Adapting The Secretary Hiring Problem for Optimal Hot-Cold Tier Placement under Top-$K$ Workloads
Ben Blamey, Fredrik Wrede, Johan Karlsson, Andreas Hellander, and, Salman Toor

TL;DR
This paper adapts the Secretary Hiring Problem to optimize hot-cold storage tier placement for top-$K$ workloads, providing a model that minimizes costs and is applicable to long-running scientific and cloud storage scenarios.
Contribution
It introduces a parameter-based algorithm for storage tier placement under top-$K$ workloads, leveraging a probabilistic model for IO behavior to optimize costs.
Findings
Optimal tier placement depends on storage and transport costs.
The model enables a priori application IO behavior modeling.
Validated with bio-chemical simulation and cloud storage case studies.
Abstract
Top-K queries are an established heuristic in information retrieval. This paper presents an approach for optimal tiered storage allocation under stream processing workloads using this heuristic: those requiring the analysis of only the top- ranked most relevant, or most interesting, documents from a fixed-length stream, stream window, or batch job. In this workflow, documents are analyzed relevance with a user-specified interestingness function, on which they are ranked, the top- being selected (and hence stored) for further processing. This workflow allows human in the loop systems, including supervised machine learning, to prioritize documents. This scenario bears similarity to the classic Secretary Hiring Problem (SHP), and the expected rate of document writes, and document lifetime, can be modelled as a function of document index. We present parameter-based algorithms for…
Click any figure to enlarge with its caption.
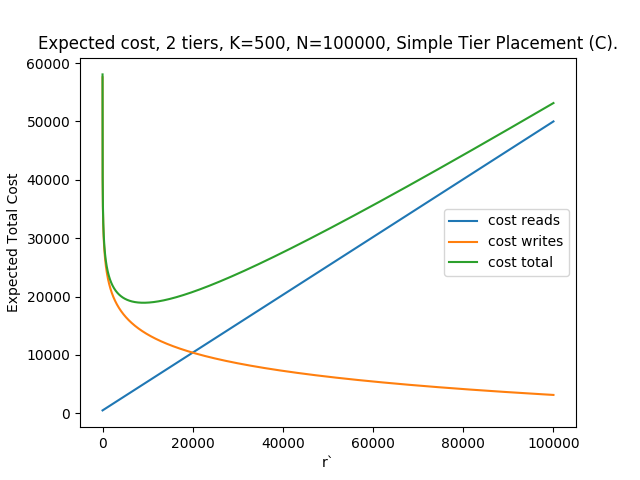 Figure 1
Figure 1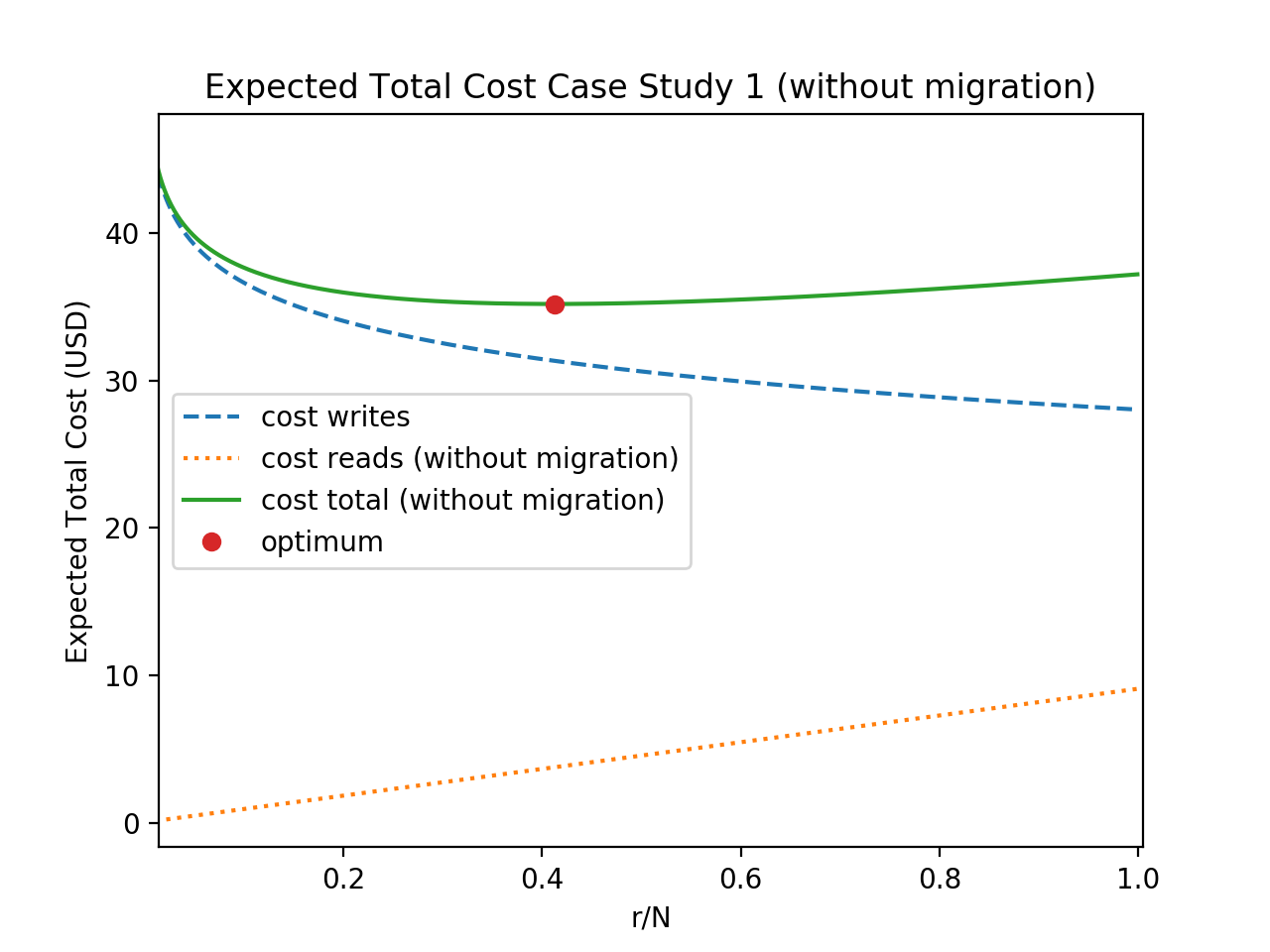 Figure 2
Figure 2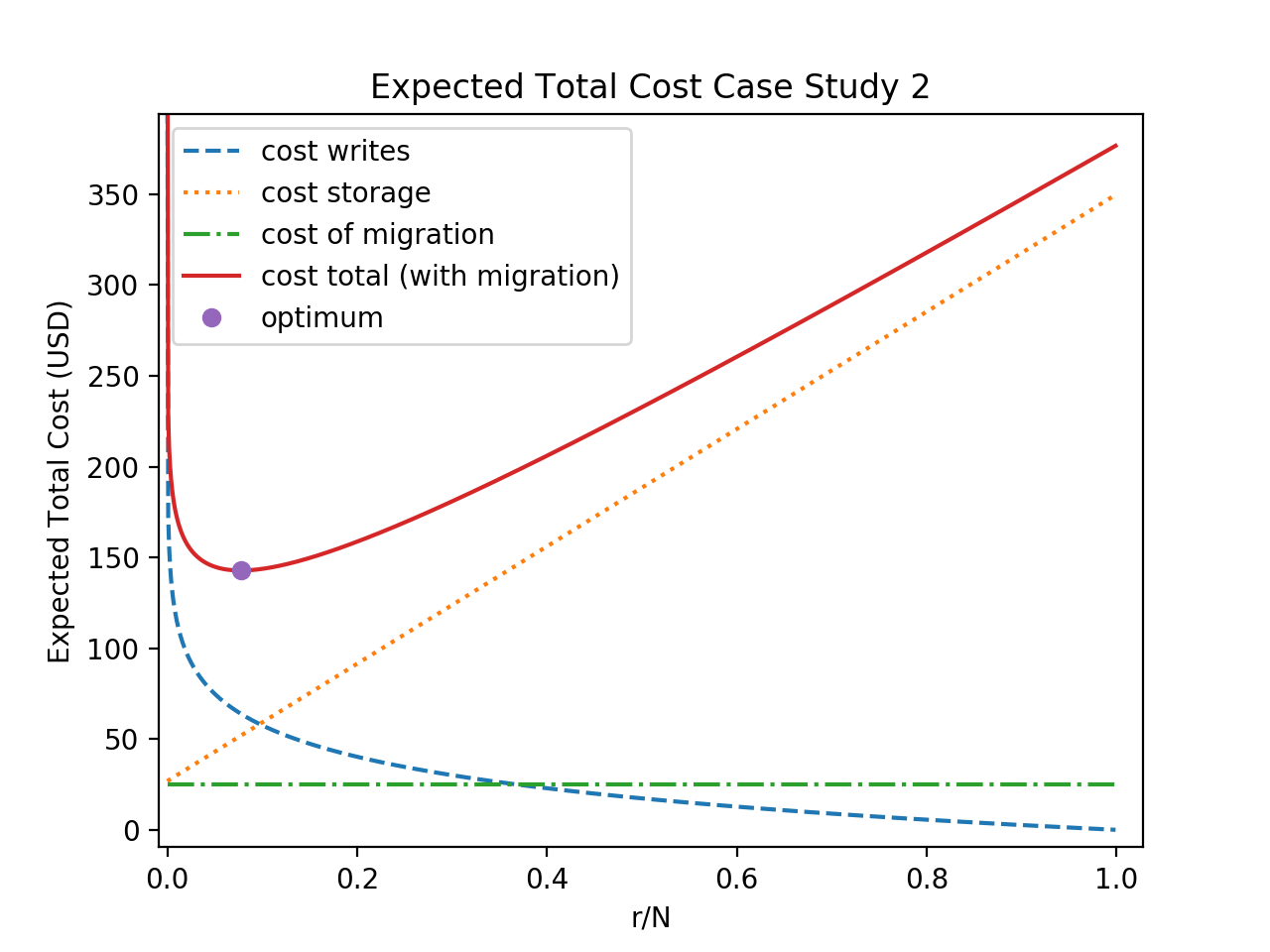 Figure 3
Figure 3 Figure 4
Figure 4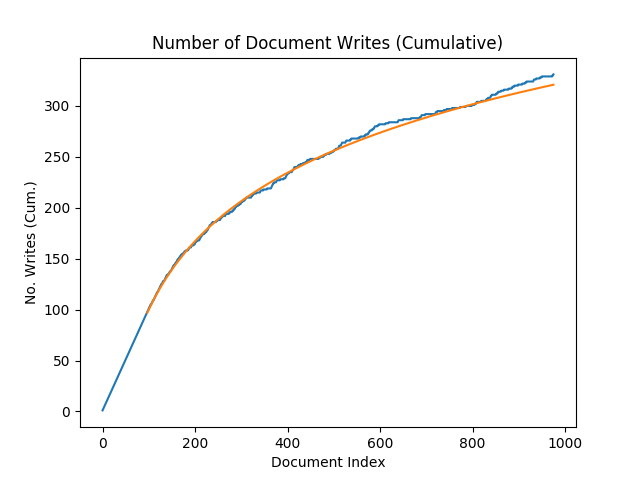 Figure 5
Figure 5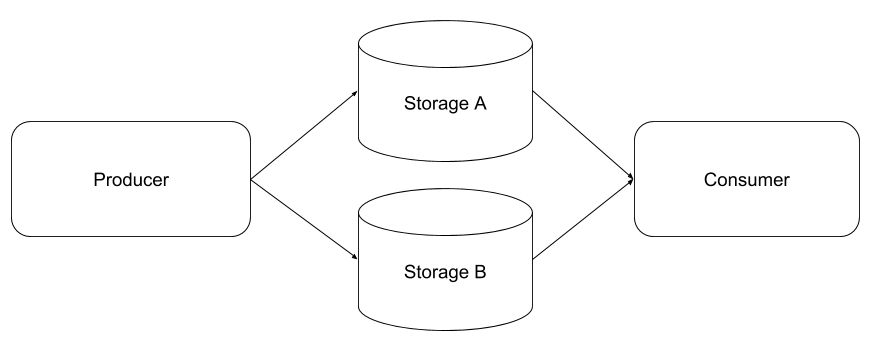 Figure 6
Figure 6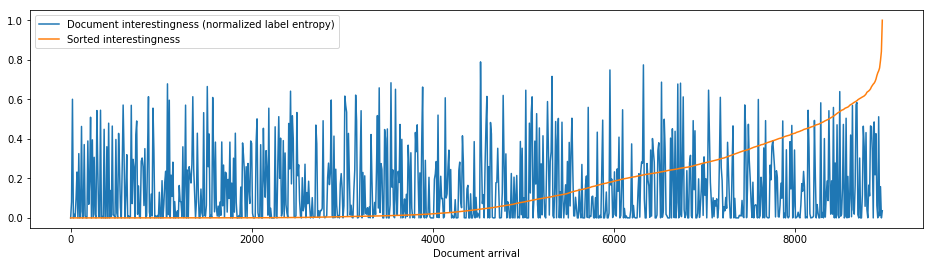 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9| N (Number of Documents) | 1e8 |
|---|---|
| K | N/100 |
| Document Size | 0.1 MB |
| Stream Duration / Window | 1 day |
| (A) Azure - PUT Cost |
0.00036 / 10,000
= 3.6e-8 / doc. |
| (A) Azure - GET Cost |
0.00036 / 10,000
= 3.6e-8 / doc. |
| (A) Azure - Rental Cost | 0.024 / GB month |
| (B) S3 - PUT Cost |
0.005 / 1,000
= 5e-6 / doc. |
| (B) S3 - GET Cost |
0.0004 / 1,000
= 4e-7 / doc. |
| (B) S3 - Rental Cost | 0.023 / GB month |
