TL;DR
This paper introduces an adaptive importance sampling method for rare event simulation in diffusion processes, leveraging a variational principle and stochastic control to optimize the change of measure.
Contribution
It develops a novel variational framework using Gibbs principles to determine optimal importance sampling measures via stochastic control and approximation.
Findings
Effective in high-dimensional settings
Reduces variance in rare event estimates
Demonstrated on toy examples
Abstract
We propose an adaptive importance sampling scheme for the simulation of rare events when the underlying dynamics is given by a diffusion. The scheme is based on a Gibbs variational principle that is used to determine the optimal (i.e. zero-variance) change of measure and exploits the fact that the latter can be rephrased as a stochastic optimal control problem. The control problem can be solved by a stochastic approximation algorithm, using the Feynman-Kac representation of the associated dynamic programming equations, and we discuss numerical aspects for high-dimensional problems along with simple toy examples.
Click any figure to enlarge with its caption.
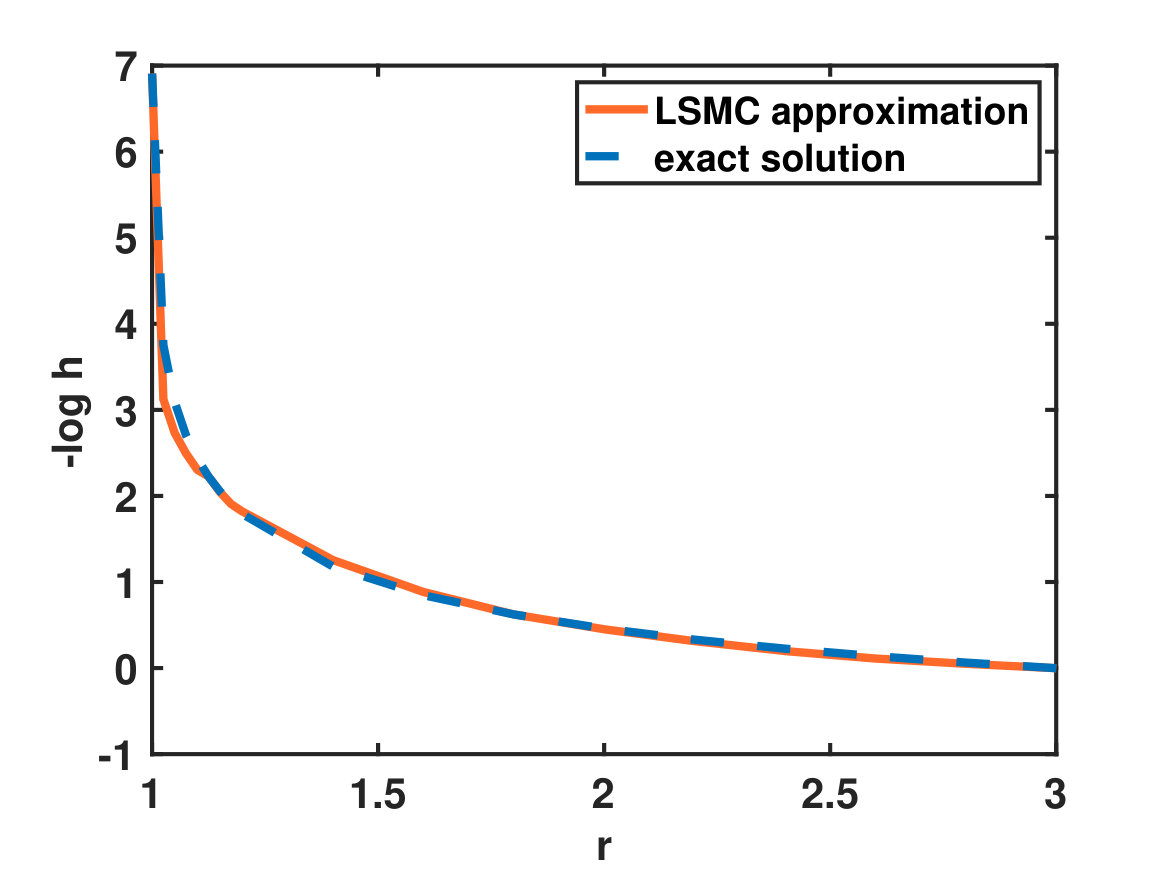 Figure 1
Figure 1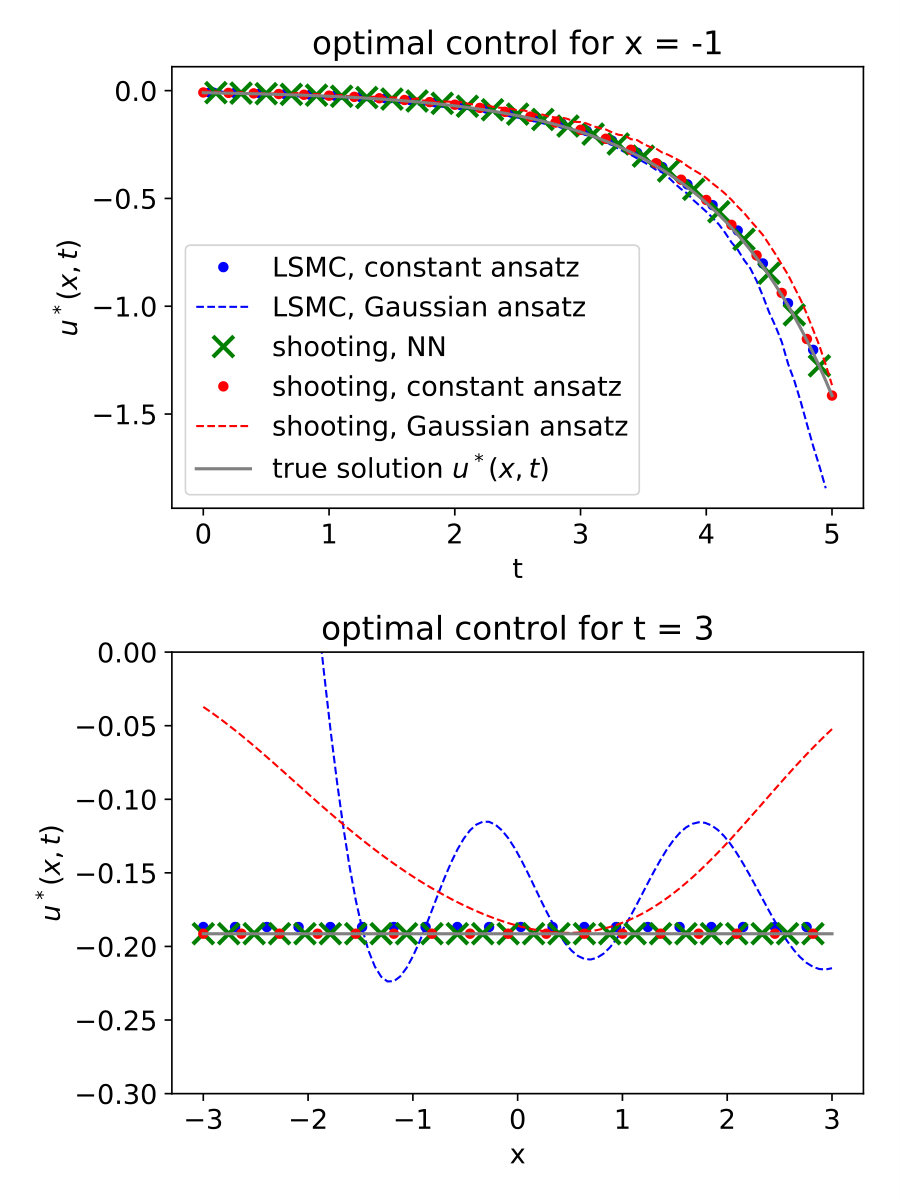 Figure 2
Figure 2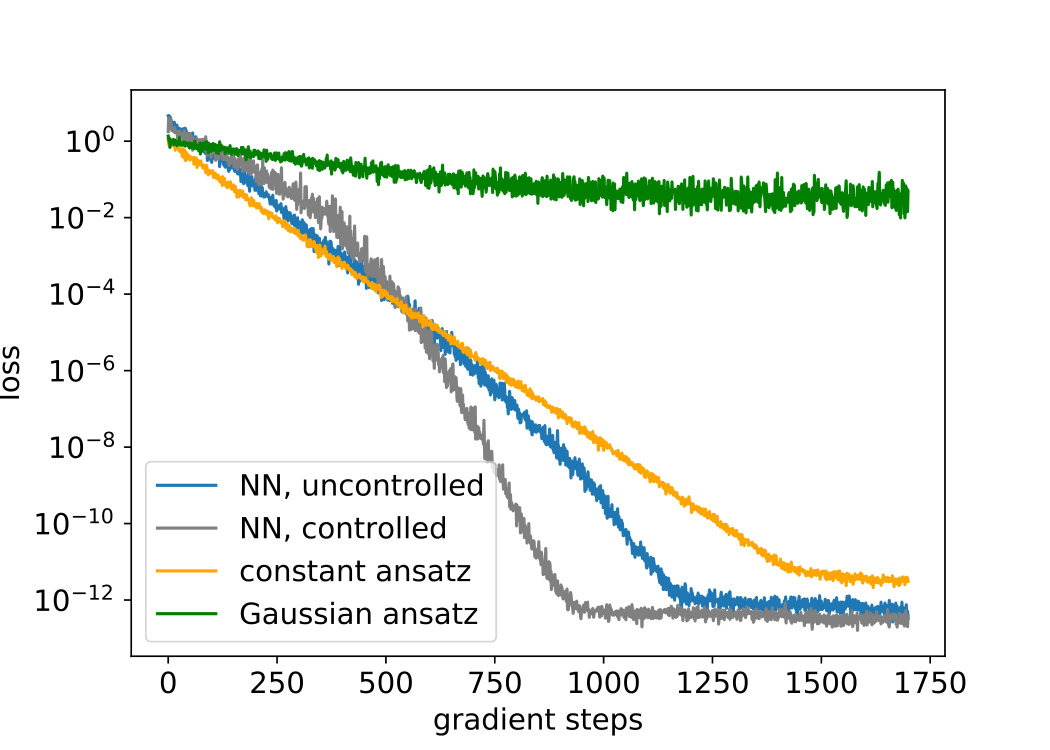 Figure 3
Figure 3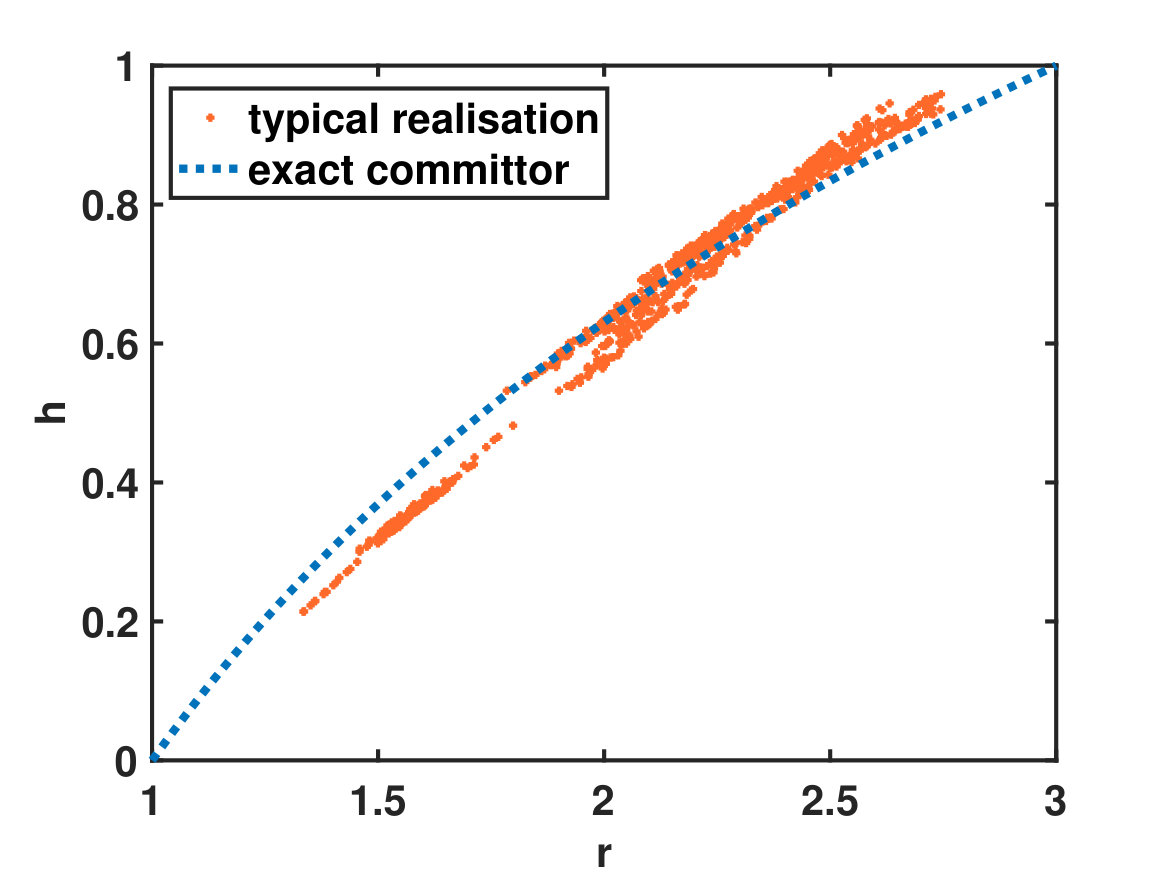 Figure 4
Figure 4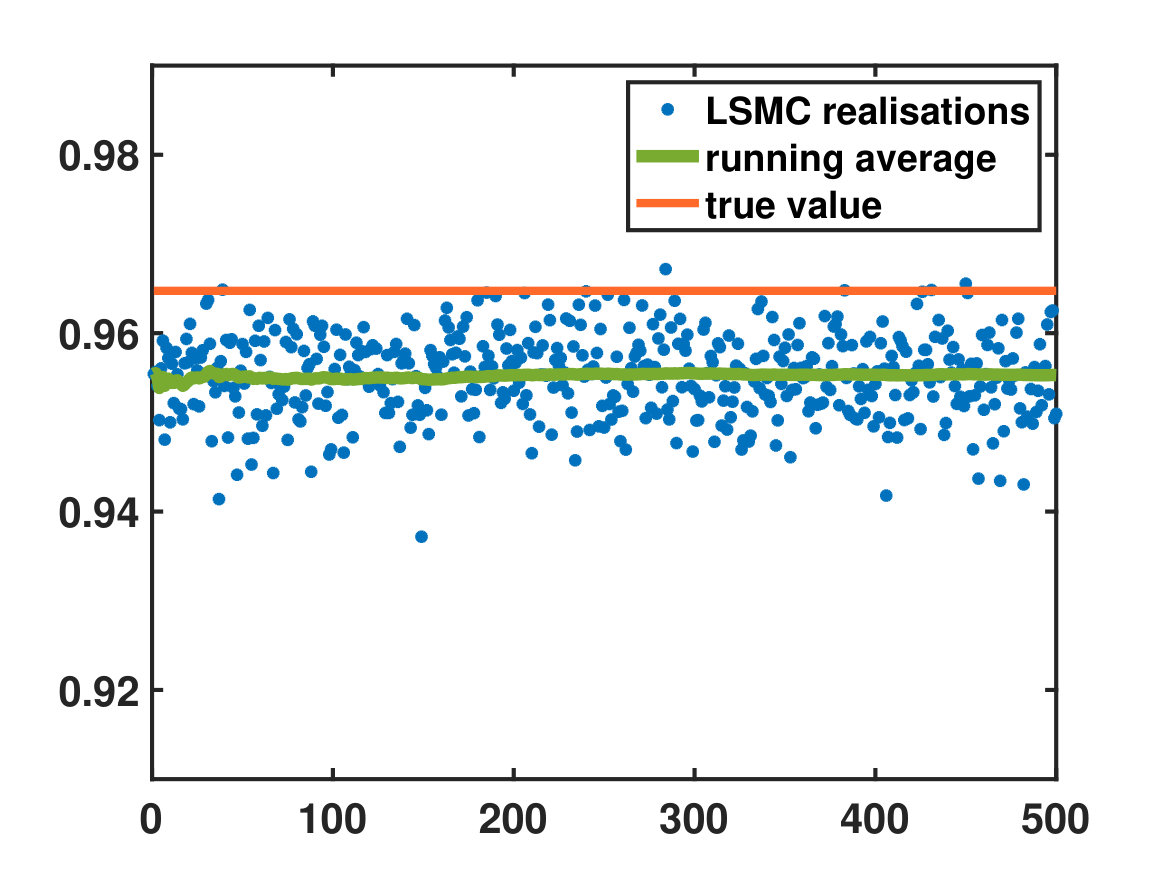 Figure 5
Figure 5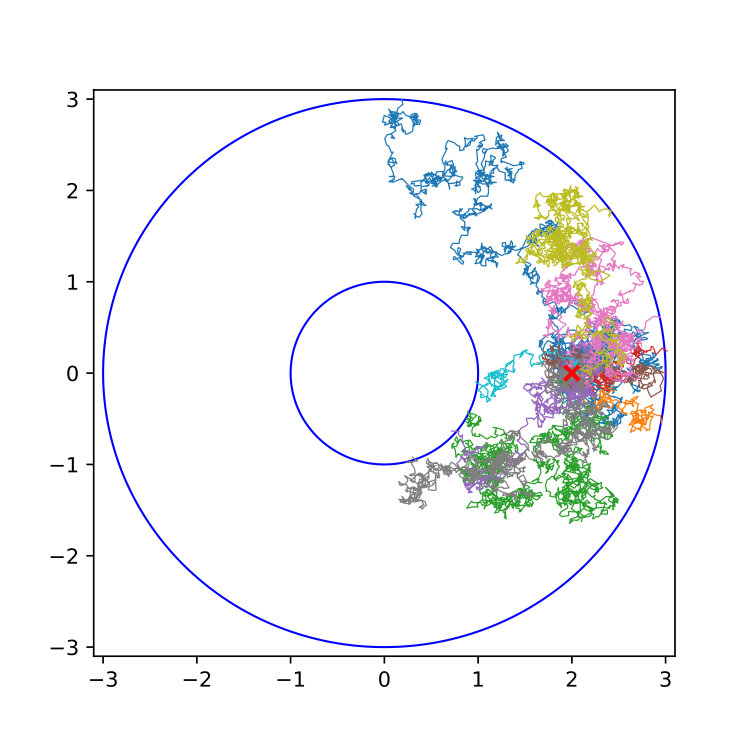 Figure 6
Figure 6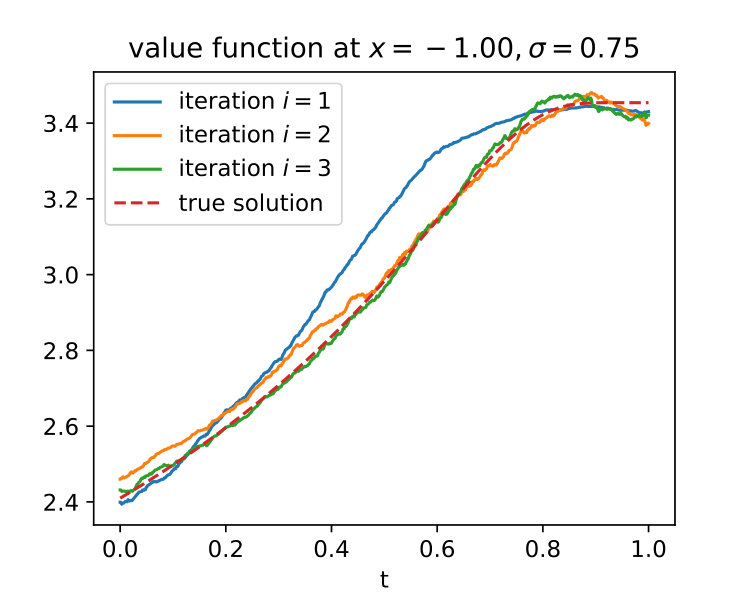 Figure 7
Figure 7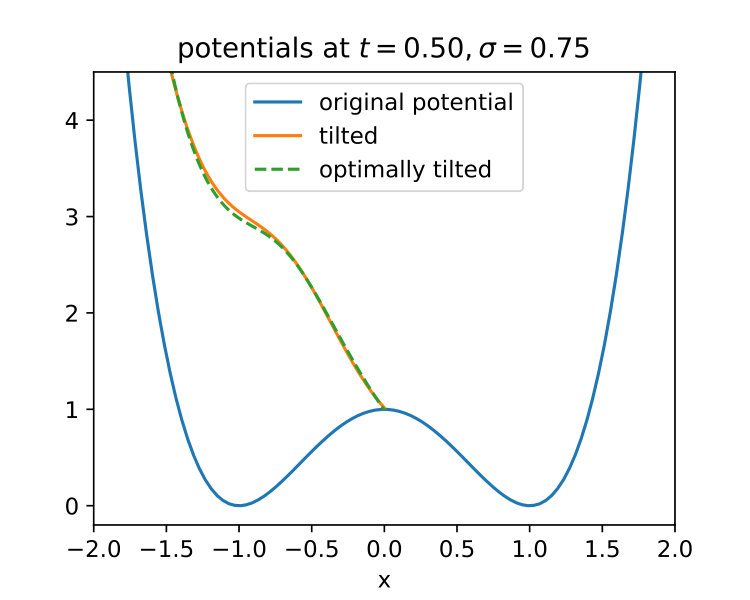 Figure 8
Figure 8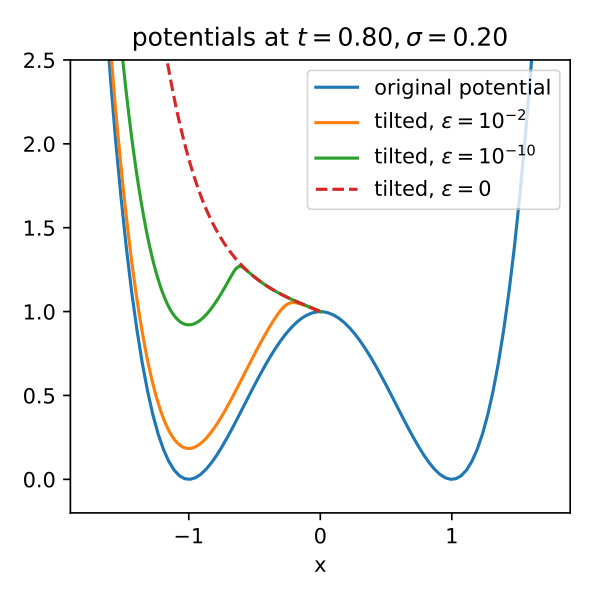 Figure 9
Figure 9| estimate | relative error | trajectories hit | |
|---|---|---|---|
| MC | 61.08 | 0.02 % | |
| IS | 2.76 | 68.15 % |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Variational approach to rare event simulation using least-squares regression
Carsten Hartmann
Institute of Mathematics, Brandenburgische Technische Universität Cottbus-Senftenberg, Cottbus, Germany
Omar Kebiri
Institute of Mathematics, Brandenburgische Technische Universität Cottbus-Senftenberg, Cottbus, Germany
Lara Neureither
Institute of Mathematics, Brandenburgische Technische Universität Cottbus-Senftenberg, Cottbus, Germany
Lorenz Richter
Institute of Mathematics, Brandenburgische Technische Universität Cottbus-Senftenberg, Cottbus, Germany
Institute of Mathematics, Freie Universität Berlin, Berlin, Germany
Abstract
