DistInit: Learning Video Representations Without a Single Labeled Video
Rohit Girdhar, Du Tran, Lorenzo Torresani, Deva Ramanan

TL;DR
DistInit introduces a novel method for learning video representations without labeled videos by distilling knowledge from image-based models, enabling effective spatiotemporal feature learning from raw, unlabeled video data.
Contribution
The paper presents a new approach that leverages image-based models as teachers to train video models without labeled videos, demonstrating effective spatiotemporal feature learning.
Findings
Outperforms standard image-to-video bootstrapping techniques by 16%.
Learns robust spatiotemporal features from uncurated raw video data.
Works across different input modalities and teacher models.
Abstract
Video recognition models have progressed significantly over the past few years, evolving from shallow classifiers trained on hand-crafted features to deep spatiotemporal networks. However, labeled video data required to train such models have not been able to keep up with the ever-increasing depth and sophistication of these networks. In this work, we propose an alternative approach to learning video representations that require no semantically labeled videos and instead leverages the years of effort in collecting and labeling large and clean still-image datasets. We do so by using state-of-the-art models pre-trained on image datasets as "teachers" to train video models in a distillation framework. We demonstrate that our method learns truly spatiotemporal features, despite being trained only using supervision from still-image networks. Moreover, it learns good representations across…
Click any figure to enlarge with its caption.
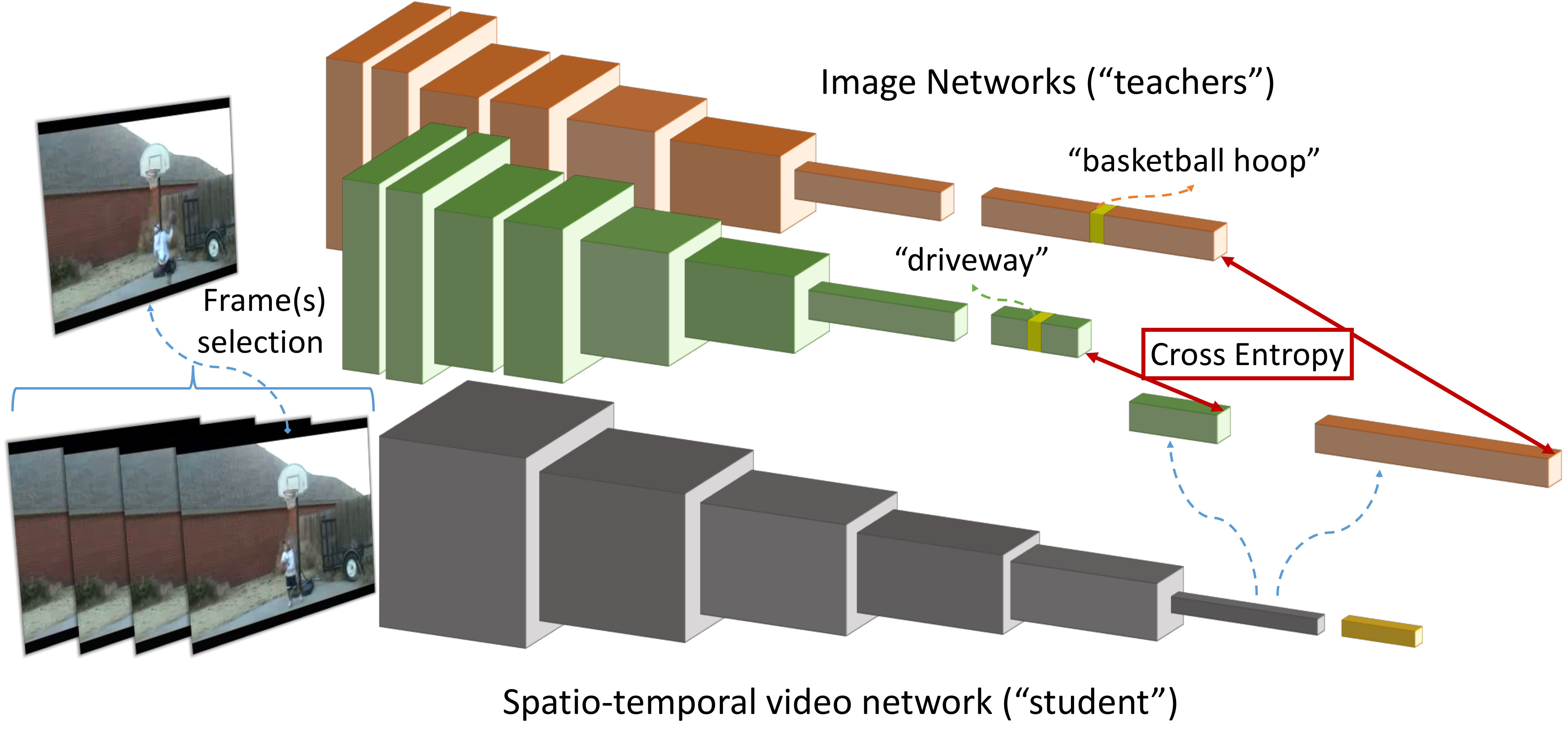 Figure 1
Figure 1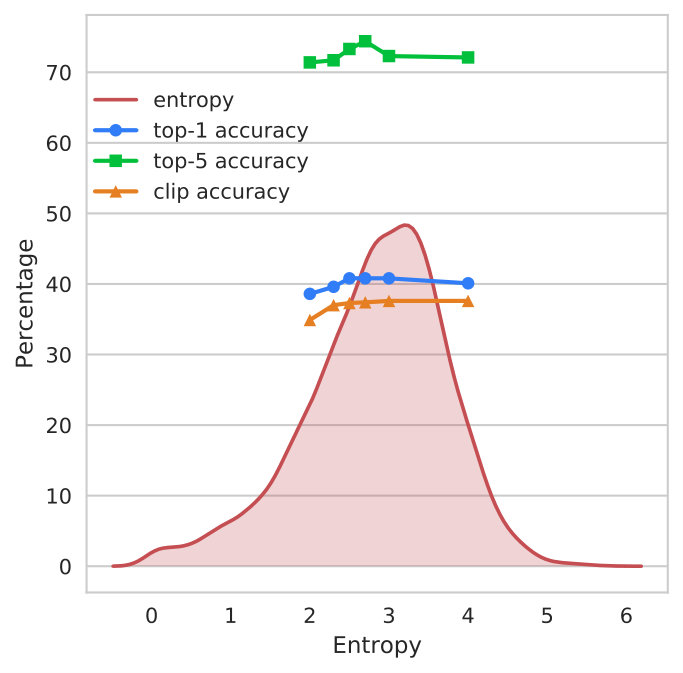 Figure 2
Figure 2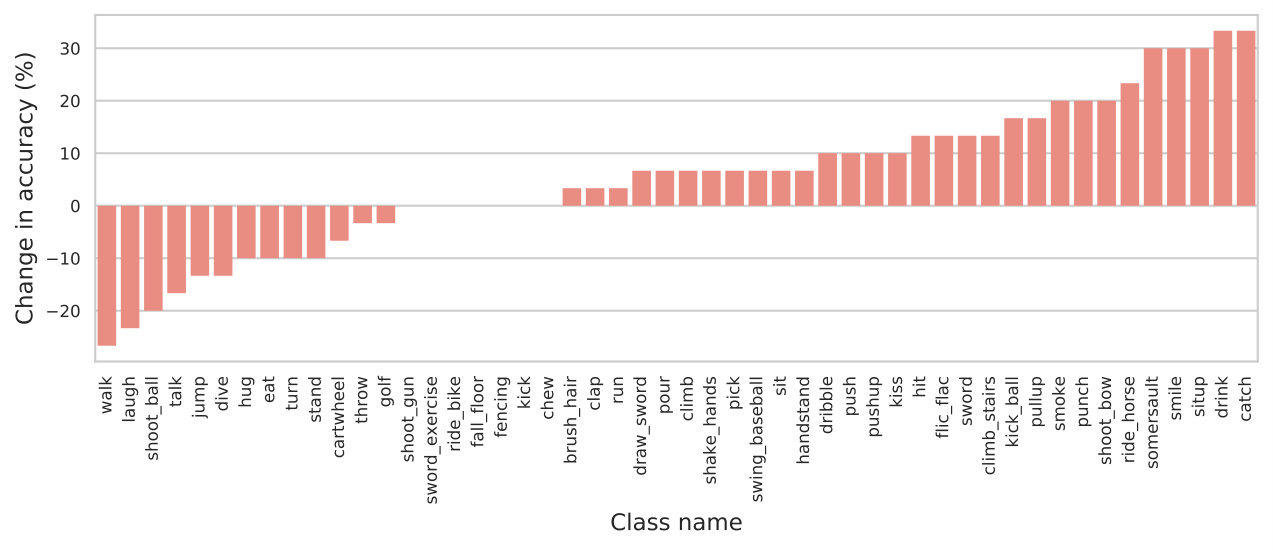 Figure 3
Figure 3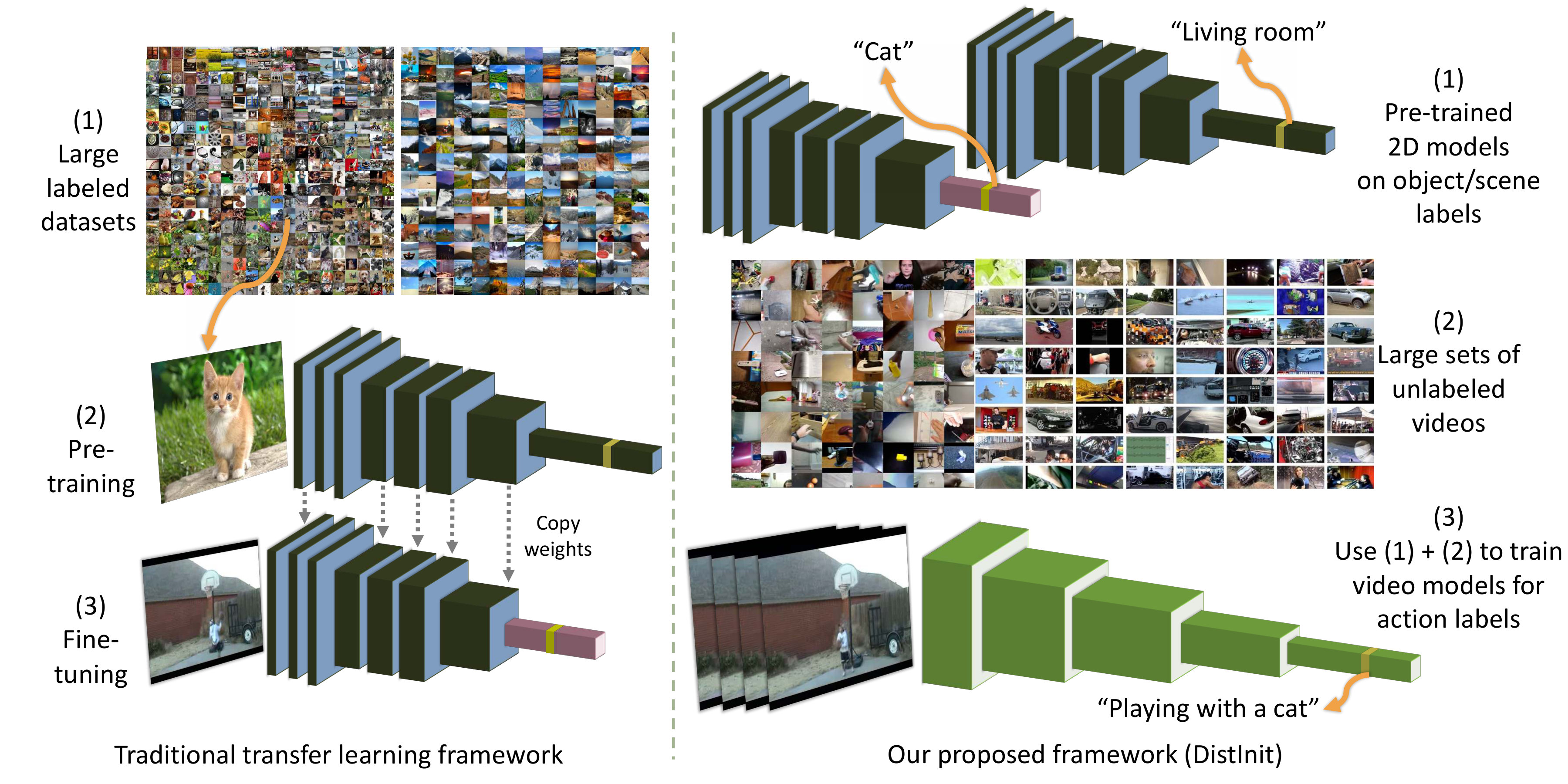 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6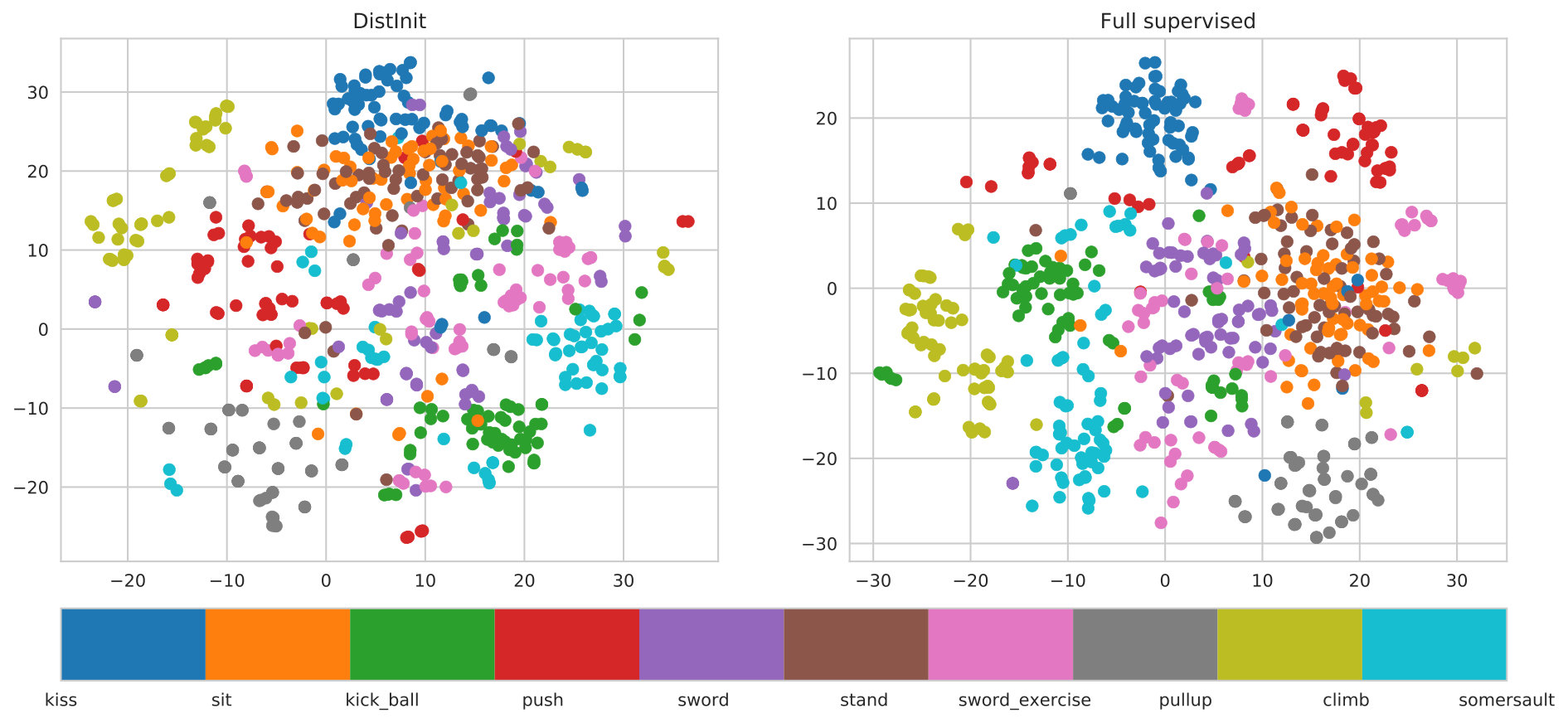 Figure 7
Figure 7| Model | Initialization | Per clip | Top 1 | Top 5 |
| Res3D- | Scratch | 24.6 | 25.4 | 55.2 |
