Asynchronous Distributed Optimization over Lossy Networks via Relaxed ADMM: Stability and Linear Convergence
Nicola Bastianello, Ruggero Carli, Luca Schenato, Marco Todescato

TL;DR
This paper introduces a modified relaxed ADMM algorithm for distributed convex optimization over lossy, asynchronous networks, proving its almost sure convergence and linear convergence under certain conditions, with numerical validation.
Contribution
It proposes a novel asynchronous, lossy network-compatible ADMM variant with proven convergence properties and convergence rate bounds, extending distributed optimization theory.
Findings
Almost sure convergence under general loss and activation models
Linear convergence in mean to a neighborhood of the optimum
Numerical results demonstrating effectiveness in various scenarios
Abstract
In this work we focus on the problem of minimizing the sum of convex cost functions in a distributed fashion over a peer-to-peer network. In particular, we are interested in the case in which communications between nodes are prone to failures and the agents are not synchronized among themselves. We address the problem proposing a modified version of the relaxed ADMM, which corresponds to the Peaceman-Rachford splitting method applied to the dual. By exploiting results from operator theory, we are able to prove the almost sure convergence of the proposed algorithm under general assumptions on the distribution of communication loss and node activation events. By further assuming the cost functions to be strongly convex, we prove the linear convergence of the algorithm in mean to a neighborhood of the optimal solution, and provide an upper bound to the convergence rate. Finally, we present…
Click any figure to enlarge with its caption.
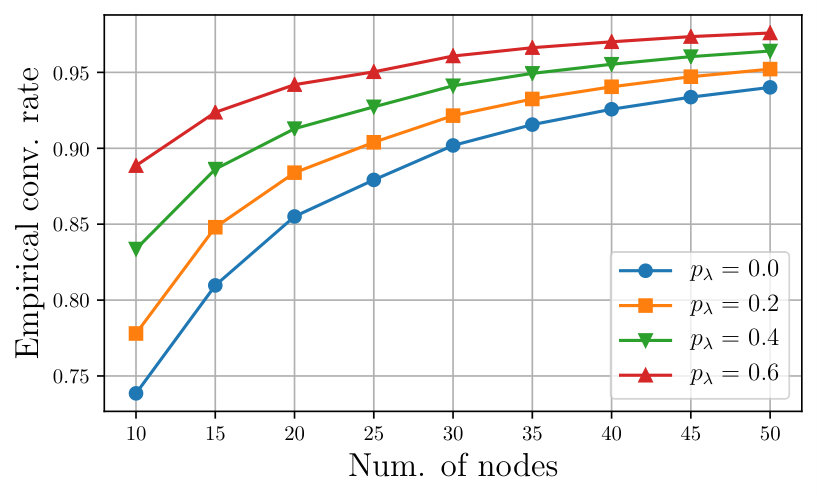 Figure 1
Figure 1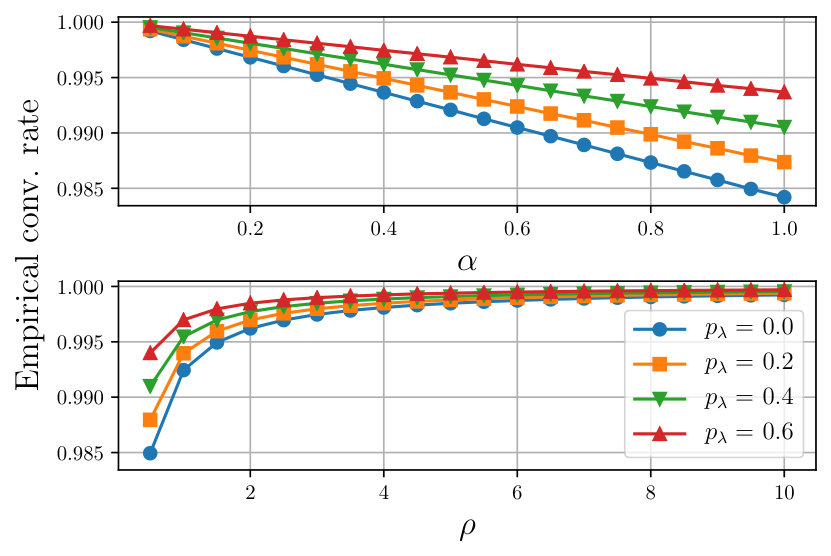 Figure 2
Figure 2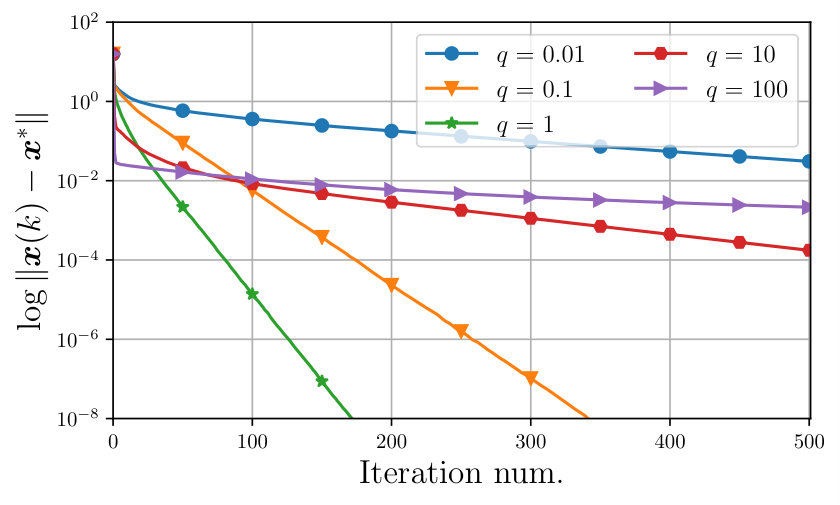 Figure 3
Figure 3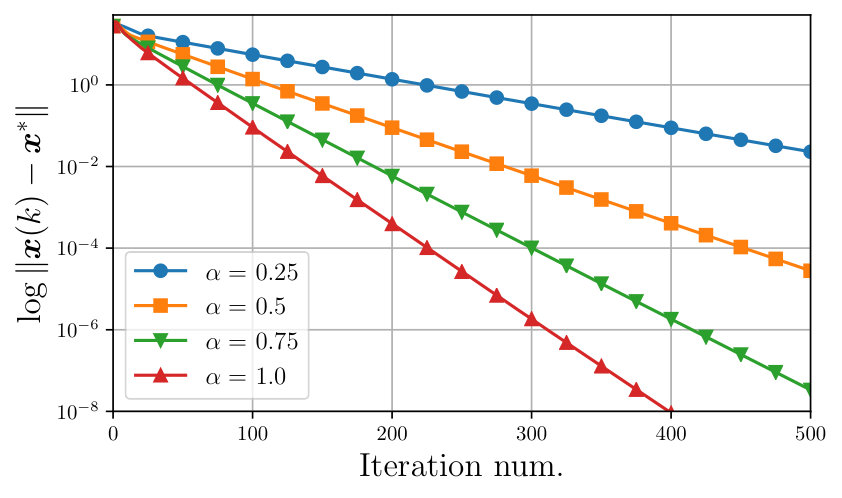 Figure 4
Figure 4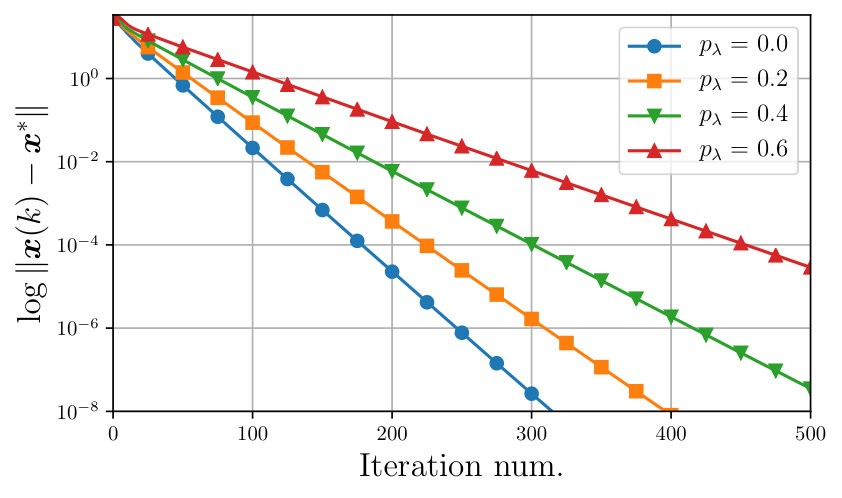 Figure 5
Figure 5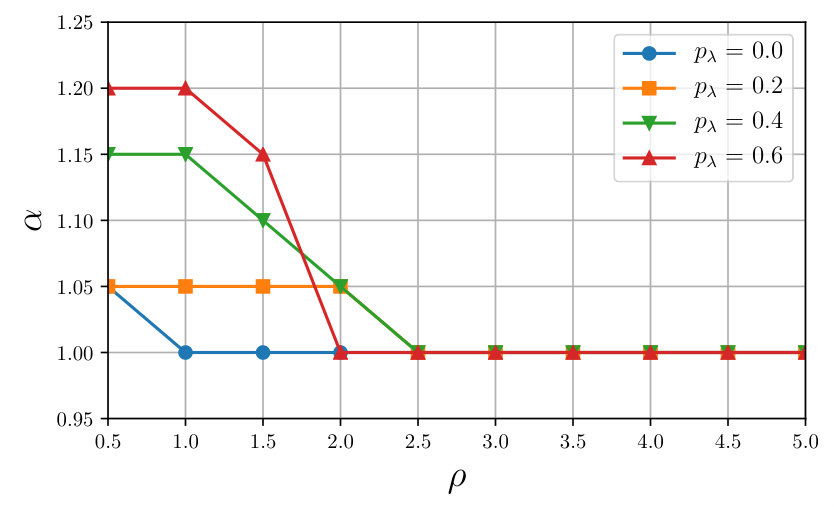 Figure 6
Figure 6| Operator R-ADMM | Lagrangian R-ADMM | |
|---|---|---|
| Memory | ||
| Transmit |
| Reference | Formulation | Linear convergence | Asynchronous updates | Packet loss | ||
| Augmented Lagrangian ADMM | Shi et al. [31] | node-based | global | ✗ | ✗ | |
| Makhdoumi & Ozdaglar [32] | node-based | global | ✗ | ✗ | ||
| Majzoobi et al. [35] | node-, edge-based | ✗ | ✗ | ✓(uniform distr.) | ||
| Chang et al. [34] | master-slave† | global | ✓(for master) | ✗ | ||
| Iutzeler et al. [33] | clustered | local | ✓(for clusters) | ✗ | ||
| Splitting ADMM | Bianchi et al. [30] | edge-based | ✗ | ✓ | ✗ | |
| Giselsson & Boyd [23] | master-slave† | global | ✗ | ✗ | ||
| Combettes & Pesquet [38] | master-slave† | global | ✓ | ✓ | ||
| Peng et al. [26] | edge-based | ✗ | ✓(one node at a time) | ✗ | ||
| This paper | edge-based | local | ✓ | ✓ | ||
| The results presented in these works do not explicitly address master-slave architectures, see Remark 5. | ||||||
| Maximum | Minimum | Mean Std | |
|---|---|---|---|
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Asynchronous Distributed Optimization over Lossy Networks via Relaxed ADMM:
Stability and Linear Convergence