We propose an adaptive importance sampling scheme for the simulation of rare events when the underlying dynamics is given by a diffusion. The scheme is based on a Gibbs variational principle that is used to determine the optimal (i.e. zero-variance) change of measure and exploits the fact that the latter can be rephrased as a stochastic optimal control problem. The control problem can be solved by a stochastic approximation algorithm, using the Feynman-Kac representation of the associated dynamic programming equations, and we discuss numerical aspects for high-dimensional problems along with simple toy examples.
When computing small probabilities associated with rare events by Monte Carlo it so happens that the variance of the estimator is of the same order as the quantity of interest. Importance sampling is a means to reduce the variance of the Monte Carlo estimator by sampling from an alternative probability distribution under which the rare event is no longer rare. The estimator must then be corrected by an appropriate reweighting that depends on the likelihood ratio between the two distributions and, depending on this change of measure, the variance of the estimator may easily increase rather than decrease. e.g. when the two probability distributions are (almost) non-overlapping. The Gibbs variational principle links the cumulant generating function (or: free energy) of a random variable with an entropy minimisation principle, and it characterises a probability measure that leads to importance sampling estimators with minimum variance. When the underlying probability measure is the law of a diffusion process, the variational principle can be rephrased as a stochastic optimal control problem, with the optimal control inducing the change of measure that minimises the variance. In this article, we discuss the properties of the control problem and propose a numerical method to solve it. The numerical method is based on a nonlinear Feynman-Kac representation of the underlying dynamic programming equation in terms of a pair of forward-backward stochastic differential equations that can be solved by least-squares regression. At first glance solving a stochastic control problem may be more difficult than the original sampling problem, however it turns out that the reformulation of the sampling problem opens a completely new toolbox of numerical methods and approximation algorithms that can be combined with Monte Carlo sampling in a iterative fashion and thus leads to efficient algorithms.