| Res3D- | ImageNet inflated | 32.5 | 35.8 | 66.2 |
| Res3D- | PlaceNet inflated | 32.5 | 35.6 | 66.2 |
| Res3D- | DistInit (ours) | 36.6 | 39.9 | 73.5 |
| R(2+1)D- | Scratch | 22.0 | 24.1 | 53.1 |
| R(2+1)D- | DistInit (ours) | 37.8 | 40.3 | 74.4 |
| R(2+1)D- | Kinetics pre-training | - | 51.0 | - |
| Model | Pick strategy | Per clip | Top 1 | Top 5 |
|---|---|---|---|---|
| R(2+1)D- | Center | 37.8 | 40.3 | 74.4 |
| R(2+1)D- | Random | 39.9 | 43.2 | 73.9 |
| R(2+1)D- | 2 Random | 39.6 | 44.0 | 73.5 |
| Loss function | Per clip | Top 1 | Top 5 |
|---|---|---|---|
| cross-entropy (over softmax) | 37.8 | 40.3 | 74.4 |
| mean squared error (over logits) | 35.6 | 39.9 | 70.5 |
| Model | Initialization | Per clip | Top 1 | Top 5 |
|---|---|---|---|---|
| Res3D- | Scratch | 30.7 | 38.7 | 70.0 |
| Res3D- | ImageNet mean inflated | 33.5 | 43.9 | 73.9 |
| R(2+1)D- | DistInit (ours) | 42.6 | 49.2 | 81.2 |
| Model | Architecture | #frames | Pre-training | Split 1 | 3-split avg |
| Misra et al. [34] | AlexNet [27] | 1 | Scratch | - | 13.3 |
| Misra et al. [34] | AlexNet [27] | 1 | Tuple verify [34] | - | 18.1 |
| Misra et al. [34] | AlexNet [27] | 1 | ImageNet | - | 28.5 |
| Two-stream (RGB) [44, 11] | VGG-M [45] | 1 | ImageNet | - | 40.5 |
| C3D [3] | Custom | 16 | Scratch | 24.3 | - |
| LSTM [3] | BN-Inception [22] | - | ImageNet | 36.0 | - |
| Two stream (RGB) [3] | BN-Inception [22] | 1 | ImageNet | 43.2 | - |
| I3D (RGB) [3] | BN-Inception [22] | 64 | ImageNet | 49.8 | - |
| Ours (RGB) | R(2+1)D-18 [51] | 32 | DistInit | 54.9 | 54.8 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
DistInit: Learning Video Representations Without a Single Labeled Video
Rohit Girdhar1 Du Tran2 Lorenzo Torresani2,3 Deva Ramanan1,4
1Carnegie Mellon University 2Facebook 3Dartmouth College 4Argo AI Work done as a part of an internship at Facebook
Abstract