Nicola Bastianello, , Ruggero Carli, , Luca Schenato, , and Marco Todescato N. Bastianello, R. Carli and L. Schenato are with the Department of Information Engineering (DEI), University of Padova, Italy. [bastian4|carlirug|schenato]@dei.unipd.it.M. Todescato is with Bosch Center for Artificial Intelligence. Renningen, Germany. [email protected] work has received funding from the Italian Ministry of Education, University and Research (MIUR) through the PRIN project no. 2017NS9FEY entitled “Realtime Control of 5G Wireless Networks: Taming the Complexity of Future Transmission and Computation Challenges”. The views and opinions expressed in this work are those of the authors and do not necessarily reflect those of the funding institution.
Abstract
In this work we focus on the problem of minimizing the sum of convex cost functions in a distributed fashion over a peer-to-peer network. In particular, we are interested in the case in which communications between nodes are prone to failures and the agents are not synchronized among themselves. We address the problem proposing a modified version of the relaxed ADMM, which corresponds to the Peaceman-Rachford splitting method applied to the dual. By exploiting results from operator theory, we are able to prove the almost sure convergence of the proposed algorithm under general assumptions on the distribution of communication loss and node activation events. By further assuming the cost functions to be strongly convex, we prove the linear convergence of the algorithm in mean to a neighborhood of the optimal solution, and provide an upper bound to the convergence rate. Finally, we present numerical results testing the proposed method in different scenarios.
Index Terms:
distributed optimization, ADMM, asynchronous update, lossy communications, operator theory, Peaceman-Rachford splitting
I Introduction
From classical control theory to more recent machine learning applications, many problems can be cast as optimization problems [1] and, in particular, as large-scale optimization problems, given the increasing importance of cyber-physical systems in engineering applications. Stemming from classical optimization theory, in order to break down the computational complexity, parallel and distributed optimization methods have been the focus of a wide branch of research [2]. Within this vast topic, typical applications foresee computing nodes to cooperate, through local information exchanges, in order to achieve a desired common goal such as
[TABLE]
where, usually, each is stored and known by one single node only.
While parallel optimization methods usually rely on a shared memory architecture to implement the communication among agents, in distributed systems a message passing architecture is employed, in which agents can exchange transmissions with a (subset) of the other agents. The message passing (or peer-to-peer) architecture however introduces some issues due to the implementation of the transmission protocols. Indeed, distributed systems may suffer from communication failures, delays, and noise, on top of the possible asynchronism of the agents’ activations. In this paper we are interested in solving the distributed problem (1) in the presence of communication (or packet) losses and asynchronism.