I Introduction
The estimation of small probabilities associated with rare events is among the most difficult problems in computational statistics. Typical examples of rare event probabilities, the precise estimation of which is important, involve protein folding, phase transitions in materials or large-scale atmospheric events, such as extreme heat waves or hurricanes. The hallmark of these rare events is that the average waiting time between the events is orders of magnitude longer than the characteristic timescale of the system—especially the timescale of the switching event itself—which renders the direct numerical simulation of rare events often infeasible.
We can distinguish between two major classes of sampling techniques: splitting methods such as RESTARTVillén-Altamirano and Villén-Altamirano (1994) or Adaptive Multilevel SplittingC rou and Guyader (2007) that decompose state space, but are still essentially based on the underlying probability distribution, and biasing methods, such as importance samplingL’Ecuyer et al. (2009) or the adaptive biasing force methodComer et al. (2015) that enhance the rare events under consideration by perturbing the underlying probability distribution and thus altering the rare events statistics; see Juneja and Shahabuddin (2006) for an overview. We should also mention sequential Monte-CarloCérou et al. (2012) that combines both worlds and that can be embedded into a splitting-like framework.
In this article, we focus on the second class of methods, namely importance sampling. Specifically, we consider diffusion processes and quantities that have the form of a cumulant generating function (or: thermodynamic free energy) and which are characterised by a Gibbs variational principle on a suitable subspace of the space of probability measures. The Gibbs variational principle expresses a fundamental duality between cumulant generating functions and relative entropy known as the Donsker-Varadhan principle in large deviations theory.Ellis (1985) In our case, the variational principle is a constrained entropy minimisation problem, the minimiser of which defines an optimal change of measure that leads to minimum (i.e. zero) variance estimators of the quantity of interest.Hartmann et al. (2017) The connection between the zero variance estimator and the Gibbs variational principle is essentially of theoretical interest, because the normalisation constant of the optimal change of measure depends on the quantity of interest.
