TL;DR
The paper introduces 4D-GVT, a method for generating spatio-temporal object proposals in stereo videos that effectively detects both known and unknown objects, enhancing generalization in real-world scenarios.
Contribution
It presents a novel 4D-GVT approach that leverages motion, stereo data, and segmentation to localize objects in 3D space and time, working well with limited labeled data.
Findings
Outperforms class-specific detection methods in unknown object scenarios.
Generalizes effectively with minimal labeled data.
Accurately localizes objects in 3D space and time.
Abstract
Many high-level video understanding methods require input in the form of object proposals. Currently, such proposals are predominantly generated with the help of networks that were trained for detecting and segmenting a set of known object classes, which limits their applicability to cases where all objects of interest are represented in the training set. This is a restriction for automotive scenarios, where unknown objects can frequently occur. We propose an approach that can reliably extract spatio-temporal object proposals for both known and unknown object categories from stereo video. Our 4D Generic Video Tubes (4D-GVT) method leverages motion cues, stereo data, and object instance segmentation to compute a compact set of video-object proposals that precisely localizes object candidates and their contours in 3D space and time. We show that given only a small amount of labeled data,…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2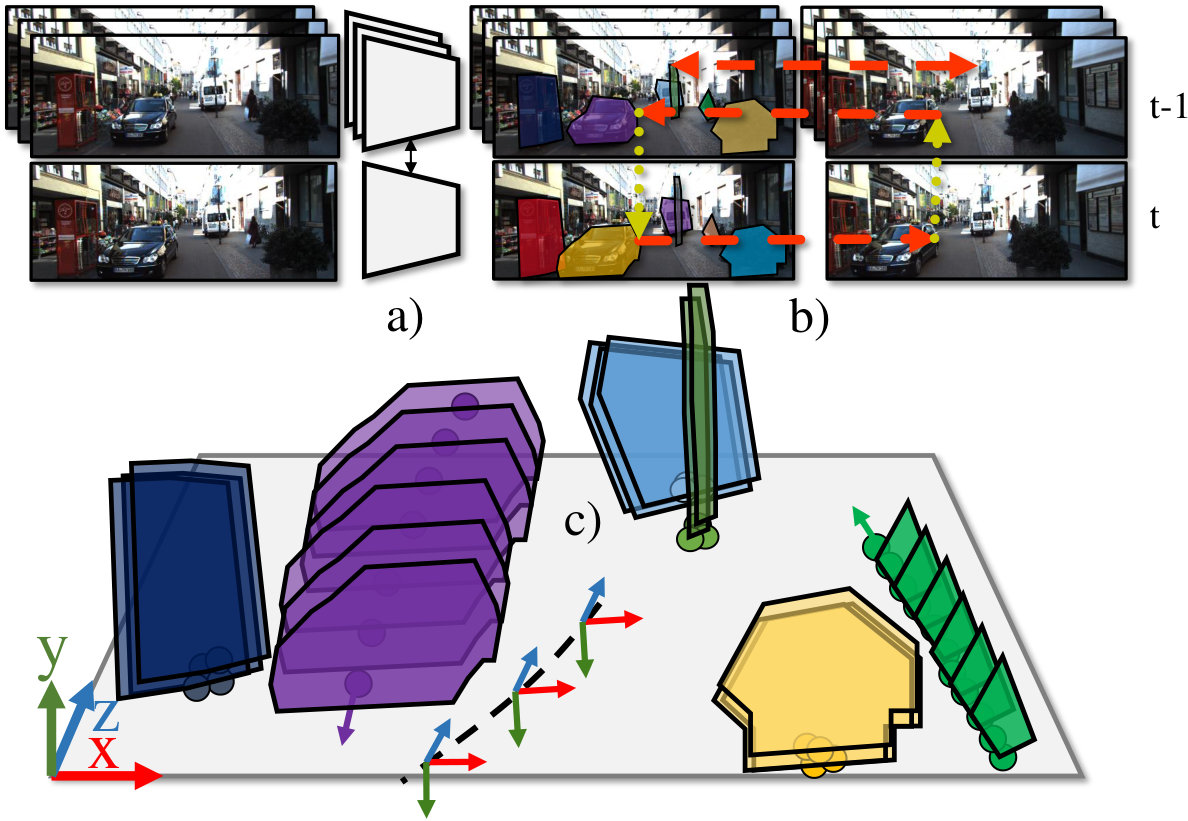 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10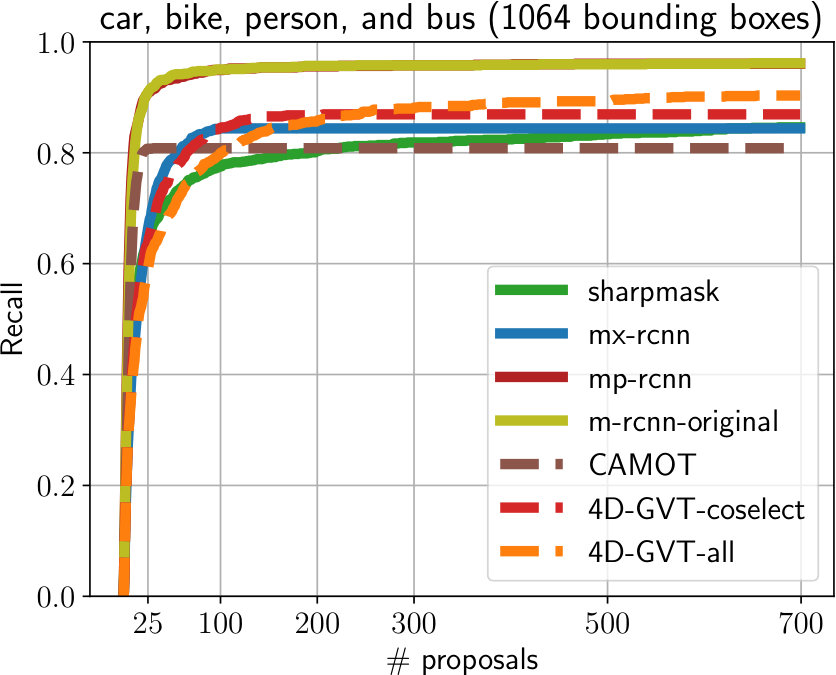 Figure 11
Figure 11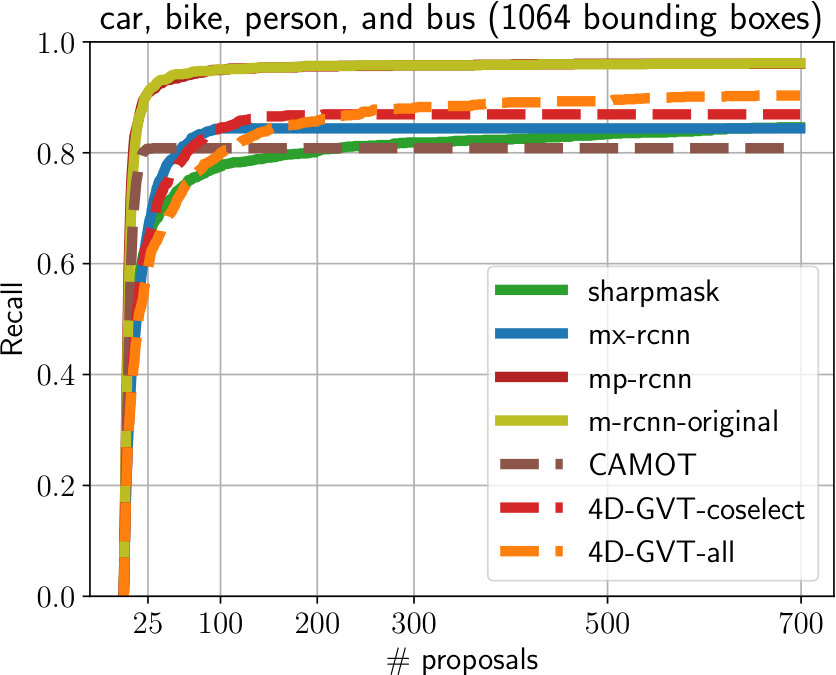 Figure 12
Figure 12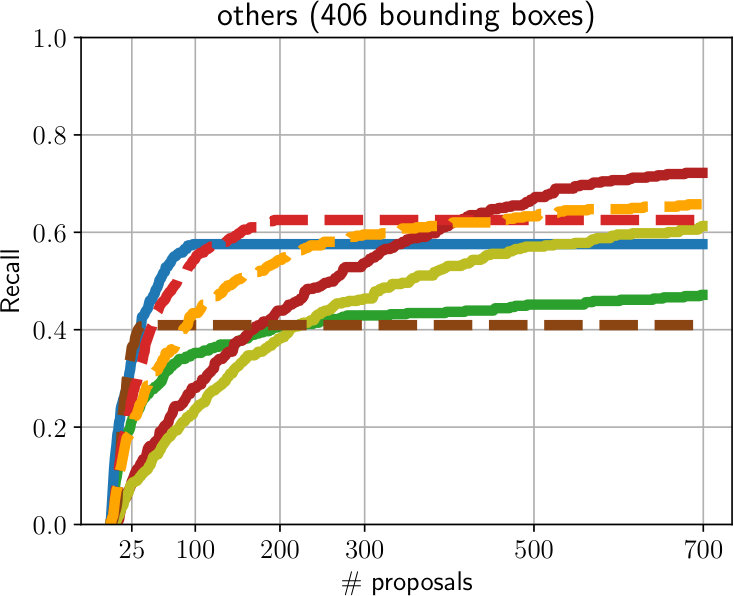 Figure 13
Figure 13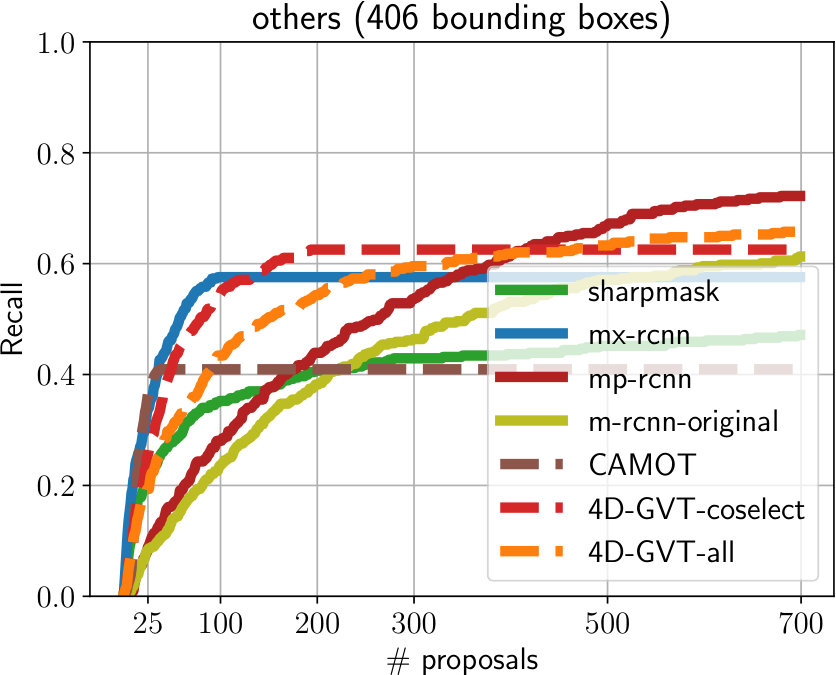 Figure 14
Figure 14 Figure 15
Figure 15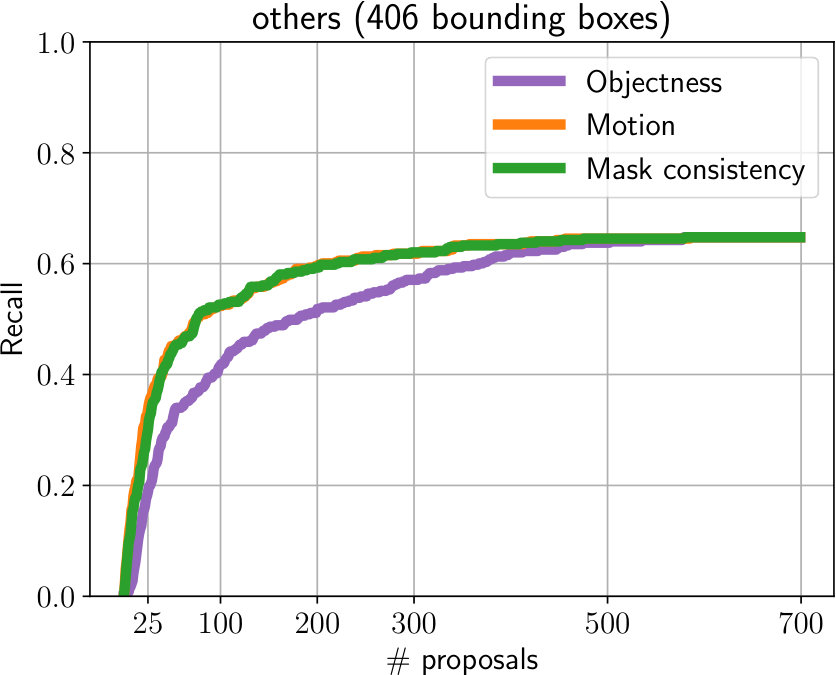 Figure 16
Figure 16| Category | Car | Person | Bike | Bus | Other | All |
| #instances | 599 | 354 | 78 | 50 | 413 | 1494 |
| Portion | 40.1% | 23.1% | 5.2% | 3.3% | 27.6% | 100% |
| Pedestrian | Car | |||
| MOTA | IDS | MOTA | IDS | |
| CIWT (KITTI) | 0.33 | 42 | 0.65 | 8 |
| CAMOT (KITTI) | 0.26 | 72 | 0.60 | 40 |
| 4D-GVT (KITTI) | 0.33 | 18 | 0.61 | 6 |
| CAMOT (COCO) | -0.05 | 214 | 0.54 | 174 |
| 4D-GVT (COCO) | 0.27 | 24 | 0.57 | 4 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
4D Generic Video Object Proposals
Aljos̆a Os̆ep, Paul Voigtlaender, Mark Weber, Jonathon Luiten, and Bastian Leibe Aljos̆a Os̆ep is with the Technical University of Munich. All other authors are with the RWTH Aachen University. E-mail: [email protected], [email protected], [email protected]
Abstract
Many high-level video understanding methods require input in the form of object proposals. Currently, such proposals are predominantly generated with the help of neural networks that were trained for detecting and segmenting a set of known object classes, which limits their applicability to cases where all objects of interest are represented in the training set. We propose an approach that can reliably extract spatio-temporal object proposals for both known and unknown object categories from stereo video. Our 4D Generic Video Tubes (4D-GVT) method combines motion cues, stereo data, and data-driven object instance segmentation in a probabilistic framework to compute a compact set of video-object proposals that precisely localizes object candidates and their contours in 3D space and time.
