Evaluation Function Approximation for Scrabble
Rishabh Agarwal

TL;DR
This paper explores learning-based approaches for Scrabble evaluation functions, experimenting with evolutionary algorithms, Bayesian Optimization, and imitation learning to improve move evaluation accuracy.
Contribution
It introduces a novel approach using imitation learning with neural networks to approximate move rankings in Scrabble, moving beyond traditional simulation-based methods.
Findings
Evolutionary algorithms and Bayesian Optimization were ineffective.
Supervised imitation learning with neural networks showed promise.
The approach enables a move ranking system based on raw board input.
Abstract
The current state-of-the-art Scrabble agents are not learning-based but depend on truncated Monte Carlo simulations and the quality of such agents is contingent upon the time available for running the simulations. This thesis takes steps towards building a learning-based Scrabble agent using self-play. Specifically, we try to find a better function approximation for the static evaluation function used in Scrabble which determines the move goodness at a given board configuration. In this work, we experimented with evolutionary algorithms and Bayesian Optimization to learn the weights for an approximate feature-based evaluation function. However, these optimization methods were not quite effective, which lead us to explore the given problem from an Imitation Learning point of view. We also tried to imitate the ranking of moves produced by the Quackle simulation agent using supervised…
Click any figure to enlarge with its caption.
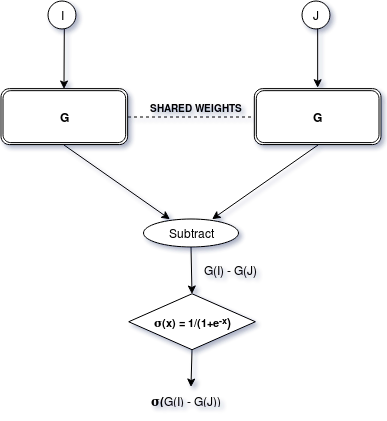 Figure 1
Figure 1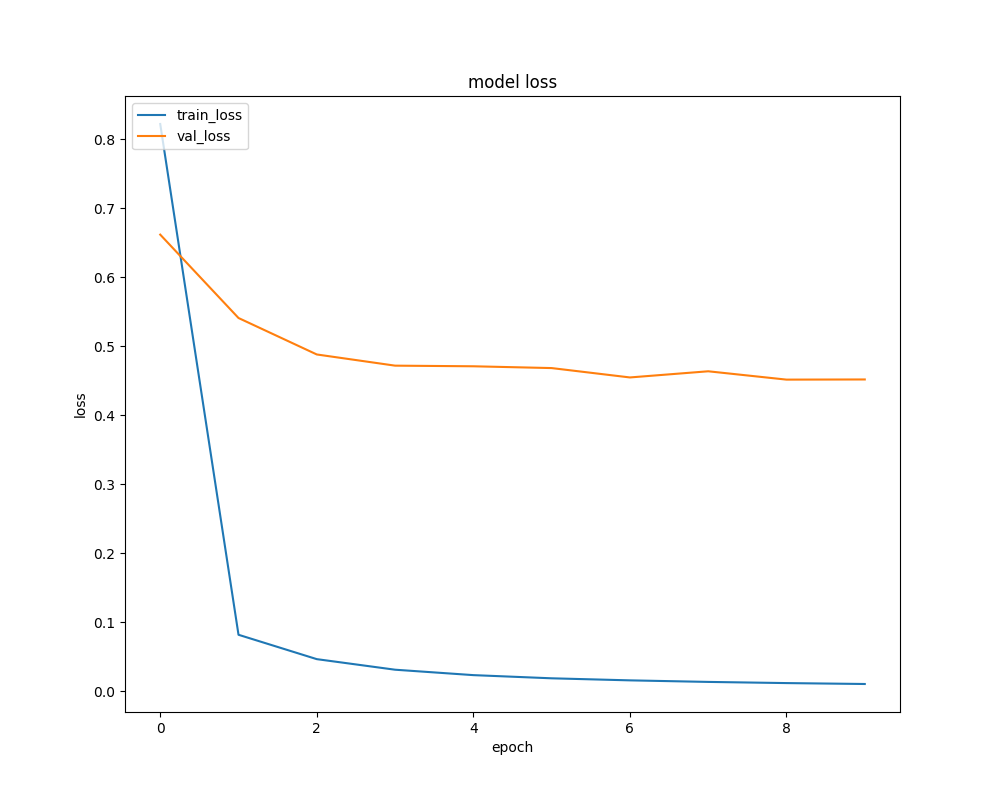 Figure 2
Figure 2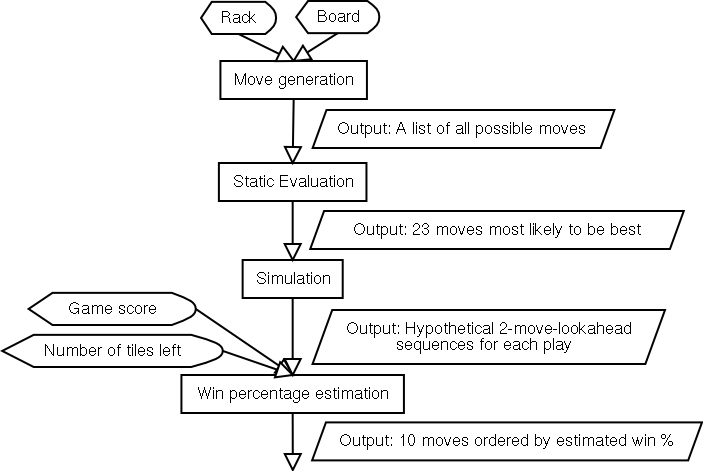 Figure 3
Figure 3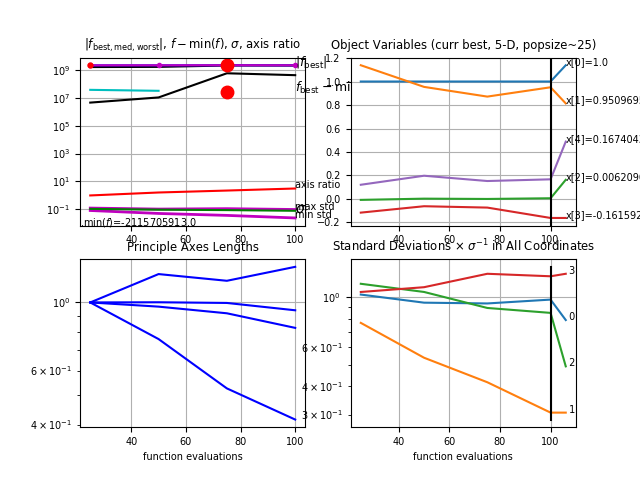 Figure 4
Figure 4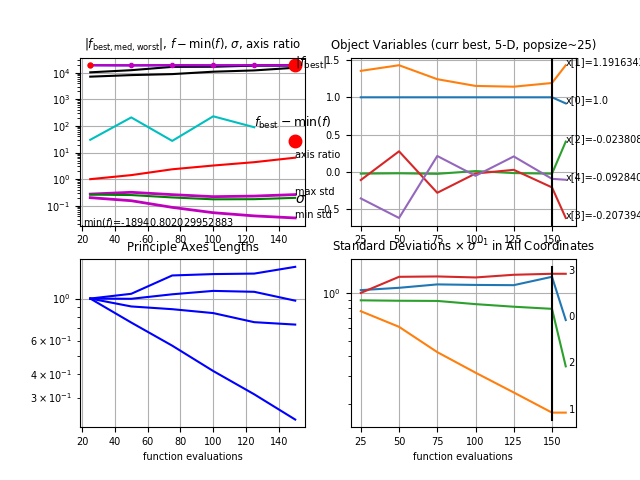 Figure 5
Figure 5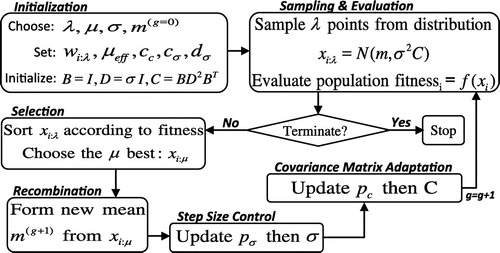 Figure 3
Figure 3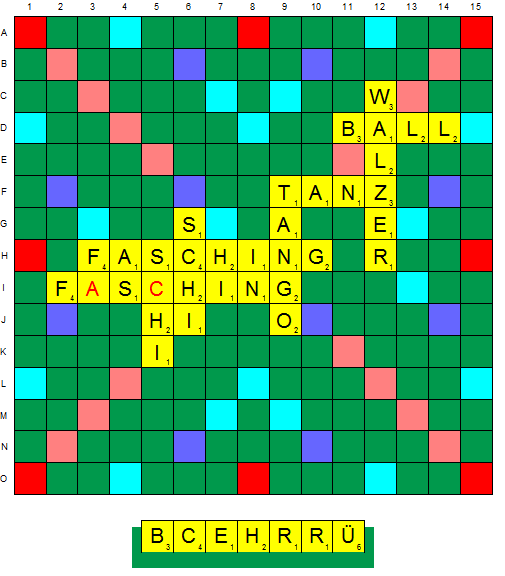 Figure 8
Figure 8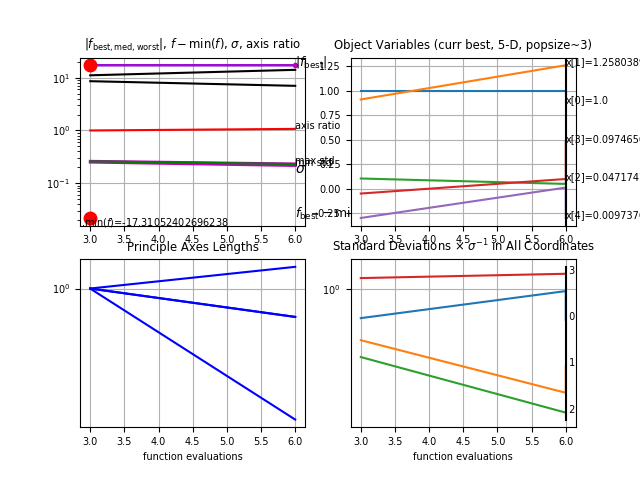 Figure 9
Figure 9Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsReinforcement Learning in Robotics · Artificial Intelligence in Games · Robotic Path Planning Algorithms
Evaluation Function Approximation for Scrabble
Bachelor Thesis Report
submitted in partial fulfillment of requirements for the degree of
Bachelor of Technology
by
Rishabh Agarwal
Roll No : 140050019
under the guidance of
Prof. Shivaram Kalyanakrishnan
Department of Computer Science and Engineering
Indian Institute of Technology Bombay
Mumbai 400076, India
Abstract
The current state-of-the-art Scrabble agents are not learning-based but depend on truncated Monte Carlo simulations and the quality of such agents is contingent upon the time available for running the simulations. This thesis takes steps towards building a learning-based Scrabble agent using self-play. Specifically, we try to find a better function approximation for the static evaluation function used in Scrabble which determines the move goodness at a given board configuration. In this work, we experimented with evolutionary algorithms and Bayesian Optimization to learn the weights for an approximate feature-based evaluation function. However, these optimization methods were not quite effective, which lead us to explore the given problem from an Imitation Learning point of view. Currently, we are trying to imitate the ranking of moves produced by the Quackle simulation agent using supervised learning with a neural network function approximator which takes the raw representation of the Scrabble board as the input instead of using only a fixed number of handcrafted features.
