TL;DR
This paper introduces a novel deep learning approach combining U-nets, GANs, and attribute classifiers to generate complete, non-occluded images of people from occluded inputs, improving recognition in crowded scenes.
Contribution
The work presents a new architecture for de-occluding people images, integrating multiple neural network types and creating two datasets for training and testing.
Findings
Outperforms previous methods in de-occlusion quality.
Uses both real and synthetic datasets for robust training.
Achieves pixel-level similarity and attribute preservation.
Abstract
When you see a person in a crowd, occluded by other persons, you miss visual information that can be used to recognize, re-identify or simply classify him or her. You can imagine its appearance given your experience, nothing more. Similarly, AI solutions can try to hallucinate missing information with specific deep learning architectures, suitably trained with people with and without occlusions. The goal of this work is to generate a complete image of a person, given an occluded version in input, that should be a) without occlusion b) similar at pixel level to a completely visible people shape c) capable to conserve similar visual attributes (e.g. male/female) of the original one. For the purpose, we propose a new approach by integrating the state-of-the-art of neural network architectures, namely U-nets and GANs, as well as discriminative attribute classification nets, with an…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2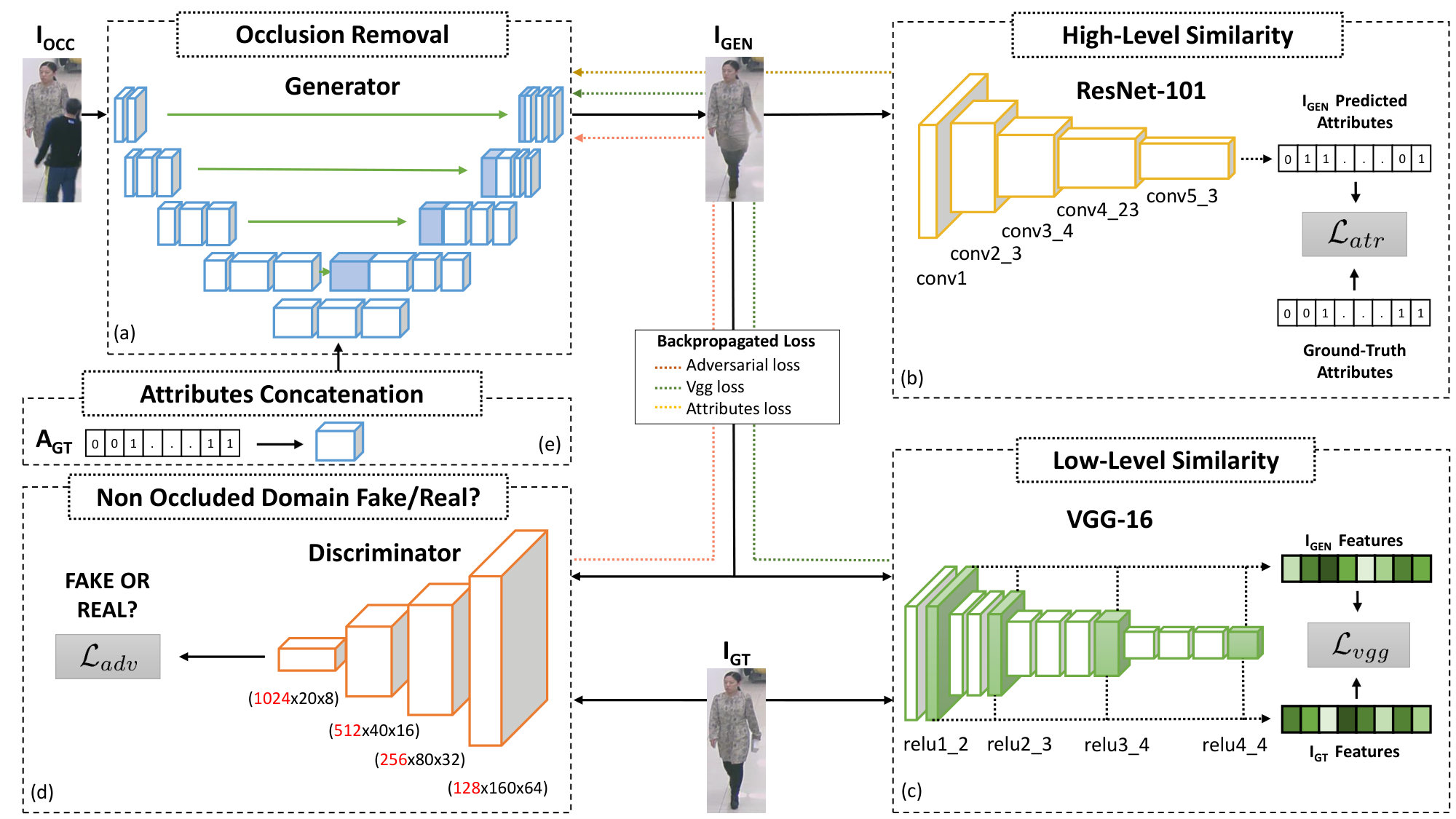 Figure 3