Video recognition models have progressed significantly over the past few years, evolving from shallow classifiers trained on hand-crafted features to deep spatiotemporal networks. However, labeled video data required to train such models have not been able to keep up with the ever-increasing depth and sophistication of these networks. In this work, we propose an alternative approach to learning video representations that require no semantically labeled videos and instead leverages the years of effort in collecting and labeling large and clean still-image datasets. We do so by using state-of-the-art models pre-trained on image datasets as “teachers” to train video models in a distillation framework. We demonstrate that our method learns truly spatiotemporal features, despite being trained only using supervision from still-image networks. Moreover, it learns good representations across different input modalities, using completely uncurated raw video data sources and with different 2D teacher models. Our method obtains strong transfer performance, outperforming standard techniques for bootstrapping video architectures with image-based models by 16%. We believe that our approach opens up new approaches for learning spatiotemporal representations from unlabeled video data.
1 Introduction
Visual recognition tasks have been revolutionized by the resurgence of convolutional neural networks (CNNs) [31, 30] along with the availability of large and well-labeled datasets [40, 60, 32]. This has caused a paradigm shift in computer vision: rather than hand-designing better features [4, 33, 29], most approaches now train deep models that learn features themselves. However, deep learning has been transformative not just because models perform well, but because models also transfer. The dominant illustration of this is the use of ImageNet pre-training [40]. It is a near-ubiquitous practice that yields strong improvements across a wide range of tasks, from image classification on small datasets [26] to pixel-labeling tasks like detection and segmentation [19]. Such pre-training is an empirically effective approach to knowledge transfer, where “knowledge” is manifested as labeled and curated datasets.
