parametrises both and with neural networks. Optimization is performed through gradient descent, using the reparameterisation trick, [5, 7].
The encoder, , is an approximate inference model which parametrises a distribution over the latent variables . A Gaussian with diagonal covariance is usually selected: . The decoder, , is a generative model that reconstructs the input from the latent variables . The prior over the latent variables is usually chosen to be .
II-B Regularization-based approaches to disentangled VAEs
The authors of [8] and [9] propose -VAE. This model reweights the ELBO by multiplying the regularization cost by . This pushes the approximate posterior to be closer to the factorial prior. In [10, 11, 12], the ELBO’s regularization cost is decomposed into the mutual information between inputs and latent variables and the total correlation of the latent space, [13]. The authors propose different modifications to the regularization term of the VAE objective, all of which aim to minimize the total correlation without decreasing the mutual information. In [14], an approach that penalizes the L2 distance between the second order moments of the aggregate approximate posterior and factorial prior is proposed.
II-C The problem with disentangling multimodal factors
In fig. 3, we show that the distribution of latent variables inferred by -VAE [8] on the MNIST test set is multimodal. Roughly, one mode belongs to each digit. When traversing any given dimension of the latent space, we are likely to pass through low probability regions, generating poor quality images, and eventually switch digits.
In models with unimodal priors, such as the ones proposed in [8, 9, 10, 11, 12, 14], multimodally distributed explanatory factors tend to occupy multiple dimensions of the latent space, becoming entangled with other attributes. We posit that expressing mode-dependent generative factors, such as the ones shown in fig. 1, can result in a multimodal approximate posterior and thus, a high cost under the ELBO’s KL term. These factors are often only learned if their impact on the reconstruction accuracy is significant enough to mitigate the large KL cost.
III Proposed Method
Let be a dataset consisting of i.i.d observations of some variable and its class label be . We propose a generative model which describes as being generated by a set of latent variables and a class label . The class probabilities are given by . Unlike [15], we treat as a continuous latent variable over which we perform inference. We will omit the superscript (i) in order to maintain notation uncluttered in the rest of this paper. The joint distribution of our variables can be factorized as: .
III-A A Lower Bound on the Joint Log-Likelihood
We formulate a variational lower bound on :
[TABLE]
This expression can be expanded and rewritten as eq. 3. See appendix A. for a complete derivation.
[TABLE]
is a reconstruction objective for our data vector given and . penalizes the approximate distribution of given for differing from the true posterior of given the class label . This item can be interpreted as a classification objective. Its value will go to [math] as approaches a one-hot vector with . It is the most important difference between our lower bound and that of a standard VAE. is constant with respect to our model’s parameters.
III-B Proposed Model: N-VAE
We place a zero mean isotropic unit variance Gaussian prior over : . We model the conditional over class labels with a categorical distribution: . Its parameters, , follow a symmetric Dirichlet distribution, as we assume all classes to be equally probable: . As the Dirichlet distribution is conjugate to the categorical, the posterior will also be a Dirichlet distribution: . Note that is a one-hot representation of the class label .
We use an isotropic Gaussian distribution for and a Dirichlet for . The neural networks that parametrise both of these approximate posteriors share parameters .
[TABLE]
We define as the concatenation of two vectors: . The class-dependent variables, , are the concatenation of a set of latent vectors, each of which is associated with a different class: . We want to explain intraclass factors of variation. We refer to as shared latent variables. They will express generative factors that are common to multiple classes. This allows for an efficient use of training samples, as these factors do not need to be learned separately for each input mode.
For a given class , we compute the variable .222We refer to the element-wise product with broadcasting by . denotes the vectorization of a matrix into a column vector. The input, , is regenerated from . The one-hot class label masks out the class-dependent latent variables for all non-relevant classes. It also introduces a class-dependent bias in the decoder’s first activation layer when is multiplied with its corresponding weight vector. The effects of this term are discussed in appendix B. The decoder is parametrized by , taking the form . The complete graphical model is displayed in fig. 4. N-VAE is closely related to [16], where domain dependent, class dependent and shared information are captured in separate latent spaces.