*To my parents, for their endless support
and for teaching me the value of hard work and discipline.*
Acknowledgement
I must acknowledge a great debt to my advisor, Professor Shivaram Kalyanakrishnan, for his constant advice has been the guiding force throughout and without which, this work would never have been possible. I also thank him for all his forbearance and wise professional counsel multiple times in the last few months.
Rishabh Agarwal
Contents
Introduction
1.1 Scrabble
Scrabble[1] is a board game, where two players alternate on forming words on a 15x15 board by placing tiles bearing a single letter onto a board. The tiles must form words which, in crossword fashion, read left to right in rows or downwards in columns, and be defined in a standard dictionary or lexicon. Also, at least one of the tiles must be placed next to an existing tile on the board. The board is also marked with “premium” squares, which multiply the number of points awarded for a given word.
The game begins with a total of 100 tiles, placed in a bag in which the letters are invisible. The set of tiles that a player holds is called the rack and each player starts off with drawing seven tiles each from the bag. The set of tiles left after a player has moved is called the rack leave and for every letter placed on the board a replacement is drawn from the bag. The game ends when one player is out of tiles and no tiles are left to draw, or both players pass. The interested reader can find more details about the rules of Scrabble here.
1.2 Why Scrabble?
Scrabble is a game of imperfect information, i.e. the current player is unaware about the rack of the opponent player, making it very hard to guess the opponent’s next move until the end of the game. Also, there is inherent randomness present in Scrabble as random letters are drawn from the bag to the current player’s rack at each round. The state space in Scrabble is also quite complex due to the tiles being marked with specific letters as opposed to being black and white. All these factors contribute to the difficulty of creating a perfect AI agent for Scrabble.
1.3 Outline
As a prerequisite to begin our exposition, we provide an overview of current state-of-the-art Scrabble agents with an high level description of the techniques employed in these agents in Chapter 2. Chapter 3 provides a detailed discussion of our approach towards the improving the evaluation function using black-box optimization methods. In Chapter 4, we shed light on our current framework involving supervised learning for approaching the problem. We conclude with a brief page of summary and directions for future work in Chapter 5.
Background
In this chapter, we cover the necessary background required for appreciation of this work. We begin by describing the main components of the Scrabble agent Maven followed by a high level description of Quackle’s artificial intelligence. Quackle is the current state-of-the-art Scrabble agent and is based on Maven. Our work builds upon the open source Quackle agent and utilizes its code available on the Internet.
2.1 Maven
Maven’s[2] game play is sub-divided into 3 phases:
Mid-game: This phase lasts from the beginning of the game up until there are 9 or fewer tiles left in the bag. In this phase, all possible moves from the given rack are generated followed by sorting using some simple heuristics. The most promising moves among these moves are evaluated using 2-ply Monte-Carlo simulation where both players are assumed to draw tiles from the bag in each turn, and are assumed to play the best move based on the aforementioned heuristics. The move which is evaluated to be best after the simulations is played during the game. 2. 2.
Pre-endgame: This phase is almost similar to the mid-game phase and is designed to attempt to yield a good end-game situation. 3. 3.
Endgame: During this phase, there are no tiles left in the bag and thus, Scrabble becomes a game of perfect information. Maven uses the search algorithm to analyze the game tree during the endgame phase.
2.2 Quackle
Quackle[3] uses a similar approach as used by Maven. Quackle’s heuristic function111Henceforth, shall be referred to as the static evaluation function used in the mid-game phase is a sum of the move score and the value of the rack leave. This leave value is computed using a precomputed database: it favors both the chance of playing a Bingo on the next turn as well as leaves that garnered high scores when they appeared on a player’s rack in a large sample of Quackle versus Quackle games. The win-percentage of each move is estimated and the move with the best win-percentage is played. Figure 2.1 presents a high level flow chart of the algorithm used in Quackle.
These are mainly two types of players present in the Quackle open source code which was used for our experiments:
Speedy Player: The player only uses only static evaluations throughout the game and no Monte-Carlo simulations. The move predicted to be the best by the static evaluation function is played at a given board configuration. 2. 2.