However, feature learning has not been quite as transformative for video understanding. Early attempts for human action recognition [24] achieved only marginal improvements over previous state-of-the-art hand-crafted features. Since then, numerous deep architectures [44, 51, 16, 15, 8, 9] have been proposed. Interestingly, most performance gains seem to arise from the recent introduction of large-scale video datasets that are carefully curated and annotated [3, 25], enabling effective pre-training. Our work introduces simple but novel approaches for pre-training with unlabeled, uncurated videos. Our approach is motivated by the following two questions:
1. What are the “right” labels for a video? Previous work tends to manually defines action ontologies in a top-down fashion [46, 28, 25] or else discovers classes from bottom-up clustering [57, 12]. Action classes may be broad – “washing” may include both washing one’s hands or washing a car [36]. Classes may also be fine-grained and nuanced, such as “snuggling with a pillow” [43]. Evidently, the right action vocabulary is unclear and largely up for debate. In contrast, object labels seem to much better understood, as they can exploit widespread linguistic knowledge bases such as WordNet. Finally, humans appear able to learn about behaviors and the dynamics of the world even without such explicit action labels. In this work, we answer this question by making use of objects to label videos.
2. How do we transfer the knowledge encoded in image datasets [40, 60, 32] into video models? As discussed earlier, the dominant approach is pre-training. However, because spatiotemporal networks structurally expect a spacetime video as input, they are difficult to (pre)train on images. As a result, many spacetime networks are intentionally designed with an image “backbone” that allows for pre-training on images. Popular examples include two-stream networks [45] and 3D CNNs that “inflate” 2D kernels to 3D [3, 10, 9]. However, this places severe restrictions on the types of video architectures that can be explored. Instead, we introduce a general approach of knowledge transfer by distillation, which allows us to transfer knowledge from arbitrary image-based teachers to any spatiotemporal architecture (Fig. 1). We refer to our approach as DistInit.