| Azure Transfer Costs (Out) | 0.087 / GB |
| S3 Transfer Costs (In) | 0 / GB |
| 0.41233169 | |
| Total Cost (, without migration, upper bound) | 35.19 |
| Other strategies… | |
| Total Cost (, with migration) | 49.29 |
| Cost all Storage A: | 37.20 |
| Cost all Storage B: | 99.12 |
| N (Number of Documents) | 1e8 |
|---|---|
| K | 5e6 (5% of N) |
| Document Size | 1 MB |
| Stream Duration / Window | 7 days |
| (A) EFS - Read | 0 |
| (A) EFS - Write | 0 |
| (A) EFS - Rental | 0.30 / GB Month |
| (B) S3 - Read | 0.000005 |
| (B) S3 - Write | 0.000005 |
| (B) S3 - Rental | 0.023 / GB Month |
| 0.078 | |
| Total Cost (, with migration) | 142.82 |
| Other strategies… | |
| Cost all Storage A | 350.00 |
| Cost all Storage B | 503.78 |
| Total Cost (, without migration, upper bound) | 415.67 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsData Management and Algorithms · Advanced Database Systems and Queries · Advanced Data Storage Technologies
Adapting The Secretary Hiring Problem for Optimal Hot-Cold Tier Placement under Top- Workloads
††thanks: [Affliations and acknowledgments blinded for review] The HASTE Project (http://haste.research.it.uu.se/) is funded by the Swedish Foundation for Strategic Research (SSF) under award no. BD15-0008, and the eSSENCE strategic collaboration for eScience.
