Active Perception based Formation Control for Multiple Aerial Vehicles
Rahul Tallamraju, Eric Price, Roman Ludwig, Kamalakar Karlapalem,, Heinrich H. B\"ulthoff, Michael J. Black, Aamir Ahmad

TL;DR
This paper introduces an active perception approach for multiple MAVs to optimize their viewpoints during cooperative human tracking, reducing uncertainty and improving accuracy in outdoor motion capture scenarios.
Contribution
It presents a novel active control method for MAVs that optimizes view-point configurations by decoupling the tracking goal into a convex quadratic objective with non-convex constraints embedded in MPC.
Findings
Real robot experiments with 3 MAVs validate the approach.
The method reduces tracking uncertainty in challenging scenarios.
Simulation results show scalability and robustness.
Abstract
Autonomous motion capture (mocap) systems for outdoor scenarios involving flying or mobile cameras rely on i) a robotic front-end to track and follow a human subject in real-time while he/she performs physical activities, and ii) an algorithmic back-end that estimates full body human pose and shape from the saved videos. In this paper we present a novel front-end for our aerial mocap system that consists of multiple micro aerial vehicles (MAVs) with only on-board cameras and computation. In previous work, we presented an approach for cooperative detection and tracking (CDT) of a subject using multiple MAVs. However, it did not ensure optimal view-point configurations of the MAVs to minimize the uncertainty in the person's cooperatively tracked 3D position estimate. In this article we introduce an active approach for CDT. In contrast to cooperatively tracking only the 3D positions of the…
Click any figure to enlarge with its caption.
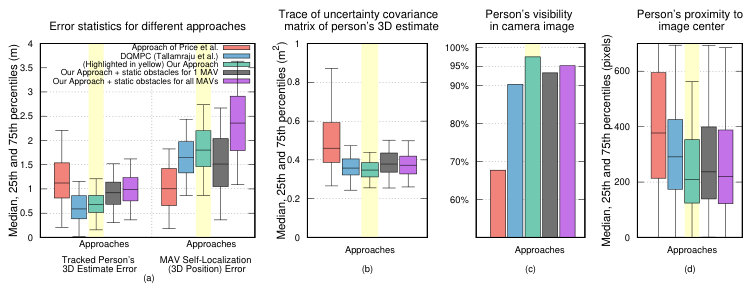 Figure 3
Figure 3 Figure 4
Figure 4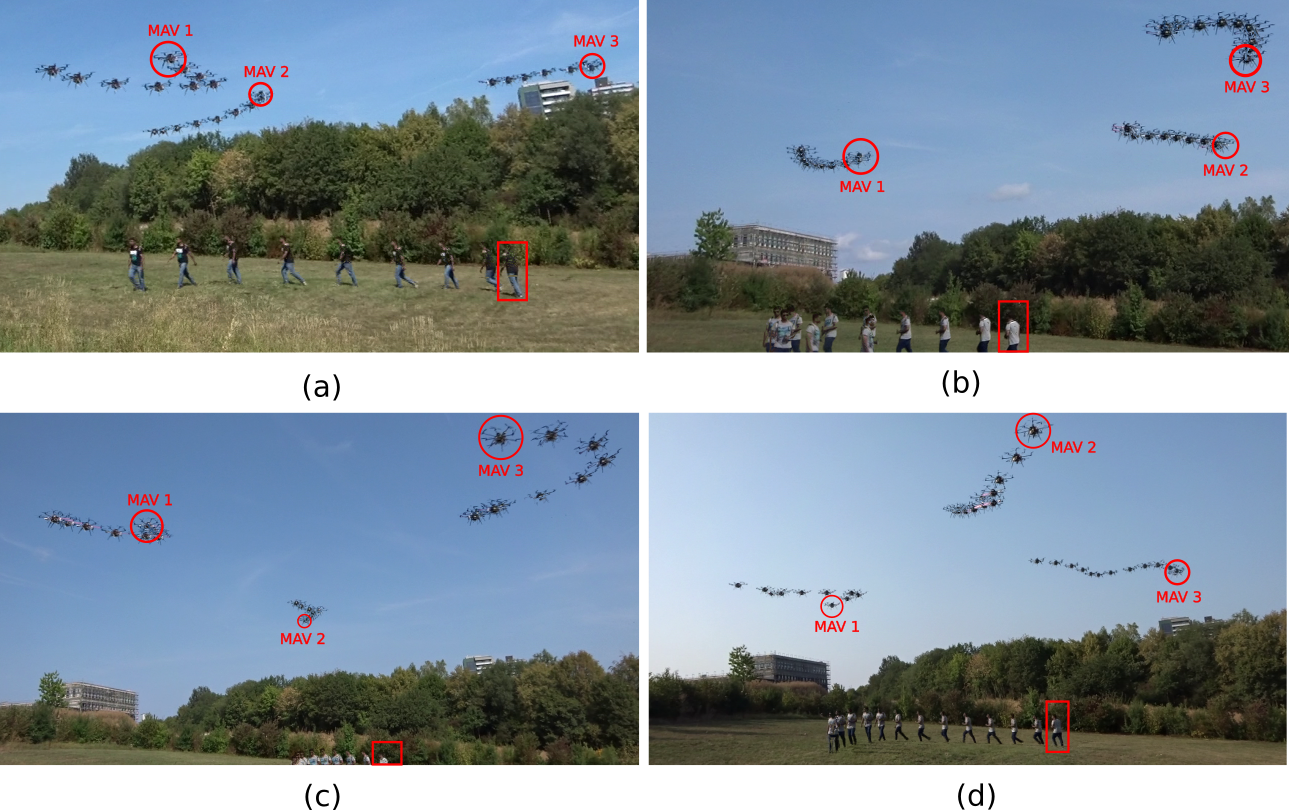 Figure 5
Figure 5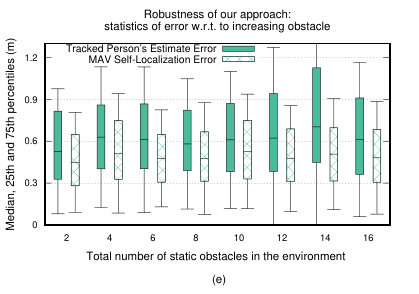 Figure 6
Figure 6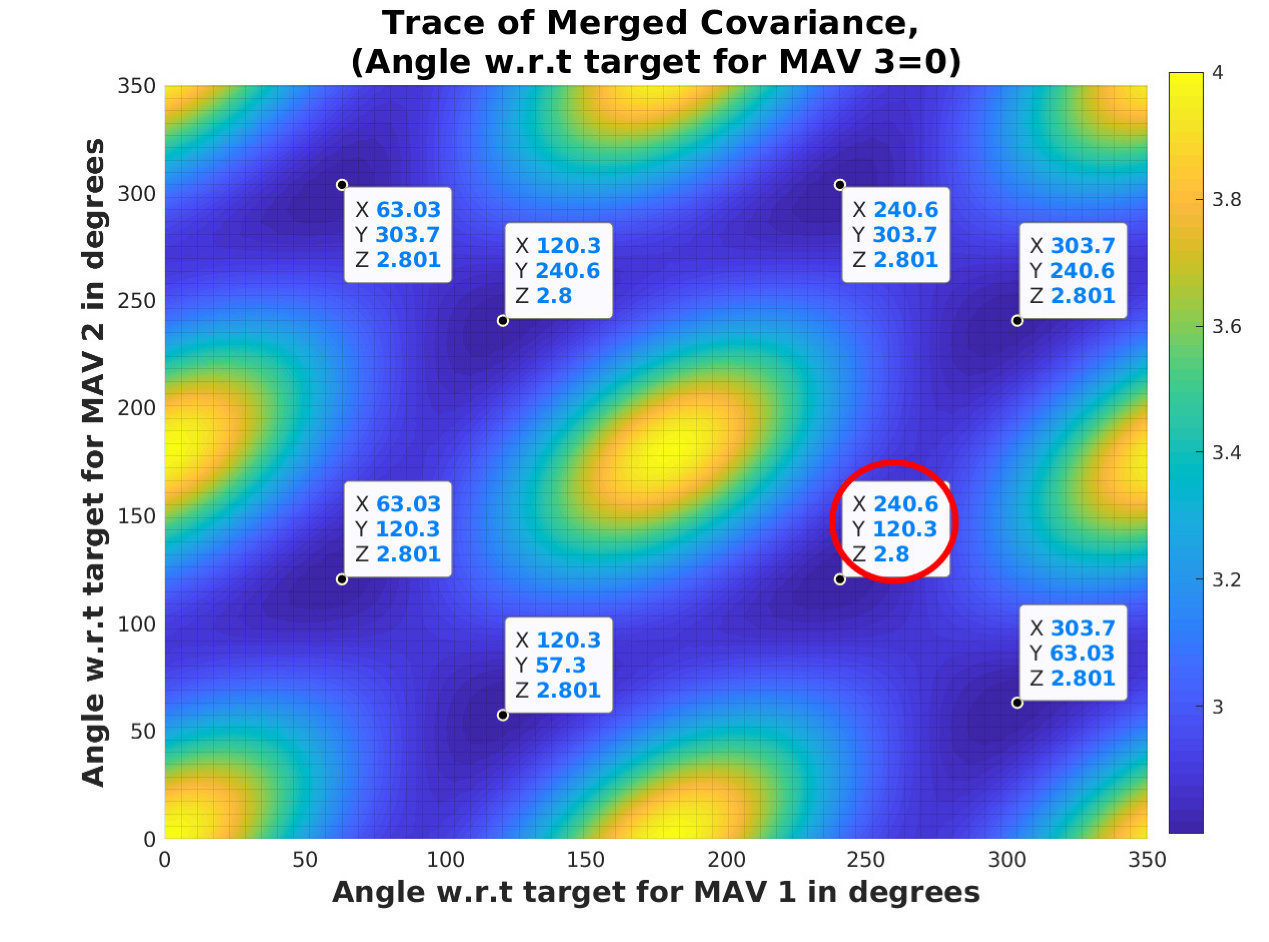 Figure 7