DistInit leads to a significant 16% improvement over from-scratch training on the HMDB dataset, getting almost half-way to the improvement provided by pretraining on a fully-supervised dataset like Kinetics [25]. From-scratch training is the defacto standard for state-of-the-art architectures that can not be initialized or inflated from image architectures [51]. While large-scale video datasets like Kinetics now provide an alternate path for pre-training, DistInit does so without requiring any video data curation. As we show in Section 4.3, it is able to learn competitive representations from an internal uncurated dataset of random web videos. This is in contrast to previous works [35, 7, 13] on unsupervised learning that use ImageNet without labels but still potentially benefit from the data curation.
2 Related Work
Feature learning: Video understanding, specifically for the task of human action recognition, is a well studied problem in computer vision. Analogously to the progress of image-based recognition methods, which have advanced from hand-crafted features [33, 4] to modern deep networks [48, 20, 45], video understanding methods have also evolved from hand-designed models [54, 53, 29] to deep spatiotemporal networks [49, 44]. However, while image based recognition has seen dramatic gains in accuracy, improvements in video analysis have been more modest. In the still-image domain, deep models have greatly benefited from the availability of well-labeled datasets, such as ImageNet [40] or Places [60].
Video datasets: Until recently, video datasets have either been well-labeled but small [28, 46, 43], or large but weakly-labeled [24, 1]. A recently introduced dataset, Kinetics [25], is currently the largest well-annotated dataset, with around 300K videos labeled into 400 categories (we note a larger version with 600K videos in 600 categories was recently released). It is nearly two orders of magnitude larger than previously established benchmarks in video classification [28, 46]. As expected, pre-training networks on this dataset has yielded significant gains in accuracy [3] on many standard benchmarks [28, 46, 43], and have won CVPR 2017 ActivityNet and Charades challenges. However, it is worth noting that this dataset was collected at a significant curation and annotation effort [25].
Video labels: The challenge in generating large-scale well-labeled video datasets stems from the fact that a human annotator has to spend much longer to label a video compared to a single image. Previous work has attempted to reduce this labeling effort through heuristics [59], but these methods still require a human annotator to clean up the final labels. There has also been some work in learning unsupervised video representations [42, 34], however has typically lead to inferior results compared to supervised features.
Pre-training: The question we pose is: since labeling images is faster, and since we already have large, well-labeled image datasets such as ImageNet, can we instead use these to bootstrap the learning of spatiotemporal video architectures? Unsurprisingly, various previous approaches have attempted this. The popular two-stream architecture [44] uses individual frames from the video as input. Hence it initializes the RGB stream of the network with weights pre-trained on ImageNet and then fine-tunes them for action classification on the action dataset. More recent variants of two-stream architectures have also initialized the flow stream [55] from weights pretrained on ImageNet by viewing optical flow as a grayscale image.
Inflation: However, such initializations are only applicable to video models that use 2D convolutions, analogous to those applied in CNNs for still-images. What about more complex, truly spatiotemporal models, such as 3D convolutional architectures [49]? Until recently, such models have largely been limited to pre-training on large but weakly-labeled video datasets, such as Sports1M [24]. Recent work [3, 9] proposed a nice alternative, consisting of inflating standard 2D CNNs kernels to 3D, by simply replicating the 2D kernels in time. While effective in getting strong performance on large benchmarks, on small datasets this approach tends to bias video models to be close to static replicas of the image models. Moreover, such initialization constrains the 3D architecture to be identical to the 2D CNN, except for the additional third dimension in kernels. This effectively restricts the design of video models to extensions of what works best in the still-image domain, which may not be the architectures for video analysis.
Distillation: Our approach is inspired by techniques that distill teacher networks into student models [21]. However, distillation typically trains smaller student models on the same data distribution used to train the teacher (with the goal of increasing efficiency). Our approach instead focuses on representation learning through pre-training. Our students are larger (3D vs 2D CNNs) and geared for different data domains (videos vs images). The most related work may be cross-modal distillation [18], which transfers supervision from RGB to flow or depth modalities. Importantly, such work focuses on the same end task, such as object detection. In contrast, we focus on task distillation, where tasks are quite different (object detection versus action classification). From this perspective, our philosophy aligns with taskonomies [58], which advocates the use of different pre-training tasks for a variety of target tasks. But rather than advocating pre-training, we pursue distillation since it allows for arbitrary changes in network topology. Other works have also used similar distillation frameworks for action recognition tasks, such as [5] which transfers supervision from frames to videos by solving a correspondence problem. Our approach is much simpler, and directly transfers supervision by matching label distributions. Finally, prior works have also shown improvements using the 2D image-based networks (‘teachers’, in our context) directly, as additional features for action recognition [6, 14], hence reinforcing our observation that scene/object information is a very useful cue for video understanding.
Domain adaptation: Our work is also related to techniques for domain adaptation (DA) [37, 41], where the goal is adapting a network to a new data distribution. Our formulation differs in that we also adapt to new tasks (object classification vs action recognition) and network architectures (2D CNNs vs 3D CNNs). We show extensive experiments with standard benchmarks and show significant improvements over inflation and other previous approaches in learning video representations for action recognition.
3 Our Approach
We now describe our approach in detail. To reiterate, our goal is to learn video representations without using any video annotations. We do so by leveraging pre-trained 2D networks, using them to supervise or “teach” the video models. Hence, we refer to the 2D pre-trained networks as “teachers” and our target video network as “student”. We make no assumption over the respective architectures of these models, i.e., we do no constrain the structure of the 3D network to be merely a 3D version of the 2D networks it learns from or to have a structure compatible with them.