Ben Blamey1, Fredrik Wrede1, Johan Karlsson2, Andreas Hellander1, and Salman Toor1
2 Discovery Sciences, Innovative Medicines, AstraZeneca, Gothenburg, Sweden
Email: [email protected]
1 Department of Information Technology, Division of Scientific Computing, Uppsala University, Sweden
Email: {Ben.Blamey, Fredrik.Wrede, Andreas.Hellander, Salman.Toor}@it.uu.se
Abstract
Top-K queries are an established heuristic in information retrieval. This paper presents an approach for optimal tiered storage allocation under stream processing workloads using this heuristic: those requiring the analysis of only the top- ranked most relevant, or most interesting, documents from a fixed-length stream, stream window, or batch job. In this workflow, documents are analyzed for relevance with a user-specified interestingness function, on which they are ranked, the top- being selected (and hence stored) for further processing. This workflow allows human in the loop systems, including supervised machine learning, to prioritize documents. This scenario bears similarity to the classic Secretary Hiring Problem (SHP), and the expected rate of document writes, and document lifetime, can be modelled as a function of document index. We present parameter-based algorithms for storage tier placement, minimizing document storage and transport costs. We show that optimal parameter values are a function of these costs. It is possible to model application IO characteristics analytically for this class of workloads. When combined with tiered storage, the tractability of the probabilistic model of IO makes it possible to optimize (and budget for) storage tier allocation a priori, without needing to monitor the application. This contrasts with (often complex) existing work on tiered storage optimization, which is either tightly coupled to specific use cases, or requires active monitoring of application IO load (a reactive approach) – ill-suited to long-running or one-off operations common in the scientific computing domain. We evaluate our model with a trace-driven simulation of a bio-chemical model exploration, and give case studies for two cloud storage case studies.
Index Terms:
secretary hiring problem, hot cold storage, hybrid storage, tiered storage, interestingness function, top-k queries, stream processing.
I INTRODUCTION
Selecting the top- documents ranked according a scoring function is known as a top- query. In this paper, we present a strategy for optimal use of tiered storage during the computation of these queries over large sequences, or streams, of documents. We show how the Secretary Hiring Problem can be adapted to reduce storage and communication costs where only the most relevant (or interesting) ranked documents are analyzed at the end of a batch, fixed-length stream, or stream window.
This approach ideally suited to workflows where it is only possible to process a subset of input data, for example, human in the loop (HITL) systems, including supervised or semi-supervised machine-learning [Wrede and Hellander, 2018], or active learning; as well as computational bottlenecks. In the case of stream processing applications, if the data input rate consistently exceeds the processing rate, some data must be removed from the processing queue, if latency is not to diverge. Unprocessed data can be archived or discarded. The top- heuristic is a sensible approach to such load shedding when resources are insufficient for processing the full stream. There is precedent for load shedding based based on relevance or importance to the context [Tatbul et al., 2003].
Regardless of processing bottlenecks, some workflows (especially in the scientific computing domain) can generate more data than is economically feasible to store. Retaining only the top- most interesting or relevant documents is a reasonable approach. In this paper, we assume a user-provided interestingness function111c.f. the notion of scoring function in much of the information retrieval literature. for document ranking, and consider optimal use of tiered storage under a generalized stream processing workflow.
A stream of length is equivalent to repeated stream analysis workload with a non-overlapping window of length , treating each window independently.
II MOTIVATION
As discussed, top- workflows are a useful approach for making best use of constrained processing (human or computstional) and storage resources – in the face of large datasets. In this section, we justify an interest in tiered storage in this context, and by implication, optimal tiered storage management.
In conventional enterprise stream processing applications, message sizes are perhaps a few KB (JSON, XML documents). Message processing frequencies may approach millions of documents a second in larger systems. For these systems, reducing latency, and increasing maximum frequency throughput are key research goals. In scientific computing, and many video and imaging related applications, message sizes can be much larger. Spatial cell simulations are often in the range 1MB-100MB (parameter sweeps can generate millions of such documents), and microscopy images are typically a few MB each. Cost, rather than absolute performance, can be more a driver. These massive workloads [Deelman and Chervenak, 2008], are different from enterprise streaming workloads, as is the economic context. In enterprise contexts, perceived data value motivates a “keep everything” strategy; whereas in a scientific context, this can be economically infeasible. Driven by these considerations, recent work explores more creative and unconventional use of cloud computing resources. For example, [Shankar et al., 2018] is a system for linear algebra on large matrices, which eschews traditional VMs and storage in RAM for object storage and FaaS.
