Raking-ratio empirical process with auxiliary information learning
Mickael Albertus

TL;DR
This paper investigates the asymptotic properties of the raking-ratio empirical process when auxiliary information is estimated from a larger sample, with applications to statistical tests.
Contribution
It extends the raking-ratio empirical process theory to cases with estimated auxiliary info from learning, under specific entropy and sample size conditions.
Findings
Established strong approximation of the process under certain conditions.
Proved weak convergence matches classical raking-ratio empirical process.
Applied results to improve statistical tests like Z-test and chi-square goodness of fit.
Abstract
The raking-ratio method is a statistical and computational method which adjusts the empirical measure to match the true probability of sets of a finite partition. We study the asymptotic behavior of the raking-ratio empirical process indexed by a class of functions when the auxiliary information is given by estimates. We suppose that these estimates result from the learning of the probability of sets of partitions from another sample larger than the sample of the statistician, as in the case of two-stage sampling surveys. Under some metric entropy hypothesis and conditions on the size of the information source sample, we establish the strong approximation of this process and show in this case that the weak convergence is the same as the classical raking-ratio empirical process. We also give possible statistical applications of these results like the strengthening of the -test and the…
Click any figure to enlarge with its caption.
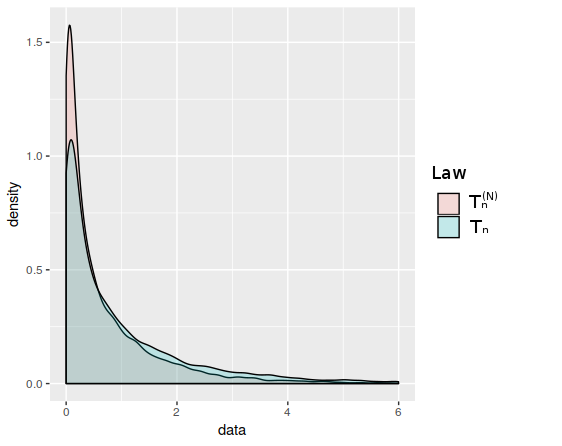 Figure 1
Figure 1Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Raking-ratio empirical process with auxiliary information learning
Mickael [email protected]
Abstract
The raking-ratio method is a statistical and computational method which adjusts the empirical measure to match the true probability of sets of a finite partition. We study the asymptotic behavior of the raking-ratio empirical process indexed by a class of functions when the auxiliary information is given by estimates. We suppose that these estimates result from the learning of the probability of sets of partitions from another sample larger than the sample of the statistician, as in the case of two-stage sampling surveys. Under some metric entropy hypothesis and conditions on the size of the information source sample, we establish the strong approximation of this process and show in this case that the weak convergence is the same as the classical raking-ratio empirical process. We also give possible statistical applications of these results like the strengthening of the -test and the chi-square goodness of fit test.
Keywords: Uniform central limit theorems, Nonparametric statistics, empirical processes, raking ratio process, auxiliary information, learning.
MSC Classification: 62G09, 62G20, 60F17, 60F05.
1 Introduction
Description. The raking-ratio method is a statistical and computational method aiming to incorporate auxiliary information given by the knowledge of probability of a set of several partitions. The algorithm modifies a sample frequency table in such a way that the marginal totals satisfy the known auxiliary information. At each turn, the method performs a simple cross-multiplication and assigns new weights to individuals belonging to the same set of a partition in order to satisfy the known constraints: it is the ”ratio” step of this method. After each modification, the previous constraints are no longer fulfilled in general. Nevertheless, under the conditions that all initial frequencies are strictly positive, if we iteratively cycle the ratio step through a finite number of partitions, the method converges to a frequency table satisfying the expected values – see [10]. It is the ”raking” step of the algorithm. The goal of these operations is therefore to improve the quality of estimators or the power of statistical tests based on the exploitation of the sample frequency table by lowering the quadratic risk when the sample size is large enough. For a numerical example of the raking-ratio method, see Appendix A.1 of [1]. For an example of a simple statistic using the new weights from the raking-ratio method see Appendix A. The following paragraph summarizes the known results for this method.