I Introduction
The main result of this paper is a novel approach for generating high-quality spatio-temporal object tube proposals for both known and unknown objects from stereo video (Fig. 1). The resulting tube proposals are localized in 3D space and capture the evolution of an object’s visible area over time, i.e., they provide a temporally consistent object segmentation over a video sequence. Such tube proposals can be useful as basic primitives for a wide variety of applications, ranging from object tracking [59, 5, 21] to action/activity recognition [16], object category discovery [56, 41, 24, 23, 42, 45, 63, 52] and zero-shot learning [64, 58, 39, 2]. 4D stereo-based reconstruction and localization in 3D space and time open further possibilities for using 4D-GVT as a building block for learning trajectory prediction [22, 11, 1] and 3D shape completion [60, 46]. These applications are of great importance for automotive applications, in which the capability to perceive and react to unseen dynamic objects is a vital safety concern (see Fig. 1).
Up to now, high-quality video-object proposals could only be generated either by 1) applying a pre-trained object detector for known classes and performing instance segmentation in every frame [12, 44]; or by 2) starting from a manual object mask initialization and applying a video object segmentation approach [54, 18]. The significant contribution of our approach is that it can provide a compact set of high-quality object tubes for multiple objects with automatic initialization and scales well to unseen object classes.
The key idea behind our approach is to make use of parallax as a cue to identify temporally consistent object tubes under egomotion of the recording vehicle. We leverage recent developments in object instance segmentation [12] and propose a simple, yet effective probabilistic approach for video proposal generation that combines image instance segmentation, stereo, and sparse scene flow cues. Our proposed 4D-GVT method extends Mask R-CNN [12] to extract frame-level object proposals and their segmentation masks for arbitrary objects. It then localizes these image regions in 3D space and predicts their 3D motion. Taking parallax as a consistency filter, our approach narrows down the potentially vast set of tube continuations to those that are consistent with the object’s perceived relative motion. As a result, 4D-GVT can quickly trim down a large initial set of frame-level region proposals and turn them into a temporally consistent set of object tubes with accurately tracked object positions.
Our experiments show that when applying our 4D-GVT proposal generator for car and pedestrian tracking on the KITTI dataset [8], it reaches close to state-of-the-art performance even when compared to dedicated tracking-by-detection methods. Additionally we compare the obtained results on the image level to those of the MaskX R-CNN, a large-scale instance segmentation approach by [17] that is trained jointly on the COCO [28] and Visual Genome [20] datasets on classes. Our results show that our approach (4D-GVT) matches accuracy/recall for known and unknown objects, despite only using knowledge about the 80 COCO classes. All code and data are available at https://github.com/aljosaosep/4DGVT.
II Related Work
**Video-Object Mining. ** Video-Object mining (VOM) refers to a task of pattern discovery in video collections. It has been used for improving detectors by mining hard-negatives for specific object categories from web-videos [47, 19], for learning new detectors of mostly single, dominant objects in videos [38] and for tracking-based semi-supervised learning, in which sparse annotations extended by tracks were leveraged to extend the amount of training data [30, 31].
The above-mentioned methods have in common that they all need to localize video tubes (or object tracks) from video. Such video tubes or object tracks can be extracted with the help of a pre-trained object detector [25, 61]. The drawback of such methods is that they can only localize objects, for which a sufficient amount of training data is available. In realistic driving scenarios, however, it is not feasible to obtain training data for every possible object of interest. For that reason, the most common approach for video-object mining and self-supervised learning in automotive scenarios is based on unsupervised segmentation of 3D sensory data (e.g., LiDAR) using information such as spatial proximity and motion cues [6, 13, 14, 49, 48].
There are a few methods that proposed similar ideas in the vision community by using image-based object proposals as leads for tracking [62, 21, 15], often leveraging stereo information [33, 35, 32, 26] or motion cues [51]. The approach most similar to ours is the category-agnostic multi-object tracker by [35]. It uses two networks, for a) proposal generation and b) track classification, in addition to high-quality dense scene flow [53] for data association. In contrast, we propose 1) a unified network that provides per-frame mask-level object proposals and a classification branch and 2) a probabilistic framework for offline video-tube generation, derived from well-established MHT theory [40]. Different to [35], our approach models long-term interactions within tubes and utilizes the full video sequence for scoring. As a result, our approach generates tubes that are significantly more stable over time, as our results demonstrate.
