"Is this an example image?" -- Predicting the Relative Abstractness Level of Image and Text
Christian Otto, Sebastian Holzki, Ralph Ewerth

TL;DR
This paper introduces a deep learning method to predict the relative abstractness level between images and text, enhancing understanding of semantic cross-modal relations for improved multimodal search.
Contribution
It proposes a novel metric and an autoencoder-based deep learning approach to determine whether an image is an abstraction of text or vice versa, with reduced labeled data requirements.
Findings
Feasibility demonstrated on a challenging test set.
Introduces a new metric for cross-modal abstractness.
Reduces labeled data needs with autoencoder architecture.
Abstract
Successful multimodal search and retrieval requires the automatic understanding of semantic cross-modal relations, which, however, is still an open research problem. Previous work has suggested the metrics cross-modal mutual information and semantic correlation to model and predict cross-modal semantic relations of image and text. In this paper, we present an approach to predict the (cross-modal) relative abstractness level of a given image-text pair, that is whether the image is an abstraction of the text or vice versa. For this purpose, we introduce a new metric that captures this specific relationship between image and text at the Abstractness Level (ABS). We present a deep learning approach to predict this metric, which relies on an autoencoder architecture that allows us to significantly reduce the required amount of labeled training data. A comprehensive set of publicly available…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5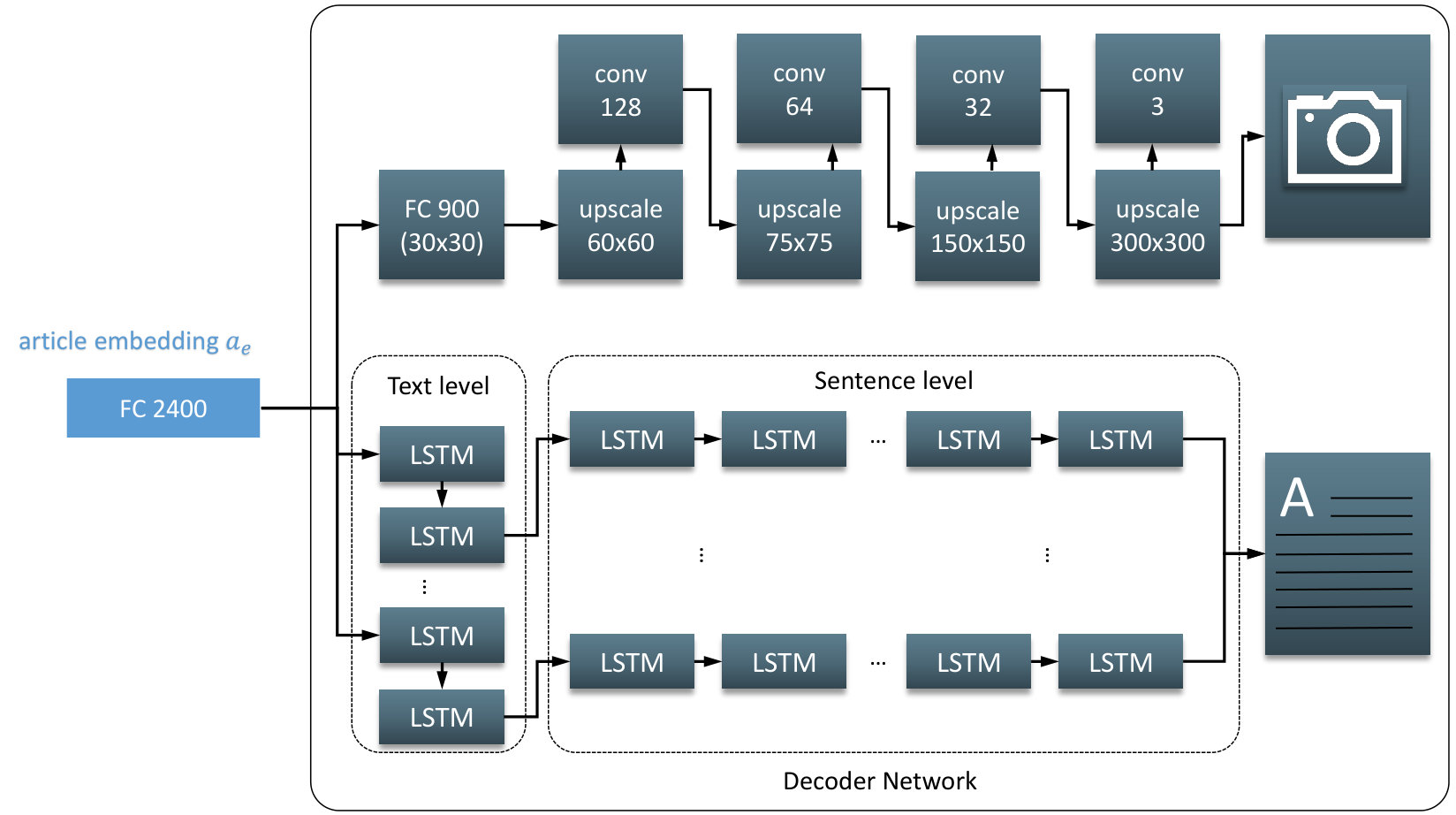 Figure 6
Figure 6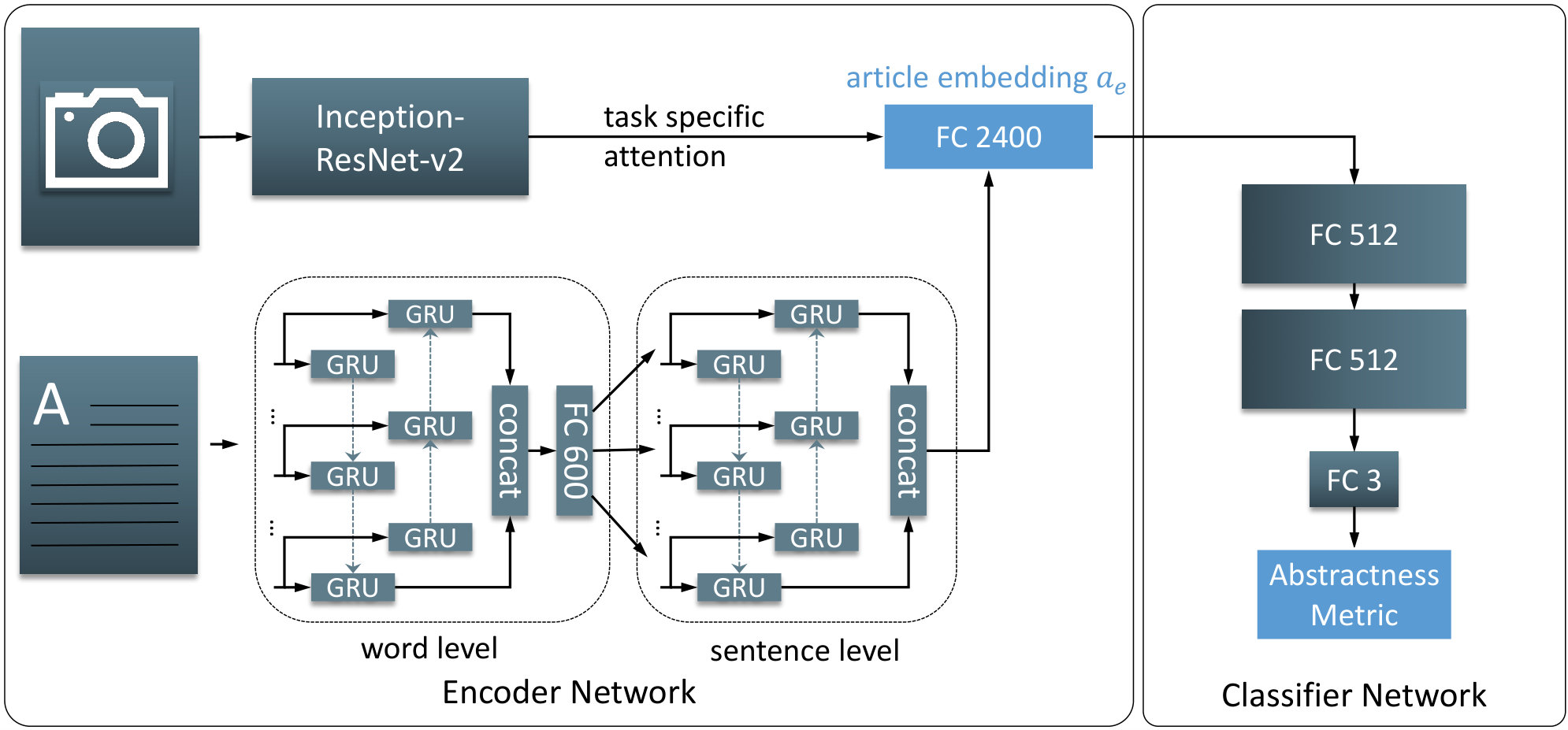 Figure 7
Figure 7 Figure 8
Figure 8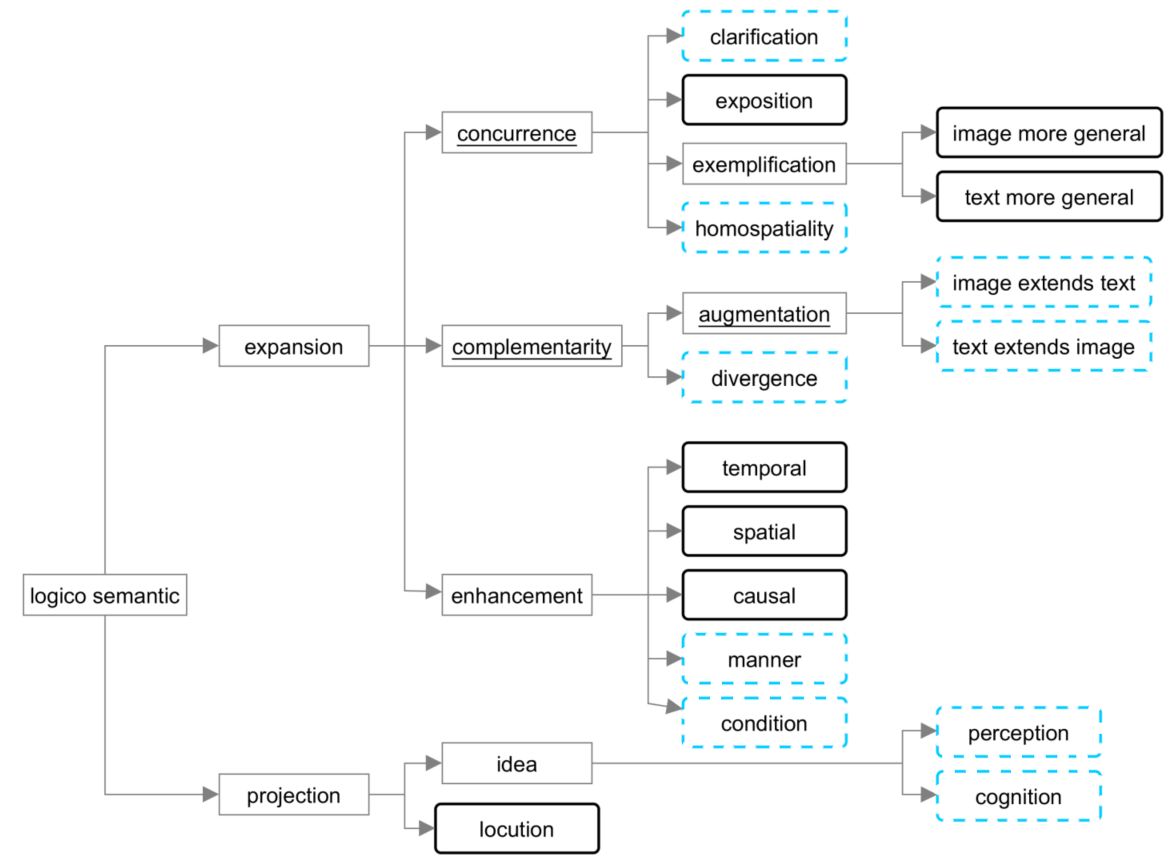 Figure 9
Figure 9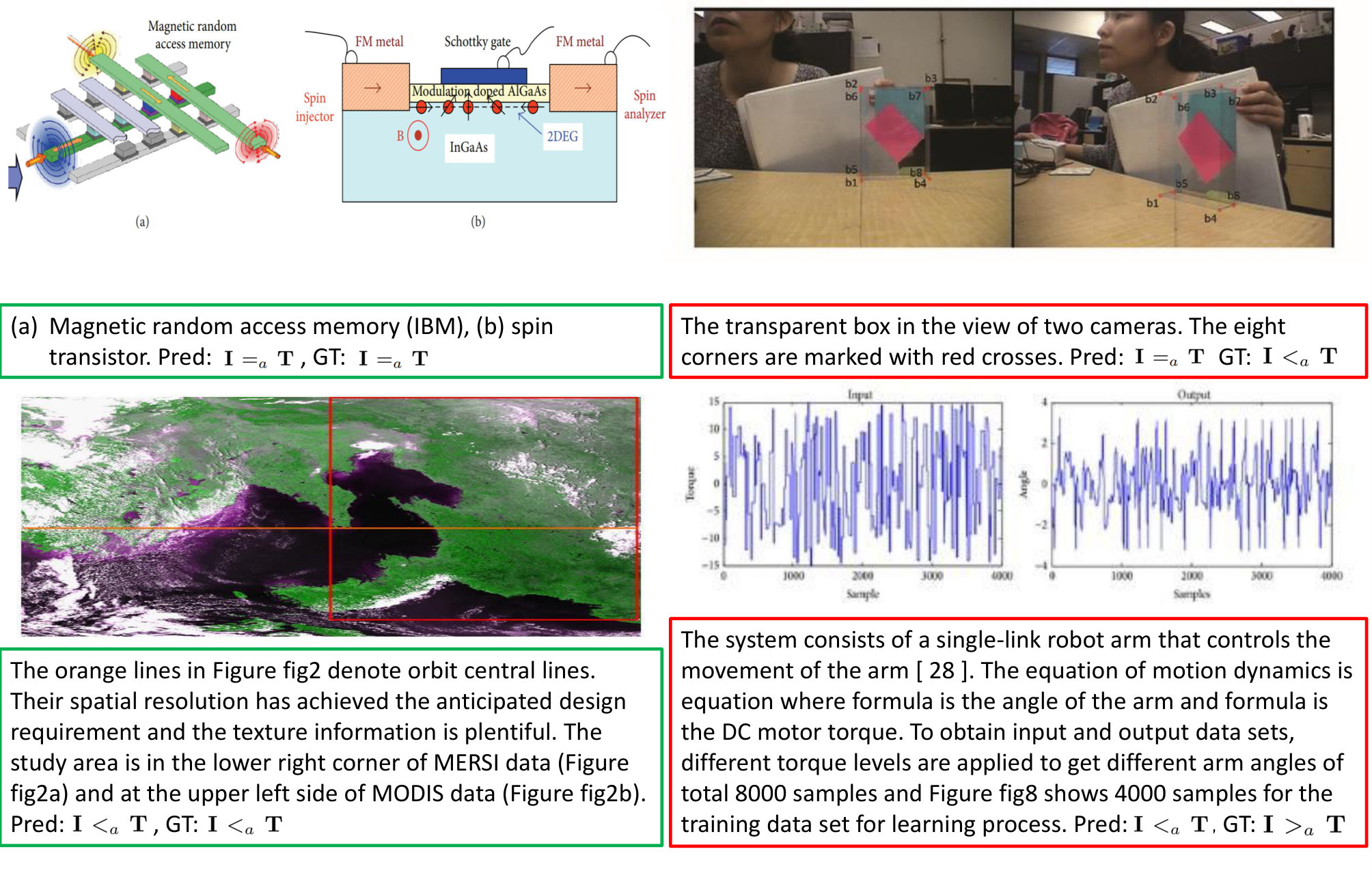 Figure 10
Figure 10| ABS | I T | I T | I T |