In addition to large messages, unusually long stream processing windows create a requirement for longer-term storage of intermediate data. In industrial research settings, microscopes can generate many hours of high-resolution imagery.
Tiered, hybrid or hierarchical storage systems typically combine a number of tiers of more expensive, high-performance media with cheaper low-performance storage. This presents an opportunity for cost savings on workloads requiring storage of large numbers of large documents for extended timeframes.
III RELATED WORK
This paper draws on three areas of literature: (a) work on top-K queries, (b) work on optimizing the use of tiered and hybrid storage; and (c) various classic discrete optimization problems which serve as their basis.
Top- queries are well studied within the information retrieval and database communities, making them a well-established heuristic for working with large datasets. See [Ilyas et al., 2008] for a survey. Two research challenges are improving query optimization in the context of distributed systems [Cao, 2004], and streams [Babcock and Olston, 2003]. Whilst this paper assumes the implementation of top- queries, our concern is instead with storage tier allocation of large documents returned by such a query, and the associated storage/transport cost-optimization problems. Note that the discovery of the top- most frequent documents [Charikar et al., 2002] is a distinct problem, outside the scope of this paper.
There is a significant body of existing work relating to hybrid, hierarchical, hot/cold and tiered storage. Broadly, the goal of this work has always been to utilize different storage devices and media, with different performance characteristics and costs, to maximize read/write performance and/or minimize costs. As new storage media (flash and SSDs) have become available, and the way we think about and pay for storage has changed (cloud computing), the basis of these optimization problems have evolved, as have the frameworks and systems to work with tiered storage.
Much of this existing work could be characterized as reactive, based on low-level file metadata available in that filesystem (file creation time/age, number; frequency and frequency of file access) – without high-level application metadata.
Early work on hybrid storage concerned management of tiers of high performance and archive disks and tape drives, respectively. In [Wilkes et al., 1996] tiers were built from different RAID configurations – and tier placement was reactive: “[migrating] data blocks between these two levels as access patterns change”. In a similar vein, continuous Markov Chain models were used in [Kraiss and Weikum, 1998], transition probabilities being estimated “through access monitoring”.
Later, the large datasets in video and multimedia-streaming services motivated access models (and tier placement strategies) specific to that context. [Sapino and Torino, 2006] adopted a reactive approach – building finite state automata from access logs, whereas [Chan and Tobagi, 2003] modelled document read frequency as a Zipf distribution. The notion of document age as a predictor of document heat (and hence tier), is a popular heuristic, nicely exemplified in [Muralidhar et al., 2014].
These techniques are not limited to hybrid storage. [Xia et al., 2008] improves on previous work which uses “file access sequence and semantic attribute”, by mining correlations between documents. [Oly and Reed, 2002] used application traces to form a Markov model to predict block access. Similarly in [Dorier et al., 2014]: “modeling the I/O behavior of any HPC application and using this model to accurately predict the spatial and temporal characteristics of future I/O operations”.
The growing popularity of SSDs motivated extensive work on hybrid HDD/SSD tier management systems, with awareness of IO characteristics of both media (e.g. random vs sequential writes). See [Niu et al., 2018] for a review. In this work, there is a strong emphasis on caching heuristics – using document age and access frequency as a predictor of future access; i.e. a reactive approach. More elaborate techniques are possible using information available from the filesystem: [Li et al., 2004] mined correlations between blocks, allowing read-ahead optimization. More recently, [Krish et al., 2016] present a system which monitors the IO workload of popular big-data processing frameworks, allocating data between HDD and SSDs accordingly. Broadly, performance improvement (constrained by cost) is the optimization objective of these systems, investment in storage tiers being made upfront.
The flexibility of cloud computing removed the need for upfront investment, and allowed optimization based primarily on reducing cost (subject to performance constraints), especially in the case of object storage and similar long-term storage platforms. The simple pricing models, multitude of available tiers and providers led to extensive work on optimized cloud storage tier placement.
[Abu-Libdeh et al., 2010] suggest RAID-style striping and replication across different CSPs for resilience and to reduce costs. In the Frugal Cloud File System [Puttaswamy et al., 2012], workloads are analyzed to adapt the size of an EBS working set, flushing to S3 (c.f. Case Study 2, section VII-B). The system is reactive, assuming that “we do not have any knowledge of when the next access will occur”. [Deal et al., 2018] move data between providers to minimize long term costs.
Many of these systems rely on the input of quantified access and performance requirements; which in practice can be difficult to formulate for real-world systems. Frameworks such as [Raghavan et al., 2014, Kakoulli and Herodotou, 2017] to manage data over multiple media, tiers and providers, according to a given input policy.
There is precedent for applying discrete optimization problems to cloud computing. [Khanafer et al., 2013] apply the ski-rental problem – first introduced for TCP caching [Karlin et al., 1990] – to make an optimal tradeoff between the cost of caching a web document, and re-computing it. With a storage focus, [Mansouri and Erradi, 2018], used dynamic programming to express represent strategies for optimal tier placement, applying the ski rental problem. This work allows proactive tier placement, but information about the file operations still needs to be provided in a form suitable for their optimization approach.