Literature. The raking-ratio method was suggested by Deming and Stephan and called in a first time ”iterative proportions” – see Section 5 of [7]. This algorithm has been initially proposed to adjust the frequency table in the aim to converge it towards the least squares solution. Stephan [11] then showed that this last statement was wrong and proposed a modification to correct it. Ireland and Kullback [8] proved that the raking-ratio method converges to the unique projection of the empirical measure with Kullback-Leibler distance on the set of discrete probability measures verifying all knowing constraints. In some specific cases, estimates for the variance of cell probabilities in the case of a two-way contingency table were established: Brackstone and Rao [5] for , Konijn [9] or Choudhry and Lee [6], Bankier [2] for and Binder and Théberge [4] for any . Results of these papers suggest the decrease of variance for the raked estimators of the cells of the table and for a finite number of iterations by providing a complex approximation of the variance of these estimators. Albertus and Berthet [1] defined the empirical measure and process associated to the raking-ratio method and have proved the asymptotic bias cancellation, the asymptotic reduction of variance and so the diminution of the quadratic risk for these process. To prove it, they showed that the raking-ratio empirical process indexed by a class of functions satisfying some metric entropy conditions converges weakly to a specific centered Gaussian process with a lower variance than the usual Brownian bridge. Under general and natural conditions that are recalled below, they proved that the variance decreases by raking among the same cycle of partitions.
Auxiliary information learning. The main motivation of this paper is when the statistician does not have the true probability of sets of a given partition but has a source of information which gives him an estimation of this probability more precisely than if he used his own sample. This source can be of different types: preliminary survey of a large sample of individuals, database processing, purchase of additional data at a lower cost, the knowledge of an expert… We suppose in our model that only the estimate of the auxiliary information is transmitted by the source. This hypothesis ensures a fast speed of data acquisition and allows a plurality of sources of information and a diversity of partitions. It is a common situation in statistics since today’s technologies like streaming data allow the collection and the transmission of such information in real time. The statistician can use this learned information as auxiliary information which is an estimate of the true one. The raking-ratio method makes it possible to combine shared information of several sources. The main statistical question of this article is whether the statistician can still apply the raking-ratio method by using the estimate of inclusion probabilities rather than the true ones as auxiliary information. We will show that the answer to this question is positive provided that we control the minimum size of the samples of the different sources of auxiliary information.
Organization. This paper is organized as follow. Main notation and results are respectively grouped at Section 2.1 and Section 2.2. Some statistical applications are given at Section 2.3. We end up by exposing all the proofs at Section 3. Appendix A contains a numerical example of the calculation of a raked mean on a generated sample. At Appendix B we do the calculation of the asymptotic variance of the raked Gaussian process in a simple case.
2 Results of the paper
2.1 Main notation
Framework. Let be i.i.d. random variables defined on the same probability space with same unknown law on some measurable space . We endow the measurable space with .
Class of functions. Let denote the set of real valued measurable functions on . We consider a class of functions such that for some and satisfying the pointwise measurability condition, that is there exists a countable subset such that for all there exists a sequence with as simple limit, that is for all . This condition is often used to ensure the -measurability of – see example 2.3.4 of [12]. For a probability measure on and let . Let be the minimimum number of balls with -radius necessary to cover and be the least number of -brackets necessary to cover , that is elements of the form with . We also assume that satisfies one of the two metric entropy conditions (VC) or (BR) discussed below.
Hypothesis** (VC).**
For , where the supremum is taken over all discrete probability measures on .
Hypothesis** (BR).**
For , , .
If we add to all elements for every and , still satisfies the same entropy condition but with a new constant or . We denote the set of real-valued functions bounded on endowed with the supremum norm . In this paper the following notations are used: for all we denote , , , and .
Empirical measures and processes. We denote the empirical measure defined by and the empirical process defined by . For , let
[TABLE]
be a partition of such that
[TABLE]
Let be the -th raking-ratio empirical measure defined recursively by and for all ,
[TABLE]
The empirical measure uses the auxiliary information given by to modify such that
[TABLE]
We denote the -th raking-ratio empirical process defined for all by
[TABLE]
This process satisfies the following property
[TABLE]
Gaussian processes. Under (VC) or (BR), is a Donsker class, that is converges weakly in to the -Brownian bridge , the Gaussian process such that is linear and for all ,
[TABLE]
For short, we denote for any . Let be the -th raking-ratio -Brownian bridge, that is a centered Gaussian process defined recursively by and for any ,
[TABLE]
Albertus and Berthet established the strong approximation and the weak convergence when goes to infinity in of to for fixed – see Proposition 4 and Theorem 2.1 of [1]. For that they used the strong approximation of the empirical process indexed by a function class satisfying (VC) or (BR) – see Theorem 1 and 2 of [3]. They gave the exact value of and showed in particular for all and that and if is such that for – see Propositions 7, 8, 9.