**Video-Object Segmentation. ** Alternatively, object instances can be mined from video using video-object segmentation (VOS), which refers to a task of segmenting objects in videos with weak supervision, typically in the form of pixel masks or bounding boxes: [55, 54, 18, 4]. Such approaches were successfully used in the context of video-based semi-supervised and self-supervised learning [30, 31, 38]. Existing methods for unsupervised video-object segmentation are limited to segmenting a single object of interest (i.e. performing object vs. background classification) [7, 50, 27, 27]. Both, weakly-supervised and unsupervised VOS methods assume that the object of interest appears from the beginning to the end of the video, with possible short occlusions. In contrast, we assume real-world automotive and robotics scenarios, where such assumptions do not hold.
**Open-set Segmentation. ** Many real-world scenarios require reliable segmentation that is not limited to a few categories for which fully labeled training data is available. MaskX R-CNN [17] tackles this problem by using partial supervision of bounding boxes to perform instance segmentation for the Visual Genome dataset that includes labels for over categories. Pham et al. [36] address the problem by fusing modern instance segmentation with traditional unsupervised methods to obtain instance segmentation for an unbounded number of categories. In contrast, our model leverages its in-built category-agnostic detection to generalize to objects of unknown categories on a video-level.
III Method
From each video-frame of the video sequence, we extract image-level object proposals (Fig. 2a), defined by object pixel masks. Next, we localize these mask proposals in 3D camera space and predict their motion by computing sparse scene flow, obtained by matching image features (Fig. 2b). Using the estimated depth and pixel mask, we localize these proposals in 3D space and associate them in space-time in order to obtain a set of 4D Video Proposal Tubes (Fig. 2c). We derive a probabilistic model from well-established MHT theory [40] that fuses objectness scores provided by the proposal network together with motion and temporal mask consistency cues and that performs an additional inference step that suppresses tubes with significant overlap in space-time. This way, we combine a learning-based method for generic instance segmentation with a powerful prior knowledge about motion/shape consistency and scene geometry in a sound probabilistic framework. In the following, we provide a detailed outline of each step of our method.
III-A Image-Level Proposals with MP R-CNN
First, we need to obtain cues for potential objects on the video-frame level. For this purpose, we propose a category-agnostic extension of Mask R-CNN, Mask Proposal R-CNN (MP R-CNN), whose classification part only disambiguates objects from the background. We achieve that by training the network in the category-agnostic setting, i.e. by merging all COCO classes into one “object” class. This way we obtain a better generalization to object categories that are not present in the training set, as confirmed experimentally in Sec. IV. In order to retain a capability to perform higher-granularity classification for objects that appear in the training set, we add a second classification head (identical to the classification head of Mask R-CNN) to this network which disambiguates between the classes. At test time, the category-agnostic classification head is used to provide confidence scores for proposals, and the second classification head is additionally evaluated to provide a posterior distribution over the classes for each proposal.
III-B 4D Video Tubes
To get from image-level proposals to 4D Video Tubes, we combine modern instance segmentation methods, trained in a category-agnostic setting, with well-understood tracking theory [25, 40]. Formally, we obtain a set of frame-level object proposals in the frame-range , where from MP R-CNN. The -th per-frame proposal is defined as . The mask for an image of size , objectness score and category information ( known COCO classes + unknown) are obtained by MP R-CNN.
This information is extended by 3D position , 3D size and velocity vector from the video sequence as follows. For each video sequence, we match local Harris corner based image features 1) of left-right images coming from stereo and 2) forward-backward in time for two consecutive neighboring frames and . Features that pass a cyclic consistency check (left, right, forward, backward) are used to estimate sparse scene flow. We triangulate left-right matches in two consecutive frames and compute difference vectors () for all successful matches. Using the same set of feature matches, we obtain an egomotion estimate by minimizing the re-projection error using non-linear least squares [10] and we finally keep left-right image matches to obtain a scene depth estimate using the feature-matching method of [9]. By cropping stereo and scene flow estimates within the estimated mask area, we robustly compute the 3D position, velocity and 3D bounding box for each proposal.
**Video Tube Proposals. ** After obtaining the per-frame object proposals for a video sequence that spans from frame [math] to , we partition these into a 4D tube proposal set, i.e., a set of video tube proposals , where each tube proposal spans from frame to .
Obtaining such partitions is a very challenging, multi-dimensional assignment problem: object proposals may originate from objects, as well as from segmentation clutter. Obtaining an exact solution to multi-frame assignment problems in tracking is NP-hard, and we need to resort to approximate solutions. One possibility would be to use an approach like MHT [40], which maintains a tree of potential associations for each possible object and to perform tree pruning in order to avoid combinatorial explosion. However, for a large number of per-frame object proposals, maintaining such a tree would be prohibitively expensive.
Instead, we resort to the forward-backward track enumeration algorithm [25], guided by the estimated scene flow. We perform a forward-backward data association by sliding a temporal window over the whole video sequence. For each video frame , we 1) extend the existing tube proposal set using and 2) attempt to start a new object tube from each unassigned proposal by performing bi-directional data association within a temporal window.
