A Review on Quantile Regression for Stochastic Computer Experiments
L\'eonard Torossian, Victor Picheny, Robert Faivre, Aur\'elien, Garivier

TL;DR
This paper empirically compares six quantile regression strategies for stochastic computer experiments, providing insights and guidelines for selecting the most suitable method based on problem characteristics.
Contribution
It introduces a comprehensive empirical evaluation of diverse quantile regression metamodels, offering practical guidelines for method selection in stochastic experiments.
Findings
Different metamodels perform variably depending on data characteristics.
Guidelines help choose the best quantile regression method for specific problem settings.
The study highlights the strengths and limitations of each approach.
Abstract
We report on an empirical study of the main strategies for quantile regression in the context of stochastic computer experiments. To ensure adequate diversity, six metamodels are presented, divided into three categories based on order statistics, functional approaches, and those of Bayesian inspiration. The metamodels are tested on several problems characterized by the size of the training set, the input dimension, the signal-to-noise ratio and the value of the probability density function at the targeted quantile. The metamodels studied reveal good contrasts in our set of experiments, enabling several patterns to be extracted. Based on our results, guidelines are proposed to allow users to select the best method for a given problem.
Click any figure to enlarge with its caption.
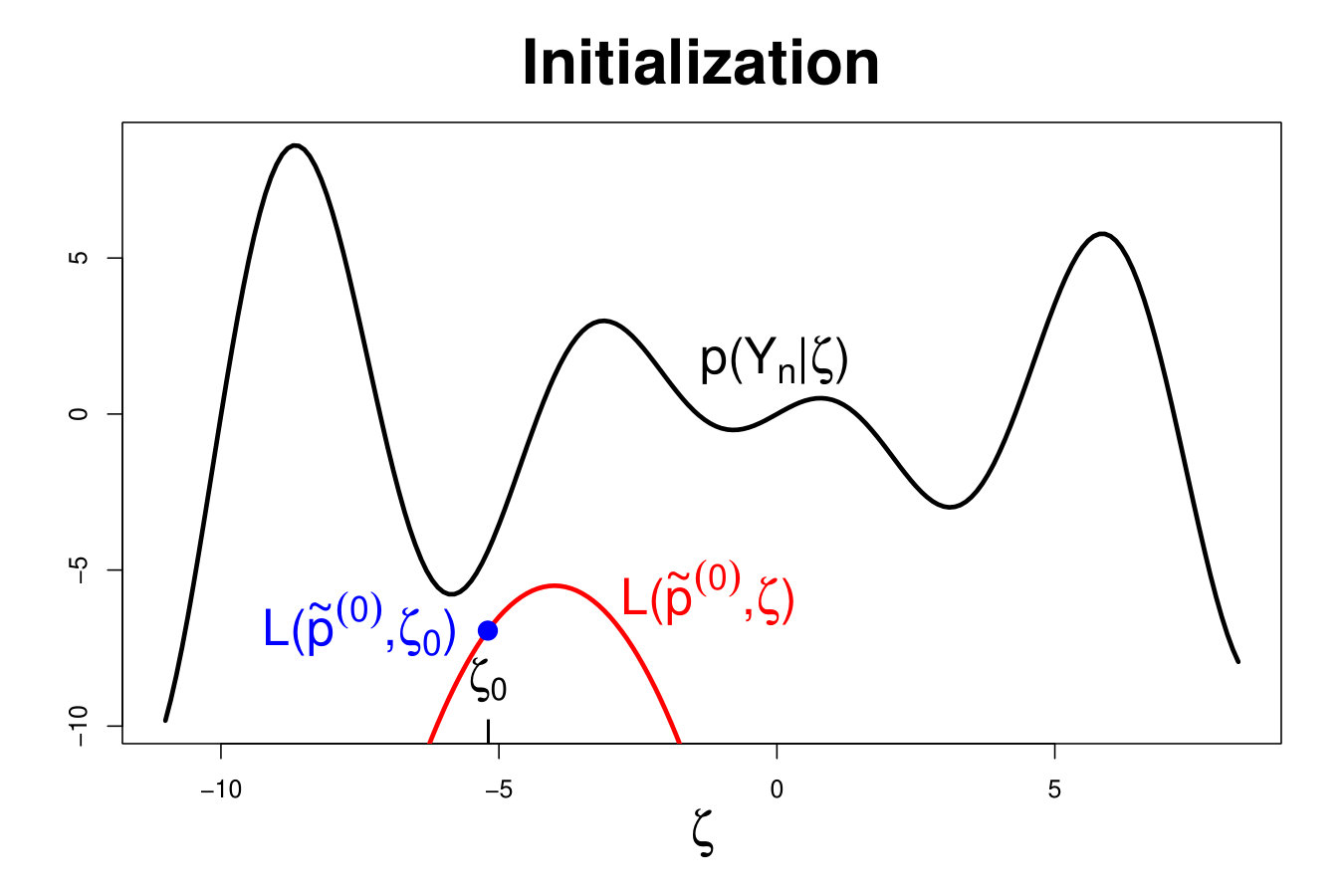 Figure 1
Figure 1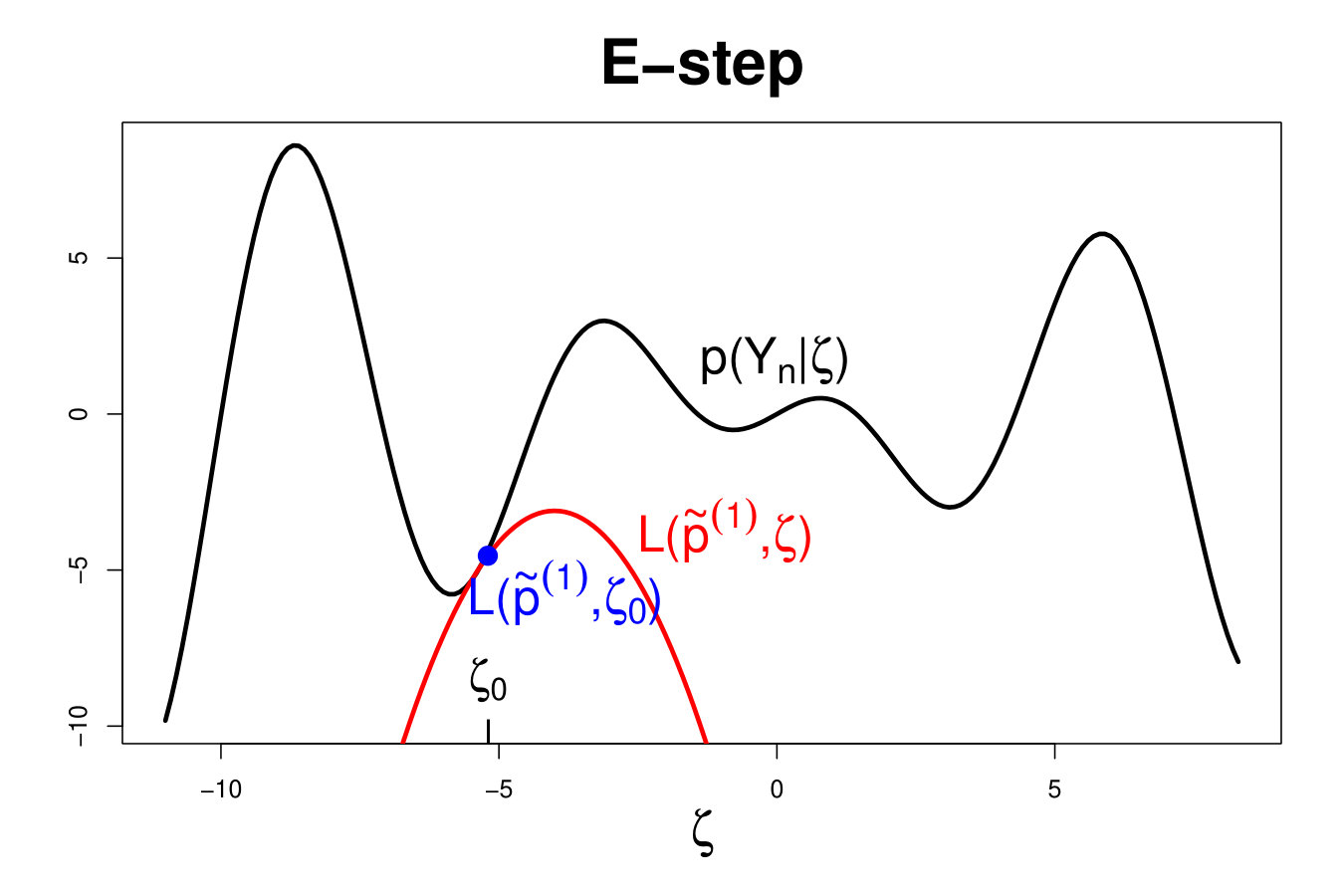 Figure 2
Figure 2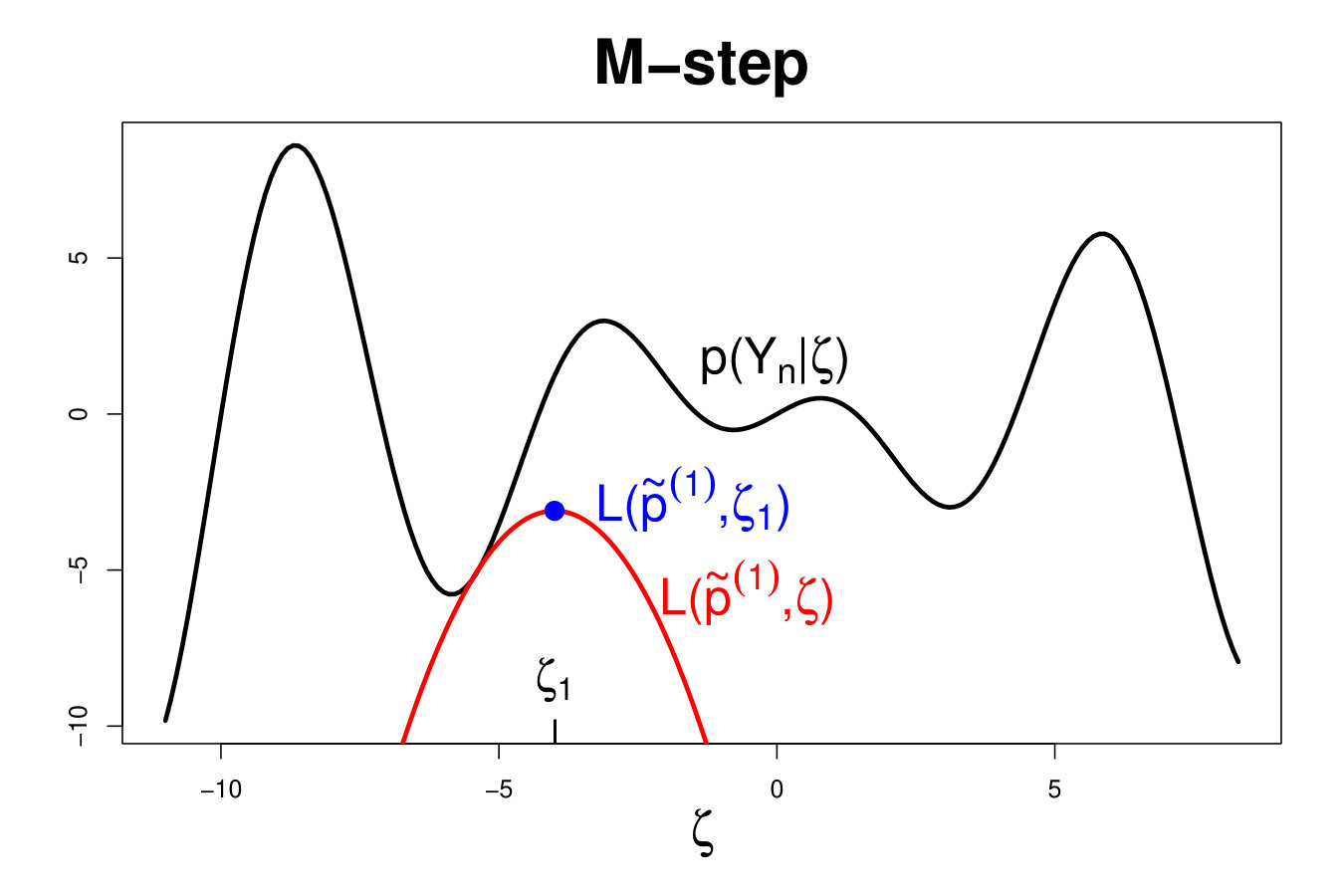 Figure 3
Figure 3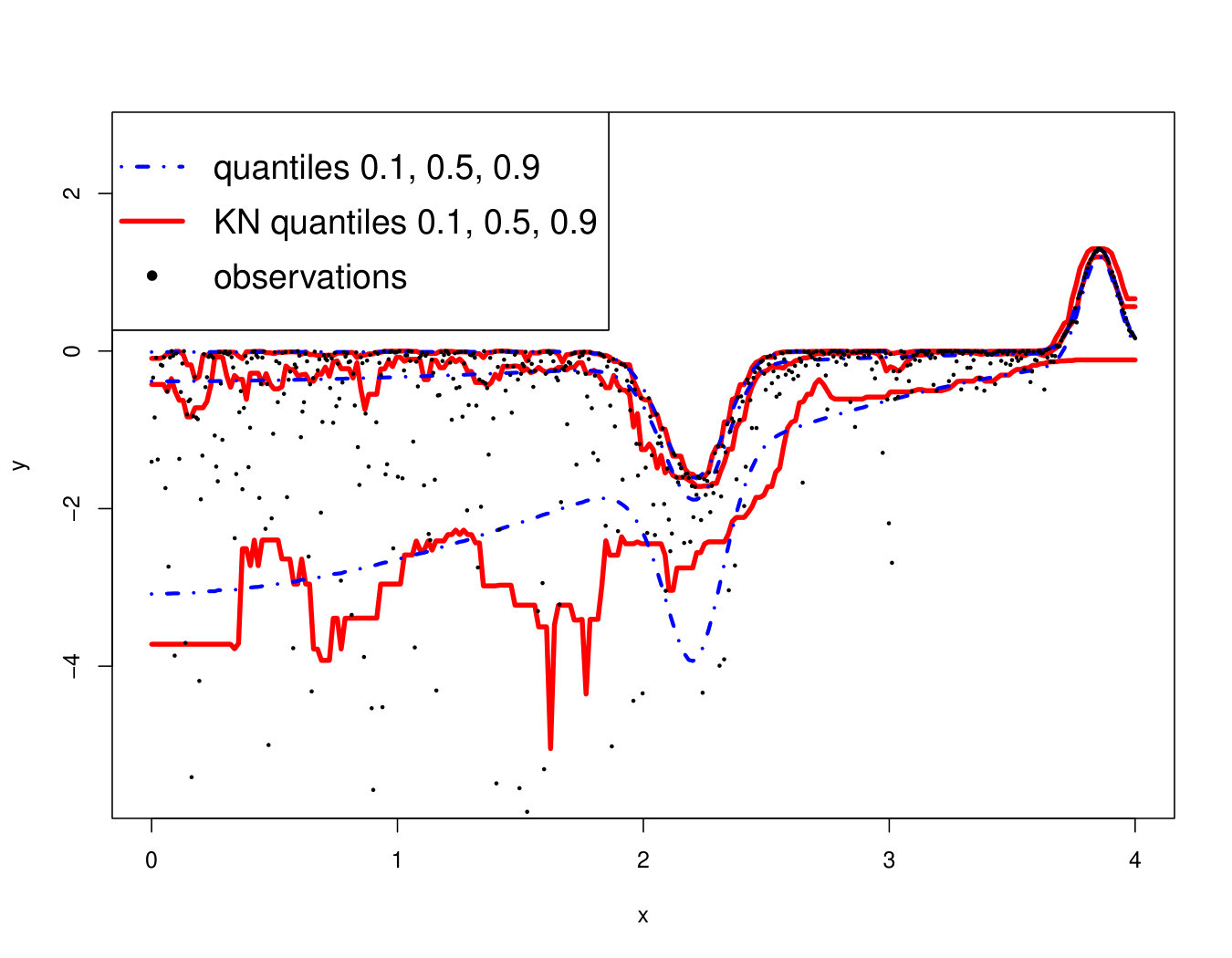 Figure 4
Figure 4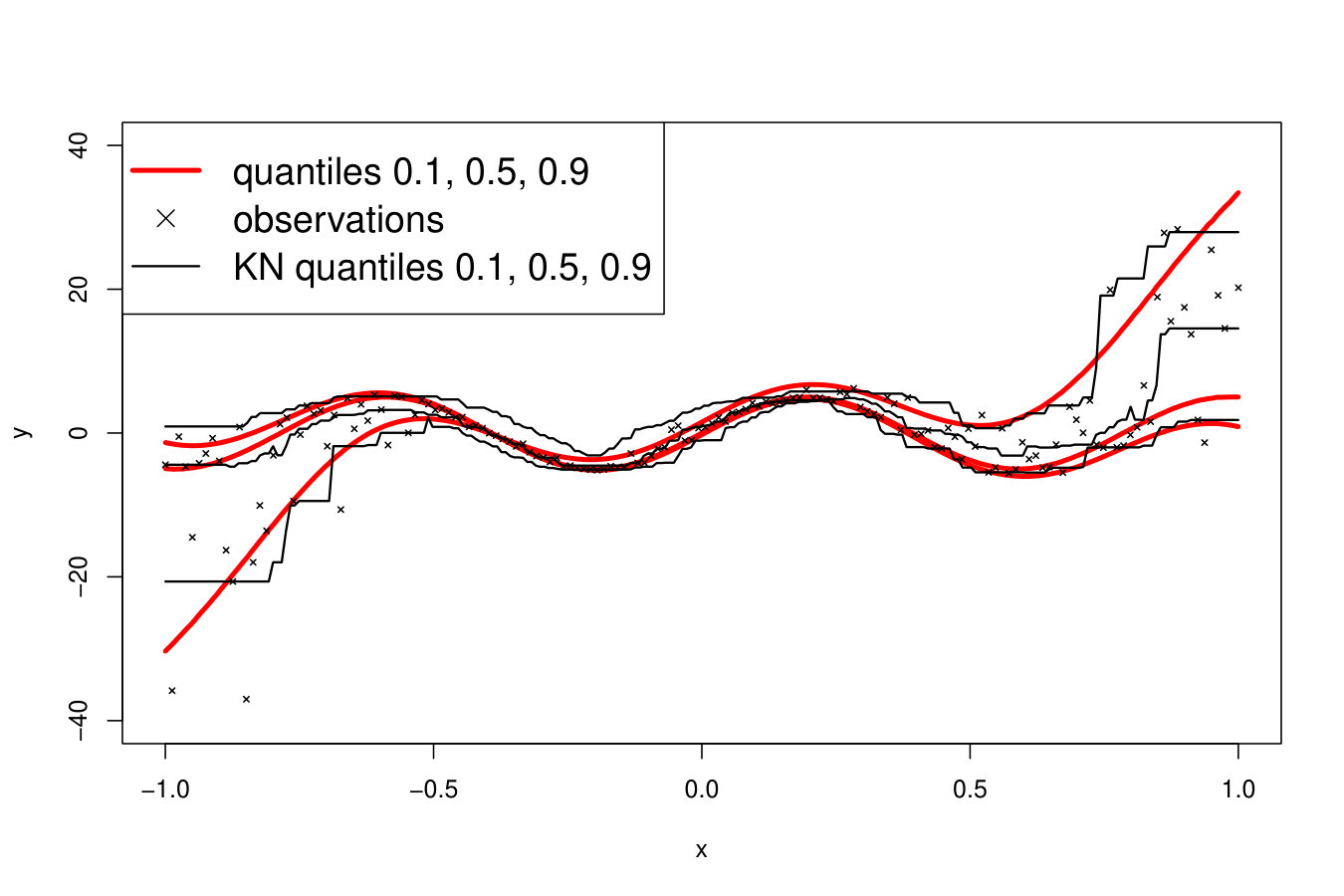 Figure 5
Figure 5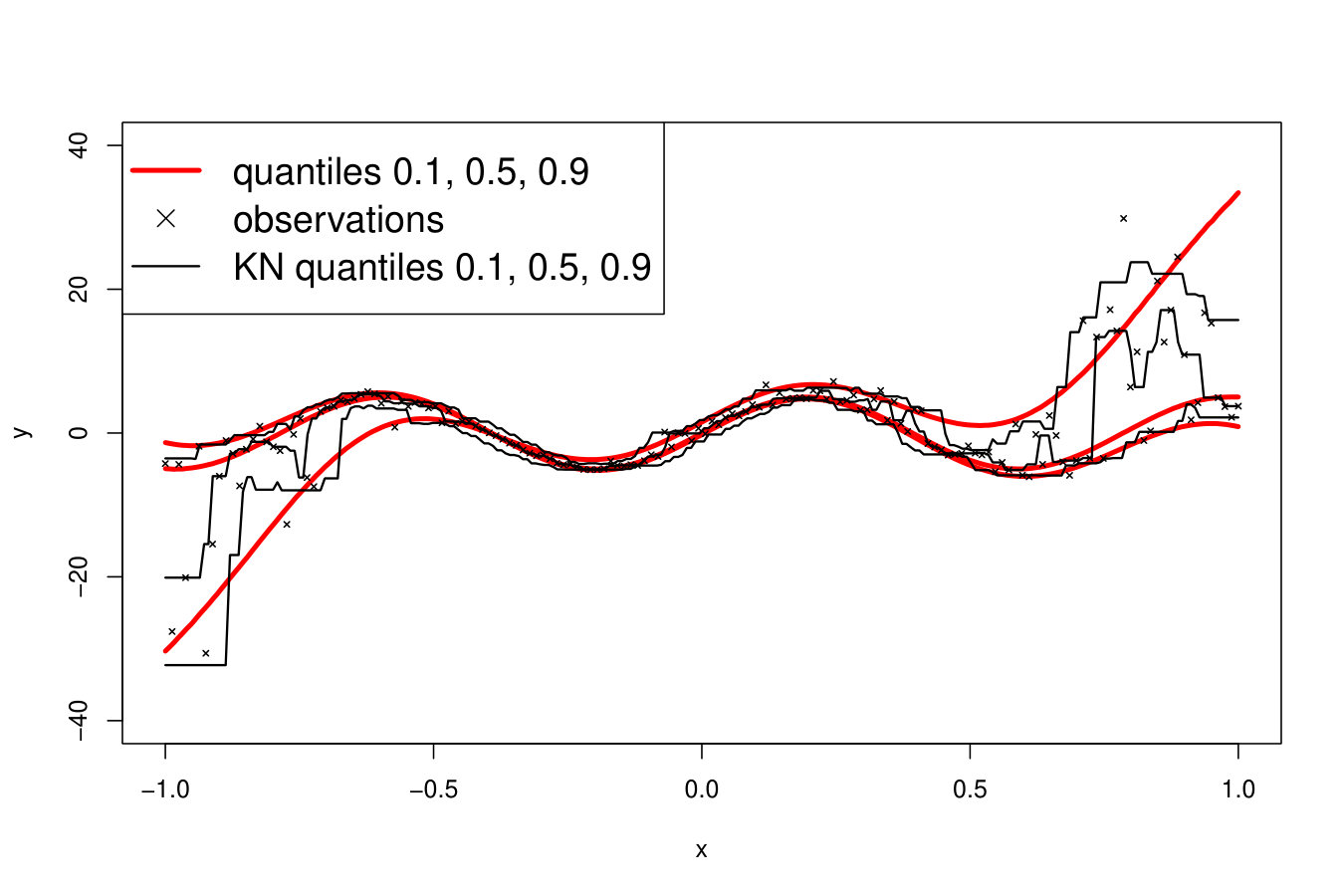 Figure 6
Figure 6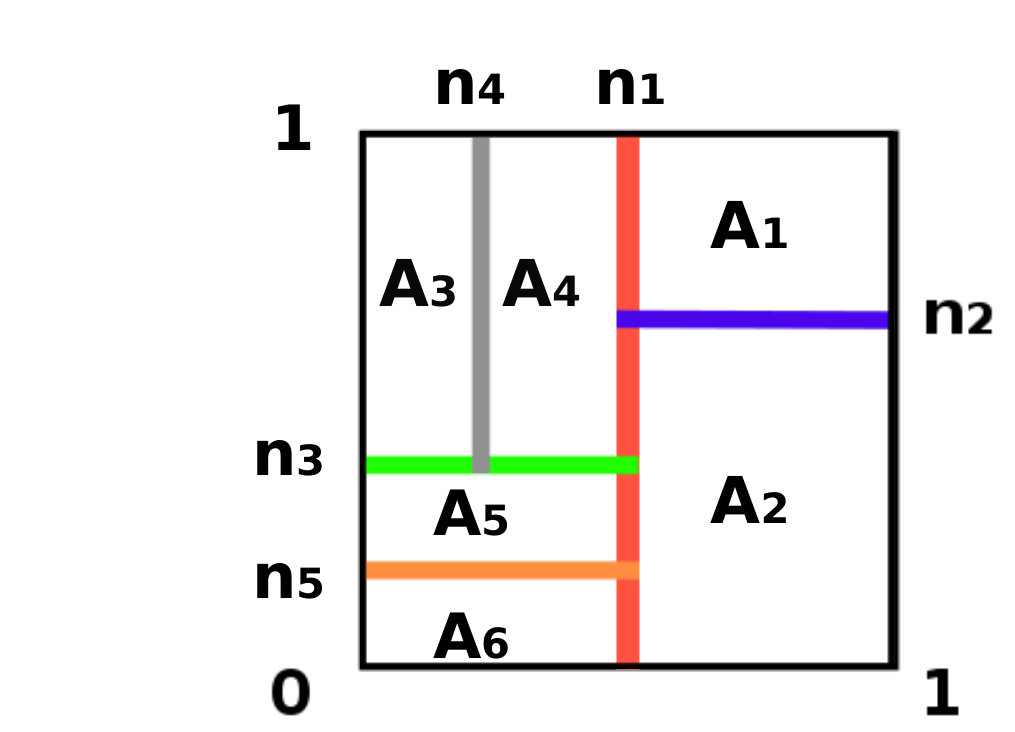 Figure 7
Figure 7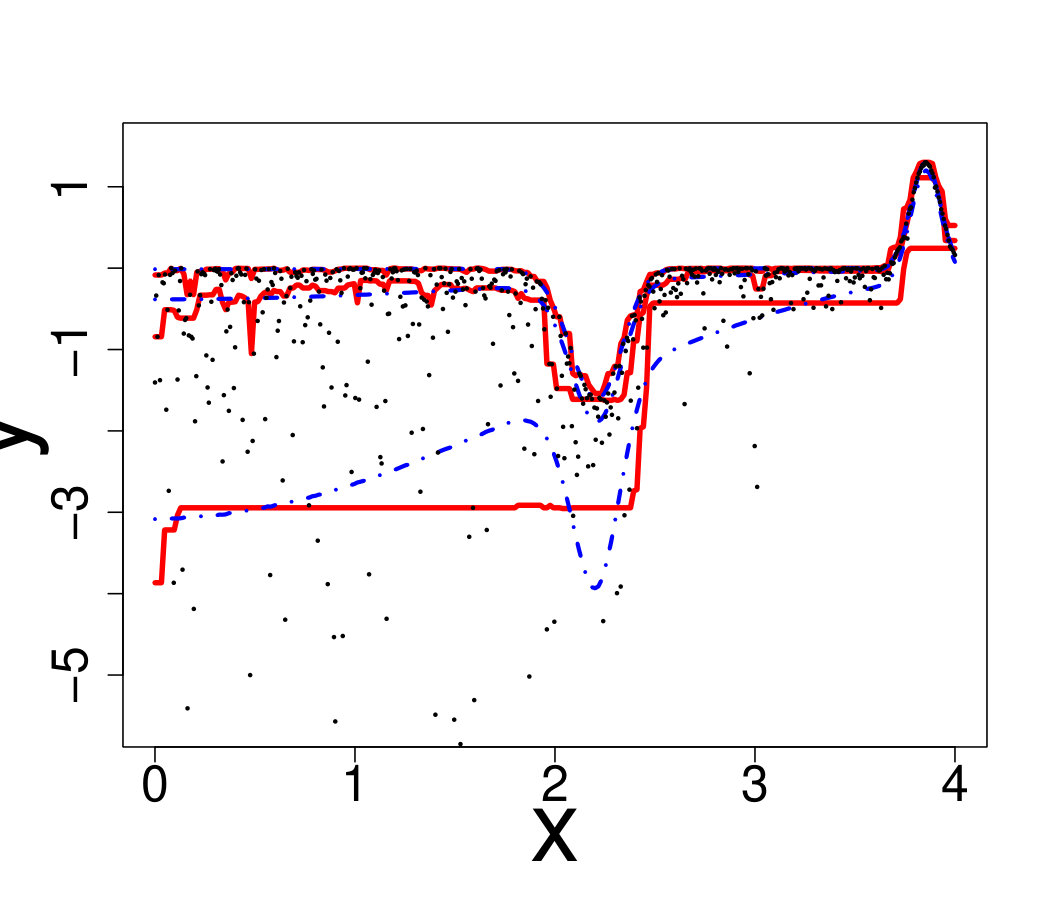 Figure 8
Figure 8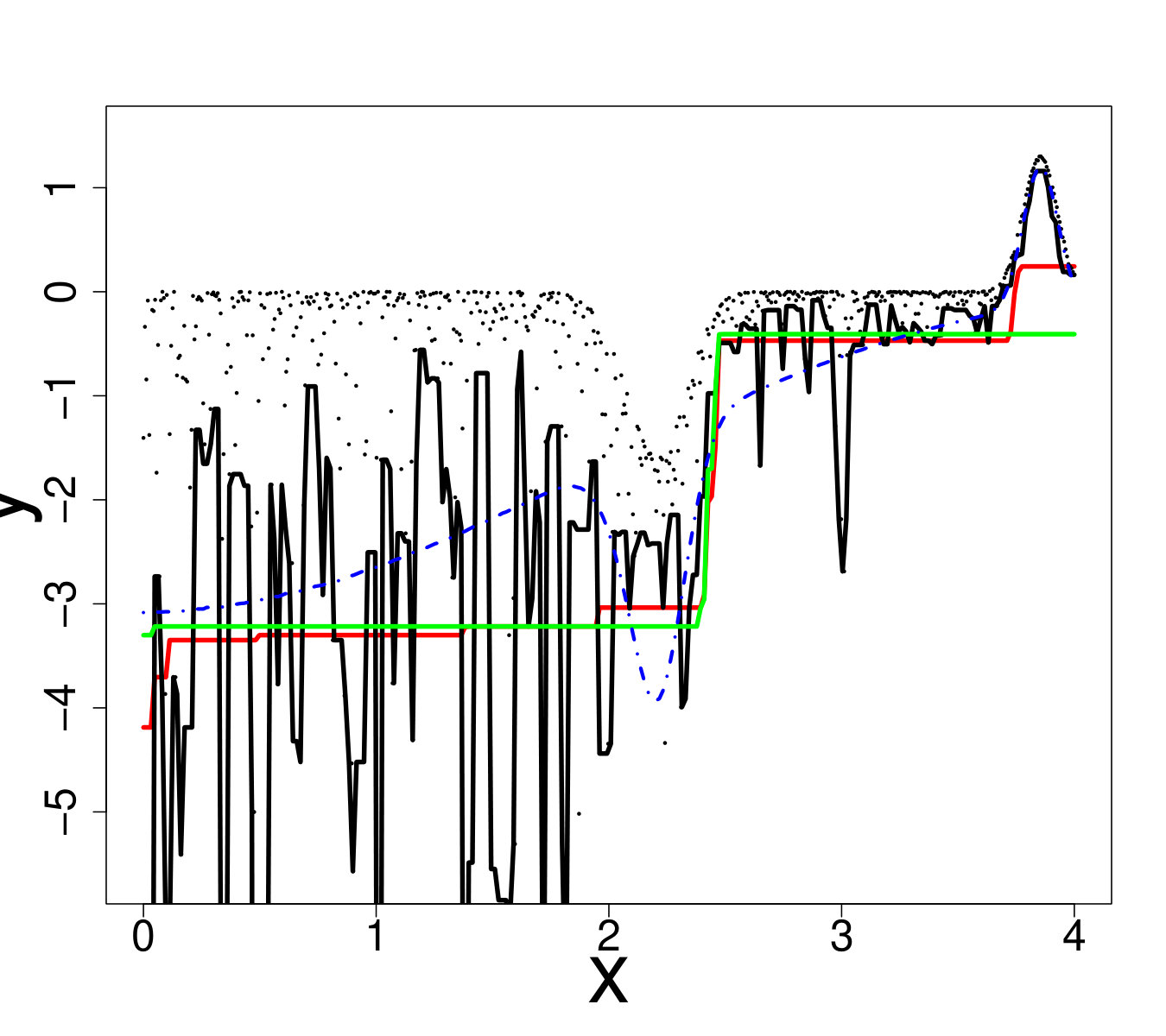 Figure 9
Figure 9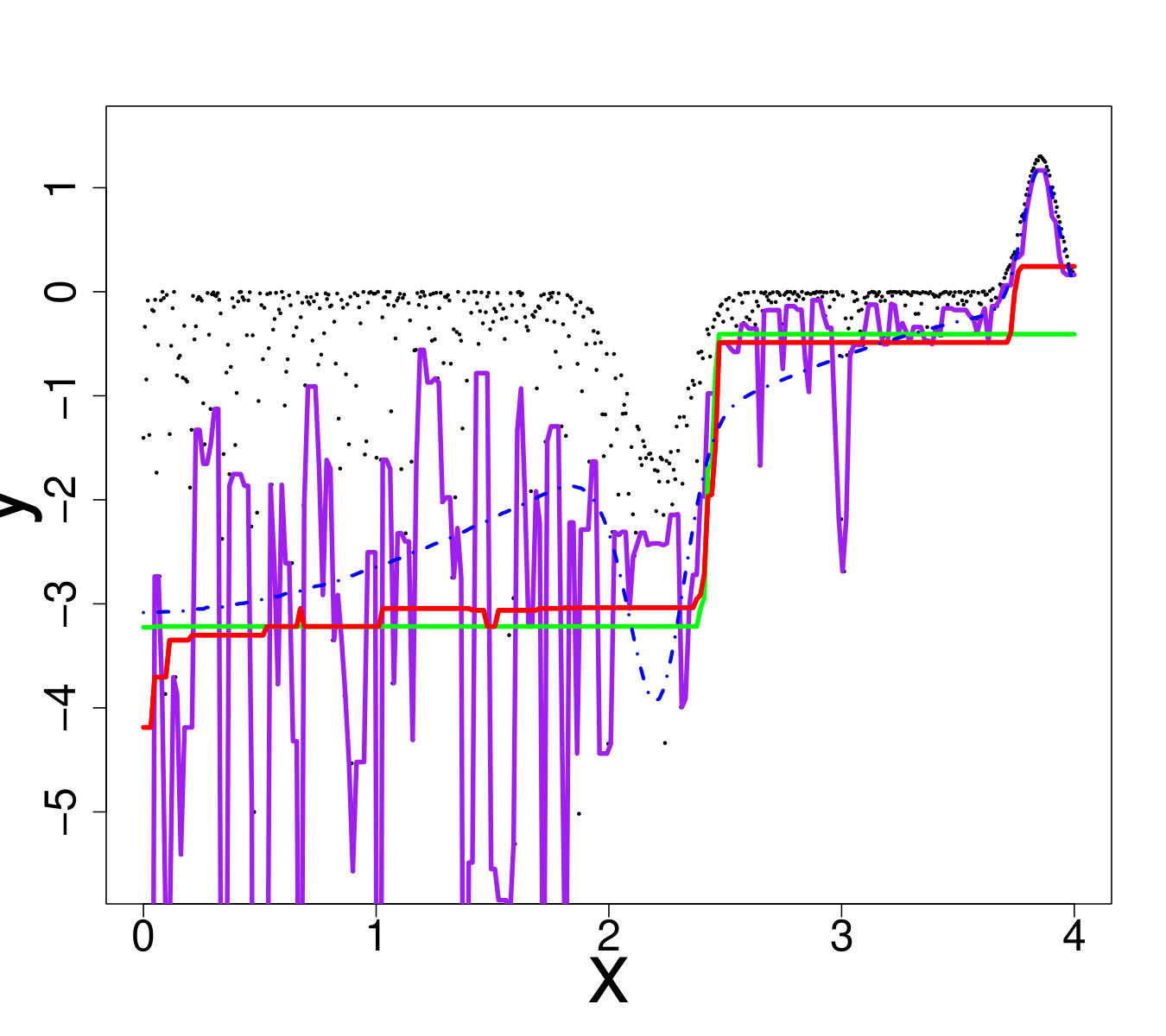 Figure 10
Figure 10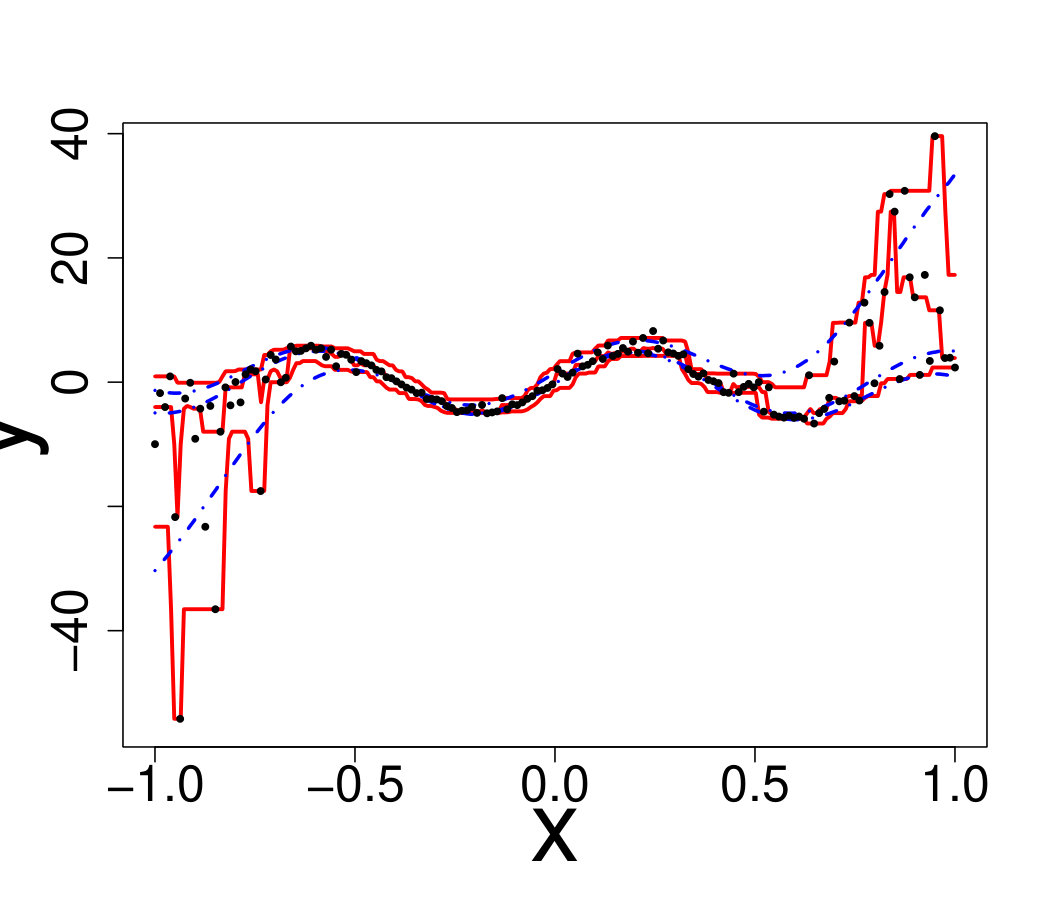 Figure 11
Figure 11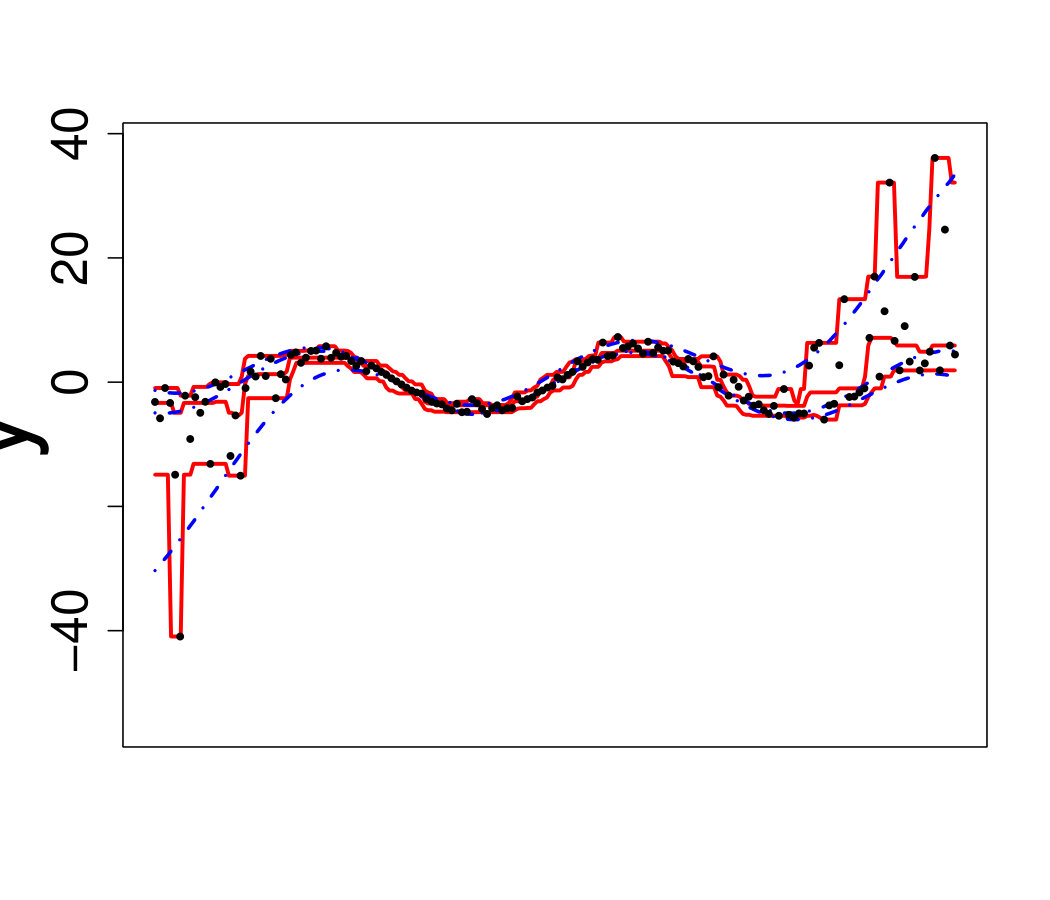 Figure 12
Figure 12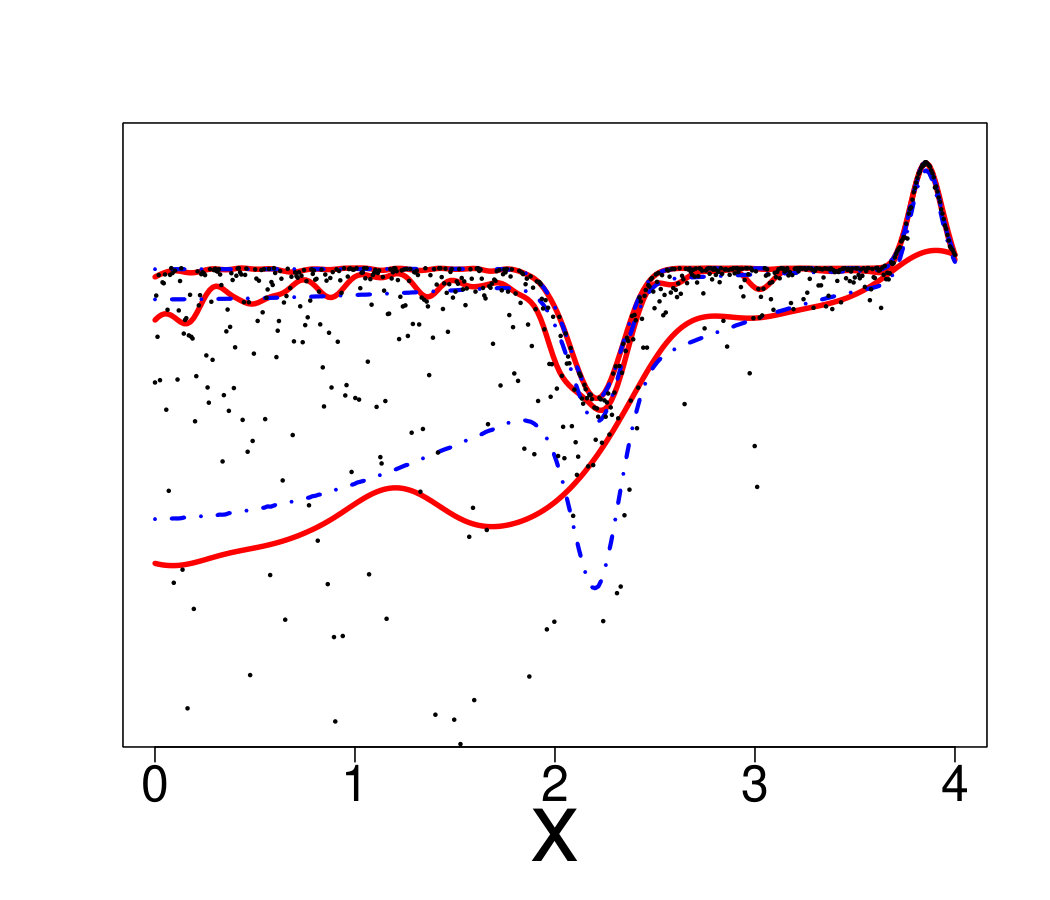 Figure 13
Figure 13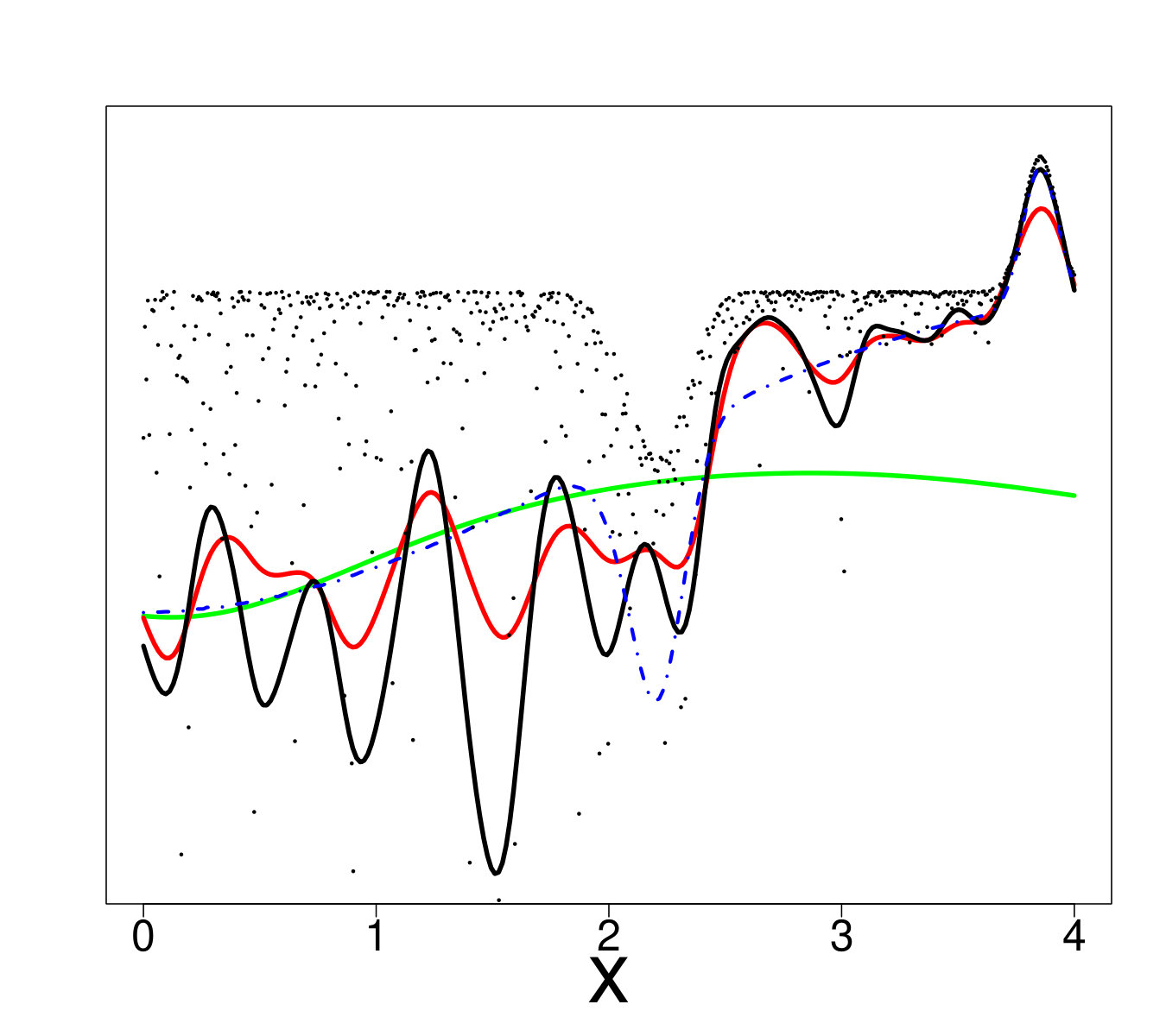 Figure 14
Figure 14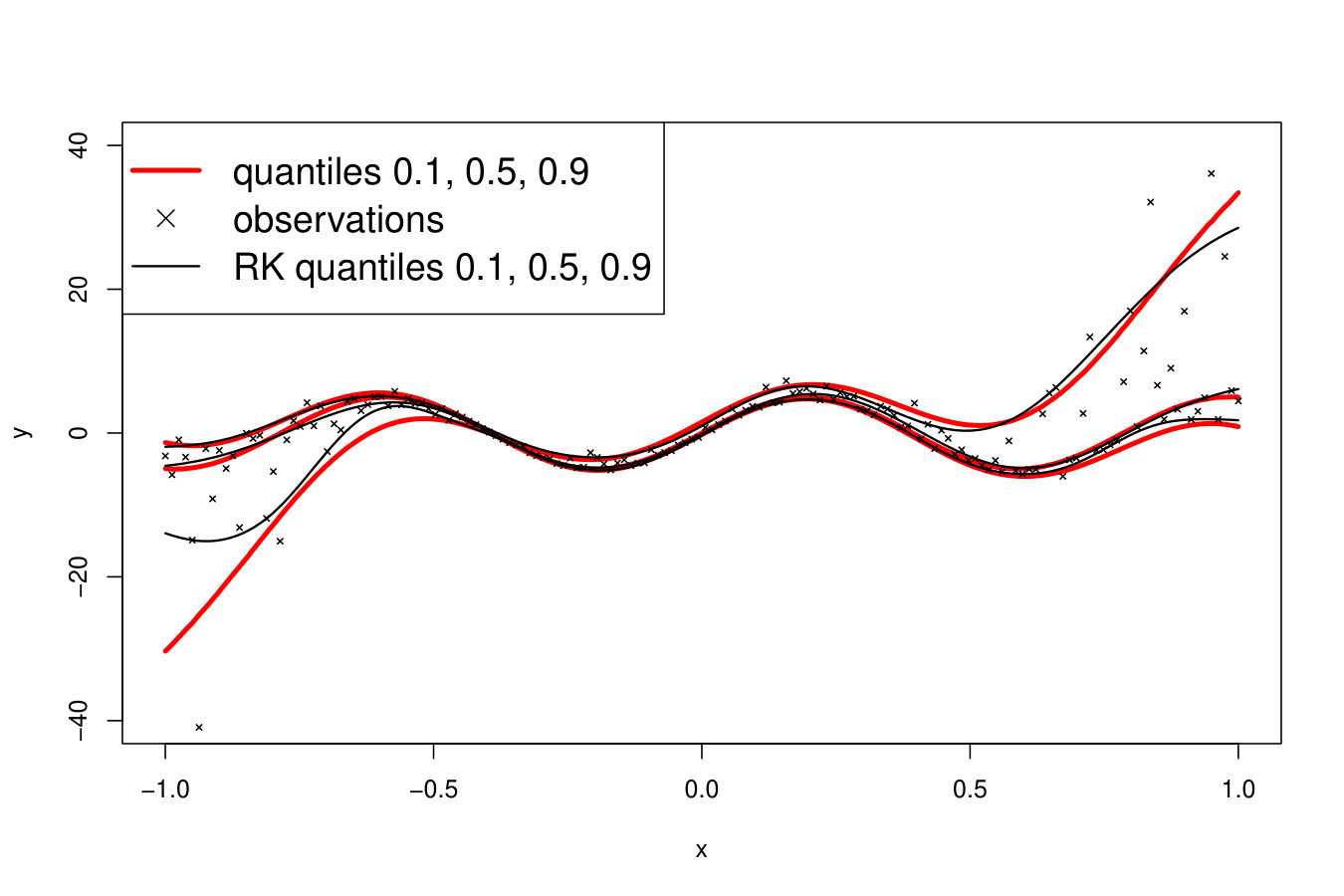 Figure 15
Figure 15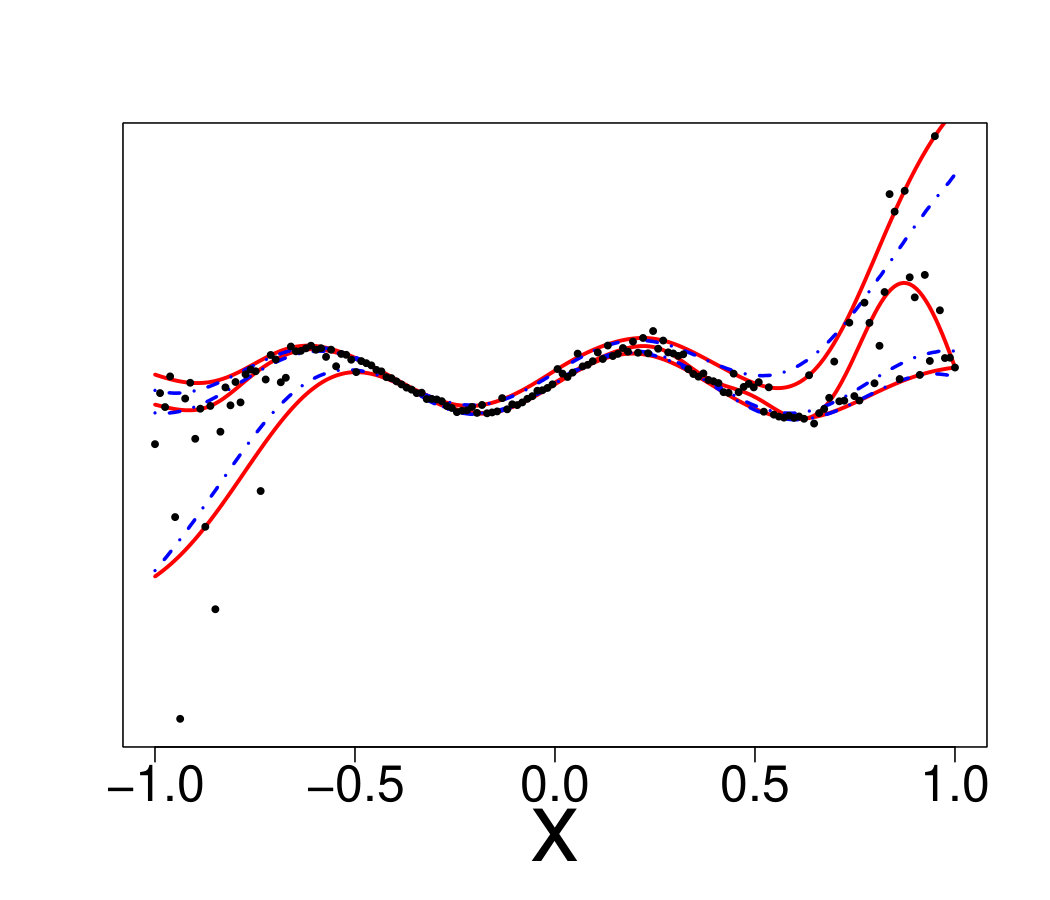 Figure 16
Figure 16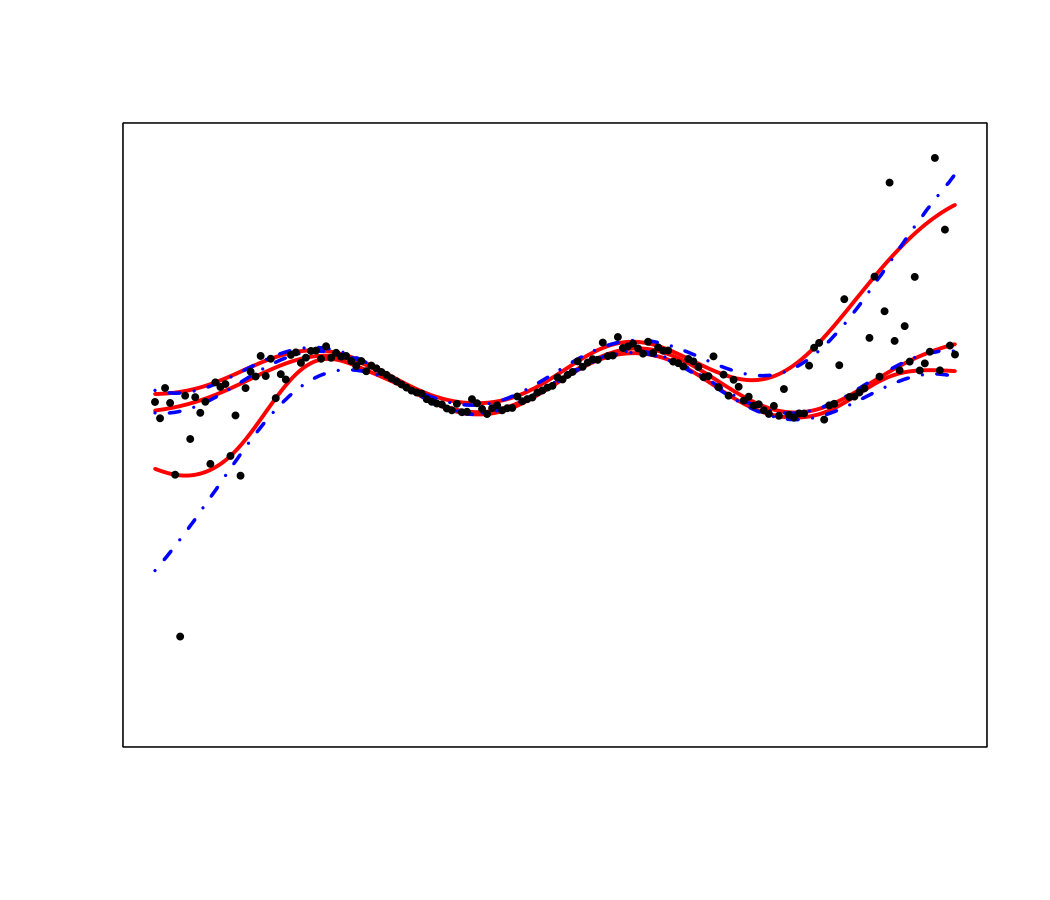 Figure 17
Figure 17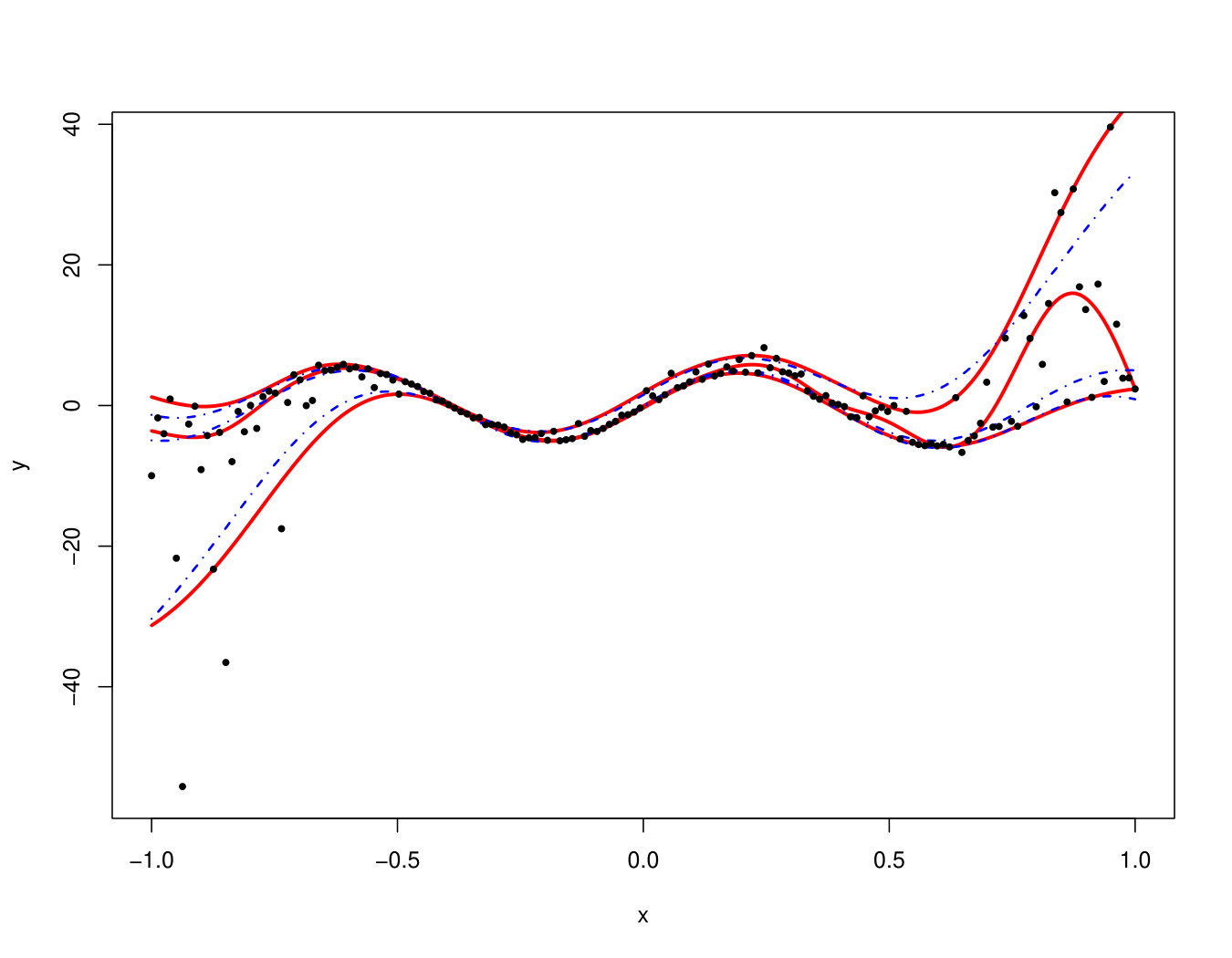 Figure 18