Figure 3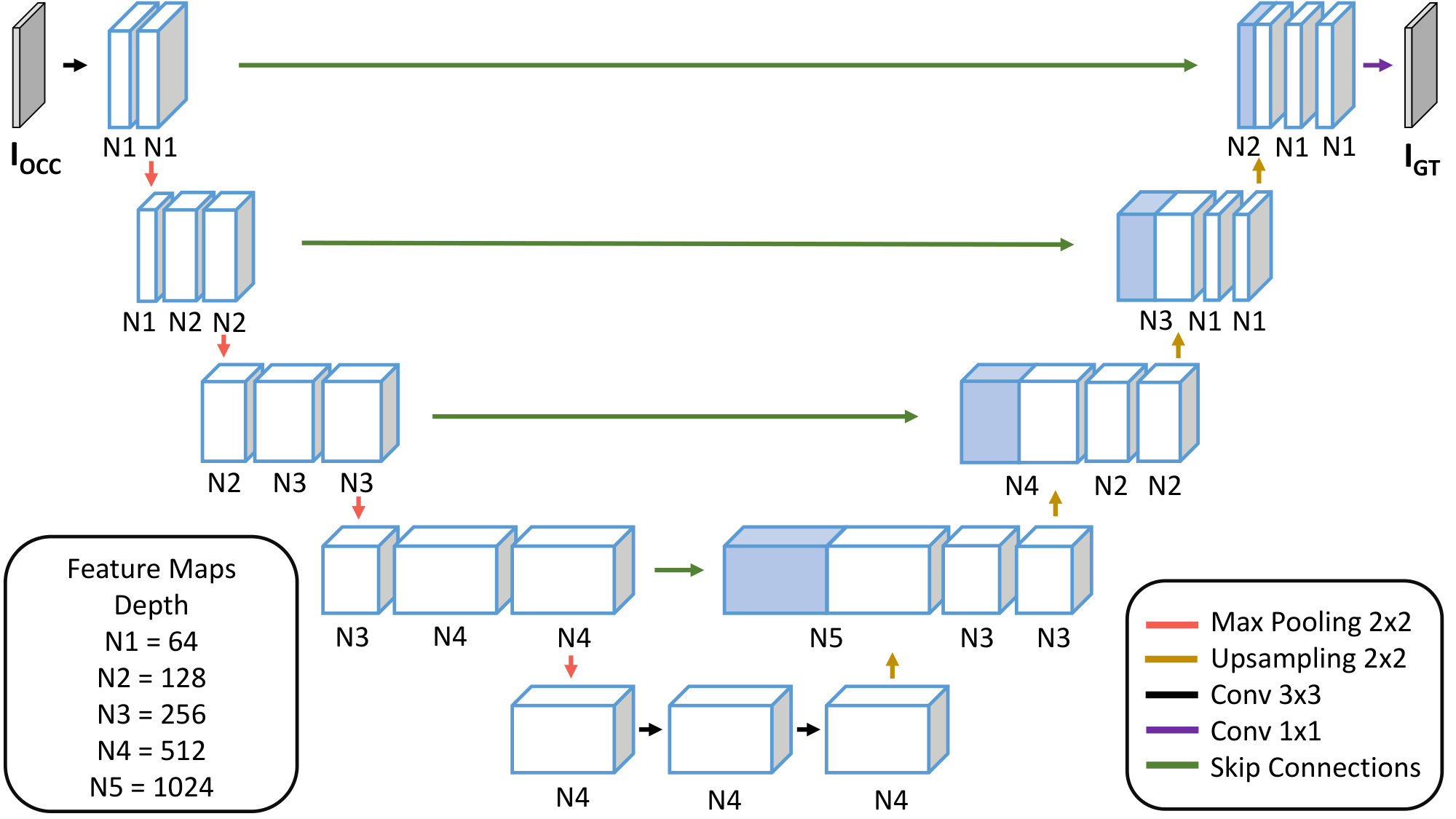 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7| Method | mean Accuracy | Accuracy | Precision | Recall | F1 | SSIM | PSNR |
|---|---|---|---|---|---|---|---|
| Occlusion | 65.74 | 51.06 | 68.72 | 64.36 | 66.47 | 0.7153 | 14.57 |
| Baseline | 70.74 | 56.55 | 70.61 | 71.78 | 71.19 | 0.7982 | 20.31 |
| VGG loss | 72.48 | 58.89 | 72.58 | 73.56 | 73.06 | 0.8293 | 20.88 |
| VGG and attr. loss | 72.18 | 59.59 | 73.51 | 73.72 | 73.62 | 0.8239 | 20.65 |
| VGG and attr. loss (+ input attr.) | 81.1 | 74.8 | 84.29 | 85.61 | 84.94 | 0.8274 | 20.7 |
| GT data | 78,66 | 66,23 | 77.85 | 79.71 | 78.77 | - | - |
| Method | mean Accuracy | Accuracy | Precision | Recall | F1 | SSIM | PSNR |
|---|---|---|---|---|---|---|---|
| Occlusion | 72.24 | 45.77 | 48.78 | 79.03 | 60.32 | 0.6148 | 18.38 |
| Baseline | 72.72 | 45.48 | 48.23 | 80.87 | 60.42 | 0.6236 | 20.49 |
| VGG loss | 78.12 | 53.11 | 55.52 | 85.65 | 67.37 | 0.7088 | 21.5 |
| VGG and attr. loss | 78.37 | 53.3 | 55.73 | 85.46 | 67.46 | 0.7101 | 21.81 |
| VGG and attr. loss (+ input attr.) | 90.86 | 72.15 | 74.0 | 95.1 | 83.23 | 0.6986 | 21.47 |
| GT data | 91.89 | 74.87 | 76.80 | 95.43 | 85.11 | - | - |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Can Adversarial Networks Hallucinate Occluded People With a Plausible Aspect?