A first class of algorithms that has been proposed to solve distributed optimization problems is that of (sub)gradient- and Newton-based methods.
Distributed gradient descent algorithms in general combine local gradient descent steps with consensus averaging, see for example [3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]. These algorithms can handle many different scenarios, with smooth and non-smooth costs, over both fixed and time-varying topologies, and over directed and undirected graphs. In general, the convergence of gradient-based methods is sub-linear for convex costs and linear for strongly convex costs. The only method that can handle both packet losses and asynchronous activations of the nodes is [14]; however, it requires a decreasing step-size and thus, implicitly, that the agents be synchronized.
Newton-based distributed algorithms have been introduced in [15, 16, 17, 18] in synchronous and lossless scenarios. Recently the scheme in [17] has been extended in [19] to asynchronous and lossy scenarios. However, in [19], the convergence is proved only locally and no characterization of the convergence rate is provided.
Other widely studied algorithms for solving distributed optimization problems are the alternating direction method of multipliers (ADMM) and the more general relaxed ADMM (R-ADMM). This class of algorithms can be defined either as augmented Lagrangian methods [20, 21], or, within an operator theoretical framework, as the dual of the (relaxed) Peaceman-Rachford splitting [22, 23]. The latter formulation will be employed in this paper and we refer to [24, 25] for a background on operator theory and its applications to convex optimization. Typically, the ADMM is derived from a Lagrangian-based formulation, while the R-ADMM is derived in an operator theoretical framework. However, it is known, see [26], that the ADMM can be seen as a particular instance of the R-ADMM, obtained setting one of the free parameters equal to a specific value. This slightly reduces the complexity of the updating equations, but the higher flexibility of R-ADMM allows to obtain better convergence properties.
The convergence of ADMM and R-ADMM for convex optimization problems is in general sub-linear, see e.g. [20, 22], and the same applies for distributed optimization. In an asynchronous scenario, sub-linear convergence can be similarly proved, adopting both the augmented Lagrangian, see [27, 28, 29], and the splitting operator formulations, see [26, 30]. Remarkably, assuming the functional costs are strongly convex, the distributed implementations of ADMM introduced in [31, 32, 33], have been shown to attain linear and global convergence when communications are synchronous and reliable. These results have been extended to asynchronous schemes in [29, 34], though the proposed analysis is limited to master-slave architectures. To the best of our knowledge, [35] is the only paper proving convergence of the synchronous ADMM in presence of lossy communications, modeled as i.i.d. binary random variables. However, no characterization of the convergence rate is provided.
The authors of [26] have derived the R-ADMM within the framework of the ARock algorithm, introduced in the context of parallel computing where agents share a common memory. In [26] and [36], it is shown that the ARock framework successfully handles asynchronous updates and delayed information attaining a sub-linear rate of convergence. However, due to the reliance of the convergence proof on the common memory, ARock it is not suitable to deal with unreliable communications. In [37, 23], the general R-ADMM algorithm is provably shown to be linearly and globally convergent, provided that the dual problem is strongly convex. This result has been extended to randomized scenarios in [30, 38]. Unfortunately, strong convexity of the dual problem, is satisfied in the networked optimization scenario of interest only if master-slave architectures are employed, thus preventing the use of fully distributed schemes.
In this paper we present and analyze a modified version of the R-ADMM algorithm which is amenable of distributed implementation in peer-to-peer networks with unreliable communications and asynchronous operations of the agents. The theoretical contribution is twofold:
- •
Deriving the R-ADMM as an application of the Peaceman-Rachford splitting, we are able to exploit recent results on randomized nonexpansive operators to establish the almost sure convergence of the proposed algorithm, provided that mild assumptions on the asynchronous and lossy nature of the network are satisfied.
- •
Further assuming that the local costs are strongly convex and twice differentiable, we show that the convergence is locally linear in mean, and provide an upper bound to the convergence rate.
A preliminary version of this paper has appeared in [39], where however no asynchronous updates are considered, and no convergence rate analysis is provided.
The remainder of the paper is organized as follows. Section II reviews some concepts in operator theory, and the R-ADMM. Section III describes the distributed implementation of R-ADMM to solve (1) and its convergence. Section IV analyzes the convergence properties of R-ADMM under asynchronous updates and communication failures. Finally, Section V presents some numerical results and Section VI concludes the paper.
II Preliminaries
This Section collects some preliminary definitions in graph theory [40] and convex analysis [41], as well as a brief review of the necessary background regarding operator theory [25] and the R-ADMM [20, 23].
II-A Notation and useful definitions
We denote by the Kronecker product, by the spectrum of a matrix , and by the distance between point and the set . (resp. ) denotes the -dimensional vector of all ones (resp. zeros). By we denote that the symmetric matrix is positive definite.
We denote a graph by , where is the set of vertices, labeled through , and is the set of undirected edges. For , by we denote the set of neighbors of node in , namely, . The degree of each node is denoted by . Moreover, in the following we write , i.e., counts twice the number of edges in the network.
Consider the scalar function . Then is said to be closed if the set is closed, and it is proper if it does not attain , see [25]. We denote by the class of convex, closed and proper functions from to . We define the convex conjugate of as for . The convex conjugate belongs to . Finally, a function is said to be -strongly convex, , if is convex. If is twice differentiable, , then strong convexity implies that for all .
II-B Notions on operator theory
By operator111The term mapping should actually be used, but in the literature the two are usually employed interchangeably. on we mean a map that assigns to each point in the corresponding point . Given an operator , by we denote the set of its fixed points, that is, .
An operator is Lipschitz continuous if there exists such that holds for any two . In particular, is said to be nonexpansive if , and contractive if . An operator is averaged if there exist and nonexpansive such that we can write . Notice that .
An operator is said to be affine if there exist and such that we can write , .
Given a function , we define the corresponding proximal operator as
[TABLE]
where is called penalty parameter, and the reflective operator as . The proximal is -averaged222This property is also called firm nonexpansiveness. while the reflective is nonexpansive. Observe that the fixed points of and coincide with the minimizers of . In general, given nonexpansive, the algorithm for finding its fixed points is the Krasnosel’skii-Mann (KM) iteration, see [25],
[TABLE]
Consider now the convex optimization problem
[TABLE]
with . Let us define the Peaceman-Rachford operator
[TABLE]
such that the minimizers of the optimization problem are . The Krasnosel’skiĭ-Mann iteration applied to the on the auxiliary variable yields the so called Peaceman-Rachford splitting (PRS):
[TABLE]
which is guaranteed to converge to a fixed point of if and , see [25]; a minimizer to (3) is recovered from the limit of the iterate by computing . As show in [25], the iteration (4) can be conveniently implemented by the following updates
[TABLE]
where is an additional auxiliary variable.