In order to minimize incorrect associations, which would lead to spurious tubes, we leverage object motion models, the rigidity of the 3D scene, and the known image formation model to guide frame-to-frame proposal data association to only a small set of feasible associations. This is done as follows (similar to [35]). Using an estimate of frame-level object proposals with 3D position , velocity and size from each frame-level proposal, we start a new tube and estimate its state recursively using a linear Kalman filter. We perform association in the following steps. First, we perform a Kalman filter prediction in order to estimate a 3D position and perform 3D position based gating in order to severely narrow down the set of feasible proposal associations. Then we predict the segmentation mask of the object in the current frame, and finally we extend the tube with the proposal that maximizes the joint association probability based on mask IoU in the image domain and 3D position, as in [35].
We obtain the mask prediction of tube for video-frame based on a 2D mask estimate of the last associated mask , the depth and egomotion estimate :
[TABLE]
where and denotes the camera projection/backprojection operator (applied element-wise), denotes the known camera matrix and performs element-wise multiplication. The matrix represents estimated motion of the tube by the Kalman filter. Thus, starting from the per-frame proposals over the video sequence, obtained from the MP R-CNN network and localized in 3D space, we have now linked these proposal segments together into a set of proposal video tubes .
**Scoring Tube Proposals. ** Following MHT theory [40], we obtain a ranked set of relevant video tube proposals by scoring tubes using log-likelihood ratios between the proposal tube and the null hypothesis tube. The null tube encodes tubes generated from random background clutter. The score of the tube is a linear combination of the tube motion score, the mask consistency score and the tube objectness score (we are omitting time indices for brevity):
[TABLE]
Intuitively, the tube motion score encodes the assumption that objects move smoothly. It takes the form of a likelihood ratio test, comparing the probability that the tube corresponds to a valid object tube to the null hypothesis that the tube was generated from random background clutter:
[TABLE]
The notation denotes that the 3D position observations originate from the tube and denotes the null tube hypothesis. The set denotes the supporting image-level proposal set of a tube, where refers to the -th frame-level proposal that supports at a certain frame . The Markovian motion assumption and conditional independence assumption of the observations originating from the null tube hypothesis lead to the following factorization of Eq. 3:
[TABLE]
[TABLE]
The likelihood that the observation originates from the tube is assumed to be Gaussian and is evaluated using the Kalman filter prediction. It measures how well the ground position of an object proposal corresponds to the Kalman filter prediction under the estimated variance at time . This is evaluated against the null hypothesis of a uniform distribution of clutter objects over the sensing area (roughly of the ground plane).
The tube mask consistency score encodes the intuition that the silhouette and position of the object in the image plane do not change significantly on a frame-to-frame level. Again, a likelihood ratio test is used, comparing the mask IoU against a null hypothesis model of no intersection:
[TABLE]
which using the Markov assumption factorizes as:
[TABLE]
[TABLE]
Here, we compute frame-to-frame mask consistency as mask intersection-over-union between the mask prediction and the (mask) observation . The null hypothesis model is a confidence threshold (base value ), obtained by hyperparameter optimization.
Finally, the tube objectness score utilizes the objectness scores estimated by the network and integrates them over the whole tube:
[TABLE]
[TABLE]
[TABLE]
Here, the likelihood ratio test compares the probability of the tube being a valid object (individual probabilities are estimated by the MP R-CNN network) against a null hypothesis model of the tube belonging to segmentation clutter. The confidence threshold is a hyperparameter.
Experimentally, we can observe (Sec. IV) that for known object categories, sequence-level objectness scores (Eq. 9) provide a great ranking cue. However, for objects which do not belong to one of the categories in the training set (80 COCO classes), scores based on temporal mask and motion consistency lead to a significantly better ranking.
**Proposal Tubes Co-Selection. ** These proposal tubes may still overlap with each other and provide competing explanations for the same image pixels. In order to obtain a compact video tube set, we perform an additional video tube co-selection step that suppresses highly-overlapping tubes. The co-selection is performed by computing a maximum a posterior probability (MAP) estimate using a Conditional Random Field (CRF) model by minimizing the following non-submodular function within batches of frames:
[TABLE]
is a binary vector whose elements indicate that the tube is selected. The unary term corresponds to the tube scoring function. The pairwise term integrates image-level temporal mask IoU within the batch and gives a penalty to overlapping tubes. Here, and are object masks of tubes and at frame , respectively. The model parameters and are optimized on a held-out validation set of the KITTI dataset [8] using random search.
To minimize the energy function (Eq. 12), we use the multi-branch algorithm by [43].
IV Experimental Evaluation
**Datasets. ** We evaluate the proposed method on two automotive datasets, KITTI [8] and Oxford RobotCar [29]. The KITTI dataset is a standard object detection and tracking benchmark in automotive scenarios. We use the KITTI Multi-Object Tracking benchmark with the car and pedestrian categories for a sequence-level evaluation of our video tubes.