Figure 18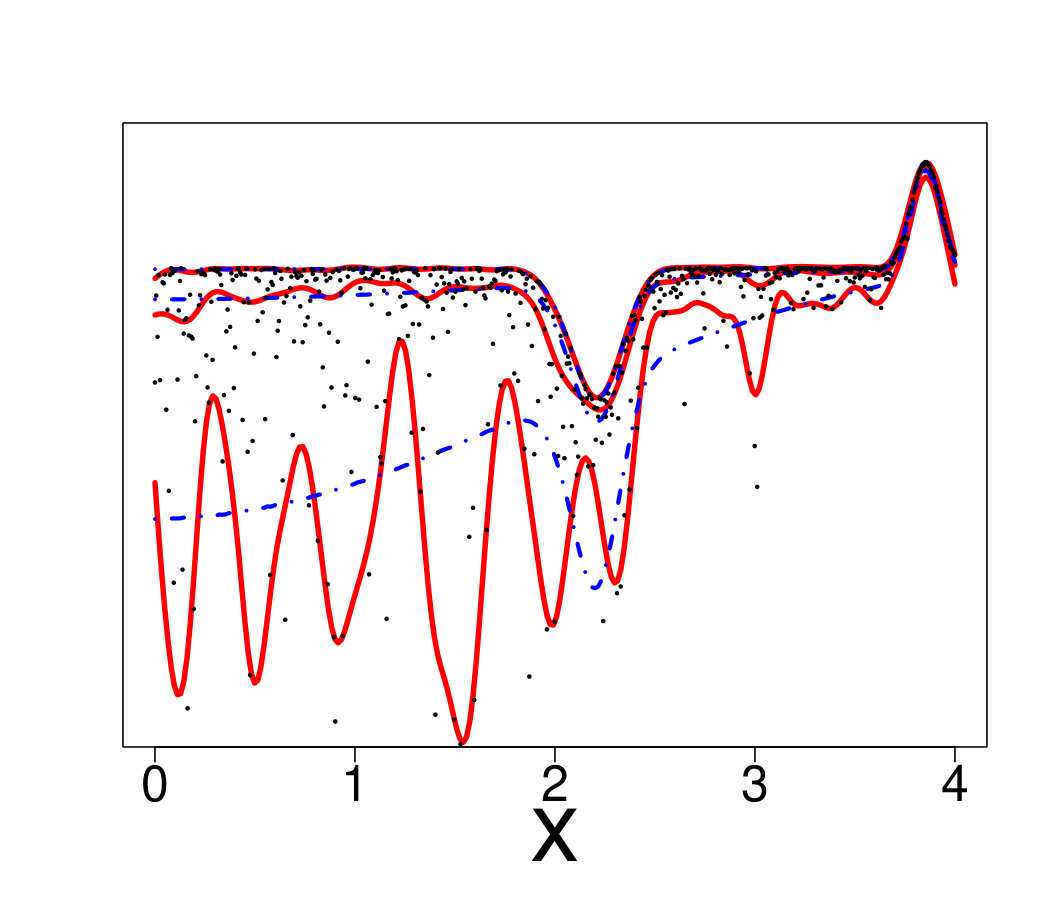 Figure 19
Figure 19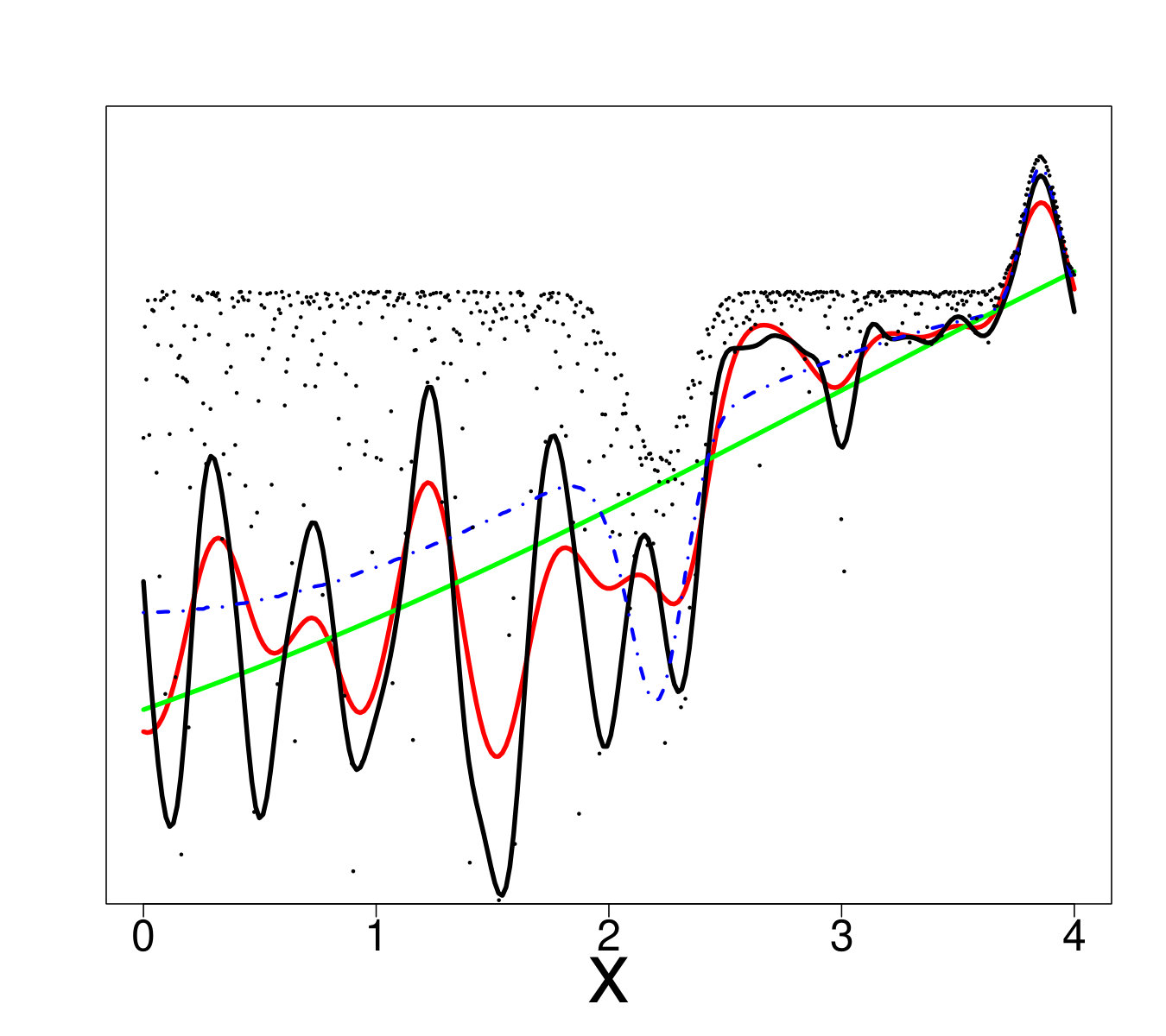 Figure 20
Figure 20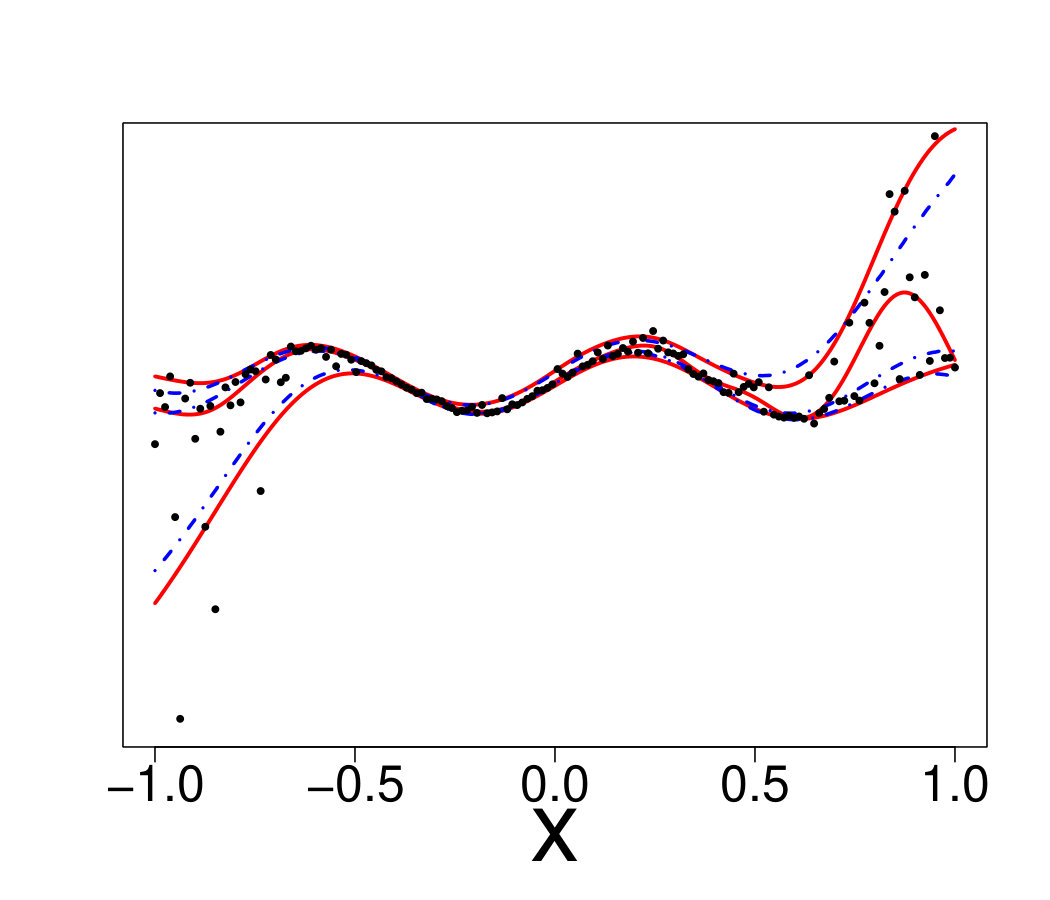 Figure 21
Figure 21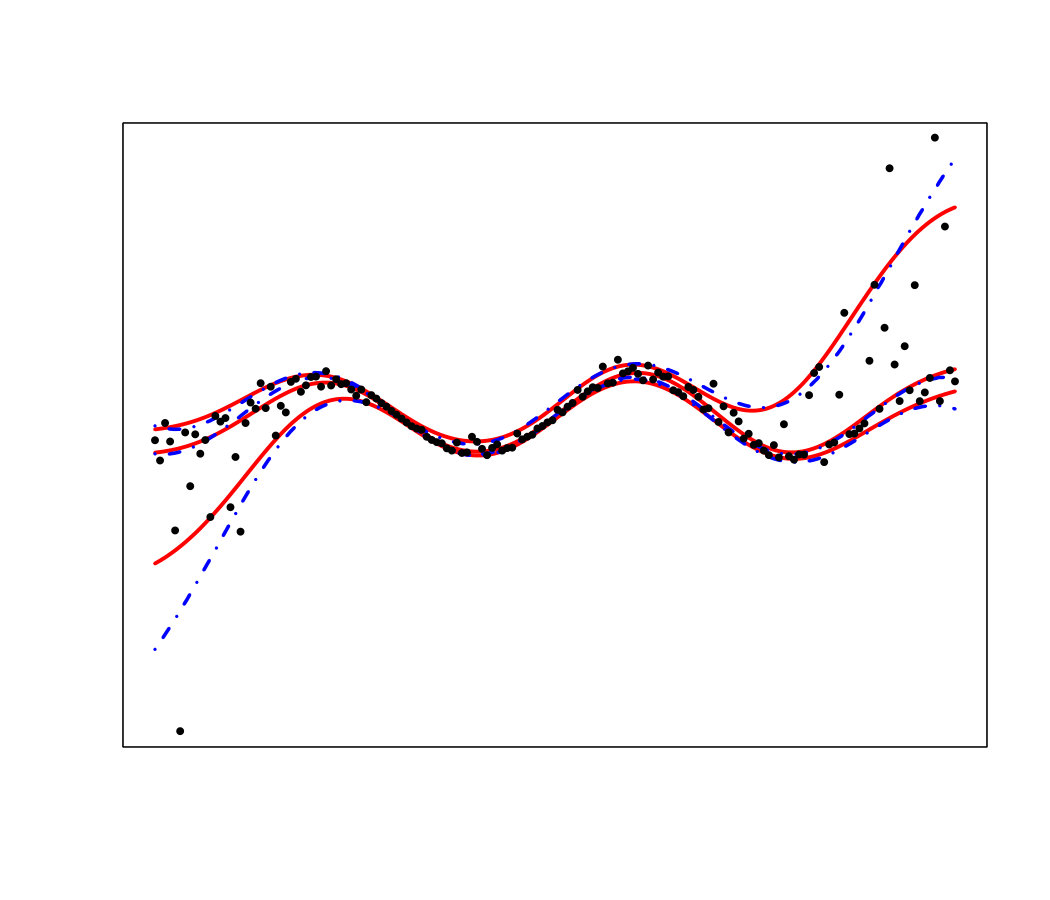 Figure 22
Figure 22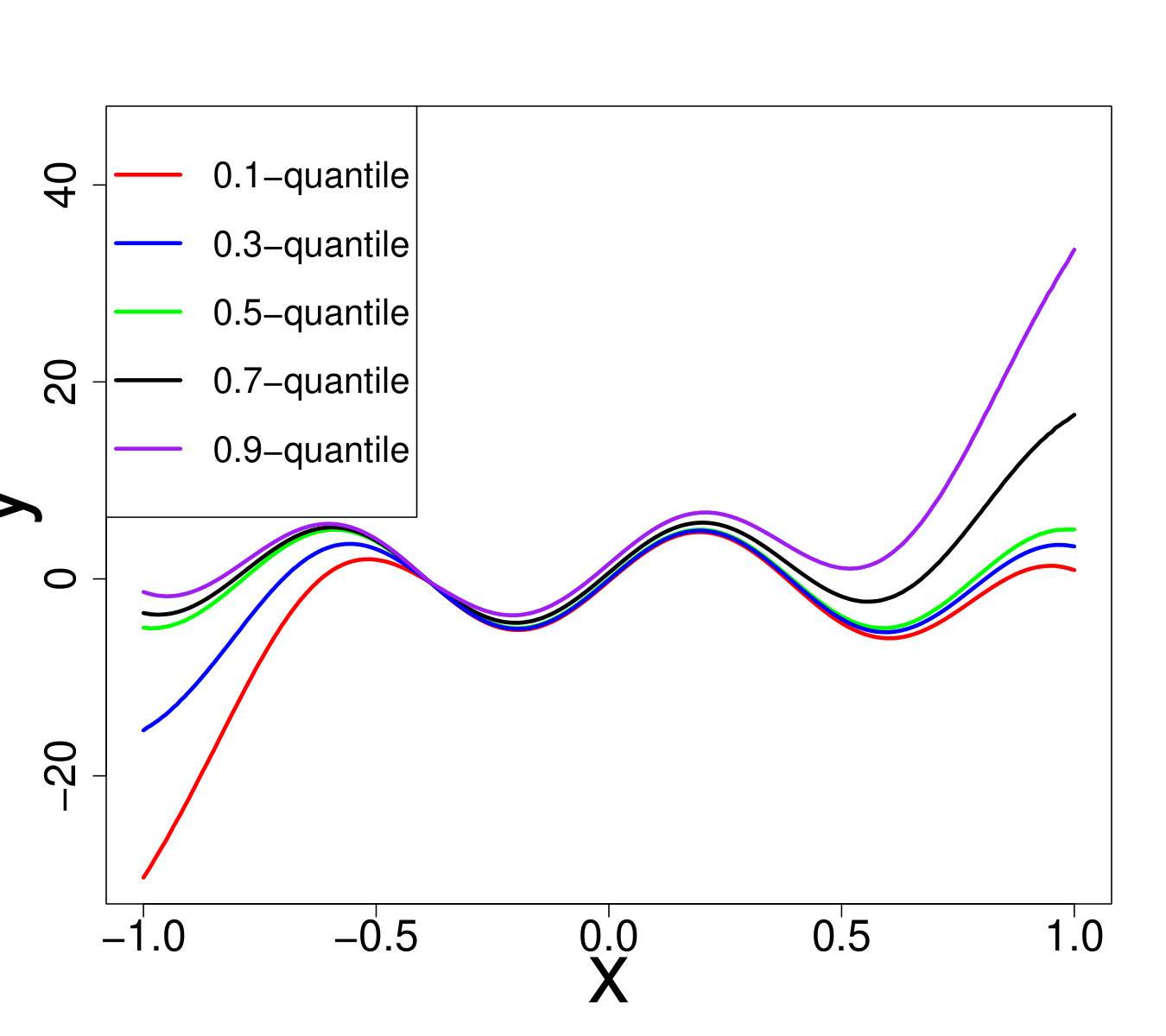 Figure 23
Figure 23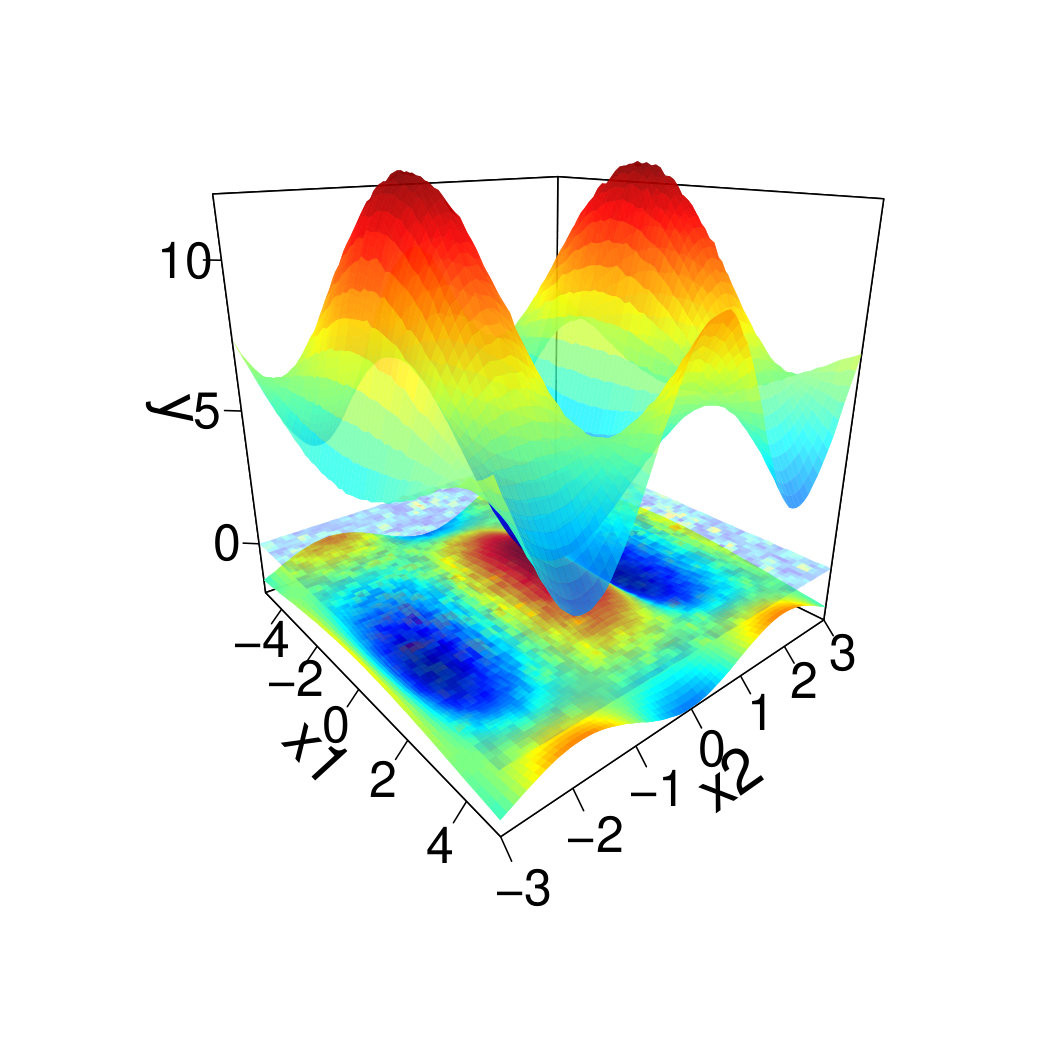 Figure 24
Figure 24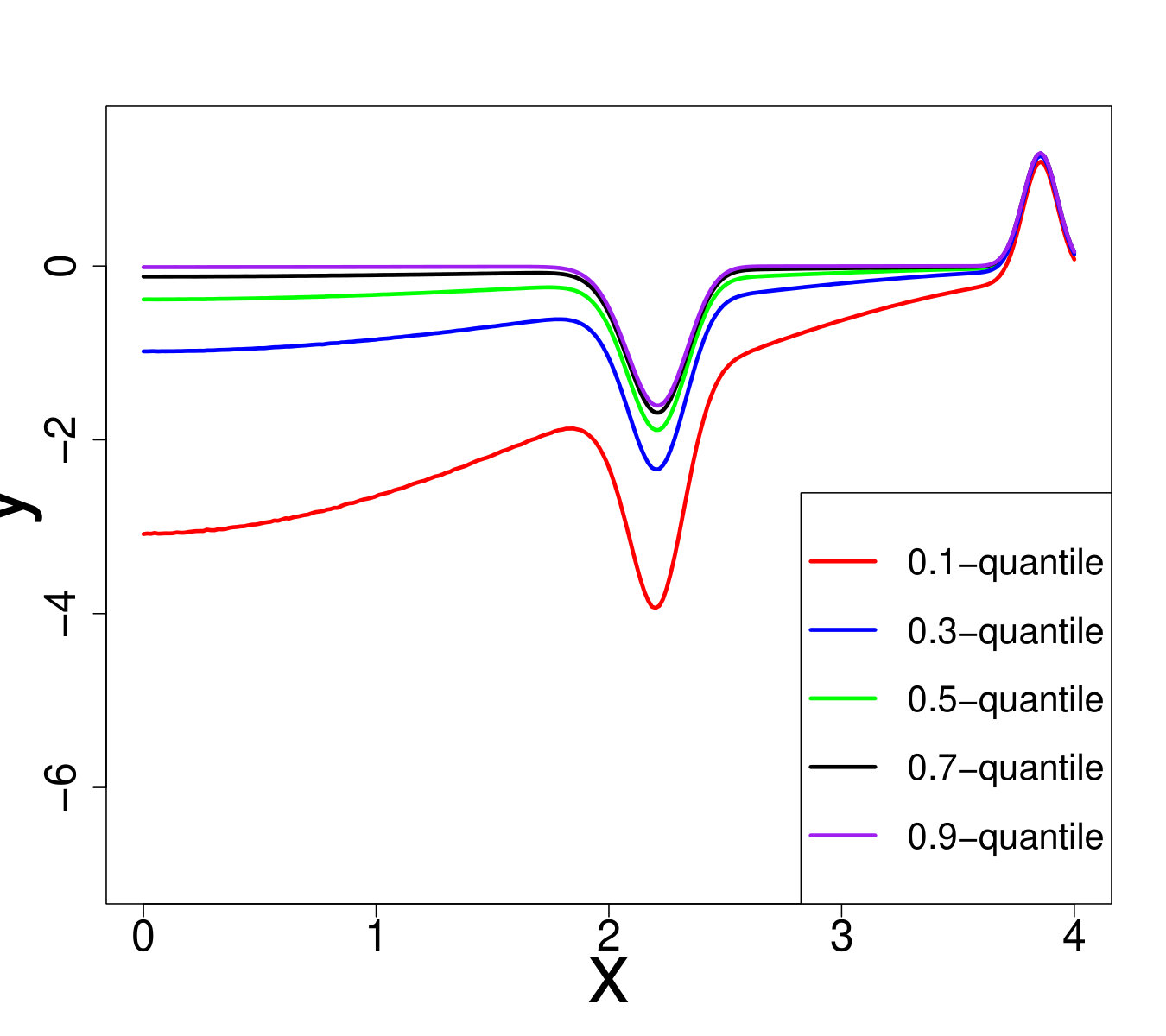 Figure 25
Figure 25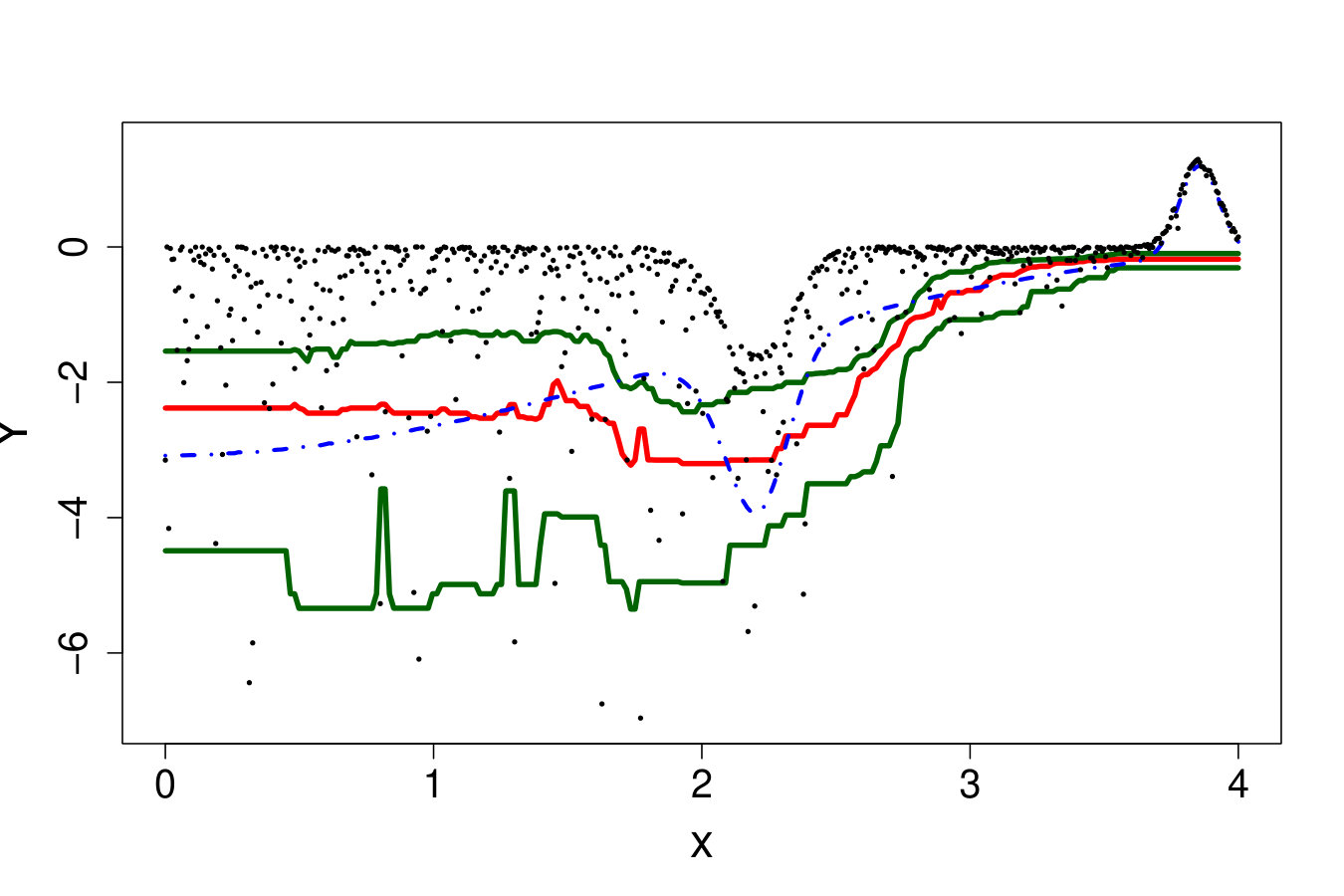 Figure 26
Figure 26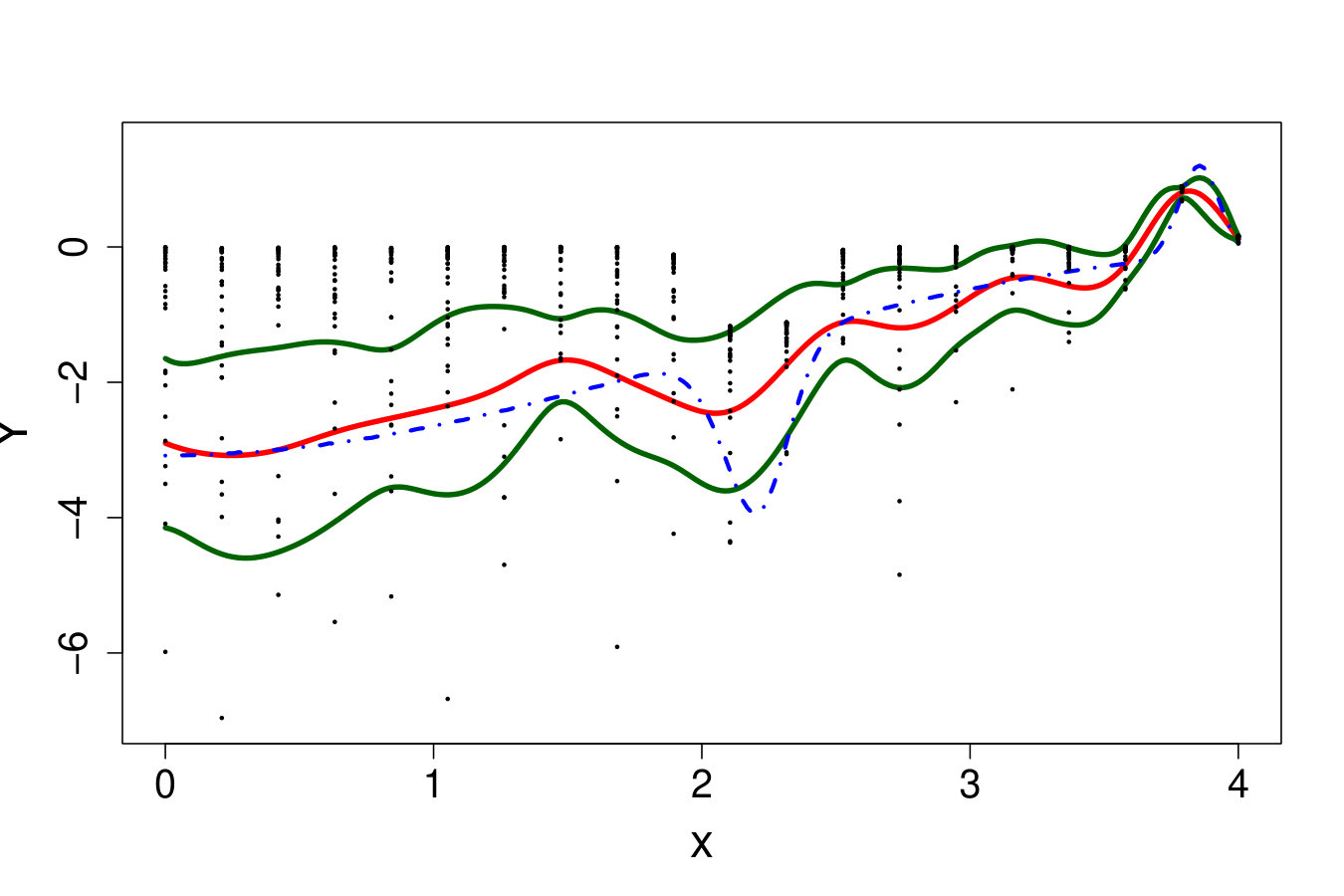 Figure 27
Figure 27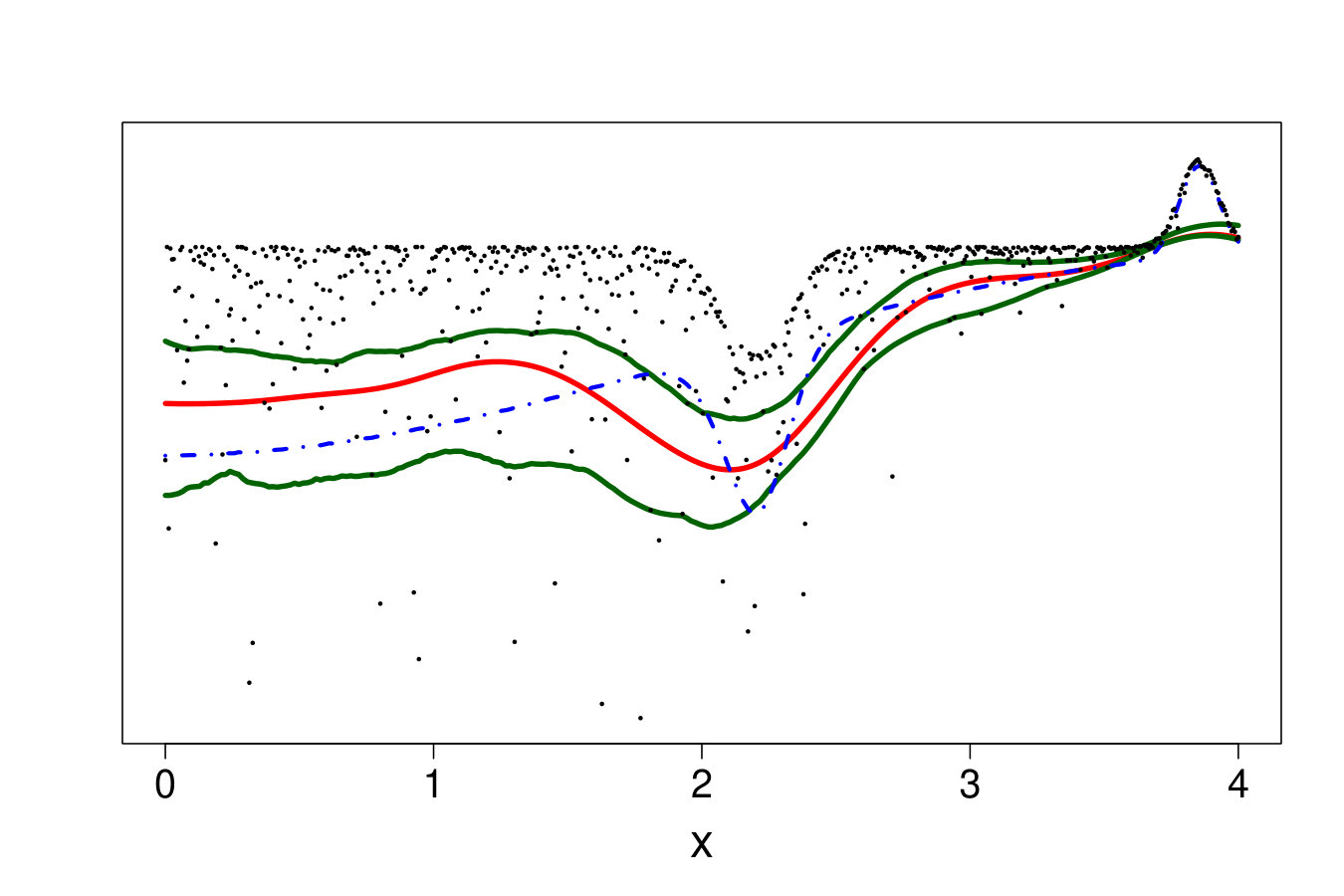 Figure 28
Figure 28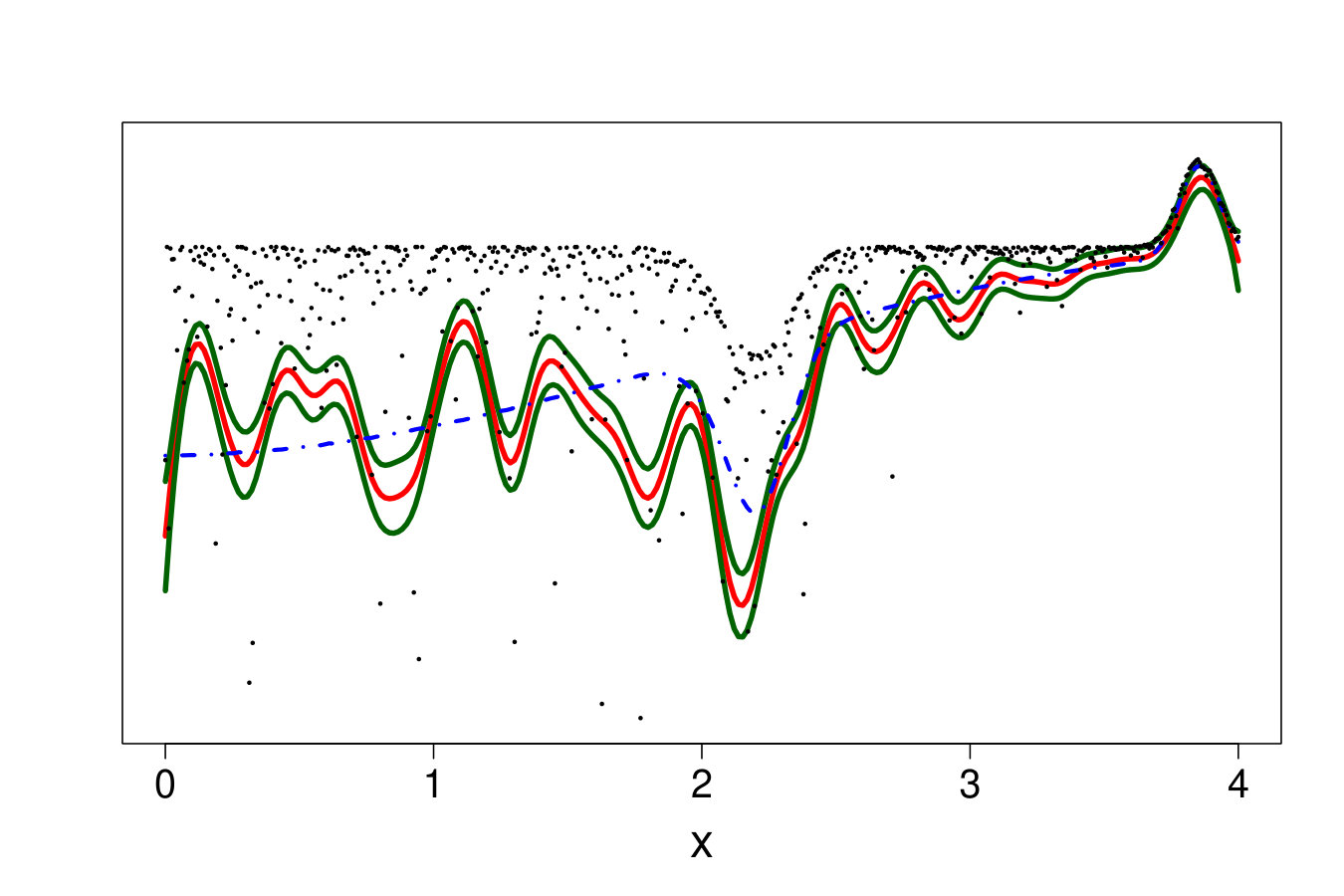 Figure 29
Figure 29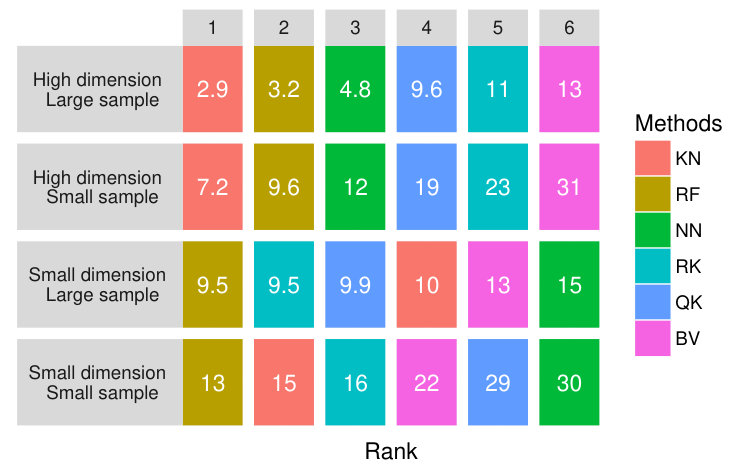 Figure 30
Figure 30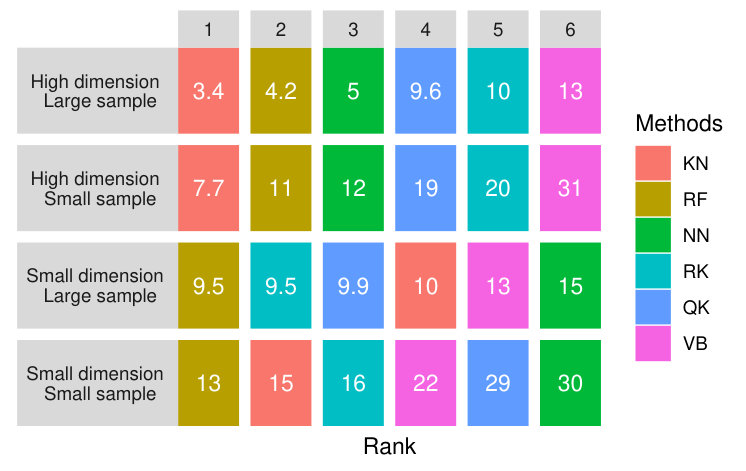 Figure 31
Figure 31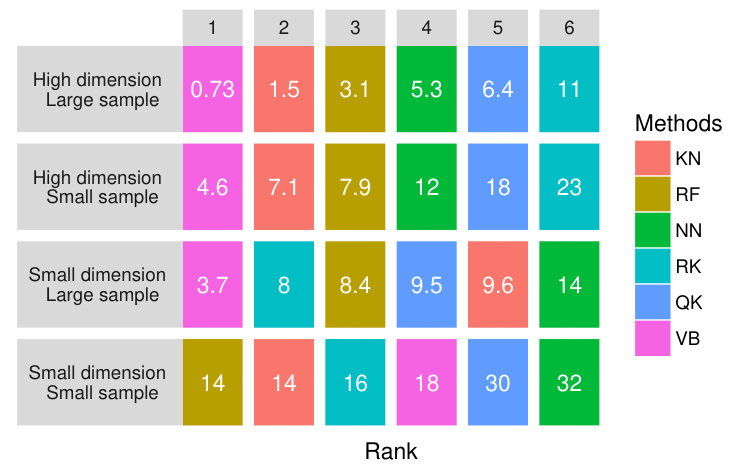 Figure 32
Figure 32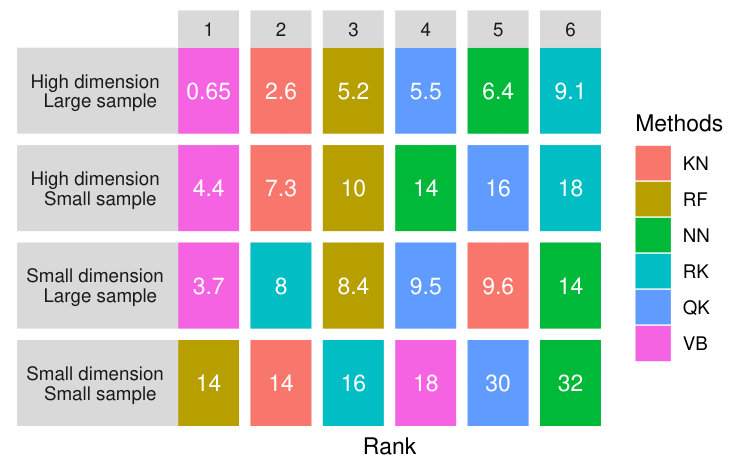 Figure 33
Figure 33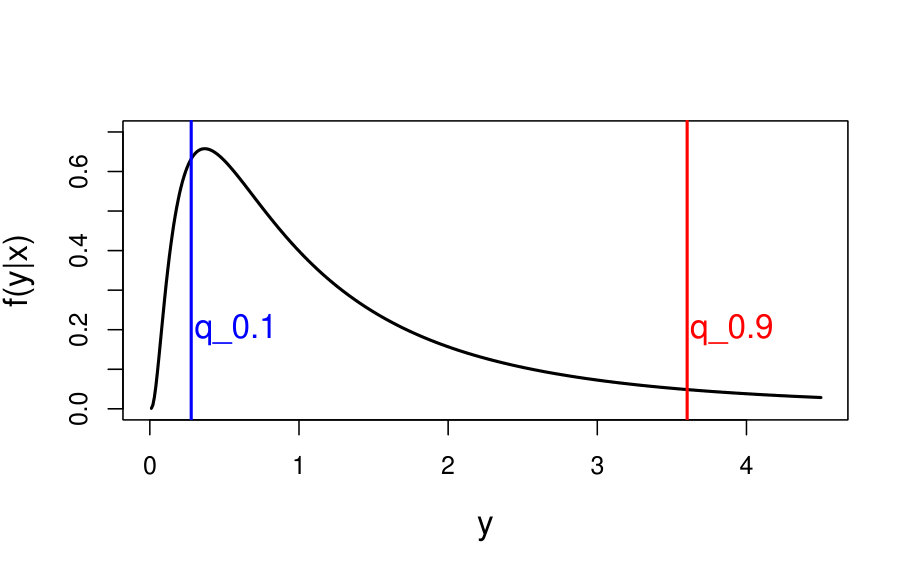 Figure 34
Figure 34 Figure 35
Figure 35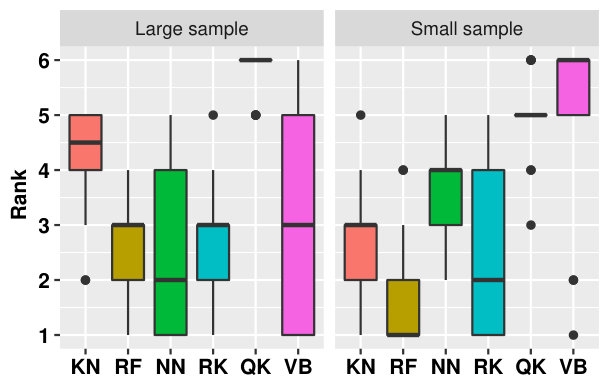 Figure 36
Figure 36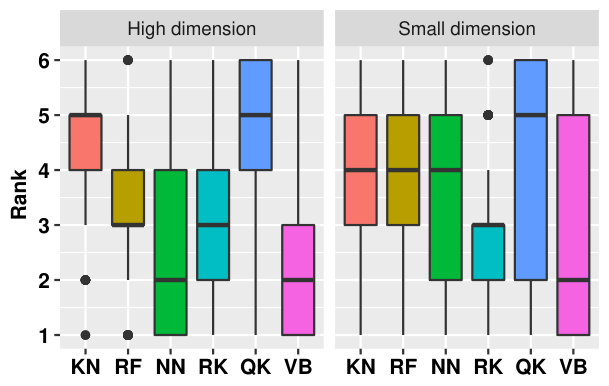 Figure 37
Figure 37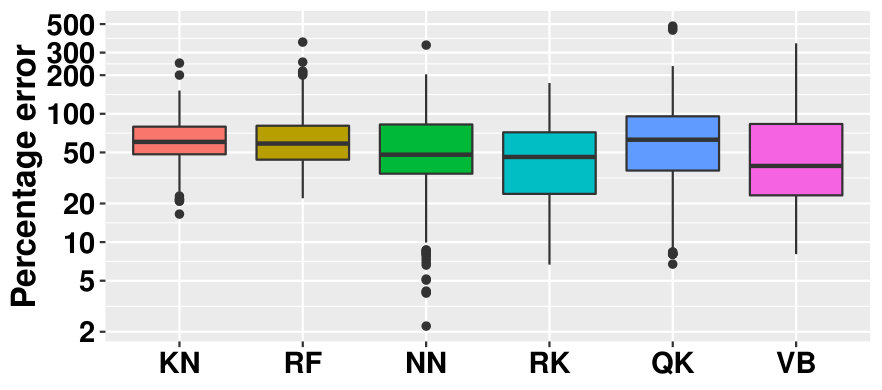 Figure 38
Figure 38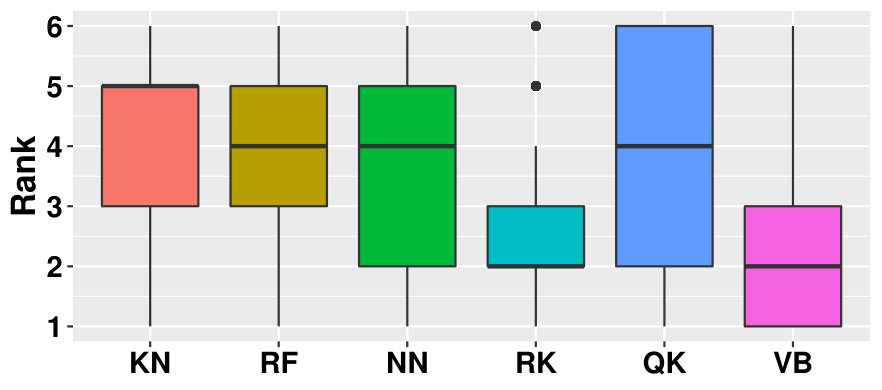 Figure 39
Figure 39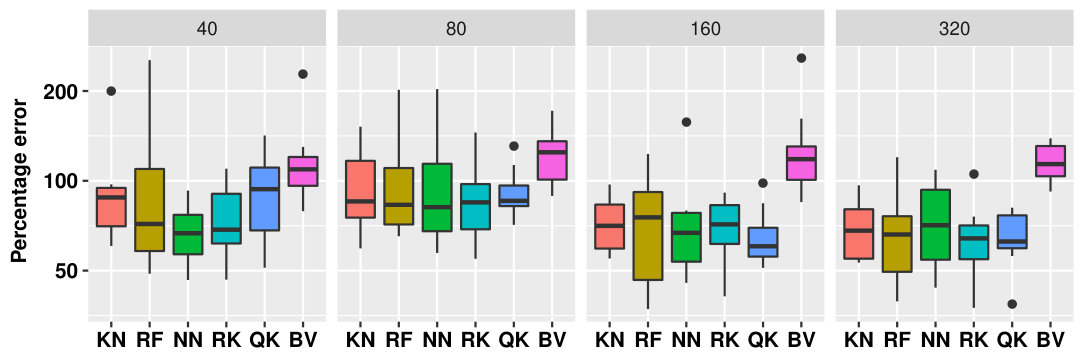 Figure 40
Figure 40| Method | Definition of | Related quantity | Complexity |