II-C Relaxed ADMM
Consider the following optimization problem
[TABLE]
where , , , and . We assume that (6) admits a finite solution. The dual problem of (6) is (see [26])
[TABLE]
where
[TABLE]
The relaxed alternating direction method of multipliers (R-ADMM) can be derived applying the PRS (4) to solve (7). In [22], it has been shown that an efficient implementation of (5) is characterized by the following updates, which involve the primal variables and , see also Appendix A:
[TABLE]
where (8a), (8b) implements (5a), while (8c), (8d) implements (5b). The convergence of the PRS guarantees, in turn, the convergence of and to an optimal solution of the primal (6). Indeed problem (6) is convex with linear constraints and strong duality holds.
The R-ADMM is a generalized version of the classical ADMM described e.g. in [20]; indeed it is possible to see that when the former recovers the latter, see Remark 3 in Section III.
III R-ADMM for Distributed Optimization
In this Section we formulate the distributed optimization problem of interest and we show how the R-ADMM is suited to solve it.
III-A Problem formulation
Consider the undirected, connected graph with nodes. We are interested in solving
[TABLE]
over the network where the cost function is known only to the -th node, and nodes can communicate only with their neighbors. We assume that (9) admits at least one finite solution.
In order to apply the R-ADMM to problem (9) we reformulate it as follows. First, a local copy of the decision variable is assigned to each agent. Therefore, as long as is connected, problem (9) is equivalent to
[TABLE]
Indeed the consensus constraints impose that any optimal solution of (10) satisfies , with a solution to (9). Introducing the bridge variables and for each edge , the consensus constraints can be equivalently rewritten as
[TABLE]
Defining the vectors and , the constraints in (11) can be compactly rewritten as333Hereafter, boldface letters will denote vectors and matrices built stacking local quantities.
[TABLE]
where
[TABLE]
, is a permutation matrix that swaps with . We remark that in general is not full row rank.
Finally, define and , where the indicator function is equal to [math] if and otherwise. Hence problem (10) can be equivalently formulated as
[TABLE]
Problem (12) is in the form of (6) and thus we can apply the R-ADMM algorithm to solve it.
III-B Distributed R-ADMM
The particular separable structure of the functions , , and of matrices , , allows us to derive simplified equations for the R-ADMM algorithm that involve only the update of the and variables, and that are amenable of distributed implementations.
Indeed, it can be shown that the equations (8) applied to problem (12) reduce to
[TABLE]
for all and . See Appendix C-A for the derivation. Observe that, since , the dimension of is equal to the dimension of , i.e., for all there are the variables and . Interestingly, one can see that (13a) can be rewritten as
[TABLE]
where denotes the -th component of the vector , see Lemma 1 in Appendix C-B. A straightforward implementation of (13) has the node storing and updating and . Notice that, while (13a) can be computed using only local information, i.e., the local cost and , update (13b) requires communication with ’s neighbors, that is, transmission of and from node . In particular we assume that node sends to node the packet
[TABLE]
and, consequently, node performs the update
[TABLE]
Algorithm 1 describes the implementation of the distributed R-ADMM.
The following convergence result is a direct consequence of the convergence of the Peaceman-Rachford splitting, proved e.g. in [25, Th. 26.11].
Proposition 1**.**
Consider problem (9) with , and let and . Then, for any initial condition , the trajectories , , generated by Algorithm 1, converge to an optimal solution of (9), i.e.,
[TABLE]
Remark 1**.**
Notice that the statement of Proposition 1 considers only the initial condition of variable and not of . The reason is related to update (13a) where it is clear that depends only on and not on .
Remark 2** **(Comparison with ARock [26]).
The formulation of the R-ADMM presented in Algorithm 1 is derived using the same idea employed in [26] of interpreting the R-ADMM as an application of the PRS to the dual problem. Also the R-ADMM algorithm proposed in [26] to solve problem (1) (see section 2.6.2), involves only the use of variables , but the actual implementation differs from Algorithm 1. Additionally, it is worth mentioning that the authors of [26] have derived the R-ADMM within the framework of the ARock algorithm, introduced in the context of parallel computing where agents share a common memory. In [26] and [36] it is shown that the ARock framework successfully handles asynchronous updates and (possibly unbounded) delayed information. However, due to the reliance of the convergence proof on the common memory, ARock is not suitable to deal with the lossy and asynchronous framework of interest in this paper.
III-C Linear local convergence for strongly convex costs
In this section we prove the local linear convergence of the distributed R-ADMM under the assumption that the local costs are strongly convex and twice continuously differentiable. Notice that, under these assumptions there exists a unique minimizer for problem (9).
It is worth stressing that for particular distributed and centralized formulations of the R-ADMM (see [31, 32, 23]), especially of the classical ADMM, it is actually possible to prove global linear convergence under milder assumptions than the ones made in this section. However the results in [31, 32, 23] can be applied only partially to the scenario of our interest and we refer to Remark 5 for a detailed discussion.
The idea behind the result of Proposition 2 below is that, in a neighborhood of the optimal solution, the strong convexity and double continuous differentiability of the local costs allow us to rewrite the Peaceman-Rachford splitting applied to the dual of the distributed problem as a perturbed affine operator. Indeed, it is possible to write the update of the auxiliary variables in compact form as
[TABLE]
where , and is such that
[TABLE]
with , is a constant vector depending on the gradient and Hessian of evaluated at , and is a vanishing function for approaching the optimum, that is,
[TABLE]
as . All the details can be found in Appendix C-B.
In Lemma 2 in Appendix C-B, it is established that the eigenvalues of are either equal to or strictly inside the unitary circle, with the eigenvalues equal to all being semi-simple. The largest (in absolute value) eigenvalue smaller than of is an upper bound to the convergence rate of the ’s trajectories toward the optimum. This fact is formally stated in the following Proposition.
Proposition 2**.**
Assume that the local costs are strongly convex and twice continuously differentiable. Then there exists such that, if , then Algorithm 1 converges linearly fast, i.e.
[TABLE]
with , and , where is the largest eigenvalue of different from one, i.e.
[TABLE]
Proof.
See Appendix C-B. ∎
While we refer to Appendix C-B for the proof of this result, hereafter we comment some interesting details. These results will play an important role also in the analysis performed in Section IV in the presence of asynchronous updates and lossy communications, which is the main novelty of this paper.
The proof of Proposition 2 relies on the following two facts:
- (i)
the set is an affine space such that, given any two fixed points , it holds ; 2. (ii)
exploiting (14) and the fact that , , is contractive, it is possible to upper bound the primal error with the auxiliary error , for any . Specifically, we have that
[TABLE]
where is a suitable constant depending on the curvature of the ’s and on the topology of ; for more details see (45) and (46) in Appendix C-B.
Since converges to a fixed point then, from (18) and fact (ii), we have . As observed in Appendix C-B, if all the were quadratic functions, then (16) would reduce to the linear update . The convergence would thus be global, linear and with rate upper bounded by .
In the proof of Proposition 2 we show that this linear convergence is not deteriorated by the presence of the nonlinear term , though the price to be paid is that the convergence is not guaranteed to be global but only local.