Federico Fulgeri Matteo Fabbri Stefano Alletto Simone Calderara Rita Cucchiara
University of Modena and Reggio Emilia
Via P. Vivarelli 10, Modena, 41125, Italy
Abstract
When you see a person in a crowd, occluded by other persons, you miss visual information that can be used to recognize, re-identify or simply classify him or her. You can imagine its appearance given your experience, nothing more. Similarly, AI solutions can try to hallucinate missing information with specific deep learning architectures, suitably trained with people with and without occlusions. The goal of this work is to generate a complete image of a person, given an occluded version in input, that should be a) without occlusion b) similar at pixel level to a completely visible people shape c) capable to conserve similar visual attributes (e.g. male/female) of the original one. For the purpose, we propose a new approach by integrating the state-of-the-art of neural network architectures, namely U-nets and GANs, as well as discriminative attribute classification nets, with an architecture specifically designed to de-occlude people shapes. The network is trained to optimize a Loss function which could take into account the aforementioned objectives. As well we propose two datasets for testing our solution: the first one, occluded RAP, created automatically by occluding real shapes of the RAP dataset created by [20] (which collects also attributes of the people aspect); the second is a large synthetic dataset, AiC, generated in computer graphics with data extracted from the GTA video game, that contains 3D data of occluded objects by construction. Results are impressive and outperform any other previous proposal. This result could be an initial step to many further researches to recognize people and their behavior in an open crowded world.
1 Introduction
While recent efforts in people detection, recognition, and tracking enabled a plethora of video-surveillance applications, e.g. people identification by [23], pose estimation by [35] and action analysis by [11], occlusion is still an open problem. The occlusion issue is well known in the people detection and tracking literature and generally affects any intelligent video surveillance system, but it is debatable whether a real solution to the problem could exist effectively. In fact, whenever an occlusion occurs we observe a removal of information from the observed scene. The occluded portion of an object, indeed, becomes unknown and, in a Parmenidean sense, it does not exist until it can be observed. For this motivation, most of the literature focused on counteracting the phenomenon conveying occlusion robustness to either detection, tracking, or re-id systems as by [48, 38, 28, 41, 2]. In the matter of fact, recovering the image content from an occlusion is feasible only in the case where the target has been previously observed e.g. in a video stream. This is the approach followed also by many tracking solutions which memorize several detected appearance of the person, to discard occlusions as “less frequent accidents” w.r.t. the normal visible appearance. Nevertheless, leveraging on the generative capabilities of GANs by [8], we aim at demonstrating that it is indeed possible to hallucinate a plausible representation of the occluded content even when it has never been previously observed, i.e. in single images.
Following on our previous work on the topic ([5]), in this paper, we introduce a novel network that leverages the generative power of GANs for hallucinating the occluded portion of the image without any guidance of an attention mechanism that could provide instance level information about the occluding person. The proposed solution aims at generating or reconstructing the image of a person which could be plausible in many senses: a) similar to images of real people, observed in the training dataset; b) acceptable at pixel level as a person shape; c) capable to preserve similar visual attributes of the ground truth de-occluded image. This is carried out by exploiting solutions for attribute classifications (e.g. male/female, young/old, with/without trousers, etc.) and integrating them in a U-net like generative and adversarial architecture.
Another major problem that arises when dealing with occlusions, through learning-based solutions, is the lack of large-scale datasets providing realisticly occluded and non-occluded pairs of images. Most of the proposed solution in literature, like the ones introduced by [5, 27, 26] paste together different people detections, or manually add random objects or textures to a non-occluded image. These processes ultimately fail to generate realistic data and are thus a liability when employed for training a neural network that aims at resolving the occlusion while keeping the rest of the image coherent (e.g. the background) and preserving the person’s attributes. To address this issue, we propose a novel, fully automatic, way to generate realistic occlusion pairs by exploiting the recent achievements in object segmentation by [9]. These results are high-fidelity occlusion pairs, where the background of the original image is preserved and the generated occlusion is more realistic. Additionally, thanks to the software provided by [6], we created the massive computer graphics generated AiC dataset (leveraging on the highly photo-realistic graphics of GTA V video-game), in which we artificially created a large collection of occluded pedestrians. Additionally, we recovered from the game engine their attributes by manually annotating just the models. To our knowledge, this is the first CG dataset for the purpose of de-occluding people having a set of annotated person attributes (e.g. sex, hair color, dress style, etc.). The dataset is pubblicly available 111http://aimagelab.ing.unimore.it/aic.