|---|---|---|---|
| KN | The -nearest points from | ||
| RF | |||
| For a layer NN | With , , , , , , | ||
| , , minimizing | |||
| NN | |||
| With minimizing | |||
| RK | s.t | ||
| and and the -quantile of | |||
| Maximizing the likelihood: | |||
| QK | |||
| Approached solution that maximize: | |||
| VB | |||
| Method | Hyperparameters |
|---|---|
| KN | number of neighbors |
| RF | maximum size of the leaves |
| NN | regularization , |
| RK | regularization , lengthscales |
| QK | length scale and variance |
| VB | length scale and variance |
| Test case 1 | Test case 2 | Test case 3 | Test case 4 | Sunflo | ||
| Dimension | 2 | 1 | 9 | 9 | ||
| Heteroscedasticity | very strong | very strong | very strong | strong | weak | |
| Shape variation | very strong | weak | weak | weak | strong | |
| pdf value | variable | small | globally very small | large | large | |
| near the | variable | large | small | small | large | |
| -quantile | variable | very small | very large | very small | small | |
| Dimension | Data size (no repetitions) | Data size (with repetitions) | ||||||
| 1 | 40 | 80 | 160 | 320 | 5 (8) | 10 (8) | 10 (16) | 16 (20) |
| 2 | 100 | 200 | 400 | 800 | 10 (10) | 20 (10) | 25 (16) | 40 (20) |