Some remarks are now in order to better cast Algorithm 1 within the existing literature. In particular Remarks 3 and 4 discuss the connection with Augmented Lagrangian-based and node-/edge-based formulations, respectively. Remark 5 provides a further discussion on the convergence rate.
Remark 3** **(Lagrangian based R-ADMM).
The R-ADMM described in section II-C can be interpreted in the framework of augmented Lagrangian methods. Indeed, define the augmented Lagrangian
[TABLE]
where is the Lagrange multipliers’ vector. Then, the R-ADMM in (8) is equivalent to the following updates, see [22] and Appendix B:
[TABLE]
In particular, given , if , then the and trajectories generated by (8) and (20) coincide, see Appendix B. Observe that, if , we recover the classical ADMM described e.g. in [20]. The choice of analyzing the more general R-ADMM relies on the fact that, by properly tuning the parameter , we can achieve better performance than the classical ADMM as observed e.g. in [42], proved in [23], and evidenced by the numerical results in Section V. Interestingly, also the augmented Lagrangian-based R-ADMM in (20) is amenable of a distributed implementation when applied to (12), which is described by the following updates
[TABLE]
Clearly, this formulation requires each node to store the variables , and , and to update them exchanging information only with its neighbors. Therefore in terms of storage requirement Algorithm 1 is better than the augmented Lagrangian formulation, as evidenced by Table I.
Remark 4** **(Node- and edge-based ADMM).
In Algorithm 1 and in the corresponding Lagrangian-based formulation, the number of variables that each node stores scales with , see Table I. This is due to the fact that each node stores an auxiliary variable for each of the edges it is part of – hence the name edge-based – incurring in a worst case memory requirement of . A different formulation of the R-ADMM, called node-based, can be given, in order to guarantee that the local storage requirement is constant, i.e. . Node-based formulations of the classical ADMM are employed e.g. in [28, 31, 32]. Notice that Algorithm 1 can be reformulated as a node-based method if each node stores and updates the variables and instead of the auxiliary variables.
However, as observed in [35], in general node-based ADMM formulations are not robust to packet losses. Indeed, the convergence of a node-based ADMM is guaranteed only if, at each iteration , the graph resulting from the removal of faulty edges is still connected. Edge-based formulations are instead necessary in order to remove this (rather demanding) assumption, such as the one proposed in [35] to handle (uniformly distributed) packet losses, and Algorithm 2 proposed in this paper. Intuitively, the use of bridge variables is necessary in order to keep track of the packets received at any given time from each of the neighbors.
Remark 5** **(Further discussion on the convergence rate).
In recent years there has been an increasing interest in characterizing the convergence rate of both centralized and distributed implementations of R-ADMM and classical ADMM. A special effort has been devoted to provide conditions under which the convergence is guaranteed to be linear. Next, it is worth summarizing some of the main results comparing them to Proposition 2. Interestingly, the distributed implementations of the standard ADMM introduced in [31] and [32] have been shown to attain global and linear convergence provided that the Lagrange multipliers satisfy some particular initializations and under the assumptions that the local costs are strongly convex and with Lipschitz continuous gradient. Though these assumptions are milder than the one made in Proposition 2, the results in [31] and [32], when interpreted in the context of the more general R-ADMM, are valid only for the case , while the result in section III-C holds true for any within the interval . Moreover, for the case , the analysis performed in [31] could be mimicked for the distributed Lagrangian-based implementation described in (21), thus obtaining a global linear rate when also for the algorithm proposed in this paper.
Concerning the general Peaceman-Rachford splitting applied to (6), the authors of [23] have shown that the R-ADMM algorithm converges linearly to an optimal solution provided that the matrix is full row rank, which guarantees that the Peaceman-Rachford operator is contractive. Under the same assumption, the linear convergence extends also to randomized updates [38]. However, in the distributed optimization scenario of interest is not full row rank, since and therefore the aforementioned convergence results cannot be applied. In particular, the loss of row rank for implies that the dual function is only convex but not strongly convex, and, hence that the Peaceman-Rachford operator is only nonexpansive. A notable exception arises when adopting master-slave architectures, which are characterized by a master node connected to other nodes (the slaves). Indeed, in this setting only one bridge variable is introduced for any edge, and thus , which is full row rank. The implementation of the ADMM in this setup envisions the slave nodes performing local updates of the primal variables, and the master node updating the dual variables.
IV Asynchronous Distributed R-ADMM over Lossy Networks
Algorithm 1 works under the standing assumption that the communication channels are reliable and that the nodes update synchronously. The goal of this Section is to relax these requirements and to show how Algorithm 1 can be modified to still guarantee convergence, under probabilistic assumptions on communication failures and asynchronous updates, and to characterize its linear convergence in mean.
IV-A Robust and Asynchronous R-ADMM
Consider Algorithm 1, and notice that node at iteration receives the packet from only if the two following conditions are satisfied: (i) node performs an update of at iteration ; and (ii) the packet is not lost.
Now, for any , let us define the set of random variables , such that the realization of is if node performs an update during the -th iteration, [math] otherwise. Similarly, provided that , we define the set of variables such that the realization of is [math] if is delivered to , otherwise. Within this formalism, we see that node can carry out an update of at iteration provided that and . To simplify the theoretical analysis, we define the set of random variables such that
[TABLE]
We make the following probabilistic Assumption on the variables .
Assumption 1**.**
The random variables are mutually independent over , namely, given and for any , they are independent if . Moreover, there exists a -uple such that
[TABLE]
for all .
Observe that Assumption 1 requires only independence over time, but not among the random variables at the same iteration . Moreover, as consequence of (22), each variable has a nonzero probability of being updated at each iteration . Assumption 1 could have been stated equivalently in terms of and , assuming nonzero probabilities for the occurrence of update and packet delivery events, and mutual independence over time.
Remark 6** **(Uniform probabilities).
Assume the random variables and are i.i.d., such that and , for all , , and . Then are uniformly distributed with probability , but in general are not independent, since all depend on .
In Algorithm 2 we describe the modified version of Algorithm 1 that can handle asynchronous updates and packet losses. If node at iteration is selected, then it updates and computes the variables , , transmitting them to its neighbors. If node receives then it updates the variable , otherwise it leaves it unchanged.
Notice that node updates the variable only if it receives the packet . Making use of the random variables , we can thus describe the update step for the auxiliary variables in the following compact form
[TABLE]
The following convergence result holds as a consequence of the convergence of the Peaceman-Rachford splitting with random coordinate updates, see [43, 30].
Proposition 3**.**
Consider problem (9) with . Assume Assumption 1 holds, and let and . Then for any initial condition , the trajectories , , generated by Algorithm 2 converge almost surely to an optimal solution of (9), that is,
[TABLE]
Proof.
See Appendix D-A. ∎
IV-B Mean linear convergence for strongly convex costs
In this section, under the assumption that the local functions are strongly convex, we prove that the mean convergence of Algorithm 2 is locally linear. Moreover we provide an upper bound to the convergence rate.