To summarize, our contributions are threefold:
- •
We propose a novel generative adversarial network that is able to solve occlusions in pedestrian images by hallucinating the missing parts while keeping both the appearance and the background coherent;
- •
We devise a new way for synthetically generating occlusion pairs that result in more realistic images when compared to other methods previously employed, also by creating a huge CG dataset;
- •
We propose a method for conditioning the occluded body part restoration on pedestrian attributes and consequently improving the generation process.
We show by experiments that the design of a conditional GAN that is aware of the attributes can acceptably hallucinate pedestrian and we experimentally demonstrate that this information is helpful in guiding the generation process. Results are interesting in terms of very high accuracy, outperforming other previous methods. We believe that our method could be useful in many computer vision systems, from surveillance, automotive to human behavior understanding tasks.
2 Related Works
Generative image modeling with deep learning techniques has received lots of attention in recent years. Works on this field can be split into two categories. The first line of works follows the unsupervised setup. Here, the variational autoencoders (VAE) proposed by [34] and [15] are the first popular methods which apply a re-parameterization trick to maximize the lower bound of the data likelihood. The most popular methods are indeed generative adversarial networks (GAN) of [8] and [30], which simultaneously learn a generator network to generate image samples, and a discriminator network to discriminate generated samples from real ones. GANs are capable of generating sharp images by exploiting the adversarial loss instead of more canonical losses such as L1 or L2.
The second group of works produces images conditioned on either categories, attributes, labels, images or texts. [42] proposed a Conditional Variational Autoencoder (CVAE) to achieve an image generation conditioned on attributes. On the other hand, [25] proposed conditional GANs (CGAN) where both the generator and the discriminator are conditioned on extra information to perform category specific image generation. [17] generated people in clothing, by conditioning on the fine-grained body part segments. [31] proposed a novel deep architecture and GAN formulation to effectively translating visual concepts from characters to pixels, by adding textual information to both generator and discriminator. They also further investigated the use of additional location, key-points, or segmentation information, to generate images as did by [33, 32]. With only these visual hints as condition and in contrast to our explicit condition on the occluded image, the control exerted over the image generation procedure is still abstract. Many works perform a conditioning over image generation not only on labels or texts but also on images. [47] generated multi-view cloth images from only a single view input by proposing a new image generation model that combines the strengths of the variational inference and the GAN framework. [1] tackled the unseen view inference by casting the problem in terms of tensor completion and adopt a factorization approach to accommodate single-view images. [13] provides a general purpose architecture that is effective at synthesizing photos from label maps, reconstructing objects from edge maps, and colorizing images, among other tasks. [44], [12], [46], [7] addressed the task of face image generation conditioned on a reference image and a specific face viewpoint. Finally, [43, 45, 29, 40] tackled the task of image inpainting where large missing regions have to be filled based on the available visual data. Our work can be seen as a particular case of inpainting, where the portion of the image to inpaint is not known a priori.
3 Method
The goal of our work is to reconstruct occluded body parts of pedestrians in different surveillance scenarios. Given an image of an occluded pedestrian as the network input, we aim at removing the obstructions and replacing them with body parts that could likely belong to the occluded person. Note that, differently from the task of inpainting, we don’t want to guide the network with the information about what portion of the image we want to remove and complete. For this purpose, we want to learn an image transformation between pairs of occluded images and not occluded images .
In order to accomplish this, we propose the training procedure depicted in Fig. 1: our pipeline takes as input the occluded image , along with the relative attributes and outputs the restored image . is then inputted to the three networks ResNet-101, VGG-16, and the Discriminator in order to compute the three components of our loss. Each loss component is then backpropagated through the input, updating only the Generator’s weights.
More precisely, to achieve a full body restoration, we train the Generator network as a feed-forward CNN with parameters . For training pairs images and their relative attributes , we solve:
[TABLE]
Here is obtained by minimizing the loss function described in the next subsection. As a result, our generator network learns a mapping from observed images to output image . This differs from what did by [13] and [25] which use random noise along with the input image.
Following [8], we further define the Discriminator network with parameters , that we train alongside with the aim of solving the adversarial min-max problem:
[TABLE]
where is the probability of being a “real” image while is the probability of being a “fake” image. The min-max formulation force to fool the , which is adversarially trained to distinguish between generated “fake” images and “real” ones. Thanks to this approach, we obtain a Generator network capable of learning solutions that are similar to not occluded images thus indistinguishable by the Discriminator. Note also that, differently from what did by [13], we do not concatenate input images to the “fake” images or to the “real” images as Discriminator input.