In order to turn the Gibbs principle into a workable numerical method, we interpret the variational principle as a stochastic optimal control problem, with the unique optimal control force (or: bias) generating the zero-variance probability measure. Specifically, we propose a reformulation of the semilinear dynamic programming equations of the optimal control problem as a pair of uncoupled forward-backward stochastic differential equations (FBSDE) that can be solved by Monte Carlo.Kebiri et al. (2018) The advantage of the FBSDE approach is that it offers good control of the variance of the resulting estimators at low additional numerical cost. One of the key results of this paper is that the control that is obtained from the solution to the FBSDE acts as a control variate that, when augmented by an additional bias, produces a whole family of zero-variance estimators. We discuss several variants of the FBSDE method, based on a parametric formulation of the least-squares Monte Carlo algorithms by Gobet et al. (2005) and a deep learning based algorithm that is due to E et al. (2017).
Related work
The idea of exploiting the variational formulation of cumulant generating functions to devise feedback control based importance sampling strategies for rare events goes back to Dupuis and Wang (2004) who suggested to approximate the optimal change of measure by vanishing viscosity solutions or subsolutions of the associated dynamic programming equations. The thus obtained change of measure can be shown to converge to the optimal exponential change of measure as the probability of the rare event goes to zero, which is implied by the fact that the zero-viscosity solution to the dynamic programming equation is the associated large deviations rate function of the rare event. As a consequence, the resulting estimators are either asymptotically efficientVanden-Eijnden and Weare (2012), when the change of measure is based on the exact viscosity solution, or log asymptotically efficientDupuis and Wang (2007), when the viscosity solution is approximated by a subsolution. The development of state-dependent importance sampling schemes, that in the context of diffusion processes can be considered as the small noise limit of the control approach considered in this article, was triggered by the observation that an exponential change of measure based on an exponential tilting with a constant tilting parameter may perform worse than standard Monte Carlo.Glasserman and Wang (1997)
The relation between large deviations principles and control has been pointed out quite early in the work by Fleming and co-workersFleming (1977); Fleming and McEneaney (1995); Fleming and Sheu (1997) and later on in the context of risk-sensitive control, Whittle (1994, 2002); Dai Pra et al. (1996); James (1992) and we should note that the underlying duality relation has also been exploited to recast certain stochastic control problems as linear elliptic or parabolic boundary value problemsKappen (2005); Todorov (2009); Schütte et al. (2012); Rawlik et al. (2012) or to solve data assimilation problems.Kappen and Ruiz (2016); Kappen et al. (2012); Reich (2018) Using FBSDE numerics to solve the dynamic programming equations associated with certain stochastic control problems, similar to the ones considered in this paper, has been recently suggested in Exarchos and Theodorou (2018), Huré et al. (2018) and Bachouch et al. (2018).
Outline of the article
The article is structured a follows: In Section II we explain the basic importance sampling problem for stochastic processes and, in case of a diffusion process, characterise the optimal change of measure in terms of a solution to an optimal control problem. Section III is devoted to the reformulation of the optimal control problem, or more precisely to the reformulation of the associated dynamic programming equation in form of an FBSDE pair; the main result of this section is that we show that there is a family of equivalent FBSDE pairs that lead to zero-variance importance sampling estimators. The numerical discretisation of the FBSDE is discussed in Section IV and illustrated with a few numerical examples in Section V. Conclusions are given in Section VI. The article contains an appendix in which the relation between the optimal change of measure and Doob’s -transform is briefly explained.
II Rare event simulation
Let be a probability space, on which we consider an -valued stochastic process . Suppose that we want to compute a small probability, such as the probability of hitting a set ,
[TABLE]
where is some a.s. finite stopping time . For example, may the first hitting time of either of the two disjoint sets , in which case is the probability to reach before , in other words: the committor probability; if is the minimum of the first hitting time of and a finite time , then is the probability that . (We assume throughout that all subsets are measurable.)
We assume that , and without digging into the details of large deviations theory, we call a rare event, simply because of this assumption that implies that is difficult to compute numerically. To understand why this is the case, consider the Monte Carlo approximation of the parameter : given independent realisations of ,
[TABLE]
is an unbiased estimator of that converges a.s. to by the law of large numbers. Moreover the variance of the estimator decreases with rate since
[TABLE]
The last equation reflects the typical Monte Carlo rate of convergence. Nevertheless the relative error (or: relative standard deviation) is unbounded as a function of :
[TABLE]
Here denotes the expectation with respect to the probability . The bottom line is that computing small probabilities such as (1) is difficult, since the number of Monte Carlo samples that is required to obtain an accurate estimate grows with .
II.1 Importance sampling
The idea of importance sampling is to reduce the variance of (2) by drawing the samples from another probability measure, say, under which the event is no longer rare. Let be absolutely continuous with respect to , so that the likelihood ratio exists. We further assume that on the set . Then, letting denote the expectation with respect to , it holds that
[TABLE]
The last equality gives rise to the importance sampling estimator
[TABLE]
where the realisations or , respectively, are independent draws from the new probability measure . It is easy to see that the estimator (4) is unbiased under , i.e. . Moreover choosing , such that
[TABLE]
the resulting importance sampling estimator has zero variance under , i.e., . We call the change of measure that reduces the variance to zero – and gives the correct answer already for – the optimal change of measure.
Note, however, that the optimal change of measure depends on the sought quantity , which is not surprising as it completely removes the randomness from the estimator, but which renders the result somewhat useless. Further notice that , in other words, the optimal change of measure is given by conditioning the original measure on the rare event .
We will later on discuss the question how to devise approximations to the optimal change of measure.
II.2 Importance sampling in path space
Throughout the rest of this paper we assume that is governed by a stochastic differential equation (SDE)
[TABLE]
where the coefficients and are such that (5) has a unique strong solution. For simplicity we further assume that has a uniformly bounded inverse. Our standard example will be a non-degenerate diffusion in an energy landscape,
[TABLE]
with smooth potential energy and constant.
We will now generalise the previous considerations to more general properties and functionals of (5). To this end, let denote an open and bounded set with smooth boundary such that ; we define
[TABLE]
to be the first exit time of the set and call the continuous functional
[TABLE]
of where are bounded and sufficiently smooth, real valued functions. Our aim is to estimate the free energy
[TABLE]
that can be considered a scaled version of the cumulant generating function of , where the expectation is understood with respect to the realisations of the Brownian motion in the uncontrolled SDE (5) for a given initial condition . Now, let be the solution of the controlled SDE
[TABLE]
with initial data . By Jensen’s inequality, Hartmann and Schütte (2012)
[TABLE]
where denotes the relative entropy or Kullback-Leibler divergence between the probability measures and , restricted to the history of the stopped process, and we have introduced the shorthands and to denote quantities generated by the controlled SDE (10).
The inequality (11) is the basis for the famous Gibbs variational principle—also known as the Donsker-Varadhan principle in its dual form—that relates the free energy with the (relative) entropy. It can be shown that equality in (11) is attained if and only if belongs to the exponential family, with .
Now, informally, Girsanov’s Theorem states that
[TABLE]
where the expectation on the right hand side is taken over all realisations of the controlled process, and
[TABLE]
denotes the log likelihood ratio between the realisations of the controlled SDE (10) and the uncontrolled SDE (5); see Ikeda and Watanabe (1989, Ch. IV.4) or Appendix C for an informal derivation of the relation (12).
The following variational characterisation of the free energy is a straightforward generalisation of the previous considerations and characterises the optimal change of measure for the free energy from to in terms of the solution to an optimal control problem.Boué and Dupuis (1998); Hartmann et al. (2017)
Theorem II.1** (Hartmann et al. (2017))**
Assuming sufficient regularity of the coefficients and the boundary of the set , the free energy is the value function of the following optimal control problem: minimise
[TABLE]
where is the solution of the controlled SDE (10) with . That is, where . The minimiser is unique and given by the feedback law
[TABLE]
Moreover, with probability one,
[TABLE]
In other words, the optimal control generates a path space measure that yields a zero-variance importance sampling estimator via the identity (12). We refer to Appendix B for a formal derivation of the underlying stochastic optimal control problem.
Importance sampling estimators
In practice, one will not have access to the optimal control and an exact simulation of the process , but rather use a numerical approximation. In this case, the variance of the importance sampling estimator will be small, but not zero. Given statistically independent numerical approximations of , all starting at , an estimator for the free energy (9) that replaces (15) is
[TABLE]
with
[TABLE]
being an unbiased estimator of the moment generating function . Here and denote the numerical approximations of the log likelihood and the path functional . Note that, even though the estimator (17) is unbiased, the estimator for is not as it follows by Jensen’s inequality that
[TABLE]
Another biased estimator of is
[TABLE]
where the bias depends on how close is to the optimal control . If is a good approximation of , this estimator may turn out to be advantageous in terms of variance. Note that, by the central limit theorem, both (17) and (19) are asymptotically normal.
III Nonlinear Feynman-Kac formula
The aim of this section is to give an alternative characterisation of the dual optimal control problem in Theorem II.1 that (a) leads to a practical stochastic approximation algorithm for computing the optimal control, even for high-dimensional problems, and (b) that gives rise to an interpretation of the optimal change of measure in the context of control variates that may have implications for the numerical implementation of adaptive importance sampling schemes.
Applying the dynamic programming principle (see e.g. Fleming and Soner (2006, Sec. IV.5)) to the stochastic control problem (14), it follows that the value function or, equivalently, the free energy solves the stationary HJB equation
[TABLE]
with the generator
[TABLE]
and the nonlinearity
[TABLE]
The boundary value problem (20)–(22) is the straighforward generalisation of the dynamic programming equation (96) to path functionals of the form (8), and under suitable regularity assumptions, it can be shownFleming and Soner (2006) that it has a classical solution .