| Reference | |||
| Martinec & Salway [22] | exposition, locution, idea | image more general, enhancement by text | text more general, enhancement by image |
| Unsworth [32] | exposition, clarification, locution, perception, cognition | text instantiates image, enhancement by text | image instantiates text, enhancement by image |
| Marsh & White [21] | compare, contrast, concentrate, compact, model | sample, exemplify, isolate, contain, locate, induce perspective, emphasize, document | graph, translate, describe, define |
| Journal | #articles | #figures | #image-text pairs |
|---|---|---|---|
| AAI | 94 | 1,217 | 3,180 |
| ACISC | 185 | 2,215 | 5,453 |
| AM | 144 | 2,304 | 6,057 |
| MPE | 8,251 | 106,435 | 273,367 |
| Sum | 8,674 | 112,171 | 288,057 |
| Journal | T I | T I | T I | Sum | Percentage |
|---|---|---|---|---|---|
| AAI | 322 | 113 | 145 | 580 | |
| ACISC | 383 | 173 | 242 | 798 | |
| AM | 354 | 169 | 169 | 858 | |
| MPE | 352 | 255 | 255 | 780 | |
| Sum | 1,411 | 710 | 895 | 3,016 | - |
| Percentage | - | - |
| Class | Image Text | Image Text | Image Text | Sum |
| I T | 90 | 7 | 3 | 100 |
| I T | 14 | 68 | 18 | 100 |
| I T | 10 | 7 | 83 | 100 |
| Precision | - | |||
| Recall | - |
| Classifier | |||
|---|---|---|---|
| Accuracy |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMultimodal Machine Learning Applications · Advanced Image and Video Retrieval Techniques · Image Retrieval and Classification Techniques
11institutetext: Leibniz Information Centre for Science and Technology (TIB), Welfengarten 1B, 30167 Hannover, Germany
11email: [email protected] 22institutetext: L3S Research Center, Leibniz Universität Hannover, Germany
”Is this an example image?” – Predicting the Relative Abstractness Level of Image and Text
Christian Otto(✉) 1122 0000-0003-0226-3608
Sebastian Holzki 22 0000-0002-1636-711X
Ralph Ewerth 1122 0000-0003-0918-6297
Abstract
te the feasibility of the approach.