Figure 7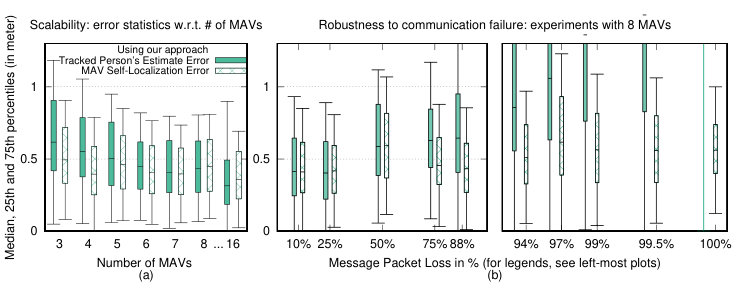 Figure 8
Figure 8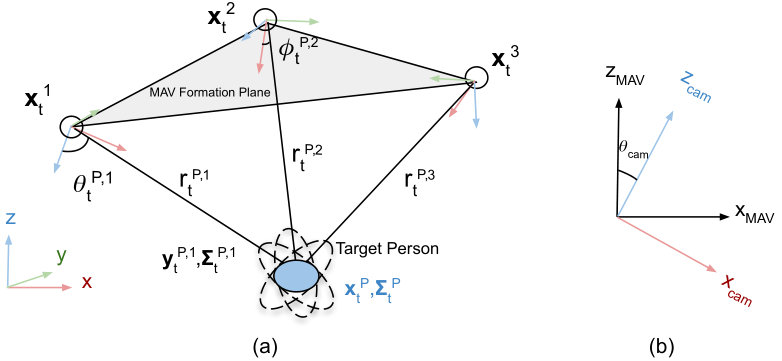 Figure 9
Figure 9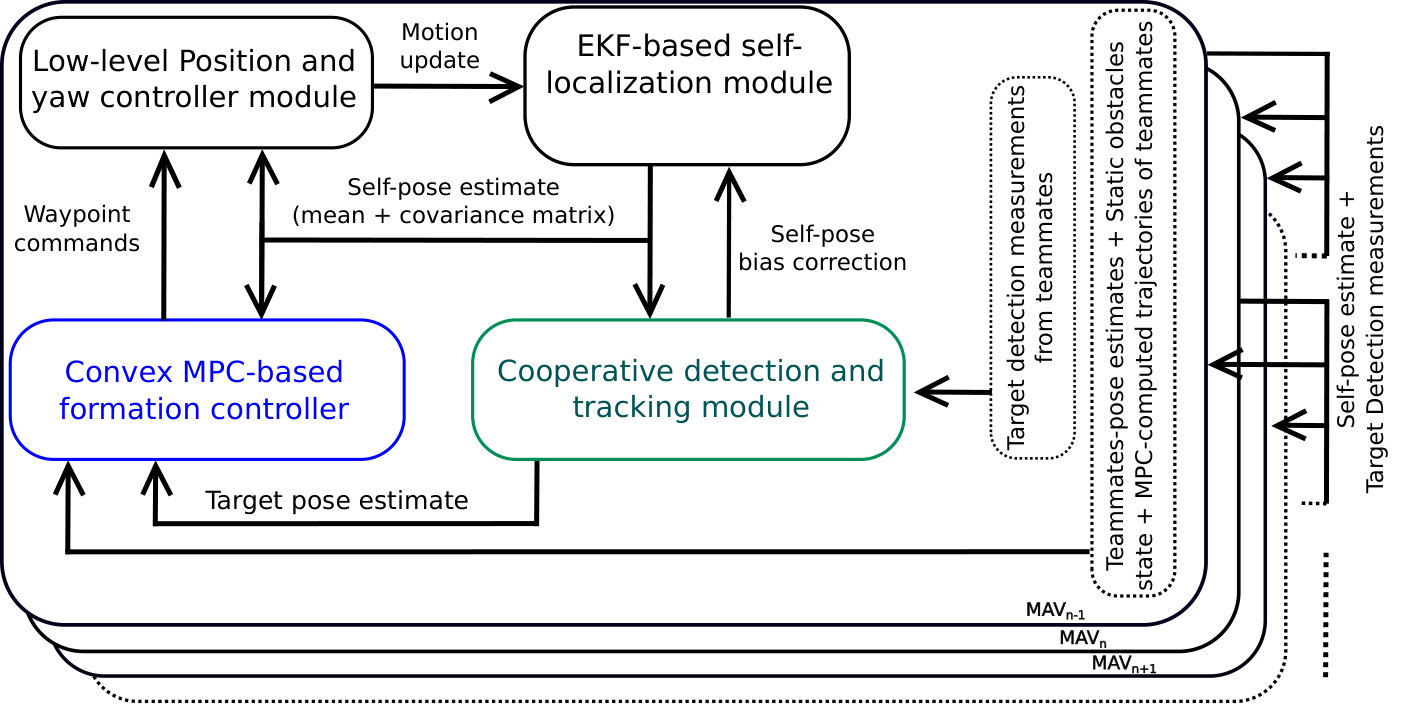 Figure 10
Figure 10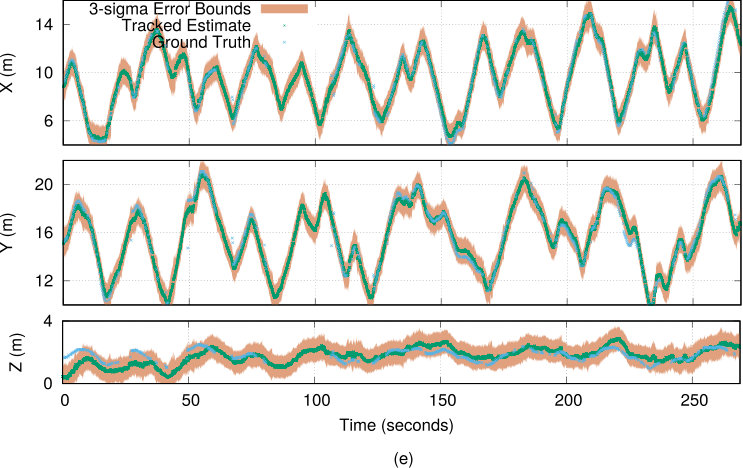 Figure 11
Figure 11Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Active Perception based Formation Control for Multiple Aerial Vehicles
Rahul Tallamraju1,3, Eric Price1, Roman Ludwig1, Kamalakar Karlapalem3,
Heinrich H. Bülthoff2, Michael J. Black1 and Aamir Ahmad1 1Max Planck Institute for Intelligent Systems, Tübingen, Germany. rahul.tallamraju, eprice, roman.ludwig, black, [email protected]2Max Planck Institute for Biological Cybernetics, Tübingen, Germany. [email protected]3Agents and Applied Robotics Group, IIIT Hyderabad, India. [email protected] Accepted to IEEE Robotics and Automation Letters 2019. DOI: 10.1109/LRA.2019.2932570The arxiv manuscript has an additional figure, Figure 5, which has been cited in the published RA-L manuscript.