| 9 | 250 | 500 | 1000 | 2000 | 25 (10) | 50 (10) | 100 (10) | 100 (20) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Multi-Objective Optimization Algorithms · Probabilistic and Robust Engineering Design · Advanced Bandit Algorithms Research
\usetikzlibrary
positioning
\xpatchcmd\linklayers\nn@lastnode\lastnode \xpatchcmd\linklayers\nn@thisnode\thisnode
A Review on Quantile Regression for Stochastic Computer Experiments
Léonard Torossian
MIAT, Université de Toulouse, INRA
and Institut de Mathématiques de Toulouse
&Victor Picheny
PROWLER.io, 72 Hills Road, Cambridge
\ANDRobert Faivre
MIAT, Université de Toulouse, INRA
&Aurélien Garivier
Univ. Lyon, ENS de Lyon
Abstract
We report on an empirical study of the main strategies for quantile regression in the context of stochastic computer experiments. To ensure adequate diversity, six metamodels are presented, divided into three categories based on order statistics, functional approaches, and those of Bayesian inspiration. The metamodels are tested on several problems characterized by the size of the training set, the input dimension, the signal-to-noise ratio and the value of the probability density function at the targeted quantile. The metamodels studied reveal good contrasts in our set of experiments, enabling several patterns to be extracted. Based on our results, guidelines are proposed to allow users to select the best method for a given problem.