Auxiliary information. For let be a random vector with multinomial law, trials and event probabilities . This random vector corresponds to the estimation of the auxiliary information of the -th auxiliary information source based on a sample of size not necessarily independent of . We study the asymptotic behavior of the raking-ratio empirical process which uses as auxiliary information instead of . By defining the sequence we suppose that this information can be estimated by different sources that would not necessarily have the same sample size but still have a sample size larger than . Let be the -th raking-ratio empirical measure with learned auxiliary information defined recursively by and for all ,
[TABLE]
This empirical measure satisfies the learned auxiliary information since
[TABLE]
We define the -th raking-ratio empirical with estimated auxiliary information defined for by
[TABLE]
2.2 Main results
For , denote and
[TABLE]
Empirical measures and are defined on the set
[TABLE]
which satisfies
[TABLE]
where The following proposition bounds the probability that deviates from a certain value.
Proposition 1**.**
For any , and , it holds under the event
[TABLE]
Under (VC) and the event there exists such that for all ,
[TABLE]
where are defined by (3.7). Under (BR) and the event there exists such that for all ,
[TABLE]
where are defined by (3.9).
Proposition 1 proves that if satisfies (VC) or (BR) then almost surely . If satisfies (VC), let define with and . If satisfies (BR), let define with . The following result establishes the strong approximation of by .
Theorem 2.1**.**
Let . There exists , a sequence of independent random variables with law and a sequence of versions of supported on a same probability space such that for all ,
[TABLE]
where is the version of derived from through (2.2).
By Borel-Cantelli lemma we have almost surely for large ,
[TABLE]
Sequence in the previous bound is the deviation from to while represents the deviation from to . Under the condition that the sample size of the sources are large enough, Theorem 2.1 implies that the sequence converges weakly to on as the same way as .
2.3 Statistical applications
Improvement of a statistical test. Any statistical test using the empirical process can be adapted to use auxiliary information to strengthen this test. It suffices to replace in the expression of the test statistic the process by if we have the true auxiliary information or by if we have an estimation of this information. The two following subsections give an example of application in the case of the -test and the chi-squared goodness of fit test. In both case, we transform the statistic of theses tests and keep the same decision procedure. In the first case, we show that this new statistical test has the same significance level but a higher power. For the second case, we prove that the confidence level decreases and that under , the new statistic goes to infinity as the same way as the usual one.
-test. This test is used to compare the mean of a sample to a given value when the variance of the sample is known. The null hypothesis is for some and a probability measure . The statistic of the classical -test is
[TABLE]
Under , asymptotically the statistic follows the standard normal distribution. We reject the null hypothesis at the level when , with the probit function. Let define the following statistics
[TABLE]
Since the law is unknown, and for are usually unknown but a consistent estimation of these variances can be used to calculate or – a concrete example of this remark is given at the following paragraph. Doing it does not change the asymptotic behavior of the random variables and , whether the hypothesis is verified or not. The statistical tests based on the reject decision and have the same significance level than the usual test based on the decision since, under , and converge weakly to – see Proposition 6 of [1]. The following proposition shows that the ratio of the beta risk of the usual -test and the new statistical test with auxiliary information goes to infinity as .
Proposition 2**.**
Assume that . Under , for all and large enough one have
[TABLE]
Z-test in a simple case. To calculate or one needs the expression of . To illustrate how to get it we work on a simple case, when the auxiliary information is given by probabilities of two partitions of two sets. More formally for we define and . By using Proposition 7 of [1] we give simple expressions of for . For the sake of simplification, let denote
[TABLE]
then,
[TABLE]
where are stochastic matrices given by (B.1), are conditional expectation vectors given by (B.2) and are the covariance matrices of and that is the matrices given by (B.3). Albertus and Berthet proved that the raked Gaussian process converges almost surely as to some centered Gaussian process with an explicit expression. The stabilization of the raking-ratio method in the case of two marginals when is fast since the Levy-Prokhorov distance between and is almost surely at most for some – see Proposition 11 of [1]. We denote the raked empirical measure after stabilization of the raking-ratio algorithm and the asymptotic variance. Let define the following statistic
[TABLE]
According to Proposition 2, the statistical test based on the reject decision has the same significance level than the usual -test based on but it is more powerful as goes to infinity. In the case of two marginals with two partitions, one can give an explicit and simple expression of the asymptotic variance. By using the notations of (2.10) one have
[TABLE]
The calculation of this variance needs the expression of so it is made at Appendix B. If we do not have the values given by (2.10) one can use their consistent estimators to estimate the value of . If then naturally the auxiliary information is useless since , so there is no reduction of the quadratic risk. If is independent of then and
[TABLE]
Chi-square test. The chi-squared goodness of fit test consists of knowing whether the sample data corresponds to a hypothesized distribution when we have one categorical variable. Let be a partition of . The null hypothesis is
[TABLE]
where and , for some probability measure . The statistic of the classical chi-squared test is
[TABLE]
Under , asymptotically the statistic follows the distribution with degrees of freedom. We reject the null hypothesis at the level when , where is the quantile function of . We want to know if the following statistics
[TABLE]
somehow improve the test. The following proposition shows that the power of the test is improved with these new statistics.