Abstract
We present a novel robotic front-end for autonomous aerial motion-capture (mocap) in outdoor environments. In previous work, we presented an approach for cooperative detection and tracking (CDT) of a subject using multiple micro-aerial vehicles (MAVs). However, it did not ensure optimal view-point configurations of the MAVs to minimize the uncertainty in the person’s cooperatively tracked 3D position estimate. In this article, we introduce an active approach for CDT. In contrast to cooperatively tracking only the 3D positions of the person, the MAVs can actively compute optimal local motion plans, resulting in optimal view-point configurations, which minimize the uncertainty in the tracked estimate. We achieve this by decoupling the goal of active tracking into a quadratic objective and non-convex constraints corresponding to angular configurations of the MAVs w.r.t. the person. We derive this decoupling using Gaussian observation model assumptions within the CDT algorithm. We preserve convexity in optimization by embedding all the non-convex constraints, including those for dynamic obstacle avoidance, as external control inputs in the MPC dynamics. Multiple real robot experiments and comparisons involving 3 MAVs in several challenging scenarios are presented.
Index Terms:
Visual Tracking; Aerial Systems: Perception and Autonomy; Multi-Robot Systems
I Introduction
Aerial motion capture (mocap) of humans in unstructured outdoor scenarios is a challenging and important problem [1, 2, 3, 4, 5]. It may directly facilitate applications like sports medicine, cinematography, or search and rescue operations. The front-end of our mocap system consists of a team of micro aerial vehicles (MAVs), autonomously detecting, tracking and following a person. The front-end is responsible for the online task of the system, which is to continuously estimate the 3D global position of the person and keep him/her centered in the field of view of their on-board camera, while he/she performs activities such as walking, running, jumping, etc. The online task is the core focus of this article. The offline task, which is not addressed in this article, is to estimate full body skeleton pose and shape using images acquired by the MAVs.
In order to develop the mocap front-end, in our previous work [1], we presented a marker-less deep neural network (DNN) based cooperative detection and tracking (CDT) algorithm. That work had two major shortcomings. First, the motion planner on each MAV did not facilitate uncertainty minimization of the person’s 3D position estimate. Second, the local motion plans generated by the MAVs using a model-predictive controller (MPC) were subsequently modified using potential fields for collision avoidance. This further led to sub-optimal trajectories and robots getting easily stuck in field local minima, e.g., stuck behind each other or behind closely spaced obstacles.
In the current work, we solve both of the aforementioned problems through a novel convex decentralized formation controller based on MPC. This new MPC actively minimizes the joint uncertainty in the tracked person’s 3D position estimate while following him/her. The key novelties are as follows.
- •
The first novel idea, which enables us to formulate this problem as a locally convex MPC, is the decoupling of the joint uncertainty minimization into i) a convex quadratic objective that maintains a threshold distance to the tracked person, and ii) constraints that enforce angular configurations of the MAVs with respect to (w.r.t.) the person. We derive this decoupling based on Gaussian observation model assumptions used within the CDT algorithm.
- •
To guarantee the safety of the motion plans, we incorporate collision avoidance constraints w.r.t. i) other MAVs, ii) the tracked person and iii) static obstacles, only as locally convex constraints. Collision avoidance and angular configuration constraints are inherently non-convex. We preserve convexity in our MPC formulation by converting them to external control input terms embedded inside the MPC dynamics, which are explicitly computed at every iteration of the MPC.
Real robot experiments and comparisons involving 3 MAVs in several challenging scenarios are presented. Figure 1 shows a multi-exposure image of a short sequence from one of these experiments. Simulation results with up to 16 robots demonstrate the robustness of our approach and scalability w.r.t. to the number of robots. We provide open-source ROS-based111https://github.com/AIRCAP/AIRCAP source code of our method.
II State-of-the-Art
Multi-robot active tracking: In [6], multi-robot trajectories are analytically derived and uncertainty bounds are identified for optimizing the fused estimate of the target position. In [7], a non-convex optimization problem is solved analytically, to minimize the trace of the fused target covariance. However, their approach is centralized and uses Gauss-Seidel relaxation to compute optimal solutions for multiple robots. Centralized non-convex optimization [8, 9] is used to track a target in stochastic environments and locally minimize the fused estimate of the target position. In [10], active perception based formation control is addressed using a decentralized non-linear MPC. However, their method only identifies sub-optimal control inputs due to the non-convexity of optimization and the lack of collision avoidance guarantees. In [11], a perception-aware MPC generates real-time motion plans which maximize the visibility of a desired target. The motion plans are, however, generated only for a single aerial robot. A marker-based multi-robot aerial motion capture system is presented in [5], where the formation control is achieved using a decentralized non-linear MPC. Scalability in the number of robots and formation collision avoidance behaviors are not explicitly addressed in their approach.
Obstacle Avoidance: Sequential convex programming is applied to solve centralized multi-robot collision-free trajectory generation [12]. Due to non-convexities which arise from obstacle avoidance constraints, the obtained solutions are locally optimal albeit fast for a given time horizon. In [10] repulsive potential field functions are employed as one of the optimization objectives to avoid collisions. This is highly limiting as obstacle avoidance cannot be guaranteed. Recent work in distributed multi-agent obstacle avoidance [13] convexifies the reciprocal velocity obstacle constraint, to characterize velocities that do not lead to a collision in a perfectly localized environment. Motivated by multi-view cinematography applications, distributed non-linear model predictive control [14] is used to identify locally optimal motion plans for aerial vehicles. In one of our previous works [15], we developed a convex optimization program to generate local collision-free motion plans, while tracking a movable pick and place static target using multiple aerial vehicles. This approach generates fast, feasible motion plans and has a linear computational complexity in the number of environmental obstacles. The work was validated only in a simulation environment and, moreover, obstacle avoidance was not guaranteed. In our current work, we consider real robots, stochasticity in the environment and bounds on repulsive potential fields to guarantee collision avoidance and generate safe local motion plans.