We will now reformulate the HJB equation as an equivalent system of forward-backward stochastic differential equations (FBSDE) that will be the basis of the numerical approximation of the optimal change of measure. To this end, we define the processes
[TABLE]
Now, by Ito’s formula, the value function satisfies
[TABLE]
which upon inserting (20) and (23) yields the following backward stochastic differential equation (BSDE)
[TABLE]
for the pair . By construction, the equation comes with the terminal condition
[TABLE]
where denotes the solution to the uncontrolled forward SDE (5). Note that, by definition, is continuous and adapted to , and is predictable and square integrable, in accordance with the interpretation of as a control variable. Further note that (25) must be understood as a backward SDE rather than a time-reversed SDE, since, by definition, at time is measurable with respect to the filtration generated by the Brownian motion , whereas a time-reversed version of would depend on via the terminal condition , which would require a larger filtration.
By exploiting the specific form of the nonlinearity (22) that appears as the driver in the backward SDE (25) and the fact that the forward process is independent of , we obtain the following representation of the solution to the dynamic programming equation (20)–(22):
[TABLE]
with boundary data
[TABLE]
The solution to (27)–(28) now is a triplet , and since is adapted, it follows that is a deterministic function of the initial data only. Since is bounded, the results in Kobylanski (2000) entail existence and uniqueness of the FBSDE (27); see also Delbaen et al. (2011) for the case of unbounded terminal cost. As a consequence, equals the value function of our control problem.
Remark 1
A remark on the role of the control variable in the BSDE is in order. In (25), let and consider a random variable that is square-integrable and -measurable where is the -Algebra generated by . Ignoring the measurability for a second, a pair of processes satisfying
[TABLE]
is , but then is not adapted unless the terminal condition is a.s. constant, because for any is not measurable with respect to . An adapted version of can be obtained by replacing by its best approximation in , i.e. by the projection . Since the thus defined process is a martingale with respect to our filtration, the martingale representation theorem asserts that must be of the form
[TABLE]
for some unique, predictable process . Subtracting the last equation from yields
[TABLE]
or, equivalently,
[TABLE]
Hence in (29) is indeed a control variable that makes adapted.
Remark 2
The above setting includes cases such as exit probabilities , in which case the free energy becomes explicitly time-dependent via the initial conditions . We only need to replace by and by an augmented process with that includes time as an extra state variable. Accordingly, the elliptic operator must be replaced by the parabolic operator .
III.1 From importance sampling to control variates
The role of the process in the FBSDE representation of the dynamic programming equation is not only to guarantee that in (27) is adapted, so that is the value function, but it can be literally interpreted as a control since , even though it is evaluated along the uncontrolled process rather than the controlled process .
We will now show that the control plays the role of a control variate that produces a zero-variance estimator.
Proposition III.1
Consider the solution of the FBSDE (27)–(28). Further let
[TABLE]
Then, with probability one,
[TABLE]
or, equivalently,
[TABLE]
where is the free energy (9).
Proof: Using (27)–(28), can be recast as
[TABLE]
where we have used that . Therefore, using the identification of with the free energy , we have
[TABLE]
which holds with probability one.
III.2 Importance sampling within control variates
Even though the importance sampling and the control variate based estimators look very similar, there is an important difference, in that is a function of the uncontrolled rather than the controlled process. Thus the second approach does not involve a change of measure which may be advantageous when the existence of the Radon-Nikodym derivative is not guaranteed, which, for example, may be the case when the stopping time is either unbounded or can become very large with a non-negligible probability. (Note that the controlled process need not be simulated at all.)
Yet, in some situations it may be difficult to sample the terminal condition by forward trajectories, in which case it may be advantageous to use importance sampling, either instead of or within the control variate scheme. To better understand the relation between the two approaches we do a change of drift in the FBSDE, so that the associated HJB equation remains the same. Specifically, consider a change of drift of the form
[TABLE]
for some adapted process that may or may not depend on the state of the process with the new drift. Under this change of drift, using the identification , the original FBSDE (27) turns into
[TABLE]
with the driver
[TABLE]
and boundary data (28), with replaced . It can be easily checked that (34)–(35) and (27) represent the same HJB equation (20).
The change of drift furnishes an exponential change of measure in the free energy functional. We will now show that, for any reasonable choice of an adapted control , say, bounded and continuous, every estimator of the form
[TABLE]
with has zero variance where the expectation on the right hand side is taken over the realisations of the FBSDE (34) with initial conditions , and
[TABLE]
Proposition III.2
*Let be adapted and such that the FBSDE (34) with driver (35) has a unique strong solution. Then, with probability one, *
[TABLE]
Proof: The argument is essentially the same as in the proof of Proposition III.1. Substituting the expressions for in the backward part of the FBSDE (34), we conclude that
[TABLE]
Thus, almost surely,
[TABLE]
where , since (34)–(35) is a Feynman-Kac representation of the HJB equation (20).
Hence we can change the drift of the forward SDE by modifying the control, without affecting the variance of the free energy estimator. Having a zero-variance estimator is of course only useful under the assumption that it is possible to solve the BSDE associated with (27) or (34), and changing the drift is also a means to reduce the variance of the numerical scheme for the BSDE. Similar ideas along these lines have been suggested by Bender and Moseler (2010) who use a change of the drift, with the aim of reducing the variance of the BSDE simulation.
More importance sampling estimators
Along the lines of the considerations in Section II.2, we define the standard (biased) estimator for as
[TABLE]
with
[TABLE]
Here and stand for the discretisations of and , and the bilinear term denotes the numerical approximations of the scalar product (37) by a suitable quadrature rule. If an accurate approximation of the control is available, another biased estimator of that may have a smaller variance than (39) is
[TABLE]
Note that due to the occurence of the bilinear term, none of the estimators will in general be unbiased for fixed .
IV Least-squares regression
We now discuss the numerical discretisation of (27) and (34). The fact that both FBSDE are decoupled implies that they can be discretised by an explicit time-stepping scheme. Specifically, we discuss two different approaches: a Monte Carlo approach that is based on a backward iteration that involves the numerical computation of conditional expectations using least-squares and that was first suggested by Gobet et al. Gobet et al. (2005) and later on refined by several authors Bender and Denk (2007); Bender and Steiner (2012); Gobet and Turkedjiev (2016), and a deep learning method that seeks to approximate the BSDE solution by a neural network with a quadratic loss function, as suggested by E et al. (2017). The convergence of the numerical schemes for an FBSDE with quadratic nonlinearities in the driver has been analysed by Turkedjiev (2013).
For the ease of notation, we confine our discussion to the FBSDE (27) and then comment on the difference to (34) whenever necessary. Thus consider the Euler-Maruyama discretisation
[TABLE]
of (27) where is an i.i.d. sequence of normalised Gaussian random variables and denotes the numerical discretisation of .
To fix notation, we denote by the discrete-time approximation to , such that . Further let be the maximum iteration number, with where is the maximum simulation time that should be chosen sufficiently large, so that either or are close to one (say, between 0.9 and 1), depending on whether the controlled or uncontrolled forward process is simulated.
IV.1 Parametric least-squares Monte Carlo
The least-squares Monte Carlo (LSMC) scheme is based on a parametric representation
[TABLE]
of the value function (or the free energy ) as a linear combination of finitely many basis functions . We assume that the are continuously differentiable, so that we can express the control by the gradient of .
Now let us introduce the shorthand
[TABLE]
for the conditional expectation with respect to the -algebra that is generated by the discrete Brownian motion . By definition, the continuous-time process is adapted to the filtration generated by . For the discretised process, this implies (cf. Remark 1)
[TABLE]
so that, with (42),
[TABLE]
using that is independent of . In order to compute from , it is convenient to replace on the right hand side by , so that we end up with the fully explicit time stepping scheme
[TABLE]
which is equivalent to (45) up to terms of order .
Note that we can use the identification of with the control and replace in the last equation by
[TABLE]
where is given by the parametric ansatz (43).
IV.1.1 Conditional expectation
We next address the question how to compute the conditional expectations with respect to . To this end, we recall that the conditional expectation can be characterised as a best approximation in :
[TABLE]
(Hence the name least-squares Monte Carlo.) Here measurability with respect to means that can be expressed as functions of . In view of (23), this suggests the approximation scheme
[TABLE]
with the shorthand
[TABLE]
Here the superscript in parentheses is used to label the independent realisations of the forward process, , the resulting values for the backward process,
[TABLE]
and the control,
[TABLE]
At the terminal time , the data are determined by
[TABLE]
and
[TABLE]
where only those realisations are taken into account that have not yet reached the boundary, i.e. ceased to exist.
IV.1.2 LSMC algorithm
The unknown coefficients have to be computed in every iteration step which makes them functions of time (i.e. ), even though the value function is not explicitly time dependent. We call the vector of the unknowns, so that the least-squares problem that has to be solved in the -th step of the backward iteration is of the form
[TABLE]
with coefficients
[TABLE]
and data
[TABLE]
Assuming that the coefficient matrix , defined by (55) has maximum rank , then the solution to (54) is given by
[TABLE]
As has been shown by Gobet et al. (2005), the thus defined scheme is strongly convergent of order 1/2 as and . Controlling the approximation quality for finite values , however, requires a careful adjustment of the simulation parameters and basis functions, especially with regard to the condition number of the matrix , and we will discuss suitable strategies to determine a good basis in Section V.