Successful multimodal search and retrieval requires the automatic understanding of semantic cross-modal relations, which, however, is still an open research problem. Previous work has suggested the metrics cross-modal mutual information and semantic correlation to model and predict cross-modal semantic relations of image and text. In this paper, we present an approach to predict the (cross-modal) relative abstractness level of a given image-text pair, that is whether the image is an abstraction of the text or vice versa. For this purpose, we introduce a new metric that captures this specific relationship between image and text at the Abstractness Level (ABS). We present a deep learning approach to predict this metric, which relies on an autoencoder architecture that allows us to significantly reduce the required amount of labeled training data. For this, a comprehensive set of publicly available scientific documents has been accumulated. Experimental results on a challenging test set demonstrate the feasibility of the approach.
Keywords:
Image-text relations, multimodal embeddings, deep learning, visual-verbal divide
1 Introduction
In this era of big data, the proliferation of multimodal web content in online news, social networks, open educational resources, video portals, etc. is increasing drastically. Graphics and pictures in multimodal documents are a powerful communication channel to illustrate, decorate, detail, summarize, or complement textual information. This is particularly true for educational and scientific material. In this context, graphical and pictorial information can be very important to support learning scenarios as, for instance, in the recently evolved field of search as learning. To enable truly multimodal recommender systems for web search, an automatic understanding of the multimodal content and the inherent cross-modal relations are a prerequisite. In this respect, however, information retrieval research did not address all possible kinds of cross-modal relations between images and text in a differentiated way111In contrast to research in communication sciences and applied liguistics where the visual/verbal divide has been researched in a very detailed way for decades.. Typically, (multimedia) information retrieval research assumes a semantic correlation in general in case image and text are placed jointly on purpose. An exception is Henning and Ewerth’s work [14] that suggest two metrics (dimensions) to differentiate image-text relations by 1.) cross-modal mutual information (CMI) and 2.) semantic correlation (SC).
In this paper, we argue that these two metrics do not completely cover all possible types of image-text relations, particularly when considering educational or scientific content. Therefore, we suggest an additional metric: the relative Abstractness Level (ABS) that measures whether an image depicts information of a related text at a more detailed or a more abstract level, or at the same level. Furthermore, we propose a deep learning approach to automatically predict the abstractness level of a given image-text pair. The system relies on an autoencoder architecture and multimodal embeddings. Since the deep learning system requires a sufficiently large amount of training data, we have gathered an appropriate dataset from a variety of Web resources. Experimental results on a demanding test set demonstrate the feasibility of the proposed system.
The paper is structured as follows. Related work is summarized in Section 2 from the perspectives of communication sciences and information retrieval. Section 3 motivates the new metric of abstractness level and explains the proposed deep learning system to automatically predict this metric, while Section 4 describes the data acquisition process for the training of the deep networks. The experimental results are presented in Section 5. Section 6 concludes the paper and outlines areas of future work.
2 Related Work
2.1 Image-Text Relations and the Visual/Verbal Divide
The interplay between visual and textual222Textual information can be considered as visual information as well, of course. Here, we denote graphical and pictorial information as visual information. information has been subject to research for decades in the fields of communication sciences and applied linguistics. One of the early attempts to comprehensively categorize the joint placement of images and text date back to Barthes [5], who set the groundwork for a lot of categorizations that developed later. For example, Martinec and Salway [22], Marsh and White [21], and Unsworth [32] build upon Barthes’ taxonomy, which defines the Status relation between an image and its accompanied text. It describes if there is a hierarchical dependency between both modalities or if they are equally important in conveying the information intended by the author. The aforementioned taxonomies extend this distinction with different interpretations of Halliday’s [13] logico-semantics, which are a linguistic method to describe different types of text clauses. The application of these fine-grained distinctions of the logico-semantics to image-text pairs result in very detailed taxonomies. Figure 1 shows the latest version of Unsworth’s extensions to Martinec and Salway’s taxonomy [22].
While these taxonomies are comprehensive, their level of detail makes it sometimes difficult to assign an image-text pair to a particular class, as criticized by Bateman [6], for instance. Recent work from the field of multimedia retrieval approaches this problem differently through two metrics that are more general and easier to infer: Henning and Ewerth [14], suggest the following two metrics (or dimensions): 1.) Cross-modal Mutual Information (CMI) is defined as the amount of shared entities or concepts in both modalities, ranging from 0 to 1; and 2.) Semantic Correlation (SC) is defined as the amount of shared meaning or context, indicating if the information contained in both modalities are aligned, uncorrelated or contradictory, i.e., ranging from -1 to 1. They show that a deep learning approach that utilizes multimodal embeddings can basically predict these interrelation metrics.