III-C Resulting objective function and optimization
N-VAE’s encoder is both a feature extractor and a classifier. For two Dirichlet distributions, can be upper bounded by the inferred class label’s negative log likelihood: , with being a constant. Using this approximation and dropping all constants with respect to model parameters, we optimize eq. 3 as:
[TABLE]
The KL divergence between the approximate posterior over and its prior distribution is calculated for all dimensions of . However, not all dimensions of are used to reconstruct every input. Most of them are masked out. The encoder learns to match the prior distribution for all dimensions of which are not assigned to the correct class, making them non-informative. In other words, the encoder learns to model class-specific factors of variation.
IV Experiments
We consider three datasets which are separated into discrete classes: MNIST, Fashion-MNIST, and the cropped Extended Yale Face Dataset B. We preprocess the latter by only keeping images with illumination angles smaller than 100°and scaling images to , [17].
The training objective is reweighed in order to discourage from learning factors of variation that are common to multiple classes:
[TABLE]
We set . However, we find that N-VAE is relatively insensitive to the value of this parameter as long as .
IV-A Detecting class-dependent factors of variation
In MNIST, there exist both class-exclusive and shared generative factors. However, in Fashion-MNIST, most of the continuous factors of variation seem to be intra-class. Classes such as sandals and t-shirts only share the factor of colour intensity. In Yale Ext B, the only continuous factors of variation are the elevation and azimuth of image illumination.
N-VAE’s KL divergence values for and act as detectors for class-dependent and shared information, fig. 5. The class-dependent variables carry the most information for Fashion-MNIST. For Yale Ext B, they are practically uninformative.
IV-B Disentangling generative factors
Latent traversals for Fashion-MNIST’s class-dependent variables are shown in fig. 6. In fig. 7, we show shared latent space traversals for the same dataset. The only generative factors which are shared among all classes seem to be color intensity and object width. In fig. 8, we show shared latent space traversals for Yale Ext B. We obtain all latent traversals by sampling values of uniformly from the range .
We do not provide class-dependent latent space traversals for Yale Ext B, as learns to be uninformative for this dataset. This is reflected in the values of from fig. 5. Changing does not affect reconstructions.
By explicitly modelling multimodally distributed generative factors through class-dependent latent variables, the shared latent space is allowed to better match the factorial prior. Consequently, N-VAE is able to learn disentangled representations without elaborate modifications to the ELBO or extensive hyerparameter tuning.
IV-C Augmenting Datasets with Generated Samples
We train classifiers with different proportions of original and artificial (generated) samples and evaluate them using the original test sets. With this method, we not only test the discriminability of our generations but also how much of the original datasets’ variability they capture. A more diverse set of generated images will better constrain the classifiers’ parameters, resulting in higher accuracy.
We compare N-VAE with the conditional VAE (CVAE), [18], the conditional GAN (CGAN), [19] and the auxiliary classifier GAN (AC-GAN), [20]. All of these models use class labels during training and allow for class-conditional sample generation. Latent variables are sampled from . A larger allows sampling from regions of latent space which are less likely under the trainset. A large enough value should allow for the extrapolation of learned generative factors, producing more extreme characteristics or new combinations of features. Our intention is to show that generative models generalize better when an appropriate latent space structure is used, not to propose a new data augmentation scheme.
On MNIST, including artificial samples has a regularization effect for most generative models as is shown in fig. 9 a); Seeing more plausible data makes it more difficult for the classifiers to overfit to specific training samples. However, N-VAE is the only model for which there is a consistent decrease in classification error as increases. It is able to produce feature configurations that complement those of the original training set. Fashion-MNIST is a more complex dataset which is harder to explain for generative models. In plot b), we see that using samples generated with N-VAE decreases the baseline classifier’s performance the least on this dataset.
We observe a significant performance decrease when training classifiers exclusively on artificial data in plots c) and d) from fig. 9. On MNIST, the conditional GAN produces the most useful samples for , N-VAE is a close second. On Fashion-MNIST, N-VAE provides the best results. In all scenarios, N-VAE performs best as increases.