Remark 3
If an explicit representation of such as (47) is not available, which, for example, is the case when the noise coefficient is controlled too, it is possible to derive a time stepping scheme for in the following way: multiplying the second equation in (42) by from the left, taking expectations and using the fact that is adapted, it follows that
[TABLE]
or, equivalently,
[TABLE]
Together with (46) or, alternatively, with
[TABLE]
we have a fully explicit scheme for .
IV.2 Deep learning based shooting method
As an alternative we discuss a modification of the deep learning based approach that has been proposed by E et al. (2017) and that is basically a clever implementation of a shooting method for two-point boundary value problems.
The idea is to approximate for every by a random variable that depends on parameters and the initial condition and that satisfies the forward iteration
[TABLE]
Here we model with a single parameter and as a neural net approximation of , where is chosen so as to minimise the quadratic loss function
[TABLE]
The choice of the loss function (62) is motivated by the fact that the exact FBSDE solution satisfies
[TABLE]
Therefore, by construction, the approximants will be adapted, with the property
[TABLE]
assuming that is sufficiently small, that sufficiently many training samples of are available to approximate the expectation in (62), and that the trained neural network is sufficiently rich (i.e. that is sufficiently large). Understanding the approximation (64) in more detail will be a subject of future research.
IV.2.1 Stochastic gradient descent
We define the central objects of the method and explain how to compute the optimal parameters. To this end, let be our generic probability space on which the family of random variables that appear in the BSDE (61) is defined. Further let and be random fields parametrised by that satisfy (61).
Letting denote independent and identically distributed realisations of the forward dynamics, an unbiased estimator of (62) is given by
[TABLE]
We suppose that the random function is differentiable in , which allows us to minimise the loss by doing stochastic gradient descent
[TABLE]
where the step size or learning rate is decreasing and satisfies the usual divergence condition
[TABLE]
By construction is an unbiased estimator of the exact gradient , when conditioned on the current iterate . The thus described algorithm is the most basic one, but it can be augmented in various ways, e.g. by using adaptive moment estimation.Kingma and Ba (2015)
V Illustrative examples
We consider three different toy examples, one of which involves pure drift-less Brownian motion and a random stopping time with a non-trivial terminal condition, one an Ornstein-Uhlenbeck process on a finite (deterministic) time horizon and another one a metastable overdamped Langevin dynamics. (The code can be found online at https://github.com/lorenzrichter/BSDE.)
V.1 Committor equation
Let , be a Brownian motion in , and consider the open and bounded set
[TABLE]
We define the sets and for and denote by
[TABLE]
the first hitting time of (see Figure 1). Letting the stopping times be the first hitting times of , the committor probability from to as a function of the initial condition is given by the function
[TABLE]
The committor function solves the elliptic boundary value problem on :
[TABLE]
with being infinitesimal generator of . By the spherical symmetry of the problem, the committor is a function of only. Using that the Laplacian of a function can be recast as
[TABLE]
the committor equation can be integrated twice to yield the explicit solution
[TABLE]
For , the function is linear. For , both enumerator and denominator are zero, but has a well-defined limit (computable by l’Hopital’s rule), namely,
[TABLE]
For , the solution converges to the constant 1 on and zero for .
The associated FBSDE has vanishing running cost, , and non-smooth terminal cost, . The numerical solution can be computed after an appropriate regularisation of the logarithm. We choose for an arbitrary . The solution to the thus regularised BSDE is related to (70) by
[TABLE]
We apply the LSMC algorithm described in Section IV.1 where we run independent forward realisations of the discrete Brownian motion
[TABLE]
with . The maximum length of the trajectories, , is set equal to 0.5 times the mean first exit time from a -dimensional hypersphere of radius that is given by , so that most, but not all trajectories have exited from by time . In order to solve the corresponding BSDE
[TABLE]
with terminal condition
[TABLE]
an adaptive basis of smooth ansatz functions , is constructed in the following way: For every we compute the empirical mean over the active realisations of the forward process , and we define Gaussian ansatz functions
[TABLE]
with constant variance and mean
[TABLE]
where is kept fixed throughout the simulation. (In some cases, it may pay off to set equal to the empirical standard deviation of for every .) The last equation admits a straightforward generalisation to the multidimensional case if it is interpreted component-wise. Another strategy in the multidimensional case that has proven useful is to place the basis functions so that, for each component, their means or centre points are equidistributed between the minimum and maximum values of the forward trajectories.
The upper panel of Figure 2 shows the value function (free energy) as a function of the initial radius for the parameters and ; the simulation parameters were set to (number of basis functions), (number of realisations), (spreading of basis functions), and (variance of Gaussian basis function). Note that even though we use globally supported radial basis functions to represent the solution of the backward SDE, the approximation of is meaningful only in a small neighbourhood of the initial value . Nevertheless it is possible to obtain a coarse representation of the value function or the committor function along single realisations, using that , by definition of the backward process (see lower panel of Figure 2).
We tested the LSMC algorithm for a 10-dimensional example, with a single initial value with , , . Figure 3 illustrates the bias coming from the fact that all forward realisations have finite length . The bias can be reduced by increasing , at the expense of increasing the computational overhead and the variance of the estimator as the variance of the LSMC coefficients (57) increases when the number of alive (i.e. non-stopped) realisations decreases. Note that the relative error in this case is below .
The deep learning based algorithm did not produce any reproducible results on the committor example.
V.2 Ornstein-Uhlenbeck process
An example for which the deep learning based shooting method is applicable is when the stopping time is deterministic (cf. Remark 2). Specifically, we consider the computation of the conditional expectation
[TABLE]
under the one-dimensional linear dynamics
[TABLE]
where we assume to be time-independent. Since the transition probability density of the process is explicitly known for all times, namely
[TABLE]
it is straightforward to compute the corresponding (now explicitly time-dependent) value function
[TABLE]
and therefore the optimal control
[TABLE]
which remarkably does not depend on .
We apply the shooting method with values and by identifying the terminal costs . Contrary to the explanation above, which aims at a hitting time example, here the control is explicitly time-dependent and we therefore need time-dependent approximations . For those we choose multiple fully connected neural networks , each with one hidden layer, batch normalisation and parameters, that are supposed to approximate for , as well as the single parameter that shall approximate .
Additionally to considering only uncontrolled forward trajectories, we add the control as described in (34)-(35). More precisely, we use the approximation of the optimal control from a previous iteration step
[TABLE]
when simulating the forward trajectories for the -th gradient step, i.e. we simulate the two processes
[TABLE]
with In our simulations we observe that the added control in the forward trajectories can accelerate the convergence of the loss function (65) as shown in Figure 4. We are able to drive the loss to zero with the Adam optimiser Kingma and Ba (2015) and a batch size . In the plots of Figure 5 we see a good agreement of the true optimal control function (82) and its neural network approximation.
In the shooting method, one can of course also use ansatz functions for the approximation of , namely
[TABLE]
where now . For the Ornstein-Uhlenbeck example, we compare the previous deep learning attempt with choosing two different sets of ansatz functions, once equidistant Gaussians as in (76) and once the “correct” basis function , which we identify due to the knowledge of the exact optimal control (82). In both cases the gradient of the loss (65) with respect to can be computed analytically and stochastic gradient descent can be performed as described above. In Figures 4 and 5 we see that both attempts yield reasonable results, however, when using Gaussians we are not able to drive the loss very close to zero. For a comparison, we additionally approximate this toy example with the LSMC attempt, choosing the same parameters as in the shooting method, and realise that this method is less robust with respect to the choice of ansatz functions and the time discretisation of the stochastic process (cf. Figure 5).
In practice and in particular in higher dimensions it is of course much more difficult to choose ansatz functions appropriately and a priori bounds for the approximation are not available. The application of neural networks to higher dimensional processes on the other hand is straightforward, however, the optimisation can become more difficult especially if the dimensions strongly interact. Particularly interesting will be the study of the shooting method in the context of metastable processes.
V.3 Double-well potential
As an example of a rare event we consider computing the probability of leaving a metastable set before time ,
[TABLE]
where the dynamics is given by the Langevin equation
[TABLE]
with a potential and a random stopping time . We recall that leaving a metastable set scales exponentially with the energy barrier and the inverse of the diffusion coefficient by Kramers law, namely
[TABLE]
The overall stopping time is defined by . Referring to the notation in this corresponds to choosing and and since the latter expression is difficult to handle numerically we consider the reguralized problem by taking for a small and note that and . We also note that the choice of can have a significant effect on the corresponding optimal control as illustrated in Figure 6 for the choice of .
By the Feynman-Kac theorem (see e.g. Øksendal (2003, Thm. 8.2.1)), the function fullfills the linear parabolic evolution equation
[TABLE]
with the boundary conditions
[TABLE]
We numerically approach this problem by using the LSMC algorithm explained in section IV.1.2, which we additionally iterate by using a previously found approximation as a control variate as explained in (34)-(35). More precisely, after the first iteration, LSMC provides approximations for , for , and we can use , corresponding to the optimal control, as an additional drift in the forward process to run LSMC once again and repeat until convergence. As a small modification to the above described algorithm we choose random initial points , which make the algorithm more stable since in particular the matrix inversion in (57) is easier if trajectories are more spread out.