2.2 Machine Learning for Multimodal Data Retrieval
In this subsection, a brief overview of methods to encode heterogeneous modalities for machine learning and multimedia retrieval approaches is given. There are several possibilities to encode data samples consisting of distinct modalities [4]. The choice of the optimal method depends on multiple factors: the type of modality to encode, the number of training samples available, the type of classification to perform and the desired interpretability of the models. One type of algorithms utilizes Multiple Kernel Learning, which is an extension of kernel-based support vector machines [8, 12]. They consist of a kernel specifically designed for each modality and thus allow for the fusion of heterogeneous data. Application domains are, for instance, multimodal affect recognition [25, 15], event detection [36], and Alzheimer’s disease classification [20]. An advantage is their flexibility in the kernel design and global optimum solutions, but they have a rather slow inference time. Deep neural networks are another technique to model multiple modalities at once. Due to their growing popularity in recent years, there is also much research on designing deep learning systems for processing multimodal data. Such research directions include approaches for audio-visual [1, 23], audio-gesture [24] and textual-visual [17, 27] data. The common idea is to encode each modality individually and fuse them in joint hidden layers. Especially well suited are these methods for encoding temporal information like sentences, which fits the problem addressed in this paper nicely. For example, Cho et al. [10] use Gated Recurrent Units (GRU) to encode sentences, but it is also possible to utilize Long-Short-Term Memory (LSTM) cells [33]. More recent extensions are shown by Jia et al.’s [16] and Rajagopalan et al.’s [26] works, which model temporal information for textual as well as for the visual components. Neural networks are also able to learn meaningful embeddings of multimodal data in an unsupervised manner via an autoencoder architecture, which not only removes the necessity for hand-crafted features but also can significantly reduce the required amount of labeled training data [14]. Cross-media and multimedia retrieval is an area of research that profits the most from techniques to bridge the semantic gap between image and text [28, 3, 18, 34]. Fan et al. [11] implement a multi-sensory fusion network, which improves the comparability of heterogeneous media features and is therefore well suited for image-to-text and text-to-image retrieval. A self-paced cross-modal subspace matching method constructing a multimodal graph is proposed by Liang et al. [19]. It is designed to preserve the intra-modality and inter-modality similarity between the input samples. Carvalho et al. [9] proposed the AdaMine model, which combines instanced-based and semantic-based losses for a joint retrieval and semantic latent space learning method. This method is utilized to retrieve recipes from pictures of food and vice versa.
3 The Abstractness Metric for Image-Text Relations
In this section, we motivate and derive the new metric of relative abstractness for image-text pairs. In this respect, we analyze the existing gap in applied linguistics and communicaton sciences, as well as information retrieval.
3.1 Analysis
Marsh and White [21] introduce three separate taxonomies that distinguish different levels (low, medium, high) of semantic relations for image-text pairs, which is similar to Henning and Ewerth’s Semantic Correlation. In other words, they distinguish between three different levels of the same metric, implying that the underlying sub-hierarchies themselves have a certain degree of overlap. Thus, it can be deduced that there is either an ambiguity issue or a missing property to make an actual distinction. With respect to some of the overlapping classes it can be observed that their distinction is based on the level of abstractness. An example is shown in Figure 2 that portrays the classes sample and exemplify by Marsh and White [21].
It shows a textual phrase and two visual representations which together in both cases create an Illustration example according to Barthes [5]. However, they belong to Marsh and White’s sample and exemplify classes, where the latter one is defined as an ideal example and the first one can be any concrete instance of the described concept. Therefore, the actual distinction is made by means of their abstractness, which is also a very important concept for scientific or educational material to improve comprehensibility.
3.2 Implications and the Abstractness Metric
We claim that the relative difference of the Abstractness Level (ABS) is an essential part in describing the relations between an image and text. To support this assumption, we list in Table 1 a number of image-text classes that contain a certain difference in abstractness by definition.
This implies that a metric describing the relative difference in the abstractness level is indeed necessary to characterize an image-text relation. We would like to emphasize the term relative, since it is important that image and text are considered jointly. Therefore, a particular image can be less abstract than a text, while it is more abstract than another one. Also, in order to differentiate between abstractness levels it is necessary to have an object of reference, or a Cross-modal Mutual Information , as it is the case for the ship example in Fig. 2.
4 Predicting the Abstractness Level of Image and Text
In this section, we present a system that automatically measures the relative abstractness level between an image and its associated text. There are no repositories and Web resources of image-text pairs that can be easily exploited to train a deep learning classifier. Consequently, we follow an autoencoder approach similar to [14], which requires much less labeled data. We gather the necessary samples from open access publications provided by Sohmen et al. [29], as explained in detail in the next subsection.