The novelty of our work is our specific focus on document storage (and transport) for top- workloads: adapting the secretary hiring problem yields strategies with closed-form expressions (in terms of costs) for optimal parameter values. By modelling the workload in this way, we can predict the expected number of document reads and writes depending on stream position; rendering the optimal placement strategy tractable – and allowing proactive tier placement (without real time monitoring). Whilst focusing on a particular class of workloads, our approach contrasts with the approach in much of the literature. To the authors’ knowledge, there is no previous work on document storage for top K workloads.
IV THE OPTIMIZATION PROBLEM
The architecture under study (Fig. 1) includes a producer and a consumer, pre-processing with a user-provided interestingness function, and two abstract storage tiers. Read and write costs are modelled independently for the two storage tiers. Transport costs can be accounted for in the storage tier read and write costs (in cloud/edge and multi-cloud cases). The consumer read the documents, and performs further analysis on the final top- documents in the source stream, beyond the scope of this paper.
Central to our approach is a user-provided interestingness function able to compute the relevance of the input documents. This could for example be a pre-trained classifier or regressor that, based on features derived from the documents, predict the likelihood of a document being prioritized for downstream analysis. Under the top- workflow, interestingness translates to the read probability according to a simple probabilistic model. Our algorithm assigns each document to a storage tier given the interestingness scores, online. This work is equally applicable to streams of data originating in the cloud (such as simulation output), as well as data from other sensors (such as microscopes) connected at the cloud edge.
A stream of documents is produced (e.g. by a microscope, or simulation running in a cluster), and analyzed for relevance by an interestingness function. Each document is ranked in turn against those already produced on the output of this function, an interestingness score.
After the production of a fixed-length stream of documents, the top- most interesting will be processed. The documents must be stored in the meantime, and possibly transferred to another location for subsequent analysis (requiring that we account for transfer costs in the optimization). Clearly, as the stream progresses, the set of most interesting documents will change, as more interesting documents are observed and stored, overwriting less-interesting documents.
More formally: consider a sequence of documents, from a stream . An interestingness function , gives , the document interestingness, inducing a rank on . We suppose and the values of over are unknown a priori. To model the cost of the reads, we assume that the top- documents will be read by the consumer after all documents have been produced.
V ALGORITHM A: The Classic Secretary Hiring Problem
First, we recap the classic secretary hiring problem. There are ranked job candidates, which are interviewed in turn. After each interview, the rank of the candidate against previous candidates is known. You can decide to (irrevocably) hire that candidate, or continue interviewing. You only know the rank of the candidates you have interviewed so far. How can you maximize the probability that you hire the best overall candidate? It can be shown that the optimal strategy is as follows [Dynkin, 1963]: for given parameter ; observe the first candidates, and hire the next candidate who ranks higher than the best candidate among the first . The optimal value of is actually a function of , the base of natural logarithms:
[TABLE]
VI ALGORITHM B: Simple Overwrite, , 1 tier
We can adapt the secretary hiring problem to tiered storage by considering documents as candidates, ranked according to an interestingness function. Furthermore, in our scenario, previous ‘best’ documents can be overwritten by the producer to ensure that the best overall are always available for further analysis. This differs from the classic SHP problem. First consider a simple example with 1 tier of capacity 1, and simply compute the expected number of writes for a stream of documents under the algorithm listed in Fig. 2. This is a simple starting example to understand the document overwrite probabilities, there is no parameter.
[TABLE]
This partial sum of the Harmonic series can be approximated:
[TABLE]
Compare with the solutions to the classic secretary hiring problems above. It is trivial to extend this approach to . Note this is unrelated to the solution for for the classic (‘hiring-only’) problem (without replacement), using a recursive approach [Kleinberg, 2015].
VII ALGORITHM C: “First r to A, the rest to B”, k 1, 2 tiers
If we extend algorithm B to more than 1 tier, we have a new optimization problem – a decision about where to save a ‘best-so-far’ document to reduce overall costs.
Intuitively, at the start of the stream, ‘best-so-far’ documents are likely to be overwritten (and unlikely to survive until the read): such documents could be written to write-optimized, or producer-local storage. Conversely, towards the end of the stream, intermediate-best documents are less likely to be overwritten, and more likely to survive and be read. Under these scenarios we can compute optimal ‘changeover’ strategies for high-performance and low-performance storage (drawing inspiration from the optimal classic SHP strategy), as well as hedging transfer costs against storage transaction costs. We can adapt the algorithm from the classic secretary hiring problem to the 2-tier case, see fig. 3. From there, we can derive expressions for the expected number of reads, and the associated costs (assuming ):
[TABLE]
[TABLE]
[TABLE]
[TABLE]
[TABLE]
[TABLE]
Expressions (9) and (10) are equivalent to the expected rate (per document) of document writes. That is, assuming that the documents are randomly ordered w.r.t the rank of their interestingness score, we see that the rate of document overwrite (i.e. write and transfer cost) is () 222The first documents will be always be written. whereas document storage costs are a linear function of time.