In our simulation, we choose equidistant Gaussian functions as in (76) and let . A reference solution is computed by a numerical discretization of (87). In the bottom panel of Figure 7 we see that after the second iteration we get quite close to the true value function, however, we have no guarantee for such a behavior and depending on we have observed that the stability of the algorithm crucially depends on the clever choice of ansatz functions and a good initial guess of a drift in the forward process. Convergence analysis of the iteration procedure is a question for further research.
As an alternative strategy for computing the rare event probabilities that we are after, which is also suitable in the case where the value function approximation does not seem to converge, one can resort to importance sampling as an additional step: The LSMC algorithm provides an approximation of the control as in (51) and we can use this—even if potentially suboptimal—in a Girsanov reweighting such as in (13). We illustrate this for , for which the value function approximation itself did not yield satisfactory results. In Table 1 we compare the importance sampling approach to naive Monte Carlo, where one does not add any drift to the forward trajectories. Here the true value is
[TABLE]
and we realize that the importance sampling approach brings a significant reduction of the relative error by, roughly, a factor of , as a consequence of which the amount of samples needed in order to reach a given accuracy is reduced by a factor of .
VI Conclusions
We have given a proof of concept that it is possible compute the optimal change of measure for rare event simulation problems with deterministic or random stopping time by solving an associated stochastic optimal control problem. The latter can be recast as a forward-backward stochastic differential equation (FBSDE) that has a nice interpretation in terms of control variates. The FBSDE can be solved by least-squares regression, and we have tested two numerical schemes: a least-squares Monte Carlo algorithm that uses predefined basis functions to represent the solution of the optimal control problem and that can be applied to—potentially high-dimensional—problems with random stopping time and non-smooth terminal cost, and a deep learning based shooting method that can be applied to systems with deterministic finite time horizon. Let us stress that both algorithms can be combined with each other, but despite of their obvious appeal, none of the methods presented should be considered as a black box algorithm that works without any a priori knowledge about the system; a careful choice of the basis functions or the hyperparameters is crucial for the variational problems to converge. Therefore future research ought to address these questions as well as the generalisation of the deep learning algorithm to problems with random stopping time.
Acknowledgement
This work was partially funded by the Deutsche Forschungsgemeinschaft (DFG) under the grant DFG-SFB 1114 “Scaling Cascades in Complex Systems”.
Appendix A Conditioning and Doob’s -transform
The optimal change of measure that minimises the variance of an importance sampling estimator can be interpreted as a conditional probability under rather general assumptions. Specifically, let be a Markov process in with infinitesimal generator . Introducing the shorthand , we define the function
[TABLE]
which is only a slight variation of the formula (1), in that all paths start at . Then, for any sufficiently small , it follows by the Markov property of that
[TABLE]
where denotes the expectation over all paths of starting at . As a consequence,
[TABLE]
which implies that is harmonic.
For simplicity, we suppose that the transition kernel of has a smooth and strictly positive transition probability on for any , with
[TABLE]
and we define
[TABLE]
Then, since is harmonic,
[TABLE]
that is, is a transition probability density for every ; we denote by the corresponding transition probability and by the corresponding process. The transformation
[TABLE]
is called an -transform, and the transformed process enjoys the familiar zero-variance property:
[TABLE]
Here denotes the likelihood ratio between the path measures and .
As before this optimal importance sampling change of measure amounts to a conditional probability.
Lemma A.1
It holds that
[TABLE]
Moreover , i.e. the law of is the law of conditioned on .
Proof: Let
[TABLE]
the expectation with respect to of any bounded and measurable function . Setting , it suffices to show that
[TABLE]
Then, by the optional stopping theorem,
[TABLE]
and the last expression is equal to one by definition of . The rest of the proof is omitted for brevity.
Appendix B Conditioning of diffusions
We will now characterise the -transform in concrete situations, specifically, when is a diffusion. To this end, we will show that the -transform can be realised by a change of drift in the SDE (5). By definition, the function is harmonic, and so it can be characterised as the solution to an elliptic boundary value problem, with the second-order differential operator
[TABLE]
We let denote an open and bounded set with , and we define
[TABLE]
to be the first exit time of the set . Then solves the boundary value problem
[TABLE]
For reasons that will become clear in a moment, we need to be strictly positive. Therefore we define a regularised indicator function . Further assuming that is invertible with uniformly bounded inverse the operator is uniformly elliptic and thus the regularised boundary value problem
[TABLE]
Then, which, by the strong maximum principle, is a strictly positive function on the closure . Now define the function that solves the nonlinear elliptic boundary value problem
[TABLE]
where we have introduced the shorthands and . Noting that
[TABLE]
we realise that (96) is the dynamic programming equation or Hamilton-Jacobi-Bellman (HJB) equation of the following optimal control problem: minimise the cost
[TABLE]
subject to
[TABLE]
with initial data . The optimal control is given by the minimiser in (97):
[TABLE]
Letting in (96), the function , considered as function of the initial conditions, converges to the viscosity solution of dynamic programming equation (96), with replaced by . Bearing in mind that , it follows that, as , the optimal control (100) realises the -transform, in that the (weak) solution of the controlled SDE
[TABLE]
with initial condition has the same law as .
Appendix C Finite-dimensional Girsanov formula
We will explain the basic idea behind Girsanov’s Theorem and the change of measure formulae (12)–(13) for finite-dimensional Gaussian measures, partly following an idea in Papaspiliopoulos and Roberts (2012).
Let be a probability measure on a measurable space , on which an -dimensional random variable is defined. Further suppose that has standard Gaussian distribution . Given a (deterministic) vector and a matrix , we define a new random variable by
[TABLE]
Since is Gaussian, so is , with mean and covariance . Now let and define the shifted Gaussian random variable
[TABLE]
and consider the alternative representation
[TABLE]
of that is equivalent to (102) if and only if
[TABLE]
has a solution (that may not be unique though). The idea of Girsanov’s Theorem is to seek a probability measure such that is standard Gaussian under , and we claim that such a should have the property
[TABLE]
or, equivalently,
[TABLE]
To show that is indeed standard Gaussian under the above defined measure , it is sufficient to check that for any measurable (Borel) set , the probability is given by the integral against the standard Gaussian density:
[TABLE]
Indeed, since is standard Gaussian under , it follows that the probability is equal to
[TABLE]
showing that has a standard Gaussian distribution under . Hence, by the definition of , it holds that
[TABLE]
for any bounded and measurable function , where denotes the expectation with respect to the reference measure . Now let
[TABLE]
Since the distribution of the pair under is the same as the distribution of the pair with under , the identity (106) entails that
[TABLE]
which is the finite dimensional analogue of (12).
References
- Bachouch et al. (2018)
Achref Bachouch, Côme Huré, Nicolas Langrené, and Huyen Pham.
Deep neural networks algorithms for stochastic control problems on finite horizon, Part 2: numerical applications.
arXiv e-prints, art. arXiv:1812.05916, Dec 2018.
- Bender and Denk (2007)
Christian Bender and Robert Denk.
A forward scheme for backward SDEs.
Stoch. Proc. Appl., 117(12):1793 – 1812, 2007.
- Bender and Moseler (2010)
Christian Bender and Thilo Moseler.
Importance sampling for backward SDEs.
Stoch. Anal. Appl., 28(2):226–253, 2010.
- Bender and Steiner (2012)
Christian Bender and Jessica Steiner.
Least-squares monte carlo for backward sdes.
In René A. Carmona, Pierre Del Moral, Peng Hu, and Nadia Oudjane, editors, Numerical Methods in Finance, pages 257–289. Springer Berlin Heidelberg, 2012.
- Boué and Dupuis (1998)
Michelle Boué and Paul Dupuis.
A variational representation for certain functionals of brownian motion.
Ann. Probab., 26(4):1641–1659, 1998.
- Cérou et al. (2012)
F. Cérou, P. Del Moral, T. Furon, and A. Guyader.
Sequential monte carlo for rare event estimation.
Stat. Comput., 22(3):795–808, 2012.
- Comer et al. (2015)
Jeffrey Comer, James C. Gumbart, Jérôme Hénin, Tony Lelièvre, Andrew Pohorille, and Christophe Chipot.
The adaptive biasing force method: Everything you always wanted to know but were afraid to ask.
The Journal of Physical Chemistry B, 119(3):1129–1151, 2015.
- C rou and Guyader (2007)
Frédéric C rou and Arnaud Guyader.
Adaptive multilevel splitting for rare event analysis.
Stoch. Anal. Appl., 25(2):417–443, 2007.
- Dai Pra et al. (1996)
P. Dai Pra, L. Meneghini, and W. Runggaldier.
Connections between stochastic control and dynamic games.
Math. Control Signals Systems, 9:303–326, 1996.
- Delbaen et al. (2011)
Freddy Delbaen, Ying Hu, and Adrien Richou.
On the uniqueness of solutions to quadratic bsdes with convex generators and unbounded terminal conditions.
Ann. Inst. H. Poincar Probab. Statist., 47(2):559–574, 2011.
- Dupuis and Wang (2004)
Paul Dupuis and Hui Wang.
Importance sampling, large deviations, and differential games.
Stochastics, 76(6):481–508, 2004.
- Dupuis and Wang (2007)
Paul Dupuis and Hui Wang.
Subsolutions of an isaacs equation and efficient schemes for importance sampling.