Championship Player: This player uses simulations in addition to static evaluations along with a perfect endgame player. This player can be provided with a particular amount of think-time222The win-rate of second player when the first player is a “Twenty Second Championship Player” i.e. it has a think-time of 20 seconds/move and the second player is a “Speedy Player” is calculated using 50000 games. to run the truncated Monte-Carlo simulations for a single turn. For example, “Five Minute Championship Player” can take as long as five minutes to decide upon the move to play in a single turn.
Please note that the win-rate of second player when both players are Speedy Players is , calculated using 50000 self-play games.
Improving the evaluation function
The static evaluation function used in Quackle takes a list of moves as input and outputs a ranked list of moves by a rough guess of how strong they are. After applying the static evaluation function to get a small number of ranked moves, the Quackle agent further uses truncated Monte-Carlo simulations to decide the best move among this moves. Our work deals with improving the static evaluation function in Quackle so that the performance of the “Speedy Player” can be improved significantly. We hypothesize that this improved evaluation function would also potentially decrease the simulation time for the “Championship Player” by predicting a smaller number of moves likely to be best at a given board configuration in Scrabble.
We extensively experimented with evolutionary approaches and Bayesian Optimization[4] to improve the evaluation function using self-play. Both of these approaches requires a fitness function[5] to estimate the goodness of a given evaluation function. We will first discuss some of the technical details regarding the fitness function followed by a discussion of the above-mentioned approaches.
3.1 Fitness Function
3.1.1 True Fitness Function
The true fitness function, for a given evaluation function is given by the win-percentage of the Scrabble agent using the given evaluation function against another agent (usually Speedy Player) using another fixed evaluation function. The win-percentage should be estimated using a large number of games, in order to keep the error-bars around the win-percentage small, leading to a reasonable estimate of the function .
Using Hoeffding’s inequality[6], the true mean of a Bernoulli random variable that has been sampled N times will lie, with probability at least 1 - , within the empirical mean . The win-rate approximated using N self-play games is estimated correctly with an error bound given by the above inequality. Using , and N = 5000 leads to a error bar of . Further, increasing N to 50000 games still leads to an error of . We can achieve slightly tighter error bounds based on KL Divergence[7] given by equations 3.1 and 3.2.
[TABLE]
where denotes the true mean of the Bernoulli and N is the number of self-play games. These equations also a error of for games for .
3.1.2 Other fitness functions
The idea of imitating the simulation agent (“Championship Player”) to improve the static evaluation function also seemed quite reasonable and in order to explore this idea more, we experimented with the fitness function , which utilized the ranking of the moves by the “Five-Minute Championship Player”. We generated 70000 board configurations, and for each board configuration b, we calculated a ranked list of size min moves out of all possible moves using the “Championship Player”. For each board configuration, a list of top min was generated using the given static evaluation function. The player was provided a score of where k is the index of the best move in among those 10 moves. The function is given by the sum of all such scores.
We also tested the fitness function given by the sum of final score differences for a “Speedy Player” over all games played between a fixed Quackle player and the “Speedy Player” which uses a static evaluation function. However, the preliminary results111 obtained a win-rate of 46% as compared to the win-rate of 44.5% obtained by using CMA-ES with 6 generations and a population size of 50. Please note that these results are correct to within as they were obtained using fitness function evaluation over 5000 games only . which we obtained by using were worse as compared to using and therefore, we didn’t use in any further experiments.
3.2 CMA-ES
We used an evolutionary algorithm[8], called CMA-ES (Covariance Matrix Adaptation Evolution Strategy)[9], to find the optimal weights for a feature-based evaluation function. An evolutionary algorithm is broadly based on the principle of biological evolution: In each generation, new individuals are generated by stochastic variation of the current parental individuals. Then, the top individuals out of are selected to become the parents in the next generation based on their fitness function value . In this manner, over the generation sequence, individuals with better and better -values are generated. Figure 3.1 presents a high level overview of the CMA-ES algorithm.