III Proposed Approach
III-A Preliminaries and Problem Statement
Let there be K MAVs tracking a person P. The pose (position and orientation) of the MAV in the world frame at time is given by . The MAVs pose uncertainty covariance matrix is denoted as . Each MAV has an on-board, monocular, perspective camera. It is important to note that the camera is rigidly attached to the MAV’s body frame, pitched down at an angle of . Hence, the pose of the camera in the MAV’s frame is (see Fig. 2). The observation measurement of the person ’s position made by MAV in its camera frame is given by a mean range , bearing and inclination (see Fig. 2) in spherical coordinates. These are associated with a zero mean measurement noise, denoted by , and respectively. We assume that these measurements are uncorrelated. In camera frame’s Cartesian coordinates these measurements are denoted as and respectively. The fused estimate of the person ’s position and uncertainty covariance in the world frame are denoted as and . These estimates are computed by each MAV fusing its own measurements, , with the measurements received from all other teammates ( ).
The MAVs operate in an environment with known static obstacles (our approach is agnostic to how these obstacles are detected) and neighboring MAVs as dynamic obstacles. The goal of each MAV is to cooperatively track the person using a replicated instance of the proposed formation control algorithm. This involves (a) minimizing the MAV’s fused estimate of the measurement uncertainty covariance and, (b) avoiding environmental obstacles.
III-B Cooperative Detection and Tracking
Fig. 3 describes our mocap front-end architecture including i) the decentralized formation controller and ii) cooperative detection and tracking (CDT) modules. In [1], the focus was on developing the CDT algorithm (green block in Fig. 3). The work in the current paper focuses on developing the formation controller (blue block in Fig. 3), which utilizes information from CDT and other modules. In CDT, each MAV runs its own instance of an EKF for fusing detections made by it and all its teammates. This results in a replicated state estimate of the person at each MAV, which is used to predict a region of interest (ROI) in future camera frames. The ROI guides the yaw of each MAV thereby ensuring that the tracked person is in the MAV’s field of view. In Sec. III-D, we use these state estimates to drive our decentralized formation controller. At every time step, the controller of MAV generates way-point positions and velocities for itself using (a) estimated state of the tracked person, (b) horizon motion plans communicated by teammates and (c) the positions of obstacles. The way-points guide MAV ’s low-level position and yaw controller.
III-C Measurement Models and Joint Uncertainty Minimization
III-C1 Measurement Model for a Single MAV
For a MAV in this sub-section we drop the superscripts and subscripts. In a supplementary multimedia file attached with this paper, we empirically show that (a) the variance of the noise in the range measurement evolves quadratically with distance to the person, i.e., , and (b) the variance of the noise in both bearing and inclination measurements are approximately constant w.r.t. the distance to the person, which we represent as and . and are positive constants specific to the system.
We now convert the measurement noise variances from spherical to Cartesian coordinates. When using converted measurements (especially when measurement noise covariance is explicitly required) and performing estimation in Cartesian coordinates, most previous works, e.g., [16], [17], consider the measurement-conditioned conversion approach as derived in [18] or [19] as one of the best approximations. Using this conversion from [18] or [19] the noise covariances in Cartesian coordinates, i.e., the elements of can be written as
[TABLE]
where and are numerical constants, are exponential functions of , are trigonometric functions of , and are functions containing trigonometric and exponential expressions involving and , respectively. Exact functions can be obtained from equations (10) of[18] or pp. , of [19].
III-C2 Assumptions in Our Scenario
Restoring the superscripts and subscripts for the spherical and Cartesian coordinate person measurements, we make the following assumptions on the MAV observation model.
Bearing Measurement: We employ a separate yaw controller [1] to guide the yaw angle of MAVs towards the tracked person. This is to ensure that the MAV’s camera is always oriented towards the tracked person. Due to this, we can assume that the measurement component is almost always approximately zero .
Inclination Measurement: We assume that the person’s inclination measurement remains close to as observed in Fig. 2. The rationale for this assumption is as follows. Due to our formation controller (as described in subsequent sub-sections) the MAVs track and follow the person while maintaining a desired altitude and distance to her/him. Consequently, the change in is negligible. Hence, we assume .
Substituting these approximate values for , and for (see beginning of this section for the latter substitution) in (III-C1) and using expressions from either [18] or [19], the elements of are obtained in a compact form as,
[TABLE]
where are constants involving exponential functions of constants and only.
III-C3 Minimizing Fused Uncertainty for MAV Formations
The minimum uncertainty in the person’s fused state estimate is achieved when the following conditions are met.
(a) The angles between the MAVs about the person’s estimated position are : Given measurements from observations of different robots (or sensors), [20] analytically derives optimal sensor geometries for unbiased and efficient passive target localization. Geometries that maximize the determinant of Fisher information matrix are identified. For K() independent measurements, the angle between sensors resulting in minimum fused uncertainty is either or . We validated this analysis by computing from for all possible angular configurations and using the recursive covariance merging equations from [21]. Fig. 4 illustrates some of the possible angular configurations. Out of these, Fig. 4 (a), (b) are examples of configurations that do not minimize . The angular configurations which minimize trace of are highlighted in yellow boxes of Fig. 5. Fig. 4 (c) is one of those configurations which minimizes and which we use in this work. It is preferred over other optimal configurations because others do not ensure a uniformly distributed visual coverage of the tracked subject. This is important as our system is motivated by outdoor motion capture of an asymmetric subject (at least in one axis).
(b) The measurement uncertainty for each individual MAV is minimized: The previous angular constraint condition minimizes the fused uncertainty for any given set of measurements from the MAVs. However, the fused covariance remains a function of each individual MAV’s measurement uncertainty, . is a function of the relative position of MAV w.r.t. the tracked person. Notice that each MAV’s position remains controllable without changing the angular configuration of the whole formation. Therefore, the fused uncertainty is completely minimized by minimizing the trace of for each MAV . How this is done is discussed in the following subsection.
III-D Decentralized Quadratic Model Predictive Control
The trace of obtained using (2) is as shown below.