V Conclusion
N-VAE explains data in terms of shared latent variables and class-dependent latent variables. We have shown the utility of this type of model for identifying and disentangling class-dependent generative factors in data. In our data augmentation experiment, N-VAE is the only model that provides more informative samples for classification as increases. This suggests that N-VAE is able to produce samples with new combinations of features, showing its capacity for generalization.
Acknowledgment
This work has been supported by the Spanish Ministry of Economy and Competitiveness and the European Social Fund through the project TIN2017-85854-C4-1-R, by the Government of Aragon (Reference Group T36_17R) and co-financed with Feder 2014-2020 ”Building Europe from Aragon.”
A: Derivation of eq. 2 and eq. 3
First, we show that our objective is a lower bound on the joint log-likelihood . Our starting point is the KL divergence between the true and approximate posteriors over and , as this is the quantity which we wish to minimise.
[TABLE]
Using the non-negativity of the KL divergence, we can write: .
We make the following modelling choices:
- •
is conditionally independent of given ; .
- •
Our inference model only takes as an input. Therefore, and .
We can rewrite eq. 2 in the following manner:
[TABLE]
B: The bias term in the decoder’s input
is obtained as . In this expression, we can see that is composed of the latent vectors predicted by the encoder, of which all but one is masked out, and a one-hot vector which results from . The latter explicitly informs the decoder about the class identity of the sample to be reconstructed. When multiplied with the corresponding weight layer, the one-hot term adds a class-dependent bias term to the decoder’s first activation layer.
The most likely value under the prior is [math]. However, when we mask out latent variables, we set most of them to this value. This makes masked latent variables indistinguishable from samples from . Without , the encoder is forced to predict distributions which place a lot of mass on large values of in order to communicate the class of to the decoder. In fig. 10, we show how the KL divergence grows for class-dependent latent variables when we remove and thus, the bias, from . The explicit encoding of discrete information allows us to describe the data’s class-dependent generative factors with distributions that more closely resemble the prior. It allows for smooth interpolation of representations in the class-conditioned latent space around zero.
C: N-VAE samples with
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Y. Bengio, A. Courville, and P. Vincent, “Representation learning: A review and new perspectives,” IEEE Transactions Pattern Analysis and Machine Intelligence , vol. 35, no. 8, pp. 1798–1828, Aug. 2013.
- 2[2] I. Higgins, N. Sonnerat, L. Matthey, A. Pal, C. P. Burgess, M. Bosnjak, M. Shanahan, M. Botvinick, D. Hassabis, and A. Lerchner, “Scan: Learning hierarchical compositional visual concepts,” in ICLR , 2018.
- 3[3] B. Esmaeili, H. Wu, S. Jain, A. Bozkurt, N. Siddharth, B. Paige, D. H. Brooks, J. Dy, and J.-W. van de Meent, “Structured disentangled representations,” in Proceedings of Machine Learning Research , K. Chaudhuri and M. Sugiyama, Eds., vol. 89. PMLR, 16–18 Apr 2019, pp. 2525–2534.
- 4[4] I. Higgins, A. Pal, A. A. Rusu, L. Matthey, C. Burgess, A. Pritzel, M. Botvinick, C. Blundell, and A. Lerchner, “Darla: Improving zero-shot transfer in reinforcement learning,” in ICML , 2017.
- 5[5] D. P. Kingma and M. Welling, “Auto-encoding variational Bayes,” in ICLR , 2014.
- 6[6] J. Tomczak and M. Welling, “Vae with a Vamp Prior,” in Proceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics , A. Storkey and F. Perez-Cruz, Eds., vol. 84. Playa Blanca, Lanzarote, Canary Islands: PMLR, 09–11 Apr 2018, pp. 1214–1223.
- 7[7] D. J. Rezende, S. Mohamed, and D. Wierstra, “Stochastic backpropagation and approximate inference in deep generative models,” in Proceedings of the 31st International Conference on Machine Learning , E. P. Xing and T. Jebara, Eds., vol. 32, no. 2. PMLR, 22–24 Jun 2014, pp. 1278–1286.
- 8[8] I. Higgins, L. Matthey, A. Pal, C. Burgess, X. Glorot, M. Botvinick, S. Mohamed, and A. Lerchner, “beta-vae: Learning basic visual concepts with a constrained variational framework,” in ICLR , 2017.