For our experiments, we ran 4-6 generations of CMA-ES with and agents using the fitness function calculated through self-play games between two “Speedy Players” as described in section 3.1.
3.2.1 Linear Evaluation Function
The linear static evaluation function scores a move based on some state-action features generated using the current board configuration and the move to be evaluated. The computed score is a dot product of the feature values with a weight vector. Note that the state-only features are not used as they will be same for all the moves at a given state and thus would not affect the ranking using a linear function. The move with the highest value of the evaluation function is played. The feature set consists of the following features:
Move Score: The score we obtain by playing the given move on the board. 2. 2.
Leave Value: A precomputed value for each rack leave generated by the Quackle code 3. 3.
Leave Playability: A value calculated for each rack leave which calculates the expected value of the move score that can be obtained after sampling letters from the bag to complete the rack and using that rack to form a word 4. 4.
Difference in consonants and vowels left on the rack 5. 5.
Number of blanks left on the rack after playing the move
The current static evaluation function in Quackle, only uses the top two features mentioned above i.e. the move score and leave value, with a weight of for each of the two features.
Figure 3.2 shows the results we obtained after running CMA-ES with above-mentioned features. As shown in the upper left plot in this figure , the value of the - min() is increasing as the generation number increases except for the last generation. The final weights with the min() (or max()) results in a win-percentage of 222This is an improvement of 0.3% over calculated over 50000 games for the second player.
We also experimented with other features such as the length of the rack leave and features corresponding to the board configuration changes after playing a move. For example, when a player plays a move on the board, new openings (positions which can be used to play a valid move) are created on the board for the opponent player. Some of these openings can also utilize premium squares. We experimented with the feature corresponding to number of such openings for each kind of premium square, leading to a total of such features. However, these new features deteriorated the maximum fitness value obtained using CMA-ES and therefore, were skipped for further experiments. The fact that the above mentioned features didn’t lead to any improvement is surprising, and we believe that this was due to the limited representation ability of the linear evaluation function.
Using CMA-ES, , as described in section 3.1.2 also didn’t lead to improvement with the above mentioned features333Surprisingly, this experiment resulted in a win-rate of 41.8% when was evaluated using 50000 games.. The baseline -value for indicates that the best move generated by the “Championship Player” is expected to lie withing the top 5 moves predicted by .
3.2.2 Non-Linear Evaluation function
Since a linear model has limited representation ability, we also experimented with evaluation functions represented by a neural network with 1-2 hidden layers and non-linear activation functions such as tanh and ReLU[10]. The neural network is only used to introduce the non-linearity in a structured manner. State-only features pertaining only to the board such as differences of vowels and consonants on the board, number of blanks on board etc. were also used as input to the network, in addition to state-action features mentioned in section 3.2.1. The results from this experiment were not encouraging and the given class of non-linear functions were not able improve upon .
3.3 Bayesian Optimization
Bayesian optimization[4] is a method of optimization of expensive cost functions without calculating derivatives. This kind of optimization employs the Bayesian technique of setting a prior over the objective function and combining it with evidence to get a posterior function. This allows an utility-based selection of the next observation using an acquisition function[11] that determines what the next query point should be. The acquisition function takes into account both sampling from areas of high uncertainty as well as areas likely to offer improvement over the current best observation.
Since our fitness functions are noisy (as only finite number of games are used to compute them), the idea of applying Bayesian optimization to find the optimal static evaluation function looked promising. However, this experiment also didn’t result in a significant improvement over the current win-rate of obtained by .
3.4 Multiple evaluation functions
Instead of using the same evaluation function for all stages444Refer to section 2.1 for detailed information about the different phases. of the game, it seemed plausible to us that a combination of evaluation functions could work better for different game stages in Scrabble. This idea has been previously employed successfully in the game of Robot Soccer[12] and already been proposed in the context of Scrabble[13] as well. Keeping the evaluation function weights fixed for the early-game555Early-game was defined as the phase of the game when the number of tiles in the bag were 80. and endgame phases, we only evolved the weights pertaining to the mid-game where the mid-game was defined to be the phase of game when the number of tiles in the bag were between 20 to 80. This experiment also proved to be futile and didn’t result in any improvement over the function .