Proposition 3**.**
Under and for all ,
[TABLE]
and if then
[TABLE]
Under and for all , almost surely there exists such that for all ,
[TABLE]
Figure 2.3 is a numerical example of Proposition 3 under . We simulate a two-way contingency table with fixed probabilities and we apply the chi-square test with the null hypothesis (2.12). With Monte-Carlo method, we simulate the law of for and the law of with the auxiliary information given by .
Costing data. Another possible statistical application is to study how to share resources – economic resource, temporal resource, material resource, … – to learn auxiliary information from inexpensive data in order to improve the study of statistics on expensive objects. More formally we have a budget , for our estimates we can buy an individual at a fixed price and for the estimation of auxiliary information , we can buy the information at a price where is the price for one individual far less than . The objective is therefore to minimize the bound proposed by Theorem 2.1 by choosing high-cost individuals and the low-cost individuals while respecting the imposed budget. So we have to satisfy the following constraint
[TABLE]
To simplify the problem we will suppose that for all , and for some . It is the case if one pay the auxiliary information from the same auxiliary information source and if one pay all information only once time. Inequality (2.16) becomes
[TABLE]
There are several ways to answer this problem. If we want only the strong approximation rate of by dominates in the uniform error of (2.8), we have to choose such that . If we take we could find the maximum value of satisfying (2.17). Since we know that
[TABLE]
If we have no way of finding the optimal – if we do not have the rate or if we want to avoid additional calculations – we can take and if one want to use the entire budget or otherwise.
3 Proof
For all this section let fix and let be the following supremum deviations
[TABLE]
where . Immediately, by Hoeffding inequality we have for all ,
[TABLE]
Now, we give useful decomposition of and which will be used in the following proofs. By using definition (2.1) of we have
[TABLE]
As the same way, by using (2.3) we have
[TABLE]
3.1 Proof of Proposition 1
We prove (2.4), (2.5) and (2.6) respectively at Step 1, Step 2 and Step 3.
Step 1. Let . With (3.3) one can write that
[TABLE]
By (3.1) and induction on (3.4), we find
[TABLE]
The right-hand side of the last inequality is increasing with which leads to (2.4). Since
[TABLE]
we can apply Talagrand inequality to control the deviation probability of as described in the next two steps.
Step 2. According to Theorem 2.14.25 of [12], if satisfies (VC) there exists a constant such that, for large enough and ,
[TABLE]
Inequalities (2.4) and (3.6) imply (2.5) for all , where are defined by
[TABLE]
Step 3. According to Theorems 2.14.2 and 2.14.25 of [12], if satisfies (BR), there exists universal constants such that for all ,
[TABLE]
where , , . Therefore (2.4) and (3.8) yields (2.6) where are defined by
[TABLE]
3.2 Proof of Theorem 2.1
According to Proposition 1, inequality (3.1) and Proposition 3 of [1], there exists such that
[TABLE]
According to Theorem 2.1 of [1], one can define on the same probability space a sequence of independent random variable with law and a sequence of versions of satisfying the following property. There exists such that for all ,
[TABLE]
where is the version of derived from through (2.2). To show (2.7) it remains to prove, by (3.5), that for all large enough and some ,
[TABLE]
Let . Decompositions of and respectively given by (3.2) and (3.3) imply that
[TABLE]
By (3.5) for we have in particular
[TABLE]
which is uniformly and roughly bounded by
[TABLE]
Let . Equality (3.11) implies also
[TABLE]
By induction of the last inequality and noticing that for all , , we have
[TABLE]
then inequality (3.12) immediately implies that
[TABLE]
Since the right-hand side of the last inequality is increasing with we find that for all ,
[TABLE]
with . There exists such that for all it holds . For we have according to (3.10) and (3.13),
[TABLE]
By using (3.10) again, the last inequality implies
[TABLE]
for all and
[TABLE]
By definition of , there exists and such that for all ,
[TABLE]
Then (2.7) is proved for and .