[TABLE]
where . Minimizing (3) ensures that each MAV improves its measurement uncertainty. However, would cause the MAVs to collide with the tracked person and other MAVs. In order to ensure the safety of the person, we limit the MAV to reach a desired circular safety surface centered at the person with a radius at a desired altitude from her/him. Hence, instead of minimizing (3), which is equivalent to minimizing , we now minimize . The latter expression is in terms of the MAV’s position and a desired position chosen on the aforementioned safety surface and lying in the direction from the MAV to the tracked person. Here, is a identity matrix. We now define the objective of our MPC running on each MAV k as follows. Minimize,
- •
the distance to the desired target surface (safety surface) around the tracked person,
- •
the difference in velocity between the MAV and the fused velocity estimate of the tracked person and,
- •
MAV control effort.
Consequently, the optimization objective of our active tracking MPC is as given below.
[TABLE]
where . The first part of this objective minimizes the input control signal and the second part ensures that the distance between desired terminal state (position and velocity) and the final horizon robot state is minimized. In order to ensure continuous and smooth person tracking, we minimize the difference in velocity of the MAV and the fused velocity estimate of the person available from the EKF. is as defined in (3) and is experimentally determined. and are custom-defined diagonal positive semi-definite weight matrices. Furthermore, the active tracking MPC is subjected to the following constraints.
- •
A non-convex constraint of maintaining a desired angular difference of w.r.t. other MAVs about the fused estimate of the person’s position .
- •
A non-convex constraint to maintain at least a distance from other obstacles.
- •
Regional and control saturation bounds for MAV states and control inputs for a horizon.
The non-convex constraints are embedded into the MPC dynamics as repulsive potential field forces [15]. The computation of these forces is discussed in Sec. III-E. The convex MPC is thus defined by the following equations.
[TABLE]
[TABLE]
The 3D translation motion of MAV is governed partly using accelerations and partly by an external control input , where is the horizon time step. The state-space translational dynamics of the robot is given by (6). Dynamics () and control transfer () matrices are given by
[TABLE]
where is the sampling time. is a real-time computed external control input representing non-convex constraints of formation configuration and obstacle avoidance. The next section details the computation of these forces.
Note that in our formulation optimality is regarding the minimization of uncertainty in the person’s 3D position jointly estimated by all MAVs. The way we formulate our MPC it cannot optimize the trajectories over the full belief space and hence transient behavior is not explicitly addressed. In our case, however, the MPC prediction time horizons are small enough (15 time steps or 1.5 seconds in total) to neglect the transient effects, as long as the MAVs are not very far away from the tracked person. Moreover, in the MPC we also minimize the difference between target person velocity and the MAV velocities, which further facilitates convergence to the desired view points.
Also, the optimal configuration may not always be feasible, especially, when the obstacles completely block or occlude the desired safety surface around the tracked person. This is inherent to our formulation because we enforce that obstacle avoidance and feasibility of trajectories take precedence (by considering them as hard constraints in MPC) over the optimality of the view points. This is important for the safety of aerial systems.
III-E Computation of External Control Input ()
Inter-MAV angular configuration constraints involve inverse-tangent operations with positive or negative arguments, making the constraint non-convex. Moreover, avoiding collisions by maintaining a minimum distance w.r.t. other MAVs and obstacles in the environment, constraint the robot to operate in non-convex regions. In our previous work [15], we introduced the concept of converting non-convex constraints into external control inputs using repulsive potential fields. In this work, we use it to enforce formation angular configuration and collision avoidance constraints. The repulsive potential field function used in this work is referred to as cotangential field function (see (17) in [22]). The magnitude of the cotangential field force is a hyperbolic function denoted as . Argument is either the Euclidean distance or the absolute angular difference between MAV and entity (another MAV or obstacle). Let and be threshold radii, where defines the region of influence of the potential field. is the distance below which the potential field value tends to infinity. Practically, this is clamped to a large positive magnitude which is derived to guarantee obstacle avoidance (see Sec. III-E3).
III-E1 Active Tracking Input
To satisfy the inter-MAV angular configuration constraints, each MAV computes its angle about the tracked person in the world frame and the angle of neighboring MAV about the tracked person . The absolute angular difference defined as , is used as the argument to compute the potential field magnitude. We compute for MAV and teammate MAV ,
[TABLE]
The factor in (10) helps avoid field local minima. This is because, if two robots have similar angles of approach (i.e., small ), the MAV farther away from the desired distance is repelled with a higher force than the MAV near the desired distance (see [15] for a detailed explanation on how these forces avoid field local-minima problems associated with potential field based planners). Factor is a small positive constant which ensures that the force magnitude is non-zero at the target surface if the desired angular difference is not yet achieved. acts in a direction which is normal to the direction of approach to the tracked person . In the plane of approach towards the person, there are two direction choices for a MAV, namely, . The direction pointing away from neighboring MAV ’s position is chosen. This choice ensures a natural deadlock resolution for robots having similar angles of approach to the tracked person. The total active tracking external control input of MAV w.r.t. all other teammate MAVs is
[TABLE]
For the active tracking control input .
III-E2 Obstacle Avoidance Input
Dynamic Obstacle Avoidance: All the teammates of MAV are considered as dynamic obstacles. The argument for in case of dynamic obstacle avoidance is the euclidean distance between MAV and teammate MAV . It is defined as . Magnitude of is computed using MAV and teammate ’s horizon motion plans. This is enforced along the direction , which is a unit vector pointing in the direction away from the teammate MAV ’s horizon motion plan. The total dynamic obstacle avoidance external input is as follows.
[TABLE]
The choice for and for dynamic obstacle avoidance are discussed in the following sub-section III-E3.
Static Obstacle Avoidance: The total external control input due to the static obstacles is as given below.