1 Introduction
Computer simulation models are now essential for performance evaluation, quality control and uncertainty quantification to assess decisions in complex systems. These computer simulators generally model systems depending on multiple input variables that can be divided into two categories: the controllable variables and the uncontrollable variables.
For example, in pharmacology, the optimal drug dosage depends on the drug formulation but also on the targeted individual (genetics, age, sex) and environmental interactions. The shelf life and performance of a manufacturing device depend on its design, but also on its environment and on some uncertainties due to the manufacturing process. The plant growth and yield depend on the genes of the plant and on the gardening techniques but also on the weather and potential diseases.
Evaluating the influence of the controllable and uncontrollable variables directly on the real-life problems can be costly and tedious. One solution is to encapsulate the systems into a computer simulation model which would reduce the cost and the time required for each test (see [40] and reference therein for computer experiments applied to clinical trials, see [35] for a computer simulation model applied to industrial design and [91, 19] for computer experiments applied to crop production).
In such computer simulation models, the links between the inputs and outputs may be too complex to be fully understood or to be formulated in a closed form. In this case, the system can be considered as a black box and formalized by an unknown function: , where denotes the compact space of controllable variables, and denotes a probability space representing the uncontrollable variables. Note that some black boxes have their outputs in a multidimensional space but this aspect is beyond the scope of the present paper.
Based on the standard constraints encountered in computer experiments, throughout this paper, we assume that the function is only accessible through pointwise evaluations ; no structural information is available regarding ; in addition, we take into account the fact that evaluations may be expensive, which drastically limits the number of possible calls to .
If the space is small enough (or highly structured), it may be possible to work directly on the space (see [42] for example). Often, however, is too complex and working on the joint space is intractable. This is the case for intrinsic stochastic simulators (see [48, 54] for examples of biological systems, where the stochasticity is driven by stochastic equations such as the Fokker-Planck or the chemical Langevin equations), or for simulators associated with a very large space (see [19] for the crop model SUNFLO that considers weather indicators on days, is a space of dimension ).
In this paper we consider the case where is too complex. We assume that has any structure and its contribution is considered as random. In contrast to deterministic systems, for any fixed , is considered as a random variable of distribution ; hence, such systems are often referred to as stochastic black boxes. In order to understand the behavior of the system of interest or to take optimal decisions, information is needed about the output distribution. An intuitive approach is to use a simple Monte-Carlo technique and to evaluate to extract statistical moments, the empirical cumulative distribution function, etc. Unfortunately, such a stratified approach is not efficient when evaluating is expensive.
Instead, we focus on surrogate models (also referred to as metamodels or statistical emulators), which are appropriate approaches in small data settings [84, 94]. Among the vast choice of surrogate models, the most popular ones include regression trees, Gaussian processes, support vector machines and neural networks. In the framework of stochastic black boxes, the standard approach consists in estimating the conditional expectation of . This case has been extensively treated in the literature and many applications, including Bayesian optimization [77], have been developed. However the conditional expectation is risk-neutral, as it does not provide information about the variability of the output, whereas pharmacologists, manufacturers, asset managers, data scientists and agronomists may need to quantify potential losses associated with their decisions.
Risk information can be introduced via heteroscedastic Gaussian processes [43, 47] in which the unknown distribution is estimated by a surrogate expectation-variance model. However, such approaches usually imply that the shape of the distribution (e.g. normal) is the same for all . Another possible approach would be to learn the unknown distribution with no strong structural hypotheses [61, 37, 31], but this requires a large number of evaluations of . Here, we focus on the conditional quantile estimation of order , a flexible way to tackle cases in which the distribution of varies markedly in spread and shape with respect to , and a classical risk-aware tool in decision theory [71].
1.1 Paper Overview
Many metamodels originally designed to estimate conditional expectations have been adapted to estimate the conditional quantile. However, despite extensive literature on estimating the quantile in the presence of spatial structure, few studies have reported on the constraints associated with stochastic black boxes. The performance of a metamodel with high dimension input is treated in insufficient details, performance based on the number of points has rarely been tackled and, to our knowledge, dependence on specific aspects of the quantile functions has never been studied. The aim of the present paper is to review quantile regression methods under standard constraints related to the stochastic black box framework, so as to provide information on the performance of the selected methods, and to recommend which metamodel to use depending on the characteristics of the computer simulation model and the data.
A comprehensive review of quantile regression is of course beyond the scope of the present work. We limit our review to the approaches that are best suited for our framework, while ensuring the necessary diversity of metamodels. In particular, we have chosen six metamodels that are representative of three main categories: approaches based on statistical order (K-nearest neighbors [KN] regression [7] and random forest [RF] regression [58]), functional or frequentist approaches (neural networks [NN] regression [18] and regression in reproducing kernel Hilbert space [RK] [86]), and Bayesian approaches based on Gaussian processes (Quantile Kriging [QK] [64] and the variational Bayesian [VB] regression [1]). Each category has some specificities in terms of theoretical basis, implementation and complexity. We begin this presentation by describing the methods in full in sections 3, 4 and 5.
In order to identify the relevant areas of expertise of the different metamodels, an original benchmark system is designed based on four toy functions and an agronomical model [19]. The dimension of the problems ranges from to and the number of observations from to . Particular attention is paid to the performance of each metamodel according to the size of the learning set, the value of the probability density function at the targeted quantile and the dimension of the problem. Sections 6 and 7 describe the benchmark system and detail its implementation, with particular focus on the tuning of the hyperparameters of each method. Full results and discussion are to be found in Sections 8 and 9, respectively.
2 Quantile emulators and design of experiments
We first provide the necessary definitions, objects and properties related to the quantile. The quantile of order of a random variable can be defined either as the (generalized) inverse of a cumulative distribution function (CDF), or as the solution to an optimization problem:
[TABLE]
is the CDF of and
[TABLE]
is the so-called pinball loss [45] (Figure 1). In the following, we only consider situations in which is strictly increasing and continuous.
Given a finite observation set composed of i.i.d samples of , the empirical estimator of can thus be introduced in two different ways:
[TABLE]
or
[TABLE]
where denotes an estimator of the CDF function. In (3) coincides with an order statistic. For example, if is the empirical CDF function then , where represents the smallest integer greater than or equal to and is the -th smallest value in the sample . The estimators (4) and (3) may coincide, but are in general not equivalent.
Similarly to (1), the conditional quantile of order can be defined in two equivalent ways:
[TABLE]
where is a random variable of distribution and is the CDF of .
In a quantile regression context, one only has access to a finite observation set \mathcal{D}_{n}=\big{\{}(x_{1},y_{1}),\allowbreak\ldots,\allowbreak(x_{n},y_{n})\big{\}}=(\mathcal{X}_{n},\mathcal{Y}_{n}) with a matrix. Estimators for (5) are either based on the order statistic as in (3) (section 3), or on a minimizer of the pinball loss as in (4) (sections 4 and 5). Throughout this work, the observation set is fixed (we do not consider a dynamic or sequential framework). Following the standard approach used in computer experiments, the training points are chosen according to a space-filling design [20] over a hyperrectangle. In particular, we assume that there are no repeated experiments: , ; most of the methods chosen in this survey (KN, RF, RK, NN, VB) work under that setting.
However, as a baseline approach, one may decide to use a stratified experimental design with i.i.d samples for a given , , extract pointwise quantile estimates using (3) and fit a standard metamodel to these estimates. The immediate drawback is that for the same budget () such experimental designs cover much less of the design space than a design with no repetition. The QK method is based on this approach.
3 Methods based on order statistics
A simple way to compute a quantile estimate is to take an order statistic of an i.i.d. sample. A possible approach is to emulate such a sample by selecting all the data points in the neighborhood of the query point , and then by taking the order statistic of this subsample as an estimator for the conditional quantile. One may simply choose a subsample of based on a distance defined on : this is what the -nearest neighbors approach does. It is common to use KN based on the Euclidean distance but of course any other distance can be used, such as Mahalanobis [93] or weighted Euclidean distance [30]. Alternatively, one may define a notion of neighborhood using some space partitioning of . That includes all the decision tree methods [16], in particular regression trees, bagging or random forest [58].
3.1 -nearest neighbors
The -nearest neighbors method was first proposed for the estimation of conditional expectations [82, 83]. Its extension to the conditional quantile estimation can be found in [7].
3.1.1 Quantile regression implementation
Define as the set of query points. KN works as follows: for each define the subset of containing the points that are the closest to the query point . Define the associated outputs, and define as the associated empirical CDF. Following (3), the conditional quantile of order can be defined as the statistical order
[TABLE]
Algorithm 1 details the implementation of the KN method.
3.1.2 Computational complexity
For a naive implementation of such an estimator, one needs to compute distances, where is the number of query points, hence for a cost in . Moreover, sorting distances in order to extract the nearest points has a cost in . Combining the two operations implies a complexity of order
[TABLE]
Note that some algorithms have been proposed in order to reduce the computational time, for example by using GPUs [34] or by using tree search algorithms [4].
3.2 Random forests
Random forests were introduced by Breiman [15] for the estimation of conditional expectations. They have been used successfully for classification and regression, especially with problems where the number of variables is much larger than the number of observations [27].
3.2.1 Overview
The basic element of random forests is the regression tree , a simple regressor built via a binary recursive partitioning process. Starting with all data in the same partition , the following sequential process is applied. At each step, the data is split into two, so that is partitioned in a way that it can be represented by a tree as it is presented Figure 2.
Several splitting criteria can be chosen (see [41]). In [58], the splitting point is the data point that minimizes
[TABLE]
where and are the mean of the left and right sub-populations, respectively. Equation (7) applies when the ’s are real-valued. In the multidimensional case, the dimension in which the split is performed has to be selected. The split then goes through and perpendicularly to the direction . There are several rules to stop the expansion of . For instance, the process can be stopped when the population of each cell is inferior to a minimal size : then, each node becomes a terminal node or leaf. The result of the process is a partition of the input space into hyperrectangles . Like the KN method, the tree-based estimator is constant on each neighborhood. The hope is that the regression trees automatically build neighborhoods from the data that should be adapted to each problem.
Despite their simplicity of construction and interpretation, regression trees are known to suffer from a certain rigidity and a high variance (see [14] for more details). To overcome this drawback, regression trees can be used with ensemble methods like bagging. Instead of using only one tree, bagging creates a set of tree based on a bootstrap version \mathcal{D}_{N,n}=\big{\{}\big{(}(x_{1_{t}},y_{1_{t}}),...,(x_{n_{t}},y_{n_{t}})\big{)}\big{\}}_{t=1}^{N} of . Then the final model is created by averaging the results among all the trees.
Bagging reduces the variance of the predictor, as the splitting criterion has to be optimized over all the input dimensions, but computing (7) for each possible split is costly when the dimension is large. The random forest algorithm, a variant of bagging, constructs an ensemble of weak learners based on and aggregates them. Unlike plain bagging, at each node evaluation, the algorithm uses only a subset of covariables for the choice of the split dimensions. Because the covariables are randomly chosen, the result of the process is a random partition of constructed by the random tree .
3.2.2 Quantile prediction
We present the extension proposed in [58] for conditional quantile regression. Let us define the leaf obtained from the tree containing a query point and
[TABLE]
[TABLE]
The ’s represent the weights illustrating the “proximity” between and . In the classical regression case, the estimator of the expectation is:
[TABLE]
In [58] the conditional quantile of order is defined as in (3) with the CDF estimator defined as
[TABLE]
Algorithm 2 details the implementation of the RF method.
3.2.3 Computational complexity
Assuming that the value of (7) can be computed sequentially for consecutive thresholds, the RF computation burden lies in the search of the splitting point that implies sorting the data. Sorting variables has a complexity in . Thus, at each node the algorithm finds the best splitting points considering only covariables (classically ). This implies a complexity of O\big{(}\tilde{d}n\log n\big{)} per node. In addition, the depth of a tree is generally upper bounded by . Then the computational cost of building a forest containing trees under the criterion (7) is
[TABLE]
[53, 95]. One may observe that RF are easy to parallelize and that contrary to KN the prediction time is very small once the forest is built.
4 Approaches based on functional analysis
Functional methods search directly for the function mapping the input to the output in a space fixed beforehand by the user. With this framework, estimating any functional of the conditional distribution implies selecting a loss (associated to ) and a function space . Thus, the estimator is obtained as the minimizer of the empirical risk associated to ,
[TABLE]
The functional space must be chosen flexible enough to extract some signal from the data. In addition, needs to have enough structure to make the optimization procedure feasible (at least numerically). In the literature, several formalisms such as linear regression [76], spline regression [56], support vector machine [92], neural networks [9] or deep neural networks [74] use structured functional spaces with different levels of flexibility.
However, using a too large can lead to overfitting, return predictors that are good only on the training set and generalize poorly. Overcoming overfitting requires some regularization (see [75, 100, 101] for instance), defining for example the regularized risk
[TABLE]
where is a penalization factor, and is either a norm for some methods (Section 4.2) or a measure of variability for others (Section 4.1). The parameter plays a major role, as it allows to tune the balance between bias and variance.
Classically, squared loss is used: it is perfectly suited to the estimation of the conditional expectation. Using the pinball loss (Eq. 2) instead allows to estimate quantiles. In this section we present two approaches based on Equation (11) with the pinball loss. The first one is regression using artificial neural networks (NN), a rich and versatile class of functions that has shown a high efficiency in several fields. The second approach is the generalized linear regression in reproducing kernel Hilbert spaces (RK). RK is a non-parametric regression method that has been much studied in the last decades (see [80]) since it appeared in the core of learning theory in the 1990’s [75, 92].
4.1 Neural Networks
Artificial neural networks have been successfully used for a large variety of tasks such as classification, computer vision, music generation, and regression [9]. In the regression setting, feed-forward neural networks have shown outstanding achievements. Here we present quantile regression neural network [18] which is an adaptation of the traditional feed-forward neural network.
4.1.1 Overview
A feed-forward neural network is defined by its number of hidden layers , its numbers of neurons per layer , and its activation functions , . Given an input vector the information is fed to the hidden layer composed of a fixed number of neurons . For each neuron , , a scalar product (noted ) is computed between the input vector and the weights of the neurons. Then a bias term is added to the result of the scalar product. The result is composed with the activation function (linear or non-linear) which is typically the sigmoid or the ReLu function [74] and the result is given to the next layer where the same operation is processed until the information comes out from the outpout layer. For example, the output of a -layers NN at is given by
[TABLE]
The corresponding architecture can be found in Figure 3.
The architecture of the NN defines . Finding the right architecture is a very difficult problem which will not be treated in this paper. However a classical implementation procedure consists of creating a network large enough (able to overfit) and then using techniques such as early stopping, dropout, bootstrapping or risk regularization to avoid overfitting [79]. In [18], the following regularized risk is used:
[TABLE]
4.1.2 Quantile regression
Minimizing Equation (13) (with respect to all the weights and biases) is in general challenging, as is a highly multimodal function. It is mostly tackled using derivative-based algorithms and multi-starts ( launching the optimization procedure times with different starting points). In the case of quantile estimation, the loss function is non-differentiable at the origin, which may cause problems to some numerical optimization procedures. To address this issue, [18] introduced a smooth version of the pinball loss function, defined as:
[TABLE]
where
[TABLE]
Note that if the optimizer is based on a first order method such as [44], then the transfer function does not require continuous derivatives. But using a second order method as it is done in the original paper implies the loss function to be twice differentiable with respect to the weights of the neural network. Then transfer functions such as logistic or hyperbolic tangent functions should be used over piecewise linear ones such as the ReLu or the PReLU functions [66].
Let us define the list containing the weights and bias of the network. To find , a minimizer of , the idea is to solve a series of problems using the smoothed loss instead of the pinball one with a sequence corresponding to decreasing values of . The process begins with the optimization with the larger value . Once the optimization converges, the optimal weights are used as the initialization for the optimization with , and so on. The process stops when the weights based on are obtained. Finally, is given by the evaluation of the optimal network at . Algorithm 3 details the implementation of the NN method.
4.1.3 Computational complexity
In [18] the optimization is based on a Newton method. Thus, the procedure needs to inverse a Hessian matrix. Without sophistication, its cost is with the size of the problem the number of parameters to optimize. Note that using a high order method makes sense here because NN has few parameters (in contrast to deep learning methods). Moreover providing an upper bound on the number of iterations needed to reach an optimal point may be really hard in practice because of the non convexity of (13). In the non-convex case, there is no optimality guaranty and the optimization could be stuck in a local minima. However, it can be shown that the convergence near a local optimal point is at least super linear (see [12] Eq. (9.33)) and may be quadratic (if the gradient is small). It implies, for each , the number of iterations until is bounded above by
[TABLE]
with the minimal decreasing rate, , the strong convexity constant of near and the Hessian Lipschitz constant (see [12] page 489). As increases very slowly with respect to , it is possible to bound the number of iterations typically by
[TABLE]
That means, near an optimal point, the complexity is , with the total number of neurons. Then using a multistart procedure implies a complexity of
[TABLE]
with .
4.2 Regression in RKHS
Regression in RKHS was introduced for classification via Support Vector Machine by [25, 39], and has been naturally extended for the estimation of the conditional expectation [29, 70]. Since, many applications have been developed (see [80, 75] for some examples), here we present the quantile regression in RKHS [86, 73].
4.2.1 RKHS introduction and formalism
Under the linear regression framework, is assumed to be under the form , with in . To stay in the same vein while creating non-linear responses, one can map the input space to a space of higher dimension (named the feature space), thanks to a feature map . Nevertheless, although large dimensional spaces enable more flexibility, it may introduce difficulties during the estimation procedure. A good trade-off can be found by combining regularized empirical risk
[TABLE]
and the RKHS formalism that is based on the representer theorem and the so-called kernel trick. Define as a -Hilbert functional space and let us assume there exists a symmetric definite positive function such that:
[TABLE]
Under this setting, is a RKHS with the reproducing kernel , that means for all and the reproducing property
[TABLE]
holds for all and all . It can be shown that working with a fixed kernel is equivalent to work with its associated functional Hilbert space. Note that the kernel choice is based on kernel properties or assumptions made on the functional space. See for instance [80], chapter 4, for some kernel definitions and properties. In the following, and denote respectively a RKHS and its kernel associated to the hyperparameters vector . is the kernel matrix obtained via .