4.1 Data Acquisition
For the purpose of legal re-use, Sohmen et al. [29] provide illustrations of publications of the open access publisher Hindawi333https://www.hindawi.com/. The majority of Hindawi articles is available under the Creative Commons Attribution License, so that they can be used for this type of research. Another advantage is that they are accessible in XML format, which makes them easier to read than files in PDF format. We crawled 288,057 image-text pairs from four different journals, namely Advances in Artificial Intelligence (AAI), Applied Computational Intelligence and Soft Computing (ACISC), Advances in Multimedia (AM) and Mathematical Problems in Engineering (MPE). The final distribution of articles is presented in Table 2.
We manually labeled more than 3,000 image-text pairs for training and testing. The data distribution of the labeled data is presented in Table 3.
Our annotation process results in a minimum number of 700 samples per image-text class which is sufficient to train a classifier that uses the embeddings of our pre-trained autoencoder network.
4.2 Representing Multimodal Data via Autoencoding
We suggest an autoencoder approach for two main reasons: First, the automatic generation of labeled training data is not possible since the available amount of annotated image-text pairs is limited. It is not reasonable to train a classifier from scratch with less than 1,000 samples per class. Second, the encoder-decoder architecture allows for adjustments that fit nicely to our scenario and also allows us to investigate if the right information is preserved by the embedding. Our design is similar to Henning and Ewerth’s [14] approach, but includes some modifications that consider the nature of figures and illustrations in scientific documents as opposed to natural images. Also, we replace some components in the encoding part with more recent system components, see Figure 3. In detail, we use a pre-trained model of the Inception-ResNet-v2 [30] without its classification layers to encode the input image as well as the preprocessing pipeline suggested by Szegedy et al. [31]. The textual information is preprocessed by removing any specific XML characters and by replacing formulas with the word ”formula”. In addition, we truncate sentences that are longer than 50 words and paragraphs longer than 30 sentences. The resulting feature vector of image encoding is then fed into the attention mechanism of the text encoding step, where, inspired by Yang et al. [35], a bidirectional recurrent neural network (RNN) architecture is used consisting of multiple GRU cells. This way the text is encoded in a hierarchical way: first on a sentence and then on a full-text level. After concatenating the image and text embedding we receive a 2,400 dimensional article embedding according to Henning and Ewerth [14] (Figure 3).
To obtain a high-quality multimodal embedding for image-text pairs, we aim at a decoder that reconstructs the image as well as text from the encoded article embedding. We compute a loss between input and output information that describes how well image and text can be reproduced from the condensed representation. A first fully-connected layer decides which parts of the embedding are important to reproduce the image and therefore generates a first 30x30 predicted reconstruction of the visual data. An alternating series of up-scaling and convolutional layers subsequently produces an image that corresponds to the size of the input image (300x300). In contrast to Henning and Ewerth [14], the convolutional layers use a kernel size of instead of , which is necessary to successfully reproduce the fine lines depicted in many scientific tables or diagrams. Another difference is the size of the convolutional layers in the pipeline, where we use (128, 64, 32, 3) opposed to (32, 8, 3). The loss between input and output image is computed using mean squared error.
The textual information is reconstructed by a hierarchical unidirectional RNN consisting of LSTM cells, which proved to be more powerful than Gated Recurrent Units (GRUs) for this task. It first generates sentence features from the article embedding and uses them afterwards on a word level to estimate the original input text. Both hierarchy layers use the batch normalization technique proposed by Ba et al. [2]. An overview of the decoder network can be seen in Figure 4. The loss between input and output is computed based on a word embedding that is based on a predefined fastText [7] vocabulary, which is reduced prior to the experiments to reduce memory usage of the model. In particular, we use the 25,000 most common words (out of about 89,000) in our dataset, which allows us to still cover 98,81% of the occurring vocabulary. All other words get the representation unk. The decoder tries to reconstruct the correct index of each word in the text from the embedding and the loss is computed using the cosine similarity between input and output feature vector.
4.3 Classifier
The result of the autoencoder training process is an encoder network that is able to produce highly expressive embeddings that compress visual as well as textual information to the key components, which are necessary to describe the content of the input. Based on these features we train a classifier network with our labeled (training) samples. This part of the network comprises three fully-connected layers (FC) of size (512, 512, 3), where the last one predicts one of the three different levels of Abstractness. The entire network architecture is displayed in Figure 3.
5 Experimental Results
This section is separated into two parts. First, we present some example results for the CNN-based autoencoder before we present experimental results for the classification of the relative Abstractness level of image and text.
5.1 Autoencoder Training
The autoencoder network was trained for 360,000 iterations at a batch size of 15, which corresponds to about 19 epochs. The distribution of training samples is shown in Table 5 and an example output of the autoencoder is depicted in Figure 5.
The example output of the autoencoder shows that the network is indeed able to coarsely reproduce the essential information of the visualizations, for instance, diagram borders, fine details on the axis, and the legend of the diagram. Also, the decoded text elements resemble the original text in length and to some extent even the semantic context.