Math. Oper. Res., 32(3):723–757, 2007.
- E et al. (2017)
Weinan E, Jiequn Han, and Arnulf Jentzen.
Deep learning-based numerical methods for high-dimensional parabolic partial differential equations and backward stochastic differential equations.
Communication in Mathematics and Statistics, 5(4):349–380, 2017.
- Ellis (1985)
Richard S. Ellis.
Entropy, Large Deviations and Statistical Mechanics.
Springer, Berlin, 1985.
- Exarchos and Theodorou (2018)
Ioannis Exarchos and Evangelos A. Theodorou.
Stochastic optimal control via forward and backward stochastic differential equations and importance sampling.
Automatica, 87:159 – 165, 2018.
- Fleming (1977)
W.H. Fleming.
Exit probabilities and optimal stochastic control.
Appl. Math. Optim., 4:329–346, 1977.
- Fleming and McEneaney (1995)
W.H. Fleming and W.M. McEneaney.
Risk-sensitive control on an infinite time horizon.
SIAM J. Control Optim., 33:1881–1915, 1995.
- Fleming and Sheu (1997)
W.H. Fleming and S.-J. Sheu.
Asymptotics for the principal eigenvalue and eigenfunction of a nearly first-order operator with large potential.
Ann. Probab., 25:1953–1994, 1997.
- Fleming and Soner (2006)
W.H. Fleming and H.M. Soner.
Controlled Markov Processes and Viscosity Solutions.
Springer, 2006.
- Glasserman and Wang (1997)
P. Glasserman and Y. Wang.
Counterexamples in importance sampling for large deviations probabilities.
Ann. Appl. Probab., 7:pp. 731–746, 1997.
- Gobet and Turkedjiev (2016)
Emmanuel Gobet and Plamen Turkedjiev.
Linear regression MDP scheme for discrete backward stochastic differential equations under general conditions.
Math. Comput., 85(299):1359–1391, 2016.
- Gobet et al. (2005)
Emmanuel Gobet, Jean-Philippe Lemor, and Xavier Warin.
A regression-based monte carlo method to solve backward stochastic differential equations.
Ann. Appl. Probab., 15(3):2172–2202, 2005.
- Hartmann and Schütte (2012)
Carsten Hartmann and Christof Schütte.
Efficient rare event simulation by optimal nonequilibrium forcing.
J. Stat. Mech. Theor. Exp., 2012:P11004, 2012.
- Hartmann et al. (2017)
Carsten Hartmann, Lorenz Richter, Christof Schütte, and Wei Zhang.
Variational characterization of free energy: Theory and algorithms.
Entropy, 19(11), 2017.
- Huré et al. (2018)
Côme Huré, Huyên Pham, Achref Bachouch, and Nicolas Langrené.
Deep neural networks algorithms for stochastic control problems on finite horizon, part I: convergence analysis.
arXiv e-prints, art. arXiv:1812.04300, Dec 2018.
- Ikeda and Watanabe (1989)
Nobuyuki Ikeda and Shinzo Watanabe.
Stochastic differential equations and diffusion processes.
North-Holland/KodanshaElsevier, 1989.
- James (1992)
Matthew James.
Asymptotic analysis of nonlinear stochastic risk-sensitive control and differential games.
Math. Control Signals Systems, 5:401–417, 1992.
- Juneja and Shahabuddin (2006)
S. Juneja and P. Shahabuddin.
Rare-event simulation techniques: An introduction and recent advances.
In Shane G. Henderson and Barry L. Nelson, editors, Simulation, volume 13 of Handbooks in Operations Research and Management Science, pages 291 – 350. Elsevier, 2006.
- Kappen and Ruiz (2016)
H. J. Kappen and H. C. Ruiz.
Adaptive importance sampling for control and inference.
J. Stat. Phys., 162(5):1244–1266, 2016.
- Kappen et al. (2012)
Hilbert J. Kappen, Vicenç Gómez, and Manfred Opper.
Optimal control as a graphical model inference problem.
Machine Learning, 87(2):159–182, May 2012.
- Kappen (2005)
H.J. Kappen.
Path integrals and symmetry breaking for optimal control theory.
J. Stat. Mech. Theor. Exp., 2005(11):P11011, 2005.
- Kebiri et al. (2018)
O. Kebiri, L. Neureither, and C Hartmann.
Adaptive importance sampling with forward backward stochastic differential equations.
Proceedings of the IHP Trimester ”Stochastic Dynamics Out of Equilibrium”, Institute Henri Poincaré (accepted), 2018.
- Kingma and Ba (2015)
Diederick P Kingma and Jimmy Ba.
Adam: A method for stochastic optimization.
In International Conference on Learning Representations (ICLR), 2015.
- Kobylanski (2000)
Magdalena Kobylanski.
Backward stochastic differential equations and partial differential equations with quadratic growth.
Ann. Probab., 28(2):558–602, 2000.
- L’Ecuyer et al. (2009)
Pierre L’Ecuyer, Michel Mandjes, and Bruno Tuffin.
Importance Sampling in Rare Event Simulation, chapter 2, pages 17–38.
John Wiley & Sons, Ltd, 2009.
- Øksendal (2003)
B. Øksendal.
Stochastic differential equations : an introduction with applications.
Springer, Berlin, 2003.
- Papaspiliopoulos and Roberts (2012)
Omiros Papaspiliopoulos and Gareth Roberts.
Importance sampling techniques for estimation of diffusion models.
In Statistical Methods for Stochastic Differential Equations, pages 329–357. Chapman and Hall/CRC, 2012.
- Rawlik et al. (2012)
K. Rawlik, M. Toussaint, and S. Vijayakumar.
On stochastic optimal control and reinforcement learning by approximate inference.
In Proc. Robotics: Science and Systems Conference (R:SS ’12), 2012.
- Reich (2018)
Sebastian Reich.
Data assimilation-the schrödinger perspective.
arXiv Preprint arXiv:1807.08351, 2018.
- Schütte et al. (2012)
C. Schütte, S. Winkelmann, and C. Hartmann.
Optimal control of molecular dynamics using Markov state models.
Math. Program. Ser. B, 134:259–282, 2012.
- Todorov (2009)
E. Todorov.
Efficient computation of optimal actions.
Proc. Natl. Acad. Sci. USA, 106(28):11478–11483, 2009.
- Turkedjiev (2013)
Plamen Turkedjiev.
Numerical methods for backward stochastic differential equations of quadratic and locally Lipschitz type.
PhD thesis, Humboldt-Universität zu Berlin, Mathematisch-Naturwissenschaftliche Fakultät II, 2013.
- Vanden-Eijnden and Weare (2012)
Eric Vanden-Eijnden and Jonathan Weare.
Rare event simulation of small noise diffusions.
Communications Pure Appl. Math., 65(12):1770–1803, 2012.
- Villén-Altamirano and Villén-Altamirano (1994)
Manuel Villén-Altamirano and José Villén-Altamirano.
Restart: A straightforward method for fast simulation of rare events.
In Proceedings of the 26th Conference on Winter Simulation, WSC ’94, pages 282–289, San Diego, CA, USA, 1994. Society for Computer Simulation International.
- Whittle (1994)
P. Whittle.
Risk-sensitivity, large deviations and stochastic control.
Eur. J. Oper. Res., 73:295–303, 1994.
- Whittle (2002)
P. Whittle.
Risk-sensitivity, a strangely pervasive concept.
Macroecon. Dyn., 6:5–18, 2002.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bachouch et al. (2018) Achref Bachouch, Côme Huré, Nicolas Langrené, and Huyen Pham. Deep neural networks algorithms for stochastic control problems on finite horizon, Part 2: numerical applications. ar Xiv e-prints , art. ar Xiv:1812.05916, Dec 2018.
- 2Bender and Denk (2007) Christian Bender and Robert Denk. A forward scheme for backward SD Es. Stoch. Proc. Appl. , 117(12):1793 – 1812, 2007.
- 3Bender and Moseler (2010) Christian Bender and Thilo Moseler. Importance sampling for backward SD Es. Stoch. Anal. Appl. , 28(2):226–253, 2010.
- 4Bender and Steiner (2012) Christian Bender and Jessica Steiner. Least-squares monte carlo for backward sdes. In René A. Carmona, Pierre Del Moral, Peng Hu, and Nadia Oudjane, editors, Numerical Methods in Finance , pages 257–289. Springer Berlin Heidelberg, 2012.
- 5Boué and Dupuis (1998) Michelle Boué and Paul Dupuis. A variational representation for certain functionals of brownian motion. Ann. Probab. , 26(4):1641–1659, 1998.
- 6Cérou et al. (2012) F. Cérou, P. Del Moral, T. Furon, and A. Guyader. Sequential monte carlo for rare event estimation. Stat. Comput. , 22(3):795–808, 2012.
- 7Comer et al. (2015) Jeffrey Comer, James C. Gumbart, Jérôme Hénin, Tony Lelièvre, Andrew Pohorille, and Christophe Chipot. The adaptive biasing force method: Everything you always wanted to know but were afraid to ask. The Journal of Physical Chemistry B , 119(3):1129–1151, 2015.
- 8C rou and Guyader (2007) Frédéric C rou and Arnaud Guyader. Adaptive multilevel splitting for rare event analysis. Stoch. Anal. Appl. , 25(2):417–443, 2007.