Imitation Learning in Scrabble
Imitation learning[14] (or Learning from Demonstrations[15]) aims to mimic expert behavior in a given task. In this technique, an agent is trained to perform a task using demonstrations by learning a mapping between observations and actions. This approach has been quite successful in AlphaGo[16] where deep neural networks were trained by a combination of supervised learning from human expert games (imitation Learning) and reinforcement learning from games of self-play.
The failure of the black-box optimizations methods made us rethink our approach for improving the static evaluation function. The observation made at the end of section 3.2.1 that the top move predicted by current static evaluation function in Scrabble lies within the top 5 moves of the best simulation Quackle agent motivated us to actually learn the evaluation function instead of evolving it using a noisy fitness function. Our main idea is to imitate the ranking produced by the Quackle simulation agent using only the static evaluation function.
4.1 Learning to Rank
We initially experimented with a neural network approximator as the static evaluation function with input as a move represented by the various state-action features (including state-only features as well) described in section 3.2.2. We trained this neural network using a fixed dataset of state-action pairs with 70000 board configurations. For each board configuration , the Quackle “Five Minute Championship Player” provides a sorted list of size min{10, }, where is the list of all possible moves at configuration . The dataset D is further split into training and validation datasets and with a ratio of 97:3.
Figure 4.1 presents the Rank-net[17] architecture for which invokes the network . For each board configuration in dataset , the network is provided with pair of moves (, ) where where L[i] denotes the element of the list . The output label, for all such pairs. The binary cross-entropy loss function used for training is given by
[TABLE]
However, results from this experiment were not very encouraging. The function approximator was only able to achieve a slightly better win-rate than . Further, the validation accuracy achieved using the ranking loss was close to the baseline accuracy() produced by . We believe that the limited representation ability of the features used for this experiment was the limiting factor in this experiment.
4.2 Raw Board Representation
The problem of designing good features for the game of Scrabble is quite important. The goodness of a board configuration depends both on spatial arrangement and on the presence or absence of sets of letters and ultimately needs consultation with the Scrabble dictionary as well. However, we think that combining these dimensions into a small number of discriminative signals is not an easy task. In order to tackle this problem, we decided to use the raw board representation of the Scrabble board as input to our evaluation function instead of using only a fixed number of hand-coded features.
AlphaGo Zero[18] used the raw board representation as input to neural networks trained using self-play and mastered the game of Go without using any human knowledge. Unlike Go, which only has white and black stones, Scrabble has 27 letters, each with a different value, and with combinations of letters having different a value from the sum of the constituents. This makes the Scrabble board a much harder proposition for a convolutional neural net(CNN[19])111Henceforth, convolutional neural net is abbreviated as CNN to model well. However, given the enormous success of AlphaGo Zero, we decided to further investigate the idea of using raw board representations for Scrabble.
A Scrabble board is encoded into a feature vector where the third dimension pertain to the different type of features used in our encoding of the Scrabble board. For a particular feature, each board position is a given a value. We used the following features for our encoding:
Whether a position is blank or not 2. 2.
Whether a position contains a particular alphabet, leading to a total of 26 features for the letters A-Z 3. 3.
The score of the tile placed on a position. All positions not containing any tiles are given a score of zero except the premium scores which are given a score of -1.
The move at a given board configuration is provided as input using the concatenation of the feature vectors and (let’s call it input1) where is the configuration obtained after playing the given move on . In addition to input1, the two features used in (denoted by input2) also provided as input to our evaluation function. The neural network consists of many residual blocks[20] of convolutional layers with batch normalization[21] and ReLU activations and is trained in a similar manner as described by figure 4.1.