3.3 Proof of Proposition 2
According to Theorem 2.1 of [1] and Theorem 2.1, we can construct i.i.d random variables with law and such that for for some , with
[TABLE]
where is a sequence with null limit. The strong approximation implies that
[TABLE]
with .If we denote the density function of then
[TABLE]
which implies
[TABLE]
For large enough
[TABLE]
Then (3.14) and (3.15) imply (2.9).
3.4 Proof of Proposition 3
Denote the product scalar of and and the random vector defined by
[TABLE]
We deal with the case at Step 1 and the case at Step 2.
Step 1. Under , , and . Statistic converges weakly to a multinormal random variable while converge weakly to according to Theorem 2.1 of [1] and Theorem 2.1. By Proposition 7 of [1], is positive definite which implies for all ,
[TABLE]
and consequently (2.13), (2.14) by definition of weak convergence.
Step 2. Under , there exists such that which implies
[TABLE]
By Borel-Cantelli and (3.10) with probability one there exists such that for all , . For , we have
[TABLE]
Since , for all there exists such that for all . Inequality (2.15) is satisfied for .
Appendix A Numerical example of a raked mean
The usual way to calculate the mean of is to sum the data multiplied by the weights . If we have the auxiliary information for we want to change iteratively the initial weights in new weights such that and
[TABLE]
for any and . Recall that it does not imply that with and . For this example one takes and one generates normal random values with fixed variances and such that the probabilities and conditional expectations are given by the following table:
[TABLE]
[TABLE]
In particular,
[TABLE]
We generate values and we obtain the following data
[TABLE]
In this case, the usual mean is the sum of all over 10 that is we assign the weight at each and we have . When we rake one time we assign the weights at individuals belonging respectively to . The raked mean for is
[TABLE]
When the algorithm is stabilized in this case the final weights are given by the following table:
[TABLE]
Notice that the cross means that we do not generate random variables belonging to due to a low value of . The final raked mean is which is closer of than the usual mean .
Appendix B Calculation of
We use the notations of the section 4.4 of [1] concerning the proof of their Proposition 11 in the aim to establish the expression of . The calculation uses the two following stochastic matrices
[TABLE]
the two following conditional expectation vectors
[TABLE]
the two following covariance matrices
[TABLE]
and the two following vectors
[TABLE]
The eigenvalues of and are 1 and . Their eigenvectors associated to and are respectively and which implies
[TABLE]
For the case of two marginals, Albertus and Berthet showed that converge almost surely to where
[TABLE]
By linearity of and the fact that for any constant one can write
[TABLE]
which implies that
[TABLE]
With some calculations we find the simple expression of given by (2.11).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Albertus and Berthet, [2019] Albertus, M. and Berthet, P. (2019). Auxiliary information: the raking-ratio empirical process. Electron. J. Stat. , 13(1):120–165.
- 2Bankier, [1986] Bankier, M. D. (1986). Estimators based on several stratified samples with applications to multiple frame surveys. Journal of the American Statistical Association , 81(396):1074–1079.
- 3Berthet and Mason, [2006] Berthet, P. and Mason, D. M. (2006). Revisiting two strong approximation results of Dudley and Philipp. 51:155–172.
- 4Binder and Théberge, [1988] Binder, D. A. and Théberge, A. (1988). Estimating the variance of raking-ratio estimators. Canad. J. Statist. , 16(suppl.):47–55.
- 5Brackstone and Rao, [1979] Brackstone, G. J. and Rao, J. N. K. (1979). An investigation of raking ratio estimators. The Indian journal of Statistics , Vol. 41:97–114.
- 6Choudhry and Lee, [1987] Choudhry, G. and Lee, H. (1987). Variance estimation for the canadian labour force survey. Survey Methodology , 13(2):147–161.
- 7Deming and Stephan, [1940] Deming, W. E. and Stephan, F. F. (1940). On a least squares adjustment of a sampled frequency table when the expected marginal totals are known. Ann. Math. Statistics , 11:427–444.
- 8Ireland and Kullback, [1968] Ireland, C. T. and Kullback, S. (1968). Contingency tables with given marginals. Biometrika , 55:179–188.