The Oxford RobotCar dataset provides a large amount of recorded data (roughly h) and covers a broad set of object classes. However, there are no object class labels available. For evaluation purposes, we labeled a subset of the video sequences (see Tab. I) in order to measure the performance of our method on known and unknown object classes.
**Evaluation on Oxford. **Using our labeled subset of the Oxford RobotCar dataset, we compare MP R-CNN and 4D-GVT to several baselines. All methods were trained on the COCO dataset, except MaskX R-CNN [17], which was trained on both COCO and Visual Genome [20] with object categories. Fig. 3 shows recall (at IoU) as a function of the number of object proposals for known object categories (in the COCO category set, left) and unknown object categories (right). For image-level evaluation (solid lines), we compare our MP R-CNN ( ) to SharpMask [37] ( ), MaskX R-CNN ( ) and standard Mask R-CNN ( ) where we merely keep the low-confidence predictions, which is a strong baseline as shown in [36]. As can be seen in Fig. 3 (left), our MP R-CNN model ( ) and Mask R-CNN ( ) perform well on known object categories while SharpMask ( ) and MaskX R-CNN ( ) achieve lower recall. On unknown object categories MaskX R-CNN performs significantly better for top- proposals per frame and provides a better ranking, which is not surprising, as it was trained on a large dataset, containing classes. In the limit of proposals per frame, MP R-CNN ( ) and Mask R-CNN ( ) achieve higher recall ( and , respectively) than MaskX R-CNN ( ) ().
We evaluate our 4D-GVT tubes (dashed lines) on the Oxford RobotCar dataset by extracting video tubes in a -frame temporal neighborhood of the labeled images. We show the results obtained using the full tube set ( ) and the set obtained after the co-selection step ( ), as explained in Sec. III-B. For known classes, we achieve comparable recall to MaskX R-CNN ( ) with both 4D-GVT variants ( , ) in the top- proposals regime.
For unknown categories, MaskX R-CNN ( ) and both 4D-GVT variants provide an excellent ranking for the top- proposals. Remarkably, our 4D-GVT proposals achieve the same recall and, most importantly, ranking capabilities as MaskX R-CNN despite being trained only on the COCO categories. Also supremely important: 4D-GVT tracks the objects and assigns temporarily consistent objects ids, which MaskX R-CNN cannot do. This clearly demonstrates that the generalization of Mask R-CNN baseline to unknown object classes can be significantly improved by leveraging parallax as consistency filter and motion cues.
A comparison to unsupervised video-object segmentation methods such as [7, 50, 27, 27] is not possible as these methods extract only a single dominant tube, while the sequences from Oxford RobotCar contain several object instances in every video-frame. However, as an additional video-level baseline, we adapt the official implementation of CAMOT [35] and replace the two-stage proposal generation and track classification with our MP R-CNN for a fair comparison. As can be seen from Fig. 3 (left), CAMOT ( ) can track several unknown objects, but achieves significantly lower recall ( vs. for 4D-GVT-coselect).
Fig. 6 compares the output of (a) our method, (b) MaskX R-CNN and (c) Mask R-CNN qualitatively. As can be seen, Mask R-CNN works very well for the classes (car, bike, person, etc.). 4D-GVT and MaskX R-CNN both segment a large variety of objects. However, only our method additionally provides temporal continuity.
**Scoring Ablation. ** We experimentally justify the design decisions for tube scoring (Oxford) in Fig. 4. Clearly, for known object categories, tube ranking based on the proposal confidence scores (objectness) obtained by MP R-CNN is a strong cue (Fig. 4, left). However, for unknown categories (Fig. 4, right), the scoring based on the mask consistency and the motion scores provide significantly stronger scoring cues. This further confirms the efficacy of utilizing prior knowledge about motion and temporal shape consistency to compensate for the lack of training data.
**Sequence-Level Evaluation. ** We demonstrate sequence-level performance by evaluating our method on our custom split of the training set111We used sequences 1,2,3,4,9,11,12,15,17,19,20 to perform model validation and the rest for the evaluation. from the KITTI Multi-Object Tracking dataset (KITTI MOT) [8]. We follow the official evaluation protocol that evaluates tracking performance using the CLEAR-MOT [3] metrics on the car and pedestrian categories, as only these categories are observed frequently enough so that a tracking evaluation is statistically meaningful. In general, we do not know the object categories of the tubes. However, we can use the information obtained from the second (category-specific) classification head (as explained in Sec. III-A) and obtain the conditional probability for a tube representing a car or pedestrian, given that it represents an object. We compare our method to the tracking-by-detection approach by [34] (CIWT), which is among the top-4 performers on the KITTI MOT benchmark (comparing methods using public detections, Regionlets [57]) and which thus provides a strong object tracking baseline. This method is tuned for tracking car and pedestrian categories only and uses dedicated motion models for those categories. In addition, we compare to a stereo-based category-agnostic tracker (CAMOT) [35] that is capable of tracking a large variety of objects. To make the comparison fair, we use the same inputs from MP R-CNN, which is trained on COCO, for CAMOT and our method. In this case, we map the COCO category person to pedestrian. As an additional experiment, we fine-tune MP R-CNN on the KITTI dataset on the car and pedestrian categories, which we can use to evaluate CIWT. Both CAMOT and 4D-GVT output bounding boxes derived from the tracked segments, whereas KITTI MOT assumes amodal bounding boxes.