5.2 Classification of the Relative Abstractness Level
As described in section 4.1, we gathered a set of about 3,000 image-text pairs that we subsequently separated into a training and test set, where the latter one consists of 100 random samples for each of the three classes. We have evaluated three different versions of the autoencoder and classifier networks.
: Train the classifier network as well as the encoder network from scratch, making it an end-to-end approach. 2. 2.
: Train the classifier network, but freeze the weights of the pre-trained encoder network. 3. 3.
: Train the classifier network and finetune the pre-trained encoder network at the same time.
Every approach was trained for about 70,000 iterations. The results are reported in Tables 4 and 5. The former shows that the classifier was able to predict the three classes successfully with a recall of 90% (), 68% () and 83% (). These results reflect the distribution of available labeled training data (cf. Table 3), which implies that these results can be improved by acquiring more annotated samples. Table 5 shows that a pre-trained autoencoder network outperforms a training from scratch, but is in turn outperformed by the transfer learning approach which finetunes and adapts the encoding process to the new task. This proves that a multimodal embedding is able to encode an image-text pair in a way that the Abstractness metric can be successfully predicted, while our autoencoder approach is able to compensate for the relatively low number of labeled training samples. Example predictions of our system are displayed in Figure 6 (left hand side: correct, right hand side: misclassified): In the top-left image-text pair, both the text and the schematic illustrations are abstract representations, in particular for ”(a)”, while in the image bottom-left the image is a concretization of the text (both predicted correctly); the image in the top-right examples depicts more relevant details than the text, whereas the line chart bottom-right provides less detailed information about the experimental context than the text. As Table 4 shows, predicting was the easiest for the system, presumably because of the amount of natural images in this class. But, if these natural images were overlaid with additional information (top right) the system struggled to find the correct assignment.
6 Conclusions
In this paper, we have introduced a novel metric that describes the relative Abstractness Level between an image and associated text. We have motivated and derived the metric based on previous work on taxonomies for image-text classes in communication sciences and applied linguistics. Until now, the large variety of image-text relations had been investigated in a differentiated way mainly in these fields. We have set these taxonomies in relation to recent work in the field of multimedia retrieval, which has modeled image-text relations in a more general manner through the metrics cross-modal mutual information and semantic correlation. In this respect, our proposed metric is a contribution to model the variety of possible semantic (cross-modal) image-text relations in a systematic manner from an information retrieval perspective. Moreover, we have proposed a deep learning architecture to automatically predict the relative, cross-modal abstractness level of image and text. The required amount of labeled training data is minimized by the incorporation of an autoencoder network. We have evaluated three different ways of training the deep network architecture. It turned out that training the classifier network and finetune the pre-trained encoder network at the same time achieved the best results with an accuracy of 80 %. In this way, an indexing method has been developed that can serve as the basis for multimodal search and retrieval, for instance, in order to search for educational and scientific content.
In the future, we plan to apply this indexing method to different scenarios in multimodal information retrieval, such as search as learning with multimedia data, e-learning, and recommender systems. For this purpose we intend to build an exploration and browsing interface based on the metrics CMI, SC and ABS. Finally, we will evaluate the usefulness of other metrics to model cross-modal relations in a systematic way.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Afouras, T., Chung, J.S., Senior, A., Vinyals, O., Zisserman, A.: Deep audio-visual speech recognition. ar Xiv preprint ar Xiv:1809.02108 (2018)
- 2[2] Ba, J.L., Kiros, J.R., Hinton, G.E.: Layer normalization. ar Xiv preprint ar Xiv:1607.06450 (2016)
- 3[3] Balaneshin-kordan, S., Kotov, A.: Deep neural architecture for multi-modal retrieval based on joint embedding space for text and images. In: Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining. pp. 28–36. ACM (2018)
- 4[4] Baltrušaitis, T., Ahuja, C., Morency, L.P.: Multimodal machine learning: A survey and taxonomy. IEEE Transactions on Pattern Analysis and Machine Intelligence (2018)
- 5[5] Barthes, R.: Image-music-text, ed. and trans. S. Heath, London: Fontana 332 (1977)
- 6[6] Bateman, J.: Text and image: A critical introduction to the visual/verbal divide. Routledge (2014)
- 7[7] Bojanowski, P., Grave, E., Joulin, A., Mikolov, T.: Enriching word vectors with subword information. ar Xiv preprint ar Xiv:1607.04606 (2016)
- 8[8] Bucak, S.S., Jin, R., Jain, A.K.: Multiple kernel learning for visual object recognition: A review. IEEE Transactions on Pattern Analysis and Machine Intelligence 36 (7), 1354–1369 (2014)