Equations (11) and (12) are shown on fig. 7, plotted against a real trace from a case study discussed in Section VIII.
In cases where transaction and communication costs dominate, documents remain in the tier in which they are written (i.e. no migration333i.e. DO_MIGRATE = False in Fig. 3.). Without migration, the number of documents stored in each platform would change throughout the stream. If rental costs are relatively small, it is simpler to use a bound (using the most expensive tier rental). Using this bound means rental costs are constant (in ). By introducing this bounded approximation, we need to check that the 2-tier changeover strategy has lower overall costs than simply using one of the tiers exclusively. Supposing the read operation occurs after the stream, we can assume the best overall documents are i.u.d. over the stream:
[TABLE]
We can differentiate (w.r.t. ), and set to zero to find :
[TABLE]
Where storage rental costs are more considerable, it can be cheaper to migrate all documents. If documents are migrated when (incurring a read/write cost independent of ), then the storage rental costs are a linear function of . The costs of the migration, and final read are constant in :
[TABLE]
As before, we can differentiate (w.r.t. ), and set to zero to find :
[TABLE]
Regardless of whether migration is performed, the approach is only valid if: . Fig. 5 shows an example of the expected total cost for varying . Below, we apply this to real-world storage problems involving online analysis of the best (or most interesting) documents in a stream.
VII-A Case Study 1: 2 Tiers in Different Clouds
Our first example is motivated by IoT/fog and multi-cloud computing scenarios. We here assume that the producer and consumer are geographically separated and situated with different cloud providers, or that the producer is at the fog/edge. Consumer-local storage has lower write transaction costs than producer local storage, yet producer and consumer are separated by a costly (or otherwise constrained) communication channel. At the start of the stream, documents are less likely to survive; intermediate documents may be better stored at the producer – and pulled to the consumer if it survives. Towards the end of the stream (window) the document is more likely to survive and be read. It may be cheaper to push the document to the consumer-local storage. For example, suppose that the data is generated at an AWS cloud, where the S3 object store is available, and the consumer is situated in an Azure Cloud (where Azure Blob Storage storage is available). This scenario is illustrated in Table I. All prices in USD444https://aws.amazon.com/s3/pricing/ - EU, Ireland (2018) 555https://azure.microsoft.com/en-us/pricing/details/storage/blobs/ - GPv1 N. Eur. 666https://azure.microsoft.com/en-us/pricing/details/bandwidth/ - N. Eur..
Fig. 4 shows the value of which minimizes the expected total cost. The cost is minimized when the first 41% of documents are saved in the producer-local storage, and the remaining documents saved to the consumer local storage.
VII-B Case Study 2: 2 Tiers in the Same Cloud
In this example, we are concerned with optimizing storage allocation within tiers in the same cloud provider or datacenter. This situation occurs frequently for scientific workflows where the application needs to balance use of more expensive but high-performing storage tiers with cheaper commodity storage. Generally, storage costs are modelled as a sum of read and write read and write costs and rental costs typically a product of document size and document lifetime. In cloud computing contexts, these costs are modelled explicitly. Under a top- processing workflow, the optimal choice of storage tier is a function of document index (and costs). At the start of the stream, when the rate of document replacement is high, storage tiers optimized for high-throughput are likely to be cheaper. Towards the end of the stream, document replacement (and hence read and write transactions) is lower, so storage tiers optimized for longer term storage may be more cost effective.
For example, consider two storage tiers in AWS: EFS, which is expensive to rent, but has low read and write costs, and the S3 object store. In this example, we include the rental costs. This scenario is illustrated in Table II.
Fig. 5 shows the value of which minimizes the expected total cost. The expected cost is minimized the first 7.8% of documents are saved in the producer-local storage (and pulled to the consumer during the migration), and the remaining documents pushed directly in the consumer local storage.
VIII EXAMPLE: A SEMI-SUPERVISED MODEL EXPLORATION WORKFLOW
The scenario in Case Study 2 in the previous section occurs frequently in cloud-based scientific computing workflows using elastic master-slave clusters. Typically, the cluster is equipped with a shared filesystem based on either instance storage or elastic block storage, in which both input data and simulation output can be written and accessed from compute nodes with low latency.
An example of a computational experimentation application from computational systems biology that is organized this way is the MOLNs virtual cluster provisioning system for scalable cloud-native simulation of gene regulatory networks [Drawert et al., 2015]. MOLNs is part of the Stochastic Simulation Service, StochSS [Drawert et al., 2016]. It exposes an API for depositing and accessing simulation output files either at a shared filesystem served from instance or block storage attached to the cluster master node, or in object storage.
A common task is to conduct very large global parameter sweeps, where a stochastic biochemical model is simulated for large numbers of parameter combinations and the output of the sweep is subsequently analyzed in depth, to map out the range of possible variations in model behavior.
These documents are in the range of 0.1-100Mb for typical models. As the parameter space under exploration has large dimensionality, a significant number of messages are generated, resulting in very large datasets.