In the scenario of Assumption 1, it is not guaranteed that the auxiliary variables are updated at each iteration . Indeed, by introducing the random diagonal matrix such that
[TABLE]
we can rewrite (16) as
[TABLE]
where , with defined in (17). This allows us to interpret Algorithm 2 as the application of a randomized and perturbed affine operator.
The goal of this section is to evaluate the behavior of the mean error as and, in particular, showing that it converges to zero linearly. The following inequality holds, see Appendix D-B for the proof:
[TABLE]
Next we show that the square of the first term on the right-hand side of (IV-B) converges to zero linearly as . Notice that this term can be rewritten as
[TABLE]
if , otherwise . A simple recursive argument shows that
[TABLE]
that is, is the evolution of a linear dynamical system which can be written in the form
[TABLE]
where is defined by
[TABLE]
The spectral properties of have been characterized in Lemma 3 in Appendix D-C. In particular the following two facts have been established. First, if has semi-simple eigenvalues in then has semi-simple eigenvalues in , while all the other eigenvalues are strictly inside the unitary circle. Second, the matrix belongs to the eigenspace generated be the eigenvectors corresponding to the eigenvalues strictly smaller than . These two facts directly imply the following result.
Proposition 4**.**
Consider (26) with . Then, there exists such that
[TABLE]
where
[TABLE]
The previous Proposition states that the convergence rate to zero of is upper bounded by the largest eigenvalue in absolute value of different from . One can show that is a suitable upper-bound also for the convergence rate to zero of the second term in the right-hand side of (IV-B). Indeed, the following Proposition holds true in a neighborhood of the optimal solution.
Proposition 5**.**
Assume that the local costs are strongly convex and twice continuously differentiable, and that Assumption 1 holds. Then there exists such that, if , then Algorithm 2 converges linearly – in mean – to the optimal solution, i.e.,
[TABLE]
with , and .
Proof.
See Appendix D-C. ∎
All the details of the derivation can be found in Appendix D-C. The next Proposition provides a matricial characterization of the operator that can be used to compute .
Proposition 6**.**
The linear operator can be equivalently described by the following matrix
[TABLE]
which is equal to
[TABLE]
Hence
[TABLE]
Proof.
See Appendix D-D. ∎
Observe that, from Assumption 1, it follows that and are both diagonal matrices. In particular, when considering the uniform scenario introduced in Remark 6, the computation of simplifies to
[TABLE]
since , and where the diagonal elements of are given by
[TABLE]
We conclude this Section with the following Remarks that emphasize some interesting properties of Algorithm 2.
Remark 7** **(Quadratic case: global linear convergence).
If the local costs are quadratic, then the linear convergence results of Proposition 2 and 5 hold globally. This is a consequence of the fact that the auxiliary variable update (24) characterizing the proposed algorithm becomes a (randomized) affine update:
[TABLE]
Remark 8** **(Convergence of randomized (R-)ADMM).
Owing to the operator theoretical interpretation of the R-ADMM, its convergence in the presence of asynchronous updates and packet losses can be guaranteed almost surely for all choices of initial conditions and of the free parameters and . On the other hand, proving convergence of the augmented Lagrangian-based interpretation of R-ADMM (see Remark 3) is not as straightforward. To the best of our knowledge, [35] is the only paper proving convergence of the standard ADMM in the presence of packet losses. Interestingly, building on the framework established by [31], the authors of [35] have proved global convergence of the ADMM in the presence of uniformly distributed packet losses. However no linear convergence has been established and, in turn, no characterization of the rate of convergence has been provided. Moreover, asynchronous scenarios have not been analyzed. On the other hand, in [34] global linear convergence of ADMM is shown in the presence of asynchronous updates, but the results hold only for master-slave architectures.
Concerning the general R-ADMM algorithm, results for lossy and asynchronous scenarios have been obtained in [26, 36, 43, 30, 38]. More precisely, in [26, 36], it is proved that the ARock algorithm converges sub-linearly with asynchronous updates and (possibly unbounded) transmission delays. However convergence is guaranteed only if a single agent updates at each iteration, while Algorithm 2 is fully parallel, i.e. guarantees convergence when an arbitrary number of agents updates simultaneously. Moreover, as already stressed in Remark 2, the presence of a common memory among the nodes makes the ARock framework not suitable to theoretically analyze the convergence properties of Algorithm 2.
In **[30, 43]** the convergence of the general R-ADMM has been shown in the presence of randomized coordinate updates. Furthermore, **[38]** proves the global, linear convergence of the randomized R-ADMM under the assumption that is full row rank. We remark that the the linear convergence result of **[38]** applies to the distributed setup of interest only for master-slave topologies, for which is full row rank [cf. Remark 5].
The review literature provided in this Remark and in Remark 5 has been conveniently summarized in Table II.
Remark 9** **(Stable parameters pairs).
Observe that both Proposition 1, for the case of reliable communications, and Proposition 3, for the randomized updating scenario, establish convergence provided that and . However, these conditions are only sufficient and not necessary and, in particular, the convergence might hold also for values of . This fact, proved in [23] under the assumption that is full row rank, can be empirically observed in Section V where, for the case of quadratic functions , the region of attraction in parameter space is larger. Moreover, despite what the intuition would suggest, the larger the packet loss uniform probability , the larger the region of convergence. However, this increased region of stability is counterbalanced by a slower convergence rate of the algorithm.
V Simulations
In this Section we present numerical results that showcase the convergence properties of the proposed Algorithm 2 in different scenarios.
V-A Error trajectories
We consider a random geometric graph with nodes, and quadratic costs , with , and . We performed a set of Monte Carlo simulations, each iterations long and averaging over realizations of the uniformly distributed packet loss and update random variables.
Fig. 1 depicts the logarithmic error for different values of when both packet losses and asynchronous updates are present. First of all we notice that, the convergence is linear. Moreover, the closer is to , the faster the convergence is; notice that, although Proposition 3 does not guarantee convergence for , this is nonetheless achieved. This result suggests that the R-ADMM is advantageous w.r.t. the standard ADMM, thus justifying its choice.
Fig. 2 depicts the logarithmic error for different values of the packet loss probability . The result is that the larger is, the slower the convergence, since the number of updates performed at each iteration decreases.
Finally, Fig. 3 depicts the stable pairs of values for different packet loss probabilities and . A pair is considered stable if it leads to convergence of Algorithm 2 over all of the Monte Carlo iterations. The curves in Fig. 3 represent the upper bound to the value of that gives stable pairs.
An interesting feature of the proposed algorithm is that the larger the packet loss probability is, the larger the stability region. This is however counterbalanced by the fact that the convergence rate increases as the packet loss grows larger [cf. Fig. 2].
V-B Convergence rate
We consider now a random geometric graph with nodes and , the same quadratic cost for each agent, and for simplicity . We evaluate the empirical convergence rate of the R-ADMM , computed as the slope of the logarithmic error trajectory averaged over Monte Carlo simulations, each iterations long. Fig. 4 depicts the results.
Notice that, as evidenced also by Fig. 1 above, the larger is, the lower the convergence rate. On the other hand, in this particular scenario the larger is , the worse the convergence rate.