Figure 2 depicts the network architecture used to train the student network. We start with teacher networks trained on standard image-level tasks, such as image classification on ImageNet. While in this work we primarily focus on classification, our architecture is generic and can also benefit from teachers trained on spatial tasks such as detection, keypoint estimation and so on, with the only difference being the definition of the distillation loss function. Also, our architecture is naturally amenable to work with an arbitrary number of teachers, which can be used in a multi-task learning framework to distill information from multiple domains into the student. Throughout the training process, these teacher networks are kept fixed, in “test” mode, and are used to extract a feature representation from the video to be used as a “target” to supervise the student network.
Since teacher networks are designed to find *objects
- in images, it is not obvious how to use them to extract features for actions in video. We propose a simple solution: pre-train the spatiotemporal action network for finding objects in frames of a video. However, our teacher networks are designed to work over images, so how do we apply them on a video? We experiment with standard approaches from the literature, including uniform or random sampling of frames [44], as well as averaging predictions from multiple different frames [55]. In this work we use the last-layer features in the form of normalized softmax predictions or (unnormalized) logits. In case of multiple frames, we average the teacher logits before computing a normalized prediction target. The student network then takes the complete video clip as input. We train it to be able to predict the features or probability distribution produced by the teacher. For this purpose, we define the last layer in the student network to be a linear layer that takes the final spatiotemporally averaged feature tensor and maps it to a number of units that matches the dimensionality of the output generated by the teacher. In case of multiple teachers, we define a linear layer per teacher, and optimize all losses jointly.
To formalize, let us denote a video as , where is the frame. In our problem formulation, we have access to a teacher that reports a prediction label at each frame. For simplicity, we assume that the teacher returns a (softmax) distribution over classification labels. We generate a distribution over labels for a video by (1) averaging the per-frame logits for the class and (2) passing the average through a softmax function with temprature (typically ):
[TABLE]
The resulting distribution is then used as soft targets for training weights associated with a student network of arbitrary architecture by means of the following objective:
[TABLE]
where is the student softmax distribution for label . Finally, we explore multi-source knowledge distillation by adding together losses from different image-based teachers:
[TABLE]
In our experiments, we explore teachers trained for object classification (ImageNet) and scene classification (Places).
We train the network using loss functions inspired from the network distillation literature [2, 21]. When using the teacher network to produce a probability distribution, we train the student to produce a matching distribution by incurring a cross entropy loss between the two distributions. As suggested in [21], we also tried using different values of temperature () to scale the logits before computing softmax and cross entropy, but found temperature value of 1 to perform best in our experiments. We also experimented with the a mean squared loss on the logits (before softmax normalization), as suggested in [2], and compare performance in Section 4.
Architecture Details: We use recent, state-of-the-art, network architectures for all experiments and comparisons. For the still-image teacher networks, we use the ResNet-50 [20] architecture, trained on different image datasets such ImageNet 1K [40] and Places 365 [60]. For the spatiotemporal (video) student architectures, we first experiment with a variant of the Res3D [50] architecture. Res3D is an improved version of the popular C3D [49] using residual connections. We denote a -layer Res3D model as Res3D-, which is compatible with the standard ResNet- [20] architecture. Since there is a one-to-one correspondence between such 2D and 3D models, the 3D models can also be initialized by inflating the learned weights from 2D models (e.g., for each channel, replicate the 2D filter weights along the temporal dimension to produce a 3D convolutional filter). Similar ideas of inflating 2D models to 3D have been proposed previously for Inception-style architectures [3], along with initialization techniques from corresponding 2D models [3, 10, 9]. The existence of a 1-to-1 mapping between the 2D and 3D models used in our experiments allows us to compare our approach to the method of inflation for initialization. However, we stress that unlike inflation, our method is applicable even in scenarios where such 1-to-1 mapping does not hold.
(2+1)D CNNs: More recently, full 3D models have been superseded by (2+1)D architectures [51], where each 3D kernel is decomposed into a 2D spatial component followed by a 1D temporal filter. Similar models have also been proposed previously [47], and are also known as P3D [38] or S3D [56] architectures. These models have proven to be more efficient, with much fewer parameters, and more effective on various standard benchmarks [56, 51]. However, these models no longer conform to standard 2D architectures because they contain additional conv and batch_norm layers that extend over time. These parameters do not exist in corresponding 2D models and so cannot be initialized with images. Nevertheless, our distillation remains applicable even in this scenario. In this work, we refer to such networks using R(2+1)D- notation, for -deep architecture.
Implementation Details: For all experiments, we use the hyperparameter values described in [51]. For distillation pre-training, we use the hyper-parameter setup for “Kinetics from-scratch training.” We use distributed Sync-SGD [17] over GPUs, starting with LR=0.01, and dropping it by 10 every 10 epochs. Weight decay is set to . We train for a total of 45 epochs, where each epoch is defined as 1M iterations. The video model is learned on 8-frames clips of 112 pixels. The network has depth of 18, which enables faster experimentation compared to the best model reported in [51] which uses 32 frames and has a depth of 34 layers. The batch size used for Kinetics training is 32/GPU, which we reduce to 24/GPU to accommodate the additional memory requirements for the teacher networks. For the finetuning experiment on smaller datasets like HMDB, we use Sync-SGD with GPUs, starting with LR=0.002, an dropping it by every 2 epochs. The weight decay is set to . We train 8 epochs, with each epoch defined as 40K steps. When training from scratch, we use initial LR of 0.01 with a step every 10 epochs, trained for total of 45 epochs.