[TABLE]
where . The tracked person is considered as an additional static obstacle for each MAV. An external control input is computed so as to enforce her/his safety. Further, multiple static obstacles placed closed together might cause the MAV to get stuck in a field local minima (as shown in [15]). To avoid these scenarios, we compute a force to penalize MAV approach angles () which have static obstacles in the line of approach. The computation of this force is similar to the active tracking force described in the previous section. The total external control input for obstacle avoidance is given by the summation
Subsequently, the total external control input acting on MAV is determined as follows.
[TABLE]
Next, we describe the considerations for choosing , and to guarantee obstacle avoidance.
III-E3 Obstacle Avoidance Guarantee
To ensure stable external control inputs and guarantee obstacle avoidance, we take into account the following important considerations.
- •
maximum tracking error () of low-level controller w.r.t generated way-point for one time step ,
- •
maximum magnitude of the MAV velocity ,
- •
self-localization uncertainty of the MAV ,
- •
localization uncertainty of teammate MAVs ,
- •
communication or packet loss with teammate MAVs.
- •
maximum cotangential force magnitude .
and corresponding to the external control input for obstacle avoidance are defined as follows.
[TABLE]
where, is the maximum eigenvalue of . is the experimentally determined maximum possible eigenvalue of the localization uncertainty of the teammate MAV . Wireless communication delays are unavoidable in real-time implementations and cannot be ignored as they affect the MAVs knowledge of teammate MAV positions. accounts for it by increasing in proportion with the communication delay between the MAVs. , which is the maximum distance a neighboring MAV can travel in seconds.
IV Experiments and Results
IV-A Real Robot Experiments
IV-A1 Setup
We use three self-developed and customized octocopter MAVs in the field experiments. The MAVs are equipped with an Intel i7 CPU, an NVidia Jetson TX1 GPU and Open Pilot Revolution flight controller system on chip. Each MAV runs the CDT algorithm (Fig. III-B) on-board and in real-time, including the deep neural network-based single shot detector (SSD-Multibox). The MAVs use on-board GPS and IMU data, acquired at 100Hz, for localization. We place Emlid Reach differential GPS receiver on each MAV and on either shoulder of the tracked person to acquire ground truth (GT) location. The data from the differential GPS is not used during real-time experiments and stored only for comparison. For a decentralized implementation, a ROS multi-master setup with communication over Wifi is used. Each MAV continuously captures and stores camera images acquired at . The MPC is evaluated at Hz using the CVXGEN convex optimization library. The horizon length is time steps corresponding to seconds. The state and velocity limits of each MAV is in and in . The control limits are defined as . The desired horizontal distance to the tracked person in all experiments is set as and the desired height as . The tracking error w.r.t. to the MPC generated way-point is , therefore we use m (see subection III-E3). w.r.t. teammate MAVs varies with the change in self localization uncertainty and communication losses. The task for each MAV in all experiments is to track and follow the person using the proposed approach. We conducted real-MAV experiments (RE), each with a -MAV formation as follows.
- •
RE 1: Approach of Price et al. [1] (duration 257s)
- •
RE 2: DQMPC (Tallamraju et al.) [15] (231s)
- •
RE 3: Our approach (269s)
- •
RE 4: Our approach with one MAV avoiding emulated virtual obstacles (278s)
- •
RE 5: Our approach with all MAVs avoiding emulated virtual obstacles (106s)
In each experiment, the person remains stationary at first. Data collection starts after all MAV’s have acquired the visual line of sight to the person and converged on a stable formation around him/her. The person then walks randomly at moderate speeds, runs or performs standard exercise movements (see attached video or here222https://youtu.be/0Al3MlwOR1I for details). In the end, MAVs are manually landed. The error in the tracked position estimate of the person is calculated as the 3D Euclidean distance between the estimated and corresponding GT provided by the differential GPS system. Error for MAV pose is calculated similarly.
IV-A2 Analysis of results
Images in Fig. 6 and Fig. 1 show short sequences from RE 1 – RE 5. Fig. 7(e) compares the corresponding GT with the tracked person’s position estimate obtained by one of the MAVs using our proposed approach in RE 3. We analyzed the estimate’s accuracy, uncertainty, and the MAV self-pose accuracy for all experiments in Fig. 7(a-b). RE 3 achieves significantly more accurate person track estimates (mean error of m) than using state of the art method in RE 1 (mean error of m), despite the worse self pose estimates of the MAVs in RE 3 (the self-localization errors were due to the high errors in the MAV’s GPS localization and may vary arbitrarily over different experiments). This showcases the ability of our approach to attain high tracking accuracy despite bad GPS reception.
Even though the state of the art approach in RE 2 achieves similar accuracy to that of our approach in RE 3, we see that our approach outperforms the former in keeping the person always in the camera image and close to the image center as shown by bar and box plots in Fig. 7(c-d). Moreover, our approach achieves least tracking uncertainty in the tracked person estimate as compared to the other two state-of-the-art methods. The presence of obstacles that the MAVs need to navigate around affects the target tracking and self pose accuracy in RE 4 and RE 5. This is mainly due to the additional maneuvering overhead to avoid obstacles. However, the ability to keep the person close to the center of the image is only slightly affected. Fig 7(c-d) compares the different approaches ability to keep the tracked person centered in each MAV’s camera view. Our approach in RE 3 not only reduces the average distance between the tracked person and each camera’s image center but also ensures the person is completely covered by the camera image in of camera frames. This is a crucial feature for a system designed for aerial motion capture.
IV-B Simulation Experiments
IV-B1 Setup
The proposed algorithm was simulated in the Gazebo. The simulations were conducted on a standalone Intel i7-3970X CPU with an NVIDIA GTX 1080 GPU. We used AscTec Hexarotor Firefly MAVs in a world of . Each MAV has a rigidly attached Asus Xtion camera with their parameters set to the real MAV camera parameters. We simulate GPS and IMU drift by imposing random-walk offset on the ground truth position. We simulate a human actor model and guide it along a pre-defined trajectory. The actor traverses on a randomly varying terrain interspersed with emulated trees. The trees create obstacles and occlusions for the hovering MAVs.