3.1 Loss Function
The definition of the loss function is crucial for the effectiveness of our Generator network. We propose the following loss formulation, composed by a weighted combination of three components:
[TABLE]
The intuition behind this loss formulation is that we want the generated images to contain real people (thanks to ), to have similar feature representations (thanks to ) and to preserve visual attributes (thanks to ) w.r.t. their non occluded ground truth versions.
The first term of Eq. (3) is the adversarial loss . This component encourages the Generator network to generate images belonging to the not occluded domain of pedestrians by fooling the Discriminator network . The adversarial component relative to the Generator network is calculated as follows:
[TABLE]
Where is the probability that is classified as “real” by the discriminator network. Minimizing instead of is preferred in order to reach a better gradient behavior as indicated by [8]. As a possible drawback, the images produced by the Generator network are forced to be realistic thanks to the Discriminator network , but they can be unrelated to the original input. For instance, the output could be a plausible image of a pedestrian displaying a very different aspect w.r.t. the input image. Thus, is essential to mix the adversarial loss with an additional loss, such as L1 or L2, that evaluate the per-pixel distance between the generated and the ground truth image. Usually, training a network using such losses leads to reasonable solutions. However, the outputs appear blurred with lack of high-frequency details.
A possible solution for generating sharper results is to adopt a different content loss, like the perceptual loss introduced by [14] and used also by [18] and [16]:
[TABLE]
where and are the dimensions of the feature maps obtained by the -th convolution after ReLU activation and before the -th max-pooling layer within the VGG16 network, pre-trained on ImageNet by [3], as done by [14].
The that we employed in our work is based on the sum of different intermediate layers of VGG16:
[TABLE]
where is taken from eq. 5 and is the set of used activations. Rather than encouraging the pixels of the output image to exactly match the pixels of the target image , we instead encourage them to have similar feature representations as computed by the VGG16 network. As demonstrated by [14] and [24], minimizing the content loss for higher layers do not preserve color and textures. As we reconstruct from early layers, instead, images tend to be perceptually similar to the target image in terms of color and texture.
Since our main purpose is not limited to naively restore the occluded parts of pedestrians, but also to maintain and highlight their attributes, we introduced an additional loss component . Like for the perceptual loss , we used a classification network as loss function. In particular, we adapted ResNet-101 by [10], pre-trained on ImageNet, to the task of multi-attribute classification. More precisely, we replaced the last two layers (the average pooling and the last fully connected layer) in order to fit the desired input shapes. Differently, from the VGG loss, we work on a higher level of abstraction, forcing the Generator network to produce images that exhibit characteristics coherent with the attributes of the person. In this case, we used a weighted binary cross entropy:
[TABLE]
Here, is the number of attributes classified by the ResNet-101, is the positive ratio of -th attribute. is the output of our attribute classification network and is the -th ground truth label.
3.2 Networks Architecture
Generator Network
Our Generator structure differs from those presented by [30] and [5]: following [36] and [13] we propose the “U-Net” like architecture depicted in Fig. 2. In particular, the structure of our network slightly differs from the one described by [36] and [13]. The network is composed by 4 down-sampling blocks and a specular number of up-sampling components. Each down-sampling block consists of 2 convolutional layers with a kernel. Each convolutional layer is followed by a batch normalization and a ReLU activation. Finally, each block has a max-pooling layer with stride 2. The up-sampling part has a very similar but overturned structure, where each block is composed by an up-sampling layer of stride 2. After that, each block is equipped with 2 convolutional layers with a kernel. The last block has an additional kernel convolution which is employed to reach the desired number of channels: 3 RGB channels in our case. A has been used as final activation. We additionally inserted skip connections between mirrored layers, in the down-sampling and up-sampling streams, in order to shuttle low-level information between input and output directly across the network. Eventually, padding is added to avoid cropping the feature maps coming from the skip connections and concatenate them directly to the up-sampling blocks outputs. Roughly speaking, our task can be seen as a particular case of image-to-image translation, where a mapping is performed between the input image and the output image. Additionally, for the specific problem we are considering, input and output share the same underlying structure despite differing in superficial appearance. Therefore, a rough alignment is present between the two images. In fact, all the non-occluded parts that are visible in the input images must be transferred to the output with no alterations. The structure of the U-Net lends itself optimally to our task, and the skip connections are fundamental for the conservation of the non-occluded image content. In this way, useful low-level information is not lost during the encoding passage: by leveraging this kind of information, we are able to maintain the appearance of visible parts in the image.
Discriminator Network
The Discriminator, instead, aims to determine if an image is true or if it has been generated. In particular, the structure is similar to the one proposed by [30], composed by 4 convolutional layers with kernel size . The resulting features are followed by one sigmoid activation function in order to obtain a probability for the classification problem. We use batch normalization before every Leaky ReLU activation, except for the first layer.