4 Experiments
We now experimentally evaluate our system. We start by introducing the datasets and benchmarks used for training and evaluation in Section 4.1. We then compare DistInit with inflating 2D models for initialization in Section 4.2. Next we ablate the various design choices in DistInit in Section 4.3, and finally compare to previous state of the art on UCF-101 [46] and HMDB-51 [28] in Section 4.4.
4.1 Datasets and Evaluation
Our method involves two stages, as typical in video understanding literature [3]: pre-training on a large, unlabeled corpus of videos using still-image models as “teachers”, followed by fine-tuning on the training split of a labeled target dataset (‘test bed’). After training, we evaluate the performance on the test set of the target dataset.
Unlabeled source videos: We experiment with a variety of different unlabeled video corpuses in Section 4.3, including Kinetics [25], Sports1M [24] and an internal set of videos. While some of these datasets do come with semantic (action) labels, we ignore such annotations and only use the raw videos. Kinetics and Sports1M contain about 300K and 1.1M videos, respectively. In this work, we drop any labels these datasets come with, and only use the videos as a large, unlabeled corpus to train video representations. The internal video set includes 1M videos without any semantic labels and randomly sampled from a larger collection. We use these diverse datasets to show that our method is not limited to any form of data curation, and can work with truly in-the-wild videos.
Target test videos: HMDB-51 [28] contains 6766 realistic and varied video clips from 51 action classes. Evaluation is performed using average classification accuracy over three train/test splits from [23], each with 3570 train and 1530 test videos. UCF-101 [46] consists of 13320 sports video clips from 101 action classes, also evaluated using average classification accuracy over 3 splits. We use the HMDB split 1 for ablative experiments, and report the final performance on all splits for HMDB and UCF in Section 4.4.
4.2 DistInit vs Inflation
Inflation: We first compare our proposed approach to inflation [3, 9], i.e., initializing video models from 2D models by inflating 2D kernels to 3D via replication over time. Note that inflation is constrained to operate on 3D models that have a one-to-one correspondence with the 2D model. Hence, we use a Res3D-18 model, which is compatible for direct inflation from ResNet-18 models. We experiment with publicly available ImageNet and PlaceNet models. We compare it with our distillation approach in Table 1, trained using an ImageNet pretrained model as the teacher. Distillation improves performance by 15% over a model trained from scratch, and 4% over a model trained with inflated weights (the current best-practice for training such models).
(2+1)D: More importantly, our approach can also be used to initialize state-of-the-art temporal architectures such as R(2+1)D [51], which do not have a natural 2D counterpart. In such a setting, the current best practice is to initialize such networks from scratch. Here, distillation improves performance by 16%. Finally, we also report the model trained using actual Kinetics labels, and as expected, that yields higher performance. Hence there is clear value to the explicit manual supervision provided in such large-scale datasets, but distillation appears to get us “half-way” there.
Visualizations: At this point, it is natural to ask why the distilled model outperforms current best-practices such as inflation? We visualize the learned representation by plotting the first layer conv filters in Figure 3. It can be seen that our distilled model learns truly spatiotemporal filters that vary in time, whereas inflation simply copies the same filter over time. Such dynamic temporal variation is readily present in the videos used for distillation, even when they are not labelled with spatiotemporal action categories. Filters pre-trained with inflation initialization never see actual video data, and so cannot encode such variation. In Figure 4 we also compare the filters learned by our R(2+1)D model via distillation vs via fully-supervised training. Our filters look quite similar to those learned through supervised learning, showing the effectiveness of our approach. In some sense, the improved performance of distillation can be readily explained by more data – networks learning from scratch see no data for pre-training, inflation networks see ImageNet, while distilled networks see both Imagenet and unlabeled videos. Our practical observation is that one can use image-based teachers to pre-train on massively large, unlabeled video datasets.
We can also analyze the effectiveness of distillation pre-training, by visualizing the correlation of the representation we learn with the classes in the task of action recognition. As explained in Figure 5, we can see that the last layer features for the same action class tend to cluster together when projected to 2D using tSNE [52].
4.3 Diagnostic Analysis
Design choices for the teacher network: We now ablate the design choices for the teacher networks. Teacher networks are required to generate a target label to supervise the video model being trained, by using images from the video clip. We experiment with picking the center frame, a random frame, or multiple random frames from the clip to compute the targets. In case of multiple frames, we average the logits before passing them through softmax to generate the target distribution. We compare these methods in Table 2, and observe higher performance when picking frames randomly. This improvement can be due to less overfitting through label augmentation. We use it in our final model.
Distillation loss: Next, we evaluate the different choices for the loss function in distillation. As already explained in Section 3, previous work has suggested different loss functions for distillation tasks. We compare two popular approaches: KL divergence over distribution and loss over logits. In the case of the former, we compute the softmax distribution from the teacher networks, as well as from the student branch that attempts to match that teacher, and use a cross entropy between the two softmax distributions as the objective to optimize. We find this objective can be well optimized using the standard hyper-parameter setup used for Kinetics training in [51]. In the case of the latter, we skip the softmax normalization step and directly compute the mean squared error between the last linear layers as the objective. Since the initial loss values are much higher, we needed to drop the learning rate by a factor of 10 to optimize this model, with all the other parameters kept the same. As Table 3 shows, we observe nearly similar downstream performance with both.
Selecting confident predictions: As some recent work [39] has shown, distillation techniques can benefit from using only the most confident predictions for training the student. We use the entropy of the predictions from the teachers as a notion of their confidence. We implement this confidence thresholding by setting a zero weight for the loss on each example, for which the teacher is not confident, or has high-entropy predictions; effectively dropping parts of the training data that are confusing for the teacher. We show the performance on dropping different amounts of data in Figure 6. The red curve shows a kernel density estimate (a PDF) of entropy values for an ImageNet teacher on the Kinetics data. At any given entropy value (), it shows the relative likelihood of a data point to have that entropy value, and (area under the curve from to ) is the percentage of data with entropy . We experiment with setting different thresholds for dropping the low-confidence data points during DistInit, and show the downstream HMDB-51 split-1 performance in the line plots. We found slightly better performance, even after dropping nearly half the data, making training faster.