IV-B2 Comparison of methods
For each of the following methods, we conducted 30 simulation runs with a MAV formation: (i) SE 1: Approach of Price et al. [1], (ii) SE 2: DQMPC (Tallamraju et al.) [15], (iii) SE 3: Our approach, and (iv) SE 4. Our approach with all MAVs avoiding emulated virtual obstacles. First 10 runs were of 120 seconds each, and next 20 runs were 180 seconds each. Figure 8 shows the statistics of this set of experiments. We clearly observe that our proposed approach with or without static obstacle avoidance outperforms both the state of the art approaches. Especially, when static obstacles are not present, our approach is able to keep the person fully in the camera image frame almost of the experiment duration. Also, it significantly outperforms all other methods in minimizing the joint uncertainty in the target position estimate.
IV-B3 Scalability Experiments
Fig. 9(a) shows the result of target tracking with our method for an increasing number of robots. We conduct 10 simulation trials for each number of robot configuration. Real-time factor for all runs in this experiment was set to . We validate the scalability of our model predictive controller by running these experiments in an environment with several static and known obstacles (in the form of trees) and perfect communication for a formation of 3 to 16 MAVs. We observe nearly linear improvement in tracking error with a higher number of robots. At the same time, we notice that computational requirements did not affect real-time performance for up to 16 robots.
IV-B4 Experiments with Communication Failure
In Fig. 9(b), the effect of inter-robot communication failure on tracking is demonstrated for our approach through experiments with 8 MAVs and simulated static obstacles. Communication losses varying from to is simulated. The results were averaged over trials per communication loss percentage. It can be observed that the tracking gets progressively worse with a higher percentage of communication loss. At communication loss, each robot relies only on its detection and does not cooperatively improve the target position estimate. Nevertheless, we observe that our approach is able to maintain an accurate target state estimate for up to 25% communication loss.
IV-B5 Experiments with increasing number of obstacles
Fig. 8(e) shows the results of our approach with increasing number of environmental obstacles. For each map, we conducted 5 trials (180 seconds each) with 5 MAVs tracking a randomly walking human model. We observe that by increasing the number of obstacles, the tracking error only slightly deteriorates. Moreover, the error in tracking is close to that of the environment with no static obstacles (see Fig. 8(a)). This result further validates our approach as the robots attain the desired configuration around the target person by navigating around randomly placed environmental obstacles.
V Conclusions and Future Work
We proposed a decentralized convex MPC-based algorithm for the MAVs to actively track and follow a moving person in outdoor environments and in the presence of static and dynamic obstacles. In contrast to cooperatively tracking only the 3D positions of the person, the MAVs actively compute optimal local motion plans, resulting in optimal view-point configurations, which minimize the uncertainty in the tracked estimate. We showed how we embed all the non-convex constraints, including those for dynamic and static obstacle avoidance, as external control inputs in the MPC dynamics. We evaluated our approach through rigorous and multiple real robot field experiments in an outdoor scenario. These experiments validate our approach and show that it significantly improves accuracy over the previous methods. In simulations, we showed results with up to 16 MAVs. These demonstrate the scalability of our method as well as its robustness to communication failures. Future work includes addressing visibility issues, e.g., occlusions of the person and assymetry of the target, which are not explicitly solved by our current approach. We also intend to extend our method to full body human pose detection.
Acknowledgments
The authors would like to thank Igor Martinovic and Mason Landry for their help with the field experiments. For the published RA-L manuscript and hence this revision on Arxiv, we thank the anonymous reviewers, associate editor and the editor Eric Marchand for their highly constructive feedback.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] E. Price, G. Lawless, R. Ludwig, I. Martinovic, H. H. Bülthoff, M. J. Black, and A. Ahmad, “Deep neural network-based cooperative visual tracking through multiple micro aerial vehicles,” IEEE Robotics and Automation Letters , vol. 3, no. 4, pp. 3193–3200, Oct 2018.
- 2[2] C. Huang, F. Gao, J. Pan, Z. Yang, W. Qiu, P. Chen, X. Yang, S. Shen, and K.-T. T. Cheng, “Act: An autonomous drone cinematography system for action scenes,” in IEEE International Conference on Robotics and Automation (ICRA) , 2018.
- 3[3] X. Zhou, S. Liu, G. Pavlakos, V. Kumar, and K. Daniilidis, “Human motion capture using a drone,” ar Xiv preprint ar Xiv:1804.06112 , 2018.
- 4[4] L. Xu, Y. Liu, W. Cheng, K. Guo, G. Zhou, Q. Dai, and L. Fang, “Flycap: Markerless motion capture using multiple autonomous flying cameras,” IEEE transactions on visualization and computer graphics , vol. 24, no. 8, 2018.
- 5[5] T. Nägeli, S. Oberholzer, S. Plüss, J. Alonso-Mora, and O. Hilliges, “Flycon: real-time environment-independent multi-view human pose estimation with aerial vehicles,” in SIGGRAPH Asia 2018 Technical Papers . ACM, 2018, p. 182.
- 6[6] F. Morbidi and G. L. Mariottini, “On active target tracking and cooperative localization for multiple aerial vehicles,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2011 . IEEE, 2011, pp. 2229–2234.
- 7[7] K. Zhou, S. I. Roumeliotis et al. , “Multirobot active target tracking with combinations of relative observations,” IEEE Transactions on Robotics , vol. 27, no. 4, pp. 678–695, 2011.
- 8[8] K. Hausman, J. Müller, A. Hariharan, N. Ayanian, and G. S. Sukhatme, “Cooperative multi-robot control for target tracking with onboard sensing,” The International Journal of Robotics Research , vol. 34, no. 13, pp. 1660–1677, 2015.