3.3 Training Details
We trained our GAN with resized input images while simultaneously providing the target image in order to compute the supervised losses. We adopted the standard approach by [8] to optimize the networks alternating gradient descent updates between the Generator and the Discriminator with . Data augmentation is performed by randomly flipping the images horizontally. We used mini-batch SGD applying the Adam solver with momentum parameters and , learning rate and a batch size of 20. Each training is performed using a Titan Xp GPU.
4 Datasets
We evaluated our method on the RAP dataset, proposed by [20], comparing state-of-the-art methods and performing the ablation study over each loss employed. In addition, we further propose a new large-scale computer-graphics dataset AiC for pedestrian attribute recognition in crowded scenes. Differently, from existing publicly available datasets, AiC is mainly focused on occlusion events.
4.1 RAP Dataset
RAP by [20] is a very richly annotated dataset with 41,585 pedestrian samples, each of which is labeled with 72 attributes as well as viewpoints, occlusions, and body parts information. In order to evaluate our method, we corrupted the dataset with occlusions. Differently, from what did by [5], where obstructions were created by cutting parts of images according to regular geometric shapes, we have adopted a more sophisticated approach that has led us to more realistic results. By exploiting the state-of-the-art performances of Mask R-CNN proposed by [9], pre-trained on the COCO Dataset ([21]), we produced segmentation masks for each person in the RAP dataset. The computed silhouettes were then used to crop people’s shapes from the dataset. Those figures are then used to reproduce the occlusions, simply by randomly overlapping the crops to each image sample of RAP dataset. In addition, to reduce the visual gap between the original image and the overlapped person, we performed a Gaussian blurring. However, this is not applied to the whole image but only to the area given by the difference between an expansion and an erosion of the segmentation mask of the overlapping image. The only constraint that we have introduced is that the occluding person must not occupy the portion of the image that has the y coordinate that exceeds the 6/7 of the image height. Each sample is computed as follows:
[TABLE]
where is the binary mask generated using Mask R-CNN and morphology operations and is a function used to translate the overlap section randomly over the destination image . The dataset is already organized in 5 random splits. Each of which contains 33,268 images for training and 8,317 for testing. As did by [20], due to the unbalanced distribution of attributes in RAP, we selected the 51 attributes that have the positive example ratio in the dataset higher than 0.01.
4.2 AiC Dataset
Most of the publicly available pedestrian attribute datasets, like RAP by [20], PETA by [4] and PA-100K by [22] does not contemplate occlusion events. They only provide samples of full visible people, completely ignoring crowded situations of pedestrians occluding each other (which is indeed common in urban scenarios). To overcome this limitation, we propose the Attributes in Crowd dataset, a novel synthetic dataset for people attribute recognition in presence of strong occlusions. AiC features 125,000 samples, all being a unique person, each of which is automatically labeled with information concerning sex, age etc. The dataset is split into 100,000 samples for training and 25,000 for testing purposes. Each of the 24 attributes is present at least in a 10% of samples which highlight a good balance in terms of labels. The collected samples feature a vast number of different body poses, in several urban scenarios with varying illumination conditions and viewpoints. Skeleton joints are also available for each identity. Joints are additionally labeled with an occlusion flag which tells if the specific body part is directly visible from the camera point of view. Moreover, each image sample has his vanilla version where each obstacle is removed from the image. Thus, for each occluded pedestrian, we know exactly how it really is behind the occlusion (this is obviously not achievable in real environments). Fig. 3 exhibits some examples of the dataset. AiC was created by exploiting the highly photo-realistic video game Grand Theft Auto V developed by Rockstar North.
5 Experimental Results
In this section, we provide details about the metrics adopted, followed by a detailed ablation study that presents qualitative and quantitative results for three different combinations of losses (that we added to the adversarial loss): MSE loss, VGG loss and a combination of VGG loss and attribute loss. We also investigate how the information about the attributes of a person can enhance the quality of the produced images. Additionally, we explain the choice of different hyperparameters, exploring their impacts. Finally, we compare our method with the most related works presented by [13] and [5].
5.1 Evaluation Metrics
Evaluating the quality of synthesized images is an open and challenging problem as stated by [37]. Traditional metrics such as per-pixel MSE do not estimate joint statistics of the result, and therefore do not extrapolate the full structure of the result. In order to more holistically evaluate the visual quality of our results, we employed two tactics. Firstly, we compared the performance of the proposed model through metrics directly calculated over the reconstructed images. Specifically, we adopted the structural similarity SSIM and the peak signal-to-noise ratio PSNR. Secondly, we measured the capability of the proposed network of being able to preserve original attributes, like gender, hairstyle or wearing jacket, by exploiting the ResNet-101 network of [10] trained on the task of multi-attribute classification. Thus, following [20], [5] and [22], we provide five evaluation metrics for the attribute classification task, namely mean Accuracy, Accuracy, Precision, Recall and F1.