Moreover, for each choice of , and , we computed , which by Proposition 5 gives a bound to the convergence rate that holds in mean. Indeed, as evidenced by Tab. III, the bound appears to be extremely tight, with a maximum difference that is less than ‰.
Finally, Fig. 5 depicts the empirical rate for complete graphs with different numbers of nodes, and for different packet loss probabilities. The cost is quadratic and equal for all the agents.
As remarked above, the larger is, the larger ; and, in this particular case, the convergence rate degrades monotonically with the number of nodes in the graph.
V-C Quartic function
In order to study the effect of curvature on the convergence of the algorithm, we considered a random graph with , , and all costs equal to
[TABLE]
Fig. 6 depicts the logarithmic error for different values of the parameter . Clearly, the curvature of the cost may deeply affect the rate of convergence.
Notice moreover that the convergence is globally linear, although the theoretical results guarantee only local linear convergence.
VI Conclusions and Future Directions
In this paper we addressed distributed convex optimization problems over peer-to-peer networks with both unreliable communications and asynchronous updates of the nodes. We proposed a modified version of the relaxed ADMM that, exploiting operator theoretical results, can be shown to converge almost surely. Moreover, by further assuming the local costs to be strongly convex, we proved local linear mean convergence of the proposed algorithm.
We have cast the proposed algorithm in the context of the literature and discussed its novelty. And finally, we have presented interesting numerical results that showcase the resilience and robustness of the proposed algorithm.
Appendix A Derivation of (8)
The Peaceman-Rachford splitting (5) applied to the dual problem (7) is characterized by the updates
[TABLE]
We show now that (28a) is equivalent to (8a) and (8b); the same argument can be applied to (28b).
By the definition of proximal operator and of it holds
[TABLE]
where we applied the definition of convex conjugate. Consider now the minimum in (29), we have
[TABLE]
and by the first optimality condition for the innermost minimization it must hold:
[TABLE]
which is exactly (8b). Substituting (31) into (30) yields
[TABLE]
and changing the sign of the cost function we obtain (8a).
Appendix B Proof of equivalence between (8) and (20)
We show that we can derive (20) from (8), thus proving their equivalence.
We derive first some equalities that will be useful in the following. By (8b) we have
[TABLE]
and using this fact into (8d) yields
[TABLE]
Moreover, substituting (33) into (8d) we obtain
[TABLE]
Consider now (8c), the following chain of equalities holds
[TABLE]
where we derived the first by subtracting , the second by adding , , and , which is allowed since they do not depend on . The third equality holds by definition of square norm and augmented Lagrangian (19). We have thus derived (20c).
Substituting (33) and (32) into (8e) yields
[TABLE]
where the second equation was obtained adding and subtracting . Finally, evaluating (35) at iteration and using (32) we get (20b).
From (8a) and using (35) at iteration we can write
[TABLE]
where the second equality was derived adding , , and which do not depend on , and the third by the definitions of square norm and augmented Lagrangian. This proves equivalence of (8a) with (20a).
Finally, by the results we derived above, we can see that if the initial conditions satisfy
[TABLE]
then the trajectories for and generated by the splitting R-ADMM and the Lagrangian R-ADMM coincide.
Appendix C Proofs of Section III
C-A Derivation of (13)
Following the derivation in [26], we show that applying the R-ADMM of (8) to the distributed problem of interest yields (13).
update
Using the particular structure of we can see that in update (8a):
[TABLE]
since each appears in constraints, i.e. rows of . Moreover
[TABLE]
since the -th row of sums over the auxiliary variables stored by . Therefore (8a) becomes
[TABLE]
which is clearly separable over the single components. Moreover, node has all the information necessary to compute .
update
Update (8c) in the distributed scenario becomes
[TABLE]
whose KKT conditions are
[TABLE]
where is the vector of Lagrange multipliers. Plugging (36a) into (36b) yields
[TABLE]
where the second equality was derived using , which implies . Finally, summing (36a) and (37) we get
[TABLE]
which means that for any and .
update
Using (8b), and substituting (38) into (8d), the auxiliary update (8e) becomes
[TABLE]
and using the definitions of , proves (13b).
C-B Proof of Proposition 2
The proof is divided in the following steps: (i) write the auxiliary update of Algorithm 1 as a perturbed affine operator; (ii) bound the primal error with the error on the auxiliary variable; (iii) show that the primal error converges linearly for a quadratic approximation; (iv) extend the result to the general case.
(i) Perturbed affine operator
From the first order optimality condition for (13a) it must hold for any
[TABLE]
Therefore using the Taylor expansion of the gradient around we have
[TABLE]
for , where is such that as . Combining (40) and (41), the latter evaluated in , yields
[TABLE]
and solving for we get
[TABLE]
Stacking the updates (42) for we can write
[TABLE]
where , and stack and , respectively.
Using the auxiliary update (39) and (43) we can write
[TABLE]
where , , and , , decays faster than the argument.
Remark 10**.**
Using the particular structure of we see that . But since for any , the Hessians are symmetric and thus is symmetric as well.
(ii) Primal error bound
We start by stating the following result.
Lemma 1**.**
The update (13a) can be rewritten as
[TABLE]
Proof.
Adding the term – which does not depend on – to the objective function in (13a) and using the definition of norm we can write
[TABLE]
where the second equality follows from definition of proximal operator, see section II-B. ∎
Denote by the strong convexity modulus of function , then we know that the proximal is -contractive [44], which implies
[TABLE]
for any . Then
[TABLE]
where
[TABLE]
(iii) Linear convergence (quadratic case)
Assume that the functions are quadratic and, more specifically, (41) holds true with the residual equal to [math]. In this case the Peaceman-Rachford operator is affine and averaged, and the auxiliary update becomes . The following result characterizes the spectral properties of .
Lemma 2**.**
The eigenvalues of are either equal to or strictly inside the unitary circle. Moreover the eigenvalues in are all semi-simple. In addition the following property holds
[TABLE]
Proof.
For affine averaged operators the eigenvalues of are all inside the circle on the complex plane with center and radius [45]. This implies that the unique eigenvalues of with unitary absolute value are in , and by convergence of the Krasnosel’skiĭ-Mann they are semi-simple.
Now let where is the algebraic (and geometric) multiplicity of . Notice that, given and , then for any . For any from (43) we have , which, by uniqueness of , implies
[TABLE]
By the nonsingularity of this condition implies , , and thus . ∎
Now by iterating we have
[TABLE]
which is satisfied also by any . Thus and combining this fact with (45) yields
[TABLE]
Since , this implies that where is the largest eigenvalue in absolute value different from of and where , see [45]. This proves the linear convergence of the primal error in the quadratic case.