From a theoretical point of view, the representer theorem implies that the minimizer of (15) lives in
[TABLE]
Combining this result to the definition (16) and the reproducing property (17), it is possible to write as:
[TABLE]
Hence, the estimation procedure becomes an optimization problem over coefficients . More precisely, finding is equivalent to minimize with respect to the quantity
[TABLE]
4.2.2 Quantile regression
Quantile regression in RKHS was introduced by [86], followed by several authors [50, 81, 23, 24, 73]. Quantile regression has two specificities compared to the general case. Firstly the loss is defined as the pinball. Secondly, to ensure the quantile property, the intercept is not regularized. More precisely, we assume that
[TABLE]
and we consider the empirical regularized risk
[TABLE]
Thus, the representer theorem implies that can be written under the form
[TABLE]
for a new query point . Since (19) cannot be minimized analytically, a numerical minimization procedure is used. [25] followed by [86] introduced non-negative variables to transform the original problem into
[TABLE]
subject to
[TABLE]
and
[TABLE]
Using a Lagrangian formulation, it can be shown (see [80] for instance) that minimizing is equivalent to the problem:
[TABLE]
It is a quadratic optimization problem under linear constraint, for which many efficient solvers exist.
The value of may be obtained from the Karush-Kuhn-Tucker slackness condition or fixed independently of the problem. A simple way to do so is to choose as the -quantile of \big{(}y_{i}-\sum_{j=1}^{n}\alpha_{j}k_{\theta}(x_{i},x_{j})\big{)}_{1\leq i\leq n}. Algorithm 4 details the implementation of the RK method.
4.2.3 Computational complexity
Let us notice two things. Firstly, the minimal upper bound complexity for solving (20) is . Indeed solving (20) without the constraints is easier and it needs . Secondly the optimization problem (20) is convex, thus the optimum is global.
There are two main approaches for solving (20), the interior point method [12] and the iterative methods like libSVM [21]. The interior point method is based on the Newton algorithm, one method is the barrier method (see [12] page 590). It is shown that the number of iterations for reaching a solution with precision is Moreover each iteration of a Newton type algorithm costs because it needs to inverse a Hessian. Thus, the complexity of an interior point method for finding a global solution with precision is
[TABLE]
On another hand, iterative methods like libSVM transform the main problem into a smaller one. At each iteration the algorithm solves a subproblem in . Contrary to the interior point methods, the number of iterations depends explicitly on the matrix . [51] shows that the number of iterations is
[TABLE]
where . Note that depends on the type of the kernel, it evolves in with an increasing value of the regularity of [22]. For more information about the eigenvalues of one can consult [13].
To summarize, it implies that the complexity of the libSVM method has an upper bound higher than the interior point algorithm. However, these algorithms are known to converge pretty fast. In practice, the upper bound is almost never reached, and thus the most important factor is the cost per iteration, rather than the number of iterations needed. This is the reason why libSVM is popular in this setting.
5 Bayesian approaches
Bayesian formalism has been used for a wide class of problems such as classification and regression [67], model averaging [11] and model selection [65]. The first Bayesian quantile regression model was introduced in [97] where the authors worked under linear frameworks combined with improper uniform priors. Nevertheless the linear hypothesis may be too restrictive to treat the stochastic black box setting. As an alternative [85] introduced a mixture modeling framework called Dirichlet process to perform nonlinear quantile regression. However the inference is performed with MCMC methods (see [36, 33] for instance), a procedure that is often costly. A possibility to overcome that drawback is the use of Gaussian process (GP). GPs are powerful in a Bayesian context because of their flexibility and their tractability (GPs are only characterized by their mean and covariance ). Using GPs, a possible approach is to use a joint modeling of the mean and variance, assuming that the distribution is Gaussian everywhere, and then to extract the quantiles of interest as it is done in [43, 47]. Nevertheless this strategy may introduce a high bias when the true output distribution is not Gaussian.
In this section we present QK and VB, two approaches that use GP as a prior for . Contrary to the joint modelling approach, here the GP prior for does not imply any structure on the output distribution, which allows the creation of very flexible quantile models.
5.1 Kriging
Kriging is based on the hypothesis that
[TABLE]
Which means for every finite set , the output \big{(}S(x_{1}),\cdots,S(x_{T})\big{)} is multivariate Gaussian. Here is the mean of the process and is a kernel function also known as the covariance function. Note that in the sequel we take in order to simplify the computations and notations. The covariance function conveys many properties of the process, so its choice should depend on the assumptions made on . A first classical assumption is that the GP is stationary, the correlation between two inputs does not depends on the location but only on the distance between the points. Then, different class of stationary kernels produce GPs with different regularities. The class of Matérn kernels is very convenient because it depends on a regularity hyperparameter that enables the end user to adapt its prior to his regularity assumptions (see [67] for more details). For example, the Matérn kernel is defined as
[TABLE]
where and
[TABLE]
with a diagonal matrix with diagonal terms the inverses of the squared length scales , .
In addition to the assumption 21, let us assume is observed with noise such that
[TABLE]
with . As a consequence the associated likelihood is Gaussian,
[TABLE]
with Because \big{(}\mathcal{Y}_{n},S(x_{*})\big{)}^{T} is a Gaussian vector of zero mean and covariance
[TABLE]
the distribution of knowing is still Gaussian (see [67] appendix A.2 for more details). Thus, it is possible to provide the distribution a posteriori for Kriging regression as
[TABLE]
with
[TABLE]
[TABLE]
As in Section 4.2, the covariance functions are usually chosen among a set of predefined ones (for example the Matérn see Eq.22), that depend on a set of hyperparameters . The best hyperparameter can be selected as the maximizer of the marginal likelihood. More precisely it follows (see [67] for instance) that
[TABLE]
where is the determinant of the matrix . Maximizing this likelihood with respect to is usually done using derivative-based algorithms, although the problem is non-convex and known to have several local maxima.
Different estimators of may be extracted based on (26). Here is fixed as . Note that this classical choice is made because the maximum a posteriori of a Gaussian distribution coincides with its mean.
5.1.1 Quantile kriging
As is a latent quantity, the solution proposed in [64] is to consider the sample corresponding to a design of experiments with different points that are repeated times in order to obtain quantile observations. For each , , let us define:
[TABLE]
and
[TABLE]
Following [64], let us assume that
[TABLE]
Note that from a statistical point of view Assumption (28) is wrong because the distribution is asymetric around the quantile but asymptotically consistent as illustrated by the central limit theorem for sample quantiles. The resulting estimator is
[TABLE]
with \mathcal{Q}_{n^{\prime}}=\big{(}\hat{q}_{\tau}(x_{1}),\dotsb,\hat{q}_{\tau}(x_{n^{\prime}})\big{)} and .
There are several possibilities to evaluate the noise variances . Here we choose to use a bootstrap technique (that is, generate bootstrapped samples of , compute the corresponding values and take the variance over those values as the noise variance) but it is possible to use the central limit theorem as it is presented in [5]. The hyperparameters are selected based on changing by . Algorithm 5 details the implementation of the QK method.
5.1.2 Computational complexity
Optimizing (27) with a Newton type algorithm implies to inverse a matrix. In addition, for each , obtaining the partial derivatives of (27) requires the computation of [67]. Thus, at each step of the algorithm the complexity is . Assuming the starting point is close to an optimal , based on the same analysis as in section 4.1.3, the complexity to find is
[TABLE]
with the Hessian Lipschitz constant.
Finally, obtaining from (29) implies inversing the matrix that is in . So the whole complexity is
[TABLE]
5.2 Bayesian variational regression
Quantile kriging requires repeated observations to obtain direct observations of the quantile and make the hypothesis of Gaussian errors acceptable. Variational approaches allow us to remove this critical constraint, while setting a more realistic statistical hypothesis on . Starting from the decomposition of Eq.23, is now assumed to follow a Laplace asymmetric distribution [98, 55], implying:
[TABLE]
with the priors on and that has to be fixed. Note that such assumption may be justified by the fact that at fixed, minimizing the empirical risk associated to the pinball loss is equivalent to maximizing the asymmetric Laplace likelihood, which is given by
[TABLE]
According to the Bayes formula, the posterior on can be written as
[TABLE]
As the normalizing constant is independent of , considering only the likelihood and the prior is enough. We obtain
[TABLE]
Because of the Laplace asymetric likelihood, contrary to the classical kriging model, here the posterior distribution (32) is not Gaussian anymore. Thus, it is not possible to provide an analytical expression for the regression model. To overcome this problem, [10] used a variational approach with an expectation-propagation (EP) algorithm [60], while [1] used a variational expectation maximization (EM) algorithm which was found to perform slightly better.
5.2.1 Variational EM algorithm
The EM algorithm was introduced in [26] to compute maximum-likelihood estimates. Since then, it has been widely used in a large variety of fields (see [57] for more details). Classically, the purpose of the EM algorithm is to find a vector of parameters that define the model and that maximizes thanks to the introduction of the hidden variables . However dealing with this classical formalism implies that is known or some sufficient statistics can be computed (see [90, 69] for more details), which is not always possible. Using the variational EM framework is a possibility to bypass this requirement [90], by approximating by a probability distribution that factorizes under the form
[TABLE]
Starting from the log-likelihood , thanks to Jensen’s inequality, it is possible to show that:
[TABLE]
where
[TABLE]
and is the Kullback-Leibler divergence:
[TABLE]
As presented on Figure 4, the EM algorithm can be viewed as a two-step optimization technique. The lower bound is first maximized with respect to (E-step) so that to minimize . Next the likelihood is directly maximized with respect to the parameter (M-step).
Classically and in the following, the E-step optimization problem is analytically solved (see [90] for details about the computation). In this particular case, the quantities are limited to conditionally conjugate exponential families. But note that different strategies have been developed to relax this assumption (generally it comes with an higher computational complexity) so that creating more flexible models (see the review [99] for instance).
5.2.2 Variational EM applied to quantile regression
Following [1], let us suppose that
[TABLE]
[TABLE]
with defining the inverse gamma distribution and for sake of simplicity, . Note that contrary to the formalism introduce with QK, here is taken as a random variable. To allow analytical computation, let us introduce an alternative definition of the Laplace distribution [55, 46]:
[TABLE]
where , and is distributed according to an exponential distribution of parameter .
The distribution of at a new point is given by averaging the output of all Gaussian models with respect to the posterior :
[TABLE]
Here the crux is to compute the posterior
[TABLE]
To do so, in [1] the authors use as hidden variables and as parameters and the variational factorization approximation
[TABLE]
The EM algorithm provides a nice formalism here. Although the goal is to find such that p\big{(}\mathcal{Y}_{n}|\mathcal{X}_{n},\boldsymbol{\theta}\big{)} is maximal, the algorithm estimates the underlying GP (i.e. p\big{(}q_{\tau},\sigma,w|\mathcal{D}_{n}\big{)}) that is able to have a likelihood as large as possible. Then the estimated value is plugged into (34) to provide the final quantity of interest.
E-step.
Because the posteriors are conjugated, it is possible to obtain an analytical expression of the optimal distribution :
[TABLE]
where
[TABLE]
and
[TABLE]
with
[TABLE]
The posterior on is a Generalized Inverse Gaussian GIG with :
[TABLE]
and
[TABLE]
Due to numerical problems, in [1] the authors use the restriction . Finding the best is done numerically. Then finding the best is equivalent to maximizing:
[TABLE]
with
[TABLE]
and
[TABLE]
M-step.
Ignoring terms that do not depend on , we obtain the lower bound:
[TABLE]
The optimization of with respect to is done using a numerical optimizer.
Recalling the goal is to compute (34), thanks to (35), we make the approximation:
[TABLE]
Then we obtain
[TABLE]
where
[TABLE]
Finally, as explained in section 5.1.1, the quantile estimator is selected as . Algorithm 6 details the implementation of the VB method.
5.2.3 Computational complexity
E-step.
The complexity of this step is in
[TABLE]
In fact the algorithm computes that implies inversing a matrix of size .
M-step.
Optimizing with a Newton type algorithm costs at each iteration (for details refer to the optimization description of (27)). Assuming the starting point is close to an optimal , based on the same analysis as in section 4.1.3, the whole complexity is in
[TABLE]
Overall complexity.
At each iteration of the EM algorithm, the computation cost is . The final complexity is obtained by multiplying by the number of iterations of the EM algorithm. Thus, the overall complexity is in
[TABLE]
6 Metamodel summary and implementation
In this section we detail our implementation procedure. After providing a summary of the six metamodels in Table 1, we present the packages we used and the hyperparameters we chose (which hyperparameters we set and which hyperparameters we optimized). We then describe the procedure we used to optimize the hyperparameters (optimization strategies and evaluation metrics).
6.1 Summary of the models
Table 1 lists the analytical expressions of the six metamodels, along with the associated underlying quantity.
6.2 Packages and hyperparameter choices
Each method depends on many parameters that can be tuned to improve performance, for example the choice of the kernel function and the value of its parameters for RK, QK and VB or the penalization factor for RK and NN. Here, to limit the computational burden, we chose to optimize only the most critical ones. When possible, for the other parameters, we applied the arbitrary choices and values made by the authors of the original papers. Most changes were made to improve robustness. Below, we describe our experimental settings, also summarized in Table 2.
Nearest Neighbors.
We set as the Euclidean distance and optimized only the size of the neighborhood.
Random forest.
In this case, the only hyperparameter we optimized was the maximum size of the leaves . Regarding the number of trees, we noticed that the metamodel needs many more trees than are needed for the estimation of the expectation. In some problems, the metamodel needs up to 5,000 trees to stabilize the variance. Thus, in our experiments we set the number of trees at 10,000 in all cases. We set the number of dimensions considered for the split at the default choice . The depth of the tree is not constrained and the splitting rule is based on Eq. 7. We used the R package QuantregForest [59].
Neural network.
Based on [18], we set the number of hidden layers at one and the transfer function as the sigmoid. The optimization algorithm is a Newton method, we set at with and the number of multistarts to optimize the empirical risk at five. We optimized the number of neurons in the hidden unit and the regularization parameter . The metamodel is generated using the R package qrnn [18].
Regression in RKHS.
The kernel was set as a Matérn 5/2. We optimized the length scale parameters and the regularization hyperparameter . Optimization (20) is done with the quadratic optimizer quadprog [89].
Quantile Kriging.
The kernel was set as a Matérn 5/2. The number of repetitions was set according to the total number of observations (see Table 4). We optimized the length scale hyperparameter and variance hyperparameter . QK is implemented in the R package DiceKriging [72].
Variational regression.
The kernel was set as a Matérn 5/2, the number of EM iterations at . We optimized the length scale hyperparameter and variance hyperparameter . The implementation is based on the Matlab code provided in [1].
6.3 Tuning the hyperparameters
In the previous section, we defined the hyperparameters we wanted to optimize for each method. In fact, once the type of metamodel is chosen, the quantile estimator is given by a function where are called hyperparameters and is metamodel dependent. Hyperparameter optimization (also known as model selection) is an essential procedure when dealing with non-parametric estimators. Although may be very efficient on , the prediction may perform very poorly on an independent dataset . The goal is to find the that provides the best possible generalized estimator. In the following, we present the validation metric used to optimize the hyperparameter values and detail the hyperparameters optimization procedure associated with each method.
6.3.1 Metrics
In the standard conditional expectation estimation, the validation and performance metrics are both based on , where is the estimator and the targeted value. With the quantile estimation procedure the two metrics are no longer the same. The goal is to find such that is as small as possible. However, is unobserved so the validation metric cannot be based on the norm. Here we present two metrics able to measure the generalization capacity of a quantile metamodel.
Bayesian metamodels (QK and VB) have their own validation metric, this is the likelihood function that can be maximized with respect to . For quantile kriging, we use (27) while in the variational approach we use (36). The optimal hyperparameters are then:
[TABLE]
The second metric available for all metamodels is -fold cross-validation associated with the pinball loss. The metric can be computed as follows. First, the data are split into parts, then the model is trained on , the training set without the -th part. The performance is evaluated on the remaining part . As the quantile minimizes the pinball loss (on ), the evaluation metric is
[TABLE]
where is the number of observations in each fold. The optimal cross-validation hyperparameters are then:
[TABLE]
In our experiments, we chose to limit the computational cost. However, we observed empirically that choosing a larger did not substantially modify the performances of the metamodels. Although cross-validation is available for QK, we chose to stay in the spirit of the methods and to only use likelihood to select hyperparameters. Our choice is supported by [5] that does not show a clear improvement using cross validation instead of maximum likelihood techniques.
6.3.2 Hyperparameters optimization procedure
Both likelihood functions come with analytical derivatives, enabling the use of gradient-based algorithms. However, since both functions are multi-modal, multi-start techniques are necessary (and generally very efficient, see [38]) to avoid being trapped in local optima. To account for the increasing difficulty of the optimization task with the dimension while limiting the computational cost, we ran optimization procedures from different starting points and chose the set of starting points based on a maximin Latin hypercube design.
For QK, the BFGS algorithm is used to optimize (27). For VB, two derivative-based optimizers are used alternately for the E- and M-steps. Since each step may lead the algorithm toward a local minimum, we chose to apply the multi-start strategy in the entire EM procedure.
Optimization of the cross-validation metric (38) is done under the black box framework, since no structural, derivative or even regularity information is available. Hence, all optimizations are carried out using the branch-and-bound algorithm named Simultaneous Optimistic Optimization (SOO) [62]. SOO is a global optimizer, hence robust to local minima.
We used [87] to parallelize the computations.
6.3.3 Oracle metamodels
Each method presented in this paper is a trade-off between power and the difficulty of finding good hyperparameters. A good method should be powerful (i.e. provide flexible fits) but easy to tune. In order to assess the strengths and weaknesses of the hyperparameter tuning methods in addition to standard metamodels, we provide what we call the oracle metamodels for each problem. Instead of using the cross-validation or likelihood metric, the oracle tunings are directly based on the evaluation metric
[TABLE]
where is the size of the test set. In a sense, they provide a upper bound on the performance of each method. This allows us to show which metamodels have the potential to tackle the problems and which are intrinsically too rigid or make poor use of information. In addition, this allows us to directly assess the quality of the validation procedure.
7 Benchmark design and experimental setting
Many factors can affect the efficiency of methods to estimate the right quantile. For our benchmark system, we considered five models or test cases to evaluate the performance of the six metamodels. We decided to focus primarily on the dimensionality of the problem, the number of training points available, the signal-to-noise ratio defined as
[TABLE]
and the pdf value at the targeted quantile for test cases in which the distribution shape and the distribution spread (i.e. level of heteroscedasticity) can vary significantly. Our two objectives were to:
discover if there is a single best method for all factors variations considered or specific choices depending on the configuration at hand, and 2. 2.
assess the performance of the quantile regression, and in particular, the configurations for which the current state-of-the-art is insufficient.
A full 3D factorial experimental design was used to analyze the efficiency of the metamodels, the 3 factors being the test case (4 test cases), the number of training points (4 levels) and the quantile order (0.1, 0.5 and 0.9). We used part of this complete design to focus our analyses on the characteristics of the test cases (dimension, pdf shape and heteroscedasticity).
7.1 Test cases and numerical experiments
Test case 1
is a d toy problem on defined as
[TABLE]
with
The signal-to-noise ratio is , it is consider as small. The pdf value varies substantially according to for all . Indeed, on the interval , for all values of , the pdf is very large (almost equal to ) because the variance of the distribution on this interval is very small. In contrast, for (resp. ) the pdf is very small in the interval (resp. ). In the pdf of the -quantile is equal to the pdf of the -quantile of a normal distribution of variance that is, for example, approximately equal to for . Because of this important variations, we consider the values of the pdf for all quantiles of interest as variable.
Test case 2
is a d toy problem on based on the Griewank function [28], defined as
[TABLE]
with
[TABLE]
and
The signal-to-noise ratio is , it is consider as small. The pdf value varies substantially according to . Indeed, for (resp. ) the pdf is small (resp. very small), more precisely the pdf of the -quantile (resp. -quantile) is equivalent to the pdf of the -quantile (resp. -quantile) of a normal distribution of variance (resp. ) with that takes values in . That implies varies with respect to as well. Note that close to the pdf is very large because of the very small variance of the associated distribution. The pdf at the -quantile is discontinuous. To the left of the -quantile the pdf is equal to the pdf at the median of a normal distribution of variance while to the right it is equal to the pdf at the median of a normal distribution of variance . To treat this discontinuity, the value of the pdf is considered as the maximum of both sides. Thus, for this particular case the pdf is considered as large.
Test case 3
is a d toy problem based on the Michalewicz function [28] on , defined as
[TABLE]
with .
The signal-to-noise ratio is , we consider it as small. The pdf value varies substantially according to and . The conditional distribution of this problem is not a classical one but it is close to the distribution of with one degree of freedom. It implies at fixed, the pdf value increases with . For the -quantile (resp. -quantile) the mean of the pdf in the interval is approximately (resp. ). According to the pdf varies as well. For the variance of the conditional distribution is very small thus the pdf near the quantiles of interest is very large. The value of the pdf at the -quantile is between the value of the pdf at the and quantile. Thus, we consider the pdf at as globally small and at and at as globally large.
Test case 4
is a d toy problem based on the Ackley function [3] on , defined as a function
[TABLE]
with
[TABLE]
and
[TABLE]
with , , and follows a log-normal distribution of parameters .
The signal-to-noise ratio is , it is consider as large. The pdf value varies substantially according to and . Indeed, for (resp. ) the pdf is large (resp. very small). At the conditional distribution of this test case is a log-normal distribution of parameters \big{(}\log R(x),1\big{)}. The expectations of the pdf value at different values of are , and . Thus, the pdf at is consider as large, the pdf at and are consider as small and very small.
To provide a better intuition about this problem, we plotted what we call the marginals. For all dimensions except the -th, the values of the input are fixed to and the -th dimension varies. Figure 7 represents the evolution of the quantiles w.r.t. the -th dimension for two different and for . In particular it shows that the difference between the and -quantile depends significantly on .
Note that on those four toy problems, the random term is defined such that the resulting distribution of would be strongly asymmetric. As is also multiplied by a factor that depends on the distribution of is also heteroscedastic. The first three toy problems are represented in Figure 5 and some illustrations of the fourth test case are available Figure 7.
Test case 5
is based on the agronomical model SUNFLO, a process-based model which was developed to simulate sunflower grain yield (in tons per hectare) as a function of climatic time series, environment (soil and climate), management practices and genetic diversity. The full description of the model is available in [19]. In the regression model we consider corresponding to nine macroscopic traits that characterize the sunflower variety. Although SUNFLO is a deterministic model, for each simulation the climatic time series are randomly chosen within a database containing years of weather records, which makes the output stochastic (see also [63] for more details).