ResNet-101 Classification Network
We trained the network with resized images with Adam as optimizer and learning rate set to . In Table 1 a comparison on the classification task with other state-of-the-art networks on RAP dataset is presented. The same network is trained independently for each dataset, in order to provide reliable metrics for both RAP and AiC.
5.2 Ablation Study
As previously stated, we investigated three loss combinations in order to clarify and highlight the solutions adopted in our work:
- •
Baseline: the Baseline architecture uses, in conjunction with the adversarial loss, the MSE loss as content loss;
- •
VGG loss: differently from the Baseline, we replaced the MSE loss with the VGG loss. The layers (1,2), (2,2), (3,3) and (4,3) are chosen as the set of activations on Eq. 6. In Eq. 3, we set to 10 and to 0 (further details about and are presented in the next subsection);
- •
VGG loss + Attr. loss: in this case, all the three losses are employed. The VGG loss always refers to the same four activation layers. The Attribute loss is computed between the output of the ResNet-101 classification network computed on the generated images and the ground truth labels provided by the datasets. In Eq. 3, we set to 10 and to 5 for RAP and to 0.01 for AiC. Note that we did not use all the available attributes of RAP dataset, but only the first 51 for the reason explained at the end of section 4.1. For AiC dataset, instead, we used all the available attributes.
In order to further investigate how some additional information about the attributes can improve the restoration process, we performed a further experiment where attributes are fed as input to the network, along with the occluded image:
- •
Entire: in this setup, we adopted both the VGG loss and the Attribute loss, along with the adversarial loss. Differently, from our main method, attributes are injected directly to the main flow of the Generator network. Specifically, the attribute vector of the occluded pedestrian is fed to a fully connected layer in order to produce a feature vector that is reshaped to match the bottleneck dimension of our Generator network.
Fig. 4 shows some qualitative results. The baseline performs considerably worse than the other setups, not being able to completely remove the occlusions on AiC (column 9 of Fig. 4). This is probably due to the fact that AiC is a more challenging dataset compared to our corrupted version of RAP. For the same reason, RAP results are overall more appealing than the ones of AiC. Moreover, no substantial difference appears between the other setups, highlighting the fact that the VGG loss is the main component that guides the network to produce high-quality results.
Table 3 and Table 4 present quantitative results for RAP and AiC respectively based on our ablation study. The tables also provide metrics referred to the occluded images before the restoration process. By observing the tables, we can state that, despite being visually indistinguishable, the images obtained from the VGG loss and from our Entire configuration produce very different results in terms of attribute metrics. We can also observe that there is no substantial difference between the VGG loss and the VGG loss with Attributes loss. In fact, RAP shows a gap of one percentage point in almost all the classification metrics, while AiC shows very little differences, probably due to the more challenging nature of AiC. Moreover, Table 3 shows that the Entire setup reach higher scores compared to the upper bound of the ground truth images. Also Table 4 shows performances that are close to the ground truth metrics when we input attribute information directly to the Generator. In fact, with attributes as input, the Generator network, by restoring the occluded images, is able to produce an output that has enhanced attribute characteristics (although this is not visible to the naked eye). As can be shown in the next subsection, further forcing the generation output on classification metrics, we can reach results that exceed the ground truth upper bound even on AiC, at a price of a drop on reconstruction metrics.
5.3 Hyperparameter Optimization
Hyperparameter tuning is a crucial aspect in designing machine learning frameworks, as the performance of an algorithm can be highly dependent on the choice of hyperparameters. In fact, and were selected using a grid search technique. In particular, we searched for a trade off between classification metrics (accuracy, precision, recall, f1) and pixel-level reconstruction metrics (PSNR, SSIM). We performed a different grid search for four different configurations combining each dataset with the two main setups: VGG loss + Attr. loss and the Entire pipeline.
For what concerns the VGG loss + Attr. loss setup, we observed that, in general, a configuration with brings to better pixel-level reconstruction metrics but poor classification performances. On the other hand, solutions with show good classification performances but low pixel-level reconstruction metrics. Also, increasing over the value of 10 does not further improve PSNR and SSIM metrics (for both RAP and AiC). The same behavior happens for : the classification metrics do not improve for values greater than 5 (for RAP) and 0.01 (for AiC). This difference of between the two datasets may be caused by the fact that AiC is more challenging than RAP. In fact, during training, the Attributes Loss on AiC is orders of magnitude greater than the same loss on RAP, thus, a smaller is needed to maintain the balance between the losses.
For what concern the Entire pipeline, we observed a different behavior on : increasing does steadily improve the classification metrics (reaching up to 98.89 mean Accuracy with ) while drastically decreasing PSNR and SSIM. This behavior happens on both RAP and AiC. By giving more importance to the Attributes Loss, the Generator network is able to enhance attribute characteristics to the point that they are highly recognizable by the classification network, at the price of not maintaining low-level similarity. Fig. 5 shows a direct consequence at qualitative level on both RAP and AiC. The first line depicts an extreme configuration of and on RAP. With no low-level constraints, the Generator network is able to mutate the color of the jacket to facilitate the ResNet-101 “jacket attribute” recognition. The second line of Fig. 5, instead, shows an example obtained using and on AiC. In this case, the behavior is completely different: due to the high diversity of attributes in AiC, the Generator learns to simply remove the obstacle, not adding (hallucinating) many details to the removed portion of the image. Adding imprecise details would, in fact, mislead the attribute classification network.