(iv) Linear convergence (general case)
Since the PRS operator is nonexpansive, it follows that and, in turn, that also the sequence is bounded. Since , by the definition of we can argue that there exists a sequence of positive numbers such that , and
[TABLE]
Therefore, by iterating (44) and exploiting (45) the primal error, for , can be bounded as
[TABLE]
where . Consider now the sequence such that , and
[TABLE]
Recalling the definition of , we know that there exists a ball centered in such that, if belongs to , , then with such that , i.e. . In this case, by a standard inductive argument, one can show that for all . Notice that in view of (18), there exists such that if then . Now from (48)
[TABLE]
from which, since for all , we get that . We conclude the proof by observing that, for any , it holds
[TABLE]
Appendix D Proofs of Section IV
D-A Proof of Proposition 3
As discussed in Section IV, loss of transmissions and asynchronous updates are taken into account by Algorithm 2 by updating a auxiliary variable only if new information is available. But since the R-ADMM is the Peaceman-Rachford splitting applied to the dual of (6), we can interpret Algorithm 2 as a randomized Peaceman-Rachford in which each coordinate of the vector is randomly updated with nonzero probability. Therefore the convergence results of [30, Theorem 3] or (a particular case of) [43, Theorem 3.2] can be applied to prove almost sure convergence to the dual solution and, in turn, by strong duality, to the primal solution.
D-B Derivation of (IV-B)
By (18) we have , and our goal is to find a bound for the right-hand side. Iterating (24) we get
[TABLE]
Multiplying by , taking the norm of (49) and using triangle inequality and submultiplicativity then yields
[TABLE]
Now, taking the expectation we get:
[TABLE]
Finally, by Jensen’s inequality for concave functions (as the square root is), we know that
[TABLE]
and using this fact into (51) yields (IV-B).
D-C Proof of Proposition 5
The proof consists of the following steps: (i) derive the auxiliary update in Algorithm 2 as a perturbed, randomized affine operator, and characterize its properties; (ii) bound the mean primal error for the quadratic approximation with the auxiliary error, which converges linearly; (iii) extend the result to the general case.
(i) Randomized perturbed affine operator
Observe that, from (23), (44) and, recalling the definition of , we can write
[TABLE]
where . Let , then since , we have for any . Thus iterating (52) and subtracting yields
[TABLE]
where by convention . Let us consider now the quadratic case that we have assuming (41) holds true with the residual equal to [math]. In this case (53) becomes
[TABLE]
By Proposition 3 we know that converges with probability one to a fixed point , in general different from , which implies from (54) that
[TABLE]
Notice that, given any two fixed points , it holds , thus for (55) to be true there must exist random variables such that
[TABLE]
where recall that . The realizations of , depend on the realizations of , and on the initial condition . In general , which implies that we are able to find the random vectors such that
[TABLE]
(ii) Mean error bound
By iterating (54), taking the expectation, exploiting (45) and Jensen’s inequality, we can write
[TABLE]
where
[TABLE]
if , otherwise . Therefore, with a simple recursive argument, we can characterize the bound for the primal error in terms of the evolution of the linear system
[TABLE]
with initial condition , and where the second equality holds since, by Assumption 1, the are independent and identically distributed.
Lemma 3**.**
The eigenvalues of the operator are all either strictly inside the unitary circle, or in . In particular, let be the random vectors such that (56) holds. Then the eigenspace of relative to is -dimensional and is generated by , .
Proof.
Taking the limit for of (57) and exploiting the property (56) proved above yields, for any initial condition :
[TABLE]
This proves that the eigenspace of relative to the eigenvalue is dimensional and it is generated by , . ∎
By Lemma 2 we have , and so (58) with initial condition implies that is orthogonal to the eigenspace generated by the eigenvectors relative to . Thus we have , which proves that the primal error converges linearly to zero. The rate of convergence is characterized by the largest eigenvalue of the linear system strictly inside the unitary circle, that is by as defined in (27).
(iii) General case
By the results of point 2) we can write
[TABLE]
for some . Moreover, in the general case, iterating (53) and exploiting the primal error bound
[TABLE]
we obtain (IV-B). Now, using (59) and the fact that are independent and identically distributed, we have
[TABLE]
Similarly to the proof of Proposition 2, we can argue that there exists a sequence of positive numbers such that , and
[TABLE]
Hence we have the following inequality
[TABLE]
and with the same argument employed in Appendix C-B the proof of Proposition 5 is complete.
Remark 11**.**
Point (ii) of this proof extends to the distributed optimization scenario the results reported in [46] for the randomized consensus problem.
D-D Proof of Proposition 6
The idea is to introduce a matrix representation of and then compute its largest eigenvalue inside the unitary circle.
Let be the vectorization operator that, given a matrix , returns the vector having in position . A useful property of is that for a triplet of matrices of suitable dimensions we can write .
Vectorizing the linear system we obtain
[TABLE]
where of coincides with the largest eigenvalue of strictly inside the unitary circle.
Using Assumption 1 we now give an explicit formula for in terms of and the expectation of . The symmetry of , see Remark 10, implies that of and thus of . Therefore, omitting the dependence on time in , we have:
[TABLE]
and by linearity of the expectation we can focus on each term separately. The first term is clearly equal to itself, while we have , and, similarly, .
The remaining terms can be computed using the following property of the Kronecker product for matrices of suitable dimensions:
- •
,
- •
,
- •
,
- •
,
- •
.
Summing and rearranging the terms (exploiting the properties of the Kronecker product) we thus prove Proposition 6.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] K. Slavakis, G. B. Giannakis, and G. Mateos, “Modeling and Optimization for Big Data Analytics: (Statistical) learning tools for our era of data deluge,” IEEE Signal Process. Mag. , vol. 31, no. 5, pp. 18–31, 2014.
- 2[2] D. P. Bertsekas and J. N. Tsitsiklis, Parallel and distributed computation: numerical methods . Prentice hall Englewood Cliffs, NJ, 1989, vol. 23.
- 3[3] A. Nedić and A. Ozdaglar, “Distributed Subgradient Methods for Multi-Agent Optimization,” IEEE Trans. Autom. Control , vol. 54, no. 1, pp. 48–61, 2009.
- 4[4] ——, Convex Optimization in Signal Processing and Communications . Cambridge University Press, 2010, ch. Cooperative Distributed Multi-Agent Optimization, pp. 340–386.
- 5[5] A. Nedić, A. Ozdaglar, and P. Parrilo, “Constrained consensus and optimization in multi-agent networks,” IEEE Trans. Autom. Control , vol. 55, no. 4, pp. 922–938, 2010.
- 6[6] I. Lobel and A. Ozdaglar, “Distributed Subgradient Methods for Convex Optimization Over Random Networks,” IEEE Trans. Autom. Control , vol. 56, no. 6, pp. 1291–1306, 2011.
- 7[7] S. Lee and A. Nedić, “Distributed Random Projection Algorithm for Convex Optimization,” IEEE J. Sel. Topics Signal Process. , vol. 7, no. 2, pp. 221–229, 2013.
- 8[8] D. Jakovetic, J. M. F. Xavier, and J. M. F. Moura, “Convergence Rates of Distributed Nesterov-Like Gradient Methods on Random Networks,” IEEE Trans. Signal Process. , vol. 62, no. 4, pp. 868–882, 2014.