We used the tools from [Wrede and Hellander, 2018], combining smart sweeps and the herein proposed methodology, to construct a support vector machine (SVM) classifier, trained to classify simulation results from a model of a gene regulatory systems as biologically interesting or not (see fig. 6).
In such smart parameter sweeps the exploration proceeds in stages. First, with relatively few simulations and interactive human-in-the-loop active learning, the model is explored and the biologist informs the system about what simulation results should be considered interesting or not, and a classifier is trained. Then, very large datasets are generated by the simulators in a full sweep and stored for downstream analysis. In this analysis, it is most productive to focus on the outputs for which the classifier were most unsure (of either class), and again let the human modeler inform the system about those examples (active learning). Hence, an interestingness function can rank the documents according to the label entropy.
As a measure of interestingness of the produced stream of simulation results, we used normalized label entropies. This approach to constructing an interestingness function is representative of many human-in-the-loop semi-supervised workflows. The underlying model in this example has 15 dimensions, with a uniform sampling of the parameter space, and a modest 10 independent samples of each parameter point, resulting in a computational experiment lasting for ~ days (with 60 cores), producing documents totalling TB of data.
IX CONCLUSIONS
Adopting a top- workflow on the basis of a user-defined interestingness function (relevant to her or his workflow and dataset) is a natural way to make best use of limited processing resources in big data workflows, such as HITL systems.
We have shown how a top- ranked stream-processing workflow model allows proactive tier placement. Approach contrasts over the many of the reactive approaches adopted in the existing literature: our approach does not require monitoring of the application – and instead allows us to predict and budget for the optimal tier a priori.
Considering the document stream as randomly sorted sequence of ranked documents resembles the Secretary Hiring Problem, and we can adapt its solutions for hierarchical storage management. The probability of document overwrite/read can be modelled for a class of workflows by introducing an interestingness function. Assuming that documents are ordered randomly (with respect to their interestingness rank) within the stream, our model of document IO holds – we have demonstrated this with an interestingness trace from a cell-simulation use case.
We have presented strategies for hierarchical storage management under the top- workflow. We include case studies of parameter optimization for scenarios with different combinations of cloud storage platforms. The simplicity of the analytic solution makes the approach readily adoptable in production systems, where other domain-specific interestingness functions are defined, work on which we are progressing.
To the authors’ knowledge there exists no other work which investigates either top- workloads, or the secretary hiring problem in the context of cloud resource allocation, or hierarchical (or related) storage systems.
X FUTURE WORK
We are extending the evaluation in Section VIII to production systems; and the inclusion of a microscopy streaming case study: in this context analysis is severely limited by the cost of storing and analyzing documents. Being able to automatically at acquisition time (i.e. online) select which documents to store and analyze further could greatly increase the value of an experiment for the same total cost. In many cases, interestingness functions can be defined that are low in processing cost and still are able to select the valuable documents. Interestingness functions can favour images of high quality (in focus and having appropriate signal levels), or images containing the object type of interest (e.g. cells of a certain type, or those with high information content).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[Abu-Libdeh et al., 2010] Abu-Libdeh, H., Princehouse, L., and Weatherspoon, H. (2010). RACS: A Case for Cloud Storage Diversity. In Proceedings of the 1st ACM Symposium on Cloud Computing , So CC ’10, pages 229–240, New York, NY, USA. ACM.
- 2[Babcock and Olston, 2003] Babcock, B. and Olston, C. (2003). Distributed top-k monitoring. In Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data , pages 28–39. ACM.
- 3[Cao, 2004] Cao, P. (2004). Efficient Top-K Query Calculation in Distributed Networks. In In PODC , pages 206–215.
- 4[Chan and Tobagi, 2003] Chan, S.-G. and Tobagi, F. A. (2003). Modeling and dimensioning hierarchical storage systems for low-delay video services. IEEE Transactions on Computers , 52(7):907–919.
- 5[Charikar et al., 2002] Charikar, M., Chen, K., and Farach-Colton, M. (2002). Finding frequent items in data streams. In International Colloquium on Automata, Languages, and Programming , pages 693–703. Springer.
- 6[Deal et al., 2018] Deal, G., Peng, Y., and Qin, H. (2018). Budget-Transfer: A Low Cost Inter-Service Data Storage and Transfer Scheme. In 2018 IEEE International Congress on Big Data (Big Data Congress) , pages 112–119.
- 7[Deelman and Chervenak, 2008] Deelman, E. and Chervenak, A. (2008). Data Management Challenges of Data-Intensive Scientific Workflows. In 2008 Eighth IEEE International Symposium on Cluster Computing and the Grid (CCGRID) , pages 687–692.
- 8[Dorier et al., 2014] Dorier, M., Ibrahim, S., Antoniu, G., and Ross, R. (2014). Omnisc’IO: A Grammar-Based Approach to Spatial and Temporal I/O Patterns Prediction. In SC 14: International Conference for High Performance Computing, Networking, Storage and Analysis , pages 623–634, New Orleans, LA, USA. IEEE.