Table II outlines the tracking results for the car and pedestrian categories. We focus on the MOTA metric and the number of ID switches (IDS). CIWT achieves the highest MOTA score () on the car category when fine-tuned on KITTI, and our 4D-GVT takes the second place (). This is due to the higher CIWT recall and that our method can only propose tubes in the near camera range (up to ), whereas CIWT can also track in farther ranges in the absence of stereo, as shown in Fig. 5. For the pedestrian category, our method and CIWT both achieve MOTA, as KITTI pedestrians mainly appear in the near-range. The proposed 4D-GVT consistently outperforms CAMOT in terms of MOTA. As expected, the fine-tuned variants perform better in terms of MOTA score, however, the generic (COCO) model yields better recall in farther camera ranges. These experiments demonstrate that our video-object proposal generator performs better than a category-agnostic tracker and can compete with top-performing tracking-by-detection methods for known object categories. Importantly, our 4D-GVT drastically reduces ID switches, which is very important for video object proposals. It is desirable to extract long video tubes from videos rather than only short fragments. Comparing the fine-tuned model, 4D-GVT commits and ID switches for car and pedestrian, respectively, compared to and (CIWT); and (CAMOT).
Additionally, we evaluate 3D localization precision on KITTI, measured as Euclidean distance (in meters) between estimated 3D positions and ground-truth trajectories. Fig. 5 shows recall and 3D localization error as a function of distance from the camera for pedestrians and cars. Both 4D-GVT and CAMOT achieve a small localization error – up to in farther camera ranges – which is not surprising, since they are both based on stereo. CIWT localizes objects using a stereo-based bottom-up segmentation method and switches to monocular localization when it cannot associate a 3D segment to a detection. This way, it can track larger objects (e.g. cars) farther than m at the price of significantly larger localization errors. This confirms that stereo-based localization is essential for high 3D localization precision.
**Runtime Analysis. ** With a small number of frame-level proposals (e.g., only cars and pedestrians, 10-20 inputs/frame), 4D-GVT requires less than s/frame. 4D-GVT can also operate with a large number of frame-level proposals to provide tubes representing unknown objects and trade-off between recall/runtime by a varying number of input proposals – proposals/frame result in a runtime of s/frame. This operation mode is intended for offline processing, e.g., collecting tubes of unknown objects. Thus, the proposed method is efficient for extracting tubes for known objects only, while it is still suitable for mining arbitrary objects from videos offline. We performed large-scale video object mining using h of stereo recordings of the Oxford RobotCar dataset. In total, we obtained video tubes, of which () are of an unknown class; these represent potentially interesting novel object categories.
V Conclusion
In this work we have proposed 4D-GVT for generic video-object tube generation. We have demonstrated that by combining modern instance segmentation methods with a well-funded tracking framework and using parallax as a consistency filter, 4D-GVT can match the recall of the recent MaskX R-CNN method (trained on a significantly larger dataset) while generating high-quality video object tubes as output that precisely localize objects in 3D.
**Acknowledgements: ** We would like to thank Bin Huang and Michael Krause for annotation work. This project was funded, in parts, by ERC Consolidator Grant DeeVise (ERC-2017-COG-773161). The experiments were performed with computing resources granted by RWTH Aachen University under project rwth0275.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] A. Alahi, K. Goel, V. Ramanathan, A. Robicquet, L. Fei-Fei, and S. Savarese. Social lstm: Human trajectory prediction in crowded spaces. In CVPR , June 2016.
- 2[2] A. Bansal, K. Sikka, G. Sharma, R. Chellappa, and A. Divakaran. Zero-shot object detection. In ECCV , 2018.
- 3[3] K. Bernardin and R. Stiefelhagen. Evaluating multiple object tracking performance: The clear mot metrics. JVIP , 2008:1:1–1:10, 2008.
- 4[4] W. Brendel and S. Todorovic. Video object segmentation by tracking regions. In ICCV , 2009.
- 5[5] W. Choi. Near-online multi-target tracking with aggregated local flow descriptor. In ICCV , 2015.
- 6[6] A. Dewan, T. Caselitz, G. D. Tipaldi, and W. Burgard. Motion-based detection and tracking in 3d lidar scans. In ICRA , 2015.
- 7[7] K. Fragkiadaki, P. A. Arbeláez, P. Felsen, and J. Malik. Learning to segment moving objects in videos. CVPR , 2015.
- 8[8] A. Geiger, P. Lenz, and R. Urtasun. Are we ready for autonomous driving? the KITTI vision benchmark suite. In CVPR , 2012.