Specifically, consists of a single convolutional block followed by 2 residual blocks and a final block. The convolutional block applies the following modules sequentially to input1:
- nosep
A convolution of 16 filters of kernel size with stride 1 2. nosep
Batch normalization 3. nosep
A rectifier nonlinearity
Each residual block applies the following modules sequentially to its input:
- nosep
A convolution of 16 filters of kernel size with stride 1 2. nosep
Batch normalization 3. nosep
A rectifier nonlinearity 4. nosep
A convolution of 16 filters of kernel size with stride 1 5. nosep
Batch normalization 6. nosep
A skip connection that adds the input to the block 7. nosep
A rectifier nonlinearity
The final block applies the following modules sequentially to its input:
- nosep
A convolution of 1 filter of kernel size with stride 1 2. nosep
Batch normalization 3. nosep
A rectifier nonlinearity 4. nosep
A fully connected linear layer to a hidden layer of size 32 5. nosep
A rectifier nonlinearity 6. nosep
A fully connected linear layer to a hidden layer of size 4 7. nosep
A rectifier nonlinearity 8. nosep
A concatenation layer which combines the previous layer input and input2 9. nosep
A fully connected linear layer to a scalar
The number of weight parameters in were approximately 1/20 times the number of training example pairs used to train .
Figure 4.2 shows the learning curves for the network . This approach led to an validation accuracy of on which was not used for training. Given these initial results, this approach looks very promising and future work may involve exploring it further.
Conclusion and Future Work
In this work, we experimented with various black-box optimization methods including CMA-ES and Bayesian Optimization to find a better feature-based static evaluation function than the one currently employed in Quackle. However, the failure of methods mentioned above for both linear and non-linear evaluation functions suggest that the limited representation ability of these feature-based techniques was a possible cause of their failure. This hypothesis is also consolidated by the poor performance of the feature-based Imitation Learning approach described in Section 4.1.
The Imitation Learning methodology utilizing raw board representations shows some signs of success and should be explored further. These are some of the possible improvements over the current approach which can be further investigated:
The loss function currently used corresponds to comparing only the top-ranked move with other moves. However, this loss function completely discards the comparison between other moves. But, to utilize our data more efficiently, these comparisons should also be used for training the neural network. A loss function incorporating all possible comparisons in a weighted manner may lead to better results. This can be achieved by implementing the LambdaRank[22] instead of our current RankNet framework. 2. 2.
Our current approach involving supervised learning can be complemented by techniques like Dataset Aggregation(DAGGER[23]), where we try to correct our predictions on new board configurations using the ranking produced by the “Championship player” while trying to preserve the correctness of our predictions on the old dataset. The reinforcement learning algorithm introduced by the AlphaGo Zero paper can also be implemented for the given problem in hand.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Wikipedia. Scrabble — wikipedia, the free encyclopedia, 2017. [Online; accessed 24-November-2017].
- 2[2] Brian Sheppard. World-championship-caliber scrabble. Artificial Intelligence , 134(1-2):241–275, 2002.
- 3[3] Jason Katz-Brown and John O’Laughlin. How quackle plays scrabble, 2005.
- 4[4] Eric Brochu, Vlad M Cora, and Nando De Freitas. A tutorial on bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning. ar Xiv preprint ar Xiv:1012.2599 , 2010.
- 5[5] Wikipedia. Fitness function — wikipedia, the free encyclopedia, 2016. [Online; accessed 24-November-2017].
- 6[6] Wikipedia. Hoeffding’s inequality — wikipedia, the free encyclopedia, 2017. [Online; accessed 24-November-2017].
- 7[7] Emilie Kaufmann and Shivaram Kalyanakrishnan. Information complexity in bandit subset selection. In Conference on Learning Theory , pages 228–251, 2013.
- 8[8] William M Spears, Kenneth A De Jong, Thomas Bäck, David B Fogel, and Hugo De Garis. An overview of evolutionary computation. In European Conference on Machine Learning , pages 442–459. Springer, 1993.