The signal-to-noise ratio is . The pdf value varies substantially according to , more precisely , and . Thus, the pdf at and at are consider as large, and the pdf at is consider as small.
In addition, the shape of the distribution varies significantly with respect to the input as illustrated Figure 6.
Numerical experiments.
On all problems, we consider four sample sizes. Those sizes depend on the dimension and are empirically chosen so that the smallest size corresponds to the minimal information required by the metamodels to work and the largest size is chosen keeping in mind the potentially high cost of simulators. Besides, our focus is on computer experiments, where data sizes rarely exceed thousands of points. For the problems, the points are generated on a uniform grid. For the and problems, the observations are taken on a Latin hypercube design optimized for a maximin criterion to ensure space-filling [32]. The same samples are used by all methods except QK, as it requires repetitions. For QK, the number of distinct points and number of repetitions depends on the budget. The different sample sizes are reported in Table 4. Finally, for each sample size and problem, 10 samples are drawn in order to assess robustness with respect to the data.
7.2 Structuration between the questions and the numerical setting
Factors.
Three factors are explicit in our benchmark system: the number of training points, the problem dimension and the quantile level. The other factors depend on the characteristics of the problem concerned: shape variation, pdf value at the quantile, level of heteroscedasticity, signal-to-noise ratio. For all four test cases, we consider three quantile levels: , and . Note that due to the asymmetry of the problems, learning for the and quantiles is not equivalent in terms of difficulty. Indeed, when the response is heteroscedastic (a variance/spread depending on ) and/or when the shape of varies in , the pdf may vary in as well. Intuitively, quantiles with large pdf values are easier to learn, as the data points may be closer to them. Figure 8 illustrates this effect. Table 3 summarizes the characteristics of our design concerning the number of training points with respect to the dimension of the test case. To make our results easier to analyze, we divided the problems into groups that allow us to focus on subsets of factors.
Focus 1: is there a universal winner?
To provide a universal ranking of the methods, we use all test cases, training points and quantile levels. As highlighted in Table 3, we created a set of different problems representative of a large number of characteristics that could be met dealing with any quantile regression problem. Note that our benchmark system is slightly biased towards small-dimensional problems, since only three-fifths of the cases have a dimension higher than two.
Focus 2: what behavior with respect to the dimension, the number of training points, signal-to-noise ratio and pdf value?
To analyze the effects of these factors on the performance of the methods, we combine toy problems , , , and the SUNFLO model. Note that once the pdf value is taking as a explanation variable, toy problem is excluded from the group because the pdf value near all the studied quantiles cannot be classified as large or small.
7.3 Performance evaluation and comparison metrics
Assessing the performance of quantile regression is not an easy task when only limited data are available. Here, since we are considering toy problems (exept for SUNFLO, in that case the true quantile values are taken as the quantiles of the years of weather records), the true quantile values can be approximated with precision, so we can evaluate the error for each emulator. The value of the criterion is privided by (39).
We chose for the problems and for the others. Now, since the problems vary in difficulty and in their response range (Figure 5), cannot be aggregated directly over several problems or configurations. To do so, we normalize this error by the error obtained by a constant model (the constant being taken as the quantile of the sample):
[TABLE]
where stands for constant quantile.
As an alternative criterion, we consider the ranks of the metamodels based on their error. Although ranks do not provide information regarding the range of errors, they are insensitive to scaling issues, which makes aggregation between configurations more sensible. They allow us to assess whereas any method consistently outperforms others, regardless of overall performance.
8 Results
8.1 Focus 1: overall performance and ranks
First, we consider the overall performance and ranks, integrated over all runs. We have considered test cases, for each test case we have generated sizes of training sets, for each test case and sample size 10 samples are drawn and for each of this occurrences we have estimated different conditional quantiles. Thus, we have experiments. They are shown as boxplots in Figure 9. Based on these ranks (Figure 9, left), VB appears to be the best solution since it is ranked either 1st or 2nd in 50% of the problems. RK is in second position, its median is the same as VB but it is generally ranked between 2nd an 3rd. In addition RK seems slightly less risky than VB in the sens that it is almost never rank 5th or 6th. KN is the worst since its median rank is equal to five.
However, all boxplots range between 1 and 6, indicating that no method is outperformed by another on all problems. This finding is reinforced by the performance boxplots (Figure 9, right), where all median performances are similar (VB and RK being the best and QK the worst which means QK may be very bad sometimes), and the variance is very large. Indeed, the errors range from 2% for NN (of the error achieved by a constant metamodel) to 500% for QK, all methods experiencing cases with more than 100% error (i.e. situations where they are worse than the constant metamodel).
8.2 Focus 2: dimension, number of training points and pdf value
8.2.1 Performance according to the constant quantile
In this section, we analyze the performance of the methods with respect to the pdf value and the number of points.
Sample size:
Figure 10 shows the performances of the methods grouped according to the size of the sample. As expected, the performances increase with the size of the sample. For size (), the distribution of of all the metamodels is almost centered around 100%, implying that these correspond to limit cases for quantile regression since the metamodels do not outperform the constant metamodel (although in some cases the error is as small as 40%). For size (), the median performance is roughly 50% (twice as accurate as the constant metamodel). BV, RK and especially NN experience situations with very accurate models. However, all the methods also experience bad performances (error greater than 100%) in the large sample regime. Unfortunately, from Figure 10 we can conclude that no method is sufficiently robust in all cases.
Signal-to-noise ratio.
Figure 12 groups performance with respect to the signal-to-noise ratio. According to the figure the performance depends to a great extent on the signal-to-noise ratio. Dealing with a high signal and considering the performance, there is a clear difference between the statistical methods (KN, RF) and the four others (RK, NN, VB, QK) while this difference is not visible in the small signal setting. The impact of the signal-to-noise ratio is strong on the performance. Dealing with a high signal, the median of the performance for NN, RK, QK, VB is close to 20% with a small variance while if the signal is small, the error is larger (the median is above 50% for all methods) and the variance is larger.
In the following we focus our interest only on cases with small signal-to-noise ratio. Indeed as the performance of RK, NN, QK and VB are close to each others, we think we do not have enough experiments to extract patterns.
Pdf value with small signal-to-noise ratio.
Figure 12 groups performance with respect to sample size (either small, i.e. level 1 and 2 or large, i.e. level 3 and 4) and pdf value (according to Table 3). According to the Figure 11, the performance depends to a great extent on the pdf value in the neighborhood of the targeted quantile. With a small , the pdf value has no significant impact on the median of the performance (except for VB) but it does have an impact on the lower bound of the error. More precisely, the median of the error does not depend on the pdf value in the case of a small pdf but sometimes the metamodel errors are sensibly smaller when the pdf is large. With large samples, both the median and the lower bound of the error depend on the pdf value. Metamodels may be very good when the pdf is large, for example times better than the constant metamodel for NN whereas the error appears to have a lower bound when the pdf is small even with large . In addition, for a problem with a small and a large pdf, the performance is similar to the performance for problems with a large and a small pdf (Figure 12, see the two columns in the center).
8.2.2 Rank in the context of a low signal-to-noise ratio
Pdf value.
Figure 13 shows clearly that when the pdf is large, VB is the best model while when the pdf is small (and the problem is heteroscedastic), VB is less good than RN, RK and KN. This observation is supported by Figure 12 which reveals a strong contrast between the performance of the VB method. QK is poor in both cases, whereas RK performs comparatively better with small pdf.
Sample size.
Figure 14 shows that the number of points has a major impact on the ranking of some methods. The ranking of QK and VB is relatively insensitive to the size of the sample. The other methods are less distinguishable when the sample size is small than when it is large. With a small sample KN, RF, NN and RK are comparable, whereas when the sample size increases, NN and RK clearly outperform KN and RF. For the largest size, NN is slightly better than VB.
Dimension.
Figure 15 groups performance based on dimension. The first contrast is the permutation between RK and NN. With a small dimension, RK is better than NN but the relative performance of NN increases w.r.t. the dimension. With small dimensions, RF and KN are comparable, but with high dimensions, RF outperforms KN.
High dimension, small pdf.
Figure 16 shows an extreme case in which the pdf is small but the dimension is high. With a small , the best method is clearly RF followed by RK and KN. VB and QK are not well ranked. With a larger , as mentioned above, NN and VB are better but with large variance, while RF, RK and KN rank less well.
9 Extensions and open questions
9.1 Effect of hyperparameter tuning
In the following we define
[TABLE]
the performance gap between the regular metamodel and its oracle performance (the loss in performance between actual hyperparameter tuning and oracle tuning). Figure 17 gives the average values of aggregated respectively over all problems and only aggregated over the problems with a large pdf, and considering the effect of dimension and sample size. In high dimension, the easiest methods to tune are KN, NN, and RF. In our study, KN and RF have a single hyperparameter to tune regardless of the dimension, and NN has two. This is clearly an advantage in terms of robustness in high dimension. The other methods are kernel-based and require the tuning of at least hyperparameters. This consistently affects RK and QK, but affects VB only in the case of small pdf, while it is the most stable method in the other cases.
With a small dimension, all the methods have roughly the same number of hyperparameters. The most noticeable change compared to the case of a high dimension is the good performance of RK, while NN becomes comparatively the most difficult method to train.
9.2 On the methods’ behavior
Statistical order methods.
As presented on Figure 11 this methods are not relevant on high signal-to-noise regime. A possible explanation is the difficulty to fit smooth variations with high amplitudes with a piecewise constant model.
Concerning the low signal-to-noise regime, it is clear from Figure 15 that KN performs poorly in a high dimension. This may be due to the irrelevance of the Euclidean distance when there is a significant increase in dimension. RF clearly outperforms KN in this situation, as it is able to produce better neighborhoods than the Euclidean distance. Overall, (compared with the other methods), RF performance increases with dimension. This may be due to the fact that it has fewer hyperparameters to tune.
Functional methods.
As presented on Figure 11 this methods are relevant on high signal-to-noise regime.
Concerning the low signal-to-noise regime, Figure 14 shows that NN works poorly in a small sample setting, but it is one of the best methods when the sample is large. This result reflects the high flexibility of NN. Too much flexibility leads to overfitting when the sample is small. In contrast, when the number of points is large, NNs are able to fit the data very well (e.g. Figure 10, Size ). According to Figures 10 and 14, RK is a robust method. Its robustness in both small and large data settings can be attributed in part to the selected kernel. If the selected kernel is sufficiently smooth (here continuous and derivable), the resulting metamodel cannot produce instable results. However, it seems (Figure 10, Size and ) that this lack of flexibility may affect the performance with an increase in the size of the data set. In this case, more flexible methods like NN may outperform RK. The contrast between RK and NN shown in Figure 15 can be explained by the level of difficulty associated with each method involved in finding good hyperparameters (as explained above).
Bayesian models.
As presented on Figure 11 this methods are relevant on high signal-to-noise regime.
Dealing with low signal-to-noise ratio the QK method under-performs comparing to others. One possible explanation is the erroneous assumption in Equation (28) that the noise is centered, which is more critical for extreme quantiles. Another possible explanation lies in the small number of replica. The local inference (that uses statistical orders) is biased and in a low signal-to-noise regime it has high variance. In addition, the increasingly bad performance of QK with an increase in dimension (Figure 10) is likely a consequence of the fact that empty areas become larger in high dimensions.
VB is one of the best methods presented in our paper. Figures 13 and 17 show that VB is also the most dependent on the pdf value. When the pdf is large, it is the best method whereas when the pdf is small (and the shape of the distribution and/or the variance depend on the input), it may be the worst. The explanation lies in the philosophy of the model. In the case of RN and RK, the model complexity (i.e. smoothness) is almost entirely related to the regularity of parameter that is selected by cross-validation. Hence, the model cannot excessively overfit and cannot perform very poorly. With Bayesian methods, the regularization is included in the model hypothesis: in our setting, the quantile is assumed to be a Gaussian process with covariance function , so performs the regularization. We observed that if the local quantity of information (roughly the product of the number of points times the pdf value in the neighborhood of the quantile) is too small comparing to the information needed to fit well the quantile, the metamodel tends to interpolate the available data. When sufficient information is available, the optimization of the marginal likelihood provides values that allow a good trade-off between flexibility and smoothness. This is likely the reason why VB is easily beaten by RN and RK when the pdf is small.
9.3 Varying shape and heteroscedasticity.
If the shape of or the variance of (heteroscedasticity) vary w.r.t. , then may vary in . Figure 18 illustrates the ability of RF, RK and VB to estimate quantiles of a distribution with a strongly varying shape. In this problem, as depicted in Figure 18 (top row), the quantiles are not perfectly estimated but the metamodels provide good indications about the shape of the true distribution. However, as can be seen in Figure 18 (bottom row), the methods can present strong instabilities. Here, for a sample virtually indistinguishable from the one leading to accurate estimates, the median estimates largely overestimate the true values for large values. Such instabilities can be partly imputed to the difficulty of the task. However, this is also because no method is actually designed to deal with strongly varying pdf, as we explain below.
An ideal method would be almost interpolant for a very large pdf but only loosely fit the data when the pdf is small. Indeed, if the pdf is very large then the output is almost deterministic, thus the metamodel should be as closer as possible to the data. In the small pdf case, a point does not provide a lot of information. Information should be extracted from a group of points, that means the metamodel must not interpolate the data. However, most of the methods presented here rely on a single hyperparameter to tune the trade-off between data fitting and generalization: the number of neighbors for KN, the maximum size of the leafs for RF and the penalization factor for NN and RK. As a result, the selected hyperparameters are the ones that are best on average. Theoretically, this is not the case for the Bayesian approaches: QK accounts for it via the error variance computed by bootstrap, and the weights (Eq. 33) allow VB to attribute different ”confidence levels” to the observations. However in practice, both methods fail to tune the values accurately, as we illustrate below. Figure 19 shows the three quantiles of toy problem 3 and their corresponding RF, RK and VB estimates. For in particular, the pdf ranges from very small ( close to 0) to very large ( close to 4). Here, RF and RK use a trade-off that globally captures the trend of the quantile, but cannot capture the small hill in the case of large . Inversely, VB perfectly fits this region but dramatic overfitting occurs on the rest of the domain.
Finally, Figure 20 illustrates that this is not an issue of hyperparameter tuning. For each method, we show the oracle estimate, a tuning that tends to underfit and another that tends to overfit. One can see that no tuning is entirely satisfactory, since capturing the region with high pdf leads to overfitting on the rest of the domain and vice-versa.
We believe that further research is necessary to obtain estimators that intrinsically account for strong heteroscedasticity and varying shape. One possible direction is the use of stacking, in the spirit of [78]. Under the stacking framework the final estimator could be
[TABLE]
where is a set of metamodel and is a set of weight functions. Choosing such that they correspond to different pdf values might provide more flexible estimates.
9.4 On the non-crossing of the quantile functions
While the quantile functions (for different quantile levels) may obviously never cross, unfortunately, their estimators may not always satisfy this property. This is a well-known issue against which none of the methods presented here is immune.
The neighborhood approaches first estimate the CDF, then extract the quantiles. If the hyperparameters are the same for all quantiles, crossing is impossible. However in our setting, different neighborhood sizes were used for different quantiles.
With functional analysis approaches, crossing may happen even if each quantile is built with the same hyperparameters. In the literature, authors have produced methods to address this issue. It could be reduced by the introduction of additional constraints in the model [86] or by the construction of a new model that intrinsically produces non-crossing curves [73]. However in both cases, the dimension of the optimization problem then increases significantly.
Finally the stochastic process approaches estimate each quantile in independent Gaussian processes, so crossing may occur. While the number of training points is larger than what we consider here ( repetitions for each input point), [17] use GP and takes into account all the quantile orders at the same time and thus ensures non-crossing.
Another approach available for all the methods presented here is related to the rearrangement of curves or isotonic regression [6, 2]. The idea is to perform many quantile regressions with a large number of different values of or a large set of bootstrapped versions of and then to rearrange the curves, thereby obtaining the whole distribution and then extracting the quantiles that by definition do not cross.
In theory, adding non-crossing constraints and predicting several quantiles simultaneously could improve the quality of the estimates (in particular as it might add some robustness). However, in practice, it also makes the model more rigid (i.e. a single regularization hyperparameter for all quantiles), and preliminary experiments have shown no gain in accuracy compared to independent predictions, despite a considerably higher computational cost. Hence, multi-quantile predictors were not considered in our study.
9.5 Assessment of prediction accuracy
To assess the accuracy of the results and the confidence that we can have in the estimation it could be useful to provide confidence intervals for the predictor. From this point of view the methods are not equal. With Bayesian approaches, theoretical confidence intervals are provided with the models. More precisely as the output model is Gaussian and as it returns the mean and the variance, confidence intervals can be created. For example the -confidence interval is provided by
[TABLE]
However as presented on Figure 21, while the confidence intervals obtained from QK seem useful, the VB model is clearly overconfident.
The statistical order methods consider that inside each neighborhood the samples are i.i.d. Based on that, it is possible to use Wilks’ formula (see [68] for instance) or deviation inequality as presented in [88] to extract confidence intervals. For example, using Chernoff’s inequality, for any , the confidence interval of order is as with
[TABLE]
and
[TABLE]
Using this method enables the confidence intervals to be data dependent. For example in Figure 21 the confidence intervals are not symmetric. Note that while the confidence intervals obtained with this technique come with theoretical guarantees, they are very conservative and they depend a lot on the size of the training set.
Finally for all methods it is possible to use a bootstrap technique to create different regression models and then to aggregate them in order to create empirical confidence intervals. For example Figure 21 shows confidence intervals using a bootstrap technique for RK. The main drawback of such method is its computational cost.
To the best of our knowledge there are no other methods that sensibly improve this results. Thus, there is still a room for improvement concerning quantile regression model assessment.
10 Summary and perspectives
10.1 General recommendations
In this presentation we have introduced six metamodels for quantile regression. In the first part of the paper we have provided a full description of the six metamodels, first focusing on their theoretical basis, then discussing their implementation procedure. This part of the paper have enabled us to highlight the similarities and differences of the methods so that providing critical perspectives on the state of the art. The second part of the paper focused on performance comparison according to the dimension of the problem, the size of the learning set, the signal-to-noise ratio and the value of the pdf at the targeted quantile. We have compared the presented methods on toy problems in dimension 1, 2, 9 and on an agronomic model in dimension 9.
Figure 22 summarizes our findings. In a nutshell, when the signal-to-noise ratio is high RK, VB, QK and NN shows good results in our experimental setting but as soon as the signal-to-noise ratio decreases, quantile regression requires larger budgets and comparing the methods seems to be more complicated. Indeed, while the rule-of-thumb for computer experiments is a budget (i.e. number of experiments) times the dimension (see [52] for instance), as we work on problems with low signal-to-noise ratio, we found that no method was able to provide a relevant quantile estimate with a number of observations less than 50 times the dimension. For larger budgets, no method works uniformly better than any other. NN and VB are best when the budget is large. When the budget is smaller, RF, RK, KN are best when the pdf is small in the neighborhood of the quantile, in other words, when little information is available. However, VB outperforms all the other methods when more information is available, that is, when the pdf is large in the neighborhood of the quantile.
10.2 Possible ways of improvement
In our benchmark, we generally followed the approaches as presented by their authors. However, most of them could be improved. The optimization scheme of NN is the computational bottleneck of the method, which makes it the most expensive method in our benchmark system. One possible improvement would be using the BFGS algorithm (see [49] for details about the BFGS algorithm applied to non-smooth functions) or the ADAM algorithm [44] to optimize directly the empirical risk associated to the pinball loss. A faster scheme would allow more restarts, and hence improve robustness.
Another improvement concerns the splitting criterion (7) of RF, which is not designed for the quantile but for the expectation. This could lead to poor estimates for problems where quantiles are weakly correlated with expectations. Defining an appropriate splitting criterion could significantly improve the performance of this method.
In our experiments, QK used a predefined number of sampling points that were heuristically defined as a trade-off between space-filling and pointwise quantile estimation accuracy. The performance of QK could be significantly improved by optimally tuning the ratio between the number of points and repetitions, in the spirit of [8].
The KN method can naturally be extended to a variant that uses the whole sample instead of the nearest points. The weights associated to each point of the sample could be based on Gaussian or triangular kernel for example. This idea has been developed in [96] to estimate the conditional expectation but we think that it could be possible to adapt this approach to the estimation of the conditional quantile.
Finally, in practice, finding the best hyperparameters was the most difficult part of the proposed benchmark system. While this aspect is often toned down by authors, we believe hyperparameters tuning is a key practical aspect that remains a challenging problem in quantile regression.
Acknowledgments
This work is part of a Ph.D. of L. Torossian funded by INRA and Région Occitanie. The authors would like to thank Edouard Pauwels for the discussions on the topic of convex and non-convex optimization and Pierre Casadebaig for its suggestions and advices concerning the crop model sunflo.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Sachinthaka Abeywardana and Fabio Ramos. Variational inference for nonparametric bayesian quantile regression. In AAAI , pages 1686–1692, 2015.
- 2[2] Jason Abrevaya. Isotonic quantile regression: asymptotics and bootstrap. Sankhyā: The Indian Journal of Statistics , pages 187–199, 2005.
- 3[3] DH Ackley. A connectionist machine for genetic hillclimbing, vol ume secs 28 of, 1987.
- 4[4] Sunil Arya, David M Mount, Nathan S Netanyahu, Ruth Silverman, and Angela Y Wu. An optimal algorithm for approximate nearest neighbor searching fixed dimensions. Journal of the ACM (JACM) , 45(6):891–923, 1998.
- 5[5] François Bachoc. Parametric estimation of covariance function in Gaussian-process based Kriging models. Application to uncertainty quantification for computer experiments . Ph D thesis, Université Paris-Diderot-Paris VII, 2013.
- 6[6] Alexandre Belloni, Victor Chernozhukov, Denis Chetverikov, and Iván Fernández-Val. Conditional quantile processes based on series or many regressors. ar Xiv preprint ar Xiv:1105.6154 , 2011.
- 7[7] Pallab K Bhattacharya and Ashis K Gangopadhyay. Kernel and nearest-neighbor estimation of a conditional quantile. The Annals of Statistics , pages 1400–1415, 1990.
- 8[8] Mickael Binois, Robert B Gramacy, and Mike Ludkovski. Practical heteroskedastic gaussian process modeling for large simulation experiments. Journal of Computational and Graphical Statistics , (just-accepted):1–41, 2018.