5.4 Comparison Against State-Of-The-Art Techniques
Since our task of de-occlusion is novel, there are no direct works to compare with. So, to match the results of our network, in addition to our previous work, we also retrained the Pix2Pix framework on both RAP and AiC.
Our Previous work
Like our current method, [5] exploits an adversarial based framework to achieve a translation from an occluded-pedestrian domain to a completely visible body domain. The main difference with our current method resides in the loss formulation: [5] minimizes a combination of adversarial loss and sum of squared error loss (SSE), completely ignoring high-level and low-level similarities. Another important difference lies in the Generator architecture: our previous work uses a simple hourglass architecture with no skip connections, while in our current method we adopted a U-net based solution. The U-net architecture shows better performances in tasks where some input information has to be shuttled directly to the output with no variation. In fact, as can be seen in Fig. 6, our previous work fails to preserve the portions of the image that should remain unchanged (especially the faces).
Pix2Pix
[13] investigates conditional adversarial networks as a general-purpose solution to image-to-image translation problems. As in our Generator network, Pix2Pix exploits a U-net based architecture. The only substantial architectural difference is in the number of convolutional layers before each downsampling and after each upsampling operation. Also, the Discriminators differs: Pix2Pix uses a patch level discriminator that only penalizes structure at the scale of patches, while in our work we adopt an image level discriminator that takes the whole image as input. A patch level discriminator models the image as a Markov random field, assuming independence between pixels separated by more than a patch diameter. This is indeed not the case when dealing with images of people. In fact, for example, the skin color of the face should match the skin color of the hands. Also, the trousers are usually made of the same color. Another significant difference lies in the content loss: Pix2Pix, like our previous work, uses a pixel-level loss (L1 instead of SSE), assuming pixel independence, and forcing pixels of the output image to exactly match the pixels of the target image. In our work, instead, we exploit a combination of high-level and low-level consistency by encouraging the overall images the have similar feature representations as computed by the VGG16 network, and similar visual attributes as computed by the ResNet-101.
From Table 5 and Table 6 it can be shown that our network perform favourably for each metric, both for RAP and AiC datasets. From Fig. 6 it also emerges that our method, despite not using attention mechanisms, is able to detect and to remove the occlusion, with no external additional information. Furthermore, differently from the works by[5] and [13], our method learns to transfer with no alterations the portion of images that are not occluded.
6 Conclusions
In this work, we presented the use of GANs for image enhancing in people attributes classification. Our generator network has been designed to overcome a common problem in surveillance scenarios, namely people occlusion. Experiments have shown that jointly enhancing images before feeding them to an attribute classification network can improve the results even when input images are affected by this issue. We think that this line of work can foster research about the problem of attribute classification in surveillance contexts, where camera resolution and positioning cannot be neglected.
Acknowledgments
The work is supported by the Italian MIUR, Ministry of Education, Universities and Research, under the project COSMOS PRIN 2015 programme 201548C5NT. We also gratefully acknowledge the support of Panasonic Silicon Valley Lab and Facebook AI Research with the donation of the GPUs used for this research.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] C.-Y. Chen and K. Grauman. Inferring unseen views of people. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 2003–2010, 2014.
- 2[2] D. Coppi, S. Calderara, and R. Cucchiara. Transductive people tracking in unconstrained surveillance. IEEE Transactions on Circuits and Systems for Video Technology , 26(4):762–775, 2016.
- 3[3] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Image Net: A Large-Scale Hierarchical Image Database. In CVPR 09 , 2009.
- 4[4] Y. Deng, P. Luo, C. C. Loy, and X. Tang. Pedestrian attribute recognition at far distance. In Proceedings of the 22Nd ACM International Conference on Multimedia , 2014.
- 5[5] M. Fabbri, S. Calderara, and R. Cucchiara. Generative adversarial models for people attribute recognition in surveillance. In Advanced Video and Signal Based Surveillance (AVSS), IEEE International Conference on . IEEE, 2017.
- 6[6] M. Fabbri, F. Lanzi, S. Calderara, A. Palazzi, R. Vezzani, and R. Cucchiara. Learning to detect and track visible and occluded body joints in a virtual world. ar Xiv preprint ar Xiv:1803.08319 , 2018.
- 7[7] A. Ghodrati, X. Jia, M. Pedersoli, and T. Tuytelaars. Towards automatic image editing: Learning to see another you. ar Xiv preprint ar Xiv:1511.08446 , 2015.
- 8[8] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In Advances in Neural Information Processing Systems 27 , pages 2672–2680. Curran Associates, Inc., 2014.