Varying the unlabeled dataset: We now try to evaluate whether our method is dependent on any specific video data source, and if it can benefit from additional data sources. We evaluate this in Table 4 and observe nearly similar performance when using different sets of videos (without labels) like Kinetics [25] and Sports1M [24]. We also experiment with an internal set of videos downloaded from the web, and still get strong DistInit performance. This shows our method is not limited to any form of data curation, and can learn from truly in-the-wild videos.
Using other teachers: Just as our model is capable of learning from more data, our model is also capable of using diverse supervision. We experiment with replacing the ImageNet teacher with a model trained on PlaceNet [60], and obtain 36.8% HMDB fine-tuning performance as opposed to 40.3% before with ImageNet. Apart from the fact that our model can learn from diverse sources of supervision, this result shows that objects actions semantic transfer is more effective than scenes actions. This makes sense as human actions are typically informed more by the objects in their environment, than the environment itself. We also tried training with both ImageNet and PlaceNet teachers jointly, and obtained a top-1 accuracy of 40.7%, suggesting that there is little benefit of adding scene cues (from Places) given object information (from ImageNet). However, teachers from unrelated domains are likely to provide more complementary information and lead to higher improvements.
Different input modalities: One of the biggest advantages of our method is that it is applicable to learn representations for any arbitrary input data modality. We experiment with optical flow, which still contributes to significant performance improvements on video tasks, even with modern video architectures, across different datasets [3]. Previous work [3, 55] has used ImageNet initialization for networks accepting flow as input. This is far from ideal since flow has much different statistics than RGB images. DistInit, on the other hand, is agnostic to the input data modality of the student network. We train the student network to learn from the input flow modality, while the teacher uses a random RGB frame from the same clip to generate the distillation target. As we show in Table 5, DistInit still produces strong initialization and improves over training from scratch or the ImageNet inflated initialization. However, due to high computational cost of computing flow, we ignore this input modality for the final comparisons.
4.4 Comparison with previous work
Finally, in Table 6 we compare our model to other standard models and initialization methods on HMDB and UCF. For these comparisons, we use the 32-frames model, tested using dense predictions (instead of uniformly sampled 10-clips) for each testing video. Here we only compare to RGB-based models for computational speed, though our approach is applicable to flow or other modalities as shown in Section 4.3. We obtain strong performance compared to standard methods, and other unsupervised feature learning techniques [34, 5]. Finally, in Figure 7 we show which classes benefit the most from the initialization provided by DistInit compared to that computed by inflation.
5 Conclusion
We describe a simple approach to transfer knowledge from image-based datasets labeled for object or scene recognition tasks, to learn spatiotemporal video models for human action recognition tasks. Much previous work has addressed this problem by constraining spatiotemporal architectures to match 2D counterparts, limiting the choice of networks that can be explored. We describe a simple approach, DistInit, based on distillation that can be used to initialize any spatiotemporal architecture. It does so by making use of image-based teachers that can leverage considerable knowledge about objects, scenes, and potentially other semantics (e.g., attributes, pose) encoded in richly-annotated image datasets. Unlike previous unsupervised learning works that depend on the curated ImageNet dataset, albeit without labels, we show our model even works on truly in-the-wild uncurated videos. We demonstrate significant improvements over standard best practices for initializing spatiotemporal models. That said, our results do not match the accuracy of models pretrained on recently-introduced, large-scale supervised video datasets. But we note that these were collected and annotated with significant manual effort. Because our approach requires only unsupervised videos, it has the potential to make use of massively-larger data for learning accurate video models.
Acknowledgments:
RG and DR were partly supported by the Intelligence Advanced Research Projects Activity (IARPA) via Department of Interior/Interior Business Center (DOI/IBC) contract number D17PC00345. The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes not withstanding any copyright annotation theron. Disclaimer: The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied of IARPA, DOI/IBC or the U.S. Government.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Sami Abu-El-Haija, Nisarg Kothari, Joonseok Lee, Paul Natsev, George Toderici, Balakrishnan Varadarajan, and Sudheendra Vijayanarasimhan. Youtube-8m: A large-scale video classification benchmark. ar Xiv preprint ar Xiv:1609.08675 , 2016.
- 2[2] Cristian Buciluǎ, Rich Caruana, and Alexandru Niculescu-Mizil. Model compression. In KDD , 2006.
- 3[3] João Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. In CVPR , 2017.
- 4[4] Navneet Dalal and Bill Triggs. Histograms of oriented gradients for human detection. In CVPR , 2005.
- 5[5] Ali Diba, Mohsen Fayyaz, Vivek Sharma, M Mahdi Arzani, Rahman Yousefzadeh, Juergen Gall, and Luc Van Gool. Spatio-temporal channel correlation networks for action classification. In ECCV , 2018.
- 6[6] Ali Diba, Vivek Sharma, and Luc Van Gool. Deep temporal linear encoding networks. In CVPR , 2017.
- 7[7] Carl Doersch, Abhinav Gupta, and Alexei A. Efros. Unsupervised visual representation learning by context prediction. In ICCV , 2015.
- 8[8] Jeff Donahue, Lisa Anne Hendricks, Sergio Guadarrama, Subhashini Venugopalan Marcus Rohrbach, Kate Saenko, and Trevor Darrell. Long-term recurrent convolutional networks for visual recognition and description. In CVPR , 2015.